一种多特异性抗体及其制备方法和用途与流程
本申请通常涉及抗体领域。更具体地,本申请涉及一种多特异性抗体及其制备方法和用途。
发明背景
众所周知,天然抗体分子大多是二价单特异性分子。然而过去半个世纪以来,得益于抗体工程化的进展,人工产生了多种双特异性和多特异性抗体的分子。其形式多种多样,包括例如单链fv抗体(scfv,huston等,proc.natl.acad.sci.usa,85:5879-5883(1988))、四价igg-scfv融合体(coloma和morrison,nat.biotechnol.,15:159-163(1997))、双链抗体(diabody)(holliger等,proc.natl.acad.sci.usa,90:6444-6448(1993))、串联scfv分子(参见例如bargou等,science321,974-977(2008))、四价igg-样双可变结构域抗体(“dvd-ig”,wu等,nat.biotechnol.,25:1290-1297(2007))、四价fab串联免疫球蛋白(“fit-ig”),(wo2015/103072,epimabbiotheraupeutics)、二价大鼠/小鼠杂合双特异性igg(lindhofer等,j.immunol.,155:219-225(1995))和双特异性crossmab结合蛋白(参见例如wo2013/026831(rocheglycartag);wo2014/167022(engmabag))。由于双特异性或多特异性的抗体能够结合两个或多个不同表位或抗原靶点,并且具备某些联合分子所缺少的新功能(参见,例如sergey等,drugdesdevelther.12:195–208(2018)中的综述),因此用于治疗各种肿瘤的双特异或多特异性的抗体受到越来越多的关注,特别是用于“t细胞重定向”的双特异性抗体。这类双特异性抗体可以同时靶向肿瘤细胞上的表面抗原和t细胞表面受体(tcr)复合物的激活组分,如cd3,从而导致靶向攻击肿瘤的细胞毒性t淋巴细胞(ctl)的激活。这类双特异性抗体的代表形式是“双特异性t细胞接合物”或“bite”抗体,例如,包含通过甘氨酸-丝氨酸(g4s)接头连接的两个scfv抗体,其中一个scfv提供肿瘤抗原(例如17-1a肿瘤抗原)的结合位点,而另一个scfv提供t细胞上cd3抗原的结合位点(mack等,proc.natl.acad.sci.usa,92:7021-7025(1995))。抗cd3×抗cd19bite抗体blinatumomab,已被美国食品和药物管理局(fda)批准用于治疗罕见形式的b细胞急性淋巴母细胞性白血病(all)。用于t细胞重定位的其他双特异性抗体形式包括但不限于四价串联双链抗体("tandab,"kipriyanov等,j.mol.biol.,293:41–56(1999);arndt等,blood,94:2562-2568(1999))和双亲和性重新靶向蛋白("dart",johnson等,j.mol.biol.,399:436-449(2010))。
众所周知,含有fc的全长双特异性抗体形式具有较长半衰期,并且具备fc效应功能。然而,全长双特异性抗体需要采用杵臼-孔洞(knobs-into-holes)(“kih”)技术(ridgway等,proteineng.,9:617-621(1996))来提高fc区的异二聚化组装和稳定性,但是异源二聚物匹配性差以及轻链错配等,仍会导致目标产物稳定性差以及一系列非目标产物的生成,导致分子表达和纯化的困难。虽然fc会赋予双特异性抗体较长的半衰期,但其也是干扰异二聚体形成的原因之一,而且fc效应功能在某些药物设计中不仅不是必需,还会对药物功能产生干扰性影响。因此为了避免fc效应,一些双特异性抗体采用单链形式,如bite、双链抗体、dart和tandab,通过肽接头连接不同的可变结构域以实现双特异性。与全尺寸单克隆抗体相比,这些分子的优点在于它们更小并且更快地进入组织和肿瘤,缺点是这些形式不含fc区,分子量通常小于60kda,会由于肾清除导致非常短的体内半衰期,并且在物理上不稳定(spiess等(2015),前述引文)。全长双特异抗体fc导致非相关重链同二聚体配对的无活性分子副产物的形成,单链双特异性抗体稳定性差半衰期短,则介于这两者之间的双链fab抗体形式,有望同时克服这些问题。但是,直接将两个或更多个fab借助一种普通连接物彼此融合的构建体可行性差,原因在于两条轻链的随机缔合仍然会产生无活性、不想要的副产物。
已有诸多双特异性或多特异性的抗体形式作为研发新治疗性抗体的可能形式。然而,到目前为止,还没有一种形式可以提供一套全面的特性,从而使其自身可以用于研发治疗大多数疾病的新型治疗性抗体。鉴于双特异性或多特异性的抗体不断增加的可能应用以及与目前可用形式相关的多变结果,仍然需要改进的形式,其可以工程化,以解决与研发治疗特定疾病的抗体相关的特定挑战。
发明概述
本文中提供一种新的双特异性抗体及其制备方法,所述双特异性抗体因错配副产物减少、目标产物增加而容易产生,比本领域已知的双特异性抗体片段显示更高的稳定性和更少的聚集。而且,这种方法可以应用于现存的抗体而无需筛选共同轻链或重链。此外,与许多单链双特异性抗体片段相比,这种新的双特异性抗体具有更高的分子量,能够防止过度肾清除从而增加其体内半衰期。
在第一方面,本申请提供了一种抗体,其包含:
a)能特异性结合第一抗原的fab片段,其中所述fab片段由一条轻链以及一条重链的ch1和可变区组成;
b)第一肽接头,所述第一肽接头的n端与所述重链融合;
c)第二肽接头,所述第二肽接头的n端与所述轻链融合,
其中所述第一肽接头和所述第二肽接头之间仅能形成一个二硫键,并且各自独立地选自以下:包含seqidno.1-2所示序列中的任一种的肽接头,其中seqidno.1-2分别为xppcpape和epapcppx,并且其中x代表除cys的任意氨基酸,或者缺失。
在第二方面,本申请提供了编码第一方面所述的抗体的核酸。
在第三方面,本申请提供了包含第二方面所述的核酸的表达载体。
在第四方面,本申请提供了一种宿主细胞,其包含第二方面所述的核酸或第三方面所述的表达载体。
在一些实施方案中,所述宿主细胞为哺乳动物细胞。哺乳动物细胞可以包括但不限于cho细胞、ns0细胞、sp2/0细胞、hek293细胞、cos细胞和per.c6细胞。
在第五方面,本申请提供了制备第一方面所述的抗体的方法,其包括:
a)培养第四方面所述的宿主细胞;和
b)从所述宿主细胞中或所述宿主细胞的培养物上清中回收所述抗体。
在第六方面,本申请提供了药物组合物,其包含第一方面所述的抗体,第二方面所述的核酸,第三方面所述的表达载体或第四方面所述的宿主细胞,以及药学上可接受的载体。
在第七方面,本申请提供了第一方面所述的抗体,第二方面所述的核酸,第三方面所述的表达载体或第四方面所述的宿主细胞在制备用于治疗、改善或预防肿瘤、自身免疫性疾病或传染性疾病的药物中的用途。
在第八方面,本申请提供了用于治疗、改善或预防个体的肿瘤、自身免疫性疾病或传染性疾病的方法,其包括向个体施用第一方面所述的抗体,第二方面所述的核酸,第三方面所述的表达载体或第四方面所述的宿主细胞。
附图说明
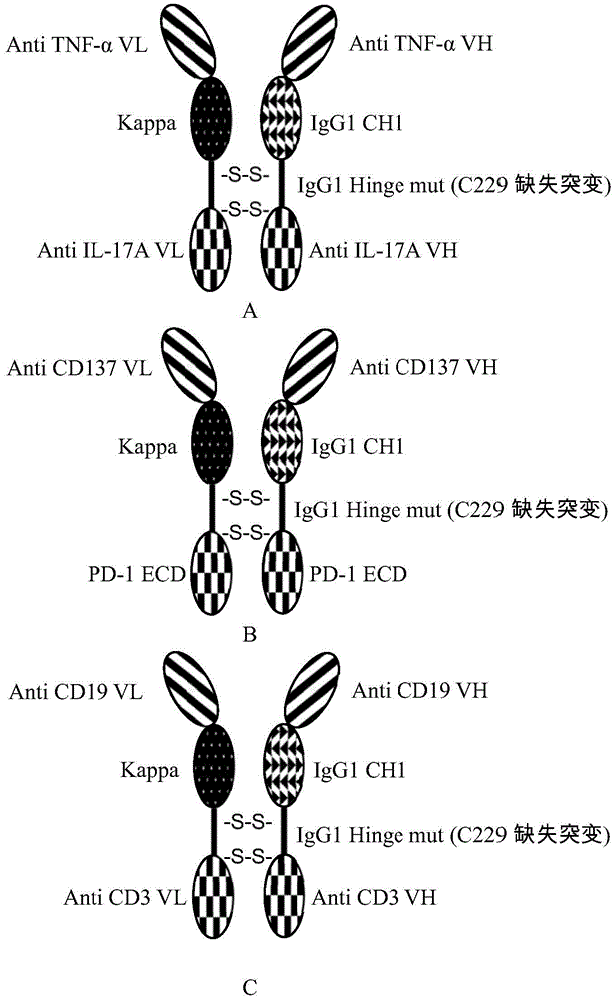
图1显示了本申请中构建的双特异性或多特异性的抗体结构示意图,其中a显示了抗tnfα×抗il-17a双特异性抗体(e1)的结构示意图;b显示了抗cd137×pd-1ecd蛋白双特异性抗体(e2)的结构示意图;c显示了抗cd3×抗cd19双特异性抗体(e3)的结构示意图;d显示了抗pd-l1×抗cd137双特异性抗体(e4)的结构示意图;e显示了抗cd3×抗cd137×pd-1ecd蛋白三特异性抗体(e5)的结构示意图。
图2显示了抗tnfα×抗il-17a双特异性抗体(e1)的纯化及sds-page电泳结果,其中a显示了抗体e1的captol亲和层析图谱,b显示了抗体e1的sds-page电泳结果,泳道m为dnamarker、泳道1为非还原条件下的sds-page电泳结果、泳道3为还原条件下的sds-page电泳结果。
图3显示了通过hplc检测抗体e1纯度的结果。
图4显示了通过fortebio测定结合亲和力的结合-解离曲线,其中a显示了抗体e1结合抗原tnf-α的结合-解离曲线,b显示了阿达木单抗结合抗原tnf-α的结合-解离曲线,c显示了抗体e1结合抗原il-17a的结合-解离曲线,并且d显示了苏金单抗结合抗原il-17a的结合-解离曲线。
图5显示了抗体e2与细胞表面抗原结合的流式细胞术结果,其中a显示了抗体e2与mc38-pdl-1细胞结合的流式细胞术结果,b显示了抗体e2与b8-cd137细胞结合的流式细胞术结果。
图6显示了本申请所构建的各特异性抗体与其相应的抗原之间的亲和力常数测定结果。
发明的详细描述
提供以下定义和方法以更好地界定本申请以及在本申请实践中指导本领域普通技术人员。除非另作说明,本申请的术语按照相关领域普通技术人员的常规用法理解。
定义
本文使用的术语“约”指所记载的数字的±10%,例如约1%指的0.9%至1.1%的范围。
本文所用的术语“抗体”是指能显示期望的生物活性的任何形式的抗体或其片段。因此,它以最广义的含义使用,具体覆盖单克隆抗体(包括全长单克隆抗体)、多克隆抗体、多特异性抗体(例如双特异性抗体)和抗体片段,只要它们能显示期望的生物活性。
