用于基于蔗糖的改善精细化学品产生的修饰微生物的制作方法
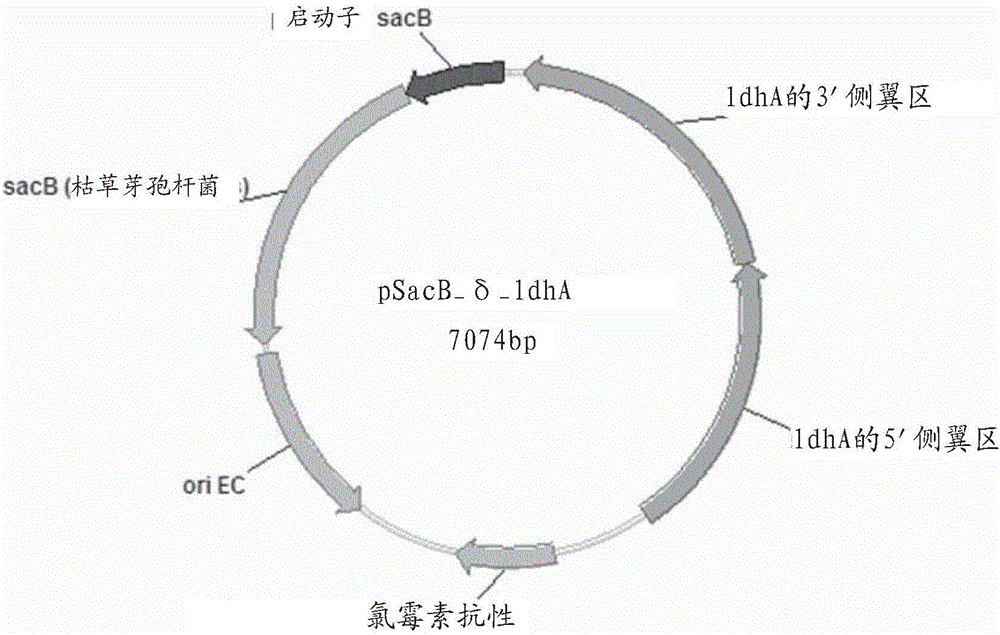
具有6个或更少碳的有机化合物如小型二羧酸是有商业意义的用途多样的化学品。例如,小型二酸类包括1,4-二酸类,如琥珀酸、苹果酸和酒石酸,和5-碳分子衣康酸。其他二酸类包括二碳草酸、三碳丙二酸、五碳戊二酸和六碳己二酸并且也存在这类二酸的许多衍生物。作为一类,这些小型二酸具有某种化学相似性并且它们在聚合物生产中的用途可以为树脂提供专化特性。这种多用性使其轻易契合下游化工基础设施市场。例如,1,4-二酸类分子满足大规模化学品马来酐的许多用途,在于它们被转化成多种工业化学品(四氢呋喃,丁内酯,1,4-丁二醇,2-吡咯烷酮)和琥珀酸盐衍生物琥珀酰胺、琥珀腈、二氨基丁烷和琥珀酸酯。酒石酸在食品、皮革、金属和印刷行业具有众多用途。衣康酸形成生产3-甲基吡咯烷酮、甲基-BDO、甲基-THF和其他的原料。尤其,琥珀酸或琥珀酸酯-这些术语在本文中互换使用-已经吸引巨大兴趣,因为已经在食品、化工和制药业中使用它作为许多工业上重要的化学品的前体。实际上,一份来自美国能源部的报告报道,琥珀酸是从生物质生产的前12大化学结构单元之一。因此,在细菌中制得二酸类的能力将具有明显的商业重要性。WO-A-2009/024294公开了产生琥珀酸的细菌菌株(其属于巴斯德菌科(Pasteurellaceae)成员,最初从瘤胃分离并能够利用甘油作为碳源),以及来自其中的保留所述能力的变体和突变株,尤其,如保藏于DSMZ(德意志微生物保藏中心(DeutscheSammlungvonMikroorganismenundZellkulturenGmbH),因霍夫街.7B,D-38124布劳恩斯切魏格,德国)的命名为DD1的细菌菌株,所述细菌菌株具有保藏编号DSM18541(ID06-614)并且具有产生琥珀酸的能力。DD1-菌株属于物种Basfiasucciniciproducens及巴斯德菌科,如依据Kuhnert等人,2010分类。WO-A-2010/092155中公开了对这些菌株的突变,其中已经破坏ldhA-基因和/或pflD-或pflA-基因,这些突变株的特征为:与WO-A-2009/024294中公开的DD1-野生型相比,在厌氧条件下显著增加从碳源如甘油或甘油和糖(如麦芽糖)的混合物产生琥珀酸。然而,基于生物的琥珀酸仍然面临以下挑战:在成本上针对基于石油化学的替代品变得有竞争力。为了发展基于生物的工业生产琥珀酸,在低成本培养基中培养细胞将重要,并且工作菌株应当最佳地能够代谢类型广泛的低成本糖原料以按照良好产率产生琥珀酸,从而可以使用最便宜的可用原料。蔗糖(俗称为糖)是由葡萄糖和果糖组成的二糖,并且它是是自然界中非常丰富并从具有光合作用能力的全部植物产生的碳源。尤其,甘蔗和糖用甜菜含有大量蔗糖,并且世界上超过60%的蔗糖目前产自甘蔗。特别地,蔗糖以十分低的成本生产,因为它可以通过蒸发/浓缩通过机械压榨甘蔗获得的提取物的简单工艺而工业产生。蔗糖作为通过微生物发酵产生化学化合物的原料因此是价廉的,并且它还发挥以下作用:保护细胞膜免受含有大量所需代谢物的外部环境影响,因此产生高浓度的所需代谢物,如Kilimann等人,(BiochimicaetBiophysicaActa,1764,2006)所示。即使蔗糖是具有上述优点(包括低价格和保护微生物免受外部环境影响的功能)的优异原料,这种碳源的缺点可以见于以下事实:众多微生物没有运输蔗糖至细胞中、降解运输的蔗糖并将降解产物与糖酵解联系的完整机制,并且因此不能利用蔗糖作为碳源。甚至在微生物具有能够利用蔗糖的机制情况下,它们也不能高效产生所需的代谢物,因为摄入和降解蔗糖作为碳源的速率十分低下。因此,本发明的一个目的是克服现有技术的缺点。特别地,本发明的目的是提供可以用于发酵产生有机化合物如琥珀酸并且可以在不牺牲生长速率或产率的情况下高效利用蔗糖作为优势碳源的微生物。优选地,所述微生物将能够利用众多低成本碳源并产生优异产量的有机化合物如琥珀酸。与用于发酵产生琥珀酸的现有技术的重组微生物相比,本发明的微生物应当以细胞基于蔗糖作为优势碳源而生长期间琥珀酸产率增加和碳产率增加为特征。实现上述目标的贡献由一种修饰的微生物提供,所述修饰的微生物与其野生型相比具有fruA-基因编码的酶的减少活性,其中修饰微生物所来自的野生型属于巴斯德菌科(Pasteurellaceae)。实现上述目标的贡献尤其由一种其中已经缺失fruA-基因或其部分的修饰的微生物提供,其中修饰微生物所来自的野生型属于巴斯德菌科(Pasteurellaceae)。令人惊讶地,已经发现,(例如通过缺失fruA-基因)减少由fruA-基因编码的酶(这种酶假定地是果糖特异性磷酸转移酶)的活性产生修饰的巴斯德菌科菌株,所述菌株与其中这种酶的活性尚未减少的相应微生物相比,以增加的有机化合物(如琥珀酸)产量为特征,特别地如果这些修饰的微生物基于蔗糖作为可同化碳源培养时。如根据Lee等人,(AppliedandEnvironmentalMicrobiology(2010),Vol.76(5),第1699-1703页))中的教导,这的确令人惊讶的,至少在产琥珀酸曼氏杆菌(Mannheimiasucciniciproducens)中,fruA-基因编码负责将果糖摄入细胞的果糖PTS-系统。当产琥珀酸曼氏杆菌基于蔗糖培养时,该二糖在细胞内部水解以获得葡萄糖-6-磷酸和果糖。然而,果糖,在水解后分泌并且由细胞使用果糖PTS-系统再次摄取。本领域技术人员将因此假定,当细胞基于蔗糖作为优势碳源培养时,fruA-基因的失活将导致琥珀酸的形成减少,因为至少一部分的二糖(即果糖)不能输入细胞中。在表述“与其野生型相比具有由x-基因编码的酶的减少活性的修饰微生物”(其中x-基因是fruA-基因和任选地,如稍后所述是ldhA-基因、pflA-基因和/或pflD-基因)的上下文中,术语“野生型”指一种微生物,其中由x-基因编码的酶的活性尚未减少,即,指其基因组以如引入x-基因(尤其引入fruA-基因和任选地ldhA-基因、pflA-基因和/或pflD-基因)的基因修饰之前的状态存在的微生物。优选地,表述“野生型”指其基因组、特别其x-基因以因进化而天然生成的状态存在的微生物。该术语可以用于完整的微生物,但是优选地用于各个基因,例如fruA--基因、ldhA-基因、pflA-基因和/或pflD-基因。术语“修饰的微生物”因此包括这样的微生物,所述微生物已经被遗传改变、修饰或工程化(例如,基因工程化),从而如与它所来自的天然存在的野生型微生物相比,显示出改变、修饰或不同的基因型和/或表型(例如,当基因修饰影响微生物的编码核酸序列时)。根据本发明的修饰微生物的具体的优选实施方案,修饰的微生物是重组微生物,其意指已经使用重组DNA获得该微生物。如本文所用的表述“重组DNA”指因利用实验室方法(分子克隆)以令来自多个来源的遗传物质在一起,产生否则在生物学生物中将不存的序列而得到的DNA序列。这种重组DNA的例子是已经向其中插入异源性DNA序列的质粒。本发明微生物所来源的野生型属于巴斯德菌科。巴斯德菌科包含大的革兰氏阴性变形菌门(Proteobacteria)家族,其成员范围从细菌如流感嗜血杆菌(Haemophilusinfluenzae)至动物与人粘膜的共生物。大部分成员作为共生物生活在鸟和哺乳动物的粘膜表面上,特别地生活在上呼吸道中。巴斯德菌科细菌通常为杆状,并且是令人瞩目的一组兼性需氧厌氧菌。它们可以与相关的肠杆菌科(Enterobacteriaceae)细菌相区别在于存在氧化酶,并且与大部分的其他相似细菌相区别在于无鞭毛。巴斯德菌科中的细菌已经基于代谢特性和16SRNA和23SRNA序列划分成多个属。许多巴斯德菌科细菌含有丙酮酸-甲酸-裂解酶基因并且能够将碳源厌氧发酵成有机酸。根据本发明的经修饰的微生物的具体的优选实施方案,已经从中衍生经修饰的微生物的野生型属于Basfia属并且特别优选已经从中衍生经修饰的微生物的野生型属于Basfiasucciniciproducens物种。最优选地,本发明修饰微生物所来源的野生型是根据布达佩斯条约保藏于DSMZ(德意志微生物保藏中心(DeutscheSammlungvonMikroorganismenundZellkulturenGmbH),德国)的Basfiasucciniciproducens菌株DD1,其具有保藏编号DSM18541。该菌株已经最初从德国起源的牛的瘤胃分离。巴氏杆菌属(Pasteurella)细菌可以从动物和优选地哺乳动物的胃肠道分离。细菌菌株DD1尤其可以从牛瘤胃分离并且能够利用甘油(包括粗制甘油)作为碳源。可以用于制备本发明修饰微生物的Basfia属其他菌株是是已经按保藏编号DSM22022保藏的Basfia菌株或已经在瑞典哥德堡大学培养物保藏中心保藏的具有保藏编号CCUG57335、CCUG57762、CCUG57763、CCUG57764、CCUG57765或CCUG57766的Basfia菌株。该菌株已经最初从德国或瑞士起源的牛的瘤胃分离。在这种情况下,特别优选本发明修饰微生物所来源的野生型具有SEQIDNO:1的16SrDNA或显示与SEQIDNO:1的至少96%、至少97%、至少98%、至少99%或至少99.9%序列同源性的序列。还优选本发明修饰微生物所来源的野生型具有SEQIDNO:2的23SrDNA或显示与SEQIDNO:2的至少96%、至少97%、至少98%、至少99%或至少99.9%序列同源性的序列。连同待用于本发明的经修饰的微生物的多种多肽或多核苷酸所提到的以百分数值计的同一性优选地计算为所比对的序列的整个全长上的残基同一性,例如,采用以下默认参数,借助来自生物信息学软件包EMBOSS(第5.0.0版,http://emboss.source-forge.net/what/)的程序needle计算的同一性(对于相当相似的序列):空位开口(空位开口罚分):10.0;空位延伸(空位延伸罚分):0.5和数据文件(软件包中包含的评分矩阵):EDNAFUL。应当指出,本发明的修饰微生物不能仅来自上文提到的野生型微生物,特别来自Basfiasucciniciproducens菌株DD1,还来自这些菌株的变体。在这种情况下,表述“菌株的变体”包括具有与野生型菌株相同或基本上相同的特征的每个菌株。在这种情况下,特别优选该变体的16SrDNA与该变体所来自的野生型具有至少90%、优选地至少95%、更优选地至少99%、更优选地至少99.5%、更优选地至少99.6%、更优选地至少99.7%、更优选地至少99.8%和最优选地至少99.9%的同一性。还特别优选该变体的23SrDNA与该变体所来自的野生型具有至少90%、优选地至少95%、更优选地至少99%、更优选地至少99.5%、更优选地至少99.6%、更优选地至少99.7%、更优选地至少99.8%和最优选地至少99.9%的同一性。在这种定义的含义下,可以例如通过用诱变化学剂、X射线或UV光处理野生型菌株获得菌株的变体。本发明修饰微生物的特征在于,相比其野生型,由fruA-基因编码的酶活性减少。酶活性减少(Δ活性)定义如下:其中,当测定Δ活性时,野生型中的活性和修饰的微生物中的活性在完全相同的条件下测定。可以例如在以上参考的Lee等人的出版物中找到用于检测和测定由fruA-基因编码的酶的活性的方法。本文公开的酶的活性减少、尤其由fruA-基因编码的酶、乳酸脱氢酶和/或丙酮酸甲酸裂合酶的活性减少可以是与所述酶在野生型微生物中的活性相比,酶活性减少至少50%、或酶活性减少至少90%或更优选地酶活性减少至少95%、或更优选地酶活性减少至少98%、或甚至更优选地酶活性减少至少99%或甚至更优选地酶活性减少至少99.9%。术语“由fruA-基因编码的酶的减少的活性”或–如下文描述–“减少的乳酸脱氢酶活性”或“减少的丙酮酸甲酸裂合酶活性”,还涵盖具有这些酶的不可检出活性的修饰微生物。术语“酶的减少的活性”例如包括由所述基因操作的(例如,基因工程化的)微生物以比所述微生物野生型表达的水平更低的水平表达酶。减少酶表达的基因操作可以包括,但不限于缺失编码酶的基因或其部分、改变或修饰与表达编码酶的基因相关联的调节序列或位点(例如,通过移除强启动子或阻遏型启动子)、修饰参与转录编码酶的基因和/或基因产物翻译的蛋白质(例如,调节蛋白、阻抑子、增强子、转录激活子等)或本领域常规的减少特定基因表达的任何其他常规手段(包括但不限于,使用敲除或阻断靶蛋白表达的反义核酸分子或其他方法)。另外,可以将去稳定化元件引入mRNA中或引入导致RNA的核糖体结合位点(RBS)劣化的基因修饰。还可能以降低翻译效率和速度的方式改变基因的密码子使用。也可以通过引入导致酶活性减少的一个或多个基因突变,获得减少的酶活性。另外,减少酶活性还可以包括失活下述活化酶的(或减少其表达),所述活化酶是激活待减少其活性的酶必需的。通过后一种方案,优选地保持待减少其活性的酶处于失活状态。由fruA-基因编码的酶活性减少的微生物可以天然地存在,即因自发性突变产生。可以通过多种技术(如化学处理或辐射)修饰某微生物以缺少或具有由fruA-基因编码的酶的显著减少活性。为此目的,微生物将例如受诱变化学剂、X射线或UV光处理。在后续步骤中,将选出这些微生物,所述微生物具有由fruA-基因编码的酶的减少活性。修饰的微生物还通过同源重组技术可获得,所述同源重组技术旨在突变、破坏或切除该微生物基因组中的fruA-基因或旨在将该基因置换为编码下述酶的相应基因,与野生型基因编码的酶相比,所述酶具有减少的活性。根据本发明修饰微生物的一个优选实施方案,通过修饰fruA-基因实现由fruA-基因编码的酶的活性减少,其中优选地通过缺失fruA-基因或至少其部分、缺失fruA-基因的调节元件或其部分如启动子序列、或通过向fruA-基因引入至少一个突变,实现这种基因修饰。在下文中,描述用于重组、尤其用于引入突变或用于缺失序列的合适技术。这项技术在本文中有时也称作“Campbell重组”(Leenhouts等人,ApplEnvMicrobiol.(1989),第55卷,第394-400页)。如本文所用,“Campbellin”指原始宿主细胞的转化体,在所述转化体中,完整环状双链DNA分子(例如质粒)已经通过单个同源重组事件(crossin事件)整合入染色体,并且所述转化体有效地导致线性化形式的所述环状DNA分子插入染色体的第一DNA序列,所述第一DNA序列与所述环状DNA分子的第一DNA序列同源。“Campbelledin”指已经整合至“Campbellin”转化体的染色体中的线性化DNA序列。“Campbellin”含有第一同源性DNA序列的重复,其每个拷贝包括并且包围同源重组交叉点的副本。如本文中所用,“Campbellout”指起源于“Campbellin”转化体的细胞,其中第二同源重组事件(crossout事件)已经在“Campbelledin”DNA的线性化的插入的DNA上所含有的第二DNA序列和与所述线性化插入物的第二DNA序列同源的染色体源的第二DNA序列之间发生,第二重组事件导致整合的DNA序列的一部分缺失(丢弃),但是,重要的,还导致整合的CampbelledinDNA的一部分(这可以小至单个碱基)留在染色体中,从而与原始宿主细胞相比,“Campbellout”细胞在染色体中含有一个或多个刻意变化(例如,单碱基置换、多碱基置换、插入异源基因或DNA序列,插入同源基因或修饰的同源基因的一个额外拷贝或多个拷贝,或插入包含多于一个上文所列的前述这些例子的DNA序列)。优选地通过对基因反向选择获得“Campbellout”细胞,所述基因含有于“Campbelledin”DNA序列的一部分(需要抛弃的部分),例如枯草芽孢杆菌(Bacillussubtilis)sacB基因,其在约5%至10%蔗糖存在下生长的细胞中表达时致死。借助或不借助反向选择,可以通过使用任何可筛选表型如,但不限于菌落形态、菌落颜色、抗生素耐药性的存在或不存在、借助聚合酶链反应判断给定DNA序列的存在或不存在、某种营养缺陷型的存在或不存在、某种酶的存在或不存在、菌落核酸杂交、抗体筛选法等筛选所需细胞,获得或鉴定所需的“Campbellout”细胞。术语“Campbellin”和“Campbellout”也可以用作多种时态的动词以指称上文所述的方法或过程。可以理解,导致“Campbellin”或“Campbellout”的同源重组事件可以在同源性DNA序列内部的DNA碱基的范围内发生,并且由于同源序列将对于这个范围的至少部分是彼此相同的,所以通常不可能确切指定交叉事件在何处发生。换句话说,不可能确切指出哪个序列最初来自插入的DNA并且哪个序列最初来自染色体DNA。另外,第一同源性DNA序列和第二同源性DNA序列通常由一个部分非同源区域隔开,并且正是这个非同源区域仍放置在“Campbellout”细胞的染色体中。优选地,第一和第二同源性DNA序列长至少约200碱基对,并且可以长达几千碱基对。然而,可以用更短或更长的序列实施该过程。例如,第一和第二同源序列的长度可以是从约500个至2000个碱基的范围,并且通过设置第一和第二同源序列具有大致相同的长度、优选地具有少于200碱基对的差异并且最优选地二者中较短者碱基对长度是较长者碱基对长度的至少70%,协助从“Campbellin”获得“Campbellout”。