用于对数据进行编码和存储的方法和装置与流程
本发明整体涉及数据存储,并且具体地讲涉及用于在模拟存储器单元中存储数据的方法和系统。
背景技术:
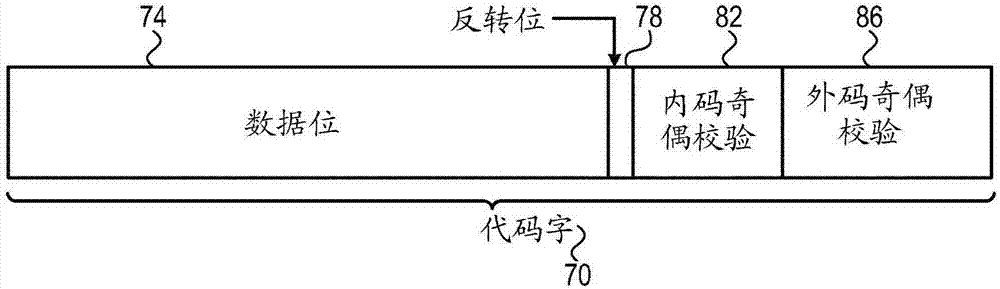
:多种类型的存储器设备诸如闪存存储器采用模拟存储器单元的阵列来存储数据。每个模拟存储器单元存储模拟值的数量,该模拟值又称为存储值,诸如电荷或电压。该模拟值表示存储在该单元内的信息。例如,在闪存存储器中,每个模拟存储器单元保持一定量的电荷。可能模拟值的范围通常被分为若干区间,每个区间对应于一个或多个数据位值。通过写入与所期望的一个或多个位对应的标称模拟值来将数据写入模拟存储器单元。通常称为单级单元(SLC)设备的一些存储器设备在每个存储器单元中存储单个信息位,即,可以对每个存储器单元进行编程以采用两个可能的编程级。通常称为多级单元(MLC)设备的较高密度设备每存储器单元存储两位或更多位,即,可对其进行编程来采用多于两个可能的编程级。例如,三级单元(TLC)设备采用八个编程级使每单元存储三位。例如,在2003年4月的IEEE论文集第91卷第4期第489-502页,由Bez等人发表的“IntroductiontoFlashMemory”中描述了闪存存储器设备,该文献以引用方式并入本文。例如,在NewYork州的NewYork市召开的1996年IEEE国际电子设备会议(IEDM)的论文集中第169-172页,由Eitan等人发表的“MultilevelFlashCellsandtheirTrade-Offs”中描述了多级闪存单元和设备,该文献以引用方式并入本文。该论文比较了几种多级闪存单元,诸如共接地、DINOR、AND、NOR和NAND单元。1999年9月21-24日在Japan的Tokyo召开的1999年固态设备与材料(SSDM)国际研讨会的论文集中第522-524页,由Eitan等人在“CanNROM,a2-bit,TrappingStorageNVMCell,GiveaRealChallengetoFloatingGateCells?”中描述了称为氮化物只读存储器(NROM)的另一种类型的模拟存储器单元,该论文以引用方式并入本文。2002年2月3-7日在California的SanFrancisco召开的2002年IEEE国际固态电路会议(ISSCC2002)的论文集中第100-101页,由Maayan等人在“A512MbNROMFlashDataStorageMemorywith8MB/sDataRate”中也描述了NROM单元,该论文以引用方式并入本文。模拟存储器单元的其他示例性类型是浮栅(FG)单元、铁电RAM(FRAM)单元、磁性RAM(MRAM)单元、电荷捕获闪存(CTF)和相变RAM(PRAM,也称为相变存储器-PCM)单元。例如,2004年5月16-19日在Serbia的Nis和Montenegro召开的第24届微电子学(MIEL)国际会议的论文集中第1卷第377-384页,由Kim和Koh在“FutureMemoryTechnologyincludingEmergingNewMemories”中描述了FRAM、MRAM和PRAM单元,该论文以引用方式并入本文。一些存储方案以每一存储器单元具有非整数数量的位的密度来存储数据。例如,美国专利7,071,849描述了允许在产品代之间使每单元状态数的增量小到1的分数位系统,通过引用将该专利的公开内容并入本文。由于每单元的状态数不是2的整数次幂,因而每单元的位数采取分数值。通常以字为单位对单元进行解码,并且可以通过调整字宽度来优化系统效率。又如,美国专利6,646,913描述了一种用于在具有由多个存储器单元形成的存储器阵列的多级非易失性存储器中存储和读取数据的方法,通过引用将该专利的公开内容并入本文。该存储器单元中的每一个存储一定数量的位,该数量为非2的整数次幂。通过这种方式,可以将一个数据字节存储到非整数数量的存储器单元中。该管理方法包括通过对预设数量的相邻存储器单元进行编程而在同一时钟周期内存储由多个字节形成的数据字。通过在同一时钟周期内读取所存储的数据字来执行读取。美国专利7,167,109中描述的方法允许在产品代之间使每单元状态数N的增量小到1,通过引用将该专利的公开内容并入本文。由于N不再是2的整数次幂,因而b取分数值,从而得到了分数位系统。在分数位系统中,以字为单位对单元进行解码。能够通过调整字宽度来优化系统效率。可以采用混合N元系统提高制造成品率和耐用寿命。美国专利7,742,335描述了用于操作多级非易失性存储器单元的方法、设备、模块和系统,通过引用将该专利的公开内容并入本文。一个方法实施方案包括向耦合至行选择线的第一单元分配能够将第一单元编程为的第一数量的编程状态。该方法还包括向耦合至行选择线的第二单元分配能够将第二单元编程为的第二数量的编程状态,其中第二数量的编程状态大于第一数量的编程状态。该方法包括在将第二单元编程为第二数量的编程状态中的一个之前将第一单元编程为第一数量的编程状态中的一个。美国专利7,848,142描述了用于对存储器单元进行编程的方法、设备、模块和系统,对存储器单元进行编程可以包括存储与表示一组存储器单元内的整数个位的数据状态对应的电荷。对存储器单元进行编程可以包括在该组的单元内存储电荷,其中电荷对应于编程状态,其中编程状态表示分数数量的位,并且其中编程状态表示数据状态的数字,该数字通过以N为基数的上舍入为整数的数表示,其中N等于2B,并且其中B等于编程状态表示的位的分数数量。美国专利7,420,841描述了一种存储器设备和一种操作存储器设备的方法,通过引用将该专利的公开内容并入本文。在该发明的一个实施方案中,存储器设备包括多个多级存储器单元,多个多级存储器单元中的每一个具有数量m个级,该数量m不与2n匹配,其中n为非零整数,并且该存储器设备还包括用于将存储器单元中的至少两个的用于写入和读取操作的级合并成一组合并状态并用于至少将该组合并状态中的2n个组合的子集转换成n个两级数据位的电路或设备。技术实现要素:本文描述的本发明的一个实施方案提供了一种用于数据存储的方法,包括通过利用至少外码和内码对数据进行编码并任选地在将编码的数据存储到存储器单元内之前使编码的数据反转而将数据存储到一组存储器单元中。从存储器单元读取编码的数据。向所读取的编码数据应用内码解码,以产生解码结果。