通用淀粉样蛋白相互作用基序(GAIM)的制作方法
通用淀粉样蛋白相互作用基序(gaim)
1.本申请要求于2018年6月15日提交的美国临时申请号62/685,757和2018年10月23日提交的美国临时申请号62/749,499的优先权,其公开内容通过引用整体并入本文。
2.本发明涉及多肽,其包含丝状噬菌体基因3蛋白(“g3p”,又被称为“p3”或“piii”)的通用淀粉样蛋白相互作用基序(gaim)的变体,使得所述多肽被部分或完全去免疫化,并显示出相对于现有技术的优异的效力、优异的结构稳定性以及增加的对淀粉样蛋白的结合特异性。涵盖了编码此类多肽的核酸分子和构建体,用此类核酸分子转化的宿主细胞,以及重组制备此类多肽的方法。另外,本发明涉及包含本文公开多肽的诊断组合物和药物组合物,涉及诊断组合物在检测淀粉样蛋白聚集体和/或诊断与错误折叠和/或聚集的蛋白有关的疾病中的用途,以及涉及药物组合物减少淀粉样蛋白负荷、防止淀粉样蛋白聚集、解聚淀粉样蛋白、或以其他方式治疗或预防与错误折叠和/或聚集的淀粉样蛋白有关的疾病,例如全身性和外周性淀粉样蛋白疾病、神经变性性疾病(包括神经变性性tau蛋白病)、以及传播性海绵状脑病(朊病毒相关疾病)的治疗和/或预防性用途。本发明的多肽包括融合蛋白及其淀粉样蛋白结合部分。
3.噬菌体g3p直接结合淀粉样蛋白纤维,并且噬菌体介导的淀粉样蛋白解聚(如,重构)取决于该初始结合步骤。参见,例如wo 2013/082114 a1,在此通过引用整体并入。发明人先前鉴定了淀粉样蛋白结合、淀粉样蛋白解聚和/或防止淀粉样蛋白聚集体形成所需的g3p的最小序列。同上。该最小序列被通用淀粉样蛋白相互作用基序(gaim)所涵盖,所述通用淀粉样蛋白相互作用基序包含g3p的n1和n2域,并导致生成能够与淀粉样蛋白结合和/或解聚淀粉样蛋白的g3p多肽(包括其突变体、片段、融合蛋白或药物组合物)。参见同上;wo 2014/055515 a1,在此通过引用整体并入。wo 2013/082114 a1和wo 2014/055515 a1中公开的g3p多肽可有效预防或治疗与错误折叠和/或聚集的淀粉样蛋白相关的疾病。同上。然而,这些g3p多肽还包含人t细胞表位,其可在患者中引起不需要的免疫应答。因此,开发了部分去免疫化的g3p多肽,其包含去除天然g3p中存在的五个t细胞表位中多达四个的突变。参见wo 2014/193935 a1,在此通过引用整体并入。
4.此外,潜在的n
‑
糖基化位点的存在限制了g3p多肽在动物细胞中的重组产生,所述g3p多肽结合淀粉样蛋白,并可用于检测、诊断、预防或治疗淀粉样蛋白相关疾病或病况。因此,产生了改进的g3p多肽,包括部分去免疫化的g3p多肽,其中潜在的n
‑
糖基化位点通过一个或多个突变被去除。参见wo 2016/090022 a8,在此通过引用整体并入。
5.尽管取得了这些进展,但本领域仍然需要更稳定、有效和特异且完全或几乎完全去免疫化的g3p多肽。
6.到目前为止,产生具有这些治疗特性的多肽面临重大挑战,至少部分是由于g3p多肽中的某些反向关系:首先,我们先前试图去除t细胞表位2(其是g3p多肽的完全去免疫化所需的)一直导致淀粉样蛋白结合能力降低。其次,我们先前尝试提高gaim的n1
‑
n2域的稳定性也一直导致淀粉样蛋白结合活性降低。例如,超稳定化的gaim变体pb113显示淀粉样蛋白结合能力较差。第三,n2域的不稳定性驱动与非淀粉样蛋白底物,如可溶性蛋白、粘性熔球结构体和非淀粉样蛋白纤维聚合物如胶原蛋白和弹性蛋白的混杂相互作用。因此,使n2
脱稳定化(destabilize)以增加淀粉样蛋白结合活性牺牲了特异性,而使n2稳定化以避免脱靶结合牺牲了与淀粉样蛋白的结合。令人惊讶的是,所有这三种反向关系都是通过生成包含“开放稳定化(open
‑
stabilized)”构象的gaim变体及其融合体的融合蛋白而克服。
7.与现有技术不同,本文所述的开放稳定化的多肽在一大批淀粉样蛋白中显示有效的淀粉样蛋白结合和重构(remodeling)活性,而保持蛋白稳定性和结合特异性。因此,在某些方面,本发明涉及开放稳定化的gaim变体(gaim),gaim
‑
免疫球蛋白(gaim
‑
ig)融合蛋白或它们的药物组合物,其至少部分去免疫化并且具有优异的淀粉样蛋白结合活性,淀粉样蛋白结合特异性和淀粉样蛋白重构活性。在一些方面,这些开放稳定化的gaim变体、gaim
‑
ig融合蛋白或它们的药物组合物在不牺牲有效且特异的淀粉样蛋白结合和不牺牲结构稳定性的情况下完全去免疫化。本文所述的开放稳定化的gaim变体和gaim
‑
ig融合体能够接合并去除脑和外周器官中的淀粉样蛋白,并构成一组新的多肽,其具有优异的检测、诊断、预防与错误折叠和/或聚集的淀粉样蛋白相关的疾病、延迟该疾病的发病和/或治疗该疾病的能力。
8.本发明的其它目的和优点部分地在下面的描述中阐述,并且从描述中将是显而易见的,或者可以通过实施本发明而获知。本发明的目的和优点将通过所附权利要求书中特别指出的要素和组合来实现和获得。应当理解的是,前面的总体描述和下面的详细描述都只是示例性和说明性的,并不限制所要求保护的发明。
9.附图简述
10.图1a是gaim n1和n2域的三级结构的图形表示(使用pdb结构2g3p示出)。进行定点诱变的β链以深灰色显示。箭头指示n1中极性残基和n2中疏水性残基的位置。图1b是本发明的gaim
‑
ig融合体的图形表示。图1c是gaim二聚体的图形表示。
11.图2描述显示faβ42中gaim相互作用序列的氢/氘(h/d)交换研究的结果。
12.图3a比较来自fd噬菌体的g3p的n1部分的氨基酸序列(seq id no:1)和来自if1噬菌体的g3p的相应n1部分的氨基酸序列(seq id no:2)的相应部分。空心框,在顶部描述pb106和gaim支架pb120(衍生自pb106)的氨基酸23
‑
28(ddktld;seq id no:3),在底部描述本发明的开放稳定化的gaim
‑
ig融合体中存在的egds(seq id no:4)取代(egds=seq id no:4)。图3b是gaim n1和n2域的三级结构的图形表示(使用pdb结构2g3p示出)。图3b中的空心框显示fd g3p中seq id no:3的位置。图3c是涉及n2域稳定化的三个慢折叠环(又称为“转角”)的图形表示。t1=转角1(fqnn;seq id no:5);t2=转角2(rqga;seq id no:6);t3=转角3(qgtdpvk;seq id no:7)。如下所示,通过诱变去除t1、t2或t3中的一个或多个使n2域稳定化。图3d描绘基于t50的选定氨基酸取代的结合和稳定性的变化。
13.图4a和图4b显示相比于gaim二聚体或单体,来自gaim
‑
ig融合体的热熔解实验的代表性数据。通过orange结合监测热熔解。通过从标准化荧光强度进行非线性拟合计算第一转变tm1。
14.图5a和图5b描绘在295nm处(图5a)和280nm处(图5b)激发的在0m盐酸胍(guhcl)(断线),2m guhcl(实线)和5m guhcl(虚线)下的gaim的荧光发射谱。图5c描绘guhcl使gaim二聚体平衡解折叠。图5c显示两次转变,第一次转变在1m和2m guhcl之间,第二次转变在2m和4m guhcl之间。在各种浓度的guhcl下绘制在340nm(激发280nm)处的相对荧光强度。图5d描绘在1.5m guhcl下的n2域解折叠。图5e描绘在2.6m guhcl下的n1域解折叠。
15.图6a和图6b描绘调节淀粉样蛋白结合的gaim残基的定位。图6a是显示与tm1相关的gaim变体的aβ42纤维结合效力的散点图(斯皮尔曼(spearman)相关系数=0.703,p<0.0001)。图6b是显示与tm1相关的gaim变体的ftau纤维结合效力的散点图(斯皮尔曼相关系数=0.878,p<0.0001)。由于elisa中未达到饱和的变体的曲线拟合不准确,因此呈现ftau结合较差的变体,ec
50
=1000nm。对于图6a和图6b,gaim支架pb120由灰色三角形表示,变体由圆圈表示。tm1的降低表明更加开放的gaim构象,导致结合增加,而具有更高tm1的稳定化变体倾向于失去结合活性。
16.图7a和图7b显示选择的gaim
‑
ig融合蛋白的淀粉样蛋白结合。图7a比较gaim支架(实心圆)及其稳定化变体的淀粉样蛋白结合。fqgn、vngv和qggk分别为seq id no:8
‑
10。图7b显示开放稳定化(但不是超稳定化)的gaim
‑
ig融合蛋白的优异结合。空心框内指示开放稳定化的多肽(除在最右边显示的超稳定化的多肽pb113外)。
17.图8a至图8d显示代表性的开放稳定化的gaim
‑
ig融合体(圆圈)与各种aβ纤维的结合,相比于对照支架与那些aβ纤维的结合(正方形)。图8a显示与aβ3
‑
42
‑
pyro纤维的结合;图8b显示与aβ1
‑
42e22q纤维的结合;图8c显示与aβ11
‑
42纤维的结合;图8d显示与aβ11
‑
42
‑
pyro纤维的结合。用于这些实验的聚集体显示出非常多样的形态,范围从不分支的长纤维(aβ1
‑
42e22q纤维)到高度锯齿形(zig
‑
zagged)的构象异构体(aβ3
‑
42
‑
pyro纤维)。pyro=焦谷氨酸。
18.图9显示n2稳定化突变对脱靶结合胶原蛋白的影响。fqgn=seq id no:8;vngv=seq id no:9;qggk=seq id no:10。
19.图10a至图10d涉及与aβ42纤维温育的不同gaim
‑
ig融合蛋白的重构效率。图10a进一步显示与由6e10 mab实现的重构比较。圆圈=平均值;棒=标准差。图10b进一步证明aβ42结合与各种gaim
‑
ig融合蛋白的重构之间的相关性。开放稳定化的gaim
‑
ig融合体由深灰色的倒置三角形表示。gaim支架由浅灰色的正面向上三角形描绘。圆圈代表其他测试的gaim
‑
ig融合体。图10c比较代表性的开放稳定化的多肽(圆圈)的重构效率相对于gaim支架(三角形)或单独的纤维(正方形)的重构效率。棒=标准差。纤维在尿素中的溶解性越大(如,tht荧光越低)表明重构效率越大。图10d示出显示在温育之前(左)和与0.8μm pb108于37℃温育6天之后(右)的aβ42纤维的透射电子显微术(tem)图像。
20.图11a至图11c涉及与tau纤维温育的不同gaim
‑
ig融合蛋白的重构效率。图11a比较代表性的开放稳定化的gaim
‑
ig融合蛋白pb108和超稳定化的融合蛋白pb113的重构效率。重构通过经处理的聚集体中taukl单体和二聚体(中间图)的存在来指示。图11b比较两种代表性的开放稳定化的gaim
‑
ig融合蛋白和gaim支架在不同浓度的融合蛋白下的重构效率。误差棒代表来自三个独立实验的标准差。图11c示出显示在温育之前(左)和与100nm pb108于37℃温育3天之后(右)的taukl纤维的tem图像。
21.图12a至图12d描绘本发明的gaim
‑
ig融合蛋白抑制淀粉样蛋白组装。误差棒代表来自三个或更多个独立实验的标准差。图12a显示aβ42纤维组装的浓度依赖性抑制。pb120(对照支架)用圆圈表示,pb108用正方形表示,pb116用三角形表示。图12b比较250nm gaim融合体下抑制aβ42纤维组装。图12c显示taukl纤维组装的浓度依赖性抑制。pb120(对照支架)用圆圈表示,pb108用正方形表示,pb116用三角形表示。图12d比较250nm gaim融合体下抑制taukl纤维组装。
22.序列简述
23.seq id no:1=aetvesclakphtensftnvwkddktldryan
24.seq id no:2=attdaeclskpafdgtlsnvwkegdsryan
25.seq id no:3=ddktld;seq id no:4=egds
26.seq id no:5=fqnn;seq id no:6=rqga;seq id no:7=qgtdpvk;
27.seq id no:8=fqgn;seq id no:9=vngv;seq id no:10=qggk
28.seq id no:11
29.maetvesclakphtensftnvwkddktldryanyegclwnaggvvvctgdetqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
30.seq id no:12=
31.maetvesclakphtensftnvwkddktldryanyegclwnaggvvvctgdetqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
32.seq id no:13=
33.maetvesclakphtensftnvwkddktldryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
34.seq id no:14=
35.maetvesclakphtensftnvwkddktldryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
36.seq id no:15=
37.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksr
wqqgnvfscsvmhealhnhytqkslslspgk
38.seq id no:16=
39.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
40.seq id no:17=
41.maetvesslakphiegsftnvwkddktldwyanyegilwkatgvvvitgdetqvyaiwvpvglaipenegggsegggsegggsegggtkppeygdtpipgyiyinpldgtyppgteqnpanpnpsleeshplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdvafhsgfnedplvaeyqgqlsylpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
42.seq id no:18=
43.maetvesslakphiegsftnvwkddktldwyanyegilwkatgvvvitgdetqvyaiwvpvglaipenegggsegggsegggsegggtkppeygdtpipgyiyinpldgtyppgteqnpanpnpsleeshplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdvafhsgfnedplvaeyqgqlsylpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
44.seq id no:19=
45.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
46.seq id no:20=
47.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnvngvltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
48.seq id no:21=
49.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrarqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
50.seq id no:22=
51.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfravngvltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
52.seq id no:23=
53.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrarqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
54.seq id no:24=
55.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfravngvltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
56.seq id no:25=
57.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
58.seq id no:26=
59.maetvesclakphtensftnvwkegdsryanyegclwaaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsg
60.seq id no:27=ggggs;seq id no:28=gggs
61.seq id no:29=
62.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
63.seq id no:30=
