一种烯键还原酶及其制备方法和应用与流程
本发明属于生物工程技术领域,具体涉及一种烯键还原酶,及其制备方法和应用。
背景技术:
在生物催化领域,高效催化的酶对催化反应的进行是至关重要的。烯键还原酶(enoate reductases,ERs)作为一类受到广泛关注的新型酶,能够高选择性地还原碳碳双键,近年来对其高效催化酶源的研究成为热点。带有吸电子基团的饱和化合物是医药、激素、香料、以及农药生产等方面的重要物质,常常需要由其α,β-不饱和化合物选择性还原获得,但吸电子基团易使烯烃钝化,对其进行选择性还原是一个富有挑战性的课题。化学合成中最常用过渡金属及其络合物对该类化合物还原,此法存在成本高,条件苛刻,产率低、会污染环境等缺点。研究表明,生物界中的烯键还原酶能够还原碳碳双键,且选择性高,产率好,条件温和,是一条环境友好的合成途径。目前对于能够进行高效催化的烯键还原酶种类研究还很少,几乎没有可以用于工业生产应用的。
在工业上,红球菌属是一个非常具有商业价值的细菌类群,许多菌株参与了氨基酸如L2亮氨酸和L2苯丙氨酸的生产以及固醇类的转化。目前红球菌的研究主要集中在腈水解酶应用上,应用范围窄。
技术实现要素:
本发明的目的之一是提供一种可用于工业生产应用的烯键还原酶,包含所述烯键还原酶基因的烯键还原酶重组表达载体或烯键还原酶重组表达转化体;本发明另一目的是提供一种制备重组烯键还原酶的方法;本发明还提供一种将烯键还原酶或重组烯键还原酶应用于烯键的还原,例如α,β-不饱和化合物中C=C双键的还原,特别是α,β-不饱和化合物中C=C双键的不对称还原。
为了实现本发明的目的,
一方面,本发明提供一种烯键还原酶基因,其碱基序列如SEQ ID No.1所示。
所述烯键还原酶基因制备步骤如下:通过引物,以紫红色红球菌Rhodococcus rhodochrous ATCC 17895的基因组为模板,经聚合酶链式反应(PCR)进行基因扩增得碱基序列如SEQ ID No.1所示的烯键还原酶基因。
一方面,本发明提供一种本发明所述的烯键还原酶基因编码的烯键还原酶,其氨基酸序列如SEQ ID No.2所示。
进一步地,本发明所述的烯键还原酶,所述的烯键还原酶的GenBank登录号为:KT321320,下文也简称烯键还原酶为RhER 2718,其来源于紫红色红球菌(Rhodococcus rhodochrous)ATCC 17895。
另一方面,本发明提供一种包含碱基序列如SEQ ID No.1所示的烯键还原酶基因的烯键还原酶重组表达载体。
所述烯键还原酶重组表达载体的制备方法如下:将碱基序列如SEQ ID No.1所示的烯键还原酶基因通过酶切后连接于载体上,即可。所述的载体可为本领域常规的各种载体,如市售的质粒、粘粒、噬菌体或病毒载体等,优选质粒pET28a(+)。
较佳的,可通过下述方法制得本发明的烯键还原酶重组表达载体:将碱基序列如SEQ ID No.1所示的烯键还原酶基因和质粒pET28a(+)用限制性内切酶NdeI和HindIII双酶切,然后用T4DNA连接酶连接,即可得本发明的烯键还原酶重组表达载体。
进一步地,本发明所述的烯键还原酶重组表达载体,其骨架为pET28a(+)。
另一方面,本发明提供一种烯键还原酶重组表达转化体,其包含本发明所述烯键还原酶的基因、或本发明所述的烯键还原酶重组表达载体。
进一步地,本发明所述的烯键还原酶重组表达载体,制备步骤如下:首先,通过引物,以紫红色红球菌Rhodococcus rhodochrous ATCC 17895的全基因组为模板,经聚合酶链式反应进行基因扩增得碱基序列如SEQ ID No.1所示的烯键还原酶基因,之后连接于载体(所述的载体可为本领域常规的各种载体,如市售的质粒、粘粒、噬菌体或病毒载体等,优选质粒pET28a(+))上得包含SEQ ID No.1所示的烯键还原酶基因的烯键还原酶重组表达载体;将本发明所述的烯键还原酶基因重组表达载体转化至宿主微生物中制得。
