构建皮肤相关基因标准型别数据库的方法及应用与流程
本发明属于基因检测
技术领域:
,特别涉及构建皮肤相关基因标准型别数据库的方法及应用。
背景技术:
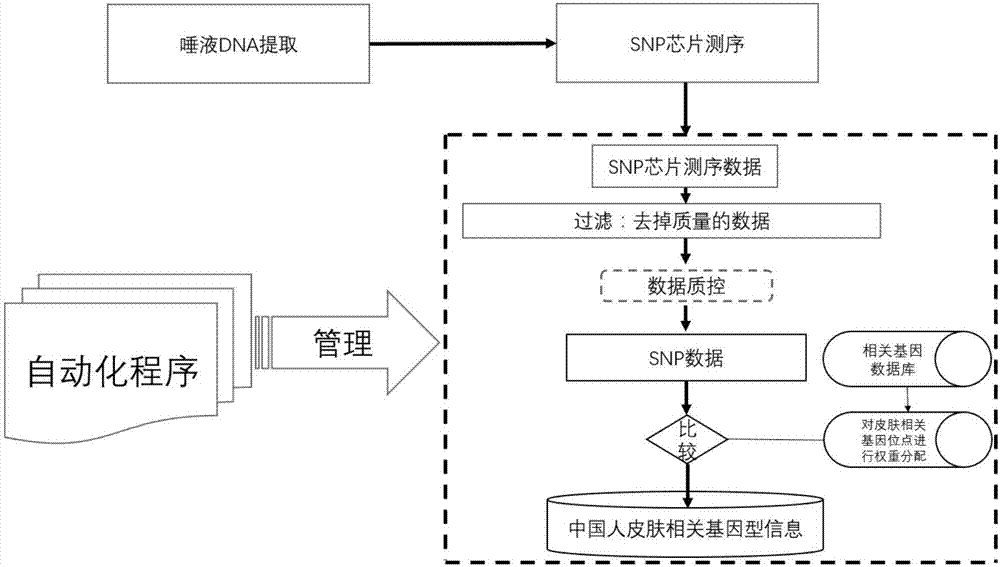
:基因是指携带有遗传信息的脱氧核糖核酸或核糖核酸序列,也称为遗传因子,是控制性状的基本遗传单位。基因通过指导蛋白质的合成来表达自己所携带的遗传信息,从而控制生物个体的性状表现。高通量测序技术以其无以伦比的通量、扩展性和速度,让研究人员以前所未有的水平研究生物系统。随着生物学研究的迅速发展,高通量测序技术已经成为一种常用技术,采用高通量测序技术,对生物的基因进行测序分析,已广泛应用于各种生命活动的研究工作中。高通量测序产出的海量数据,正在以几何级数增长,如何从这些数据中找到有用的信息,已经成为科研工作者面临的困扰。由于高通量测序数据的不断增加,如何对这些数据进行深入有效的挖掘和管理,对于生物信息学工作者是一个极大的考验,特别是针对皮肤基因检测这个新兴的领域,更是加大了难度。目前全世界范围内还没有专业的皮肤相关基因数据库,特别是中国人特有的皮肤相关基因数据库,目前全世界范围内的基因数据主要以欧美人群为主,辅以少量的亚洲人基因数据,这种现状对于中国的研究人员,特别是研究皮肤相关基因的科研人员来说,是极其不利的。通过构建中国人皮肤相关基因标准型别数据库,对基因测序得来的中国人特有的皮肤基因数据进行管理已经迫在眉睫。技术实现要素:本发明的目的在于提供一种构建皮肤相关基因标准型别数据库的方法及其应用,并通过该方法构建首个中国人皮肤相关基因标准型别数据库,为后续的中国人皮肤相关基因研究奠定基础。为解决上述技术问题,本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法,其特征在于,包含下述步骤:(1)提取样本基因组dna,进行基因测序,得到样本基因测序数据;(2)对所述基因测序数据进行数据分析,得到样本基因型数据;(3)整理公共基因数据库中皮肤相关基因位点,并对所述皮肤相关基因位点进行权重分配,得到皮肤相关基因位点的权重分配数据;(4)将所述样本基因型数据与所述皮肤相关基因位点的权重分配数据进行比对,得到样本特有的皮肤相关基因信息;(5)根据所述样本特有的皮肤相关基因信息建立打分模型,对基因位点突变导致的表型发生的概率进行打分,得到基因位点突变导致的表型发生的概率分值;(6)以所述样本基因型数据、所述样本特有的皮肤相关基因信息和所述基因位点突变导致的表型发生的概率分值,构建皮肤相关基因标准型别数据库。相对于现有技术,本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法,旨在用价格低廉的基因测序技术和数据分析技术,构建皮肤相关基因标准型别数据库,以所构建的皮肤相关基因标准型别数据库为皮肤基因研究奠定基础、并促进个性化皮肤护理的发展。优选地,在本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法中,步骤(1)中对样本基因组dna进行测序的方法为snp芯片测序。本发明通过快速价格低廉的snp芯片高通量测序,以更低的价格和资金投入得到与新一代(ngs)测序技术同等的基因数据,直接捕获的是目标区域基因数据,相当于去除了无关的数据,使得得到的数据冗余度更少,这样即可节省数据分析时间,以及计算成本和人力成本,最终快速构建皮肤相关基因标准型别数据库。