一种多目标检测方法、装置及存储介质与流程
本发明涉及目标检测技术,尤其涉及一种多目标检测方法、装置及存储介质。
背景技术:
在计算机视觉领域,“目标检测”主要利用计算机图像处理技术对目标物进行实时检测,自动识别图像上指定的目标物的位置和类别,在智能化交通系统、智能监控系统和军事目标检测等领域具有广泛的应用。
常用的目标检测方法中,首先,通过在图像中确定约1000-2000个候选框,将每个候选框内的图像块缩放至相同大小,并输入到卷积神经网络(r-cnn,regionproposal-convolutionalneuralnetwork)中进行特征提取;然后,对候选框中提取出的特征使用分类器判别是否属于一个特征类;最后,对属于某一特征的候选框用回归器进行位置调整,从而实现特定场景下单一类型的目标物的检测。使用上述方案进行目标检测时,当需要对密集场景下的对多个类型的目标物进行检测时,需要针对多个类型目标物分别建立神经网络模型分别进行训练和识别,从而影响了了目标检测的效率。
技术实现要素:
为解决现有存在的技术问题,本发明实施例提供一种多目标检测方法、装置及存储介质,可以有效地提高目标检测的效率。
为达到上述目的,本发明实施例的技术方案是这样实现的:
本发明实施例提供了一种多目标检测方法,包括:
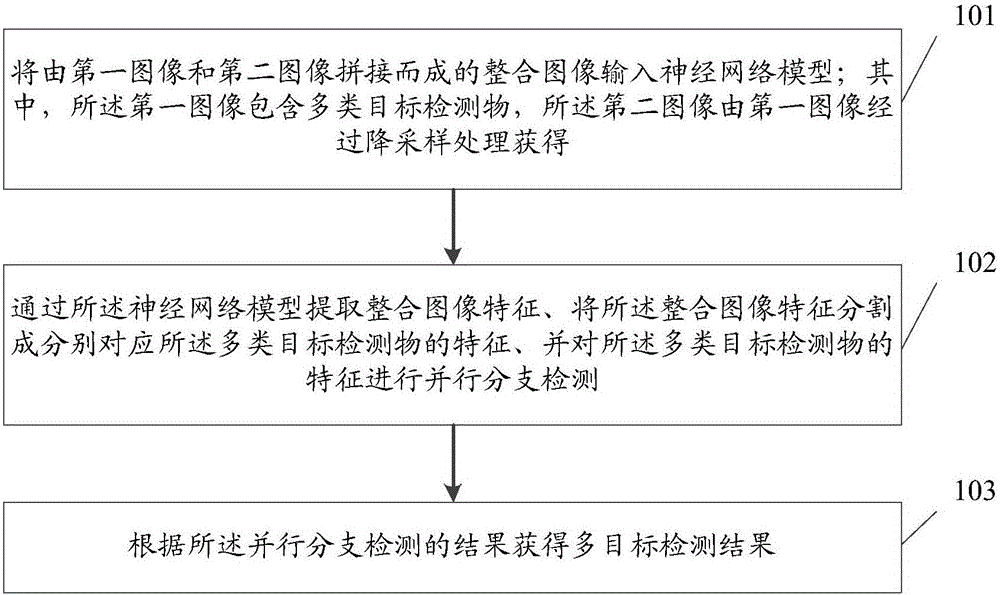
将由第一图像和第二图像拼接而成的整合图像输入神经网络模型;其中,所述第一图像包含多类目标检测物,所述第二图像由第一图像经过降采样处理获得;
通过所述神经网络模型提取整合图像特征、将所述整合图像特征分割成分别对应所述多类目标检测物的特征、并对所述多类目标检测物的特征进行并行分支检测;
根据所述并行分支检测的结果获得多目标检测结果。
上述方案中,所述神经网络模型包括第一神经网络、与所述第一神经网络进行级联的切分层及与所述切分层级联的多个第二神经网络;所述通过所述神经网络模型提取整合图像特征、将所述整合图像特征分割成分别对应所述多类目标检测物的特征、并对所述多类目标检测物的特征进行并行分支检测,包括:
所述第一神经网络以所述整合图像作为输入,提取所述整合图像特征作为输出;所述切分层以所述整合图像特征作为输入,分割成分别与所述多类目标检测物对应的特征向量作为输出;所述第二神经网络分别与所述多类目标检测物对应,所述第二神经网络分别以对应的目标检测物的特征向量作为输入,对所述目标检测物的特征向量进行并行分支判断分别获得所述目标检测物的判断结果作为输出。
上述方案中,所述第一神经网络为卷积神经网络,所述第二神经网络为长短期记忆网络。
上述方案中,所述切分层包括转置层,所述转置层与所述卷积神经网络的全连接层进行级联,用于对所述全连接层输出的整合图像特征进行转置。
上述方案中,所述切分层还包括与所述转置层进行级联的剪切层,所述剪切层用于将所述转置层输出的转置结果中符合设定条件的数据进行删除;其中,所述符合设定条件的数据为所述卷积神经网络的卷积层进行卷积过程中,由同时覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据。
上述方案中,所述剪切层,还用于对所述转置层输出的转置结果根据所删除的数据的位置切分成分别对应所述多类目标检测物的多个特征向量,以作为所述长短期记忆网络的输入。
上述方案中,所述将由第一图像和第二图像拼接而成的整合图像输入神经网络模型之前,还包括:
获取所述第一图像,根据所述第一图像中所述目标检测物的显示参数确定降采样参数;
根据所述降采样参数对所述第一图像进行降采样处理,获得所述第二图像;
将所述第一图像与所述第二图像进行拼接形成所述整合图像。
上述方案中,所述根据所述并行分支检测的结果获得多目标检测结果之前,还包括:
判断所述多个目标检测物是否被遮挡;
所述根据所述并行分支检测的结果获得多目标检测结果,包括:
当所述多个目标检测物未被遮挡时,将所述多个目标检测物的特征与对应的标准模型进行相似判断,根据判断的结果获得多目标检测结果;
当所述多个目标检测物中至少一个被遮挡时,调整被遮挡的目标检测物对应的相似阈值,对所述多个目标检测物的特征与对应的所述标准模型进行相似判断,根据判断的结果获得多目标检测结果。
上述方案中,所述根据所述并行分支检测的结果获得多目标检测结果,包括:
根据设定的相似阈值对并行分支检测的结果进行相似判断,获得相似判断结果;
对所述第二图像进行升采样;
确定所述相似判断结果对应的目标检测物位于所述升采样后的第二图像的位置信息;
生成包含所述位置信息和所述相似判断结果的目标检测结果。
上述方案中,所述将由第一图像和第二图像拼接而成的整合图像输入神经网络模型之前,还包括:
获取包含多类目标对象的第一样本图像;将所述第一样本图像输入目标检测网络进行训练,所述目标检测网络包括卷积神经网络及与所述卷积神经网络的全连接层连接的降采样参数分支,所述降采样参数分支包括多个全连接层;
通过训练直至得到与所述多类目标对象达到不同目标比例时对应的候选降采样参数。
上述方案中,所述通过训练直至得到与所述多类目标对象达到不同目标比例时对应的候选降采样参数之后,还包括:
根据所述候选降采样参数对所述第一样本图像进行降采样,获得第二样本图样;
将所述第一样本图像与所述第二样本图像进行拼接形成样本拼接图像;
将所述样本拼接图像输入初始的神经网络模型进行训练,所述初始的神经网络模型包括用于提取样本拼接图像特征的初始的卷积神经网络、用于将所述样本拼接图像特征分割成分别对应所述多类目标对象的特征的切分层及对所述多类目标对象的特征进行并行分支检测的初始的长短期神经网络;
通过训练直至所述长短期神经网络的损失函数满足收敛条件,得到训练后的神经网络模型。
本发明实施例还提供了一种多目标检测装置,包括:
输入模块,用于将由第一图像和第二图像拼接而成的整合图像输入神经网络模型;其中,所述第一图像包含多类目标检测物,所述第二图像由第一图像经过降采样处理获得,所述神经网络模型用于提取整合图像特征、将所述整合图像特征分割成分别对应所述多类目标检测物的特征、并对所述多类目标检测物的特征进行并行分支检测;
第一获取模块,用于根据所述并行分支检测的结果获得多目标检测结果。
本发明实施例还提供了另一种多目标检测装置,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,
其中,所述处理器用于运行所述计算机程序时,实现上述的多目标检测方法。
本发明实施例还提供了一种存储介质,存储有计算机程序,所述计算机程序被处理器执行时,实现上述的多目标检测方法。
通过实施本发明实施例所提供的技术方案,可以具有以下有益效果:
通过提取包含多目标检测物的第一图像以及由第一图像降采样得到的第二图像拼接形成整合图像的特征,将提取到的特征进行分割,分割成对应多类目标检测物的特征、并对该多类目标检测物的特征进行并行分支检测,实现多目标检测物的图像特征进行同时检测的目的,可以降低检测过程中的计算量,较少检测时间,有效地提高目标检测的效率。
附图说明
图1为本发明实施例提供的一种多目标检测方法的流程示意图;
图2为本发明实施例提供的一种图像拼接的示意图;
图3为本发明实施例提供的一种拼接后的整合图像输入神经网络模型进行处理的示意图;
图4为本发明实施例提供的一种卷积运算的示意图;
图5为本发明实施例提供的一种经过转置之后的图像特征的示意图;
图6为本发明实施例提供的一种获得整合图像的流程示意图;
图7为本发明实施例提供的一种获得降采样参数的流程示意图;
