信息处理装置和方法、记录介质与程序与流程
本技术涉及一种信息处理装置和方法、记录介质以及程序,并且更具体而言,涉及一种提高数据传送速度的信息处理装置和方法、记录介质以及程序。
背景技术:
通常,作为通过光的照射来将信号记录到其或者从中再现信号的一次写入光学记录介质,例如,广泛使用光盘记录介质(在后文中,简称为光盘),例如,蓝光光盘(BD注册商标)(例如,参考专利文档1).
在使用这种光盘记录或再现数据时,有一种称为条带化(striping)的技术,用于在多于一个的通道内进行记录或再现。在条带化中,同时从光盘上的多个不同区域中读取数据,或者同时将数据记录到那些多个区域中。
引用列表
专利文献
专利文献1:特开2010-49793号公报
技术实现要素:
本发明要解决的问题
在这点上,通常,在光盘中,将地址连续分配给连续记录区域。因此,在光盘中的多于一个通道内执行记录或再现时,条带化效率降低,并且这造成数据传送效率降低。
更具体而言,例如,在每个通道的数据以较小的记录单位交替地记录在连续记录区域内的情况下,由于在读取数据时,为了访问目标区域,频繁发生近旁寻道(local seek,局部寻道)和旋转延迟,所以数据传送速度降低。
进一步,例如,在数据分成较大的单位用于条带化时,即,成大条带长度,如果记录目标数据的尺寸小,则在记录或读取数据时,在一些部分中不执行条带化,或者根本不执行条带化。这降低了数据传送速度。
鉴于以上内容,作出本技术,并且本技术可以提高数据传送速度。
问题的解决方案
在根据本技术的第一方面的记录介质中,连续记录区域被以预定尺寸分成多个仿真区(pseudo zone,虚拟区、伪区),并且对所述仿真区的各区域设定地址,使得多个仿真区的集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错。
所述地址可以是逻辑地址,并且可对所述记录区域内的连续区域设定连续物理地址。
作为在仿真区内记录或再现的最小单位的块体可以包括作为逻辑访问的最小单元的多个扇区,并且可对在所述块体内的连续的扇区设定连续地址。
所述记录介质可以记录用于规定将被设置为仿真区的区域的信息、用于规定仿真区的尺寸的信息、用于规定构成仿真区组的仿真区的数量的信息、以及用于规定在构成仿真区组的仿真区中的每个区域的地址的信息中的至少一个,作为管理信息。
所述记录介质可以是光盘。
所述光盘可以具有两个面,并且在每个面上,设置包括记录区域的一个或多个记录层。
所述记录区域可以包括用于记录用户数据的用户数据区域以及与所述用户数据区域不同的并且其尺寸可变的可变区域。
所述可变区域可以是记录用于管理记录区域的管理信息的扩展管理区域以及用作缺陷区域的交替物的交替区域中的至少一个区域。
所述可变区域的尺寸可以是所述仿真区的尺寸的整数倍。
根据本技术的第一方面,将连续记录区域分成具有预定尺寸的多个仿真区,多个仿真区的集合构成仿真区组,并且对所述仿真区的各个区域设定地址,使得所述地址在构成仿真区组的多个仿真区之间交错。
根据本技术的第二方面,一种信息处理装置包括:多个访问处理单元,其被配置成通过对记录介质执行访问控制来记录或再现数据,其中,将连续记录区域以预定尺寸分成多个仿真区,并且对所述仿真区的各个区域设定地址,使得多个仿真区的集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错;以及控制单元,其被配置成控制所述多个访问处理单元,使得所述多个访问处理单元根据控制同时执行对所述记录介质的访问。
可以使得所述地址是逻辑地址,并且连续物理地址被设定给在所述记录区域内的连续区域。
作为在仿真区内记录或再现的最小单位的块体可以包括作为逻辑访问的最小单位的多个扇区,并且所述连续地址被设定给在所述块体内的连续的扇区。
所述记录介质可以记录用于规定作为目标用于设定仿真区的区域的信息、用于规定仿真区的尺寸的信息、用于规定构成仿真区组的仿真区的数量的信息、以及用于规定在构成仿真区组的仿真区中的每个区域的地址的信息中的至少一个,作为管理信息。
所述记录介质可以是光盘。
同时执行对所述记录介质的访问控制的访问处理单元的数量可以是构成仿真区组的仿真区的数量的整数倍。
同时执行对所述记录介质的访问控制的访问处理单元的数量可以是构成仿真区组的仿真区的数量的约数。
所述控制单元可以控制多个访问处理单元,使得在所述多个访问处理单元中的一些访问处理单元同时将数据记录到所述记录介质中时,所述多个访问处理单元中的其他访问处理单元同时再现记录在所述记录介质内的数据。
同时记录数据的访问处理单元的数量可以与同时再现记录数据的访问处理单元的数量相同。
根据本技术的第二方面的信息处理方法包括以下步骤:由多个访问处理单元通过对记录介质执行访问控制来记录或再现数据,其中,将连续记录区域分成具有预定尺寸的多个仿真区,并且对所述仿真区的各个区域设定地址,使得多个仿真区的集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错;并且控制所述多个访问处理单元,使得所述多个访问处理单元根据控制同时执行对所述记录介质的访问。
根据本技术的第二方面,访问处理单元被配置成通过对记录介质执行访问控制来记录或再现数据,其中,将连续记录区域分成具有预定尺寸的多个仿真区,多个仿真区的集合构成仿真区组,并且对所述仿真区的各个区域设定地址,使得所述地址在构成仿真区组的多个仿真区之间交错;并且控制所述多个访问处理单元,使得所述多个访问处理单元根据控制同时执行对所述记录介质的访问。
本发明的效果
根据本技术的第一和第二方面,可以提高数据传送速度。
在此处,在此处描述的效果并非始终设置任何限制,并且可以获得在本说明书中描述的任一效果。
附图说明
图1是用于说明光盘的示图。
图2是用于说明光盘的物理地址和逻辑地址的示图。
图3是用于说明在多于一个通道内执行的条带化操作的示图。
图4是示出仿真区组和仿真区(simulated zone)的实例的示图。
图5是用于说明在多于一个通道内执行的条带化操作的示图。
图6是示出仿真区组和仿真区的实例的示图。
图7是示出仿真区组和仿真区的实例的示图。
图8是示出仿真区组和仿真区的实例的示图。
图9是示出仿真区组和仿真区的实例的示图。
图10是示出仿真区组和仿真区的实例的示图。
图11是用于说明仿真区设置的示图。
图12是用于说明仿真区设置的示图。
图13是用于说明仿真区设置的示图。
图14是用于说明交替处理的示图。
图15是用于说明交替处理的示图。
图16是用于说明交替处理的示图。
图17是用于说明交替处理的示图。
图18是用于说明交替处理的示图。
图19是用于说明交替处理的示图。
图20是用于说明交替处理的示图。
图21是用于说明交替处理的示图。
图22是用于说明备用区域保存的示图。
图23是用于说明备用区域保存的示图。
图24是用于说明备用区域保存的示图。
图25是用于说明备用区域保存的示图。
图26是用于说明备用区域保存的示图。
图27是示出记录/再现系统的配置实例的示图。
图28是示出光盘的配置实例的示图。
图29是示出记录/再现装置的配置实例的示图。
图30是说明仿真区设置处理的流程图。
图31是说明记录处理的流程图。
图32是说明再现处理的流程图。
具体实施方式
在后文中,将参考附图,描述本技术的应用的实施方式。
<第一实施方式>
<光盘和条带化>
首先,将描述本技术的概要。
本技术涉及一种将数据记录到其中和从其中读取数据的记录介质以及用于将数据记录到记录介质中或从记录介质中再现数据的记录/再现装置。在此处,在本技术中作为数据写入其中并且从其中读取数据的主体的记录介质可以是任何类型的记录介质,并且在下面,将在记录介质是光盘的假定下给出说明。
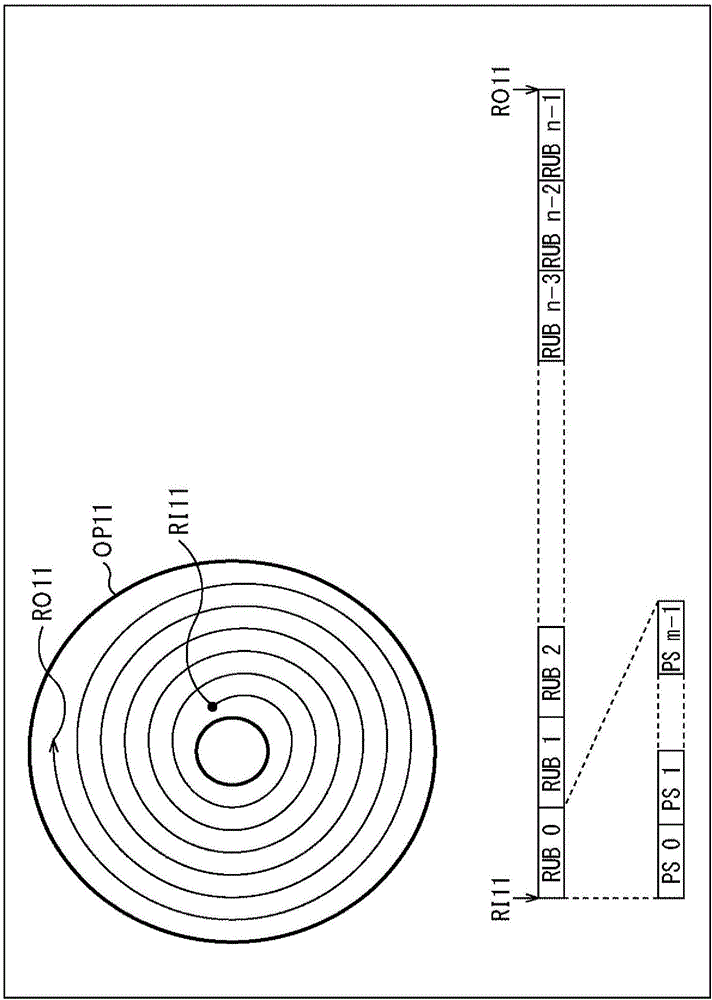
例如,如图1所示,一般的光盘具有螺旋状区域(螺旋)。在该实例中,光盘OP11具有从在光盘OP11的中心附近的最内部的记录位置RI11到在光盘OP11的外周边的最外面的记录位置RO11的螺旋,并且该螺旋是数据记录区域。例如,螺旋设置在光盘OP11的岸(land)或沟(groove)上或者岸和沟两者上,并且在光盘OP11具有多个记录层时,螺旋设置在各个记录层上。
进一步,在最内部的记录位置RI11与最外面的记录位置RO11之间的螺旋分成预定尺寸的记录单位块(RUB)。
RUB是光盘OP11上数据记录或再现的最小单位,并且一个RUB大小的区域(块)也称为集群(cluster,簇)。在下面,一个记录单位块(RUB)大小的区域简称为RUB。
通常,在光盘OP11的每个记录层内,在从最内周侧到最外周侧或者从最外周侧到最内周侧的某个方向上记录数据,使得半径的位置单纯地增大或减小。在此处,更具体而言,即使螺旋可以从中游开始使用或者记录可以在螺旋的中游结束,螺旋的使用方向也是一个方向。
在以这种方式用作记录区域的螺旋被延长时,螺旋变成如在图的下部所示。换言之,螺旋由从最内部的记录位置RI11到最外面的记录位置RO11连续排列的多个RUB构成。
在该实例中,具有字母RUB N(在此处,N=0,1,...,n-1)的矩形表示一个RUB并且螺旋由数量为"n"的RUB构成。进一步,以RUB为单位执行到光盘OP11中的记录或者从光盘OP11中的再现。例如,在BD的情况下,一个RUB是65536个字节的区域。
每个RUB由多个物理扇区构成。一个物理扇区对应于作为在对光盘OP11的数据记录或者再现中的逻辑访问的最小单位的一个逻辑扇区。
在该实例中,具有字母PS M(在此处,M=0,1,…,m-1)的矩形表示一个物理扇区并且一个RUB由数量为m的连续物理扇区构成。例如,在BD的情况下,一个RUB由32个物理扇区构成,并且一个物理扇区是2048个字节的区域。
进一步,在光盘OP11中,作为物理地址的物理扇区号(PSN)分别以物理扇区为单位分配,并且在记录层中在从最内周侧到最外周侧的方向上或者从最外周侧到最内周侧的方向上以连续的次序分配PSN。
进一步,例如,如图2所示,假设光盘OP11包括L0层到L2层这三层,作为记录层。在该实例中,在表示各个记录层的矩形的图中,左端表示作为与上述最内部的记录位置RI11对应的位置的最内周侧的端部,并且在表示各个记录层的矩形的图中,右端表示作为与上述最外面的记录位置RO11对应的位置的最外周侧的端部。
在每个记录层的记录区域内,按照从最内周侧到最外周侧的顺序,具有由字母“Inner Zone(内部区)”表示的内部区、扩展区域、用户数据区域、扩展区域、以及由字母“Outer Zone(外部区)”表示的外部区。
在此处,扩展区域是例如扩展管理区域或将其设定为作为交替区域的备用区域的区域,并且用户数据区域是用户指示记录的数据记录到其中的区域。例如,用于管理用户数据区域和备用区域的管理信息记录到扩展管理区域中。
在光盘OP11内具有多个记录层时,连续的PSN分配给在每个记录层内的连续区域。在该实例中,连续的PSN分配给在L0层中从最内部的记录位置RI11到最外面的记录位置RO11按行排列的各个物理扇区。
类似地,连续的PSN分配给在L1层中从最外面的记录位置RO11到最内部的记录位置RI11按行排列的各个物理扇区,并且连续的PSN分配给在L2层中从最内部的记录位置RI11到最外面的记录位置RO11按行排列的各个物理扇区。在此处,PSN在各个记录层之间不连续。
进一步,在图2示出的光盘OP11中,在每个记录层内限定用户数据区域,并且在所有记录层中,通过用户数据区域分配作为逻辑地址的连续逻辑扇区号(LSN)给用户数据区域。
换言之,限定PSN与LSN之间的对应关系,使得在光盘OP11中的LSN变成连续的。在这种情况下,在用户数据区域中,逻辑扇区和物理扇区一一彼此对应,并且以0开始的序号分配给各个逻辑扇区作为LSN。
在该实例中,在图中的L0层中的用户数据区域的左端的位置被设定为LSN=0,并且从LSN=0的位置起,将连续的LSN分配给在L0层中的用户数据区域,使得LSN随着在图中向右前进变得更大,直到在图中的L0层中的用户数据区域的右端的位置。
然后,在图中的L1层中的用户数据区域的右端的位置的LSN与在图中的L0层中的用户数据区域的右端的LSN是连续的,并且将连续的LSN分配给在L1层中的用户数据区域,使得LSN随着从在图中的L1层中的用户数据区域的右端向左端向左前进而变得更大。
同样,在图中的L2层中的用户数据区域的左端的位置的LSN与在图中的L1层中的用户数据区域的左端的LSN是连续的,并且将连续的LSN分配给在L2层中的用户数据区域,使得LSN随着从在图中的L2层中的用户数据区域的左端向右端向右前进而变得更大。
如上所述,在通用光盘中,分配了PSN和LSN。
在通过这种方式在光盘的用户数据区域中限定连续的RUB时,以RUB为单位记录由用户指定的数据(在后文中也称为用户数据),并且从用户数据区域等中读取记录的用户数据。
在记录和再现用户数据时,通过执行其中在多于一个通道内同时执行记录操作和再现操作的条带化操作,可以提高数据传送速度。
例如,在执行到光盘的记录和从光盘中再现的记录/再现装置中,具有两个光学拾取头。光学拾取头之一的记录/再现称为通道A的记录/再现,并且另一个光学拾取头的记录/再现称为通道B的记录/再现。
