对人员的行为进行检测的装置和系统的制作方法
本发明涉及视觉检测领域,更具体地,涉及对人员的行为进行检测的装置和系统。
背景技术:
当期国内外反恐和治安形势相对复杂,因此在主要城市的人员流动密集区域如地铁、机场、公交车、公交站等地点一般都配备了安保人员。
而执行任务的安保人员一般由人力外包公司或者安保公司提供给使用方,出于效率最大化考虑,外包公司或者安保公司可能会通过将同一组人员完成某项工作后再赶赴其他地点执行任务等方式,最大限度的使用安保人员,提高公司的收益。但随之而来的问题是因为安保人员工作时间和强度增加,其专注程度下降,疲劳工作的情况增加,人为因素导致安保漏洞的可能性大大增加。
为避免出现上述问题,安保人员使用方需要一套系统来完成相关工作:通过人脸识别完成考勤,并确保值班人员与排班表一致;通过深度学习对值班人员进行诸如疲劳状态、专注度等的行为检测;和,对于发现的问题及时反馈至后台和责任人,以便实时的进行干预。
行为检测一般分为疲劳检测和违规动作检测。(执勤)疲劳是指安保人员由于睡眠不足或长时间持续执勤造成的反应能力下降,这种下降表现在安保人员困倦、打磕睡、操作失误或完全丧失安保能力等。早期的疲劳检测主要是从医用角度出发,借助医疗器件进行生理特征测量的,研究疲劳磕睡产生的原因和其他诱发因素,寻找能够降低这种危险的方法。另外一种方法是研制智能报警系统,防止安保人员在磕睡状态下执勤。例如,利用一些信号处理方法,获取安保人员眨眼频率和持续时间等疲劳数据,用以判断安保人员是否打磕睡或睡着。违规动作指在安保人员在执勤过程中,做出的一些影响执勤的动作或行为,比如打电话、玩手机、抽烟、交头接耳等。违规动作检测一般通过计算机视觉的方式来解决,针对不同的动作分别采用不同的算法。由于各种算法差异较大,如果全部部署到移动端太过庞大冗余,一般很少会在移动端应用。
技术实现要素:
本发明针对现有传感器技术方案成本高、传统图像识别技术方案冗余复杂的特点,提出一种基于神经网络的端到端的计算机视觉检测方案,一体化解决安保人员上下班考勤,岗位匹配,疲劳执勤、抽烟、打电话动作检测等诸多需求。本发明采用卷积神经网络提取特征,检测各个瞬时时间点目标人体的状态(眼睛开闭、嘴巴开闭、打电话、抽烟等),在一定时间内综合判断目标人体的疲劳状态和执勤违规状态,并在安保人员疲劳执勤或者做出违规动作的时候发出报警信号。
本发明提供了一种对人员的行为进行检测的装置,被构造为对包括人员的视频和/或图像进行处理,以在各帧图像中同时检测人员的眼部状态、嘴部状态、香烟状态和电话状态,其中,所述检测装置使用基于卷积神经网络的算法进行上述检测,该卷积神经网络包括至少一个卷积层、至少一个residual层、一个全局池化层和一个全连接层,其中,各卷积层都依次设置有一个bn层和一个leakyrelu层。
本发明提供了基于神经网络的安保人员身份和行为人员行为检测端到端的检测系统,解决了传统检测方式成本高或者传统图像处理计算冗余复杂等问题,通过一个系统统一输出所有的判断结果,一步到位。相比传统的图像检测手段,本发明采用的深度学习的方式无需做图像增强方面的预处理,可以适应光照不均匀、目标特征多样化、背景复杂等各种极端环境,且支持针对场景的增量训练,在实际使用过程中,通过定期适当的人工干预校准训练样本,提升在专用场景下的准确率。本发明同时包括了人脸检测和行为检测,能够高效的进行相关人员行为的分析和预警,解决了传统方案中两者需要不同的系统或产品来完成,接口复杂,响应速度慢等问题。
通过以下参照附图对示例性实施例的描述,本发明的其他特征将变得清楚。
附图说明
