一种室内定位方法及其装置与流程
本发明涉及大数据计算、人工智能、图像识别和云计算等技术领域,特别是涉及一种室内定位方法及其装置。
背景技术:
目前,随着人类科学技术的不断发展,深度学习(Deep Learning)正在成为机器学习领域的一个新兴领域。近几年,有关深度学习的应用越来越广,已经涉及到语音识别、图像识别、自然语言处理等领域。深度学习并将继续影响到机器学习和人工智能的其它关键领域。
随着全球定位系统(GPS)、北斗等卫星导航的民用化,各种导航极大的方便了人们的出行,室外的定位也越来越精准,但是,目前对于室内定位,卫星发射的无线电波在穿透钢筋混泥土的墙壁时,将会有极大的衰减,甚至在室内就接收不到卫星的信号,因此,无法通过卫星来进行室内导航。
目前,现有的的室内定位方法,都会受到外界环境的干扰,含有诸多不确定因素,导致室内定位误差很大,无法实现精确的室内定位,并且需要借助专门的硬件设备才能实现定位,这些硬件设备后续维修费用高且需要耗费大量的电能,增加了人们的日常经济支出,从而造成无法广泛地推广应用。
因此,目前迫切需要开发出一种技术,其可以让人们方便、可靠且精确地实现室内定位,无需借助专门的硬件设备,满足用户对室内定位功能的要求,减少人们的日常经济支出,提高用户的工作和生活品质。
技术实现要素:
有鉴于此,本发明的目的是提供一种室内定位方法及其装置,其可以让人们方便、可靠且精确地实现室内定位,无需借助专门的硬件设备,满足用户对室内定位功能的要求,减少人们的日常经济支出,提高用户的工作和生活品质,具有重大的生产实践意义。
为此,本发明提供了一种室内定位方法,包括步骤:
第一步:建立预设卷积神经网络,所述卷积神经网络包括依次对所输入的图像进行处理的输入层、隐含层和输出层;
第二步:预先采集预设室内场景内的多个场景图片作为多个采样样本,并预先标记每个采样样本在整个预设室内场景平面图中的位置,并所述多个采样样本输入到所述预设卷积神经网络中,对所述预设卷积神经网络进行训练,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练;
第三步:在需要定位当前用户位置的预设室内场景内,实时拍摄一张室内场景图片;
第四步:将所实时拍摄的室内场景图片输入到已完成训练的所述预设卷积神经网络中,识别获得与该实时拍摄的室内场景图片的相似度最高的采样样本,并以识别获得的该采样样本在整个预设室内场景平面图中的位置作为该实时拍摄的室内场景图片在整个预设室内场景平面图中的位置;
第五步:根据该实时拍摄的室内场景图片在整个预设室内场景平面图中的位置,在整个预设室内场景平面图中进行位置标注并实时显示。
其中,在第二步中,所述预先采集预设室内场景内的多个场景图片通过对预先拍摄的室内场景视频进行帧采样获取得到,或者直接通过摄像头拍照获得。
其中,在第二步中,所述预先采集的室内场景内的多个场景图片通过互联网网络传输至分布式文件系统HDFS中进行存储。
其中,所述第二步具体包括以下步骤:
预先采集预设室内场景内的多个场景图片作为多个采样样本;
然后通过网络传输至预设数据库进行存储;
然后利用MapReduce编程模型,采用所述预设数据库中的采样样本数据作为训练数据而输入到所述预设卷积神经网络中;
对所述预设卷积神经网络进行训练,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练。
其中,在所述第二步中,利用MapReduce训练所述预设卷积神经网络的具体处理过程包括以下步骤:
首先,初始化所述预设卷积神经网络;
然后,接收多个采样样本;
接着,正向传递计算损失函数;
然后,实时计算实际输出与目标输出的误差大小;
接着,利用随机梯度下降算法来调整所述预设卷积神经网络的权重和偏置;
最后,判断调整所述预设卷积神经网络的权重和偏置的次数是否达到预定的迭代次数;如果达到,则判断完成对所述预设卷积神经网络的训练;如果未达到,需要继续对所述预设卷积神经网络进行训练,继续调整权重和偏置,直到达到预定的迭代次数为止。
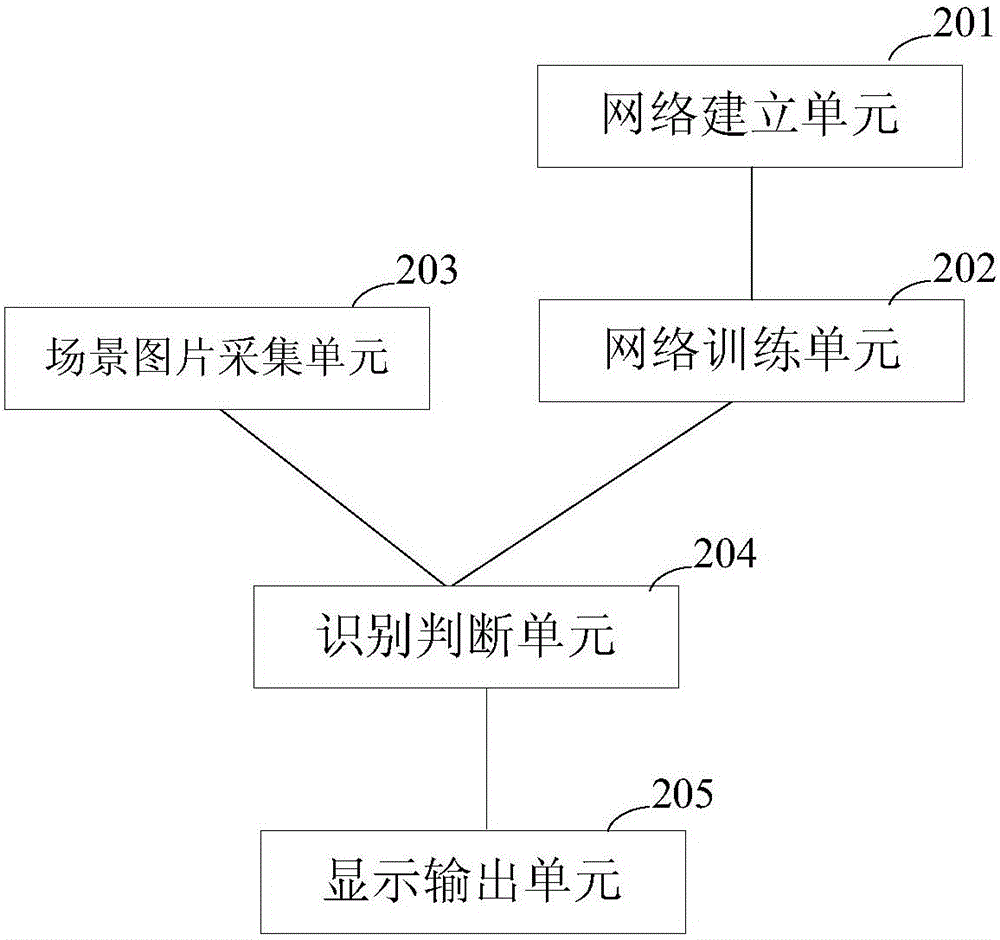
