控制车辆的方法和系统与流程
本发明总体上涉及控制车辆,并且更具体地,涉及利用神经网络控制自主或半自主驾驶车辆。
背景技术:
由车辆(自主驾驶车辆或者执行自主驾驶模式的车辆)采用的几种控制系统预测车辆的将来的安全运动或路径,两者都是为了避开如其它车辆或行人的障碍物,但也优化与车辆操作相关联的一些标准。目标状态可以是固定位置、移动位置、速度矢量、区域或其组合。周围的环境(如道路边缘、行人及其它车辆)通过车辆的传感器感测和/或至少部分地根据先验给定信息获知。
用于理解车辆周围的环境的一个重要信息来源是由车载感知传感器(如摄像头、立体摄像头、激光雷达(lidar)、超声传感器及雷达)感测的信息。可以直接从车载感知传感器的测量结果来检测和识别车辆周围的对象,举例来说,如u.s.9195904中所述的。所识别的对象可以被用于确定车辆的环境的动态地图。这种动态地图可以用于预测车辆的运动。然而,检测和/或识别对象以及构建动态地图的方法花费时间和计算资源。
因此,希望简化确定和控制车辆运动的过程。
技术实现要素:
一些实施方式的目的是,提供一种利用神经网络来控制车辆的运动的系统和方法。这些实施方式基于这样的认识,即,所述神经网络可以预先(例如,离线)训练,并且重新用于在线控制车辆的运动。
一些实施方式的另一目的是提供这样一种神经网络,即,其可以减少车辆运动控制应用中的对象检测和识别的必要性。例如,一个实施方式的目的是,提供一种不使用动态地图来促进车辆的运动控制的神经网络。
一些实施方式基于这样的认识,即,车辆可以经历无限多的环境。为此,使用所有可能的环境来训练该神经网络是不可能的或者至少是不切实际的。例如,考虑不同国家在驾驶之间的差异;不同车辆有不同的颜色,存在关于车道宽度的不同规定、不同数量的车道,并且当地的驾驶规定(如限速、不同的车道标记以及避让规则)组成无数环境。然而,独立于环境,在一个国家(比方说,瑞典)开车的经历为还能够例如在美国开车提供坚实的基础。
一些实施方式基于这样的认识,即,尽管存在可以围绕驾驶车辆的无限数量的环境,从而导致要处理大量的信息,但仅仅有限的(即,有限或接近有限)的来自这些环境的信息的子集被用于做出驾驶决定。例如,人类的五种感官所感受的关于世界的许多部分对于做出驾驶决定是冗余的。例如,一个人驾驶的车辆前方的汽车是黑色、黄色还是白色并不重要:重要的是它是一辆有速度的汽车。类似地,道路一侧树木的树叶是绿色还是黄色并不重要。事实上,由于树木位于道路一侧而不是在道路上,因此只要可以避免道路偏离,树木对于做出明智决定采取哪条路径来说无关紧要。
为此,一些实施方式基于这样的认识,即,仅在环境中感测的信息的子集与做出驾驶决定相关。此外,在不同的环境中,可以考虑类似类型的信息,如指示在车辆附近行驶的汽车的位置和速度的信息。这样的信息可以被用于训练神经网络,这可以简化设计神经网络的训练,并有助于避免利用动态地图来促进对车辆的运动控制。例如,一个实施方式将与做出驾驶决定相关的信息处理为对车辆运动的约束。
除了不同环境的数量,还可以存在可能出现并且自主汽车需要对此做出反应的无数种情况,然而,尽管可能出现各种不同类型的情况,但仅有有限数量的动作被采取来处理该特定情况。作为示例,考虑本车辆在双车道上行驶时前方车辆突然减速的情况。无论前方驾驶员刹车的方式如何,存在有限数量的不同动作来避免碰撞,例如,比前方车辆更快地减速或者改变车道(若可能的话)。
为此,一些实施方式基于这样的认识,即,可以将神经网络设计成,将指示环境的时间系列信号变换为车辆的参考轨迹,从而指定车辆运动的目标。例如,在一个实施方式中,神经网络包括同时训练的编码子网络和解码子网络。训练编码子网络以将时间系列信号变换成指示对车辆运动的约束的信息,这类似于选择与做出驾驶决定相关的信息。训练解码子网络以根据指示针对车辆运动的约束的信息来生成参考轨迹。对该子网络进行训练,以做出有关按给定时间在特定情形下采取的动作或者具有的目标的决定。按这种方式,多个潜在参考轨迹的最终结果和为确定参考轨迹所需的信息由神经网络考虑。