包含在说明书中并构成说明书的一部分的附图例示了本发明的示例性实施例、特征和方面,并且与文字说明一起用来解释本发明的原理。
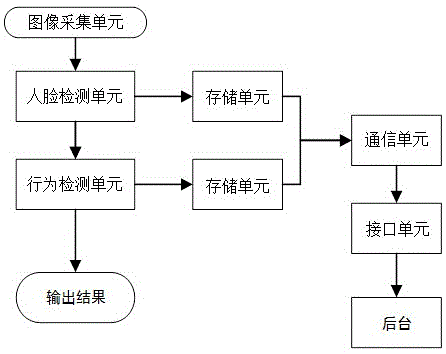
图1为根据本发明一个方面的检测系统的模块示意图。
图2为根据本发明一个方面的人脸检测过程的示意图。
图3为根据本发明一个方面的检测过程的示意图。
图4是根据本发明一个方面的卷积神经网络的结构示意图。
图5是根据本发明一个方面的疲劳或违规状态的检测流程图。
具体实施方式
下面将参照附图详细描述本发明的各种示例性实施例、特征和方面。应当指出,除非另外具体说明,在这些实施例中描述的部件、数字表示和数值的相对配置不限制本发明的范围。应当指出,下面的实施例并不限制权利要求中记载的本发明的范围,并且并非这些实施例中描述的特征的全部组合均是本发明所必须的。
为解决上述问题,如图1所示,本发明提供对人员行为进行检测的系统,包括:图像采集单元、行为检测单元和数据存储单元(或称“存储模块”)。优选地,检测系统还包括人脸检测单元和报警单元。除此之外,本发明的系统还包括用于与外部通信的通信单元和接口单元。
作为示例,图像采集单元优选利用高分辨率图像采集装置,例如照相机、摄像头等,采集固定范围(火灾高发区域,例如森林、居民区、地下室、高架线、城市中诸如商场等人流量大的公共区域等)的视频和/或图像,并将采集到的视频和/或图像通过例如rtsp协议分别发送到检测单元和数据存储单元。其中,摄像头包括但不限于模拟摄像头、ip摄像头等。图像采集单元被构造为连续不断地记录相关人员的行为,从而形成包括多帧图像的视频。图像会被传送到下文将要描述的行为检测单元或人脸检测单元中进行特征提取和运算。或者,满足预定条件的帧图像(例如,第5帧,第10帧,第15帧,第20帧,以此类推等)会被传送到下文将要描述的行为检测单元或人脸检测单元中进行特征提取和运算。
作为示例,行为检测单元对图像采集单元采集到的视频和/或图像进行处理,根据预存模型和网络进行特征提取,判断监控区域内值班人员是否存在疲劳、打电话、玩手机、抽烟等违规状态。如未发生异常,则继续进行检测;如发现异常,保存异常信息和图像/视频资料,存储到数据存储单元,并通过有线或无线方式传回后台预警;其所述的行为检测单元包括算法和计算硬件两部分,硬件包括但不限于通用gpu,嵌入式gpu,cpu,人工智能专用芯片等。以下对算法部分进行详细说明。
<图像的处理>
如图3所示,本发明的检测系统(行为检测单元)能够通过卷积神经网络提取视频或图像中的特征并进行分类,分别检测出图像中人体各个部位的位置和状态,以及香烟和电话的存在与否及他们各自的位置。然后,直接由卷积神经网络得出眼部和嘴部的开闭状态、吸烟状态(或称抽烟状态)、打电话状态(或称通话状态)等。各个状态的连续时长或次数可被计算出。若检测到连续性的闭眼或者哈欠则可以确定人员处于疲劳状态,系统可以输出对应的警告信号;若检测到存在吸烟和通话的情况,则可以确定人员处于违规状态,此时也可输出相应的警告信息或直接作为报警输出。
<<卷积神经网络结构概述>>
首先,作为概述,本发明的卷积神经网络由一系列1*1和3*3的卷积层组成,每个卷积层后都会跟一个bn层和一个leakyrelu层。同时,为了解决由于卷积网络深度增加而导致的性能下降的问题,还引入了residual层,最后在卷积神经网络的末尾加入全局池化层以及全连接层,再使用softmax进行分类。其中,卷积的步长(strides)默认为(1,1),“padding”(在卷积时是否丢掉边界像素点)默认为same(即在卷积时padding默认的边长为1,采用0填充(在卷积运算前,在图像的周围补一圈0,然后再做卷积)。优选地,在本发明的网络中,padding优选始终采用same的方式。
