一种易于纯化的人表皮生长因子融合蛋白及其核酸分子、一种人表皮生长因子制备方法与流程
本发明涉及生物工程技术领域,尤其涉及一种易于纯化的人表皮生长因子融合蛋白及其核酸分子、一种人表皮生长因子制备方法。
背景技术:
人表皮生长因子(humanepidermalgrowthfactor,hegf)由53个氨基酸残基组成,分子量为6216,等电点4.6,分子内有6个半胱氨酸,形成3对二硫键,使得hegf对热、蛋白酶作用都较为稳定。
hegf具有多种生物活性:(1)激活激酶,与特异性的egfr结合,激活并维持皮肤组织、角膜、肺、气管上皮组织细胞等一系列细胞的生长繁殖;(2)调节钙离子浓度,在过表达egfr的a431细胞中,hegf能迅速促进钙的内流,从而调节钙离子浓度;(3)基因活化,通过影响基因转录效率和调节特定基因的表达;(4)生长抑制,hegf可抑制上皮肿瘤细胞a431、人乳腺癌细胞、鳞癌细胞等多种不同类型的培养细胞,对于某些细胞而言,低浓度的hegf具有刺激作用,高浓度则表现为抑制作用,如人子宫内膜细胞rl95-2、鼠肠细胞系r1e-1。因此hegf可应用于外科伤口的愈合、溃疡病的治疗和化妆品等领域。
早期的hegf主要从尿液中提取,产量非常低,1000l尿液仅能获得不到2mg的hegf,也有从唾液、母乳、血液中提取,但产量都很低,目前几乎不使用这种方法来获得hegf。
1988年,marchi等人采用化学法合成hegf,但是由于hegf含有3对二硫键、多种官能团氨基酸残基,合成的产物纯度、活性和产率都不高,无法进行大规模生产。
近年来,随着基因工程技术的发展,人们更期望借助基因工程技术获得高纯度、高活性的hegf。如甘人宝等人(中国专利号cn00127953.x、cn200510025289.3、cn201110235048.7)采购分泌技术进行表达,能获得高达150-452mg/l的表达量,但需要严格控制发酵条件,并经盐析、疏水层析、离子交换层析、凝胶过滤等步骤纯化,才能获得纯品。郑春阳等人(中国专利号201210272216.4)将hegf基因与opt-sumo基因进行融合,获得高达102mg/l的可溶表达量,但并未报道后续纯化过程。万一等人(中国专利号201210181522.7)将hegf与内含肽、几丁质结合域融合表达,以包涵体形式表达,经过复性、内含肽自切、硫酸铵沉淀、离子交换层析等步骤纯化获得高纯度hegf。但是,几丁质亲和介质价格昂贵,可重复使用次数较少,载量低,限制了该技术的工业化应用。
可见,现有的hegf制备方法制备成本过高,尤其是分离纯化步骤繁琐、成本高、得率低,这些问题限制了hegf的大规模应用。
技术实现要素:
本发明为了克服现有人表皮生长因子制备方法繁琐、成本高、产率低的缺陷,提供了一种易于纯化的人表皮生长因子融合蛋白及其核酸分子、一种人表皮生长因子制备方法。
为了实现上述发明目的,本发明提供以下技术方案:
本发明提供了一种易于纯化的人表皮生长因子融合蛋白,包括金属螯合亲和蛋白、c端可自切的多肽和hegf。
优选的,所述金属螯合亲和蛋白包括histag标签、hatag标签或含多个半胱氨酸的标签。
优选的,所述histag标签由2~10个连续的组氨酸组成。
优选的,所述c端可自切的多肽包括金黄色葡萄球菌分选酶a、瘟疫病毒n段蛋白酶或集包藻dna解旋酶的全部或部分。
优选的,所述人表皮生长因子融合蛋白从n端到c端的顺序依次包括:金属螯合亲和蛋白、c端可自切的多肽和hegf。
本发明还提供了一种编码上述技术方案所述人表皮生长因子融合蛋白的核酸分子,包括编码金属螯合亲和蛋白、c端可自切的多肽和hegf的核苷酸序列。
优选的,所述核酸分子的核苷酸序列如seqidno.1所示。
本发明还提供了一种人表皮生长因子的制备方法,包括以下步骤:
(1)重组表达前述技术方案所述的人表皮生长因子融合蛋白,分离得到包涵体;
(2)溶解包涵体后取上清液,对上清液进行金属螯合亲和层析:以上清液上样后,先以变性洗脱液进行洗脱使蛋白变性,再减少或消除蛋白变性因素的洗脱液进行洗脱使蛋白复性,淋洗层析柱,收集淋洗液,干燥,即得人表皮生长因子。
优选的,所述步骤(2)中,所述变性洗脱液中包括变性剂,所述变性剂包括ph调节剂、重金属盐、尿素、脲或盐酸胍中的一种或多种。
优选的,所述步骤(2)中,以蒸馏水或缓冲溶液淋洗层析柱。
与现有技术相比,本发明的有益效果:
1、本发明提供了一种易于纯化的人表皮生长因子融合蛋白,包括金属螯合亲和蛋白、c端可自切的多肽和hegf。本发明所述融合蛋白在变性条件下具有金属螯合特异性结合的能力(金属螯合亲和蛋白提供该功能),当融合蛋白与金属特异性结合后改变变性条件使融合蛋白复性,复性的融合蛋白能自行切割(c端可自切的多肽提供该功能),获得成熟的53个氨基酸组成的rhegf,不含多余的其他氨基酸。本发明构建的融合蛋白易于纯化,与常规纯化方式相比,在确保纯度高的情况下有效的简化了纯化流程,降低hegf生产成本。
2、同时,与现有技术(201210181522.7)相比,本发明去除了融合蛋白中的cbd几丁质结合域,提高了融合蛋白中hegf占整个融合蛋白的质量比例,在等质量融合蛋白情况下,hegf的产量更高。
3、本发明还提供了一种人表皮生长因子的制备方法,重组表达上述融合蛋白后,进行金属螯合亲和层析制备得到hegf。本发明所述的制备方法仅需一步即可完成纯化,有效简化了蛋白分离的步骤,提高生产效率、节约成本。而且本发明所述制备方法是在层析柱上完成复性,避免了常规稀释复性或透析复性带来的大体积,更适合工业化放大生产,并且复性效率比稀释复性或透析复性效率高。
4、与现有技术(201210181522.7)相比,本发明采用金属螯合亲和层析代替几丁质亲和层析,大幅降低成本,可更多次的重复使用,载量高,并且保持了亲和层析纯化效果的优势。
5、融合蛋白游离切割后容易产生沉淀,柱上切割可以避免这个问题。
附图说明
图1为实施例1中histag-intein和hegfpcr扩增产物电泳检测图;其中,m-纽龙生物dnamarkeriip;1-histag-intein扩增产物;2-hegf扩增产物;
图2为实施例1中pet-histag-intein-hegf质粒酶切检测图;其中,m-纽龙生物dnamarkeriip;1-pet-histag-intein-hegf质粒酶切产物;
图3为实施例1中pet-histag-intein-hegf质粒结构图;
图4为图5100l罐发酵电泳检测图;其中,m-纽龙生物proteinmarker,1-诱导前,2-诱导1h,3-诱导2h,4-诱导3h,5-诱导4h;
图5为实施例2中菌体破碎与包涵体洗涤电泳检测图;其中,m-纽龙生物proteinmarker,1-破碎上清,2-破碎沉淀,3-包涵体洗涤上清,4-洗涤后包涵体;
图6为实施例3中ni-tedff柱上复性、切割和纯化电泳检测图;m-纽龙生物proteinmarker,1-溶解的包涵体上清(上柱前),2-上样穿透,3-洗脱的rhegf,4-洗脱的histag-intein标签;
图7为实施例3中sec-hplc分析rhegf的结果图;
图8为实施例4中maldi-tof-ms检测rhegf的结果;
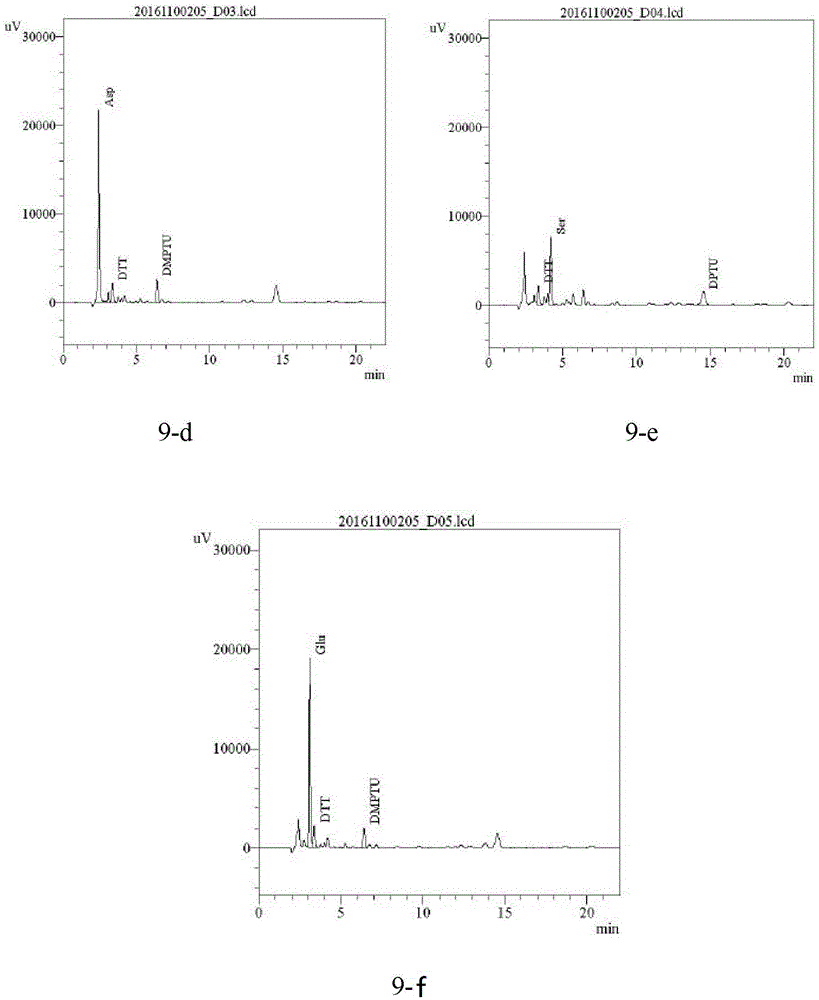
图9为实施例4中rhegfn端氨基酸序列测定结果;其中9-a为标准品校准测试,9-b为第1个氨基酸,9-c为第2个氨基酸,9-d为第3个氨基酸,9-e为第4个氨基酸,9-f为第5个氨基酸;
图10为实施例4中rhegf刺激balb/c3t3细胞增殖(mtt法)的结果。
具体实施方式
本发明提供了一种易于纯化的人表皮生长因子融合蛋白,包括金属螯合亲和蛋白、c端可自切的多肽和hegf。
在本发明中,所述融合蛋白中的金属螯合亲和蛋白提供与金属离子特异性结合的功能,为进一步的金属螯合亲和层析提供基础条件。本发明选择金属螯合亲和蛋白作为介质构建融合蛋白,相比于常规技术手段中采用的几丁质亲和介质成本更低。在本发明中,所述金属螯合亲和蛋白包括但不限于histag标签、hatag(kdhlihnvhkefhahnk)标签或含多个半胱氨酸的标签(例如hnrygcgcc);更优选的,所述histag标签由2~10个连续的组氨酸组成;最优选的,所述histag标签由6~8个连续的组氨酸组成。
在本发明中,所述c端可自切的多肽为所述融合蛋白提供在变性后复性的条件下自切的功能,以便在纯化时将hegf从融合蛋白中切除,实现融合蛋白的断裂,释放目的产物(hegf)。在本发明中,所述c端可自切的多肽包括但不限于金黄色葡萄球菌分选酶a、瘟疫病毒n段蛋白酶或集包藻dna解旋酶的全部或部分。本发明优选的,采用集胞藻dna解旋酶部分基因片段;更优选为集胞藻dna解旋酶迷你内含肽基因(sspdnabmini-intein)。本发明优选的,在c端可自切的多肽的n端引入金属螯合亲和蛋白。
在本发明中,所述融合蛋白中的hegf为能编码53个成熟人表皮生长因子的氨基酸序列。本发明优选的,为了提高表达量,对hegf的编码序列进行密码子偏好优化,如本发明实施例中对hegf的核苷酸序列进行了优化,如seqno.2所示。
在本发明中,所述融合蛋白从n端到c端的顺序优选的依次包括:金属螯合亲和蛋白、c端可自切的多肽和hegf。
