使用差异性标记的等位基因特异性探针分析混合样品的基于阵列的方法与流程
相关申请的交叉引用本申请要求于2017年6月2日提交的美国临时专利申请第62/514,681号、于2017年6月2日提交的美国临时专利申请第62/514,714号以及于2017年6月2日提交的美国临时专利申请第62/514,629号的优先权,所述美国临时专利申请出于所有目的通过引用整体并入本文中。本公开提供了可用于基于阵列对混合核酸群体分析的方法和系统,所述方法和系统包含对混合核酸群体的各个亚群进行基因分型和拷贝数分析。本公开还提供了用于诊断从生物得到的混合核酸群体中遗传异常的方法和系统。例如,本文公开了可用于使用以非侵入性方式从怀孕女性或患者获得的样品来诊断胎儿遗传异常或肿瘤遗传异常的方法和系统。这些样品可以包括衍生自血液、血浆、血清、尿液、粪便或唾液的混合核酸群体。
背景技术:
:对从单一组织来源(如血液、尿液或唾液)中获得的但含有不同的核酸亚群的混合核酸群体(例如dna和rna样品)的分析,已经引起了研究界和医疗界的极大兴趣。可以使用合适的方法来分析从怀孕女性得到的无细胞dna(或rna)衍生的混合核酸群体,以确定胎儿特征,包括疾病遗传。类似地,可以分析从癌症患者得到的无细胞dna(或rna)衍生的混合核酸群体,以确定各种特征,如肿瘤恶性度、肿瘤起源或药物敏感性。尽管对此类混合核酸群体的分析可能由于各种亚群之间的高度相似性而在技术方面变得很复杂,但是通过如放血或尿液/唾液收集等程序以低廉、快速且非侵入性的方式获得适当的混合核酸样品的便利性减轻了分析的难度。分析无细胞dna、核酸测序的一种模式是信息性的,但所述模式在每个样品上的成本高昂且耗时。微阵列分析比测序更便宜且更快速,但是微阵列产品的当前商业实施例不会容易地支持在存在于混合核酸群体中的不同的亚群与高度相似的亚群之间进行区分。由于母体样品中胎儿dna的浓度低并且血样样品中低浓度的肿瘤dna含有循环肿瘤细胞,因此单一测定或低的多重测定是不可能在非整倍体胎儿(例如,21号染色体的三体性)与整倍体胎儿之间或癌症患者的肿瘤细胞与健康细胞之间进行区分。例如,胎儿dna在血液中的存在可以介于总无细胞dna的水平的4%与15%之间;从特定胎儿染色体衍生的dna将表示此类胎儿dna的二十三分之一。三体的检测将需要对上述背景中低到1-2%的信号变化进行可靠的检测。此外,由于可通过非侵入性采样方法衍生的核酸的量有限,使得所述分析更加复杂。例如,在典型的测定中,由10ml全血制成的母体样品可以产生5到15ng的纯化无细胞dna。由于这些非侵入性方法所带来的当前的挑战,大多数孕妇都接受产前测试,包括母体血清筛查和/或超声测试,以确定如由13、18和21三体引起的那些风险等常见出生缺陷的风险。然而,此类测试的敏感性和特异性非常差,导致假阳性率较高。由于这种常规测试的假阳性率很高,因此个体通常必须进行侵入性诊断测试的后续测试,如妊娠11到14周之间的绒毛膜绒毛取样(cvs)或妊娠15周后的羊膜穿刺术。这些侵入性程序携带有1%左右的流产的风险(参见mujezinovic和alfirevic,《产科学与妇科学(obstet.gynecol)》,110:687-694(2011)。当前的胎儿细胞分析通常涉及核型分析或荧光原位杂交(fish),并且不提供关于单基因性状的信息。因此,需要另外的测试来识别单基因疾病和病症。因为产前诊断对于具有染色体异常和局部遗传异常的妊娠的管理会是至关重要的,因此准确且早期的诊断对于允许在分娩之前或期间进行介入治疗并且防止对新生儿造成的灾难性后果是重要的。同样地,在癌症方面,出于诊断癌症的目的,已经开发了如等强大的工具。然而,此类样品通常是在侵入性程序中得到的活检样品,成本高并且对患者有潜在风险。通过使用基于微阵列的技术,研究者能够识别单个阵列上大量的单核苷酸多态性(snp),这使得能够对受试者的遗传异常进行快速且准确的检测。一个此类产品的实例是一来自affymetrix的snp检测微阵列产品,被称为所述产品提供来自固体肿瘤样品的全基因组拷贝数和杂合性丢失(loh)状况。此类技术是癌症诊断中的强大工具,因为其有助于克服由于处理来自高度降解的ffpe样品中有限量的dna的难度而带来的重大挑战。参见例如美国专利第8,190,373号。但是,此类技术也应用于许多它领域中。具体地,遗传异常解释了多种病理,包括由染色体非整倍性(例如,唐氏综合症)引起的病理、特异性基因中的种系突变(例如,镰状细胞性贫血)和由体细胞突变(例如癌症)引起的病理,并且在许多情况下,此类遗传异常的检测由于侵入性诊断程序而变得复杂。因此,开发一种基于微阵列的测试对于分子诊断领域而言将是有益的,所述基于微阵列的测试的敏感性和特异性足以检测通过非侵入性方式获得的混合核酸群体的样品中的遗传异常与低假阳性和假阴性率。最近,ariosadiagnostics报告了涉及对来自母体血液中的无细胞dna进行基于微阵列的分析以检测胎儿非整倍性的存在的研究。参见例如,stokowski等人,《产前诊断(prenataldiagnosis)》35:1243-1246(2015)。此类方法涉及分析来自非多态性基因座(即,预期与母亲和胎儿两者均相同的基因座)的大量信号,以通过简单地测量在给定的基因座中从母体dna和胎儿dna两者中检测的总信号的波动来估计染色体拷贝数。这需要一种借此阵列被配置成询问非多态性基因座以确定基础染色体的拷贝数的设计策略。此外,至少在一些情况下,将多态性基因座用于估计拷贝数在测试胎儿非整倍性的背景下具有下游优势,因为其保留了确定哪个亲本有助于拷贝数变异的可能性。然而,基于对应于多态性位点的信号的拷贝数分析可能具有挑战性,并且在分析来自不同群体的样品时,这些挑战会放大。因此需要开发改进的方法(以及所有相关联的组成、系统、装置和仪器),所述改进的方法利用基于微阵列的分析的高通量基因分型能力生成来自单个询问位点组的数据(例如,来自混合dna群体中的单个多态性基因座组中的数据),所述数据之后可以用于对混合核酸群体内的主要dna群体和次要dna群体内的给定基因座或染色体进行基因分型并估计其拷贝数。本文描述了用于分析混合核酸样品以检测靶多核苷酸的拷贝数的差异(如检测指示染色体非整倍性的拷贝数变体)的方法和系统以及对甚至以低水平存在于混合核酸群体内的此类靶多核苷酸进行基因分型的方法。技术实现要素:提供本
发明内容是为了引入本公开的各个方面,这些方面将在下面的详细描述中作进一步介绍。本
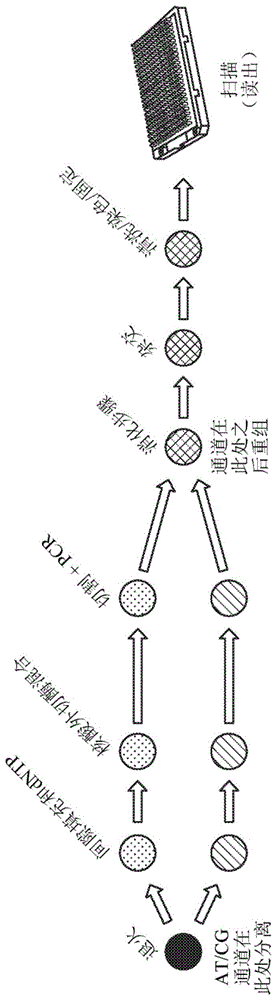
发明内容不旨在用于限制所要求保护的主题的范围。根据以下书面详细说明,所要求保护的主题的其它特征、细节、用途和优点将是显而易见的,所述详细说明包括在附图中示出并且在所附权利要求中定义的那些方面。在一方面,本公开提供了用于分析从生物获得的核酸样品的方法。所述核酸样品可以包括dna和/或rna,或其合成衍生物。所述核酸样品可以包括无细胞dna和/或无细胞rna。在一些实施例中,所述核酸样品包括混合核酸群体。含有所述混合核酸群体的所述核酸样品可以从单个生物中体获得。所述混合核酸群体可以包括胎儿来源和母体来源的核酸。所述混合核酸群体可以包括源自肿瘤细胞和正常细胞的核酸。本文所述的方法可以进一步包括从生物获得或衍生含有混合核酸群体的核酸样品。任选地,所述获得或衍生包括以下步骤中的任何一者或多者:标记(包括批量标记或随机标记)、单分子标记、扩增、与其它核酸序列的连接、环化、杂交、靶选择、甲基化或结合到甲基化特异性试剂、抗体结合、靶标捕获、沉淀、洗脱等。在一些实施例中,所述混合核酸样品包括主要亚群和次要亚群。所述主要亚群任选地按大于所述混合核酸群体中总核酸的50%存在。所述主要亚群可以按大于所述核酸样品中总核酸的50%存在。在一些实施例中,所述主要亚群和次要亚群各自包括位于第一染色体区域中的靶序列。所述主要亚群和次要亚群的所述靶序列可以是相同的序列或重叠的序列。在一些实施例中,所述靶序列是含有多态性位点。所述多态性位点可以包括任选地在同一位点含有第一核苷酸变体和/或第二核苷酸变体的序列。在一些实施例中,所述多态性序列包括单核苷酸多态性(snp)。所述snp可以包括其同一性限定了所述多态性位点的等位基因变体的单核苷酸。所述多态性位点可以包括主要等位基因或次要等位基因或两者(例如,在二倍体生物的情况下)。在一些实施例中,本文所述的方法(以及相关的组成、试剂盒和系统)涉及关注的某些基因序列的选择性富集。所述选择性富集可以包括靶向扩增,所述靶向扩增可以以单重形式或多重形式执行。在一些实施例中,所描述的方法可以包括使用靶标特异性引物或探针。任选地,所述方法包括使用分子倒置探针。在一些实施例中,所述方法包括使所述引物或所述探针(例如,所述分子倒置探针)与靶序列杂交。任选地,可以以靶标特异性方式延伸所述引物或所述探针。在一些实施例中,所述探针是在多态性位点附近或上游杂交的分子倒置探针。所述方法可以包括通过掺入其同一性对应于所述多态性位点中的一个或多个多态性的所述序列的核苷酸来延伸所述引物或所述探针。在一些实施例中,本文所述的方法包括对所述多态性位点进行基因分型。在另外的实施例中,所述基因分型包括将含有所述核酸群体或从所述核酸群体衍生的并且含有所述多态性位点的至少一种核酸片段与寡核苷酸探针杂交。所述寡核苷酸探针任选地可以位于其它探针的阵列内,或者可以与存在于阵列中的另一寡核苷酸探针杂交。在一些实施例中,所描述的方法进一步包括使用检测器从所述寡核苷酸阵列检测指示所述第一核苷酸变体存在或不存在的第一信号(“a信号”)。在一些实施例中,所描述的方法包括检测指示所述第二核苷酸变体存在或不存在的第二信号(“b信号”)。在一些实施例中,所描述的方法可以包括检测来自同一阵列的所述第一信号和所述第二信号两者。在一些实施例中,所述第一信号可以指示所述多态性位点的第一等位基因形式(“a等位基因”)存在或不存在。所述第二信号可以指示所述多态性位点的第二等位基因形式(“b等位基因”)存在或不存在。在一些实施例中,所述主要亚群包括所述a等位基因并且所述次要亚群包括所述b等位基因。在一些实施例中,所描述的方法进一步包括任选地使用所述a信号、所述b信号或所述a信号和所述b信号两者对所述主要亚群、所述次要亚群或主要亚群和所述次要亚群两者进行基因分型。在一些实施例中,所描述的方法进一步包括任选地使用所述a信号、所述b信号或所述a信号和所述b信号两者估计或计算包括所述主要亚群、所述次要亚群或所述主要亚群和所述次要亚群两者中的所述多态性位点的所述靶核酸序列的拷贝数。所述方法可以包括使用所述a信号、所述b信号或所述a信号和所述b信号两者计算所述第一染色体区域的拷贝数。所述方法可以包括检测非整倍性存在或不存在。在一些实施例中,所述方法可以包括使用所述a信号、所述b信号或所述a信号和所述b信号两者计算从所述主要亚群和所述次要亚群衍生的核酸的相对比例。所述方法可以包括使用所述a信号、所述b信号或所述a信号和所述b信号两者来计算所述核酸样品的胎儿分数。在一些实施例中,所述方法可以进一步包括以下步骤中的任何一者或多者:(a)使用所述第一信号和所述第二信号确定所述次要亚群中的所述第一染色体区域的拷贝数;(b)使用所述第一信号和所述第二信号确定所述主要亚群中的第一染色体区域的拷贝数;(c)使用所述第一信号和所述第二信号确定所述次要亚群的所述多态性位点的基因型;(d)使用所述第一信号和所述第二信号确定所述主要亚群的所述多态性位点的基因型,以及(e)进一步包括使用所述第一信号和所述第二信号确定所述混合核酸群体中的所述主要亚群和所述次要亚群的相对量。在另一方面,本公开提供了用于确定从生物中获得的混合核酸样品中的拷贝数变异的方法,所述方法包含以下步骤中的一者或多者:a.分离基因组dna以形成含有混合核酸群体的混合核酸样品,所述混合核酸群体包括主要亚群和次要亚群;b.使所述核酸样品与线性分子倒置探针汇集物接触以提供复性混合物,所述复性混合物包含多个线性分子倒置探针dna片段复合体;c.将所述复性混合物分成第一通道组和物和第二通道组合物;d.将脱氧核苷酸的混合物添加到所述第一和第二通道组合物中的每一者,其中添加到所述第一通道组合物的所述脱氧核苷酸的混合物与添加到所述第二通道组合物的所述脱氧核苷酸的混合物不同;e.将所述第一通道组合物和第二通道组合物与连接酶接触以形成第一环化探针组合物和第二环化探针组合物;f.任选地,将所述第一环化探针组合物和所述第二环化探针组合物与第一核酸外切酶接触以切割剩余的线性分子倒置探针和核酸片段;g.切割所述第一环化探针组合物和所述第二探针组合物以形成含有或衍生自所述核酸群体的核酸片段;h.扩增含有或衍生自所述核酸群体的所述第一核酸片段和所述第二核酸片段;i.将含有或衍生自所述核酸群体的所述第一核酸片段和所述第二核酸片段组合;j.消化含有或衍生自所述核酸群体的所述第一核酸片段和所述第二核酸片段;k.将含有或衍生自所述核酸群体的并且含有所述多态性位点的至少一种核酸片段与寡核苷酸阵列的寡核苷酸探针杂交;l.标记含有或衍生自所述核酸群体的表面结合的第一核酸片段和第二核酸片段,所述核酸群体具有结合到所述第一核苷酸变体的第一试剂和结合到所述第二核苷酸变体的第二试剂;以及m.分析针对所述第一试剂具有特异性的信号强度和所述第二试剂的信号强度,以确定染色体的拷贝数。在另一方面,本公开提供了可用于检测胎儿拷贝数变化的试剂盒,其包含:a.捕获装置,所述捕获装置具有多个核酸片段,所述多个核酸片段对应于连接到所述核酸片段的至少一个染色体靶区域;b.多个分子探针,所述多个分子探针可以与包括主要亚群和次要亚群的混合核酸群体杂交,其中所述主要亚群和所述次要亚群各自包括位于第一染色体区域中并且含有多态性位点的靶序列,其中所述多态性位点可以包括第一核苷酸变体和第二核苷酸变体的组合;以及c.用于对所述多态性位点进行基因分型和检测所述多态性位点的说明书。本公开的这些方面和其它实施例可以通过以下列举的条款进一步描述:1.一种用于分析从生物获得的混合核酸样品的方法,其包含:从生物获得或衍生含有混合核酸群体的核酸样品,所述混合核酸群体包括主要亚群和次要亚群,其中所述主要亚群和所述次要亚群各自包括位于第一染色体区域中并且含有多态性位点的靶序列,其中所述多态性位点可以包括第一核苷酸变体、第二核苷酸变体或所述第一核苷酸变体和所述第二核苷酸变体两者;对所述多态性位点进行基因分型,其中所述基因分型包括:(a)将含有或衍生自所述核酸群体的并且含有所述多态性位点的至少一个核酸片段与寡核苷酸阵列的寡核苷酸探针杂交;以及(b)使用检测器从所述寡核苷酸阵列检测指示第一核苷酸变体存在或不存在的第一信号(“a信号”)和指示第二核苷酸变体存在或不存在的第二信号(“b信号”)。任选地,所述第一核苷酸变体对应于第一等位基因变体并且所述第二核苷酸变体对应于第二等位基因变体。2.根据条款1所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述次要亚群中所述第一染色体区域的拷贝数。3.根据条款1所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述主要亚群中所述第一染色体区域的拷贝数。4.根据条款1所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述次要亚群的所述多态性位点的基因型。5.根据条款1所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述主要亚群的所述多态性位点的基因型。6.根据条款1所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述混合核酸群体中所述主要亚群和所述次要亚群的相对量。7.根据前述条款中任一项所述的方法,其中所述主要亚群和所述次要亚群源自所述生物中的不同来源。8.根据前述条款中任一项所述的方法,其中所述混合核酸群体包括无细胞dna。9.根据条款8所述的方法,其中所述无细胞dna是从所述生物的血液、血浆、血清、尿液、粪便或唾液获得或衍生的。10.根据前述条款中任一项所述的方法,其中所述生物包括肿瘤,所述主要亚群包括或衍生自正常组织并且所述次要亚群包括或衍生自所述肿瘤。