在此处,在假设这两个光学拾取头访问相同的记录层时,例如,如图3的箭头Q11所示,由通道A的光学拾取头PC11和通道B的光学拾取头PC12同时执行数据存取。
在此处,在图3中,一个矩形表示构成用户数据区域的一个RUB,并且在RUB中的数字字母表示连续排列的RUB的序号。在图3的说明中,RUB的数字也称为RUB序号。进一步,在图中,实线箭头表示数据存取的方向,这些方向是数据记录的方向和数据读取的方向。
在由箭头Q11表示的实例中,两个通道存取一条数据。换言之,光学拾取头PC11访问在用户数据区域内的区域T11,同时,光学拾取头PC12访问邻接区域T11的区域T12。
在多个通道通过由两个通道以种方式共享来同时记录或再现一系列数据时,与单个通道执行记录和再现的情况相比,可以提高数据传送速度。
然而,在条带化操作中,以较小单位执行数据分配时,频繁发生近旁寻道或旋转延迟,并且不能提高数据传送速度。
例如,如箭头Q12所示,在以RUB为单位划分这一系列数据并且将其分配给这两个通道A和B时,通道A要再现的数据以及通道B要再现的数据交替地排列在用户数据区域内。
然后,在访问由在图中的实线箭头表示的RUB序号0的RUB之后,光学拾取头PC11执行由在图中的虚线箭头表示的寻道操作和旋转延迟,并且访问RUB序号2的RUB。然后,同样,光学拾取头PC11重复以访问一个RUB的数据,然后执行寻道操作和旋转延迟,并且访问一个RUB的数据。
进一步,光学拾取头PC12执行与光学拾取头PC11的操作相似的操作,并且分别访问一个RUB的数据。在此处,例如,基本上同时执行对RUB序号a(在此处,a=0,2,4,...)的RUB的访问以及对RUB序号a+1的RUB的访问。
在每隔一个RUB排列分配给相同通道的区域的情况下,在数据记录和读取期间,频繁发生寻道操作和旋转延迟,并且不能提高数据传送速度。
进一步,例如,如箭头Q13所示,在8个RUB被设置为条带长度并且执行对具有10个RUB的量的数据的访问时,从数据的开头开始的8个RUB的长度的部分分配给通道A,并且两个RUB的数据的剩余部分分配给通道B。
因此,如箭头Q13所示,光学拾取头PC11按照顺序从RUB序号0的RUB到RUB序号7的RUB进行访问,并且同时,光学拾取头PC12按照顺序从RUB序号8的RUB到RUB序号9的RUB进行访问。
例如,在记录数据的情况下,当在记录/再现装置侧待要记录到RUB序号8的RUB中的数据已经从高阶主计算机中被传输时,可以基本上同时开始对RUB序号0的RUB的记录以及对RUB序号8的RUB的记录。
在这种情况下,基本上同时执行对在用户数据区域内的区域T21和T23的访问。换言之,执行条带化操作。
另一方面,在光学拾取头PC11访问区域T22时,光学拾取头PC12处于无数据存取的状态中。换言之,不执行条带化操作。这是因为在完成对区域T23的访问时,对分配给通道B的数据的存取完成了。
在以较大单位分配数据的情况下,即,通过具有大条带长度这种方式,在存取具有小尺寸的数据时,仅仅部分执行条带化操作,并且不能充分提高数据传送速度。
进一步,例如,如由箭头Q14所示,在8个RUB被设置为条带长度并且存取5个RUB的数据的情况下,根本不执行条带化操作。在这种情况下,在5个RUB中的所有数据分配给通道A,并且没有数据被分配给通道B。
因此,由对应于通道A的光学拾取头PC11执行所有数据的读取,并且不执行条带化操作。通过这种方式,在数据长度比条带长度短时,根本不执行条带化操作,并且不能提高数据传送速度。
根据以上描述,在条带长度相对于要记录或再现的数据的尺寸设置为合适的长度时,适当地执行条带化操作,并且这提高了数据传送速度。
然而,由于要记录或再现的数据的尺寸根据数据而不同,所以条带长度对于各条数据有时太长或太短。因此,与上述实例一样,不能提高数据传送速度。
进一步,在条带长度太长时,除非在记录/再现装置侧内以某个量缓冲要记录的数据,否则有时不能通过多于一个通道来同时开始记录。
<仿真区和访问顺序>
鉴于以上内容,根据本技术,通过将连续记录区域分成由多个RUB构成的小节,使用那些小节作为仿真区,将多个仿真区用作一个组,并且在构成该组的仿真区之中交错访问顺序(将顺序交换),来提高数据传送速度。
更具体而言,例如,如图4所示,假设以两个通道对在单个记录层内的记录区域执行访问。
在此处,在图4中,由箭头W11表示的单个矩形表示例如作为用户数据区域的记录区域,并且在用户数据区域内的每个矩形表示一个RUB。进一步,在每个RUB内写入的序号表示在访问记录区域时RUB待访问的顺序。在后文中,表示RUB的待访问顺序的序号也称为RUB访问序号。
进一步,由箭头W12到W14分别表示的每个矩形表示一个RUB,并且在RUB中的每个矩形表示一个物理扇区。进一步,在物理扇区内写入的序号表示物理扇区的访问顺序。在后文中,表示物理扇区的访问的顺序的序号也称为扇区访问序号。例如,扇区访问序号的顺序对应于LSN的顺序。
在图4的实例中,连续排列的4个RUB被假定为仿真区,并且由连续排列的2个仿真区的集合被假定为仿真区组。换言之,在该实例中,仿真区尺寸设置为4个RUB,并且在相同的记录层内彼此邻接排列的2个仿真区被假定为一个仿真区组。进一步,一个RUB由32个连续物理扇区构成。
在此处,为了简化说明之目的,仿真区尺寸设置为4个RUB;然而,实际上,尺寸优选地是几百个RUB或几千个RUB。
在图4的实例中,在构成单个仿真区组的仿真区之间,作为RUB访问序号的RUB的访问顺序被交错。
例如,在第一仿真区组内,假设首先访问并且具有RUB访问序号0的RUB是在第一仿真区的开头的RUB,并且假设被第二访问并且具有RUB访问序号1的RUB是在第二仿真区的开头的RUB。
然后,假设被第三访问并且具有RUB访问序号2的RUB是在第一仿真区内的第二RUB,并且假设被第四访问并且具有RUB访问序号3的RUB是在第二仿真区内的第二RUB。
通过这种方式,在每个仿真区组内,将RUB访问序号交替地分配给两个仿真区,并且在仿真区内,规定RUB的访问顺序,使得RUB访问序号在更接近开头部分的RUB中变得更小。
进一步,如箭头W12到W14所示,在每个单个的RUB内,使得按照顺序从RUB的物理扇区的开头到最后一个物理扇区进行访问。换言之,扇区访问序号在RUB之间不交错,并且按照物理扇区的布置顺序(依次)顺次访问在RUB中的物理扇区。
因此,在该实例中,将扇区访问序号0到31分配给在具有RUB访问序号0的RUB中的各物理扇区。进一步,将扇区访问序号32到63分配给在具有RUB访问序号0之后的RUB访问序号1的RUB中的各个物理扇区。
在对记录区域访问时,按照通过这种方式分配的RUB访问序号的顺序,读取或写入数据,更具体而言,按照扇区访问序号的顺序。
在光盘中,将连续PSN分配给在记录层内连续排列的物理扇区。因此,在将LSN分配给各个物理扇区(逻辑扇区),以便与物理扇区的访问顺序匹配时,PSN的顺序和LSN的顺序不匹配。因此,根据本技术,使用稍后描述的仿真区管理信息,并且管理在PSN与LSN之间的对应关系。
如上所述,通过定义仿真区和仿真区组并且在仿真区之间交错RUB访问序号,即,以RUB为单位在仿真区之间交错LSN,例如,如图5所示,可以提高数据传送速度。
在此处,在图5中,每个矩形表示一个RUB,并且写入RUB内的序号表示RUB访问序号。进一步,在图中的实线箭头表示数据访问方向(记录区域),并且在图中的虚线箭头表示寻道操作或旋转延迟。进一步,在图5中,相同的附图标记应用于与在图3的情况下的那些部分对应的部分中,并且省略其说明。
在图5的实例中,8个RUB设置为一个仿真区,并且连续排列的2个仿真区构成一个仿真区组。然后,多个仿真区组在记录区域的访问方向上连续排列。
在此处,假设将对位于仿真区组的开头的仿真区的访问分配给光学拾取头PC11,并且将对位于仿真区组的尾部的仿真区的访问分配给光学拾取头PC12。
在这种情况下,如箭头Q21所示,光学拾取头PC11顺序访问从具有RUB访问序号0的RUB起连续排列的RUB。然后,在访问具有RUB访问序号14的RUB之后,如在图中的虚线所示,光学拾取头PC11通过执行寻道操作等跳到具有RUB访问序号16的RUB,并且顺序访问连续排列的RUB,直到具有RUB访问序号30的RUB。
进一步,同样,在顺序访问从具有RUB访问序号1的RUB开始连续排列的RUB直到具有RUB访问序号15的RUB之后,光学拾取头PC12跳到具有RUB访问序号17的RUB,并且顺序访问连续排列的RUB。在此处,由于例如光学拾取头PC11的访问操作和光学拾取头PC12的访问操作同时执行,所以基本上同时执行对具有RUB访问序号0的RUB的访问以及对具有RUB访问序号1的RUB的访问。
根据本技术,通过执行将由多个连续RUB构成的仿真区分配给一个通道的这种访问控制,即使在访问具有大尺寸的数据时,也可以保持对一个仿真区发生一次寻道操作。因此,通过适当地定义仿真区的巨大性(尺寸),可以减少寻道操作等的发生的次数,并且可以提高数据传送速度。
进一步,根据本技术,即使在要访问的数据的尺寸小时,例如,如箭头Q22所示,也有效地执行条带化,并且可以提高数据传送速度。
换言之,在由箭头Q22表示的实例中,要访问的数据的尺寸是5个RUB。因此,对具有两个RUB的大小的区域T31和区域T33执行条带化,并且不执行条带化的部分仅仅是一个RUB数据的小数部分,其是区域T32的部分。通过该配置,可以提高条带化效率,并且这提高了数据传送速度。
换言之,在该实例中,由于一系列数据分成RUB单位并且交替地分配给两个通道,所以基本上相同量的数据分配给两个通道。因此,在两个通道中同时记录或再现数据的情况下,由于分配的数据不会不均匀地仅仅分配给一个通道,所以可以提高条带化效率,并且这提高了数据传送速度。
如上所述,根据本技术,通过在仿真区之间以RUB为单位(即,LSN)交错访问顺序,可以提高数据传送速度,而与要记录或再现的数据的尺寸无关。此外,在记录数据时,即使当在记录/再现装置侧内缓冲少量要记录的数据时,也可以基本上同时执行在各个通道的每一个内的记录。
进一步,在图4示出的实例中,在仿真区之间交替地分配RUB访问序号的实例;然而,可以以多个RUB为单位在仿真区之间交替地分配RUB访问序号。
在此处,实际上,不分配RUB访问序号,并且根据由RUB访问序号表示的访问顺序,确定各个物理扇区的LSN。
通过这种方式,例如,在以多个RUB为单位分配RUB访问序号时,将RUB访问序号分配给各个RUB,如图6所示。在此处,在图6中,由箭头W21表示的矩形表示作为例如用户数据区域的一个记录区域,并且在用户数据区域内的每个矩形表示一个RUB。进一步,写入每个RUB内的序号表示RUB访问序号。
进一步,由箭头W22到W24表示的每个矩形表示一个RUB,并且在RUB中的每个矩形表示一个物理扇区。进一步,在每个物理扇区内写入的序号表示扇区访问序号。
在图6的实例中,假设连续排列的4个RUB用作一个仿真区,并且由连续排列的2个仿真区的集合用作一个仿真区组。进一步,一个RUB由32个连续物理扇区构成。
在每个仿真区组中,在仿真区之间以两个RUB为单位交替地分配RUB访问序号。
例如,在第一仿真区组内,在第一仿真区内的第一和第二RUB的RUB访问序号设置为0和1,并且在第二仿真区内的第一和第二RUB的RUB访问序号设置为2和3。
进一步,在第一仿真区内的第三和第四RUB的RUB访问序号设置为4和5,并且在第二仿真区内的第三和第四RUB的RUB访问序号设置为6和7。
因此,在每个仿真区组内,在第一仿真区内访问两个连续的RUB之后,在第二仿真区内的两个连续的RUB被访问。进一步,访问在第一仿真区内的稍后的两个连续的RUB,并且最后访问在第二仿真区内的稍后的两个连续的RUB。
在此处,实际上,由于将单个仿真区分配给单个通道,所以各个分配的通道同时访问在仿真区组内的第一仿真区和第二仿真区。
如上所述,在每个仿真区组内,在仿真区之间交替地分配两个RUB访问序号,并且限定RUB访问序号,使得RUB访问序号在更接近仿真区的开头时变得更小。
进一步,如箭头W22到W24所示,在一个RUB内,按照顺序依次访问在RUB中的第一物理扇区到最后物理扇区。
通过这种方式在仿真区之间交替地分配两个RUB访问序号,可以增大一个通道可以完成对具有两个RUB的尺寸的数据的访问的可能性。在这种情况下,虽然条带化效率较低,但是可以提高多线程操作效率,即同时读取多个文件的操作的效率。
进一步,在两个通道对在一个记录层内的记录区域执行同时访问的情况下,在例如如图7所示限定RUB访问顺序时,这增大了要访问的数据的两个连续的RUB的部分放在仿真区内的连续的两个RUB的区域内的概率。在此处,在图7中,由箭头W31表示的矩形表示作为例如用户数据区域的一个记录区域,并且在用户数据区域内的每个矩形表示一个RUB。进一步,写入每个RUB内的序号表示RUB访问序号。
进一步,分别由箭头W32到W34表示的每个矩形表示一个RUB,并且在RUB中的每个矩形表示一个物理扇区。进一步,在每个物理扇区内写入的序号表示扇区访问序号。