此外,本发明还提供了一种室内定位装置,包括:
网络建立单元,用于建立预设卷积神经网络,所述卷积神经网络包括依次对所输入的图像进行处理的输入层、隐含层和输出层;
网络训练单元,与网络建立单元相连接,用于预先采集预设室内场景内的多个场景图片作为多个采样样本,并预先标记每个采样样本在整个预设室内场景平面图中的位置,并所述多个采样样本输入到所述预设卷积神经网络中,对所述预设卷积神经网络进行训练,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练;
场景图片采集单元,用于在需要定位用户位置的预设室内场景内,实时拍摄一张室内场景图片,然后发送给识别判断单元;
识别判断单元,分别与网络训练单元和场景图片采集单元相连接,用于将所述场景图片采集单元发来的实时拍摄的室内场景图片,输入到所述网络训练单元完成训练的所述预设卷积神经网络中,识别获得与该实时拍摄的室内场景图片的相似度最高的采样样本,并以识别获得的该采样样本在整个预设室内场景平面图中的位置作为该实时拍摄的室内场景图片在整个预设室内场景平面图中的位置,然后发送给显示输出单元;
显示输出单元,与识别判断单元相连接,用于根据所述识别判断单元发来的所述实时拍摄的室内场景图片在整个预设室内场景平面图中的位置,在整个预设室内场景平面图中进行位置标注并实时显示。
其中,所述预先采集预设室内场景内的多个场景图片通过对预先拍摄的室内场景视频进行帧采样获取得到,或者直接通过摄像头拍照获得。
其中,所述网络训练单元与分布式文件系统HDFS相连接,所述网络训练单元用于将所述预先采集的室内场景内的多个场景图片可以通过互联网网络传输至分布式文件系统HDFS中进行存储。
其中,所述网络训练单元用于预先采集预设室内场景内的多个场景图片作为多个采样样本,然后通过网络传输至预设数据库进行存储,然后利用MapReduce编程模型,采用所述预设数据库中的采样样本数据作为训练数据而输入到所述预设卷积神经网络中,对所述预设卷积神经网络进行训练,直到使得所述预设卷积神经网络的模型收敛。
其中,所述网络建立单元和网络训练单元为所述装置安装上的中央处理器CPU、数字信号处理器DSP或者单片机MCU;
所述场景图片采集单元为具有图片拍摄功能的移动终端。
由以上本发明提供的技术方案可见,与现有技术相比较,本发明提供了一种室内定位方法及其装置,其可以让人们方便、可靠且精确地实现室内定位,无需借助专门的硬件设备,满足用户对室内定位功能的要求,减少人们的日常经济支出,提高用户的工作和生活品质,具有重大的生产实践意义。
附图说明
图1为本发明提供的一种室内定位方法的流程图;
图2为本发明提供的一种室内定位装置的结构方框图;
图3为本发明提供的一种室内定位方法及其装置所建立的基本神经网络的模型示意图。
图4为本发明提供的一种室内定位方法及其装置所建立的室内场景检测识别的卷积神经网络模型示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面结合附图和实施方式对本发明作进一步的详细说明。
图1为本发明提供的一种室内定位方法的流程图;
参见图1,本发明提供的一种室内定位方法,包括以下步骤:
步骤S101:建立预设卷积神经网络(Convolutional Neural Network,CNN)(参见图3,图4所示),所述预设卷积神经网络包括依次对所输入的图像进行处理的输入层、隐含层(所述隐含层包含预设多个卷积层、预设多个池化层和预设全连接层)和输出层;
步骤S102:预先采集预设室内场景内的多个场景图片作为多个采样样本,并预先标记每个采样样本在整个预设室内场景平面图中的位置,并所述多个采样样本输入到所述预设卷积神经网络中,对所述预设卷积神经网络进行训练,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练;
步骤S103:在需要定位当前用户位置的预设室内场景内,实时拍摄一张室内场景图片;