本文所用的术语“抗原”是指能被选择性结合剂如抗体结合的分子或分子部分,还能用于动物中以制备能结合该抗原的表位的抗体。抗原可以具有一个或多个结合表位。本文所述的抗原可以包括但不限于大多数蛋白质、细菌、病毒、细菌外毒素,多糖(如肺炎球菌的荚膜多糖)和类脂等。
本文所用的术语“特异性结合”是本领域熟知的术语,并且测定抗体与抗原此类特异性结合的方法也为本领域所熟知。例如,在一些实施方案中,“特异性结合”是指抗体与预期的靶标结合,但不与其他靶标显著结合。相比与其他表位的结合,抗体以明显增加的亲和力和/或以更长的持续时间结合预期的靶表位。
本文所用的术语“抗原结合片段”包括抗体的基本上保留其结合活性的片段或衍生物。因此,术语“抗原结合片段”指全长抗体的一部分,通常是其抗原结合区或可变区。抗原结合片段的实例包括但不限于:fab片段、fab’片段、f(ab’)2片段、fv片段、双体、单链抗体分子如sc-fv以及从抗体片段形成的多特异性抗体。还认为,抗原结合片段可包括不会实质上改变其结合活性的保守氨基酸置换。
本文所用的术语“fab片段”包含一条轻链以及一条重链的ch1和可变区。fab分子的重链不能与另一个重链分子形成二硫键。
本文所用的术语“fab’片段”含有一条轻链以及一条重链的部分或片段,所述部分或片段含有vh结构域和ch1结构域以及在ch1和ch2结构域之间的区域,使得在2个fab’片段的两条重链之间可以形成链间二硫键,以形成f(ab’)2分子。
本文所用的术语“f(ab’)2片段”含有两条轻链和两条重链,所述重链含有在ch1和ch2结构域之间的恒定区的一部分,使得在两条重链之间形成链间二硫键。f(ab’)2片段因而由两个fab’片段组成,而两个fab’片段通过两条重链之间的二硫键连接在一起。
本文所用的术语“fv片段”包含来自重链和轻链的可变区,但是缺少恒定区。
本文所用的术语“单链fv”或“scfv”,是指包含抗体的vh结构域和vl结构域的抗体片段,其中这些结构域以单一多肽链形式存在。通常,fv多肽还包含vh结构域和vl结构域之间的多肽接头,所述接头使scfv能够形成期望的结构以进行抗原结合。
本文所用的术语“双体”指具有两个抗原结合位点的小抗体片段,所述片段在同一多肽链中包含重链可变结构域(vh)和与之连接的轻链可变结构域(vl)(vh-vl或vl-vh)。通过使用短得不能让同一链上的两个结构域之间发生配对的接头,各结构域被迫与另一条链的互补结构域发生配对,从而产生两个抗原结合位点。
本文所用的术语“超变区”指抗体的负责抗原结合的氨基酸残基。超变区包含来自“互补决定区”或“cdr”的氨基酸残基(例如轻链可变结构域中的残基24-34(lcdr-1)、50-56(lcdr-2)和89-97(lcdr-3)和重链可变结构域中的残基31-35(hcdr-1)、50-65(hcdr-2)和95-102(hcdr-3);kabat等人,(1991)sequencesofproteinsofimmunologicalinterest,第5版,publichealthservice,nationalinstitutesofhealth,bethesda,md.,和/或来自“超可变环”的氨基酸残基(即轻链可变结构域中的残基26-32(l1)、50-52(l2)和91-96(l3)和重链可变结构域中的残基26-32(h1)、53-55(h2)和96-101(h3);chothia和lesk,(1987)j.mol.biol.196:901-917。“框架区”或“fr”残基,是指本文定义为cdr残基的超变区残基之外的那些可变结构域残基。
本文所用的术语“肽接头”是指用于连接两个多肽的,相对柔性的肽分子。本申请中所用的肽接头只含有一个半胱氨酸,从而能够在两个肽接头之间形成一个稳定的二硫键。
本文所用的术语“结合部分”是指能够与其它物质特异性结合的部分,其可以包括但不限于抗体或其抗原结合片段、配体和受体等。本申请中的抗体所含的结合部分可以使该抗体靶向结合部分特异性结合的靶标。
本文使用的术语“肿瘤相关抗原”指肿瘤细胞单独表达或主要表达或过表达的任何分子(例如蛋白、肽、脂质、碳水化合物等),以使所述抗原与肿瘤相关。肿瘤相关抗原可以是仅一种类型的肿瘤表达的抗原,以使所述肿瘤抗原仅与一种类型的肿瘤相关或者仅是一种类型的肿瘤所特有的。可选地,肿瘤抗原可以是多种类型肿瘤相关或者特有的肿瘤抗原。例如,肿瘤相关抗原可以被乳腺癌细胞和结肠癌细胞都表达,但不被正常的、非肿瘤或非癌细胞所表达。示例性的肿瘤相关抗原为肿瘤细胞表面抗原,这类抗原更利于为治疗性和诊断性抗体所识别。
本文所述的术语“单克隆抗体”指从基本同质的抗体群中获得的抗体,即构成该群抗体的单个抗体之间是相同的,除了可以少量存在的可能自然发生的变异外。单克隆抗体高度特异性的针对单一抗原表位。本文公开的单克隆抗体不限于抗体来源或其制备方式(例如,通过杂交瘤、噬菌体挑选、重组表达、转基因动物等)。该术语包括在“抗体”定义下的完整免疫球蛋白以及其片段等。
“表达载体”是指包含重组多核苷酸的载体,所述重组多核苷酸包含与待表达的核苷酸序列可操作地连接的表达控制序列。表达载体包含用于表达的足够的顺式作用元件;用于表达的其它元件可以由宿主细胞或体外表达系统提供。表达载体包括本领域已知的所有那些,如掺入重组多核苷酸的粘粒,质粒(例如,裸露的或包含在脂质体中)和病毒(如慢病毒、逆转录病毒、腺病毒和腺相关病毒)。
具体实施方式
通常双特异性抗体片段的构造,是将抗体的vl与vh通过(g4s)n连接肽串联,其稳定性差,基因表达水平低,表达产物容易产生聚集,且体内半衰期较短。众所周知,铰链区在抗体的重链中的作用,一方面是提供柔性结构保证抗体两个手臂可以充分结合抗原,另一方面是提供两对以上的二硫键以产生稳定的同源二聚体结构。但是,在构造双特异性抗体时,希望尽量产生异源二聚体而减少同源二聚体,传统方法是通过ch3的氨基酸突变引入knobs-into-holes结构,或者通过突变引入电荷相反的氨基酸来促进异源二聚体形成,但是仍然无法解决轻链错配问题。而且某些情况下,不需要fc效应功能,需要另行突变以去除fc的效应,或者直接去除fc而采用f(ab)2或fab形式,这时就很难在fab段上引入促进异二聚化的氨基酸突变。本发明创造性地利用抗体铰链区中二硫键的稳定作用,将突变的抗体铰链区分别融合到fab抗体的重链和轻链c-末端,使得1)重链和轻链之间仅在突变的抗体铰链区处形成一对二硫键,而天然ch1和cl间形成的一对二硫键则不变;2)同时重链可变区和轻链可变区的非共价作用提供了叠加的稳定因素。综合而言,由于缺少第二稳定因素(铰链区天然存在的两对二硫键)和第三稳定性因素(天然重链的fc段,尤其是ch3部分的非共价二聚化作用),重链之间同二聚体的稳定性显著降低;而轻链与重链之间由于增加了一对二硫键而稳定性增加,因此产生的轻、重链异二聚体稳定性大大高于同二聚体,异二聚体在表达产物中占比极高,同二聚体在表达产物中占比极低,甚至不会产生稳定产物。微量的重链或轻链自身同二聚体,可以采用针对ch1或者cl的亲和纯化介质有效去除。因此通过本发明,可以很容易地获得稳定的高纯度的目标双特异性抗体。
因此,本申请提供了改进的双特异性的或多特异性的抗体,其可以容易地通过重组表达产生并且能够同时靶向结合两个不同抗原或同一抗原的不同表位,或更多不同抗原的多个表位。
在第一方面,本申请提供了一种抗体,其包含:
a)能特异性结合第一抗原的fab片段,其中所述fab片段由一条轻链以及一条重链的ch1和可变区组成;
b)第一肽接头,所述第一肽接头的n端与所述重链融合;
c)第二肽接头,所述第二肽接头的n端与所述轻链融合,
其中所述第一肽接头和所述第二肽接头之间仅能形成一个二硫键,并且各自独立地选自以下:包含seqidno.1-4所示序列中的任一种的肽接头,其中seqidno.1-2分别为xppcpape和epapcppx,并且其中x代表除cys的任意氨基酸,或者缺失。
在一些实施方案中,所述第一肽接头和/或所述第二肽接头可以为天然抗体的铰链区,其中可以对铰链区进行仅保留一个半胱氨酸的缺失突变。
在优选的实施方案中,所述第一肽接头和/或所述第二肽接头可以为c229缺失突变的igg1铰链区。
在一些实施方案中,所述第一肽接头和所述第二肽接头是相同的。
在一些实施方案中,所述第一肽接头和所述第二肽接头是不相同的。
对抗体的氨基酸序列进行编号以鉴定等同位置,目前针对抗体存在多种不同的编号方案。kabat方案(kabat等,1991)是基于相同结构域类型的序列之间的高序列变异区域的位置而开发的。其对抗体重链(vh)和轻链(vλ和vκ)可变结构域的编号不同。chothia方案(al-lazikani,1997)与kabat方案相同,但校正了在第一个vh互补决定区(cdr)周围插入注释的位置,使其对应于结构环。本申请中的抗体是按照kabat方案来编号的。
在一些实施方案中,第一方面所述的抗体可以通过其第一肽接头和/或第二肽接头的c端融合另一结合部分,从而使得抗体的结合价为二价或者三价。
举例来说,第一方面所述的抗体可以通过其第一肽接头或第二肽接头的c端融合第一结合部分,从而形成双特异性的抗体。所述第一结合部分可以选自抗体或其抗原结合片段、配体和受体。在一些实施方案中,第一方面所述的抗体可以分别通过其第一肽接头和第二肽接头的c端融合第一结合部分和第二结合部分,从而形成双特异性(第一结合部分和第二结合部分相同的情况下)或三特异性的抗体(第一结合部分和第二结合部分不相同的情况下)。所述第一结合部分和所述第二结合部分可以各自独立地选自抗体或其抗原结合片段、配体和受体。