11.根据前述条款中任一项所述的方法,其中所述生物是怀孕女性,所述混合核酸群体是从所述怀孕女性的血液获得的无细胞dna,所述主要亚群包括或衍生自母体核酸获,并且所述次要亚群包括或衍生自胎儿核酸。12.根据条款11所述的方法,其中所述次要亚群包括胎儿dna,所述胎儿dna按不大于所述核酸样品中总dna的20%存在。13.根据条款12所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的15%。14.根据条款12所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的10%。15.根据条款12所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的5%。16.根据条款1所述的方法,其中所述胎儿dna不大于所述核酸样品中的总无细胞dna的15%并且不小于1%。17.根据前述条款中任一项所述的方法,其中所述混合核酸群体含有或衍生自无细胞dna,所述无细胞dna在所述生物的血液中按不大于5ng/ml并且不小于0.1ng/ml的浓度存在。18.根据条款1所述的方法,其中所使用的混合核酸群体的量不大于50ng、40ng、30ng、15ng、10ng、5ng、3ng或1ng。19.根据条款1所述的方法,其中所述多态性位点包括双等位基因snp,所述第一核苷酸变体是所述snp的第一等位基因变体(“a等位基因”)并且所述第二核苷酸变体是所述snp的第二等位基因变体(“b等位基因”)。20.根据前述条款中任一项所述的方法,其中所述检测器包括第一检测通道和第二检测通道,并且所述方法进一步包括检测所述第一检测通道中所述第一信号和所述第二检测通道中所述第二信号的步骤。21.根据条款19所述的方法,其中所述snp可以包括所述a等位基因或所述b等位基因,并且其中snp基因型可以对所述a等位基因(“aa”)是纯合的,对所述b等位基因(“bb”)是纯合的或是杂合的(“ab”)。22.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括使所述核酸样品与线性分子倒置探针汇集物接触以提供复性混合物。23.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含至少1,000个线性分子倒置探针。24.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含至少5,000个线性分子倒置探针。25.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含至少10,000个线性分子倒置探针。26.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含至少20,000个线性分子倒置探针。27.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含少于200,000个线性分子倒置探针。28.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含少于100,000个线性分子倒置探针。29.根据条款22所述的方法,其中所述线性分子倒置探针汇集物包含少于80,000个线性分子倒置探针。30.根据条款22到29中任一项所述的方法,其中至少50%的所述线性分子倒置探针汇集物结合来自染色体1、5、13、18、21、x和y的dna片段。31.根据条款22到29中任一项所述的方法,其中至少60%的所述线性分子倒置探针汇集物结合来自染色体1、5、13、18、21、x和y的dna片段。32.根据条款22到29中任一项所述的方法,其中至少70%的所述线性分子倒置探针汇集物结合来自染色体1、5、13、18、21、x和y的dna片段。33.根据条款22到29中任一项所述的方法,其中线性分子倒置探针的总数与dna片段拷贝的总数的比率为约40,000:1。34.根据条款22到29中任一项所述的方法,其中线性分子倒置探针的总数与dna片段拷贝的总数的比率至少为15,000:1。35.根据条款22到29中任一项所述的方法,其中线性分子倒置探针的总数与dna片段拷贝的总数的比率至少为30,000:1。36.根据条款22到29中任一项所述的方法,其中线性分子倒置探针的总数与dna片段拷贝的总数的比率小于100,000:1。37.根据条款22到29中任一项所述的方法,其中线性分子倒置探针的总数与dna片段拷贝的总数的比率小于60,000:1。38.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括将所述复性混合物分成第一通道组合物和第二通道组合物。39.根据条款38所述的方法,其中所述第一通道组合物具有datp和dttp的混合物。40.根据条款38或39所述的方法,其中所述第一通道组合物基本上不含dgtp或dctp。41.根据条款38到40中任一项所述的方法,其中所述第二通道组合物包含dgtp和dctp的混合物。42.根据条款38到41中任一项所述的方法,其中所述第二通道组合物基本上不含datp或dttp。43.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括将脱氧核苷酸混合物添加到所述第一通道组合物和所述第二通道组合物中的每一者,其中添加到所述第一通道组合物的所述脱氧核苷酸混合物与添加到所述第二通道组合物的所述脱氧核苷酸混合物不同。44.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括使所述第一通道组合物和所述第二通道组合物与连接酶接触以形成第一环化探针组合物和第二环化探针组合物。45.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括切割所述第一环化探针组合物和所述第二探针组合物以形成含有或衍生自所述核酸核酸群体的核酸片段。46.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括扩增含有或衍生自所述核酸群体的第一核酸片段和第二核酸片段。47.根据前述条款中任一项所述的方法,其中所述扩增步骤在聚合酶存在的情况下实施。48.根据条款47所述的方法,其中所述聚合酶是包含所述聚合酶和聚合酶抑制剂的热启动聚合酶。49.根据条款48所述的方法,其中当温度为至少40℃时,所述聚合酶抑制剂与所述聚合酶解离。50.根据前述条款中任一项所述的方法,其中所述基因分型步骤进一步包括组合含有或衍生自所述核算群体的所述第一核酸片段和所述第二核酸片段。51.根据前述条款中任一项所述的方法,其中所述检测步骤进一步包括用结合到所述第一等位基因变体的第一试剂和结合到所述第二等位基因变体的第二试剂标记含有或衍生自所述核酸群体的表面结合的第一核酸片段和第二核酸片段。52.根据条款51所述的方法,其中所述第一试剂包含抗体。53.根据条款51或52所述的方法,其中所述第一试剂包含第一靶序列的一部分的互补序列。54.根据条款51到53中任一项所述的方法,其中所述第一试剂进一步包含与所述互补序列缀合的识别元件。55.根据条款54所述的方法,其中所述识别元件是生物素。56.根据条款51到55中任一项所述的方法,其中所述第一试剂进一步包含荧光标记的抗生物素蛋白。57.根据条款51到56中任一项所述的方法,其中所述第一试剂进一步包含结合抗生物素蛋白的抗体。58.根据条款57所述的方法,其中结合抗生物素蛋白的所述抗体用生物素标记。59.根据条款51到58中任一项所述的方法,其中所述第一试剂进一步包含结合所述识别元件的抗体。60.根据条款59所述的方法,其中结合所述识别元件的抗体用报道分子标记。61.根据条款51到60中任一项所述的方法,其中所述第一试剂包含荧光团。62.根据条款61所述的方法,其中所述第一试剂的所述荧光团具有介于约640nm与约680nm之间的荧光发射峰。63.根据条款61或62所述的方法,其中所述第一试剂的所述荧光团为别藻蓝蛋白。64.根据条款51所述的方法,其中所述第二试剂包含所述第二靶序列的一部分的互补序列。65.根据条款64所述的方法,其中所述第二试剂进一步包含与所述互补序列缀合的识别元件。66.根据条款65所述的方法,其中所述识别元件是fam。67.根据条款64到66中任一项所述的方法,其中所述第二试剂进一步包含结合所述识别元件的第一抗体。68.根据条款64到66中任一项所述的方法,其中所述第二试剂进一步包含结合所述第一抗体的第二抗体。69.根据条款68所述的方法,其中所述第一抗体、所述第二抗体或所述第一抗体和所述第二抗体两者均用荧光团标记。70.根据条款69所述的方法,其中所述第二试剂的所述荧光团的具有介于约560nm与约600nm之间的荧光发射峰。71.根据条款70所述的方法,其中所述第二试剂的所述荧光团为别藻蓝蛋白。72.根据前述条款中任一项所述的方法,其中接触所述无细胞dna组合物的所述步骤在小于50μl的反应体积中进行。73.根据前述条款中任一项所述的方法,其中接触所述无细胞dna组合物的所述步骤在小于40μl的反应体积中进行。74.根据前述条款中任一项所述的方法,其中接触所述无细胞dna组合物的所述步骤在小于30μl的反应体积中进行。75.根据前述条款中任一项所述的方法,其中接触所述无细胞dna组合物的所述步骤在小于20μl的反应体积中进行。76.一种用{于检测胎儿拷贝数变异的试剂盒,其包含:a.捕获装置,所述捕获装置具有多个核酸片段,所述多个核酸片段对应于连接到所述核酸片段的至少一个染色体靶区域;b.多个分子探针,所述多个分子探针能够与包括主要亚群和次要亚群的混合核酸群体杂交,其中所述主要亚群和所述次要亚群各自包括位于第一染色体区域中并且含有多态性位点的靶序列,其中所述多态性位点可以包括第一核苷酸变体和第二核苷酸变体的组合;以及c.用于对所述多态性位点进行基因分型和检测所述多态性位点的说明书。77.根据条款74所述的试剂盒,其中所述捕获装置是微阵列。78.根据条款74或75所述的试剂盒,其中所述染色体靶区域位于染色体1、5、13、18、21、x和y中的一者或多者上。79.根据条款74到76中任一项所述的试剂盒,其中分子探针被设计成对染色体1、5、13、18、21、x和y中的一者或多者上的单核苷酸多态性进行基因分型。80.根据前述条款中任一项所述的方法,其中所述胎儿dna为所述核酸样品中总dna的约30%。81.根据前述条款中任一项所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的30%。82.根据前述条款中任一项所述的方法,其中所述胎儿dna超过所述核酸样品中总dna的30%。83.一种用于检测胎儿中的拷贝数的方法,其包含:从作为怀孕女性的受试者获得生物样品,所述生物样品包含了含有位于第一染色体上的靶核酸序列的母体来源和胎儿来源两者的核酸,所述靶核酸序列含有单核苷酸多态性(snp)的多态性位点;生成含有或衍生自所述靶核酸序列的核酸片段群;进行第一测定,所述第一测定包含:(a)使所述核酸片段群与含有第一寡核苷酸探针的寡核苷酸阵列接触,所述第一寡核苷酸探针被配置成与含有所述snp的所述多态性位点的所述靶核酸序列杂交;以及(b)使用检测器检测第一信号和第二信号,所述第一信号指示所述寡核苷酸探针与所述群体的含有所述snp的第一等位基因变体(“a等位基因”)的一个或多个核酸片段杂交,所述第二信号指示所述寡核苷酸探针与所述群体的含有所述snp的第二等位基因变体(“b等位基因”)的一个或多个核酸片段杂交;以及使用所述第一信号和所述第二信号确定以下任何一者或多者:(i)胎儿中所述第一染色体的拷贝数;(ii)所述snp的胎儿基因型;(iii)所述snp的母体基因型;以及(iv)所述样品的胎儿分数。84.根据条款83所述的方法,其进一步包含针对存在于所述样品中的所述snp的所述等位基因变体,计算观察到的b等位基因频率(baf)。85.根据条款84所述的方法,其进一步包括使用所述baf计算所述样品的所述胎儿分数。86.根据条款84所述的方法,其中所述snp的所述多态性位点可以对所述a等位基因(“aa”)是纯合的,对所述b等位基因(“bb”)是纯合的或是杂合的(“ab”)。87.根据条款83到86中任一项所述的方法,其中所述检测器具有第一检测通道和第二检测通道,并且所述基因分型进一步包括在所述第一通道中检测所述第一信号并且在所述第二通道中检测所述第二信号。88.根据条款87所述的方法,其中所述第一通道中的所述第一信号指示所述核酸群体中存在的a等位基因的量,并且所述第二信号指示核酸群体处存在的b等位基因的量。89.根据条款88所述的方法,其中确定胎儿中所述第一染色体的所述拷贝数包含确定第一值与第二值的比率。90.根据条款86所述的方法,其进一步包括确定第一母体snp基因型。91.根据条款83所述的方法,其中所述核酸样品包括母体血液、血浆或血清,并且母体来源和胎儿来源两者的所述核酸包括无细胞dna(cfdna)。92.根据条款83所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的20%。93.根据条款83所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的15%。94.根据条款83所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的10%。95.根据条款83所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的5%。96.根据条款83所述的方法,其中所述胎儿dna不大于所述核酸样品中的总无细胞dna的15%并且不小于1%。97.根据条款83所述的方法,其中所述胎儿dna为所述核酸样品中总dna的约30%。98.根据条款83所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的30%。99.根据条款83所述的方法,其中所述胎儿dna超过所述核酸样品中总dna的30%。100.根据条款89所述的方法,其进一步包含通过以下方式计算所述第一值:归一化并汇总所述第一信号以获得归一化且汇总的第一信号值;归一化所述第二信号以获得归一化且汇总的第二信号值;以及将所述归一化且汇总的第一信号值添加到归一化且汇总的第二信号值以获得所述第一值。101.根据条款100所述的方法,其中通过以下方式获得所述第二值:对充当参考样品的额外生物样品进行第一测定,并且鉴定具有与所述第一母体snp基因型相对应的snp基因型的参考样品;根据对所述参考样品进行所述第一测定,关于所述额外生物样品获得在所述第一通道中检测到的指示所述snp的所述多态性位点中存在的a等位基因的量的第一信号参考信号,并且获得指示所述多态性位点处存在的b等位基因的量的第二参考信号。102.根据条款101所述的方法,其中所述额外生物样品来自非怀孕个体。103.根据条款101所述的方法,其中所述额外生物样品包括来自怀孕女性的一些样品和来自非怀孕个体的一些样品。104.根据条款101所述的方法,其中所述额外生物样品包括来自怀孕女性的在与来自所述作为怀孕女性的受试者的所述生物样品相同的寡核苷酸阵列上测定的样品。105.一种用于分析从生物获得的混合核酸样品的方法,其包含:从生物获得或衍生含有混合核酸群体的核酸样品,所述混合核酸群体包括主要亚群和次要亚群,所述主要亚群和所述次要亚群各自包括位于第一染色体区域中并且含有多态性位点的靶序列,其中所述多态性位点可以包括第一核苷酸变体和第二核苷酸变体的任何组合;以及对所述多态性位点进行基因分型,其中所述基因分型包括:(a)将衍生自所述混合核酸群体的并且含有所述多态性位点的至少一个核酸片段与寡核苷酸阵列的寡核苷酸探针杂交;以及(b)使用检测器从所述寡核苷酸阵列检测指示第一核苷酸变体存在或不存在的第一信号(“a信号”)和指示第二核苷酸变体存在或不存在的第二信号(“b信号”)。