步骤S104:将所实时拍摄的室内场景图片输入到已完成训练的所述预设卷积神经网络中,识别获得与该实时拍摄的室内场景图片的相似度最高的采样样本,并以识别获得的该采样样本在整个预设室内场景平面图中的位置作为该实时拍摄的室内场景图片在整个预设室内场景平面图中的位置;
步骤S105;根据该实时拍摄的室内场景图片在整个预设室内场景平面图中的位置,在整个预设室内场景平面图中进行位置标注并实时显示。
在本发明中,参见图3,图4所示,所述卷积神经网络包括依次对所输入快递单图片进行处理的输入层、隐含层(所述隐含层包含预设多个卷积层、预设多个池化层和预设全连接层)和输出层。
对于所述预设卷积神经网络,其中具有的输入层的作用是为了将图片数据(如室内场景图片)送入卷积神经网络,以便于后续处理;卷积层的作用是提取图片的局部区域特征;池化层不改变输入输出特征图数量,仅对输入的特征图进行降维操作,降维的方式采用选取卷积窗口中数值最大的神经元作为有效的输出神经元,这样减少了大量计算;全连接层的作用是为了从上一层的输出中提取更具区分性的特征;输出层的作用是为了分类出与所输入的图片相似度最高的采样样本,具体可以通过上次的输入以及与下一层之间的权重,得到相应的输出值。
参见图3,对于本发明建立的预设卷积神经网络,其具有的隐含层1或者隐含层2中包括预设数目的卷积层和池化层。通过该预设卷积神经网络,可以对所输入的图片(例如室内场景图片)进行优化处理。
在本发明中,参见图3,图4所示,所述预设卷积神经网络包括依次对所输入室内场景图片进行处理的输入层、隐含层(包含预设多个卷积层、预设多个池化层和预设多个全连接层)和输出层。
对于所述预设卷积神经网络,其中具有的输入层的作用是为了将图片数据(如所输入的包含文字、标志性图画等信息在内的某室内场景图片)送入预设卷积神经网络,以便于后续处理;
卷积层的作用是提取图片的局部区域特征;池化层不改变输入输出特征图数量,仅对输入的特征图进行降维操作,降维的方式采用选取卷积窗口中数值最大的神经元作为有效的输出神经元,这样减少了大量计算;全连接层的作用是为了从上一层的输出中提取更具区分性的特征;输出层的作用是为了分类出室内场景位置信息,具体可以通过上次的输入以及与下一层之间的权重,得到相应的输出值。
对于本发明,具体实现上,包含文字信息或商标信息等的某室内场景图片作为输入层的数据,输入图片的大小不受限制。举例说明,若输入图片大小48×48像素点,也就是说把每个像素点看成神经元,输入的神经元个数为48×48=2304个。卷积层可以由32个不同的特征映射图组成。每一个特征图的大小是48×48像素点,卷积窗口大小为5×5像素点,这样利用输入特征图与输出特征图大小的关系公式:
以上公式中,w0代表输入特征图的宽度,h0代表输入特征图的高度,w1代表输出特征图的宽度,h1代表输出特征图的高度,pad为增加特征图边缘像素点,kernel_size为卷积核大小也就是卷积窗口大小,stride为卷积核移动步长,也就是卷积核在输入特征图上移动的像素点个数,比如输入的图片尺寸213×213,经数据层传递给第一个卷积层时,卷积层的卷积核kernel_size参数为5×5,pad为1,stride为2,卷积层输出的特征图尺寸w1×h1,分别代表的含义为卷积核kernel_size大小为5×5,增加1个特征图边缘像素点,在输入特征图上移动的2个像素点,根据以上公式,计算输出特征图的宽度w1为106,输出特征图的高度h1为106,即输出特征图尺寸106×106。之后的卷积神经网络计算中,前一层的输出特征图尺寸w1×h1作为后一层的输入特征图尺寸w0×h0输入,比如卷积层数据传递给池化层时,池化层的输入特征图尺寸等于上一层卷积层的特征图输出尺寸。
经过卷积层输出的特征图大小为45×45像素点,同时卷积层中32个不同的特征映射图提取了输入图像不同的边缘特征,将得到的特征传递给下一层的池化层,池化层的步长stride为2,卷积窗口为3×3,池化层不改变输入输出特征图数量,仅对输入的特征图进行降维操作,降维的方式采用选取卷积窗口中数值最大的神经元作为有效的输出神经元,这样减少了大量计算,同样利用以下输入特征图与输出特征图大小的关系公式:
通过这两个卷积运算公式,可以算出降维后的卷积特征图尺寸为22×22像素点,输出特征图的个数仍然为32,再经下一个卷积层,卷积窗口大小为3×3像素点,步长stride为1,卷积特征图个数为128,同理利用公式可得输出特征图大小为像素点20×20,输出特征图个数为128,这一层卷积运算操作,对输入特征图进行了更深层次的边缘特征提取。再将提取到的特征图输送给池化层进行降维操作,算得输出特征图大小为10×10像素点,输出特征图的个数为128,然后送入全连接层,全连接层将所有输入神经元作为输入向量,与输出向量相连接,全连接层最终要将数据传送给输出层进行分类,如分类得出室内场景的位置信息,在后续处理步骤中,可以将位置信息输出给用户的终端并在终端显示具体位置。
在本发明中,在步骤S102中,所述预先采集预设室内场景内的多个场景图片可以通过对预先拍摄的的室内场景视频进行帧采样获取得到,也可以直接通过摄像头拍照获得(即是直接通过手机等移动终端上的摄像头所拍照获得的室内场景图片)。
需要说明的是,在步骤S102中,本发明对预设卷积神经网络训练的目的是为了调节网络中的权重。
在本发明中,具体实现上,在步骤S102中,所述预先采集的室内场景内的多个场景图片可以通过互联网网络传输至分布式文件系统HDFS(Hadoop Distributed File System)中进行存储。HDFS是Hadoop云计算平台的分布式计算中的数据存储系统。
具体实现上,所述步骤S102具体为:预先采集(通过手机等移动终端的摄像头)预设室内场景内的多个场景图片作为多个采样样本,然后通过网络传输至预设数据库(例如分布式文件系统HDFS)进行存储,然后利用MapReduce编程模型,采用所述预设数据库中的采样样本数据作为训练数据而输入到所述预设卷积神经网络中,对所述预设卷积神经网络(Convolutional Neural Network,CNN)进行训练,得到最优的卷积神经网络参数,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练。
在本发明中,需要说明的是,具体实现上,对于所述步骤S102,利用MapReduce训练所述预设卷积神经网络的具体处理过程可以包括以下步骤:
首先,初始化所述预设卷积神经网络;
然后,接收多个采样样本(即作为训练样本使用);
接着,正向传递计算损失函数;
然后,实时计算实际输出与目标输出的误差大小;
接着,利用随机梯度下降算法来调整所述预设卷积神经网络的权重和偏置;
最后,判断调整所述预设卷积神经网络的权重和偏置的次数是否达到预定的迭代次数;如果达到,则判断完成对所述预设卷积神经网络的训练,并输出分类标准;如果未达到,需要继续对所述预设卷积神经网络进行训练,继续调整权重和偏置,直到达到预定的迭代次数为止。
在本发明中,所述训练数据需要采用室内场景图片或者提取视频帧,要求输入的图片无污损,图片大小不受限制,但是图片要尽可能包含文字、标志性图画等,将准备好的训练数据集进行格式转换,转换成lmdb格式,然后送入之前本发明搭建好的预设卷积神经网络模型中进行检测、识别、分类,最终要将检测到的结果在终端(手机,平板电脑)显示出室内的位置定位。
在本发明中,具体实现上,需要说明的是,采用了caffe深度学习框架。卷积神经网络的输入是图像信息,要先做输入数据的预处理,即将图像信息转换成lmdb数据格式,以向量的形式输入到深度学习框架caffe卷积神经网络的数据层(Data),数据层信息包括输入图片数量,图像通道数,图像高度和图像宽度。图像的每一个像素点可以看做神经元,神经元与神经元之间的连线称为权重(wi),神经元信息存储在caffe框架的底层Blob数据结构中,数据层的底层Blob用来传给卷积层(Convolution),卷积层的操作是对图像进行特征提取,卷积层的信息包括输入图像数量,输出图像数量,图像高度和宽度,以及卷积核的大小,还有卷积的步长。同样将处理后的数据存储到底层Blob数据结构体中,然后传递给池化层(Pooling),池化层将对卷积层提取的图像特征进行降维操作,在尽量不影响图像信息损失的前提下,以减少矩阵计算量,再将得到的信息存储到Blob数据结构体,传递给全连接层(Fully Connected),全连接层将结果送给输出层,输出层用来计算分类得分。