<<卷积神经网络结构的第一实施例>>
以下,参照图4来详细说明本发明的卷积神经网络的具体结构。
首先,由图像采集单元采集的视频或一系列图像被输入到第1卷积层(“convolutional”),以对图像进行初步的特征提取。在此,以尺寸为256*256的图像作为示例进行说明。本领域技术人员可以理解,还可以输入其他尺寸的图像。当然,后续的卷积结构也会因输入图像的尺寸不同而发生相应的变化,例如增加或减少卷积层,增加或减少卷积核大小及数量,增加或较少residual层的数量或改变residual在网络中的位置等。作为示例,第1卷积层的卷积核大小被构造为3*3,卷积核数量被设置为32。经该层处理后,输出尺寸为256*256的图像。
接着,第1卷积层输出的图像进入第2卷积层,以对图像进行下采样,缩小图像尺寸。第2卷积层的卷积核大小被构造为3*3/2,卷积核数量被设置为64。第2卷积层将图像的尺寸缩小为128*128并输出。
接着,第2卷积层输出的图像进入第3组合层,以提取特征并增加网络深度。第3组合层包括第31卷积层、第32卷积层和residual层。其中,第31卷积层的卷积核大小被构造为1*1,卷积核数量被设置为32;第32卷积层的卷积核大小被构造为3*3,卷积核数量被设置为64。经该层处理后,仍输出尺寸为128*128的图像。
接着,第3组合层输出的图像进入第4卷积层,以对图像进行下采样,缩小图像尺寸。第4卷积层的卷积核大小被构造为3*3/2,卷积核数量被设置为128。经该层处理后,输出尺寸为64*64的图像。
接着,第4卷积层输出的图像依次进入2个(2x)第5组合层,以提取特征并增加网络深度。每个第5组合层均包括第51卷积层、第52卷积层和residual层。其中,第51卷积层的卷积核大小被构造为1*1,卷积核数量被设置为64;第52卷积层的卷积核大小被构造为3*3,卷积核数量被设置为128。经2个第5组合层的处理后,仍输出尺寸为64*64的图像。
接下来,第5组合层输出的图像进入第6卷积层,以对图像进行下采样,缩小图像尺寸。第6卷积层的卷积核大小被构造为3*3/2,卷积核数量被设置为256。经该层处理后,输出尺寸为32*32的图像。
继续,第6卷积层输出的图像依次进入4个第7组合层,以提取特征并增加网络深度。每个第7组合层包括第71卷积层、第72卷积层和residual层。其中,第71卷积层的卷积核大小被构造为1*1,卷积核数量被设置为128;第72卷积层的卷积核大小被构造为3*3,卷积核数量被设置为256。经该层处理后,仍输出尺寸为32*32的图像。
然后,第7组合层输出的数据进入第8卷积层,以对图像进行下采样,缩小图像尺寸。第8卷积层的卷积核大小被构造为3*3/2,卷积核数量被设置为512。经该层处理后,输出尺寸为16*6的图像。
再然后,第8卷积层输出的图像依次进入4个第9组合层,以提取特征并增加网络深度。每个第9组合层包括第91卷积层、第92卷积层和residual层。其中,第91卷积层的卷积核大小被构造为1*1,卷积核数量被设置为256;第92卷积层的卷积核大小被构造为3*3,卷积核数量被设置为512。经该层处理后,仍输出尺寸为16*16的图像。
继续,第9组合层输出的图像进入第10卷积层,以对图像进行下采样,缩小图像尺寸。第10卷积层的卷积核大小被构造为3*3/2,卷积核数量被设置为1024。经该层处理后,输出尺寸为8*8的图像。