依据内码的解码结果,有条件地使所读取的数据的至少部分反转。在一些实施方案中,内码包括有效字码的反转并非始终产生另一有效字码的代码,并且应用内码解码包括对所读取的编码数据和所读取的编码数据的反转版本中的至少一者进行解码。在其他实施方案中,应用内码解码包括对所读取的编码数据和所读取的编码数据的反转版本两者进行解码,并且有条件地反转所读取的数据的至少部分包括只有在反转版本的解码结果无错并且所读取的编码数据的解码结果非无错时使所读取的数据的至少部分反转。在其他实施方案中,存储数据包括存储与数据有关的表示存储的数据是否受到了反转的反转指示,读取编码数据包括对反转指示进行读取和解码,并且应用内码解码包括依据反转指示仅对所读取的编码数据解码或者仅对所读取的编码数据的反转版本解码。在一个实施方案中,有条件地反转所读取的数据的至少部分包括在所读取的编码数据的解码结果与反转指示矛盾时,指示不能决定是否要对所读取的数据进行反转。在另一个实施方案中,内码包括错误检测代码,并且有条件地反转所读取的数据的至少部分包括在解码结果等于向全1字应用内码解码的结果时使所读取的数据的至少部分反转,以及在解码结果无错时不使所读取的数据的至少部分反转。在另一个实施方案中,有条件地反转所读取的数据的至少部分包括在所读取的编码数据的解码结果与所读取的编码数据的反转版本的解码结果矛盾时,指示不能决定是否要对所读取的数据进行反转。根据本发明的一个实施方案,还提供了包括存储器(该存储器包括存储器单元阵列)和存储电路的装置。存储电路被配置为通过利用至少外码和内码对数据编码并任选地在将编码的数据存储到存储器单元中之前使编码的数据反转而将数据存储到一组存储器单元中,从存储器单元读取编码的数据,向所读取的编码数据应用内码解码以产生解码结果,以及依据内码的解码结果有条件地反转所读取的数据的至少部分。根据本发明的一个实施方案,还提供了一种用于数据存储的方法,包括在第一编程阶段中通过将该组中的存储器单元编程至一组初始编程级而将第一数据存储到一组存储器单元中。在紧随第一编程阶段之后的第二编程阶段中,通过识别该组中在第一编程阶段中被编程至初始编程级的预定义部分子集中的相应级的存储器单元而将第二数据存储到该组中。仅对所识别的存储器单元采用第二数据编程,从而将所识别的存储器单元中的至少一些设定到不同于初始编程级的一个或多个附加编程级。通过仅读取第一数据的部分子集而识别第二数据被编程到的存储器单元。从所识别的存储器单元读取第二数据。在一些实施方案中,存储第一数据包括存储多个数据页,并且识别存储器单元包括仅读取多个页的部分子集。在其他实施方案中,存储第一数据包括存储最低有效位(LSB)页和中央有效位(CSB)页,并且存储第二数据包括存储最高有效位(MSB)页,并且识别存储器单元包括仅读取LSB页或CSB页。在其他实施方案中,读取LSB页或CSB页包括采用单个读取命令读取LSB页或CSB页。在其他实施方案中,读取第二数据包括采用两个读取阈值来从识别的存储器单元中读取MSB页。根据本发明的一个实施方案,还提供了包括存储器(该存储器包括存储器单元阵列)和存储电路的用于数据存储的装置。存储电路被配置为通过将组中的存储器单元编程至一组初始编程级而在第一编程阶段中将第一数据存储到该组存储器单元中,并且在紧随第一编程阶段的第二编程阶段中,通过识别该组中在第一编程阶段被编程至初始编程级的预定义部分子集中的相应级的存储器单元,并且仅对所识别的存储器单元采用第二数据进行编程,从而将所识别的存储器单元中的至少一些设定至与初始编程级不同的一个或多个附加编程级,由此将第二数据存储到该组中,通过仅读取第一数据的部分子集而识别第二数据被编程到的存储器单元,以及从所识别的存储器单元读取第二数据。根据本发明的一个实施方案,还提供了一种用于数据存储的方法,包括在一组存储器单元中识别该组中将被编程至给定编程状态的预期数量的存储器单元。依据将被编程至给定编程状态的预期数量的存储器单元来设定给定编程状态与相邻编程状态之间的隔离度。采用设定的隔离度对该组中的存储器单元进行编程。在一些实施方案中,通过根据预定义划分比划分给定编程状态而形成相邻编程状态,并且识别预期数量的存储器单元包括采用划分比来估算被编程至给定编程级的存储器单元的数量。在其他实施方案中,对存储器单元进行编程包括将存储器单元设定到多个存储器状态,使得相邻存储器状态之间的相应隔离度是非均匀的。根据本发明的一个实施方案,还提供了包括存储器(该存储器包括存储器单元阵列)和存储电路的用于数据存储的装置。存储电路被配置为在一组存储器单元中识别该组中将被编程至给定编程状态的预期数量的存储器单元,依据将被编程至给定编程状态的预期数量的存储器单元来设定给定编程状态和相邻编程状态之间的隔离度,以及采用设定的隔离度对该组中的存储器单元进行编程。根据本发明的一个实施方案还提供了一种用于数据存储的方法,包括在第一编程阶段中通过将每一组中的存储器单元编程至相应一组初始编程级而将第一数据存储到多组存储器单元中。在紧随第一编程阶段之后的第二编程阶段中,通过识别每一组中的在第一编程阶段中被编程至初始编程级的预定义部分子集中的相应级的可用存储器单元而将第二数据存储到多个组中。仅对所识别的可用存储器单元采用第二数据进行编程,使得从存储器单元组中的固定位置开始对给定组的第二数据进行编程,而不管可用存储器单元的实际数量的变化如何,由此将可用存储器单元中的至少一些存储器单元设定到不同于初始编程级的一个或多个附加编程级。在一些实施方案中,该方法包括通过访问固定位置处的存储器单元来读取给定组的第二数据。在其他实施方案中,第二数据包括多个数据字,并且每一数据字的大小大于多组存储单元中的每组存储器单元中的可用单元的实际数量。在其他实施方案中,读取第二数据包括通过仅从在其内对给定数据字进行了编程的一组或多组存储器单元读取第一数据而读取多个数据字中的给定数据字。在一个实施方案中,该方法包括在采用第二数据对所识别的可用单元所做的编程留下了所识别的可用单元中的一者或多者未被编程时,采用第三数据对未编程的存储器单元进行编程。在另一个实施方案中,第二数据包括多个数据字,该数据字的数据字大小不超过多组存储器单元中的每组存储器单元中的可用存储器单元的数量。根据本发明的一个实施方案,还提供了包括存储器(该存储器包括存储器单元阵列)和存储电路的用于数据存储的装置。