基于CPU和GPU的异构千核高通量处理系统及其修改方法与流程
本发明涉及芯片领域,尤其涉及一种基于cpu和gpu的异构千核高通量处理系统及其修改方法。
背景技术:
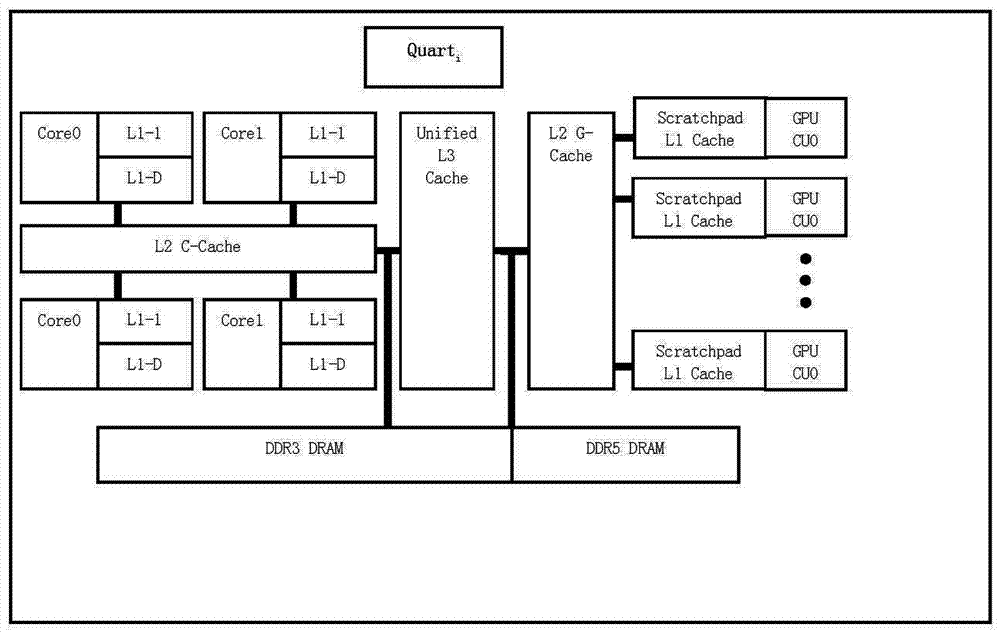
:随着众核设计、三维芯片制造等技术的发展,单位面积晶体管的数量将会继续按照摩尔定律增长,这种趋势将会使处理器的设计延续更多的计算核心,更大的共享高速缓存(cache),从而使得单片千核处理器的应用也不再遥远。与此同时,异构计算机系统的研究及应用也成为学术界和工业界的热点。异构多核处理器能获得比对称多核处理器和非对称多核处理器更好的性能。图形处理器(gpu)等作为加速计算部件处理数据流或者向量数据的作用越来越受到重视,各主流处理器制造商也相继推出新型的异构多核处理器,如amd的fusion架构处理器,intel的xeonphi架构处理器,nvidia的denver项目和armbig.little等,这些新型异构处理器依赖大量高性能的流处理/向量计算单元/超标量顺序处理单元作为协处理器加速浮点运算,增加多线程并发度,提高系统性能。当前独立式gpu的异构计算机系统在数据传输、计算核心启动、cache—致性管理和数据同步方面产生大量的额外开销。nvidiateslac2050gpu与显存通信的峰值带宽达到144gb/s,而主机和gpu通过pci-e相连的峰值传输带宽却只有8gb/s。这种数据传输速率之间的巨大差异是导致独立式异构计算机访存系统性能瓶颈的重要因素。例如,memcpy函数将一个128k字节的数据从主机cpu端传输到gpu端所产生的物理传输延迟占整个数据传输时间的70%。daga等人证明真正的单片异构系统计算机,如amd的加速处理单元较前两类异构系统具有更好的性能。hwu等人也同样指出gpu端和cpu端数据传输的巨大开销是异构系统发展的瓶颈。因此,随着千核处理器计算核心数量的增加,如何有效降低cpu和gpu之间传输数据的开销是提高gpu和cpu之间数据交换速度的主要难题之一。kelm等人采用软硬件协同设计的方法提出了混合式内存模型,避免了数据块的复制操作和多地址空间,减小了消息通信开销和片上的cache目录面积。但是数据块的一致性状态转换结构非常复杂,软硬件状态转换的同步过程是cache一致性的瓶颈。ham等人提出的异构内存系统采用层次化的缓冲区桥接变相位内存模块和动态随机访问内存模块,采用分离控制的方式提高系统的能效率。power等提出的cpu-gpu异构系统一致性机制是采用区域缓冲区和区域目录的结构提高异构系统的cache—致性。hechtman等人采用共享虚存的方式维持异构多核系统的cache一致性,认为cpucache是按照访问时延最优化设计的,gpucache是按照访问吞吐率最优化设计的,很难共享二者的cache数据块。因此,需要采用一个独立的目录结构来共享数据块,以避免cpu和gpu间通过访问片外内存来交换数据块的巨大开销。裴颂文等人提出的面向异构千核计算机的统一的物理内存访问框架能协调gpu端和cpu端的数据交换,通过异构核心间交叉式直接访问对方物理内存地址空间的方式来避免显式的数据交换,从而降低数据传输的额外开销,提高存储访问效率。amd等发起的异构系统架构是一个统一的计算框架,为避免cpu和gpu显式地传输数据而提出基于用户空间队列机制和抢占式上下文交换技术的逻辑地址空间的单一的访问方式。目前,异构千核处理器系统中的数据块访问仍然缺乏统一的高效的物理内存地址访问方法。技术实现要素:本发明的目的旨在至少解决上述技术缺陷之一,提供一种基于cpu和gpu的异构千核高通量处理系统及其的修改方法。本发明提供一种基于cpu和gpu的异构千核高通量处理系统,所述处理系统包括多个tile计算单元,开关总线,三级融合的数据缓存器,cpu和gpu的内存接口以及动态随机存取存储器,每个tile计算单元通过开关总线分别与三级融合的数据缓存器及cpu和gpu的内存接口连接,所述三级融合的数据缓存器及cpu和gpu的内存接口均与所述动态随机存取存储器以直接访问所述动态随机存取存储器,其中,每个tile计算单元包括多个quart计算单元,且多个quart计算单元之间通过高速交叉网络互连;每个quart计算单元包括多个cpu计算核心单元和多个gpu计算核心单元,且具有共享的三级数据缓存器用于采用缓存一致性目录机制以缓存cpu数据块和gpu数据块,所述三级数据缓存器用于保存cpu计算核心单元的数据块和gpu计算核心单元的数据块;以及所述每个cpu计算核心单元和每个gpu计算核心单元具有各自独立的一级数据缓存器,所述多个cpu计算核心单元具有共享的cpu二级数据缓存器,所述多个gpu计算核心单元具有共享的gpu二级数据缓存器。