本发明还提供了一种编码上述技术方案所述人表皮生长因子融合蛋白的核酸分子,包括编码金属螯合亲和蛋白、c端可自切的多肽和hegf的核苷酸序列。在本发明的实施例所示,所述核酸分子的编码序列优选的如seqidno.1所示。
在本发明的具体实施方式中,通过引物的方式将编码金属螯合亲和蛋白的核苷酸序列引入到编码c端可自切的多肽的核苷酸序列的n端,例如采用如seqidno.3和seqidno.4所示的引物对扩增c端可自切的多肽的核苷酸序列,得到如seqidno.5所示的核苷酸序列histag-nitein。
sspf(seqidno.3):atacgcccatgggcagcagccatcatcatcatcatcacaacggtaacaacggtctc;
sspr(seqidno.4):gttgtgtacaatgatgtcattcg。
本发明还提供了一种人表皮生长因子的制备方法,包括以下步骤:
(1)重组表达前述技术方案所述的人表皮生长因子融合蛋白,分离得到包涵体;
(2)溶解包涵体后取上清液,对上清液进行金属螯合亲和层析:以上清液上样后,先以变性洗脱液进行洗脱使蛋白变性,再减少或消除蛋白变性因素的洗脱液进行洗脱使蛋白复性,淋洗层析柱,收集淋洗液,干燥,即得人表皮生长因子。
本发明首先重组表达前述技术方案所述的人表皮生长因子融合蛋白,分离得到包涵体。具体的,本发明将上述技术方案所述的核酸分子插入表达载体的多克隆位点,得到重组表达载体;将重组表达载体导入宿主细胞中,得到重组表达细胞。培养所述重组表达细胞即可得到本发明所述易于纯化的人表皮生长因子融合蛋白。
在本发明中,所述表达载体为任意能够表达本发明所述融合蛋白的表达载体,包括但不限于pet系列表达载体。在本发明中,所述宿主细胞为任意能够用于表达所述重组表达载体的细胞,包括但不限于大肠杆菌。本发明优选的根据宿主细胞的密码子偏好性对hegf的编码序列进行优化,以提高hegf在宿主细胞中的表达量。
在本发明中,所述人表皮生长因子融合蛋白进行重组表达后,以包涵体的形式存在。采用本领域常规方法将重组表达的包涵体分离即可。
得到包涵体后,本发明将溶解包涵体后取上清液,对上清液进行金属螯合亲和层析:以上清液上样后,先以变性洗脱液进行洗脱使蛋白变性,再减少或消除蛋白变性因素的洗脱液进行洗脱使蛋白复性,淋洗层析柱,收集淋洗液,干燥,即得人表皮生长因子。
本发明所述制备方法的一个显著特点是,采用一步金属螯合亲和层析进行融合蛋白的纯化、复性、自切割、目标物纯化,省去传统制备方法的很多步骤。与gst亲和层析、mbp亲和层析、几丁质亲和层析相比,金属螯合亲和层析能在蛋白变性的情况下进行特异性亲和捕获目标蛋白,并且金属螯合亲和层析还具有载量高、价格低、重复使用次数多等特点,同时金属螯合亲和层析对应的标签很短,如上述提到的histag,仅2~10个氨基酸。
金属螯合亲和层析的类型有很多,按照层析介质的骨架不同,有多糖类的,如葡聚糖、纤维素、琼脂糖等;有高聚合物类的,如聚苯乙烯、聚丙烯酸、聚乙烯醇等;有无机类的,如硅胶、磁珠等,有膜式的,如聚醚砜膜等。按照配基不同,有亚氨基二乙酸型(ida)、次氮基三乙酸(nta)、三羧甲基乙二胺(ted)、羧甲基天冬氨酸(cm-asp)等。按照螯合的离子不同,有铜离子(cu2+)、镍离子(ni2+)、钴离子(co2+)、铁离子(fe3+)、锌离子(zn2+)等。这些类型及其组合均适用于本发明。
但本发明优选高度交联的琼脂糖为骨架的金属螯合亲和层析,具有孔径大、流速快、载量高的特点;另一方面优选的配基为ida、nta、ted,更优选ted作为金属螯合亲和层析的配基,具有螯合金属牢固、不易脱落、耐受还原剂、一定浓度的强螯合剂、特异性强等特点;再另一方面,更优选ni2+作为螯合的金属,具有亲和力强、特异性高、载量高的特点。综合所述,最优选ni-ted琼脂糖凝胶ff作为一步金属螯合亲和层析的介质。
本发明中用于一步金属螯合亲和层析的样品一般为包涵体,需要通过变性剂溶解,常见的变性剂,如脲、盐酸胍等,均适合本发明,常用的浓度为2~10mol/l。在一个优选的方案中,使用脲的浓度为6~8mol/l进行溶解。为促进包涵体溶解,一般需要在一定温度下搅拌一段时间,常用的温度为25~40℃,时间为1-8h,在一个优选的方案中使用了30℃搅拌2h进行溶解。