存储电路被配置为通过将每组中的存储器单元编程至相应的一组初始编程级而在第一编程阶段中将第一数据存储到多组存储器单元中,并且在紧随第一编程阶段的第二编程阶段中,通过识别每组中在第一编程阶段中被编程至初始编程级的预定义部分子集中的相应级的可用存储器单元,并且仅对所识别的可用存储器单元采用第二数据编程,使得从存储器单元组中的固定位置开始对给定组的第二数据编程,而不管可用存储器单元的实际数量的变化如何,以便将可用存储器单元中的至少一些可用存储器单元设定到不同于初始编程级的一个或多个附加编程级,由此将第二数据存储到该多个组中。结合附图从下文中对本发明的实施方案的详细描述将更完全地理解本发明,在附图中:附图说明图1是示意性地示出了根据本发明的一个实施方案的存储器系统的框图;图2是示意性地示出了根据本发明的一个实施方案的数据代码字的图示;图3A和图3B是示出了根据本发明的实施方案用于在每单元采用非整数数量位的存储数据的编程级分布的图示;图4A和图4B是示意性地示出了根据本发明的实施方案用于在可用存储器单元中按照已知的偏移量存储数据的两种技术的图示;图5是示意性地示出了根据本发明的一个实施方案用于在可用存储器单元中按照已知的偏移量写入数据的方法的流程图;图6是示意性地示出了根据本发明的一个实施方案用于读取在可用存储器单元中按照已知的偏移量写入的数据的方法的流程图。具体实施方式概述相对于采用整数数量的情况,每单元采用非整数数量的位进行数据存储可具有优势,因为可以在总级数不限于2的整数次幂的情况下分别采用提高或者降低的数量的编程级,因而能够实现存储密度或可靠性的提高。本发明的实施方案提供了用于对每一存储器单元采用非整数数量位来管理数据存储的改进方法和系统。所公开的实施方案采用两阶段编程方案的几种变型。例如,在2011年7月28日提交的转让给了本专利申请的受让人的美国专利申请13/192,501中描述了此类两阶段编程方案的各种示例,通过引用将该专利的公开内容并入本文。在此类方案中,在第一编程阶段中,采用数量为2的整数次幂的编程级对存储器单元编程。在第二编程阶段中,仅在每者在第一阶段中被编程至一个或多个所选择级的组中的某一级的单元内存储附加位。这些单元适于第二阶段中的编程,并且本文还将这些单元称为“可用单元”。可用单元的确切数量具有数据相关性,因而是变化的。因此,在一些实施方案中,任选地使在第一阶段中写入的数据页发生位翻转(即,使位的极性发生反转),以确保有足够数量的可用单元存储第二阶段数据。然而,在数据经受错误校正和/或错误检测代码时,位翻转可能存在问题,因为此时反转的有效字码未必还是有效字码。不保证每一反转的代码字都映射至另一有效字码的代码的示例包括循环冗余代码(CRC)和Bose-Chaudhuri-Hocquenghem(BCH)。在一个实施方案中,编码方案采用内码和外码。例如,可以将内码(例如,CRC或BCH)与外码(例如,低密度奇偶校验-LDPC)一起使用,以便识别要对迭代LDPC解码器提前终止或者要解决捕获集境况的条件。在一些实施方案中,通过相应的反转位指示所存储的代码字的极性,该反转位通常(但未必一定)嵌入在代码字内。在一个实施方案中,内码包括错误检测代码,诸如CRC代码(或者错误检测模式内的BCH代码)。从存储器单元读取数据,对外码解码,并向所读取的数据和经反转的相同数据都应用CRC解码(有可能与外解码器并行)。基于是否有任一CRC解码指示未发现错误(并且有可能基于反转位)来确定极性。在另一个实施方案中,根据所读取的数据中的反转位的极性仅应用一次CRC解码。在另一个实施方案中,将CRC解码器的结果与零字(指示无反转)和等于应用于全1字(指示曾应用了反转)的CRC的字都进行比较。在另一个实施方案中,内码包括纠错码,诸如BCH代码(被配置到错误校正操作模式),并且向所读取的数据和经反转的相同数据这两者都应用解码。根据两个BCH解码器中的任何解码器的结果是否是可解码的,即,是否无错来确定代码字的极性。在一些实施方案中,在(上述两阶段编码方案的)第一阶段中对每一存储器单元进行编程,以采用四个初始级中的一个初始级,四个初始级中的两个初始级被选择用于第二阶段。在第二阶段中,仅对被编程至两个所选择的级中的一个所选择的级的单元写入附加位。因而,在第二阶段中所选择的级的单元占有率大致是对半划分的,从而得到了总共六个级,其中有四个级大致是受到半数占据的。由于根据这一方案,单元中有一半存储3位/单元,并且另一半存储2位/单元,因而该设备的存储平均数为2.5位/单元。在所公开的采用上述六级编程方案的实施方案中,用于将三位组合映射至各编程级的专用方案被设计为能够在无需读取在第一阶段中编程的全部数据的情况下识别在第二阶段中编程的单元。在一个实施方案中,通过利用两个读取阈值仅读取中央有效位(CSB)页而执行单元的识别。在另一个实施方案中,单元的识别涉及利用单个读取阈值仅读取最低有效位(LSB)页。因而所公开的技术避免了读取和解码的不必要操作。在一些实施方案中,将不采取均匀的级间隔,而是基于各个级的单元占有率确定编程级之间的阈值电压间隔。在此类实施方案中,将占有率低的相邻级之间的间隔或隔离度设定为比占有率高的相邻级之间的间隔更加靠近。例如,可以采用此类非均匀间隔实现跨越所有级的均匀读取错误概率。在一些实施方案中,将具有N位的大小的字(例如,编码的数据的N位代码字)写入到N单元的组中,该组又称为单元组。在此类实施方案中,在第一阶段中存储之前应用任选的位反转,以确保在第二阶段中具有足够的级占有率(即,足够数量的可用单元),如上文所述。如果此外还在第二阶段中对三个级(出自第一阶段采用的四个级)进行划分,那么每一单元组中只有大约3/4的单元可用于存储附加位。在一些实施方案中,在四个单元组的可用单元中存储三个N位代码字。将每一代码字分成两个区段,在可用单元中按照某些固定的偏移量将两个区段写入到两个独立的单元组中。在一个示例性实施方案中,用尽所有的可用单元顺次写入代码字的区段。在该实施方案中,写入每一区段的可用单元之间的偏移量具有数据相关性。为了读取代码字,通过至少自未写入相应区段的任何区段的单元组读取数据来估算相应区段的偏移量。在其他实施方案中,在每一单元组中的可用单元中按照已知的固定偏移量写入代码字的区段。通过利用固定偏移量,对给定代码字的区段的读取将仅需从写入该代码字的区段的单元组读取数据。之后,合并所读取的区段,以恢复原始代码字。因而采用已知偏移量能够避免读取和解码的不必要操作。