然后,第10卷积层输出的图像依次进入2个第11组合层,以提取特征并增加网络深度。每个第11组合层包括第111卷积层、第112卷积层和residual层。其中,第111卷积层的卷积核大小被构造为1*1,卷积核数量被设置为512;第112卷积层的卷积核大小被构造为3*3,卷积核数量被设置为1024。经该层处理后,输出尺寸为8*8的图像。
接着,第11组合层输出的图像依次进入全局池化层和全连接层,以进行分类。在全局池化层对得到的特征图8*8进行全局池化,得到一个特征点。在全连接层,使用输入维度为256、输出维度为2的两层神经网络对所述特征点进行处理,其中第一层神经网络通过tanh激活函数,第二层神经网络连接softmax函数。
<<卷积神经网络结构的第二实施例>>
如果为了减少网络的参数和计算量,一方面可适当的减小网络的参数,另一方面可以裁掉一部分网络层,而不显著地影响网络精度。例如,在第一具体实施例的基础上可以稍加变形得到第二具体实施例。这里将不描述与第一实施例相同的卷积层和组合层的参数设置和排列方式。第二实施例与第一具体实施例不同之处在于2点:第一,第二实施例不具有第7组合层,即,第6卷积层输出的图像直接进入第8卷积层。第二,第二实施例在第11组合层之后,增加了一个第12卷积层和一个第13组合层。
作为示例,第12卷积层的卷积核大小被构造为3*3/2,卷积核数量被设置为1024。经该层处理后,输出尺寸为8*8的图像。
作为示例,第13组合层包括第131卷积层、第132卷积层和residual层。其中,第131卷积层的卷积核大小被构造为1*1,卷积核数量被设置为512;第132卷积层的卷积核大小被构造为3*3,卷积核数量被设置为1024。经该层处理后,仍输出尺寸为8*8的图像。之后,该图像进入全局池化层。
<<卷积神经网络的训练方法及参数>>
卷积层中的卷积核与全连接层使用服从均值为0、标准差为0.1的高斯分布随机数进行初始化,偏置项使用服从区间为[0,1]的均匀分布随机数进行初始化。
批处理层中,动量设置为0.95,常量设置为0.01。
使用adadelta梯度下降算法训练权重,批处理大小设置为64。
按照一定比例设置数据的训练集、验证集和测试集,在20代的训练后,每一代都进行验证集的测试,结果最好的那一代训练模型会被保存并用于测试集的测试,其结果即为整个学习的结果。
设置全部数据迭训练周期为100代,在训练时,训练集中的正负样本比为10:1,每一代训练中,依次打乱20%的负样本与全部正样本进行训练,直至全部负样本训练完完成一个训练周期。
上述实验方法及参数是经过大量实验在科学研究的基础上获得的。这些方法和参数对于本发明所述的人员环境而言十分适用,尤其是在检测眼部状态、嘴部状态、吸烟状态和通话状态时尤为显著。
<疲劳或违规状态的判断>
视频或图像经过卷积神经网络特征提取,并预先将图像划分为11*11个小格子,以每个格子为中心,分别随机产生5个随机候选框,在最后一层的全连接层对每一个候选框进行分类,以此得到每个候选框的分类结果以及位置;在网络训练中,拟定以下几种状态:图像中人员眼部或者嘴部的位置以及开闭状态、人员是否举起手机贴合在脸部的状态、手机的位置、香烟的位置;状态判断或者报警条件:
-疲劳状态:眼部处于闭合的状态即为眼部疲劳表征,若眼部闭合的连续时长超过3s(即,闭眼预定时长,例如3s,5s,10s等),则认定处于闭眼疲劳状态;嘴部处于大张的状态即为嘴部疲劳表征,若嘴部大张连续时长超过1s(即,哈欠预定时长,例如2s)并在哈欠设定时间期间(例如,至少60s,100,120s等)内检测到3次及以上,则认定处于哈欠疲劳状态。闭眼疲劳状态和哈欠疲劳状态统称疲劳状态。