在本发明中,包涵体溶解后的上清几乎包含了所有的融合蛋白,可以直接上层析柱进行复性、纯化,在一项优选的复性方案中,包括降低变性剂浓度,进行复性,如先后使用含8mol/l、6mol/l、4mol/l、2mol/l、1mol/l、0mol/l的脲溶液梯度过柱进行复性,或使用单一低浓度的脲进行清洗层析柱复性,如6mol/l、4mol/l、2mol/l、1mol/l、0.5mol/l等浓度;例如,在一优选方案中使用1mol/l脲进行清洗。在另一项优选的复性方案中,以降低还原剂的浓度,促进hegf分子中的二硫键正确折叠,浓度的降低可以使用先后梯度的方式,如0~10mmol/l的β-巯基乙醇、0~5mmol/l的dtt、0-10mmol/l的半胱氨酸等;在一优选方案中使用了1mol/l、0.1mmol/l、0mmol/l的β-巯基乙醇先后梯度清洗层析柱促进hegf二硫键的正确折叠。为尽量减少融合蛋白发生自切,选择较高的ph进行清洗,如ph8.0以上的缓冲液。在复性的清洗层析过程中,也同时纯化了融合蛋白。
在本发明的具体实施例中,用于溶解包涵体的缓冲液优选的包括:50mmtris-hcl、150mmnacl、8m脲、5mm咪唑、3mmβ-巯基乙醇和1mmedta,ph8.5。在本发明中,采用缓冲液溶解包涵体的温度优选为28~35℃,更优选为30℃。在本发明中,采用缓冲液溶解包涵体的时间优选为1.5~3h,更优选为2h。本发明将包涵体溶解后,优选的通过离心方式进行固液分离,收集上清液;除离心外还可以采用其他本领域已知的固液分离方式,本发明对此无特殊限定。
本发明所述制备方法在一步金属螯合亲和层析过程中,获得复性和纯化的融合蛋白不需要从柱上洗脱下来,可以直接在进行酶切,本发明所述融合蛋白含有的c端可自切的多肽允许在变性后复性的条件下进行高效自切割。如本发明实施例中采用的内含肽可在ph6~8的条件下自切割,本发明综合后续样品保存的需要,采用相应缓冲液切割,省去置换缓冲液的过程,如采用磷酸盐缓冲液,tris盐酸缓冲液等,在一优选方案中采用ph7.0的磷酸盐缓冲液。
具体的,本发明将溶解包涵体后得到的上清液上样到金属螯合亲和层析柱后,变性洗脱液洗脱的目的是为了使融合蛋白与金属螯合亲和层析柱中的介质螯合,从而融合蛋白吸附在层析柱介质上,去除上清液中非融合蛋白的杂质,以实现纯化目的。在本发明中,所述变性洗脱液中包括变性剂,所述变性剂包括但不限于ph调节剂、重金属盐、尿素、脲或盐酸胍中的一种或多种。
在本发明中,变形洗脱液洗脱后,以减少或消除蛋白变性因素的洗脱液进行洗脱,使融合蛋白复性。本发明所述减少或消除蛋白变性因素的洗脱液即为减少或消除变性剂的洗脱液,根据使用的变性洗脱液不同而具体选择。本发明使融合蛋白复性是为了给自切割创造性条件,即c端可自切的多肽在复性条件下会自行切割。
在本发明中,使融合蛋白复性后,优选的封闭层析柱前后出口,静置18~36h,此时融合蛋白在层析柱内发生自切。在本发明中,所述静置时间优选为24h;所述静置的温度优选为22~26℃。
在本发明中,待融合蛋白复性后自切完成,本发明对层析柱进行淋洗,所得淋洗液中为自切后的hegf蛋白。在本发明中,优选的采用蒸馏水或缓冲溶液对层析柱进行淋洗,采用水或缓冲溶液淋洗能够省却常规纯化步骤中对洗脱液的去除步骤,简化纯化操作。在本发明中,所述缓冲溶液包括但不限于tris-hcl溶液。
下表总结了本发明与传统hegf融合蛋白制备工艺,传统制备工艺至少需要6步及以上的操作,耗时将近一周,在由于长时间的纯化过程,可能造成样品的降解;多步操作造成样品损失过多,比如假设每步90%得率,6步操作后总得率也仅50%左右;多步操作所使用的原材料等成本也明显增加,在部分步骤还可能需要使用昂贵的原材料,如采用bcd融合需要使用几丁质介质纯化,价格昂贵,载量低,使用次数少。本发明所述的制备方法仅需一步金属螯合亲和层析工艺,可以避免上述的缺点,整个操作过程不超过24h,大幅降低目标物在纯化过程中的降解;一步操作,总收率高;金属螯合亲和层析介质价格低廉,载量高,可重复使用次数多,特别优选的ni-ted琼脂糖凝胶ff耐受性好,金属离子脱落低;所有操作均在层析柱上进行,不需要额外的置换缓冲液;与稀释或透析复性相比,不需要大体积容器,非常适合放大。
表1传统hegf制备工艺与一步金属螯合亲和层析工艺比较
下面结合实施例对本发明提供的技术方案进行详细的说明,但是不能把它们理解为对本发明保护范围的限定。
实施例1:表达载体pet-histag-intein-hegf的构建
(1)设计引物对sspf/sspr从购自neb的ptwin1载体中扩增sspdnabmini-intein基因片段并在5’端添加histag编码基因序列和ncoi酶切识别位点及保护碱基。
用于intein基因调取和添加histag的引物序列:
sspf:atacgcccatgggcagcagccatcatcatcatcatcacaacggtaacaacggtctc(seqidno.3);
