利用pspG基因缺失菌株通过发酵生产L‑氨基酸的方法与流程
本发明属于生物工程
技术领域:
,特别涉及一种通过发酵生产l-氨基酸的方法。
背景技术:
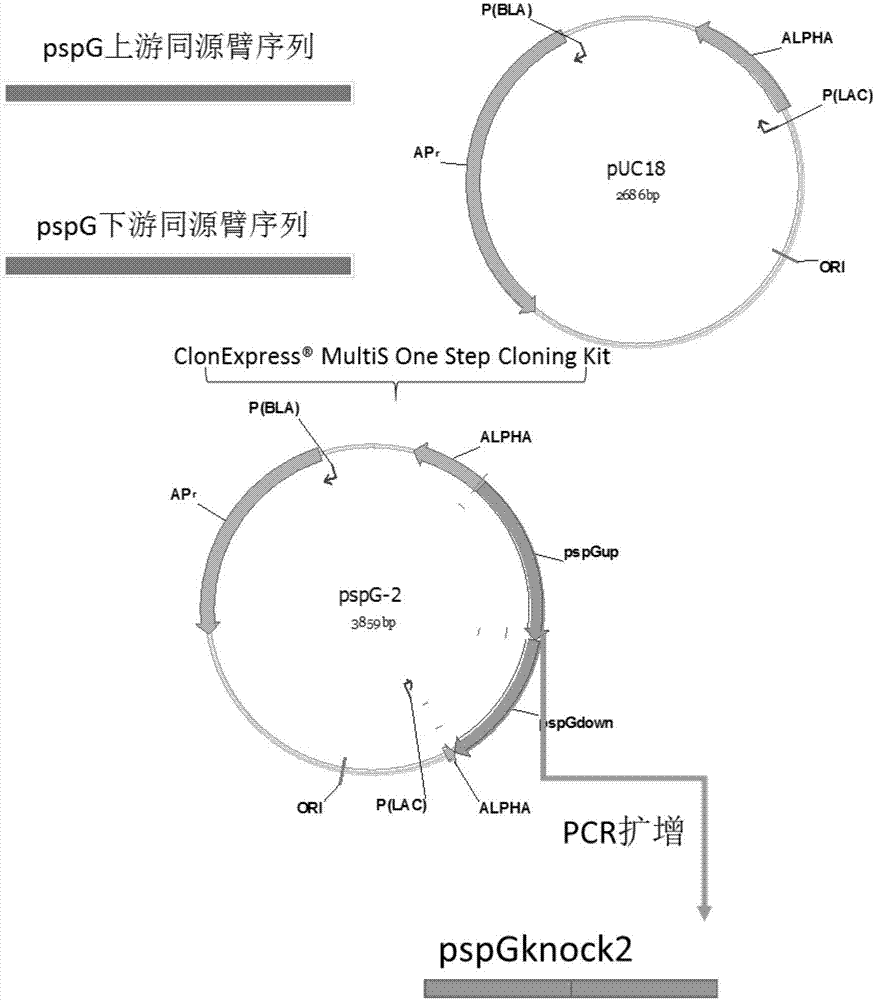
:在工业上,目前l-氨基酸的生产方法主要为生物发酵法,即通过具有l-氨基酸生产能力的各种微生物的发酵来生产l-氨基酸,因此具有l-氨基酸生产能力菌株的获得是l氨基酸生产方法的核心。目前获得l氨基酸生产菌株的方法主要有两种,一种是通过对野生型微生物(野生型菌株)进行诱变的方法,使其具有营养缺陷,并使其对某些代谢物产生拮抗作用,从而获得优良的工业生产菌株。近年来随着基因工程技术的发展,重组dna技术已经开始普遍应用于微生物代谢工程改造方面,使其成为另外一种重要的获得l-氨基酸生产菌株的方法。比如,通过提高目标产品合成途径中关键酶的表达,来达到提高微生物l-氨基酸生产能力(cn1305002a);再比如,通过提高目标产品的分泌蛋白的表达,来达到提高微生物l-氨基酸生产能力(cn1260393a);或者,通过降低某些基因的表达,来达到提高微生物l-氨基酸生产能力(cn1607246a);在或者,通过敲除某些基因,使其失活,来达到提高微生物l-氨基酸生产能力(cn1466630a)。pspg的表达产物是一个内膜蛋白,表达受到西格玛(54)-rna聚合酶的调控,并受到噬菌体休克蛋白pspf的激活作用和噬菌体休克蛋白pspa的抑制作用。相关研究表明其过表达会造成细胞的移动性能变慢。目前,对于其对于l氨基酸合成是否有影响还没有相关的报道。技术实现要素:本发明的目的是提供一种利用pspg基因缺失菌株通过发酵生产l-氨基酸的方法,以提高l-氨基酸产量和转化率。为实现上述目的,本发明采用的技术方案为:一种利用pspg基因缺失菌株通过发酵生产l-氨基酸的方法,通过在培养基中培养属于肠杆菌科,并具有l-氨基酸生产能力的细菌,该细菌于培养前进行了修饰,使得pspg基因缺失,并从细菌的培养基或细胞收集l-氨基酸,来生产l-氨基酸。进一步的,采用pspg基因缺失的菌株atcc21151δpspg,通过发酵的方法生产得到l-苏氨酸。所述pspg基因缺失的菌株atcc21151δpspg通过下述方法构建得到:首先,制备菌株atcc21151的感受态细胞;利用质粒pkd46进行转化,获得atcc21151/pkd46菌株;然后,利用基因片段pspgknock1转化atcc21151/pkd46菌株的感受态细胞,获得的转化子利用引物pspg1-f/pspg1-r进行验证,验证正确的菌株命名为atcc21151δpspg::sacbcm;最后,利用基因片段pspgknock2转化atcc21151δpspg::sacbcm菌株的感受态细胞,获得的转化子利用引物pspg2-f/pspg2-r进行验证,验证正确的菌株命名为atcc21151δpspg,至此l-苏氨酸生产所用的pspg基因缺失的菌株atcc21151δpspg构建完毕。进一步的,采用pspg基因缺失的菌株mg1655/pwsk-lysc*-dapa*δpspg,通过发酵的方法生产得到l-赖氨酸。所述pspg基因缺失的菌株mg1655/pwsk-lysc*-dapa*δpspg通过下述方法构建得到:首先,制备菌株atcc21151的感受态细胞;利用质粒pkd46进行转化,获得mg1655/pwsk-lysc*-dapa*(pkd46)菌株;然后,利用基因片段pspgknock2转化mg1655/pwsk-lysc*-dapa*(pkd46)菌株的感受态细胞,获得的转化子利用引物pspg2-f/pspg2-r进行验证,验证正确的菌株命名为mg1655/pwsk-lysc*-dapa*δpspg::sacbcm;最后,利用基因片段pspgknock2转化mg1655/pwsk-lysc*-dapa*δpspg::sacbcm菌株的感受态细胞,获得的转化子利用引物pspg2-f/pspg2-r进行验证,验证正确的菌株命名为mg1655/pwsk-lysc*-dapa*δpspg,至此l-赖氨酸生产所用的pspg基因缺失的菌株mg1655/pwsk-lysc*-dapa*δpspg构建完毕。所述菌株mg1655/pwsk-lysc*-dapa*通过下述方法构建得到:利用多片段重组的方法构建以低拷贝质粒pwsk29为出发载体,包含dapa基因表达框和lysc基因表达框的质粒pwsk-lysc-dapa;以质粒pwsk-lysc-dapa为基础构建dapa和lysc突变体过表达质粒,得到质粒pwsk-lysc*-dapa*;将质粒pwsk-lysc*-dapa*电转化至大肠杆菌mg1655;获得的菌株命名为mg1655/pwsk-lysc*-dapa*。有益效果:本发明提供的方法,采用pspg基因缺失的大肠杆菌菌株,通过发酵的方法生产得到l-氨基酸,并通过一些列的试验验证,pspg基因的缺失,其功能或者其相关序列的缺失,对于l-氨基酸发酵有利,有助于氨基酸产量和转化率的的提升。附图说明图1为基因片段pspgknock1的构建过程示意图;图2为基因片段pspgknock2的构建过程示意图;图3为基因质粒pwsk-lysc-dapa的构建过程示意图。具体实施方式本发明实施例所用的l-苏氨酸生产菌株为大肠杆菌atcc21151,来源于美国典型微生物菌株菌种保藏中心(atcc)。本发明实施例所用的l-赖氨酸生产菌株为大肠杆菌mg1655(atcc47076),来源于美国典型微生物菌株菌种保藏中心(atcc)。dna聚合酶购自北京全式金公司的fastpfu;限制性内切酶及dna连接酶等均购自fermentas公司;酵母粉和蛋白胨购自英国oxoid公司产品;琼脂粉和抗生素购自北京索来宝;葡萄糖、硫酸铵等常用化学试剂均购自国药。质粒提取试剂盒和琼脂糖凝胶电泳回收试剂盒均购自上海生工,多片段重组试剂盒(multisonestepcloningkit)购自南京诺唯赞生物科技有限公司,相关操作均严格按照说明书执行;xl-ⅱ定点突变试剂盒购自天津博鑫生物科技有限公司,相关操作均严格按照说明书执行;质粒构建测序验证和基因缺失测序工作由华大基因完成;dh5α感受态细胞购自北京全式金公司。lb培养基成分:酵母粉5g/l,蛋白胨10g/l,nacl10g/l,固体培养基中添加2%的琼脂粉。