进一步地,本发明所述的烯键还原酶重组表达转化体,其中,所述的引物为:
上游引物为GGAATTCCATATGGTTGCAGTAAAGCCTT(如SEQ ID No.3所示),
下游引物为CCCAAGCTTTTACGCCTTGGTATCAATAG(如SEQ ID No.4所示)。
另一方面,本发明提供一种烯键还原酶重组表达转化体,其通过将本发明所述的烯键还原酶基因重组表达载体转化至宿主微生物中制得。
进一步地,本发明所述的烯键还原酶重组表达转化体,其中,所述的宿主微生物可为本领域常规的各种宿主微生物,只要能满足重组表达载体可稳定的自行复制,且所携带的本发明的烯键还原酶基因可被有效表达即可;优选地,所述的宿主微生物为大肠杆菌。
进一步地,本发明所述的烯键还原酶重组表达转化体,其中,进一步优选地,所述的宿主微生物为大肠埃希氏菌(E.coli)BL21(DE3)。
一方面,本发明提供一种包含本发明所述烯键还原酶基因的重组菌或转基因细胞系。
进一步地,所述烯键还原酶基因通过导入宿主菌或细胞制得重组菌或转基因细胞系。
一方面,本发明提供一种重组烯键还原酶的制备方法,其通过培养本发明所述的烯键还原酶重组表达转化体,获得重组烯键还原酶。
所述重组烯键还原酶的制备方法中,所述培养的步骤的方法和条件没有特殊限制,可以根据宿主类型和所选培养方法等因素的不同按本领域普通知识进行适当的选择,只要使重组表达转化体能够生长并产生本发明的重组烯键还原酶即可。
进一步地,本发明所述的制备方法,将包含碱基序列如序列表中SEQ ID No.1所示的烯键还原酶的重组大肠杆菌(重组表达转化体)接种于含卡那霉素的LB培养基中培养;
当培养液的光密度OD600达到0.5-0.6,在终浓度为0.1-1.0mmol/L的异丙基-β-D-硫代吡喃半乳糖苷的诱导下,即可高效表达重组烯键还原酶。
进一步地,本发明所述的制备方法,优选培养液的光密度OD600达到0.55时,在终浓度为0.5mmol/L的异丙基-β-D-硫代吡喃半乳糖苷的诱导下,即可高效表达重组烯键还原酶。
进一步地,本发明所述的制备方法,所述诱导的时间优选20-30℃,更优选为22℃。所述诱导的时间优选15-25h,更优选20h。
进一步地,本发明所述的制备方法,所述的LB培养基包括酵母膏5g/L,蛋白胨10g/L,NaCl 10g/L,pH 7.0。
进一步地,按照本发明所述的制备方法,高效表达重组烯键还原酶后,可按本领域常规方法收集待用,一般可为下述方法中任一种:(1)收集培养液中的细胞、洗涤、冷冻干燥、得冻干细胞,具体的操作步骤优选:将培养液离心(转速一般为8000-10000rpm)去除上清液,收集细胞,生理盐水洗涤(优选2次),冷冻干燥,得冻干细胞。(2)将收集的培养液中的细胞进行细胞破壁处理、离心、取上清液、即得粗酶液,具体的操作步骤优选:将收集的培养液中的细胞重新悬浮于本领域常用的pH 6.5-7.5的缓冲液(如磷酸盐缓冲液,优选pH7.0,50mmol/L的磷酸-磷酸钾缓冲液)中,进行细胞破壁。所述的细胞破壁的方法可采用常规方法,如超声处理,优选条件为功率400W,超声4s,间歇6s,重复99轮。细胞破壁后的离心的速度较佳的为8000-10000rpm。(3)按方式(2)制备粗酶液,将粗酶液进一步冷冻干燥的粗酶液。
一方面,本发明提供一种本发明所述的烯键还原酶或重组烯键还原酶在不对称还原α,β-不饱和化合物中C=C双键中的应用。
进一步地,本发明提供的应用,其中,在辅酶NADH的存在下,在所述的烯键还原酶或在重组烯键还原酶的作用下,将作为底物的α,β-不饱和化合物进行不对称还原反应,制得带吸电子基团的化合物(包括光学活性的带吸电子基团的化合物)。所述的烯键还原酶或重组烯键还原酶作为催化剂还原α,β-不饱和化合物中C=C双键以制备带吸电子基团的化合物。
进一步地,所述的α,β-不饱和化合物为α,β-不饱和酮类化合物或酮酯类化合物,进一步地优选为在α位有取代基的α,β-不饱和化合物。所述的α,β-不饱和化合物在反应液中的浓度较佳的为1-15mmol/L,优选为10mmol/L。