sspr:gttgtgtacaatgatgtcattcg(seqidno.4);
调取后histag-intein序列(seqidno.5):
atgggcagcagccatcatcatcatcatcacaacggtaacaacggtctcgaactgcgcgagtccggagctatctctggcgatagtctgatcagcctggctagcacaggaaaaagagtttctattaaagatttgttagatgaaaaagattttgaaatatgggcaattaatgaacagacgatgaagctagaatcagctaaagttagtcgtgtattttgtactggcaaaaagctagtttatattctaaaaactcgactaggtagaactatcaaggcaacagcaaatcatagatttttaactattgatggttggaaaagattagatgagctatctttaaaagagcatattgctctaccccgtaaactagaaagctcctctttacaattgtcaccagaaatagaaaagttgtctcagagtgatatttactgggactccatcgtttctattacggagactggagtcgaagaggtttttgatttgactgtgccaggaccacataactttgtcgcgaatgacatcattgtacacaac。
(2)根据公知的人表皮生长因子的53个氨基酸序列,设计符合大肠杆菌三联体密码子使用偏好的dna序列,送南京金斯瑞生物科技有限公司优化合成,设计引物对hef/her从含hegf优化序列的合成模板中扩增hegf基因片段并在5’端添加部分sspdnabmini-intein序列和nrui酶切识别位点及保护碱基,在3’端添加xhoi酶切识别位点及保护碱基。
用于hegf基因调取的引物序列:
hef:atacgctcgcgaatgacatcattgtacacaacaacagcgattctgaatgc(seqidno.6);
her:atacgcctcgagttaacgcagttcccacc(seqidno.7);
调取的hegf序列(seqidno.8):
aacagcgattctgaatgcccgctgagtcacgatggctattgcctgcatgacggtgtttgtatgtacatcgaagctctggataaatacgcatgcaattgtgtggttggctatatcggtgaacgttgtcaataccgcgacctgaaatggtgggaactgcgttaa。
(3)回收pcr扩增产物(电泳检测如图1),将histag-intein片段使用ndei/nrui酶切处理,hegf片段使用nrui/xhoi酶切处理,同时使用ndei/xhoi酶切处理pet28a载体,回收酶切好的三个片段,一起共连接过夜后转化dh5α感受态细胞,从转化平板上挑取阳性克隆扩大培养后提取质粒,使用ndei/xhoi酶切检测,图2显示酶切的条带大小和预期相符(约700bp),将该质粒命名为pet-histag-intein-hegf,质粒结构如图3所示,测序显示序列正确,表达的基因与氨基酸序列如图4所示,将该质粒转化bl21(de3)表达菌株,命名工程菌为pet-histag-intein-hegf/bl21。
histag-intein-hegf融合蛋白的编码序列(seqidno.1):
atgggcagcagccatcatcatcatcatcacaacggtaacaacggtctcgaactgcgcgagtccggagctatctctggcgatagtctgatcagcctggctagcacaggaaaaagagtttctattaaagatttgttagatgaaaaagattttgaaatatgggcaattaatgaacagacgatgaagctagaatcagctaaagttagtcgtgtattttgtactggcaaaaagctagtttatattctaaaaactcgactaggtagaactatcaaggcaacagcaaatcatagatttttaactattgatggttggaaaagattagatgagctatctttaaaagagcatattgctctaccccgtaaactagaaagctcctctttacaattgtcaccagaaatagaaaagttgtctcagagtgatatttactgggactccatcgtttctattacggagactggagtcgaagaggtttttgatttgactgtgccaggaccacataactttgtcgcgaatgacatcattgtacacaacaacagcgattctgaatgcccgctgagtcacgatggctattgcctgcatgacggtgtttgtatgtacatcgaagctctggataaatacgcatgcaattgtgtggttggctatatcggtgaacgttgtcaataccgcgacctgaaatggtgggaactgcgttaa。