106.根据条款105所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述次要亚群中所述第一染色体区域的拷贝数。107.根据条款105所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述主要亚群中所述第一染色体区域的拷贝数。108.根据条款105所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述次要亚群的所述多态性位点的基因型。109.根据条款105所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述主要亚群的所述多态性位点的基因型。110.根据条款105所述的方法,其进一步包括使用所述第一信号和所述第二信号确定所述混合核酸群体中所述主要亚群和所述次要亚群的相对量。111.根据前述条款中任一项所述的方法,其中所述主要亚群和所述次要亚群源自所述生物中的不同来源。112.根据条款105所述的方法,其中所述检测器包括第一检测通道和第二检测通道,并且所述方法进一步包括检测所述第一检测通道中所述第一信号和所述第二检测通道中所述第二信号的步骤。113.根据前述条款中任一项的方法,其中所述混合核酸群体包括无细胞dna。114.根据条款111所述的方法,其中所述无细胞dna是从所述生物的血液、血浆、血清、尿液、粪便或唾液获得或衍生的。115.根据前述条款中任一项所述的方法,其中所述生物包括肿瘤,所述主要亚群包括或衍生自正常组织并且所述次要亚群包括或衍生自所述肿瘤。116.根据上述条款中任一项所述的方法,其中所述生物是怀孕女性,所述混合核酸群体是从所述女性的血液获得的无细胞核酸,所述主要亚群是母体核酸并且所述次要亚群包括或衍生自胎儿核酸。117.根据条款116所述的方法,其中所述次要亚群包括胎儿dna,所述胎儿dna按不大于所述核酸样品中总dna的40%存在。118.根据条款116所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的25%。119.根据条款116所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的15%。120.根据条款116所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的5%。121.根据条款116所述的方法,其中所述胎儿dna不大于所述核酸样品中总无细胞dna的15%并且不小于1%。122.根据条款116所述的方法,其中所述胎儿dna为所述核酸样品中总dna的约30%。123.根据条款116所述的方法,其中所述胎儿dna不大于所述核酸样品中总dna的30%。124.根据条款116所述的方法,其中所述胎儿dna超过所述核酸样品中总dna的30%。125.根据前述条款中任一项所述的方法,其中所述混合核酸群体含有或衍生自无细胞dna,所述无细胞dna在所述生物的血液中按不大于5ng/ml并且不小于0.1ng/ml的浓度存在。126.根据条款105所述的方法,其中所使用的混合核酸群体的量不大于50ng、40ng、30ng、15ng、10ng、5ng、3ng、或1ng。127.根据条款105或116所述的方法,其中所述多态性位点包括双等位基因snp,所述第一核苷酸变体是所述snp的第一等位基因变体(“a等位基因”)并且所述第二核苷酸变体是所述snp的第二等位基因变体(“b等位基因”)。128.根据条款127所述的方法,所述双等位基因snp可以包括所述第一等位基因变体(“a等位基因”)或所述第二等位基因变体(“b等位基因”)中的一者或两者,并且其中所述snp基因型可以对所述a等位基因(“aa”)是纯合的,对所述b等位基因(“bb”)是纯合的或是杂合的(“ab”)。129.根据条款127所述的方法,其进一步包括针对所述核酸样品中的所述snp,计算观察到的b等位基因频率(baf)。130.根据条款129所述的方法,其进一步包括使用所述baf计算所述样品的所述胎儿分数。131.根据条款105或116所述的方法,其中所述第一信号指示所述多态性位点中存在的a等位基因的量并且所述第二信号指示所述多态性位点处存在的b等位基因的量。132.根据条款105、116或131所述的方法,其中所述生物是怀孕女性,并且其中所述方法进一步包括通过确定第一值与第二值的比率来确定胎儿中所述第一染色体区域的拷贝数。133.根据条款132所述的方法,其进一步包括通过将所述第一信号或其归一化值与所述第二信号或其归一化值相加来计算所述第一值。134.根据条款133所述的方法,其进一步包括使用所述第一信号和所述第二信号来确定第一母体snp基因型。135.一种方法,其包括:使用来自怀孕女性的一个或多个额外的生物样品执行根据条款134所述的方法并且鉴定具有与所述第一母体snp基因型相对应的snp基因型的额外生物样品的子集;以及通过以下方式获得第二值:从另外的生物样品的所述子集中的每个额外样品取得a信号与b信号的总和并且获得所述总和的中间值作为所述第二值。136.根据条款105、115或116所述的方法,其中所述多态性位点包括核苷酸突变,所述第一核苷酸变体是所述靶核酸序列的突变形式,并且所述第二核苷酸变体是所述多态性位点的野生型形式,所述a信号指示突变形式的量并且所述b信号指示所述样品中野生型形式的量。137.一种用于检测核酸样品中拷贝数变异的系统,所述系统包含:探针微阵列;扫描仪;处理器;以及用指令编码的存储器,所述指令用于实施前述权利要求83到136中任一项所提及的处理。138.一种位于非暂时性计算机可读介质中的计算机程序产品,其存储有指令,所述指令用于实施前述条款83到137中任一项所提及的处理。附图说明图1是根据本公开的用于分析混合核酸样品的方法的图解视图,所述图解视图示出了将混合核酸样品分离成a/t通道和c/g通道,并且然后重新组合若干个步骤,之后用于杂交和染色步骤。图2是在根据本公开的方法中使用的分子倒置探针(mip)的图解视图。图3是mip过程的图解视图,所述图解视图从左到右示出了mip在snp位置上与核酸结合,所述snp位置被间隙填充并连接以形成环化mip;处理所述核酸样品与核酸外切酶;切割所述环化mip;扩增所述经切割mip的一部分;并且消化所述扩增产物。图4是使用寡核苷酸阵列杂交图3所示的扩增产物进行和染色的图解视图,所述图解视图示出了与寡核苷酸阵列上的探针杂交的扩增产物,并且进一步示出了用第一染料或第二染料检测所述经杂交产物。图5展示了根据本发明的实施例的样品处理系统。图6展示了根据本发明的实施例的由图5的系统实施的参考样品处理器的高级框图。图7展示了根据本发明的实施例的由图5的系统实施的受试者样品处理器的高级框图。图8展示了根据本发明的实施例的参考样品处理方法。图9展示了根据本发明的实施例的受试者样品处理方法。图10展示了可由计算机程序产品配置的以执行本发明的实施例的示例性计算机系统。虽然参考以上图式描述了本发明,但是附图旨在是说明性的,并且其它实施例与本公开的精神一致,并且处于本公开的范围内。具体实施方式本公开具有许多优选实施例,并且本公开由于本领域技术人员已知的细节的原因依赖于许多专利、申请和其它参考文献。因此,当在下面引用或重复专利、申请或其它参考文献时,应当理解,出于所有目的以及所陈述的主张通过引用将其整体并入本文。贯穿本公开,可以以范围格式呈现本公开的各个方面。应当理解,采用范围格式的描述仅仅是出于方便和简洁的目的,并且不应该将其解释为是对本公开的范围的非灵活限制。因此,应将范围描述视为具有确切公开的所有可能的子范围以及所述范围内的单个数值。例如,应将如从1至6的范围的描述视为具有确切公开的子范围,如从1到3、从1到4、从1到5、从2到4、从2到6、从3到6等,以及该范围内的单个数字,例如1、2、3、4、5和6。无论范围的有多广,此均适用。除非另外说明,否则本公开的实践可以采用在本领域技术范围内的有机化学、聚合物技术、分子生物学(包括重组技术)、细胞生物学、生物化学以及免疫学的常规技术和描述。此类常规技术包括聚合物阵列合成、杂交、连接和使用标记物检测杂交。合适技术的具体说明可以参考本文下述实例。然而,当然也可以使用其它等效的常规程序。此类常规技术和说明可以在以下标准实验室手册中找到:如《基因组分析:实验室手册系列(第i到iv卷)(genomeanalysis:alaboratorymanualseries(vols.i-iv))》):《使用抗体:实验室手册(usingantibodies:alaboratorymanual)》,《细胞:实验室手册(cells:alaboratorymanual)》《pcr引物:实验室手册(pcrprimer:alaboratorymanual)》《分子克隆:实验室手册(:alaboratorymanual)》(全部由冷泉港实验室出版社(coldspringharborlaboratorypress)出版),stryer,l.(1995),生物化学(biochemistry)(第4版),freeman,纽约,gait,《寡核苷酸合成:一种实用方法(oligonucleotidesynthesis:apracticalapproach”,1984,irl出版社,伦敦,nelson和cox(2000),lehninger,《生物化学原理(principlesofbiochemistry)》(第三版),w.h.freeman出版社,纽约,纽约州,和berg等,(2002)《生物化学(biochemistry)》(第5版),w.h.freeman出版社,纽约,纽约州,出于所有目的将其全部内容通过引用整体并入本文。定义如在本申请中所用的,单数形式“一个/一种(a、an)”和“所述(the)”包括复数个提及物,除非上下文另外明确指明。例如,术语“试剂”包括多种试剂(包括其混合物)。出于所有目的将本文引用的所有参考文献通过引用以其整体并入本文。就任何参考文献包含以与本文阐述的定义和公开不一致的方式定义或使用权利要求术语而言,以本申请的定义和公开内容为准。如本文所用的,“等位基因”是指细胞、个体或群体中核酸序列(如基因)的一种特定形式,所述特定形式与所述基因的序列中至少一个(通常不止一个)变异位点的核酸序列中相同基因的其它形式不同。在这些变异位点上,不同等位基因之间不同的序列被称为“变异”、“多态性”“突变”。序列中的变体可以作为snp、snp的组合、单倍型甲基化模式、插入、缺失等的结果而出现。等位基因可以包含单个核苷酸的变体形式、来自染色体上关注区域的核苷酸连续序列的变体形式或来自关注染色体区域的多个单核苷酸(不一定都是连续的)的变体形式。在每个常染色体特定的染色体位置或“基因座”,一个从双亲中的一方继承,另一个从双亲中的另一方继承,例如一个遗传自母亲,一个遗传自父亲。如果一个个体在一个基因座上有两个不同的等位基因,则这个个体在所述基因座上就为“杂合的”。如果一个个体在一个基因座上有两个相同的等位基因,则这个个体在所述基因座上就为“纯合的”。如本文所用的,“阵列”或“微阵列”包含支持物,优选为固体支持物,核酸探针连接到所述支持物。优选的阵列通常包含多个不同的在不同的已知位置偶联到底物表面的核酸探针。这些[1}阵列{2}也被描述为“微阵列”或通俗地称为“芯片”,本领域中已经对其进行了广泛的描述,例如美国专利第5,143,854号、5,445,934号、第5,744,305号、第5,677,195、第5,800,992号、第6,040,193号、第5,424,186号和fodor等人,《科学(science)》,251:767-777号(1991)。出于所有目的,其各自通过引用以其整体并入本文。所述探针可以为任何大小或任何序列,并且可以包括合成核酸,及其类似物或衍生物或修饰,只要所得的阵列可以在任何合适的条件下与具有足够特异性的核酸样品杂交以区分样品的不同靶核酸序列即可。在一些实施例中,所述阵列的探针的长度为至少5、10或20个核苷酸。在一些实施例中,所述探针的长度不超过25、30、50、75、100、150、200或500个核苷酸。例如,所述探针的长度可以介于10与100个核苷酸之间。阵列通常可以使用多种技术生产,例如机械合成方法或结合光刻方法和固相合成方法的光导向合成方法。在例如美国专利第5,384,261号和第6,040,193号中描述了使用机械合成方法合成这些阵列的技术,所述美国专利出于所有目的以全文引用的方式并入本文中。尽管优选平面阵列表面,但是可以将所述阵列构建在实际上为任何形状的表面上或甚至多个表面上。阵列可以为三维基质、珠、凝胶、聚合物表面、纤维(如光纤)、玻璃或任何其它合适的底物上的核酸(参见美国专利第5,770,358号、第5,789,162号、第5,708,153号、第6,040,193号和第5,800,992号,所述美国专利出于所有目的以全文引用的方式并入本文中)。在一些实施例中,可结合本文所述的方法和系统使用的阵列包含可从赛默飞世尔科技公司(thermofisherscientific)(前身为艾菲矩阵公司(affymetrix))商购获得的、品牌名称为的阵列,用于多种目的,包含多种真核物种和原核物种的基因分型和基因表达监测。阵列随附的手册中公开了用于制备用于杂交到阵列的样品的方法和杂交条件,例如,制造商提供的与产品(例如ffpe测定试剂盒及相关产品)相关的手册。如本文所用,“无细胞核酸”是指在生物内存在但不包括在任何完整细胞内的核酸分子。所述无细胞核酸可以包括dna(“无细胞dna”)或rna(“无细胞rna”)或其衍生物或类似物。所述无细胞核酸可以从血液、血浆、唾液或尿液中获得。所述无细胞dna或rna可以包括循环的无细胞dna或rna,即在血液的血浆部分中发现的无细胞dna或rna。应当理解,本领域技术人员已知许多用于从样品(如人血浆、血清、尿液、粪便或唾液)中获得无细胞dna的方法和试剂盒。如本文所用的,“基因组”指代或表示编码到生物的dna中的生物的完整的单拷贝基因指令集。基因组可以为多染色体的,使得所述dna在细胞中分布在多个单独的染色体之间。例如,在人体中,有22对染色体,外加与性别相关的xx或xy对。如本文所用的,“基因分型”是指从一个或多个核苷酸位置处的核酸样品中确定核酸序列信息。所述核酸样品可以包括或衍生自任何合适的来源(包括基因组或转录组)。在一些实施例中,基因分型可以包含确定个体在一个或多个多态性位点携带哪个或哪些等位基因。例如,基因分型可以包括或确定个体携带一组多态性位点中的一个或多个snp的哪个或哪些等位基因。例如,在一些个体中,基因组中的特定核苷酸可以为a,而在其它个体中其可以为c。在所述位置具有a的个体具有a等位基因,而具有c的个体具有b等位基因。在二倍体生物中,个体将具有包括多态性位置的序列的两个拷贝,因此所述个体可以具有a等位基因和b等位基因,或者具有a等位基因的两个拷贝或b等位基因的两个拷贝。具有b等位基因的两个拷贝的个体对b等位基因是纯合的,具有a等位基因的两个拷贝的个体对b等位基因是纯合的,具有每种等位基因的一个拷贝的个体是杂合的。可以将阵列设计为在这三种可能结果中的每一种之间进行区分。多态性位置可以具有两个或更多个可能的等位基因,并且可以将所述阵列设计为区分所有可能的组合。在一些实施例中,基因分型包括在野生型核酸的情况下检测在基因组中自发出现的单核苷酸突变。在一些实施例中,基因分型包括从母体血液样品中确定胎儿血型。任选地,基因分型包括检测人体血液中是否存在肿瘤。在一些实施例中,可以通过其它技术(如测序)加工包括关注的序列(例如一个或多个snp或突变)的一个或多个多核苷酸(或多核苷酸的一部分或多个部分、多核苷酸的扩增产物或多核苷酸的补体)。因此,在一些实施例中,可以对多核苷酸进行测序以进行基因分型或确定是否存在多态性或突变。