-吸烟状态:只要检测到香烟的存在且香烟靠近嘴部即被定义为吸烟状态。若此种状态在吸烟设定时间期间(例如5s,10s,20s等)内达到3次或4次或5次(吸烟预定次数),则可以判定人员正在违规吸烟。
-通话状态:人员举起手机并将其贴合在脸部被定义为通话状态,若该状态连续例如5s以上(即,通话预定时长,例如6s,8s,15s等)则可以判定人员正在违规通话。
作为闭眼疲劳状态的检测示例,在视频流检测过程中,当第一次检测到眼部处于闭合状态时,记录当前的时间(例如10:10:10)和/或记录当前帧的编号(即,时间或编号,下同)。在后面连续检测的过程中,若连续检测到该种状态,则连续累计变量,如若后面的检测中连续几帧或紧接着的下一帧检测不到该种状态,说明眼睛睁开,就中断统计,此段期间的变量值(单位:帧)或者开始时间到结束记录之间的时间差值(单位:秒(s))就是闭眼状态的连续时长。本发明设定闭眼最大连续时间(即,闭眼预定时长)为3s。本领域技术人员知晓,4s、5s等其他时间也可被设定为闭眼最大连续时间。
作为示例,若第1-10帧均未检测到眼部处于闭合状态,则闭眼起始时间和闭眼连续时长均设置为0。若在第11帧检测到眼部处于闭合状态,则记录当前的时间,例如为10:10:10,并将该时间设置为闭眼起始时间。若直到第20帧检测到眼部一直处于闭合状态,则持续更新当前时间直到第20帧的时间,例如为10:10:11,则闭眼连续时长为1s,未达到闭眼预定时长,此时不能判定人员处于闭眼疲劳状态。若在第21帧检测到眼部处于睁开状态,则表示人员并未处于连续闭眼的状态,排除疲劳工作的可能。此时闭眼起始时间和闭眼连续时长均被更新为0。可替换地,若第11帧到第20帧期间,以及在第21帧到第60帧期间的连续图像中检测到眼部一直处于闭合状态,则被记录的当前时间不断刷新(从第12帧的时间开始记录,一直刷新到第60帧的时间)到第60帧的时间,例如为10:10:15,则闭眼连续时长被更新为5s。此时,由于闭眼连续时长达到(本实施例为超过)闭眼预定时长(例如3s),则认定人员处于睡眠或瞌睡状态,触发报警单元发出声音或光的报警,并控制将相关图像或视频传送到外部设备(例如中控台)。报警后,闭眼起始时间和闭眼连续时长均被重置为0,进入下一轮检测。
作为哈欠疲劳状态的检测示例,在视频流检测过程中,当第一次检测到嘴部处于大张状态时,记录当前的时间(例如10:10:10)和/或记录当前帧的编号。在后面连续检测的过程中,如若连续检测到该种状态,则连续累计变量,若后面的检测中连续几帧或紧接着的下一帧检测不到该种状态,就中断统计,此段期间的变量值(单位:帧)或者开始时间到结束记录之间的时间差值(单位:秒(s))就是哈欠状态的连续时长。本发明设定哈欠最大连续时间(即,哈欠预定时长)为1s。本领域技术人员知晓,其他时间也可被设定为哈欠最大连续时间。
作为示例,若第1-10帧均未检测到嘴部处于大张状态,则将哈欠起始时间和哈欠连续时长均设置为0。若在第11帧检测到嘴部处于大张状态,则记录当前的时间,例如为10:10:10,并将该时间设置为哈欠起始时间。若在直到第15帧仍然检测到嘴部一直处于大张状态,则记录当前的时间,例如为10:10:10’30,则哈欠连续时长为0.5s。此时,未达到哈欠预定时长(本实施例为1s),因此不能判定人员处于哈欠疲劳状态。若从第11帧开始一直到第40帧检测到嘴部一直处于大张状态,则被记录的当前时间不断刷新(从第12帧的时间开始记录,一直记录到第60帧的时间)到第40帧的时间,例如为10:10:12,则哈欠连续时长被更新为2s。