多功能呼叫分机的制作方法
本发明涉及多功能呼叫分机,属于医疗设备领域。
背景技术:
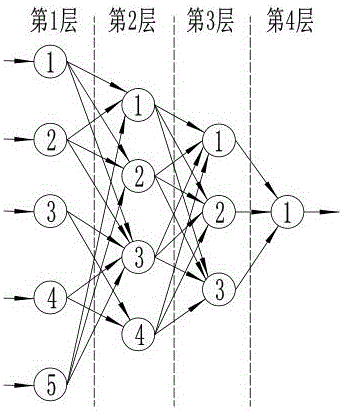
:呼叫分机主要配合护士站主机使用,与主机之间对讲通讯。由于医院的床位较多,网络带宽无法满足多分机同时通讯的要求。现有技术中没有提供一种解决方案用于对呼叫分机的传输数据进行筛检、压缩以降低对带宽的需求。技术实现要素:为将降低呼叫分机对带宽的需求,本发明提出了一种多功能呼叫分机。本发明技术方案如下:多功能呼叫分机,包括主控芯片,还包括各自分别与主控芯片相连接的麦克风、扬声器以及接收模块,所述主控芯片还通过一级缓存连接有判别模块,所述判别模块通过二级缓存连接有发送模块;所述判别模块基于FPGA芯片,所述FPGA芯片内搭建有用于判别无效语音数据片段的BP神经网络,所述BP神经网络判别无效语音数据片段的方法步骤为:(A)主控芯片将麦克风收录的语音转化为语音数据,将该语音数据中50Hz以下及1200Hz以上的频段全部滤除,再将滤除后的语音数据以3s为单位分割为语音数据序列并将该语音数据序列存放在一级缓存中;主控芯片从一级缓存中依次读取语音数据序列中的元素,分别作如下处理:(A-1)记该元素的整体平均分贝值为x1,、整体码率为x2;(A-2)对该元素进行频域分析,以50Hz为起点,计算每过50Hz分贝值的变化率,记录第一个变化率大于0.1dB/Hz的频率值为x3、第一个变化率小于-0.1dB/Hz的频率值为x4;若未找到符合条件的x3,则将x3设定为50Hz,若未找到符合条件的x4,则将x4设定为1200Hz;(A-3)计算x3至x4频段的平均分贝值为x5;(A-4)将x1、x2、x3、x4和x5作为一组输入数据存储至一级缓存中;(B)将一级缓存中的各组输入数据依次传送至判别模块的BP神经网络中进行判别;该BP神经网络沿输入至输出方向依次设置有输入层、预处理层、中间层和输出层;所述输入层包括用于输入x1的输入单元一、用于输入x2的输入单元二、用于输入x3的输入单元三、用于输入x4的输入单元四和用于输入x5的输入单元五;所述预处理层包括预处理单元一、预处理单元二、预处理单元三和预处理单元四;所述中间层包括中间单元一、中间单元二和中间单元三;所述输出层包括输出单元;所述输入层、预处理层、中间层和输出层分别为BP神经网络的第1层、第2层、第3层和第4层;所述输入单元一、输入单元二、输入单元三、输入单元四和输入单元五分别为第1层的第1单元、第2单元、第3单元、第4单元和第5单元;所述预处理单元一、预处理单元二、预处理单元三和预处理单元四分别为第2层的第1单元、第2单元、第3单元和第4单元;所述中间单元一、中间单元二和中间单元三分别为第3层的第1单元、第2单元和第3单元;所述输出单元为第4层的第1单元;设第l层第i单元的输出值为偏置项为激活函数为fi(l)(),第l层的单元总数为n(l),第l层第j单元的输出值传递至第l+1层第i单元时的权值为则对于第1层:对于第2至4层:设和恒为0;BP神经网络根据输入的数据判断出该元素是否为无效语音数据片段,若为无效语音数据片段则将该元素替换为空白音数据;(C)判别模块将替换处理过的语音数据序列传送至二级缓存中。进一步地:所述预处理层各单元的激活函数为:fi(l)(x)=e3x+3x3-1e2x+1-x,x≥0sin(x5),x<0.]]>进一步地:所述中间层和输出层各单元的激活函数为:fi(l)(x)=max(0,x-0.2)。