在其他实施方案中,选择第二阶段中的数据大小,以便配合单元组中的最低可用单元数量,并由此简化数据读取和写入操作。然而,在此类实施方案中,第一编程阶段和第二编程阶段可能需要单独的不同编码方案,从而使整个编码方案更加复杂。系统描述图1是示意性地示出了根据本发明的一个实施方案的存储器系统20的框图。系统20可用于各种主机系统和设备中,诸如用于计算设备、蜂窝电话或其他通信终端、可移动存储器模块(例如“随身盘”或“闪存驱动器”设备)、固态硬盘(SSD)、数码相机、音乐和其他媒体播放器和/或在其中存储并检索数据的任何其他系统或设备中。系统20包括在存储器单元阵列28中存储数据的存储器设备24。存储器阵列包括多个模拟存储器单元32。在本专利申请的语境以及在权利要求书中,术语“模拟存储器单元”用于描述保持物理参数诸如电压或电荷的连续模拟值的任何存储器单元。阵列32可包括任何种类的固态模拟存储器单元,诸如NAND、NOR和电荷捕获闪存(CTF)闪存单元、相变RAM(PRAM,也称为相变存储器(PCM))、氮化物只读存储器(NROM)、铁电RAM(FRAM)、磁性RAM(MRAM)和/或动态RAM(DRAM)单元。尽管本文中描述的实施方案主要是指模拟存储器,但是所公开的技术也可以与各种其他存储器类型结合使用。存储在单元中的电荷级别和/或写入到单元中和从单元中读出的模拟电压或电流在本文统称为模拟值、存储值或模拟存储值。尽管本文中描述的实施方案主要处理阈值电压,但是本文中描述的方法和系统也可以与任何其他适当种类的存储值结合使用。系统20通过对单元编程以采用相应的编程状态(也称为编程级)来在模拟存储器单元中存储数据。编程级从可能级的有限集合中选择,并且每个级对应于某一标称存储值。例如,能够通过将四个可能的标称存储值中的一个可能的标称存储值写入到单元中来对2位/单元MLC进行编程以采用四种可能的编程级中的一种可能的编程级。本文中描述的技术主要处理每一存储器单元的非整数数量位的存储密度,即,编程级的数量并非2的整数次幂。存储器设备24包括读/写(R/W)单元36,该读写单元将存储器设备中存储的数据转换成模拟存储值并将它们写入存储器单元32中。在另选的实施方案中,R/W单元不执行这种转换,但提供有电压样本,即,单元中存储的存储值。当从阵列28中读取数据时,R/W单元36将存储器单元32的存储值转换为具有一位或多位的整数分辨率的数字样本。数据通常写入组中的存储器单元(这称为页面)中并从其中读取。在一些实施方案中,R/W单元能够通过将一个或多个负的擦除脉冲应用于单元来擦除一组单元32。由存储器控制器40执行在存储器设备24内存储数据和从其检索数据。存储器控制器40包括用于与存储器设备24、处理器48和纠错码(ECC)单元50通信的接口44。所公开的技术可通过存储器控制器40、通过R/W单元36或两者来执行。因此,在当前语境下,存储器控制器40和R/W单元36被统称为执行所公开技术的存储电路。存储器控制器40与主机52通信以用于接收存储在存储器设备中的数据以及用于输出从存储器设备检索的数据。ECC单元50采用适当的ECC对要存储的数据编码,并对从存储器检索的数据的ECC解码。可以采用任何适当类型的ECC,例如,低密度奇偶校验(LDPC)、Reed-Solomon(RS)或Bose-Chaudhuri-Hocquenghem(BCH)。在一些实施方案中,除了包含纠错码之外,ECC单元50还包括另一种(通常更小的)纠错码或错误检测代码。可以用于此类附加代码的示例性代码包括用于错误校正的BCH和用于错误检测的循环冗余代码(CRC)。编码方向内的ECC单元50的输出又称为“代码字”。可以通过硬件,例如,采用一个或多个专用集成电路(ASIC)或现场可编程门阵列(FPGA)实施存储器控制器40。另选地,存储器控制器可包括运行合适软件的微处理器,或硬件元件和软件元件的组合。图1的配置是纯粹为了概念清晰的原因而示出的示例系统配置。也可以采用任何其他适当的存储器系统配置。例如,尽管图1的示例示出了单个存储器设备,但是在另选的实施方案中,存储器控制器40可以控制多个存储器设备24。为了清楚起见,已从附图中省略了对于理解本发明的原理非必需的元件,诸如各种接口、寻址电路、计时和排序电路及调试电路。在图1示出的示例系统配置中,存储器设备24和存储器控制器40作为两个单独的集成电路(IC)来实现。然而,在另选的实施方案中,存储器设备和存储器控制器可被集成到单个多芯片封装(MCP)或片上系统(SoC)中的独立半导体模片上,并且可通过内部总线互连。此外另选地,存储器控制器电路的部分或全部可以存在于在上面设置了存储器阵列的同一模片上。此外另选地,存储器控制器40的一些或全部功能能够在软件中实施并通过处理器或主机系统的其他元件执行。在一些实施方案中,主机52和存储器控制器40可在同一模片上制造,或在同一设备封装中的单独模片上制造。在一些实施方案中,存储器控制器40包括通用处理器,其在软件中编程以执行本文所述的功能。软件可以例如通过网络以电子形式下载到处理器,或者另选地或除此之外,其可以在非暂态有形介质诸如磁性、光学、或电子存储器上被提供和/或存储。在阵列28的示例配置中,存储器单元32以多个行和列的形式布置,并且每个存储器单元包括浮栅晶体管。每一行中的晶体管的栅极由字线连接,并且每一列中的晶体管的源极由位线连接。在当前语境下,“行”一词是按照常规的含义使用的,意在表示由公共字线馈送的一组存储器单元,并且“列”一词则表示受到公共位线馈送的一组存储器单元。术语“行”和“列”不暗指存储器单元相对于存储器设备具有某一物理取向。存储器阵列通常被划分为多个存储器页面,即,被编程并同时读取的存储器单元组。在一些实施方案中,将存储器页再分成扇区。可以按照各种方式将页映射至字线。每一字线可以存储一个或多个页面。可以将给定页面存储到字线的所有存储器单元内或者存储到存储器单元的子集内(例如,奇阶或偶阶的存储器单元)。通常在包含多个页面的块内实施单元的擦除。典型的存储器设备可以包括成千上万的擦除块。在典型的每单元二位的MLC设备中,每一擦除块大约为32条字线,每条字线包括几万个单元。往往将这样的设备的每条字线分成四页(奇阶/偶阶单元、单元的最低/最高有效位)。在每一擦除块具有32条字线的每单元三位设备中,每擦除块将具有192页,并且在每单元四位设备中,每块将具有256页。或者,还可以采用其他块尺寸和配置。