进一步地,所述带吸电子基团的化合物具有光学活性。
进一步地,本发明所述的应用,其中,所述α,β-不饱和化合物的结构式如式(I)或式(II)所示
其中,M为CR1R2、NR3;
Q为C=O、CR4R5;
R为氢、烷基或硝基;当R为硝基时,Q为CH2;
n为0、1、2;
R1、R2各自独立地为氢或烷基;
R3为芳基基团;
R4和R5各自独立地为氢或烷基;
R6为取代或非取代烷基、烯基;
R7为氢或烷基。
进一步地,本发明所述的应用,其中R为氢、C1-4烷基或硝基;当R为硝基时,Q为CH2;
n为0、1、2;
R1、R2各自独立地为氢或C1-4烷基;
R3为取代或非取代C6-12芳基;
R4和R5各自独立地为氢或C1-4烷基;
R6为取代或非取代C1-4烷基、C2-4烯基;
R7为氢或C1-4烷基。
进一步地,本发明所述的应用,其中制备步骤如下:在pH 5-9、NADH辅酶、本发明所述的还原酶的条件下,将α,β-不饱和化合物中C=C双键进行不对称还原,制得带吸电子基团的化合物。
进一步地,本发明所述的应用,其中,在制备步骤中,
α,β-不饱和化合物的浓度为1-15mmol/L;所述的还原酶或重组酶的用量为80-400μg/L;辅酶NADH的用量为10-15mmol/L;所述的磷酸盐缓冲液浓度为50mmol/L,pH为5-9;所述的不对称还原反应的温度为20-40℃。
进一步地,本发明所述的应用,其中,在制备步骤中,
所述的α,β-不饱和化合物的浓度为10mmol/L;所述的还原酶或重组酶的用量为400μg/L;辅酶NADH的用量为12.5mmol/L;所述的磷酸盐缓冲液浓度为50mmol/L,pH为7.0;所述的不对称还原反应的温度为30℃。
进一步地,本发明所述的应用,其中,所述的不对称还原反应的时间为反应完全为准。
按常规方法,所述的烯键还原酶或其重组酶可采用下述形式加入反应体系:将粗酶液直接加入反应体系,或者将悬浮或溶解有冻干细胞或粗酶粉的pH 5-9、优选6-7的缓冲液加入反应体系。所述的缓冲液种类可谓本领域常用的各种缓冲液,优选磷酸盐缓冲液。所述的缓冲液的浓度可为50-100mmol/L。本发明优选pH 7.0、50mmol/L的磷酸-磷酸钾缓冲液。所述的烯键还原酶或其重组酶的量为催化有效量以上,一般为80-400μg/L,优选200-400μg/L。
所述的不对称还原反应的温度一般为20-40℃,优选25-35℃。所述的不对称还原反应的时间以反应完全为准,一般为1-24小时。
本发明的重组还原酶的辅酶依赖类型为NADH,所述的辅酶NADH的量可为10-15mmol/L。
所述的不对称还原反应的溶剂体系可为通常的缓液体系。所述的缓冲液同前述。
不对称还原反应结束后,可按照本领域常规方法从反应液中提取(S)或(R)-型带吸电子基团的饱和化合物。
在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。本发明所用试剂盒原料均市售可得。
本发明使用的术语“烷基”或“烷基基团”,表示含有1至20个碳原子,饱和的直链或支链一价烃基基团,其中,所述烷基基团可以任选地被一个或多个本发明描述的取代基所取代。除非另外详细说明,烷基基团含有1-20个碳原子。在一实施方案中,烷基基团含有1-12个碳原子;在另一实施方案中,烷基基团含有1-6个碳原子;在又一实施方案中,烷基基团含有1-4个碳原子;还在一实施方案中,烷基基团含有1-3个碳原子。
烷基基团的实例包含,但并不限于,甲基(Me、-CH3),乙基(Et、-CH2CH3),正丙基(n-Pr、-CH2CH2CH3),异丙基(i-Pr、-CH(CH3)2),正丁基(n-Bu、-CH2CH2CH2CH3),异丁基(i-Bu、-CH2CH(CH3)2),仲丁基(s-Bu、-CH(CH3)CH2CH3),叔丁基(t-Bu、-C(CH3)3),正戊基(-CH2CH2CH2CH2CH3),2-戊基(-CH(CH3)CH2CH2CH3),3-戊基(-CH(CH2CH3)2);