在一些实施方案中,所述第一结合部分和/或所述第二结合部分可以选自二价、三价或更多价的抗体片段,从而使得最终的抗体为三价、四价或更多价。本领域技术人员可以根据需要选择合适的抗体片段与所述第一肽接头和/或第二肽接头融合。
在一些实施方案中,所述抗原结合片段选自fab片段、fab’片段、f(ab’)2片段、fv片段、双体和单链抗体分子如sc-fv。
所述能特异性结合第一抗原的fab片段、所述第一结合部分和所述第二结合部分可以各自独立地来源于单克隆抗体。
在一些实施方案中,本申请中所用的单克隆抗体可以选自以下的一种或多种:阿达木单抗(adalimumab)、苏金单抗(secukinumab)、利妥昔单抗(rituximab)、曲妥珠单抗(trastuzumab)、吉妥珠单抗-奥佐米星(gemtuzumabozogamicin)、阿仑单抗(alemtuzumab),贝伐单抗(bevacizumab)、西妥昔单抗(cetuximab)、帕尼单抗(panitumumab)、奥法木单抗(ofatumumab)、伊匹单抗(ipilimumab)、贝伦妥单抗-维多汀(brentuximabvedotin)、地诺单抗(denosumab)、帕妥珠单抗(pertuzumab),obinutuzumab、雷莫芦单抗(ramucirumab)、3f8、阿巴伏单抗(abagovomab)、阿德木单抗(adecatumumab)、阿夫土珠单抗(afutuzumab)、培化阿珠单抗(alacizumab(pegol))、阿麦妥昔(amatuximab)、阿泊珠单抗(apolizumab)、巴维昔单抗(bavituximab)、贝妥莫单抗(bectumomab)、贝利木单抗(belimumab)、贝伐珠单抗(bivatuzumab)、莫-坎妥珠单抗(cantuzumabmertansine)、拉-坎妥珠单抗(cantuzumab(ravtansine))、卡罗单抗-喷地肽(capromab(pendetide))、卡妥索单抗(catumaxomab)、泊-西他珠单抗(citatuzumab(bogatox))、西妥木单抗(cixutumumab)、clivatuzumab(tetraxetan)、可那木单抗(conatumumab)、达西珠单抗(dacetuzumab)、达洛珠单抗(dalotuzumab)、地莫单抗(detumomab)、drozitumab、依美昔单抗(ecromeximab)、依决洛单抗(edrecolomab)、埃罗妥珠单抗(elotuzumab)、enavatuzumab、恩司昔单抗(ensituximab)、依帕珠单抗(epratuzumab)、厄马索单抗(ertumaxomab)、伊瑞西珠(etaracizumab)、法利珠单抗(farletuzumab)、fbta05、flanvotumab、加利昔单抗(galiximab)、吉妥珠单抗(gemtuzumab)、ganitumab、吉瑞昔单抗(girentuximab)、格莱木单抗-维多汀(glembatumumab(vedotin))、替-伊莫单抗(ibritumomabtiuxetan)、icrucumab、伊戈伏单抗(igovomab)、拉-英达西单抗(indatuximabravtansine)、英妥木单抗(intetumumab)、伊珠单抗-奥佐米星(inotuzumabozogamicin)、伊匹木单抗(ipilimumab)(mdx-101)、伊妥木单抗(iratumumab)、拉贝珠单抗(labetuzumab)、来沙木单抗(lexatumumab)、林妥珠单抗(lintuzumab)、莫-洛伏珠单抗(lorvotuzumab(mertansine))、鲁卡木单抗(lucatumumab)、鲁昔单抗(lumiliximab)、马帕木单抗(mapatumumab)、马妥珠单抗(matuzumab)、米拉珠单抗(milatuzumab)、米妥莫单抗(mitumomab)、莫加珠单抗(mogamulizumab)、moxetumomab(pasudotox)、他那可单抗(nacolomab(tafenatox))、他那莫单抗(naptumomab(estafenatox))、narnatumab、奈昔木单抗(necitumumab)、尼妥珠单抗(nimotuzumab)、nivolumab、nr-lu-10、olaratumab、莫奥珠单抗(oportuzumab(monatox))、奥戈伏单抗(oregovomab)、帕尼单抗(panitumumab)、帕妥珠单抗(pertuzumab)、普立木单抗(pritumumab)、雷妥莫单抗(racotumomab)、radretumab、、罗妥木单抗(robatumumab)、奥马珠单抗(omalizumab)、西罗珠单抗(sibrotuzumab)、司妥昔单抗(siltuximab)、帕他普莫单抗(taplitumomab(paptox))、替妥莫单抗(tenatumomab)、替妥木单抗(teprotumumab)、替西木单抗(ticilimumab)、曲美木单抗(tremelimumab)、替加珠单抗(tigatuzumab)、西莫白介素单抗(tucotuzumab(celmoleukin))、ublituximab、乌瑞鲁单抗(urelumab)、维妥珠单抗(veltuzumab)、伏洛昔单抗(volociximab)、伏妥昔单抗(votumumab)和扎鲁木单抗(zalutumumab)。
本申请的抗体能结合的抗原可以是细胞相关蛋白,例如细胞(t细胞、内皮细胞或肿瘤细胞)膜上的细胞表面蛋白,也可以是可溶性蛋白。抗原还可以是任何医学上相关的蛋白,例如在疾病或感染期间上调的那些蛋白,例如受体和/或它们相应的配体。细胞表面蛋白的具体实例包括但不限于粘附分子例如整合素、e-选择蛋白、p-选择蛋白或l-选择蛋白、cd2、cd3、cd4、cd5、cd7、cd8、cd11a、cd11b、cd18、cd19、cd20、cd23、cd25、cd33、cd38、cd40、cd45、cd69、cd134、icos、cd137、cd27、癌胚抗原(cea)、tcr、mhci类和mhcii类抗原、vegf以及这些蛋白的受体。可溶性蛋白包括白细胞介素(例如il-1、il-2、il-3、il-4、il-5、il-6、il-8、il-12、il-16或il-17),病毒抗原(例如呼吸道合胞病毒或巨细胞病毒抗原),免疫球蛋白(例如ige),干扰素(例如干扰素α、干扰素β或干扰素γ),肿瘤坏死因子-α(tnfα),肿瘤坏死因子-β,集落刺激因子(例如g-csf或gm-csf)和血小板源性生长因子(例如pdgf-α和pdgf-β)以及它们的受体(适当时)。其他抗原包括细菌细胞表面抗原、细菌毒素、病毒(例如流感病毒、ebv、hepa、b和c)、生物恐怖试剂、放射性核素和重金属、及蛇和蜘蛛毒和毒素。
可以被本申请的抗体结合的其他抗原包括血清载体蛋白,允许细胞介导的效应子功能招募的多肽,和核素螯合蛋白。
在一些实施方案中,可以被本申请的抗体结合的抗原为肿瘤相关抗原,其包括下述中的任何一种或多种:cd20、her2、egfr、cd33、cd52、vegf、ctla-4、cd30、rankl、her2、vegf-r2、her3、a33抗原、cd5、cd19、cd22、cd23(ige受体)、ca242抗原、5t4、vegfr-1、cd33、cd37、cd40、cd44、cd51、cd52、cd56、cd74、cd80、cd152、cd200、cd221、ccr4、npc-1c、波形蛋白、胰岛素样生长因子-1受体(igf-1r)、甲胎蛋白、癌胚抗原(cea)、整合素αvβ3、整合素α5β1、成纤维细胞活化蛋白、fap-α、tag-72、muc1、muc16、前列腺特异性膜抗原(pmsa)、egp40泛癌抗原、糖蛋白epcam、程序性死亡-1、肝再生磷酸酶3(prl-3)、lewis-y抗原、gd2、磷脂酰肌醇聚糖-3(gpc3)和间皮素。
所述第一结合部分和所述第二结合部分还可以各自独立地选自配体和受体。
“受体”是指任何能够同激素、神经递质、药物或细胞内信号分子结合并能引起细胞功能变化的生物大分子。受体本身至少含有两个活性部位:一个是识别并结合配体的活性部位;另一个是负责产生应答反应的功能活性部位,这一部位只有在与配体结合形成二元复合物并变构后才能产生应答反应,由此启动一系列的生化反应,最终导致靶细胞产生生物效应。受体能够与其配体特异性结合。通常,将受体的胞外区作为本申请中的结合部分
“配体”是指能够与其受体结合的任何分子。大多数配体是亲水性的生物大分子,如细胞因子,蛋白质多肽类激素、水溶性激素、前列腺素、亲水性神经递质等,由于不能通透靶细胞膜进入胞内,因此,这类配体信号分子的受体是定位于靶细胞膜上。
pd-1(程序性死亡受体1),是一种重要的免疫抑制分子,为免疫球蛋白超家族,是一个268氨基酸残基的膜蛋白。以pd-1为靶点的免疫调节对抗肿瘤、抗感染、抗自身免疫性疾病及器官移植存活等均有重要的意义。其配体pd-l1也可作为靶点,相应的抗体也可以起到相同的作用。pd-1或pd-l1可以充当在本申请中的结合部分,例如第一结合部分和/或第二结合部分。优选地,pd-1的胞外区,即pd-1ecd充当本申请中的结合部分。