一些存储器设备包括两个或更多单独的存储器单元阵列,该阵列常常称为平面。由于每一平面在相继的写入操作之间具有某一“繁忙”周期,因而可以交替地向不同平面写入数据,以提高编程速度。在每单元采用非整数数量位的情况下存储数据在每单元采用非整数数量位的情况下存储数据等价于对存储器单元进行编程,从而采用数量非2的整数次幂的编程级或编程状态。在一些实施方案中,系统20采用两阶段编程方案,从而在每单元采用非整数数量位的情况下存储数据。在第一阶段中,采用2的整数次幂的数量的编程级对存储器单元进行编程。例如,在TLC设备中,首先仅采用四个级(来自八个可能的级)对单元进行编程。在第二阶段中,可以仅对在第一阶段中被编程至第一阶段的各个级中的某些级的单元采用附加位进行编程。在八级TLC示例中,被选择为用于第二阶段中的编程的第一阶段级包括一组的一个、两个或三个级,从而分别得到总数为五个、六个或七个的级。在第二阶段中,附加位的值(“0”或“1”)确定相应的单元是保持在第一阶段中单元被编程至的编程级,还是被编程至另一通常更高的不同于第一阶段的所有级的编程级。因而,在第二阶段中对在第一阶段中以给定数量的单元填充的编程级进行大约对半的划分,其采用相似的“0”和“1”位普遍性。例如,在上文引述的美国专利申请13/192,501中描述了这样的两阶段编程方案的各种示例。在一些实施方案中,所要编程的数据包括单独的数据页,例如,具有有序的位有效性的页面。存储电路在第一阶段中存储位有效性低于最高有效位(或最有效位)的页面,并且在第二阶段中仅存储最有效数据页。例如,在TLC设备中,存储电路在第一阶段中存储最低有效位(LSB)和中央有效位(CSB)页。之后,存储电路基于在第一阶段中存储的数据在第二阶段期间存储最有效位(MSB)页。下文将联系图3A和图3B描述第一阶段编程级和第二阶段编程级、级划分和位组合的方案映射到编程级的示例。用于对反转的代码字解码的方法当在第二阶段中对数据(例如,MSB数据)编程时,填充将要划分的编程级的单元的总数具有数据相关性,而且可能发现该数量是不够的。在一些实施方案中,任选地反转在第一阶段中写入的数据页的位极性,以确保将在第二阶段中划分的级具有足够的单元填充。此外,在数据还受到错误校正编码时,反转数据的常规解码可能不可行,因为反转后的数据可能不包括有效字码。为了提高存储可靠性,在一些实施方案中,存储电路采用适当的编码方案保护所要编程的数据,通常通过ECC单元50实施该编码方案。图2是示意性地示出了根据本发明的一个实施方案的代码字70的图示。在图2的示例中,代码字70包括数据位74(例如,第一阶段中的LSB或CSB数据)、反转位78、内码奇偶校验位82和外码奇偶校验位86。在当前的示例中,奇偶校验位86包括由ECC单元50一并应用于数据位74、反转位78和内码奇偶校验位82的LDPC码。因而,数据位74、反转位78、内码奇偶校验位82和外码奇偶校验位86的集合包含LDPC代码字。此外,在图2的示例中,奇偶校验位82包括由ECC单元50应用于数据位74和反转位78的CRC或BCH代码。在描述的配置中,LDPC外码可以对内码奇偶校验位82中的错误进行校正,其将实现采用内码提早终止LDPC解码迭代或者采用内码消除在紧随外解码之后出现的残余错误,如下文所述。图2的配置是纯粹为了概念清晰的原因而示出的示例性配置,并且也可以采用其他适当的配置。例如,还可以采用其他适当的代码、编码方案和尺寸以及代码字70的不同元的排序。在一些实施方案中,例如可以将内码82(例如,包括CRC或BCH代码)与LDPC代码86一起使用,从而识别在对LDPC代码字迭代解码之时提早终止的条件,或检测并缓解LDPC解码器中的捕获集境况。又如,在内码包括纠错码(例如,BCH)时,可以将代码82用于缓解在LDPC解码器的输出处残留的错误(“错误平层”)。2010年10月28日提交的美国专利申请12/913,815描述了几种用于执行迭代解码期间的提早终止的方法,该申请被转让给本专利申请的受让人且其公开内容通过引用并入本文。在一些实施方案中,存储电路最初将反转位78设定为“0”,并且任选地使整个代码字70发生反转或位翻转,以确保在所要划分的级中具有足够的由单元所做的级填充,如上文所述。在读取数据时,存储电路从阵列28检索代码字,并采用ECC单元50应用解码。如果解码后的位反转78等于“1”,那么存储电路在位74被交付给主机之前将代码字的数据位翻转回来。然而,为了使解码正常运行,每一反转后的代码字都应当还包括有效字码。换句话讲,编码方案的每一有效字码都应当通过反转映射至另一有效字码。通过包含代码的奇偶校验矩阵的每一行具有偶数加权(即,该行包括偶数个非零元)的要求,能够将LDPC代码设计为支持这样的特性,即,对于每一有效字码,位翻转将产生另一有效字码。然而,这一特性在CRC代码和BCH代码中难以实现或者不可能实现。在接下来的描述中,我们假定外码(例如,LDPC)支持上述的反转有效字码的有效性的特性。现在我们将描述几种用于对代码字70解码并决定该代码字是否在存储之前受到了反转并因此应当被反转回去的方法。在所公开的实施方案中,内码82包括不确保相应的位翻转代码字的有效性的代码。在接下来的描述中,X表示CRC或BCH代码字。例如,X可以包括数据位74、反转位78和奇偶校验位82。此外,使~X表示X的位翻转版本,并且CRC(X)或BCH(X)表示解码操作。而且,ZEROS和ONES分别表示全“0”和全“1”位序列。在本专利申请的语境下以及在权利要求书中,内码解码既指错误检测代码,又指纠错码。我们首先将描述内码82包括错误检测代码的几种实施方案。尽管所述描述主要涉及采用CRC编码的实施方案,但是也可以采用任何其他适当的错误检测代码,例如,被配置为在错误检测模式下操作的BCH代码。根据错误检测代码的特性,如果X没有错误,那么CRC(X)=ZEROS,并且另一方面,向错误的代码字应用CRC解码而得到ZEROS的概率是非常低的。在一个实施方案中,ECC单元50应用两种CRC解码操作,即CRC(X)和CRC(~X)(有可能是并行的)。如果CRC(X)=ZEORS,那么存储电路将代码字70视为是在未反转的状态下存储的。如果另一方面,CRC(~X)=ZEROS,那么认为代码字70受到了反转。否则(即,在两个CRC解码器中没有任何一者产生ZEROS结果时),仍然不满足LDPC迭代解码器提早终止的标准。