术语“烯基”表示含有2-12个碳原子的直链或支链一价烃基,其中至少有一个不饱和位点,即有一个碳-碳sp2双键,其中,所述烯基基团可以任选地被一个或多个本发明所描述的取代基所取代,其包括“cis”和“tans”的定位,或者"E"和"Z"的定位。在一实施方案中,烯基基团包含2-8个碳原子;在另一实施方案中,烯基基团包含2-6个碳原子;在又一实施方案中,烯基基团包含2-4个碳原子。烯基基团的实例包括,但并不限于,乙烯基(-CH=CH2)、烯丙基(-CH2CH=CH2)等等;
术语“芳基”表示含有6-14个环原子,或6-12个环原子,或6-10个环原子的单环、双环和三环的碳环体系,其中,至少一个环体系是芳香族的,其中每一个环体系包含3-7个原子组成的环,且有一个或多个附着点与分子的其余部分相连。术语“芳基”可以和术语“芳香环”交换使用。芳基基团的实例可以包括苯基、萘基和蒽。所述芳基基团可以独立任选地被一个或多个本发明所描述的取代基所取代。
所述烷基基团为甲基(Me、-CH3),乙基(Et、-CH2CH3),正丙基(n-Pr、-CH2CH2CH3),异丙基(i-Pr、-CH(CH3)2),正丁基(n-Bu、-CH2CH2CH2CH3);
所述烯基基团包含2-8个碳原子的直链或支链一价烃基,;
所述芳基基团包括苯基、萘基和蒽,所述芳基基团可以独立任选地被一个或多个取代基所取代。
像本发明所描述的,本发明的化合物可以任选地被一个或多个取代基所取代,如上面的通式化合物,或者像实施例里面特殊的例子,子类,和本发明所包含的一类化合物。应了解“任选取代的”这个术语与“取代或非取代的”这个术语可以交换使用。一般而言,术语“取代的”表示所给结构中的一个或多个氢原子被具体取代基所取代。除非其他方面表明,一个任选的取代基团可以在基团各个可取代的位置进行取代。当所给出的结构式中不只一个位置能被选自具体基团的一个或多个取代基所取代,那么取代基可以相同或不同地在各个位置取代。取代基包括氢、烷基、烯基、卤素、硝基、氰基、醛基、酮基等。
另外,需要说明的是,除非以其他方式明确指出,在本发明中所采用的描述方式“各…独立地为”与“…各自独立地为”和“…独立地为”可以互换,均应做广义理解,其既可以是指在不同基团中,相同符号之间所表达的具体选项之间互相不影响,也可以表示在相同的基团中,相同符号之间所表达的具体选项之间互相不影响。
附图说明
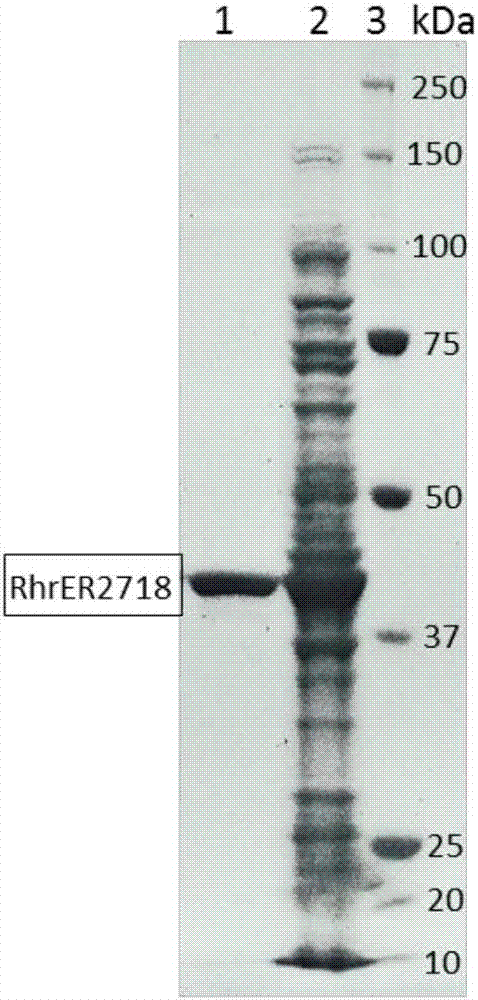
图1为实施例2中重组烯键还原酶RhER 2718的粗酶液的聚丙烯凝胶电泳图。
图2为实施例2中纯化后的重组烯键还原酶RhER 2718的聚丙烯凝胶电泳图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。下列实施例中未注明具体条件的实验方法,按照常规方法和条件,或按照商品说明书选择。
本发明所用试剂盒原料均市售可得,如质粒pET28a(+)购买自德国默克,NADH购买自Sigma-Aldrich,所有化学品都购自Sigma-Aldrich(Schnelldorf、德国)且没有进一步纯化。
实施1大肠埃希氏菌(E.coli)BL21(DE3)/pET28a(+)-RhER 2718的构建RhER 2718基因的扩增
根据如SEQ ID No.1所示的碱基序列,设计引物序列如下:
上游引物:GGAATTCCATATGGTTGCAGTAAAGCCTT
下游引物:CCCAAGCTTTTACGCCTTGGTATCAATAG
其中,上游引物下划线部分为NdeI酶切位点,下游引物下划线部分为HindIII酶切
位点。
