一种表达蛋白质或多肽的方法及其专用表达盒与流程
本发明涉及生物技术领域,具体涉及一种表达蛋白质或多肽的方法及其专用表达盒。
背景技术:
油料作物的种子中的三酰甘油与油体蛋白组成一个0.2-0.5μm的球体,这个球体被称为油体。油体蛋白是小分子量(15-26kD)的碱性疏水蛋白,在种子中特异表达,为油体所特有,对维持油体的稳定极为重要,占油体总重量的1-4%。
不同物种来源的油体蛋白的分子量不同,但都具有3个基本的结构域,即:N端40-60个氨基酸组成的两亲性区域(兼具亲水性和亲脂性),这一区域分布于油体表面朝向胞浆的一面;中间68-74个氨基酸的保守区域,为伸入油体内部的反式平行β-折叠结构,这一区域的氨基酸序列在不同来源的油体蛋白中高度保守;位于或靠近C端的33-40个氨基酸组成的α-螺旋结构域,该结构域兼具亲水和亲脂性,其带正电荷的基团朝向油体表面的磷脂层,带负电荷的部分位于油体表面朝向胞浆的一面。通过对不同植物油体蛋白氨基酸序列的研究发现,不同油体蛋白分子间除中部疏水区域高度保守外,N端和C端氨基酸序列差异很大。
技术实现要素:
本发明所要解决的技术问题是如何表达蛋白质或多肽。
为解决上述技术问题,本发明首先提供了表达盒Ⅰ。
本发明所提供的表达盒Ⅰ自上游至下游依次可包括如下元件:植物油体蛋白基因的启动子、融合基因Ⅰ和终止序列;
所述融合基因Ⅰ中可含有区段甲和区段乙;所述区段甲编码植物油体蛋白;所述区段乙编码目的物或目的物的前体;所述目的物可为蛋白质或多肽。
所述融合基因Ⅰ中,5’末端为起始密码子,3’末端为终止密码子,中间为连续的编码区。
所述目的物的前体在生物体中可自发形成目的物。
所述融合基因Ⅰ还可包括一个以上区段丙;所述区段丙编码蛋白标签。
当融合基因Ⅰ中包括2个以上区段丙时,每个区段丙可以编码不同的蛋白标签。
所述融合基因Ⅰ还可包括区段丁;所述区段丁可为蛋白酶的酶切识别序列。
所述融合基因Ⅰ自上游至下游依次可包括如下区段:所述区段丙、所述区段甲、所述区段丁和所述区段乙。所述区段丙具体可编码6×His标签。
所述融合基因Ⅰ自上游至下游依次可包括如下区段:第一个所述区段丙、所述区段甲、第二个所述区段丙和所述区段乙。第一个所述区段丙与第二个所述区段丙编码不同的蛋白标签。第一个所述区段丙具体可编码6×His标签。第二个所述区段丙具体可编码8×His标签。
所述目的物可为鲑鱼降钙素。所述目的物的前体可为鲑鱼降钙素的前体。
所述区段乙可为如下b1)或b2)或b3)或b4)所示的DNA分子:
b1)具有序列表中序列1自5′末端起第22至120位核苷酸所示的DNA分子;
b2)核苷酸序列是序列表中序列1自5′末端起第22至120位所示的DNA分子;
b3)与b1)或b2)限定的核苷酸序列具有85%或85%以上同一性,且编码所述鲑鱼降钙素的前体的DNA分子;
b4)在严格条件下与b1)或b2)限定的核苷酸序列杂交,且编码所述鲑鱼降钙素的前体的DNA分子。
所述表达盒Ⅰ的核苷酸序列具体可如序列表中序列4所示。
含有上述任一所述表达盒Ⅰ的重组载体Ⅰ也属于本发明的保护范围。
所述重组载体Ⅰ可为重组质粒丙。所述重组质粒丙和所述重组质粒pBO-sCT2301的唯一不同在于:将重组质粒pBO-sCT2301中鲑鱼降钙素的前体的编码基因(序列表中序列4自5′末端起第1363至1461位所示)替换为编码目的物或目的物的前体的基因。
所述重组载体Ⅰ可为重组质粒丁。所述重组质粒丁和重组质粒pBO-G2301的唯一区别在于:将重组质粒pBO-G2301的限制性内切酶BamHⅠ和XhoⅠ识别序列间的小片段替换为编码目的物或目的物的前体的基因。
所述重组载体Ⅰ具体可为重组质粒pBO-sCT2301。所述重组质粒pBO-sCT2301为将载体pCAMBIA2301的限制性内切酶HindⅢ和EcoRI识别序列间的小片段替换为序列表中序列4所示的DNA分子,得到的重组质粒。所述重组质粒pBO-sCT2301表达序列表中序列5所示的蛋白质。
所述重组载体Ⅰ具体可为重组质粒pBO-sCT2301-DZ。所述重组质粒pBO-sCT2301和所述重组质粒pBO-sCT2301-DZ的唯一不同在于:所述重组质粒pBO-sCT2301中鲑鱼降钙素前体的编码基因(即sCT基因)为序列表中序列4自5′末端起第1363至1461位所示,所述重组质粒pBO-sCT2301-DZ中鲑鱼降钙素的前体的编码基因(即sCT-DZ基因)为序列表中序列7自5′末端起第22至120位所示。所述重组质粒pBO-sCT2301-DZ表达序列表中序列5所示的蛋白质。
所述重组载体Ⅰ具体可为重组质粒pBO-G2301。所述重组质粒pBO-sCT2301和所述重组质粒pBO-G2301的唯一不同在于:所述重组质粒pBO-sCT2301的限制性内切酶BamHⅠ和XhoⅠ识别序列间的小片段为序列表中序列1自5′末端起第7至126位所示的DNA分子,所述重组质粒pBO-G2301的限制性内切酶BamHⅠ和XhoⅠ识别序列间的小片段为序列表中序列8自5′末端起第7至1353位所示的DNA分子。所述重组质粒pBO-G2301表达序列表中序列9所示的蛋白质。
为解决上述技术问题,本发明还提供了表达盒Ⅱ。
本发明所提供的表达盒Ⅱ自上游至下游依次可包括如下元件:植物油体蛋白基因的启动子、融合基因Ⅱ和终止序列;
所述融合基因Ⅱ中可含有所述区段甲和区段戊;所述区段戊为供编码目的物或目的物的前体的基因插入的插入位点;所述目的物为蛋白质或多肽。所述目的物的前体在生物体中可自发形成目的物。
所述融合基因Ⅱ中,5’末端为起始密码子,3’末端为终止密码子,中间为连续的编码区。
所述融合基因Ⅱ还可包括一个以上区段丙;所述区段丙编码蛋白标签。
当融合基因Ⅱ中包括2个以上区段丙时,每个区段丙可以编码不同的蛋白标签。
所述融合基因Ⅱ还可包括区段丁;所述区段丁可为蛋白酶的酶切识别序列。
所述融合基因Ⅱ自上游至下游依次可包括如下区段:所述区段丙、所述区段甲、所述区段丁和所述区段戊。所述区段丙具体可编码6×His标签。
所述融合基因Ⅱ自上游至下游依次可包括如下区段:第一个所述区段丙、所述区段甲、第二个所述区段丙和所述区段戊。第一个所述区段丙与第二个所述区段丙编码不同的蛋白标签。第一个所述区段丙具体可编码6×His标签。第二个所述区段丙具体可编码8×His标签。
所述目的物可为鲑鱼降钙素。所述目的物的前体可为鲑鱼降钙素的前体。
含有上述任一所述表达盒Ⅱ的重组载体Ⅱ也属于本发明的保护范围。
上述任一所述植物油体蛋白基因的启动子可为油菜油体蛋白(GenBank号为X94225.1)基因的启动子。所述油菜油体蛋白(GenBank号为X94225.1)基因的启动子的核苷酸序列具体可如序列表中序列4自5′末端起第1至875位所示。
上述任一所述“所述区段甲编码植物油体蛋白”中的所述植物油体蛋白可为芝麻油体蛋白(GenBank号为AAB58402.1)。当所述区段甲编码芝麻油体蛋白(GenBank号为AAB58402.1)时,所述区段甲的核苷酸序列具体可如序列表中序列4自5′末端起第913至1341位所示。
上述任一所述终止序列可为Nos polyA终止子。所述Nos polyA终止子的核苷酸序列具体可如序列表中序列4自5′末端起第1474至1721位所示。
上述任一所述蛋白酶可为满足如下条件的蛋白酶:所述蛋白酶对于所述融合基因Ⅰ或融合基因Ⅱ的表达产物的酶切位置为特定氨基酸残基与其前一位氨基酸残基之间;所述特定氨基酸残基为目的物的第一个氨基酸残基。
上述任一所述蛋白酶具体可为肠激酶。
为解决上述技术问题,本发明还提供了一种制备目的物或目的物的前体的方法。
本发明所提供的制备目的物的方法依次包括如下步骤:
(1)将上述任一所述重组载体Ⅰ导入受体植物,得到转基因植物;
(2)取转基因植物的种子,提取油体;
(3)利用所述蛋白标签从所述油体中纯化所述融合蛋白;
(4)取步骤(3)得到的融合蛋白,用蛋白酶进行酶切;
(5)从步骤(4)的酶切产物中分离目的物;
(6)醋酸化;
(7)脱盐;
所述目的物为蛋白质或多肽。。