优选地,本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法中,步骤(2)中对所述基因测序数据进行数据分析的方法具体包括:(i)将所述基因测序数据导入beadstudio芯片数据分析软件进行分析,得到样本的snp分型数据;(ii)对所述样本的snp分型数据进行过滤,去除低质量数据;(iii)进行数据质控,保证snp位点检出率大于90%。优选地,本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法中,步骤(3)中所述的公共基因数据库包括snpedia、dbsnp、clinvar、1000g、hgmd、omim、bgap中的至少一种。更进一步地,本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法中,步骤(3)所述的皮肤相关基因位点优选包含选自c10orf71、fads1、fads2、fth1、il23r、jmjd1c、mc4r、pdxdc1、hla-c、il10、il13、il-18r、loc643723、sell、tra、b4galt1、bach2、exoc2、fut8、grm5、herc2、ikzf1基因的至少一种。优选地,步骤(3)中,对皮肤相关基因位点进行权重分配时的影响因素至少包含如下所述中的一种或几种:(a)所述位点是否有全基因组关联分析分类数据库重复实验;(b)所述位点是否与皮肤表观症状具有直接性状关联;(c)所述位点是否有湿实验位点验证;(d)所述位点所属个体的种族;(e)所述位点的皮肤相关论文发表的影响因子。上述权重分配的步骤校正了特殊位点对最后表型预测的概率的影响,有效地提高了预测的准确度。具体地,本发明的实施方式所提供的构建皮肤相关基因标准型别数据库的方法中,步骤(5)中根据所述样本特有的皮肤相关基因信息建立打分模型的方法包括:单个突变位点算法模型和多个突变位点算法模型。其中,所述的单个突变位点算法模型为:pr(d)=pr(d|g1)pr(g1)+pr(d|g2)pr(g2)+pr(d|g3)pr(g3)其中,pr(d)为单个位点突变导致的表型发生的概率;or为比值比;pr(g)为基因型频率;g1\g2\g3分别为三种基因型。所述多个突变位点算法模型为:其中,or*m代表单个snp的特定基因型的or值,综合所有的变位点计算出orc*值;orc*值为带有某些特定基因型组合表型特征的个体,其表型相较于该个体所在种群平均表型的比值,odds(d)通过pr(d)求出;为多个位点突变导致的表型发生的概率。进一步地,本发明的实施方式也提供上述构建皮肤相关基因标准型别数据库的方法在皮肤个性化护理中的应用。另外,本发明的实施方式还提供根据上述方法构建的中国人皮肤相关基因标准型别数据库。附图说明图1是本发明具体实施方式中的snp芯片测序流程图;图2是本发明具体实施方式中的数据分析流程图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的各实施方式进行详细的阐述。然而,本领域的普通技术人员可以理解,在本发明各实施方式中,为了使读者更好地理解本申请而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本申请各权利要求所要求保护的技术方案。1.