包含可被O-糖基化的多肽区的融合多肽的制作方法
包含可被o
‑
糖基化的多肽区的融合多肽
技术领域
1.本发明涉及包含靶多肽和o
‑
可糖基化多肽区的融合多肽,含有该融合多肽的药物组合物;以及一种增加靶多肽体内持续时间的方法,其包括融合o
‑
可糖基化多肽区的步骤。
背景技术:
2.当通过除静脉内施用以外的方法施用时,大多数蛋白质或肽药物缩短维持体内活性的时间,并且具有低吸收率。当需要长期药物治疗时,存在必须以短的剂量间隔重复和连续注射这些药物的不便。为了消除这种不便,需要开发在单次施用中连续释放药物的技术。为了满足这些需要,正在开发用于连续释放的缓释制剂。
3.例如,正在积极地进行对缓释剂型的研究,其中制备用生物可降解聚合物基质包封蛋白质或肽药物形式的细颗粒,并且药物在施用时逐渐释放,同时基质物质逐渐分解并在体内除去。
4.例如,美国专利号5,416,017公开了使用透明质酸浓度为0.01至3%的凝胶的促红细胞生成素的缓释注射剂,日本未审查专利公开号(hei)1
‑
287041公开了在透明质酸浓度为1%的凝胶中含有胰岛素的缓释注射剂,日本未审查专利公开号(hei)2
‑
213公开了在透明质酸浓度为5%的凝胶中含有降钙素、依降钙素或人靶多肽的缓释制剂。在这种制剂中,溶解在透明质酸凝胶中的蛋白质药物以低速通过具有高粘度的凝胶基质,因此可以表现出缓释效果。然而,其缺点在于,由于高粘度,不容易通过注射施用,凝胶在注射后容易被体液稀释或分解,使得难以持续释放药物超过一天。
5.同时,存在这样的实例:其中使用具有疏水性的透明质酸衍生物(例如透明质酸
‑
苄基酯)通过乳液溶剂萃取法制备固体微粒(n.s.nightlinger等,proceed.intern.symp.control.rel.bioact.mater.,22nd,paper no.3205(1995);l.ilum等,j.controlled rel.,29,133(1994))。当使用疏水性透明质酸衍生物制备药物释放制剂颗粒时,必须使用有机溶剂,因此,蛋白质药物可能与有机溶剂接触而变性,并且由于透明质酸衍生物的疏水性,蛋白质变性的可能性高。
6.因此,为了改善蛋白质或肽药物的体内持续时间,需要与现有研究不同的方面的方法。
技术实现要素:
7.技术问题
8.本发明提供一种技术,其中o
‑
可糖基化多肽(例如免疫球蛋白的铰链区等)与靶多肽连接形成融合多肽,从而与不和o
‑
可糖基化多肽区融合的情况相比,增加靶多肽的体内半衰期,并因此增加体内持续时间,并增加给药间隔。
9.一个实例提供包含靶多肽和o
‑
可糖基化多肽区的融合多肽。
10.在融合多肽中,o
‑
可糖基化多肽区可包含在靶多肽的n
‑
末端和/或c
‑
末端。
11.融合多肽中所含的o
‑
可糖基化多肽区的总数可以是1以上,例如1至10、1至8、1至
6、1至4、2至10、2至8、2至6、2至4(例如1、2、3、4、5、6、7、8、9或10)。
12.在一个实施方式中,融合多肽可以由以下通式表示:
13.n'
‑
(z)n
‑
y
‑
(z)m
‑
c'[通式]
[0014]
在上式中,
[0015]
n'是所述融合多肽的n
‑
末端,c'是所述融合多肽的c
‑
末端,
[0016]
y是所述靶多肽,
[0017]
z是o
‑
可糖基化多肽区,
[0018]
n是位于融合多肽的n
‑
末端(结合到靶多肽的n
‑
末端)的o
‑
可糖基化多肽区的数量,并且为0至10的整数(即0、1、2、3、4、5、6、7、8、9、10)、0至7、0至5、1至10、1至7、1至5或1至3,
[0019]
m是位于融合多肽的c
‑
末端(结合到靶多肽的c
‑
末端)的o
‑
可糖基化多肽区的数量,并且为0至10的整数(即0、1、2、3、4、5、6、7、8、9、10)、0至7、0至5、1至10、1至7、1至5或1至3,
[0020]
n和m中至少一个不为0,和
[0021]
n+m是融合多肽中所含的o
‑
可糖基化多肽区的总数,并且是1至10、1至8、1至6、1至4、2至10、2至8、2至6或2至4的整数。
[0022]
融合多肽中所含的n+m个o
‑
可糖基化多肽区可各自独立地选自包括o
‑
可糖基化氨基酸残基的多肽部分。例如,包含o
‑
可糖基化氨基酸残基的多肽部分可以是免疫球蛋白的铰链区。在一个实施方式中,o
‑
可糖基化多肽区可各自独立地选自由免疫球蛋白d(igd)的铰链区和免疫球蛋白a(iga,如iga1)的铰链区组成的组(即,n+m个免疫球蛋白的铰链区可以彼此相同或不同)。
[0023]
与未和o
‑
可糖基化多肽区融合的靶多肽相比,与o
‑
可糖基化多肽区融合的靶多肽在体内(或血液中)的稳定性(持续时间)增加(例如体内或血液中的半衰期的延长)。
[0024]
另一个实施方式提供编码融合多肽的核酸分子。
[0025]
另一个实施方式提供包含该核酸分子的重组载体。
[0026]
另一个实施方式提供包含该重组载体的重组细胞。
[0027]
另一个实施方式提供用于生产在体内(或血液)中具有增加的半衰期的靶多肽的方法(其包括在细胞中表达重组载体的步骤),或用于生产含有在体内(或血液)中具有增加的半衰期的靶多肽的融合多肽的方法。
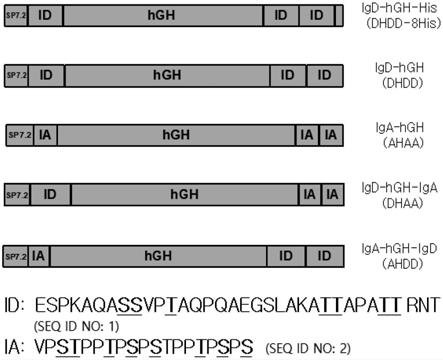
[0028]
另一个实施方式提供增加靶多肽的体内持续时间的方法(其包括将靶多肽与o
‑
可糖基化多肽区融合(或连接或结合)的步骤),或增加靶多肽(蛋白质或肽)药物的体内(或血液)稳定性和/或增加体内(或血液)半衰期的方法。在一个实施方式中,融合步骤可以包括将一个或多个o
‑
可糖基化多肽区与靶多肽的n
‑
末端和/或c
‑
末端通过接头或不利用接头融合(或连接或结合)的步骤。融合(或连接或结合)步骤可以在体外进行。
[0029]
另一个实施方式提供一种药物组合物,其包含选自由以下组成的组中的至少一种:融合多肽、编码该融合多肽的核酸分子、含有该核酸分子的重组载体、以及含有该重组载体的重组细胞。
[0030]
另一个实施方式提供一种使用选自由以下组成的组中的至少一种生产药物组合物的方法:融合多肽、编码该融合多肽的核酸分子、含有该核酸分子的重组载体、以及含有
该重组载体的重组细胞。
[0031]
另一个实施方式提供其用于制备药物组合物的应用,所述药物组合物包含选自由以下组成的组中的至少一种:融合多肽、编码融合多肽的核酸分子、含有该核酸分子的重组载体和含有该重组载体的重组细胞。
[0032]
另一个实施方式提供o
‑
可糖基化多肽区在促进靶多肽(蛋白或肽)药物的体内(或血液)稳定性和/或增加体内(或血液)半衰期方面的应用。具体而言,一个实施方式提供一种用于增强靶多肽(蛋白质或肽)药物的体内(或血液)稳定性和/或增加其体内(或血液)半衰期的组合物,该靶多肽(蛋白质或肽)药物包含o
‑
可糖基化多肽区。
[0033]
技术方案
[0034]
本公开提供融合多肽的形式,其中o
‑
可糖基化多肽区,如免疫球蛋白的铰链区与靶多肽融合,从而提供当体内应用靶多肽时,能够增强体内(或血液)稳定性和/或体内(或血液)维持期并增加施用间隔的技术。
[0035]
一个实施方式提供包含靶多肽和o
‑
可糖基化多肽区的融合多肽。
[0036]
在融合多肽中,o
‑
可糖基化多肽区可包含在靶多肽的n
‑
末端和/或c
‑
末端。
[0037]
融合多肽中所含的o
‑
可糖基化多肽区的总数可以是1以上,例如1至10、1至8、1至6、1至4、2至10、2至8、2至6、2至4(例如1、2、3、4、5、6、7、8、9或10)。
[0038]
在一个实施方式中,融合多肽可以由以下通式表示:
[0039]
n'
‑
(z)n
‑
y
‑
(z)m
‑
c'[通式]
[0040]
在上式中,
[0041]
n'是所述融合多肽的n
‑
末端,c'是所述融合多肽的c
‑
末端,
[0042]
y是所述靶多肽,
[0043]
z是o
‑
可糖基化多肽区,
