一种检测MTHFR基因rs1801131多态位点基因型的方法及试剂盒与流程
本发明属于分子检测领域,具体涉及一种检测mthfr基因rs1801131多态位点基因型的方法及试剂盒。
背景技术:
5,10-亚甲基四氢叶酸还原酶【5,10-methylenetetrahydrofolatereductase,mthfr】是叶酸代谢系统中的关键酶,其编码基因的某些多态性可导致酶活性降低,引起叶酸代谢障碍,从而引发多种疾病,涉及(1)妇幼保健类:神经管缺陷、先天性心脏病、唇腭裂、妊娠期高血压疾病,自发性流产;(2)肿瘤类:肺癌、胃癌、大肠癌等;(3)高血压、冠心病、脑梗塞、脑溢血;(4)精神类疾病等。
mthfr基因rs1801131单核苷酸多态位点(相关序列数据见图1)系开放读码框第1286位碱基发生a→c的突变【a1286c,文献旧称a1298c,对应于genbank中mrna序列nm_005957.4的1515位碱基或基因组序列ng_013351.1的16685位碱基),导致多肽链第429位的谷氨酸变为丙氨酸(np_005948.3:p.glu429ala】,携带mthfr1286c等位基因的酶活性为野生型的68%左右,因而阻碍了叶酸代谢,引起一系列疾病发病风险增加。检测该位点基因型,可指导孕妇合理补充叶酸,预测唇腭裂、唐氏综合症、神经管缺陷等新生儿出生缺陷;还可作为5-氟尿嘧啶(5-fu)化疗疗效和毒副作用的良好预测指标;还可提示脑卒中、冠心病和静脉血栓的高风险性等。
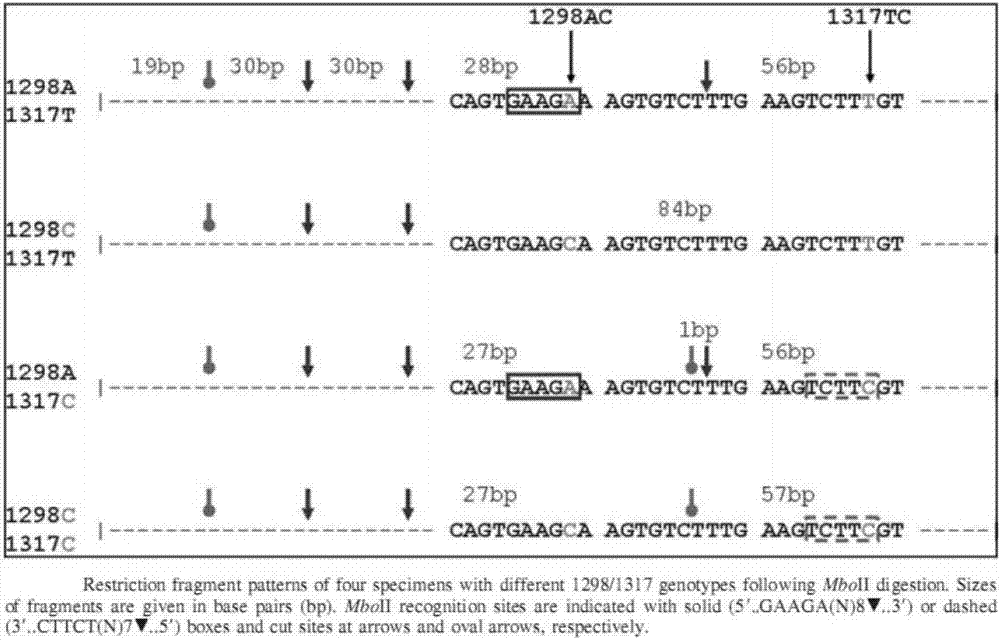
目前,检测mthfr基因rs1801131位点基因型的方法有pcr-rflp、sanger双脱氧链终止法测序、基质辅助激光解吸电离飞行时间质谱、荧光定量pcr、焦磷酸测序、基因芯片、高分辨率熔解曲线法(hrm)等,除pcr-rflp法外,其他方法均需昂贵设备或试剂,操作相对繁琐,检测周期长,检测成本高,部分方法还存在结果不稳定、重复性差等缺点。相反,pcr-rflp法操作简单,对仪器设备要求低,便于应用,但文献报道该位点大多采用限制性核酸内切酶mboii进行检测,存在一定的弊端,因为多态位点临近的一个mboii识别序列有可能导致分型错误,详见文献【allenra,gatalicaz,knezeticj,hatcherl,vogeljs,dunnst.acommon1317tcpolymorphisminmthfrcanleadtoerroneous1298acgenotypingbypcr-reandtaqmanprobeassays[j].genettest,2007,11(2):167-173.】的具体分析(图2)。
此外,也有使用fnu4hi、ajui来检测该位点的【相关文献分别为下述(1)、(2)】,它们均为稀有的限制性核酸内切酶,价格昂贵,760元/20次酶切反应(见thermoscientific公司官网报价);另外,pcr产物中不含内对照酶切位点,酶切不完全时残留的pcr产物可能会导致基因型误判。比如在ajui酶切方法中,pcr产物为189bp,a等位基因酶切完全后将产生147bp、32bp、10bp片段,c等位基因无切割位点,将保持和pcr产物一样大小(189bp)的片段。如果一个aa型的样品酶切不完全,既有147、32bp条带,又残留189bp片段,将很可能会被误判为ac型样品。
(1)weisbergi,tranp,christensenb,sibanis,rozenr.asecondgeneticpolymorphisminmethylenetetrahydrofolatereductase(mthfr)associatedwithdecreasedenzymeactivity[j].molgenetmetab,1998,64(3):169-172.