histag-intein-hegf融合蛋白的氨基酸序列(seqidno.2):
mgsshhhhhhngnnglelresgaisgdslislastgkrvsikdlldekdfeiwaineqtmklesakvsrvfctgkklvyilktrlgrtikatanhrfltidgwkrldelslkehialprklessslqlspeieklsqsdiywdsivsitetgveevfdltvpgphnfvandiivhnnsdsecplshdgyclhdgvcmyiealdkyacncvvgyigercqyrdlkwwelr
实施例2:表达菌株的发酵
(1)培养基的配制
种子培养基:lb培养基
发酵培养基:蛋白胨20g/l,酵母粉30g/l,磷酸氢二钾0.2g/l,硫酸镁0.2g/l,泡敌0.04%
补料培养基:50%葡萄糖
(2)将实施例1构建的pet-histag-intein-hegf/bl21工程菌接种至含50ml种子培养基的摇瓶中,37℃、220rpm活化过夜,然后接种至含200ml种子培养基的摇瓶中,37℃、220rpm培养至od600nm>0.6;再转接4瓶含500ml种子培养基的摇瓶中,37℃、220rpm培养至od600nm>0.6,作为发酵种子液。
将2000ml种子液接种至含50l发酵培养基的100l发酵罐中,设置温度37℃、通气量1vvm、搅拌转速400rpm,补料发酵,控制残糖1~5g/l,14%氨水调节ph6.8,当od600nm>10.0时,加入终浓度0.1mmol/l的iptg进行诱导4~6h。
发酵不同的时间点取样进行sds-page电泳检测,结果如图4。
实施例3:rhegf的纯化
用管式离心机对实施例2得到的发酵液离心,收集菌体约3kg,高压均质机破碎细胞,立式高速离心机13000rpm离心30min,收集沉淀,沉淀经buffera(50mmtris-hcl,500mmnacl,1mmedta,20mmdtt,1%tritonx-100,ph8.5)、bufferb(50mmtris-hcl,150mmnacl,5mmdtt,1mmedta,ph8.5)洗涤,获得约0.8kg包涵体。菌体破碎与包涵体洗涤见图5。
包涵体以50g/l在bufferc(50mmtris-hcl,150mmnacl,8m脲,5mm咪唑,3mmβ-巯基乙醇,1mmedta,ph8.5)中30℃搅拌2h溶解,13000rpm离心30min收集上清。
收集的包涵体溶解上清上已平衡好的5lni-tednupharoseff(纽龙生物)层析柱,用bufferd(50mmtris-hcl,150mmnacl,1m脲,5mm咪唑,1mmβ-巯基乙醇,1mmedta,ph8.5)以20~50cm/h的流速洗柱30min以上;然后用buffere(50mmtris-hcl,150mmnacl,5mm咪唑,0.1mmβ-巯基乙醇,1mmedta,ph8.5)以20~50cm/h的流速洗柱30min以上;再用bufferf(50mmtris-hcl,150mmnacl,1mmedta,ph8.5)以20-50cm/h的流速洗柱30min以上。复性结束后,用bufferg(20mmnah2po4-na2hpo4,ph7.0)以100cm/h的流速清洗3个柱体积,停止泵,关闭层析柱前后进出口,于25℃静置24h进行自切。
自切后,用bufferg洗出目的蛋白,即为高纯度的rhegf,约15.3g。结合在柱上的histag-intein标签用bufferh(20mmnah2po4-na2hpo4,500mm咪唑,ph7.0)洗脱,最后层析柱直接用0.1mnaoh清洗再生。
图6为ni-tedff柱上复性、切割和纯化的sds-page电泳检测结果,融合蛋白自切后经bufferg洗脱,为单一条带,sec-hplc检测纯度为96.2%(图7),实现一步ni-tedff亲和层析完成复性、融合蛋白纯化、切割、目标蛋白纯化、标签去除等功能。
实施例4:hegf的鉴定
质谱检测分子量:委托杭州意诚默迪生物科技有限公司,对rhegf进行maldi-tof-ms检测,图8显示带1个电荷的分子量为6218.6,带2个电荷的分子量为3110.2,结果与hegf理论值6216相符。
