一种疾病基因组数据库的构建方法和疾病基因组数据库与流程
本发明涉及基因数据库技术领域,具体涉及一种疾病基因组数据库的构建方法和疾病基因组数据库。
背景技术:
基因数据库是集合所有已知核酸的核苷酸序列,单核苷酸多态性、结构、性质以及相关描述,包括它们的科学命名、来源物种分类名称、参考文献等信息的资料库。
公开号为CN1733915A的中国专利文献公开了一种基因序列数据处理方法,特别涉及水稻全基因组假基因数据库构建方法。包括将计算机系统中构建已知水稻全基因组序列的本地数据库;利用BLAST程序对前述数据库进行搜索比对,获取标准BLAST格式的比对结果;使用Bioperl中的SeqIO模块分析比对结果,获取记录假基因和基因特征值数据的信息文件;去除冗余的假基因和基因数据;对假基因的筛选和分类;和以假基因对应的特征值作为数据项标识建立假基因的数据库。利用该专利提供的方法,可以对水稻乃至其他植物的假基因进行全基因组范围的搜索和分析,为研究和探索作物遗传、变异、进化提供分子证据。
公开号为CN107346372A的中国专利文献公开了一种应用于基因突变解读的数据库的构建方法,包括:人工全面检索国际上公认的一级数据库,从该一级数据库中获取相关数据资源,对所述数据资源进行分析分解,提取与可干预基因及其位点的相关信息,搜集相关科学文献,提取最新研究进展信息,整合分析所述数据资源及最新研究进展信息,形成内容知识包,建立基因突变解读数据库。该数据库可使对基因突变的解读过程流程化、规范化,使对解读结果具有准确性和完整性。
现有人类基因数据库系统,往往没有样本个体的基因信息,只有一些人群的统计信息,也没有个体与个体之间比较功能。
技术实现要素:
本发明的目的在于提供一种疾病基因组数据库的构建方法和疾病基因组数据库,采用本发明的构建方法能够建立疾病与基因信息的关系数据库,并方便查询。
为实现上述目的,本发明提供一种疾病基因组数据库的构建方法,所述方法包括:
构建内部数据库和公共数据库,所述内部数据库用于输入和储存病人疾病和基因相关数据,所述公共数据库用于输入和储存公开的疾病和基因相关数据;
构建公共数据库查询模块,所述公共数据库查询模块用于从所述内部数据库查询公共数据库的数据。
可选的,所述方法还包括:构建内部数据库查询模块,所述内部数据库查询模块用于从所述内部数据库查询内部数据库的数据。
可选的,构建内部数据库的步骤包括:
构建第一储存模块,用于储存所述病人疾病和基因相关数据;
构建第一输入模块,用于将病人疾病和基因相关数据输入所述第一储存模块中。
可选的,构建公共数据库的步骤包括:
构建第二储存模块,用于储存公开的疾病和基因相关数据;
构建第二输入模块,用于将公开的疾病和基因相关数据输入所述第二储存模块中。
可选的,输入模块的输入方式为自动输入并自动匹配储存模块的数据格式或为人工输入。
本发明还提供一种疾病基因组数据库,所述疾病基因组数据库包括:
内部数据库,用于输入和储存病人疾病和基因相关数据;
公共数据库,用于输入和储存公开的疾病和基因相关数据;
公共数据库查询模块,用于从所述内部数据库查询公共数据库的数据。
可选的,所述疾病基因组数据库还包括内部数据库查询模块,用于从所述内部数据库查询内部数据库的数据。
可选的,所述内部数据库包括:
第一储存模块,用于储存所述病人疾病和基因相关数据;
第一输入模块,用于将病人疾病和基因相关数据输入所述第一储存模块中。
可选的,所述公共数据库包括:
第二储存模块,用于储存公开的疾病和基因相关数据;
第二输入模块,用于将公开的疾病和基因相关数据输入所述第二储存模块中。
可选的,输入模块包括:
自动输入模块,用于自动输入数据并自动匹配储存模块的数据格式;
人工输入模块,用于人工输入数据。
本发明具有如下优点:
本发明的构建方法构建疾病与基因信息的关系数据库,该数据库可以包括疾病信息、样本信息、基因信息和临床其他信息,可以通过相互查询,快速的搜寻信息,提高疾病诊断效率。同时可以对以往病例数据做维护,形成基于现有数据的新的数据库内容,便于比较新的个体数据与已有数据的查询。
附图说明
图1是本发明方法一种具体实施方式的流程示意图。
图2是本发明基因组数据库一种具体实施方式的结构示意图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
图1是本发明方法一种具体实施方式的流程示意图。如图1所示,所述方法包括如下步骤。
步骤S1:构建内部数据库和公共数据库,所述内部数据库用于输入和储存病人疾病和基因相关数据,所述公共数据库用于输入和储存公开的疾病和基因相关数据;其中,构建内部数据库的步骤可以包括:构建第一储存模块,用于储存所述病人疾病和基因相关数据;构建第一输入模块,用于将病人疾病和基因相关数据输入所述第一储存模块中。构建公共数据库的步骤可以包括:构建第二储存模块,用于储存公开的疾病和基因相关数据;构建第二输入模块,用于将公开的疾病和基因相关数据输入所述第二储存模块中。第一储存模块用于储存病人的疾病和基因数据,为每个病人建立档案,并储存临床信息;所述第二储存模块可以储存来自文献、公共数据库或者其它来源的公开数据。输入模块的输入方式可以为自动输入并自动匹配储存模块的数据格式,例如直接从基因检测结果输出直接作为输入;或为人工输入,例如输入病人的疾病和基因数据可以为手动输入,例如通过鼠标、键盘、语音等方式输入,而输入公开的疾病和基因相关数据可以采用从相关网站自动接收的方式,例如通过API数据接口直接与相关网站进行对接,或者通过直接下载后输入。
步骤S2:构建公共数据库查询模块,所述公共数据库查询模块用于从所述内部数据库查询公共数据库的数据。该步骤可以通过相互查询,快速的搜寻信息,提高疾病诊断效率。
进一步地,当内部数据库中的数据积累到一定程度以后,可以作为一个数据来源进行查询,因此,所述方法还可以包括步骤S3:构建内部数据库查询模块,所述内部数据库查询模块用于从所述内部数据库查询内部数据库的数据。该步骤可以对以往病例数据做维护,形成基于现有数据的新的数据库内容,便于比较新的个体数据与已有数据的查询。
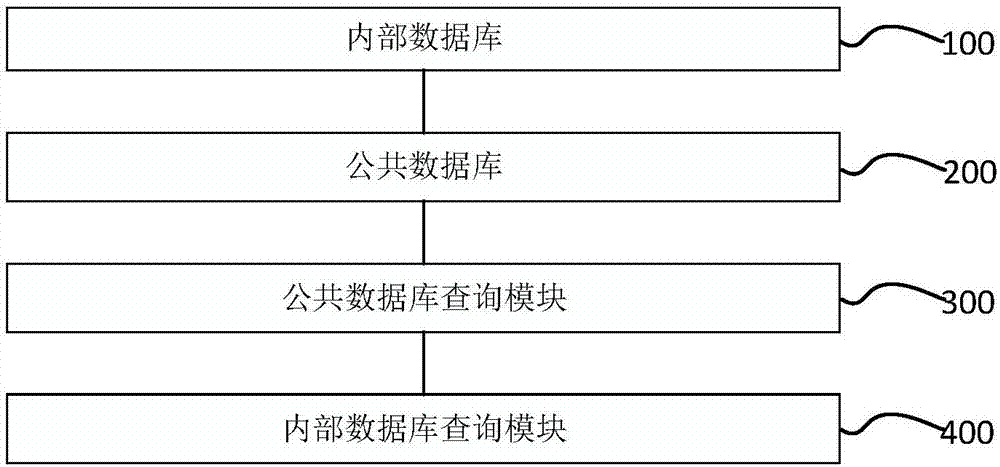
图2是本发明基因组数据库一种具体实施方式的结构示意图。如图2所示,所述疾病基因组数据库包括如下部分。
内部数据库100,用于输入和储存病人疾病和基因相关数据;
公共数据库200,用于输入和储存公开的疾病和基因相关数据;
公共数据库查询模块300,用于从所述内部数据库查询公共数据库的数据。
根据本发明,所述疾病基因组数据库还优选包括内部数据库查询模块400,用于从所述内部数据库查询内部数据库的数据,以对以往病例数据做维护,形成基于现有数据的新的数据库内容,便于比较新的个体数据与已有数据的查询。
由于本发明数据库相关内容和优点已经在构建方法部分阐述,在此不再赘述。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!
- 油菜BnaSPT1基因在促进双子叶植物角果生长中的应用的制造方法与工艺
- 油菜BnaSPT3基因在促进双子叶植物角果生长中的应用的制造方法与工艺
- 一种OsGA3ox1基因在水稻雄性不育株系创制中的应用的制造方法与工艺
- 水稻紫叶基因PL1的分子标记及其鉴定方法和应用与制造工艺
- 一种番茄PSY 1基因的CRISPR‑Cas9体系构建及其应用的制造方法与工艺
- OsARD1基因在提高水稻耐水淹方面的应用的制造方法与工艺
- 一种烟草干旱响应基因NtXERICO及其克隆方法与应用与制造工艺
- 一种小麦耐盐基因及其应用的制造方法与工艺
- 水稻FAH基因在水稻育性控制中的应用的制造方法与工艺
- 水稻大粒基因GS12紧密连锁的分子标记及应用的制造方法与工艺