测序可以通过本领域中各种可用的方法完成,例如sanger测序方法,其可通过美国应用生物系统公司(appliedbiosystems)的基因分析仪进行,或通过下一代测序(ngs)方法(例如赛默飞世尔科技公司的iontorrentngs或illuminangs)进行。术语“染色体”是指活细胞的衍生自染色质的并包括dna和蛋白质组分(特别是组蛋白)的遗传性基因载体。本文采用了常规国际公认的个体人类基因组染色体编号系统。对于给定的多染色体基因组,单个染色体的大小可以因类型而异,也可以因基因组而异。对于人类基因组,给定染色体的整个dna质量通常大于100,000,000bp。例如,整个人类基因组的大小约为3×109bp。最大染色体(染色体编号1)包括约2.4×108bp,而最小的染色体(染色体编号22)包括约5.3×107bp。在一些实施例中,与本公开的方法和系统相关的关注染色体包括与染色体异常相关的那些染色体,如染色体13、18、21、x和y。还应当理解,与特定染色体异常(例如非整倍性)不相关的其它染色体作为参考染色体结合本公开的方法和系统可能受到关注。应当理解,参考染色体可以是基因组中与特定染色体异常(如非整倍性)无关的任何染色体,如染色体1和5。如本文所用的,“染色体区域”是指染色体的一部分。任何单个染色体区域的实际物理尺寸或范围都可能有很大差异。术语“区域”不一定是特定的一个或多个基因的定义,因为区域不必特别考虑单个基因的特定编码片段(外显子)。在一些实施例中,染色体区域包括至少一个多态性位点。如本文所用的,“染色体异常”或“染色体畸形”可以包括任何遗传异常,包括但不限于非整倍性,如21三体(又称为唐氏综合症);18三体(又称为爱德华兹综合症);13三体(又称为巴陶氏综合症);xxy(又称为克氏综合症(klinefelter'ssyndrome));18单体;x(又称为特纳综合症);xyy(又称为雅各氏综合症)或xxx(又称为x三体);与流产可能性增加有关的三体(例如15、16或22三体);等等,以及其它遗传变异,如突变、插入、添加、缺失、易位、点突变、三核苷酸重复障碍和/或snp。尽管本公开描述了与胎儿染色体异常的检测有关的某些实例和实施例,但是应当理解,本文描述的方法和系统可以用于检测其它疾病状态(如癌症)中的染色体异常。如本文所用的,“母体样品”可以为从妊娠哺乳动物得到的包括胎儿和母体无细胞dna两者的任何样品。优选地,用于本公开的母体样品是通过相对非侵入性的方式获得的,例如采血、收集唾液或尿液,或其它用于从受试者提取外围样品的标准技术。如本文所用的,“核苷酸”是指糖基磷酸糖组合。核苷酸为核酸序列(dna和rna)的单体单元。术语核苷酸包括核糖核苷三磷酸atp、utp、ctg、gtp和脱氧核糖核苷三磷酸(dntp),如datp、dctp、ditp、dutp、dgtp、dttp或其衍生物。此类衍生物包括例如[αs]datp、7-脱氮-dgtp和7-脱氮-datp、以及在含有这些衍生物的核酸分子上赋予核酸酶抗性的核苷酸衍生物。如本文所用的,术语核苷酸还指双脱氧核苷三磷酸酯(ddntp)和其衍生物。双脱氧核苷三磷酸酯的说明性实例包括但不限于ddatp、ddctp、ddgtp、dditp和ddttp。如本文所用的,“多态性”是指群体中出现两个或更多个遗传确定的替代性序列。所述替代性序列可以包括仅在一个或几个单独的生物中出现的等位基因(例如自然发生的变异)或自发产生的突变。“多态性位点”可以指一个或多个发生核酸序列差异的核酸位置。多态性可以包含一个或多个碱基改变、插入、重复或缺失。多态性基因座可以与一个碱基对一样小。多态性位点包含限制片段长度多态性、可变串联重复数(vntr)、高变区、小卫星、二核苷酸重复、三核苷酸重复、四核苷酸重复、简单序列重复和插入元件。将第一个识别出的变体或等位基因形式任意指定为参考形式,将其它变体或等位基因形式指定为替代性或变体或突变等位基因。在选定核酸群体中出现最频繁的变体或等位基因形式有时被称为野生型形式。在一些实施例中,可以将所述野生型形式称为“主要亚群”,而可以将突变称为ta“次要亚群”。在一些实施例中,可以将出现更频繁的等位基因称为“主要亚群”,而可以将更罕见或出现更不频繁的等位基因称为“次要亚群”。二倍体生物的等位基因形式可以为纯合的或杂合的。双列多态性具有两种形式。三链多态性具有三种形式。两种核酸之间的多态性可以自然发生,也可以是由暴露于化学物质、酶或其它试剂或与之接触引起,或者由暴露于对核酸造成损伤的试剂(例如紫外线辐射、诱变剂或致癌物)引起。snp是人类群体中两个替代性碱基以明显的频率(>1%)出现的位置,并且是最常见的人类遗传变异类型。如本文所用的,“从生物获得的样品”包括但不限于几乎任何生物的任何数量的组织或体液,如血液、尿液、血清、血浆、淋巴液、唾液、粪便和阴道分泌物。在一些实施例中,从生物获得的样品可以为哺乳动物的样品。并且在一些实施例中,从生物获得的样品可以为人类的样品。在一些实施例中,从生物获得的样品可以为母体样品。基因分型在一些实施例中,本公开中描述的方法包括基因分型的步骤。基因分型可以包括确定靶核酸序列内至少一个核苷酸的序列。在一些实施例中,基因分型的步骤涉及分析包括主要亚群和次要亚群的混合核酸群体,其中主要亚群和次要亚群各自包括位于第一染色体区域并包括多态性位点的靶序列。在一些实施例中,本文所述的方法用于对主要亚群进行基因分型。在一些实施例中,本文所述的方法用于对次要亚群进行基因分型。在一些实施例中,本文描述的方法用于对主要亚群和次要亚群两者进行基因分型。应当理解,基因分型可以以任何有助于鉴定核酸样品的靶序列中多态性位点的方式实施。在一些实施例中,可结合本公开使用的基因分型方法包括可用于snp检测方法。用于snp检测的平台在本领域是众所周知的。合适的基因分型方法包括单核苷酸延伸的变型、使用等位基因特异性探针、基于连接的等位基因鉴别等。在基于阵列的测定中,可以使用多种基因分型方法。在一些实施例中,将阵列表面分成多个特征,每个特征包括多个位点,这些位点包括被配置为结合到特定靶核酸序列的基本相同的寡核苷酸的拷贝。可以检测和定量核酸分子与阵列上不同位置的杂交。一种合适的方法是使用任何包括仅选择性地结合到某些等位基因而不结合到其它等位基因的等位基因特异性探针的阵列。在其它实施例中,阵列包括探针,其与等位基因的所有不同形式非选择性结合,但是随后以等位基因特异性方式延伸或修饰以产生等位基因特异性产物。例如,可以通过模板依赖性核苷酸聚合将阵列的探针延长。替代性地,可以通过标签寡核苷酸的序列依赖性连接将探针延长,所述标签寡核苷酸可以包括信号产生部分。仍然可以在阵列外产生等位基因特异性产物(例如,等位基因特异性核苷酸延伸产物或连接产物),然后与包括在各种延伸产物之间进行区分的探针的阵列杂交。可以检测和定量从阵列发出的指示核酸分子与特定阵列探针杂交的信号。基因分型阵列产品的实例包括affymetrix阵列和affymetrixoncoscan阵列(赛默飞世尔科技公司(thermofisherscientific))以及illumina的和阵列。基于合适的阵列的基因分型方法在以下文献中进行了描述:例如hoffman等人,《基因组学(genomics)》,98(2):79-89(2011)和shen等人,《突变研究(mutationresearch)》,573:70-82(2005),两者均以其整体并入本文。一种用于对核酸序列的变异进行基因分型的方法(包括通过使用微阵列)是分子转化探针(mip)测定。参见例如美国专利第6,858,412号,其总体上与mip测定实施相关,该专利通过引用以其整体并入本文。通常,mip探针至少包括5'-靶序列、3'-靶序列、5'-引物位点和/或3'-引物位点、标签序列和一个或多个切割位点。在一个示例性实施例中,可结合本公开使用的mip探针可以如图2所示表示。图2的mip探针包括对应于作为已知snp基因座的染色体区域上的靶序列的基因组同源性1和基因组同源性2。基因组同源性1和基因组同源性2被设计成在探针已经与核酸片段(例如无细胞dna片段)杂交之后在探针中具有一个核苷酸间隙。可与本公开的一些实施例结合使用的mip探针除了包括基因组同源性1和基因组同源性2之外,还包括第一引物结合位点和第二引物结合位点、标签序列和两个分裂位点。应当理解的是,可将mip探针汇集物应用于本文所述的方法和系统,用于在混合核酸样品中对snp进行多重检测。例如,在一些实施例中,可以从可商购获得的mip探针组中采集mip探针汇集物,所述mip探针组与可从赛默飞世尔科技公司获得的产品结合使用。例如,在一些实施例中,可以从所述产品中采集对应于染色体13、18、21、x和y中的snp基因座的约48,000个mip探针的汇集物。另外,可以理解的是,可以从产品中采集额外mip探针汇集物(如对应于染色体1和5上的snp基因座的mip探针),以用作参考探针。在一些实施例中,所述mip探针汇集物中至少50%、至少60%或至少70%的mips与来自染色体1、5、13、18、21、x和y的dna片段结合。在一些实施例中,所述mip探针汇集物包含至少1,000个mips、至少5,000个mips、至少10,000个mips或至少20,000个mips。在一些实施例中,所述mip探针汇集物包含少于200,000个、少于100,000个或少于80,000个mips。图3示出了可结合本公开使用的示例性mip测定过程。简而言之,在复性步骤中,可以将所述mip探针与位于包括多态性位点的第一染色体区域中的靶序列杂交。复性步骤可以根据本领域中通常公知的任何方法实施,尤其是可以根据可商购获得的mip探针组的制造商说明书进行。复性步骤提供多个线性分子倒置探针-dna片段的复合物,使得基因组同源性1序列和基因组同源性2序列与含有多态性位点的染色体区域杂交,并且杂交探针末端之间有一个核苷酸间隙。在一些实施例中,dna片段或混合核酸群体的总量小于50ng、小于40ng、小于30ng、小于20ng、小于15ng或小于10ng。在一些实施例中,mips的总数与dna片段拷贝的总数的比率为至少约15,000:1或至少约30,000:1。在一些实施例中,mips的总数与dna片段拷贝的总数的比率小于100,000:1或小于60,000:1。在一些实施例中,mips的总数与dna片段拷贝的总数的比率为约40,000:1。在一些实施例中,复性步骤以小于50μl、小于40μl、小于30μl、小于20μl或小于15μl的反应体积进行。在一些实施例中,所述反应体积为至少5μl或至少10μl。在一些实施例中,混合核酸群体含有或衍生自存在于生物的血液、血清和/或血浆中的浓度为不大于5ng/ml且不低于0.1ng/ml的无细胞dna。在一些实施例中,混合核酸群体含有或衍生自存在于生物的血液、血清和/或血浆中的浓度为小于5ng/ml、小于4ng/ml、小于3ng/ml、小于2ng/ml、小于1ng/ml、小于0.5ng/ml或小于0.3ng/ml的无细胞dna。在一些实施例中,混合核酸群体含有或衍生自存在于生物的血液、血清和/或血浆中浓度为大于0.1ng/ml、大于0.2ng/ml、大于0.3ng/ml、大于0.5ng/ml、大于1ng/ml、大于2ng/ml或大于3ng/ml的无细胞dna。在完成复性步骤之后,可以将复性混合物分成或不分成第一通道和第二通道,取决于特定的基因分型应用。在一些实施例中,可以将复性混合物分成第一通道和第二通道(如图1所示)。在此实施例中,将复性混合物分成第一通道组成和第二通道组成,其可以通过基因分型过程继续进行。在一些实施例中,不将复性混合物分成第一通道和第二通道,而是作为单个反应进行。在一些实施方案中,可以对复性混合物进行连接步骤(也称为“间隙填充”步骤),以在线性分子mip的基因组同源性1和基因组同源性2之间的间隙中掺入核苷酸,如图3所示。间隙填充反应可以用本领域中任何已知的方法实现。例如,可以将脱氧核苷酸(datp、dctp、dgtp、dttp、dutp)的混合物以及聚合酶、连接酶和反应成分添加到反应混合物中,在约60℃下孵化约10分钟,随后在37℃下孵化其它约1分钟。复性和连接后,mip可能会环化。在一些实施例中,添加到第一和第二通道中的核苷酸可以是相同的或不同的。在一些在向间隙填充反应中添加不同的脱氧核苷酸组是有利的实施例中,添加到所述通道中的一个的脱氧核苷酸可以为datp和dttp,而添加到另一个通道中的脱氧核苷酸可以为dctp和dgtp。应当理解,可以将不同的脱氧核苷酸混合物添加到任一通道。以这种方式,每个通道可以选择性地检测第一环化探针组合物和第二环化探针组合物中的不同snp等位基因。在一些实施例中,信道可以基本上不含dgtp、dctp或其混合物。在一些实施例中,信道可以基本上不含datp、dttp或其混合物。应当理解,在间隙填充步骤中使用的连接酶不是特别优选的,并且可以为本领域已知的任何连接酶,并且可以基于本领域任何已知的标准方案。许多连接酶是已知的,并且适用于与本公开结合用于间隙填充反应。参见例如,lehman,《科学(science)》,186:790-797(1974);engler等人,《dna连接酶(dnaligases)》,第3-30页,boyer编辑,《酶(theenzymes)》,第15b卷,(学术出版社(academicpress),纽约,1982);等等。用于mip间隙填补反应的可选连接酶包括但不限于t4dna连接酶、t7dna连接酶、大肠杆菌dna连接酶、taq连接酶、pfu连接酶和tth连接酶。使用此类连接酶的方案是公知的(参见例如,barany,《pcr方法和应用》,1:5-16(1991);marsh等人,《策略(strategies)》,5:73-76(1992);等等)。在一些实施例中,所述连接酶可以为热稳定的或(嗜热)连接酶,如pfu连接酶、tth连接酶、taq连接酶和扩增酶tmdna连接酶(epicentretechnologies,麦迪逊,威斯康星州)。在一些实施例中,当存在一种以上的相应环化探针组合物时,可以对其进行核酸外切酶消化步骤,如图3所示。核酸外切酶消化步骤的目的是从生物获得的核酸样品中将任何剩余的核酸片段消化/去除,并将任何剩余的未环化的mip消化/去除。应当理解,这一任选的消化步骤可以通过去除可能干扰pcr反应的核酸片段来改善随后的pcr扩增,或者可以形成干扰这一过程中稍后对样品进一步处理的嵌合产物。合适的3'核酸外切酶包括但不限于核酸外切酶i、核酸外切酶iii、核酸外切酶vii、核酸外切酶v和聚合酶,因为许多聚合酶都具有出色的核酸外切酶活性等。在任选除去未环化的mips片段和dna片段后,可将环化探针(在一些实施方案中为第一环化探针和第二环化探针)切割以形成第一线性化探针组合物和第二线性化探针组合物。应当理解,切割可以根据本领域已知的适用于结合本教导使用的任何方法来完成。在一些实施例中,一个或多个环化探针(例如第一和/或第二环化探针)是单链的。在一些实施例中,所述个或多个环化探针是双链的。在一些实施例中,将环化探针切割以形成线性化探针。在一些实施例中,存在一种或多种用于将探针线性化的酶。在一些实施例中,可以使用能够切割单链核酸的酶来将所述探针线性化。在一些实施例中,这种切割单链核酸的酶是尿嘧啶-n-糖基化酶。在一些其它实施例中,可以使用一种或多种限制酶来将所述探针线性化。在一些实施例中,切割的步骤可以通过向线性化探针组合物中添加酶(如尿嘧啶-n-糖基化酶或{}限制酶)来催化a,并且在一些实施例中,第一和第二线性化探针组合物将圆形探针切割以形成第一线性化探针组合物和第二线性化探针组合物。