图8为本发明实施例提供的一种获得降采样参数的示意图;
图9为本发明实施例提供的一种获得神经网络模型的流程示意图;
图10为本发明实施例提供的一种多目标检测装置的结构示意图;
图11为本发明实施例提供的另一种多目标检测装置的结构示意图;
图12为本发明实施例提供的另一种多目标检测方法的流程示意图;
图13为本发明实施例提供的一种监控场景的示意图;
图14为本发明实施例提供的另一种监控场景的示意图;
图15为本发明实施例提供的又一种监控场景的示意图。
具体实施方式
以下结合说明书附图及具体实施例对本发明技术方案做进一步的详细阐述。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
对本发明进行进一步详细说明之前,对本发明实施例中涉及的名词和术语进行说明,本发明实施例中涉及的名词和术语适用于如下的解释。
1)包围盒(boundingbox),指的是将目标检测物框定起来的一个封闭空间,通过将复杂的目标检测物封装在简单的包围盒中,用简单的包围盒形状来近似代替目标检测物的复杂几何形状,以提高几何运算的效率。
2)目标检测物或目标对象,指的是监控系统在采集目标环境中的图像时,由包围盒框定的人、车辆(包括轿车、卡车、公交车和自行车等)和各种动物等目标。需要说明的是,一个包围盒可以框定一个或多个小的目标检测物。
3)卷积神经网络(cnn,convolutionalneuralnetwork),通常包含以下几种层:
卷积(conv,convolutional)层,卷积神经网路中每个卷积层均由多个卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。其中,设置多个卷积层的目的是提取输入的不同特征,如第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级。
线性整流(relu,rectifiedlinearunits)层,也称激励层,使神经网络各层之间的具有非线性关系的特性。
池化(pool,pooling)层,由于卷积层之后会得到维度很大的图像特征,池化层将大维度的特征降为低维度的图像特征。
全连接(fc,fully-connected)层,把所有局部特征结合变成全局特征。
4)长短期记忆(lstm,long-shorttermmemory)网络,包括有以下三种门限结构:遗忘门、输入门、输出门。其中,遗忘门用于决定哪些信息从单元状态中抛弃,输入门用于决定单元状态中保存哪些信息,输出门用于决定要输出什么信息。
请参考图1,为本发明实施例提供的一种多目标检测方法的流程示意图,所述多目标检测方法应用于多目标检测装置,在实际应用中,该装置可以实施为如监控系统,所述方法包括:
步骤101:将由第一图像和第二图像拼接而成的整合图像输入神经网络模型;其中,所述第一图像包含多类目标检测物,所述第二图像由第一图像经过降采样处理获得。
由于在传统的目标检测网络中,对单一目标检测物进行目标检测时,对目标检测物的框定均采用标准化的包围盒,其中该标准化的包围盒的尺寸只需要与单一目标检测物的尺寸进行适配。而本申请实施例所提供的多目标检测方法中,对于一个场景中不同类型的目标检测物而言,当将包含多类目标检测物的待检测原始图像进行特征提取时,标准化的包围盒并不能针对每个目标检测物的特征或大小进行框定,例如,对于场景中较小的目标检测物,标准化的包围盒可以保证该目标检测物的精准框定描述;但是相对于较大的目标检测物,标准化的包围盒可能无法完全覆盖该目标检测物,以至于丢失重要训练特征。