然而,即使自主驾驶车辆在任何给定的时间可以采取的动作或目标的数量有限,也可以选择无数个控制命令来到达希望目标。例如,在决定改变车道时,转向指令可以在一组连续的不同转向力矩中选择。而且,油门和制动命令都可以在全加速和全减速之间的连续设定中选择,并且为了准确了解在特定场景和特定环境中的特定时刻输出什么命令,可能要求无限的计算资源。一些实施方式基于这样的认识,即,尽管可以在控制动作、期望的将来轨迹,或将来路径的大量组合当中选择,但无论控制动作的确切值如何,车辆应遵循的都可以保持不变。
为此,一些实施方式基于这样的认识,即,在确定参考轨迹之后,运动轨迹(例如,指定控制命令)可以稍后作为后处理步骤来确定。按这种方式,在神经网络之外处理用于遵循参考轨迹的控制动作的大量不同组合。而且,神经网络与不同类型的车辆的特定动力学分离,并且相同的神经网络可以由不同类型和型号的车辆重复使用。
因此,一个实施方式公开了一种控制车辆的方法。所述方法包括:利用至少一个传感器生成指示所述车辆附近的环境相对于所述车辆的运动的变化的时间系列信号;从存储器选择被训练以将时间系列信号变换成所述车辆的参考轨迹的神经网络;将所述时间系列信号提交给所述神经网络,以生成作为时间的函数的参考轨迹,该参考轨迹满足关于所述车辆的位置的时间约束和空间约束;确定跟踪所述参考轨迹同时满足关于所述车辆的运动的约束的运动轨迹;以及控制所述车辆的运动以遵循所述运动轨迹。所述方法的至少一些步骤通过在工作上能够连接至所述存储器和所述传感器的处理器来执行。
另一实施方式公开了一种控制车辆的系统。所述系统包括:至少一个传感器,该至少一个传感器用于感测所述车辆附近的环境,以生成指示所述环境相对于所述车辆的运动的变化的时间系列信号;存储器,该存储器存储被训练以将时间系列信号变换成所述车辆的参考轨迹的神经网络;至少一个处理器,该至少一个处理器被配置用于将所述时间系列信号提交给从所述存储器中选择的所述神经网络,以生成作为时间的函数的参考轨迹,该参考轨迹满足关于所述车辆的位置的时间约束和空间约束,并且该至少一个处理器确定跟踪所述参考轨迹同时满足有关所述车辆的所述运动的约束的运动轨迹;以及控制器,该控制器控制所述车辆的运动以遵循所述运动轨迹。
又一实施方式公开了提供了一种包含有可通过处理器执行的程序的非暂时性计算机可读存储介质,该程序用于执行方法。所述方法包括:生成指示所述车辆附近的环境相对于所述车辆的运动的变化的时间系列信号;选择被训练以将时间系列信号变换成所述车辆的参考轨迹的神经网络;将所述时间系列信号提交给所述神经网络,以生成作为时间的函数的参考轨迹,该参考轨迹满足关于所述车辆的位置的时间约束和空间约束;确定跟踪所述参考轨迹同时满足关于所述车辆的所述运动的约束的运动轨迹;以及控制所述车辆的所述运动以遵循所述运动轨迹。
附图说明
图1a是驾驶车辆的示例性环境。
图1b是驾驶车辆的示例性环境。
图1c是减少车辆运动控制中的计算的神经网络的一个实施方式的示意图。
图1d是根据一些实施方式的用于控制车辆的系统的框图。
图1e是根据一些实施方式的用于控制车辆的运动的方法的流程图。
图1f是根据一个实施方式的路径规划系统的总体结构。
图2a是在具有道路边界的道路上行驶的车辆的示意图。
图2b是例示一些实施方式背后的直觉的示意图。
图3是根据一些实施方式的路径规划系统与车辆控制器之间的交互作用的示意图。
图4a是由一些实施方式采用的可能传感器配置和从传感器到参考轨迹的映射的示例性示意图。
图4b是根据一些实施方式的由车辆的一串传感器的测量结果构建的时间系列信号的示例。
图4c是根据一些实施方式的半自主驾驶车辆的相关内部的示例性场景。
图4d是根据一些实施方式的用于将传感器数据过滤并组织成时间系列信号的方法的示例性框图。
图5是在训练神经网络时考虑的、关于车辆的运动的示例规范。