抗生素浓度为:氨苄青霉素100ug/ml,卡那霉素30ug/ml,氯霉素15ug/ml。l-苏氨酸和l-赖氨酸检测方法:通过安捷伦液相仪,利用zorbaxeclipseaaa(氨基酸分析)色谱柱对发酵液中的l-赖氨酸和l-苏氨酸进行分析,相关操作均严格按照说明书执行。葡萄糖分析方法采用山东科学院生产的sba-40d生物传感分析仪进行检测。实施例1pspg敲除片段的构建大肠杆菌基因敲除采用经典的red重组方法,因此需要有进行重组的基因片段。相关基因片段构建方法如下:首先,根据ncbi公布的大肠杆菌mg1655的基因组序列设计引物pspgup1-f/pspgup1-r和pspgdown1-f/pspgdown1-r,见表1,以大肠杆菌mg1655基因组为模板pcr扩增得到pspg基因上下游个600-700bp的同源臂基因片段,序列如序列表中seqidno.19及seqidno.20所示,pcr扩增参数为98℃2min;98℃20s,63℃20s,72℃1min,循环30次,72℃延伸10min;根据质粒ploi4162基因序列,设计引物sacbcm-f/sacbcm-r,见表1,以质粒ploi4162为模板,pcr扩增氯霉素(cm)和蔗糖致死基因(sacb)基因序列,pcr扩增参数为98℃2min;98℃20s,55℃20s,72℃2min,循环30次;根据质粒puc18基因序列,设计引物puc1-f/puc1-r,见表,1,扩增线性puc18基因片段,pcr扩增参数为98℃2min;98℃20s,55℃20s,72℃2min,循环30次;72℃延伸10min。获得基因片段通过凝胶电泳回收。利用multisonestepcloningkit对上述获得片段进行连接,具体方法参见试剂盒说明。构建可用于扩增敲除pspg基因的基因片段的载体,具体构建过程见图1。经华大基因公司测序正确后,质粒命名为pspg1。根据质粒pspg1基因序列,设计引物pspg1-f/pspg1-r,以质粒pspg1为模板pcr扩增第一次pspg基因敲除的基因片段pspgknock1,pcr扩增参数为98℃2min;98℃20s,58℃20s,72℃3min,循环30次。获得基因片段通过凝胶电泳回收,用于进行pspg基因第一轮敲除。然后,根据ncbi公布的大肠杆菌mg1655的基因组序列设计引物pspgup2-f/pspgup2-r和pspgdown2-f/pspgdown2-r,见表1,以大肠杆菌mg1655基因组为模板pcr扩增得到pspg基因上下游各600-700bp的同源臂基因片段,序列如序列表中seqidno.19及seqidno.20所示,pcr扩增参数为98℃2min;98℃20s,62℃20s,72℃1min,循环30次,72℃延伸10min;根据质粒puc18基因序列,设计引物puc2-f/puc2-r,见表1,扩增线性puc18基因片段,pcr扩增参数为98℃2min;98℃20s,57℃20s,72℃2min,循环30次;72℃延伸10min。获得基因片段通过凝胶电泳回收。利用multisonestepcloningkit对上述获得片段进行连接,具体方法参见试剂盒说明。构建可用于扩增敲除pspg基因的基因片段的载体,具体构建过程见图2。经华大基因公司测序正确后,质粒命名为pspg2。根据质粒pspg2基因序列,设计引物pspg2-f/pspg2-r,以质粒pspg2为模板pcr扩增第二次pspg基因敲除的基因片段pspgknock2,pcr扩增参数为98℃2min;98℃20s,55℃20s,72℃3min,循环30次。获得基因片段通过凝胶电泳回收,用于进行pspg基因第二轮敲除。表1引物实施例2l-赖氨酸生产菌株构建利用大肠埃希氏菌mg1655菌株(atcc47076)来构建一株可以生产l-赖氨酸的菌株。具体方法如下。1.过表达二氢吡啶二羧酸合酶(dapa)和天冬氨酸激酶iii(lysc)基因质粒构建利用多片段重组的方法构建了以低拷贝质粒pwsk29为出发载体,包含dapa基因表达框和lysc基因表达框的质粒。具体方法如下所述:首先,根据ncbi公布的大肠杆菌mg1655的基因组序列设计引物lysc-f/lysc-r和dapa-f/dapa-f,见表2,以大肠杆菌mg1655基因组为模板pcr扩增得到带有自身启动子的dapa和lysc基因片段,序列如序列表中seqidno.22及seqidno.23所示,pcr扩增参数为98℃2min;98℃20s,65℃20s,72℃2min,循环30次;72℃延伸10min。根据质粒pwsk29基因序列,设计引物pwsk-f/pwsk-r,扩增线性pwsk29基因片段,pcr扩增参数为98℃2min;98℃20s,60℃20s,72℃3min,循环30次;72℃延伸10min。获得基因片段通过凝胶电泳回收。然后,利用multisonestepcloningkit对上述获得片段进行连接,具体方法参见试剂盒说明。构建过表达二氢吡啶二羧酸合酶(dapa)和天冬氨酸激酶iii(lysc)基因质粒pwsk-lysc-dapa,具体构建过程见图3。经华大基因公司测序正确后进行下一步试验。2.dapa和lysc突变体过表达质粒的构建野生型的dapa基因和lysc基因是受到l-赖氨酸的反馈抑制的,因此为了解除l-赖氨酸对其的反馈抑制,增加其在细胞内的酶活力,对其进行了点突变,以pwsk-lysc-dapa为基础构建了dapa和lysc突变体过表达质粒。具体方法如下所述。首先,设计利用stratagene系列xl-ⅱ定点突变试剂盒,通过引物lysct352if/lysct352ir(见表2)对质粒pwsk-lysc-dapa进行pcr引入突变位点,获得的质粒基因片段经过pcr产物回收,除去pcr体系中的酶及缓冲体系中的盐离子后,采用dpni酶37摄氏度酶切1h除去甲基化的模板质粒dna,处理后的质粒转入感受态细胞tran10(购自北京全式金生物技术有限公司),经测序验证,所获得的正确突变质粒命名为pwsk-lysc*-dapa,携带的lysc突变体核苷酸序列如序列表中seqidno.24所示。