以紫红色红球菌(Rhodococcusrhodochrous)ATCC 17895的全基因组DNA为模板,进行PCR扩增,获得RhER 2718基因。PCR体系为:2×Tag PCR MasterMix 15μL,上游引物和下游引物各1μL(0.3μmol/L),DNA模板2μL(0.1μg)和ddH2O 11μL。PCR扩增步骤为:(1)95℃,预变性3min;(2)94℃,变性1min;(3)55℃退火30s;(4)72℃延伸90s;其中步骤(2)~(4)循环30次;(5)72℃继续延伸10min,冷却至4℃保存。PCR产物经琼脂糖凝胶电泳纯化,利用琼脂糖凝胶DNA回收试剂盒回收700~900bp区间的目标条带。
1.重组表达载体,即重组表达质粒pET28a(+)-RhER 2718的制备
在37℃下,将所得PCR产物用限制性内切酶NdeI和HindIII双酶切12h;pET28a(+)载体用限制性内切酶NdeI和HindIII双酶切12h得到线性pET28a(+)载体;将双酶切后的PCR产物的基因片段与线性pET28a(+)载体用TADNA连接酶在4℃下连接过夜,得到重组表达质粒pET28a(+)-RhER 2718。
2.重组表达转化体,即大肠埃希氏菌(E.coli)BL21(DE3)/pET28a(+)-RhER 2718的构建
将重组表达质粒pET28a(+)-RhER 2718转入大肠埃希氏菌(E.coli)DH5α感受态细胞中,在含有卡那霉素的抗性平板上对阳性重组体进行筛选,挑取单克隆,培养重组菌,待质粒扩增后提取质粒,重新转化至大肠埃希氏菌(E.coli)BL21(DE3)感受态细胞中,即获得重组表达转化体大肠埃希氏菌(E.coli)BL21(DE3)pET28a(+)-RhER 2718,菌落PCR验证阳性克隆。
实施例2重组烯键还原酶的制备
将实施例1中所得的大肠埃希氏菌(E.coli)BL21(DE3)pET28a(+)-RhER 2718接种于含卡那霉素(终浓度50mg/L)的LB培养基(包含酵母膏5g/L,蛋白胨10g/L,NaCl 10g/L)中,37℃震荡培养过夜。再按1%(v/v)的接种量将种子液接种到装有500mL相同的LB培养基的的2L三角瓶中,置37℃、180rpm摇床培养,当培养液的OD600达到0.5-0.6时,加入终浓度为0.5mmol/L的IPTG作为诱导剂,22℃诱导20h。
将所得培养液在9000rpm下离心去除上清液,收集湿细胞。取部分湿细胞用生理盐水洗涤两次,冷冻干燥,即得冻干细胞,备用。另取部分湿细胞悬浮于pH 7.0、50mmol/L的磷酸-磷酸钾缓冲液中得悬浮液,在冰浴中超声破碎,离心收集上清液,即为重组烯键还原酶的粗酶液。所得重组烯键还原酶的粗酶液经聚丙烯酰胺凝胶电泳图分析具体结果如图1所示。
质粒pET28a(+)是一种带有组氨酸标签的表达质粒,用该质粒表达的烯键还原酶RhER2718带有一个组氨酸标签,通过His trap Ni-NTA亲和色谱柱、AKTAprime蛋白纯化仪对目标蛋白进行一步纯化。所用洗脱液为磷酸-磷酸钾缓冲液和咪唑的水溶液液。先把粗酶液进到高液体系,利用磷酸-磷酸钾缓冲液洗脱,把其他酶洗脱下来,目标酶因为有组氨酸标签会被吸附在镍柱上,然后利用咪唑水溶液把目标酶从镍柱上洗脱下来,收集。收集的重组烯键还原酶的酶液经聚丙烯酰胺凝胶电泳图分析,具体结果如图2所示。
重组蛋白绝大部分以可溶性形式存在。聚丙烯酰胺凝胶电泳图经BandScan软件分析得,表达的目的蛋白重组烯键还原酶RhER 2718约占粗酶液总蛋白的60%。
实施例3重组烯键还原酶的活力测定
重组烯键还原酶的还原反应活力测定:反应体系为1mL,包含pH 7.0、50mmol/L磷酸-磷酸钾缓冲液,加入0.1mmol/LNADH,2mmol/L 2-甲基环戊烯酮,在30℃保温2分钟后加入适量由实施例2制备的重组烯键还原酶的粗酶液,迅速摇匀,检测340nm处吸光值的变化。
酶活力的计算公式为:酶活力(U)=EW×V×103/(6220×1);式中,EW为1min内340nm处吸光度的变化;V为反应液的体积,单位为mL;6220为摩尔消光系数,单位为L/(mol/cm);1为光程距离,单位为cm。