在图7的实例中,假设连续排列的4个RUB用作一个仿真区,并且由2个连续的仿真区的集合用作一个仿真区组。进一步,单个RUB由32个连续物理扇区构成。
在每个仿真区组中,在仿真区内,在仿真区之间交替地分配RUB访问序号,使得将连续的RUB访问序号优选地分配给两个相邻的RUB。
例如,在第一仿真区组内,在第二仿真区内的第一RUB的RUB访问序号设置为0,并且在第一仿真区内的第一和第二RUB的RUB访问序号分别设置为1和2。然后,在第二仿真区内的第二和第三RUB的RUB访问序号分别设置为3和4,并且在第一仿真区内的第三和第四RUB的RUB访问序号分别设置为5和6。进一步,在第二仿真区内剩余的第四RUB的RUB访问序号设置为7。
进一步,在由箭头W32到W34表示的各个RUB的每一个内,按照顺序依次访问在RUB中的第一物理扇区到最后物理扇区。
通过这种方式,在连续的RUB访问序号尽可能分配给在仿真区内彼此相邻的两个RUB并且在仿真区之间以RUB或者两个RUB为单位交替地分配RUB访问序号时,这提高了可以在单个通道内完成对具有两个RUB的尺寸的数据的访问的可能性。这样做,可以提高多线程操作效率。
进一步,在上面已经说明了由在单个记录层内的记录区域内的仿真区的集合设置为一个仿真区组的实例;然而,仿真区组可以由在相同的记录层和不同的记录层内的仿真区构成。
在这种情况下,例如,将RUB访问序号分配给各个RUB,如图8所示。在此处,在图8中,由箭头W41到W42分别表示的每个矩形表示作为例如用户数据区域的一个记录区域,并且在用户数据区域内的每个矩形表示一个RUB。进一步,写入每个RUB内的序号表示RUB访问序号。
在此处,例如,由箭头W41表示的记录区域是设置在光盘的正面的记录层内的记录区域,并且由箭头W42表示的记录区域是设置在光盘的背面的记录层内的记录区域。
在图8中,假设连续排列的4个RUB用作一个仿真区,并且假设由包括在正面的记录层内连续排列的2个仿真区以及在背面的记录层内连续排列的2个仿真区的四个仿真区的集合用作一个仿真区组。
在每个仿真区组中,按照顺序在4个仿真区内以RUB为单位分配RUB访问序号,并且在仿真区内,限定RUB访问序号,使得更接近开头的RUB具有更小的RUB访问序号。
例如,在第一仿真区组内,在正面的第一仿真区内的第一RUB的RUB访问序号设置为0,并且在正面的第二仿真区内的第一RUB的RUB访问序号设置为1。进一步,在背面的第一仿真区内的第一RUB的RUB访问序号设置为2,并且在背面的第二仿真区内的第一RUB的RUB访问序号设置为3。
进一步,在正面的第一仿真区内的第二RUB、在正面的第二仿真区内的第二RUB、在背面的第一仿真区内的第二RUB以及在背面的第二仿真区内的第二RUB的RUB访问序号分别设置为4到7。
同样,在正面的第一仿真区内的第三RUB、在正面的第二仿真区内的第三RUB、在背面的第一仿真区内的第三RUB以及在背面的第二仿真区内的第三RUB的RUB访问序号分别设置为8到11。
进一步,在正面的第一仿真区内的第四RUB、在正面的第二仿真区内的第四RUB、在背面的第一仿真区内的第四RUB以及在背面的第二仿真区内的第四RUB的RUB访问序号分别设置为12到15。
在此处,例如,一个RUB由32个连续物理扇区构成,并且按照顺序依次访问在RUB中的第一物理扇区到最后物理扇区。
在该实例中,如箭头Q31所示,连续的RUB访问序号优选地分配给在相同记录层内的仿真区。换言之,优选在一记录层内分配RUB访问序号。
在这种情况下,如箭头Q32所示,与在记录层之间分配连续的RUB访问序号的情况(在后文中也称为记录层间优先权)相比,要访问的数据的相邻RUB的部分放在相同记录层内的可能性更高。
在此处,由箭头Q31表示的两个矩形表示在图的上部示出的第一仿真区组,并且由箭头Q32表示的两个矩形表示在图的上部示出的第一仿真区组,其中,基于记录层间优先权,重新分配RUB访问序号。
在由箭头Q32表示的实例中,由于在不同的记录层之间交替地分配RUB访问序号,所以要依次访问的两个RUB始终在两个不同的记录层内。另一方面,在由箭头Q31表示的实例中,具有两个连续的RUB访问序号的RUB优选地设置在相同的记录层内。
进一步,甚至在仿真区组由在相同的记录层内的仿真区和在不同的记录层内的仿真区构成的情况下,连续的RUB访问序号还可以优选地分配给在相同的仿真区内的连续的RUB。
在这种情况下,RUB访问序号分配给RUB,例如,如图9或图10所示。
在此处,在图9和图10中,由箭头W51、W52、W61以及W62分别表示的每个矩形表示作为例如用户数据区域的一个记录区域,并且在用户数据区域内的每个矩形表示一个RUB。进一步,写入每个RUB内的序号表示RUB访问序号。进一步,例如,一个RUB由32个连续物理扇区构成,并且按照顺序顺次访问在RUB中的第一物理扇区到最后物理扇区。
例如,在图9示出的实例中,假设由箭头W51表示的记录区域是在光盘的正面设置的记录层内的记录区域,并且由箭头W52表示的记录区域是在光盘的背面设置的记录层内的记录区域。
在图9中,假设串联排列的4个RUB用作一个仿真区,并且假设由总共包括在正面的记录层内连续排列的2个仿真区以及在背面的记录层内的2个仿真区的四个仿真区的集合用作一个仿真区组。
在每个仿真区组中,将RUB访问序号以RUB为单位分配给这4个仿真区。
在这种情况下,在从作为RUB访问序号分配的目标的仿真区移动到在另一个记录层中的仿真区时,使放在离作为最后分配目标的仿真区更远的侧的仿真区成为作为下一个分配目标的仿真区。进一步,在将RUB访问序号分配给在所有4个仿真区的最后仿真区内的RUB之后,与分配给RUB的最后RUB访问序号连续的RUB访问序号分配给与该RUB相邻的RUB。
例如,在第一仿真区组内,在正面的第二仿真区内的第一RUB的RUB访问序号设置为0,并且在正面的第一仿真区内的第一RUB的RUB访问序号设置为1。进一步,在背面的第二仿真区内的第一RUB的RUB访问序号设置为2,并且在背面的第一仿真区内的第一RUB的RUB访问序号设置为3。
进一步,在背面的第一仿真区内的第二RUB、在背面的第二仿真区内的第二RUB、在正面的第一仿真区内的第二RUB以及在正面的第二仿真区内的第二RUB的RUB访问序号分别设置为4到7。
同样,在正面的第二仿真区内的第三RUB、在正面的第一仿真区内的第三RUB、在背面的第二仿真区内的第三RUB以及在背面的第一仿真区内的第三RUB的RUB访问序号分别设置为8到11。
进一步,在背面的第一仿真区内的第四RUB、在背面的第二仿真区内的第四RUB、在正面的第一仿真区内的第四RUB以及在正面的第二仿真区内的第四RUB的RUB访问序号分别设置为12到15。
通过这种方式,在图9的实例中,优选地使具有两个连续的RUB访问序号的RUB放在相同的记录层内。
进一步,例如,在图10的实例中,由箭头W61表示的记录区域是在光盘的正面设置的记录层内的记录区域,并且由箭头W62表示的记录区域是在光盘的背面设置的记录层内的记录区域。
在图10中,假设连续排列的4个RUB用作一个仿真区,并且假设由包括在正面的记录层内连续排列的2个仿真区以及在背面的记录层内连续排列的2个仿真区的四个仿真区的集合用作一个仿真区组。
在每个仿真区组中,按照顺序在4个仿真区内以RUB为单位分配RUB访问序号。
在这种情况下,在从作为RUB访问序号分配的目标的仿真区移动到在另一个记录层中的仿真区时,使放在离作为最后分配目标的仿真区更近的侧的仿真区成为作为下一个分配目标的仿真区。进一步,在将RUB访问序号分配给在所有4个仿真区的最后仿真区内的RUB之后,与分配给RUB的最后RUB访问序号连续的RUB访问序号分配给与该RUB相邻的RUB。
例如,在第一仿真区组内,在正面的第二仿真区内的第一RUB的RUB访问序号设置为0,并且在正面的第一仿真区内的第一RUB的RUB访问序号设置为1。进一步,在背面的第一仿真区内的第一RUB的RUB访问序号设置为2,并且在背面的第二仿真区内的第一RUB的RUB访问序号设置为3。
进一步,在背面的第二仿真区内的第二RUB、在正面的第二仿真区内的第二RUB、在正面的第一仿真区内的第二RUB以及在背面的第二仿真区内的第二RUB的RUB访问序号分别设置为4到7。
同样,在背面的第一仿真区内的第三RUB、在背面的第二仿真区内的第三RUB、在正面的第二仿真区内的第三RUB以及在正面的第一仿真区内的第三RUB的RUB访问序号分别设置为8到11。
进一步,在正面的第一仿真区内的第四RUB、在背面的第一仿真区内的第四RUB、在背面的第二仿真区内的第四RUB以及在正面的第二仿真区内的第四RUB的RUB访问序号分别设置为12到15。
在此处,在上面已解释了一个仿真区组由在单个记录层内或者在两个记录层内设置的仿真区构成。然而,例如,一个仿真区组可以由在四个或更多个记录层内提供的仿真区构成,使得在4层光盘等的情况下,一个仿真区组由在4个记录层的各个层内提供的4个仿真区构成。
进一步,如上所述,在光盘上的螺旋的数量可以比可以在记录/再现装置中同时记录或再现的通道的数量更少或更多。例如,在光盘上的螺旋的数量比在记录/再现装置中的通道的数量更少时,在每个记录层内的记录区域分成多个仿真区,并且在相同记录区域内的多个仿真区优选地包含在相同的仿真区组内。
<关于仿真区设置>
在此处,说明了光盘的记录层包括内部区、扩展区域、用户数据区域以及外部区。
现在,例如,如在图11的箭头Q41所示,在记录区域内包括扩展区域和用户数据区域的区域称为数据区。在这种情况下,在一个记录层内的记录区域由内部区、数据区以及外部区构成。
在这种情况下,可以使在记录区域内的任何区域成为仿真区,换言之,可以在记录区域内的任何区域内设置仿真区;然而,根据成为仿真区的区域,需要一些尝试。在此处,为了简单起见,图11示出了光盘仅仅包括一个记录层;然而,在光盘包括多于一个记录层时,处理类似。
例如,如箭头Q42所示,可以使包括内部区、数据区以及外部区的整个光盘成为仿真区。要注意的是,在图11中,使用虚线显示的每个矩形表示一个仿真区。
在该实例中,在整个记录区域的尺寸不是仿真区的尺寸的整数倍大小时,例如,在记录区域的开头或尾部,可以不完全是仿真区,该仿真区没有定义的仿真区尺寸,或者可以具有因其奇怪的尺寸而使其不是仿真区的区域。
进一步,如箭头Q43所示,可以仅仅使数据区成为仿真区。在这种情况下,如果数据区的尺寸设置为仿真区尺寸的整数倍,则可以简化仿真区的管理。
进一步,如箭头Q44所示,可以在构成数据区的扩展区域内设置备用区域,并且可以使包括备用区域和用户数据区域的整个数据区成为仿真区。在这种情况下,如果各个备用区域和用户数据区域形成为具有仿真区尺寸的整数倍的尺寸,则可以固定仿真区的边界位置。换言之,例如,在备用区域与用户数据区域之间的边界位置始终用作在仿真区之间的边界位置,并且可以简化仿真区的区域管理。
进一步,如箭头Q45所示,在数据区内设置扩展管理区域和备用区域,并且可以使备用区域和用户数据区域成为仿真区,而不将扩展管理区域用作仿真区。在这种情况下,如果使扩展管理区域、备用区域以及用户数据区域具有仿真区尺寸的整数倍的尺寸,则固定仿真区的边界位置。换言之,例如,在扩展管理区域与备用区域之间的边界位置以及在备用区域与用户数据区域之间的边界位置始终用作在仿真区之间的边界位置,使得可以简化仿真区的区域管理。
在此处,在这种情况下,在使备用区域和用户数据区域具有仿真区尺寸的整数倍的尺寸时,在某些情况下,可以移动在仿真区之间的边界位置;然而,在扩展管理区域与备用区域之间的边界位置以及在备用区域与用户数据区域之间的边界位置始终用作在仿真区之间的边界位置。
进一步,如箭头Q46所示,在数据区内设置扩展管理区域和备用区域,但是仅仅用户数据区域可以用于设置仿真区,而不将扩展管理区域和备用区域用作仿真区。
通过这种方式,除了用户数据区域以外,数据区还可以包括扩展管理区域或备用区域,并且通过适当地设置扩展管理区域、备用区域以及用户数据区域的尺寸,可以容易管理仿真区的区域。
例如,如在图12的箭头Q51所示,在数据区内设置备用区域,备用区域和用户数据区域用于构成仿真区,并且假设限定在仿真区之间的边界位置,如在图中的虚线所示。
在此处,使用在图中的虚线表示的每个矩形表示一个仿真区,并且在图中的箭头表示在仿真区之间的边界位置。
在该实例中,由于备用区域和用户数据区域具有仿真区尺寸的整数倍的尺寸,所以在备用区域与用户数据区域之间的边界位置用作在仿真区之间的边界位置,并且没有具有奇怪尺寸(odd size)的任何仿真区。
另一方面,如箭头Q52所示,假设在数据区内设置扩展管理区域和备用区域,并且仅仅备用区域和用户数据区域用于设置仿真区。
在这种情况下,在扩展管理区域没有仿真区尺寸的整数倍的尺寸时,根据是否设置扩展管理区域,仿真区的边界位置移动,如在图中连接表示在仿真区之间的边界位置的箭头的虚线所示。进一步,如箭头W71所示,可以生成具有片段尺寸的仿真区。
因此,根据本技术,在数据区内尺寸可变的可变区域,并且更具体而言,在设置扩展管理区域、备用区域或用户数据区域时,优选地使那些区域的尺寸是仿真区尺寸的整数倍的尺寸。这样做,可以防止移动在仿真区之间的边界位置或者发生具有奇怪尺寸的仿真区,并且可以简化区域管理。