为了能够实现针对包含多目标检测物的待检测图像对多目标检测物的同时检测,本发明实施例根据一个场景或者不同场景中的多类目标检测物之间的不同大小比例,其中,每一类目标检测物的数量可能是一个或者多个,采用自适应方法来得到较大目标检测物的降采样参数,对包含多类目标检测物的待检测原始图像(第一图像)进行降采样处理,得到压缩后的降采样处理后的图像(第二图像),并将第一图像和第二图像拼接形成整合图像,将包含第一图像和第二图像的整合图像输入神经网络模型。如图2所示,以多目标检测方法应用于道路摄像头监控场景为例,道路监控图像(a)为道路摄像头获取的某一帧图像,由于标准化的包围盒无法对图像(a)左下角的车辆进行精准框定,此时,取消对图像(a)左下角的车辆进行框定,从而得到图像(b),将图像(b)作为待检测原始图像(第一图像),其中的car指的是车辆,ped指的是行人,x、y用于表示车辆或行人在道路监控图像中的坐标位置,假设道路监控图像(a)(第一图像)的的尺寸为640×480,较大目标检测物(如面包车)的显示尺寸为100×100,此时标准化的包围盒无法对该较大目标检测物实现精准框定,根据该较大目标检测物的尺寸及标准化的包围盒的框定尺寸对该道路监控图像(a)进行降采样处理,得到尺寸为256×192的降采样处理后的道路监控图像(c)(第二图像),此时该较大目标检测物在道路监控图像(c)的显示尺寸为40×40,可以被标准化的包围盒实现精准框定,然后,将道路监控图像(b)(第一图像)和降采样处理后的道路监控图像(c)(第二图像)进行拼接形成整合图像(d)。在整合图像中对于在第一图像中不能被标准化的包围盒进行精准框定的目标检测对象,可以在进行降采样处理后的第二图像中框定,即通过标准化的包围盒在第二图像中对该较大目标检测物体进行框定,可以避免丢失图像特征;对于在第一图像中能被标准化的包围盒进行精准框定的目标检测对象,则可以在第一图像中直接进行框定,如图2中的图像(b)和图像(c)所示,整合图像由图像(b)和图像(c)拼接形成,人作为较小的目标检测物可以直接在道路监控图像(a)中通过标准化的包围盒框定,面包车作为较大的目标检测物则在降采样处理后的道路监控图像(c)中被标准化的包围盒框定,其中,第一图像为图像(b),第二图像为图像(c)。
步骤102:通过所述神经网络模型提取整合图像特征、将所述整合图像特征分割成分别对应所述多类目标检测物的特征、并对所述多类目标检测物的特征进行并行分支检测。
在可选的实施例中,所述神经网络模型包括第一神经网络、与所述第一神经网络进行级联的切分层及与所述切分层级联的多个第二神经网络。其中,第一神经网络用于提取整合图像特征。切分层用于将所述整合图像特征分割成分别对应所述多类目标检测物的特征。第二神经网络的数量分别与所述多类目标检测物的数量对应,每一第二神经网络形成与对应类的目标检测物进行检测的一条分支。
对于步骤102,包括:所述第一神经网络以所述整合图像作为输入,提取所述整合图像特征作为输出;所述切分层以所述整合图像特征作为输入,分割成分别与所述多类目标检测物对应的特征向量作为输出;所述第二神经网络分别与所述多类目标检测物对应,所述第二神经网络分别以对应的目标检测物的特征向量作为输入,对所述目标检测物的特征向量进行并行分支判断分别获得所述目标检测物的判断结果作为输出。
这里,所述第一神经网络可以为卷积神经网络,所述第二神经网络可以为长短期记忆网络。