图6是由一些实施方式使用的深度神经网络的框图。
图7是根据一些实施方式的训练神经网络的示意图。
具体实施方式
一些实施方式的目的是,提供一种利用神经网络来控制车辆的运动的系统和方法。这些实施方式基于这样的认识,即,所述神经网络可以预先(例如,离线)训练,并且重新用于在线控制所述车辆的运动。
一些实施方式的另一目的是提供这样一种神经网络,即,其可以减少车辆运动控制应用中的对象检测和识别的必要性。例如,一个实施方式的目的是提供一种不使用动态地图来促进车辆的运动控制的神经网络。
如本文所使用的,车辆可以是能够感测其环境并且在没有人类输入的情况下导航的任何车辆。这种车辆的示例包括自主驾驶车辆和半自主驾驶车辆。例如,一些实施方式基于这样的认识,即,用于供车辆遵循的将来参考轨迹可以直接通过传感器数据来确定,而不是首先根据传感器数据确定动态地图,然后在路径规划组件中使用该地图。如本文所使用的,参考轨迹可以是具有时间信息的路径,因此隐含或明确地包括速度信息,但参考轨迹也可以指没有时间信息的路径。一些实施方式基于这样的认识,即,尽管驾驶员在一生中遇到无数个场景和环境,但驾驶员对场景做出反应的结果动作和后续路径的数量是有限的。
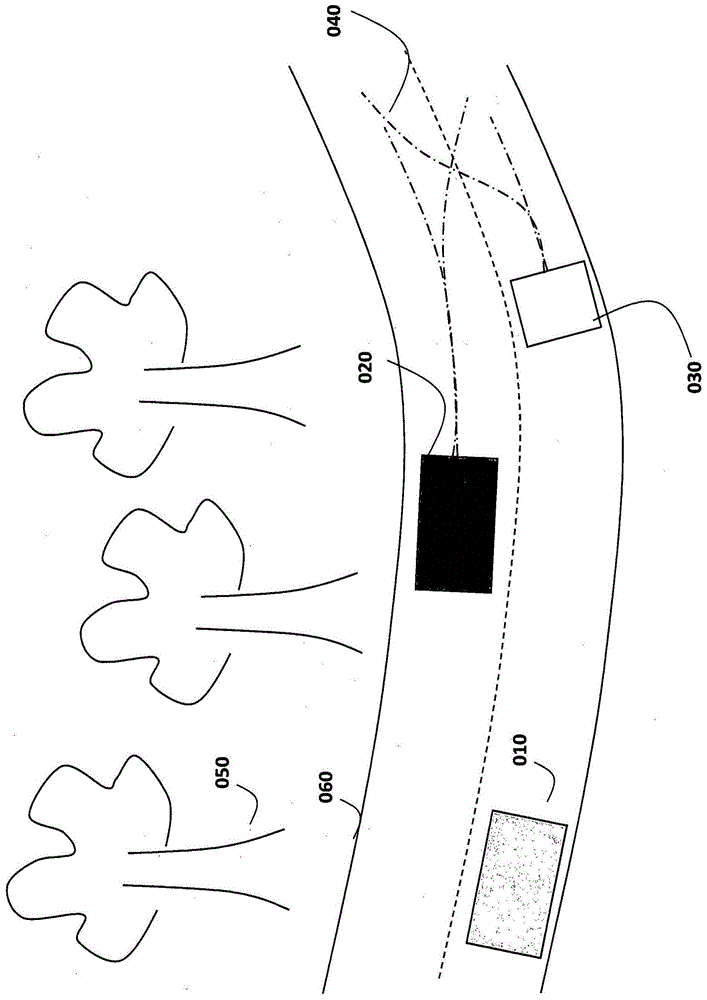
图1a和图1b示出了示例环境,其中,自主驾驶车辆010在具有道路边界060的双车道道路的右车道中行驶。在路上出现的是车辆020和车辆030。人类的五种感官共同给出了对环境的完整描述。每个场景都会给出略有不同的传感器输出组合,比较图1a与图1b,其中树050的位置略有不同,其它车辆020和030的颜色不同,给出一个略有不同的环境。因此,在外推这个时,学习如何单独对所有不同组合做出反应,对于周围环境的每个微小变化来说是压倒性的。然而,在不同环境中存在与导航车辆相关的类似元素,并且人脑学习传感器输出中与在各种条件、情形以及环境下驾驶车辆相关的那些部分。
例如,在比较图1a与图1b时,很明显,树位置050是无关紧要的,因为树木在道路边界060之外,它们不得超出。而且,对于自主驾驶车辆来说,在确定合适的运动时重要的不是车辆020和030的不同颜色。然而,必要的是其它车辆采取的将来路径040,因为自主驾驶车辆要行驶的路径依赖于此。即,在图1a和图1b中,在决定车辆的将来路径应该是什么时,重要的是道路上其它车辆的运动。
在改变车道时,转向指令可以在一组连续的不同转向力矩中选择。而且,油门和制动命令都可以在全加速和全减速之间的连续设定中选择,并且为了准确了解在特定场景和特定环境中的特定时刻输出什么命令,会要求无限的计算资源。然而,尽管驾驶方式给出了不同的控制命令来实现预期路径,但在给定情形下车辆应遵循的期望路径对于不同的驾驶员来说是类似的。
用于理解周围的环境的一个信息来源是来自车载感知传感器(如摄像头、立体摄像头、激光雷达、超声传感器以及雷达)的原始输入数据。利用该输入数据,可以识别和检测对象。随后,可以将关于对象的信息发送至路径规划器,路径规划器在预测该车辆的将来安全路径时使用该信息。然而,这种方法的缺点在于大量计算花费在了检测对象上并提供冗余或与路径规划器无关的信息。
因此,一些实施方式基于这样的认识,即,车辆的避开障碍物的将来平稳路径可以通过将一序列输入数据(如图像序列)映射到车辆的预测路径中来实现,其中,车辆可以是任何类型的移动运输系统,包括客车、移动机器人或探测车(rover)。例如,如果客车行驶在道路上并且存在缓慢行驶的前车,通过分析来自安装在车辆上的至少一个摄像头的一序列图像帧,本发明的一些实施方式确定避开根据图像确定的对象的车辆路径存在于场景中,其中,避开障碍物的路径包括改变车辆的车道,或者保持同一车道但减慢到前车的速度。输入数据可以包括图像帧的衍生物、激光雷达数据、全球定位信息(gps)或来自其它传感器(如惯性传感器)的传感器数据,或者作为所述输入数据的组合。