64.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfrnvngvltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
65.seq id no:31=
66.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegg
gsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrarqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
67.seq id no:32=
68.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdetqcyghwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfravngvltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
69.seq id no:33=
70.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrarqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
71.seq id no:34=
72.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqnnrfravngvltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
73.seq id no:35=
74.maetvesclakphtensftnvwkegdsryanyegclwnaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
75.seq id no:36=
76.maetvesclakphtensftnvwkegdsryanyegclwaaggvvvctgdehqcygtwvpiglaipenegggsegggsegggsegggtkppeygdtpipgytyinpldgtyppgteqnpanpnpsleesqplntfmfqgnrfrnrqgaltvytgtftqgtdpvktyyqytpvssramydaywngkfrdcafhsgfnedpfvceyqgqssdlpqppanaggesgggsgggsegggsegggsegggsegggsgggsgsgarsdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
77.seq id no:37=
78.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcaggaacagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
79.seq id no:38=
80.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaaaacaaccgcttcaggaacgtgaacggagtgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
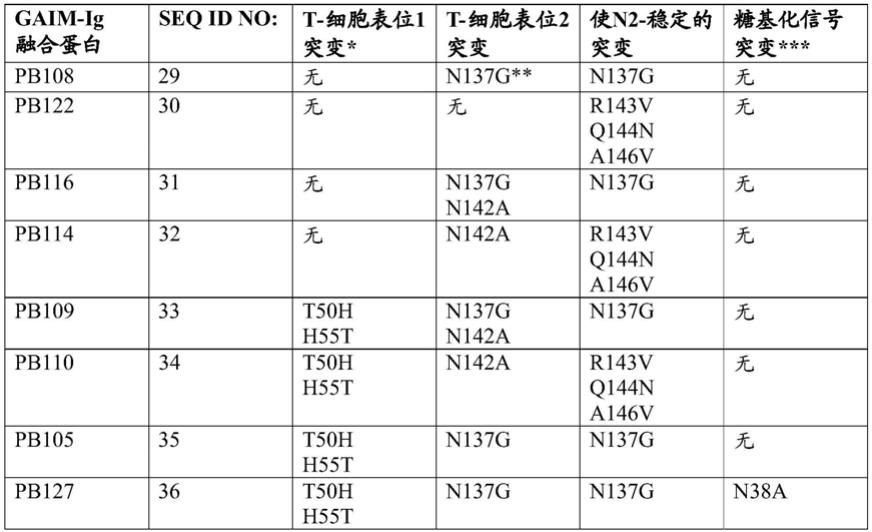
81.seq id no:39=
82.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcagggctagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgat
gcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
83.seq id no:40=
84.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaaaacaaccgcttcagggccgtgaacggagtgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
85.seq id no:41=
86.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagcaccagtgctacggaacttgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcagggctagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
87.seq id no:42=
88.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagcaccagtgctacggaacttgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaaaacaaccgcttcagggccgtgaacggagtgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcg
gga
89.seq id no:43=
90.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagcatcagtgctacggaacctgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcaggaacagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
91.seq id no:44=
92.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtgggccgccggtggagtggtcgtctgcaccggggatgagcatcagtgctacggaacctgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcaggaacagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcggga
93.seq id no:45=
94.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcaggaacagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggag
gagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga
95.seq id no:46=
96.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaaaacaaccgcttcaggaacgtgaacggagtgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga
97.seq id no:47=
98.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcagggctagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcg
ggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga
99.seq id no:48=
100.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagactcagtgctacggacactgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaaaacaaccgcttcagggccgtgaacggagtgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga
101.seq id no:49=
102.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagcaccagtgctacggaacttgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcagggctagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctat
gtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga\
103.seq id no:50=
104.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcaccggggatgagcaccagtgctacggaacttgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaaaacaaccgcttcagggccgtgaacggagtgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga
105.seq id no:51=
106.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtggaacgccggtggagtggtcgtctgcactggggatgagcaccagtgctacggaacctgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacg
tacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcaggaacagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga
107.seq id no:52=
108.atggccgaaaccgtggaatcatgtctggcgaagccccataccgagaactccttcaccaacgtctggaaagagggcgacagccgctacgccaactacgagggctgcctgtgggccgccggtggagtggtcgtctgcactggggatgagcaccagtgctacggaacctgggtgcctatcggactggccattcccgagaacgaggggggtggtagcgaaggcggcggatcggaaggcggaggatctgagggagggggaaccaagcctccggaatacggcgacactccgatccccgggtatacgtacatcaatccgctggacgggacctacccgcctggaactgagcagaacccggccaacccaaaccctagcctcgaggaatcccagccgttgaacaccttcatgttccaagggaaccgcttcaggaacagacagggagcgctgaccgtgtacactggcaccttcacacaaggcaccgaccccgtcaagacctactaccagtacactcctgtgtcctcgcgggctatgtacgatgcgtactggaatgggaagtttcgggactgcgctttccactccggcttcaacgaggatccattcgtgtgcgaatatcagggccagagctccgacctcccccaaccccctgcaaacgccggcggagaatccggagggggatcaggaggcggaagcgaagggggtggatccgaaggaggcggatccgagggtggaggctccgaagggggaggctctggtggtggctccggatcgggagccagatctgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcacgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatg a
109.seq id no:53=hhhhhh;seq id no:54=edgs
110.定义
111.在本发明的上下文中以及在使用每个术语的特定上下文中,本说明书中使用的术语通常具有本领域中的普通含义。某些术语在下文或说明书中的其他地方讨论,以为实际工作人员提供描述本发明的组合物和方法以及如何制备和使用它们的额外指导。冠词“一个”和“一种”是指该冠词的语法对象中的一个/种或多个/种(即,至少一个/种)。除非上下文另外明确指出,否则术语“或”意指术语“和/或”并与其可互换使用。在本申请中,单数的使用包括复数,除非另有明确说明。此外,术语“包括”以及其他形式,例如“包含”和“含有”的使用不是限制性的。本文所述的任何范围将被理解为包括端点以及端点之间的所有值。
112.术语“g3p”单独使用或在诸如“g3p
‑
衍生的”或“g3p融合体”的术语中使用时,是指任何野生型或重组丝状噬菌体g3p蛋白,包括保留结合淀粉样蛋白能力的g3p的片段、变体和突变体。这些术语不应当理解为限于任何特定的丝状噬菌体g3p。
113.术语“丝状噬菌体”和“噬菌体”在本文可互换使用,并且包括野生型和重组丝状噬菌体两者。
114.如本文所用,术语“野生型丝状噬菌体”是指自然界发现的丝状噬菌体,在任何核苷酸或氨基酸序列数据库中已被指示为“野生型”的丝状噬菌体,可商购并表征为“野生型”的丝状噬菌体,以及通过传代获得相对于前述任一者的非重组突变的丝状噬菌体。
115.如本文所用,术语“域”意指具有一些独特物理特征或独特作用的多肽或蛋白质的区域,包括例如由多肽链的部分组成的独立折叠结构。域可包含多肽独特物理特征的序列,或者它可以包含保留其结合特性(如,其保留结合第二域的能力)的物理特征片段。域可以与另一域缔合。例如,g3p n2域结合f
‑
菌毛,而g3p n1域结合tola。
116.如本文所用,“通用淀粉样蛋白相互作用基序”或“gaim”是指两个域的多肽(g3p的n1和n2域),其使用作为分子内表面衬里的疏水和极性残基两者的组合来介导淀粉样蛋白结合。gaim单体的n1和n2域具有芳香族氨基酸的不对称分布。gaim n2域包含11个酪氨酸(tyr)残基和1个暴露的色氨酸(trp)残基;n1域包含3个trp和3个tyr残基。n1和n2域采用倒马蹄形构象,并通过复杂的氢键网络以闭合构象(锁定构象)保持在一起(weininger等,2009)。域间接头中脯氨酸的顺
‑
反异构化导致氢键的逐步断裂和两个域的部分开放。gaim的n1和n2域的“开放”重排使n1的β链4和5(包含极性残基)和n2的β链9和10(包含芳香族/疏水残基)暴露,并允许与淀粉样蛋白结合。参见图1a。
117.如本文所用,“对照支架”或“gaim支架”对应于gaim
‑
ig融合蛋白pb120,具有seq id no:11的氨基酸序列。gaim支架的gaim部分具有seq id no:12的氨基酸序列。pb120衍生自具有seq id no:13的氨基酸序列的pb106。pb106的gaim部分具有seq id no:14的氨基酸序列。
118.如本文所用,“pb106+edgs”(以seq id no:54公开的“edgs”)表示具有如seq id no:15提供的氨基酸序列的开放构象多肽。“pb106+edgs”(以seq id no:54公开的“edgs”)的gaim部分具有seq id no:16的氨基酸序列。
119.如本文所用,“超稳定化的”gaim或gaim融合体是指具有seq id no:17的氨基酸序列的gaim
‑
ig融合体pb113。pb113的gaim部分具有seq id no:18的氨基酸序列。
120.术语“gaim
‑
ig融合体”、“gaim
‑
ig融合蛋白”和“gaim融合体”在本文中可互换使用,是指包含直接或通过小接头与免疫球蛋白恒定区连接的g3p gaim域的多肽。如图1b中所示,本发明的gaim
‑
ig融合体的fc区二聚化,产生包含直接或通过小接头与免疫球蛋白恒
定区连接的gaim的两个拷贝的复合物。本发明的gaim融合体可进一步包含信号序列。本发明考虑了具有任何免疫球蛋白恒定区的gaim融合体,例如igg(例如igg1、igg2、igg3或igg4)、igd、iga、ige或igm的免疫球蛋白恒定区。在一些方面,gaim
‑
ig融合体是开放稳定化的gaim
‑
ig融合体。在一些方面,gaim
‑
ig融合体被部分或完全去免疫化。
121.如本文所用,“gaim二聚体”是指本文所述的gaim
‑
ig融合体的两个gaim域。图1c以图形表示gaim二聚体。
122.术语“开放稳定化的融合体”、“开放稳定化的gaim
‑
ig融合体”、“开放稳定化的变体”和“开放稳定化的gaim
‑
ig变体”在本文中可互换使用,并且是指在融合体的gaim部分中包含至少一种开放构象突变和至少一种稳定化突变的gaim