具体而言,如在图13的箭头Q61所示,在使备用区域和用户数据区域的尺寸是仿真区尺寸的整数倍的尺寸时,如果备用区域被设为数据区,则在备用区域与用户数据区域之间的边界位置用作在仿真区之间的边界位置。进一步,不生成具有奇怪尺寸的仿真区。
在此处,在图13中的虚线表示的每个矩形表示一个仿真区,并且在图中的箭头表示在仿真区之间的边界位置。
在此处,在使备用区域的尺寸不是仿真区尺寸的整数倍的尺寸的情况下,发生如箭头Q62所示的移动一些边界位置的不方便性。例如,在由箭头W81表示的仿真区中,设置备用区域和用户数据区域,并且作为由箭头W82和W83表示的示出的仿真区,可以生成具有奇怪尺寸的仿真区,或者会移动在仿真区之间的边界位置。
如上所述,在记录区域内设置仿真区时,通过使可变区域的尺寸成为仿真区尺寸的整数倍,可以简化仿真区的区域管理。
在此处,例如,在光盘是称为区域恒定线速度(ZCLV)介质或区域恒定角速度(ZCAV)介质的介质时,以同心图案划分ZCLV介质或ZCAV介质的记录区域。然后,从在ZCLV介质或ZCAV介质内的记录区域中划分的每个区域称为区。在这种情况下,例如,优选地使每个区的尺寸成为仿真区尺寸的整数倍。这防止在两个区上设置一个仿真区,并且可以简化仿真区等的管理。
进一步,在ZCLV介质或ZCAV介质中,由于旋转速度或传送速度的关系可以在区之间不同,所以优选地不在两个区上设置一个仿真区组。然而,甚至在ZCLV介质或ZCAV介质的情况下,在构成仿真区组的仿真区放在不同的螺旋内时,即使在两个区上设置仿真区,在记录操作或再现操作内也不发生不方便性。
例如,在设置给相同的记录层的岸和沟分别用作一个螺旋(轨道)时,岸和沟分别具有构成相同的仿真区组的一个仿真区。进一步,假设在两个区上设置一个仿真区。在这种情况下,在两个通道同时访问那些仿真区时,由于基本上同时发生对在那些仿真区内的区边界的访问,所以可以在这两个通道内执行并行处理,并且几乎不发生条带化效率的降低。
在此处,已作为一个实例描述了设置在相同的记录层内的岸和沟,作为不同的螺旋;然而,甚至在构成相同的仿真区组的不同仿真区分别设置到在中立记录层(indifferent recording layers)内的岸或沟中时,也可以在多于一个通道内执行并行处理。
<关于交替处理>
接下来,说明交替处理和备用区域管理。
在交替处理中,对于因光盘故障而不能记录数据的故障块体(缺陷),即,例如,逻辑扇区(物理扇区)或RUB,从提前保持的备用区域中分配用作故障块体的代替物的块体。然后,分配给故障块体的逻辑地址(LSN)重新分配给代替块体。
这样做,甚至在具有故障块体(在后文中简称为缺陷或缺陷区域)的光盘上,可以提出密集逻辑地址空间。换言之,可以访问光盘,而不管具有还是没有缺陷位置。
更具体而言,例如,如图14所示,记录区域包括用户数据区域和备用区域,并且由用户指定的用户数据记录在用户数据区域内。
要注意的是,在图中,每个方形表示一个块体。在此处,一个块体可以是例如逻辑扇区(物理扇区)或RUB,并且假设每个块体是逻辑扇区而给出以下说明。进一步,在下面,在需要特别区分逻辑扇区和物理扇区时,它们可以也简称为扇区。
在该实例中,在图中从左边将逻辑地址(LSN)分配给构成用户数据区域的每个块体(每个扇区)。无论是否执行条带化,在记录用户数据时,在由具有连续的LSN的扇区构成的区域内记录用户数据。
现在,例如,在试图将数据记录到具有LSN为m的扇区DP11中时,假设扇区DP11具有缺陷并且不能记录数据,并且执行交替处理。换言之,例如,选择在备用区域内的扇区DN11,作为是作为交替主体(即,交替物)的扇区DP11的替换的扇区,指示将被记录到扇区DP11中的数据记录到作为交替物的扇区DN11中,并且将扇区DP11的LSN设置为m。
进一步,随后,在试图将数据记录到具有LSN为n的扇区DP12中时,假设扇区DP12具有缺陷并且不能记录数据,并且执行交替处理。换言之,例如,选择在备用区域内的扇区DN12,作为交替物,被指示为记录到扇区DP12中的数据记录到作为交替物的扇区DN12中,并且将扇区DP12的LSN设置为n。
在此处,如上所述,基本上将LSN分配给用户数据区域。因此,将LSN分配给备用区域中在交替处理中被设定为交替物的块体(扇区);然而,不将LSN分配给不被设置为交替物的块体,即,未使用的块体。
进一步,执行交替处理的时间可以是任意时间;然而,通常,每当在记录操作期间发现缺陷时,在备用区域内保存替换块体,并且对交替物执行数据记录和LSN重新分配。
进一步,在执行交替处理时,生成并且保存表示在交替主体与交替物之间的对应关系的信息,使得可以识别在物理地址(PSN)与逻辑地址(LSN)之间的对应关系。
例如,使用称为缺陷列表(DFL)的表来管理在交替主体与交替物之间的这种对应关系。
一般的DFL储存DFL条目,包括交替主体的PSN以及针对每个缺陷的交替物的PSN。
例如,每当执行交替处理时,在DFL内生成和存储一个DFL条目。进一步,通常,在交替处理中,将连续的交替块体分配给连续缺陷,并且在这些连续缺陷与连续缺陷的连续交替块体之间的对应关系表示为两个(一对)DFL条目。
在通过这种方式执行交替处理时,由于LSN重新分配给扇区,所以在LSN与PSN之间的对应关系改变。
例如,在除了用户数据区域以外,数据区还包括一个扩展管理区域和两个备用区域并且在用户数据区域内没有缺陷时,在逻辑地址空间与物理地址空间之间的对应关系如图15所示。
在此处,在图15中,纵轴和横轴分别表示LSN和PSN。在该实例中,由于在用户数据区域内没有缺陷,所以LSN相对于PSN线性(通过线性关系)改变。进一步,在该实例中,不限定其与LSN的对应关系的扩展管理区域和备用区域没有LSN。换言之,从逻辑地址空间中看不到这些扩展管理区域和备用区域。
另一方面,在除了用户数据区域以外,数据区还包括一个扩展管理区域和两个备用区域并且在用户数据区域内具有缺陷时,例如,在逻辑地址空间与物理地址空间之间的对应关系如图16所示。在此处,在图16中,纵轴和横轴分别表示LSN和PSN。
在该实例中,由于在用户数据区域内具有PSN为P的区域是单个缺陷区域,所以在缺陷区域内执行交替处理,并且在其他区域内不执行交替处理。
因此,在用户数据区域内除了具有PSN为P的区域以外的区域中,LSN相对于PSN线性改变。进一步,在作为缺陷区域的具有PSN为P的区域中,执行交替处理,并且在备用区域内具有PSN为P'的区域用作缺陷区域的交替区域。换言之,将具有L的LSN分配给在备用区域内具有PSN为P'的区域。
在通过这种方式执行交替处理时,生成并且在DFL中加入表示交替主体的PSN为P以及交替物的PSN为P'的DFL条目。在这种情况下,从逻辑地址空间中看不到作为交替主体的PSN为P的缺陷区域。
进一步,在除了用户数据区域以外,在数据区内还提供一个扩展管理区域和两个备用区域并且在用户数据区域内具有连续缺陷时,例如,在逻辑地址空间与物理地址空间之间的对应关系如图17所示。在此处,在图17中,纵轴和横轴分别表示LSN和PSN。
在该实例中,由于在用户数据区域内具有PSN为P1到P2的区域是连续缺陷区域,所以在连续缺陷区域内执行交替处理,并且在其他区域内不执行交替处理。
因此,在用户数据区域内除了具有PSN为P1到P2的区域以外的区域中,LSN相对于PSN线性改变。进一步,在作为缺陷区域的具有PSN P1到P2的区域中,执行交替处理,并且在备用区域内具有PSN P1'到P2'的区域用作缺陷区域的交替区域。换言之,将LSN L1和L2分配给在备用区域内具有PSN为P1'到P2'的区域。
在通过这种方式执行交替处理时,生成并且在DFL中加入表示具有PSN为P1到P2的区域作为交替主体以及具有PSN为P1'到P2'的区域作为交替物的两个(一对)DFL条目。在这种情况下,由于在连续缺陷区域的交替前后之间的对应关系表示为与连续缺陷区域的长度(范围)无关的一组DFL条目,所以这可以防止DFL扩展。
在此处,在多于一个通道内同时执行记录操作并且在多于一个通道内同时发生缺陷时,可以具有划分备用区域的问题。
例如,在如图18的箭头Q71所示,数据区包括用户数据区域和备用区域时,考虑划分一条数据并且同时使用通道A的光学拾取头PC11和通道B的光学拾取头PC12记录数据。
在此处,在图18中,每个方形表示在记录区域内的一个块体,并且在该实例中,假设一个块体表示一个扇区。进一步,在图18中,相同的附图标记应用于与在图13中的部分对应的部分中,并且根据需要省略其说明。
在由箭头Q71表示的实例中,光学拾取头PC11将数据记录到其中的区域具有连续缺陷区域T41,同样,光学拾取头PC12将数据记录到其中的区域具有连续缺陷区域T42。在此处,假设光学拾取头PC11和PC12在图中朝着右边记录数据。
在此处,连续缺陷区域T41由具有LSN为a、b以及c的三个扇区DP21到DP23构成,并且连续缺陷区域T42由具有LSN为x、y以及z的三个扇区DP31到DP33构成。
在这种情况下,如箭头Q72所示,假设光学拾取头PC11和光学拾取头PC12从预定扇区朝着在图中的右侧同时写入数据。然后,如箭头Q73所示,在光学拾取头PC11找出作为缺陷区域的扇区DP21的同时,光学拾取头PC12找出作为缺陷区域的扇区DP31。
在这种情况下,如箭头Q74所示,执行交替处理。换言之,选择在备用区域内的扇区DN21,作为扇区DP21的交替物,并且计划记录到作为交替主体的扇区DP21中的数据DA(1)由光学拾取头PC11记录到作为交替物的扇区DN21中。进一步,已分配给扇区DP21的为a的LSN重新分配给扇区DN21。
同样,选择在备用区域内的扇区DN22,作为扇区DP31的交替物,并且计划记录到作为交替主体的扇区DP31中的数据DB(1)由光学拾取头PC12记录到作为交替物的扇区DN22中。进一步,分配给扇区DP31的x的LSN重新分配给扇区DN22。
在通过这种方式执行交替处理时,如图19所示,光学拾取头PC11和光学拾取头PC12分别将数据写入在扇区DP21和扇区DP31之后的区域中。在此处,在图19中,相同的附图标记应用于与在图18中的部分对应的部分中,并且根据需要省略其解释。
在该实例中,如箭头Q81所示,光学拾取头PC11和PC12试图分别在扇区DP22和DP32内写入数据;然而,那些扇区也是缺陷区域,并且这同时再次造成交替处理。
然后,如箭头Q82所示,选择在备用区域内的扇区DN23,作为扇区DP22的交替物,并且计划记录到作为交替主体的扇区DP22中的数据DA(2)由光学拾取头PC11记录到作为交替物的扇区DN23中。进一步,分配给扇区DP22的为b的LSN重新分配给扇区DN23。
同样,选择在备用区域内的扇区DN24,作为扇区DP32的交替物,并且计划记录到作为交替主体的扇区DP32中的数据DB(2)由光学拾取头PC12记录到作为交替物的扇区DN24中。进一步,分配给扇区DP32的为y的LSN重新分配给扇区DN24。
进一步,由于分别在扇区DP22和DP32之后的扇区DP23和DP33也是缺陷区域,所以在那些扇区中执行交替处理,并且如箭头Q83所示,在备用区域内的单个区域T51内交替地记录不同通道的数据。
换言之,选择在备用区域内的扇区DN25,作为扇区DP23的交替物,并且计划记录到作为交替主体的扇区DP23中的数据DA(3)由光学拾取头PC11记录到作为交替物的扇区DN25中。进一步,选择在备用区域内的扇区DN26,作为扇区DP33的交替物,并且计划记录到作为交替主体的扇区DP33中的数据DB(3)由光学拾取头PC12记录到作为交替物的扇区DN26中。
在基本上同时在每个通道内找出连续缺陷区域时,在备用区域内的单个区域T51中分割和记录不同通道的数据。换言之,引起备用区域的分段。
具体而言,最初假设连续记录数据DA(1)到DA(3),并且同样,最初假设连续记录数据DB(1)到DB(3)。然而,在该实例中,由于基本上同时在2个通道内找出连续缺陷区域,所以在区域T51中分割和记录最初假设连续记录的数据块。
在发生作为数据分段的这种分割时,这可以造成降低的数据传送速度或DFL的扩展,例如,如图20所示。在此处,在图20中,相同的附图标记应用于与在图18或19中的部分对应的部分中,并且根据需要省略其解释。
在该实例中,如箭头Q91所示,在分配给通道A的数据之中,最初假设连续记录到扇区DP21到DP23中的数据DA(1)到DA(3)由交替处理记录到扇区DN21、DN23以及DN25中。因此,在通道A内再现数据时,如在图中的实线箭头和虚线箭头所示,在开始读取数据并且在紧接扇区DP21之前的扇区中读取数据之后,执行扇区DN21的寻道操作,并且从扇区DN21中读取数据。进一步,在执行到扇区DN23的寻道操作并且读取数据之后,执行到扇区DN25的寻道操作并且读取数据,并且进一步执行紧接在扇区DP23之后的扇区的寻道操作。
在通过这种方式分割数据时,在备用区域内的区域T51中频繁发生近旁寻道,并且这降低了数据传送速度(再现速度)。