在另一个实施方案中,ECC单元50仅基于反转位78的值执行一种CRC解码。如果反转位指示无反转(“0”),那么ECC单元50对CRC(X)解码。否则,该位将指示代码字受到过反转,并且ECC单元50将对CRC(~X)解码。如果相应的CRC解码结果等于ZEORS,那么ECC单元50可以执行LDPC解码迭代的提早终止。在另一个实施方案中,解码方案有赖于内码为线性代码。根据线性特性,CRC(~X+ONES)=CRC(~X)+CRC(ONES),其中,“+”表示逐位XOR。然而,由于X=~X+ONES,因而我们推断出ZEROS=CRC(X)=CRC(~X)+CRC(ONES)。在示例性实施方案中,ECC单元50执行CRC解码,并检查结果等于CRC(ONES)还是等于ZEORS,从而分别识别出代码字受到过反转还是没受到过反转。需注意,对于每一不同的内码而言,需要预先计算值CRC(ONES)并且仅对其存储一次。在以上所述的实施方案中,ECC单元50可能(在个别情况下)遇到CRC(·)解码的结果和位翻转78的解码值之间的冲突。此外,应用CRC(X)和CRC(~X)的结果可能不总是能够得到是否要对所读取的数据进行反转的最终决定。在此类情况下,为ECC单元提供适当的指示。在发生这样的冲突或无定论情况时,ECC单元50可以采用任何适当的解码方法。例如,ECC单元50可以决定不终止LDPC迭代解码器。上文在错误检测代码的语境下描述的实施方案中的一些也适用于纠错码。现在,我们描述内码82包括纠错码诸如BCH(被配置到错误校正操作模式)的一个实施方案。ECC单元50应用两种解码操作,即BCH(~X)和BCH(X)。如果只有~X或X之一是可解码的,即,对无错结果进行解码,那么存储电路分别将代码字70视作是位翻转或非位翻转的。如果~X和X两者都是可解码的,或者两者都未能生成无错结果,那么可以采用某一其他标准确定反转状态,例如,基于具有(在紧随解码之后)最低数量的错误的标准。其他标准包括例如解码之后与反转位的一致性或者错误模式的加权。在另选的实施方案中,ECC单元50指示非决定性的结果或者多重解码结果。在将内纠错码用于“错误平层”境况的实施方案中,很少有必要应用内码解码器,并因此(每代码字)对BCH解码两次将只引起少量的计算增加。在上文描述的实施方案中,我们一般假定在外码中将反转的有效字码映射至其他有效字码。在其他不确保这一特性的实施方案中,也可以向外码应用与上文针对内码描述的类似的解码方案。读取在第二编程阶段中存储的数据图3A和图3B是示出了根据本发明的实施方案用于在每单元采用非整数数量位来存储数据的编程级分布的图示。将图3A和图3B的每者划分成上部和下部,分别示出第一编程阶段和第二编程阶段之后的编程级和相应的单元占有率。在所公开的实施方案中,根据图3A和图3B,我们采用下层TLC设备,将在第一阶段中采用四个级对该设备的存储器单元32进行编程,在第二阶段中将对四个级中的两个级做进一步划分。由于每一单元在第一阶段之后存储两位信息,并且将单元中的一半编程为在第二阶段中存储附加位,因而设备最终将平均存储2.5位/单元(采用八个TLC级中的六个)。在图3A中,L0、L1、L3和L5表示能够在第一阶段中将存储器单元32编程到的四个级。将级L0、L1、L3和L5中的每者分别映射至相应的位偶组合,即,“11”、“10”、“00”和“01”。在每一这样的位偶组合中,各个位对应于独立的数据流或页。在接下来的描述中,左侧位对应于LSB页位,并且右侧位对应于CSB页位(即,“10”表示LSB=“1”并且CSB=“0”)。在第二编程阶段中,仅采用附加位(MSB)对在第一阶段中被编程至级L1或L3的单元进行进一步编程。需注意,由于根据所选择的位到级映射,CSB位在级L0和L5中等于“1”,并且在级L1和L3中等于“0”,因而能够通过仅审查CSB位而识别出处于级L1和L3上的单元。这一特性还简化了MSB数据读取,如下文所述。如图3A所示,附加位的编程将对L1上的单元填充做出划分,从而使各单元中约有一半保留在L1上,而其余的另一半单元则被编程至L2。类似地,L3上的单元中大约有一半被编程至L4,而另一半的单元则在L3上保持不变。因而,在第二阶段中被编程至级L1、L2、L3、L4中的一者的单元根据相应的位分配“100”、“101”、“001”或“000”存储三位信息。在每一这样的位三元组内,左侧、中间和右侧的位对应于相应的单独数据流,例如,LSB、CSB或MSB数据页。由于在第二阶段中未对级L0和L5编程,因而分配给这些级的相应位三元组被表示为“11x”或“01x”,其中“11”和“01”是先前的位偶组合(来自第一阶段),并且最右侧的“x”表示未编程的附加位。现在,我们将描述用于采用图3A和图3B中描述的编程级配置读取TLC设备中存储的数据的几种方法。如下所述,与LSB和CSB数据两者都应读取以识别采用附加位编程的单元的常规方法不同,所公开的方法中的一些能够通过最初仅读取CSB或LSB数据而识别出采用MSB数据编程的单元。在一个实施方案中,参照图3A,为了读取MSB页,存储电路首先识别在第二阶段中采用附加位进行了编程,即被编程至级L1…L4的存储单元。该存储电路首先读取LSB和CSB页中的每者并向其应用ECC解码,并识别在位三元组的最左侧位偶中存储位值“10”或“00”的存储器单元。在另一个实施方案中,存储电路采用单个读取命令中的读取阈值TH_CSB_LO和TH_CSB_HI(图3A中)仅读取CSB数据并对其进行ECC解码。图3A中所示的编程级和位到级映射的配置使得存储电路能够避免因读取LSB和CSB数据而导致的不必要的读取和解码操作。之后,存储电路识别CSB位等于“0”的单元。为了读取在所识别的单元内写入的数据(例如,MSB数据),存储电路例如采用两个读取阈值(未示出),从而将一个阈值置于L1和L2之间,并且将另一阈值置于L3和L4之间。在图3B中,在第一阶段中将级L0、L1、L2和L4映射至相应的位偶“11”、“10”、“00”和“01”。在第二阶段中,存储电路仅将附加位编程至在第一阶段中被编程至L2或L4的存储器单元。因而,L2上的单元中大约一半的级被移至L3,并且L4上的单元中一半的级被移至L5。将L2、L3、L4和L5级映射至相应的位三元组“001”、“000”、“010”和“011”。级L0和L1在第二阶段中不被编程,并且被映射至相应的位三元组“11x”和“10x”。