此时,由于哈欠连续时长达到(本实施例为超过)哈欠预定时长(例如1s),则哈欠次数被从0更新为1,此时表示人员打了一次哈欠,同时哈欠起始时间和哈欠连续时长均被更新为0。检测过程继续.此后,若在直到第100帧才检测到嘴部再次处于大张状态,则记录当前时间,例如为10:10:16,则记录当前的时间,并将该时间设置为哈欠起始时间。若从第100帧开始直到第140帧检测到嘴部一直处于大张状态,则被记录的当前时间不断刷新(从第101帧的时间开始记录,一直记录到第140帧的时间)到第140帧的时间,例如为10:10:18,则哈欠连续时长被更新为2s。此时,由于哈欠连续时长达到(本实施例为超过)哈欠预定时长(例如1s),则哈欠次数被从1更新为2,此时表示人员打了2次哈欠,同时哈欠起始时间和哈欠连续时长均被更新为0。以此类推。若在第一次哈欠的哈欠起始时间开始的哈欠设定时间期间(例如,30s,40s,50s)内,检测到哈欠次数为4次(或5次或6次)大于哈欠预定次数3次,则表明人员处于哈欠疲劳状态。此时触发报警单元发出声音或光的报警,并控制将相关图像或视频传送到外部设备(例如中控台)。报警后,哈欠起始时间、哈欠连续时长和哈欠次数均被重置为0,进入下一轮检测。
作为吸烟违规状态的检测示例,在视频流检测过程中,当检测到香烟存在且第一次检测到香烟靠近嘴部时,则吸烟次数被设置为1。在后面连续检测的过程中,如若检测到该种状态,则连续累计变量。本发明设定吸烟最大次数(即,吸烟预定次数)为3次。本领域技术人员知晓,4次、5次等其他次数也可被设定为吸烟预定次数。
作为示例,若第1-10帧均未检测到香烟,则将吸烟次数设置为0。若在第11帧检测到香烟且其靠近嘴部直到第20帧香烟远离嘴部,则吸烟次数递增1。若在第50帧再次检测到香烟靠近嘴部直到第60帧香烟远离嘴部,则吸烟次数再次递增1变为2。以此类推。若在吸烟设定时间期间(例如,10s,20s,60s,90s,120s等)内吸烟次数增加至3次或4次或5次等,则表示人员处于吸烟违规状态,此时触发报警单元发出声音或光的报警,并控制将相关图像或视频传送到外部设备(例如中控台)。报警后,吸烟次数被重置为0,进入下一轮检测。
作为通话违规状态的检测示例,在视频流检测过程中,当第一次检测到电话处于嘴部附近时,记录当前的时间(例如10:10:10)和/或记录当前帧的编号。在后面连续检测的过程中,若连续检测到该种状态,则连续累计变量,若后面的检测中连续几帧或紧接着的下一帧检测不到该种状态,就中断统计,此段期间的变量值(单位:帧)或者开始时间记录到结束记录之间的时间差值(单位:秒(s))就是打电话状态的连续时长。本发明设定打电话最大连续时间(即,通话预定时长)为5s。本领域技术人员知晓,10s等其他时间也可被设定为通话最大连续时间。
作为示例,若第1-10帧均未检测到电话位于嘴部附近,则将通话起始时间和通话连续时长均设置为0。若在第11帧检测到电话处于嘴部附近,则记录当前的时间,例如为10:10:10,并将该时间设置为通话起始时间。若直到第20帧检测到电话一直处于嘴部附近,则持续更新当前时间直到第20帧的时间,例如为10:10:11,则通话连续时长为1s,未达到通话预定时长,此时不能判定人员处于通话违规状态。若在第21帧检测到电话离开嘴部,则判定人员并未处于通话状态,排除违规的可能。此时通话起始时间和通话连续时长均被更新为0。可替换地,若第11帧到第20帧期间,以及在第21帧到第60帧期间的连续图像中检测到电话一直处于嘴部附近,则被记录的当前时间不断刷新(从第12帧的时间开始记录,一直记录到第60帧的时间)到第50帧的时间,例如为10:10:15,则通话连续时长被更新为5s。此时,由于通话连续时长达到通话预定时长(例如5s),则认定人员处于通话违规状态,触发报警单元发出声音或光的报警,并控制将相关图像或视频传送到外部设备(例如中控台)。报警后,通话起始时间和通话连续时长均被重置为0,进入下一轮检测。