为解决上述技术问题,本发明还提供了表达目的物的方法。
本发明所提供的表达目的物的方法,具体可为方法一,依次可包括如下步骤:
(1)在上述任一所述重组载体Ⅱ中的所述区段戊插入目的基因,得到含有目的基因的重组载体;所述目的基因为编码所述目的物或所述目的物的前体的基因;所述目的物为蛋白质或多肽;
(2)将含有目的基因的重组载体导入受体植物,得到转基因植物;
(3)通过培养所述转基因植物得到所述目的物。
上述步骤(1)中,“在上述任一所述重组载体Ⅱ中的所述区段戊插入目的基因”是在不影响基因的编码框的前提下进行的。
本发明所提供的表达目的物的方法,具体可为方法二,依次可包括如下步骤:
(1)将上述任一所述重组载体Ⅰ导入受体植物,得到转基因植物;
(2)通过培养所述转基因植物得到目的物;所述目的物为蛋白质或多肽。
上述方法中,所述受体植物具体可为油菜品种中双4号。
上述方法中,所述目的物存在或主要存在于转基因植物的种子中。
上述方法中,所述目的物的前体在生物体中可自发形成目的物。
上述方法中,所述“培养所述转基因植物得到目的物”还依次可包括如下步骤:
(4)取转基因植物的种子,提取油体;
(5)利用所述蛋白标签从所述油体中纯化所述融合蛋白;
(6)取步骤(5)得到的融合蛋白,用蛋白酶进行酶切;
(7)从步骤(6)的酶切产物中分离目的物;
(8)醋酸化;
(9)脱盐。
所述“提取油体”的步骤可为:先粉碎转基因植物的种子,然后用提取缓冲液提取;所述提取缓冲液为含2.0-3.0mM EDTA和400-600mM NaCl的pH7.5-8.5、15-25mM Tris-HCl缓冲液。所述粉碎的程度可为200目。所述提取缓冲液具体可为含2.5mM EDTA和500mM NaCl的pH8.0、20mM Tris-HCl缓冲液。
上述方法中,所述蛋白标签可为6×His标签。
所述“利用所述蛋白标签从所述油体中纯化所述融合蛋白”可采用镍离子螯合磁珠进行纯化,具体步骤如下:
(1)取离心管,加入步骤(2)提取的油体和Buffer A,充分混匀,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体丁,下层为溶液丁;
(2)取一新的离心管,加入油体丁和Buffer A,充分混匀;然后加入镍离子螯合磁珠,充分悬浮后置于旋转混合仪上温育60min;最后通过磁性分离,将所述镍离子螯合磁珠转移到新的离心管中;
(3)完成步骤(2)后,取装有所述镍离子螯合磁珠的离心管,加入Buffer B,用移液器轻轻吹打数次,使所述镍离子螯合磁珠重新悬浮,然后通过磁性分离,将所述镍离子螯合磁珠转移到新的离心管中;
(4)重复步骤(3)两次;
(5)完成步骤(4)后,取装有所述镍离子螯合磁珠的离心管,加入Buffer C,用移液器轻轻吹打数次,使所述镍离子螯合磁珠重新悬浮,然后通过磁性分离,收集上清液;
(6)将步骤(5)收集的上清液利用分子量为3kD的超滤管进行超滤浓缩,浓缩液即为纯化的融合蛋白。
所述镍离子螯合磁珠的商品名称为BeaverBeadsTM IDA-Nickel,具体可为苏州海狸生物医学工程有限公司的产品,产品编号为70501-5。
所述Buffer A可为含500mM NaCl和10mM咪唑的pH7.4、20mM磷酸钠缓冲液。
所述Buffer B可为含500mM NaCl和50mM咪唑的pH7.4、20mM磷酸钠缓冲液。
所述Buffer C可为含500mM NaCl和500mM咪唑的pH7.4、20mM磷酸钠缓冲液。
所述“用蛋白酶进行酶切”步骤如下:向步骤(3)纯化的融合蛋白,加入酶切buffer和肠激酶,得到酶切反应体系(酶切反应体系中,融合蛋白的浓度为1mg/mL,肠激酶的加入量为每100μg融合蛋白乙加入1U肠激酶);然后21℃酶切16h,收集上清液。
所述“分离目的物”可采用阳离子交换层析进行分离。所述阳离子交换层析柱为美国GE公司的SP-Sepharose fast flow(5×1mL)。具体步骤如下:
(1)将1体积份步骤(4)收集的上清液和3体积份pH3.0、10mM柠檬酸钠缓冲液混合,得到混合液;然后将混合液用0.22μM的滤膜过滤,得到上样液;
(2)取SP-Sepharose fast flow(5×1mL),先用10个柱体积的pH3.0、10mM柠檬酸钠缓冲液预平衡;
(3)完成步骤(2)后,取步骤(1)得到的上样液,进行上样;
(4)完成步骤(3)后,用10个柱体积的pH3.0、10mM柠檬酸钠缓冲液洗脱至紫外检测基线平稳(检测波长为220nm);
(5)完成步骤(4)后,用含400mM NaCl的pH3.0、10mM柠檬酸钠缓冲液进行洗脱,收集洗脱峰约5-10mL的洗脱溶液。
所述醋酸化的步骤可为:调节步骤(5)分离的目的物的pH值至1.0-3.0,然后加入醋酸钠处理40-80min。所述醋酸化的步骤具体可为:取步骤(5)分离的目的物,用磷酸调节pH值至2.0,得到溶液1;取1体积份溶液1,加入3体积份浓度为333mM的醋酸钠水溶液,得到溶液2;取所述溶液2,室温放置60min。
所述脱盐可为反相色谱脱盐。所述脱盐的具体步骤如下:
(1)取Amberchrom CG300md resin,用10个柱体积的0.1%(v/v)醋酸水溶液洗脱至电导率基线平稳;
(2)完成步骤(1)后,用10个柱体积的浓度为250mM醋酸钠水溶液洗脱至pH值基线平稳;
(3)完成步骤(2)后,取步骤5得到的溶液3,进行上样;
(4)完成步骤(3)后,用10个柱体积的浓度为250mM醋酸钠水溶液洗脱至pH值基线平稳。
(5)完成步骤(4)后,用10个柱体积的0.1%(v/v)醋酸水溶液洗脱(流速为5mL/min)至电导率基线平稳;
(6)完成步骤(5)后,用40%(v/v)乙醇水溶液洗脱(流速为2mL/min),收集洗脱峰约5-10mL的洗脱溶液。
所述Amberchrom CG300md resin具体可为北京慧德易科技有限责任公司的产品。
上述方法中,所述蛋白酶对于所述融合基因Ⅰ或融合基因Ⅱ的表达产物的酶切位置为特定氨基酸残基与其前一位氨基酸残基之间;所述特定氨基酸残基为目的物的第一个氨基酸残基。所述蛋白酶具体可为肠激酶。
上述方法中,所述目的物可为鲑鱼降钙素。
上述任一所述鲑鱼降钙素的前体可为氨基酸序列如序列表中序列5自N末端起第158至190位所示的蛋白质。
实验证明,将重组质粒pBO-sCT2301或重组质粒pBO-sCT2301-DZ导入油菜品种中双4号,得到转基因植物,然后培养该转基因植物,进一步得到鲑鱼降钙素;将重组质粒pBO-G2301导入油菜品种中双4号,得到转基因植物,然后培养该转基因植物,进一步得到狂犬病病毒CVS株糖蛋白(GenBank号为KF660244.1)。可见,利用本发明所提供的方法可以表达蛋白质或多肽,具有重要的应用价值。
附图说明
图1为实施例1步骤二中6的实验结果。
图2为实施例1步骤二中7的实验结果。
图3为实施例1步骤二中7的实验结果。
图4为实施例1步骤二中7的实验结果。
图5为实施例1步骤二8中(1)的实验结果。
图6为实施例1步骤二8中(2)的实验结果。
图7为实施例1中步骤三的实验结果。
图8为实施例1中步骤四的实验结果。
图9为实施例3步骤二中8的实验结果。
图10为实施例3中步骤三的实验结果。
具体实施方式
下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。
下述实施例中的实验方法,如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
油菜品种中双4号记载于如下文献中:罗晓辉,叶明海.“中双4号”育苗移栽高产栽培[J].上海农业科技,1999年05期.在下文中,油菜品种中双4号简称中双4号。
油菜品种青油14号记载于如下文献中:苏有志.甘蓝型春油菜新品种—青油14号[J].中国农技推广,1997年03期.在下文中,油菜品种青油14号简称青油14号。
豫芝4号记载于如下文献中:曹玉平.豫芝4号.农业科技通讯,1991年11期.