在一些实施方案中,与上文的图3A中的描述类似,左侧、中间和右侧的位对应于相应的LSB、CSB和MSB数据页。在一个实施方案中,为了读取MSB数据,存储电路首先采用在图3B中以TH_LSB表示的单个读取阈值仅读取LSB页并对其解码(与对LSB和CSB页二者都进行读取和解码形成了对照),由此识别采用附加位进行编程的单元。该实施方案相对于上文的图3A的实施方案(其中读取需要两个读取阈值)具有优势,因为更大数量的读取阈值通常将增加页面读取时间。此外,与图3A的方法类似,只需要两个读取阈值读取MSB数据。之后,存储电路采用两个读取阈值从所识别的单元读取MSB数据,两个读取阈值中一个置于L2和L3之间,并且另一个置于L4和L5之间。通过采用图3B中所示的编程级和位到级映射的配置,存储电路能够有效地读取MSB页并避免因读取LSB和CSB数据两者而导致的不必要的读取和解码操作。从上面的描述和附图可以看出,在第二阶段中进行附加位的编程通常会在不同的级之间形成不均匀的单元占有率。例如,图3B中的被编程至级L2…L5的每者的单元的数量约为被编程至L0或L1的单元的数量的一半。如图3B所示,级之间的阈值电压(VTH)间隔或隔离度和每一级的单元占有率(连同其他因素)影响相邻级分布之间的重叠量。由于这一重叠与读取错误概率密切相关,因而单元占据存在差异的级之间的均匀间隔可能导致跨越各个级存在不均匀的(并且非最优的)读取错误概率。在一些实施方案中,基于各个级的单元占有率对分配给不同编程级的阈值电压进行设定,从而实现跨越所有级的均匀读取错误概率。为了针对不同的单元占有率进行补偿,应当将相邻的高度填充级之间的距离(即,阈值电压差)设定为大于填充度较低的相邻级之间的距离。在图3B的示例性配置中,ΔL01表示L0和L1之间的电压差,并且ΔL23、ΔL34和ΔL45分别表示L2-L3、L3-L4以及L4-L5之间的电压差。在一个实施方案中,通过基于级占有率调整间隔,使得ΔL01大于电压差ΔL23、ΔL34和ΔL45(在当前示例中假定它们是相似的)中的每者,存储电路将跨越各个编程级实现均匀的读取错误概率。此外,应当将L1和L2之间的间隔配置为大于ΔL23、ΔL34和ΔL45,但是小于ΔL01。在一些实施方案中,存储电路可以附加地基于级占有率以外的因素确定编程级之间的电压间隔。例如,2008年7月11日提交的美国专利7,925,936描述了用于通过调整级间间隔而针对具有不同位有效性的页的读取中执行的不同数量的读取操作进行补偿,由此跨越各个编程级实现均匀的读取错误概率的几种方法,通过引用将该专利的公开内容并入本文。图3A和图3B的配置是纯粹为了概念清晰的原因而示出的示例性配置,并且也可以采用其他适当的配置。例如,在另选的实施方案中,也可以采用其他编程级、级数、级划分方案、位到级映射、读取阈值和/或级间间隔。在第二阶段中按照已知偏移量存储数据例如,考虑采用七个编程级在TLC设备中存储数据。在一些实施方案中,存储电路采用上文描述的两阶段编程方法的适当变型存储数据。在一个示例性实施方案中,存储电路在第一阶段中采用例如如图3A的上部所示的四个级来存储LSB和CSB数据。因此,在当前的示例中,在第二阶段中将对三个级,例如,图3A上部的L0、L1和L3进行划分。在一些实施方案中,存储电路将LSB、CSB和MSB数据表示的数据流单独编码到代码字诸如代码字70中。在一个实施方案中,存储电路对N单元组中的存储器单元32进行编程,并且还将有待存储的数据编码到N位代码字中,如本文中所述。在接下来的描述中,术语“单元组”或者仅仅组是指同时被编程的一组N单元。需注意,尽管我们假定所存储的数据在相应的代码字中受到ECC编码,但是所公开的方法还适用于存储原始的非编码的数据。存储电路采用四个编程级写入(在第一阶段中)N位LSB代码字和CSB代码字。如下文进一步所述,在每一单元组中,可用单元的数量小于N,但是在第一阶段中存储电路将确保这一数字超过0.75·N(通常只有少量的超出)。因此,尽管不能将完整的MSB代码字存储到单个单元组中,但是可以将三个N位代码字存储到四个单元组中。在下面的表1中,我们演示了用于在四个单元组之间对三个N位代码字进行划分的技术。在表1中,MSB0…MSB2表示MSB代码字,并且CW0…CW3表示单元组。表1中的条目描绘了从每一代码字取出并写入到相应单元组中的可用单元内的位的数量。例如,将来自MSB0的0.25·N位和来自MSB1的0.5·N位编程到CW1内。又如,在CW1和CW2之间对MSB1位进行对半划分。MSB0MSB1MSB2CW00.75·N00CW10.25·N0.5·N0CW200.5·N0.25·NCW3000.75·N表1:在单元组中划分代码字位在一些实施方案中,如果有必要,存储电路在第一阶段中通过反转LSB、CSB或这两种代码字对数据进行预处理,从而确保至少有0.75·N个单元可用于将MSB数据存储到相应的单元组中。可以将可用单元的组划分成两个互补的子组,使得一个子组包含0.75·N个单元,并且另一个子组包含被称为“附加单元”的其余单元。由于第一阶段中四个级中的每者的单元占有率取决于所存储的实际数据,因而附加单元的数量也具有数据相关性。可以采用各种配置在四个单元组之间划分三个MSB代码字的位。上文的表1介绍了一种这样的示例,而下文将描述附加的示例。在一个实施方案中,将每一代码字划分成两个区段,在可用单元中按照某些偏移量将两个区段存储到两个不同的单元组中。存储电路用尽每一单元组中的所有可用单元将代码字MSB0…MSB2的各区段连续地存储到CW0…CW3中。使Ni表示单元组CWi内的可用单元的数量,并且Ei表示相应的附加单元的数量。在该实施方案中,在可用单元中按照变化的偏移量存储代码字的区段。需注意,在当前语境下,仅衡量每一单元组中的可用单元之间的偏移量。因而,例如零偏移量涉及单元组中的第一可用单元。要读取给定MSB代码字,存储电路需要通过从存储其他代码字的区段的单元组读取低有效性数据来估算各个区段的存储所依照的相应偏移量。例如,在当前的实施方案中,存储电路将MSB0位的N0=0.75·N+E0以零偏移量存储到CW0内(即,第一区段),并且将MSB0位的其余部分(即,第二区段)以零偏移量存储到CW1内。之后,存储电路在紧随MSB0第二区段之后,即从偏移量N-N0=0.25·N-E0开始,立即将第一MSB1区段存储到CW1内。