本申请的抗体可以在其fab的c-端引入ch2-ch3结构域。ch2-ch3结构域可以与肽接头连接,或者与第一结合部分和/或第二结合部分的c-端连接。所述ch2-ch3结构域,任选地,以kih突变、引入半胱氨酸残基、引入一个或多个盐桥突变以促进异二聚化,这样的添加导致提高的异二聚体的稳定性。本文中的盐桥包括氢键和静电相互作用,如可以在谷氨酸和赖氨酸残基之间发生的盐桥。
天然抗体的重链和轻链分别包括可变区(即v区)和恒定区(即c区)。重链的恒定区和轻链的恒定区分别称为ch和cl。不同型(κ或λ)ig的cl长度基本一致,但是不同类ig的ch长度不同,例如igg、iga和igd包括ch1、ch2和ch3,而igm和ige则包括chl、ch2、ch3和ch4。
在第二方面,本申请提供了编码第一方面所述的抗体的核酸。
在优选的实施方案中,所述核酸可以是适合在宿主细胞中表达的密码子优化的核酸。例如根据密码子的简并性,其仍然编码同样的蛋白质。根据所用宿主细胞进行密码子优化的方法是本领域技术人员公知的。
在第三方面,本申请提供了包含第二方面所述的核酸的表达载体。
可以使用任何合适的表达载体。例如,原核克隆载体包括来自大肠杆菌的质粒,如colel、pcrl、pbr322、pmb9、puc、pksm和rp4。原核载体还包括噬菌体dna如m13和其它丝状单链dna噬菌体的衍生物。可用于酵母的载体的实例是2μ质粒。用于在哺乳动物细胞中表达的合适载体包括以下众所周知的衍生物:sv-40、腺病毒、逆转录病毒衍生的dna序列以及衍生自功能性哺乳动物载体(如上述那些)和功能性质粒和噬菌体dna的组合的穿梭载体。
另外的真核表达载体为本领域已知的(例如,pj.southern&p.berg,j.mol.appl.genet,1:327-341(1982);subramani等人,mol.cell.biol,1:854-864(1981);kaufinann&sharp,"amplificationandexpressionofsequencescotransfectedwithamodulardihydrofolatereductasecomplementarydnagene,"j.mol.biol,159:601-621(1982);kaufhiann&sharp,mol.cell.biol,159:601-664(1982);scahill等人,"expressionandcharacterizationoftheproductofahumanimmuneinterferondnageneinchinesehamsterovarycells,"proc.nat'lacad.sciusa,80:4654-4659(1983);urlaub&chasin,proc.nat'lacad.sciusa,77:4216-4220,(1980),将其全部通过引用并入本文)。
可用于本发明的表达载体含有至少一个表达控制序列,其与待表达的dna序列或片段可操作连接。将控制序列插入载体中以控制和调节克隆的dna序列的表达。有用的表达控制序列的实例是lac系统,trp系统,tac系统,trc系统,噬菌体λ的主要操纵子和启动子区,fd外壳蛋白的控制区,酵母的糖酵解启动子,例如3-磷酸甘油酸激酶的启动子,酵母酸性磷酸酶的启动子,例如pho5,酵母α-交配因子的启动子,以及来源于多瘤病毒、腺病毒、逆转录病毒和猿猴病毒的启动子,例如sv40的早期和晚期启动子和已知控制原核或真核细胞及其病毒或其组合的基因表达的其它序列。
在第四方面,本申请提供了一种宿主细胞,其包含第二方面所述的核酸或第三方面所述的表达载体。
在一些实施方案中,所述宿主细胞为哺乳动物细胞。哺乳动物细胞可以包括但不限于cho细胞、ns0细胞、sp2/0细胞、hek293细胞、cos细胞和per.c6细胞。本领域技术人员能够根据需要选择适合的宿主细胞。
在第五方面,本申请提供了制备第一方面所述的抗体的方法,其包括:
a)培养第四方面所述的宿主细胞;和
b)从所述宿主细胞中或所述宿主细胞的培养物上清中回收所述抗体。
在第六方面,本申请提供了药物组合物,其包含第一方面所述的抗体,第二方面所述的核酸,第三方面所述的表达载体或第四方面所述的宿主细胞,以及药学上可接受的载体。
第六方面的药物组合物可按制药领域的常规方法制备成所需的剂型。在一些实施方案中,所述药物组合物优选为液体或悬浮液剂型。
在一些实施方案中,所述药学上可接受的载体为不减弱免疫细胞活力以及功能、不影响抗体或其抗原结合片段与抗原特异性结合的载体,包括但不限于细胞培养基、缓冲液、生理盐水和平衡盐溶液等。缓冲液的实例包括等渗磷酸盐、醋酸盐、柠檬酸盐、硼酸盐以及碳酸盐等。在具体的实施方案中,所述药学上可接受的载体为含1%血清的磷酸盐缓冲液。
本文公开的抗体及其药物组合物能够用于治疗、改善或预防个体的肿瘤、自身免疫性疾病或传染性疾病。
在第七方面,本申请提供了第一方面所述的抗体,第二方面所述的核酸,第三方面所述的表达载体或第四方面所述的宿主细胞在制备用于治疗、改善或预防肿瘤、自身免疫性疾病或传染性疾病的药物中的用途。
在第八方面,本申请提供了用于治疗、改善或预防个体的肿瘤、自身免疫性疾病或传染性疾病的方法,其包括向个体施用治疗有效量的第一方面所述的抗体,第二方面所述的核酸,第三方面所述的表达载体或第四方面所述的宿主细胞。
“治疗”既指治疗性处理,也指预防性或防止性的措施,其目的就是预防或减缓(减轻)目标病理状态或病症。需要治疗的个体包括那些已经存在所述病症的个体,还包括那些将发展为该病症的或欲对其病症进行预防的个体。因此,本文中欲被治疗的个体已经被诊断为患有该病症或倾向于或易患该病症。
本文使用的术语“个体”是指哺乳动物,包括但不限于灵长类动物、牛、马、猪、绵羊、山羊、狗、猫以及诸如大鼠和小鼠的啮齿类动物。优选地,哺乳动物为非人类的灵长类或者人类。特别优选的哺乳动物是人。
在某些实施方案中,所述肿瘤为原发性癌症或转移性癌症。在具体的实施方案中,肿瘤选自肺癌例如非小细胞肺癌、结直肠癌、膀胱癌、造血系统癌症例如白血病、乳腺癌、胃癌、胃食管结合部腺癌、b淋巴细胞型非霍奇金淋巴瘤、霍奇金淋巴瘤,间变大细胞淋巴瘤、头颈癌例如头颈部鳞状细胞癌、恶性胶质瘤,肾癌、黑色素瘤、前列腺癌、骨癌、骨巨细胞瘤、胰腺癌、肉瘤、肝癌、皮肤鳞癌、甲状腺癌、宫颈癌、鼻咽癌、子宫内膜癌,或上述肿瘤的转移癌。
在某些实施方案中,所述自身免疫性疾病可以包括系统性红斑狼疮、类风湿关节炎、硬皮病、系统性血管炎、皮肌炎和自身免疫性溶血性贫血等。
在某些实施方案中,所述传染性疾病包括呼吸道传染病、消化道传染病、血液传染病、体表传染病和性传染病等。在具体的实施方案中,传染性疾病可以包括但不限于流行性感冒,肺结核,腮腺炎,麻疹,百日咳、蛔虫病,细菌性痢疾,甲型肝炎、乙型肝炎,疟疾,流行性乙型脑炎,丝虫病、血吸虫病,沙眼,狂犬病,破伤风、淋病、梅毒、艾滋病等。
本文中所用的“治疗有效量”可以根据具体情况而定,本领域普通技术人员根据实际所需药量可以很容易地掌握,如可根据患者体重、年龄和病症情况来确定。
本说明书和权利要求书中,词语“包括”、“包含”和“含有”意指“包括但不限于”,且并非意图排除其他部分、添加物、组分、或步骤。
应该理解,在本发明的特定方面、实施方案或实施例中描述的特征、特性、组分或步骤,可适用于本文所描述的任何其他的方面、实施方案或实施例,除非与之矛盾。
上述公开内容总体上描述了本申请,通过下面的实施例进一步示例本申请。描述这些实施例仅为说明本申请,而不是限制本申请的范围。尽管本文中使用了特殊的术语和值,这些术语和值同样被理解为示例性的,并不限定本申请的范围。除非特别指明,本说明书中的实验方法和技术为本领域常规的方法和技术。对于其它没有特别注明厂家的材料和设备等,其通常是可通过商业途径常规获得的。
实施例
在本申请的实施例和对比例中,如没有特别指明,所用原料和试剂皆为常规的,可通过市购获得。
关于实施例1-5中使用的载体pqkd1101-tnfα、pqk1114-il-17a、puc57igg1ch1-hingemut和puc57kappa-hingemut、puc57人pd-l1ecd、pqkzw106higg1ch1-hingemut、pqkzw106lkappa-hingemut、triad5h、triad5l、puc57pd-l1vl-kappa-hingemut、载体puc57pd-l1vh-igg1ch1hingemut、puc57pd-l1vl-kappa-hingemut、puc57抗cd3scfv,其均为各实施例中用作扩增模板的重组载体。
实施例1:抗tnfα×抗il-17a双特异性抗体的制备、表达与鉴定材料
抗tnfα单克隆抗体阿达木单抗的vh和vl编码核酸序列以及抗il-17a单克隆抗体苏金单抗的vh和vl编码核酸序列,均通过dna合成方式获得(通用生物系统(安徽)有限公司),各编码序列分别插入表达全合成的载体pqkd1101(通用生物系统(安徽)有限公司)和pqk1114(通用生物系统(安徽)有限公司)中,得到的产物分别称为pqkd1101-tnfα和pqk1114-il-17a。igg1ch1-hingemut(即包括c229缺失的igg1铰链区)的编码核酸序列以及kappa-hingemut(包括c229缺失突变的igg1铰链区)编码核酸序列同样通过dna合成方式获得,分别克隆于载体puc57(通用生物系统(安徽)有限公司),得到的产物分别称为puc57igg1ch1-hingemut(c229缺失突变)和puc57kappa-hingemut(c229缺失突变)。