(2)machnikg,zapalam,pelce,gasecka-czaplam,kaczmarczykg,okopienb.anewandimprovedmethodbasedonpolymerasechainreaction-restrictionfragmentlengthpolymorphism(pcr-rflp)forthedeterminationofa1298cmutationinthemethylenetetrahydrofolatereductase(mthfr)gene[j].annclinlabsci,2013,43(4):436-440.
技术实现要素:
针对现有技术中所存在的不足,本发明选用另一种限制性核酸内切酶hinfi来进行mthfr基因rs1801131位点的基因分型,它不仅价格极其便宜(380元/400次),而且便于设置内对照酶切位点作为酶切的内部质控,确保了分型的准确性。
本发明所采取的技术方案是:
一种检测mthfr基因rs1801131多态位点基因型的方法,包括如下步骤:
(1)提取待检样品基因组dna;
(2)针对特定的限制性核酸内切酶,设计pcr引物对,所述pcr引物对扩增得到的产物含有一个内对照酶切位点及一个包含rs1801131多态位点的识别序列,所述的多态位点识别序列只有在多态位点为其中一种碱基的情况下被所述限制性核酸内切酶识别;
(3)利用步骤(2)所设计的pcr引物对对待检样品基因组dna进行pcr扩增;
(4)利用特定的限制性核酸内切酶对pcr产物进行酶切;
(5)根据酶切产物的电泳图谱确定mthfr基因rs1801131位点的基因型。
所述限制性核酸内切酶为hinfi;所述的内对照酶切位点的碱基序列符合gantc模式,其中n=a、t、c、g四种碱基中的任何一种;所述的多态位点识别序列符合gaatm模式,其中m为多态位点碱基,m=a、c两种碱基中的任何一种,当m为c时,该识别序列能够被限制性核酸内切酶hinfi识别并切割。
所述的内对照酶切位点与多态位点之间的距离以其酶切产物能够被区分为准。
作为其中一个方案,所述pcr引物对中的正向引物倒数第1位碱基为t,与mthfr基因的第16684位也即多态位点前1位碱基错配,使得mthfr基因第16681~16685位的碱基序列gaagm在pcr后变为gaatm,所述mthfr基因在genbank上的登录号为ng_013351.1。
所述pcr引物对中的反向引物的靶序列位于mthfr基因第16961~16965位碱基序列gactc之后;又或者是:所述反向引物倒数第3位碱基为t,与mthfr基因的第16896位碱基错配,使得mthfr基因第16893~16897位碱基序列gagac在pcr后变为gagtc,可被限制性核酸内切酶hinfi识别并切割。
作为优选的,凡是含有错配碱基的引物,其5′端均附加了一段与模板无关的附加序列,旨在增加多态位点、内对照酶切位点被酶切开和未被酶切开的片段之间的长度差异,提高电泳的分辨率。所有附加序列中不应含有hinfi酶切位点。
作为优选的,所述的pcr引物对为下列任一组:
引物对1
f1:5′-ctaatacgactgactatagggagaggggaggagctgaccagtgaat-3′(seqidno.1),
r1:5′-tcatcgttccagggcaggcaagt-3′(seqidno.2);
引物对2
f2:5′-acatccactttgcctttctcggaggagctgaccagtgaat-3′(seqidno.3),