合适的限制酶包含但不限于aatii、acc65i、acci、acii、acli、acui、afei、aflii、afliii、agei、ahdi、alei、alui、alwi、alwni、apai、apali、apeki、apoi、asci、asei、asisi、avai、avaii、avrii、baegi、baei、bamhi、bani、banii、bbsi、bbvci、bbvi、bcci、bceai、bcgi、bcivi、bcli、bfai、bfuai、bfuci、bgli、bglii、blpi、bmgbi、bmri、bmti、bpmi、bpul0i、bpuei、bsaai、bsabi、bsahi、bsai、bsaji、bsawi、bsaxi、bscri、bscyi、bsgi、bsiei、bsihkai、bsiwi、bsli、bsmai、bsmbi、bsmfi、bsmi、bsobi、bsp1286i、bspcni、bspdi、bspei、bsphi、bspmi、bspqi、bsrbi、bsrdi、bsrfi、bsrgi、bsri、bsshii、bsski、bsssi、bstapi、bstbi、bsteii、bstni、bstui、bstxi、bstyi、bstz17i、bsu36i、btgi、btgzi、btsci、btsi、cac8i、clai、cspci、cviaii、cviki-1、cviqi、ddci、dpni、dpnii、drai、draiii、drdi、eaci、eagi、eari、ecii、eco53ki、econi、ecoo109i、ecop15i、ecori、ecorv、fati、faui、fnu4hi、foki、fsei、fspi、haeii、haeiii、hgai、hhai、hincii、hindiii、hinfi、hinpli、hpai、hpaii、hphi、hpy166ii、hpy188i、hpy188iii、hpy99i、hpyav、hpych4iii、hpych4iv、hpych4v、kasi、kpni、mboi、mboii、mfei、mlui、mlyi、mmei、mnli、msci、msei、msli、mspali、mspi、mwoi、naei、nari、nb.bbvci、nb.bsmi、nb.bsrdi、nb.btsi、ncii、ncoi、ndei、ngomiv、nhei、nlaiii、nlaiv、nmeaiii、noti、nrui、nsii、nspi、nt.alwi、nt.bbvci、nt.bsmai、nt.bspqi、nt.bstnbi、nt.cvipii、paci、paer7i、pcii、pflfi、pflmi、phoi、plei、pmei、pmli、ppumi、pshai、psii、pspgi、pspomi、pspxi、psti、pvui、pvuii、rsai、rsrii、saci、sacii、sali、sapi、sau3ai、sau96i、sbfi、scai、scrfi、sexai、sfani、sfci、sfii、sfoi、sgrai、smai、smli、snabi、spei、sphi、sspi、stui、styd4i、styi、swai、t、taqαi、tfii、tlii、tsei、tsp45i、tsp509i、tspmi、tspri、tth111i、xbai、xcmi、xhoi、xmai、xmni和zrai。应当理解,可以将mip探针设计成包括一个或多个限制位点,并且在一些实施例中,可以将其设计成包括两个限制位点。在将mip设计成具有两个限制位点的情况下,本领域技术人员将理解如何设计mip,使得限制酶将选择性地作用于mip的每个切割位点。如上所述,可以将mip探针设计成具有一个或两个引物位点。如本文所用的,“通用引物位点”是通用引物将与之杂交的位点。通常,“通用”是指单个引物或引物组用于多个扩增反应。例如,在对100个不同的靶序列进行检测或基因分型时,所有的mip可以共享相同的通用引物序列,从而使得能够使用单个引物组对100个不同的探针进行多重扩增。这使得合成更加容易(例如仅制备一组引物),从而降低了成本,并在杂交动力学方面具有优势。最重要的是,使用此类引物极大地简化了多路复用,因为扩增多个探针仅需两个引物。通常,通用引物序列/引物各自的长度范围为约12到约40个碱基对。合适的通用引物序列是本领域技术人员已知的,并且特别包括本文中举例说明的那些序列。在一些实施例中,还将mip设计成具有将使得能够使用双色系统对两个通道探针进行特异性检测的标签序列或条形码序列。在这样的实例中,线性化探针一端(5'-端或3'-端,取决于应用和检测平台)的通用引物序列将包括特定序列,以识别特定颜色标记。因此,将mip设计为在通用引物的两个通用3'-和5'-末端之间具有限制位点是有利的。一旦将环化探针切割形成线性化探针,即可在存在第一尾引物的情况下对探针进行第一线性化探针组合物的扩增步骤,以形成第一扩增产物组合物,并在第二尾引物的存在下对探针进行扩增第二线性化探针组合物,以形成第二扩增产物组合物,其中第一尾引物具有与第二尾引物不同的尾序列。扩增步骤可以通过任何本领域已知的方法实施。pcr反应可以在存在可用于本发明的聚合酶(如usdtaq)的情况下实施。在一些实施例中,所述扩增步骤在存在包含聚合酶和聚合酶抑制剂的热启动聚合酶的情况下实施。在一些实施例中,当温度为至少40℃时,聚合酶抑制剂与聚合酶分离。在一些实施例中,所述扩增步骤在存在钛taq聚合酶的情况下实施。在一些实施例中,所述扩增步骤在存在铂superfidna聚合酶的情况下实施。本公开还考虑了某些优选实施例中的样品制备方法。在进行基因分型之前或进行基因分型的同时,可以通过多种机制将基因组样品扩增,其中一些机制可以采用pcr。参见例如《pcr技术:dna扩增的原理和应用(pcrtechnology:principlesandapplicationsfordnaamplification)》(h.a.erlich编辑,弗雷曼出版社(freemanpress),纽约,纽约州,1992);《pcr方案:方法和应用指南(pcrprotocols:aguidetomethodsandapplications)》(innis等人编辑,academicpress,圣地亚哥,加利福尼亚州,1990);mattila等人,《核酸研究(nucleicacidsres.)》,19,4967(1991);eckert等人,《pcr方法和应用(pcrmethodsandapplications)》1,17(1991);pcr(mcpherson等人编辑,irl出版社(irlpress),牛津);以及美国专利第4,683,202号、第4,683,195号、第4,800,159号、第4,965,188号和第5,333,675号,出于所有目的将其全部通过引用以其整体并入本文。可以在所述阵列上将所述样品扩增。参见例如美国专利第6,300,070号和美国专利申请序列号第09/513,300号,其通过引用并入本文。其它合适的扩增方法包括:连接酶链反应(lcr)(例如wu和wallace,《基因组学(genomics)》,4,560(1989),landegren等人,《科学(science)》,241,1077,(1988)和barringer等人,《基因(gene)》,89:117(1990))、转录扩增(kwoh等人,proc.natl.acad.sci.usa,86,1173(1989)和wo88/10315)、自持续序列复制(guatelli等人,《美国国家科学院学报(proc.nat.acad.sci.usa)》,87,1874(1990)和wo90/06995)、靶多核酸序列的选择性扩增(美国专利第6,410,276号)、共有序列引发的聚合酶链反应(cp-pcr)(美国专利美国专利第4,437,975号)、任意引发的聚合酶链反应(ap-pcr)(美国专利第5,413,909号、第5,861,245号)和基于核酸的序列扩增(nasba)。(参见美国专利第5,409,818号、第5,554,517号和第6,063,603号,其各自通过引用并入本文)。其它可以使用的扩增方法包括:qbeta复制酶(在pct专利申请第pct/us87/00880号中进行了描述)、等温扩增方法(如sda)(在walker等人,1992,核酸研究(nucleicacidsres.),20(7):1691-6,1992中进行了描述)和滚环扩增(在美国专利第5,648,245号中进行了描述)。其它可以使用的扩增方法在美国专利第5,242,794号、第5,494,810号、第4,988,617号、美国专利第09/854,317号、第8,673,560号和第8,728,728号以及美国公开第20030143599号进行了描述,其全部通过引用并入本文。在一些实施例中,通过多重基因座特异性pcr对dna进行扩增。例如,可以使用赛默飞世尔公司的产品对dna进行扩增。在一个实施例中,使用接合体连接和单引物pcr对dna进行扩增。也可以使用其它可用的扩增方法,如平衡的pcr(makrigiorgos等人(2002),《自然生物技术(natbiotechnol)》,第20卷,第936-9页)。在扩增步骤完成之后,在将核酸样品分成两个通道用于单独等位基因检测的实施例中,可以将第一扩增产物组合物和第二扩增产物组合物组合以形成包含第一扩增产物和第二扩增产物的扩增产物混合物。然后,第一和第二扩增产物准备好进行杂交和附标记。在一些实施例中,经过杂交和附标记步骤的扩增产物组合物可以通过基于阵列-的检测进行分析。代替性地,可以通过其它技术(如常规测序或大规模平行测序)处理所述扩增产物组合物。因此,在一些实施例中,可以如下所述任选地切割的扩增产物组合物进行基于测序的检测。所述测序可以通过本领域可用的各种方法来完成,例如涉及掺入一种或多种链终止核苷酸的方法,例如sanger测序方法,其可通过例如来自美国应用生物系统公司的遗传分析仪来完成。在其它实施例中,所述测序可包括执行下一代测序(ngs)方法,例如进行引物延伸并且随后进行基于半导体的检测(例如赛默飞世尔科技公司的iontorrenttm系统)或通过荧光检测(例如illumina系统)。在一些实施例中,扩增完成后,可以使用一种或多种酶将所述扩增产物组合物切割。在一些实施例中,所述扩增产物组合物(例如第一和/或第二扩增产物组合物)具有限制酶识别位点。在一些实施例中,可以通过向所述扩增产物组合物中添加限制酶对切割步骤进行催化,并且在一些实施例中,是通过在所述第一和第二扩增产物组合物中加入限制酶对切割步骤进行催化。合适的限制酶包含但不限于aatii、acc65i、acci、acii、acli、acui、afei、aflii、afliii、agei、ahdi、alei、alui、alwi、alwni、apai、apali、apeki、apoi、asci、asei、asisi、avai、avaii、avrii、baegi、baei、bamhi、bani、banii、bbsi、bbvci、bbvi、bcci、bceai、bcgi、bcivi、bcli、bfai、bfuai、bfuci、bgli、bglii、blpi、bmgbi、bmri、bmti、bpmi、bpul0i、bpuei、bsaai、bsabi、bsahi、bsai、bsaji、bsawi、bsaxi、bscri、bscyi、bsgi、bsiei、bsihkai、bsiwi、bsli、bsmai、bsmbi、bsmfi、bsmi、bsobi、bsp1286i、bspcni、bspdi、bspei、bsphi、bspmi、bspqi、bsrbi、bsrdi、bsrfi、bsrgi、bsri、bsshii、bsski、bsssi、bstapi、bstbi、bsteii、bstni、bstui、bstxi、bstyi、bstz17i、bsu36i、btgi、btgzi、btsci、btsi、cac8i、clai、cspci、cviaii、cviki-1、cviqi、ddci、dpni、dpnii、drai、draiii、drdi、eaci、eagi、eari、ecii、eco53ki、econi、ecoo109i、ecop15i、ecori、ecorv、fati、faui、fnu4hi、foki、fsei、fspi、haeii、haeiii、hgai、hhai、hincii、hindiii、hinfi、hinpli、hpai、hpaii、hphi、hpy166ii、hpy188i、hpy188iii、hpy99i、hpyav、hpych4iii、hpych4iv、hpych4v、kasi、kpni、mboi、mboii、mfei、mlui、mlyi、mmei、mnli、msci、msei、msli、mspali、mspi、mwoi、naei、nari、nb.bbvci、nb.bsmi、nb.bsrdi、nb.btsi、ncii、ncoi、ndei、ngomiv、nhei、nlaiii、nlaiv、nmeaiii、noti、nrui、nsii、nspi、nt.alwi、nt.bbvci、nt.bsmai、nt.bspqi、nt.bstnbi、nt.cvipii、paci、paer7i、pcii、pflfi、pflmi、phoi、plei、pmei、pmli、ppumi、pshai、psii、pspgi、pspomi、pspxi、psti、pvui、pvuii、rsai、rsrii、saci、sacii、sali、sapi、sau3ai、sau96i、sbfi、scai、scrfi、sexai、sfani、sfci、sfii、sfoi、sgrai、smai、smli、snabi、spei、sphi、sspi、stui、styd4i、styi、swai、t、taqαi、tfii、tlii、tsei、tsp45i、tsp509i、tspmi、tspri、tth111i、xbai、xcmi、xhoi、xmai、xmni和zrai。在一些实施例中,用于切割所述第一和第二扩增产物组合物的限制酶是相同或不同的。在使用相同的限制酶切割所述第一和第二扩增产物组合物的一些实施例中,使用限制酶haeiii切割其存在于所述第一和第二扩增产物中的特异性位点。应当理解,可以将包括本发明的扩增经mip探针的扩增产物组合物设计成包括一个或多个限制位点。在将mip设计成具有两个或多个限制位点的情况下,本领域技术人员将理解如何设计mip,使得限制酶将选择性地作用于mip的每个切割位点。在一些实施例中,对所述扩增产物组合物进行切割在将所述第一和第二扩增产物组合物组合以形成扩增产物混合物{之前或之后进行。检测将至少一个含有或衍生自核酸群体并含有多态性位点的核酸片段与寡核苷酸阵列的寡核苷酸探针杂的步骤可以根据本领域任何已知的方法来完成,具体可以结合可与本公开结合使用的任何平台(如axiom2.0试剂盒)一起收到的说明书。在一些实施例中,杂交步骤进一步包括固定的步骤。所述固定可以包括使用合适的固定试剂将寡核苷酸阵列与其杂交的核酸接触。在一些实施例中,固定步骤在杂交步骤完成之后进行。在一些实施例中,固定步骤恰好在杂交步骤(例如在将经过杂交的阵列洗涤并用菌株混合物染色之后)之后进行。因此,在一些实施例中,可以对所述阵列按该顺序进行杂交、洗涤、染色和固定以及其它步骤。可以基于光谱可区别的探针(例如2个不同的染料标记探针,如taqman或锁定核酸探针(通用探针库,roche))对不同的引物对扩增序列进行区分。在这种方法中,将所有探针组合成单个反应体积,并基于每个探针发出的颜色的差异进行区分。例如,可以将靶向一个多核苷酸(例如测试染色体例如染色体21)的探针缀合到具有第一颜色的染料,并且可以将反应中靶向第二个多核苷酸(例如参考染色体,例如染色体1)的探针缀合到第二颜色的染料。然后,颜色的比率反映测试染色体和参考染色体之间的比率。说明性地,所述第一和第二扩增产物组合物包含核酸序列,在一些实施例中,所述核酸序列对应于通道组合物。例如,来自所述第一通道的扩增产物组合物可以包含第一核酸序列,并且来自第二通道的扩增产物组合物可以包含第二核酸序列。说明性地,第一和第二核酸序列可以结合或杂交不同的试剂来测量所述扩增产物的量。在一些实施例中,所述扩增产物组合物被直接标记和测量。可以将所述第一和第二扩增产物组合物在单个阵列上重新组合和检测,或者可以将其保持分离并在至少2个分离的阵列上检测。在使用单个阵列的实施例中,可以用不同的报道分子标记所述第一和第二扩增产物组合物中的每一个,以使得能够在所述阵列上识别第一和第二产物组合物。在使用至少2个阵列的实施例中,可以用相同或不同的报道分子标记所述第一和第二扩增产物组合物。