芝麻油体蛋白的GenBank号为AAB58402.1。油菜油体蛋白的GenBank号为X94225.1。狂犬病病毒CVS株糖蛋白的GenBank号为KF660244.1。
下述实施例中的光暗交替培养(即光照培养和暗培养交替)的条件为:25℃。光照培养时的光照强度为15000Lx。光暗交替培养的周期具体为:14h光照培养/10h黑暗培养。
MS0培养基:将NH4NO3 1650mg、KNO3 1900mg、KH2PO4 170mg、MgSO4·7H2O 370mg、CaCl2·2H2O 440mg、FeSO4·7H2O 27.80mg、Na2EDTA 37.30mg、MnSO4·4H2O 22.30mg、ZnSO4·7H2O 8.60mg、H3BO3 6.20mg、KI 0.83mg、Na2MOO4·2H2O 0.25mg、CuSO4·5H2O 0.025mg、COCl2·6H2O 0.025mg、肌醇100.00mg、VB10.1mg、VB60.5mg、烟酸0.5mg、甘氨酸2.0mg和琼脂7g溶于1L蒸馏水,调节pH值至5.8。
载体pUC57为百奥迈科生物技术有限公司的产品,产品目录号为BK0033。载体pEASY-T1为北京全式金生物技术有限公司的产品,产品目录号为CT101。载体pCAMBIA2301为华越洋生物(北京)科技有限公司的产品,产品目录号为VECT0310。λDNA/EcoRI+HindⅢMarker为北京康润生物科技有限公司的产品,产品目录号为M125-01。粉碎机为绍兴市科宏仪器有限公司的产品,产品型号为EW-100。鲑鱼降钙素标准品为北京华大蛋白质研发中心有限公司合成。密钙息为Novartis Pharma Stein AG公司的产品。
载体pTΩ4a:将载体pUC19的限制性内切酶HindⅢ和EcoRI识别序列间的小片段替换为序列表中序列10所示的DNA分子得到的重组质粒。载体pUC19为TaKaRa公司的产品,货号为D3219。
实施例1、利用转基因油菜油体表达系统表达鲑鱼降钙素
一、重组质粒pBO-sCT2301的构建
1、人工合成序列表中序列1所示的双链DNA分子。序列表中序列1中,自5′末端起第1至6位为限制性内切酶BamHⅠ的识别序列,第7至21位为肠激酶的识别序列,第22至120位为鲑鱼降钙素的前体的编码基因(以下简称sCT基因),第121至126位为两个终止密码子,第127至132位为限制性内切酶XhoⅠ的识别序列。
2、将步骤1合成的双链DNA分子连接至载体pUC57,得到重组质粒psCT。
3、提取豫芝4号开花后5周的种子的总RNA,然后该总RNA用M-MLV反转录出第一链cDNA,得到芝麻的cDNA。以芝麻的cDNA为模板,采用引物Olem5:
5′-CTGCAGATGCATCATCACCATCATCATGCGGACGAACC-3′(下划线为限制性内切酶PstI的识别序列)和引物Olem3:5′-ATGGGATCCCGGTCTTATTACATCTTGGCTTC-3′(下划线为限制性内切酶BamHI的识别序列)进行PCR扩增,获得PCR扩增产物。反应条件为:94℃30s,58℃30s,72℃1min,35个循环;72℃延伸10min。
经测序,该PCR扩增产物的核苷酸序列如序列表中的序列2所示。序列表中序列2中,自5′末端起第1至6位为限制性内切酶PstI的识别序列,第7至9位为起始密码子ATG(编码甲硫氨酸),第10至27位为编码6×His标签的核苷酸序列,第28至456位为编码芝麻油体蛋白自N末端起第2至144位的核苷酸序列,第457至462位为限制性内切酶BamHI的识别序列。
4、将步骤3获得的PCR扩增产物连接至载体pEASY-T1,得到重组质粒甲。
5、用限制性内切酶PstI和BamHI双酶切重组质粒甲,回收465bp的DNA片段甲。
6、用限制性内切酶PstI和BamHI双酶切载体pTΩ4a,回收约2.7kb的载体骨架甲。
7、将DNA片段甲和载体骨架甲进行连接,得到中间载体甲。
8、用限制性内切酶BamHⅠ和XhoⅠ双酶切重组质粒psCT,回收132bp的DNA片段乙。
9、用限制性内切酶BamHⅠ和XhoⅠ双酶切中间载体甲,回收约3.0kb的载体骨架乙。
10、将DNA片段乙和载体骨架乙进行连接,得到中间载体乙。
11、以油菜品种青油14的基因组DNA为模板,采用引物NP5:
5′-ATTCAAGCTTGTCGGATCATGACGTTTCCAG-3′(下划线为限制性内切酶HindⅢ的识别序列)和引物NP3:5′-GCTTCTGCAGAATTGAGAGAGATCGAAGAG-3′(下划线为限制性内切酶PstI的识别序列)进行PCR扩增,获得PCR扩增产物。反应条件为:94℃30s,58℃30s,72℃1min,35个循环;72℃延伸10min。
经测序,该PCR扩增产物的核苷酸序列如序列表中的序列3所示。序列表中的序列3中,自5′末端起第5至10位为限制性内切酶HindⅢ的识别序列,第11至885位为油菜油体蛋白的启动子的核苷酸序列,第896至901位为限制性内切酶PstI的识别序列。
12、用限制性内切酶HindⅢ和PstI双酶切步骤11获得的PCR扩增产物,回收905bp的DNA片段丙。
13、用限制性内切酶HindⅢ和PstI双酶切中间载体乙,回收约3.1kb的载体骨架丙。
14、将DNA片段丙和载体骨架丙进行连接,得到中间载体丙。
15、用限制性内切酶HindⅢ和EcoRI双酶切中间载体丙,回收约2.0kb的DNA片段丁。
16、用限制性内切酶HindⅢ和EcoRI双酶切载体pCAMBIA2301,回收约11.6kb的载体骨架丁。
17、将DNA片段丁和载体骨架丁进行连接,得到重组质粒pBO-sCT2301。
根据测序结果,对重组质粒pBO-sCT2301进行结构描述如下:将载体pCAMBIA2301的限制性内切酶HindⅢ和EcoRI识别序列间的小片段替换为序列表中序列4所示的DNA分子。重组质粒pBO-sCT2301表达序列表中序列5所示的融合蛋白甲。
序列表中序列4中,自5′末端起第1至875位为油菜油体蛋白的启动子的核苷酸序列,第886至891位为限制性内切酶PstI的识别序列,第892至894位为起始密码子ATG(编码甲硫氨酸),第895至912位为编码6×His标签的核苷酸序列,第913至1341位为编码芝麻油体蛋白自N末端起第2至144位的核苷酸序列,第1342至1347位为限制性内切酶BamHI的识别序列,第1348至1362位为肠激酶的识别序列,第1363至1461位为鲑鱼降钙素的前体的编码基因,第1462至1467位为两个终止密码子,第1468至1473位为限制性内切酶XhoⅠ的识别序列,第1474至1721位为Nos polyA终止子的核苷酸序列。
序列表中序列5中,自N末端起第1位为甲硫氨酸(起始氨基酸),第2至7位为6×His标签,第8至150位为芝麻油体蛋白自N末端起第2至144位,第153至157位为肠激酶的识别位点,第158至190位为鲑鱼降钙素的前体。
二、油菜遗传转化
1、农杆菌侵染液的制备
(1)采用电击法将重组质粒pBO-sCT2301导入根癌农杆菌LBA4404,得到重组农杆菌,命名为LBA4404/pBO-sCT2301。
(2)将LBA4404/pBO-sCT2301的单克隆接种至5mL含100mg/L卡那霉素(Kanamycin,Kan)和50mg/L利福平(Rifampicin,Rif)的YEB液体培养基,28℃、200rpm振荡培养12h,得到培养菌液1。
(3)将1mL培养菌液1接种至50mL含100mg/L Kan和50mg/L Rif的YEB液体培养基,28℃、200rpm振荡培养至OD600nm值为0.3~0.4,得到培养菌液2。
(4)取步骤(3)得到的培养菌液2,4℃、5000rpm离心5min,收集菌体1。
(5)取步骤(4)收集的菌体1,用含1.0mg/L 6-BA的MS0培养基重悬,然后4℃、5000rpm离心5min,收集菌体2。
(6)取步骤(5)收集的菌体2,用含100mg/L乙酰丁香酮(Acetosyringone,As)的MS0培养基重悬,得到农杆菌侵染液。以含100mg/L As的MS0培养基为参照,调整农杆菌侵染液的OD600nm值至0.15~0.25。
2、中双4号的子叶的获得
取中双4号的种子,先用75%(v/v)的乙醇水溶液浸泡2min,然后用次氯酸钠水溶液(由1体积份次氯酸钠溶液(有效氯≥10.0)和4体积份水混合而成)浸泡10min,最后用无菌水反复冲洗,沥干后接种于MS0培养基上,光暗交替培养5d,得到中双4号的材料。
取中双4号的材料,剪取子叶(尽量靠近生长点),得到中双4号的子叶。
3、侵染
取步骤2获得的中双4号的子叶,置于离心管,然后加入农杆菌侵染液(OD600nm值为0.2)浸泡10min。
4、共培养
完成步骤3后,将所述中双4号的子叶转移至共培养培养基上(子叶需正面朝上)共培养4d。
共培养培养基:含1.25mg/L NAA、5.0mg/L 6-BA和5.0mg/L AgNO3的MS0培养基。
共培养条件:25℃,暗培养。
5、选择培养
完成步骤4后,将所述中双4号的子叶转移至选择培养基上(子叶需正面朝上),光暗交替培养4d。
选择培养基:含1.0mg/L NAA、3.0mg/L 6-BA和100mg/L头孢噻吩(cefalotin,Cf)的MS0培养基。
6、分化培养
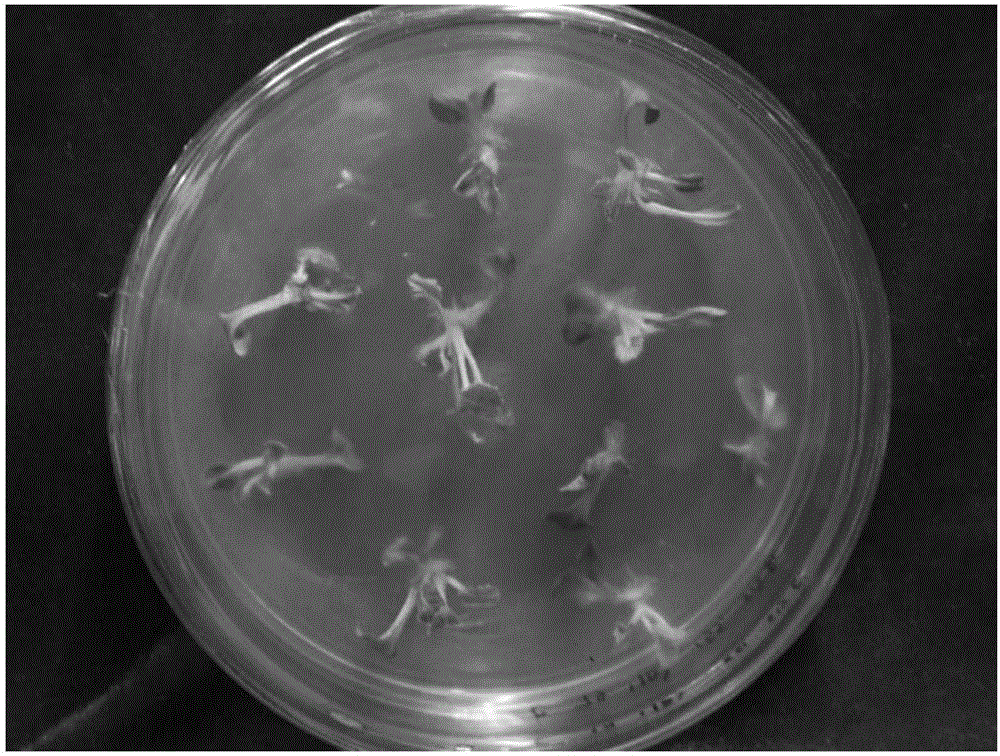
完成步骤5后,将所述中双4号的子叶转移至分化培养基上(子叶需正面朝上),光暗交替培养4周,得到长约1cm的分化芽(见图1)。
分化培养基:含0.2mg/L NAA、2.0mg/L 6-BA、40mg/L Kan、100mg/L Cf的MS0培养基。
7、生根培养
完成步骤6后,将所述分化芽转移至生根培养基上,光暗交替培养2周,获得拟转sCT基因油菜(见图2和图3),然后将拟转sCT基因油菜移栽至营养土正常培养(见图4)。
生根培养基:含100mg/L Kan和100mg/L Cf的MS0培养基。
随机选择6株拟转sCT基因油菜,依次命名为Siv1、Siv3、Siv4、Siv7、Siv11和Siv12。
8、分子检测
(1)PCR检测
分别提取步骤7获得的6株拟转sCT基因油菜叶片的基因组DNA并作为模板,以CT5:
5'-GCCGGTCTCATTCTTACC-3'和CT3:5'-CTCAGCCTCGAGTTACTATCC-3'为引物进行PCR扩增,得到PCR扩增产物。用等体积超纯水代替拟转sCT基因油菜的叶片的基因组DNA,作为阴性对照。用等体积重组质粒pBO-sCT2301的DNA代替拟转sCT基因油菜的叶片的基因组DNA,作为阳性对照。
PCR反应程序为:94℃预变性5min;94℃变性30s,55℃退火1min,72℃延伸1min,35个循环;72℃延伸10min,4℃保持。
PCR扩增反应完成后,取10μL PCR扩增产物进行1%琼脂糖凝胶电泳。实验结果见图5(泳道1为λDNA/EcoRI+HindⅢMarker,泳道2为Siv1,泳道3为Siv3,泳道4为Siv4,泳道5为Siv7,泳道6为Siv11,泳道7为Siv12,泳道8为阳性对照,泳道9为阴性对照)。结果表明,如果以拟转sCT基因油菜的叶片的基因组DNA为模板,能够扩增出约433bp的条带,则该拟转sCT基因油菜即为转sCT基因油菜;阴性对照不能获得433bp的条带;阳性对照可以获得433bp的条带。
(2)RT-PCR检测
编码芝麻油体蛋白的基因(以下简称芝麻油体基因)是在种子中特异表达的基因,一般在开花后4-6周的种子中开始转录,9-11周的种子中mRNA的含量达到最高水平,种子的成熟后期的mRNA含量急剧降低。
(a)提取待测油菜(Siv1、Siv3、Siv4、Siv7、Siv11或Siv12)开花后9-11周的种子的总RNA,然后该总RNA用M-MLV反转录出第一链cDNA,得到待测油菜的cDNA。待测油菜的cDNA中,DNA浓度为500ng/μL。
(b)以步骤(a)得到的待测油菜的cDNA为模板,以CT5:5'-GCCGGTCTCATTCTTACC-3'和CT3:5'-CTCAGCCTCGAGTTACTATCC-3'为引物进行RT-PCR扩增,得到PCR扩增产物。用等体积超纯水代替待测油菜的cDNA,作为阴性对照。
PCR反应程序为:94℃预变性5min;94℃变性30s,55℃退火1min,72℃延伸1min,35个循环;72℃延伸10min,4℃保持。
PCR扩增反应完成后,取10μL PCR扩增产物进行1%琼脂糖凝胶电泳。实验结果见图6(泳道1为λDNA/EcoRI+HindⅢMarker,泳道2为Siv1,泳道3为Siv3,泳道4为Siv4,泳道5为阴性对照)。结果表明,如果以拟转sCT基因油菜的cDNA为模板,能够扩增出约433bp的条带,则该拟转sCT基因油菜即为转sCT基因油菜,说明sCT基因已经整合到中双4号的基因组,并转录表达;阴性对照不能获得433bp的条带。
PCR检测和RT-PCR检测的结果完全一致。因此,Siv1、Siv3、Siv4、Siv7、Siv11和Siv12均为转sCT基因油菜。
待Siv1成熟后收集种子,然后进行繁育和PCR检测,直至获得纯合种子。将该纯合种子命名为Siv1种子,进行后续实验。
三、鲑鱼降钙素的提取和纯化
1、转sCT基因油菜油体的提取
提取缓冲液为含2.5mM EDTA和500mM NaCl的pH8.0、20mM Tris-HCl缓冲液。
(1)取5g步骤二收集的Siv1种子,用粉碎机粉碎(粉碎程度200目),得到油菜籽粉。
(2)完成步骤(1)后,取离心管(规格为50mL),加入油菜籽粉和30mL提取缓冲液,充分混匀,然后置于冰上30min。
(3)完成步骤(2)后,取所述离心管,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体甲,下层为溶液甲。
(4)完成步骤(3)后,取一新的离心管(规格为50mL),加入收集的油体甲和30mL提取缓冲液,充分混匀,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体乙,下层为溶液乙。
(5)完成步骤(4)后,取一新的离心管(规格为50mL),加入收集的油体乙和30mL提取缓冲液,充分混匀,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体丙,下层为溶液丙。
收集油体丙,备用。
2、His-tag初步纯化
镍离子螯合磁珠的商品名称为BeaverBeadsTM IDA-Nickel,具体为苏州海狸生物医学工程有限公司的产品,产品编号为70501-5。
Buffer A为含500mM NaCl和10mM咪唑的pH7.4、20mM磷酸钠缓冲液。
Buffer B为含500mM NaCl和50mM咪唑的pH7.4、20mM磷酸钠缓冲液。
Buffer C为含500mM NaCl和500mM咪唑的pH7.4、20mM磷酸钠缓冲液。
(1)取离心管,加入油体丙和30mL Buffer A,充分混匀,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体丁,下层为溶液丁。
(2)取一新的离心管,加入油体丁和10mL Buffer A,充分混匀;然后加入1mL镍离子螯合磁珠,充分悬浮后置于旋转混合仪上温育60min;最后通过磁性分离,将所述镍离子螯合磁珠转移到新的离心管中。
(3)完成步骤(2)后,取装有所述镍离子螯合磁珠的离心管,加入10mL Buffer B,用移液器轻轻吹打数次,使所述镍离子螯合磁珠重新悬浮,然后通过磁性分离,将所述镍离子螯合磁珠转移到新的离心管中。
(4)重复步骤(3)两次。
(5)完成步骤(4)后,取装有所述镍离子螯合磁珠的离心管,加入5mL Buffer C,用移液器轻轻吹打数次,使所述镍离子螯合磁珠重新悬浮,然后通过磁性分离,收集上清液。
(6)将步骤(5)收集的上清液利用分子量为3kD的超滤管进行超滤浓缩,获得融合蛋白乙的浓缩液。
鲑鱼降钙素主要用于治疗骨质疏松症。通过基因工程法生产鲑鱼降钙素,主要是在大肠杆菌或酵母中表达鲑鱼降钙素,但由于鲑鱼降钙素C端第32位氨基酸不能酰胺化,因此表达出的鲑鱼降钙素的生物学活性仅为100-200U/mg;而天然的鲑鱼降钙素的生物学活性为4500U/mg。已有研究结果表明,鲑鱼降钙素的前体(氨基酸序列如序列表中序列5自N末端起第158至190位所示)通过植物自身的酰胺化系统,可转化为鲑鱼降钙素。
融合蛋白乙的氨基酸序列如序列表中序列6所示,且其C末端酰胺化。融合蛋白乙在转sCT基因油菜体内经过如下转化得到:转sCT基因油菜中首先表达融合蛋白甲,之后通过自身的酰胺化系统,将融合蛋白甲转化为C末端酰胺化的融合蛋白乙。
3、肠激酶酶切
(1)取融合蛋白乙的浓缩液,加入酶切buffer和肠激酶,得到酶切反应体系;酶切反应体系中,融合蛋白乙的浓度为1mg/mL,肠激酶的加入量为每100μg融合蛋白乙加入1U肠激酶。
酶切buffer和肠激酶均为大肠杆菌表达重组肠激酶中的组件;大肠杆菌表达重组肠激酶具体可为上海翊圣生物科技有限公司的产品,产品目录号为20401ES80。
(2)完成步骤(1)后,取所述酶切反应体系,先21℃酶切16h,然后4℃、15000g离心20min,收集上清液。
4、阳离子交换纯化
将步骤3收集的上清液在AKTA蛋白纯化系统上经阳离子交换层析纯化,得到鲑鱼降钙素溶液。具体步骤如下:
(1)将1体积份步骤3收集的上清液和3体积份pH3.0、10mM柠檬酸钠缓冲液混合,得到混合液(电导率为7mS/cm);然后将混合液用0.22μM的滤膜过滤,得到上样液。
(2)取SP-Sepharose fast flow(5×1mL)(美国GE公司的产品),先用10个柱体积的pH3.0、10mM柠檬酸钠缓冲液预平衡(流速为1mL/min)。
(3)完成步骤(2)后,取步骤(1)得到的上样液,进行上样(流速为0.5mL/min)。
(4)完成步骤(3)后,用10个柱体积的pH3.0、10mM柠檬酸钠缓冲液洗脱(流速为1mL/min)至紫外检测基线平稳(检测波长为220nm)。
(5)完成步骤(4)后,用含400mM NaCl的pH3.0、10mM柠檬酸钠缓冲液进行洗脱(流速为0.5mL/min),收集洗脱峰约5-10mL的洗脱溶液。
5、醋酸化
(1)取步骤4收集的洗脱溶液,先加入磷酸调节pH值至2.0,得到溶液1。
(2)取1体积份溶液1,加入3体积份浓度为333mM的醋酸钠水溶液,混合均匀,得到溶液2。
(3)取所述溶液2,室温放置60min,得到溶液3。
6、反相色谱脱盐及冻干
Amberchrom CG300md resin为北京慧德易科技有限责任公司的产品。
(1)取Amberchrom CG300md resin,用10个柱体积的0.1%(v/v)醋酸水溶液洗脱(流速为5mL/min)至电导率基线平稳。
(2)完成步骤(1)后,用10个柱体积的浓度为250mM醋酸钠水溶液洗脱(流速为5mL/min)至pH值基线平稳。
(3)完成步骤(2)后,取步骤5得到的溶液3,进行上样(流速2mL/min)。
(4)完成步骤(3)后,用10个柱体积的浓度为250mM醋酸钠水溶液洗脱(流速为5mL/min)至pH值基线平稳。
(5)完成步骤(4)后,用10个柱体积的0.1%(v/v)醋酸水溶液洗脱(流速为5mL/min)至电导率基线平稳。
(6)完成步骤(5)后,用40%(v/v)乙醇水溶液洗脱(流速为2mL/min),收集洗脱峰约5-10mL的洗脱溶液。
(7)用冷冻干燥机将步骤(6)收集的洗脱溶液冻干至粉末,即鲑鱼降钙素粉末。-20℃备用。
取1mg鲑鱼降钙素粉末,加入1mL超纯水溶解,得到鲑鱼降钙素溶液。
将鲑鱼降钙素溶液和浓度为1mg/mL鲑鱼降钙素标准品水溶液进行SDS-PAGE。
实验结果见图7(1为蛋白Marker,2为鲑鱼降钙素标准品水溶液,3为鲑鱼降钙素溶液)。结果表明,鲑鱼降钙素溶液中含有鲑鱼降钙素,纯度约90%。每10g步骤二收集的Siv1种子产生0.2mg鲑鱼降钙素(以100%纯度计)。
四、鲑鱼降钙素的HPLC检测
使用配有Agilent Zorbax SB C18柱(5.0μm,150mm×2.1mm)的Agilent 1200液相色谱仪分析步骤三中的鲑鱼降钙素溶液和浓度为1mg/mL的鲑鱼降钙素标准品水溶液。进样量20μL。流动相由0.1%(v/v)三氟乙酸(trifluoroacetic acid,TFA)水溶液(A液)和0.1%(v/v)TFA乙腈溶液(B液)组成,流速为0.2mL/min,使用流动相中B液递增、A液递减的梯度洗脱条件进行梯度洗脱,具体如下(%均为体积百分比):0-8min,流动相中B液的体积百分含量由10%匀速升至30%;8-50min,流动相中B液的体积百分含量由30%匀速升至55%;50-55min,流动相中B液的体积百分含量由55%匀速升至100%。检测波长为210nm。