[0044]
n是位于融合多肽的n
‑
末端(结合到靶多肽的n
‑
末端)的o
‑
可糖基化多肽区的数量,并且为0至10的整数(即0、1、2、3、4、5、6、7、8、9、10)、0至7、0至5、1至10、1至7、1至5或1至3,
[0045]
m是位于融合多肽的c
‑
末端(结合到靶多肽的c
‑
末端)的o
‑
可糖基化多肽区的数量,并且为0至10的整数(即0、1、2、3、4、5、6、7、8、9、10)、0至7、0至5、1至10、1至7、1至5或1至3,
[0046]
n和m中至少一个不为0(例如,如果n为0,则m不为0,并且如果m为0,则n不为0),和
[0047]
n+m是融合多肽中所含的o
‑
可糖基化多肽区的总数,并且是1至10、1至8、1至6、1至4、2至10、2至8、2至6或2至4的整数。
[0048]
在一个实施方式中,当靶多肽的活性位点位于n
‑
末端时,o
‑
可糖基化多肽区可与c
‑
末端融合(即n为0,m不为0),并且当活性位点位于c
‑
末端时,o
‑
可糖基化多肽区可与n
‑
末端融合(即n不为0,m为0)。
[0049]
融合多肽中所含的n+m个o
‑
可糖基化多肽区可各自独立地选自含有o
‑
可糖基化氨基酸残基的多肽。例如,含有o
‑
可糖基化氨基酸残基的多肽部分可以是免疫球蛋白的铰链区。在一个实施方式中,o
‑
可糖基化多肽区可各自独立地选自由免疫球蛋白d(igd)的铰链区和免疫球蛋白a(iga,例如iga1)的铰链区组成的组。n+m个免疫球蛋白的铰链区可以彼此相同或不同。
[0050]
在一个实施方式中,当融合多肽中所含的n+m个o
‑
可糖基化多肽区同时位于融合多肽的n
‑
末端和c
‑
末端时(即,当一个或多个o
‑
可糖基化多肽区各自独立地存在于融合多肽的n
‑
末端和c
‑
末端时),位于n
‑
末端的o
‑
可糖基化多肽区和位于c
‑
末端的o
‑
可糖基化多肽区的类型和数量可以彼此相同或不同。在一个实施方式中,位于n
‑
末端的一个或多个(例如1、2、3、4、5、6、7、8、9或10个)o
‑
可糖基化多肽区都是igd的铰链区或iga(例如iga1)的铰链区,或者可以以各种顺序包含一个或多个(例如1、2、3、4、5、6、7、8、9或10个)igd的铰链区和一个或多个(例如1、2、3、4、5、6、7、8、9或10个)iga(例如iga1)的铰链区。位于c
‑
末端的免疫球蛋白的一个或多个铰链区都是igd的铰链区或iga(例如iga1)的铰链区,或者可以以各种顺序包含igd的一个或多个铰链区和一个或多个iga(例如iga1)的铰链区。
[0051]
在另一个实施方式中,当融合多肽中所含的所有n+m个o
‑
可糖基化多肽区仅位于融合多肽的n
‑
末端时(即当一个或多个o
‑
可糖基化多肽区仅存在于融合多肽的n
‑
末端时),一个或多个(例如1、2、3、4、5、6、7、8、9或10个)o
‑
可糖基化多肽区都是igd的铰链区或iga的铰链区,或者可以以各种顺序包含一个或多个(例如1、2、3、4、5、6、7、8、9或10个)igd的铰链区和一个或多个(例如1、2、3、4、5、6、7、8、9或10个)iga的铰链区。
[0052]
在另一个实施方式中,当融合多肽中所含的所有n+m个o
‑
可糖基化多肽区仅位于c
‑
末端时(即当一个或多个o
‑
可糖基化多肽区仅存在于融合多肽的c
‑
末端时),一个或多个(例如1、2、3、4、5、6、7、8、9或10个)o
‑
可糖基化多肽区都是igd的铰链区或iga(例如iga1)的铰链区,或者可以以各种顺序包含一个或多个(例如1、2、3、4、5、6、7、8、9或10个)igd的铰链区和一个或多个(例如1、2、3、4、5、6、7、8、9或10个)iga的铰链区(例如iga1)。
[0053]
o
‑
可糖基化多肽区(当存在两个以上o
‑
可糖基化多肽区时,每个区)可包括1个以上、2个以上、3个以上、4个以上、5个以上、6个以上、或7个以上(上限为100、50、25、20、19、18、17、16、15、14、13、12、11、10、9或8)(例如1、2、3、4、5、6、7或8个)o
‑
可糖基化多肽残基(o
‑
可糖基化氨基酸残基)。例如,o
‑
可糖基化多肽区(当存在两以上o
‑
可糖基化多肽区时,每个区)可包括1至10或3至10个o
‑
糖基化残基(o
‑
可糖基化氨基酸残基)。
[0054]
在一个实施方式中,o
‑
可糖基化多肽区可以选自免疫球蛋白(例如人免疫球蛋白)的一个或多个铰链区,例如,它可以是igd铰链区、iga铰链区或其组合。
[0055]
igd可以是人igd(例如,uniprokb p01880(恒定区;seq id no:7)等),并且igd的铰链区可以是选自由以下组成的组中的至少一种:
[0056]
多肽(“igd铰链”),其包含氨基酸序列粗体所示的氨基酸残基是o
‑
糖基化残基(总共7个)”,或基本上由所述氨基酸序列组成,
[0057]
包含seq id no:1的氨基酸序列中5个以上、7个以上、10个以上、15个以上、20个以上、22个以上、或24个以上(上限是34或33个)的连续氨基酸(含有1个以上、2个以上、3个以上、4个以上、5个以上、6个以上、或7个o
‑
糖基化残基)的多肽,或基本上由所述氨基酸组成的多肽(“igd铰链的一部分”;例如,包含seq id no:1中的5个以上连续氨基酸(含有“ssvpt”(seq id no:9))的多肽,或包含7个以上连续氨基酸(含有“ttapatt”(seq id no:10))的多肽),和
[0058]
多肽,其包含:igd(例如,seq id no:7)中34个以上或35个以上连续氨基酸(含有seq id no:1的氨基酸序列(igd铰链)),或含有igd铰链一部分的7个以上、10个以上、15个
以上、20个以上、22个以上或24个以上连续氨基酸,或基本上由igd(seq id no:7)中的氨基酸组成(“igd铰链的延伸”;例如,"espkaqass vptaqpqaeg slakattapa ttrntgrgge ekkkekekee qeeretktp"(seq id no:11)中的seq id no:1,或包含34个以上或35个以上含有igd铰链的一部分的连续氨基酸。
[0059]
iga可以是人iga(例如iga1(uniprokb p01876,恒定区;seq id no:8)等),并且iga的铰链区可以是选自由以下组成的组的至少一种:
[0060]
多肽(“iga铰链”),其包含氨基酸序列其包含氨基酸序列以粗体显示的氨基酸残基是o
‑
糖基化残基(总共8个)”,或基本上由所述氨基酸序列组成,
[0061]
多肽,其包含seq id no:2的氨基酸序列中5个以上、6个以上、7个以上、8个以上、9个以上、10个以上、12个以上、15个以上、17个以上、或18个连续氨基酸,所述连续氨基酸含有1个以上、2个以上、3个以上、4个以上、5个以上、6个以上、7个以上或8个o
‑
糖基化残基,或所述多肽基本上由所述氨基酸组成(“iga铰链的一部分”;例如,包含seq id no:2中的8个以上或9个以上连续氨基酸的多肽,所述连续氨基酸含有"stpptpsp"(seq id no:12),和
[0062]
多肽(“iga铰链的延伸”),其包含iga(例如iga1(seq id no:8))中的19个以上或20个以上连续氨基酸,所述连续氨基酸含有iga(例如iga1)铰链中seq id no:2的氨基酸序列,或所述多肽包含iga(例如iga1)铰链的一部分的7个以上、10个以上、12个以上、15个以上、17个以上或18个连续氨基酸,或基本上由所述氨基酸序列组成。
[0063]
在另一个实施方式中,o
‑