图1c示出了用于减少车辆运动控制中的计算的神经网络的一个实施方式的示意图。训练神经网络080接收预定大小的时间系列信号070(指示车辆附近的环境变化),并将时间系列信号070变换成车辆的参考轨迹090,即,车辆在没有感测和建模干扰情况下理想上应遵循的轨迹。利用神经网络的这个限定,由于存在对编码到神经网络中的轨迹的预测,可以保证车辆运动的平稳性。
图1d示出了根据本发明一些实施方式的控制车辆的系统99的框图。车辆可以是旨在自主或半自主地执行的任何类型的系统。该系统可以包括人类操作员110,并且在这种情况下,系统是半自主的,并且包括超驰和相应地允许驾驶员110的动作的可能性。作为例子,系统100可以是四轮乘用车。可能的系统的另一个例子是差速驱动移动机器人。第三个例子是工业机器人操纵器。在本详细描述中,贯穿全文始终使用汽车来例示本发明。
车辆100包括感测车辆附近环境的至少一个传感器120。该传感器可以有几种类型。例如,该传感器可以是提供环境的一系列摄像头图像的视频摄像头,或者可以是提供由激光雷达扫描仪捕捉的环境的三维点的激光雷达。传感器设置也可以是不同传感器的组合。例如,视频摄像头可以与全球定位系统(gps)组合,全球定位系统提供摄像头的位置信息和/或摄像头获取的图像序列的原点。
另外或者另选地,摄像头和gps可以与加速度计组合,然后与两个传感器组合可以给出与图像序列相关联的速度和加速度信息。一个传感器可以是惯性测量单元(imu)。例如,imu可以包括:3轴加速度计、3轴陀螺仪和/或磁力计。imu可以提供速度、取向和/或其它位置相关信息。随着时间的推移,传感器将传感器信号121提供给路径规划系统130。
系统99还包括存储至少一个神经网络的存储器140。存储在存储器140中的神经网络被训练,以将时间系列信号131映射至车辆的将来预测轨迹。另外或者另选地,在一个实施方式中,存储器140存储一组神经网络,该组神经网络中的每个神经网络被训练以考虑不同驾驶方式,以将时间系列信号映射至车辆的参考轨迹。
例如,系统99可以确定用于控制车辆的驾驶方式,并且从存储器中选择141与所确定的驾驶方式相对应的神经网络141。例如,驾驶方式可以基于来自车辆的用户的输入来确定。另外或另选地,如果车辆是半自主驾驶车辆,那么在车辆按手动模式驾驶时,可以学习该车辆的驾驶员的驾驶方式。另外或另选地,系统99可以基于时间系列信号131本身来选择神经网络。例如,针对不同的驾驶情形(例如,由外部输入110给出的),选择141不同的神经网络。
路径规划系统130接收一序列传感器信号121并生成时间系列信号131。存储器140向路径规划系统130提供神经网络141,该路径规划系统确定参考轨迹132。另外,除了传感器输入以外,还可以将希望的航路点(waypoint)(即,中间期望位置)提供给神经网络。航路点的用途是将所选择的轨迹引导至期望的路径。在另一实施方式中,还为了训练网络而提供航路点。在各种实施方式中,参考轨迹132可以被表示为一序列笛卡尔坐标(时间与每个坐标相关联)、车辆的一序列位置和速度以及车辆的一序列航向中的一个或组合。
系统99还可以包括一组控制器150,用于确定跟踪参考轨迹132的一组控制参考151。该组控制参考被发送至车辆的致动器160以供执行。例如,在无法预见和/或未建模的影响的情况下,例如由于环境170或传感器120的不确定性,或者神经网络141中的有限精度,车辆的运动轨迹101可以与参考轨迹132略微不同。然而,控制器150确保运动轨迹101在有界误差(boundederror)的情况下接近参考轨迹132。例如,控制器150可以包括失效模式控制器,当轨迹132或者150中的其它控制器失效时,其充当安全层。
图1e示出了根据本发明一些实施方式的控制车辆的运动的方法的流程图。该方法生成170a指示车辆附近的环境相对于该车辆的运动的变化的时间系列信号171。使用170至少一个传感器的一序列测量结果来生成时间系列信号171。时间系列信号171可以根据车辆的各种传感器的测量结果生成,并且可以包括关于车辆周围的对象和环境的信息。时间系列信号也可以利用车辆的位置和速度进行细化。