实验结果见图8(A为鲑鱼降钙素标准品水溶液,B为步骤三中的鲑鱼降钙素溶液):步骤三中的鲑鱼降钙素溶液与鲑鱼降钙素标准品水溶液的目的峰出峰时间基本一致(见图8中箭头标注,出峰时间约为6.0min)。结果表明,步骤三中的鲑鱼降钙素溶液中含有鲑鱼降钙素。
五、检测鲑鱼降钙素的生物学活性
Vr:CD1(ICR)小鼠为北京维通利华实验动物技术有限公司的产品。钙测定试剂盒为北京中生北控生物科技股份有限公司的产品。
1、取30只体重为24-26g的健康Vr:CD1(ICR)小鼠,随机分成鲑鱼降钙素组、密钙息组和生理盐水组(每组10只,雌雄各半),禁食10-12h(仅给蒸馏水)后,分别进行如下处理:
鲑鱼降钙素组:尾静脉注射步骤三中的鲑鱼降钙素溶液(注射剂量为0.1mL/只);
密钙息组:尾静脉注射密钙息(注射剂量为0.5IU/只);
生理盐水组:尾静脉注射0.9%(0.9mg/100mL)生理盐水(注射剂量为0.1mL/只)。
2、完成步骤1 60min后,每只小鼠先腹腔注射10%(10mg/100mL)水合氯醛水溶液(注射剂量为0.15mL/只),再分别从眼眶取血,室温静置2h;最后3000g离心15min,上清液即为血清。
3、完成步骤2后,取血清,按照钙测定试剂盒的操作步骤,用全自动生化分析测定每只小鼠的血钙浓度。
实验结果见表1。结果表明,密钙息组小鼠的血钙浓度比生理盐水组降低20%,鲑鱼降钙素组小鼠的血钙浓度比生理盐水组降低23%,方差分析差异极显著。因此,使用步骤一至步骤三的方法获得的鲑鱼降钙素溶液具有降低血钙的生物学活性。
表1
实施例2、利用转基因油菜油体表达系统表达鲑鱼降钙素
按照实施例1步骤一至步骤三的方法,将步骤一中的重组质粒pBO-sCT2301替换为重组质粒pBO-sCT2301-DZ,其它步骤均不变,得到鲑鱼降钙素溶液;每10g油菜种子产生0.16mg鲑鱼降钙素(以100%纯度计)。
重组质粒pBO-sCT2301-DZ的构建方法为:按照实施例1步骤一的方法,将步骤1中“人工合成序列表中序列1所示的双链DNA分子”替换为“人工合成序列表中序列7所示的双链DNA分子”,其它步骤均不变,得到重组质粒pBO-sCT2301-DZ。重组质粒pBO-sCT2301-DZ也表达序列表中序列5所示的融合蛋白甲。
序列表中序列7中,自5′末端起第1至6位为限制性内切酶BamHⅠ的识别序列,第7至21位为肠激酶的识别序列,第22至120位为鲑鱼降钙素的前体的编码基因(以下简称sCT-DZ基因),第121至126位为两个终止密码子,第127至132位为限制性内切酶XhoⅠ的识别序列。重组质粒pBO-sCT2301和重组质粒pBO-sCT2301-DZ的唯一不同在于:重组质粒pBO-sCT2301的鲑鱼降钙素的前体的编码基因(即sCT基因)为序列表中序列1自5′末端起第22至120位所示,重组质粒pBO-sCT2301-DZ的鲑鱼降钙素的前体的编码基因(即sCT-DZ基因)为序列表中序列7自5′末端起第22至120位所示。
实施例3、利用转基因油菜油体表达系统表达狂犬病病毒CVS株糖蛋白
一、重组质粒pBO-G2301的构建
1、人工合成序列表中序列8所示的双链DNA分子。序列表中序列8中,自5′末端起第1至6位为限制性内切酶BamHⅠ的识别序列,第7至30位为编码8×His标签的核苷酸序列,第31至1347位为狂犬病病毒CVS株糖蛋白(以下简称G蛋白)的编码基因(以下简称G基因),第1348至1353位为两个终止密码子,第1354至1359位为限制性内切酶XhoⅠ的识别序列。
2、将步骤1合成的双链DNA分子连接至载体pUC57,得到重组质粒phG。
3、用限制性内切酶BamHⅠ和XhoⅠ双酶切重组质粒phG,回收1359bp的DNA片段1。
4、用限制性内切酶BamHⅠ和XhoⅠ双酶切实施例1步骤一构建的重组质粒pBO-sCT2301,回收约13.0kb的载体骨架1。
5、将DNA片段1和载体骨架1进行连接,得到重组质粒pBO-G2301。重组质粒pBO-G2301表达序列表中序列9所示的融合蛋白。序列表中序列9中,自N末端起第1位为甲硫氨酸(起始氨基酸),第2至7位为6×His标签,第8至150位为芝麻油体蛋白自N末端起第2至144位,第153至160位为8×His标签,第161至599位为G蛋白。
重组质粒pBO-sCT2301和重组质粒pBO-G2301的唯一不同在于:重组质粒pBO-sCT2301的限制性内切酶BamHⅠ和XhoⅠ识别序列间的小片段为序列表中序列1自5′末端起第7至126位所示的DNA分子,重组质粒pBO-G2301的限制性内切酶BamHⅠ和XhoⅠ识别序列间的小片段为序列表中序列8自5′末端起第7至1353位所示的DNA分子。
二、油菜遗传转化
1、农杆菌侵染液的制备
(1)采用电击法将重组质粒pBO-G2301导入根癌农杆菌LBA4404,得到重组农杆菌,命名为LBA4404/pBO-G2301。
(2)将LBA4404/pBO-G2301的单克隆接种至5mL含100mg/L Kan和50mg/L Rif的YEB液体培养基,28℃、200rpm振荡培养12h,得到培养菌液甲。
(3)将1mL培养菌液甲接种至50mL含100mg/L Kan和50mg/L Rif的YEB液体培养基,28℃、200rpm振荡培养至OD600nm值为0.3~0.4,得到培养菌液乙。
(4)取步骤(3)得到的培养菌液乙,4℃、5000rpm离心5min,收集菌体甲。
(5)取步骤(4)收集的菌体甲,用含1.0mg/L 6-BA的MS0培养基重悬,然后4℃、5000rpm离心5min,收集菌体乙。
(6)取步骤(5)收集的菌体乙,用含100mg/L As的MS0培养基重悬,得到农杆菌侵染液。以含100mg/L As的MS0培养基为参照,调整农杆菌侵染液的OD600nm值至0.15~0.25。
2、中双4号的子叶的获得
取中双4号的种子,先用75%(v/v)的乙醇水溶液浸泡2min,然后用次氯酸钠水溶液(由1体积份次氯酸钠溶液(有效氯≥10.0)和4体积份水混合而成)浸泡10min,最后用无菌水反复冲洗,沥干后接种于MS0培养基上,光暗交替培养5d,得到中双4号的材料。
取中双4号的材料,剪取子叶(尽量靠近生长点),得到中双4号的子叶。
3、侵染
取步骤2获得的中双4号的子叶,置于离心管,然后加入农杆菌侵染液(OD600nm值为0.2)浸泡10min。
4、共培养
完成步骤3后,将所述中双4号的子叶转移至共培养培养基上(子叶需正面朝上)共培养4d。
共培养培养基:含1.25mg/L NAA、5.0mg/L 6-BA和5.0mg/L AgNO3的MS0培养基。
共培养条件:25℃,暗培养。
5、选择培养
完成步骤4后,将所述中双4号的子叶转移至选择培养基上(子叶需正面朝上),光暗交替培养4d。
选择培养基:含1.0mg/L NAA、3.0mg/L 6-BA和100mg/L头孢噻吩(cefalotin,Cf)的MS0培养基。
6、分化培养
完成步骤5后,将所述中双4号的子叶转移至分化培养基上(子叶需正面朝上),光暗交替培养4周,得到长约1cm的分化芽。
分化培养基:含0.2mg/L NAA、2.0mg/L 6-BA、40mg/L Kan、100mg/L Cf的MS0培养基。
7、生根培养
完成步骤6后,将所述分化芽转移至生根培养基上,光暗交替培养2周,获得拟转G基因油菜。
生根培养基:含100mg/L Kan和100mg/L Cf的MS0培养基。
随机选择3株拟转G基因油菜,依次命名为BG1、BG2和BG3。
8、分子检测
分别提取步骤7获得的3株拟转G基因油菜叶片的基因组DNA并作为模板,以G5:
5’-CCATATATACCATCCCGGAC-3’和G3:5’-CTCTTATCGTAAGGGTCCAAG-3’为引物进行PCR扩增,得到PCR扩增产物。用等体积超纯水代替拟转G基因油菜的叶片的基因组DNA,作为阴性对照。用等体积重组质粒pBO-G2301的DNA代替拟转G基因油菜的叶片的基因组DNA,作为阳性对照。
PCR反应程序为:94℃预变性5min;94℃变性30s,56℃退火1min,72℃延伸1min,30个循环;72℃延伸10min,4℃保持。
PCR扩增反应完成后,取10μL PCR扩增产物进行1%琼脂糖凝胶电泳。
实验结果见图9(泳道1为λDNA/EcoRI+HindⅢMarker,泳道2为BG1,泳道3为BG2,泳道4为BG3,泳道5为阴性对照)。结果表明,如果以拟转G基因油菜的叶片的基因组DNA为模板,能够扩增出约436bp的条带,则该拟转G基因油菜即为转G基因油菜;阴性对照不能获得436bp的条带;阳性对照可以获得436bp的条带。
因此,BG1、BG2和BG3均为转G基因油菜。
待BG1成熟后收集种子,然后进行繁育和PCR检测,直至获得纯合种子。将该纯合种子命名为BG1种子,进行后续实验。
三、目的蛋白的检测
提取步骤二收集的BG1种子的油体蛋白,具体步骤如下:
1、取5g步骤二收集的BG1种子,用粉碎机粉碎,得到油菜籽粉。
2、完成步骤1后,取离心管(规格为50mL),加入油菜籽粉和30mL提取缓冲液,充分混匀,然后置于冰上30min。
3、完成步骤2后,取所述离心管,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体甲,下层为溶液甲。
4、完成步骤3后,取一新的离心管(规格为50mL),加入收集的油体甲和30mL提取缓冲液,充分混匀,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体乙,下层为溶液乙。
5、完成步骤4后,取一新的离心管(规格为50mL),加入收集的油体乙和30mL提取缓冲液,充分混匀,4℃、15000g离心30min。离心后,液相体系呈现两层分层,上层为油体丙,下层为溶液丙。
6、完成步骤5后,取油体丙,加入1mL提取缓冲液,混匀,得到混合溶液。