烯键还原酶每单位酶活力定义为在上述条件下,每分钟催化氧化1μmol NADH所需的酶量,蛋白含量采用Brandford法测定。结果为:重组烯键还原酶的还原反应活性为0.92U/mg。
实施例4-14重组烯键还原酶催化还原α,β-不饱和化合物的C=C双键
在1.5mL磷酸-磷酸钾缓冲液(50mmol/L、pH 7.0)中加入12.5mmol/LNADH和400μg/mL的重组烯键还原酶液,分别加入终浓度为10mmol/L的各种底物(结构式如表1所示),30℃下,1000rpm震荡反应4h。反应结束后加入等体积的乙酸乙酯萃取两次,合并萃取液,用无水硫酸钠干燥过夜,通过气相色谱(毛细管柱CP Sil 5CB或手性毛细管柱Mega-Dex Det Beta和CP-Chirasil-Dex CB)分析测定底物转化率和还原产物的ee值,结果如表1所示。
转化率及产物ee值的检测方法如下:
实施例4-14使用气相色谱(毛细管柱CP Sil 5CB)分析底物的转化率,载气氮气,进样口温度280℃,检测器FID温度280℃。其他条件如下:
实施例4-9:柱温50℃保留3min;以3℃/min升温至65℃,保留1min;以30℃/min升温至150℃,保留2min;以50℃/min升温至250℃,保留1min;以50℃/min升温至270℃,保留1min;以50℃/min升温至330℃,保留1min。
实施例10:柱温50℃保留3min;以3℃/min升温至60℃,保留3min;以3℃/min升温至70℃,保留1min;以30℃/min升温至150℃,保留2min;以50℃/min升温至270℃,保留1min;以50℃/min升温至330℃,保留1min。
实施例11:柱温60℃保留1min;以10℃/min升温至65℃,保留10min;以30℃/min升温至135℃,保留2min;以35℃/min升温至330℃,保留2min。
实施例12:柱温50℃保留1min;以30℃/min升温至90℃,保留20min;以50℃/min升温至250℃,保留1min;以50℃/min升温至330℃,保留1min。
实施例13:柱温50℃保留1min;以30℃/min升温至150℃,保留2min;以30℃/min升温至180℃,保留5min;以30℃/min升温至250℃,保留1min;以30℃/min升温至270℃,保留1min;以30℃/min升温至330℃,保留1min。
实施例14:使用气相色谱(手性毛细管柱CP-Chirasil-Dex CB)分析转化率和产物ee值,载气氮气,进样口温度280℃,检测器FID温度280℃:柱温120℃保留3min;以10℃/min升温至150℃,保留4min;以15℃/min升温至225℃,保留1min。
实施例7和实施例10使用气相色谱(手性毛细管柱Mega-Dex Det Beta)分析产物ee值,载气氮气,进样口温度280℃,检测器FID温度280℃:柱温75℃保留2min;以10℃/min升温至110℃,保留7min;以30℃/min升温至230℃,保留2min。
表1:重组烯键还原酶催化还原α,β-不饱和化合物的C=C双键的结果
从上表可知,本发明提供和制备的烯键还原酶或重组烯键还原酶可作为催化剂应用于共轭C=C双键的不对称还原,适用的化合物范围广,具有优异的催化活性,可获得高转化率、高光学纯度的带吸电子基团饱和化合物,且反应条件温和、对环境友好,具有很好的工业应用开发前景。底物转化率可达99%,还原产物的ee可达到100%。
以上仅为本实用新型的优选实施例而已,并不用于限制本实用新型,对于本领域的技术人员来说,本实用新型可以有各种更改和变化。凡在本实用新型的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本实用新型的保护范围之内。
SEQUENCE LISTING
<110> 中山大学
<120> 一种烯键还原酶及其制备方法和应用
<130> 2017