‑
ig融合体。本文所述的开放稳定化的变体的开放构象突变是用seq id no:4(egds)取代seq id no:3(ddktld;相对于seq id no:13和seq id no:15的氨基酸24
‑
29)。稳定化突变可以是n2稳定化突变,例如选自用seq id no:8(fqgn)取代seq id no:5(fqnn;相对于seq id no:13的氨基酸137
‑
140;相对于seq id no:15的氨基酸135
‑
138),用seq id no:9(vngv)取代seq id no:6(rqga;相对于seq id no:13的氨基酸145
‑
148;相对seq id no:15的氨基酸143
‑
146),用seq id no:10(qggk)取代seq id no:7(qgtdpvk;相对于seq id no:13的氨基酸158
‑
164;相对于seq id no:15的氨基酸156
‑
162),或它们的组合。其他n2稳定化突变如下所述。如本文所述的开放稳定化的融合体可进一步包含一个或多个取代、插入或缺失。例如,可进一步修饰开放稳定化的gaim
‑
ig融合体,以降低或消除免疫原性,去除潜在的糖基化位点,或进一步调节对淀粉样蛋白的结合活性或特异性。
123.如本文所用,“基本上由给定氨基酸序列组成”的本发明的gaim
‑
ig融合蛋白可进一步包括连接融合体的gaim域和fc域的小接头,n末端信号序列或其片段,n末端甲硫氨酸的缺失(δm1)或n末端甲硫氨酸和丙氨酸二者的缺失(δm1和δa2),和/或融合体的fc域的c末端赖氨酸(k)的缺失。
124.如本文所用,“小接头”是指长度至多25个氨基酸的肽接头,其连接gaim
‑
ig融合体的gaim域和fc域。如下文进一步描述,连接gaim
‑
ig融合体的gaim和fc域的示例性“小接头”可包含富含gs的序列或可包含氨基酸序列ars。
125.如本文所用,“信号序列”是指存在于本发明多肽的n
‑
末端的约16至30个氨基酸的短肽。例如,信号序列可包含genbank ref seq np_518911.1的18个氨基酸n末端序列。信号序列被真核细胞用来分泌本发明的多肽。它通常在分泌前从多肽上切割下来,因此通常不存在于所分泌的多肽中。
126.术语“淀粉样蛋白”或“淀粉样蛋白纤维”在本文中用作三级结构的通用术语,该三级结构是通过几种不同蛋白中的任何一种的错误折叠或聚集形成的,并且包括垂直于纤维轴堆叠的β
‑
片层的有序排列。sunde et al.,j.mol biol.(1997)273:729
‑
39。
127.如本文所用,淀粉样蛋白可由以下蛋白中的任何一种形成:雄激素受体;载脂蛋白ai;载脂蛋白aii;载脂蛋白aiv;apo血清(aposerum)淀粉样蛋白a;aβ;abri;adan;atrophin
‑
1;心钠素;ataxin;降钙素;γ
‑
晶状蛋白;半胱氨酸蛋白酶抑制剂c;纤维蛋白原;凝溶胶蛋白;亨廷顿蛋白;胰岛素;胰岛淀粉样蛋白多肽;免疫球蛋白κ轻链;免疫球蛋白λ轻链;角膜
‑
上皮素(kerato
‑
epithelin);角蛋白;粘乳素(lactahedrin);乳铁蛋白;溶菌酶;肺表面活性剂蛋白c;medin;牙源性成釉细胞相关蛋白;朊病毒蛋白;降钙素原;催乳素;精
胶蛋白i;血清淀粉样蛋白a;超氧化物歧化酶i;β2
‑
微球蛋白;tata盒结合蛋白;tau;甲状腺素运载蛋白;以及α
‑
突触核蛋白,或以上的组合。如本文所用,淀粉样蛋白也可由上述蛋白中的任何一种的截短或翻译后修饰形式形成。“淀粉样蛋白”或“淀粉样蛋白纤维”包括淀粉样蛋白的不同或多种构象或形态。
128.如本文所用,“毒性寡聚物”是指通常形成淀粉样蛋白的开启
‑
途径(on
‑
pathway)中单体的小组装体或聚集体。
129.示例性淀粉样蛋白包括在阿尔茨海默氏病中形成的淀粉样蛋白
‑
β聚集体,其包含β
‑
淀粉样蛋白肽“aβ”,从人淀粉样蛋白前体蛋白(happ)切割的39至43个氨基酸的内部片段。aβ包括截短的和翻译后修饰的形式。例如,aβ40是aβ的短小形式,而更为原纤维形成性的同等型aβ42是长形式。aβ的其他实例包括但不限于n
‑
截短的aβ11
‑
42、aβ11
‑
42
‑
pyro、aβ3
‑
42
‑
pyro和aβ1
‑
42
‑
e22q
‑
dutch突变。参见levy et al,1990;van broeckhoven et al,1990。其他示例性淀粉样蛋白包括α
‑
突触核蛋白(与帕金森氏病相关),亨廷顿蛋白(与亨廷顿氏病相关),tau(与阿尔茨海默氏病相关),朊病毒蛋白的异常构象,prp
sc
、以及与各种淀粉样变性疾病相关的淀粉样蛋白,包括但不限于:免疫球蛋白轻链(κ或λ)、甲状腺素运载蛋白、凝胶溶素和胰岛淀粉样多肽。在整个说明书中提供了另外的实例,并且是本领域技术人员已知的(参见,例如,aguzzi(2010),和eichner and radford,mol.cell(2011)43:8
‑
18)。除非指定蛋白质或肽,否则术语“淀粉样蛋白”或“淀粉样蛋白纤维”的使用不应当理解为限于任何特定的蛋白、形态、疾病或病况。
130.术语“beta淀粉样肽”与“β淀粉样肽”、“βap”、“βa”和“aβ”同义。所有这些术语均指衍生自人淀粉样前体蛋白(happ)的淀粉样蛋白形成肽。
131.如本文所用,“prp蛋白”、“prp”和“朊病毒”是指能够在适当条件下诱导形成导致蛋白错误折叠疾病的聚集体的多肽。例如,正常的细胞朊病毒蛋白(prp
c
)在适当的条件下被转化为导致疾病的相应羊瘙痒症同种型(prp
sc
),所述疾病例如但不限于牛海绵状脑病(bse)(疯牛病)、猫海绵状猫脑病、库鲁病、克罗伊茨费尔特
‑
雅各布病(cjd)、gerstmann
‑
scheinker病(gss)和致命性家族性失眠症(ffi)。
132.如本文所用,“与错误折叠和/或聚集的淀粉样蛋白有关的疾病”包括但不限于,阿尔茨海默氏病;早发性阿尔茨海默氏病;晚发性阿尔茨海默氏病;症状前阿尔茨海默氏病;al淀粉样变性;肌萎缩侧索硬化(als);肌萎缩侧索硬化/帕金森症
‑
痴呆症综合征(parkinsonism
‑
dementia complex);嗜银颗粒痴呆症(argyrophilic grain dementia);主动脉内侧淀粉样变性(aortic medial amyloidosis);apoai淀粉样变性;apoaii淀粉样变性;apoaiv淀粉样变性;心房淀粉样变性;英国型/丹麦型痴呆;白内障;皮质基底变性(corticobasal degeneration);与倒睫相关的角膜淀粉样变性;半胱氨酸蛋白酶抑制剂c斑块相关疾病(cystatin c plaque
‑
related disease);半胱氨酸蛋白酶抑制剂c斑块相关冠心病(cystatin c plaque
‑
related coronary disease);半胱氨酸蛋白酶抑制剂c斑块相关肾脏病;皮肤苔藓状淀粉样变性(cutaneous lichen amyloidosis);拳击员痴呆(dementia pugilistica);齿状核红核苍白球丘脑下部核萎缩(dentatorubral
‑
pallidoluysian atrophy);弥漫性神经原纤维缠结伴钙化(neurofibrillary tangles with calcification);路易体痴呆(dementia with lewy bodies);唐氏综合征;家族性淀粉样变性心肌病(familial amyloidotic cardiomyopathy,fac);家族性淀粉样多神经病
(familial amyloidotic polyneuropathy,fap);家族性英国型痴呆(familial british dementia);家族性丹麦型痴呆(familia danish dementia);家族性脑病(familial encephalopathy);家族性地中海热(familial mediterranean fever);纤维蛋白原淀粉样变性(fibrinogen amyloidosis);芬兰型遗传性淀粉样变性(finnish hereditary amyloidosis);额颞叶痴呆伴帕金森病(frontotemporal dementia with parkinsonism);额颞叶变性(frontotemporal lobar degeneration,ftld);额颞叶痴呆;hallervorden
‑
spatz病;血液透析相关淀粉样变性;遗传性脑淀粉样血管病(hereditary cerebral amyloid angiopathy);遗传性脑出血伴淀粉样变性(hereditary cerebral hemorrhage with amyloidosis);遗传性格子状角膜营养不良(hereditary lattice corneal dystrophy);亨廷顿氏病;冰岛型遗传性脑淀粉样血管病(icelandic hereditary cerebral amyloid angiopathy);包涵体肌炎(inclusion
‑
body myositis);注射局部淀粉样变性(injection
‑
localized amyloidosis);胰岛淀粉样多肽淀粉样变性(islet amyloid polypeptide amyloidosis);溶菌酶淀粉样变性;多发性骨髓瘤;强直性肌营养不良;c型尼曼
‑
匹克病(niemann
‑
pick disease type c);伴发神经原纤维缠结的非关岛型运动神经元病(non
‑
guamanian motor neuron disease with neurofibrillary tangles);帕金森氏病;外周淀粉样变性(peripheral amyloidosis);匹克病(pick’s disease);垂体催乳素瘤;脑炎后帕金森病;朊病毒蛋白脑淀粉样血管病;朊病毒介导的疾病;库鲁病(kuru);克罗伊茨费尔特
‑
雅各布病(creutzfeldt
‑
jakob disease,cjd);gerstmann
‑‑
scheinker病(gss);致命性家族性失眠症(ffi);羊瘙痒症(scrapie);海绵状脑病(spongiform encephalopathy);肺泡蛋白沉着症;进行性皮质下神经胶质增生;进行性核上性麻痹;老年性系统性淀粉样变性;血清aa淀粉样变性;脊髓延髓肌肉萎缩症(spinal and bulbar muscular atrophy);脊髓小脑性共济失调(sca1、sca3、sca6或sca7);亚急性硬化性全脑炎(subacute sclerosing panencephalitis);系统性淀粉样变性;家族性淀粉样变性;野生型淀粉样变性;缠结性痴呆(tangle only dementia);和tau蛋白病(tauopathies)。参见例如chiti&dobson,annu rev biochem(2006)75:333
‑
66;和josephs et al.,acta neuropathol(2011)122:137
‑
153。迫切需要预防和/或减少淀粉样蛋白聚集体形成(即错误折叠和/或聚集的蛋白),以治疗或减轻这些疾病的症状或严重程度。
133.如本文所用,“减少淀粉样蛋白”的多肽、组合物、配制剂或核酸完成以下一项或多项:抑制淀粉样蛋白形成,引起淀粉样蛋白解聚,引起淀粉样蛋白重构,促进淀粉样蛋白清除,抑制淀粉样蛋白聚集,阻断和/或防止毒性寡聚物的形成,和/或促进毒性寡聚物的清除。
134.描述为“解聚”或“介导解聚”的本发明的多肽、核酸或组合物减少已经形成的聚集体。可以通过滤器阱测定(filter trap assay)(wanker et al.,methods enzymol(1999)309:375
‑
86)或本领域已知的其他方法来测量解聚。滤器阱测定可用于既检测聚集体又监测由本发明的组合物介导的解聚。在存在增加浓度的解聚剂的情况下,解聚被检测为滤器上淀粉样蛋白保留的减少,如染色减少所示。
135.描述为“保护神经元免受淀粉样蛋白损伤”的本发明的多肽、核酸或组合物防止新的淀粉样蛋白的积聚和/或防止毒性寡聚物的形成。描述为“保护神经元免受淀粉样蛋白损
伤”的本发明的产品或组合物可以预防性地服用。产品或组合物是否保护神经元免受淀粉样蛋白损伤可通过如wo2014/055515(在此通过引用整体并入)中所述的神经元细胞培养物细胞毒性测定法测量。
136.描述为“重构”淀粉样蛋白的本发明的多肽、核酸或组合物引起纤维构象异构体部分或完全转化为无定形聚集体。重构可通过利用尿素的变性研究(如,对于aβ形式)或sarkosyl可溶性测定(如,对于tau形式)来测量。可以通过淀粉样蛋白结合硫黄素t(tht)的损失或失败,导致tht荧光降低检测增加的重构。重构还可使用透射电子显微镜法(tem)检测。
137.描述为“抑制淀粉样蛋白聚集”的本发明的多肽、核酸或组合物部分或完全防止淀粉样蛋白聚集。淀粉样蛋白聚集的抑制可以通过tht荧光测定法来测量(如,荧光越低表明淀粉样蛋白聚集的百分比越低)。
138.如本文结合噬菌体、蛋白质、多肽或氨基酸序列(例如gaim变体)所用,术语“变体”是指与参考物相比包含至少一个氨基酸差异(至少一个作为取代、插入或缺失的突变)的相应物质。在某些实施方案中,与参考序列相比,“变体”具有高氨基酸序列同源性和/或保守氨基酸取代,缺失和/或插入。在一些实施方案中,与参考序列相比,变体具有不超过25、20、17、15、12、10、9、8、7、6、5、4、3、2或1个氨基酸差异。与参考序列相比,如本文所述的变体可以保留或提高:淀粉样蛋白结合活性,淀粉样蛋白结合特异性和/或蛋白质量。如本文所述的变体可被去糖基化。如本文所述的变体可减少或消除免疫原性。
[0139]“保守取代”是指基本上不改变g3p蛋白或g3p淀粉样蛋白结合片段的化学、物理和/或功能性质的第二氨基酸取代第一氨基酸(如,g3p蛋白或淀粉样蛋白结合片段保留相同的电荷、结构、极性、疏水性/亲水性,和/或保留诸如识别、结合和/或减少淀粉样蛋白能力的功能)。这类保守的氨基酸修饰是基于氨基酸侧链取代基的相对相似性,例如它们的疏水性、亲水性、电荷、大小等。可与保守取代互换且并考虑了上述各种特征的示例性氨基酸组是本领域技术人员公知的,包括:精氨酸和赖氨酸;谷氨酸和天冬氨酸;丝氨酸和苏氨酸;谷氨酰胺和天冬酰胺;以及缬氨酸,亮氨酸和异亮氨酸。
[0140]
术语“免疫原性的”或“免疫原性”在本文中用于指组合物在已暴露于该组合物的哺乳动物中引发免疫应答的能力。在某些方面,本发明涉及具有降低的免疫原性或被完全去免疫化的多肽或组合物。完全去免疫化表明通过那些表位序列中的一个或多个突变去除了存在于天然gaim氨基酸序列中的全部5个t细胞识别表位。这类去免疫化的突变可构成表位中一个或多个氨基酸残基的取代、插入或缺失,或者可构成部分或全部缺失表位性序列。
[0141]
g3p的通用淀粉样蛋白相互作用基序(gaim)及其gaim
‑
ig融合体
[0142]
通用淀粉样蛋白相互作用基序(gaim)是包含g3p的n1和n2域的二域多肽。gaim n2域由三个不同的结构元件组成:结构类似于n1的球形部分(holliger et al.(1999)j mol biol,288:649
‑
57),α
‑
螺旋和与n1域形成广泛h键网络的无序区域。n2铰链区还包含几个脯氨酸残基,其中一个(p213)与将gaim维持在开放的tola结合能力状态有关。gaim单体的n1和n2域具有芳香族氨基酸的不对称分布。gaim n2域包含11个酪氨酸(tyr)残基和1个暴露的色氨酸(trp)残基;n1域包含3个trp和3个tyr残基。因此,酪氨酸和色氨酸残基的固有荧光允许分别监测n2和n1域的构象性变化(martin and schmid(2003)j mol biol,405:989
‑
1003),从而检测gaim的开放构象。
[0143]
h/d交换研究表明,gaim与aβ42纤维的中央核心结合。如图2证明,h/d交换研究还表明,gaim接合原纤维核心上的不连续序列,并结合富含芳香族残基(如,aβ42中的残基17
‑
25)和脂肪族残基(如,aβ42中的残基残基31
‑
40)的序列。这导致淀粉样蛋白组装的强烈抑制和纤维有效重构为无定形聚集体(krishnan et al.(2014)j mol biol,426:2500
‑
19)。
[0144]
在一些方面,多肽或包含该多肽的组合物包含gaim变体。在一些实施方案中,与参考序列相比,gaim变体具有不超过25个氨基酸的差异。在一些实施方案中,与参考序列相比,gaim变体具有不超过17个氨基酸的差异。在一些实施方案中,与参考序列相比,gaim变体具有不超过10个氨基酸的差异。在一些实施方案中,变体与参考序列相比具有不超过7个氨基酸的差异。在一些实施方案中,参考序列是seq id no:12(pb120的gaim部分)。在一些实施方案中,参考序列是seq id no:14(pb106的gaim部分)。在一些实施方案中,参考序列是seq id no:16(“pb106+edgs”(以seq id no:54公开的“edgs”)的gaim部分)。
[0145]
除非另有说明,否则所有gaim氨基酸序列编号均基于seq id no:16的氨基酸序列,并且所有gaim