该方法例如从存储器140中选择175被训练以将时间系列信号变换成车辆的参考轨迹的神经网络172,并且确定175向神经网络提交该时间系列信号的参考轨迹176。该神经网络被训练以生成作为时间的函数的参考轨迹176,其满足关于车辆位置的时间约束和空间约束。如在此引用的,车辆位置的时间和空间约束是对车辆在该车辆应该满足的特定将来时刻的位置的要求,以便保证车辆不与其它障碍物(如其它车辆或行人)碰撞,确保车辆不会驶离道路,并且为感知和神经网络训练中的缺陷提供鲁棒性。时间约束和空间约束的示例包括车辆位置偏离道路中间的界限、在给定时间步偏离期望位置的界限、当到达期望位置时的时间偏差的界限、与道路上的障碍物的最小距离以及完成车道变换应花费的时间。
该方法确定180跟踪参考轨迹176同时满足车辆173的运动约束的运动轨迹181。如在此引用的,车辆的运动约束是车辆运动应满足的要求,以便为车辆的使用者和环境提供安全且平稳的驾乘。虽然车辆的空间约束确保车辆在时间和地点的某些组合下按期望那样表现,但车辆的运动约束涉及为到达车辆的不同位置而使用的运动。对车辆运动的约束的示例包括当前加速度的变化以及车辆的航向角(headingangle)和航向速度(headingrate)的界限、偏离车辆期望速度分布的界限、车辆横向速度的界限、与周围车辆速度偏差的界限以及在完成变道或在超过另一辆车时的速度和航向分布。
运动轨迹可以按几种方式确定,但一般原则是将参考轨迹映射至运动轨迹,其中,运动轨迹可以但不一定是参考轨迹的低级别表示。例如,参考轨迹可以包括车辆的位置分布,但是负责车辆致动的控制器不能以位置分布作为输入,而是诸如车轮滑移、速度分布、车轮转向角或某一其它表示的其它实体。确定运动轨迹也满足去除或至少抑制神经网络172未捕捉的剩余不确定性的影响的目的。例如,神经网络没有明确地学习车辆的动力学,因为这对于神经网络而言在计算上是禁止的。然而,对于自动控制方面的技术人员来说,可以通过来自控制界的技术来考虑车辆的动力学。
在一些实施方式中,使用模型预测控制器确定运动轨迹,模型预测控制器将参考轨迹映射至车辆车轮的转向轨迹的运动并且映射至车辆车轮的速度轨迹的运动,同时考虑对车辆运动的测量,也就是说,该控制器可以是反馈控制器。在另一实施方式中,前述模型预测控制器代替地将参考轨迹映射至车辆的期望车轮滑移轨迹和车辆车轮的期望转向轨迹。要承认的是,将参考轨迹映射至车辆的运动轨迹的任何技术(如查寻表、lyapunov控制、基于学习的控制)都可以用于该目的,但模型预测控制已经被用作了示例,这是因为其可以明确地解释车辆的运动约束,确保给出参考轨迹的神经网络和在确定运动轨迹时都考虑相同的约束。还要承认的是,运动轨迹可以分成两部分;上面解释的一个反馈部分,和一个前馈部分,前馈部分确定在没有任何外部干扰的情况下会发生的运动轨迹。
该方法控制车辆的运动以遵循该运动轨迹。例如,该方法将运动轨迹181映射185至控制命令182,并且根据该控制命令来控制190车辆的运动。该方法的步骤由车辆的处理器执行,该处理器在工作上能够连接至存储器140和至少一个传感器120。而且,可以将确定180视为确定运动轨迹181,该运动轨迹181包括用于车辆的致动器的一组命令,以使车辆根据目标移动。
图1f示出了根据本发明一个实施方式的路径规划系统130和存储器140的总体结构。路径规划系统130包括至少一个处理器180,用于执行路径规划系统130的模块。处理器180连接131、141至存储神经网络142的存储器140。存储器140还存储143选择神经网络142的逻辑,神经网络142被训练成优选的驾驶方式。存储器140还将传感器数据121存储144给定时段,处理器180使用传感器数据121来构建时间系列信号。