r2:5′-caggaaacagctatgaccaagcccttccaggtggaggact-3′(seqidno.4)。
一种用于检测mthfr基因rs1801131多态位点基因型的引物对,其扩增得到的产物含有一个内对照酶切位点及一个包含rs1801131多态位点的识别序列;所述内对照酶切位点能够被所述限制性核酸内切酶识别、切割;所述的多态位点识别序列只有在多态位点为其中一种碱基的情况下被所述限制性核酸内切酶识别;所述内对照酶切位点与多态位点之间的距离以其酶切产物能够被区分为准。
所述的内对照酶切位点的碱基序列符合gantc模式,n=a、t、c、g四种碱基中的任何一种;所述的多态位点识别序列符合gaatm模式,其中m为多态位点碱基,m=a、c两种碱基中的任何一种;所述的限制性核酸内切酶为hinfi。
作为优选的,所述pcr引物对中的正向引物倒数第1位碱基为t,与mthfr基因的第16684位碱基错配,使得mthfr基因第16681~16685位序列gaagm在pcr后变为gaatm,所述mthfr基因在genbank上的登录号为ng_013351.1。
所述pcr引物对中的反向引物靶序列位于mthfr基因第16961~16965位碱基序列gactc之后;又或者是:所述反向引物倒数第3位碱基为t,与mthfr基因的第16896位碱基错配,使得mthfr基因第16893~16897位碱基序列gagac在pcr后变为gagtc,可被限制性核酸内切酶hinfi识别并切割。
作为优选的,凡是含有错配碱基的引物,其5′端均附加了一段与模板无关的附加序列,旨在增加多态位点、内对照酶切位点被酶切开和未被酶切开的片段之间的长度差异,提高电泳的分辨率。所有附加序列中不应含有hinfi酶切位点。
作为优选的,所述的pcr引物对为下列任一组:
引物对1
f1:5′-ctaatacgactgactatagggagaggggaggagctgaccagtgaat-3′(seqidno.1),
r1:5′-tcatcgttccagggcaggcaagt-3′(seqidno.2);
引物对2
f2:5′-acatccactttgcctttctcggaggagctgaccagtgaat-3′(seqidno.3),
r2:5′-caggaaacagctatgaccaagcccttccaggtggaggact-3′(seqidno.4)。
一种用于检测mthfr基因rs1801131多态位点基因型的试剂盒,其包括以上所述的用于检测mthfr基因rs1801131多态位点基因型的引物对及对应的限制性核酸内切酶。
本发明的有益效果是:
本发明在基于pcr-rflp的方法检测mthfr基因rs1801131多态位点基因型的过程中,采用了一种不同于现有报道的限制性核酸内切酶hinfi,避免了最常用的mboⅱ酶切检测时多态位点下游15nt处tcttc序列的干扰【因为tcttc的反向互补序列为gaaga,野生型等位基因a所在的序列也为gaag
附图说明
图1:genbankdbsnp数据库中rs1801131多态位点及前后相关序列,m为多态位点碱基,m=a或c。
图2:文献分析认为使用限制性核酸内切酶mboⅱ鉴定rs1801131位点基因型,临近序列会干扰结果判断,故结果的准确性无法保证。
图3:mthfr基因rs1801131多态位点前后各500个碱基的序列(参考https://www.ncbi.nlm.nih.gov/nuccore/ng_013351.1,第16685位碱基为多态位点碱基,此序列显示野生型等位基因的碱基a)