基因组dna提取与snp芯片测序(snp芯片测序流程参见附图1所示)1.1口腔黏膜拭子dna抽提1.1.1取一支口腔黏膜拭子置于2ml的ep管中。1.1.2依次加入750μlpbs、250μlbl、25μlpk,颠倒轻摇充分混匀,56℃放置30分钟,其间颠倒混匀3次。1.1.3轻轻挑出棉签,加入450μl无水乙醇,剧烈颠倒轻摇,充分混匀。注:上述各操作步骤中适当力度充分混匀非常重要,混匀不充分严重降低产量,必要时如样品粘稠不易混匀时可以涡旋振荡15秒混匀,但不可用手剧烈振荡,以免剪切dna。1.1.4将上一步所得溶液分两次全部转入一个吸附柱中(吸附柱放入收集管中),12,000rpm离心60秒,倒掉收集管中的废液,将吸附柱放回收集管中。1.1.5向吸附柱中加入500μlkbbuffer,12,000rpm离心60秒,弃废液,将吸附柱放回收集管中。1.1.6向吸附柱中加入500μl漂洗液washbuffer(请先检查是否已加入无水乙醇!),12,000rpm离心60秒,弃掉废液,将吸附柱放回收集管中。1.1.7重复5.1.2.6操作一次。1.1.8将吸附柱放回空收集管中,12,000rpm离心5分钟。1.1.9取出吸附柱cb3,放入一个干净的离心管中,在吸附膜的中间部位加80-100μl洗脱缓冲液elutionbuffer(洗脱缓冲液事先在65-70℃水浴中预热),室温放置5分钟,12,000rpm离心2分钟。将得到的溶液重新加入离心吸附柱中,室温放置2分钟,12,000rpm离心2分钟。注:洗脱体积越大,洗脱效率越高,如果需要dna浓度较高,可以适当减少洗脱体积,但是最小体积不应少于80μl,体积过小降低dna洗脱效率,减少dna产量。1.2采用biomate-3s检测dna浓度.dna纯度:a260/a280的比值为1.7-1.9(dna),a260/a230的比值大于2.0。按上述方法抽提200uledta抗凝血液,最后的洗脱体积为100ul,得到的dna浓度约为20-60ng/ul。1.3snp芯片测序1.3.1测定dna浓度,并统一标化成50ng/μl。进行infinium610-quadassay分析需要的dna样本量为200ng。1.3.2在样本中加入0.1nnaoh使dna变性为单链,经中和后加入全基因组扩增试剂,在37℃恒温条件下过夜孵育,扩增后的dna总量可达初始上样量的2000-3000倍。1.3.3扩增后的产物,经过可控的且不需要凝胶电泳的酶解处理,成为片段化的dna。该过程利用终点式(end-point)片段化方法,以防止样本的过度片段化。1.3.4通过加入异丙醇沉淀dna片段,片段化的dna在4℃下离心富集,从而得以纯化。1.3.5沉淀后的dna在空气中干燥后,加入杂交缓冲试剂使dna沉淀重新溶解。1.3.6将重悬后的dna样本与准备好的芯片杂交,置于杂交炉内反应过夜。在杂交过程中,片段化后的dna经过变性,与位点特异的50个碱基退火,而这50个特异碱基连接在芯片的610,000种微珠(bead)中的一个上,一个微珠类型对应检测一个snp或cnv位点。1.3.7洗去未杂交的和非特异杂交的dna,以便后续的染色和延伸。以捕获到的dna为模板,在芯片上进行单碱基的延伸反应,在芯片上加上可检测的标签基团,从而区分样本的snp类型。包被芯片:将反应完成的芯片放入xc4试剂中,使其表面包裹上一层粘性透明液体,再将其放入真空环境下干燥1小时,从而将芯片包被,保护其信号稳定较长的时间。