计算的方法是用分类得分计算公式:y=wix+bi;其中,y为输出神经元,wi为权重,x为输入神经元,bi为偏置,参见图3所示(图中,隐含层1或者隐含层2中包括预设数目的卷积层和池化层),最终输出的输出神经元y与分类的预设标签yt在输出层进行误差计算(loss)。本发明的目标就是将误差loss尽可能变小,使得接近0。损失函数采用Softmax with loss(即Softmax损失函数)。
Softmax损失函数的计算公式为
其中,z为对应的类别,如在商场里XX火锅店,XX品牌折扣店等,yi为第i个类别的线性预测结果,共m个类别。同样,本发明要将得到的loss再进行反向传播,利用反向传播算法(BP)用于更新权重值和偏重,使得正向传播loss越来越接近于0值。利用公式,采用的链式法则如下:
其中,为第P层,第i个隐含层(隐含层指卷积层,全连接层等),Loss为输出误差,为第P层,第i个权重值。
此外,还利用公式为第P层的权重,第i个更新权重值,lr为学习率(用于更新权重值),这样就可以更新权重同理,偏置权重bi,利用如下公式获得:
也可更新偏置权重如此反复运算,就可以获得最优的权重偏置权重使得误差loss最小,即可训练一个好的神经网络模型,通过检测到的文字信息、商标信息以及店铺的某些标志性信息(如门口张贴的某明星代言等)。
为了详细说明本发明的具体实施方式及验证本发明的有效性,将本发明提出的方法应用于室内定位。将对某个预设室内场景做数据采集(即采集多个采样样本),并训练预设卷积神经网络模型,然后任意一个用户用手机对此场景进行拍照(拍照信息尽可量包含文字、商标或者标志性图画等),上传至云端(例如作为预设数据库的分布式文件系统HDFS),最终接收到云端的反馈,从而,每个用户都可以得知自己位于特定的预设室内场景的具体位置,即实现了室内定位。
基于以上技术方案可知,对于本发明,需要说明的是,本发明提供的一种室内定位方法,与目前其它的室内定位方法相比,不需要给室内场景安装硬件,也就谈不上后期硬件的维护费用,只需要用户用手机、平板电脑等移动终端拍一张照片上传至云端(例如作为预设数据库的分布式文件系统HDFS),等待云端反馈给用户的定位信息即可。这种定位方法不仅准确度很高而且很方便,对外界的抗干扰能力更强,最重要的是不需要使用者购买任何定位产品,只需要一部能拍照的智能手机等移动终端就能完成室内的定位。
对于本发明,其可以根据目前云计算技术的不同处理技术的特点,将深度学习与实时云技术技术相结合,将两类不同的云计算技术融合,以深度学习为支撑,系统大大提高场景图片识别的准确率;以实时云计算为支撑,系统能够大大提高场景图片的处理速度与效率。
基于上述本发明提供的一种室内定位方法,参见图2,本发明提供的一种室内定位装置,包括:
网络建立单元201,用于建立预设卷积神经网络(Convolutional Neural Network,CNN),所述卷积神经网络包括依次对所输入的图像进行处理的输入层、预设多个卷积层、预设多个池化层、预设全连接层和输出层;
网络训练单元202,与网络建立单元201相连接,用于预先采集预设室内场景内的多个场景图片作为多个采样样本,并预先标记每个采样样本在整个预设室内场景平面图中的位置,并所述多个采样样本输入到所述预设卷积神经网络中,对所述预设卷积神经网络进行训练,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练;
场景图片采集单元203,用于在需要定位用户位置的预设室内场景内,实时拍摄一张室内场景图片,然后发送给识别判断单元204;
识别判断单元204,分别与网络训练单元202和场景图片采集单元203相连接,用于将所述场景图片采集单元203发来的实时拍摄的室内场景图片,输入到所述网络训练单元202完成训练的所述预设卷积神经网络中,识别获得与该实时拍摄的室内场景图片的相似度最高的采样样本,并以识别获得的该采样样本在整个预设室内场景平面图中的位置作为该实时拍摄的室内场景图片在整个预设室内场景平面图中的位置,然后发送给显示输出单元205;