然后,设计利用stratagene系列xl-ⅱ定点突变试剂盒,通过引物dapae84t-f/dapae84t-r(见表2)对质粒pwsk-lysc*-dapa进行pcr引入突变位点,获得的质粒基因片段经过pcr产物回收,除去pcr体系中的酶及缓冲体系中的盐离子后,采用dpni酶37摄氏度酶切1h除去甲基化的模板质粒dna,处理后的质粒转入感受态细胞tran10,经测序验证,所获得的正确突变质粒命名为pwsk-lysc*-dapa*,携带的dapa突变体核苷酸序列如序列表中seqidno.25所示。3.l-赖氨酸生产菌株shg01的构建及发酵验证将前面构建好的质粒pwsk-lysc*-dapa*电转化至大肠杆菌mg1655;获得的菌株命名为mg1655/pwsk-lysc*-dapa*。然后,对其进行l-赖氨酸发酵能力的验证。发酵培养基如下:葡萄糖40g/l,硫酸铵10g/l,磷酸0.6ml/l,氯化钾0.8g/l,甜菜碱0.4g/l,硫酸镁1.2g/l,硫酸锰0.03g/l,硫酸亚铁0.03g/l,玉米浆有机氮0.4g/l,5%消泡剂0.5ml/l,苏氨酸0.2g/l,卡那霉素50ug/ml。利用500ml装入30ml发酵培养基的三角瓶进行发酵实验,接种2mllb过夜培养的菌液,在37℃、200rpm条件下发酵。利用稀释的氨水控制ph6.8,发酵32h。菌株mg1655/pwsk-lysc*-dapa*发酵32h后,l-赖氨酸产量为4.7g/l。表2引物名称序列pwsk-fgctgcctgtagttctgacgaagcataaagtgtaaagcctggggtgccpwsk-rgcgctagcgcaggttgcagcacatccccctttcgclysc-fggatgtgctgcaacctgcgctagcgcaggcclysc-rggagaagagttcacgtttattatataaagacgctggttaacagagtacaggctcgdapa-fctctgttaaccagcgtctttatataataaacgtgaactcttctcccagcdapa-rccaggctttacactttatgcttcgtcagaactacaggcagcglysct352i-fgtggcattaatccttgataccaccggttcaacctccactglysct352i-rgtatcaaggattaatgccacgctcacttctgacgtggtgadapae84t-fcgctaacgctactgcgaccgccattagcctgacgdapae84t-rcgtcaggctaatggcggtcgcagtagcgttagcg实施例3pspg基因缺失菌株构建1.l-苏氨酸生产菌株atcc21151δpspg基因缺失突变株构建l-苏氨酸生产菌株atcc21151基因敲除方法采用经典的red重组方法,参考相关文献进行。具体操作过程如下:首先,制备菌株atcc21151的感受态细胞,具体感受态细胞制备和转化过程参考j.萨姆布鲁克(sambrook)等编写的《分子克隆实验指南》;利用质粒pkd46进行转化,获得atcc21151/pkd46菌株;然后,利用基因片段pspgknock1转化atcc21151/pkd46菌株的感受态细胞,获得的转化子利用引物pspg1-f/pspg1-r进行验证,验证正确的菌株命名为atcc21151δpspg::sacbcm。最后,利用基因片段pspgknock2转化atcc21151δpspg::sacbcm菌株的感受态细胞,获得的转化子利用引物pspg2-f/pspg2-r进行验证,验证正确的菌株命名为atcc21151δpspg,至此l-苏氨酸生产菌株atcc21151δpspg基因缺失突变株构建完毕。2.l-赖氨酸生产菌株mg1655/pwsk-lysc*-dapa*δpspg基因缺失突变株构建l-赖氨酸生产菌株mg1655/pwsk-lysc*-dapa*基因敲除方法采用经典的red重组方法,参考相关文献进行。具体操作过程如下:首先,制备菌株mg1655/pwsk-lysc*-dapa*的感受态细胞,具体感受态细胞制备和转化过程参考j.萨姆布鲁克(sambrook)等编写的《分子克隆实验指南》;利用质粒pkd46进行转化,获得mg1655/pwsk-lysc*-dapa*(pkd46)菌株;然后,利用基因片段pspgknock2转化mg1655/pwsk-lysc*-dapa*(pkd46)菌株的感受态细胞,获得的转化子利用引物pspg2-f/pspg2-r进行验证,验证正确的菌株命名为mg1655/pwsk-lysc*-dapa*δpspg::sacbcm。最后,利用基因片段pspgknock2转化mg1655/pwsk-lysc*-dapa*δpspg::sacbcm菌株的感受态细胞,获得的转化子利用引物pspg2-f/pspg2-r进行验证,验证正确的菌株命名为mg1655/pwsk-lysc*-dapa*δpspg,至此l-赖氨酸生产菌株mg1655/pwsk-lysc*-dapa*δpspg基因缺失突变株构建完毕。实施例4pspg基因缺失对l-苏氨酸发酵的影响为了验证pspg基因缺失对于l-苏氨酸发酵的影响,利用摇瓶发酵的方法对菌株atcc21151和菌株atcc21151δpspg进行发酵验证,具体过程如下:发酵培养基如下表3所示:表3将上述l-苏氨酸生产菌株单菌落分别接种5mllb液体培养基,37℃,220rpm培养12h。按照初始od为0.2转接装有20ml发酵培养基的500ml三角瓶,37℃,220rpm培养32h,检测l-苏氨酸的浓度。菌株最终产量结果如表4所示,对照菌株atcc21151中l-苏氨酸产量为5.3g/l,pspg基因缺失的菌株atcc21151δpspg中l-苏氨酸产量为6.2g/l,比出发菌株提高了17.0%,表明在大肠杆菌中部分或全部缺失pspg内膜蛋白能够提高l-苏氨酸的产量。表4菌株l-苏氨酸g/latcc211515.3atcc21151δpspg6.2实施例5pspg基因缺失对l-赖氨酸发酵的影响为了验证pspg基因缺失对于l-赖氨酸发酵的影响,利用摇瓶发酵的方法对菌株mg1655/pwsk-lysc*-dapa*和菌株mg1655/pwsk-lysc*-dapa*δpspg进行发酵验证,具体过程如下:发酵培养基如下表5所示:表5成分浓度g/l葡萄糖50硫酸铵8磷酸二氢钾3七水合硫酸镁1.5酵母粉4七水合硫酸亚铁0.03一水合硫酸亚锰0.03将上述l-赖氨酸生产菌株单菌落分别接种5ml含有100μg/ml卡那霉素的lb液体培养基,37℃,220rpm培养12h。