进一步,如箭头Q92所示,由连续扇区构成的区域T41的交替物变成扇区DN21、DN23以及DN25,这些扇区是非连续区域,使得需要更多的DFL条目并且DFL的消耗增大。
因此,根据本技术,在每个通道内保存用作交替物的连续区域,并且通过为每个通道保持保存的连续区域,防止交替处理的数据分割,并且提高数据传送速度。
例如,如图21的箭头Q101所示,在数据区包括用户数据区域和备用区域的情况下,由通道A的光学拾取头PC11和通道B的光学拾取头PC12同时分段和记录一个数据块。在此处,在图21中,相同的附图标记应用于与在图18到图20中的部分对应的部分中,并且根据需要省略其解释。
如箭头Q101所示,假设光学拾取头PC11和PC12在图中朝着右边写入数据,并且同时,光学拾取头PC11到达作为缺陷区域的扇区DP21,光学拾取头PC12到达作为缺陷区域的扇区DP31。
在这种情况下,如箭头Q102所示,保存连续区域T61,作为通道A的交替区域,并且执行交替处理。换言之,选择在连续区域T61的开头的扇区DN31,作为扇区DP21的交替物,并且最初假设记录在扇区DP21中的数据DA(1)记录到作为交替物的扇区DN31中。
进一步,与上面基本上同时,如箭头Q103所示,保存连续区域T62,作为通道B的交替区域,并且执行交替处理。换言之,选择在连续区域T62的开头的扇区DN41,作为扇区DP31的交替物,并且最初假设记录在扇区DP31中的数据DB(1)记录到作为交替物的扇区DN41中。
然后,在数据写入再次开始时,由于在扇区DP21之后的扇区DP22也是缺陷区域,所以在通道A中再次执行交替处理,同样,由于在扇区DP31之后的扇区DP32也是缺陷区域,所以在通道B中再次执行交替处理。
然后,如箭头Q104所示,选择在连续区域T61内排第二的扇区DN32,作为扇区DP22的交替物,并且最初假设记录在扇区DP22中的数据DA(2)记录到作为交替物的扇区DN32中。同样,选择在连续区域T62内排第二的扇区DN42,作为扇区DP32的交替物,并且最初假设记录在扇区DP32中的数据DB(2)记录到作为交替物的扇区DN42中。
进一步,由于在扇区DP22之后的扇区DP23和在扇区DP32之后的扇区DP33也是缺陷区域,所以执行交替处理。结果,如箭头Q105所示,最初假设记录在扇区DP23中的数据DA(3)记录到作为在连续区域T61中的交替物的扇区DN33中,并且最初假设记录在扇区DP33中的数据DB(3)记录到作为在连续区域T62中的交替物的扇区DN43中。
在此处,在用户数据记录到在为预定通道而保存的备用区域内保持的整个区域中并且全部消耗该区域的情况下,在随后发现新缺陷时,为预定通道保存在备用区域中的新区域,并且该区域用作交替物。
进一步,在完成在预定通道内的单个缺陷区域或连续缺陷区域的交替处理时,释放为预定通道保存的连续备用区域,然后,备用区域可以保持可用于任何其他通道。
在通过这种方式针对交替处理为每个通道保存专用连续区域时,在用户数据区域内的连续缺陷区域通过在备用区域内的连续区域来交替(替换,alternate)。
通过这种配置,甚至在多于一个通道内基本上同时执行交替处理时,由于连续缺陷可以交替到连续交替区域中,所以这提高了数据传送速度,并且防止DFL扩展。
在此处,在图21中,解释了仿真区不用于用户数据区域中的情况;然而,甚至在仿真区用于用户数据区域等中的情况下,同样,通过保存每个通道的连续交替区域,在仿真区内的连续缺陷区域可以交替到连续交替区域中。这提高了数据传送速度,并且防止DFL扩展。
<关于备用区域>
进一步,根据本技术,解释了在执行交替处理时为执行交替处理的通道保存在备用区域内的连续区域;然而,可以任意地确定可以同时为各通道保存多少区域或者在备用区域内记录用户数据的方式。
例如,在作为记录/再现目标的光盘是具有正面和背面这两个面(作为DS0面和DS1面)的一次性写入光盘并且具有分别在岸和沟上设置记录区域的岸/沟格式的情况下,如图22所示,可以使用备用区域。
在此处,在该实例中,关于光盘,在包括同时在每侧的两个通道的总共4个通道中,对光盘执行访问,并且各个通道分别称为通道A到D。进一步,假设由通道A和B执行到光盘的DS0面的写入和读取,并且由通道C和D执行到光盘的DS1面的写入和读取。
在图22中,由箭头W91到W94表示的记录区域表示分别设置在DS0面上的岸、在DS0面上的沟、在DS1面上的岸以及在DS1面上的沟的记录区域,并且在那些记录区域内,设置用户数据区域和备用区域。在此处,在该实例中,未示出诸如内部区等的部分区域。
在此处,在相同的记录层内设置由箭头W91表示的在DS0面上的岸以及由箭头W92表示在DS0面上的沟,同样,在相同的记录层内设置由箭头W93表示的在DS1面上的岸以及由箭头W94表示在DS1面上的沟。
进一步,在各个记录区域内的每个方形表示一个物理扇区,并且在每个物理扇区中的数字表示PSN。在这种情况下,将连续的PSN分别分配给在每个记录层内的岸和沟的记录区域。
进一步,在该实例中,仿真区设置在用户数据区域内,并且仿真区不设置在备用区域内。然后,设置给在DS0面上的岸的仿真区Z0、设置给在DS0面上的沟的仿真区Z1、设置给在DS1面上的岸的仿真区Z0以及设置给在DS1面上的沟的仿真区Z1设置为一个仿真区组。
在这种情况下,例如,通道A到D的每个光学拾取头分别将用户数据写入在DS0面上的仿真区Z0、在DS0面上的仿真区Z1、在DS1面上的仿真区Z0以及在DS1面上的仿真区Z1中并且从中读取用户数据。
进一步,在该实例中,在每个记录区域内设置备用区域AE11到AE14,并且在执行交替处理时,可以同时保存最多四个备用区域。在此处,在备用区域AE11到AE14内的阴影区域是已经用作交替物的区域,这些区域是记录用户数据的区域。因此,在图中的阴影区域的右侧端的位置是可以接下来开始记录的位置,该位置是下一个可写入地址(NWA)的位置。
进一步,例如,在预定通道中执行交替处理时,在备用区域AE11到AE14之中的具有最少量的已记录用户数据并且目前不保存的备用区域被保持为预定通道使用的备用区域(交替区域)。
更具体而言,例如,在图22中,具有最少量的记录的用户数据的备用区域(即,具有最小NWA的备用区域)是备用区域AE14。进一步,具有第二最少量的记录的用户数据的备用区域是备用区域AE13。
此时,在通道A到D中同时执行将用户数据记录到每个仿真区中。在这种条件下,还未保存任何备用区域。然后,假设用户数据的记录继续,并且在通道A中发生交替处理。
在这种情况下,在交替处理中保存具有最小NWA的备用区域AE14,作为用于通道A内的备用区域。然后,为在通道A内用户数据的记录失败的仿真区内的区域(缺陷区域)定义备用区域AE14内的交替区域,并且通道A将用户数据记录到交替区域中。在这种情况下,交替区域是以NWA开始的区域。
在通过这种方式为通道A保存备用区域AE14的条件下,除了通道A以外的其他通道不能将备用区域AE14内的区域用作交替区域。
进一步,在保存备用区域AE14时,即,在交替处理中将用户数据写入备用区域AE14时,假设在通道B中发生交替处理。在这种情况下,在目前未保存的备用区域AE11到AE13之中,为通道B保存具有最小NWA的备用区域AE13,并且通道B将用户数据记录到备用区域AE13中作为交替物的区域中。
然后,在通道A结束交替处理时,释放为通道A保存的备用区域AE14,同样,在通道B结束交替处理时,释放为通道B保存的备用区域AE13。
在通过这种方式保存备用区域时,可以由交替处理在相同的备用区域内记录分配给不同通道的用户数据,也就是最初假设记录在不同的记录层或仿真区内的用户数据。
进一步,例如,在由预定通道保存备用区域,并且执行交替处理,并且在备用区域内不再具有空白区域(不记录数据的区域)时,为预定通道保存新的备用区域。在这种情况下,虽然释放了已保存的备用区域,但是留下了一些可记录的区域,并且随后,用户数据不能记录到备用区域中。
在此处,在图22示出的实例中,例如,在8个通道内同时执行记录的情况下,在多于4个通道内同时执行交替处理时,可以具有必须停滞直到释放一个备用区域的通道。进一步,在图22中,可以在备用区域内设置仿真区。
进一步,例如,在作为记录/再现目标的光盘是具有正面和背面这两个表面(DS0面和DS1面)的光盘并且具有设置在岸或沟中的一个的记录区域的情况下,如图23所示,可以使用备用区域。
在图23中,由箭头W101和W102表示的记录区域表示分别设置在DS0面和DS1面上的记录区域,并且在记录区域内,设置用户数据区域和备用区域。在此处,在该实例中,未示出部分区域(例如,内部区等)。进一步,在各个记录区域内的每个方形表示一个物理扇区,并且在每个物理扇区内的序号表示PSN。
在此处,与在图22中的情况一样,关于光盘,假设在包括每侧的两个通道的总共4个通道中,对光盘执行访问。具体而言,由通道A和B执行到光盘的DS0面的写入和读取,并且由通道C和D执行到光盘的DS1面的写入和读取。
在图23中,仿真区设置在用户数据区域内,并且仿真区不设置在备用区域内。然后,一个仿真区组由四个仿真区构成,包括在DS0面上设置的记录区域内的仿真区Z0和Z1以及在DS1面上设置的记录区域内的仿真区Z0和Z1。
在这种情况下,例如,通过通道A到D的光学拾取头分别将用户数据写入在DS0面上的仿真区Z0、在DS0面上的仿真区Z1、在DS1面上的仿真区Z0以及在DS1面上的仿真区Z1中并且从中读取用户数据。
进一步,在该实例中,在DS0面上的整个备用区域分成两个,并且形成为备用区域AE21和AE22,同样,在DS1面上的整个备用区域分成两个,并且形成为备用区域AE23和AE24。
在此处,假设保存或释放备用区域AE21到AE24,与图22的上述情况一样。
在这种情况下,例如,假设在通道A到D中同时开始将用户数据记录到各个仿真区中,并且在通道A中发生交替处理。
因此,保存在备用区域AE21到AE24之中的具有最少量的记录的用户数据的备用区域,并且由通道A将用户数据记录到作为在备用区域内的交替物的区域中。在此处,例如,假设为通道A保存备用区域AE21。
进一步,在保存备用区域AE21的情况下,在通道B中发生交替处理时,保存在备用区域AE22到AE24的剩余备用区域之中的具有最少量的记录的用户数据的备用区域,并且由通道B记录用户数据。
而且,在该实例中,与图22的情况一样,在为预定通道保存备用区域并且执行交替处理的情况下,在备用区域内不再具有空白区域时,为预定通道保存新的空间区域。
进一步,例如,在光盘是具有岸/沟格式的一次性写入光盘的情况下,与图22的情况一样,如图24所示,可以使用备用区域。
而且,在该实例中,与图22的情况一样,假设在包括通道A到D的总共4个通道内执行对光盘的访问。
在图24中,由箭头W111到W114表示的记录区域表示分别设置在DS0面上的岸、在DS0面上的沟、在DS1面上的岸以及在DS1面上的沟的记录区域。在此处,在相应记录区域内的阴影区域表示作为交替主体的区域的区域或者用作交替物的区域。
进一步,在该实例中,给设置在DS0面上的岸的记录区域提供备用区域AE31,给设置在DS1面上的岸的记录区域提供备用区域AE32,设置到沟的记录区域不用作备用区域。具体而言,备用区域AE31和AE32分别是由具有连续的PSN的物理扇区构成的区域。
因此,在该实例中,在交替处理期间,可以同时保存最多2个备用区域。在保存备用区域时,保存具有最少量的记录的用户数据(最小NWA)并且目前未保存的备用区域。
例如,假设在不保存任何备用区域并且具有最小NWA的备用区域是备用区域AE31的条件下,在通道A到D中同时将用户数据记录到各个仿真区中。
在这种情况下,在通道A中发生交替处理时,为通道A保存备用区域AE31,将用户数据记录到设置为备用区域AE31的交替物的区域中。随后,在通道A的交替处理结束时,释放为通道A保存的备用区域AE31。
进一步,在备用区域AE31和AE32被保存的条件下,在预定通道内最新发生交替处理时,预定通道保持为停滞(stand)直到释放一个备用区域。
在通过这种方式保存备用区域时,可以由交替处理在相同的备用区域内记录分配给不同通道的用户数据,即,最初假设记录到不同记录层或仿真区中的用户数据。
进一步,例如,在预定通道保存备用区域并且交替处理执行中时,在备用区域内不再具有更多空白区域时,为预定通道保存新备用区域。
在此处,在图24的实例中,解释了优先保存在这两个备用区域之中具有最小NWA的备用区域;然而,可以优先保存与交替处理所在的记录层放置在同一记录层的备用区域。这是因为在要记录或再现的记录层改变时,通常需要相应地重新调整伺服系统,并且如果交替主体和交替物在相同的记录层内,则更有效。
进一步,可以以预定块体为单位保存备用区域。例如,在光盘是具有与图22的情况一样的岸/沟格式的一次性写入光盘的情况下,可以如图25所示地使用备用区域。
而且,在这种情况下,与图22的情况一样,包括通道A到D的总共4个通道执行对光盘的访问。进一步,通道A和B的光学拾取头提供给磁头(head)A,并且通道C和D的光学拾取头提供给磁头B。