可糖基化多肽区可以是包含以下表1中所例举的蛋白质(例如,包含选自由seq id no:23至113组成的组中的氨基酸序列的蛋白质)中的5个以上、7个以上、10个以上、12个以上、15个以上、17个以上、20个以上、22个以上、25个以上、27个以上、30个以上、32个以上或35个以上连续氨基酸(上限是40、50、60、70、80、90、100、150、200、250、300,或每种蛋白质中的氨基酸总数)的多肽区,或基本上由所述氨基酸序列组成,所述连续氨基酸含有1个以上、2个以上、5个以上、7个以上、10个以上、12个以上、15个以上、17个以上、20个以上、22个以上(例如1至10、3至10;或1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个)o
‑
可糖基化氨基酸残基(o
‑
糖基化位点)。优选本文所用的o
‑
可糖基化多肽区不影响靶多肽的功能。下表1中例举的蛋白质的o
‑
可糖基化多肽区可选自不参与全长蛋白质的内在功能的区域。这使得o
‑
可糖基化多肽区只起增加半衰期的作用而不影响靶多肽的功能:
[0064]
【表1】
[0065]
[0066]
[0067]
[0068]
[0069]
[0070]
[0071]
[0072][0073]
在融合多肽中,实际含有的o
‑
聚糖的总数可为13以上、14以上、15以上、16以上、17以上、18以上、19以上、20以上、或21以上(最大值由上述o
‑
可糖基化多肽区的数量和各o
‑
可糖基化多肽区中含有的o
‑
糖基化残基的数量确定),或理论上含有的o
‑
聚糖的总数可为20以上、21以上、23或24以上(最大值由上述o
‑
可糖基化多肽区的数量和各o
‑
可糖基化多肽区中含有的o
‑
糖基化残基的数量确定)。此外,当体内(例如,在血液中)施用时,融合多肽中实际上包含的o
‑
聚糖的总数可与稳定性相关。具体地,随着融合多肽中实际包含的o
‑
聚糖的总数增加,融合多肽或在融合多肽中包含的靶多肽的体内稳定性可增加(即,体内(血液中)半衰期增加和/或体内(血液中)浓度增加和/或体内(血液中)降解速率降低等)。
[0074]
当融合多肽包括两个以上o
‑
可糖基化多肽区时,融合多肽在靶多肽与o
‑
可糖基化多肽区之间,和/或在o
‑
可糖基化多肽区之间可进一步包括肽接头。在一个实施方式中,所述肽接头可以是重复含有一个或多个gly(g)和一个或多个ser(s)的gs接头,例如,它可以是(ggggs)n(其中n是作为ggggs(seq id no:13)重复次数(例如,1、2、3、4或5)的1至10或1至5的整数),但不限于此。
[0075]
与未和o
‑
可糖基化多肽区融合的靶多肽相比,融合多肽中与o
‑
可糖基化多肽区融合的靶多肽在体内(或血液中)的稳定性(持续时间)增加(例如体内或血液中的半衰期的增加)。
[0076]
另一个实施方式提供编码该融合多肽的核酸分子。
[0077]
另一个实施方式提供包含该核酸分子的重组载体。
[0078]
另一个实施方式提供包含该重组载体的重组细胞。
[0079]
另一个实施方式提供用于生产在体内(或血液中)具有增加的半衰期的靶多肽的方法(其包括在细胞中表达重组载体的步骤),或用于生产含有在体内(或血液中)具有增加的半衰期的靶多肽的融合多肽的方法。
[0080]
另一个实施方式提供一种增加靶多肽的体内持续时间的方法,其包括将靶多肽与o
‑
可糖基化多肽区融合(或连接或结合)的步骤。在一个实施方式中,融合步骤可包括通过
接头或不通过接头将一个或多个o
‑
糖基化多肽区融合(或连接或结合)至靶多肽的n
‑
末端和/或c
‑
末端的步骤。融合(或连接或结合)步骤可以在体外进行。
[0081]
另一个实施方式提供一种药物组合物,其包含选自由以下组成的组中的至少一种:融合多肽、编码该融合多肽的核酸分子、含有该核酸分子的重组载体、以及含有该重组载体的重组细胞。
[0082]
另一个实施方式提供其用于制备药物组合物的应用,所述药物组合物包含选自由以下组成的组中的至少一种:融合多肽、编码该融合多肽的核酸分子、含有该核酸分子的重组载体、以及含有该重组载体的重组细胞。
[0083]
另一个实施方式提供o
‑
可糖基化多肽区用于增强靶多肽(蛋白质或肽)药物的体内(或血液)稳定性和/或增加其体内(或血液)半衰期的应用。具体地,一个实施方式提供一种用于增强包含o
‑
可糖基化多肽区的多肽(蛋白质或肽)药物的体内(或血液)稳定性和/或增加其体内(或血液)半衰期的组合物。如本文所用,增强稳定性和/或增加半衰期是指与不含o
‑
可糖基化多肽区的多肽(蛋白质或肽)相比,稳定性得到改善和/或半衰期得到增加。
[0084]
在下文中,将更详细地描述本公开:
[0085]
靶多肽(y)可以是选自所有可溶性蛋白中的至少一种。在一个实施方式中,靶多肽是具有期望的体内活性(例如,对特定疾病或病症的预防、缓解和/或治疗活性,和/或作为标志物的活性,或者代替活生物体必需的物质的活性)的蛋白和/或多肽(例如,包括约100个以下或约50个以下氨基酸)。例如,其可以是选自由以下组成的组中的至少一种:酶促活性蛋白或肽(例如,蛋白酶、激酶、磷酸酶等)、受体蛋白或肽、转运蛋白或肽、无菌和/或或内毒素结合多肽、结构蛋白或肽、免疫原性多肽、抗体模拟蛋白(例如蛋白支架、fc
‑
融合蛋白等)、毒素、抗生素、激素、生长因子和疫苗等。
[0086]
在一个实施方式中,靶多肽可以是选自由以下组成的组中的至少一种:激素、细胞因子、组织纤溶酶原激活子和免疫球蛋白等(例如,抗体或其抗原结合片段或变体)、抗体模拟蛋白(例如蛋白质支架、fc融合蛋白等)。
[0087]
在另一个实施方式中,靶多肽可以包括选自由以下组成的组中的至少一种:生长激素(例如人生长激素(hgh))、p40、bmp
‑
1(骨形态发生蛋白
‑
1)、生长激素释放激素、生长激素释放肽、干扰素(例如、干扰素
‑
α、
‑
β、
‑
γ等)、干扰素受体(例如、水溶性i型干扰素受体等)、g
‑
csf(粒细胞集落刺激因子)、gm
‑
csf(粒细胞
‑
巨噬细胞集落刺激因子)、胰高血糖素样肽(例如glp
‑
1等)、胰岛素样生长因子(igf)、g蛋白偶联受体、白介素(例如白介素
‑
1、
‑
2、
‑
3、
‑
4、
‑
5、
‑
6、
‑
7、
‑
8、
‑
9、
‑
10、
‑
11、
‑
12、
‑
13、
‑
14、
‑
15、
‑
16、
‑
17、
‑
18、
‑
19、
‑
20、
‑
21、
‑
22、
‑
23、
‑
24、
‑
25、
‑
26、
‑
27、28、
‑
29、
‑
30等)、白介素受体(例如il
‑
1受体、il
‑
4受体等)、酶(例如葡萄糖脑苷脂酶、艾杜糖醛酸
‑2‑
硫酸酯酶、α
‑
半乳糖苷酶
‑
a、半乳糖苷酶α和β、α
‑
l
‑
艾杜糖醛酸酶、丁酰胆碱酯酶、几丁质酶、谷氨酸脱羧酶、伊米苷酶、脂肪酶、尿酸酶、血小板活化因子乙酰水解酶、中性内肽酶、髓过氧化物酶等)、白介素或细胞因子结合蛋白(例如il
‑
18bp、tnf结合蛋白等)、巨噬细胞活化因子、巨噬细胞肽、b细胞因子、t细胞因子、蛋白a、过敏抑制剂、细胞坏死糖蛋白、免疫毒素、淋巴毒素、肿瘤坏死因子、肿瘤抑制因子、转移生长因子、α
‑
1抗胰蛋白酶、白蛋白、α
‑
乳清蛋白、载脂蛋白
‑
e、促红细胞生成素、高度糖基化的促红细胞生成素、血管生成素;血红蛋白、凝血酶、凝血酶受体激活肽、血栓调节素、血液因子vii、血液因子viia、血液因子ix、血液因子ix、血液因子xiii、纤溶酶原活化因子、血纤蛋白结合
肽、尿激酶、链激酶、水蛭素、蛋白c、c反应蛋白、肾素抑制剂、胶原酶抑制剂、超氧化物歧化酶、瘦素、血小板源性生长因子、上皮生长因子、表皮生长因子、血管生成抑制素、血管紧张素、骨生长因子、骨刺激蛋白、降钙素、胰岛素、心钠素、软骨诱导因子、依降钙素、结缔组织活化因子、组织因子途径抑制剂、卵泡刺激激素、促黄体生成激素、促黄体生成激素释放激素、神经生长因子(例如神经生长因子、睫状神经营养因子、af
‑
1(轴突生成因子