示例性单通道系统包括affymetrix的“genechip”、illumina的“beadchip”、安捷伦(agilent)单通道阵列(single-channelarrays)、appliedmicroarrays的“codelink”阵列以及eppendorf的“dualchip&silverquant”。可以多种方式检测扩增产物组合物与阵列的杂交,包含荧光部分、比色部分、化学发光部分等的直接或间接连接。在一些实施方案中,可以通过检测检测荧光团标记的试剂、放射性同位素标记的试剂、含银标记物标记的试剂或化学萤光标记的试剂来检测和定量探针-靶杂交,以确定靶中核酸序列的相对丰度。在一些实施例中,所述扩增产物组合物使萤光用荧光团标记物、放射性同位素标记物、含银标记物或化学标记物直接标记。许多对用于标记dna的方法的全面综述提供了适用于产生本发明的加标记的寡核苷酸标签的指导。此类综述包含haugland,《荧光探针和研究化学手册(handbookoffluorescentprobesandresearchchemicals)》,第九版(molecularprobes,inc.,eugene,2002);keller和manak,《dna探针(dnaprobes)》,第2版(stockton出版社(stocktonpress),纽约,1993);《寡核苷酸和类似物:一种实用方法(oligonucleotidesandanalogues:apracticalapproach)》(eckstein编辑,irl出版社(irlpress),牛津,1991);wetmur,《生物化学和分子生物学批判评论(criticalreviewsinbiochemistryandmolecularbiology)》,26:227-259(1991);fung等人,美国专利第4,757,141号;hobbs,jr.等人,美国专利第5,151,507号;cruickshank,美国专利第5,091,519号。在一些实施例中,可以将一种或多种荧光染料用作标记物。在以下文献中对一些示例性染料进行了描述:menchen等人,在美国专利第5,188,934号(4,7-二氯荧光素染料);begot等人,美国专利第5,366,860号(可光谱分辨罗丹明染料);lee等人,美国专利第5,847,162号(4,7-二氯罗丹明染料);khanna等人,美国专利第4,318,846号(醚取代荧光素染料);lee等人,美国专利第5,800,996号(能量转移染料);lee等人,美国专利第5,066,580号(呫吨染料):mathies等人,美国专利第5,688,648号(能量转移染料);maceivicz(美国专利申请第2005/0250147号);以及faham等人,(美国专利第7,208,295号);等等。可能的检测方法包括直接检测报告分子。在一些实施例中,扩增产物组合物的互补寡核苷酸包含荧光/发光/显色标记物,或者可以随后与额外化合物(例如免疫染色、适体)反应以产生信号。在一些实施例中,取代用于检测的半抗原标记的探针,标记探针可以具有直接缀合的荧光团,其将消除抗体介导的信号扩增。如本文所述,扩增产物组合物可以通过标志物侧翼的引物从pcr产生。这些扩增子可以单独产生,也可以在多重反应产生。在一些实施例中,可以将经扩增的产物组合物通过不对称pcr从多态性侧翼的一种引物产生为ss-dna,或产生为从与引物相连的启动子体外转录的rna。例如,可以将荧光标记物直接作为含染料核苷酸引入扩增产物组合物中,或者在扩增后使用染料-链霉亲和素复合物结合到掺入的含生物素的核苷酸上。说明性地,对于通过不对称pcr产生的扩增产物组合物,可将报道分子(例如荧光染料)可以直接连接到引物的5'端。在一些实施例中,扩增产物组合物可以使用tdt和生物素化的datp在3'端进行标记。说明性地,这可以针对每个单独的间隙填充反应进行。在一些实施例中,使用tdt和生物素化的atp进行3'标记使得读出一种颜色、两个芯片。在用检测剂直接或间接标记之前或在其期间,将扩增产物组合物与所述阵列杂交。在杂交步骤之后或在其期间,可以引入结合扩增产物组合物的第一核酸序列的第一试剂。所述第一试剂可以被配置成结合到存在于来自所述第一通道的扩增产物中的第一核酸序列。在一些实施例中,所述第一试剂包含与第一靶序列(例如第一核酸序列)的一部分互补的序列。说明性地,所述第一和第二扩增产物组合物包含核酸序列,在一些实施例中,所述核酸序列对应于通道组合物。例如,来自所述第一通道的扩增产物组合物可包含第一核酸序列,并且来自所述第二通道的扩增产物组合物可包含第二核酸序列。在杂交步骤之后或在其期间,可以引入结合扩增产物组合物的第一核酸序列的第一试剂。所述第一试剂可以被配置成结合到存在于来自所述第一通道的扩增产物中的第一核酸序列。在一些实施例中,所述第一试剂包含与第一靶序列(例如第一核酸序列)的一部分互补的序列。在一些实施例中,所述第一试剂包含第一互补序列和缀合到所述第一互补序列的第一识别元件。所述第一识别元件的说明性实例包括荧光团、生物素、肽标签或其组合,或本领域已知的任何可接受的识别元件。在一些实例中,所述第一试剂包含缀合到所述第一互补序列的生物素。所述第一试剂可以进一步包含结合到所述第一识别元件的第一报道分子标记的缀合物,如图4所示。所述第一报道分子标记的缀合物可以为抗生物素蛋白、抗体、适体或其组合,或任何已知的结合所述识别要素的可接受缀合物。在一些实施例中,所述第一报道分子标记的缀合物可以用第一报道分子标记。在一些实施例中,所述第一报道分子为荧光团。在一些实施例中,所述第一试剂可以进一步包含第一缀合物抗体,如图4所示。在说明性实施例中,所述第一缀合物抗体结合到所述第一报道分子标记的缀合物。在一些实施例中,所述第一缀合物抗体包含识别元件。在一些实施例中,所述第一缀合物抗体的识别元件可以与所述第一识别元件相同。在一些实例中,所述第一缀合物抗体可以用生物素标记。在一些实施例中,所述第一报道分子标记的缀合物结合缀合到第一互补序列的识别要素、第一缀合物抗体或结合缀合到第一互补序列的识别要素和第一缀合物抗体两者,如图4所示。在一些实施例中,所述第一报道分子标记的缀合物结合缀合到第一互补序列的识别要素和第一缀合物抗体两者,所述第一报道分子标记的缀合物中的每一个包含相同的第一报道分子。所述第一报道分子可以为荧光团、酶标签(如hrp)、放射性同位素或其组合,或通常在生化测定中使用的任何合适的报道分子,如图4所示。在一些实施例中,所述荧光团可以具有介于约640nm与约680nm之间的发射峰。在一些实施例中,所述荧光团为别藻蓝蛋白。在杂交步骤之后或过程中,可以引入结合所述扩增产物组合物的第一核酸序列的第二试剂,如图4所示。在一些实施例中,所述第二试剂包含与第二靶序列的一部分(例如第二核酸序列)互补的序列。在一些实施例中,所述第二试剂包含第二互补序列和缀合到所述第二互补序列的第二识别元件,如图4所示。所述第二识别元件的说明性实例包括荧光团、生物素、肽标签或其组合,或本领域已知的任何可接受的识别元件。在一些实施例中,所述第二试剂包含缀合到所述第二互补序列的荧光团。在一些实施例中,所述荧光团可以为fam。所述第二试剂可以进一步包含结合到所述第二识别元件的第二报道分子标记的缀合物,如图4所示。所述第二报道分子标记的缀合物可以包含抗生物素蛋白、抗体、适体或其组合,或任何已知的结合所述识别元件的可接受缀合物。在一些实施例中,所述第二报道分子标记的缀合物包含抗体。在一些实施例中,所述第二报道分子标记的缀合物可以用第二报道分子标记。在一些实施例中,所述第二报道分子为荧光团。在一些实施例中,所述第二试剂可以进一步包含第二缀合物抗体,如图4所示。在说明性实施例中,所述第二缀合物抗体结合到所述第二报道分子标记的缀合物。在一些实施例中,所述第二缀合物抗体包含识别元件。在一些实施例中,所述第二缀合物抗体的识别元件可以与所述第二识别元件相同。在一些实例中,所述第二缀合物抗体可以用fam标记。在一些实施例中,所述第二报道分子标记的缀合物结合缀合到第二互补序列的识别要素、第二缀合物抗体或结合缀合到第二互补序列的识别要素和第二缀合物抗体两者,如图4所示。在一些实施例中,所述第二报道分子标记的缀合物结合缀合到第二互补序列的识别要素和第二缀合物抗体两者,所述第二报道分子标记的缀合物中的每一个包含相同的第二报道分子。所述第二报道分子可以为荧光团、酶标签(如hrp)、放射性同位素或其组合,或通常在生化测定中使用的任何合适的报道分子,如图4所示。在一些实施例中,所述荧光团可以具有介于约560nm与约600nm之间的发射峰。在一些实施例中,所述荧光团为藻红蛋白。应当理解,在一些实施例中,所述第一试剂可以被配置成结合从所述第一通道得到的扩增产物组合物,并且所述第二试剂可以被配置成结合衍生自所述第二通道的扩增产物组合物。同样应当理解,在一些实施例中,所述第一试剂可以被配置成结合从所述第二通道得到的扩增产物组合物,并且所述第二试剂可以被配置成结合衍生自所述第一通道的扩增产物组合物。因此,在一些实施例中,所述第一试剂的报道分子(例如所述一个或多个荧光团)与所述第二试剂的报道分子(例如所述一个或多个荧光团)不同,如图4所示。在一些实施例中,一组探针(例如一组靶向测试染色体(例如染色体21)的探针)可以靶向靶多核苷酸的不同区域,但所述组中的每个探针具有相同的通用引物结合位点。在一些情况下,每个探针具有相同的探针结合位点。在一些情况下,所述反应中的两个或更多个探针可以具有不同的探针结合位点。在一些情况下,将添加到此类反应的探针缀合到相同的信号剂(例如相同颜色的荧光团)。在一些情况下,将不同的信号剂(例如,两种不同的颜色)缀合到一个或多个探针。寡核苷酸探针还可包含与连接到标记物(如染料或荧光染料)的探针(例如taqman探针)互补的序列。在一些情况下,taqman探针与一种染料(例如fam、vic、tamra、rox)结合。在其它情况下,寡核苷酸上存在一个以上的taqman探针位点,并且每个位点能够结合到不同的taqman探针(例如具有不同类型染料的taqman探针)。也可能存在多个具有与本文所述寡核苷酸探针的序列相同的序列的taqman探针位点。通常,taqman探针可能只结合到本文所述寡核苷酸探针上的位点,而不结合到基因组dna,但是在一些情况下,taqman探针可以结合基因组dna。分析在一些实施例中,所公开的方法(以及相关的组合物、系统、仪器和软件)包括分析从所述阵列获得的数据的步骤,以分析应用于所述阵列的核酸样品(或其衍生物)的性质。在一些实施例中,核酸样品包括含有主要亚群和次要亚群的混合核酸群体。在一些实施例中,所公开的方法可以包括使用检测器检测来自所述寡核苷酸阵列的一个或多个信号。任选地,所述检测包括检测指示第一核苷酸变体存在或不存在的信号(“第一信号”或“a信号”)。第一核苷酸变体任选地对应于第一等位基因变体。任选地,所述检测包括检测指示第二核苷酸变体存在或不存在的信号(“第二信号”或“b信号”)。第二核苷酸变体任选地对应于第二等位基因变体。在一些实施例中,所公开的方法可以包括使用所述第一信号和所述第二信号确定所述次要亚群中第一染色体区域的拷贝数。在一些实施例中,所公开的方法可以包括使用所述第一信号和所述第二信号确定所述主要亚群中第一染色体区域的拷贝数。在一些实施例中,所公开的方法可以包括使用所述第一信号和所述第二信号确定所述次要亚群的多态性位点的基因型。在一些实施例中,所公开的方法可以包括使用所述第一信号和所述第二信号确定所述主要亚群的多态性位点的基因型。在一些实施例中,所公开的方法可以包括使用所述第一信号和所述第二信号确定混合核酸群体中主要亚群和次要亚群的相对量。在一些实施例中,所述方法可以包含计算所述第一信号与所述第二信号的比或所述信号的对数比。在一些实施例中,所述方法包括分析来自被配置成与含有多态性位点的靶核酸杂交的阵列特征的a信号和b信号,并且使用a信号和b信号来确定主要和次要亚群内多态性位点的基因型,以及主要和次要亚群内多态性位点的拷贝数(或相对拷贝数)。在一些实施方案中,在探针阵列的情况下,所公开的方法和系统涉及对与来自生物的核酸样品中存在的第一和第二核苷酸变体相关的信号进行分析以测量拷贝数,所述核酸样品包括混合核酸群体。在一个实施例中,相对于核酸样品的混合核酸群体内的次要亚群,对拷贝数(例如,染色体和/或染色体区域和/或特定核苷酸序列的拷贝数)进行测量(例如估计)。在一个实施例中,核酸样品从怀孕的母亲获得,并且包括对应于母亲的dna的主要核酸亚群和对应于胎儿dna的次要亚群。在另一个实施例中,所述核酸样品从患有癌症或其它肿瘤的个体中获得,并且主要核酸亚群对应于来自非肿瘤细胞的dna,次要亚群对应于来自肿瘤细胞的dna。一些实施例也适用于需要测量含有混合核酸群体(至少包括主要亚群和次要亚群)的核酸样品的拷贝数的各种其它情况。在一些实施方案中,对应于与多态性位点相关的核苷酸变体杂交的探针的信号用于测量从生物获得的核酸样品中混合核酸群体的微小亚群的拷贝数。在一些实施例中,探针阵列包括用于多态位点的多个探针,多态位点可用于测量样品中的潜在拷贝数变化,并且来自多个探针的预选支组的信号用于估计胎儿分数(或者在其它实施例中为与样品相关联的另一类型亚群的分数),预选的探针支组是根据探针的性能使用用于根据信号值预测等位基因频率的模型选择的。在一些实施例中,多态性基因座基因型特异性的参考信号值用于检测拷贝数变化。以下段落描述了分析混合核酸群体和确定混合核酸群体的不同亚群体(例如主要和次要亚群)中存在的特定基因座的基因型和/或拷贝数的方法的各种实施方案。图5展示了根据本发明的实施例的样品处理系统2100。所述系统包括含有探针的阵列,所述探针对关注的染色体(例如染色体13、18、21、x和y)中的多态性基因座以及假定为二倍体的代表性参考染色体(例如染色体1和5)具有特异性。所述阵列上不同位点处的不同探针被配置成选择性地与所述阵列杂交之前产生的等位基因特异性延伸产物杂交,因此不同的等位基因特异性延伸产物将与阵列上的不同位点杂交,即使所述产物与所述位点仅相差一个核苷酸。然后处理经杂交等位基因特异性产物,以产生与存在的经杂交产物的量成比例的可检测信号。这一信号产生处理过程根据axiom2.0试剂盒(目录号#901758)随附的axiom2.0手册中概述的步骤执行。对从所述阵列发出的信号进行检测和分析,如下文所述。样品处理系统包含探针阵列2101、扫描仪2102和计算机2103,所述计算机可通过计算机程序2104配置成处理从扫描仪2102接收的数据。本领域技术人员将会理解,将会存在样品处理系统(如系统2100)的各种其它组件,但是在此未单独示出,所述组件包括例如用于处理各种流体的流体处理系统(包括例如将放置成与探针阵列2101接触的生物样品、各种清洗液、缓冲液和其它流体),以及用于处理和传输一个或多个探针阵列(如探针阵列2101)的自动加载器(包括用于与流体处理系统和扫描仪2102相互作用的定位探针阵列)。在一个实施例中,对探针阵列2101进行优化以用于分析从怀孕女性得到的生物样品。在特定的实施例中,探针阵列2101包含用于一个或多个染色体上的多个多态性位点的探针,每个多态性位点与单核苷酸多态性相关。在一些实施例中,探针阵列2101包含对应于:染色体1和5上10,867个或更多个独特的snp;染色体13上7,559个或更多个独特的snp;染色体18上4,855个或更多个独特的snp;染色体21上2,083个或更多个独特的snp;染色体x上1,0661个独特的snp;和染色体y上593个独特的snp的探针。在一个实施例中,所述探针阵列包括约2-50个或更多个对应于每个snp的重复探针。在一些实施例中,在阵列空间约束限制了具有大量探针和大量重复的能力的情况下,通过采用较少的重复次数(例如2-6)来改善结果,从而使得大量独特探针(用于不同的多态性基因座)可以适合大小相当的阵列。下表i示出了一种可能的实现方案(仅出于说明目的),其中给定大小的探针阵列的重复次数相对较低(一些探针为重复2次,另一些探针重复6次),并且独特探针的数量相对较高:表i在替代性实施例中,在不脱离将独特探针的数量相对于阵列空间最大化同时所述阵列上仍具有一些重复探针的实施例的情况下,可以对上述数量进行显著改变。