其活性在本发明的修饰微生物中减少的fruA-基因优选地包含选自以下的核酸:a)具有SEQIDNO:3的核苷酸序列的核酸;b)编码SEQIDNO:4的氨基酸序列的核酸;c)与a)或b)的核酸至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%同一的核酸,同一性是在a)或b)的核酸总长度范围内的同一性;d)编码氨基酸序列的核酸,所述氨基酸序列与a)或b)的核酸编码的氨基酸序列至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%同一,同一性是在a)或b)的核酸编码的氨基酸序列的总长度范围内的同一性;e)能够在严格条件下与根据a)或b)的任一核酸的互补序列杂交的核酸;和f)与a)或b)的任一核酸编码相同的蛋白质,但因遗传密码简并性而与上文a)或b)的核酸不同的核酸。如本文中所用,术语“杂交”包括“核酸分子的链通过碱基配对作用与互补链结合的任意过程”(J.Coombs(1994)DictionaryofBiotechnology,StocktonPress,NewYork)。杂交和杂交的强度(即,核酸分子之间结合的强度)受此类因素影响,如核酸分子之间的互补性程度、所涉及条件的严格性、所形成杂合体的Tm和核酸分子内部的G:C比。如本文中所用,术语“Tm”用来指“解链温度”。解链温度是双链核酸分子群体一半解离成单链的温度。用于计算核酸分子的Tm的等式是本领域熟知的。如标准参考文献所示,当核酸分子处于1MNaCl的水溶液中时,可以通过等式:Tm=81.5+0.41(%G+C)计算来进行Tm值的简单估计(见例如,Anderson和Young,QuantitativeFilterHybridization,inNucleicAcidHybridization(1985))。其他参考文献包括更复杂计算法,这些算法考虑了结构特征及序列特征以计算Tm。严格条件是本领域技术人员已知的并且可以在CurrentProtocolsinMolecularBiology,JohnWiley&Sons,N.Y.(1989),6.3.1-6.3.6中找到。特别地,术语“严格性条件”指这些条件,其中作为互补核酸分子(DNA、RNA、ssDNA或ssRNA)的片段或与互补核酸分子(DNA、RNA、ssDNA或ssRNA)相同的100个或更多个连续核苷酸、150个或更多个连续核苷酸、200个或更多个连续核苷酸或250个或更多个连续核苷酸在等同于在50℃在7%十二烷基硫酸钠(SDS)、0.5MNaPO4、1mMEDTA中杂交同时在50℃或65℃、优选地在65℃于2×SSC、0.1%SDS中洗涤的条件下与特定核酸分子(DNA、RNA、ssDNA或ssRNA)杂交。优选地,该杂交条件等同于在50℃在7%十二烷基硫酸钠(SDS)、0.5MNaPO4、1mMEDTA中杂交,同时在50℃或65℃、优选地65℃于1×SSC、0.1%SDS中洗涤,更优选地,该杂交条件等同于在50℃在7%十二烷基硫酸钠(SDS)、0.5MNaPO4、1mMEDTA中杂交,同时在50℃或65℃、优选地在65℃于0.1×SSC、0.1%SDS中洗涤。优选地,互补核苷酸与fruA核酸的片段或完整fruA核酸杂交。备选地,优选的杂交条件涵盖在65℃在1×SSC中或在42℃在1×SSC和50%甲酰胺中杂交,随后在65℃在0.3×SSC中洗涤或在50℃在4×SSC中或在40℃在6×SSC和50%甲酰胺中杂交,随后在50℃在2×SSC中洗涤。其他优选的杂交条件是0.1%SDS、0.1xSSD和65℃。可以通过上文提到的“Campbell重组”缺失或其中通过上文提到的“Campbell重组”引入至少一个突变的fruA-基因或其部分优选地包含如上文定义的核酸。具有SEQIDNO:3的核苷酸序列的核酸对应于Basfiasucciniciproducens-菌株DD1的fruA-基因。根据本发明的修饰微生物的优选实施方案,修饰的微生物不以蔗糖介导的甘油分解代谢阻遏为特征。显示蔗糖介导的甘油分解代谢阻遏的微生物例如在WO-A-2012/030130中公开。另外,优选是在本发明的修饰微生物中,不缺失选自pta-基因和ackA-基因的至少一个基因。优选地,既不缺失ptA-基因,又不缺失ackA-基因。在这种情况下,特别优选在本发明的修饰微生物中,由pta-基因编码的酶(其是磷酸转乙酰酶)的活性、由ackA-基因编码的酶(其是乙酸盐激酶)的活性或由pta-基因编码的酶的活性和由ackA-基因编码的酶的活性与野生型中这种酶/这些酶的相应活性相比,不减少。根据本发明修饰微生物的又一个优选的实施方案,这种微生物不仅特征为fruA-基因编码的酶的活性减少,与野生型相比,还特征如下:i)减少的丙酮酸甲酸裂合酶活性,ii)减少的乳酸脱氢酶活性,iii)减少的丙酮酸甲酸裂合酶活性和减少的乳酸脱氢酶活性。存在乳酸脱氢酶缺陷和/或存在丙酮酸甲酸裂合酶活性缺陷的修饰微生物在WO-A-2010/092155、US2010/0159543和WO-A-2005/052135中公开,其中就减少微生物中、优选地巴氏杆菌属细菌细胞中、特别优选地Basfiasucciniciproducens菌株DD1中乳酸脱氢酶和/或丙酮酸甲酸裂合酶活性的不同方法而言,通过引用方式并入所述文献的公开内容。用于确定丙酮酸甲酸裂合酶活性的方法例如由AsanumN.和HinoT.在“EffectsofpHandEnergySupplyonActivityandAmountofPyruvate-Formate-LyaseinStreptococcusbovis”,Appl.Environ.Microbiol.(2000),第66卷,第3773-3777页中公开,并且用于确定乳酸脱氢酶活性的方法是例如由Bergmeyer,H.U.,BergmeyerJ.和Grassl,M.(1983-1986)在“MethodsofEnzymaticAnalysis”,第3版,第III卷,第126-133页,VerlagChemie,Weinheim中公开。在这种情况下,优选通过失活ldhA-基因(其编码乳酸脱氢酶;LdhA;EC1.1.1.27或EC1.1.1.28)实现乳酸脱氢酶活性的减少并且通过失活pflA-基因(其编码丙酮酸甲酸裂合酶的激活蛋白;PflA;EC1.97.1.4)或pflD-基因(其编码丙酮酸甲酸裂合酶;PflD;EC2.3.1.54)实现丙酮酸甲酸裂合酶活性的减少,其中优选地通过以下方式实现这些基因(即ldhA、pflA和pflD)的失活:缺失这些基因或其部分,缺失这些基因的调节元件或至少其部分或向这些基因引入至少一个突变,其中这些修饰优选地借助如上文所述的“Campbell重组”进行。其活性在本发明的修饰微生物中减少的ldhA-基因优选地包含选自以下的核酸:α1)具有SEQIDNO:9的核苷酸序列的核酸;α2)编码SEQIDNO:10的氨基酸序列的核酸;α3)与α1)或α2)的核酸至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%相同的核酸,同一性是在α1)或α2)的核酸总长度范围内的同一性;α4)编码氨基酸序列的核酸,所述氨基酸序列与α1)或α2)的核酸编码的氨基酸序列至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%相同,同一性是在α1)或α2)的核酸编码的氨基酸序列的总长度范围内的同一性;α5)能够在严格条件下与根据α1)或α2)的任何核酸的互补序列杂交的核酸;和α6)编码与α1)或α2)的任何核酸相同的蛋白质,但因遗传密码简并性而与上文α1)或α2)的核酸不同的核酸。其活性在本发明的修饰微生物中减少的pflA-基因优选地包含选自以下的核酸:β1)具有SEQIDNO:11的核苷酸序列的核酸;β2)编码SEQIDNO:12的氨基酸序列的核酸;β3)与β1)或β2)的核酸至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%相同的核酸,同一性是在β1)或β2)的核酸总长度范围内的同一性;β4)编码氨基酸序列的核酸,所述氨基酸序列与β1)或β2)的核酸编码的氨基酸序列至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%相同,同一性是在β1)或β2)的核酸编码的氨基酸序列的总长度范围内的同一性;β5)能够在严格条件下与根据β1)或β2)的任何核酸的互补序列杂交的核酸;和β6)编码与β1)或β2)的任何核酸相同的蛋白质,但因遗传密码简并性而与上文β1)或β2)的核酸不同的核酸。其活性在本发明的修饰微生物中减少的pflD-基因优选地包含选自以下的核酸:γ1)具有SEQIDNO:13的核苷酸序列的核酸;γ2)编码SEQIDNO:14的氨基酸序列的核酸;γ3)与γ1)或γ2)的核酸至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%相同的核酸,同一性是在γ1)或γ2)的核酸总长度范围内的同一性;γ4)编码氨基酸序列的核酸,所述氨基酸序列与γ1)或γ2)的核酸编码的氨基酸序列至少70%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%、最优选地100%相同,同一性是在γ1)或γ2)的核酸编码的氨基酸序列的总长度范围内的同一性;γ5)能够在严格条件下与根据γ1)或γ2)的任何核酸的互补序列杂交的核酸;和γ6)编码与γ1)或γ2)的任何核酸相同的蛋白质,但因遗传密码简并性而与上文γ1)或γ2)的核酸不同的核酸。在这种情况下,优选本发明的修饰微生物还包含:A)ldhA-基因或至少其部分的缺失、ldhA-基因调节元件或至少其部分的缺失或向ldhA-基因引入至少一个突变;B)pflD-基因或至少其部分的缺失、pflD-基因调节元件或至少其部分的缺失或向pflD-基因引入至少一个突变;C)pflA-基因或至少其部分的缺失、pflA-基因调节元件或至少其部分的缺失或向pflA-基因引入至少一个突变;D)ldhA-基因或至少其部分的缺失、ldhA-基因调节元件或至少其部分的缺失或向ldhA-基因引入至少一个突变和pflD-基因或至少其部分的缺失、pflD-基因调节元件或至少其部分的缺失或向pflD-基因引入至少一个突变;或E)ldhA-基因或至少其部分的缺失、ldhA-基因调节元件或至少其部分的缺失或向ldhA-基因引入至少一个突变和pflA-基因或至少其部分的缺失、pflA-基因调节元件或至少其部分的缺失或向pflA-基因引入至少一个突变。本发明的修饰微生物的具体的优选实施方案是:-Basfia属的修饰的细菌细胞和特别优选物种Basfiasucciniciproducens的修饰的细菌细胞,其中已经缺失fruA-基因或至少其部分或其中已经在fruA-基因中引入至少一个突变,其中进一步优选修饰的细菌细胞不以蔗糖介导的甘油分解代谢阻遏为特征;-Basfia属的修饰的细菌细胞和特别优选物种Basfiasucciniciproducens的修饰的细菌细胞,其中已经缺失fruA-基因或至少其部分或其中已经在fruA-基因中引入至少一个突变,并且其中与野生型相比,减少乳酸脱氢酶的活性,优选地通过修饰ldhA-基因、尤其通过修饰下述ldhA-基因,所述ldhA-基因具有根据SEQIDNO:9的核酸序列并且编码具有根据SEQIDNO:10的氨基酸序列的LdhA,其中进一步优选修饰的微生物不以蔗糖介导的甘油分解代谢阻遏为特征;-Basfia属的修饰的细菌细胞和特别优选物种Basfiasucciniciproducens的修饰的细菌细胞,其中已经缺失fruA-基因或至少其部分或其中已经在fruA-基因中引入至少一个突变,并且其中与野生型相比,减少丙酮酸甲酸裂合酶的活性,优选地通过修饰pflA-基因或pflD-基因、尤其通过修饰下述pflA-基因或通过修饰下述pflD-基因,所述pflA-基因具有根据SEQIDNO:11的核酸序列并且编码具有根据SEQIDNO:12的氨基酸序列的PflA,所述pflD-基因具有根据SEQIDNO:13的核酸序列并且编码具有根据SEQIDNO:14的氨基酸序列的PflD,其中进一步优选修饰的细菌细胞不以蔗糖介导的甘油分解代谢阻遏为特征;-Basfia属的修饰的细菌细胞和特别优选物种Basfiasucciniciproducens的修饰的细菌细胞,其中已经缺失fruA-基因或至少其部分或其中已经在fruA-基因中引入至少一个突变,并且其中与野生型相比,减少乳酸脱氢酶和丙酮酸甲酸裂合酶的活性,优选地通过修饰ldhA-基因和pflA-基因、尤其通过修饰下述ldhA-基因或通过修饰下述pflA-基因减少乳酸脱氢酶和丙酮酸甲酸裂合酶的活性,所述ldhA-基因具有根据SEQIDNO:9的核酸序列并且编码具有根据SEQIDNO:10的氨基酸序列的LdhA,所述pflA-基因具有根据SEQIDNO:11的核酸序列并且编码具有根据SEQIDNO:12的氨基酸序列的PflA,或通过修饰ldhA-基因和pflD-基因、尤其通过修饰下述ldhA-基因或通过修饰下述pflD-基因减少乳酸脱氢酶和丙酮酸甲酸裂合酶的活性,所述ldhA-基因具有根据SEQIDNO:9的核酸序列并且编码具有根据SEQIDNO:10的氨基酸序列的LdhA,所述pflD-基因具有根据SEQIDNO:13的核酸序列并且编码具有根据SEQIDNO:14的氨基酸序列的PflD,其中进一步优选修饰的细菌细胞不以蔗糖介导的甘油分解代谢阻遏为特征。进一步通过产生有机化合物的方法提供解决一开始所提到问题的促进手段,所述方法包括:I)在包含蔗糖作为可同化碳源的培养基中培养根据本发明的修饰微生物以允许修饰的微生物产生有机化合物,因而获得包含有机化合物的发酵液;II)从过程步骤I)中获得的发酵液回收有机化合物。在过程步骤I)中,将根据本发明的修饰微生物在包含蔗糖作为可同化碳源的培养基中培养以允许修饰的微生物产生有机化合物,因而获得包含有机化合物的发酵液。可以通过本发明方法产生的优选有机化合物包括羧酸如甲酸、乳酸、丙酸、2-羟基丙酸、3-羟基丙酸、3-羟基丁酸、丙烯酸、丙酮酸或这些羧酸的盐、二羧酸如丙二酸、琥珀酸、苹果酸、酒石酸、戊二酸、衣康酸、己二酸或其盐,三羧酸如柠檬酸或其盐,醇如甲醇或乙醇、氨基酸如L-天冬酰胺、L-天冬氨酸、L-精氨酸、L-异亮氨酸、L-甘氨酸、L-谷氨酰胺,L-谷氨酸、L-半胱氨酸、L-丝氨酸、L-酪氨酸、L-色氨酸、L-苏氨酸、L-缬氨酸、L-组氨酸、L-脯氨酸、L-甲硫氨酸、L-赖氨酸、L-亮氨酸等。根据本发明方法的一个优选实施方案,有机化合物是琥珀酸。如本发明上下文中所用,术语“琥珀酸”应当以其最广意义理解并且还涵盖其盐(即,琥珀酸盐),例如碱金属盐,如Na+盐和K+盐,或碱土金属盐,如Mg2+盐和Ca2+盐,或琥珀酸的铵盐或酐。优选地在培养基中在约10℃至60℃或20℃至50℃或30℃至45℃范围内的温度在5.0至9.0或5.5至8.0或6.0至7.0的pH温育本发明的修饰微生物。优选地,有机化合物,尤其琥珀酸,在无氧条件下产生。可以借助常规技术建立无氧条件,例如通过使反应介质组分排气并且通过以例如0.1至1或0.2至0.5vvm流速引入二氧化碳或氮气或其混合物和任选地氢,维持厌氧条件。可以借助常规技术建立需氧条件,例如通过以例如0.1至1或0.2至0.5vvm流速引入空气或氧气。如果需要,可以在过程中应用0.1至1.5巴的略微较高压力。可同化碳源优选地是蔗糖。根据本发明方法的一个优选实施方案,可同化碳源不是甘油和蔗糖的混合物。在这种情况下,优选基于可同化碳源(二氧化碳除外)的总重量,至少50wt.%、优选地至少75wt.%、更优选地至少90wt.%、甚至更优选地至少95wt.%和最优选地至少99wt.%的可同化碳源是蔗糖。另外优选基于可同化碳源的总重量,小于50wt.%、优选地小于25wt.%,更优选地小于10wt.%,甚至更优选地小于5wt.%和最优选地小于1wt.%的可同化碳源是甘油。将可同化碳源的初始浓度调节至、优选地将蔗糖的初始浓度调节至5至100g/l、优选地5至75g/l和更优选地5至50g/l范围内的值,并且可以在培养期间维持所述初始浓度处于所述范围内。反应介质的pH可以通过添加合适的碱控制,所述碱例如是氨气、NH4HCO3、(NH4)2CO3、NaOH、Na2CO3、NaHCO3、KOH、K2CO3、KHCO3、Mg(OH)2、MgCO3、Mg(HCO3)2、Ca(OH)2、CaCO3、Ca(HCO3)2、CaO、CH6N2O2、C2H7N和/或其混合物。如果发酵过程期间形成的有机化合物是羧酸或二羧酸,则尤其需要这些碱性中和剂。在作为有机化合物的琥珀酸情况下,Mg(OH)2是特定优选的碱。本发明的发酵步骤I)可以例如在搅拌式发酵罐、鼓泡塔和环流反应器中进行。可以在Chmiel:“Bioprozesstechnik:EinführungindieBioverfahrenstechnik”,第1卷"中找到可能方法类型的综合概览,包括搅拌器类型和几何设计。