7、取一新的离心管(规格为50mL),加入500μL步骤6得到的混合溶液和1mL乙醚,充分混匀,4℃、12000g离心4min。离心后,液相体系呈现三层分层,收集中间相。
8、完成步骤7后,将收集的中间相置于一新的离心管(规格为50mL)中,然后加入1mL乙醚,4℃、12100g离心4min,收集上层液相。
9、向步骤8收集的上层液相中加入1mL乙醚,4℃、12100g离心4min,收集沉淀。
10、将步骤9收集的沉淀,冷冻抽干30min(目的为除去残留的乙醚),得到样品甲。
11、将500μL氯仿和250μL甲醇充分混匀后洗涤样品甲,然后4℃、12100g离心8min,收集沉淀。
12、将500μL氯仿、250μL甲醇和250μL无菌水充分混匀后洗涤步骤11收集的沉淀,然后4℃、12100g离心8min,收集沉淀。
13、将500μL氯仿、250μL甲醇和250μL无菌水充分混匀后洗涤步骤12收集的沉淀,然后4℃、12100g离心8min,收集沉淀。将该沉淀吹干,-70℃保存。步骤13收集的沉淀即为BG1种子的油体蛋白。
按照上述步骤,将BG1种子替换为中双4号种子,其它步骤均不变,得到中双4号种子的油体蛋白。
取步骤13收集的沉淀,加入水溶解,得到浓度为1mg/mL的BG1种子的油体蛋白溶液。
取中双4号种子的油体蛋白,加入水溶解,得到浓度为1mg/mL的中双4号种子的油体蛋白溶液。
将BG1种子的油体蛋白溶液和中双4号种子的油体蛋白溶液进行SDS-PAGE。
实验结果见图10(从左至右依次为:BG1种子的油体蛋白溶液、中双4号种子的油体蛋白溶液和蛋白Marker)。结果表明,BG1种子的油体蛋白溶液中含有66.12kD的蛋白,与预期蛋白大小完全一致;而中双4号种子的油体蛋白溶液中则不含有66.12kD的蛋白。
<110> 中国农业科学院生物技术研究所
<120> 一种表达蛋白质或多肽的方法及其专用表达盒
<160> 10
<170> PatentInversion3.5
<210>1
<211>132
<212>DNA
<213>人工序列
<220>
<223>
<400>1
ggatccgatg atgacgataa gtgctcaaac ttgtctacct gtgttcttgg taagttgtct 60
caggaacttc acaagttgca aacctaccca aggactaaca ctggttctgg aaccccagga 120
tagtaactcg ag 132
<210>2
<211>465
<212>DNA
<213>人工序列
<220>
<223>
<400>2
ctgcagatgc atcatcacca tcatcatgcg gacgaacccc acgaccagcg ccccaccgac 60
gtcatcaaga gctacctccc cgaaaagggt ccctccacct ctcaagtcct cgccgtcgtg 120
accctcttcc ccctcggcgc cgtcctcctc tgcctagccg gtctcattct taccgggacc 180
atcatcggcc tcgccgtcgc caccccgctc ttcgtcatct tcagccccat cttggtcccc 240
gccgccctaa ccatcgccct agccgtcacc ggtttcttga cctccggagc tttcggcatc 300
accgccctgt cctcgatttc gtggttgctg aactacgtta ggcgaatgcg ggggagcttg 360
ccagagcagc tggatcatgc acggcggcgc gtgcaggaga cggtgggcca gaagacaagg 420
gaggcggggc agagaagcca agatgtaata agaccgggat cccat 465
<210>3
<211>905
<212>DNA
<213>人工序列
<220>
<223>
<400>3
attcaagctt gtcggatcat gacgtttcca gaaaacatcg agcaagctct caaagctgac 60
ctctttcgga tcgtactgaa cccgaacaat ctcgttatgc cccgtcgtct ccgaacagac 120
atcctcgtaa gtaggattgt cgacgaatcc atggctatac ccaacctccg tcttcgtcac 180
gcctggaacc ctctggtaag ccaattccgc tccccagaag caaccggcgc cgaattgcgc 240
gaattgctga ccaggcgaag gaacatcgtc gtcgggtcct tgtgcgattg cggaggaagc 300
cgccgggtcg ggttggggac gagacccgaa tccgagcctg gtgaataggt tgttcatcgg 360
agatttatag acggagatgg atcgagcggt tttggggaaa ggggaagtgg gtttggctct 420
tttggataga gagagtgcag ctttggcgag agactggaga ggtttagaga gagacacggc 480
ggagattacc ggaggagagg cgacgataga tagcattatc gaagggacgg gagaaagagt 540
gacgtggaga aataagaaac cgttaagagt cggatattta ttatattaaa agcccactgg 600
gcctaaaccc atttaaacaa gacaagataa atgggccgtg tgtgagtgtt aacgttcggt 660
ttcaaatgcc aacgccattg gaacaaaaca aacgtgtcct caagtaaacc cctgtcgttt 720
acacctcaat ggctgcatgg tgaagccatt aacacgtggc gtagaatgca tgacgacgcc 780
attgacacct gactctcttt ccttctcttc atatatctct aatcaattca acactcattg 840
tcatagctat tcggaaaata tatacacatc cttttctctt cgatctctct caattctgca 900
gaagc 905
<210>4
<211>1721
<212>DNA
<213>人工序列
<220>
<223>
<400>4
gtcggatcat gacgtttcca gaaaacatcg agcaagctct caaagctgac ctctttcgga 60
tcgtactgaa cccgaacaat ctcgttatgc cccgtcgtct ccgaacagac atcctcgtaa 120
gtaggattgt cgacgaatcc atggctatac ccaacctccg tcttcgtcac gcctggaacc 180
ctctggtaag ccaattccgc tccccagaag caaccggcgc cgaattgcgc gaattgctga 240
ccaggcgaag gaacatcgtc gtcgggtcct tgtgcgattg cggaggaagc cgccgggtcg 300
ggttggggac gagacccgaa tccgagcctg gtgaataggt tgttcatcgg agatttatag 360
acggagatgg atcgagcggt tttggggaaa ggggaagtgg gtttggctct tttggataga 420
gagagtgcag ctttggcgag agactggaga ggtttagaga gagacacggc ggagattacc 480
ggaggagagg cgacgataga tagcattatc gaagggacgg gagaaagagt gacgtggaga 540
aataagaaac cgttaagagt cggatattta ttatattaaa agcccactgg gcctaaaccc 600
atttaaacaa gacaagataa atgggccgtg tgtgagtgtt aacgttcggt ttcaaatgcc 660
aacgccattg gaacaaaaca aacgtgtcct caagtaaacc cctgtcgttt acacctcaat 720
ggctgcatgg tgaagccatt aacacgtggc gtagaatgca tgacgacgcc attgacacct 780
gactctcttt ccttctcttc atatatctct aatcaattca acactcattg tcatagctat 840
tcggaaaata tatacacatc cttttctctt cgatctctct caattctgca gatgcatcat 900
caccatcatc atgcggacga accccacgac cagcgcccca ccgacgtcat caagagctac 960
ctccccgaaa agggtccctc cacctctcaa gtcctcgccg tcgtgaccct cttccccctc 1020
ggcgccgtcc tcctctgcct agccggtctc attcttaccg ggaccatcat cggcctcgcc 1080
gtcgccaccc cgctcttcgt catcttcagc cccatcttgg tccccgccgc cctaaccatc 1140
gccctagccg tcaccggttt cttgacctcc ggagctttcg gcatcaccgc cctgtcctcg 1200
atttcgtggt tgctgaacta cgttaggcga atgcggggga gcttgccaga gcagctggat 1260
catgcacggc ggcgcgtgca ggagacggtg ggccagaaga caagggaggc ggggcagaga 1320