显示输出单元205,与识别判断单元204相连接,用于根据所述识别判断单元204发来的所述实时拍摄的室内场景图片在整个预设室内场景平面图中的位置,在整个预设室内场景平面图中进行位置标注并实时显示。
在本发明中,所述卷积神经网络包括依次对所输入快递单图片进行处理的输入层、预设多个卷积层、预设多个池化层、预设多个全连接层和输出层。
对于所述预设卷积神经网络,其中具有的输入层的作用是为了将图片数据(如室内场景图片)送入卷积神经网络,以便于后续处理;卷积层的作用是提取图片的局部区域特征;池化层不改变输入输出特征图数量,仅对输入的特征图进行降维操作,降维的方式采用选取卷积窗口中数值最大的神经元作为有效的输出神经元,这样减少了大量计算;全连接层的作用是为了从上一层的输出中提取更具区分性的特征;输出层的作用是为了分类出与所输入的图片相似度最高的采样样本,具体可以通过上次的输入以及与下一层之间的权重,得到相应的输出值。
参见图3,对于本发明建立的预设卷积神经网络,其具有的隐含层1或者隐含层2中包括预设数目的卷积层和池化层。通过该预设卷积神经网络,可以对所输入的图片(例如室内场景图片)进行优化处理。
在本发明中,参见图3,图4所示,所述预设卷积神经网络包括依次对所输入室内场景图片进行处理的输入层、隐含层(包含预设多个卷积层、预设多个池化层和预设多个全连接层)和输出层。
对于所述预设卷积神经网络,其中具有的输入层的作用是为了将图片数据(如所输入的包含文字、标志性图画等信息在内的某室内场景图片)送入预设卷积神经网络,以便于后续处理;
卷积层的作用是提取图片的局部区域特征;池化层不改变输入输出特征图数量,仅对输入的特征图进行降维操作,降维的方式采用选取卷积窗口中数值最大的神经元作为有效的输出神经元,这样减少了大量计算;全连接层的作用是为了从上一层的输出中提取更具区分性的特征;输出层的作用是为了分类出室内场景位置信息,具体可以通过上次的输入以及与下一层之间的权重,得到相应的输出值。
对于本发明,具体实现上,包含文字信息或商标信息等的某室内场景图片作为输入层的数据,输入图片的大小不受限制。举例说明,若输入图片大小48×48像素点,也就是说把每个像素点看成神经元,输入的神经元个数为48×48=2304个。卷积层可以由32个不同的特征映射图组成。每一个特征图的大小是48×48像素点,卷积窗口大小为5×5像素点,这样利用输入特征图与输出特征图大小的关系公式:
以上公式中,w0代表输入特征图的宽度,h0代表输入特征图的高度,w1代表输出特征图的宽度,h1代表输出特征图的高度,pad为增加特征图边缘像素点,kernel_size为卷积核大小也就是卷积窗口大小,stride为卷积核移动步长,也就是卷积核在输入特征图上移动的像素点个数,比如输入的图片尺寸213×213,经数据层传递给第一个卷积层时,卷积层的卷积核kernel_size参数为5×5,pad为1,stride为2,卷积层输出的特征图尺寸w1×h1,分别代表的含义为卷积核kernel_size大小为5×5,增加1个特征图边缘像素点,在输入特征图上移动的2个像素点,根据以上公式,计算输出特征图的宽度w1为106,输出特征图的高度h1为106,即输出特征图尺寸106×106。之后的卷积神经网络计算中,前一层的输出特征图尺寸w1×h1作为后一层的输入特征图尺寸w0×h0输入,比如卷积层数据传递给池化层时,池化层的输入特征图尺寸等于上一层卷积层的特征图输出尺寸。
经过卷积层输出的特征图大小为45×45像素点,同时卷积层中32个不同的特征映射图提取了输入图像不同的边缘特征,将得到的特征传递给下一层的池化层,池化层的步长stride为2,卷积窗口为3×3,池化层不改变输入输出特征图数量,仅对输入的特征图进行降维操作,降维的方式采用选取卷积窗口中数值最大的神经元作为有效的输出神经元,这样减少了大量计算,同样利用以下输入特征图与输出特征图大小的关系公式:
通过这两个卷积运算公式,可以算出降维后的卷积特征图尺寸为22×22像素点,输出特征图的个数仍然为32,再经下一个卷积层,卷积窗口大小为3×3像素点,步长stride为1,卷积特征图个数为128,同理利用公式可得输出特征图大小为像素点20×20,输出特征图个数为128,这一层卷积运算操作,对输入特征图进行了更深层次的边缘特征提取。再将提取到的特征图输送给池化层进行降维操作,算得输出特征图大小为10×10像素点,输出特征图的个数为128,然后送入全连接层,全连接层将所有输入神经元作为输入向量,与输出向量相连接,全连接层最终要将数据传送给输出层进行分类,如分类得出室内场景的位置信息,在后续处理步骤中,可以将位置信息输出给用户的终端并在终端显示具体位置。
在本发明中,在网络训练单元202中,所述预先采集预设室内场景内的多个场景图片可以通过对预先拍摄的室内场景视频进行帧采样获取得到,也可以直接通过摄像头拍照获得(即是直接通过手机等移动终端上的摄像头所拍照获得的室内场景图片)。
需要说明的是,在网络训练单元202中,本发明对预设卷积神经网络训练的目的是为了调节网络中的权重。
在本发明中,具体实现上,所述网络训练单元202与分布式文件系统HDFS相连接,所述网络训练单元202用于将所述预先采集的室内场景内的多个场景图片可以通过互联网网络传输至分布式文件系统HDFS(Hadoop Distributed File System)中进行存储。HDFS是Hadoop云计算平台的分布式计算中的数据存储系统。
具体实现上,所述网络训练单元202具体用于预先采集(通过手机等移动终端的摄像头)预设室内场景内的多个场景图片作为多个采样样本,然后通过网络传输至预设数据库(例如分布式文件系统HDFS)进行存储,然后利用MapReduce编程模型,采用所述预设数据库中的采样样本数据作为训练数据而输入到所述预设卷积神经网络中,对所述预设卷积神经网络(Convolutional Neural Network,CNN)进行训练,得到最优的卷积神经网络参数,直到使得所述预设卷积神经网络的模型收敛,完成所述预设卷积神经网络的训练。
在本发明中,需要说明的是,具体实现上,对于所述网络训练单元202,利用MapReduce训练所述预设卷积神经网络的具体处理过程可以包括以下步骤:
首先,初始化所述预设卷积神经网络;
然后,接收多个采样样本(即作为训练样本使用);
接着,正向传递计算损失函数;
然后,实时计算实际输出与目标输出的误差大小;
接着,利用随机梯度下降算法来调整所述预设卷积神经网络的权重和偏置;
最后,判断调整所述预设卷积神经网络的权重和偏置的次数是否达到预定的迭代次数;如果达到,则判断完成对所述预设卷积神经网络的训练,并输出分类标准;如果未达到,需要继续对所述预设卷积神经网络进行训练,继续调整权重和偏置,直到达到预定的迭代次数为止。
为了详细说明本发明的具体实施方式及验证本发明的有效性,将本发明提出的方法应用于室内定位。将对某个预设室内场景做数据采集(即采集多个采样样本),并训练预设卷积神经网络模型,然后任意一个用户用手机对此场景进行拍照,上传至云端(例如作为预设数据库的分布式文件系统HDFS),最终接收到云端的反馈(通过云端上设置的识别判断单元204识别获得),从而,每个用户都可以得知自己位于特定的预设室内场景的具体位置,即实现了室内定位。
在本发明中,所述训练数据需要采用室内场景图片或者提取视频帧,要求输入的图片无污损,图片大小不受限制,但是图片要尽可能包含文字、标志性图画等,将准备好的训练数据集进行格式转换,转换成lmdb格式,然后送入之前本发明搭建好的预设卷积神经网络模型中进行检测、识别、分类,最终要将检测到的结果在终端(手机,平板电脑)显示出室内的位置定位。