n端测序:委托中国科学院上海生命科学研究院,对rhegf进行n端测序检测,图9检测结果显示n端5个氨基酸序列为nh2-asn-ser-asp-ser-glu,与天然hegf相符。
细胞生物活性检测:采用mtt法,balb/3t3细胞按3000个/孔接种到96孔板中培养过夜,将rhegf用0.4%fbs-rpmi1640维持培养基配成50iu/ml,再按4倍梯度稀释,每梯度设4个重复,同时设置阴性对照,作用细胞48h后加mtt,反应4h后吸出培养液,每孔加100μldmso,培养箱中培养10min,用酶标仪测定od570nm吸收值。根据酶标仪读数和样品浓度拟合曲线,如图10,计算ec50值为0.113ng/ml。
由以上实施例可以看出,本发明提供的融合蛋白易于纯化,仅需进行一步金属螯合亲和层析即可获得纯度高的hegf,操作简便,可有效节约生产成本,提高效率。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
序列表
<110>杭州纽龙日尚生物制品有限公司
<120>一种易于纯化的人表皮生长因子融合蛋白及其核酸分子、一种人表皮生长因子制备方法
<160>8
<170>siposequencelisting1.0
<210>1
<211>690
<212>dna
<213>人工序列(artificialsequence)
<400>1
atgggcagcagccatcatcatcatcatcacaacggtaacaacggtctcgaactgcgcgag60
tccggagctatctctggcgatagtctgatcagcctggctagcacaggaaaaagagtttct120
attaaagatttgttagatgaaaaagattttgaaatatgggcaattaatgaacagacgatg180
aagctagaatcagctaaagttagtcgtgtattttgtactggcaaaaagctagtttatatt240
ctaaaaactcgactaggtagaactatcaaggcaacagcaaatcatagatttttaactatt300
gatggttggaaaagattagatgagctatctttaaaagagcatattgctctaccccgtaaa360
ctagaaagctcctctttacaattgtcaccagaaatagaaaagttgtctcagagtgatatt420
tactgggactccatcgtttctattacggagactggagtcgaagaggtttttgatttgact480
gtgccaggaccacataactttgtcgcgaatgacatcattgtacacaacaacagcgattct540
gaatgcccgctgagtcacgatggctattgcctgcatgacggtgtttgtatgtacatcgaa600
gctctggataaatacgcatgcaattgtgtggttggctatatcggtgaacgttgtcaatac660
cgcgacctgaaatggtgggaactgcgttaa690
<210>2
<211>229
<212>prt
<213>人工序列(artificialsequence)
<400>2
metglyserserhishishishishishisasnglyasnasnglyleu
151015
gluleuarggluserglyalaileserglyaspserleuileserleu
202530
alaserthrglylysargvalserilelysaspleuleuaspglulys
354045
aspphegluiletrpalaileasngluglnthrmetlysleugluser
505560
alalysvalserargvalphecysthrglylyslysleuvaltyrile
65707580
leulysthrargleuglyargthrilelysalathralaasnhisarg
859095
pheleuthrileaspglytrplysargleuaspgluleuserleulys
100105110
gluhisilealaleuproarglysleugluserserserleuglnleu
115120125
serprogluileglulysleuserglnseraspiletyrtrpaspser
130135140