在本发明的各个实施方式中,认识到,从传感器数据学习路径比从传感器数据学习控制命令更加高效,原因有很多。例如,通过训练一个或几个神经网络来从数据中学习将来轨迹,本发明为汽车中的乘客提供平稳驾乘、更好的燃油效率以及不太突然的运动。
图2a示出了在具有道路边界210的道路200上行驶的车辆250的示意图。道路包括障碍物220。车辆的目标是在继续停留在路上并避开障碍物220的同时达到240,优选地在保持接近某一预定义路径230的情况下。根据传感器数据,至少一个神经网络已经被离线训练以将时间系列信号映射至轨迹270。相反,如果采取从传感器数据至控制命令的映射,那么不涉及预测。因此,违反了模型误差和传感器误差的鲁棒性,如本领域技术人员应当理解的。虽然仍可以避开障碍物220,但平稳度要低得多。
效率的另一个例子是使用神经网络将时间系列信号映射至参考轨迹而不是控制命令,允许将经训练的神经网络应用于不同的车辆。如果采取映射至控制命令,那么特定映射还有训练取决于所采用的特定车辆,因为不同车辆有不同的系统、参数,如将车辆带到给定位置的传动比、转向齿轮比等。相反,如果使用从时间系列信号至参考轨迹的映射,那么在映射中没有暗示特定的车辆动力学,所以系统和方法都与车辆无关。
图2b示出了例示一些实施方式背后的直觉的示意图,所述直觉与人类的学习和行为有关。例如,考虑一个人打算从a点走到b点的情况,如图2b所描绘的,其中存在障碍物220。一个人感测环境一段时间,决定如何走290到目标b,然后执行该计划。尽管每个人的路径可能不同,但差异的原因是每个人的偏好和决策略有不同,而不是每个人的肢体的肌肉力量或尺寸,那么如何执行计划就不那么重要了。然后,回到图1d,对环境的感测对应于传感器120的感测,决定如何走对应于路径规划130,并且计划的执行对应于控制器150。
图3示出了根据一些实施方式的路径规划系统与车辆控制器之间的交互作用的示意图。例如,在本发明的一些实施方式中,车辆的控制器150是转向控制器351和制动/油门控制器352,其控制与车辆的运动相关联的不同实体。例如,转向控制器351可以将来自路径规划系统330的参考轨迹映射至车辆的运动轨迹,这包括车辆方向盘的一序列角度。例如,制动控制模块352可以将速度的参考轨迹映射至车辆的制动压力和发动机油门命令轨迹。
图4a示出了由一些实施方式采用的可能传感器配置和从传感器到参考轨迹的映射的示例性示意图。在该示例性示意图中,传感器配置400包括以下各项:全球定位系统(gps)407;惯性测量单元(imu)406;航路点或一组航路点(目的地)405;j个摄像头408、k个雷达404、l个激光雷达409以及m个超声传感器403。传感器测量结果被映射410至时间系列信号。该时间系列信号可以以多种方式表示。
图4b示出了根据一些实施方式的由车辆的一串传感器的测量结果构建的时间系列信号的示例。在该示例中,一串传感器中的一项对应于所有传感器在给定时间步的测量结果,形成固定的预定大小的输入矢量。例如,考虑在要使用三个时刻的传感器数据时的场景。框411对应于时间t=-2的传感器数据,框412对应于时间=t_1的传感器数据,并且框413对应于时间t=0(当前时间)的传感器数据等等。可以训练几个神经网络。一组航路点(即,车辆的中间期望目的地)例如从汽车导航系统给出,并且可以被用来训练神经网络以处理不同的场景。
根据一些实施方式,可以针对不同的驾驶方式训练不同的神经网络。例如,一个神经网络可以被训练用于激进驾驶,另一神经网络可以被训练用于正常驾驶,而又一个神经网络可以被训练用于谨慎驾驶。例如,当训练相应网络时,可以将不同的收集数据标记为不同的驾驶方式,然后将特定网络瞄准不同的驾驶方式。