‑
1)、脑
‑
利钠肽、神经胶质源性神经营养因子、轴突导向因子(netrin)、中性粒细胞抑制因子、神经营养因子、神经营养素等)、甲状旁腺激素、松弛素、分泌素、生长调节素、肾上腺皮质激素、胰高血糖素、胆囊收缩素、胰腺多肽、胃泌素释放肽、促肾上腺皮质激素释放因子、甲状腺刺激激素、自趋素(autotaxin)、乳铁蛋白、肌生长抑制素、受体(例如tnf受体(例如tnfr(p75))、tnfr(p55)等)、il
‑
1受体、vegf受体、egf受体、b细胞活化因子受体等)、受体拮抗剂(il1
‑
ra等)、细胞表面抗原(例如cd2、3、4、5、7、11a、11b、18、19、20、23、25、33、38、40、45、69等)、病毒疫苗抗原、抗体(例如单克隆抗体、多克隆抗体)、抗体片段(例如scfv、fab、fab'、f(ab')2和fd)、病毒源性疫苗抗原及其变体/片段(例如、维持所需功能和/或结构的变体/片段)、抗体模拟蛋白(例如、蛋白支架、fc
‑
融合蛋白等)、但不限于此。
[0088]
抗体可以是任何同种型(例如、iga(iga1、iga2等)、igd、igg(igg1、igg2、igg3、igg4等)、igm或ige),并且抗体片段是保留原始抗体的抗原结合能力的抗原结合片段,并且可以是包含至少约20个氨基酸,例如至少约100个氨基酸的抗体的任何片段(例如cdr、fab、fab'、f(ab)2、fd、fv、scfv、scfv
‑
fc等)。fab片段包括轻链的可变结构域(vl)和恒定结构域(cl)以及重链的可变结构域(vh)和第一恒定结构域(ch1)。fab
′
片段与fab片段的不同之处在于,从铰链区到ch1结构域的羧基末端添加了包含至少一个半胱氨酸残基的氨基酸残基。fd片段仅包含vh和ch1结构域,而f(ab')2片段通过二硫键或化学反应将fab'片段配对而产生。scfv(单链fv)片段以一条多肽链的形式存在,因为它包含通过肽接头连接的vl和vh域。抗体模拟蛋白可以指除抗体以外的包括能够结合特定抗原的位点的任何蛋白质。例如,其可以是选自由以下组成的组中的至少一种:抗体模拟蛋白质支架,例如重复体(repebody);fc融合蛋白,例如纳米抗体和肽抗体(fc和抗原结合多肽的融合蛋白),但不受此限制。
[0089]
在另一个实施方式中,靶多肽可以是选自由所有分泌蛋白组成的组中的至少一种。
[0090]
上述靶多肽可以是哺乳动物来源的(分离自哺乳动物的)多肽,包括灵长类动物,例如人和猴,以及啮齿动物例如小鼠和大鼠,并且可以是例如人来源的(分离自人的)多肽。
[0091]
在本文提供的包含靶多肽和o
‑
可糖基化多肽区的融合多肽中,靶多肽和o
‑
可糖基化多肽区和/或两个以上o
‑
可糖基化多肽区可以直接共价或非共价连接((例如,没有接头),或可以通过合适的接头(例如,肽接头)连接。肽接头可以是由1至20、1至15、1至10、2至20、2至15或2至10个任意氨基酸组成的多肽,并且其中所含氨基酸的类型不受限制。肽接头可以包括例如gly、asn和/或ser残基,并且还可以包括中性氨基酸,例如thr和/或ala,但不限于此,并且适合肽接头的氨基酸序列是本领域已知的。在一个实施方式中,肽接头可以是gs接头,其重复地包含一个或多个gly(g)和一个或多个ser(s),例如,它可以是(ggggs)n(其中n是ggggs(seq id no:13)的重复数量,并且可以是1至10的整数或1至5的整数(1、2、3、4或5)),但不限于此。
[0092]
另外,融合多肽可含有总共1个以上或总共2个以上(例如2至10、2至8、2至6、2至5、
2至4、2或3个)o
‑
可糖基化多肽区。当融合多肽含有两个以上o
‑
可糖基化多肽区时,融合多肽可以是这样的多肽:其中两个以上o
‑
可糖基化多肽区与靶多肽的n
‑
末端或c
‑
末端结合,或者一个或多个o
‑
可糖基化多肽区各自独立地与靶多肽的n末端和c末端结合(在这种情况下,与靶多肽的n末端和c末端结合的铰链区的类型和数量可以是相同或不同)。在这种情况下,上述肽接头可以进一步包含在o
‑
可糖基化多肽区之间和/或在o
‑
可糖基化多肽区与人靶多肽之间。
[0093]
本文提供的融合多肽可以重组或合成产生的,并且可以不是天然存在的。
[0094]
与未和o
‑
糖基化多肽区融合的靶多肽相比,本文提供的融合多肽中包含的靶多肽在哺乳动物中的体内(或血液)半衰期可以增加约1.5倍以上,约2倍以上,约2.5倍以上,约3倍以上,约3.5倍以上,约4倍以上,约5倍以上,约6倍以上,约7倍以上,约8倍以上,约9倍以上,或约10倍以上。
[0095]
由于以此方式增加了靶多肽的半衰期,因此与其中未连接o
‑
可糖基化多肽区的形式的靶多肽相比,其中结合o
‑
可糖基化多肽区的融合多肽形式的靶多肽具有可以延长给药间隔的优点。
[0096]
可以通过常规化学合成方法或重组方法来产生包括靶多肽和o
‑
可糖基化多肽区的融合多肽。
[0097]
如本文所用,术语“载体”是指用于在宿主细胞中表达靶基因的表达手段,并且可以例如选自由质粒载体,粘粒载体和噬菌体载体、病毒载体(例如腺病毒载体、逆转录病毒载体和腺相关病毒载体等)组成的组。在一个实施方式中,可以基于质粒(例如,pcdna系列、psc101、pgv1106、pacyc177、cole1、pkt230、pme290、pbr322、puc8/9、puc6、pbd9、phc79、pij61、plafr1、phv14、pgex系列、pet系列、puc19等)、噬菌体(例如λgt4λb、λ
‑
charon、λδz1、m13等)或病毒(例如sv40等)制备可用于重组载体的载体,但不限于此。
[0098]
在重组载体中,编码融合多肽的核酸分子可以可操作地连接至启动子。术语“可操作地连接”是指核酸表达调节序列(例如启动子序列)和不同的核酸序列之间的功能性连接。调节序列可以“可操作地连接”以调节不同核酸序列的转录和/或翻译。
[0099]
重组载体通常可以构建为用于克隆的载体或用于表达的表达载体。作为表达载体,可以使用本领域中用于在植物、动物或微生物中表达外源蛋白的常规载体。重组载体可以通过本领域已知的各种方法构建。
[0100]
重组载体可以使用真核细胞作为宿主来表达。当真核细胞作为宿主表达时,重组载体可以包括要表达的核酸分子以及上述启动子、核糖体结合位点和分泌信号序列(参见韩国未审查专利公开号2015
‑
0125402)和/或转录/翻译终止序列。另外,在真核细胞中运行的复制起点可以包括f1复制起点、sv40复制起点、pmb1复制起点、腺复制起点、aav复制起点和/或bbv复制起点等,但不限于此。此外,可以使用源自哺乳动物细胞基因组的启动子(例如金属硫蛋白启动子)或源自哺乳动物病毒的启动子(例如腺病毒晚期启动子、牛痘病毒7.5k启动子、sv40启动子、巨细胞病毒启动子和hsv的tk启动子),并且可以使用通常可作为分泌信号序列使用的所有分泌信号序列。例如,可以使用韩国未审查专利公开号2015
‑
0125402中描述的分泌信号序列,但不限于此,并且可以包括聚腺苷酸化序列作为转录终止序列。
[0101]
重组细胞可通过将重组载体引入(转化或转染)合适的宿主细胞中而获得。宿主细
胞可以选自能够稳定和连续克隆或表达重组载体的所有真核细胞。可以用作宿主的真核细胞包括酵母(酿酒酵母)、昆虫细胞、植物细胞、动物细胞等,其实例包括源自小鼠的细胞(例如、cop、l、c127、sp2/0、ns
‑
0、ns
‑
1、at20或nih3t3),大鼠(例如pc12、pc12h、gh3或mtt),仓鼠(例如bhk、cho、gs基因缺陷性cho或dhfr基因缺陷性cho),猴(例如cos(cos1、cos3、cos7等)、cv1或vero),人(例如hela、hek
‑
293、视网膜来源的per
‑
c6、二倍体成纤维细胞、骨髓瘤细胞或hepg2)或其他动物细胞(例如,mdck等),昆虫细胞(例如,sf9细胞、sf21细胞、tn