图4:mthfr基因rs1801131多态位点基因分型引物f1、r1与模板对应关系图(模板序列参考http://www.ncbi.nlm.nih.gov/nuccore/ng_013351.1),其中snp位于第16685位;上游引物相关序列与基因组序列同向,下游引物相关序列与基因组序列反向互补。按5′→3′的方向,f1倒数第1位碱基t与模板错配,使得原序列gaagm在pcr后变为gaatm,以达到用hinfi甄别多态位点的目的。pcr产物在多态位点的下游含有固有的hinfi识别序列gactc【对应于mthfr基因的第16961~16965位碱基】。另f1的5′端附加了一段与模板无关的附加序列,旨在增加多态位点被酶切开和未被酶切开的片段之间的长度差异,提高电泳的分辨率。该附加序列中不应含有hinfi酶切位点。本实施例中所采用的附加序列为:
ctaatac
ctaatac
图5:mthfr基因rs1801131多态位点基因分型引物f2、r2与模板对应关系图(模板序列参考http://www.ncbi.nlm.nih.gov/nuccore/ng_013351.1),其中snp位于第16685位;上游引物相关序列与基因组序列同向,下游引物相关序列与基因组序列反向互补。按5′→3′的方向,f2倒数第1位碱基t与模板错配,该错配使得原序列gaagm在pcr后变为gaatm,以达到用hinfi甄别多态位点的目的。r2倒数第3位碱基a的错配将在pcr产物中形成一个hinfi识别序列gagtc作为内对照酶切位点。f2、r2均为带有5′端附加序列的长链错配引物,旨在增加被酶切开和未被酶切开的片段之间的电泳区分度。f25′端附加序列为通用测序引物t7(17base):acatccactttgcctttctc(seqidno.7);r25′端附加序列为通用测序引物m13r:caggaaacagctatgacc(seqidno.8)。
图6:引物对1扩增的pcr产物琼脂糖凝胶电泳图【用凝胶成像系统看胶,m:dl2000dna分子量标记;1-10:402bppcr产物】。
图7:引物对1扩增的pcr产物琼脂糖凝胶电泳图【用紫外透射仪看胶,m:dna分子量标记dnamarkerⅰ,北京庄盟国际生物基因科技有限公司;1-13:402bppcr产物】;
图8:引物对1扩增的pcr产物经hinfi酶切用于鉴定mthfr基因rs1801131多态位点基因型的电泳图谱【所有样品基本酶切完全。m:dna分子量标记lowladder,广州东盛生物科技有限公司;p:pcr产物(402bp);1、4、7、9、10:杂合子ac;2、3、5、8、12:野生型纯合子aa;6、11:突变型纯合子cc】。
图9:引物对1扩增的pcr产物经hinfi酶切用于鉴定mthfr基因rs1801131多态位点基因型的电泳图谱【所有样品均有不同程度的酶切不完全现象。m:dna分子量标记lowladder,广州东盛生物科技有限公司;p:pcr产物(402bp);1、3、4、6、7、8、9:野生型纯合子aa;2、5:杂合子ac;10:突变型纯合子cc】。
图10:mthfr基因rs1801131多态位点3种基因型样品使用引物对1扩增的pcr产物测序峰图,从左至右依次为野生型纯合子aa、杂合子ac、突变型纯合子cc,加框的碱基为多态位点碱基。
图11:使用引物对2通过pcr-rflp鉴定mthfr基因rs1801131位点基因型的电泳图谱,左边为本色图,右边为反色图【3种基因型样品均酶切不完全,有pcr产物或中间产物残留。m:dna分子量标记marker1,广州东盛生物科技有限公司;p:pcr产物(289bp);1:突变型纯合子cc;2:杂合子ac;3:野生型纯合子aa】。