igg1ch1-hingemut和kappa-hingemut的核苷酸序列如下:
1.1抗tnfα×抗il-17a双特异性抗体表达载体的制备
1.1.1双特异性抗体重链表达载体pqke1h的构建
分别以pqkd1101-tnfα、pqk1114-il-17a和puc57igg1ch1-hingemut为模板,使用金牌mixpcr试剂盒(tsingke公司),按照试剂盒的说明书,分别扩增抗tnfα抗体vh、抗il-17a抗体vh以及igg1ch1-hingemut(c229缺失突变),其扩增产物大小分别约为0.4kb,0.42kb和0.4kb;同时以限制性内切酶ecori(neb,r3101s)和sapi(neb,r0712s)对全合成载体pqkx1(通用生物系统(安徽)有限公司)进行酶切,将所得的三种pcr扩增产物(连接顺序从5’到3’为:tnfα抗体vh-ch1-hingemut-抗il-17a抗体vh)和酶切载体以bm无缝克隆试剂盒(博迈德公司),按照试剂盒的说明书,进行重组连接以获得重链表达载体pqke1h。
pcr扩增引物对如下:
1.1.2双特异性抗体轻链表达载体pqke1l的构建
分别以pqkd1101-tnfα、pqk1114-il-17a和puc57kappa-hingemut为模板,使用金牌mixpcr试剂盒(tsingke公司),按照试剂盒的说明书,分别扩增抗tnfα抗体vl、抗il-17a抗体vl以及kappa-hingemut(c229缺失突变),其扩增产物大小分别约为0.36kb,0.36kb和0.42kb;同时以限制性内切酶ecori(neb,r3101s)和sapi(neb,r0712s)对全合成载体pqkx2(通用生物系统(安徽)有限公司)进行酶切,将所得的三种pcr扩增产物(连接顺序从5’到3’为:tnfα抗体vl-kappa-hingemut-抗il-17a抗体vl)和酶切载体以bm无缝克隆试剂盒(博迈德公司),按照试剂盒的说明书,进行重组连接以获得轻链表达载体pqke1l。
pcr扩增引物对如下:
1.1.3重组质粒的扩增和制备
将如上获得的重链表达载体pqke1h和轻链表达载体pqke1l分别转化至大肠杆菌(e.coli)top10中。挑取单克隆并鉴定后,在含有氨苄青霉素(终浓度为100mg/l)的lb培养基中培养16小时,培养条件为37℃,200rpm振荡培养。以8000×g离心20分钟收集细菌。使用nucleobondxtramidi试剂盒(macherey-nagel),按照试剂盒的说明书,对质粒进行分离提取,以1ml的无菌超纯水进行洗脱,最后使用nanodrop微量分光光度计测定质粒浓度。
1.2抗体的表达
将重链表达载体pqke1h和轻链表达载体pqke1l共同转染hek293细胞进行表达。转染前24小时,将1.5×106的hek293(atcc,编号:crl-1573)细胞接种于含有100mlopm-293cd05无血清培养基(奥浦迈,cat:81075-001)的500ml摇瓶中,培养条件为36.5℃,7.5%co2,120rpm悬浮培养。转染时,将重组质粒pqke1h和pqke1l按照1:1的重量比(dna总量为100μg)于10mlopm-293cd05培养基中混合,随后加入100μlpei(浓度为3mg/ml),迅速涡旋混匀,室温静止孵育15分钟。然后将该混合物加入至上述细胞培养物中。细胞在36.5℃,7.5%co2,120rpm/min条件下继续培养7天以收获表达的抗体。该抗体指由质粒pqke1h和pqke1l表达的抗tnfα×抗il-17a双特异性抗体,抗体命名为e1,结构如图1中的a所示。
1.3抗体的纯化
将收获的细胞培养物于3000×g离心20min,收集上清并用0.45μm过滤器过滤。用20mmpb和150mmnacl的混合缓冲液(ph7.4)平衡5mlcaptol亲和层析柱(ge),流速5ml/min,体积大于5cv。将过滤后的样品液以5ml/min流速上样。上样完成后,用20mmpb和150mmnacl的混合缓冲液(ph7.4)洗涤captol亲和层析柱,流速5ml/min。用50mm柠檬酸(ph3.0)缓冲液进行洗脱,流速5ml/min,收集完整洗脱峰,同时用1mtrishcl(ph9.0)缓冲液调节收集到的洗脱液的ph至7.0左右(图2a)。纯化产物经超滤管超滤,将tris-柠檬酸缓冲液置换成商品化的pbs缓冲液。将所获蛋白用sds-page和考马斯亮蓝染色检测(图2b),使用nanodrop微量分光光度计测定蛋白浓度,计算蛋白产量为55mg/l。
1.4抗体的鉴定
1.4.1hplc测定抗体纯度
经captol纯化的抗体,通过hplc(安捷伦1260ii)sec检测其纯度。色谱柱为sepax水溶性体积排阻色谱柱,流动相为50mmpb+300mmnaclph7.0,上样量为10μg,流速1ml/min,等度洗脱20min。结果如图3所示,其单体纯度≥90%。
1.4.2fortebio测定抗体亲和力
纯化的抗体使用分子互作仪fortebiooctetqk(moleculardevices公司)测定其亲和力常数kd。通过fab-ch1的传感器(sensor)来固定e1抗体以及对照抗体阿达木单抗(abbvie)和苏金单抗(novartis),固定体积均为200μl,固定浓度均为0.25μm。抗原人tnf-α(义翘神州,cat:10602-h01h)和人il-17a(义翘神州,cat:12047-h07y)分别按照浓度600nm,300nm,150nm和75nm浓度、总体积200μl上样。结合-解离曲线如图4所示,亲和力常数测定结果如图6所示。
实施例2:抗cd137×pd-1ecd蛋白双特异性抗体的制备、表达与鉴定
2.1抗cd137×pd-1ecd蛋白双特异性抗体表达载体的制备
表达载体构建及质粒扩增的具体操作流程参照实施例1,其中对于pd-1ecd蛋白而言,其扩增模板为puc57人pd-1ecd,其含有插入到载体puc57中的合成的人pd-1胞外区核酸序列(人pd-1胞外区核酸序列参见ncbi数据库np_005009.2和参考文献eszterlázár-molnáretal.,“structure-guideddevelopmentofahigh-affinityhumanprogrammedcelldeath-1:implicationsfortumorimmunotherapy”,ebiomedicine17(2017)30-44)(通用生物系统(安徽)有限公司)。全合成载体pqkzw106higg1ch1-hingemut(通用生物系统(安徽)有限公司)含有抗cd137抗体重链的vh部分(序列参见专利号:us-2019-0284292-a1)以及igg1ch1-hingemut(铰链区c229缺失突变),对此载体进行ecori酶切,回收后与上述puc57人pd-1ecd的pcr产物进行重组酶连(连接顺序从5’到3’为:cd137抗体vh-ch1-hingemut-pd-1ecd),获得最终的重链表达载体,命名为pqke2h;同样地,全合成载体pqkzw106lkappa-hingemut(通用生物系统(安徽)有限公司)含有抗cd137抗体轻链的vl部分(序列参见专利号:us-2019-0284292-a1)以及kappa-hingemut(铰链区c229缺失突变),也对该载体以ecori酶切,回收后与上述puc57人pd-1ecd的pcr产物进行重组酶连(连接顺序从5’到3’为:cd137抗体vl-kappa-hingemut-pd-1ecd),获得最终的轻链表达载体,命名为pqke2l。
所用的引物对如下:
2.2抗体的表达
参照实施例1所描述的流程进行转染,其中转染细胞为hek293atcc,编号:crl-1573),转染体积为100ml。转染后的细胞于500ml摇瓶中悬浮培养7天后收获抗体,培养条件为36.5℃,7.5%co2,120rpm/min。所得抗体指由质粒pqke2h和pqke2l表达的抗cd137×pd-1ecd蛋白双特异性抗体,抗体命名为e2,结构如图1中的b所示。
2.3抗体的纯化
参照实施例1所描述的流程进行纯化,经缓冲液置换后使用nanodrop微量分光光度计测定蛋白浓度,计算蛋白产量为35mg/l。
2.4抗体的鉴定
2.4.1hplc测定抗体纯度
参照实施例1,以hplc测定抗体e2的纯度,单体纯度≥90%。
2.4.2fortebio测定抗体亲和力
具体流程参照实施例1。通过fab-ch1的传感器来固定e2抗体,固定浓度为0.25μm。抗原人pd-l1(义翘神州,cat:10084-hnah)和人cd137(义翘神州,cat:10041-h002h)分别按照浓度600nm,300nm,150nm和75nm浓度、总体积200μl上样。亲和力常数测定结果如图6所示。
2.4.3流式细胞术检测抗体与细胞结合活性
2.4.3.1抗体与mc38-pd-l1细胞结合活性