神经网络模型通过提取整合图像中的多目标检测物的图像特征并对多目标检测物分别对应的特征通过并行的分支进行训练和识别,从而实现多目标检测物的同时检测。其中,提取多目标检测物的图像特征可以是基于已知的图像数据集预训练得到的神经网络,如bp神经网络、卷积神经网络等实现。本申请实施例中,神经网络模型中提取多目标检测物的图像特征采用卷积神经网络实现。由于需要对多类目标检测物进行同时检测,在提取多目标检测物的图像特征后,为了实现将多类目标检测物对应的特征分别输入到对应的分支进行处理,神经网络模型还通过将提取的多目标检测物的图像特征分割成分别与所述多类目标检测物对应的特征向量,从而可采用分别可针对单类目标检测物进行训练和识别的多个已知神经网络形成并行的分支,对多类目标检测物通过所述分支进行并行处理,以分别对应不同类的目标检测物的训练要求。其中,对多目标检测物分别对应的特征通过并行的分支进行训练和识别可以基于分别对应于所述多类目标检测物的神经网络,如循环神经网络、长短期神经网络等实现。本申请实施例中,神经网络模型中对多目标检测物分别对应的特征通过并行的分支进行训练和识别采用分别与所述多类目标检测物对应的多个长短期神经网络实现。在一个可选的具体实施例中,所述神经网络模型的前半部分为卷积神经网络,利用卷积神经网络提取输入整合图像特征,所述神经网络模型的后半部分是多个分支平行的长短期记忆网络,分别对应不同类目标;此外,卷积神经网络和长短期记忆网络之间设置了切分层,该切分层将卷积神经网络输出的整合图像特征分割成分别与所述多类目标检测物对应的特征向量。
在卷积神经网络中,其基本流程为input→[[conv→relu]×n→pool]×m→[fc→relu]×k→fc,其中,input表示图像输入,[conv→relu]表示对图像数据进行卷积和线性整流过程,其中,[conv→relu]处理过程的次数为n次;[[conv→relu]×n→pool]表示对图像数据进行n次卷积和线性整流之后,进行池化,其中,[[conv→relu]×n→pool]处理过程的次数为m次;[fc→relu]表示进行全连接和线性整流的处理过程,其中,全连接过程指的是把所有局部特征结合变成全局特征,[fc→relu]处理过程的次数为k次。其中,0≤n≤3,m≥0,0≤k<3。
在可选的实施例中,所述切分层所述切分层包括转置层,所述转置层与所述卷积神经网络的全连接层进行级联,用于对所述全连接层输出的整合图像特征进行转置。
这里,在卷积神经网络的最后一层全连接层之后,设置一个转置层,与全连接层进行级联。因此,监控系统通过转置层,可以将全连接层输出的整合图像特征(整合图像特征可以以矩阵或向量的形式表示)乘上适应的比例参数,以获得符合长短期记忆网络的要求的特征向量,其中,比例参数可以根据长短期记忆网络对特征向量的维度要求进行设定。例如,全连接层输出维度为n×c×w×h的向量,通过转置层将维度为n×c×w×h的向量转置为维度为(n×w×h)×c×1×1的向量,其中n是批次大小,c是通道数量,w是网格宽度,h是网格高度,以符合长短期记忆网络的要求,即转置的目的是使输入长短期记忆网络的向量的维度,符合长短期记忆网络的维度要求,如转置前的维度为n×c×w×h,不符合长短期记忆网络的维度要求,转置后的维度为(n×w×h)×c×1×1,符合长短期记忆网络的维度要求。
在可选的实施例中,所述切分层还包括与所述转置层进行级联的剪切层,所述剪切层用于将所述转置层输出的转置结果中符合设定条件的数据进行删除;其中,所述符合设定条件的数据为所述卷积神经网络的卷积层进行卷积过程中,由同时覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据。
在可选的实施例中,所述剪切层,还用于对所述转置层输出的转置结果根据所删除的数据的位置切分成分别对应所述多类目标检测物的多个特征向量,以作为所述长短期记忆网络的输入。
需要说明的是,由于多类目标检测物的特征包含于全连接层输出的同一个整合图像特征中,因此,需要在神经网络模型中增加一层剪切层,对整合图像特征中同时由覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据进行删除,避免该卷积处理所产生的数据对检测结果产生影响。