图12:使用引物对2检出的3种基因型样品的测序峰图,从上至下依次为野生型纯合子aa、突变型纯合子cc、杂合子ac(多态位点如箭头所指)。每张图的右半部分用下划线显示的序列gagtc为错配引物引入的内对照酶切位点。多态位点前一位的碱基t(加了下划线的),系上游引物的错配碱基引入。
具体实施方式
下面结合实施例对本发明作进一步的说明,但并不局限于此。
实施例1
本实施例设计了一对引物,上游引物3′端使用了一个错配碱基,pcr扩增后形成多态位点识别序列gaatm【m=a、c碱基。突变型等位基因c的相应序列为gaatc,能被限制性核酸内切酶hinfi识别;野生型等位基因a的相应序列为gaata,不能被hinfi识别】,下游引物为常规引物,可与mthfr基因的第17018~17040位碱基序列反向互补。pcr产物包含一个固有的hinfi识别序列gactc用作酶切内对照。具体方案如下:
1.基因组dna提取
采用口腔拭子基因组dna提取试剂盒,按说明书的操作步骤提取基因组dna。dna来源不限于此,任何体细胞来源的dna均可。
2.引物设计
调取mthfr基因rs1801131多态位点前后各500bp的序列【见图1、图3】,利用primerpremier5.0软件设计针对该位点的特异性分型引物。其中,上游引物的3′端需毗邻多态位点,且倒数第1位碱基为t,这样方可通过pcr扩增引进一个识别序列gaatm,其中t由错配碱基引入,突变型等位基因的相应序列为gaatc,能为hinfi识别,野生等位基因a的相应序列为gaata,不能为hinfi识别,故可用hinfi甄别多态位点。上游引物5′端附加一段与模板无关的序列,旨在增加多态位点被酶切开和未被酶切开的片段之间的长度差异,提高电泳的分辨率。
根据上述思路,设计了如下一对引物:
f1:5′-ctaatacgact
r1:5′-tcatcgttccagggcaggcaagt-3′(seqidno.2)
其中f1的5′端附加了一段序列ctaatac
该对引物的具体位置及与模板的对应关系见图4(为方便起见,图中正向引物相关序列与模板序列方向一致,反向引物相关序列与模板序列反向互补)。
该对引物扩增的pcr产物大小为402bp。
完全酶切后,3种基因型样品的条带如下:
野生型纯合子aa:324.5、77.5
杂合子ac:324.5、280、77.5、44.5
突变型纯合子cc:280、77.5、44.5
根据324.5bp、280bp两个片段的组合情况就可区分3种基因型。
如果酶切不完全,将会残留pcr产物或其它中间条带,通过与pcr产物、marker对照,本系统可以轻易识别,并且可以根据图谱中的特征条带324.5bp、280bp来判定基因型。
3.目的片段的pcr扩增及鉴定
pcr反应体系:
pcr反应条件:
pcr产物用1.5%的琼脂糖凝胶电泳鉴定。
4.pcr产物的酶切分型
本实施例使用的限制性核酸内切酶为thermoscientific的快速限制性核酸内切酶hinfi。
酶切体系总体积为30μl,具体配方如下:
其中pcr产物的量可以视pcr产物的浓度加以调整,通常为10~26μl,相应的ddh2o随之加以改变。
酶切在37℃水浴锅中进行,时间为15min~30min;然后于65℃水浴保温20min以灭活内切酶。酶切产物行3%琼脂糖凝胶电泳,通过观察电泳图谱以确定基因型。
5.测序验证本方法的准确性
选取上述pcr-rflp法检出的3种基因型样品各1例,将相应的pcr产物进行sanger法测序,结果表明,本发明所设计的分型引物,可以对mthfr基因rs1801131多态位点的基因型进行准确的检测。
6.实际检测案例
提取受检者基因组dna,利用引物对f1、r1进行pcr扩增,利用限制性核酸内切酶hinfi对pcr产物进行酶切。
图6、7为pcr产物琼脂糖凝胶电泳图,条带非常单一,说明引物的特异性非常高;