‑
ig氨基酸序列编号均基于seq id no:15的氨基酸序列,其构成通过短接头ars在c端末端与人igg1
‑
fc氨基酸序列融合的seq id no:16。
[0146]
本发明的多肽包含本文所述的任何gaim变体。本文公开的gaim变体包含用seq id no:4(egds)取代seq id no:3(ddktld;相对于seq id no:13的氨基酸24
‑
29)。这种取代存在于参考序列seq id no:16中,并导致本发明的gaim变体具有开放构象(“开放”或“解锁”)gaim变体。
[0147]
本发明的gaim变体还包括选自以下的至少一组另外的氨基酸变化:(i)替代性t细胞表位1
‑
去免疫化变化,(ii)t细胞表位2
‑
去免疫化变化,和(iii)n2稳定化变化。
[0148]
在一些实施方案中,至少另一组氨基酸变化增加淀粉样蛋白亲和力,而仍在t细胞表位1中被去免疫化。在参考seq id no:16中,去免疫化的t细胞表位1跨越氨基酸g47至h55。该序列中的h55导致去免疫化;野生型g3p(其中t细胞表位1未被去免疫化)在相应位置处具有苏氨酸。尽管对于包含在seq id no:16的氨基酸55处的苏氨酸至组氨酸变化的g3p多肽变体,淀粉样蛋白亲和力仍然明显,但是该亲和力相对于野生型有所降低。令人感兴趣的是,已经报道天然g3p中存在的序列ygt是tola结合基序(s pommier et al,j.bacteriol.(2005),187(21),pp.7526
‑
34)。不受理论的束缚,我们认为gaim
‑
淀粉样蛋白结合可能需要与g3p
‑
tola结合相似的氨基酸相互作用。因此,我们探索了通过进行h55t取代(如,恢复为野生型t细胞表位1序列)来再生seq id no:16中的53ygt55序列,并在当前再生的t细胞表位中寻找会影响去免疫化的替代性取代。我们发现,t50取代引起t细胞表位1的去免疫化而不影响淀粉样蛋白亲和力。因此,在一些实施方案中,本发明的gaim变体包含伴随h55t取代的t50取代。在这些实施方案的一些方面,t50取代是t50r、t50k、t50g或t50h。在这些实施方案的至少一方面,t50取代是t50h。
[0149]
在一些实施方案中,至少另一组氨基酸变化使t细胞表位2去免疫化而不显著改变淀粉样蛋白亲和力。在参考seq id no:16中,t细胞表位2从氨基酸m134跨越到n142(参见,美国专利号9,988,444b2和美国专利公开us2018/0207231a1,各自通过引用整体并入),并且与相应的野生型g3p序列相比未变化。在本发明之前,我们尚不能在没有淀粉样蛋白结合的显著降低和/或所产生的gaim的稳定性显著降低的情况下使该表位去免疫化。现在我们已经发现用另一种氨基酸取代n142和/或n137使t细胞表位2去免疫化,而对淀粉样蛋白结
合或稳定性没有显著影响。因此,在一些实施方案中,本发明的gaim变体包含n142的取代。在这些实施方案的一些方面,n142取代是n142a。在可选择的实施方案中,本发明的gaim变体包含n137的取代。在这些实施方案的一些方面,n137取代是n137g。在其他可选择的实施方案中,本发明的gaim变体包含n137的取代和n142的取代。在这些实施方案的一些方面,n137取代是n137g,并且n142取代是n142a。
[0150]
在一些实施方案中,至少另一组氨基酸变化增加n2的稳定性。这些变化靶向seq id no:16中存在的一个或多个所谓的慢折叠环,它们跨越氨基酸135
‑
138(fqnn;seq id no:5;转角1),143
‑
146(rqga;seq id no:6;转角2)和156
‑
162(qgtdpvk;seq id no:7;转角3),如图3c描绘。我们已经发现,这些中的一个或多个区域中的某些氨基酸取代和/或缺失会增加gaim中n2的稳定性。因此,在一些实施方案中,至少另一组氨基酸变化选自:(i)n137g;(ii)r143v、q144n、以及任选地a146v、a146t或a146k;和(iii)v161g,t158、d159和p160的缺失,任选地q156v或q156y,以及任选地g157n。如上文提供,通过去除转角1处的慢折叠环而使n2稳定化的n137g取代还使t细胞表位2去免疫化。在这些实施方案的一些方面,gaim变体在转角1、转角2和转角3的仅一者中包含氨基酸变化,例如以下之一:(i)n137g;(ii)r143v、q144n、以及任选地a146v、a146t或a146k;和(iii)v161g,t158,d159和p160的缺失,任选地q156v或q156y,以及任选地g157n。在这些实施方案的一些方面,gaim变体在转角的至少两个中包含氨基酸变化,例如以下中的两个:(i)n137g;(ii)r143v、q144n、以及任选地a146v、a146t或a146k;和(iii)v161g,t158、d159和p160的缺失,任选地q156v或q156y,以及任选地g157n。在这些实施方案的一些方面,氨基酸变化是n137g,在氨基酸135
‑
138处产生seq id no:8。在这些实施方案的一些方面,氨基酸变化是r143v、q144n和a146v,在氨基酸143
‑
146处产生seq id no:9。在这些实施方案的一些方面,氨基酸变化是t158、d159和p160的缺失以及取代v161g,在氨基酸156
‑
162处产生seq id no:10作为替代。在这些实施方案的至少一个方面,gaim变体不包含所有三个转角中的氨基酸变化。
[0151]
在一些实施方案中,本发明的多肽包含gaim变体,其具有选自任何上述替代性t细胞表位1
‑
去免疫化变化的至少一组氨基酸变化和选自任何上述t细胞表位2去免疫化变化的至少一组氨基酸变化。
[0152]
在一些实施方案中,gaim变体具有选自任何上述替代性t细胞表位1
‑
去免疫化变化的至少一组氨基酸变化和选自任何上述n2稳定化变化的至少一组氨基酸变化。
[0153]
在一些实施方案中,gaim变体具有选自任何上述t细胞表位2
‑
去免疫化变化的至少一组氨基酸变化和选自任何上述n2
‑
稳定化变化的至少一组氨基酸变化。
[0154]
在一些实施方案中,gaim变体具有选自任何上述替代性t细胞表位1
‑
去免疫化变化的至少一组氨基酸变化,选自任何上述t细胞表位2
‑
去免疫化变化的至少一组氨基酸变化,以及选自任何上述n2
‑
稳定化变化的至少一组氨基酸变化。
[0155]
可从本文针对该给定类型描述的任何变化中,为每种前述变化类型选择一组特定的氨基酸变化。各组氨基酸变化的非限制性实例可以在表1中找到。
[0156]
表1.相对于seq id no:16的开放稳定化的gaim
‑
ig融合体的突变
[0157][0158]
*通过相对于野生型g3p的t55h取代使seq id no:16的t细胞表位1去免疫化。在开放稳定化的gaim
‑
ig融合体中的t
‑
细胞表位1中的突变代表替代的去免疫化突变。
[0159]
**n137g取代使t
‑
细胞表位2去免疫化并使n2域稳定化。
[0160]
***通过相对于野生型g3p的t40g突变使seq id no:16去糖基化。在开放稳定化的gaim
‑
ig融合体中的潜在糖基化信号中的突变代表另外的去糖基化取代。
[0161]
本发明的多肽包含去糖基化的gaim变体。使参考序列seq id no:16去糖基化,因为其包含相对于野生型g3p的t40g突变,从而将天然nat糖基化信号改变为nag。其他去糖基化的g3p突变体和/或变体的实例可在美国专利公开us 2018/0207231a1中找到。然而,在天然糖基化信号中具有不同和/或另外的去糖基化突变的gaim变体也是本发明的一部分。例如,三氨基酸序列nx(t/s)(其中x是任何氨基酸)是已知的糖基化信号。用除半胱氨酸以外的任何氨基酸取代该序列中的天冬酰胺(n)将破坏糖基化信号。类似地,用除半胱氨酸以外的任何氨基酸取代该序列中的苏氨酸(t)或丝氨酸(s)将破坏糖基化信号。
[0162]
因此,在一些实施方案中,与seq id no:16相比,本文所述的gaim变体包含用除半胱氨酸以外的任何氨基酸取代n38,并且还包含替代的t细胞表位1
‑
去免疫化变化,t细胞表位2去免疫化变化和/或n2稳定变化中的一个或多个。在这些实施方案的一些方面,n38的取代是n38a。在这些实施方案的一些方面,gaim变体进一步包含将g40取代为除半胱氨酸以外的任何氨基酸。
[0163]
在一些可选择的实施方案中,与seq id no:16相比,本文所述的gaim变体包含用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,并且进一步包含t细胞表位1去免疫化变化,t细胞表位2去免疫化变化和/或n2稳定化变化中的一个或多个。
[0164]
seq id no:16包含n末端氨基酸m1和a2。动物细胞系中gaim的重组产生可导致缺少m1或者m1和a2二者的多肽(“n末端截短”)。此类n末端截短不影响淀粉样蛋白结合活性。因此,在一些实施方案中,除了包含t细胞表位1
‑
去免疫化变化、t细胞表位2
‑
去免疫化变化和/或n2稳定化变化的一个或多个之外,gaim变体任选地缺少seq id no:16的氨基酸1(δ
m1)或者氨基酸1和2(δm1和δa2)二者。如本文所用,缺少氨基酸1或者氨基酸1或2二者的gaim变体可指n端截短(即,翻译后去除)或缺失突变。
[0165]
在一些实施方案中,gaim变体是seq id no:16的变体,其包含取代n137g。在这些实施方案的一些方面,gaim变体缺少氨基酸1(如,δm1)。在这些实施方案的一些方面,gaim变体缺少氨基酸1和2(如,δm1和δa2)。在这些实施方案的一些方面,gaim变体进一步包含用除半胱氨酸以外的任何氨基酸取代n38,用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,或者用除半胱氨酸以外的任何氨基取代n38和用除半胱氨酸以外的任何氨基酸取代g40两者。在这些实施方案的至少一方面,n38取代是n38a。
[0166]
在一些实施方案中,gaim变体是seq id no:16的变体,其包含r143v、q144n和任选地a146v、a146t或a146k。在某些实施方案中,gaim变体是seq id no:16的变体,其包含r143v、q144n和a146v。在这些实施方案的一些方面,gaim变体另外缺少氨基酸1(如,δm1)。在这些实施方案的一些方面,gaim变体另外缺少氨基酸1和2(如,δm1和δa2)。在这些实施方案的一些方面,gaim变体进一步包含用除半胱氨酸以外的任何氨基酸取代n38,用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,或者用除半胱氨酸以外的任何氨基取代n38和用除半胱氨酸以外的任何氨基酸取代g40两者。在这些实施方案的至少一方面,n38取代是n38a。
[0167]
在一些实施方案中,gaim变体是seq id no:16的变体,其包含用任何其他氨基酸取代t50,取代h55t和取代n137g。在这些实施方案的至少一方面,t50的取代选自t50h、t50g、t50k和t50r。在这些实施方案的至少一方面,t50的取代是t50h。在这些实施方案的一些方面,gaim变体进一步(i)包含n142a取代;(ii)包含n38和/或g40的去糖基化突变;(iii)缺少氨基酸1或氨基酸1和2二者;或(iv)它们的任何组合。例如,在这些实施方案的一些方面,gaim变体缺少氨基酸1(如,δm1)。在这些实施方案的一些方面,gaim变体缺少氨基酸1和2(如,δm1和δa2)。在这些实施方案的一些方面,gaim变体进一步包含用除半胱氨酸以外的任何氨基酸取代n38,用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,或者用半胱氨酸以外的任何氨基取代n38和用除半胱氨酸以外的任何氨基酸取代g40两者。在这些实施方案的至少一方面,n38取代是n38a。
[0168]
在某些实施方案中,gaim变体是seq id no:16的变体,其包含取代n137g和n142a。在这些实施方案的一些方面,gaim变体进一步(i)包含用任何其他氨基酸取代t50以及取代h55t;(ii)包含n38和/或g40的去糖基化突变;(iii)缺少氨基酸1或者氨基酸1和2二者;或(iv)它们的任何组合。在这些实施方案的某些方面,t50的取代选自t50h、t50g、t50k和t50r。在这些实施方案的至少一方面,t50的取代是t50h。在这些实施方案的一些方面,gaim变体缺少氨基酸1(如,δm1)。在这些实施方案的一些方面,gaim变体缺少氨基酸1和2(如,δm1和δa2)。在这些实施方案的一些方面,gaim变体进一步包含用除半胱氨酸以外的任何氨基酸取代n38,用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,或者用除半胱氨酸以外的任何氨基取代n38和用除半胱氨酸以外的任何氨基酸取代g40两者。在这些实施方案的至少一方面,n38取代是n38a。
[0169]
在某些实施方案中,gaim变体是seq id no:16的变体,其包含以下取代:n142a、r143v、q144n,以及任选地a146v、a146t或a146k。在某些实施方案中,gaim变体是seq id no:16的变体,其包含以下取代:n142a、r143v、q144n和a146v。在这些实施方案的一些方面,
gaim变体进一步(i)包含用任何其他氨基酸取代t50以及取代h55t;(ii)包含n38和/或g40的去糖基化突变;(iii)缺少氨基酸1或者氨基酸1和2二者;或(iv)它们的任何组合。在这些实施方案的一些方面,t50的取代选自t50h、t50g、t50k和t50r。在这些实施方案的至少一方面,t50的取代是t50h。在这些实施方案的一些方面,gaim变体缺少氨基酸1(δm1)。在这些实施方案的一些方面,gaim变体缺少氨基酸1和2(δm1和δa2)。在这些实施方案的一些方面,gaim变体进一步包含用除半胱氨酸以外的任何氨基酸取代n38,用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,或者用除半胱氨酸以外的任何氨基取代n38和用除半胱氨酸以外的任何氨基酸取代g40两者。在这些实施方案的至少一方面,n38取代是n38a。
[0170]
在某些实施方案中,gaim变体是seq id no:16的变体,其包含以下取代:δt158、δd159、δp160、v161g和任选地(i)q156v或q156y和/或(ii)g157n。在这些实施方案的某些方面,gaim变体是seq id no:16的变体,其包含以下取代:δt158、δd159、δp160和v161g。在这些实施方案的一些方面,gaim变体进一步(i)包含用任何其他氨基酸取代t50以及取代h55t;(ii)包含n38和/或g40的去糖基化突变;(iii)缺少氨基酸1或者氨基酸1和2二者;或(iv)它们的任何组合。在这些实施方案的一些方面,t50的取代选自t50h、t50g、t50k和t50r。在这些实施方案的至少一方面,t50的取代是t50h。在这些实施方案的一些方面,gaim变体缺少氨基酸1(δm1)。在这些实施方案的一些方面,gaim变体缺少氨基酸1和2(δm1和δa2)。在这些实施方案的一些方面,gaim变体进一步包含用除半胱氨酸以外的任何氨基酸取代n38,用半胱氨酸、苏氨酸或丝氨酸以外的任何氨基酸取代g40,或用除半胱氨酸以外的任何氨基取代n38和用除半胱氨酸以外的任何氨基酸取代g40两者。在这些实施方案的至少一方面,n38取代是n38a。
[0171]
在至少一个实施方案中,本发明的多肽包含具有seq id no:19的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:20的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:21的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:22的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:23的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:24的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:25的氨基酸序列的gaim变体。在至少一个实施方案中,本发明的多肽包含具有seq id no:26的氨基酸序列的gaim变体。
[0172]
上述gaim变体中的任何一种可在c端末端直接或通过短接头融合至免疫球蛋白恒定区,以产生gaim
‑
ig融合蛋白。本文所述的gaim
‑