从上述处理系统的方案可以看出,通过设计有效地三级cache一致性访问机制,并给相应的物理内存地址的数据块分配统一的状态标识位,可以有效地管理融合的三级数据cache和支持交叉式直接访问统一的物理内存地址空间,从而可以有效避免数据副本的传输开销,降低系统访存指令的数量,提高系统的计算性能,实现cpu和gpu之间的内存高速直接交换。本发明还提供一种基于cpu和gpu的异构千核高通量处理系统的修改方法,所述修改方法包括:当根据cpu处理单元的访存指令和纯计算指令发起数据块的读写操作时,判断数据块的状态标志位;当数据块的状态标志位为(0,0)时,可以访问该数据块;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则对该数据块采用写回法;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块不属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则根据mesi协议对该数据块进行修改和更新;当数据块的状态标志位为(1,1),则对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器;当数据块的状态标志位为(0,1),先请求获得所述gpu处理单元的授权并将该数据块的状态标志位修改为(1,1),接着对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器。从上述修改方法的方案可以看出,通过设计有效地三级cache一致性访问机制,并给相应的物理内存地址的数据块分配统一的状态标识位,可以有效地管理融合的三级数据cache和支持交叉式直接访问统一的物理内存地址空间,从而可以有效避免数据副本的传输开销,降低系统访存指令的数量,提高系统的计算性能,实现cpu和gpu之间的内存高速直接交换。附图说明图1为本发明的cpu和gpu的异构千核高通量处理系统一种实施例的结构示意图;图2为本发明的quart计算单元一种实施例的结构示意图。具体实施方式为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。本发明提供一种实施例的cpu和gpu的异构千核高通量处理系统,如图1所示,所述控制方法包括:所述处理系统包括多个tile计算单元,开关总线1,三级融合的数据缓存器2,cpu和gpu的内存接口3以及动态随机存取存储器4,每个tile计算单元通过开关总线分别与三级融合的数据缓存器及cpu和gpu的内存接口连接,所述三级融合的数据缓存器2及cpu和gpu的内存接口3均与所述动态随机存取存储器4即统一的物理内存以直接访问所述动态随机存取存储器,其中,每个tile计算单元包括多个quart计算单元,且多个quart计算单元之间通过高速交叉网络互连;每个quart计算单元包括多个cpu计算核心单元和多个gpu计算核心单元,且具有共享的三级数据缓存器用于采用缓存一致性目录机制以缓存cpu数据块和gpu数据块,所述三级数据缓存器用于保存cpu计算核心单元的数据块和gpu计算核心单元的数据块;以及所述每个cpu计算核心单元和每个gpu计算核心单元具有各自独立的一级数据缓存器,所述多个cpu计算核心单元具有共享的cpu二级数据缓存器,所述多个gpu计算核心单元具有共享的gpu二级数据缓存器。也就是说,如图1所示,异构千核高通量处理系统是由三级计算单元组成,分别是cpu/gpu计算核心级、quart计算簇级和tile计算簇级。4个cpu计算核心组成的cpu簇和12个gpu计算核心组成的gpu簇,共同构成quart计算簇。该单元内的4个cpu和12个gpu有各自独立的一级cache即数据缓存器,12个gpu共享二级gpu数据cache,4个cpu共享二级cpu数据cache。因此,每个quart共包含16个异构计算单元。4个quart组成一个tile,quart之间通过高速交叉网络互连,每个tile含64个异构计算单元,并采用多端口队列机制分离访存指令和纯计算指令。每个quart配置有一个cache管理处理器(cachemanagementprocessor,cmp)负责为quart中各计算核心预取和管理数据块。异构千核高通量处理系统采用分离式访存和计算指令的设计,便于重叠访存和计算指令,提高指令流水线效率以及延迟隐藏异构系统间数据传输的长时间开销。16个tile通过高速多端口交叉开关即开关总线1网络连接,共享三级融合的cache即三级融合的数据缓存器2,该cache既可以为gpu计算核心缓存数据,也可以为cpu计算单元缓存数据,并支持交叉式直接访问统一的物理内存(即动态随机存取存储器dram)。