1.3.8将处理好的芯片放入扫描仪中,利用激光激发芯片上单碱基延伸产物的荧光基团,扫描仪获取由荧光基团发出的荧光,并生成高分辨率的图片。由此所得的数据直接导入beadstudio软件进行分析,从而就得到每个样本的snp分型数据。2数据分析(数据分析流程参见附图2所示)2.1snp芯片数据过滤,去掉低质量的数据。2.2过滤后数据质控,保证snp位点检出率大于90%,过滤后的数据为snp数据,即基因型数据。2.3对公共数据库中与皮肤相关的基因进行数据整合,公共数据库包括但不限于snpedia、dbsnp、clinvar、1000g、hgmd、omim、dbgap;所述皮肤相关基因位点包含选自c10orf71、fads1、fads2、fth1、il23r、jmjd1c、mc4r、pdxdc1、hla-c、il10、il13、il-18r、loc643723、sell、tra、b4galt1、bach2、exoc2、fut8、grm5、herc2、ikzf1基因的至少一种。2.4根据以下影响因素对皮肤相关基因位点进行权重分配:(a)所述位点是否有全基因组关联分析分类数据库重复实验:权重+3:全基因组关联分析分类数据库,snpedia数据库,或者文献中有重复实验,权重+0:无重复。(b)所述位点是否与皮肤表观症状具有直接性状关联:权重+4分:有直接性状关联,直接性状关联指的是跟表观症状一致(如皱纹,痘痘,色斑,雀斑等),权重+0分:间接从机制方面关联的性状(如胶原蛋白生成,油脂分泌等)或者无关联。(c)所述位点是否有湿实验位点验证:权重+5分:ncbi的snp数据库中有sampleid,并且湿实验内容与皮肤机制或者功效原料相关,权重+0分:ncbi的snp数据库中没有sampleid,或者湿实验内容与皮肤机制或者功效原料不相关。(d)所述位点所属个体的种族:权重+5分,位点所属个体为中国人,权重+4分,位点所属个体为东亚人(包括、日本、韩国、朝鲜和蒙古共五个国家),权重+3分,位点所属个体为亚洲人(见附录),权重+2分,位点所属个体为其他种族。(e)所述位点的皮肤相关论文发表的影响因子:+2分,位点的皮肤相关论文发表在cns上,+1分,位点的皮肤相关论文发表在其他杂志上。附录:权重分配因素中的亚洲人包括:东南亚:越南、老挝、柬埔寨、缅甸、泰国、马来西亚、新加坡、印度尼西亚、菲律宾、文莱、东帝汶等国家和地区;南亚:包括斯里兰卡、马尔代夫、巴基斯坦、印度、孟加拉国、尼泊尔、不丹;西亚:包括伊朗、土耳其、塞浦路斯、叙利亚、黎巴嫩、巴勒斯坦、以色列、约旦、伊拉克、科威特、沙特阿拉伯、也门、阿曼、阿拉伯联合酋长国、卡塔尔、巴林、格鲁吉亚、亚美尼亚和阿塞拜疆;中亚:包括土库曼斯坦、乌兹别克斯坦、吉尔吉斯斯坦、塔吉克斯坦、哈萨克斯坦和阿富汗斯坦;北亚:包括土库曼斯坦、乌兹别克斯坦、吉尔吉斯斯坦、塔吉克斯坦、哈萨克斯坦和阿富汗斯坦)2.5将样本基因型数据与皮肤相关基因位点的权重分配数据进行比对,得到样本特有的皮肤相关基因信息;。下表1和下表2分别为对公共数据库数据中与皮肤相关的基因进行整合后,得到的皮肤美白相关基因位点数据库和皮肤痘痘相关基因位点数据库。(其中,maf为位点人群频率,riskallele为高风险基因型,allele2为较低风险基因型,snps为基因位点名称,weight为基因位点的权重,mean为一种位点均一化值,cov为另一种位点均一化值,gene_name为位点所属基因,yn_id为申请人设置的id。)表1皮肤美白相关基因位点数据库2.6找到样本特有的皮肤相关基因信息。