因此,在读取MSB1第一区段时,存储电路应当首先读取存储在CW0内的LSB和CSB数据并对其解码,识别并计量可用单元N0的数量,计算E0=N0-0.75·N并采用E0估算第一MSB1区段的实际偏移量(或者等价地计算N-N0)。有关MSB2代码字的区段的读取有类似的讨论成立。因此,在该示例中,读取存储在CW1和CW2内的MSB1区段还涉及读取存储在另一单元组(即CW0)内的数据。在下文描述的另选实施方案中,存储电路在可用单元中按照已知偏移量存储MSB区段。这样能够实现对MSB数据的有效读取,因为在偏移量已知的情况下读取给定MSB代码字只需读取存储该代码字的区段的单元组中存储的数据。图4A和图4B是示意性地示出了用于在可用存储器单元中按照已知偏移量存储数据的两种技术的图示。考虑在通过CW0…CW3表示的四个单元组中写入通过MSB0、MSB1和MSB2表示的三个N位MSB代码字。如上所述,在七级TLC示例中,四个单元组中的每个单元组包括相应数量的Ni=0.75·N+Ei个可用单元,其中Ei包括附加单元。在图4A中,将每一代码字MSBi(i=0…3)划分成两个以MSBi_A和MSBi_B表示的区段,每一区段具有已知的预定义尺寸。MSB0_A区段包括0.75·N个位,并且以零偏移量存储到CW0内。将包含0.25·N个位的MSB0_B区段也以零偏移量存储到CW1内。将MSB1区段划分成MSB1_A和MSB1_B区段,它们每者具有0.5·N个位。紧随MSB0_B位之后,即,按照0.25·N个单元的已知偏移量将MSB1_A区段存储到CW1内。将MSB1_B区段按照零偏移量存储到CW2内,从而形成用于存储MSB2_A第一区段的0.5·N个单元的已知偏移量,MSB2_A第一区段包含0.25·N个位。MSB2_B第二区段包括0.75·N个位,并且以零偏移量存储到CW3内。表2总结了如图4A所示的MSB区段在单元组CW0…CW3中的分配。表2:根据图4A按照已知偏移量分配代码字在图4B中,用尽所有可用单元按照已知偏移量写入每一MSB代码字的第一区段。在另一单元组中按照零偏移量写入代码字的其余位(即第二区段)。尽管将每一MSBi代码字划分为尺寸取决于Ei的区段MASBi_A和MSBi_B,但是区段仍然是按照已知的固定偏移量进行定位的。表3总结了根据图4B的MSB代码字段在相应的单元组中的分配。表3:根据图4B在单元组中分配代码字在上述实施方案中,包含MSB代码字在内的所有代码字共享共同的N位尺寸。一方面,这简化了编码/解码和写入/读取操作以及相关电路。然而,另一方面,需要将每一N位MSB代码字存储到不止一个单元组中,如上文所述。在另选的实施方案中,MSB代码字仅包括0.75·N个位(被称为短MSB代码字)。由于每一N单元组包括Ni≥0.75·N个可用单元,因而短MSB代码字始终能够适配到单元组中。然而,短MSB代码字的编码方案不同于N位代码字的编码方案,其应当采用其他数据分割和奇偶校验位。因此,ECC单元50可以包括用于短MSB代码字的独立专用编码器/解码器。图5是示意性地示出了根据本发明的一个实施方案用于在可用存储器单元中按照已知的偏移量写入MSB数据的方法的流程图。图5的方法与图4B中所示的MSB数据在单元组中的分配一致。在该方法开始时,假定存储电路已经执行了将LSB和CSB数据写入CW0…CW3的第一编程阶段,并且三个代码字MB0…MB2准备被编程。该方法开始于存储电路在单元识别步骤200中识别每一单元组CWi内的可用于对MSB数据进行编程的单元。使Ni表示CWi内的可用单元的数量,并且Ei=N-Ni表示相应的附加单元的数量。随后方法前进至MSB0编程步骤204。在步骤204中,存储电路用尽所有可用CW0单元以零偏移量将MSB0的前0.75·N+E0位编程到CW0内。之后存储电路以零偏移量将MB0的其余0.25·N-E0个位编程到CW1内。接下来,存储电路在相应的步骤208和212中对MSB1和MSB2代码字进行编程。存储电路按照偏移量0.25·N将MSB1写入CW1内并在CW2内继续。类似地,存储电路按照偏移量0.5·N将MSB2写入CW2内,并按照零偏移量将其余MSB2位写入CW3内。图6是示意性地示出了根据本发明的一个实施方案用于读取在可用存储器单元中按照已知的偏移量写入的MSB数据的方法的流程图。该方法开始于存储电路在识别已编程单元步骤250中识别采用MSB数据进行了编程的单元。例如,从表3中显然可以看出,要独立地仅读取MSB0、MSB1或MSB2代码字中的一者,仅分别识别{CW0和CW1}、{CW1和CW2}或{CW2和CW3}中的采用附加位编程的单元就足够了。要读取MSB0、MSB1或MSB2,存储电路进行至相应的读取步骤254、258或262。在步骤254中,存储电路将CW0内的所有可用单元(即N0=0.75·N+E0个位)读取成以MSB0_A表示的临时区段。之后存储电路计量所读取的位N0的数量,计算E0=N0-0.75·N,并将来自CW1的可用单元的前0.25·N-E0个位读取成以MSB0_B表示的临时区段。之后存储电路将两个临时区段连接起来,以生成完整的MSB0代码字。在读取步骤258和262中,存储电路根据图4B和表3以适当的区段尺寸和偏移量类似地读取MSB1或MSB2代码字。图4A、图4B、图5和图6是纯粹为了概念清晰的原因而示出的示例性配置,并且也可以采用其他适当的配置。例如,也可以采用其他适当数量的代码字和单元组。又如,可以选择代码字区段在单元组中的其他排序方案,例如,在MSB2_A和MBS0_B或MSB1_B之间进行交换。在图4A、图4B、图5和图6中所述的实施方案中,在第二阶段期间,通常跳过附加单元。然而,在另选的实施方案中,存储电路可以采用附加单元存储用户、存储管理和/或任何其他类型的数据。应当理解,上文所描述的实施方案以实施例的方式引用,并且本发明不限于上文已特别示出或描述的内容。相反地,本发明的范围包括上文所描述的各种特征的组合和子组合两者,以及本领域的技术人员在阅读前述描述时将想到的且在现有技术中未公开的所述各种特征的变型和修改。在本专利申请中以引用方式并入的文献被认为是本申请不可分割的一部分,但如果任何术语在这些并入的文献中被定义成与本说明书中明确地或隐含地作出的定义相冲突,应仅考虑本说明书中的定义。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1