在图25中,由箭头W121到W124表示的记录区域表示分别设置到DS0面上的岸、DS0面上的沟、DS1面上的岸以及DS1面上的沟的记录区域。在此处,在该实例中,未示出部分区域,例如,内部区等,并且在各个记录区域内的阴影区域表示作为交替主体的区域或者用作交替物的区域。
进一步,在该实例中,给设置在DS0面上的岸的记录区域提供备用区域AE41,给设置在DS1面上的岸的记录区域提供备用区域AE42,设置到沟的记录区域不用作备用区域。尤其地,备用区域AE41和AE42分别是由具有连续的PSN的物理扇区构成的区域。
进一步,通过分成具有预定尺寸的块体来使用备用区域AE41和AE42。在该实例中,备用区域AE41分成四个块体BL11到BL14,并且备用区域AE42分成四个块体BL15到BL18。然后,为各个通道保存相应的块体。
注意,仅仅分配给相同磁头的数据可以记录到块体中。例如,假设通道A使用块体BL11,并且在交替处理中,将用户数据记录到块体BL11中。在这种情况下,在作为未使用的记录区域的空白区域是在块体BL11中时,仅仅由通道A或B可以在交替处理中将用户数据写入空白区域中,并且通道C或D不能写入该用户数据。
在用户数据写入用户数据区域中时,例如,具有小NWA的4个块体用作可以进行保存的可保存块体。在预定通道内发生交替处理时,在那些可保存块体之中选择预定通道可以使用(可以写入)并且目前未保存的块体。
进一步,保存在所选块体之中的具有最小NWA的块体,作为预定通道在交替处理中使用的交替区域。然后,通过交替处理在预定通道中将用户数据记录到保存的块体中,并且在交替处理结束时,释放保存了的块体。
在图25示出的实例中,具有未使用的记录区域,并且具有小NWA的块体BL13、BL14、BL16以及BL17是可保存块体。在此处,例如,在块体BL14和BL17中,记录通过通道A或B提供给磁头A写入的用户数据。因此,块体BL14和BL17是可以仅仅由通道A或B用作备用区域的块体。
在此处,例如,在块体由预定通道保存并且交替处理执行中时,在块体内没有空白区域时,为预定通道保存新块体。进一步,例如,在8个通道内同时执行记录并且在预定通道内发生交替处理时没有可保存块体的情况下,保持预定通道停滞,直到释放一个块体。
进一步,在图25中,解释了仅仅提供给相同磁头的通道可以使用一个块体,然而,如图26所示,所有通道可以将用户数据写入一个块体中。
在此处,在图26中,相同的附图标记应用于与在图25中情况中的部分对应的部分中,并且根据需要省略其解释。进一步,在各个记录区域内的阴影区域表示作为交替主体的区域或者用作交替物的区域。
在图26示出的实例中,在用户数据写入用户数据区域中时,例如,具有小NWA的块体是可保存块体。然后,在预定通道内发生交替处理时,为预定通道保存在可保存块体之中的具有最小NWA并且目前未保存的块体,并且通过交替处理将用户数据记录到保存的块体中。进一步,在交替处理结束时,释放保存了的块体。
在图26示出的实例中,具有未使用的记录区域,并且具有小NWA的块体BL13、BL14、BL17以及BL18是可保存块体。
在此处,在可保存块体之中,具有最小NWA的块体是块体BL17。因此,例如,在块体BL13、BL14、BL17以及BL18为可保存的条件下发生交替处理时,块体BL17作为交替区域被保存并且使用。此时,虽然通道C写入的用户数据已经记录在块体BL17内,但是任何其他通道可以使用在块体BL17内的空白区域。
在此处,例如,在为预定通道保存块体并且执行交替处理的同时,在块体内没有空白区域时,为预定通道保存新块体。
进一步,例如,在8个通道等内同时执行记录时,可以针对同时执行记录的通道的数量准备可保存块体,或者可保存块体的数量可以比同时执行记录的通道的数量更少。在可保存块体的数量比同时执行记录的通道的数量更少的情况下,在发生交替处理但是所有块体被保存时,可以保持通道停滞直到释放一个块体。
<记录/再现系统的配置实例>
接下来,将描述应用本技术的记录/再现系统的特定实施方式。例如,如图27所示,配置应用本技术的记录/再现系统。
在图27示出的记录/再现系统包括主计算机11、记录/再现装置12以及光盘13。
主计算机11接收例如管理员等的操作,与记录/再现装置12交换各种信息或数据,并且指示记录/再现装置12对光盘13记录或者再现用户数据。例如,主计算机11指示记录/再现装置12每个区域的尺寸或条带长度等,例如,扩展管理区域、备用区域、仿真区等。
根据主计算机11的指令,记录/再现装置12将用户数据记录到光盘13中,该光盘插入记录/再现装置12中或者将从光盘13中读取的各种数据提供给主计算机11。
例如,光盘13是具有正面和背面这两个面并且具有岸/沟格式的一次性写入光盘等,并且如上所述,在光盘13的记录区域中,虚拟设置由记录/再现装置12管理的仿真区或仿真区组。
<光盘的配置实例>
在此处,描述光盘13的特定配置实例。例如,光盘13包括多个记录层,如图28所示。
在图28中,在图中的左边表示光盘13的最内周侧,并且在图中的右边表示在光盘13中的最外周侧。进一步,光盘13具有DS0面和DS1面,并且可以同时将数据写入那些表面中并且从那些表面中读取数据。
光盘13的DS0面包括L0层、L1层以及L2层,同样,DS1面包括L0层、L1层以及L2层。在图28的实例中,按照在图中从上到下的顺序,具有在DS1面上的L2层、在DS1面上的L1层、在DS1面上的L0层、在DS0面上的L0层、在DS0面上的L1层、以及在DS0面上的L2层。
注意,在后文中,当没有特别需要区分各层是DS0面还是DS1面时,其也简称为层。因此,例如,在提及L1层时,表示在DS0面上的L1层、在DS1面上的L1层、或者在DS0面和DS1面上的L1层。
在DS0面和DS1面上的每层主要包括用户数据区域、备用区域以及光盘管理区域(DMA)或DMA镜像区域。在此处,备用区域以及DMA区域和DMA镜像区域的一部分是管理员等可以任意设置并且不必需提供的可变区域。
用户数据区域是记录作为用户规定的数据的用户数据的区域,并且将根据用户的指令将待记录的用户数据记录到在用户数据区域内具有连续LSN的区域中。在图28中,由字母“用户数据区域(User Data Area)”表示的区域是用户数据区域。
进一步,备用区域是在执行交替处理时记录用户数据的区域,即,用作用户数据区域的交替物的交替区域。
在图28中,DS0面的“备用00”到“备用05”和DS1面的“备用10”到“备用15”分别表示备用区域,并且最多这12个区域可以设置为在光盘13上的备用区域。
在光盘13上,在用户数据区域中检测连续缺陷时,连续缺陷区域可以通过交替处理交替到连续备用区域中。
在此处,在光盘13格式化时,基于在管理区域或扩展管理区域内记录的内部备用区域尺寸或外部备用区域尺寸的值,例如来定义备用区域的尺寸。
例如,在内部区侧的备用00、备用03、备用04、备用10、备用13以及备用14的尺寸由内部备用区域尺寸限定。进一步,在外部区侧的备用01、备用02、备用05、备用11、备用12以及备用15的尺寸由外部备用区域尺寸限定。
进一步,提供给光盘13的DMA区域和DMA镜像区域是管理区域或扩展管理区域,在这些区域内记录用于管理用户数据区域或备用区域的管理信息。将DMA区域提供给在DS0面上的每层,并且将DMA镜像区域提供给在DS1面上的每层。
在图28的实例中,DS0面的“DMA0”到“DMA7”分别表示DMA区域,并且DS1面的“DMA-镜像0”到“DMA-镜像7”分别表示DMA镜像区域。
具体而言,提供给在DS0面上的L1层的内部区的DMA0、提供给在DS0面上的L2层的内部区的DMA1、提供给在DS1面上的L1层的内部区的DMA-镜像0以及提供给在DS1面上的L2层的内部区的DMA-镜像1是提前限定的固定管理区域。
另一方面,在L0层的最内周侧提供的DMA2和DMA-镜像2以及在L0层的最外周侧提供的DMA3和DMA-镜像3放在DS0面和DS1面上,作为用户可以设置的扩展管理区域。
同样,在DS0面和DS1面上,具有在L1层的最外周侧提供的DMA4和DMA-镜像4、在L1层的最内周侧提供的DMA5和DMA-镜像5、在L2层的最内周侧提供的DMA6和DMA-镜像6、以及在L2层的最外周侧提供的DMA7和DMA-镜像7,作为用户可以设置的扩展管理区域。
每个DMA区域是在DS0面上提供的并且用于执行交替处理的区域,并且在DS0面上的DMA区域管理交替信息,该信息是与整个光盘13(即,DS0面和DS1面)的交替处理(更具体而言上述DFL)相关的信息。进一步,每个DMA区域记录仿真区管理信息,用于规定仿真区或仿真区组,其虚拟设置为构成数据区的用户数据区域、DMA区域、备用区域等。记录在DMA区域内的信息也记录到在DS1面上的DMA镜像区域中,使得信息被复制。
进一步,在DMA区域之中的DMA0和DMA1被设置为固定尺寸。另一方面,在光盘13格式化时,可以基于设置限定除了DMA0和DMA1以外的DMA区域的尺寸。换言之,DMA2到DMA7的尺寸可变。
在这种情况下,在光盘13格式化时,基于在管理区域或扩展管理区域内记录的内部DMA/DMA-镜像区域尺寸或外部DMA/DMA-镜像区域尺寸的值,限定DMA区域的尺寸。
例如,在内部区侧的DMA2、DMA5以及DMA6的尺寸由内部DMA/DMA-镜像区域尺寸限定。进一步,在外部区侧的DMA3、DMA4以及DMA7的尺寸由外部DMA/DMA-镜像区域尺寸限定。
与DMA区域一样,每个DMA镜像区域是在DS1面上提供的并且用于执行交替处理的区域,并且在DS1面上的DMA镜像区域管理与整个光盘13(即,DS0面和DS1面)的交替处理相关的交替信息。进一步,在每个DMA镜像区域中,也记录仿真区管理信息。记录在DMA镜像区域内的信息是与记录在DS0面上的DMA区域内的信息相同的信息,使得信息被复制。
在DMA镜像区域之中的DMA-镜像0和DMA-镜像1的尺寸是固定的。进一步,在光盘13格式化时,可以基于设置限定除了DMA-镜像0和DMA-镜像1以外的DMA镜像区域的尺寸。
在这种情况下,在光盘13格式化时,基于在管理区域内记录的内部DMA/DMA-镜像区域尺寸或外部DMA/DMA-镜像区域尺寸的值,限定DMA镜像区域的尺寸。
例如,在内部区侧的DMA-镜像2、DMA-镜像5以及DMA-镜像6的尺寸由内部DMA/DMA-镜像区域尺寸限定。进一步,在外部区侧的DMA-镜像3、DMA-镜像4以及DMA-镜像7的尺寸由外部DMA/DMA-镜像区域尺寸限定。
进一步,在光盘13上,提供未示出的DMA锚定区域。在DMA锚定区域中,在DMA区域和DMA镜像区域内发生交替处理时,记录DMA区域和DMA镜像区域的分割信息。换言之,每当因在DMA区域或DMA镜像区域内的缺陷等而发生分割(交替处理)时,记录与分割相关的信息。
在此处,在该实例中,在图28示出的配置描述为光盘13的配置;然而,在本技术应用于光盘中时,只要将连续PSN分配给在光盘中的连续记录区域,就可以使用任何配置。换言之,光盘13的层配置或在每个记录层内的区域配置可以成任何配置。
例如,在图28示出的实例中,在DS0面上提供DMA区域,并且在DS1面上提供DMA镜像区域;然而,可以在DS0面或DS1面中的一个上提供DMA区域和DMA镜像区域。进一步,DMA镜像区域不提供给光盘13,并且仅仅可以提供DMA区域。在这种情况下,例如,在在DS0面和DS1面这两者或者其中的一个上提供DMA区域,并且在一些DMA区域中记录相同的信息,以复制该信息。
<记录/再现装置的配置实例>
接下来,描述在图27示出的记录/再现装置12的更详细的配置实例。记录/再现装置12是将数据写入光盘13中和从光盘中读取数据的光盘驱动器,并且记录/再现装置12具有例如如图29所示的配置。
记录/再现装置12包括主机接口(I/F)21、控制器22、存储器23、记录/再现处理单元24-1-1到24-2-2、磁头25-1和25-2以及主轴马达26。
主机I/F 21与主计算机11通信,以交换数据或命令。例如,主机I/F21将从主计算机11中提供的各种命令和数据提供给控制器22。进一步,主机I/F 21将从控制器22中提供的各种信息或者从光盘13中读取的各种信息提供给主计算机11。
控制器22控制记录/再现装置12的整个操作。例如,控制器22是由一个控制芯片构成的驱动控制器。
例如,控制器22将从主机I/F 21中提供的数据提供给记录/再现处理单元24-1-1到24-2-2,并且将从记录/再现处理单元24-1-1到24-2-2中提供的数据提供给主机I/F 21。
进一步,例如,控制器22基于从主机I/F 21中提供的命令,控制记录/再现处理单元24-1-1到24-2-2和主轴马达26,以将诸如用户数据等数据记录到光盘13中或者从光盘13中读取诸如用户数据等数据。
控制器22包括管理单元41、交替处理单元42以及交替管理单元43。
管理单元41管理光盘13的每个区域。进一步,在光盘13上的用户数据区域、DMA区域、DMA镜像区域等内具有缺陷等并且不能记录数据时,交替处理单元42执行交替处理。交替管理单元43选择或者保存在交替处理中用作交替物的区域。