经过1500份中国人基因检测,建立了小型中国人皮肤基因数据,数据库部分原型详见下表2所示:表2中国人皮肤美白相关位点信息数据库2.7通过找到的信息建立打分模型,对现有数据进行打分。2.7.1单个突变位点算法模型对于单个突变位点导致的表型,基于该表型在人群或种族中的表型比率以及突变位点在人群或种族中的基因型频率,可直接计算该突变导致的表型。pr(d)=pr(d|g1)pr(g1)+pr(d|g2)pr(g2)+pr(d|g3)pr(g3)其中,pr(d)为单个位点突变导致的表型发生的概率,or为比值比,pr(g)为基因型频率;g1\g2\g3分别为三种基因型。具体来说,or值的全称是oddratio,又称比值比,对于发病率很低的疾病来说,or值即是相对危险度的精确估计值。logistic回归中,or值是衡量某个因素的危险性:or值=1,表示该因素对疾病的发生不起作用;or值>1,表示该因素是危险因素;or值<1,表示该因素是保护因素。2.7.2多个突变位点算法模型其中,or*m代表单个snp的特定基因型的or值,综合所有的变位点计算出orc*值;orc*值为带有某些特定基因型组合表型特征的个体,其表型相较于该个体所在种群平均表型的比值,odds(d)通过pr(d)求出;为多个位点突变导致的表型发生的概率。2.8将最终的基因型、打分、基因型信息存入mysql数据库。下表3为中国人皮肤美白相关样本打分数据库。表3中国人皮肤美白相关样本打分数据库idsample_idscoretypecreate_time138449286202017/9/2715:56238449665802017/9/2715:563hcb8000000107696602017/9/2715:56436732867402017/9/2715:575hcb8000000107666602017/9/2715:57638501506602017/9/2715:57738508706602017/9/2715:578201733116602017/9/2715:579201607698602017/9/2715:57以上表2和表3为根据本专利方法建立的中国人皮肤基因相关数据库,目前已建立了1500人的中国人相关基因标准型别数据库,随着样本量的增大,该数据库将会越来越完善,最终将构建中国首个大型中国人皮肤相关基因标准型别数据库。本领域的普通技术人员可以理解,上述各实施方式是实现本发明的具体实施例,而在实际应用中,可以在形式上和细节上对其作各种改变,而不偏离本发明的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 油菜BnaSPT1基因在促进双子叶植物角果生长中的应用的制造方法与工艺
- 油菜BnaSPT3基因在促进双子叶植物角果生长中的应用的制造方法与工艺
- 一种OsGA3ox1基因在水稻雄性不育株系创制中的应用的制造方法与工艺
- 水稻紫叶基因PL1的分子标记及其鉴定方法和应用与制造工艺
- 一种番茄PSY 1基因的CRISPR‑Cas9体系构建及其应用的制造方法与工艺
- OsARD1基因在提高水稻耐水淹方面的应用的制造方法与工艺
- 一种烟草干旱响应基因NtXERICO及其克隆方法与应用与制造工艺
- 一种小麦耐盐基因及其应用的制造方法与工艺
- 水稻FAH基因在水稻育性控制中的应用的制造方法与工艺
- 水稻大粒基因GS12紧密连锁的分子标记及应用的制造方法与工艺