图4c示出了半自主驾驶车辆的相关内部或用户界面的示例性场景,也就是说,车辆的操作人员可以通过与车辆的方向盘或仪表板440c相关联的按钮450c来决定是以手动模式还是以自主模式驾驶。仪表板400c包括操作人员可以用来驾驶车辆的方向盘410c和用于示出车辆的不同模式(如速度和传感器输出)的显示器420c。当采用手动模式时,通过打开学习模式460c,神经网络学习操作人员的驾驶方式并随后识别该驾驶方式,模仿操作人员的驾驶方式。操作人员或车辆的另一用户也可以选择手动输入操作模式440c。还包括示出车辆的规划路径和周围的环境的可视化模块430c以及用于变得可用时通过无线电(overtheair)添加新驾驶方式或改进已包括的车辆驾驶方式的按钮470c。440c中还包括汽车导航系统或等同系统,操作人员可以使用汽车导航系统来插入车辆的最终目的地,然后汽车导航系统向车辆提供航路点或中间目标位置。
图4d示出了根据一些实施方式的用于将传感器数据409d过滤并组织成时间系列信号的方法400d的示例性框图。例如,输入信号滤波器410d可以通过将imu(提供对车辆速度的推导)和gps信息411d(提供车辆位置)处理为状态估计量420d来预处理和确定新信号,以与单独使用该信号相比提供更准确的位置和速度信息421d。滤波器410d还可以通过处理给出指示车辆运动的空间约束的信息的不同传感器数据412d(如激光雷达和摄像头数据)来确定新信号431d(通过融合不同的传感器430d,从而提供新的传感器信号431d)。输入信号滤波器410d还可以被用于改进例如从汽车导航系统给出的一组航路点或目标位置。该组航路点也可以与其它传感器数据412d融合。模块450d使改进的状态数据421d与融合数据431d同步,以确保它们对应于同一时刻。另选地,模块450d可以将改进的状态数据421d与未合并数据413d同步,但具有一组改进的航路点。最后,使用同步的传感器数据451d来创建460d时间系列信号,所述时间系列信号被发送461d至神经网络470d。
图5例示了在训练神经网络时考虑的、关于行驶在路上的车辆的运动的可能规范的示例性列表。参考轨迹隐含地限定了车辆运动的多个规范,其在控制车辆运动时,理想情况下应当满足。关于运动的规范可以映射至车辆运动的约束。例如,关于车辆运动的规范可以要求车辆继续停留在道路上500。可能的附加规范可以要求车辆应当以标称速度520在车道的中间行驶510。标称速度可以由道路速度限制给出,或者可以由车辆的驾驶员或乘客给出。例如,规范还可以要求车辆保持对周围障碍物的安全裕度。另外,另一可能规范是保持与同一车道中的车辆的安全距离540,这可以与530相同但通常不必相同。出于乘客舒适性、燃油消耗、磨损或其它原因,该规范可以要求车辆的平稳行驶550。根据要训练的特定网络的期望驾驶方式,不同规范可以具有彼此不同的相对重要性。
图6示出了由一些实施方式使用的深度神经网络的框图。例如,在一个实施方式中,深度神经网络包括两个部分。第一部分是编码器子网络610,其以指示车辆运动的约束的表示601对时间系列信号611进行编码,这使得能够实现有效的路径规划。第二部分包括解码器子网络620,其被训练为根据指示车辆运动的约束的信息601来生成参考轨迹621。编码器网络和解码器网络都被实现为递归神经网络611。要明白的是,任何给定数量的递归神经网络都可以用于预期目的。编码器网络610的目标是提取生成参考轨迹所需的信息。例如,当一个人在高速公路上行车时,车辆附近有障碍物,关于前方几百米处的树木中的鸟或障碍物的信息不太重要。
在每个时刻,传感器测量612(举例来说,如关于图4d所描述的),或者来自摄像头的图像或来自激光雷达的三维点坐标,或者这两者中的一个与gps信息和目的地(由机器中配备的感测装置捕获并由汽车导航系统给出的)相结合,连同位置信息一起被输入至编码器网络。编码器网络通过神经计算层处理数据,神经计算层由内积和修正线性单元非线性运算组成。在每个时刻的编码器网络的输出是周围环境的抽象表示,其可以由解码器网络用于生成参考轨迹。
在每个时刻,解码器网络620将由编码器网络610计算的表示601作为输入并输出参考轨迹。该轨迹可以以几种方式限定,例如,限定为一序列点坐标621,或者限定为具有速度信息的一序列点坐标,或其组合。解码器网络620逐个地生成点坐标621。应注意,解码器网络620是非因果的并且可以生成将来轨迹。