ilevalserilethrgluthrglyvalglugluvalpheaspleuthr
145150155160
valproglyprohisasnphevalalaasnaspileilevalhisasn
165170175
asnseraspserglucysproleuserhisaspglytyrcysleuhis
180185190
aspglyvalcysmettyrileglualaleuasplystyralacysasn
195200205
cysvalvalglytyrileglygluargcysglntyrargaspleulys
210215220
trptrpgluleuarg
225
<210>3
<211>56
<212>dna
<213>人工序列(artificialsequence)
<400>3
atacgcccatgggcagcagccatcatcatcatcatcacaacggtaacaacggtctc56
<210>4
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>4
gttgtgtacaatgatgtcattcg23
<210>5
<211>528
<212>dna
<213>人工序列(artificialsequence)
<400>5
atgggcagcagccatcatcatcatcatcacaacggtaacaacggtctcgaactgcgcgag60
tccggagctatctctggcgatagtctgatcagcctggctagcacaggaaaaagagtttct120
attaaagatttgttagatgaaaaagattttgaaatatgggcaattaatgaacagacgatg180
aagctagaatcagctaaagttagtcgtgtattttgtactggcaaaaagctagtttatatt240
ctaaaaactcgactaggtagaactatcaaggcaacagcaaatcatagatttttaactatt300
gatggttggaaaagattagatgagctatctttaaaagagcatattgctctaccccgtaaa360
ctagaaagctcctctttacaattgtcaccagaaatagaaaagttgtctcagagtgatatt420
tactgggactccatcgtttctattacggagactggagtcgaagaggtttttgatttgact480
gtgccaggaccacataactttgtcgcgaatgacatcattgtacacaac528
<210>6
<211>50
<212>dna
<213>人工序列(artificialsequence)
<400>6
atacgctcgcgaatgacatcattgtacacaacaacagcgattctgaatgc50
<210>7
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>7
atacgcctcgagttaacgcagttcccacc29
<210>8
<211>162
<212>dna
<213>人工序列(artificialsequence)
<400>8
aacagcgattctgaatgcccgctgagtcacgatggctattgcctgcatgacggtgtttgt60
atgtacatcgaagctctggataaatacgcatgcaattgtgtggttggctatatcggtgaa120
cgttgtcaataccgcgacctgaaatggtgggaactgcgttaa162
- 还没有人留言评论。精彩留言会获得点赞!
- UCP1在人重组FGF21蛋白活性检测中的应用的制造方法与工艺
- UCP3在人重组FGF21蛋白活性检测中的应用的制造方法与工艺
- 原核表达载体及rbFGF‑2表达方法与工程菌和应用与流程
- 一种利用鱼卵母细胞提取物诱导成纤维细胞重编程为成骨细胞样细胞的试剂盒及方法与流程
- 控制影响角化细胞和/或成纤维细胞和真皮的皮肤失调和皮肤老化的组合产品和美容组合物的制造方法与工艺
- 在CHO细胞中rhIL‑12表达系统的构建方法与制造工艺
- 人皮肤成纤维细胞诱导为神经细胞的方法与应用与制造工艺
- 一种制备人皮肤成纤维细胞膜片的细胞培养基和使用方法与制造工艺
- 检测人FGFR3基因突变的引物组及其试剂盒的制造方法与工艺
- 一种氧调控性碱性成纤维细胞生长因子修饰细胞的方法与制造工艺