图8为pcr产物完全酶切电泳图谱,可非常清晰直观地判断基因型;
图9所有样品均有不同程度的酶切不完全现象,本方案可清楚加以识别,且不影响基因型判断。
图10为本方案检出的3种基因型样品的测序峰图,测序结果完全吻合。
实施例2
本实施例既使用错配的上游引物通过pcr扩增形成多态位点识别序列gaatm【m=a、c碱基。突变型等位基因c的相应序列为gaatc,能被限制性核酸内切酶hinfi识别;野生型等位基因a的相应序列为gaata,不能被hinfi识别】,又通过错配的下游引物通过pcr扩增形成一个hinfi识别序列用作酶切内对照。具体方案如下:
1.基因组dna提取
采用口腔拭子基因组dna提取试剂盒,按说明书的操作步骤提取基因组dna。dna来源不限于此,任何体细胞来源的dna均可。
2.引物设计
调取mthfr基因rs1801131多态位点前后各500bp的序列(见图1、图3),利用primerpremier5.0软件设计针对该位点的特异性分型引物。其中,上游引物的3′端需毗邻多态位点,且倒数第1位碱基为t,这样方可通过pcr扩增引进一个识别序列gaatm,其中t由错配引物引入,突变型等位基因的相应序列为gaatc,能为hinfi识别,野生等位基因a的多态位点相应序列为gaata,不能为hinfi识别,故可用hinfi甄别多态位点。下游引物倒数第3位采用错配碱基a将基因组模板序列gag
f2:5′-acatccactttgcctttctcggaggagctgaccagtgaa
引物f2、r2除了在3′端均含一个错配碱基外,5′端各自附加了一段与模板基本无关的序列。
上述引物的具体位置及与模板的对应关系见图5(为方便起见,图中正向引物的相关序列与模板序列方向一致,反向引物的相关序列与模板序列反向互补)。
上述引物的pcr产物大小均为289bp。
完全酶切后,3种基因型样品的条带如下:
野生型纯合子aa:250.5、38.5
杂合子ac:250.5、212
突变型纯合子cc:212、38.5
根据250.5bp、212bp两个片段的组合情况就可区分3种基因型。
如果酶切不完全,将会残留pcr产物或其它中间条带,通过与pcr产物、marker对照,本系统可以轻易识别,并且可以根据图谱中的特征条带250.5bp、212bp来判定基因型。
3.目的片段的pcr扩增及鉴定
pcr反应体系:
pcr反应条件:
pcr产物用1.5%的琼脂糖凝胶电泳鉴定。
4.pcr产物的酶切分型
本实施例使用的限制性核酸内切酶为thermoscientific的快速限制性核酸内切酶hinfi。
酶切体系总体积为30μl,具体配方如下:
其中pcr产物的量可以视pcr产物的浓度加以调整,通常为10~26μl,相应的ddh2o随之加以改变。
酶切在37℃水浴锅中进行,时间为15min~30min;然后于65℃水浴保温20min以灭活内切酶。酶切产物行3%琼脂糖凝胶电泳,通过观察电泳图谱以确定基因型。
5.测序验证本方法的准确性
选取上述pcr-rflp法检出的3种基因型样品各1例,将相应的pcr产物进行sanger法测序,结果表明,本发明所设计的分型引物,可以对mthfr基因rs1801131多态位点的基因型进行准确的检测。
6.实际检测案例
提取受检者基因组dna,利用引物对(f2、r2)进行pcr扩增,利用限制性核酸内切酶hinfi对pcr产物进行酶切。
图11为使用引物对(f2、r2)通过pcr-rflp鉴定mthfr基因rs1801131位点酶切图谱,尽管有残留的pcr产物或酶切中间产物,但并不妨碍基因型的判断,在反色图中尤为清晰。