在具体实施中,图2所示,各cpu计算核心和gpu计算核心分别含有私有的一级cache(如cpu中含有core0、core1、core2、core3,gpu中含有12个scratchpadl1cache)。每个quart内的cpu计算核心共享二级cpu数据cache(l2c–cache),gpu计算核心共享二级gpu数据cache(l2g-cache)。二级cpu数据cache和二级gpu数据cache是独立的物理cache;所有的64个quart共享统一的三级数据cache(unifiedl3cache),混合式缓存cpu数据块和gpu数据块。gpu和cpu数据块在三级数据cache采用cache一致性目录机制实现同步和一致性管理。在具体实施中,所述三级融合的数据缓存器2用于保存一级数据缓存器的中的数据块,共享的cpu二级数据缓存器中的数据块,共享的gpu二级数据缓存器中的数据块以及共享的三级数据缓存器中的数据块。在具体实施中,所述处理系统还包括与所述开关总线连接的系统编译器5,所述系统编译器5用于将6个标识位分配给每个quart计算单元,其中高4位表示tile计算单元的编号,低2位表示某个tile计算单元内的quart计算单元的编号。通过将6个标识位分配给每个quart计算单元,可以细粒度刻画数据块的所有者。在具体实施中,所述系统编译器5还用于对三级融合的数据缓存器中的每个数据块分配2个状态标志位。具体的,2个状态标志位具体包括以下:状态标志位(0,0),状态标志位(1,0),状态标志位(0,1)以及状态标志位(1,1)。通过数据块的状态标识位区分数据块的所有者属性,而且数据块的状态标识位随着数据块的处理过程以更新,另外数据块状态标识位功能如下表所示。状态位说明0,0无状态,新数据块,cpu计算核心和gpu计算核心均可以无限制访问1,0cpu私有数据块:数据块的所有者属于cpu计算核心,gpu只能读,不能写此块0,1gpu私有数据块:数据块的所有者属于gpu计算核心,cpu只能读,不能写此块1,1共享数据块:数据块的所有者既属于gpu计算核心,又属于cpu计算核心,cpu和gpu都可以对该数据块进行读写操作在具体实施中,如图1所示,所述处理系统还包括cpu处理单元6和gpu处理单元7,所述cpu处理单元6和gpu处理单元7分别与所述开关总线1连接,用于根据每个数据块中的状态标志位和每个quart计算单元的6个标识位对所述三级融合的数据缓存器中的数据块进行更新和同步。在具体实施中,所述cpu处理单元6用于:当数据块的状态标志位为(0,0)时,可以访问该数据块;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则对该数据块采用写回法;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块不属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则根据mesi协议对该数据块进行修改和更新;当数据块的状态标志位为(1,1),则对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器;当数据块的状态标志位为(0,1),先请求获得相应的gpu计算核心的授权并将该数据块的状态标志位修改为(1,1),接着对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器。在具体实施中,所述gpu处理单元7用于:当数据块的状态标志位为(0,0)时,可以访问该数据块;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则对该数据块采用写回法;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块不属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则根据mesi协议对该数据块进行修改和更新;当数据块的状态标志位为(1,1),则对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到gpu计算核心单元的一级数据缓存器和共享的二级数据缓存器;当数据块的状态标志位为(0,1),先请求获得相应的cpu计算核心的授权并将该数据块的状态标志位修改为(1,1),接着对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器。