正常复苏的mc38细胞(协和细胞资源中心,资源编号:3111c0001ccc000523)至少传代培养3代以上,转染前24h对细胞进行传代,并接种到6孔板中。转染当天将pei(sigma,cat:764647)和合成质粒penterpd-l1(通用生物系统(安徽)有限公司)复苏至室温,取5μg质粒加入至500μl的dmem培养基中(gibco,ref:11965-092),再加入15μg的pei,立即旋涡振荡15min,然后将混合物轻轻滴加至细胞培养液中,放置与培养箱中继续培养24-48h。48h后更换含有为2μg/ml嘌呤霉素的10%fbs的dmem培养基。3天后细胞出现大规模死亡,可以轻轻拍瓶壁,将上清弃去,贴壁良好的细胞即为可能的稳转细胞株。8-10天后视细胞生长状态,消化细胞并铺到96孔板中,筛选单克隆细胞株。期间一直用含有2μg/ml嘌呤霉素10%fbs的dmem培养基加压培养。最终得到的细胞株被命名为mc38-pd-l1。此细胞株基因组中转入了人pd-l1胞外区基因,其可以稳定表达人pd-l1胞外区蛋白并且展示在细胞膜上。将复苏并培养了超过3代的mc-38-pd-l1细胞以10mlpbs洗1次,1ml0.05%胰酶消化1min,加入4ml含有10%fbs的1640培养基,吹打均匀后收集细胞,1000rpm/min离心5min,重悬计数,调整细胞密度为1×105个细胞/ml。组别设为空白组,阳性对照组,二抗组和e2组,先向各组的管中加入10μl的上述细胞悬液。在e2组的管中加入100ng的e2bsab,室温孵育30min,用3ml含有4%fbs的pbs缓冲液清洗,1000rpm/min离心5min,以50μl的含有4%fbs的pbs缓冲液重悬;空白组加入0.5μl的水;阳性对照组加入pe抗人pd-l1(biolegend,克隆号:29e-2a3)0.5μl;e2组和二抗组分别加入0.5μl的apc抗人ig轻链k(biolegend,克隆号:tb28-2)。混匀于室温避光孵育30min。孵育完成后以含有4%fbs的pbs缓冲液清洗各组的管,1000rpm/min离心5min,以100μl含有4%fbs的pbs缓冲液重悬,上流式细胞仪(艾森,仪器型号:novocyte)检测。结果如图5中的a所示。
2.4.3.2抗体与mc38-cd137细胞结合活性
mc38-cd137细胞也是一种通过稳转方式将人cd137整合入mc38细胞(协和细胞资源中心,资源编号:3111c0001ccc000523)基因组的工程化细胞株,其特点是可以在细胞膜上展示表达人cd137蛋白。该细胞株的构建参照2.4.3.1中mc38-pd-l1的构建流程,其中质粒为pentercd137(通用生物系统(安徽)有限公司)。细胞具体实验流程参照3.4.3.1,组别设为空白组,阳性对照组,二抗组和e2组。其中阳性对照组加入0.5μl的apc抗人4-1bb,二抗组加入0.5μl的apc抗人ig轻链k(biolegend,克隆号:tb28-2),e2组则先加入100ng的e2bsab室温孵育30min并清洗后再加入0.5μl的apc抗人ig轻链k。所有样品经孵育再清洗并以100μl含有4%fbs的pbs缓冲液重悬,上流式细胞仪检测。结果如图5中的b所示。
实施例3:抗cd3×抗cd19双特异性抗体的制备、表达与鉴定3.1抗cd3×抗cd19双特异性抗体表达载体的制备
表达载体构建及质粒扩增的具体操作流程参照实施例1,其中重链扩增模板为triad5h和puc57igg1ch1-hingemut。triad5h为前期全合成的质粒(通用生物系统(安徽)有限公司),其含有通过dna合成的blincyto(amgen)中的抗cd19vh编码核酸序列、pasotuxizumab(bayer)的抗cd3单克隆抗体的vh编码核酸序列(通用生物系统(安徽)有限公司)。其中以triad5h为模板扩增出抗cd19vh片段和抗cd3vh片段,以puc57igg1ch1-hingemut为模板扩增出igg1ch1-hingemut(c229缺失突变)片段,对全合成载体pqkx1(通用生物系统(安徽)有限公司)进行sapi和ecori双酶切,回收相应的pcr产物和酶切产物,进行重组酶连(连接顺序从5’到3’为:抗cd19抗体vh-ch1-hingemut-抗cd3抗体vh),获得最终的重组质粒命名为pqke3h。轻链扩增模板为triad5l和puc57kappa-hingemut。triad5l为前期全合成的质粒(通用生物系统(安徽)有限公司),其含有通过dna合成的bite双抗中的抗cd19vl编码核酸序列、pasotuxizumab(bayer)的抗cd3单克隆抗体的vl编码核酸序列(通用生物系统(安徽)有限公司)。其中以triad5l为模板扩增出抗cd19vl片段和抗cd3vl片段,以puc57kappa-hingemut为模板扩增出kappa-hingemut(c229缺失突变)片段,对全合成载体pqkx2进行sapi和ecori双酶切,回收相应的pcr产物和酶切产物,进行重组酶连(连接顺序从5’到3’为:抗cd19抗体vl-kappa-hingemut-抗cd3抗体vl),获得最终的重组质粒命名为pqke3l。
所用的引物对如下:
3.2抗体的表达
参照实施例1所描述的流程进行转染,其中转染细胞为hek293(atcc,编号:crl-1573),转染体积为100ml。转染后的细胞于500ml摇瓶中悬浮培养7天后收获抗体,培养条件为36.5℃,7.5%co2,120rpm/min。所得抗体指由质粒pqke3h和pqke3l表达的抗cd3×抗cd19双特异性抗体,抗体命名为e3,结构如图1中的c所示。
3.3抗体的纯化
参照实施例1所描述的流程进行纯化,经缓冲液置换后使用nanodrop微量分光光度计测定蛋白浓度,计算蛋白产量为59mg/l。
3.4抗体的鉴定
3.4.1hplc测定抗体纯度
参照实施例1以hplc测定抗体e3的纯度,单体纯度≥90%。
3.4.2fortebio测定抗体亲和力
具体流程参照实施例1。通过fab-ch1的传感器来固定e3抗体,固定浓度为0.25μm。抗原人cd3(义翘神州,cat:10977-h02h)和人cd19(义翘神州,cat:11880-h02h)分别按照浓度600nm,300nm,150nm和75nm浓度上样,体积均为200μl。亲和力常数测定结果如图6所示。
实施例4:抗pd-l1×抗cd137双特异性抗体的制备、表达与鉴定4.1抗pd-l1×抗cd137双特异性抗体表达载体的制备
表达载体构建及质粒扩增的具体操作流程参照实施例1,其中合成载体puc57pd-l1vh-igg1ch1hingemut(其含有通过dna合成的阿特珠单克隆抗体,atezolizumab,roche)的抗pd-l1vh编码核酸序列和igg1ch1hingemut(c229缺失突变,且铰链区d224-s242倒转)编码核酸序列(通用生物系统(安徽)有限公司),和载体pqkzw106higg1ch1-hingemut(通用生物系统(安徽)有限公司)分别用来扩增抗pd-l1vh-igg1ch1hingemut和抗cd137vh片段,对pqkx1载体(通用生物系统(安徽)有限公司)进行sapi和ecori双酶切,回收相应的pcr产物和酶切产物,进行重组酶连(连接顺序从5’到3’为:抗pd-l1抗体vh-ch1-hingemut-抗cd137抗体vh),获得最终的重组质粒命名为pqke4h。载体puc57pd-l1vl-kappa-hingemut(其含有通过dna合成的阿特珠单克隆抗体中的抗pd-l1vl编码核酸序列和kappa-hingemut(c229缺失突变,且铰链区d224-s242倒转)编码核酸序列(通用生物系统(安徽)有限公司)与载体pqkzw106lkappa-hingemut(通用生物系统(安徽)有限公司),分别用来扩增抗pd-l1vl-kappa-hingemut和anti-cd137vl片段。对pqkx2载体(通用生物系统(安徽)有限公司)进行sapi和ecori双酶切,回收相应的pcr产物和酶切产物,进行重组酶连(连接顺序从5’到3’为:抗pd-l1抗体vl-kappa-hingemut-抗cd137抗体vl),获得最终的重组质粒命名为pqke4l。
igg1ch1-hingemut和kappa-hingemut如下:
所用的引物对如下:
4.2抗体的表达
参照实施例1所描述的流程进行转染,其中转染细胞为hek293(atcc,编号:crl-1573),转染体积为100ml。转染后的细胞于500ml摇瓶中悬浮培养7天后收获抗体,培养条件为36.5℃,7.5%co2,120rpm/min。所得抗体指由质粒pqke4h和pqke4l表达的抗pd-l1×抗cd137双特异性抗体,抗体命名为e4,结构如图1中的d所示。
4.3抗体的纯化
参照实施例1所描述的流程进行纯化,经缓冲液置换后使用nanodrop微量分光光度计测定蛋白浓度,计算蛋白产量为38mg/l。
4.4抗体的鉴定
4.4.1hplc测定抗体纯度
参照实施例1以hplc测定抗体e4的纯度,单体纯度≥90%。
4.4.2fortebio测定抗体亲和力
具体流程参照实施例1。通过fab-ch1的传感器来固定e4抗体,固定浓度为0.25μm。抗原人pd-l1(义翘神州,cat:10084-hnah)和人cd137(义翘神州,cat:10041-h002h)分别按照浓度600nm,300nm,150nm和75nm浓度、总体积200μl上样。亲和力常数测定结果如图6所示。
实施例5:抗cd3×抗cd137×pd-1ecd蛋白三特异性抗体的制备、表达与鉴定
5.1抗cd3×抗cd137×pd-1ecd蛋白三特异性抗体表达载体的制备