这里,对于由覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据的删除,可以通过以下例子进行示意性说明,请参阅图3,假设图3中的(e)为整合图像特征,(f)为卷积核,其中,第3-5行为第一图像和第二图像的区域的特征,那么,通过卷积之后,忽略卷积神经网络中的线性整流和池化过程,那么,全连接层输出图3中的(g)卷积结果,由于(g)卷积结果中的第2行的数据由(e)中的第3-5行数据(即第一图像和第二图像的区域的特征)获得的,那么,避免(g)卷积结果中的第2行的数据对检测结果产生影响,删除(g)卷积结果中的第2行。
对整合图像特征中同时由覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据进行删除,并进行相应的剪切,便可获得关于目标检测物的特征向量。举例来说,请参阅图4,为本实施例提供的一种经过转置之后的图像特征的示意图,假设第4行为同时由覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据,对其进行删除,那么,获得1-4行和6-10行的数据,其中,1-4行的数据为第一图像的特征,第6-10行的数据为第二图像的特征。在可选的实施例中,整合图像经过卷积神经网络和切分层的处理之后,获得与所述多类目标检测物对应的特征向量,该特征向量为符合长短期记忆网络的numpy格式数据(包括隐藏状态和记忆状态),作为长短期记忆网络输入。
步骤102:根据所述并行分支检测的结果获得多目标检测结果。
在可选的实施例中,步骤102之前,还包括:判断所述多个目标检测物是否被遮挡;因此,对于步骤102,其具体的实现方式包括:
当所述多个目标检测物未被遮挡时,将所述多个目标检测物的特征与对应的标准模型进行相似判断,根据判断的结果获得多目标检测结果;
当所述多个目标检测物中至少一个被遮挡时,调整被遮挡的目标检测物对应的相似阈值,对所述多个目标检测物的特征与对应的所述标准模型进行相似判断,根据判断的结果获得多目标检测结果。
可知,在进行多目标检测过程中,根据目标检测物是否被遮挡,可以将步骤102划分为以下两种场景:
场景1:多个目标检测物未被遮挡。
当多个目标检测物未被遮挡时,将所述多个目标检测物的特征与对应的标准模型进行相似判断,根据判断的结果获得多目标检测结果。
在可选的实施例中,所述将所述多个目标检测物的特征与对应的标准模型进行相似判断,包括:确定所述多个目标检测物的特征与对应的标准模型之间的相似度,将所述相似度与对应的相似阈值进行判断,根据判断的结果获得多目标检测结果。
这里,所述相似阈值用于衡量神经网络模型输出的关于多个目标检测物的特征所归属的类别,例如,当神经网络模型输出的某个目标检测物的特征,与标准模型的特征之间的相似度大于或等于相似阈值时,表示该某个目标检测物与标准模型属于同一类别。
对于当多个目标检测物未被遮挡的情况,如图5所示,假设出现车辆未被遮挡的情况,且车辆的相似阈值为s=0.5,那么,整合图像在输入神经网络模型后,获得多个目标检测物的特征与对应的标准模型之间的相似度,使用相似阈值s对多个目标检测物的特征进行相似判断,特征相似度大于s时,将该目标检测物归类为车辆。
场景2:多个目标检测物中至少一个被遮挡。
在密集场景中,可能会出现多个目标检测物重叠在一起,或有部分覆盖的情况,针对这一情况,提出了一下解决方案:当多个目标检测物中至少一个被遮挡时,调整被遮挡的目标检测物对应的相似阈值,对多个目标检测物的特征与对应的相似阈值进行相似判断,根据判断的结果获得多目标检测结果。