图6和图7展示了用于实施本发明的示例性实施例的参考样品信号处理系统和受试者样品信号处理系统的框图。图8和图9展示了根据本发明的示例性实施例的由图6和图7的参考信号处理系统和主题信号处理系统实施的详细处理方法。图6-9的系统和方法可以在计算机(如图5的计算机2103)上实施。在一些替代性实施例中,这些系统和方法可以通过与计算机2103进行通信的计算机网络来实施。在此类替代方案中,可能将存储用于执行本发明的实施例的指令的计算机程序产品的全部或部分存储在远程网络计算机上,而不是存储在终端用户计算机上。图6展示了参考样品处理器2200。根据本发明的实施例,处理器2200包括用于处理来自参考样品的信号数据的各种处理模块。图6所示的具体要素在本发明的各种替代性实施例中不一定全部需要。同样,在替代性实施例中,特定要素以及在某些情况下这些要素的分布可以与所示的有所不同。如将在以下其它附图的上下文中进一步讨论的,在一些实施例中,参考处理器2200的部分可以用于处理多个,其中所述受试者样品也用作参考样品受试者样品。然而,为了说明和解释清楚,仅在处理参考样品的上下文中描述了参考处理器2200。数据储存库2207存储从已将参考样品引入到并选择性地杂交到的扫描探针阵列产生的信号文件。探针信号处理模块2201接收并处理从储存库2207接收的信号。模块2201对信号进行归一化和汇总,这将在图8-9的上下文中进一步解释。基因分型模块2202使用归一化和汇总的信号值来进行基因分型,以提供每个参考样品相对于每个snp的基因型。模块2203为每个snp的每个基因型创建模型参考信号,并将其存储在参考信号储存库(例如数据文件)2208中。模块2204使用来自模块2202的基因分型数据来创建将信号值与两个信号通道中每一个的拷贝数相关联的模型)如将在图8的上下文中进一步描述的)。模块2205使用模块2204生成的模型计算每个参考样品中每个标记物的b等位基因频率(“baf”)。使用从数据储存库2209检索的已知参考拷贝数数据,将与跨参考样品相同的等位基因拷贝数和相同标志物相对应的baf值彼此比较和/或与根据已知拷贝数计算的baf值进行比较。基于所述比较,模块2205识别从信号中计算的b等位基因频率最能预测实际等位基因拷贝数的标志物,并将其保存在胎儿分数标志物选择储存库2211中。将所识别的标记物保存以用于以后确定受试者母体样品(例如怀孕的女性患者的样品)中的胎儿分数。模块2206分别处理单个参考样品的信号,以计算相对于存储在储存库2208中的参考信号的对数比。模块2206将结果存储在参考对数比率储存库2210中。图7展示了受试者样品处理器2300。根据本发明的实施例,处理器2300包括用于处理来自受试者(例如患者)样品的信号数据的各种处理模块。图7所示的具体要素在本发明的各种替代性实施例中不一定全部需要。同样,在替代性实施例中,特定要素以及在某些情况下这些要素的分布可以与所示的有所不同。数据储存库2307存储从已将受试者样品引入到并选择性地杂交到的扫描探针阵列产生的信号文件。探针信号处理模块2301接收并处理从储存库2307接收的信号。模块2301执行与模块2201相同的处理,这将在图8-9的上下文中进一步解释。基因分型模块2302使用从模块2301接收的归一化和汇总的信号值来执行基因分型,以提供每个受试者样品相对于每个snp的基因型。所示实施例包括模块2303,所述模块使用来自在同一样品盘上处理的多个受试者样品的信号来为每个snp的每个基因型创建模型参考信号,并且模块2303将所述信号存储在参考信号储存库(例如数据文件)2308中。注意,在一些实施例中,从先前参考测定获得的模型参考信号先前已经由参考处理器(如图6所示的处理器2200)确定。在此类替代方案中,受试者样品处理器(如处理器2300)不一定需要单独的模型参考信号确定模块(如图7的模块2303)。然而,如果参考数据是从较早测定的不同样品盘获得的,使用受试者样品创建模型参考样品的益处是可以最大程度地减少可能归因于特定样品盘特性和/或测定条件的影响。模块2304使用来自模块2302的基因分型数据和来自将a信号与a等位基因拷贝数和b信号与b等位基因拷贝数相关联的模块2204的标志物特异性模型,以将a信号值转换成a拷贝数,并且将b信号值转换成b拷贝数,然后计算每个标志物的b等位基因频率(baf)。如将在图9的上下文中更详细描述的,胎儿分数计算器2305使用baf值的分布来计算估计的胎儿分数。胎儿分数分析器2309确定所述样品是否具有足够的胎儿分数以用于评估非整倍性。如果是,则胎儿分数分析器2309使用胎儿分数来根据胎儿分数估值更新预期信号的参考值,这将在图9的上下文中进一步描述。模块2306处理单个受试者样品,以获得对应于每个标志物的信号相对于合适参考信号的对数比,并将所述对数比存储在储存库2310中。具体地,模块2306使用对应于所述标志物的主要亚群的确定基因型(例如母体dna的基因型)的参考信号(将在图9的上下文中进一步描述),以获得所述标志物的受试者信号值相对于参考值的对数比值。在优选实施例中,使用估计的胎儿分数来确定异常对数比的预期信号阈值。然而,在替代性实施例中,不一定使用确定的胎儿分数来确定异常对数比的预期信号;相反,可以使用任何与正常对数比不相称的参数来确定。模块2311分析对数比值以确定是否达到调用非整倍性的阈值。图8展示了参考样品处理方法2400。在一个实施例中,方法2400由图6的参考处理器2200执行。图8所示的具体步骤在本发明的各种替代性实施例中不一定全部需要。同样,在替代方案中,具体步骤以及顺序(在某些情况下)可以与所示顺序有所不同。步骤2401使用从扫描仪2102(图5中示出)接收的信号数据创建信号数据文件。扫描仪2102检测每个标志物的两个不同通道中的探针信号,第一通道对应于所述标志物的a等位基因,第二通道对应于所述标志物的b等位基因。在该实施例中,将探针设计成具备标志物特异性但是可在不同的通道中根据探针与之杂交的标志物的等位基因(a或b)检测到。注意,在替代性实施例中,可以使用用于标志物的每个等位基因的不同探针。步骤2402-2404执行初始探针信号处理。具体而言,步骤2402将通用信号协变量调节器归一化应用于信号。在一个实施例中,这一处理相对于变量(如例如鸟嘌呤和胞嘧啶含量(gc含量)和探针片段长度)对信号进行归一化。步骤2403应用分位数归一化。步骤2404对重复探针值进行汇总。在一个实例中,这包含相对于每个参考样品针对每个标志物确定与a等位基因杂交的所有重复探针的中值信号值(a信号)和与b等位基因杂交的所有重复探针的中值信号值(b信号)。步骤2405相对于每个标志物对每个参考样品进行基因型分析。步骤2409然后如下创建对应于每个标志物的三种可能基因型中的每一种的参考信号:对于第一标志物,将所述标志物的第一参考样品的a信号添加到所述标志物的第一参考样品的b信号,以相对于第一参考获得第一标志物的组合的a+b信号。相对于第一标志物,对所有其它参考样品重复这一过程。然后,确定具有特定基因型的所有参考中第一个标志物的中值信号。例如,对于标记物1,将具有该标志物的aa基因型的所有参考的中值信号值(a+b)存储为参考信号。类似地,对于标记物1,将具有该标志物的bb基因型的所有参考的中值信号值(a+b)存储为单独的参考信号。对于标记物1,存储具有ab基因型的所有参考的中值信号值(a+b)。对于由探针阵列询问的每个标志物重复此过程。下表ii中示出了以此方式确定的染色体1中三个不同标志物的归一化参考信号(a+b)的实例:表ii在一些实施例中,可以如下对每个参考样品在步骤2410、2412、2413、2415和2411计算对数比并进一步进行处理。步骤2410针对每个参考样品根据是否已将标记物的基因型分型为aa、bb或ab将每个标志物的对数比确定为所述标志物的参考样品信号与适当的中值参考信号(例如,上表ii中的值)的对数比。步骤2412将通用对数比协变量归一化应用于所述对数比。步骤2413在每个样品的基础上最优地应用中值常染色体归一化。具体来说,如果给定样品跨所有染色体的中值对数比的中值不为0,则按照使中值为中值0所需的增量来调整所有值。步骤2415通过再次应用中值常染色体归一化来任选地应用盘调整,但是这一跨盘上的所有样品根据需要应用适当的增量调整以使中值为中值0。步骤2411按染色体或其它关注单元对每个参考样品进行汇总。在一个实施例中,该单元可以为染色体臂,或者更小或更长的关注区。在一个实施例中,这通过将给定染色体上所有标志物的所有对数比的中值作为给定样品的所述染色体的汇总值来完成。在替代性实施例中,可以使用平均值或其它汇总方法。步骤2414存储每个参考样品的归一化对数比的结果。步骤2406-2408用于选择确定受试者样品的胎儿分数时优选使用的特定标志物。选择证明对所述纯合基因型中的至少一种具有良好的b等位基因频率预测能力的标记物。步骤2406使用来自步骤2404的汇总信号和来自步骤2405的基因型来创建将信号值与每个标志物的每个等位基因的拷贝数相关联的模型。在一个实施例中,所述模型为线性模型。在另一个实施例中,所述模型为非线性模型,如例如langmuir模型。现在进一步详细描述一种用于创建线性模型的方法。然而,所描述的方法当然可以在替代性实施例中有所变化。在一个实施例中,为所有常染色体标志物创建两个模型(a模型和b模型),其中三个可能的基因型中的每一个由至少两个参考样品表示。a模型将a信号值与a拷贝数关联,b模型将b信号值与b拷贝数关联。首先,根据表iii,将标志物的参考样品的基因型转换为“a拷贝数”和“b拷贝数”:表iii基因型a拷贝数b拷贝数aa20ab11bb02然后,分别对(i)标志物的所有参考样品的所有a信号值(相对于a拷贝数)和(ii)标志物的所有参考样品的所有b信号值(相对于b拷贝数)分别进行加权线性回归。在一个实施例中,基于每个拷贝数的预测标准差来应用权重。通过对观察到的参考信号的观察到的标准差进行线性回归来确定预测的标准差。拷贝数cni(其中i=0、1或2)的得出的预测标准差在本文用“psdcni”标注。然后,当对观察到的信号值与拷贝数进行加权线性回归时,通过将观察值乘以1/(psdcni)2来对观察值进行加权,其中psdcni为对应于与标志物的参考样品的基因型相关联的拷贝数的预测标准差。对a信号值和对应的a拷贝数使用上述加权线性回归,以生成以下a模型等式的a截距和a斜率参数值:a信号=a截距+a斜率*a拷贝数并且,对b信号值和对应的b拷贝数使用上述加权线性回归,以生成以下b模型等式的b截距和b斜率参数值:b信号=b截距+b斜率*b拷贝数。使用上述a模型等式和b模型等式,步骤2407分别基于特定标志物的a信号值和b信号值(注意,a信号为使用所有重复探针的a信号的中值的汇总信号,b信号为使用所有重复探针的b信号的中值的汇总信号)来预测单个参考样品的a拷贝数(pa拷贝数)和b拷贝数(pb拷贝数)。因此,pa拷贝数=(a信号–a截距)/a斜率,而pb拷贝数=(b信号–b截距)/b斜率。使用预测的拷贝数如下计算每个参考样品中的每个标志物的baf:pb拷贝数/(pa拷贝数+pb拷贝数)。步骤2407(基于来自2406的模型)计算来自具有足够参考信息的每个标记的参考样品的已知拷贝数信息的baf。然后,在步骤2408中,将相同标志物和基因型的计算的baf相互比较。基于这一比较,选择aa基因型的计算baf具有最低标准差的标志物作为aabaf,选择bb基因型的计算baf具有最低标准差的标志物作为bbbaf。基于来自受试者样品的信号进行选择,以供以后估计胎儿分数时使用。图9示出了受试者样品处理方法2500。在一个实施例中,方法2500由图7的受试者样品处理器2300执行。图8所示的具体步骤在本发明的各种替代性实施例中不一定全部需要。同样,在替代方案中,具体步骤以及顺序(在某些情况下)可以与所示顺序有所不同。步骤2501、2502、2503、2504和2505与图8的方法2400的步骤2401、2402、2403、2404和2405基本相同并且在此将不再详细描述,但是应注意,方法2500的上下文中的步骤是在通过扫描从怀孕女性获得的受试者(例如,患者)样品而获得的数据文件上执行的。与步骤2404类似,步骤2504的结果是针对全部重复探针的汇总a通道信号(例如,中值信号值)与每个受试者样品的每个标志物的a等位基因(a信号)杂交以及针对全部重复探针的汇总b通道信号(例如中值信号值)与每个受试者样品的每个标志物的b等位基因(b信号)杂交。步骤2505与步骤2405相似,获得相对于每个标志物的每个受试者样品的基因型。步骤2505确定了母亲的表观基因型或主要亚群的基因型,但是推测来自怀孕女性的样品包括胎儿分数。在一些实施例中,在相同的样品盘上处理的几种不同的受试者母体样品可以用于产生参考信号,用于随后的对数比计算。在这些实施例中,步骤2518按基因型对全部受试者样品的汇总信号进行分类,从而以与先前描述的图8中的步骤2409相同的方式确定参考信号。唯一的区别在于,步骤2518使用了当前样品盘上的当前受试者样品来确定基因型特异性参考信号。然而,在不包括步骤2518的替代实施例中,可以替代使用针对先前在不同样品盘上分析的一组参考样品而确立的(例如,如通过图8的步骤2409所确立的)基因型特异性参考信号。步骤2507计算在图8的步骤2408中识别的标志物的b等位基因频率(baf),对此,如图9的步骤2505中确定的受试者样品的母体基因型为aa或bb。在计算baf之前,步骤2507以与图8的步骤2407的上下文中描述的方式相同的方式,即,使用参考模型(如图8的步骤2406中确定的模型)将a信号值转换为预测的a拷贝数并且将b信号值转换为预测的b拷贝数。步骤2508识别经计算的baf值满足或超过表明胎儿基因型为ab(即,不同于母亲的基因型,其中母亲的基因型对于步骤2508中使用的每个标志物而言为aa或bb)的阈值的标志物。在一个实施例中,当标志物的母体基因型为aa时,介于约0.015与0.2之间的baf表明与aa不同并且触发选择标志物来确定胎儿分数的胎儿基因型。同样,在这些实施例中,当母体基因型对于所述标志物而言为bb时,介于约0.8与0.985之间的baf表明胎儿基因型与bb不同并且触发选择标志物来确定胎儿分数。然而,在替代实施例中,在不脱离本发明的此方面的范围的情况下,可以改变这些范围或者可以将不同的范围用于不同的标志物。步骤2509使用所选择的标志物来估计胎儿分数。具体地,在一个实施例中,所选标志物的胎儿分数估计如下。对于母亲的基因型为aa的标志物而言,基于方程baf=α/2(即,α=2*baf)估计胎儿分数α。此等式的依据为以下:如果母亲为aa并且胎儿为ab,则b拷贝数=α并且a拷贝数=2*(1–α)+α=2–α。因此,a拷贝数+拷贝数=2–α+α=2。以类似的方式,如果母亲的基因型为bb,则基于等式baf=1–β/2估计胎儿分数β。此等式的依据为以下:如果母亲为bb并且胎儿为ab,则b拷贝数=2(1–β)+β=2–β且a拷贝数=β。因此,a拷贝数+b拷贝数=2并且baf=(2–β)/2=1–β/2。步骤2510针对使用受试者的样品进行非整倍体筛选,确定在步骤2509中确定的胎儿分数是否足够高和/或足够可靠。在一个实施例中,步骤2510通过以下两个阶段确定胎儿分数的充分性/可靠性:首先,确定母亲的基因型为aa的标志物的足够高的分数α是否≥3%,并且母亲的基因型为bb的标志物的足够高的分数β是否≥3%。使用3%阈值可能会根据使用的特定测定的噪声而有所不同。然而,在一个实施例中,可以假设噪声水平使得母亲和胎儿两者均为aa(或bb)的一些标志物将显示对应于胎儿分数的baf超过3%。关于标志物的阈值的百分比必须满足3%,在一个实施例中,如果母亲为aa的少于20%的标志物的α≥3%或者如果母亲的基因型为aa的少于9%的标志物的β≥3%,则拒绝测试。在替代实施例中,可以改变相应的阈值20%和9%。通常,这些阈值是旨在优化特异性和敏感性的根据经验确定的阈值,并且这些阈值在一些情况下可以根据测定噪声而变化以支持这些性能测量中的任一种。