ig融合蛋白的免疫球蛋白恒定区可以是igg(包括igg1、igg2、igg3和igg4)、iga、igd、ige或igm的免疫球蛋白恒定区。在一些方面,免疫球蛋白恒定区是igg。在某些方面,igg是igg1。在其他方面,igg是igg2。在一些实施方案中,免疫球蛋白恒定区是人免疫球蛋白恒定区。在一些实施方案中,免疫球蛋白恒定区是人igg的fc部分或其片段。适用于本发明的融合蛋白的人igg的fc部分包括野生型或经修饰的fc部分。例如,相对于野生型fc,人igg的合适的经修饰的fc部分可以使融合蛋白稳定化和/或增加其半衰期。经修饰的fc的非限制性实例包括在美国专利号7,083,784,美国专利号7,217,797,美国专利号7,217,798,美国专利申请号14/214,146和wo
‑
1997034631中公开的那些。在至少一个实施方案中,免疫球蛋白恒定区是人igg1的fc部分。在至少一个实施方
案中,免疫球蛋白恒定区是人igg2的fc部分。在一些实施方案中,gaim
‑
ig融合蛋白的免疫球蛋白恒定区包含c末端赖氨酸(如,k485)。在其他实施方案中,gaim
‑
ig融合体缺少c末端赖氨酸(如,δk485)。
[0173]
在一些实施方案中,gaim
‑
ig融合蛋白基本上由包含本文公开的任何gaim变体和人igg(如,人iggl)的fc部分的多肽组成。在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:19所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:19所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:19和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:29(pb108)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:29的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0174]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:20所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:20所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:20和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:30(pb122)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:30的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0175]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:21所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:21所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:21和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:31(pb116)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:31的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0176]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:22所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:22所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:22和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:32(pb114)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:32的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δ
a2和δk485)。
[0177]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:23所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:23所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:23和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:33(pb109)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:33的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0178]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:24所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:24所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:24和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:34(pb110)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:34的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0179]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:25所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:25所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:25和人igg(如,人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:35(pb105)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:35的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0180]
在至少一个实施方案中,gaim
‑
ig融合蛋白基本上由与seq id no:26所述序列至少95%、96%、97%、98%或99%相同的序列和人igg(如,人igg1)的fc部分组成。在该实施方案的一些方面,gaim
‑
ig融合蛋白的gaim部分的氨基酸序列与seq id no:26所述序列相差10
‑
15、1
‑
10或1
‑
5个保守取代。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:26和人igg(例如人igg1)的fc部分组成。例如,在一些方面,gaim
‑
ig融合蛋白基本上由seq id no:36(pb127)的氨基酸序列组成。在该实施方案的其他方面,gaim
‑
ig融合蛋白基本上由seq id no:36的变体组成,其中该变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0181]
在本发明的一些方面,本文所述的gaim
‑
ig融合体的gaim部分和ig部分通过小接头连接。在一些实施方案中,小接头富含甘氨酸、丝氨酸和/或苏氨酸,其包含至少80%、
laboratory,n.y.以及ausubel et al.1989,current protocolsin molecular biology,greene publishing associates and wiley lnterscience,n.y.)。可选择地,本发明的多肽可利用已知的合成方法如固相合成来合成。合成技术是本领域众所周知的(参见,例如merrifield,1973,chemical polypeptides,(katsoyannis and panayotis编)pp.335
‑
61;merrifield 1963,j.am.chem.soc.85:2149;davis et al.1985,biochem.intl.10:394;finn et al.1976,the proteins(第3版)2:105;erikson et al.1976,the proteins(第3版)2:257;美国专利号3,941,763)。可选择地,最终的构建体可以与重组产生的融合蛋白共享基本相同的功能,但仅利用非重组技术(例如连接化学)来产生。融合蛋白的成分可利用与对g3p表达和g3p突变描述的相同一般方法来制备。
[0188]
在一些实施方案中,可以将多肽与标记序列,例如促进融合多肽纯化的肽融合(单独或在与另一蛋白融合或掺入载体分子外)。标记氨基酸序列可以是六组氨酸肽(seq id no:53),例如pqe载体(qiagen,mississauga,ontario,canada)中提供的标签,等等,其中许多是可商购的。例如,如gentz et al.,proc.natl.acad.sci.(1989)86:821
‑
824所述,六组氨酸(seq id no:53)提供了融合蛋白的方便纯化。可用于纯化的另一种肽标签血凝素(ha)标签对应于源自流感ha蛋白的表位(wilson et al.,(1984)cell 37:767)。
[0189]
药物组合物
[0190]
在一些实施方案中,本发明提供药物组合物,其包含含有本文所述gaim变体的任何多肽,任选地与药学上可接受的载体、稀释剂或赋形剂一起。“药物组合物”是指治疗有效量的具有生理学上合适的载体和/或赋形剂的如本文中所述的组合物。药物组合物不对生物体造成明显刺激。短语“生理上合适的载体”和“药学上可接受的载体”可互换使用,是指不对生物体造成明显刺激并且不消除所施用组合物的生物活性和性质的载体或稀释剂。术语“赋形剂”是指添加到药物组合物以进一步促进活性成分施用的惰性物质。实例包括但不限于盐水、碳酸钙、磷酸钙、各种糖和淀粉类型、纤维素衍生物、明胶、植物油、聚乙二醇和表面活性剂,包括例如聚山梨酯(polysorbate)20。
[0191]
可使用一种或多种包含赋形剂和助剂的生理学上可接受的载体(其有利于将活性成分加工成药学上可使用的组合物)以常规方式配制根据本发明使用的药物组合物。适当的配制剂取决于所选择的施用途径和所递送的组合物的性质(如,多肽的大小和溶解性)。在这些实施方案的一个方面,药物组合物配制用于注射或输注到患者的血液。在这些实施方案的另一方面,药物组合物配制用于直接施用于患者的脑或中枢神经系统,例如通过直接髓内、鞘内或心室内注射。
[0192]
本文中所述的组合物可配制用于胃肠外施用,例如通过推注或连续输注。用于胃肠外施用的药物组合物包括水溶性形式的组合物的水溶液。此外,活性成分的悬浮液可制备为油性或基于水的注射悬浮液。合适的亲脂性溶剂或媒介物包括脂肪油如芝麻油,或合成脂肪酸酯如油酸乙酯、甘油三酯或脂质体。水性注射悬浮液可含有增加悬浮液粘度的物质,如羧甲基纤维素钠、山梨糖醇或葡聚糖。任选地,悬浮液还可含有合适的稳定剂或增加活性成分的溶解性以允许制备高度浓缩的溶液的药剂(例如表面活性剂如聚山梨酯(tween20))。可以使用基于蛋白的药剂(如,例如白蛋白)来阻止本发明的多肽吸附至递送表面(即,iv袋、导管、针等)。
[0193]
对于口服施用,药物组合物可通过将本文所述的多肽与本领域公知的药学上可接
受的载体组合来配制。
[0194]
配制剂可以以单位剂量形式呈现于例如小瓶、安瓿或多剂量容器中,任选地具有添加的防腐剂。组合物可以是在油性或水性媒介物中的悬浮液、溶液或乳液,并且可含有配制药剂,如悬浮剂、稳定剂和/或分散剂。单一剂型可以为液体或固体形式。单一剂型可以不经修饰直接施用于患者或者可以在施用前稀释或复溶。在某些实施方案中,单一剂型可以以推注形式施用,例如单次注射、单次口服剂量,包括含有多个片剂、胶囊、丸剂等的口服剂量。在可选择的实施方案中,可在一段时间内施用单一剂型,如通过输注,或经由植入的泵,如icv泵。在后一种实施方案中,单一剂型可以是预填充适量的包含gaim变体的多肽的输液袋或泵储器。可选择地,输液袋或泵储器可正好在对患者施用前通过将适当剂量的包含gaim变体的多肽与输液袋或泵储器溶液混合来制备。
[0195]
本发明的另一方面包括制备本发明的药物组合物的方法。用于制备药物的技术可以参见例如“remington's pharmaceutical sciences”,mack publishing co.,easton,pa.(最新版本),其通过引用整体并入本文。
[0196]
适用于本发明上下文的药物组合物包括其中以有效实现预期目的的量含有活性成分的组合物。
[0197]
治疗或诊断有效量的确定完全在本领域技术人员的能力范围内,特别是鉴于本文中提供的详细公开内容。
[0198]
可单独调整剂量量和间隔以提供足以治疗或诊断特定脑疾病、病症或状况的噬菌体展示媒介物的脑水平(最小有效浓度,mec)。mec将随每种制剂而异,但可从体外数据估算。实现mec所必需的剂量取决于个体特征。
[0199]
还可使用mec值确定剂量间隔。制剂应当利用方案施用,所述方案将高于mec的脑水平维持10至90%的时间,优选30至90%的时间,最优选50至90%的时间。
[0200]
根据待治疗的疾病的严重性和响应性,给药可以是单次或多次施用,其中治疗过程持续数天至数周或直到实现治愈或实现疾病状态的减少。
[0201]
当然,待施用的组合物的量将取决于治疗或诊断的受试者、痛苦的严重性、处方医生的判断等。
[0202]
如果需要的话,本发明的组合物可呈现于包装或分配器装置中,如fda批准的试剂盒,其可含有一种或多种含有活性成分的单位剂型。包装可以例如包括金属或塑料箔,如泡罩包装。包装或分配器装置可附有施用说明。
[0203]
包装或分配器还可容纳与容器相关的通知,其形式由监管药品生产、使用或销售的政府机构规定,所述通知反映了该机构批准组合物或人或兽医施用的形式。例如,此类通知可以是美国食品和药物管理局批准用于处方药的标签或批准的产品插页。包含在相容的药物载体中配制的本发明的制剂的组合物也可以被制备、放置于适当的容器中,并标记用于治疗指定的疾病,如本文进一步详述。
[0204]
治疗用途
[0205]
本发明的另一方面涉及本发明的多肽、核酸分子或组合物中的任何一种在治疗与错误折叠和/或聚集的淀粉样蛋白相关的一种或多种疾病中的用途,包括但不限于涉及以下任何一种的那些疾病:甲状腺素运载蛋白、免疫球蛋白轻链(κ或λ)、faβ42、fαsyn或ftau。
[0206]
在治疗的上下文中,术语“患者”、“受试者”和“受体”可互换使用,并且包括人以及
其它哺乳动物。在一些实施方案中,患者是对与蛋白质错误折叠疾病相关的生物标志物呈阳性的人。在一个实施方案中,如通过利用florbetapir的pet成像检测,患者表现出β
‑
淀粉样蛋白沉积物。
[0207]
术语“治疗”及其同源词是指减轻、减缓或逆转表现出疾病的一种或多种临床症状的患者的疾病进展。“治疗”也指减轻、减缓或逆转表现出疾病的一种或多种临床症状的患者的疾病症状。在一个实施方案中,如通过利用florbetapir的pet成像检测,患者表现出β
‑
淀粉样蛋白沉积物,并且β
‑
淀粉样蛋白沉积物的数量通过治疗减少。在一个实施方案中,如通过本发明的多肽或多肽组合物检测,患者表现出β
‑
淀粉样蛋白沉积物,并且β
‑
淀粉样蛋白沉积物的数量通过治疗减少或维持。在另一个实施方案中,如通过pet成像检测,患者表现出任何类型的淀粉样蛋白沉积物,并且患者的认知功能通过治疗改善。认知功能的改善可以通过mckhann et al.,alzheimer’s&dementia7(3):263
‑
9(2011)的方法和测试来测定。
[0208]“预防”或“防止”(在本文中可互换使用)不同于治疗,并且指在任何临床症状出现前将多肽、核酸或组合物施用于个体。涵盖使用本发明的多肽、核酸或其组合物中任一者的预防。预防可以牵涉仅仅基于一种或多种遗传标志物而已知处于增加的患病风险或确定患病的个体。许多遗传标志物已被鉴定用于各种蛋白质错误折叠疾病。例如,具有happ中的瑞典型突变、印第安纳型突变或伦敦型突变中的一种或多种的个体处于增加的患早发性阿尔茨海默氏病的风险,因而是预防的候选者。同样,具有亨廷顿蛋白基因中的三核苷酸cag重复序列的个体,特别是具有36个或更多个重复序列的个体将最终患亨廷顿氏病,因而也是预防的候选者。
[0209]
与错误折叠和/或聚集的淀粉样蛋白相关或以其为特征的疾病包括与错误折叠的淀粉样蛋白、聚集的淀粉样蛋白、或者错误折叠和聚集的淀粉样蛋白二者相关(如,至少部分地由其引起或相关联)的疾病。可形成淀粉样蛋白的肽或蛋白如以上所述。例如,在一些实施方案中,淀粉样蛋白由aβ形成,包括但不限于aβ40、aβ42、n
‑
截短的aβ11
‑
42、aβ11