表达载体构建及质粒扩增的具体操作流程参照实施例1。以实施例2中的pqke2h为重链表达载体;以puc57抗cd3scfv(其含有抗cd3单克隆抗体(pasotuxizumab,bayer))的vh-vl编码核酸序列,通过dna合成方式获得(通用生物系统(安徽)有限公司),编码序列插入表达载体puc57中)和实施例2中的pqke2l为模板,分别经pcr扩增抗cd3scfv片段和抗cd137vl-pd-1ecd片段,同时对pqkx2载体(通用生物系统(安徽)有限公司)进行sapi和ecori双酶切,将回收的两种pcr产物和酶切产物,进行重组酶连(连接顺序从5’到3’为:抗cd3scfv-抗cd137vl-kappa-hingemut-pd-1ecd),获得最终的重组质粒命名为pqke5l。
所用的引物对如下:
5.2抗体的表达
参照实施例1所描述的流程进行转染,其中转染细胞为hek293(atcc,编号:crl-1573),转染体积为100ml。转染后的细胞于500ml摇瓶中悬浮培养7天后收获抗体,培养条件为36.5℃,7.5%co2,120rpm/min。所得抗体指由质粒pqke5h和pqke5l表达的抗cd3×抗cd137×pd-1ecd蛋白三特异性抗体,抗体命名为e5,结构如图1中的e所示。
5.3抗体的纯化
参照实施例1所描述的流程进行纯化,经缓冲液置换后使用nanodrop微量分光光度计测定蛋白浓度,计算蛋白产量为11mg/l。
5.4抗体的鉴定
5.4.1hplc测定抗体纯度
参照实施例1以hplc测定抗体e5的纯度,单体纯度≥90%。
5.4.2fortebio测定抗体亲和力
具体流程参照实施例1。通过fab-ch1的传感器来固定e5抗体,固定浓度为0.25μm。抗原人cd3(义翘神州,cat:10977-h02h)、人cd137(义翘神州,cat:10041-h002h)和人pd-l1(义翘神州,cat:10084-hnah)分别按照浓度600nm,300nm,150nm和75nm浓度、总体积200μl上样。亲和力常数测定结果如图6所示。
虽然,上文中已经用一般性说明及具体实施方案对本申请的技术方案作了详尽的描述,但在这些技术方案的基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本申请要求保护的范围。
序列表
<110>北京免疫方舟医药科技有限公司
<120>一种多特异性抗体及其制备方法和用途
<130>19c13145cn
<160>44
<170>siposequencelisting1.0
<210>1
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<221>site
<222>(1)..(1)
<223>xaa可以为除cys之外的任何氨基酸或不存在
<400>1
xaaproprocysproalaproglu
15
<210>2
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<221>site
<222>(8)..(8)
<223>xaa可以为除cys之外的任何氨基酸或不存在
<400>2
gluproalaprocysproproxaa
15
<210>3
<211>363
<212>dna/rna
<213>人工序列(artificialsequence)
<400>3
gctagcaccaagggcccatccgtcttccccctggcaccctcctccaagagcacctctggg60
ggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcg120
tggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctca180
ggactctactccctcagcagcgtggtgaccgtgccctccagcagcttgggcacccagacc240
tacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagccc300
aaatcttgtgacaaaactcacacaccaccgtgcccagcacctgaactcctggggggaccg360
tca363
<210>4
<211>375
<212>dna/rna
<213>人工序列(artificialsequence)
<400>4
cgaactgtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatct60
ggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacag120
tggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggac180
agcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgag240
aaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaag300
agcttcaacaggggagagtgtgacaaaactcacacaccaccgtgcccagcacctgaactc360
ctggggggaccgtca375
<210>5
<211>43
<212>dna/rna
<213>人工序列(artificialsequence)
<400>5
tgtggctgagaggtgccagatgtgaagtgcagctggtggagtc43
<210>6
<211>46
<212>dna/rna
<213>人工序列(artificialsequence)
<400>6
gacggatgggcccttggtgctagcactagacactgtgaccagggta46
<210>7
<211>45
<212>dna/rna
<213>人工序列(artificialsequence)
<400>7
ctgaactcctggggggaccgtcatgtgaagtgcagctggtggaat45
<210>8
<211>47
<212>dna/rna
<213>人工序列(artificialsequence)
<400>8
tgattatgatcaatgaattcatcagctagacactgtcaccagagtgc47
<210>9
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>9
taccctggtcacagtgtctagtgctagcaccaagggcccatccg44
<210>10
<211>46
<212>dna/rna
<213>人工序列(artificialsequence)
<400>10
attccaccagctgcacttcacatgacggtccccccaggagttcagg46
<210>11
<211>42
<212>dna/rna
<213>人工序列(artificialsequence)
<400>11
tgtggctgagaggtgccagatgtgacattcagatgactcaga42
<210>12
<211>47
<212>dna/rna
<213>人工序列(artificialsequence)
<400>12
acagatggtgcagccacagttcgcttgatctcgacttttgtgccctg47
<210>13
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>13
ctgaactcctggggggaccgtcagaaatcgtcctcactcagagc44
<210>14
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>14
attatgatcaatgaattcactatttgatctcaagccgagtgcct44
<210>15
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>15
cagggcacaaaagtcgagatcaagcgaactgtggctgcaccatc44
<210>16
<211>47
<212>dna/rna
<213>人工序列(artificialsequence)
<400>16
gggctctgagtgaggacgatttctgacggtccccccaggagttcagg47
<210>17
<211>43
<212>dna/rna
<213>人工序列(artificialsequence)
<400>17
ctgaactcctggggggaccgtcaccaggatggttcttagactc43
<210>18
<211>48
<212>dna/rna
<213>人工序列(artificialsequence)
<400>18
tggctgattatgatcaatgaattctcacaccagggtttggaactggcc48
<210>19
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>19
tgtggctgagaggtgccagatgtcaggttcagttgcagcagtct44