本发明的上述实施例仅为示例性的。视频帧的选取可以是定时的,也可以是非定时的,在此不做限制。例如,可以每隔10毫秒或0.5秒截取1帧视频,也可以在前100帧是以每10毫秒为单位截取视频,后100帧以每5毫秒截取视频。例如,可能在10:10:10选取第1帧图像,在10:10:11选取第10帧图像,在10:10:15选取第100帧图像。另外,上述示例以记录时间来判断时长、次数等。本领域技术人员也可以通过记录当前帧的编号的方式来判断时长、次数等,这不作为对本发明的限制。
作为示例,数据存储单元主要用于存储图像采集单元获得的视频和图像资料,并在需要的时候支持视频回放、及数据备份等功能。数据存储单元可接驳支持onvif、psia、rtsp协议的第三方摄像机和主流品牌摄像机;支持ipv4、ipv6、http、upnp、ntp、sadp、snmp、pppoe、dns、ftp、onvif、psia等网络协议;支持最大64路网络视频接入;支持监控摄像头多种主流分辨率接入;支持图像本地回放与查询;支持将检测单元的检测结果发送给报警单元;支持将检测单元的检测结果发送给其他需要对接的平台。
作为示例,如图2所示,人脸检测单元在接收到图像采集单元传输的图像和视频数据后,根据预存模型和网络进行特征提取,并与数据库中记录的人员特征进行比对,确认被考勤人员的身份;人员身份确认后再进一步与值班表进行比对,确认当前岗位的值班人员与值班表相符。如考勤人员身份无法验证或与指标表不符,保存异常信息和图像/视频资料,并存储到数据存储单元,并通过传输单元传回后台预警;其所述的考勤单元包括算法和计算硬件两部分,硬件包括但不限于通用gpu,嵌入式gpu,cpu,人工智能专用芯片等。
人脸检测单元执行如下步骤:采用目前性能优越的人脸检测算法mtcnn;本发明的mtcnn由第一级网络和第二级网络构成。其中,第一级网络可以看做一个随机森林,每一个树的模型都是一样的。所有输入的图像尺寸均被缩小,并利用p_net检测图像中类似人脸的所有区域。经由此,大概可以去掉70%与人脸无关的图像。在减少70%的图像的情况下且在减少了第一级网络会检测到疑似人脸区域数量的同时,不会将人脸区域遗漏掉,由此可大大降低算法复杂度。“70%”这个数值要根据具体场景进行设置,包括会出现的最大人数数量、人脸占用的像素点数等。其中,第二级网络用r_net对第一级网络检测到的人脸进行重新确认,以获得仅包括人脸的图像。这同样大大降低了误警率。与现有mtcnn算法不同的是,本发明的改进的mtcnn不需要第三级网络,即不需要对五官进行检测。
作为示例,第一级网络对图像进行检测时,需要对图像进行不同程度的缩放,对每一个缩放图像都用p_net进行检测。现有的mtcnn需要采用10个缩放值左右,这是考虑到待测图像中含有的人体较多,而本发明中已将人体提取出来,所以只需采用4个、3个甚至更少数量的缩放值。这样经过第一级网络提取出的疑似人脸区域数量只有现有的mtcnn的五分之一左右,加上本发明中的mtcnn不使用第三级网络,本发明的改进后的mtcnn算法在保持性能的同时,运行速度提高了接近8倍,适用于大部分的嵌入式设备。例如,若利用全志a64芯片,则单帧图像的运行时间由200ms左右提升到20到30ms。