‑
42
‑
pyro、aβ3
‑
42
‑
pyro、aβ1
‑
42
‑
e22q
‑
dutch突变、或它们的组合。在一些实施方案中,淀粉样蛋白由朊病毒蛋白,例如prp
sc
形成。在一些实施方案中,淀粉样蛋白由甲状腺素运载蛋白形成。在一些实施方案中,淀粉样蛋白由免疫球蛋白轻链如免疫球蛋白κ轻链和/或免疫球蛋白λ轻链形成。在一些实施方案中,淀粉样蛋白由tau形成。在一些实施方案中,淀粉样蛋白由α
‑
突触核蛋白形成。
[0210]
与错误折叠和/或聚集的淀粉样蛋白相关或以其为特征的疾病如上所述。许多上述折叠错误和/或聚集的淀粉样蛋白疾病都发生在中枢神经系统(cns)。cns中发生的疾病的非限制性实例是帕金森氏病;阿尔茨海默氏病;额颞叶痴呆(ftd),包括具有以下临床综合征的患者:行为异常型ftd(bvftd)、进行性非流畅性失语(pnfa)和词义性痴呆(sd);额颞叶变性(ftld);以及亨廷顿氏病。本发明的多肽、核酸和组合物可用于治疗以中枢神经系统(cns)中发生的错误折叠和/或聚集的淀粉样蛋白为特征的疾病。
[0211]
蛋白的错误折叠和/或聚集也可发生在cns之外。淀粉样变性a(aa)(其前体蛋白是血清急性期载脂蛋白,saa)和多发性骨髓瘤(前体蛋白免疫球蛋白轻链和/或重链)是两种广为人知的在cns之外发生的蛋白错误折叠和/或聚集的蛋白疾病。其它实例包括涉及由以下形成的淀粉样蛋白的疾病:α2
‑
微球蛋白、甲状腺素运载蛋白(如,fap、fac、ssa)、(apo)血
清aa、载脂蛋白ai、aii和aiv、凝溶胶蛋白(如,fap的芬兰型)、免疫球蛋白轻链(κ或λ)、溶菌酶、纤维蛋白原、半胱氨酸蛋白酶抑制剂c(如,脑淀粉样血管病,遗传性脑出血伴淀粉样变性,冰岛型)、降钙素、原降钙素、胰岛淀粉样蛋白多肽(如,iapp淀粉样变性)、心钠素、催乳素、胰岛素、乳粘素、角膜
‑
上皮素、乳铁蛋白、牙源性成釉细胞相关蛋白和精胶蛋白i。可将本发明的多肽、核酸和组合物用于治疗涉及在cns之外发生的蛋白的错误折叠和/或聚集的疾病。
[0212]
与错误折叠和/或聚集的淀粉样蛋白相关或以其为特征的疾病还可涉及tau病变。综述于lee et al.,annu.rev.neurosci.24:1121
‑
159(2001)。tau蛋白是中枢和外周神经系统神经元二者的轴突中表达的微管关联蛋白。涵盖神经变性tau蛋白病(有时称为tau蛋白病)。tau蛋白病的实例包括阿尔茨海默氏病、肌萎缩侧索硬化/帕金森
‑
痴呆综合征、嗜银颗粒痴呆、皮质基底变性、克罗伊茨费尔特
‑
雅各布病、拳击员痴呆、弥漫性神经原纤维缠结伴钙化、唐氏综合征、额颞叶痴呆(包括与染色体17有关的前颞痴呆伴帕金森病)、gerstmann
‑‑
scheinker病、hallervorden
‑
spatz病、强直性肌营养不良、c型尼曼
‑
皮克病、伴发神经原纤维缠结的非关岛型运动神经元病、皮克氏病、脑炎后帕金森病、朊病毒蛋白脑淀粉样血管病、进行性皮质下神经胶质增生、进行性核上性麻痹、亚急性硬化性全脑炎以及缠结性痴呆。这些疾病中的一些还可包含纤维淀粉样蛋白β肽的沉积物。例如,阿尔茨海默氏病表现出淀粉样蛋白β沉积和tau病变二者。类似地,朊病毒介导的疾病,如克罗伊茨费尔特
‑
雅各布病、朊病毒蛋白脑淀粉样血管病和gerstmann
‑‑
scheinker综合征也可以具有tau病变。因此,指出疾病是“tau蛋白病”不应当被理解将该疾病排除在其它神经变性或者错误折叠和/或聚集的淀粉样蛋白疾病分类或分组之外,其仅仅为了方便而提供。可使用本发明的多肽和组合物治疗神经变性性疾病以及涉及tau病变的疾病。
[0213]
在一些实施方案中,多肽、药物组合物或配制剂是用于在表现出与淀粉样蛋白存在相关的症状或对与蛋白质错误折叠疾病相关的生物标志物呈阳性的患者中减少淀粉样蛋白的方法,包括向患者施用有效量的如本文中所述的药物组合物或配制剂。在一些实施方案中,多肽、药物组合物或配制剂是用于在表现出与淀粉样蛋白存在相关的症状或对与蛋白质错误折叠疾病相关的生物标志物呈阳性的患者中维持淀粉样蛋白水平的方法,包括向患者施用有效量的如本文中所述的药物组合物或配制剂。在这些实施方案的一些方面,生物标志物为β
‑
淀粉样蛋白,其可通过放射性药物florbetapir(av
‑
45,eli lilly)来检测。在这些实施方案的一些方面,施用途径为鞘内注射或输注、直接心室内注射或输注、实质内注射或输注,或者静脉内注射或输注。
[0214]
在一些实施方案中,多肽、药物组合物或配制剂是用于在患者中解聚或重构淀粉样蛋白的方法。在一些实施方案中,多肽、药物组合物或配制剂是用于减少脑中淀粉样蛋白形成的方法。在一些实施方案中,本发明的多肽、药物组合物或配制剂是用于促进脑中淀粉样蛋白清除的方法。在一些实施方案中,本发明的多肽、药物组合物或制剂是用于抑制脑中淀粉样蛋白聚集的方法。在一些实施方案中,本发明的多肽、药物组合物或配制剂是用于清除脑中毒性寡聚物的方法中。在一些实施方案中,本发明的多肽、药物组合物或制剂是用于预防脑中毒性寡聚物形成的方法。在一些实施方案中,本发明的多肽、药物组合物或配制剂是用于保护神经元免受淀粉样蛋白损伤的方法。在一些实施方案中,多肽、药物组合物或配制剂是用于减少α
‑
突触核蛋白聚集体的细胞间传播的方法。在一些实施方案中,多肽、药物
组合物或配制剂是用于阻断α
‑
突触核蛋白聚集体的细胞间传播的方法。在这些实施方案的一些方面,通过鞘内注射或输注、直接心室内注射或输注、实质内注射或输注、或者静脉内注射或输注,将多肽、药物组合物或配制剂向有此需要的患者施用。
[0215]
在一些实施方案中,本发明的多肽、药物组合物或配制剂是用于导致脑中aβ
‑
淀粉样蛋白沉积物解聚的方法,包括将有效量的多肽、药物组合物或配制剂直接注射至有此需要的患者的脑,从而导致脑中aβ
‑
淀粉样蛋白沉积物的减少。在其他实施方案中,本发明的多肽、药物组合物或配制剂是用于导致脑中aβ
‑
淀粉样蛋白沉积物解聚的方法,包括将有效量的多肽、药物组合物或配制剂静脉内递送注射至有此需要的患者,从而导致脑中aβ
‑
淀粉样蛋白沉积物的减少。
[0216]
在一个实施方案中,用于保护神经元免受淀粉样蛋白损伤的本发明的药物组合物或配制剂是预防性给予的。
[0217]
在一些实施方案中,患者对与蛋白质错误折叠和/或聚集疾病相关的生物标志物呈阳性。在一个实施方案中,生物标志物是β
‑
淀粉样蛋白,并且用于检测β
‑
淀粉样蛋白的试剂是florbetapir(av45,eli lilly)。
[0218]
与基于抗体的现有技术疗法(例如6e10)不同,如本文所述的gaim
‑
ig融合体靶向淀粉样蛋白的核心而不是非结构化或部分结构化的n
‑
末端残基,并表现出优异的重构活性(图10a)。因此,在一些实施方案中,本发明的多肽、药物组合物或配制剂是用于重构淀粉样蛋白的方法。在这些实施方案的一些方面,施用途径是鞘内注射或输注、直接心室内注射或输注、实质内注射或输注、或者静脉内注射或输注。
[0219]
通常,本文公开的多肽与现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白至少一样有效地结合淀粉样蛋白。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地结合淀粉样蛋白。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地重构淀粉样蛋白。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地抑制淀粉样蛋白聚集。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地清除毒性寡聚物。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地减少α
‑
突触核蛋白聚集体的细胞间传播。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地检测淀粉样蛋白。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地预防与错误折叠和/或聚集的淀粉样蛋白相关的疾病。在一些实施方案中,本文公开的多肽比现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白更有效地治疗与错误折叠和/或聚集的淀粉样蛋白相关的疾病。在一些实施方案中,与现有技术中公开的m13噬菌体g3p或g3p的变体或融合蛋白相比,本文公开的多肽在患者中引发更小的免疫应答。在至少一个实施方案中,本文公开的多肽在患者中不引发免疫应答。
[0220]
在另一实施方案中,上述的任何疾病可通过任何合适的途径如吸入和静脉内输注,直接向患者施用单独或与合适的载体如脂质纳米颗粒、聚合物载体或诸如病毒载体的载体结合的本发明的核酸分子(即,编码包含gaim变体的多肽,所述gaim变体表现出降低的免疫原性或无免疫原性,并具有结合淀粉样蛋白、解聚/重构淀粉样蛋白、和/或抑制淀粉样
蛋白聚集的能力)来治疗。编码包含gaim变体的多肽的核酸分子可以是dna或rna。
[0221]
诊断
[0222]
诊断组合物是本发明涵盖的,并且可包含本发明上述多肽(如,包含gaim变体的多肽,例如包含gaim
‑
ig融合体的多肽)中的任何一种。因此,在一些实施方案中,将本文所述的多肽、药物组合物和配制剂用于与本文所述的各种疾病相关的诊断应用中。例如,可将本发明的多肽与淀粉样蛋白的结合用于检测结合的淀粉样蛋白。类似地,在体内或体外用作显像剂时,本发明多肽的结合可以是本文所述的蛋白错误折叠、蛋白聚集或神经变性性疾病诊断的一部分。
[0223]
在一些实施方案中,将本文所述的多肽用作淀粉样蛋白显像剂,其中所述显像剂可检测淀粉样蛋白并诊断与错误折叠和/或聚集的淀粉样蛋白相关的疾病。由于本文所述的多肽结合淀粉样蛋白,与纤维类型无关,因此它们可以成像和检测任何淀粉样蛋白聚集体(αβ、tau、α
‑
突触核蛋白、甲状腺素运载蛋白、免疫球蛋白轻链等),并且可诊断一大批淀粉样蛋白相关的疾病和病况。在一些实施方案中,用作淀粉样蛋白显像剂的多肽进一步包含可检测的标记物。
[0224]
利用标记蛋白的标准技术,可将各种标记物附着到包含如本文所述的gaim变体的多肽。标记物的实例包括荧光标记物和放射性同位素标记物。可使用多种放射性同位素标记物,但一般而言,标记物通常选自放射性同位素标记物,包括但不限于
18
f、
11
c、和
123
i。这些和其他放射性同位素可利用公知的化学方法附着到蛋白。在一个实施方案中,标记物利用正电子发射断层摄影术(pet)来检测。然而,用于检测放射性同位素的任何其它合适的技术也可用来检测放射性示踪剂。
[0225]
本发明的多肽和组合物可与对β
‑
淀粉样蛋白特异的显像剂如例如f18
‑
av
‑
45(eli lilly)组合用作诊断显像剂。由于本发明的诊断组合物和β
‑
淀粉样蛋白特异性显像剂一起使用会导致基于差异检测的非β
‑
淀粉样蛋白聚集体的检测,在一个实施方案中,本发明的诊断组合物与β
‑
淀粉样蛋白显像剂组合用作显像剂来检测非β
‑
淀粉样蛋白聚集体。
[0226]
在一些实施方案中,将本文所述的多肽或其组合物用于检测包括脑在内的cns中的β
‑
淀粉样蛋白。
[0227]
本发明的诊断组合物可以使用与治疗组合物所述相同的途径施用。在一些实施方案中,施用途径是鞘内注射或输注、直接心室内注射或输注、实质内注射或输注、或静脉内注射或输注。
[0228]
重组技术
[0229]
在一些方面,本发明涉及包含编码本发明的多肽的核酸序列的寡核苷酸。例如,如本文所公开,本发明涉及编码包含gaim变体的多肽的核酸序列,包括包含直接或通过小接头附着至免疫球蛋白恒定区的gaim变体的多肽。通常,编码包含gaim变体或gaim
‑
ig融合体的多肽的核酸使用常规重组dna技术来制备,例如克隆突变体gaim域,直接dna合成,或通过利用例如m13序列作为探针从文库中分离相应的dna来制备。参见例如sambrook et al.1989,molecular cloning alaboratory manual,cold spring harbor laboratory,n.y.;ausubel et al.1989,current protocols in molecular biology,greene publishing associates and wiley lnterscience,n.y。编码包含gaim变体或gaim
‑
ig融合体的多肽的核酸还可按照以下实施例中提供的方法来制备。
[0230]
为了重组产生,可将本发明的任何核酸序列插入合适的表达载体中,该载体包含转录和翻译所插入的编码序列所必需的元件,或者在rna病毒载体的情况下,复制和翻译所必需的元件。将编码核酸以适当的阅读框插入至载体。因此,本发明提供了包含本发明核酸的载体。此类载体包括但不限于dna载体、噬菌体载体、病毒载体、逆转录病毒载体等。载体可包括例如杆状病毒、花椰菜花叶病毒、烟草花叶病毒、ri质粒或ti质粒。利用载体与进行表达的所选宿主细胞的相容性的公知常识,本领域技术人员可以选择在其中克隆本发明核酸的合适载体。这可以在哺乳动物细胞、植物细胞、昆虫细胞、细菌细胞、真菌细胞、转基因动物细胞等的任一种中完成。适用于产生本文所述多肽的示例性哺乳动物细胞包括但不限于hek293细胞、hek293来源的细胞、cho细胞、cho来源的细胞、hela细胞和cos细胞。示例性细菌细胞包括但不限于大肠杆菌细胞。示例性植物细胞包括但不限于浮萍细胞。参见,例如,美国专利号8,022,270。这些细胞类型中每种的适当载体是本领域众所周知的,并且通常是可商购的。非限制性的示例性转染方法描述于sambrook et al.,molecular cloning,alaboratory manual,第3版cold spring harbor laboratory press(2001)。可根据本领域已知的方法在所期望的宿主细胞中瞬时或稳定地转染核酸。
[0231]
在至少一个实施方案中,核酸编码包含seq id no:19的氨基酸序列的多肽。在至少一个实施方案中,核酸编码包含seq id no:20的氨基酸序列的多肽。在至少一个实施方案中,核酸编码包含seq id no:21的氨基酸序列的多肽。在至少一个实施方案中,核酸编码包含seq id no:22的氨基酸序列的多肽。在至少一个实施方案中,核酸编码包含seq id no:23的氨基酸序列的多肽。在至少一个实施方案中,核酸编码包含seq id no:24的氨基酸序列的多肽。在至少一个实施方案中,核酸编码包含seq id no:25的氨基酸序列的多肽。在至少一个实施方案中,该核酸编码包含seq id no:26的氨基酸序列的多肽。
[0232]
在至少一个实施方案中,核酸编码基本上由seq id no:19和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本上由seq id no:20和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本上由seq id no:21和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本上由seq id no:22和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本上由seq id no:23和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本上由seq id no:24和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本由seq id no:25和人igg(如,人igg1)的fc部分组成的多肽。在至少一个实施方案中,核酸编码基本上由seq id no:26和人igg(如,人igg1)的fc部分组成的多肽。
[0233]
在一些实施方案中,核酸编码基本上由seq id no:29(pb108)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:30(pb122)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:31(pb116)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:32(pb114)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:33(pb109)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:34(pb110)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:35(pb105)的氨基酸序列组成的多肽。在一些实施方案中,核酸编码基本上由seq id no:36(pb127)的氨基酸序列组成的多