‑
368细胞、bti
‑
tn
‑
5b1
‑
4细胞等),杂交瘤等,但不限于此。
[0102]
可以在上述合适的宿主细胞中表达编码本文提供的融合多肽的核酸分子,从而产生与非融合形式相比具有改善的体内稳定性的靶多肽,或包含该靶多肽的融合多肽。产生融合多肽的方法可以包括培养含有核酸分子的重组细胞的步骤。培养步骤可以在正常培养条件下进行。此外,生产方法还可包括在培养步骤之后从培养物中分离和/或纯化融合多肽的步骤。
[0103]
核酸分子或包含其的重组载体向宿主细胞的运输(引入)可以使用本领域公知的运输方法。当宿主细胞是真核细胞时,可用的运输方法可以包括显微注射、磷酸钙沉淀、电穿孔、脂质体介导的转染、基因轰击等,但不限于此。
[0104]
通过使用选择标记所表达的表型,可以根据本领域公知的方法容易地进行选择经转化的(引入了重组载体的)宿主细胞的方法。例如,如果选择标记是特异性的抗生素抗性基因,则可以通过在含有抗生素的培养基中培养来容易地选择引入了重组载体的重组细胞。
[0105]
融合多肽可用于预防和/或治疗与靶多肽的缺乏和/或功能异常有关的任何疾病,或者能够通过靶多肽的活性进行治疗、缓解或改善。因此,在一个实施方式中,提供了一种药物组合物,其包含选自由以下组成的组中的至少一种:融合多肽、编码该融合多肽的核酸分子、包含该核酸分子的重组载体和包含该重组载体的重组细胞。药物组合物可以是用于预防和/或治疗与靶多肽的缺乏和/或功能异常有关的疾病或其中靶多肽具有治疗和/或预防作用的疾病的药物组合物。另一个实施方式提供了用于预防和/或治疗与融合蛋白中包含的靶多肽的缺乏和/或功能异常有关的疾病或其中靶多肽具有治疗和/或预防作用的疾病的方法,该方法包括向需要预防或治疗与融合蛋白中包含的靶多肽的缺乏和/或功能异常有关的疾病或其中靶多肽具有治疗和/或预防作用的疾病的患者施用选自由以下组成的组中的至少一种:融合多肽、编码该融合多肽的核酸分子、包含该核酸分子的重组载体和包含该重组载体的重组细胞。该方法可以进一步包括在施用步骤之前鉴定患者的步骤,所述患者需要预防或治疗与融合蛋白中包含的靶多肽的缺乏和/或功能异常有关的疾病或其中靶多肽具有治疗和/或预防作用的疾病。
[0106]
药物组合物可以包含药学上有效量的一种或多种活性成分,所述活性成分选自由融合多肽、核酸分子、重组载体和重组细胞组成的组。药学上有效量是指能够获得预期效果的活性成分的含量或剂量。药物组合物中活性成分的含量或剂量可根据多种因素而变化,例如配制方法、给药方法、年龄、体重、患者的性别或疾病状况、饮食、施用时间、给药间隔、施用途径、排泄速度和反应敏感性。例如,活性成分的单剂量可以在0.001至1000mg/kg、0.01至100mg/kg、0.01至50mg/kg、0.01至20mg/kg或0.01至1mg/kg的范围内。
[0107]
另外,药物组合物除活性成分外还可包含药学上可接受的载剂。载剂通常在配制
包含蛋白质、核酸或细胞的药物时使用,并且可以是选自由以下组成的中的至少一种:乳糖、右旋糖、蔗糖、山梨糖醇、甘露醇、淀粉、阿拉伯树胶、磷酸钙、藻酸盐、明胶、硅酸钙、微晶纤维素、聚乙烯吡咯烷酮、纤维素、水、糖浆、甲基纤维素、羟基苯甲酸甲酯、羟基苯甲酸丙酯、滑石、硬脂酸镁、矿物油等,但不限于此。药物组合物可以进一步包含选自由以下组成的中的至少一种:稀释剂、赋形剂、润滑剂、湿润剂、甜味剂、调味剂、乳化剂、助悬剂、防腐剂等,其通常用于制造药物组合物。
[0108]
施用药物组合物的对象可以是哺乳动物,包括诸如人和猴等灵长类动物,以及诸如小鼠,大鼠等啮齿动物,或衍生自它们的细胞、组织、细胞培养物或组织培养物。
[0109]
药物组合物可以通过口服或肠胃外施用来施用,或者可以通过接触细胞施用组织或体液来施用。具体地,在肠胃外施用的情况下,可以通过静脉内注射、皮下注射、肌内注射、腹膜内注射、内皮施用、局部施用、鼻内施用、肺内施用、直肠施用等进行施用。由于蛋白质或肽在口服施用时被消化,因此口服组合物应配制成能用活性剂包被或受保护以避免在胃中降解。
[0110]
另外,药物组合物可以是在油或水性介质中的溶液、悬浮液、糖浆或乳剂的形式,或者可以以提取物、粉剂、粉剂、颗粒剂、片剂或胶囊剂的形式,并且为了配制,可以进一步包括分散剂或稳定剂。
[0111]
有益效果
[0112]
本文提供的与o
‑
可糖基化的多肽区融合的靶多肽在施用于体内时具有长的持续时间,因此可以延长给药间隔并减少剂量,这在易于施用和/或经济方面具有有利的效果,并且可以有效地应用于其中需要靶多肽治疗的领域。
附图说明
[0113]
图1是示意性示出根据一个实施方式的融合多肽igd
‑
hgh
‑
his(dhdd
‑
8his)、igd
‑
hgh(dhdd)、iga
‑
hgh(ahaa)、igd
‑
hgh
‑
iga(dhaa)和iga
‑
hgh
‑
igd(ahdd)的结构的图。
[0114]
图2是显示通过q
‑
tof质谱分析根据一个实施方式的融合多肽igd
‑
hgh的结果的图。
[0115]
图3是显示通过ief(等电聚焦)分析的融合多肽igd
‑
hgh
‑
his的异构体分布的结果。
[0116]
图4是显示通过q
‑
tof质谱分析根据一个实施方式的融合多肽igd
‑
hgh
‑
his的结果的图。
[0117]
图5是示意性示出根据一个实施方式的融合多肽杜拉鲁肽(dulaglutide)
‑
id和杜拉鲁肽
‑
id2的结构的图。
[0118]
图6是显示通过ief(等电聚焦)分析的融合多肽杜拉鲁肽
‑
id2的异构体分布的结果。
[0119]
图7是显示与施用hgh时相比,在施用融合多肽igd
‑
hgh后血液浓度随时间变化的图。
[0120]
图8是显示与施用hgh时相比,在施用融合多肽igd
‑
hgh
‑
his后血液浓度随时间变化的图。
[0121]
图9是显示在施用融合多肽iga
‑
hgh f3、iga
‑
hgh f4和iga
‑
hgh f5后血液浓度随
时间变化的图。
[0122]
图10是显示与施用杜拉鲁肽(trulicity)时相比,在施用融合多肽杜拉鲁肽
‑
id2(pgigg4dd)后血液浓度随时间变化的图。
具体实施方式
[0123]
在下文中,将参考以下实施例详细描述本公开。然而,这些实施例仅出于说明的目的,并且本公开的范围不受这些实施例的限制。
[0124]
实施例1:融合多肽的产生
[0125]
1.1.含有人生长激素(hgh)作为靶多肽的融合多肽的产生
[0126]
产生了融合多肽igd
‑
hgh
‑
his(dhdd
‑
8his)、igd
‑
hgh(dhdd)、iga
‑
hgh(ahaa)、igd
‑
hgh
‑
iga(dhaa)和iga
‑
hgh
‑
igd(ahdd)(参见图1;igd和iga1序列的下划线部分是能够执行o
‑
糖基化的部分),其中将igd铰链iga1铰链或igd铰链和iga1铰链的组合与靶多肽(人生长激素:hgh;seq id no:3)融合。融合多肽中包含的每个部分的氨基酸序列总结在下表2中。
[0127]
【表2】
[0128][0129]
1.1.1.igd
‑
hgh(dhdd)
[0130]
用bamhi(限制位点:ggatcc)和noti(限制性位点:gcggccgc)处理作为pcdna3.1(+)的变体(invitrogen,cat.no.v790
‑
20)的质粒paf
‑
d1g1(包括韩国专利号10
‑
1868139b1的启动子)),其中插入有编码'(n
‑
末端)
‑
[bamhi限制性位点
‑
信号肽(seq id no:4)
‑
igd铰链(igdh1;seq id no:1)
‑
人生长激素(hgh;seq id no:3)
‑
igd铰链(igdh1;seq id no:1)
‑
igd铰链(igdh1;seq id no:1)