在本发明的方法中,可用的常见变例是本领域技术人员(例如在Chmiel,HammesandBailey:“BiochemicalEngineering”中)已知或解释的以下变体,如分批发酵、补料分批、重复补料分批或另外伴随或不伴随生物质再循环的连续发酵。取决于生产菌株,可以用空气、氧、二氧化碳、氢气、氮气或适宜气体混合物实现鼓泡以实现良好产量(YP/S)。在过程步骤I)中产生有机酸、尤其琥珀酸的特别优选条件是:可同化碳源:蔗糖温度:30℃至45℃pH:5.5至7.0供应的气体:CO2在过程步骤I)中进一步优选,可同化碳源、优选地蔗糖,转化成有机化合物,优选地转化成琥珀酸,其中碳产率YP/S是至少0.5g/g直至约1.18g/g;例如碳产率YP/S为至少0.6g/g、至少0.7g/g、至少0.75g/g、至少0.8g/g、至少0.85g/g、至少0.9g/g、至少0.95g/g、至少1.0g/g、至少1.05g/g或至少1.1g/g(有机化合物/碳,优选地琥珀酸/碳)。在过程步骤I)中还优选,可同化碳源、优选地蔗糖,转化成有机化合物,优选地转化成琥珀酸,其中比生产率产量(specificproductivityyield)是至少0.6ggDCW-1h-1有机化合物,优选地琥珀酸,或是至少0.65ggDCW-1h-1、至少0.7ggDCW-1h-1、至少0.75ggDCW-1h-1或至少0.77ggDCW-1h-1有机化合物,优选地琥珀酸。在过程步骤I)中还优选,蔗糖转化成有机化合物,优选地转化成琥珀酸,有机化合物、优选地琥珀酸的空间时间产率是至少2.2g/(L×h)或至少2.5g/(L×h)、至少2.75g/(L×h)、至少3g/(L×h)、至少3.25g/(L×h)、至少3.5g/(L×h)、至少3.7g/(L×h)、至少4.0g/(L×h)至少4.5g/(L×h)或至少5.0g/(L×h)有机化合物,优选地琥珀酸。根据本发明方法的另一个优选实施方案,在工艺步骤I)中修饰的微生物将至少20g/L,更优选地至少25g/l和甚至更优选地至少30g/l蔗糖转化成至少20g/l、更优选地至少25g/l和甚至更优选地至少30g/l有机化合物、优选地琥珀酸。如本文所述的不同产量参数(“碳产率”或“YP/S”;“比生产率产量”;或“空间-时间-产率(STY)”)是本领域熟知的并且例如由Song和Lee,2006所述那样测定。“碳产率”和“YP/S”(各自以产生的有机化合物的质量/消耗的可同化碳源的质量表述)在本文中作为同义词使用。比生产率产量描述每小时和每升发酵液每g生物质产生的产物(如琥珀酸)的量。称作“DCW”的干细胞重量的量描述了生物化学反应中有生物活性的微生物的量。该值作为g产物/gDCW/小时(即ggDCW-1h-1)给出。空间-时间-产率(STY)定义为在整个培养时间范围内考虑时在发酵过程中形成的有机化合物的总量对培养物体积的比率。空间-时间-产率也称作“体积生产率”。在过程步骤II)中,从过程步骤I)中获得的发酵液回收有机化合物、优选地琥珀酸。通常,回收方法包括步骤:将重组微生物从发酵液作为所谓“生物质”分离。用于取出生物质的方法是本领域技术人员已知的,并且包括过滤、沉积和浮选或其组合。因此,生物质可以用例如离心机、分离器、倾析器、滤器或在浮选装置中取出。为了最大限度回收有价值的产物,经常建议洗涤生物质,例如以渗滤形式洗涤。方法的选择取决于发酵液中的生物质含量和生物质的特性,并且还取决于生物质与有机化合物(即有价值产物)的相互作用。在一个实施方案中,可以将发酵液消毒或巴氏消毒。在又一个实施方案中,浓缩发酵液。取决于要求,该浓缩可以分批或连续地进行。应当如此选择压力和温度范围,从而首先不出现产物受损,并且其次必须最少使用装置和能量。熟练选择用于多步蒸发的压力和温度水平尤其能够节省能量。回收过程还可以包括其中进一步纯化有机化合物、优选地琥珀酸的额外纯化步骤。然而,如果有机化合物通过如下文描述的化学反应转化成次级有机产物,则取决于反应类别和反应条件,不必然要求进一步纯化有机化合物。为了纯化过程步骤II)中获得的化合物,优选地纯化琥珀酸,可以例如使用本领域技术人员已知的方法,如结晶、过滤、电渗析和色谱。在琥珀酸作为有机化合物的情况下,例如,可以通过以下方式分离琥珀酸:通过使用氢氧化钙、氧化钙、碳酸钙或碳酸氢钙中和并过滤沉淀物,将琥珀酸通过作为琥珀酸钙产物沉淀来分离。通过用硫酸酸化作用,随后过滤以移除沉淀的硫酸钙(石膏),从沉淀的琥珀酸钙回收琥珀酸。所产生的溶液可以通过离子交换色谱进一步纯化以除去不想要的残余离子。备选地,如果氢氧化镁,碳酸镁或其混合物已经用来中和发酵液,则可以酸化过程步骤I)中获得的发酵液以转化培养基中所含的琥珀酸镁成为酸形式(即琥珀酸),后者随后可以通过冷却酸化的培养基而结晶。其他合适的纯化过程的例子在EP-A-1005562,WO-A-2008/010373,WO-A-2011/082378,WO-A-2011/043443,WO-A-2005/030973,WO-A-2011/123268和WO-A-2011/064151和EP-A-2360137中公开。根据本发明方法的一个优选实施方案,该过程还包含过程步骤:III)通过至少一个化学反应,将过程步骤I)中获得的发酵液内所含的有机化合物转化成或将过程步骤II)中获得的已回收有机化合物转化成与该有机化合物不同的次级有机产物。在琥珀酸作为有机化合物的情况下,优选的次级有机产物选自琥珀酸酯及其聚合物、四氢呋喃(THF)、1,4-丁二醇(BDO)、γ-丁内酯(GBL)和吡咯烷酮。根据一个用于产生THF、BDO和/或GBL的优选实施方案,这种方法包括:b1)将过程步骤I)或II)中获得的琥珀酸直接催化氢化成THF和/或BDO和/或GBL或b2)将过程步骤I)或II)中获得的琥珀酸和/或琥珀酸盐化学酯化成其相应双低级烷基酯并将所述酯后续催化氢化成THF和/或BDO和/或GBL。根据一个用于产生吡咯烷酮的优选实施方案,这种方法包括:b)将过程步骤I)或II)中获得的琥珀酸铵盐按本身已知的方式化学转化成吡咯烷酮。关于制备这些化合物的详情,参考US-A-2010/0159543和WO-A-2010/092155。进一步通过本发明的修饰微生物用于发酵产生有机化合物的用途提供了解决一开始所提到问题的促进手段。优选的有机化合物是已经与本发明方法相联系时提到的那些化合物,琥珀酸是最优选的有机化合物。另外,发酵产生有机化合物、优选地琥珀酸的优选条件是已经与本发明方法的过程步骤I)相联系时描述的那些条件。现在借助附图和非限制性例子更详细地解释本发明。图1显示质粒pSacB(SEQIDNO:5)的示意性图谱。图2显示质粒pSacBΔldhA(SEQIDNO:6)的示意性图谱。图3显示质粒pSacBΔpflA(SEQIDNO:7)的示意性图谱。图4显示质粒pSacBΔfruA(SEQIDNO:8)的示意性图谱。实施例实施例1:用于转化Basfiasucciniciproducens的一般方法菌株野生型DD1(保藏DSM18541)DD1ΔldhADD1ΔldhAΔfruADD1ΔldhAΔpflADD1ΔldhAΔpflAΔfruADD1ΔfruA表1:实施例中提到的DD1-野生型和突变体的命名使用以下方案,通过电穿孔法,用DNA转化BasfiasucciniciproducensDD1(野生型):为了制备预培养物,将DD1从冷冻贮存物接种至100ml摇瓶中的40mlBHI(心脑浸液;Becton,DickinsonandCompany)。孵育在37℃;200转/分钟过夜进行。为了制备主培养物,将100mlBHI置于250ml摇瓶中并用预培养物接种至最终OD(600nm)0.2。孵育在37℃,200转/分钟进行。在大约0.5、0.6和0.7的OD时收获细胞,将沉淀物用10%冷甘油在4℃洗涤1次并重悬于2ml10%甘油(4℃)中。将100μl感受态细胞与2-8μg质粒-DNA混合并且在冰上在宽度0.2cm的电穿孔杯中保持2分钟。电穿孔按以下条件进行:400Ω;25μF;2.5kV(GenePulser,Bio-Rad)。在电穿孔后立即添加1ml冰冷的BHI,并且孵育在37℃进行大约2小时。将细胞铺种在含5mg/L氯霉素的BHI上并且在37℃孵育2-5天直至转化体的菌落可见。将克隆分离并在含5mg/L氯霉素的BHI上再划线直至获得克隆纯化。实施例2:缺失构建体的产生基于载体pSacB(SEQIDNO:5)构建突变/缺失质粒。图1显示质粒pSacB的示意图。从Basfiasucciniciproducens的染色体DNA通过PCR扩增应当缺失的染色体片段的5’-和3’-侧翼区(各自大约1500bp),并且使用标准技术,将它们引入所述载体中。正常情况下,将至少80%的ORF靶向以缺失。以如此方式,构建了乳酸脱氢酶ldhA的缺失质粒pSacB_δ_ldhA(SEQIDNO:6)、丙酮酸甲酸裂合酶活化酶pflA的缺失质粒pSacB_δ_pflA(SEQID.NO.7)和推定性果糖特异性磷酸转移酶fruA的缺失质粒pSacB_δ_fruA(SEQIDNo:8)。图2、图3和图4分别显示质粒pSacB_δ_ldhA、pSacB_δ_pflA和pSacB_δ_fruA的示意性图谱。在pSacB的质粒序列(SEQIDNO:5)中,sacB基因含于碱基2380-3801。sacB-启动子含于碱基3802-4264。氯霉素基因含于碱基526-984。大肠杆菌复制起点(oriEC)含于碱基1477-233(参见图1)。在pSacB_δ_ldhA的质粒序列(SEQIDNO:6)中,与Basfiasucciniciproducens的基因组同源的ldhA基因5’侧翼区含于碱基1519-2850,而与Basfiasucciniciproducens的基因组同源的ldhA基因3’侧翼区含于碱基62-1518。sacB基因含于碱基5169-6590。sacB-启动子含于碱基6591-7053。氯霉素基因含于碱基3315-3773。大肠杆菌复制起点(oriEC)含于碱基4266-5126(参见图2)。在pSacB_δ_pflA的质粒序列(SEQIDNO:7)中,与Basfiasucciniciproducens的基因组同源的pflA基因5’侧翼区含于碱基1506-3005,而与Basfiasucciniciproducens的基因组同源的pflA基因3’侧翼区含于碱基6-1505。sacB基因含于碱基5278-6699。sacB-启动子含于碱基6700-7162。氯霉素基因含于碱基3424-3882。大肠杆菌复制起点(oriEC)含于碱基4375-5235(参见图3)。在pSacB_δ_fruA的质粒序列(SEQIDNO:8)中,与Basfiasucciniciproducens的基因组同源的fruA-基因3’侧翼区含于碱基1506-3005之间,而与Basfiasucciniciproducens的基因组同源的fruA-基因5’侧翼区含于碱基6-1505之间。sacB-基因含于碱基5278-6699之间。sacB-启动子含于碱基6700-7162之间。氯霉素基因含于碱基3424-3882之间。大肠杆菌复制起点(oriEC)含于碱基952-1812之间(参见图4)。实施例3:产生改进的琥珀酸酯产生菌株a)将BasfiasucciniciproducensDD1用pSacB_delta_ldhA如上文所述转化并“Campbelledin”以产生“Campbellin”菌株。通过产生质粒进入Basfiasucciniciproducens基因组的整合事件的条带的PCR证实转化和整合入Basfiasucciniciproducens基因组中。随后使用含有蔗糖的琼脂平板作为反向选择培养基,对“Campbellin”菌株“Campbelledout”,从而选择出sacB基因(功能)丧失。因此,将“Campbellin”菌株在25-35ml非选择性培养基(不含抗生素的BHI)中在37℃,220转/分钟孵育过夜。随后将过夜培养物在新鲜制备的含有BHI的蔗糖平板上(10%,无抗生素)划线并且在37℃孵育过夜(“第一次蔗糖转移”)。从第一次转移获得的单菌落再次在新鲜制备的含有BHI的蔗糖平板上(10%)划线并且在37℃孵育过夜(“第二次蔗糖转移”)。重复这个程序直至在蔗糖中最少完成5次转移(“第三、第四、第五次糖转移”)。术语“第一至第五次蔗糖转移”指在含有sacB-果聚糖-蔗糖酶基因的载体的染色体整合后菌株转移到含有蔗糖和生长培养基的琼脂平板上,目的在于选出sacB基因和包围质粒序列丢失的菌株。将来自第五次转移平板的单菌落接种到25-35ml非选择性培养基(不含抗生素的BHI)上并且在37℃,220转/分钟孵育过夜。将过夜培养物连续稀释并铺种在BHI平板上以获得孤立的单菌落。通过氯霉素敏感性证实含有野生型状态的ldhA基因座或ldhA基因突变/缺失的“Campbelledout”菌株。通过PCR分析鉴定并且证实这些菌株当中的突变/缺失突变体。这导致ldhA-缺失突变体BasfiasucciniciproducensDD1ΔldhA。b)将BasfiasucciniciproducensDD1ΔldhA用pSacB_delta_pflA如上文所述转化并“Campbelledin”以产生“Campbellin”菌株。通过PCR证实转化和整合。随后如先前所描述将“Campbellin”菌株“Campbelledout”。通过PCR分析鉴定并且证实这些菌株当中的缺失突变体。这导致ldhApflA-双缺失突变体BasfiasucciniciproducensDD1ΔldhAΔpflA。c)BasfiasucciniciproducensDD1ΔldhAΔpflA用pSacB_δ_fruA如上文所述转化并“Campbelledin”以产生“Campbellin”菌株。通过PCR证实转化和整合。随后如先前所描述将“Campbellin”菌株“Campbelledout”。通过PCR分析鉴定并且证实这些菌株当中的缺失突变体。这导致ldhApflDfruA-三重缺失突变体BasfiasucciniciproducensDD1ΔldhAΔpflAΔfruA。d)将BasfiasucciniciproducensDD1用pSacB_δ_fruA如上文所述转化并“Campbelledin”以产生“Campbellin”菌株。通过PCR证实转化和整合。随后如先前所描述将“Campbellin”菌株“Campbelledout”。通过PCR分析鉴定并且证实这些菌株当中的缺失突变体。这导致fruA-缺失突变体BasfiasucciniciproducensDD1ΔfruA。实施例4:基于蔗糖培养DD1和DD1ΔfruADD1-菌株的生产率与突变株DD1ΔfruA的生产率在蔗糖作为碳源存在下比较。利用下文描述的培养基和温育条件,分析生产率。1.培养基制备培养基的组成和制备如下表2(培养基CGM)、表3(微量元素溶液1)、表4(维生素溶液1)和表5(培养基LSM_1)中所述。化合物浓度[g/L]酵母提取物(BioSpringer)10.0CaCl2×2H2O0.2MgCl2×6H2O0.2(NH4)2SO42.0NaCl1.0K2HPO43.0MgCO350.0NaHCO38.4葡萄糖52表2:基于葡萄糖培养的培养基组成(培养基CGM)表3:痕量元素溶液1的组成。表4:维生素溶液1的组成表5:基于蔗糖培养的LSM_1培养基的组成。2.培养和分析为了培养预培养物,来自新鲜培养的BHI-琼脂平板(在37℃在无氧条件下温育过夜)的细菌用来接种100ml含有表2中所述的50mlCGM液体培养基连同CO2-气氛的带气密性丁基橡胶瓶塞的血清瓶至OD600=0.75。将各瓶在37℃和170转/分钟(振摇直径:2.5cm)温育。为了培养主培养物,2.5ml在CGM培养基中的细菌培养物(在11小时温育后)用来接种100ml含有表5中所述的50mlLSM_1液体培养基连同CO2-气氛的带气密性丁基橡胶瓶塞的血清瓶。在24小时后,通过HPLC(表13和表14中描述HPLC方法)对蔗糖的消耗量和羧酸的产生定量。通过使用分光光度计(Ultrospec3000,AmershamBiosciences,乌普萨拉,瑞典)测量600nm处吸光度(OD600),测量细胞生长。3.结果表6中显示采用DD1和DD1ΔfruA的培养实验的结果。基于蔗糖时,fruA的缺失导致显著增强的琥珀酸浓度和琥珀酸的增强碳产量。表6:基于蔗糖时DD1-菌株和DD1ΔfruA菌株的培养a培养时间b底物(蔗糖)的消耗量c琥珀酸,乳酸,甲酸,乙酸,丙酮酸和乙醇的形成gSA产率(SA/消耗底物的比率)h发现乙酸,乳酸,苹果酸,和甲酸的检测限在给定的HPLC方法中低于0.01g/l实施例5:基于蔗糖培养DD1ΔldhA和DD1ΔldhAΔfruADD1ΔldhA-菌株的生产率与突变株DD1ΔldhAΔfruA的生产率在蔗糖作为碳源存在下比较。利用下文描述的培养基和温育条件,分析生产率。1.培养基制备培养基(培养基P)的组成和制备如下表7中所述。表7:基于蔗糖培养的培养基P的组成。2.