如果样品通过可靠性阈值(如例如上面提及的那些阈值)则跨相关标志物的中值α和中值β在一个实施例中被用于估计胎儿分数。任选地,如果待接受的样品的α和β不在彼此指定的百分点数之内,则应用另外的可靠性阈值并拒绝样品。在一个实施例中,指定的百分点数为2%到3%(例如,如果α=4%且β=8%,则认为估计不够可靠)。然而,在一些实施例中,不应用该另外的可靠性阈值。如果α和β的值(例如,平均值或加权平均值)指示胎儿分数小于4%,一旦α和β确立并被认为可接受,则拒绝样品。如果步骤2510的结果是否定的,则步骤2511拒绝样品。推测,在大多数情况下,可以从怀孕女性得到另一个样品,以便日后在需要时进行测试。在一些替代实施例中,基于以上关于可靠性和/或充分性拒绝的各种标准而对受试者样品的任何拒绝仅是有条件的,并且如果在步骤2517中分析的相关对数比(下文进一步讨论)足够极端而不能清楚地指示非整倍性,则仍潜在地考虑有条件地拒绝的样品。如果步骤2510的结果是肯定的,则优选地,步骤2512使用所估计的胎儿分数来更新用于对数比的阈值。步骤2513基于所确定的标志物的母体基因型选择适当的参考信号(例如,针对特定标志物,选择上面表iii所示的对应于母体基因型的三个参考信号之一),并且确定相关标志物的受试者样品的信号(汇总a信号+汇总b信号)与相关所选择的参考信号的对数比。在步骤2515、2516、2519和2514中执行与上文图8的步骤2412、2413、2415和2411的上下文中分别描述的处理类似的进一步的处理。步骤2517分析所得的归一化对数比,并且如果该比率高于指示像差的阈值,则调用非整倍性。正常样品的理论对数比为0,而对于胎儿分数为5%的三体样品,所述理论对数比为log2((2*0.95+3*0.05)/2)=0.03562。然而,在特定实施的实施例中,可以凭经验确定并考虑衰减因子。例如,在衰减因子为0.8的实施例中,当胎儿分数为5%时胎儿三体性的预测对数比为0.8*0.03562。在一个此实施例中(即,胎儿分数为5%并且与测定相关的衰减为0.8),调用非整倍性的阈值对数比可以介于0.02与0.03之间。然而,替代实施例可以使用其它阈值或其它方法来计算衰减。可以使用有形体现在信息载体(例如,非暂时性机器可读存储装置)中的计算机程序产品来实施本文所述的系统、设备和方法,以供可编程处理器执行;并且可以使用由此类处理器执行的一个或多个计算机程序实施本文所述的方法步骤,包括图8和图9以及替代实施例中的方法的步骤中的一者或多者。计算机程序是可以在计算机中直接或间接使用的以执行某种活动或产生某种结果的一组计算机程序指令。计算机程序可以以包括编译语言或解释性语言的任何形式的编程语言编写,并且所述计算机程序可以以任何形式部署,所述形式包括作为单独的程序或作为适合于在计算环境中使用的模块、部件、子例程或其它单元。图10示出了计算机系统2600的实例,所述计算机系统中的一者或多者可以提供图5的计算机2103的部件或替代物中的一者或多者。计算机系统2600执行计算机程序产品2660(其可以是例如图5的实施例的计算机程序产品2104)中含有的指令代码。计算机程序产品2660包含电子可读介质中的可执行代码,所述电子可读介质可以指示一个或多个计算机(如计算机系统2600)执行完成通过本文所提及的实施例执行的示例性方法步骤的处理。所述电子可读介质可以是以电子方式存储信息的任何非暂时性介质并且可以例如通过网络连接本地或远程访问。在替代实施例中,所述介质可以是暂时性的。介质可以包含多个在地理上分散的介质,所述介质各自被配置成在不同的位置和/或在不同的时间存储可执行代码的不同部分。电子可读介质中的可执行指令代码指示所展示的计算机系统2600实施本文所述的各种示例性任务。通常将在软件中实现用于指示实施本文所述的任务的可执行代码。然而,本领域技术人员将理解,在不脱离本公开的情况下,计算机或其它电子装置可以利用硬件中实现的代码来执行许多或全部识别的任务。本领域技术人员将理解,可以找到可执行代码的实施本公开的精神和范围内的示例性方法的许多变型。计算机程序产品2660中含有的代码或代码的副本可驻留在通信耦合到系统2600的一个或多个永久性存储介质(未单独示出)中,以供在永久性存储装置2670中加载和存储和/或驻留在存储器2610中,以供处理器2620执行。计算机系统2600还包括i/o子系统2630和外围装置2640。i/o子系统2630、外围装置2640、处理器2620、存储器2610和永久性存储装置2670通过总线2650耦合。与可以含有计算机程序产品2660的永久性存储装置2670和任何其它永久性存储类似,存储器2610是非暂时性介质(即使实施为典型的易失性计算机存储装置)。此外,本领域技术人员将理解,除了存储用于实施本文中所述的处理的计算机程序产品2660之外,存储器2610和/或永久性存储装置2670可以被配置成存储本文所提及和所展示的各种数据元素。本领域技术人员将理解,计算机系统2600仅展示了其中可以实施根据本公开的计算机程序产品的系统的一个实例。为了引用替代性实施例的仅一个实例,包括在根据本公开的计算机程序产品中的指令的执行可以分布在多个计算机上,如例如分布式计算机网络的计算机上。虽然已关于所展示的实施例对本文所公开的方法和系统进行了具体描述,但是应当理解,可以基于本公开作出各种更改、修改和改编并且所述更改、修改和改编旨在处于本发明的范围内。应当理解,本公开的范围和精神不限于本文明确描述的实施例,相反,其旨在覆盖包括在由以上和以下提及的各个实施例所例示的基本原理的范围内的各种修改和等效布置。试剂盒还公开了用于执行所公开的方法的试剂盒。所述试剂盒可以包含分子倒置探针试剂汇集物,所述分子倒置探针汇集物被设计成用于扩增多个靶序列。选择靶序列,使得其各自包括关注的多态位点。可以将分子倒置探针池化到含有2个或更多个不同的序列捕获探针的容器中。所述试剂盒可以进一步包含接合体衔接子、通用引物、dntp、连接酶、缓冲液和聚合酶。所述试剂盒可以用于扩增靶序列的集合。可以通过以下方式进行扩增:对样品进行片段化、将接合体连接到片段、将捕获探针与接合体连接的片段杂交、延伸所述捕获探针并且使用一对通用引物对所延伸的捕获探针进行扩增。所述试剂盒也可以包括用于读取和分析微阵列数据的计算机系统。另外,所述试剂盒可以包括用于杂交和标记靶序列的微阵列芯片。应用本文所述的方法和系统可以用于检测多种类型的遗传异常,所述异常指示疾病的存在或发生疾病的可能性。例如,如本文所述的,本公开可以用于检测母体样品中的拷贝数变异,所述母体样品包括主要亚群和次要亚群,其中所述主要亚群和所述次要亚群各自包括位于第一染色体区域并且含有多态性位点的靶序列。在一些实施例中,主要群体为母体dna。在一些实施例中,次要群体为胎儿dna。在一些实施例中,所述胎儿dna不大于核酸样品中总dna的15%、或不大于核酸样品中总dna的10%或不大于核酸样品中总dna的5%。在一些实施例中,根据本文所述的方法对主要亚群进行基因分型。在一些实施例中,根据本文所述的方法对次要亚群进行基因分型。在一些实施例中,样品包括来自不同亚群(例如主要亚群和次要亚群)的混合核酸群体。在一个实施例中,样品含有母体核酸(主要亚群)和胎儿核酸(次要亚群)的混合物。在一个实施例中,来自每个亚群的核酸是无细胞dna。在一些实施例中,样品中胎儿dna的量的范围为样品中dna总量的约1%到约50%。在一些实施例中,样品中胎儿dna的量为样品中dna总量的约1%、约5%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%或约50%,或上述任何介于中间的量。在一些实施例中,样品中胎儿dna的量不大于样品中dna总量的约1%、约5%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%或约50%,或上述任何介于中间的量。在一些实施例中,样品中胎儿dna的量多于或不小于样品中dna总量的约1%、约5%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%或约50%,或上述任何介于中间的量。在一些实施例中,可以根据本文公开的各种方法处理的样品中的混合核酸群体包括来自主要来源和次要来源的无细胞dna。在一些实施例中,混合核酸群体是从全血、血浆、血清或一些其它体液分离的循环dna。在一些实施例中,混合核酸群体包括母体无细胞dna和胎儿无细胞dna。在一些实施例中,样品中混合核酸群体的量的范围为一纳克或多纳克(ng)到约一毫克或多毫克(mg)。在一些实施例中,混合核酸群体的量为约1ng、约3ng、约5ng、约10ng、约15ng、约30ng、约40ng、约50ng、约100ng、约150ng、约300ng、约400ng、约500ng、约1mg、约3mg、约5mg或更多,或上述任何介于中间的量。在一些实施例中,使用的混合核酸群体的量不大于约50ng、约40ng、约30ng、约15ng、约10ng、约5ng、约3ng或约1ng。在一些实施例中,混合核酸群体的量为约或小于约50ng、约40ng、约30ng、约15ng、约10ng、约5ng、约3ng或约1ng。在一些实施例中,根据本文公开的各种方法处理的样品包括衍生自全血、血浆、血清、尿液、粪便或唾液中的一种或多种的混合核酸群体。在一些实施例中,混合核酸群体可以衍生自血液。在一些实施例中,可以对血液(例如,全血)进行进一步处理以提供从其中制备样品的混合核酸群体的血浆和/或血清。在一些实施例中,所公开的方法(以及相关的组成、试剂盒和系统)可用于检测少量全血、血浆、血清或其它体液中的遗传变化。例如,用于制备样品的混合核酸群体的体液(例如全血、血浆、血清或唾液)的量的范围可以为约0.1到几毫升(ml)。在一些实施例中,用于制备混合核酸群体的全血、血浆、血清或其它体液的量为约0.1ml、约0.25ml、约0.5ml、约0.75ml、约1ml、约1.5ml、约2ml、约2.5ml、约3ml、约3.5ml、约4ml、约4.5ml、约5ml、约5.5ml、约6ml、约6.5ml、约7ml、约7.5ml、约8ml、约8.5ml、约9ml、约9.5ml或约10ml,或上述任何介于中间的量。在使用全血提供样品的混合核酸群体的一些实施例中,血液的量为约或小于0.1ml、0.25ml、约0.5ml、约0.75ml、约1ml、约1.5ml、约2ml、约2.5ml或约3ml。在一些实施例中,血液的量不大于约0.25ml、约0.5ml、约0.75ml、约1ml、约1.5ml、约2ml、约2.5ml或约3ml。在使用血浆或血清提供样品的混合核酸群体的一些实施例中,血浆或血清的量为约或小于0.1ml、0.25ml、约0.5ml、约0.75ml、约1ml、约1.5ml、约2ml、约2.5ml或约3ml。在一些实施例中,血浆或血清的量不大于约0.25ml、约0.5ml、约0.75ml、约1ml、约1.5ml、约2ml、约2.5ml或约3ml。本文所述的方法和系统还可以用于检测生物样品中的循环肿瘤细胞,例如含有主要亚群和次要亚群的血液,其中所述主要亚群和所述次要亚群各自包括位于第一染色体区域并且含有多态性位点的靶序列。在一些实施例中,可以对次要亚群进行基因分型,以识别癌症的已知遗传标记物,如snp、染色体倒位、染色体缺失,染色体插入等等。应当理解,许多癌症标志物是本领域已知的。实例实例1:复性如通常所述针对可从赛默飞世尔(thermofisher)获得的oncoscantmffpe测定试剂盒(目录号#902293)执行复性。简而言之,在冰上制备96个样品的测定微孔盘。向每个孔中添加10μldna。dna样品可以是分析性gdna样品(剪切至中值长度为170bp);在三体处于0、约5%或约10%时与三体gdna混合的gdna与分析性gdna的分析性混合物(剪切至中位长度为170bp);或通过magmax(可从赛默飞世尔获得)提取试剂盒方法从10-20ml的母体血液样品纯化的临床无细胞dna(cfdna)。通过将oncoscantmffpe测定试剂盒的缓冲液a与含有来自oncoscantm库的约48,000个mip的探针混合物混合来制备复性主混合物(amm)。向每个dna样品加入约2.24μl的amm,并且然后将试剂混合、涡旋和离心。将所述微孔盘置于热循环仪中并根据oncoscantmffpe测定协议温育过夜。实例2:间隙填充和通道分离如通常所述针对oncoscantmffpe测定执行间隙填充。简而言之,将缓冲液a、dntp和切割缓冲液在冰上解冻。将sap重组酶与缓冲液a和间隙填充酶混合物混合。将2μl所制备的混合物添加到来自实例1的微孔盘中。然后将孔的内容物相等地分离到两个新的微孔盘,以产生两个通道。将微孔置于热循环仪中,并且使用如oncoscantm手册中描述的间隙填充程序温育11分钟。实例3:添加dntp将2.4μl的atp/ttp混合物或gtp/ctp添加到含有如实例2中描述的dna的孔中。将微孔盘放回热循环仪中以完成间隙填充程序。实例4:核酸外切酶处理通过将来自oncoscantm试剂盒的外切混合物与甘油混合来制备外切主混合物(emm),并且如oncoscantmffpe测定中描述的处理所述孔。简而言之,添加2μl的emm并且在来自实例3的微孔盘中将其与溶液混合。将所述微孔盘置于热循环仪中并且继续根据oncoscantmffpe测定的程序。实例5:切割和pcr通过将切割缓冲液与切割酶混合根据oncoscantmffpe测定制备切割主混合物(cmm)。通过将补体混合物(a/t或c/g)与钛taq混合(可从clontech获得)来制备pcr混合物。将15.0μl的cmm添加到来自实例4的微孔盘的孔中并混合。将15.0μl的pcr混合物添加到适当的孔中并混合。将所述微孔盘置于热循环仪中,并且根据如oncoscantmffpe测定中描述的切割-pcr程序进行温育。实例6:消化根据oncoscantmffpe测定执行消化步骤。简而言之,将缓冲液b在冰上解冻。通过将缓冲液b与haeiii和exoi酶混合根据oncoscantmffpe测定制备haeiii主混合物(h3mm)。将40μl的h3mm添加到新的微孔盘上的每个样品孔中。向每个填充孔中,将10μl的a/t产品与10μl的c/g产品混合并混合。将所述盘置于热循环仪中并使用haeiii消化程序根据oncoscantmffpe测定进行温育。实例7:变性和杂交根据可从塞默飞世尔获得的axiom2.0试剂盒(目录号#901758)并用来自所述试剂盒的试剂执行变性和杂交。简而言之,将hybe混合物在冰上解冻并且然后以82.3μl/孔吸移到微孔盘。将来自实例6的36μl的消化产物添加到含有hybe混合物的每个孔中。将所述盘在室温下温育25分钟。然后在热循环仪中将微孔盘以95℃温育10分钟,然后以49℃温育至少3分钟。将来自每个孔的约100μl的变性产物添加到来自axiom2.0试剂盒的hybe托盘中,并且将所述盘置于genetitantm多通道(gtmc)仪器中并温育23.5小时。实例8:清洗、固定和染色通常根据axiom2.0手册对hybe托盘进行清洗和染色。简而言之,通过将150μl的axiom保持缓冲液添加到微孔盘的每个孔中来制备保持托盘。根据axiom2.0手册制备稳定/固定溶液,并且将150μl的溶液添加到微孔盘的每个孔中。根据axiom2.0手册制备第一染色混合物,并且通过使用多克隆抗体对其进行修饰,并且将105μl的溶液添加到两个微孔盘的每个孔中。根据axiom2.0手册制备第二染色混合物,并且通过使用多克隆抗体对其进行修饰,并且然后将105μl的溶液添加到微孔盘的每个孔中。将托盘添加到gtmc仪器中。gtmc仪器根据axiom2.0手册执行清洗、染色、固定和保持填充。实例9:收集数据根据axiom2.0方案,对来自实例8中的经染色托盘进行成像。根据实例10收集并分析数据。实例10:数据分析分析实例9中获得的数据以确定胎儿分数并检测如上所述的前述部分的染色体非整倍性。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1