<210>20
<211>45
<212>dna/rna
<213>人工序列(artificialsequence)
<400>20
gacggatgggcccttggtgctagcagaagagactgtcactgtggt45
<210>21
<211>45
<212>dna/rna
<213>人工序列(artificialsequence)
<400>21
cctgaactcctggggggaccgtcagaggtgcagctggttgaatct45
<210>22
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>22
gattatgatcaatgaattcatcagctagaaactgtgaccagtgt44
<210>23
<211>46
<212>dna/rna
<213>人工序列(artificialsequence)
<400>23
ggcaccacagtgacagtctcttctgctagcaccaagggcccatccg46
<210>24
<211>45
<212>dna/rna
<213>人工序列(artificialsequence)
<400>24
gccagattcaaccagctgcacctctgacggtccccccaggagttc45
<210>25
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>25
ctgtggctgagaggtgccagatgtgacatccagctgacccagtc44
<210>26
<211>42
<212>dna/rna
<213>人工序列(artificialsequence)
<400>26
gacagatggtgcagccacagttcgcttgatttccagcttggt42
<210>27
<211>46
<212>dna/rna
<213>人工序列(artificialsequence)
<400>27
cctgaactcctggggggaccgtcacagacagtggtcacccaagagc46
<210>28
<211>43
<212>dna/rna
<213>人工序列(artificialsequence)
<400>28
tgattatgatcaatgaattcactacaaaactgtcagcttggtg43
<210>29
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>29
ggaggcaccaagctggaaatcaagcgaactgtggctgcaccatc44
<210>30
<211>48
<212>dna/rna
<213>人工序列(artificialsequence)
<400>30
aggctcttgggtgaccactgtctgtgacggtccccccaggagttcagg48
<210>31
<211>363
<212>dna/rna
<213>人工序列(artificialsequence)
<400>31
gctagcaccaagggcccatccgtcttccccctggcaccctcctccaagagcacctctggg60
ggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcg120
tggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctca180
ggactctactccctcagcagcgtggtgaccgtgccctccagcagcttgggcacccagacc240
tacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagccc300
aaatcttgttcaccgggagggctgctcgaacctgcaccatgcccgccaacacacactaaa360
gac363
<210>32
<211>375
<212>dna/rna
<213>人工序列(artificialsequence)
<400>32
cgaactgtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatct60
ggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacag120
tggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggac180
agcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgag240
aaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaag300
agcttcaacaggggagagtgttcaccgggagggctgctcgaacctgcaccatgcccgcca360
acacacactaaagac375
<210>33
<211>44
<212>dna/rna
<213>人工序列(artificialsequence)
<400>33
ctgtggctgagaggtgccagatgtgaggtgcagctggttgaatc44
<210>34
<211>60
<212>dna/rna
<213>人工序列(artificialsequence)
<400>34
tggcgggcatggtgcaggttcgagcagccctcccggtgaacaagatttgggctcaacttt60
<210>35
<211>58
<212>dna/rna
<213>人工序列(artificialsequence)
<400>35
ctcgaacctgcaccatgcccgccaacacacactaaagacgaagtgcagctggttcagt58
<210>36
<211>47
<212>dna/rna
<213>人工序列(artificialsequence)
<400>36
ctgattatgatcaatgaattctcaagaggacactgtgaccagggtgc47
<210>37
<211>43
<212>dna/rna
<213>人工序列(artificialsequence)
<400>37
ctgtggctgagaggtgccagatgtgacatccagatgacccagt43
<210>38
<211>59
<212>dna/rna
<213>人工序列(artificialsequence)
<400>38
tggcgggcatggtgcaggttcgagcagccctcccggtgaacactctcccctgttgaagc59
<210>39
<211>57
<212>dna/rna
<213>人工序列(artificialsequence)
<400>39
ctcgaacctgcaccatgcccgccaacacacactaaagacgacatcgtgatgacccag57
<210>40
<211>49
<212>dna/rna
<213>人工序列(artificialsequence)
<400>40
ctgattatgatcaatgaattctcacttgatttccaccttggtgcctccg49
<210>41
<211>48
<212>dna/rna
<213>人工序列(artificialsequence)
<400>41
ctgtggctgagaggtgccagatgtgaggtgcagctggttgaatctggc48
<210>42
<211>47
<212>dna/rna
<213>人工序列(artificialsequence)
<400>42
ggagactgggtcatcacgatgtccaaaactgtcagcttggtgcctcc47
<210>43
<211>47
<212>dna/rna
<213>人工序列(artificialsequence)
<400>43
aggcaccaagctgacagttttggacatcgtgatgacccagtctccag47
<210>44
<211>49
<212>dna/rna
<213>人工序列(artificialsequence)
<400>44
ctgattatgatcaatgaattctcacaccagggtttggaactggccggct49
- 还没有人留言评论。精彩留言会获得点赞!
- 用于治疗HBV感染和相关病症的三特异性结合分子的制造方法与工艺
- 对磺胺类药物具有特异性的固相微萃取纤维的制备方法与流程
- 一种检测猪初乳中抗PEDV特异性IgA抗体的夹心ELISA试剂盒的制造方法与工艺
- 用于施用CD19xCD3双特异性抗体的给药方案的制造方法与工艺
- 双特异性抗‑VEGF/抗‑ANG‑2抗体及其在治疗眼血管疾病中的应用的制造方法与工艺
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 双特异性四价抗体及其制造和使用方法与制造工艺
- 利用特异性挥发物筛选昆虫相关嗅觉蛋白的方法与制造工艺
- 使用与表面偶联的单特异性四聚抗体复合物组合物从样品中分离出靶实体的方法与制造工艺
- 抗-WT1/HLA双特异性抗体的制造方法与工艺