agccaagatg taataagacc gggatccgat gatgacgata agtgctcaaa cttgtctacc 1380
tgtgttcttg gtaagttgtc tcaggaactt cacaagttgc aaacctaccc aaggactaac 1440
actggttctg gaaccccagg atagtaactc gaggctgagt aaggttaact ttgagtatta 1500
tggcattgga aaagccattg ttctgcttgt aatttactgt gttctttcag ttttgttttc 1560
ggacatcaag ttaaccaaaa aaaaaaaaaa aaaaaaaaat tttaccaaaa aaaaaaaaaa 1620
aaaaaaaaaa atttccccaa aaaaaaaaaa aaaaaaaaaa atttaaagag ctcgaatttc 1680
cccgatcgtt caaacatttg gcaataaagt ttcttaagat t 1721
<210>5
<211>190
<212>PRT
<213>人工序列
<220>
<223>
<400>5
Met His His His His His His Ala Asp Glu Pro His Asp Gln Arg Pro
1 5 10 15
Thr Asp Val Ile Lys Ser Tyr Leu Pro Glu Lys Gly Pro Ser Thr Ser
20 25 30
Gln Val Leu Ala Val Val Thr Leu Phe Pro Leu Gly Ala Val Leu Leu
35 40 45
Cys Leu Ala Gly Leu Ile Leu Thr Gly Thr Ile Ile Gly Leu Ala Val
50 55 60
Ala Thr Pro Leu Phe Val Ile Phe Ser Pro Ile Leu Val Pro Ala Ala
65 70 75 80
Leu Thr Ile Ala Leu Ala Val Thr Gly Phe Leu Thr Ser Gly Ala Phe
85 90 95
Gly Ile Thr Ala Leu Ser Ser Ile Ser Trp Leu Leu Asn Tyr Val Arg
100 105 110
Arg Met Arg Gly Ser Leu Pro Glu Gln Leu Asp His Ala Arg Arg Arg
115 120 125
Val Gln Glu Thr Val Gly Gln Lys Thr Arg Glu Ala Gly Gln Arg Ser
130 135 140
Gln Asp Val Ile Arg Pro Gly Ser Asp Asp Asp Asp Lys Cys Ser Asn
145 150 155 160
Leu Ser Thr Cys Val Leu Gly Lys Leu Ser Gln Glu Leu His Lys Leu
165 170 175
Gln Thr Tyr Pro Arg Thr Asn Thr Gly Ser Gly Thr Pro Gly
180 185 190
<210>6
<211>189
<212>PRT
<213>人工序列
<220>
<223>
<400>6
Met His His His His His His Ala Asp Glu Pro His Asp Gln Arg Pro
1 5 10 15
Thr Asp Val Ile Lys Ser Tyr Leu Pro Glu Lys Gly Pro Ser Thr Ser
20 25 30
Gln Val Leu Ala Val Val Thr Leu Phe Pro Leu Gly Ala Val Leu Leu
35 40 45
Cys Leu Ala Gly Leu Ile Leu Thr Gly Thr Ile Ile Gly Leu Ala Val
50 55 60
Ala Thr Pro Leu Phe Val Ile Phe Ser Pro Ile Leu Val Pro Ala Ala
65 70 75 80
Leu Thr Ile Ala Leu Ala Val Thr Gly Phe Leu Thr Ser Gly Ala Phe
85 90 95
Gly Ile Thr Ala Leu Ser Ser Ile Ser Trp Leu Leu Asn Tyr Val Arg
100 105 110
Arg Met Arg Gly Ser Leu Pro Glu Gln Leu Asp His Ala Arg Arg Arg
115 120 125
Val Gln Glu Thr Val Gly Gln Lys Thr Arg Glu Ala Gly Gln Arg Ser
130 135 140
Gln Asp Val Ile Arg Pro Gly Ser Asp Asp Asp Asp Lys Cys Ser Asn
145 150 155 160
Leu Ser Thr Cys Val Leu Gly Lys Leu Ser Gln Glu Leu His Lys Leu
165 170 175
Gln Thr Tyr Pro Arg Thr Asn Thr Gly Ser Gly Thr Pro
180 185
<210>7
<211>132
<212>DNA
<213>人工序列
<220>
<223>
<400>7
ggatccgatg atgacgataa gtgctctaac ctttctactt gcgttttggg aaagttgtct 60
caagagcttc ataagcttca aacttaccca agaactaaca ccggatctgg aactccagga 120
tagtaactcg ag 132
<210>8
<211>1359
<212>DNA
<213>人工序列
<220>
<223>
<400>8
ggatcccatc atcaccatca tcaccatcac aagtttccca tatataccat cccggacgag 60
ttggggccat ggtccccaat tgacatacat cacttatctt gcccgaataa cctagtagtg 120
gaggatgaag gatgcactaa cctctctgag ttctcctaca tggaactgaa agttggctac 180
atatccgcaa ttaaagtgaa cggattcaca tgtacaggag tggtcacaga ggccgagacg 240
tatactaact tcgtcggtta cgttacaact acctttaaaa ggaaacactt cagaccgacc 300
ccagacgcat gcagggcagc gtataattgg aaaatggctg gcgatcctag atatgaagag 360
tcactccaca acccttatcc ggattatcac tggttgagaa ctgtccgaac aacaatcgaa 420
agcctcataa tcatcagtcc atcagtcact gacttggacc cttacgataa gagtcttcac 480
tcacgtgtct ttcctggggg caagtgttcg ggtatcactg ttagttcgac gtactgttcg 540
actaatcacg attataccat ttggatgcct gagaatccgc gtccaagaac gccatgtgat 600
attttcacga atagtagggg taagcgagag tcaaatggca ataagacatg tggtttcgtt 660
gacgagcgtg gtctttacaa gtctttgaag ggtgcttgca gattgaagct ctgtggagtt 720
ctcggactta gacttatgga tggaacgtgg gttgctaccc agacatcgga cgagactaag 780
tggtgtcctc cggatcagct ggtaaacctt catgatttta ggtcagatga gattgaacat 840
cttgtggtgg aagagttagt gaaaaagcgt gaagaatgcc tcgatgccct tgagtctatc 900
atgaccacca agagcgttag cttcaggagg ttgtctcatt tacgtaagtt agtcccaggc 960
ttcggaaaag cgtacaccat ttttaacaaa accttgatgg aagccgatgc tcattacaaa 1020
tccgtccgaa cttggaacga aattatccct tctaaggggt gcctgaaagt cggaggaaga 1080
tgccaccctc atgtgaacgg tgttttcttt aacggactga tacttggtcc cgatgatcat 1140
gttctgatcc ccgaaatgca atcctcactc ctacagcaac acatggagct acttgagagc 1200
agcgtaatcc ctctcatgca tcctctcgct gatccttcta ctgttttcaa ggagggggac 1260
gaagctgaag actttgttga ggtgcatttg ccagacgttt acaagcaaat ttctggtgtg 1320
gacctaggac ttcccaactg gggtaaataa tgactcgag 1359
<210>9
<211>599
<212>PRT
<213>人工序列
<220>
<223>
<400>9
Met His His His His His His Ala Asp Glu Pro His Asp Gln Arg Pro
1 5 10 15
Thr Asp Val Ile Lys Ser Tyr Leu Pro Glu Lys Gly Pro Ser Thr Ser
20 25 30