存储器23将各种数据提供给控制器22并且从控制器22中接收各种数据,并且用作控制器22的工作区域。例如,从主计算机11中提供的并且记录到光盘13中的数据也暂时记录在存储器23内。
记录/再现处理单元24-1-1到24-2-2根据控制器22的控制,控制光学拾取头51-1-1到51-2-2,并且执行信号处理或伺服操作,用于记录或再现数据。换言之,记录/再现处理单元24-1-1到24-2-2控制到光盘13的记录以及在光盘13内记录的数据的再现。
例如,记录/再现处理单元24-1-1和24-1-2给提供给磁头25-1的光学拾取头51-1-1和51-1-2提供从控制器22中提供的数据,并且将该数据记录到光盘13中。
进一步,例如,记录/再现处理单元24-1-1和24-1-2给控制器22提供从光盘13中读取的并且从光学拾取头51-1-1和51-1-2中提供的数据。
在此处,在下面,在不特别需要区分记录/再现处理单元24-1-1和24-1-2时,它们也简称为记录/再现处理单元24-1。进一步,在下面,在不特别需要区分光学拾取头51-1-1和51-1-2时,它们也简称为光学拾取头51-1。
进一步,例如,记录/再现处理单元24-2-1和24-2-2给设置给磁头25-2的光学拾取头51-2-1和51-2-2提供从控制器22中提供的数据,以将该数据记录到光盘13中。
进一步,例如,记录/再现处理单元24-2-1和24-2-2给控制器22提供从光盘13中读取的并且从光学拾取头51-2-1和51-2-2中提供的数据。
在此处,在下面,在不特别需要区分记录/再现处理单元24-2-1和24-2-2时,它们也简称为记录/再现处理单元24-2,并且在不特别需要区分记录/再现处理单元24-1和24-2时,它们也简称为记录/再现处理单元24。进一步,在下面,在不特别需要区分光学拾取头51-2-1和51-2-2时,它们也简称为光学拾取头51-2,并且在不特别需要区分光学拾取头51-1和51-2时,它们也简称为光学拾取头51。进一步,在下面,在不特别需要区分磁头25-1和25-2时,它们也简称为磁头25。
将光学拾取头51-1-1和51-1-2设置给磁头25-1,并且根据记录/再现处理单元24-1的控制,驱动磁头25-1。
根据记录/再现处理单元24-1的控制,光学拾取头51-1对光盘13发射与从记录/再现处理单元24-1中供应的数据对应的激光,并且记录数据。进一步,根据记录/再现处理单元24-1的控制,光学拾取头51-1对光盘13发射激光,接收激光的反射光,并且将通过接收光所获得的数据提供给记录/再现处理单元24-1,作为读取的数据。
同样,给磁头25-2提供光学拾取头51-2-1和51-2-2,并且根据记录/再现处理单元24-2的控制,驱动磁头25-2。
根据记录/再现处理单元24-2的控制,光学拾取头51-2对光盘13发射与从记录/再现处理单元24-2中提供的数据对应的激光,以记录数据。进一步,根据记录/再现处理单元24-2的控制,光学拾取头51-2对光盘13发射激光,接收激光的反射光,并且将通过接收光所获得的数据提供给记录/再现处理单元24-2,作为读取的数据。
在此处,例如,在光盘13中,光学拾取头51-1在其上记录或再现数据的面是上述DS1面,并且光学拾取头51-2在其上记录或再现数据的表是上述DS0面。
通过这种方式,在记录/再现装置12中,这四个光学拾取头51中的每个分别用作一个记录/再现通道,并且这四个通道可以同时执行记录和再现数据。
通过根据控制器22的控制来旋转驱动主轴,主轴马达26旋转附接至主轴的光盘13。
<仿真区设置处理的说明>
接下来,描述记录/再现装置12的特定操作。
例如,在光盘13置于(插入)记录/再现装置12中并且指示将光盘13格式化时,记录/再现装置12将光盘13格式化,此时,也执行仿真区设置处理,以同时设置仿真区。在此处,可以在任何时间执行仿真区设置处理,例如,在光盘13发货之前或之后。
在下面,参考图30的流程图,描述记录/再现装置12的仿真区设置处理。
在步骤S11中,管理单元41控制记录/再现处理单元24从光盘13中读取管理信息。
换言之,管理单元41指示记录/再现处理单元24读取管理信息,并且记录/再现处理单元24根据管理单元41的指令控制光学拾取头51,以从光盘13的DMA区域或DMA镜像区域中读取管理信息。
根据记录/再现处理单元24的控制,光学拾取头51将激光照射在光盘13上,接收来自光盘13的反射光,并且经由记录/再现处理单元24将通过光电转换所获得的管理信息提供给管理单元41。
在步骤S12中,管理单元41接收用于设置仿真区的信息的输入。
例如,管理员根据需要操作主计算机11并且规定在光盘13的记录区域内设置仿真区的目标区域、仿真区的尺寸、构成仿真区组的仿真区的数量、以及在仿真区组中分配LSN的方式。然后,主计算机11通过主机I/F21将对应于管理员的操作的信号提供给控制器22的管理单元41。
在步骤S13中,管理单元41基于在步骤S12的处理中从主计算机11中提供的信息,生成仿真区管理信息。
例如,管理单元41生成用于规定在光盘13的记录区域内设置仿真区的目标区域的目标区域信息、用于规定仿真区的尺寸的仿真区尺寸信息、用于规定构成仿真区组的仿真区的数量的仿真区数量信息、以及用于规定在仿真区组中分配LSN的方式的地址顺序信息。然后,管理单元41将包括目标区域信息、仿真区尺寸信息、仿真区数量信息以及地址顺序信息的信息设置为仿真区管理信息。
通过仿真区管理信息,可以限定和管理仿真区组的配置以及在仿真区组内的每个区域的LSN,这是对扇区的访问顺序。
在此处,可以提前确定构成仿真区组的仿真区的数量以及在仿真区组中分配LSN的方式。在这种情况下,可以使仿真区管理信息不包括仿真区数量信息和地址顺序信息。进一步,作为仿真区尺寸信息的代替物,用于规定仿真区组的尺寸的信息可以包含在仿真区管理信息内。
在下面,在提前确定构成仿真区组的仿真区的数量以及在仿真区组中分配LSN的方式的前提下给出说明。
更具体而言,例如,管理单元41将从管理信息的内部备用区域尺寸、外部备用区域尺寸、内部DMA/DMA-镜像区域尺寸以及外部DMA/DMA-镜像区域尺寸中需要的信息设置为目标区域信息。
在此处,内部备用区域尺寸和外部备用区域尺寸是表示分别在内部区侧和外部区侧的备用区域的尺寸的信息。进一步,内部DMA/DMA-镜像区域尺寸和外部DMA/DMA-镜像区域尺寸是是表示分别在内部区侧和外部区侧的DMA区域或DMA镜像区域的尺寸的信息。
因此,基于这些信息,可以规定在数据区内提供的每个区域(例如,DMA区域、DMA镜像区域、备用区域以及用户数据区域)的尺寸和位置。
例如,在备用区域和用户数据区域是用于设置仿真区的目标区域的情况下,可以基于内部DMA/DMA-镜像区域尺寸和外部DMA/DMA-镜像区域尺寸,规定从在内部区侧的备用区域的开头位置到在外部区侧的备用区域的结束位置的区域。
进一步,例如,在仅仅用户数据区域是用于设置仿真区的目标区域的情况下,可以基于内部备用区域尺寸、外部备用区域尺寸、内部DMA/DMA-镜像区域尺寸和外部DMA/DMA-镜像区域尺寸,规定用户数据区域的位置和尺寸。
在此处,扩展管理区域(DMA区域和DMA镜像区域)的尺寸、备用区域的尺寸以及用户数据区域的尺寸分别设置为仿真区尺寸的整数倍。
进一步,管理单元41基于例如管理员规定的仿真区的尺寸,生成仿真区尺寸信息。
进一步,例如,如图22所示,限定构成仿真区组的仿真区的数量。
在图22示出的实例应用于在图28示出的光盘13中时,构成仿真区组的仿真区的数量设置为4。进一步,包括在DS0面上的在Lk层(在此处,k=0、1或2)内的两个仿真区以及在DS1面上的在Lk层内的两个仿真区的总共4个仿真区设置为一个仿真区组。进一步,在仿真区组中,在各个仿真区之间,例如,将LSN分配给构成每个仿真区的扇区,使得按照与在图8示出的RUB访问序号的顺序相似的顺序访问各个RUB,并且在每个RUB中按照PSN的顺序,访问各个扇区。
可以基于如上所述生成的包括目标区域信息和仿真区尺寸信息的仿真区管理信息以及提前规定的在仿真区组内的仿真区的数量和在仿真区组内的LSN分配,规定仿真区组的配置或每个区域的LSN。换言之,设置仿真区组和仿真区。
在步骤S14中,管理单元41将仿真区管理信息提供给记录/再现处理单元24,并且控制记录/再现处理单元24,以将仿真区管理信息记录到光盘13的管理区域或扩展管理区域中。记录/再现处理单元24根据从管理单元41中提供的仿真区管理信息,控制光学拾取头51,以将仿真区管理信息记录到光盘13的作为DMA区域和DMA镜像区域的管理区域或扩展管理区域中。
在记录仿真区管理信息时,仿真区设置处理结束。
如上所述,记录/再现装置12在光盘13的记录区域内设置仿真区和仿真区组,并且将用于规定仿真区组和构成仿真区组的仿真区的仿真区管理信息记录到光盘13中。
这样做,因为假设多个仿真区是一组并且访问顺序可以以预定单位在仿真区之间交错。结果,可以提高数据传送速度。换言之,与要记录或再现的用户数据的尺寸无关,在记录或再现的情况下,将数据基本上均匀地分配给全部多个通道,并且,除了在仿真区之间的边界部分以外,可以在每个通道内的连续区域内访问数据。
此外,由于使构成数据区的每个区域的尺寸成为仿真区尺寸的整数倍,所以可以更容易管理仿真区。
<记录处理的说明>
在仿真区管理信息记录到光盘13中时,可以在记录/再现装置12中同时使用4个通道,来记录用户数据。在下面,参考图31的流程图,描述记录/再现装置12的记录处理。
在光盘13插入记录/再现装置12内的条件下,在每个记录/再现通道内同时执行记录处理,并且主计算机11开始记录用户数据。进一步,在下面,正在聚焦的通道也称为处理目标通道,并且下面参考图31解释的记录处理是处理目标通道的记录处理。
在步骤S41中,管理单元41控制记录/再现处理单元24,以从光盘13中读取仿真区管理信息。
换言之,管理单元41指示记录/再现处理单元24读取仿真区管理信息,并且记录/再现处理单元24根据管理单元41的指令控制光学拾取头51,从光盘13的DMA区域或DMA镜像区域中读取仿真区管理信息。
根据记录/再现处理单元24的控制,光学拾取头51将激光照射在光盘13上,通过接收和光电转换来自光盘13的反射光,读取仿真区管理信息,并且通过记录/再现处理单元24将仿真区管理信息提供给管理单元41。
基于读取的仿真区管理信息,控制器22可以认识到仿真区设置在数据区内的哪个区域、仿真区组的配置以及在PSN与LSN之间的对应关系。在此处,可以在记录处理开始之前,预先读取仿真区管理信息。进一步,作为在步骤S41中的处理,执行在各个记录/再现通道中共有的一个处理。
在步骤S42中,控制器22将经由主机主机I/F 21从主计算机11中提供的具有写入命令的用户数据提供给记录/再现处理单元24,包括记录目的地的PSN,并且将用户数据记录到用户数据区域中。
在这种情况下,控制器22基于LSN划分用户数据,并且根据对在仿真区组内的扇区的访问顺序,将数据分配给每个通道。然后,控制器22提供将被分配给处理目标通道的用户数据的分割部分的数据以及与将要记录数据的LSN对应的PSN给记录/再现处理单元24,其与处理目标通道对应。
基于从控制器22中提供的用户数据以及用户数据的记录目的地的PSN,记录/再现处理单元24控制光学拾取头51,以将用户数据记录到由用户数据区域规定的区域中,该区域是PSN规定的区域。
因此,在逻辑地址空间内具有连续LSN的区域中记录用户数据;然而,在物理地址空间内,根据仿真区的配置以及在仿真区内的每个区域的LSN将数据记录为条带化。
在步骤S43中,控制器22确定是否正确地记录用户数据。
例如,在用户数据记录操作期间发生错误(例如,伺服错误)时,或者在验证用户数据,仅仅在记录之后从光盘13中读取的用户数据与指示记录的用户数据不匹配时,确定是否正确地记录用户数据。
在步骤S43中,在确定正确地记录用户数据时,处理继续进入步骤S48。
另一方面,在步骤S43中确定未正确地记录用户数据时,处理继续进入步骤S44并且执行交替处理。
换言之,在步骤S44中,交替管理单元43在备用区域内为处理目标通道选择交替区域。
例如,如图22所示,假设具有4个备用区域,包括作为交替区域的备用区域AE11到AE14。在这种情况下,交替管理单元43在目前未为另一个通道保存的备用区域AE11到AE14的各备用区域之中选择具有最小NWA的备用区域,作为处理目标通道的交替区域。
在步骤S45中,交替管理单元43保存在步骤S44的处理中选择的交替区域,作为处理目标交替区域。
在步骤S46中,交替处理单元42执行交替处理,并且将不能记录的用户数据记录到在步骤S45的处理中保存的交替区域中。
换言之,交替处理单元42将不能记录的用户数据和保存的交替区域的PSN提供给与处理目标通道对应的记录/再现处理单元24,并且指示记录/再现处理单元24将用户数据记录到交替物中。然后,基于从交替处理单元42中提供的用户数据和交替物的PSN,记录/再现处理单元24控制光学拾取头51,以将用户数据记录到在备用区域内的规定区域中,即,规定的PSN识别的区域。