肽。如上所述,这些实施方案包括编码seq id no:29、30、31、32、33、34、35或36的变体的核酸,其中变体缺少氨基酸1(δm1)、氨基酸1和2(δm1和δa2)、氨基酸485(δk485)、氨基酸1和485(δm1和δk485)、或者氨基酸1、2和485(δm1、δa2和δk485)。
[0234]
在一些实施方案中,编码本发明多肽的核酸包含seq id no:37。在一些实施方案中,核酸包含seq id no:38。在一些实施方案中,核酸包含seq id no:39。在一些实施方案中,核酸包含seq id no:40。在一些实施方案中,核酸包含seq id no:41。在一些实施方案中,核酸包含seq id no:42。在一些实施方案中,核酸包含seq id no:43。在一些实施方案中,核酸包含seq id no:44。在一些实施方案中,包含seq id no:37、38、39、40、41、42、43或44中的任一个的核酸进一步包含编码igg(如,人igg1或igg2)的fc部分的核酸。在至少一个实施方案中,编码开放稳定化的gaim变体的核酸和编码igg的fc部分的核酸通过编码小接头的核酸连接。在至少一个实施方案中,核酸编码小接头ars。在一些实施方案中,核酸进一步编码信号序列。在一些实施方案中,核酸进一步编码具有genbank ref seq np_510891.1的18个氨基酸的n
‑
末端序列的信号序列。
[0235]
在至少一个实施方案中,编码本发明多肽的核酸是seq id no:45。在至少一个实施方案中,核酸是seq id no:46。在至少一个实施方案中,核酸是seq id no:47。在至少一个实施方案中,核酸是seq id no:48。在至少一个实施方案中,核酸是seq id no:49。在至少一个实施方案中,核酸是seq id no:50。在至少一个实施方案中,核酸是seq id no:51。在至少一个实施方案中,核酸是seq id no:52。
[0236]
用于转化的载体通常包含用于鉴定转化子的选择性标志物。在细菌系统中,这可包括抗生素抗性基因,例如氨苄青霉素或卡那霉素。用于培养的哺乳动物细胞的选择性标志物包括赋予诸如新霉素、潮霉素和氨甲蝶呤的药物抗性的基因。选择性标志物可以是可扩增的选择性标志物。一种可扩增的选择性标志物是dhfr基因。另一种可扩增的标志物是dhfrr edna(simonsen and levinson,pnas(1983)80:2495)。选择性标志物由thilly(mammalian cell technology,butterworth publishers,stoneham,ma)审查,并且选择性标志物的选择完全在本领域普通技术人员的能力范围内。表达系统的表达元件的强度和特异性不同。取决于所使用的宿主/载体系统,许多合适的转录和翻译元件中的任何一种,包括组成型和诱导型启动子,均可在表达载体中使用。例如,在细菌系统中克隆时,可使用诱导型启动子,例如噬菌体λ的pl、plac、ptrp、ptac(ptrp
‑
lac杂合启动子)等;在昆虫细胞系统中克隆时,可使用诸如杆状病毒多面体启动子等启动子;在植物细胞系统中克隆时,可使用源自植物细胞基因组的启动子(如,热休克启动子;rubisco小亚基的启动子;叶绿素a/b结合蛋白的启动子)或植物病毒(如,camv的35s rna启动子;tmv的外壳蛋白启动子;在哺乳动物细胞系统中克隆时,可使用源自哺乳动物细胞基因组的启动子(如,金属硫蛋白启动子)或源自哺乳动物病毒的启动子(如,腺病毒晚期启动子;痘苗病毒7.5k启动子);当产生包含表达产物的多个拷贝的细胞系时,可将基于sv40、bpv和ebv的载体与适当的选择性标志物一起使用。在使用植物表达载体的情况下,编码本发明表达产物的线性或非环化形式的序列的表达可由许多启动子中的任何一个驱动。例如,可使用病毒启动子,如camv的35s rna和19s rna启动子(brisson et al.,nature(1984)310:511
‑
514),或tmv的外壳蛋白启动子(takamatsu et al.,embo j(1987)6:307
‑
311);或者,可使用植物启动子如rubisco的小亚基(coruzzi et al.,embo j.(1984)3:1671
‑
1680;broglie et al.,science(1984)
224:838
‑
843)或热休克启动子,如大豆hsp17.5
‑
e或hsp17.3
‑
b(gurley et al.,mol.cell.biol.(1986)6:559
‑
565)。可使用ti质粒、ri质粒、植物病毒载体、直接dna转化、显微注射、电穿孔等将这些构建体引入植物细胞中。参见例如weissbach&weissbach 1988,methods for plant molecular biology,academic press,ny,section viii,pp.421
‑
463;和grierson&corey 1988,plant molecular biology,2d ed.,blackie,london,ch.7
‑
9。在可用于产生本发明蛋白的一种昆虫表达系统中,将苜蓿银纹夜蛾(autographa californica)核多角体病病毒(nuclear polyhidrosis virus)(acnpv)用作表达外源基因的载体。该病毒草地贪夜蛾细胞中生长。可将编码序列克隆到病毒的非必需区(如,多面体基因)中,并放置于acnpv启动子(如,多面体启动子)的控制下。成功插入编码序列导致多面体基因失活并产生非封闭的重组病毒,即缺少由多面体基因编码的蛋白性外壳的病毒。将这些重组病毒用于感染表达插入基因的草地贪夜蛾细胞。参见例如smith et al.,j.viral.(1983)46:584;美国专利号4,215,051。这种表达系统的其他实例见ausubel et al.编1989,current protocols in molecular biology,vol.2,greene publish.assoc.&wiley lnterscience。
[0237]
在哺乳动物宿主细胞中,可使用几种基于病毒的表达系统中的任何一种。在将腺病毒用作表达载体的情况下,可将编码序列连接至腺病毒转录/翻译控制复合体,例如晚期启动子和三分型前导序列。然后通过体外或体内重组可将该融合基因插入至腺病毒基因组。插入病毒基因组的非必需区域(如,区域e1或e3)将产生重组病毒,该重组病毒在被感染的宿主中是活的且能够表达肽(参见例如logan&shenk,pnas(1984)81:3655)。可选择地,可使用痘苗7.5k启动子(mackett et al.,pnas(1982)79:7415;mackett et al.,j.viral.(1984)49:857;panicali et al.,pnas(1982)79:4927)。其他病毒表达系统包括腺相关病毒和慢病毒。
[0238]
在另一个实施方案中,本发明提供了宿主细胞,其携带含有本发明核酸的载体。将本发明的载体转染或转化至宿主细胞或以其他方式获取至宿主细胞的方法是本领域已知的。在合适的条件下培养时,携带载体的细胞将产生本发明的多肽。如上所述,合适的宿主细胞包括但不限于哺乳动物细胞、转基因动物细胞、植物细胞、昆虫细胞、细菌细胞和真菌细胞。例如,合适的宿主细胞包括但不限于hek293细胞、hek293来源的细胞、cho细胞、cho来源的细胞、hela细胞和cos细胞。
[0239]
包含核酸构建体(如,载体)的宿主细胞在适当的生长培养基中生长。如本文所用,术语“适当的生长培养基”是指具有细胞生长所需营养素的培养基。可使用本领域已知的技术从培养基中分离重组产生的本发明的多肽。
[0240]
用于重组产生本发明的多肽的载体和细胞的具体实例在以下实施例中列出。
实施例
[0241]
实施例1:tauk18p301l表达、纯化和纤维组装
[0242]
如针对tau
‑
mtbr所述(krishnan et al.(2014)j mol biol,426:2500
‑
19),表达并纯化对应于具有p213l突变的tau
‑
441(2n4r)残基244
‑
372的人tauk18p301l片段。tau
‑
k18p301l纤维通过以下组装:向含2mm dtt的0.1m乙酸钠ph 7.0缓冲液中的40μm tauk18p301l单体添加40μm低分子量肝素(fisher scientific),并于37℃温育3天。通过硫
黄素t(thioflavin t)(tht)确认纤维形成。
[0243]
实施例2:aβ纤维组装
[0244]
将aβ1
‑
42(rpeptide)、n
‑
截短的aβ11
‑
42(bachem)、aβ11
‑
42
‑
pyro(anaspec)、aβ3
‑
42
‑
pyro(anaspec)和aβ1
‑
42
‑
e22q(anaspec)溶解于六氟异丙醇(hfip)中,并于室温温育24小时,直到形成澄清溶液。将肽溶液于真空下干燥1小时。纤维按照stine等,2003年的方法进行组装。将100微克aβ肽溶解于40μl dmso中,于10mm hcl溶液中稀释至1140μl,并于37℃以500rpm摇动温育24小时。通过tht确认纤维形成。
[0245]
实施例3:gaim
‑
ig融合蛋白的产生
[0246]
在面向gaim域的内部沟的β链中进行对照支架pb120的位点特异性诱变(图1a)。这些β链,n1域中的4和5以及n2域中的9和10在gaim闭合状态下促进域间相互作用,并防止暴露tola结合位点(hoffman
‑
thoms et al.(2013)j biol chem,288:12979
‑
91),先前显示该结合位点与gaim中的淀粉样蛋白结合基序部分重叠(krishnan et al.(2014)j mol biol,426:2500
‑
19)。此外,对参与n1
‑
n2域组装的n2
‑
铰链区以及对f
‑
菌毛结合重要的n2中的特定区域中的位点进行突变(weininger et al.(2009)pnas,106:12335
‑
40;deng and perham(2002)j mol biol,319:603
‑
14),以研究在噬菌体感染期间gaim淀粉样蛋白结合活性如何转化为其功能。
[0247]
利用expi293
tm
表达系统(thermo fisher scientific)根据制造商的说明表达gaim
‑
ig融合蛋白。蛋白的纯化在20mm磷酸钠(ph 7.0)中的mabselecttm suretm柱(ge healthcare lifesciences)上进行,然后在20cv内利用akta
tm pure fplc系统在ph 4.0至ph 3.6的20mm乙酸钠中进行梯度洗脱。将融合蛋白透析至d
‑
pbs(ph 7)中,并过滤灭菌(旋转柱,millipore)。蛋白纯度通过nupage
tm 4
‑
12%bis
‑
tris凝胶系统利用mes sds运行缓冲液(thermo fisher scientific),随后instantblue
tm
染色液(expedeon)进行分析。此外,使用ultimate
tm 3000uhplc聚焦系统(thermofisher scientific)中的g3000sw xl,7.8mm idx30cm,5μm柱(tosoh biosciences),将分析sec用于评估gaim igg融合体的纯度。对于每个样品,将7.5μg蛋白注入sec柱,在d
‑
pbs流动相中以0.5ml/min的流速进行分离。使用chromeleon
tm 7软件分析峰纯度。gaim igg融合体变体由atum合成。
[0248]
实施例4:gaim二聚体的产生
[0249]
于37℃利用(ides)酶(genovis)2小时从gaim
‑
ig融合体产生gaim二聚体,该酶特异性地将融合体夹在免疫球蛋白铰链处以产生通过两个二硫键连接的gaim二聚体(图1c)。切割继之以通过capto
tm adhere根据制造商的方案与fc分离。在mes sds运行缓冲液中分离的nupage
tm4‑
12%bis
‑
tris凝胶系统上确认gaim二聚体的纯度。于25℃在具有增加浓度的胍(sigma)的100mm磷酸钾(ph 7.0)中温育gaim二聚体(0.5μm)2小时。在10mm腔室中,280nm激发后310mm和340nm处以及295nm激发后360nm处测量荧光。利用假设荧光发射与盐酸胍浓度线性相关的二态折叠模型来分析数据。在sds
‑
page凝胶上确认预期的分子大小和fc片段的清除后,对蛋白进行解折叠研究。
[0250]
实施例5:通过orange结合测定监测gaim的热解折叠
[0251]
进行orange结合测定以监测gaim域分离和n2域的稳定性。在水溶液中
orange与闭合构象的折叠的gaim结合较差。当gaim的两个域解离并暴露疏水残基时,染料与暴露的疏水表面结合并显示出增强的荧光。在96孔板中将pbs中的1微摩尔gaim
‑
ig融合体与20倍过量的orange(invitrogen目录号s
‑
6650)混合并密封。在roche480rt
‑
pcr中,通过以0.24℃/分钟的速度从20℃持续升温至95℃来监测热解折叠。激发设置为465nm,发射设置为580nm,熔融因子为1,定量因子为10,最大集成时间为2秒。记录荧光信号的任意单位,并相对于0
‑
100的量表(layton and hellinga,2011)标准化。
[0252]
通过orange结合监测的gaim单体的热解折叠显示约43℃的单一转变,其对应于域开放和n2解折叠转变(图4a至图4b)。根据实施例4获得的gaim二聚体显示与溶液中的单体相同的熔解概况,而溶液中的gaim
‑
ig融合体在热解折叠时显示三次不同的转变(图4a至图4b)。如gaim单体和二聚体中看到,第一次转变tm1发生在约44℃(图4b)。在64℃和81℃的两次额外转变类似于fc域解折叠转变(traxlmayr et al.,2012,biochim biophys acta,1824:524
‑
529)。比较gaim特异性tm1显示,gaim和fc域保留为独立的折叠域,并且在嵌合分子中未产生新的结构元件。
[0253]
实施例6:在igg融合二聚体中gaim保持其天然构象稳定性
[0254]
通过固有荧光,利用盐酸胍(guhcl)诱导的gaim二聚体的解折叠来研究igg融合体中gaim的构象稳定性。如实施例4所述产生gaim二聚体,并于25℃在0、2和5m guhcl溶液中平衡2小时。trp残基在295nm处的选择性激发显示gaim二聚体荧光强度在0至2m浓度之间变化最小,而发射λmax(345nm)未变化(图5a)。在5m guhcl下,trp荧光红移15nm(λmax360 nm),并且荧光强度显著比0和2m样品两者更高。然后,在280nm处激发gaim二聚体(trp和tyr残基)并记录荧光发射光谱(图5b)。340nm处的荧光发射强度在0至2m guhcl之间降低,然后在5m guhcl下增加相似的边际(margin)。在g3p中也观察到类似的光谱变化(martin and schmid,2003,j mol biol,328:863
‑
75),表明gaim
‑
ig融合变体中的gaim保留了天然g3p中gaim的天然构象稳定性。
[0255]
通过在一定浓度范围的guhcl中记录310、340和360nm处的荧光发射强度,我们生成了gaim二聚体的详细变性概况。在280nm激发时,gaim二聚体在340nm处显示双相变性概况(图5c)。第一次转变发生在1至2m guhcl之间,下一次发生在2至3m guhcl之间。然后,我们将310nm(激发280nm)和360nm(激发295nm)变性概况拟合到二态蛋白解折叠模型(图5d至图5e),并分别计算1.5m和2.6m guhcl下n2和n1域变性转变。在1.5m guhcl下的第一次转变代表两个域n1和n2的分离以及不太稳定的n2域的同时解折叠。第二次转变代表在2.6m guhcl下更稳定的n1域的解折叠。这些值对应于先前报道的g3p中的变性转变(martin and schmid,2003,j mol biol,328:863
‑
75)。因此,这些数据表明,gaim
‑
ig融合体中gaim二聚体的各个gaim形成独立的折叠单元,并采用类似于来自丝状噬菌体的g3p tip蛋白的构象。
[0256]
实施例7:gaim
‑
ig融合体结合aβ和tau纤维
[0257]
将50微升50mm碳酸盐缓冲液(ph 9.6)中的aβ纤维(0.8μm)或tauk18p301l纤维(1μm)添加到96孔板(thermo fisher)的每个孔中,并于4℃温育16小时。将孔用dpbs
‑
tween(0.05%)洗涤3次,并且用dpbs洗涤2次,然后于室温用superblock
tm
(thermo scientific)封闭1.5小时。将孔用pbs洗涤3次。将gaim
‑
ig融合体以指定浓度添加到高浓度
的pbs
‑
t(14.7mm kh2po4,80.6mm na2hpo4‑
7h2o,27mm kcl,1.38m nacl,0.05%tween)中,并于37℃温育2小时,然后在dpbs
‑
tween(0.05%)中洗涤3次,并用dpbs洗涤3次。于37℃加入以1:5000稀释于含0.2%明胶的dpbs
‑
tween(0.05%)中的人特异性fc
‑
hrp抗体(jackson immunoresearch,目录号109