也就是说,cpu处理单元6或gpu处理单元7(处理单元是指cpu的处理器核心或gpu流计算单元),不是某个quart中的4个cpu计算核心,对融合的三级cache中的数据块更新和同步的基本原则是:如果cpu处理单元6或gpu处理单元7发起的修改操作是对本tile及本quart的私有三级数据cache块(私有三级数据cache块是指数据cache块的所有者属于cpu或gpu计算核心),则执行传统的写回机制,在减少总线通信带宽的条件下保证cache数据一致性。如果cpu处理单元6或gpu处理单元7发起的修改操作是针对本quart外的共享三级数据cache块(共享三级数据cache块是指数据cache块的所有者既属于gpu计算核心,又属于cpu计算核心),为了保证cache的严格一致性,则采用写直达法并反向同步到一级数据cache和二级数据cache或者gpu的一级数据cache和二级共享数据cache。面向融合的三级数据cache及统一的物理内存地址空间,对于典型的标识为(1,0),(0,1)和(1,1),数据块进行修改操作时,cpu处理单元6和gpu处理单元7分别修改数据块的基本操作规则包括以下六项:规则一:如果cpu处理单元6修改标记为cpu计算核心且是本tile及本quart私有的三级数据cache的数据块,则对三级数据cache的数据块采用写回法;若cpu修改标记为cpu却不是本tile及本quart私有的三级数据cache的数据块,则根据传统cache一致性协议mesi(modified,exclusive,share,andinvalid)修改和更新cache数据块;规则二:如果cpu处理单元6修改标记为共享的三级数据cache的数据块,则对三级数据cache的数据块采用写直达,修改数据块的状态标识到cpu私有状态,并反向同步到cpu的l1和12数据cache;规则三:如果cpu处理单元6修改标记为gpu计算核心的私有三级cache数据块,则先请求获得相应gpu计算核心的授权,并将数据块修改到共享状态,然后执行规则二。规则四:如果gpu处理单元7修改标记为gpu计算核心且是本tile及本quart私有的三级数据cache的数据块,则对三级数据cache的数据块采用写回法;若gpu修改标记为gpu却不是本tile及本quar私有的三级数据cache的数据块,则根据传统cache一致性协议mesi修改和更新cache数据块。规则五:如果gpu处理单元7修改标记为共享的三级数据cache的数据块,则对三级数据cache的数据块采用写直达,修改数据块的状态标识到gpu私有状态,并反向同步到gpu全局cache和共享cache。规则六:如果gpu处理单元7修改标记为cpu计算核心的私有三级cache数据块,则先请求获得相应cpu计算核心的授权,并将数据块修改到共享状态,然后执行规则五。基于以上六项关于修改三级cache数据块的基本规则,由cpu和gpu的访存指令和纯计算指令发起的读写操作可以同时访问三级cache和统一的物理内存。从上述处理系统的方案可以看出,通过设计有效地三级cache一致性访问机制,并给相应的物理内存地址的数据块分配统一的状态标识位,可以有效地管理融合的三级数据cache和支持交叉式直接访问统一的物理内存地址空间,从而可以有效避免数据副本的传输开销,降低系统访存指令的数量,提高系统的计算性能,实现cpu和gpu之间的内存高速直接交换。在具体实施中,本发明还提供一种实施例的基于cpu和gpu的异构千核高通量处理系统的修改方法,所述修改方法包括:当根据cpu处理单元的访存指令和纯计算指令发起数据块的读写操作时,判断数据块的状态标志位;当数据块的状态标志位为(0,0)时,可以访问该数据块;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则对该数据块采用写回法;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块不属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则根据mesi协议对该数据块进行修改和更新;当数据块的状态标志位为(1,1),则对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器;当数据块的状态标志位为(0,1),先请求获得相应的gpu计算核心的授权并将该数据块的状态标志位修改为(1,1),接着对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到cpu计算核心单元的一级数据缓存器和共享的二级数据缓存器。