图12为使用引物对(f2、r2)检出的3种基因型样品的测序峰图,测序结果完全吻合。从上至下依次为野生型纯合子aa、突变型纯合子cc、杂合子ac(多态位点如箭头所指)。每张图的右半部分用下划线显示的序列gagtc为错配碱基引入的内对照酶切位点。多态位点前一位的碱基t(加了下划线的),系上游引物的错配碱基引入。
以上实施例仅为介绍本发明的优选案例,对于本领域技术人员来说,在不背离本发明精神的范围内所进行的任何显而易见的变化和改进,都应被视为本发明的一部分。
sequencelisting
<110>广东药科大学
<120>一种检测mthfr基因rs1801131多态位点基因型的方法及试剂盒
<130>
<160>8
<170>patentinversion3.5
<210>1
<211>46
<212>dna
<213>人工序列
<400>1
ctaatacgactgactatagggagaggggaggagctgaccagtgaat46
<210>2
<211>23
<212>dna
<213>人工序列
<400>2
tcatcgttccagggcaggcaagt23
<210>3
<211>40
<212>dna
<213>人工序列
<400>3
acatccactttgcctttctcggaggagctgaccagtgaat40
<210>4
<211>40
<212>dna
<213>人工序列
<400>4
caggaaacagctatgaccaagcccttccaggtggaggact40
<210>5
<211>24
<212>dna
<213>人工序列
<400>5
ctaatacgactgactatagggaga24
<210>6
<211>24
<212>dna
<213>人工序列
<400>6
ctaatacgactcactatagggaga24
<210>7
<211>20
<212>dna
<213>人工序列
<400>7
acatccactttgcctttctc20
<210>8
<211>18
<212>dna
<213>人工序列
<400>8
caggaaacagctatgacc18
- 还没有人留言评论。精彩留言会获得点赞!
- 一种基于HRM检测基因多态性的引物组合物的应用的制作方法与工艺
- MDR1基因多态性检测体系及其试剂盒的制作方法与工艺
- GSTP1基因多态性检测体系及其试剂盒的制作方法与工艺
- 一种检测MTHFR基因rs1801131多态位点基因型的方法及试剂盒与流程
- 检测10个位点耳聋基因多态性的SNaPshot试剂盒的制造方法与工艺
- 一种检测人类CYP2C19基因多态性的方法及试剂盒与流程
- CDA基因多态性检测体系及其试剂盒的制造方法与工艺
- 检测22个位点耳聋基因多态性的SNaPshot试剂的应用的制造方法与工艺
- 检测22个位点耳聋基因多态性的SNaPshot试剂盒的制造方法与工艺
- DHFR基因多态性检测体系及其试剂盒的制造方法与工艺
- 一种胞苷脱氨酶基因单核苷酸多态性检测试剂盒的制作方法
- 基因单核苷酸多态性位点快速检测试剂盒的制作方法
- 一种基于黄牛Angptl8基因单核苷酸多态性的分子育种方法
- 肉鸭otxr基因单核苷酸多态性及其检测方法和应用
- 高血压易感基因SCN7A单核苷酸多态性位点rs7565062的检测试剂盒的制作方法
- 一种黄牛PPARβ基因单核苷酸多态性的检测方法及分子育种方法
- 一种检测黄牛Leptin基因单核苷酸多态性的方法
- 人PLIN1基因rs2289487位点多态性检测方法及试剂盒的制作方法
- 人PON1基因rs854560位点多态性检测方法及试剂盒的制作方法
- 测定人TERT基因rs4975605位点多态性的方法及试剂盒的制作方法