按照10%的接种量转接装有20ml发酵培养基的500ml三角瓶,37℃,220rpm培养36h,检测l-赖氨酸的浓度。菌株最终产量结果如表6所示,对照菌株mg1655/pwsk-lysc*-dapa*中l-赖氨酸产量为4.5g/l,pspg基因缺失的菌株mg1655/pwsk-lysc*-dapa*δpspg中l-赖氨酸产量为6.0g/l,比出发菌株提高了27.7%,表明在大肠杆菌中部分或全部pspg内膜蛋白能够提高l-赖氨酸的产量。表6菌株l-赖氨酸g/lmg1655/pwsk-lysc*-dapa*4.7mg1655/pwsk-lysc*-dapa*δpspg6.0以上所述仅是本发明的优选实施方式,应当指出:对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。sequencelisting<110>徐州工程学院<120>利用pspg基因缺失菌株通过发酵生产l-氨基酸的方法<130>2017<160>35<210>1<211>34<212>dna<213>人工序列<223>人工序列的描述:引物puc1-f<400>1gccacgcgcccgccgggtaccgagctcgaattcg34<210>2<211>37<212>dna<213>人工序列<223>人工序列的描述:引物puc1-r<400>2aaccccgaaagccgggatcctctagagtcgacctgca37<210>3<211>31<212>dna<213>人工序列<223>人工序列的描述:引物pspgup1-f<400>3tctagaggatcccggctttcggggttaagcc31<210>4<211>54<212>dna<213>人工序列<223>人工序列的描述:引物pspgup1-r<400>4cgataactcaaaaaatacggcatgacaaaaaagccaatcacaaaaagtagttcc54<210>5<211>51<212>dna<213>人工序列<223>人工序列的描述:引物sacbcm-f<400>5tggcttttttgtcatgccgtattttttgagttatcgagattttcaggagct51<210>6<211>42<212>dna<213>人工序列<223>人工序列的描述:引物sacbcm-r<400>6gcgcaatagtgacagcagcctgaatcaggcatttgagaagca42<210>7<211>42<212>dna<213>人工序列<223>人工序列的描述:引物pspgdown1-f<400>7ctgattcaggctgctgtcactattgcgcctctaacagattca42<210>8<211>38<212>dna<213>人工序列<223>人工序列的描述:引物pspgdown1-r<400>8aattcgagctcggtacccggcgggcgcgtggcaggtta38<210>9<211>34<212>dna<213>人工序列<223>人工序列的描述:引物puc2-f<400>9gccacgcgcccgccgggtaccgagctcgaattcg34<210>10<211>37<212>dna<213>人工序列<223>人工序列的描述:引物puc2-r<400>10aaccccgaaagccgggatcctctagagtcgacctgca37<210>11<211>31<212>dna<213>人工序列<223>人工序列的描述:引物pspgup2-f<400>11tctagaggatcccggctttcggggttaagcc31<210>12<211>53<212>dna<213>人工序列<223>人工序列的描述:引物pspgup2-r<400>12gaggcgcaatagtgacaggcatgacaaaaaagccaatcacaaaaagtagttcc53<210>13<211>46<212>dna<213>人工序列<223>人工序列的描述:引物pspgdown2-f<400>13tggcttttttgtcatgcctgtcactattgcgcctctaacagattca46<210>14<211>38<212>dna<213>人工序列<223>人工序列的描述:引物pspgdown2-r<400>14aattcgagctcggtacccggcgggcgcgtggcaggtta38<210>15<211>14<212>dna<213>人工序列<223>人工序列的描述:引物pspg1-f<400>15tttcggggttaagc14<210>16<211>19<212>dna<213>人工序列<223>人工序列的描述:引物pspg1-r<400>16ggcgggcgcgtggcaggtt19<210>17<211>15<212>dna<213>人工序列<223>人工序列的描述:引物pspg2-f<400>17ctttcggggttaagc15<210>18<211>18<212>dna<213>人工序列<223>人工序列的描述:引物pspg2-r<400>18gcgggcgcgtggcaggtt18<210>19<211>640<212>dna<213>人工序列<223>人工序列的描述:pspg上游同源臂基因序列<400>19ggctttcggggttaagcccgaaagaaaaccgtgaaatcccgccgctcgattatccgcgtgtgtatcaactgaagcgtgactttccgcatctgacaatgtcgattaacggtggtatcaagtcgctggaagaggccaaagcacacctgcaacatatggatggcgtgatggtcgggcgcgaggcgtatcagaatccgggtattctggcggcggtagaccgggagatctttggttcctcggataccgatgccgatccggtggcggtagtgcgcgccatgtatccgtacattgagcgtgaactcagccaggggacgtatctcggccatattacccggcatatgttgggcttgttccagggtattcctggcgcgcggcagtggcggcgttatttaagtgaaaatgcccataaagcgggtgcagacattaatgtgctggaacacgcgctcaaactggtggcggataagcgttaacttttcaccaaaaagtagtcaaattcaccacgccctgcgcaccgtcgcggggcgttttgctgttaaatcaatagattatttttggcatgattcttgtaatgccagcaagagatttcatatttgggagagcatcatgctggaactactttttgtgattggcttttttgtcatgc640<210>20<211>533<212>dna<213>人工序列<223>人工序列的描述:pspg下游同源臂基因序列<400>20ctgtcactattgcgcctctaacagattcatcgtgctgtaccctacatacagccgaactataaaaagaaagggcttcccaggtggaagccctatttcttttatggaatcagcaggctggaaccttgcgtcgcccggctttccagaatctcatgcgcacgctgcgcatccttcagcggatatttctgctgctcggcgacatcgaccttaatcacaccgctggcaatcaaagagaacagttcattactggcctcggttaattcctcccgcgtggtgatatagccttgcagggaagggcgtgtcacatacaacgagcctttttgattgagaatgcctaagttcacaccggtaaccgcacctgatgagttgccaaaactgaccattaagccgcggcgttgcaggcaatccagcgaccgttcccaggtgtctctgcccacggaatcgtacaccacgcgcactttcttaccgccggtgatctcttttaaccgctcgaccagatcctcttcacgatagttaataacctgccacgcgcccgc533<210>21<211>2546<212>dna<213>人工序列<223>人工序列的描述:sacbcm基因序列<400>21cgtattttttgagttatcgagattttcaggagctaaggaagctaaaatggagaaaaaaatcactggatataccaccgttgatatatcccaatggcatcgtaaagaacattttgaggcatttcagtcagttgctcaatgtacctataaccagaccgttcagctggatattacggcctttttaaagaccgtaaagaaaaataagcacaagttttatccggcctttattcacattcttgcccgcctgatgaatgctcatccggaattccgtatggcaatgaaagacggtgagctggtgatatgggatagtgttcacccttgttacaccgttttccatgagcaaactgaaacgttttcatcgctctggagtgaataccacgacgatttccggcagtttctacacatatattcgcaagatgtggcgtgttacggtgaaaacctggcctatttccctaaagggtttattgagaatatgtttttcgtctcagccaatccctgggtgagtttcaccagttttgatttaaacgtggccaatatggacaacttcttcgcccccgttttcaccatgggcaaatattatacgcaaggcgacaaggtgctgatgccgctggcgattcaggttcatcatgccgtttgtgatggcttccatgtcggcagaatgcttaatgaattacaacagtactgcgatgagtggcagggcggggcgtaatttttttaaggcagttattggtgcccttaaacgcctggtgctacgcctgaataagtgataataagcggatgaatggcagaaattcgaaagcaaattcgacccggtcgtcggttcagggcagggtcgttaaatagccgctagatctaagtaaatcgcgcgggtttgttactgataaagcaggcaagacctaaaatgtgtaaagggcaaagtgtatactttggcgtcaccccttacatattttaggtctttttttattgtgcgtaactaacttgccatcttcaaacaggagggctggaagaagcagaccgctaacacagtacataaaaaaggagacatgaacgatgaacatcaaaaagtttgcaaaacaagcaacagtattaacctttactaccgcactgctggcaggaggcgcaactcaagcgtttgcgaaagaaacgaaccaaaagccatataaggaaacatacggcatttcccatattacacgccatgatatgctgcaaatccctgaacagcaaaaaaatgaaaaatatcaagttcctgaattcgattcgtccacaattaaaaatatctcttctgcaaaaggcctggacgtttgggacagctggccattacaaaacgctgacggcactgtcgcaaactatcacggctaccacatcgtctttgcattagccggagatcctaaaaatgcggatgacacatcgatttacatgttctatcaaaaagtcggcgaaacttctattgacagctggaaaaacgctggccgcgtctttaaagacagcgacaaattcgatgcaaatgattctatcctaaaagaccaaacacaagaatggtcaggttcagccacatttacatctgacggaaaaatccgtttattctacactgatttctccggtaaacattacggcaaacaaacactgacaactgcacaagttaacgtatcagcatcagacagctctttgaacatcaacggtgtagaggattataaatcaatctttgacggtgacggaaaaacgtatcaaaatgtacagcagttcatcgatgaaggcaactacagctcaggcgacaaccatacgctgagagatcctcactacgtagaagataaaggccacaaatacttagtatttgaagcaaacactggaactgaagatggctaccaaggcgaagaatctttatttaacaaagcatactatggcaaaagcacatcattcttccgtcaagaaagtcaaaaacttctgcaaagcgataaaaaacgcacggctgagttagcaaacggcgctctcggtatgattgagctaaacgatgattacacactgaaaaaagtgatgaaaccgctgattgcatctaacacagtaacagatgaaattgaacgcgcgaacgtctttaaaatgaacggcaaatggtacctgttcactgactcccgcggatcaaaaatgacgattgacggcattacgtctaacgatatttacatgcttggttatgtttctaattctttaactggcccatacaagccgctgaacaaaactggccttgtgttaaaaatggatcttgatcctaacgatgtaacctttacttactcacacttcgctgtacctcaagcgaaaggaaacaatgtcgtgattacaagctatatgacaaacagaggattctacgcagacaaacaatcaacgtttgcgccaagcttcctgctgaacatcaaaggcaagaaaacatctgttgtcaaagacagcatccttgaacaaggacaattaacagttaacaaataaaaacgcaaaagaaaatgccgatattgactaccggaagcagtgtgaccgtgtgcttctcaaatgcctgattcaggctg2546<210>22<211>1750<212>dna<213>人工序列<223>人工序列的描述:lysc基因序列<400>22cctgcgctagcgcaggccagaagaggcgcgttgcccaagtaacggtgttggaggagccagtcctgtgataacacctgagggggtgcatcgccgaggtgattgaacggctggccacgttcatcatcggctacaggggctgaatcccctgggttgtcaccagaagcgttcgcagtcgggcgtttcgcaagtggtggagcacttctgggtgaaaatagtagcgaagtatcgctctgcgcccacccgtcttccgctcttcccttgtgccaaggctgaaaatggatcccctgacacgaggtagttatgtctgaaattgttgtctccaaatttggcggtaccagcgtagctgattttgacgccatgaaccgcagcgctgatattgtgctttctgatgccaacgtgcgtttagttgtcctctcggcttctgctggtatcactaatctgctggtcgctttagctgaaggactggaacctggcgagcgattcgaaaaactcgacgctatccgcaacatccagtttgccattctggaacgtctgcgttacccgaacgttatccgtgaagagattgaacgtctgctggagaacattactgttctggcagaagcggcggcgctggcaacgtctccggcgctgacagatgagctggtcagccacggcgagctgatgtcgaccctgctgtttgttgagatcctgcgcgaacgcgatgttcaggcacagtggtttgatgtacgtaaagtgatgcgtaccaacgaccgatttggtcgtgcagagccagatatagccgcgctggcggaactggccgcgctgcagctgctcccacgtctcaatgaaggcttagtgatcacccagggatttatcggtagcgaaaataaaggtcgtacaacgacgcttggccgtggaggcagcgattatacggcagccttgctggcggaggctttacacgcatctcgtgttgatatctggaccgacgtcccgggcatctacaccaccgatccacgcgtagtttccgcagcaaaacgcattgatgaaatcgcgtttgccgaagcggcagagatggcaacttttggtgcaaaagtactgcatccggcaacgttgctacccgcagtacgcagcgatatcccggtctttgtcggctccagcaaagacccacgcgcaggtggtacgctggtgtgcaataaaactgaaaatccgccgctgttccgcgctctggcgcttcgtcgcaatcagactctgctcactttgcacagcctgaatatgctgcattctcgcggtttcctcgcggaagttttcggcatcctcgcgcggcataatatttcggtagacttaatcaccacgtcagaagtgagcgtggcattaacccttgataccaccggttcaacctccactggcgatacgttgctgacgcaatctctgctgatggagctttccgcactgtgtcgggtggaggtggaagaaggtctggcgctggtcgcgttgattggcaatgacctgtcaaaagcctgcggcgttggcaaagaggtattcggcgtactggaaccgttcaacattcgcatgatttgttatggcgcatccagccataacctgtgcttcctggtgcccggcgaagatgccgagcaggtggtgcaaaaactgcatagtaatttgtttgagtaaatactgtatggcctggaagctatatttcgggccgtattgattttcttgtcactatgctcatcaataaacgagcctgtactctgttaaccagcgtctttat1750<210>23<211>1279<212>dna<213>人工序列<223>人工序列的描述:dapa基因序列<400>23ataataaacgtgaactcttctcccagcatcgccaggcgactgtcttcaatattacagccgcaactactgacatgacgggtgatggtgttcacaattccagggcgatcggcacccaacgcagtgatcaccagataatgttgcgatgacagtgtcaaactggttattcctttaaggggtgagttgttcttaaggaaagcataaaaaaaacatgcatacaacaatcagaacggttctgtctgcttgcttttaatgccataccaaacgtaccattgagacacttgtttgcacagaggatggcccatgttcacgggaagtattgtcgcgattgttactccgatggatgaaaaaggtaatgtctgtcgggctagcttgaaaaaactgattgattatcatgtcgccagcggtacttcggcgatcgtttctgttggcaccactggcgagtccgctaccttaaatcatgacgaacatgctgatgtggtgatgatgacgctggatctggctgatgggcgcattccggtaattgccgggaccggcgctaacgctactgcggaagccattagcctgacgcagcgcttcaatgacagtggtatcgtcggctgcctgacggtaaccccttactacaatcgtccgtcgcaagaaggtttgtatcagcatttcaaagccatcgctgagcatactgacctgccgcaaattctgtataatgtgccgtcccgtactggctgcgatctgctcccggaaacggtgggccgtctggcgaaagtaaaaaatattatcggaatcaaagaggcaacagggaacttaacgcgtgtaaaccagatcaaagagctggtttcagatgattttgttctgctgagcggcgatgatgcgagcgcgctggacttcatgcaattgggcggtcatggggttatttccgttacggctaacgtcgcagcgcgtgatatggcccagatgtgcaaactggcagcagaagggcattttgccgaggcacgcgttattaatcagcgtctgatgccattacacaacaaactatttgtcgaacccaatccaatcccggtgaaatgggcatgtaaggaactgggtcttgtggcgaccgatacgctgcgcctgccaatgacaccaatcaccgacagtggtcgtgagacggtcagagcggcgcttaagcatgccggtttgctgtaaagtttagggagatttgatggcttactctgttcaaaagtcgcgcctggcaaaggttgcgggtgtttcgcttgttttattactcgctgcctgtagttctgac1279<210>24<211>1750<212>dna<213>人工序列<223>人工序列的描述:lysc*基因序列<400>24cctgcgctagcgcaggccagaagaggcgcgttgcccaagtaacggtgttggaggagccagtcctgtgataacacctgagggggtgcatcgccgaggtgattgaacggctggccacgttcatcatcggctacaggggctgaatcccctgggttgtcaccagaagcgttcgcagtcgggcgtttcgcaagtggtggagcacttctgggtgaaaatagtagcgaagtatcgctctgcgcccacccgtcttccgctcttcccttgtgccaaggctgaaaatggatcccctgacacgaggtagttatgtctgaaattgttgtctccaaatttggcggtaccagcgtagctgattttgacgccatgaaccgcagcgctgatattgtgctttctgatgccaacgtgcgtttagttgtcctctcggcttctgctggtatcactaatctgctggtcgctttagctgaaggactggaacctggcgagcgattcgaaaaactcgacgctatccgcaacatccagtttgccattctggaacgtctgcgttacccgaacgttatccgtgaagagattgaacgtctgctggagaacattactgttctggcagaagcggcggcgctggcaacgtctccggcgctgacagatgagctggtcagccacggcgagctgatgtcgaccctgctgtttgttgagatcctgcgcgaacgcgatgttcaggcacagtggtttgatgtacgtaaagtgatgcgtaccaacgaccgatttggtcgtgcagagccagatatagccgcgctggcggaactggccgcgctgcagctgctcccacgtctcaatgaaggcttagtgatcacccagggatttatcggtagcgaaaataaaggtcgtacaacgacgcttggccgtggaggcagcgattatacggcagccttgctggcggaggctttacacgcatctcgtgttgatatctggaccgacgtcccgggcatctacaccaccgatccacgcgtagtttccgcagcaaaacgcattgatgaaatcgcgtttgccgaagcggcagagatggcaacttttggtgcaaaagtactgcatccggcaacgttgctacccgcagtacgcagcgatatcccggtctttgtcggctccagcaaagacccacgcgcaggtggtacgctggtgtgcaataaaactgaaaatccgccgctgttccgcgctctggcgcttcgtcgcaatcagactctgctcactttgcacagcctgaatatgctgcattctcgcggtttcctcgcggaagttttcggcatcctcgcgcggcataatatttcggtagacttaatcaccacgtcagaagtgagcgtggcattaatccttgataccaccggttcaacctccactggcgatacgttgctgacgcaatctctgctgatggagctttccgcactgtgtcgggtggaggtggaagaaggtctggcgctggtcgcgttgattggcaatgacctgtcaaaagcctgcggcgttggcaaagaggtattcggcgtactggaaccgttcaacattcgcatgatttgttatggcgcatccagccataacctgtgcttcctggtgcccggcgaagatgccgagcaggtggtgcaaaaactgcatagtaatttgtttgagtaaatactgtatggcctggaagctatatttcgggccgtattgattttcttgtcactatgctcatcaataaacgagcctgtactctgttaaccagcgtctttat1750<210>25<211>1279<212>dna<213>人工序列<223>人工序列的描述:dapa*基因序列<400>25ataataaacgtgaactcttctcccagcatcgccaggcgactgtcttcaatattacagccgcaactactgacatgacgggtgatggtgttcacaattccagggcgatcggcacccaacgcagtgatcaccagataatgttgcgatgacagtgtcaaactggttattcctttaaggggtgagttgttcttaaggaaagcataaaaaaaacatgcatacaacaatcagaacggttctgtctgcttgcttttaatgccataccaaacgtaccattgagacacttgtttgcacagaggatggcccatgttcacgggaagtattgtcgcgattgttactccgatggatgaaaaaggtaatgtctgtcgggctagcttgaaaaaactgattgattatcatgtcgccagcggtacttcggcgatcgtttctgttggcaccactggcgagtccgctaccttaaatcatgacgaacatgctgatgtggtgatgatgacgctggatctggctgatgggcgcattccggtaattgccgggaccggcgctaacgctactgcgaccgccattagcctgacgcagcgcttcaatgacagtggtatcgtcggctgcctgacggtaaccccttactacaatcgtccgtcgcaagaaggtttgtatcagcatttcaaagccatcgctgagcatactgacctgccgcaaattctgtataatgtgccgtcccgtactggctgcgatctgctcccggaaacggtgggccgtctggcgaaagtaaaaaatattatcggaatcaaagaggcaacagggaacttaacgcgtgtaaaccagatcaaagagctggtttcagatgattttgttctgctgagcggcgatgatgcgagcgcgctggacttcatgcaattgggcggtcatggggttatttccgttacggctaacgtcgcagcgcgtgatatggcccagatgtgcaaactggcagcagaagggcattttgccgaggcacgcgttattaatcagcgtctgatgccattacacaacaaactatttgtcgaacccaatccaatcccggtgaaatgggcatgtaaggaactgggtcttgtggcgaccgatacgctgcgcctgccaatgacaccaatcaccgacagtggtcgtgagacggtcagagcggcgcttaagcatgccggtttgctgtaaagtttagggagatttgatggcttactctgttcaaaagtcgcgcctggcaaaggttgcgggtgtttcgcttgttttattactcgctgcctgtagttctgac1279<210>26<211>47<212>dna<213>人工序列<223>人工序列的描述:引物pwsk-f<400>26gctgcctgtagttctgacgaagcataaagtgtaaagcctggggtgcc47<210>27<211>35<212>dna<213>人工序列<223>人工序列的描述:引物pwsk-r<400>27gcgctagcgcaggttgcagcacatccccctttcgc35<210>28<211>31<212>dna<213>人工序列<223>人工序列的描述:引物lysc-f<400>28ggatgtgctgcaacctgcgctagcgcaggcc31<210>29<211>55<212>dna<213>人工序列<223>人工序列的描述:引物lysc-r<400>29ggagaagagttcacgtttattatataaagacgctggttaacagagtacaggctcg55<210>30<211>49<212>dna<213>人工序列<223>人工序列的描述:引物dapa-f<400>30ctctgttaaccagcgtctttatataataaacgtgaactcttctcccagc49<210>31<211>42<212>dna<213>人工序列<223>人工序列的描述:引物dapa-r<400>31ccaggctttacactttatgcttcgtcagaactacaggcagcg42<210>32<211>40<212>dna<213>人工序列<223>人工序列的描述:引物lysct352i-f<400>32gtggcattaatccttgataccaccggttcaacctccactg40<210>33<211>40<212>dna<213>人工序列<223>人工序列的描述:引物lysct352i-r<400>33gtatcaaggattaatgccacgctcacttctgacgtggtga40<210>34<211>34<212>dna<213>人工序列<223>人工序列的描述:引物dapae84t-f<400>34cgctaacgctactgcgaccgccattagcctgacg34<210>35<211>34<212>dna<213>人工序列<223>人工序列的描述:引物dapae84t-r<400>35cgtcaggctaatggcggtcgcagtagcgttagcg34当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1