在本发明中,具体实现上,需要说明的是,采用了caffe深度学习框架。卷积神经网络的输入是图像信息,要先做输入数据的预处理,即将图像信息转换成lmdb数据格式,以向量的形式输入到深度学习框架caffe卷积神经网络的数据层(Data),数据层信息包括输入图片数量,图像通道数,图像高度和图像宽度。图像的每一个像素点可以看做神经元,神经元与神经元之间的连线称为权重(wi),神经元信息存储在caffe框架的底层Blob数据结构中,数据层的底层Blob用来传给卷积层(Convolution),卷积层的操作是对图像进行特征提取,卷积层的信息包括输入图像数量,输出图像数量,图像高度和宽度,以及卷积核的大小,还有卷积的步长。同样将处理后的数据存储到底层Blob数据结构体中,然后传递给池化层(Pooling),池化层将对卷积层提取的图像特征进行降维操作,在尽量不影响图像信息损失的前提下,以减少矩阵计算量,再将得到的信息存储到Blob数据结构体,传递给全连接层(Fully Connected),全连接层将结果送给输出层,输出层用来计算分类得分,计算的方法是用分类得分计算公式:y=wix+bi;其中,y为输出神经元,wi为权重,x为输入神经元,bi为偏置,参见图3所示(图中,隐含层1或者隐含层2中包括预设数目的卷积层和池化层),最终输出的输出神经元y与分类的预设标签yt在输出层进行误差计算(loss)。本发明的目标就是将误差loss尽可能变小,使得接近0。损失函数采用Softmax with loss(即Softmax损失函数)。
Softmax损失函数的计算公式为
其中,z为对应的类别,如在商场里XX火锅店,XX品牌折扣店等,yi为第i个类别的线性预测结果,共m个类别。同样,本发明要将得到的loss再进行反向传播,利用反向传播算法(BP)用于更新权重值和偏重,使得正向传播loss越来越接近于0值。利用公式,采用的链式法则如下:
其中,为第P层,第i个隐含层(隐含层指卷积层,全连接层等),Loss为输出误差,为第P层,第i个权重值。
此外,还利用公式为第P层的权重,第i个更新权重值,lr为学习率(用于更新权重值),这样就可以更新权重同理,偏置权重bi,利用如下公式获得:
也可更新偏置权重如此反复运算,就可以获得最优的权重偏置权重使得误差loss最小,即可训练一个好的神经网络模型,通过检测到的文字信息、商标信息以及店铺的某些标志性信息(如门口张贴的某明星代言等)。
在本发明中,具体实现上,所述网络建立单元201和网络训练单元202可以分别为本发明装置安装上的中央处理器CPU、数字信号处理器DSP或者单片机MCU。
在本发明中,具体实现上,所述场景图片采集单元203可以为任意一种具有图片拍摄功能的设备,优选为手机、平板电脑等移动终端。
在本发明中,具体实现上,所述识别判断单元204可以为安装在云端(例如作为预设数据库的分布式文件系统HDFS)上的中央处理器CPU。
在本发明中,具体实现上,所述显示输出单元205可以为任意一种具有显示功能的设备,例如可以为液晶显示器。
基于以上技术方案可知,对于本发明,需要说明的是,本发明提供的一种室内定位装置,与目前其它的室内定位方法相比,不需要给室内场景安装硬件,也就谈不上后期硬件的维护费用,只需要用户用手机、平板电脑等移动终端拍一张照片上传至云端(例如作为预设数据库的分布式文件系统HDFS),等待云端反馈给用户的定位信息即可。这种定位方法不仅准确度很高而且很方便,对外界的抗干扰能力更强,最重要的是不需要使用者购买任何定位产品,只需要一部能拍照的智能手机等移动终端就能完成室内的定位。
对于本发明,其可以根据目前云计算技术的不同处理技术的特点,将深度学习与实时云技术技术相结合,将两类不同的云计算技术融合,以深度学习为支撑,系统大大提高场景图片识别的准确率;以实时云计算为支撑,系统能够大大提高场景图片的处理速度与效率。
综上所述,与现有技术相比较,本发明提供了一种室内定位方法及其装置,其可以让人们方便、可靠且精确地实现室内定位,无需借助专门的硬件设备,满足用户对室内定位功能的要求,减少人们的日常经济支出,提高用户的工作和生活品质,具有重大的生产实践意义。
通过使用本发明提供的技术,可以使得人们工作和生活的便利性得到很大的提高,极大地提高了人们的生活水平。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!