进一步地,BP神经网络的训练方法为:在背景噪声频率为20Hz、80Hz、150Hz、200Hz、360Hz、500Hz、750Hz、1000Hz、1500Hz、2000Hz且各自均无人声的环境中分别录制100条时长30s的无效样本语音数据,并在背景噪声频率为20Hz、80Hz、150Hz、200Hz、360Hz、500Hz、750Hz、1000Hz、1500Hz、2000Hz且各自均具有人声的环境中分别录制100条时长30s的有效样本语音数据;将2000条样本语音数据各自分别以3s为单位分割为语音数据序列,将所有语音数据序列的20000个元素进行乱序排列构成样本序列,依次读取样本序列中的元素:对于每一元素,记该元素的整体平均分贝值为x1,、整体码率为x2,对该元素进行频域分析,以50Hz为起点,计算每过50Hz分贝值的变化率,记录第一个变化率大于0.1dB/Hz的频率值为x3、第一个变化率小于-0.1dB/Hz的频率值为x4,若未找到符合条件的x3,则将x3设定为50Hz,若未找到符合条件的x4,则将x4设定为1200Hz,计算x3至x4频段的平均分贝数为x5,将x1、x2、x3、x4和x5作为一组训练样本输入数据;将20000组训练样本输入数据结合各元素原所对应的有效/无效期待结果对BP神经网络训练,训练时保持和恒为0。进一步地:所述主控芯片还连接有FM模块。进一步地:所述主控芯片还连接有显示屏。进一步地:所述主控芯片还连接有存储模块。相对于现有技术,本发明具有以下优点:(1)本发明具有基于FPGA的判别模块,能够利用训练好的神经网络算法根据语音数据片段的特征信息判别出是否为人声内容空白的无效语音数据片段,并将无效语音数据片段替换为空白音数据,压缩了传输语音数据的大小,降低了呼叫分机对带宽的需求;(2)本检测方法利用神经网络对语音数据进行判别,具有非线性逼近能力强、判断效率高和准确率高的优点;(3)神经网络中引入了预处理层,由于每个人的人声频率范围较为集中,因此预处理层中对部分权数进行了强制设定,并将第一个变化率大于0.1dB/Hz的频率值x3和第一个变化率小于-0.1dB/Hz的频率值x4这两种相关性较明显但又无法完全合并的特征信息进行了非完全性的合并处理,然后再将预处理层的结果输出到中间层中,保证了后续的计算过程中x3和x4始终保有一定的相关性,从而提高了判断结果的准确性,同时也提高了训练的效率;(4)预处理层的激活函数设定充分考虑了x3和x4两个特征信息非完全性合并处理在计算效率、微分求解难度和相关性保留方面的要求,具有求解、训练效率高和判断准确性高的优点。附图说明图1为本发明所提出的多功能呼叫分机的结构示意图。图2为BP神经网络的结构示意图。具体实施方式下面结合附图详细说明本发明的技术方案:如图1,多功能呼叫分机,包括主控芯片,还包括各自分别与主控芯片相连接的麦克风、扬声器以及接收模块,所述主控芯片还通过一级缓存连接有判别模块,所述判别模块通过二级缓存连接有发送模块;所述主控芯片还连接有FM模块、液晶显示屏和存储模块,所述存储模块可以是内置存储芯片也可以是通过USB接口接入本呼叫分机的优盘装置。病人可通过本呼叫分机与主机通讯,还可以通过扬声器收听FM广播,或欣赏存储模块中的音乐。液晶显示屏还可显示病人的姓名、年龄等相关信息。所述判别模块基于FPGA芯片,所述FPGA芯片内搭建有用于判别无效语音数据片段的BP神经网络,所述BP神经网络判别无效语音数据片段的方法步骤为:(A)主控芯片将麦克风收录的语音转化为语音数据,考虑到人声频率范围为65至1100Hz,将该语音数据中50Hz以下及1200Hz以上的频段全部滤除,再将滤除后的语音数据以3s为单位分割为语音数据序列并将该语音数据序列存放在一级缓存中;主控芯片从一级缓存中依次读取语音数据序列中的元素,分别作如下处理:(A-1)记该元素的整体平均分贝值为x1,、整体码率为x2;(A-2)对该元素进行频域分析,以50Hz为起点,计算每过50Hz分贝值的变化率,记录第一个变化率大于0.1dB/Hz的频率值为x3、第一个变化率小于-0.1dB/Hz的频率值为x4;若未找到符合条件的x3,则将x3设定为50Hz,若未找到符合条件的x4,则将x4设定为1200Hz;(A-3)计算x3至x4频段的平均分贝值为x5;(A-4)将x1、x2、x3、x4和x5作为一组输入数据存储至一级缓存中;(B)将一级缓存中的各组输入数据依次传送至判别模块的BP神经网络中进行判别;该BP神经网络沿输入至输出方向依次设置有输入层、预处理层、中间层和输出层;所述输入层包括用于输入x1的输入单元一、用于输入x2的