在一些实施方式中,编码器网络和解码器网络都是递归神经网络,用于允许所得网络的动态时间行为。可以利用各种版本的递归神经网络(如长期短期记忆递归神经网络,或堆叠递归神经网络)。递归神经网络可以具有多个层。每一层都可以是完全连接或卷积的。
图7示出了根据一些实施方式的训练神经网络的示意图。训练710使用训练集的传感器输入序列701和对应的期望轨迹702来生成rnn的权重720。通常来说,训练人工神经网络包括应用训练算法,有时被称为“学习”算法,训练集可以包括一组或更多组输入以及一组或更多组输出,其中每组输入对应于一组输出。训练集中的一组输出包括当对应一组输入被输入至神经网络时希望该神经网络生成的一组输出。
例如,一个实施方式按端到端方式训练神经网络,如网络080。训练710涉及利用奖励(reward)将一序列传感器数据701映射至将来轨迹702,诸如车辆的路径703和速度704,其中,已经预先定义了深度神经网络的奖励。例如,可以基于期望的驾驶方式和/或车辆运动的规范来选择奖励。参照图5描述了这种规范的示例。
训练数据可以包括来自车载传感器的输入时间系列信号和期望输出车辆轨迹,例如但不是必须的,作为相对于车辆的一序列笛卡尔坐标给出。另外,训练数据可以包括期望速度分布,例如由车辆的乘客给出,并且输入数据可以根据正在训练的当前驾驶方式进行标记。可以根据优选驾驶方式的数量训练几个神经网络,并且对应标记数据针对每种驾驶方式来定制神经网络。
例如,车辆的操作员或另一用户可以选择要使用的驾驶方式,或者操作员可以选择让车辆决定适于车辆当前用户的驾驶方式,然后从车辆的存储器中选择。输出轨迹可以包括速度信息,或者可以在没有伴随时间信息的情况下加以描述。时间系列信号被发送至编码器网络以计算指示车辆运动的约束的信息。然后将该信息传递给解码器网络以生成与所需轨迹匹配的输出轨迹。所生成的轨迹与期望轨迹之间的不匹配提供了用于更新神经网络权重的监督信号。训练可以经由现成的前馈神经网络训练算法实现,如随机梯度下降和动量算法(stochasticgradientdescentwithmomentalgorithm)。解码器网络和编码器网络一起训练,因为如果两个网络被分开训练,则没有针对编码器网络的输出目标,并且没有针对解码器网络的输入信号。而且,递归神经网络的结构确保可以通过观察过去的轨迹来学习将来的轨迹。
也可以利用模拟不同驾驶方式的仿真数据来完成网络的训练。利用这样的方法,尽管未完美地匹配真正的驾驶员,但训练阶段和数据收集量可以显著减少。
本发明的上述实施方式可以按许多方式中的任一种来实现。例如,这些实施方式可以利用硬件、软件或其组合来实现。当按软件来实现时,软件代码可以在任何合适处理器或处理器集合上执行,而不管设置在单一计算机中还是分布在多个计算机当中。这种处理器可以被实现为集成电路,在集成电路组件中具有一个或更多个处理器。然而,处理器可以利用采用任何合适格式的电路来实现。
另外或者另选地,上述实施方式可以被实现为包含有可通过处理器执行的程序的非暂时性计算机可读存储介质,该程序用于执行各个实施方式的方法。
而且,在此概述的各种方法或处理可以被编码为可以在采用多种操作系统或平台中的任一种的一个或更多个处理器上执行的软件。另外,这种软件可以利用许多合适编程语言和/或编程或脚本工具中的任一种来编写,而且还可以被编译为在框架或虚拟机上执行的可执行机器语言代码或中间代码。通常情况下,该程序模块的功能可以如在各种实施方式中所希望的组合或分布。
而且,本发明的实施方式可以被具体实施为已经提供了示例的方法。作为该方法的一部分执行的动作可以按任何合适方式来安排。因此,即使在例示性实施方式中被示出为顺序动作,也可以构造按与所例示相比不同的次序来执行动作的实施方式,其可以包括同时执行一些动作。
- 还没有人留言评论。精彩留言会获得点赞!