进一步地,第一级网络采用小框架的4层卷积神经网络,输入图像尺寸为12×12×3。第二级网络采用小框架的4层卷积神经网络,输入图像尺寸为24×24×3。作为示例,卷积神经网络的训练方法及参数,具体如下:
卷积层中的卷积核与全连接层使用服从均值为0、标准差为0.1的高斯分布随机数进行初始化。
使用随机梯度下降算法训练权重,批处理大小设置为128,训练时只对70%损失较小的数据进行反向传播。
训练样本使用了15000张正面人脸图,50000张不含人脸图像和50000张部分人脸图像,训练集中正样本,负样本,部分样本三种样本的比例为3:1:1,正面人脸图像来自多个开源的人脸图像集和具有人脸定位坐标的图像集,部分人脸图像大部分通过正面人脸图像的截取获得,将所有数据分别裁剪为12×12×3和24×24×3两种尺寸。
按照一定比例设置数据的训练集、验证集和测试集,在10代的训练后,每一代都进行验证集的测试。本领域技术人员可根据已知的指示设置迭代次数以及训练集、验证集和测试集的比例。
设置全部数据迭代训练周期为1000代。更多(1200代,2000代)或更少(500代,800代)的迭代训练周期也是可以的。
本领域技术人员可以理解,上述训练方法及参数中出现的数据不是限制性的。本领域技术人员可以根据应用场景的不同而采用不同的图像尺寸、训练样本和迭代周期,以保证运算速度和精度同时得到优化。
简化后的人脸检测算法在性能保持的同时,运行速度提高了接近8倍,适用于大部分的嵌入式设备。
作为示例,报警单元包括现场模式和后台模式。在接收到检测单元的报警信息后,通过声、光、电等不同传感器在图像采集单元布置的现场发出预警,提醒周围有警情发生。或者,报警单元还可以发送实时信号到系统对接的应急管理部门预警平台,信息内容包括:摄像头编号,摄像头位置,警情发生时间,警情类型,现场图像/视频等。帮助应急管理部门快速判断和决策,缩短响应时间。
如图5所示为本发明的对人员行为进行检测的方法的示意流程图。在步骤s501中,获得人员的眼部状态、嘴部状态、香烟状态和通话状态。接着,在步骤s502中,同时检测眼部状态是否符合闭眼状态、嘴部状态是否符合哈欠状态、香烟状态是否符合吸烟状态和电话状态是否符合通话状态,并进一步判断是否存在人员处于闭眼疲劳状态、哈欠疲劳状态,吸烟违规状态和通话违规状态。最后,在步骤s503中,若上述任一状态符合疲劳或违规状态,则发出报警。优选地,获得的表明人员处于疲劳或违规状态的视频或图片可以被传送到外部设备,例如中控室或安保室。
本发明提供了基于神经网络的人员行为检测端到端的检测方式,解决了传统检测方式成本高或者传统图像处理计算冗余复杂等问题,通过一种网络统一输出所有的判断结果,一步到位。相比传统的图像检测手段,本发明采用的深度学习的方式无需做图像增强方面的预处理,可以适应光照不均匀、目标特征多样化、背景复杂等各种极端环境,且支持针对场景的增量训练,在实际使用过程中,通过定期适当的人工干预校准训练样本,提升在专用场景下的准确率。
每个卷积层后都会跟一个bn层和一个leakyrelu,且引入了residual层解决网络因为深度导致的性能下降问题;训练方法和参数也是经过大量实验验证得到的较好的技巧和参数。应用层面:卷积算法在人员行为检测上的应用,端到端直接解决检测问题,简化传统的复杂、冗余的检测手段。
以上对本发明所提供的检测装置和系统进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!