输入单元二、用于输入x3的输入单元三、用于输入x4的输入单元四和用于输入x5的输入单元五;所述预处理层包括预处理单元一、预处理单元二、预处理单元三和预处理单元四;所述中间层包括中间单元一、中间单元二和中间单元三;所述输出层包括输出单元;所述输入层、预处理层、中间层和输出层分别为BP神经网络的第1层、第2层、第3层和第4层;所述输入单元一、输入单元二、输入单元三、输入单元四和输入单元五分别为第1层的第1单元、第2单元、第3单元、第4单元和第5单元;所述预处理单元一、预处理单元二、预处理单元三和预处理单元四分别为第2层的第1单元、第2单元、第3单元和第4单元;所述中间单元一、中间单元二和中间单元三分别为第3层的第1单元、第2单元和第3单元;所述输出单元为第4层的第1单元;设第l层第i单元的输出值为偏置项为激活函数为fi(l)(),第l层的单元总数为n(l),第l层第j单元的输出值传递至第l+1层第i单元时的权值为则对于第1层:对于第2至4层:设和恒为0,此设置的原因是:每个人的人声频率范围通常较为集中,即x3与x4差值不会过大,因此预处理层中对部分权数进行了强制设定,并将x3和x4这两种相关性较明显但又无法完全合并的特征信息进行了非完全性的合并处理,然后再将预处理层的结果输出到中间层中,保证了后续的计算过程中x3和x4始终保有一定的相关性,从而提高了判断结果的准确性,同时也提高了训练的效率;BP神经网络根据输入的数据判断出该元素是否为无效语音数据片段,若为无效语音数据片段则将该元素替换为空白音数据;(C)判别模块将替换处理过的语音数据序列传送至二级缓存中。所述预处理层各单元的激活函数为:fi(l)(x)=e3x+3x3-1e2x+1-x,x≥0sin(x5),x<0.]]>该激活函数的设定充分考虑了x3和x4两个特征信息非完全性合并处理后在计算效率、微分求解难度和相关性保留方面的要求,具有求解、训练效率高和判断准确性高的优点;所述中间层和输出层各单元的激活函数为:fi(l)(x)=max(0,x-0.2)。该BP神经网络的训练方法为:在背景噪声频率为20Hz、80Hz、150Hz、200Hz、360Hz、500Hz、750Hz、1000Hz、1500Hz、2000Hz且各自均无人声的环境中分别录制100条时长30s的无效样本语音数据,并在背景噪声频率为20Hz、80Hz、150Hz、200Hz、360Hz、500Hz、750Hz、1000Hz、1500Hz、2000Hz且各自均具有人声的环境中分别录制100条时长30s的有效样本语音数据;取样时,应尽可能的选择不同的环境,并安排声线相互不同的人员参与人声的录制;将2000条样本语音数据各自分别以3s为单位分割为语音数据序列,将所有语音数据序列的20000个元素进行乱序排列构成样本序列,依次读取样本序列中的元素:对于每一元素,记该元素的整体平均分贝值为x1,、整体码率为x2,对该元素进行频域分析,以50Hz为起点,计算每过50Hz分贝值的变化率,记录第一个变化率大于0.1dB/Hz的频率值为x3、第一个变化率小于-0.1dB/Hz的频率值为x4,若未找到符合条件的x3,则将x3设定为50Hz,若未找到符合条件的x4,则将x4设定为1200Hz,计算x3至x4频段的平均分贝数为x5,将x1、x2、x3、x4和x5作为一组训练样本输入数据;将20000组训练样本输入数据结合各元素原所对应的有效/无效期待结果对BP神经网络训练,训练时保持和恒为0。病人由于健康状况等原因,在通讯时常出现阶段性的声音停歇,因而传输的语音数据体积较大,占用了相当部分的带宽。为了将语音数据中人声内容为空白的片段去除,以减小对带宽的需求,本方案通过使用判别模块,根据语音数据片段的特征信息判别出无效语音数据片段,而后将无效语音数据片段替换为体积极小的空白音数据后再由二级缓存通过发送模块传输至主机,压缩了传输语音数据的大小,降低了呼叫分机对带宽的需求。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1