进一步,在交替处理用于用户数据区域内的单个缺陷区域或连续缺陷区域时,其中,不能够记录用户数据的缺陷区域,并且将用户数据正确地记录到单个交替区域或连续交替区域中,交替管理单元43释放为处理目标通道保存的备用区域。
在步骤S47中,管理单元41响应于交替处理,生成表示交替主体和交替物的DFL条目,并且通过将生成的DFL条目加入DFL中,更新缺陷列表(DFL),然后,该处理继续进入步骤S48。
在步骤S43中确定正确地记录用户数据或者在步骤S47中更新DFL后,控制器22在步骤S48中确定是否结束记录处理。例如,在全部记录了主计算机11指示的用户数据时,确定结束该处理。
在步骤S48中确定不结束该处理时,该处理返回步骤S42,并且重复上述处理。
另一方面,在步骤S48中确定结束该处理时,在步骤S49中,管理单元41生成新管理信息,并且将该信息记录到光盘13的DMA区域或DMA镜像区域中。
例如,响应于用户数据记录或DFL更新,通过对提前从光盘13中读取的管理信息增加修改或者增加新信息,管理单元41更新管理信息。
然后,管理单元41将更新的管理信息提供给记录/再现处理单元24,并且记录/再现处理单元24基于从管理单元41中提供的管理信息,管理光学拾取头51,以将管理信息记录到光盘13的DMA区域或DMA镜像区域中。在此处,作为步骤S49的处理,在每个记录/再现通道中执行共同的处理。
在记录管理信息时,随后,从记录/再现装置12中弹出(移除)光盘13,并且记录处理结束。
如上所述,记录/再现装置12按照特定的访问顺序将用户数据记录到构成仿真区组的每个相应仿真区中。这可以提高条带化效率并且提高数据传送速度。
进一步,在发生交替处理时,通过将备用区域中的连续区域保存为处理目标通道的交替区域,并且记录用户数据,即使在多个通道中同时发生交替处理时,连续缺陷区域也可以简单地交替到连续交替区域中。这防止交替处理分割数据,提高数据传送速度,并且减少了DFL的消耗量。
在此处,即使在将管理信息等记录到管理区域或扩展管理区域中期间发生交替处理时,通过执行与步骤S44到S46的处理相似的处理,以将管理信息记录到交替物中,也可以与用户数据的情况一样提高数据传送速度。
<再现处理的说明>
进一步,在记录/再现装置12中,可以使用4个通道同时再现用户数据。在下面,参考图32的流程图,说明记录/再现装置12的再现处理。
在光盘13插入记录/再现装置12内的条件下,在主计算机11指示再现用户数据时,该再现处理开始。
在步骤S81中,管理单元41控制记录/再现处理单元24,以从光盘13中读取管理信息。
换言之,管理单元41指示记录/再现处理单元24读取管理信息,并且记录/再现处理单元24根据管理单元41的指令控制光学拾取头51,以从光盘13的DMA区域或DMA镜像区域中读取管理信息。
根据记录/再现处理单元24的控制,光学拾取头51向光盘13上发射激光,并且通过记录/再现处理单元24,将通过接收和光电转换来自光盘13的反射光而读取的管理信息提供给管理单元41。
通过这种方式读取管理信息,可以从包含在管理信息内的仿真区管理信息中识别在PSN与LSN之间的对应关系。在此处,在开始再现处理之前,可以提前读取管理信息。
在步骤S82中,控制器22响应于通过主机主机I/F 21从主计算机11中提供的读取命令,从光盘13中读取指示的用户数据。
换言之,控制器22将与读取命令规定的LSN对应的PSN提供给每个记录/再现处理单元24,并且控制记录/再现处理单元24根据仿真区组内的扇区的访问序号,即,根据在LSN与PSN之间的对应关系,从用户数据区域中读取用户数据。
在这种情况下,控制器22给与每个通道对应的记录/再现处理单元24提供要从中读取数据的PSN,使得可以在每个通道内分别读取分配给每个通道的数据。
基于从控制器22中提供的PSN,记录/再现处理单元24控制光学拾取头51,以从规定的PSN识别的区域中读取用户数据。然后,记录/再现处理单元24将读取的用户数据提供给控制器22。通过该配置,在四个通道中同时从构成仿真区组的每个仿真区中读取数据。
进一步,控制器22将从与每个通道对应的记录/再现处理单元24中提供的划分的用户数据重新配置成一条用户数据,并且通过主机I/F 21将将获得的用户数据提供给主计算机11。
在通过这种方式读取用户数据时,再现处理结束。
如上所述,记录/再现装置12按照特定的访问顺序从构成仿真区组的每个仿真区中读取用户数据。这提高了数据传送速度。
在此处,在以上说明中,作为一个实例,描述了将一条数据分成多条数据并且在多于一个通道内同时记录或再现的情况。然而,即使在多于一个通道内同时记录或再现多于一条用户数据(即,多个流)时,通过上述仿真区设置处理、记录处理以及再现处理,也可以提高数据传送速度。
进一步,在上述记录处理中,说明了在4个通道内同时执行记录操作的情况;然而,例如,可以同时执行记录和再现,使得在光学拾取头51-1-2记录数据的同时,光学拾取头51-1-1读取记录的数据。在这种情况下,例如,同时执行记录的通道的数量和同时执行再现的通道的数量可以设置为相同的数量。例如,在磁头25的一个通道内记录的同时,记录的数据可以在其他通道内读取和验证等。
进一步,例如,记录或再现的通道的数量可以是构成仿真区组的仿真区的数量的整数倍。例如,在同时记录或再现的通道的数量是8个通道,并且构成仿真区组的仿真区的数量是4时,通过使用这8个通道,可以同时执行对构成2个仿真区组的8个仿真区的记录和再现。
另一方面,例如,同时记录或再现的通道的数量可以是构成仿真区组的仿真区的数量的约数(除了1以外)。作为这种实例,例如,可以具有同时记录或再现的通道的数量是2个通道并且构成仿真区组的仿真区的数量是4的实例。在这种情况下,例如,通过两个通道,可以对一个仿真区同时执行记录或再现。
在这种情况下,与这两个通道对应的两个光学拾取头51在一个仿真区内同时分别访问不同的区域。在此处,例如,控制器22需要使用存储器23来适当地设置读取的数据或者要记录的数据。
进一步,在一个或多个通道内同时记录和再现数据时,将一个通道分配给两个相邻的仿真区并且对那两个仿真区执行记录和再现数据。在这种情况下,而且,控制器22需要使用存储器23等来适当地排列数据。
进一步,除了在多于一个通道内同时执行记录或再现的情况以外,在单个通道内对多个记录部分执行记录的情况下,本技术也可以提供相似的效果。
在此处,上述系列处理可以由硬件执行或者由软件执行。在这系列处理由软件执行时,例如,构成软件的程序安装到控制器22或记录/再现处理单元24的未示出的非易失性存储器中。
在这种情况下,例如,上述系列处理由控制器22执行,或者记录/再现处理单元24执行在未示出的存储器内记录的程序。
在此处,由控制器22或者记录/再现处理单元24执行的程序可以是根据在本说明书中描述的顺序按照时间顺序执行处理的程序,或者可以是在发送请求时并行或者在必要时执行处理的程序。
进一步,本技术的实施方式不限于上述实施方式,并且在本技术的范围内,可以进行各种变化。
进一步,在以上流程图中说明的每个步骤可以由一个装置执行或者可以由多个装置共享和执行。
进一步,在一个步骤包括不止一个处理时,包含在该步骤内的多个处理可以由一个装置执行或者可以由多个装置共享和执行。
进一步,在本说明书中描述的效果可以仅仅是实例,并且可以具有其他效果。
进一步,本技术可以具有以下配置。
(1)一种记录介质,其中,
将连续记录区域分成具有预定尺寸的多个仿真区,并且
对所述仿真区的各个区域设定地址,使得多个仿真区的集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错。
(2)根据(1)所述的记录介质,其中,所述地址是逻辑地址,并且连续物理地址被设定给所述记录区域内的连续区域。
(3)根据(1)或(2)所述的记录介质,其中,作为在仿真区内的最小记录或再现单位的块体包括作为逻辑访问的最小单位的多个扇区,并且所述连续地址被设定给所述块体内的连续扇区。
(4)根据(1)到(3)中任一项所述的记录介质,其中,所述记录介质记录用于规定将被设置为仿真区的区域的信息、用于规定仿真区的尺寸的信息、用于规定构成仿真区组的仿真区的数量的信息、以及用于规定在构成仿真区组的仿真区中的每个区域的地址的信息中的至少一个,作为管理信息。
(5)根据(1)到(4)中任一项所述的记录介质,其中,所述记录介质是光盘。
(6)根据(5)所述的记录介质,其中,所述光盘具有两个面,并且在每个面上,设置包括记录区域的一个或多个记录层。
(7)根据(1)到(6)中任一项所述的记录介质,其中,所述记录区域包括用于记录用户数据的用户数据区域以及与所述用户数据区域不同的并且其尺寸可变的可变区域。
(8)根据(7)所述的记录介质,其中,所述可变区域是用于记录管理信息以管理记录区域的扩展管理区域以及用作缺陷区域的交替物的交替区域中的至少一个区域。
(9)根据(7)或(8)所述的记录介质,其中,所述可变区域的尺寸是所述仿真区的尺寸的整数倍。
(10)一种信息处理装置,包括:
多个访问处理单元,其被配置成通过对记录介质执行访问控制来记录或再现数据,其中,将连续记录区域分成具有预定尺寸的多个仿真区,并且设置所述仿真区的各个区域的地址,使得多个仿真区的集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错;以及
控制单元,其被配置成控制所述多个访问处理单元,使得所述多个访问处理单元根据控制同时执行对所述记录介质的访问。
(11)根据(10)所述的信息处理装置,其中,所述地址是逻辑地址,并且连续物理地址被设定给在所述记录区域内的连续区域。
(12)根据(10)或(11)所述的信息处理装置,其中,作为在仿真区内的最小记录或再现单位的块体包括作为逻辑访问的最小单位的多个扇区,并且所述连续地址被设定给在所述块体内的连续扇区。
(13)根据(10)到(12)中任一项所述的信息处理装置,其中,所述记录介质记录用于指定区域作为用于设置仿真区的目标的信息、用于规定仿真区的尺寸的信息、用于规定构成仿真区组的仿真区的数量的信息、以及用于规定在构成仿真区组的仿真区中的每个区域的地址的信息中的至少一个,作为管理信息。
(14)根据(10)到(13)中任一项所述的信息处理装置,其中,所述记录介质是光盘。
(15)根据(10)到(14)中任一项所述的信息处理装置,其中,同时执行对所述记录介质的访问控制的访问处理单元的数量是构成仿真区组的仿真区的数量的整数倍。
(16)根据(10)到(14)中任一项所述的信息处理装置,其中,同时执行对所述记录介质的访问控制的访问处理单元的数量是构成仿真区组的仿真区的数量的约数。
(17)根据(10)到(16)中任一项所述的信息处理装置,其中,所述控制单元控制多个访问处理单元,使得在所述多个访问处理单元中的一些访问处理单元同时将数据记录到所述记录介质中时,所述多个访问处理单元中的其他访问处理单元同时再现记录在所述记录介质内的数据。
(18)根据(17)所述的信息处理装置,其中,同时记录数据的访问处理单元的数量与同时再现记录数据的访问处理单元的数量相同。
(19)一种信息处理方法,包括以下步骤:
由多个访问处理单元通过对记录介质执行访问控制来记录或再现数据,其中,将连续记录区域分成具有预定尺寸的多个仿真区,并且设置所述仿真区的各个区域的地址,使得多个仿真区的集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错;并且
控制所述多个访问处理单元,使得所述多个访问处理单元根据控制同时执行对所述记录介质的访问。
(20)一种使计算机执行包括以下步骤的处理的程序:
由多个访问处理单元通过对记录介质执行访问控制来记录或再现数据,其中,将连续记录区域分成具有预定尺寸的多个仿真区,并且设置所述仿真区的各区域的地址,使得多个仿真区集合构成仿真区组,并且所述地址在构成仿真区组的多个仿真区之间交错;并且
控制所述多个访问处理单元,使得所述多个访问处理单元根据控制同时执行对所述记录介质的访问。
附图标记列表
12:记录/再现装置
13:光盘
22:控制器
24-1-1到24-2-2、24:记录/再现处理单元
25-1、25-2、25:磁头
41:管理单元
42:交替处理单元
43:交替管理单元
51-1-1到51-2-2、51:光学拾取头
- 还没有人留言评论。精彩留言会获得点赞!
- 图像编码设备、图像编码方法、记录介质和程序以及图像解码设备、图像解码方法、记录介 ...的制作方法
- 颜色变换方法、颜色变换程序以及记录介质的制作方法
- 信息处理设备、信息记录介质、信息处理方法和程序的制作方法
- 供需计划装置、供需计划方法、供需计划程序及记录介质的制作方法
- 信息处理器、信息处理器的控制方法、程序和信息贮存介质的制作方法
- 数据生成装置、数据生成方法、数据生成程序及记录介质的制作方法
- 描绘装置、曝光描绘装置、记录有程序的记录介质以及描绘方法
- 摄像装置、校准方法、程序以及记录介质的制作方法
- 生活行动估计系统、生活行动估计装置、生活行动估计程序及记录介质的制作方法
- 信号转换装置和方法以及程序和记录介质的制作方法