<160> 4
<170> PatentIn version 3.3
<210> 1
<211> 1104
<212> DNA
<213> Rhodococcus rhodochrous
<400> 1
gtgagtgtgt tgttcgagcc tttgaccctg cgtggcgtca ccatcccgaa ccgcgtctgg 60
atggcaccga tgtgccagta ctcggccgac gtcatcggcg accaggtcgg agtgcccaac 120
gagtggcatc gcacgcatct ggtgagccgt gcaatcggcg gcaccggcct gattctcacc 180
gaggcgacgg ccgtcagtcc cgaaggccgg atatcggcag ctgatctggg gatttggaac 240
gacacgcagg cgcaagcctt cgccgagatc aacgcgcaac tcgcgtactt cggcgcagtg 300
cccggaatcc agttggcgca cgccggacga aaagcgtcga cgcaggttcc gtggcgcggc 360
ggcaagagcc tgcccgccga cgaccgactc tcgtggcaga cggttgcccc gagcgcggtt 420
ccgttcggtc accttgccga tccggtcgag ctcaccacgg agggcatcga gaaggtcgtc 480
gcggacttcg cagcggcggc tacccgcgca ttgaaggccg aattcaaggt cgtggaaatt 540
cacgcggccc acggatacct gatccatcag ttcctctccc ccgagagcaa caagcgaacg 600
gaccgctacg gaggcagctt cgagaaccgc attcgattgc tcctcgaaat cctgacagca 660
gtccgcgagg tgtggccggc cgagctaccg ctcttcgtcc gggtctcggc gaccgattgg 720
ctgacggaag agcgtgggct cgaggtcgac agctggaccg cggatcagac cgttgccctg 780
gccaacatcc tctccgatta cggggtcgat ctcgtcgacg tctccaccgg cggcaattca 840
ccggcggcac agattccggt ggaaccggga taccaggttc cgttcgcccg tcgcctgcag 900
aacgagagcc tgctaccggc cgccgccgtc ggcctcatca ccgaacccga acaggccgag 960
aagatcgtcg aagacggaag cgcagtggcg gtgctcctcg gccgcgaact gttgcgtgat 1020
ccgtactggg cgcgccgggc ggcacgggaa ctgaacgccg aggtcggacc acatatcccg 1080
tcgcagtacg cccgcgcctt ctag 1104
<210> 2
<211> 367
<212> PRT
<213> Rhodococcus rhodochrous
<400> 2
Met Ser Val Leu Phe Glu Pro Leu Thr Leu Arg Gly Val Thr Ile Pro
1 5 10 15
Asn Arg Val Trp Met Ala Pro Met Cys Gln Tyr Ser Ala Asp Val Ile
20 25 30
Gly Asp Gln Val Gly Val Pro Asn Glu Trp His Arg Thr His Leu Val
35 40 45