在具体实施中,所述修改方法还包括:当根据gpu处理单元的访存指令和纯计算指令发起数据块的读写操作时,判断数据块的状态标志位;当数据块的状态标志位为(0,0)时,可以访问该数据块;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则对该数据块采用写回法;当数据块的状态标志位为(1,0)且根据quart计算单元的6个标识位判断该数据块不属于当前tile计算单元及当前quart计算的三级数据缓存器中的数据块时,则根据mesi协议对该数据块进行修改和更新;当数据块的状态标志位为(1,1),则对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到gpu计算核心单元的一级数据缓存器和共享的二级数据缓存器;当数据块的状态标志位为(0,1),先请求获得相应的cpu计算核心的授权并将该数据块的状态标志位修改为(1,1),接着对该数据块采用写直法,并将该数据块的状态标识位修改为(1,0),以及反向同步到gpu计算核心单元的一级数据缓存器和共享的二级数据缓存器。也就是说,cpu处理单元6或gpu处理单元7(处理单元是指cpu的处理器核心或gpu流计算单元),不是某个quart中的4个cpu计算核心,对融合的三级cache中的数据块更新和同步的基本原则是:如果cpu处理单元6或gpu处理单元7发起的修改操作是对本tile及本quart的私有三级数据cache块(私有三级数据cache块是指数据cache块的所有者属于cpu或gpu计算核心),则执行传统的写回机制,在减少总线通信带宽的条件下保证cache数据一致性。如果cpu处理单元6或gpu处理单元7发起的修改操作是针对本quart外的共享三级数据cache块(共享三级数据cache块是指数据cache块的所有者既属于gpu计算核心,又属于cpu计算核心),为了保证cache的严格一致性,则采用写直达法并反向同步到一级数据cache和二级数据cache或者gpu的一级数据cache和二级共享数据cache。面向融合的三级数据cache及统一的物理内存地址空间,对于典型的标识为(1,0),(0,1)和(1,1),数据块进行修改操作时,cpu处理单元6和gpu处理单元7分别修改数据块的基本操作规则包括以下六项:规则一:如果cpu处理单元6修改标记为cpu计算核心且是本tile及本quart私有的三级数据cache的数据块,则对三级数据cache的数据块采用写回法;若cpu修改标记为cpu却不是本tile及本quart私有的三级数据cache的数据块,则根据传统cache一致性协议mesi(modified,exclusive,share,andinvalid)修改和更新cache数据块;规则二:如果cpu处理单元6修改标记为共享的三级数据cache的数据块,则对三级数据cache的数据块采用写直达,修改数据块的状态标识到cpu私有状态,并反向同步到cpu的l1和12数据cache;规则三:如果cpu处理单元6修改标记为gpu计算核心的私有三级cache数据块,则先请求获得相应gpu计算核心的授权,并将数据块修改到共享状态,然后执行规则二。规则四:如果gpu处理单元7修改标记为gpu计算核心且是本tile及本quart私有的三级数据cache的数据块,则对三级数据cache的数据块采用写回法;若gpu修改标记为gpu却不是本tile及本quar私有的三级数据cache的数据块,则根据传统cache一致性协议mesi修改和更新cache数据块。规则五:如果gpu处理单元7修改标记为共享的三级数据cache的数据块,则对三级数据cache的数据块采用写直达,修改数据块的状态标识到gpu私有状态,并反向同步到gpu全局cache和共享cache。规则六:如果gpu处理单元7修改标记为cpu计算核心的私有三级cache数据块,则先请求获得相应cpu计算核心的授权,并将数据块修改到共享状态,然后执行规则五。基于以上六项关于修改三级cache数据块的基本规则,由cpu和gpu的访存指令和纯计算指令发起的读写操作可以同时访问三级cache和统一的物理内存。从上述修改的方案可以看出,通过设计有效地三级cache一致性访问机制,并给相应的物理内存地址的数据块分配统一的状态标识位,可以有效地管理融合的三级数据cache和支持交叉式直接访问统一的物理内存地址空间,从而可以有效避免数据副本的传输开销,降低系统访存指令的数量,提高系统的计算性能,实现cpu和gpu之间的内存高速直接交换。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1