‑
noti限制性位点]
‑
(c
‑
末端)'以制备重组载体pdhdd
‑
d1g1,从而产生包含靶多肽(人生长激素)和免疫球蛋白(igd)的铰链区的融合多肽(总共293aa(不包括信号肽);o
‑
可糖基化位点
‑
总共21个;在下文中,称为“igd
‑
hgh”)。
[0131]
将所制备的重组载体pdhdd
‑
d1g1引入expicho
‑
s
tm
细胞(thermo fisher scientific),并在expicho表达培养基(thermo fisher scientific;400ml)中培养12天(分批补料培养;第1天和第5天补料),以产生融合多肽igd
‑
hgh。理论上,融合多肽igd
‑
hgh
具有32.2kda的分子量(不包括o
‑
聚糖)和21个o
‑
聚糖。
[0132]
将通过表达重组载体产生的融合多肽igd
‑
hgh纯化,并使用q
‑
tof质谱分析o
‑
glyan位点占有率。
[0133]
具体而言,通过在aktatm纯化器(ge healthcare life sciences)上安装由对hgh具有结合特异性的captureselecttm人生长激素亲和基质(life technologies)制成的柱,并加载样品来进行第一纯化过程。初步洗涤用平衡缓冲液进行,并用20mm柠檬酸ph 3.0或0.1m乙酸ph 3.0洗脱。该过程完成后,立即使用2m tris buffer将洗脱液调节至ph 7.0,并保持冷冻状态,直到下一个纯化过程为止。
[0134]
通过应用阴离子交换色谱法并使用tmae作为树脂来进行第二纯化过程。将通过第一步骤获得的冷冻样品溶解后,测量电导率,并用注射用水稀释样品,使其具有适合加载的电导率,然后用0.22um pes过滤系统(corning,美国)进行预处理。将柱安装在akta avant(ge healthcare life sciences)上,并加载样品。根据电导率以梯度形式进行洗脱以进行分离,并根据洗脱峰对级分进行分离和合并。
[0135]
在纯化过程中进行浓缩或缓冲液交换,以制备分析样品和动物实验样品。将样品置于amicon ultra system(millipore)中,在低温下离心并进行浓缩或渗滤。将25mm磷酸钠ph 7.0用作分析用缓冲液,并使用pbs缓冲液制备动物实验样品。
[0136]
在纯化过程、浓缩过程或渗滤后测量样品的浓度,其中使用氨基酸序列计算物质的消光系数,使用紫外分光光度计(g1103a,agilent technologies)测量280nm和340nm的吸光度,并使用以下公式计算。
[0137][0138]
在动物实验样品的情况下,在施用前将其用pbs缓冲液稀释至预定浓度,并在生物安全柜中用0.22μm注射器过滤器(millex
‑
gv,0.22μm,millipore)过滤,然后以冷冻状态储存直至后续施用。
[0139]
通过q
‑
tof质谱分析igd
‑
hgh的结果示于图2(y轴:%;x轴:质量;峰上方显示的7至21的数字为o
‑
聚糖数)。如图2所示,在igd
‑
hgh中,o
‑
聚糖的分布为7至21,o
‑
聚糖的平均数量为13.5。
[0140]
1.1.2.igd
‑
hgh
‑
his
[0141]
为了便于纯化,合成了表3中的引物以在igd
‑
hgh的c末端添加8his
‑
标签(实施例1.1.1)。
[0142]
【表3】
[0143]
[0144]
使用每种引物进行pcr,然后使用适当的引物组合再次进行重叠pcr,从而最终获得693bp的pcr产物('(n
‑
末端)
‑
[psti限制性位点
‑
信号肽(seq id no:4)
‑
igd铰链(igdh1;seq id no:1)
‑
人生长激素(hgh;seq id no:3)
‑
igd铰链(igdh1;seq id no:1)
‑
igd铰链(igdh1;seq id no:1)
‑
8his
‑
noti限制性位点]
‑
基因编码(c
‑
末端)')。然后,分别用psti和noti处理pdhdd
‑
d1g1和pcr产物,接着连接以最终制备用于制备融合多肽的重组载体pdhdd
‑
8his
‑
d1g1(总301aa(不包括信号肽);o
‑
可糖基化位点
‑
共21个);下文中称为'igd
‑
hgh
‑
his'),其包括靶多肽(人生长激素)和免疫球蛋白(igd)的铰链区和8his标签。
[0145]
将通过重组载体的表达产生的融合多肽igd
‑
hgh
‑
his纯化,并且使用ief(等电聚焦)分析和q
‑
tof质谱分析了o
‑
聚糖位点占有率。
[0146]
具体地,用于纯化过程的第一柱是作为阴离子交换树脂的tmae,并且从培养液中部分分离出igd
‑
hgh
‑
his,并作为第一洗脱液洗脱。然后,将第一洗脱液供应至作为第二柱的his
‑
tag结合柱(金属亲和树脂),且选择性洗脱igd
‑
hgh
‑
his作为第二洗脱液。然后,将第二洗脱液供应至作为第三柱的阴离子交换树脂tmae,以除去唾液酸含量低的级分,并作为第三洗脱液洗脱。然后将第三洗脱液供应至作为第四柱的凝胶过滤柱,以除去多聚体和片段化的蛋白质,从而获得第四洗脱液。
[0147]
更具体地,其包括以下步骤。
[0148]
步骤1:用含tmae,0.5x25cm(4ml),v=150cm/hr,10mm三乙醇胺(ph 7.0)的缓冲液平衡。加载培养液后,用平衡缓冲液洗涤柱一次,并以线性梯度洗脱包含10mm三乙醇胺和250mm氯化钠(ph 7.0)的洗脱缓冲液,以获得第一洗脱液。
[0149]
步骤2:用含ni
‑
nta his*bind、1.0x5cm(4ml)、v=80cm/hr、10mm磷酸钠,1m氯化钠、10mm咪唑(ph 7.0)的缓冲液平衡。加载第一洗脱液后,用平衡缓冲液将色谱柱洗涤一次,并且以线性梯度洗脱含有10mm磷酸钠、1m氯化钠和500mm咪唑(ph 7.0)的洗脱缓冲液,以获得第二洗脱液。
[0150]
步骤3:渗滤
[0151]
步骤4:用含有tmae、0.5x25cm(4ml)、v=150cm/hr,10mm三乙醇胺(ph 7.0)的缓冲液平衡。加载第二洗脱液后,用平衡缓冲液将色谱柱洗涤一次,并且以线性梯度洗脱含有10mm三羟苯胺和100mm氯化钠(ph 7.0)的洗脱缓冲液,以获得第三洗脱液。
[0152]
步骤5:超滤
[0153]
步骤6:用含有sephacryl s
‑
100、1.6x30cm(60ml)、v=30cm/hr、20mm磷酸钠、140mm氯化钠、ph 7.0的缓冲液平衡。加载第三洗脱液后,用平衡缓冲液洗脱单体级分以获得第四洗脱液。
[0154]
所得第四洗脱液的异构体分布示于图3。在图3中,igd
‑
hgh
‑
his的理论pi值为6.65。低于该值的值意味着igd
‑
hgh
‑
his是o
‑
糖基化的,唾液酸结合至该o
‑
聚糖上从而变得酸性更强。
[0155]
通过q
‑
tof质谱分析igd
‑
hgh
‑
his的结果示于图4(y轴:%;x轴:质量;峰上方显示的7到21的值是o
‑
聚糖的数量)。如图4所示,在igd
‑
hgh
‑
his中,o
‑
聚糖的分布为8到21,o
‑
聚糖的平均数量为14.7。
[0156]
1.1.3.iga
‑
hgh(ahaa)
[0157]
在实施例1.1.1中构建的重组载体pdhdd
‑
d1g1中,构建了具有相同构型的重组载
体pahaa
‑
d1g1,不同之处在于分别用iga1铰链的编码基因替换三个igd铰链的编码基因(一个在hgh的n末端侧,两个在hgh的的c末端侧,总共三个),然后以与实施例1.1.1相同的方式表达以产生具有iga1铰链(iga;seq id no:2)
‑
人生长激素(hgh;seq id no:3)
‑
iga1铰链(iga;seq id no:2)
‑