Gln Val Leu Ala Val Val Thr Leu Phe Pro Leu Gly Ala Val Leu Leu
35 40 45
Cys Leu Ala Gly Leu Ile Leu Thr Gly Thr Ile Ile Gly Leu Ala Val
50 55 60
Ala Thr Pro Leu Phe Val Ile Phe Ser Pro Ile Leu Val Pro Ala Ala
65 70 75 80
Leu Thr Ile Ala Leu Ala Val Thr Gly Phe Leu Thr Ser Gly Ala Phe
85 90 95
Gly Ile Thr Ala Leu Ser Ser Ile Ser Trp Leu Leu Asn Tyr Val Arg
100 105 110
Arg Met Arg Gly Ser Leu Pro Glu Gln Leu Asp His Ala Arg Arg Arg
115 120 125
Val Gln Glu Thr Val Gly Gln Lys Thr Arg Glu Ala Gly Gln Arg Ser
130 135 140
Gln Asp Val Ile Arg Pro Gly Ser His His His His His His His His
145 150 155 160
Lys Phe Pro Ile Tyr Thr Ile Pro Asp Glu Leu Gly Pro Trp Ser Pro
165 170 175
Ile Asp Ile His His Leu Ser Cys Pro Asn Asn Leu Val Val Glu Asp
180 185 190
Glu Gly Cys Thr Asn Leu Ser Glu Phe Ser Tyr Met Glu Leu Lys Val
195 200 205
Gly Tyr Ile Ser Ala Ile Lys Val Asn Gly Phe Thr Cys Thr Gly Val
210 215 220
Val Thr Glu Ala Glu Thr Tyr Thr Asn Phe Val Gly Tyr Val Thr Thr
225 230 235 240
Thr Phe Lys Arg Lys His Phe Arg Pro Thr Pro Asp Ala Cys Arg Ala
245 250 255
Ala Tyr Asn Trp Lys Met Ala Gly Asp Pro Arg Tyr Glu Glu Ser Leu
260 265 270
His Asn Pro Tyr Pro Asp Tyr His Trp Leu Arg Thr Val Arg Thr Thr
275 280 285
Ile Glu Ser Leu Ile Ile Ile Ser Pro Ser Val Thr Asp Leu Asp Pro
290 295 300
Tyr Asp Lys Ser Leu His Ser Arg Val Phe Pro Gly Gly Lys Cys Ser
305 310 315 320
Gly Ile Thr Val Ser Ser Thr Tyr Cys Ser Thr Asn His Asp Tyr Thr
325 330 335
Ile Trp Met Pro Glu Asn Pro Arg Pro Arg Thr Pro Cys Asp Ile Phe
340 345 350
Thr Asn Ser Arg Gly Lys Arg Glu Ser Asn Gly Asn Lys Thr Cys Gly
355 360 365
Phe Val Asp Glu Arg Gly Leu Tyr Lys Ser Leu Lys Gly Ala Cys Arg
370 375 380
Leu Lys Leu Cys Gly Val Leu Gly Leu Arg Leu Met Asp Gly Thr Trp
385 390 395 400
Val Ala Thr Gln Thr Ser Asp Glu Thr Lys Trp Cys Pro Pro Asp Gln
405 410 415
Leu Val Asn Leu His Asp Phe Arg Ser Asp Glu Ile Glu His Leu Val
420 425 430
Val Glu Glu Leu Val Lys Lys Arg Glu Glu Cys Leu Asp Ala Leu Glu
435 440 445
Ser Ile Met Thr Thr Lys Ser Val Ser Phe Arg Arg Leu Ser His Leu
450 455 460
Arg Lys Leu Val Pro Gly Phe Gly Lys Ala Tyr Thr Ile Phe Asn Lys
465 470 475 480
Thr Leu Met Glu Ala Asp Ala His Tyr Lys Ser Val Arg Thr Trp Asn
485 490 495
Glu Ile Ile Pro Ser Lys Gly Cys Leu Lys Val Gly Gly Arg Cys His
500 505 510
Pro His Val Asn Gly Val Phe Phe Asn Gly Leu Ile Leu Gly Pro Asp
515 520 525
Asp His Val Leu Ile Pro Glu Met Gln Ser Ser Leu Leu Gln Gln His
530 535 540
Met Glu Leu Leu Glu Ser Ser Val Ile Pro Leu Met His Pro Leu Ala
545 550 555 560
Asp Pro Ser Thr Val Phe Lys Glu Gly Asp Glu Ala Glu Asp Phe Val
565 570 575
Glu Val His Leu Pro Asp Val Tyr Lys Gln Ile Ser Gly Val Asp Leu
580 585 590
Gly Leu Pro Asn Trp Gly Lys
595
<210>10
<211>1383
<212>DNA
<213>人工序列
<220>
<223>
<400>10
aagcttcata cagagctcaa tgacaagaag aaaatcttcg tcaacatggt ggagctctct 60
tacgaacgac acgattgtct actccaaaaa tatcaaagat acagtctcag aagaccaaag 120
ggcaattgag acttttcaac aaagggtaat atccggaaac ctcctcggat tccattgccc 180
agctatctgt cactttattg tgaagatagt ggaaaaggaa ggtggctcct tacaatgcca 240
tcattgcgat aaaggaaagg ccatcgttga agatgcctct gccgacagtg gtcccaaaga 300
tggaccccca cccacgagga gcatcgtgga aaaagaagac gttccaacca cgtcttcaaa 360
gcaagtggat tgatgtgata ctccaaaaat atcaaagata cagtctcaga agaccaaagg 420
gcaattgaga cttttcaaca aagggtaata tccggaaacc tcctcggatt ccattgccca 480
gctatctgtc actttattgt gaagatagtg gaaaaggaag gtggctcctt acaatgccat 540
cattgcgata aaggaaaggc catcgttgaa gatgcctctg ccgacagtgg tcccaaagat 600
ggacccccac ccacgaggag catcgtggaa aaagaagacg ttccaaccac gtcttcaaag 660
caagtggatt gatgtgatat ctccactgac gtaagggatg acgcacaatc ccactatcct 720
tcgcaagacc cttcctctat ataaggaagt tcatttcatt tggagaggac acgctgaaat 780
cacctctaga ggatccatcc tatttttaca acaattacca acaacaacaa acaacaaaca 840
acattacaat tactatttac aaataacaat ggactgcagg tcgactctag aggatcccct 900
actcgaggct gagtaaggtt aactttgagt attatggcat tggaaaagcc attgttctgc 960
ttgtaattta ctgtgttctt tcagttttgt tttcggacat caagttaacc aaaaaaaaaa 1020
aaaaaaaaaa aaattttacc aaaaaaaaaa aaaaaaaaaa aaaaatttcc ccaaaaaaaa 1080
aaaaaaaaaa aaaaatttaa agagctcgaa tttccccgat cgttcaaaca tttggcaata 1140
aagtttctta agattgaatc ctgttgccgg tcttgcgatg attatcatat aatttctgtt 1200
gaattacgtt aagcatgtaa taattaacat gtaatgcatg acgttattta tgagatgggt 1260
ttttatgatt agagtcccgc aattatacat ttaatacgcg acgcgataga aaacaaaata 1320
tagcgcgcaa actaggataa attatcgcgc gcggtgtcat ctatgttact agatcgggaa 1380
ttc 1383
- 还没有人留言评论。精彩留言会获得点赞!