Ser Arg Ala Ile Gly Gly Thr Gly Leu Ile Leu Thr Glu Ala Thr Ala
50 55 60
Val Ser Pro Glu Gly Arg Ile Ser Ala Ala Asp Leu Gly Ile Trp Asn
65 70 75 80
Asp Thr Gln Ala Gln Ala Phe Ala Glu Ile Asn Ala Gln Leu Ala Tyr
85 90 95
Phe Gly Ala Val Pro Gly Ile Gln Leu Ala His Ala Gly Arg Lys Ala
100 105 110
Ser Thr Gln Val Pro Trp Arg Gly Gly Lys Ser Leu Pro Ala Asp Asp
115 120 125
Arg Leu Ser Trp Gln Thr Val Ala Pro Ser Ala Val Pro Phe Gly His
130 135 140
Leu Ala Asp Pro Val Glu Leu Thr Thr Glu Gly Ile Glu Lys Val Val
145 150 155 160
Ala Asp Phe Ala Ala Ala Ala Thr Arg Ala Leu Lys Ala Glu Phe Lys
165 170 175
Val Val Glu Ile His Ala Ala His Gly Tyr Leu Ile His Gln Phe Leu
180 185 190
Ser Pro Glu Ser Asn Lys Arg Thr Asp Arg Tyr Gly Gly Ser Phe Glu
195 200 205
Asn Arg Ile Arg Leu Leu Leu Glu Ile Leu Thr Ala Val Arg Glu Val
210 215 220
Trp Pro Ala Glu Leu Pro Leu Phe Val Arg Val Ser Ala Thr Asp Trp
225 230 235 240
Leu Thr Glu Glu Arg Gly Leu Glu Val Asp Ser Trp Thr Ala Asp Gln
245 250 255
Thr Val Ala Leu Ala Asn Ile Leu Ser Asp Tyr Gly Val Asp Leu Val
260 265 270
Asp Val Ser Thr Gly Gly Asn Ser Pro Ala Ala Gln Ile Pro Val Glu
275 280 285
Pro Gly Tyr Gln Val Pro Phe Ala Arg Arg Leu Gln Asn Glu Ser Leu
290 295 300
Leu Pro Ala Ala Ala Val Gly Leu Ile Thr Glu Pro Glu Gln Ala Glu
305 310 315 320
Lys Ile Val Glu Asp Gly Ser Ala Val Ala Val Leu Leu Gly Arg Glu
325 330 335
Leu Leu Arg Asp Pro Tyr Trp Ala Arg Arg Ala Ala Arg Glu Leu Asn
340 345 350
Ala Glu Val Gly Pro His Ile Pro Ser Gln Tyr Ala Arg Ala Phe
355 360 365
<210> 3
<211> 29
<212> DNA
<213> 未知
<400> 3
ggaattccat atggttgcag taaagcctt 29
<210> 4
<211> 29
<212> DNA
<213> 未知
<400> 4
cccaagcttt tacgccttgg tatcaatag 29
- 还没有人留言评论。精彩留言会获得点赞!