iga1铰链(iga;seq id no:2)的融合多肽(参见图1;以下简称为“iga
‑
hgh”)。融合多肽iga
‑
hgh理论上具有24个o
‑
聚糖。通过参照实施例1.1.1中描述的方法纯化通过表达重组载体产生的融合多肽iga
‑
hgh。
[0158]
作为通过q
‑
tof质谱分析纯化的iga
‑
hgh的结果,iga
‑
hgh中o
‑
聚糖的平均数量在级分3中为12.8,在级分4中为14.3,在级分5中为15.6。
[0159]
1.1.4.igd
‑
hgh
‑
iga(dhaa)
[0160]
将其中用bamhi和noti切割实施例1.1.1中制备的重组载体pdhdd
‑
d1g1的7574bp载体,与其中用bamhi和kasi切割pdhdd
‑
d1g1的489bp的插入物i、以及其中用kasi和noti切割实施例1.1.3中使用的重组载体pahaa
‑
d1g1的383bp插入物ii连接,从而构建重组载体pdhaa
‑
d1g1,使其具有相同的构型,不同之处在于在重组载体pdhdd
‑
d1g1中的3个igd铰链(1个在hgh的n末端侧,2个在hgh的c末端侧,总共3个),在3'末端侧的两个被iga1铰链的编码基因取代。以与实施例1.1.1相同的方式表达重组载体pdhaa
‑
d1g1,以产生具有igd铰链(igd;seq id no:1)
‑
人生长激素(hgh;seq id no:3)
‑
iga1铰链(iga;seq id no:2)
‑
iga1铰链(iga;seq id no:2)构型的融合多肽。融合多肽igd
‑
hgh
‑
iga理论上具有23个o
‑
聚糖。
[0161]
1.1.5.iga
‑
hgh
‑
igd(ahdd)
[0162]
将其中用bamhi和noti切割实施例1.1.1中制备的重组载体pdhdd
‑
d1g1的7574bp载体,与其中用bamhi和kasi切割实施例1.1.3中使用的pahaa
‑
d1g1的444bp的插入物i、以及其中用kasi和noti切割实施例1.1.1中使用的pdhdd
‑
d1g1的473bp的插入物ii连接,从而构建重组载体padd
‑
d1g1,使其具有相同的构型,不同之处在于,在三个igd铰链编码基因的5'末端的一个被iga1铰链的编码基因代替,然后以与实施例1.1.1相同的方式表达以产生具有下述构型的融合多肽:iga1铰链构型(iga;seq id no:2)
‑
人生长激素(hgh;seq id no:3)
‑
igd铰链(igd;seq id no:1)
‑
igd铰链(igd;seq id no:1)(参见图1;下文称为'iga
‑
hgh
‑
igd')。融合多肽iga
‑
hgh
‑
igd理论上具有22个o
‑
聚糖。
[0163]
1.2.目的蛋白:glp
‑1‑
fc融合蛋白
[0164]
制备融合多肽杜拉鲁肽
‑
id(包括一个igd铰链区)和杜拉鲁肽
‑
id2(包括两个igd铰链区)(见图5),其中将igd铰链其中将igd铰链与靶多肽(glp
‑
1(胰高血糖素样肽
‑
1)
‑
fc融合蛋白:glp
‑1‑
fc)融合。glp
‑1‑
fc融合蛋白以二聚体形式存在。编码的氨基酸序列总结在下表4中。
[0165]
【表4】
[0166][0167]
1.2.1.杜拉鲁肽
‑
id1
[0168]
使用表达glp
‑1‑
fc的表达载体pgig4(包括韩国专利no.10
‑
1868139b1的启动子)作为模板,该表达载体是pcdna3.1(+)的变体(invitrogen,cat.no.v790
‑
20),并使用表4中的引物igg4mch2_f和igg4id_r进行pcr,以获得659bp经修饰igg4的pcr产物(migg4)。并且,将实施例1.1.1中制备的pdhdd
‑
d1g1用作模板,并且使用表4中的引物igg4id_f和id_notr进行pcr,以获得129bp(id1)和231bp(id2)的pcr产物。将获得的659bp的migg4 pcr产物和129bp的id1 pcr产物纯化,然后将其用作模板。使用下表5中的引物igg4mch2_f和id_notr进行重叠pcr,以获得770bp的pcr产物('(n
‑
末端)
‑
[modified igg4 fc part(including bsrgi限制性位点))
‑
igd铰链(igdh1;seq id no:1)
‑
noti限制性位点]
‑
基因编码(c
‑
末端)')。
[0169]
【表5】
[0170][0171]
将其中用bamhi和noti切割实施例1.1.1中制备的pdhdd
‑
d1g1的7574bp载体,与其中用bamhi和bsrgi切割pgig4的607bp的插入物i、以及其中用bsrgi和noti切割通过重叠pcr获得的770bp pcr产物的403bp的插入物ii连接,以制备重组载体pgig4d
‑
d1g1,以产生包含靶多肽(glp
‑1‑
fc)和免疫球蛋白(igd)的铰链区的融合多肽(总共309aa(不包括信号肽);o
‑
糖基化位点
‑
总共7个,以二聚体形式存在,因此最终是14个);在下文中,称为'杜拉鲁肽
‑
id1')。
[0172]
1.2.2.杜拉鲁肽
‑
id2
[0173]
将实施例1.2.1中获得的659bp的migg4 pcr产物和231bp的id2 pcr产物用作模板,并使用表4中的引物igg4mch2_f和id_notr进行重叠pcr,以获得882bp的pcr产物('(n
‑
末端)
‑
[经修饰igg4 fc部分(包括bsrgi限制性位点)
‑
igd铰链(igdh1;seq id no:1)
‑
igd铰链(igdh1;seq id no:1)
‑
noti限制性位点)
‑
基因编码(c
‑
末端)')。
[0174]
将其中用bamhi和noti切割实施例1.1.1中制备的pdhdd
‑
d1g1的7574bp载体,与其中用bamhi和bsrgi切割pgig4的607bp的插入物i、以及其中用bsrgi和noti切割通过重叠pcr获得的882bp pcr产物的505bp的插入物ii连接,以制备重组载体pgig4d
‑
d1g1,以产生包含靶多肽(glp
‑1‑
fc)和免疫球蛋白(igd)的两个铰链区的融合多肽(总共343aa(不包括信号肽);o
‑
糖基化位点
‑
总共14个,因为其以二聚体形式存在,因此为28个);在下文中,称为'杜拉鲁肽
‑
id2')。
[0175]
将通过表达重组载体产生的融合多肽杜拉鲁肽
‑
id2纯化,并使用等电聚焦(ief)分析和q
‑
tof质谱分析o
‑
聚糖位点占有率。
[0176]
具体地,通过使用物质的fc区的蛋白a亲和色谱法分离和纯化蛋白,然后依次进行阴离子交换色谱和疏水相互作用色谱法并纯化。
[0177]
培养液用0.22μm的滤膜过滤,注入用平衡缓冲液(10mm磷酸钠,150mm氯化钠,ph 7.4)平衡的蛋白a亲和树脂中,然后用平衡缓冲液洗涤。洗涤后,用洗脱缓冲液(100mm柠檬酸钠,ph 3.5)洗脱蛋白质,并收集峰。
[0178]
使收集的洗脱液与20mm tris ph 8.0进行缓冲液交换。
[0179]
注入经缓冲液交换的样品,并将其纯化至阴离子交换色谱(source 15q,ge healthcare)中。
[0180]
所用的平衡缓冲液和洗脱缓冲液分别为20mm tris,ph 8.0;20mm tris,0.5m nacl和ph 8.0。平衡缓冲液和洗脱缓冲液分别用作通道a和b,以在浓度梯度条件下洗脱蛋白质并收集峰。
[0181]
所收集的蛋白质溶液进一步使用疏水相互作用色谱(丁基琼脂糖凝胶,ge healthcare)纯化。
[0182]
所用的平衡缓冲液和洗脱缓冲液分别为0.1m磷酸钠ph 6.0、1.8硫酸铵,ph 8.0和0.1m磷酸钠ph 6.0。平衡缓冲液和洗脱缓冲液分别用作通道a和b,以在浓度梯度条件下洗脱蛋白质并收集峰。