‑
035
‑
008)45分钟。在dpbs
‑
tween(0.05%)中洗涤2次并在dpbs中洗涤2次后,用tmb溶液(thermo fisher)显影信号,通过添加0.25n hcl终止反应,并用m1000 pro读板仪记录450nm处的吸光度。
[0258]
通过elisa发现面向gaim的内部沟的n1和n2残基中的大多数突变影响aβ1
‑
42纤维结合(图6a)。突变的gaim变体的结合活性在0.7nm至175nm ec
50
的范围内,代表与faβ42的结合亲和力变化超过250倍。结合效力(ec
50
)与第一次熔解转变(tm1)之间有强的相关性(p值10
‑4,r
s
=0.703)。tm1的降低表示具有增加的结合的gaim的更加开放的构象,具有更高tm1的稳定化变体趋于失去它们的结合活性。这表明当域间相互作用减弱时gaim中的淀粉样蛋白纤维结合基序被暴露,并且与表明gaim结合是温度依赖性的先前数据(krishnan et al.(2014)j mol biol,426:2500
‑
19)一致。
[0259]
为了辨别对faβ42的结合活性变化是否转化至其他淀粉样蛋白,通过elisa对变体子集测试与从tau的微管结合区形成的淀粉样蛋白纤维的结合。比较gaim
‑
ig变体对faβ42和ftau的结合活性(ec
50
)(p值10
‑4,r
s
=0.878;图6b)显示,gaim
‑
ig对两种不同淀粉样蛋白的结合活性的紧密相关性(p值10
‑4,r
s
=0.862)。
[0260]
实施例8:开放稳定化的gaim
‑
ig融合蛋白的结合优于稳定化的gaim
‑
ig融合蛋白
[0261]
gaim中使n2域稳定化且有利于与n1域的更强相互作用的几种突变导致淀粉样蛋白结合降低。通过用qggk(seq id no:10)取代q
156
gtdpvk
162
环(seq id no:7)来消除n2域中含脯氨酸的环,使tm1增加3.6℃,并导致18倍的faβ42结合损失(图7a)。同样,f
135
qnn
138
(seq id no:5)至fqgn(seq id no:8)和r
143
qga
146
(seq id no:6)至vngv(seq id no:9)的氨基酸取代使n2(tm1)稳定,分别为1.8℃和2.5℃。与gaim支架相比,这些稳定的变体显示出降低的faβ42结合活性(图7a)。类似地,引入q128h突变,其使n2铰链亚域和n1的相互作用稳定,从而降低纤维结合(图7a)。n2域中t1、t2或t3的取代都降低了与胶原蛋白的非特异性结合,但是q128h显示微小增加1.4倍(图9)。这类突变体表明,gaim变体的淀粉样蛋白结合活性的效力与其稳定性之间存在相反关系。
[0262]
为了产生gaim的更加开放的构象,用来自丝状噬菌体if1的同源序列egds(seq id no:4)代替n1中的d
24
dktld
29
(seq id no:3)环(图3a),并与n2稳定化突变(如,在图3c中所示的一个或多个转角/环处)结合进行测试。测试了假定开放和n2稳定化的gaim变体的蛋白质量和淀粉样蛋白结合活性。所有开放稳定化的变体均表现出改善的纤维结合活性,具有ec
50
<1.5nm;与更加暴露和可及的淀粉样蛋白纤维结合位点一致(图7b)。一个例外是具有超稳定化n2的egds(seq id no:4)变体(pb113;seq id no:17;tm1=52.7℃),其包含组合的全部三个n2稳定化突变(f
135
qgn
138
、v
143
ngv
146
和q
156
ggk
162
)(分别为seq id no:8、9、10),导致损失faβ42结合活性(图7b)。这可能是由于通过引入域内相互作用或通过过度稳定化n2域,n2中的主要结构变化掩盖gaim中淀粉样蛋白相互作用位点。具有增加的纤维结合的开放稳定化变体失去了tm1和faβ42结合之间的相关性,表明这些变体中淀粉样蛋白结合位点和n2稳定性的解偶联。所有egds
‑
n2(以seq id no:4公开的“egds”)稳定化变体通过sds
‑
page显示良好的蛋白质量,并通过尺寸排阻色谱法(sec)以单体呈现。另外,sec的保留时间
发生了迁移,这进一步表明更加开放的gaim构象异构体分子。
[0263]
实施例9:gaim
‑
ig融合体靶向具有多种多样形态的多个淀粉样蛋白
[0264]
测试了开放稳定化的gaim
‑
ig融合体接合不同类型和构象的aβ聚集体的能力。将各种修饰的aβ肽纤维化,并测量gaim
‑
ig融合体与这些聚集体的结合亲和力。在与aβ42相同的条件下,将n截短的aβ11
‑
42、aβ11
‑
42
‑
pyro、aβ3
‑
42
‑
pyro和aβ1
‑
42
‑
e22q
‑
dutch突变(levy et al,1990;van broeckhoven et al,1990)聚集,并通过tht(图8a
‑
8d)和tem(数据未显示)确认纤维形成。利用这些肽形成的聚集体显示非常多样的形态。例如,pyro
‑
glu 3
‑
42形成在其结构上有几个弯曲的纤维,e22q变体形成光滑的长纤维,而11
‑
42肽形成几个短纤维。通过elisa发现开放稳定化的变体pb108和支架pb120都与这些纤维接合。pb108显示与各种聚集体的结合相比pb120改善了约20倍,ec
50
为0.9
‑
1.9nm(图8a
‑
8d)。类似地,对其他测试的开放稳定化的gaim
‑
ig融合体观察到优异的结合(表2)。
[0265]
表2.开放稳定化的gaim
‑
ig融合体结合并重构淀粉样蛋白
[0266][0267]
*nd=未采集数据
[0268]
表3.开放稳定化的gaim
‑
ig融合体靶向多种淀粉样蛋白
[0269][0270]
*nd=未采集数据。除非另外指明,否则通过elisa确定结合,
[0271]
表2和表3进一步显示开放稳定化的gaim
‑
ig融合体结合不同类型和构象的淀粉样蛋白的能力。例如,表2和表3均显示开放稳定化的gaim
‑
ig融合体以低纳摩尔亲和力结合aβ42和taukl,以及表3进一步证明它们以低纳摩尔亲和力结合形态多样的免疫球蛋白轻链(lc)和甲状腺素运载蛋白(ttr)聚集体。这些数据显示,与对照支架相比在多种多样的一批淀粉样蛋白纤维间的优异靶向性,并且与先前的nmr研究一致,该nmr研究表明gaim接合aβ42纤维中的中部和c末端序列(krishnan et al.(2014)j mol biol,426:2500
‑
19)。
[0272]
实施例10:gaim
‑
ig融合体特异性结合淀粉样蛋白
[0273]
为了排除非特异性结合,以高浓度(1.8μm,比真实底物如faβ42的ec
50
高100倍)测试gaim
‑
ig融合体与其他纤维种类如胶原蛋白的脱靶结合。于37℃将d
‑
pbs中225纳克/孔的人胶原蛋白(sigma目录号c5483)在96孔板(thermo fisher scientific)上固定16小时,接着在superblock
tm
(thermo fisher scientific)中于室温封闭1小时。将pbs
‑
tween(0.05%)中的gaim
‑
ig融合体于37℃温育1小时,接着在pbs
‑
tween(0.05%)中进行3次5分钟洗涤。添加pbs
‑
tween(0.05%)中1:5000的人特异性fc
‑
hrp抗体(jackson immunoresearch,目录号109
‑
035
‑
008),于37℃下45分钟,接着在pbs
‑
tween(0.05%)中洗涤3次5分钟和在pbs中洗涤2次5分钟。用tmb溶液(sigma)产生信号,通过加入0.25n hcl终止反应,并用tecanm1000pro读板仪记录450nm处的吸光度。gaim
‑
ig融合体通过elisa显示与非淀粉样蛋白底物的最小结合(krishnan et al.(2014)j mol biol,426:2500
‑
19)。
[0274]
实施例11:开放稳定化的gaim
‑
ig融合体显示增强的aβ纤维重构
[0275]
在低保留微离心管(fisher scientific 02
‑
681
‑
320)中进行重构测定。这些测定
中使用的缓冲液包含0.05%叠氮化钠来防止微生物生长。为了确保任何样品中都没有蛋白酶污染,所有重构的复合物均在sds
‑
page凝胶上运行,并检查任何降解。对于使用<1μm纤维的测定,取而代之,利用蛋白质印迹分析确认蛋白质量。
[0276]
将aβ42纤维(2.5μm)在有或没有gaim
‑
ig融合变体的情况下于37℃共温育3天。然后将等分试样的复合物与不同浓度的尿素一起温育。将尿素中复合物的tht荧光针对尿素浓度作图。将固定尿素浓度下的重构效率绘制为相比于未进行任何gaim
‑
ig融合体处理情况下的纤维的tht荧光损失百分比。
[0277]
选择具有不同aβ42纤维结合效力的gaim
‑
ig融合体,以确定重构效率是否取决于结合效力和开放构象状态。图10a显示在相同条件和浓度下与aβ42纤维一起温育的不同gaim融合体的重构效率。与低纳摩尔faβ42结合的开放稳定化变体显示重构活性增加2倍到3倍,其中与对照支架(35%)相比,平均重构活性为83%。图10b揭示了改变的faβ42结合与重构活性之间的正相关,使得具有优异aβ结合的gaim
‑
ig融合体也显示优异的重构活性。
[0278]
图10a至图10c以及透射电子显微术数据(参见实施例13;图10d),进一步证明开放稳定化的gaim
‑
ig融合体重构淀粉样蛋白纤维以引起纤维状架构的损失,这与仅仅粘附和掩盖纤维状结构相反。例如,当在增加浓度的尿素中温育但未暴露于gaim
‑
ig融合体时,aβ42纤维抵抗变性,并如通过tht荧光测量,显示1m尿素中的结构变化少于10%(图10c)。在较高的尿素浓度下,tht荧光急剧下降,表明纤维状结构的损失。相反,用亚化学计量量的gaim
‑
ig融合体处理的纤维开始显示在1m尿素下tht结合减少30
‑
90%。该发现表明,gaim
‑
ig融合体结合并改变纤维状结构至不能结合tht的状态,并且gaim重构活性在不同gaim ig融合体之间变化,其中开放稳定化的gaim
‑
ig融合体表现出高重构活性。
[0279]
实施例12:开放稳定化的gaim
‑
ig融合体显示增强的tauk18p301l纤维重构
[0280]
还通过将tau
‑
k18p301l纤维与gaim
‑
ig融合体共温育来进行重构测定,以证明聚集体的重构对于淀粉样蛋白是通用的。
[0281]
在低保留微离心管(fisher scientific 02
‑
681
‑
320)中进行重构测定。这些测定中使用的缓冲液包含0.05%叠氮化钠来防止微生物生长。为了确保任何样品中都没有蛋白酶污染,所有重构的复合物均在sds
‑
page凝胶上运行,并检查任何降解。对于使用<1μm纤维的测定,取而代之,利用蛋白质印迹分析确认蛋白质量。
[0282]
与faβ42纤维不同,tau
‑
k18p301l纤维易于在低浓度尿素溶液中溶解。因此,利用sarkosyl可溶性测定研究gaim
‑
ig融合体针对tau
‑
k18p301l的重构效率。将tauk18p301l纤维(1μm)在有或没有gaim
‑
ig融合变体的情况下于37℃温育5天。将纤维和复合物在有或没有1%sarkosyl的情况下温育15分钟,然后以100,000g向下旋转30分钟。小心地除去每个样品的上清液,并将其上样至4
‑
12%的凝胶(invitrogen)上。将蛋白转移到硝酸纤维素膜并探测tauk18p301l。重构百分比通过使用biorad chemidoc
tm
系统定量凝胶带来计算。
[0283]
与1%sarkosyl温育时,使用tau
‑
k18p310l在体外组装的纤维(未暴露于gaim
‑
ig融合体)显示溶解抗性。相比于未处理的纤维,gaim
‑
ig融合体处理的tau
‑
k18p301l纤维更容易溶于1%sarkosyl中(图11a),表明这些纤维也可像faβ42一样重构。当与不同浓度的gaim
‑
ig融合体温育时,这些纤维以浓度依赖的方式溶解(图11b)。
[0284]
将pb120的重构效率与开放稳定化的gaim igg融合体的重构效率进行比较。pb113
(一种具有降低的感染性的超稳定化、无二硫化物的gaim(kather et al.,2005,j mol biol,354:666
‑
78))对aβ1
‑
42或tau
‑
k18p301l纤维没有结合活性(数据未显示),并且添加作为阴性对照。与pb120相比,开放稳定化的gaim
‑
ig融合蛋白显示增强的重构活性(图11b),而pb113没有重构活性(图11a)。
[0285]
共温育样品时,我们研究了gaim融合体是否重构tau
‑
k18p301l纤维并释放可溶性tauk18p301l物质。在产生有效重构的gaim融合浓度(如,10
‑
250nm),在尚未进行sarkosyl处理的复合物上清液中未见可溶性物质(图11a),表明结合gaim融合体后,重构的物质不释放可溶性tauk18p301l物质或单体。
[0286]
实施例13:开放稳定化的gaim
‑
ig融合体导致淀粉样蛋白纤维失去纤维架构
[0287]
将aβ1
‑
42纤维(15μl的20μm样品)涂在碳涂层的铜网格上(tedpella目录号01844
‑
f)。然后将样品用0.5ml水轻轻洗涤,倒置并漂浮在一滴2%乙酸铀酰溶液中。30秒后,取出网格,并且通过使用滤纸从网格边缘吸走多余的液体来干燥。使用fei tecnai
tm spirit tem对纤维成像。图10d显示用亚化学计量的开放稳定化的gaim
‑
ig融合体温育的aβ42纤维的代表性tem图像。当暴露于开放稳定化的gaim
‑
ig融合体时,aβ42纤维失去其纤维架构(图10d)。类似地,tem分析表明,与开放稳定化的gaim
‑
ig融合体共温育时,tau
‑
k18p301l纤维失去了其特征性的纤维构象(图11c)。
[0288]
实施例14:开放稳定化的gaim
‑
ig融合体显示对淀粉样蛋白聚集的增加的抑制
[0289]
通过与aβ42单体于37℃共温育10小时,测试了开放稳定化的gaim
‑
ig融合蛋白的组装抑制活性。淀粉样蛋白纤维形成之后进行tht荧光,并与没有gaim的情况下以及在阴性对照pb113存在下的纤维形成进行比较。
[0290]
将100微克经hfip处理的aβ1
‑
42(rpeptide)单体样品溶解在80μl dmso中,通过移液、涡旋彻底混合,并在5.4ml d
‑
pbs中稀释至4.04μm的最终aβ1
‑
42浓度。将gaim
‑
ig融合体样品在pbs中稀释为10、2.5、0.63和0.16μm的中间储备溶液。将80微升aβ1
‑
42单体溶液分配至黑色圆底96孔板(lvl,目录号225.ls.pp)的每个孔中。将10微升的每种gaim
‑
ig融合体储备溶液添加到含有aβ1
‑
42的孔中,然后添加10μl tht(在pbs中的33μm),每个孔的最终浓度为3.2μm aβ1
‑
42和3.3μm tht。将板用透明膜密封,并在tecanm1000 pro读板仪中每20分钟记录430/485nm处(ex/em)的tht荧光,持续14小时,期间于37℃温育,其中每20分钟垂直摇动3秒。相对于未处理的aβ42孔(阳性对照孔),计算每种gaim
‑
ig融合体浓度的aβ42聚集的百分比。
[0291]
以所指示浓度添加10小时时,开放稳定化的gaim
‑
ig融合体显示剂量依赖性的组装抑制作用(图12a)。与对照支架pb120相比,开放稳定化的融合体进一步显示增加的装配抑制活性(图12a至图12b)。例如,在250nm时,代表性的开放稳定化的gaim
‑
ig融合体pb108和pb116显示相比于pb120,阻断纤维形成增加40
‑
20%(图12b)。亚化学计量量的开放稳定化的gaim
‑
ig融合体有效阻断淀粉样蛋白原纤维形成的能力表明,该融合体通过与生长的纤维中或参与成核依赖性纤维组装的种子中的核心β链结合来阻断淀粉样蛋白纤维的形成(krishnan et al.(2014)j mol biol,426:2500
‑
19)。
[0292]
类似地,开放稳定化的gaim
‑
ig融合体显示针对tau纤维的剂量依赖性组装抑制作用(图12c)。tauk18p301l组装反应如下设定:在不同浓度的gaim融合体(0
‑
500nm)存在下,于37℃在具有2μm低分子量肝素(fisher scientific)的0.1m乙酸钠缓冲液(ph 7.0)中温
育10μm的tau单体3天。组装反应的tht荧光通过将样品对5μm tht溶液中稀释至1μm至来记录。gaim对tauk18p301l组装的抑制作用通过比较没有gaim融合体情况下的tauk18p301l的组装来计算。
[0293]
全长tau或截短序列如mtbr或k18的体外纤维组装需要肝素的存在,以促进成核和随后的组装。在肝素存在下,所测试的gaim融合体抑制ftaukl组装。此外,与pb120相比,开放稳定化的gaim融合体好3倍至5倍地阻断成核(图12c至图12d)。这些结果共同表明,开放稳定化的gaim融合体结合aβ和tau开启
‑
途径中间体两者,并抑制淀粉样蛋白聚集体的组装。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1