培养和分析为了培养主培养物,来自新鲜培养的BHI-琼脂平板(在37℃在无氧条件下温育过夜)的细菌用来接种100ml含有表7中所述的50ml液体培养基(培养基P)连同CO2-气氛的带气密性丁基橡胶瓶塞的血清瓶至OD600=0.75。将各瓶在37℃和170转/分钟(振摇直径:2.5cm)温育。在24小时后,通过HPLC(表13和表14中描述HPLC方法)对蔗糖的消耗量和羧酸的产生定量。通过使用分光光度计(Ultrospec3000,AmershamBiosciences,乌普萨拉,瑞典)测量600nm处吸光度(OD600),测量细胞生长。3.结果表8中显示采用DD1ΔldhA和DD1ΔldhAΔfruA的培养实验的结果。基于蔗糖时,fruA的缺失导致显著增强的琥珀酸浓度和琥珀酸的增强碳产量。表8:基于蔗糖时DD1ΔldhAΔpflA-菌株和DD1ΔldhAΔpflAΔfruA-菌株的培养a培养时间b底物(蔗糖)的消耗量c琥珀酸,乳酸,甲酸,乙酸,丙酮酸和乙醇的形成gSA产率(SA/消耗底物的比率)h发现乙酸,乳酸,苹果酸,和甲酸的检测限在给定的HPLC方法中低于0.01g/l实施例6:基于蔗糖培养DD1ΔldhAΔpflA和DD1ΔldhAΔpflAΔfruADD1ΔldhAΔpflA-菌株的生产率与突变株DD1ΔldhAΔpflAΔfruA的生产率在蔗糖作为碳源存在下比较。利用下文描述的培养基和温育条件,分析生产率。1.培养基制备培养基(LSM_2)的组成和制备如下表9、表10和表11中所述。表9:痕量元素溶液2的组成。表10:维生素溶液2的组成。表11:基于蔗糖培养的LSM_2培养基的组成。2.培养和分析为了培养主培养物,来自新鲜培养的BHI-琼脂平板(在37℃在无氧条件下温育过夜)的细菌用来接种100ml含有表11中所述的50ml液体培养基LSM_2连同CO2-气氛的带气密性丁基橡胶瓶塞的血清瓶至OD600=0.75。将各瓶在37℃和160转/分钟(振摇直径:2.5cm)温育。在24小时后,通过HPLC(表13和表14中描述HPLC方法)对蔗糖的消耗量和羧酸的产生定量。通过使用分光光度计(Ultrospec3000,AmershamBiosciences,乌普萨拉,瑞典)测量600nm处吸光度(OD600),测量细胞生长。3.结果表12中显示采用DD1ΔldhAΔpflA和DD1ΔldhAΔpflAΔfruA的培养实验的结果。基于蔗糖时,fruA的缺失导致显著增强的琥珀酸浓度和琥珀酸的增强碳产量。表12:基于蔗糖时DD1ΔldhAΔpflA-菌株和DD1ΔldhAΔpflAΔfruA-菌株的培养a培养时间b底物(蔗糖)的消耗量c琥珀酸,乳酸,甲酸,乙酸,丙酮酸和乙醇的形成gSA产率(SA/消耗底物的比率)h发现乙酸,乳酸,苹果酸,和甲酸的检测限在给定的HPLC方法中低于0.01g/l表13:分析琥珀酸、甲酸、乳酸、乙酸、丙酮酸和乙醇的HPLC方法(ZX-THF50)表14:分析蔗糖的HPLC方法(Fast-CH)序列SEQIDNO:1(菌株DD1的16SrDNA的核苷酸序列)tttgatcctggctcagattgaacgctggcggcaggcttaacacatgcaagtcgaacggtagcgggaggaaagcttgctttctttgccgacgagtggcggacgggtgagtaatgcttggggatctggcttatggagggggataacgacgggaaactgtcgctaataccgcgtaatatcttcggattaaagggtgggactttcgggccacccgccataagatgagcccaagtgggattaggtagttggtggggtaaaggcctaccaagccgacgatctctagctggtctgagaggatgaccagccacactggaactgagacacggtccagactcctacgggaggcagcagtggggaatattgcacaatggggggaaccctgatgcagccatgccgcgtgaatgaagaaggccttcgggttgtaaagttctttcggtgacgaggaaggtgtttgttttaataggacaagcaattgacgttaatcacagaagaagcaccggctaactccgtgccagcagccgcggtaatacggagggtgcgagcgttaatcggaataactgggcgtaaagggcatgcaggcggacttttaagtgagatgtgaaagccccgggcttaacctgggaattgcatttcagactgggagtctagagtactttagggaggggtagaattccacgtgtagcggtgaaatgcgtagagatgtggaggaataccgaaggcgaaggcagccccttgggaagatactgacgctcatatgcgaaagcgtggggagcaaacaggattagataccctggtagtccacgcggtaaacgctgtcgatttggggattgggctttaggcctggtgctcgtagctaacgtgataaatcgaccgcctggggagtacggccgcaaggttaaaactcaaatgaattgacgggggcccgcacaagcggtggagcatgtggtttaattcgatgcaacgcgaagaaccttacctactcttgacatccagagaatcctgtagagatacgggagtgccttcgggagctctgagacaggtgctgcatggctgtcgtcagctcgtgttgtgaaatgttgggttaagtcccgcaacgagcgcaacccttatcctttgttgccagcatgtaaagatgggaactcaaaggagactgccggtgacaaaccggaggaaggtggggatgacgtcaagtcatcatggcccttacgagtagggctacacacgtgctacaatggtgcatacagagggcggcgataccgcgaggtagagcgaatctcagaaagtgcatcgtagtccggattggagtctgcaactcgactccatgaagtcggaatcgctagtaatcgcaaatcagaatgttgcggtgaatacgttcccgggccttgtacacaccgcccgtcacaccatgggagtgggttgtaccagaagtagatagcttaaccttcggggggggcgtttaccacggtatgattcatgactggggtgaagtcgtaacaaggtaaccgtaggggaacctgcggSEQIDNO:2(菌株DD1的23SrDNA的核苷酸序列)agtaataacgaacgacacaggtataagaatacttgaggttgtatggttaagtgactaagcgtacaaggtggatgccttggcaatcagaggcgaagaaggacgtgctaatctgcgaaaagcttgggtgagttgataagaagcgtctaacccaagatatccgaatggggcaacccagtagatgaagaatctactatcaataaccgaatccataggttattgaggcaaaccgggagaactgaaacatctaagtaccccgaggaaaagaaatcaaccgagattacgtcagtagcggcgagcgaaagcgtaagagccggcaagtgatagcatgaggattagaggaatcggctgggaagccgggcggcacagggtgatagccccgtacttgaaaatcattgtgtggtactgagcttgcgagaagtagggcgggacacgagaaatcctgtttgaagaaggggggaccatcctccaaggctaaatactcctgattgaccgatagtgaaccagtactgtgaaggaaaggcgaaaagaaccccggtgaggggagtgaaatagaacctgaaaccttgtacgtacaagcagtgggagcccgcgagggtgactgcgtaccttttgtataatgggtcagcgacttatattatgtagcgaggttaaccgaataggggagccgaagggaaaccgagtcttaactgggcgtcgagttgcatgatatagacccgaaacccggtgatctagccatgggcaggttgaaggttgggtaacactaactggaggaccgaaccgactaatgttgaaaaattagcggatgacctgtggctgggggtgaaaggccaatcaaaccgggagatagctggttctccccgaaatctatttaggtagagccttatgtgaataccttcgggggtagagcactgtttcggctagggggccatcccggcttaccaacccgatgcaaactgcgaataccgaagagtaatgcataggagacacacggcgggtgctaacgttcgtcgtggagagggaaacaacccagaccgccagctaaggtcccaaagtttatattaagtgggaaacgaagtgggaaggcttagacagctaggatgttggcttagaagcagccatcatttaaagaaagcgtaatagctcactagtcgagtcggcctgcgcggaagatgtaacggggctcaaatatagcaccgaagctgcggcatcaggcgtaagcctgttgggtaggggagcgtcgtgtaagcggaagaaggtggttcgagagggctgctggacgtatcacgagtgcgaatgctgacataagtaacgataaaacgggtgaaaaacccgttcgccggaagaccaagggttcctgtccaacgttaatcggggcagggtgagtcggcccctaaggcgaggctgaagagcgtagtcgatgggaaacgggttaatattcccgtacttgttataattgcgatgtggggacggagtaggttaggttatcgacctgttggaaaaggtcgtttaagttggtaggtggagcgtttaggcaaatccggacgcttatcaacaccgagagatgatgacgaggcgctaaggtgccgaagtaaccgataccacacttccaggaaaagccactaagcgtcagattataataaaccgtactataaaccgacacaggtggtcaggtagagaatactcaggcgcttgagagaactcgggtgaaggaactaggcaaaatagcaccgtaacttcgggagaaggtgcgccggcgtagattgtagaggtatacccttgaaggttgaaccggtcgaagtgacccgctggctgcaactgtttattaaaaacacagcactctgcaaacacgaaagtggacgtatagggtgtgatgcctgcccggtgctggaaggttaattgatggcgttatcgcaagagaagcgcctgatcgaagccccagtaaacggcggccgtaactataacggtcctaaggtagcgaaattccttgtcgggtaagttccgacctgcacgaatggcataatgatggccaggctgtctccacccgagactcagtgaaattgaaatcgccgtgaagatgcggtgtacccgcggctagacggaaagaccccgtgaacctttactatagcttgacactgaaccttgaattttgatgtgtaggataggtgggaggctttgaagcggtaacgccagttatcgtggagccatccttgaaataccaccctttaacgtttgatgttctaacgaagtgcccggaacgggtactcggacagtgtctggtgggtagtttgactggggcggtctcctcccaaagagtaacggaggagcacgaaggtttgctaatgacggtcggacatcgtcaggttagtgcaatggtataagcaagcttaactgcgagacggacaagtcgagcaggtgcgaaagcaggtcatagtgatccggtggttctgaatggaagggccatcgctcaacggataaaaggtactccggggataacaggctgataccgcccaagagttcatatcgacggcggtgtttggcacctcgatgtcggctcatcacatcctggggctgaagtaggtcccaagggtatggctgttcgccatttaaagtggtacgcgagctgggtttaaaacgtcgtgagacagtttggtccctatctgccgtgggcgttggagaattgagaggggctgctcctagtacgagaggaccggagtggacgcatcactggtgttccggttgtgtcgccagacgcattgccgggtagctacatgcggaagagataagtgctgaaagcatctaagcacgaaacttgcctcgagatgagttctcccagtatttaatactgtaagggttgttggagacgacgacgtagataggccgggtgtgtaagcgttgcgagacgttgagctaaccggtactaattgcccgagaggcttagccatacaacgctcaagtgtttttggtagtgaaagttattacggaataagtaagtagtcagggaatcggctSEQIDNO:3(来自菌株DD1的fruA-基因的核苷酸序列)TTGAAGGATAAGCCGATGAATATTTTTCTTACGCAATCACCAAATTTAGGTCGTGCAAAAGCGTTTTTATTGCACCAGGTTTTGGCTGCCGCAGTAAAACAACAAAATCATCAACTGGTAGAAAATGCCGAACAAGCGGATTTAGCGATTGTTTTCGGTAAAACTTTGCCGAATTTGACCGCACTTTTAGGTAAAAAAGTGTATTTGGCGGATGAAGAACAAGCGTTGAATGCGCCTGAAAATACCGTCGCGCAGGCATTAACCGAGGCTGTGGATTATGTTCAACCGGCGCAACAGGACGTGCAACCCGCAACTGCTTCCGGTATGAAAAATATCGTGGCGGTTACCGCTTGTCCGACCGGGGTGGCGCACACCTTTATGTCTGCCGAGGCGATTACAACCTACTGCCAACAGCAAGGTTGGAATGTAAAAGTGGAAACCAGAGGTCAAGTCGGTGCGAACAATATTATTTCTGCGGAAGATGTGGCGGCGGCCGATTTAGTCTTTATCGCTACGGATATTAATGTGGATTTAAGCAAATTCAAAGGAAAACCGATGTATCGTACTTCAACGGGCTTAGCATTGAAGAAAACCGCACAGGAATTTGATAAAGCCTTTAAAGAAGCGACGATTTATCAGGGTGAAGAAACTACAACCACCACAGAAACACAAACTTCAGGCGAGAAAAAAGGTGTATATAAACATCTTATGACCGGGGTTTCCCATATGTTACCGCTTGTCGTTGCCGGCGGTTTATTGATTGCTATTTCGTTTATGTTCGGTATTGAGGCGTTTAAAGACGAAAACATCGCAGGCGGCTTGCCGAAAGCATTAATGGATATCGGCGGCGGTGCGGCGTTCCACTTAATGATTGCCGTATTTGCAGGTTATGTTGCATTCTCTATTGCAGACCGTCCGGGGTTAGCCGTAGGTCTTATCGGCGGTATGCTTGCCACATCCGCCGGTGCCGGTATTTTGGGCGGTATTATCGCGGGTTTTCTTGCCGGTTATGTAGTGAAATTCCTGAATGATGCCATTCAACTGCCAGCCAGTTTAACTTCGTTAAAACCGATTTTAATTCTGCCTTTATTAGGTTCGGCGATCGTCGGCTTGGCCATGATTTATTTATTAAATCCACCGGTTGCTGCGGCAATGAATGCGCTAACCGAATGGTTAAAAGGTTTGGGCTCGGCAAACGCGCTGGTGTTGGGTGCGATTCTTGGCGGTATGATGTGTATCGATATGGGCGGTCCGGTAAACAAAGCCGCTTATGTATTCGGTACGGGCATGATTGGTTCACAGGTTTATACGCCGATGGCTGCGGTAATGGCTGCGGGTATGGTACCGCCTTTAGGAATGGCGATTGCCACCTGGATTGCGCGCGCTAAATTTAACGCAAGCCAACGTGATGCGGGTAAAGCTTCATTCGTACTAGGTTTATGCTTTATTTCCGAAGGTGCGTTACCGTTTGTTGCCGCCGACCCTGTACGCGTGATTGTTTCAAGTGTAATTGGCGGAGCCATTGCCGGCGCAATTTCTATGAGCCTTGCCATTACGCTGCAAGCGCCTCACGGCGGTTTATTCGTGATTCCGTTTGTGTCGCAACCGTTAATGTATTTGGGTGCGATTGCCGTAGGCGCCTTAACAACCGGCGTTCTTTACGCAATTATCAAACCGAAACAAGCTGCGGAATAASEQIDNO:4(由以上fruA-基因编码的酶的氨基酸序列)MKDKPMNIFLTQSPNLGRAKAFLLHQVLAAAVKQQNHQLVENAEQADLAIVFGKTLPNLTALLGKKVYLADEEQALNAPENTVAQALTEAVDYVQPAQQDVQPATASGMKNIVAVTACPTGVAHTFMSAEAITTYCQQQGWNVKVETRGQVGANNIISAEDVAAADLVFIATDINVDLSKFKGKPMYRTSTGLALKKTAQEFDKAFKEATIYQGEETTTTTETQTSGEKKGVYKHLMTGVSHMLPLVVAGGLLIAISFMFGIEAFKDENIAGGLPKALMDIGGGAAFHLMIAVFAGYVAFSIADRPGLAVGLIGGMLATSAGAGILGGIIAGFLAGYVVKFLNDAIQLPASLTSLKPILILPLLGSAIVGLAMIYLLNPPVAAAMNALTEWLKGLGSANALVLGAILGGMMCIDMGGPVNKAAYVFGTGMIGSQVYTPMAAVMAAGMVPPLGMAIATWIARAKFNASQRDAGKASFVLGLCFISEGALPFVAADPVRVIVSSVIGGAIAGAISMSLAITLQAPHGGLFVIPFVSQPLMYLGAIAVGALTTGVLYAIIKPKQAAESEQIDNO:5(质粒pSacB的完整核苷酸序列)tcgagaggcctgacgtcgggcccggtaccacgcgtcatatgactagttcggacctagggatatcgtcgacatcgatgctcttctgcgttaattaacaattgggatcctctagactccataggccgctttcctggctttgcttccagatgtatgctctcctccggagagtaccgtgactttattttcggcacaaatacaggggtcgatggataaatacggcgatagtttcctgacggatgatccgtatgtaccggcggaagacaagctgcaaacctgtcagatggagattgatttaatggcggatgtgctgagagcaccgccccgtgaatccgcagaactgatccgctatgtgtttgcggatgattggccggaataaataaagccgggcttaatacagattaagcccgtatagggtattattactgaataccaaacagcttacggaggacggaatgttacccattgagacaaccagactgccttctgattattaatatttttcactattaatcagaaggaataaccatgaattttacccggattgacctgaatacctggaatcgcagggaacactttgccctttatcgtcagcagattaaatgcggattcagcctgaccaccaaactcgatattaccgctttgcgtaccgcactggcggagacaggttataagttttatccgctgatgatttacctgatctcccgggctgttaatcagtttccggagttccggatggcactgaaagacaatgaacttatttactgggaccagtcagacccggtctttactgtctttcataaagaaaccgaaacattctctgcactgtcctgccgttattttccggatctcagtgagtttatggcaggttataatgcggtaacggcagaatatcagcatgataccagattgtttccgcagggaaatttaccggagaatcacctgaatatatcatcattaccgtgggtgagttttgacgggatttaacctgaacatcaccggaaatgatgattattttgccccggtttttacgatggcaaagtttcagcaggaaggtgaccgcgtattattacctgtttctgtacaggttcatcatgcagtctgtgatggctttcatgcagcacggtttattaatacacttcagctgatgtgtgataacatactgaaataaattaattaattctgtatttaagccaccgtatccggcaggaatggtggctttttttttatattttaaccgtaatctgtaatttcgtttcagactggttcaggatgagctcgcttggactcctgttgatagatccagtaatgacctcagaactccatctggatttgttcagaacgctcggttgccgccgggcgttttttattggtgagaatccaagcactagcggcgcgccggccggcccggtgtgaaataccgcacagatgcgtaaggagaaaataccgcatcaggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaaggacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaaggccggccgcggccgccatcggcattttcttttgcgtttttatttgttaactgttaattgtccttgttcaaggatgctgtctttgacaacagatgttttcttgcctttgatgttcagcaggaagctcggcgcaaacgttgattgtttgtctgcgtagaatcctctgtttgtcatatagcttgtaatcacgacattgtttcctttcgcttgaggtacagcgaagtgtgagtaagtaaaggttacatcgttaggatcaagatccatttttaacacaaggccagttttgttcagcggcttgtatgggccagttaaagaattagaaacataaccaagcatgtaaatatcgttagacgtaatgccgtcaatcgtcatttttgatccgcgggagtcagtgaacaggtaccatttgccgttcattttaaagacgttcgcgcgttcaatttcatctgttactgtgttagatgcaatcagcggtttcatcacttttttcagtgtgtaatcatcgtttagctcaatcataccgagagcgccgtttgctaactcagccgtgcgttttttatcgctttgcagaagtttttgactttcttgacggaagaatgatgtgcttttgccatagtatgctttgttaaataaagattcttcgccttggtagccatcttcagttccagtgtttgcttcaaatactaagtatttgtggcctttatcttctacgtagtgaggatctctcagcgtatggttgtcgcctgagctgtagttgccttcatcgatgaactgctgtacattttgatacgtttttccgtcaccgtcaaagattgatttataatcctctacaccgttgatgttcaaagagctgtctgatgctgatacgttaacttgtgcagttgtcagtgtttgtttgccgtaatgtttaccggagaaatcagtgtagaataaacggatttttccgtcagatgtaaatgtggctgaacctgaccattcttgtgtttggtcttttaggatagaatcatttgcatcgaatttgtcgctgtctttaaagacgcggccagcgtttttccagctgtcaatagaagtttcgccgactttttgatagaacatgtaaatcgatgtgtcatccgcatttttaggatctccggctaatgcaaagacgatgtggtagccgtgatagtttgcgacagtgccgtcagcgttttgtaatggccagctgtcccaaacgtccaggccttttgcagaagagatatttttaattgtggacgaatcaaattcagaaacttgatatttttcatttttttgctgttcagggatttgcagcatatcatggcgtgtaatatgggaaatgccgtatgtttccttatatggcttttggttcgtttctttcgcaaacgcttgagttgcgcctcctgccagcagtgcggtagtaaaggttaatactgttgcttgttttgcaaactttttgatgttcatcgttcatgtctccttttttatgtactgtgttagcggtctgcttcttccagccctcctgtttgaagatggcaagttagttacgcacaataaaaaaagacctaaaatatgtaaggggtgacgccaaagtatacactttgccctttacacattttaggtcttgcctgctttatcagtaacaaacccgcgcgatttacttttcgacctcattctattagactctcgtttggattgcaactggtctattttcctcttttgtttgatagaaaatcataaaaggatttgcagactacgggcctaaagaactaaaaaatctatctgtttcttttcattctctgtattttttatagtttctgttgcatgggcataaagttgcctttttaatcacaattcagaaaatatcataatatctcatttcactaaataatagtgaacggcaggtatatgtgatgggttaaaaaggatcggcggccgctcgatttaaatcSEQIDNO:6(质粒pSacB_δ_ldhA的完整核苷酸序列)tcgagaggcctgacgtcgggcccggtaccacgcgtcatatgactagttcggacctagggatgggtcagcctgaacgaaccgcacttgtatgtaggtagttttgaccgcccgaatattcgttataccttggtggaaaaattcaaaccgatggagcaattatacaattttgtggcggcgcaaaaaggtaaaagcggtatcgtctattgcaacagccgtagcaaagtggagcgcattgcggaagccctgaagaaaagaggcatttccgcagccgcttatcatgcgggcatggagccgtcgcagcgggaagcggtgcaacaggcgtttcaacgggataatattcaagtggtggtggcgaccattgcttttggtatggggatcaacaaatctaatgtgcgttttgtggcgcattttgatttatctcgcagcattgaggcgtattatcaggaaaccgggcgcgcggggcgggacgacctgccggcggaagcggtactgttttacgagccggcggattatgcctggttgcataaaattttattggaagagccggaaagcccgcaacgggatattaaacggcataagctggaagccatcggcgaatttgccgaaagccagacctgccgtcgtttagtgctgttaaattatttcggcgaaaaccgccaaacgccatgtaataactgtgatatctgcctcgatccgccgaaaaaatatgacggattattagacgcgcagaaaatcctttcgaccatttatcgcaccgggcaacgtttcggcacgcaatacgtaatcggcgtaatgcgcggtttgcagaatcagaaaataaaagaaaatcaacatgatgagttgaaagtctacggaattggcaaagataaaagcaaagaatactggcaatcggtaattcgtcagctgattcatttgggctttgtgcaacaaatcatcagcgatttcggcatggggaccagattacagctcaccgaaagcgcgcgtcccgtgctgcgcggcgaagtgtctttggaactggccatgccgagattatcttccattaccatggtacaggctccgcaacgcaatgcggtaaccaactacgacaaagatttatttgcccgcctgcgtttcctgcgcaaacagattgccgacaaagaaaacattccgccttatattgtgttcagtgacgcgaccttgcaggaaatgtcgttgtatcagccgaccagcaaagtggaaatgctgcaaatcaacggtgtcggcgccatcaaatggcagcgcttcggacagccttttatggcgattattaaagaacatcaggctttgcgtaaagcgggtaagaatccgttggaattgcaatcttaaaatttttaactttttgaccgcacttttaaggttagcaaattccaataaaaagtgcggtgggttttcgggaatttttaacgcgctgatttcctcgtcttttcaatttyttcgyctccatttgttcggyggttgccggatcctttcttgactgagatccataagagagtagaatagcgccgcttatatttttaatagcgtacctaatcgggtacgctttttttatgcggaaaatccatatttttctaccgcactttttctttaaagatttatacttaagtctgtttgattcaatttatttggaggttttatgcaacacattcaactggctcccgatttaacattcagtcgcttaattcaaggattctggcggttaaaaagctggcggaaatcgccgcaggaattgcttacattcgttaagcaaggattagaattaggcgttgatacgctggatcatgccgcttgttacggggcttttacttccgaggcggaattcggacgggcgctggcgctggataaatccttgcgcgcacagcttactttggtgaccaaatgcgggattttgtatcctaatgaagaattacccgatataaaatcccatcactatgacaacagctaccgccatattatgtggtcggcgcaacgttccattgaaaaactgcaatgcgactatttagatgtattgctgattcaccgwctttctccctgtgcggatcccgaacaaatcgcgcgggcttttgatgaactttatcaaaccggraaagtacgttatttcggggtatctaactatacgccggctaagttcgccatgttgcaatcttatgtgaatcagccgttaatcactaatcaaattgagatttcgcctcttcatcgtcaggcttttgatgacggtaccctggattttttactggaaaaacgtattcaaccgatggcatggtcgccacttgccggcggtcgtttattcaatcaggatgagaacagtcgggcggtgcaaaaaacattactcgaaatcggtgaaacgaaaggagaaacccgtttagatacattggcttatgcctggttattggcgcatccggcaaaaattatgccggttatggggtccggtaaaattgaacgggtaaaaagcgcggcggatgcgttacgaatttccttcactgaggaagaatggattaaggtttatgttgccgcacagggacgggatattccgtaacatcatccgtctaatcctgcgtatctggggaaagatgcgtcatcgtaagaggtctataatattcgtcgttttgataagggtgccatatccggcacccgttaaaatcacattgcgttcgcaacaaaattattccttacgaatagcattcacctcttttaacagatgttgaatatccgtatcggcaaaaatatcctctatatttgcggttaaacggcgccgccagttagcatattgagtgctggttcccggaatattgacgggttcggtcataccgagccagtcttcaggttggaatccccatcgtcgacatcgatgctcttctgcgttaattaacaattgggatcctctagactccataggccgctttcctggctttgcttccagatgtatgctctcctccggagagtaccgtgactttattttcggcacaaatacaggggtcgatggataaatacggcgatagtttcctgacggatgatccgtatgtaccggcggaagacaagctgcaaacctgtcagatggagattgatttaatggcggatgtgctgagagcaccgccccgtgaatccgcagaactgatccgctatgtgtttgcggatgattggccggaataaataaagccgggcttaatacagattaagcccgtatagggtattattactgaataccaaacagcttacggaggacggaatgttacccattgagacaaccagactgccttctgattattaatatttttcactattaatcagaaggaataaccatgaattttacccggattgacctgaatacctggaatcgcagggaacactttgccctttatcgtcagcagattaaatgcggattcagcctgaccaccaaactcgatattaccgctttgcgtaccgcactggcggagacaggttataagttttatccgctgatgatttacctgatctcccgggctgttaatcagtttccggagttccggatggcactgaaagacaatgaacttatttactgggaccagtcagacccggtctttactgtctttcataaagaaaccgaaacattctctgcactgtcctgccgttattttccggatctcagtgagtttatggcaggttataatgcggtaacggcagaatatcagcatgataccagattgtttccgcagggaaatttaccggagaatcacctgaatatatcatcattaccgtgggtgagttttgacgggatttaacctgaacatcaccggaaatgatgattattttgccccggtttttacgatggcaaagtttcagcaggaaggtgaccgcgtattattacctgtttctgtacaggttcatcatgcagtctgtgatggctttcatgcagcacggtttattaatacacttcagctgatgtgtgataacatactgaaataaattaattaattctgtatttaagccaccgtatccggcaggaatggtggctttttttttatattttaaccgtaatctgtaatttcgtttcagactggttcaggatgagctcgcttggactcctgttgatagatccagtaatgacctcagaactccatctggatttgttcagaacgctcggttgccgccgggcgttttttattggtgagaatccaagcactagcggcgcgccggccggcccggtgtgaaataccgcacagatgcgtaaggagaaaataccgcatcaggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaaggacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaaggccggccgcggccgccatcggcattttcttttgcgtttttatttgttaactgttaattgtccttgttcaaggatgctgtctttgacaacagatgttttcttgcctttgatgttcagcaggaagctcggcgcaaacgttgattgtttgtctgcgtagaatcctctgtttgtcatatagcttgtaatcacgacattgtttcctttcgcttgaggtacagcgaagtgtgagtaagtaaaggttacatcgttaggatcaagatccatttttaacacaaggccagttttgttcagcggcttgtatgggccagttaaagaattagaaacataaccaagcatgtaaatatcgttagacgtaatgccgtcaatcgtcatttttgatccgcgggagtcagtgaacaggtaccatttgccgttcattttaaagacgttcgcgcgttcaatttcatctgttactgtgttagatgcaatcagcggtttcatcacttttttcagtgtgtaatcatcgtttagctcaatcataccgagagcgccgtttgctaactcagccgtgcgttttttatcgctttgcagaagtttttgactttcttgacggaagaatgatgtgcttttgccatagtatgctttgttaaataaagattcttcgccttggtagccatcttcagttccagtgtttgcttcaaatactaagtatttgtggcctttatcttctacgtagtgaggatctctcagcgtatggttgtcgcctgagctgtagttgccttcatcgatgaactgctgtacattttgatacgtttttccgtcaccgtcaaagattgatttataatcctctacaccgttgatgttcaaagagctgtctgatgctgatacgttaacttgtgcagttgtcagtgtttgtttgccgtaatgtttaccggagaaatcagtgtagaataaacggatttttccgtcagatgtaaatgtggctgaacctgaccattcttgtgtttggtcttttaggatagaatcatttgcatcgaatttgtcgctgtctttaaagacgcggccagcgtttttccagctgtcaatagaagtttcgccgactttttgatagaacatgtaaatcgatgtgtcatccgcatttttaggatctccggctaatgcaaagacgatgtggtagccgtgatagtttgcgacagtgccgtcagcgttttgtaatggccagctgtcccaaacgtccaggccttttgcagaagagatatttttaattgtggacgaatcaaattcagaaacttgatatttttcatttttttgctgttcagggatttgcagcatatcatggcgtgtaatatgggaaatgccgtatgtttccttatatggcttttggttcgtttctttcgcaaacgcttgagttgcgcctcctgccagcagtgcggtagtaaaggttaatactgttgcttgttttgcaaactttttgatgttcatcgttcatgtctccttttttatgtactgtgttagcggtctgcttcttccagccctcctgtttgaagatggcaagttagttacgcacaataaaaaaagacctaaaatatgtaaggggtgacgccaaagtatacactttgccctttacacattttaggtcttgcctgctttatcagtaacaaacccgcgcgatttacttttcgacctcattctattagactctcgtttggattgcaactggtctattttcctcttttgtttgatagaaaatcataaaaggatttgcagactacgggcctaaagaactaaaaaatctatctgtttcttttcattctctgtattttttatagtttctgttgcatgggcataaagttgcctttttaatcacaattcagaaaatatcataatatctcatttcactaaataatagtgaacggcaggtatatgtgatgggttaaaaaggatcggcggccgctcgatttaaatcSEQIDNo:7(质粒pSacB_δ_pflA的完整核苷酸序列)tcgagtcaatgcggatttgacttatgatgtggcaaacaaccgatttccgattattactacacgtaaaagttattggaaagcggcgattgcggagtttctgggttatatccgcggctacgataatgcggcggatttccgtaaattaggagcaaaaacctgggatgccaacgctaatgaaaatcaggtatggctgaataaccctcatcgcaaaggcaccgacgacatggggcgcgtttacggcgtacagggcagagcctggcgtaagcctaacggcgaaaccgttgatcaattacgcaaaattgtcaacaatttaagtcgcggcattgatgatcgcggcgaaattctgacctttttaaacccgggcgaattcgatctcggttgtctgcgcccttgtatgtacaatcacacgttttctttgctgggcgatacgctttatttaaccagttatcaacgctcctgtgacgtacctttaggcttgaatttcaatcaaattcaagtatttacattcttagctttaatggcgcagattaccggtaaaaaagccggtcaggcatatcacaaaatcgtcaatgcgcatatttacgaagaccagctggaactaatgcgcgacgtgcagttaaaacgcgaaccgttcccgtcgccaaaactggaaattaatccggacattaaaacccttgaagatttagaaacctgggtaaccatggatgatttcaacgtcgttggttaccaatgccacgaaccgataaaatatccgttctcggtataaaccgacaaaagtgcggtcaaaaatttaatattttcatctgttatagaaaatatttttcaacataaaatctagggatgcctgtttggcgtccgtaaatacgcagaaaaatattaaatttttgaccgcacttttttcatctcaattaacagcctgataattcttatggatcaacaaattagctttgacgaaaaaatgatgaatcgagctcttttccttgccgacaaggcggaagctttaggggaaattcccgtaggtgccgtattggtggatgaacggggcaatatcattggtgaaggctggaacctctctattgtgaactcggatcccaccgcccatgccgaaattattgcgttgcgtaacgccgcgcagaaaatccaaaattaccgcctgctcaataccactttatacgtgactttagaaccctgcaccatgtgcgccggcgcgattttacacagccgaatcaaacgcttggtattcggggcgtccgattacaaaaccggtgcggtgggttccagatttcatttttttgaggattataaaatgaatcatggggttgagatcacaagcggtgtcttacaggatcaatgcagtcagaagttaagccgctttttccaaaagcgcagggaacagaaaaaacaacaaaaagctaccgcacttttacaacacccccggcttaactcctctgaaaaatagtgacaaaaaaaccgtcataatgtttacgacggtttttttatttcttaatatgcccttaaataatcaacaaaatatagcaagaagattatagcaaagaatttcgtttttttcagagaatagtcaaatcttcgcaaaaaactaccgcacttttatccgctttaatcaggggaattaaaacaaaaaaattccgcctattgaggcggaatttattaagcaataagacaaactctcaattacattgattgtgtaaacgtacgagtgatgacgtcttgttgttgctctttagttaatgagttgaaacgaaccgcgtaacctgaaacacgaatggttaattgcgggtatttttccggattttccatcgcgtctaacaacatttcacggttaagaacgttaacattcaagtgttgaccgccttccactgtcgcttcatgatggaaataaccgtccattaaaccggcaaggttgcgtttttgcgcttcgtcatctttacctaatgcgttcggtacgatagagaaggtatatgaaataccgtctttcgcgtaagcgaacggaagtttagccacagaagtaagtgaagcaaccgcacctttttggtcacgaccgtgcattgggtttgcacccggtccgaatggcgcgcctgctcgacgaccgtccggagtattaccggttttcttaccgtataccacgttagaagtgatagtcaggatagattgtgtcggagttgcgttgcggtaagttttgtgtttttgaacttttttcatgaaacgttcaactaagtctaccgctaaatcatcaacacgcggatcattgttaccgaattgcggatattcgccttcaatttcgaagtcgatagcaacattcgaggccacgacattaccgtctttatctttgatgtcgccgcgaatcggtttaactttcgcatatttgattgcggataatgagtccgcagccacggaaagacccgcgataccgcaagccattgtacggaatacgtcgcgatcgtggaacgccatcaatgccgcttcatatgcatatttatcgtgcatgaagtggatgatgttcaatgcggttacatattgagtcgccaaccagtccatgaaactgtccatacgttcgattacggtatcgaaattcaatacttcgtctgtaatcggcgcagttttaggaccgacttgcataccatttttctcatcgataccgccgttaattgcgtataacatagttttagctaagtttgcgcgcgcaccgaagaattgcatttgtttacctacgaccatcggtgatacgcagcatgcgattgcatagtcatcgttgttgaagtcaggacgcattaagtcatcattttcgtattgtacggaggaagtatcaatagatactttcgcacagaaacgtttgaacgcttcaggtaattgttcggaccaaagaatagttaagtttggttccggagaagtacccatagtgtataaagtatgtaatacgcggaagctgtttttagttaccaacggacgaccgtctaagcccataccggcgatagtttcggttgccctctagactccataggccgctttcctggctttgcttccagatgtatgctctcctccggagagtaccgtgactttattttcggcacaaatacaggggtcgatggataaatacggcgatagtttcctgacggatgatccgtatgtaccggcggaagacaagctgcaaacctgtcagatggagattgatttaatggcggatgtgctgagagcaccgccccgtgaatccgcagaactgatccgctatgtgtttgcggatgattggccggaataaataaagccgggcttaatacagattaagcccgtatagggtattattactgaataccaaacagcttacggaggacggaatgttacccattgagacaaccagactgccttctgattattaatatttttcactattaatcagaaggaataaccatgaattttacccggattgacctgaatacctggaatcgcagggaacactttgccctttatcgtcagcagattaaatgcggattcagcctgaccaccaaactcgatattaccgctttgcgtaccgcactggcggagacaggttataagttttatccgctgatgatttacctgatctcccgggctgttaatcagtttccggagttccggatggcactgaaagacaatgaacttatttactgggaccagtcagacccggtctttactgtctttcataaagaaaccgaaacattctctgcactgtcctgccgttattttccggatctcagtgagtttatggcaggttataatgcggtaacggcagaatatcagcatgataccagattgtttccgcagggaaatttaccggagaatcacctgaatatatcatcattaccgtgggtgagttttgacgggatttaacctgaacatcaccggaaatgatgattattttgccccggtttttacgatggcaaagtttcagcaggaaggtgaccgcgtattattacctgtttctgtacaggttcatcatgcagtctgtgatggctttcatgcagcacggtttattaatacacttcagctgatgtgtgataacatactgaaataaattaattaattctgtatttaagccaccgtatccggcaggaatggtggctttttttttatattttaaccgtaatctgtaatttcgtttcagactggttcaggatgagctcgcttggactcctgttgatagatccagtaatgacctcagaactccatctggatttgttcagaacgctcggttgccgccgggcgttttttattggtgagaatccaagcactagcggcgcgccggccggcccggtgtgaaataccgcacagatgcgtaaggagaaaataccgcatcaggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaaggacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaaggccggccgcggccgccatcggcattttcttttgcgtttttatttgttaactgttaattgtccttgttcaaggatgctgtctttgacaacagatgttttcttgcctttgatgttcagcaggaagctcggcgcaaacgttgattgtttgtctgcgtagaatcctctgtttgtcatatagcttgtaatcacgacattgtttcctttcgcttgaggtacagcgaagtgtgagtaagtaaaggttacatcgttaggatcaagatccatttttaacacaaggccagttttgttcagcggcttgtatgggccagttaaagaattagaaacataaccaagcatgtaaatatcgttagacgtaatgccgtcaatcgtcatttttgatccgcgggagtcagtgaacaggtaccatttgccgttcattttaaagacgttcgcgcgttcaatttcatctgttactgtgttagatgcaatcagcggtttcatcacttttttcagtgtgtaatcatcgtttagctcaatcataccgagagcgccgtttgctaactcagccgtgcgttttttatcgctttgcagaagtttttgactttcttgacggaagaatgatgtgcttttgccatagtatgctttgttaaataaagattcttcgccttggtagccatcttcagttccagtgtttgcttcaaatactaagtatttgtggcctttatcttctacgtagtgaggatctctcagcgtatggttgtcgcctgagctgtagttgccttcatcgatgaactgctgtacattttgatacgtttttccgtcaccgtcaaagattgatttataatcctctacaccgttgatgttcaaagagctgtctgatgctgatacgttaacttgtgcagttgtcagtgtttgtttgccgtaatgtttaccggagaaatcagtgtagaataaacggatttttccgtcagatgtaaatgtggctgaacctgaccattcttgtgtttggtcttttaggatagaatcatttgcatcgaatttgtcgctgtctttaaagacgcggccagcgtttttccagctgtcaatagaagtttcgccgactttttgatagaacatgtaaatcgatgtgtcatccgcatttttaggatctccggctaatgcaaagacgatgtggtagccgtgatagtttgcgacagtgccgtcagcgttttgtaatggccagctgtcccaaacgtccaggccttttgcagaagagatatttttaattgtggacgaatcaaattcagaaacttgatatttttcatttttttgctgttcagggatttgcagcatatcatggcgtgtaatatgggaaatgccgtatgtttccttatatggcttttggttcgtttctttcgcaaacgcttgagttgcgcctcctgccagcagtgcggtagtaaaggttaatactgttgcttgttttgcaaactttttgatgttcatcgttcatgtctccttttttatgtactgtgttagcggtctgcttcttccagccctcctgtttgaagatggcaagttagttacgcacaataaaaaaagacctaaaatatgtaaggggtgacgccaaagtatacactttgccctttacacattttaggtcttgcctgctttatcagtaacaaacccgcgcgatttacttttcgacctcattctattagactctcgtttggattgcaactggtctattttcctcttttgtttgatagaaaatcataaaaggatttgcagactacgggcctaaagaactaaaaaatctatctgtttcttttcattctctgtattttttatagtttctgttgcatgggcataaagttgcctttttaatcacaattcagaaaatatcataatatctcatttcactaaataatagtgaacggcaggtatatgtgatgggttaaaaaggatcggcggccgctcgatttaaatcSEQIDNO:8(质粒pSacB_fruA的完整核苷酸序列)tcgagtaggagtaactcaaggtcaccgtttgcgttttgttgccgaaggtgcgcaggcacagcaggcgattgaagccatcgctaaagaaattgcggcgggcttgggtgagcctgtttccgccgttccgccggcagaaccggatactattgaagtcgctaacccggcgacaccggaagttgagcaaccaaaatccgacagtatcgaagcggtttttgtgattaataatgaaaacggtctgcatgctcgtcctgcggcgactttagtgaatgaagtcaaaaaatataatgcgtcggtggcggttcgtaatttagatcgcgacggtgggttagtgagcgctaaaagcatgatgaaaatcgttgcattaggtgcgacaaaaggttctcgtctgcattttgtcgccaccggtgaagaagctcaacaagcgattgacggtatcggtgcggcaatcgcggcaggtttaggagaataaacaatggcaaaagtggcaacaattacattaaacgccgcctatgatttggtcgggcgtttaaaacgcattgaattgggcgaagtgaatacggtggaaaccctcggtttattccctgccggtaaaggtatcaatgtggctaaggtgttgaatgacttagatgttgaagtcgcggtcggtggttttctcggtgaagataacgtaggcgatttcgagcatttattccaacaacaaggtttgcaggataaattccagcgggttgccggtaaaacccgaataaacgtaaaaatcaccgaaacggacgcggatgtaacggatttgaattttcttggttatcaaatcagtgaacaggattggcggaaatttaccgcagattctctcgcttattgtaaagaattcgacatcgttgccgtgtgtggcagtttgccccgcggcgtaacggcggatatgtttcaaagctggttaagtcaattacatcaagcgggtgtaaaagtcgtactagatagtagtaatgccgcattaacagcaggtcttaaagcaaatccttggttagtgaaaccgaatcaccgcgaattagaagcctgggtcggccatgagttaccgactttgaaagacatcattgacgccgcaaaacaattaaaagcacaagggatagccaatgttattatttccatgggcgcaaacggctcattatggctaagtgataacggcgtgattttggctcagccgccgaaatgtgaaaacgtagtaagcacagtcggtgccggcgattcgatggtcgcaggtttaatttatggttttgtaaataatttatctcaacaagaaacattggcgtttgcaagtgcggtatctgccttcgccgtttcacaaagtaacgtaggtgtcagtgatcgcaagttgctcgacccaatcttagcaaatgtaaaaatcacaacgattgaaggataagccgatgaatatttttcttacgcaatcaccaaatttaggtcgtgcaaaagcgtttttattgcaccaggttttggctgccgcagtaaaacaatttcctaatcaagcataaagcctttgtttatctcaaaacaaaggctttttttataagtattccgctttgcccgaactaatagaaaaattggcagacaaaagaagtgttcatagcacaggaggaacaatatggatttcaatgcaattttaaatcaagttttaagtgccgctcaggaaaccgttaagaaaacggcaagcggcaatagcacaacggataaagtggcaaaaatcggtggcggtgcagcggctatcggcgtgctttcgatgattttcgggcgcaccggcggagcggggcttgcaaaattaggctcgcttgccgcattaggcagccttgcttatcaggcttaccaggattatcaacataaacaaagccaagttgtaccggttactgaaacggaatttacccaaagcgtacaacaatcggcggaactcagcaaagtgattttgcaggcaatgattgcggcggcggctgcagacggcgcgatttccgaccaggaacaacaagcgattttaagccaagccggcgatgatgcggaagtacagcagtggattcggcaagaaatgtatcaaccggcaacagtgcgggaaatcgcccaacaagtgggtgataatcaggcattagcatcacaggtgtatctggcggcaagaatggtttgcgccgatttagcacgcaaagaaattgttttcttagcaaatttagcgcaagcgttggggttagatgaagcgcttgtagaacagttagaaaaacaggcgggtttctgatttaatcattccgcgatgtgcaaagtgcggtcaaaaataacgatttttttaccgcacttttgcatttgcaagacgtttcgaaaatgcctgttctaacttctattaaaacccttcttctaaaattttctccaataactcaaataccagcaacactcgtttgggagtaatggtttgataaggacggtagaggtaaattccccaaatcaaggtttcctcattagagaagactacttgtaactcgccggaatcaagataggatttacagtcatgatacattatcggcgcgaaaatcctgccggataagaccgccggtaacaagcttttaatatcgctggtgataaccgtcggcttagttagaattatgggttgttcacccatcatccagtcccatactttgccggtcttaggatttaaaatatagcctaccggaaaattggcggctaaatcaaaaacgtcttttggcaatccggttttagcgataagactaggtgctgccacgataggctcttgtaggtcagtaatctttttcgccacccaatgatcttcgggcgtgcggctgatgcgaataccgatatcaatttggtcatccaccgctttgagcgtatcgaaatccgtgcgccagtcaatctgaatatccggatagggcgcaagtgcggttagtaatcgcaataaaattttatccgcataatcggaaggcggtaacgtaatccgcactaagccggaaaggctctcttccgcatctagactccataggccgctttcctggctttgcttccagatgtatgctctcctccggagagtaccgtgactttattttcggcacaaatacaggggtcgatggataaatacggcgatagtttcctgacggatgatccgtatgtaccggcggaagacaagctgcaaacctgtcagatggagattgatttaatggcggatgtgctgagagcaccgccccgtgaatccgcagaactgatccgctatgtgtttgcggatgattggccggaataaataaagccgggcttaatacagattaagcccgtatagggtattattactgaataccaaacagcttacggaggacggaatgttacccattgagacaaccagactgccttctgattattaatatttttcactattaatcagaaggaataaccatgaattttacccggattgacctgaatacctggaatcgcagggaacactttgccctttatcgtcagcagattaaatgcggattcagcctgaccaccaaactcgatattaccgctttgcgtaccgcactggcggagacaggttataagttttatccgctgatgatttacctgatctcccgggctgttaatcagtttccggagttccggatggcactgaaagacaatgaacttatttactgggaccagtcagacccggtctttactgtctttcataaagaaaccgaaacattctctgcactgtcctgccgttattttccggatctcagtgagtttatggcaggttataatgcggtaacggcagaatatcagcatgataccagattgtttccgcagggaaatttaccggagaatcacctgaatatatcatcattaccgtgggtgagttttgacgggatttaacctgaacatcaccggaaatgatgattattttgccccggtttttacgatggcaaagtttcagcaggaaggtgaccgcgtattattacctgtttctgtacaggttcatcatgcagtctgtgatggctttcatgcagcacggtttattaatacacttcagctgatgtgtgataacatactgaaataaattaattaattctgtatttaagccaccgtatccggcaggaatggtggctttttttttatattttaaccgtaatctgtaatttcgtttcagactggttcaggatgagctcgcttggactcctgttgatagatccagtaatgacctcagaactccatctggatttgttcagaacgctcggttgccgccgggcgttttttattggtgagaatccaagcactagcggcgcgccggccggcccggtgtgaaataccgcacagatgcgtaaggagaaaataccgcatcaggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaaggacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaaggccggccgcggccgccatcggcattttcttttgcgtttttatttgttaactgttaattgtccttgttcaaggatgctgtctttgacaacagatgttttcttgcctttgatgttcagcaggaagctcggcgcaaacgttgattgtttgtctgcgtagaatcctctgtttgtcatatagcttgtaatcacgacattgtttcctttcgcttgaggtacagcgaagtgtgagtaagtaaaggttacatcgttaggatcaagatccatttttaacacaaggccagttttgttcagcggcttgtatgggccagttaaagaattagaaacataaccaagcatgtaaatatcgttagacgtaatgccgtcaatcgtcatttttgatccgcgggagtcagtgaacaggtaccatttgccgttcattttaaagacgttcgcgcgttcaatttcatctgttactgtgttagatgcaatcagcggtttcatcacttttttcagtgtgtaatcatcgtttagctcaatcataccgagagcgccgtttgctaactcagccgtgcgttttttatcgctttgcagaagtttttgactttcttgacggaagaatgatgtgcttttgccatagtatgctttgttaaataaagattcttcgccttggtagccatcttcagttccagtgtttgcttcaaatactaagtatttgtggcctttatcttctacgtagtgaggatctctcagcgtatggttgtcgcctgagctgtagttgccttcatcgatgaactgctgtacattttgatacgtttttccgtcaccgtcaaagattgatttataatcctctacaccgttgatgttcaaagagctgtctgatgctgatacgttaacttgtgcagttgtcagtgtttgtttgccgtaatgtttaccggagaaatcagtgtagaataaacggatttttccgtcagatgtaaatgtggctgaacctgaccattcttgtgtttggtcttttaggatagaatcatttgcatcgaatttgtcgctgtctttaaagacgcggccagcgtttttccagctgtcaatagaagtttcgccgactttttgatagaacatgtaaatcgatgtgtcatccgcatttttaggatctccggctaatgcaaagacgatgtggtagccgtgatagtttgcgacagtgccgtcagcgttttgtaatggccagctgtcccaaacgtccaggccttttgcagaagagatatttttaattgtggacgaatcaaattcagaaacttgatatttttcatttttttgctgttcagggatttgcagcatatcatggcgtgtaatatgggaaatgccgtatgtttccttatatggcttttggttcgtttctttcgcaaacgcttgagttgcgcctcctgccagcagtgcggtagtaaaggttaatactgttgcttgttttgcaaactttttgatgttcatcgttcatgtctccttttttatgtactgtgttagcggtctgcttcttccagccctcctgtttgaagatggcaagttagttacgcacaataaaaaaagacctaaaatatgtaaggggtgacgccaaagtatacactttgccctttacacattttaggtcttgcctgctttatcagtaacaaacccgcgcgatttacttttcgacctcattctattagactctcgtttggattgcaactggtctattttcctcttttgtttgatagaaaatcataaaaggatttgcagactacgggcctaaagaactaaaaaatctatctgtttcttttcattctctgtattttttatagtttctgttgcatgggcataaagttgcctttttaatcacaattcagaaaatatcataatatctcatttcactaaataatagtgaacggcaggtatatgtgatgggttaaaaaggatcggcggccgctcgatttaaatcSEQIDNO:9(来自菌株DD1的ldhA-基因的核苷酸序列)ttgacaaaatcagtatgtttaaataaggagctaactatgaaagttgccgtttacagtactaaaaattatgatcgcaaacatctggatttggcgaataaaaaatttaattttgagcttcatttctttgattttttacttgatgaacaaaccgcgaaaatggcggagggcgccgatgccgtctgtattttcgtcaatgatgatgcgagccgcccggtgttaacaaagttggcgcaaatcggagtgaaaattatcgctttacgttgtgccggttttaataatgtggatttggaggcggcaaaagagctgggattaaaagtcgtacgggtgcctgcgtattcgccggaagccgttgccgagcatgcgatcggattaatgctgactttaaaccgccgtatccataaggcttatcagcgtacccgcgatgcgaatttttctctggaaggattggtcggttttaatatgttcggcaaaaccgccggagtgattggtacgggaaaaatcggcttggcggctattcgcattttaaaaggcttcggtatggacgttctggcgtttgatccttttaaaaatccggcggcggaagcgttgggcgcaaaatatgtcggtttagacgagctttatgcaaaatcccatgttatcactttgcattgcccggctacggcggataattatcatttattaaatgaagcggcttttaataaaatgcgcgacggtgtaatgattattaataccagccgcggcgttttaattgacagccgggcggcaatcgaagcgttaaaacggcagaaaatcggcgctctcggtatggatgtttatgaaaatgaacgggatttgtttttcgaggataaatctaacgatgttattacggatgatgtattccgtcgcctttcttcctgtcataatgtgctttttaccggtcatcaggcgtttttaacggaagaagcgctgaataatatcgccgatgtgactttatcgaatattcaggcggtttccaaaaatgcaacgtgcgaaaatagcgttgaaggctaaSEQIDNO:10(来自菌株DD1的LdhA的氨基酸序列)MTKSVCLNKELTMKVAVYSTKNYDRKHLDLANKKFNFELHFFDFLLDEQTAKMAEGADAVCIFVNDDASRPVLTKLAQIGVKIIALRCAGFNNVDLEAAKELGLKVVRVPAYSPEAVAEHAIGLMLTLNRRIHKAYQRTRDANFSLEGLVGFNMFGKTAGVIGTGKIGLAAIRILKGFGMDVLAFDPFKNPAAEALGAKYVGLDELYAKSHVITLHCPATADNYHLLNEAAFNKMRDGVMIINTSRGVLIDSRAAIEALKRQKIGALGMDVYENERDLFFEDKSNDVITDDVFRRLSSCHNVLFTGHQAFLTEEALNNIADVTLSNIQAVSKNATCENSVEGSEQIDNO:11(来自菌株DD1的pflA-基因的核苷酸序列)atgtcggttttaggacgaattcattcatttgaaacctgcgggacagttgacgggccgggaatccgctttattttatttttacaaggctgcttaatgcgttgtaaatactgccataatagagacacctgggatttgcacggcggtaaagaaatttccgttgaagaattaatgaaagaagtggtgacctatcgccattttatgaacgcctcgggcggcggagttaccgcttccggcggtgaagctattttacaggcggaatttgtacgggactggttcagagcctgccataaagaaggaattaatacttgcttggataccaacggtttcgtccgtcatcatgatcatattattgatgaattgattgatgacacggatcttgtgttgcttgacctgaaagaaatgaatgaacgggttcacgaaagcctgattggcgtgccgaataaaagagtgctcgaattcgcaaaatatttagcggatcgaaatcagcgtacctggatccgccatgttgtagtgccgggttatacagatagtgacgaagatttgcacatgctggggaatttcattaaagatatgaagaatatcgaaaaagtggaattattaccttatcaccgtctaggcgcccataaatgggaagtactcggcgataaatacgagcttgaagatgtaaaaccgccgacaaaagaattaatggagcatgttaaggggttgcttgcaggctacgggcttaatgtgacatattagSEQIDNO:12(来自菌株DD1的PflA的氨基酸序列)MSVLGRIHSFETCGTVDGPGIRFILFLQGCLMRCKYCHNRDTWDLHGGKEISVEELMKEVVTYRHFMNASGGGVTASGGEAILQAEFVRDWFRACHKEGINTCLDTNGFVRHHDHIIDELIDDTDLVLLDLKEMNERVHESLIGVPNKRVLEFAKYLADRNQRTWIRHVVVPGYTDSDEDLHMLGNFIKDMKNIEKVELLPYHRLGAHKWEVLGDKYELEDVKPPTKELMEHVKGLLAGYGLNVTYSEQIDNO:13(来自菌株DD1的pflD-基因的核苷酸序列)atggctgaattaacagaagctcaaaaaaaagcatgggaaggattcgttcccggtgaatggcaaaacggcgtaaatttacgtgactttatccaaaaaaactatactccgtatgaaggtgacgaatcattcttagctgatgcgactcctgcaaccagcgagttgtggaacagcgtgatggaaggcatcaaaatcgaaaacaaaactcacgcacctttagatttcgacgaacatactccgtcaactatcacttctcacaagcctggttatatcaataaagatttagaaaaaatcgttggtcttcaaacagacgctccgttaaaacgtgcaattatgccgtacggcggtatcaaaatgatcaaaggttcttgcgaagtttacggtcgtaaattagatccgcaagtagaatttattttcaccgaatatcgtaaaacccataaccaaggcgtattcgacgtttatacgccggatattttacgctgccgtaaatcaggcgtgttaaccggtttaccggatgcttacggtcgtggtcgtattatcggtgactaccgtcgtttagcggtatacggtattgattacctgatgaaagataaaaaagcccaattcgattcattacaaccgcgtttggaagcgggcgaagacattcaggcaactatccaattacgtgaagaaattgccgaacaacaccgcgctttaggcaaaatcaaagaaatggcggcatcttacggttacgacatttccggccctgcgacaaacgcacaggaagcaatccaatggacatattttgcttatctggcagcggttaaatcacaaaacggtgcggcaatgtcattcggtcgtacgtctacattcttagatatctatatcgaacgtgacttaaaacgcggtttaatcactgaacaacaggcgcaggaattaatggaccacttagtaatgaaattacgtatggttcgtttcttacgtacgccggaatacgatcaattattctcaggcgacccgatgtgggcaaccgaaactatcgccggtatgggcttagacggtcgtccgttggtaactaaaaacagcttccgcgtattacatactttatacactatgggtacttctccggaaccaaacttaactattctttggtccgaacaattacctgaagcgttcaaacgtttctgtgcgaaagtatctattgatacttcctccgtacaatacgaaaatgatgacttaatgcgtcctgacttcaacaacgatgactatgcaatcgcatgctgcgtatcaccgatggtcgtaggtaaacaaatgcaattcttcggtgcgcgcgcaaacttagctaaaactatgttatacgcaattaacggcggtatcgatgagaaaaatggtatgcaagtcggtcctaaaactgcgccgattacagacgaagtattgaatttcgataccgtaatcgaacgtatggacagtttcatggactggttggcgactcaatatgtaaccgcattgaacatcatccacttcatgcacgataaatatgcatatgaagcggcattgatggcgttccacgatcgcgacgtattccgtacaatggcttgcggtatcgcgggtctttccgtggctgcggactcattatccgcaatcaaatatgcgaaagttaaaccgattcgcggcgacatcaaagataaagacggtaatgtcgtggcctcgaatgttgctatcgacttcgaaattgaaggcgaatatccgcaattcggtaacaatgatccgcgtgttgatgatttagcggtagacttagttgaacgtttcatgaaaaaagttcaaaaacacaaaacttaccgcaacgcaactccgacacaatctatcctgactatcacttctaacgtggtatacggtaagaaaaccggtaatactccggacggtcgtcgagcaggcgcgccattcggaccgggtgcaaacccaatgcacggtcgtgaccaaaaaggtgcggttgcttcacttacttctgtggctaaacttccgttcgcttacgcgaaagacggtatttcatataccttctctatcgtaccgaacgcattaggtaaagatgacgaagcgcaaaaacgcaaccttgccggtttaatggacggttatttccatcatgaagcgacagtggaaggcggtcaacacttgaatgttaacgttcttaaccgtgaaatgttgttagacgcgatggaaaatccggaaaaatacccgcaattaaccattcgtgtttcaggttacgcggttcgtttcaactcattaactaaagagcaacaacaagacgtcatcactcgtacgtttacacaatcaatgtaaSEQIDNO:14(来自菌株DD1的PflD的氨基酸)MAELTEAQKKAWEGFVPGEWQNGVNLRDFIQKNYTPYEGDESFLADATPATSELWNSVMEGIKIENKTHAPLDFDEHTPSTITSHKPGYINKDLEKIVGLQTDAPLKRAIMPYGGIKMIKGSCEVYGRKLDPQVEFIFTEYRKTHNQGVFDVYTPDILRCRKSGVLTGLPDAYGRGRIIGDYRRLAVYGIDYLMKDKKAQFDSLQPRLEAGEDIQATIQLREEIAEQHRALGKIKEMAASYGYDISGPATNAQEAIQWTYFAYLAAVKSQNGAAMSFGRTSTFLDIYIERDLKRGLITEQQAQELMDHLVMKLRMVRFLRTPEYDQLFSGDPMWATETIAGMGLDGRPLVTKNSFRVLHTLYTMGTSPEPNLTILWSEQLPEAFKRFCAKVSIDTSSVQYENDDLMRPDFNNDDYAIACCVSPMVVGKQMQFFGARANLAKTMLYAINGGIDEKNGMQVGPKTAPITDEVLNFDTVlERMDSFMDWLATQYVTALNIIHFMHDKYAYEAALMAFHDRDVFRTMACGIAGLSVAADSLSAIKYAKVKPIRGDIKDKDGNVVASNVAIDFEIEGEYPQFGNNDPRVDDLAVDLVERFMKKVQKHKTYRNATPTQSILTITSNVVYGKKTGNTPDGRRAGAPFGPGANPMHGRDQKGAVASLTSVAKLPFAYAKDGISYTFSIVPNALGKDDEAQKRNLAGLMDGYFHHEATVEGGQHLNVNVLNREMLLDAMENPEKYPQLTIRVSGYAVRFNSLTKEQQQDVITRTFTQSM当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1