[0183]
通过等电聚焦(ief)分析收集的峰而获得的杜拉鲁肽
‑
id2的异构体分布示于图6中。在图6中,杜拉鲁肽
‑
id2的理论pi值为5.78,但是在级分#3的情况下,该值低于此值意味着杜拉鲁肽
‑
id2被o
‑
糖基化,并且该o
‑
聚糖与唾液酸连接并且变得酸性更强。
[0184]
作为通过q
‑
tof质谱分析杜拉鲁肽
‑
id2级分#3的结果,id最多可进行26次,o
‑
聚糖的平均数为17.5。
[0185]
最终纯化的蛋白质溶液用与trulicity(柠檬酸钠水合物:2.74mg/ml,无水柠檬酸:0.14mg/ml,d
‑
甘露醇:46.4mg/ml,聚山梨酯80:0.20mg/ml,ph 6.0
‑
7.0)相同的赋形剂进行缓冲液交换,浓缩并用作动物pk测试的测试材料。
[0186]
实施例2:融合多肽(体内)的药代动力学性质(pk谱)测试
[0187]2‑
1.目标蛋白:人生长激素(hgh)
[0188]
将实施例1.1中制备的融合多肽igd
‑
hgh、igd
‑
hgh
‑
his、iga
‑
hgh f3(实施例1.1.3的级分3)、iga
‑
hgh f4(实施例1.1.3的级分4)和iga
‑
hgh f5(实施例1.1.3的执行级分5)以2mg/kg的剂量皮下施用至sd大鼠(orientbio,7周龄,约300g;n=3),并测试药代动力学。在0、0.5、1、2、4、6、8、24、48小时进行采样,并且为了进行比较,以与上述相同的方式以2mg/kg的剂量皮下施用hgh(eutropin,lg chem),并进行测试。
[0189]
如上所述向sd大鼠施用后,将在时间点收集的血液离心以获得血清。使用人生长激素quantikine elisa试剂盒(r&d systems)进行elisa,并在确认了血液中的hgh和融合多肽(igd
‑
hgh、igd
‑
hgh
‑
his、iga
‑
hgh fp3、iga
‑
hgh fp4和iga
‑
hgh fp5)根据时间点的浓度。利用该数据,使用用于pk分析的软件(winnonlin(certara l.p.)等)计算包括auc(曲线下面积)在内的参数。
[0190]2‑1‑
1.hgh vs.igd
‑
hgh
[0191]
hgh和igd
‑
hgh的pk结果示于表6和图7中。
[0192]
【表6】
[0193][0194]
(c
max
:最大血液浓度,t
max
:达到峰值血液浓度的时间,auc
inf
:血液浓度
‑
时间曲线下的面积,其是通过从最后一个可测量的采血时间点外推到无限时间而计算出的,auc
last
:直到最后一个可测量的采血时间点的血液浓度
‑
时间曲线,t
1/2
:消除半衰期,auc
extp
(%):[(auc
inf
–
auc
last
)/auc
inf
]*100)
[0195]
如从表6和图7中可以看出的,能够确认与未和铰链区融合的hgh相比,与铰链区融合的hgh(igd
‑
hgh)的半衰期增加了约3.3倍。
[0196]2‑1‑
2.hgh vs.igd
‑
hgh
‑
his
[0197]
hgh和igd
‑
hgh
‑
his的pk结果示于表7和图8中。
[0198]
【表7】
[0199][0200]
(c
max
:最大血液浓度,t
max
:达到峰值血液浓度的时间,auc
inf
:血液浓度
‑
时间曲线下的面积,其是通过从最后一个可测量的采血时间点外推到无限时间而计算出的,auc
last
:直到最后一个可测量的采血时间点的血液浓度
‑
时间曲线,t
1/2
:消除半衰期,auc
extp
(%):[(auc
inf
–
auc
last
)/auc
inf
]*100)
[0201]
如从表7和图8中可以看出的,能够确认与未和铰链区融合的hgh相比,与具有his=tag的铰链区融合的hgh(igd
‑
hgh
‑
his)的半衰期增加了约2.6倍。
[0202]2‑1‑
3.iga
‑
hgh(o
‑
聚糖数量对pk的影响)
[0203]
为了观察o
‑
聚糖数量对pk的影响,每个iga
‑
hgh级分的pk结果示于表8和图9中。
[0204]
【表8】
[0205][0206]
(c
max
:最大血液浓度,t
max
:达到峰值血液浓度的时间,auc
inf
:血液浓度
‑
时间曲线下的面积,其是通过从最后一个可测量的采血时间点外推到无限时间而计算出的,auc
last
:直到最后一个可测量的采血时间点的血液浓度
‑
时间曲线,t
1/2
:消除半衰期,auc
extp
(%):[(auc
inf
–
auc
last
)/auc
inf
]*100)
[0207]
如从表8和图9中可以看出的,能够确认半衰期随着o
‑
聚糖数量的增加而增加。
[0208]2‑
2.靶蛋白:glp
‑1‑
fc融合蛋白(glp
‑1‑
fc,杜拉鲁肽)
[0209]
将实施例1.2中制备的融合多肽杜拉鲁肽
‑
id2以0.1mg/kg的剂量皮下施用至sd大鼠(orientbio,7周龄,约300g;n=3),并测试药代动力学。在0、0.5、1、2、4、6、8、24、48、96和
144小时进行采样,为了比较,以0.1mg/kg的剂量皮下施用杜拉鲁肽(trulicity,lilly korea),并进行测试。
[0210]
如上向sd大鼠施用后,将按照时间点收集的血液离心以获得血清。使用抗glp
‑
1抗体(novousbio)和抗人igg4 fc抗体(sigma
‑
aldrich)进行elisa,并确认血液中杜拉鲁肽
‑
id2按照时间点的浓度。利用该数据,使用用于pk分析的软件(winnonlin(certara l.p.)等)计算包括auc(曲线下面积)在内的参数。
[0211]
所得结果示于表9和图10中。
[0212]
【表9】
[0213][0214]
(c
max
:最大血液浓度,t
max
:达到峰值血液浓度的时间,auc
inf
:血液浓度
‑
时间曲线下的面积,其是通过从最后一个可测量的采血时间点外推到无限时间而计算出的,auc
last
:直到最后一个可测量的采血时间点的血液浓度
‑
时间曲线,t
1/2
:消除半衰期,auc
extp
(%):[(auc
inf
–
auc
last
)/auc
inf
]*100)
[0215]
如从表9和图10中可以看出的,能够确认与未和铰链区融合的杜拉鲁肽相比,与铰链区融合的glp
‑1‑
fc(杜拉鲁肽
‑
id2)的半衰期增加了约1.5倍。此外,c
max
为约1/5,auc
last
为约1/3。
[0216]
从以上描述中,本领域技术人员将理解,可以以其他特定形式来实现本公开,而不改变其技术思想或其必要特征。就这一点而言,应当理解,上述实施方式在所有方面都是说明性的而非限制性的。本公开的范围应被解释为,从后述的权利要求的含义和范围得到的所有改变或修改,而不是以上的详细描述及其等同概念,均包括在本公开的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 杂色鲍血蓝蛋白Ⅰ和Ⅱ型亚基基因及克隆方法
- 一种多负电荷血红蛋白α亚基的制作方法
- 包含吡唑-o-葡萄糖苷衍生物的药物组合物的制作方法
- 一种格列吡嗪长效缓释制剂及其制备方法
- 用于治疗i型糖尿病、ii型糖尿病、葡萄糖耐量降低或高血糖症的sglt-2抑制剂的制作方法
- 包含sglt2抑制剂、dpp-iv抑制剂和任选的另一种抗糖尿病药的药物组合物及其用途的制作方法
- 包含吡喃葡萄糖基-取代的苯衍生物的药物组合物的制作方法
- 包含sglt2抑制剂与dpp-iv抑制剂的药物组合物的制作方法
- 用于处理自我监测血糖(smbg)数据从而提高糖尿病患者自我管理的方法、系统和计算机 ...的制作方法
- 用于预防和治疗代谢病的方法和新颖的吡唑-o-葡萄糖苷衍生物的制作方法