例如,在检测出较大目标后,重新定位其包围盒所在区域,判断是否有其它目标检测物在此区域中重叠或被覆盖,若有,则包围盒所框定的目标检测物的图像特征将会有所缺失,使得到的目标检测物相对参考物的相似度有所降低,此时,需要降低相似阈值,以保证在重叠情况将被遮挡的目标检测物检测出来。举例来说,如图5所示,假设图5中出现车辆被遮挡的情况,且车辆的相似阈值为0.5,那么,整合图像在输入神经网络模型后,获得多个目标检测物的特征与对应的标准模型之间的相似度,并调整该相似阈值,即相似阈值由0.5降至t,其中,0.1<t<0.5,然后使用调整后的相似阈值t对多个目标检测物的特征进行相似判断,特征相似度大于t时,将该目标检测物归类为车辆,因此,保证了在重叠情况下,对目标检测物实现准确的检测。
在可选的实施例中,步骤102,可以包括:根据设定的相似阈值对并行分支检测的结果进行相似判断,获得相似判断结果;
对所述第二图像中的目标检测物进行升采样;
确定所述相似判断结果对应的目标检测物位于所述升采样后的第二图像的位置信息;
生成包含所述位置信息和所述相似判断结果的目标检测结果。
由于神经网络模型进行多目标检测物体识别中,采用的整合图像是由经过进行降采样处理后的第二图像与第一图像拼接形成的,也即,对第二图像中的目标检测物是采用降采样的条件下进行训练的,因此,在检测出第二图像中的目标检测物时,可以对第二图像进行升采样,通过升采样得到与原始图像(第一图像)尺寸大小和/或分辨率相等的升采样图像,此时,确定所述目标检测物在升采样图像中的位置信息,从而生成包含位置信息和相似判断结果的目标检测结果。需要说明的是,对第二图像进行升采样包括对第二图像中的目标检测物和框定该目标检测物的包围盒进行升采样,从而通过升采样后的包围盒确定目标检测物在升采样图像中的位置信息。
请参阅图6,步骤101之前,需要获得整合图像,对于整合图像的获得的方法,可以包括以下步骤。
步骤1011:获取包含多类目标检测物的第一图像,根据所述第一图像中所述目标检测物的显示参数确定降采样参数。
这里,所述显示参数包括显示尺寸、分辨率等参数。所述目标检测物的类型根据不同的场景所采集到的待检测图像中包含的待检测物体的类型确定,以道路摄像头检测场景为例,目标检测物可以包括:人、汽车、公交车、自行车以及各种动物等。
在本发明实施例中,监控系统在目标场景中采集图像,获得包含多类目标检测物的第一图像,然后,根据第一图像中的目标检测物的显示尺寸或分辨率确定降采样参数。
步骤1012:根据所述降采样参数对所述第一图像进行降采样处理,获得所述第二图像。
传统的方式中,使用标准化的包围盒对所有目标检测物进行框定,如果目标检测物较大,将无法实现精准框定,以至丢失重要训练特征。因此,在本发明实施例中,监控系统在确定降采样参数之后,根据该降采样参数对第一图像进行降采样处理,获得降采样后的图像,其中,通过降采样处理对图像进行压缩后,获得的图像的尺寸和分辨率比原图小。
举例来说,如图2中的图像(a)、(b)、(c)和(d)所示,其中,图像(a)为针对道路摄像头检测场景所采集的待检测原始图像,目标检测物为车辆和行人,该待检测原始图像的尺寸为640×480,图像(a)中的目标检测物中的面包车无法被包围盒精准的框定,目标检测物中的行人能被包围盒精准的框定,根据面包车的尺寸以及包围盒的框定尺寸,设定降采样参数scale=0.4,那么,监控系统使用降采样参数对图(a)进行降采样处理,处理所使用的映射关系式为:
{picture1:x1,y1}→{picture2:x1*scale,y1*scale}
其中,picture1为第一图像,即图像(a)或图像(b),因此,通过降采样处理之后,得到picture2,尺寸大小为size=(640×0.4)×(480×0.4)=256×192,picture2为第二图像,即图像(c)。
步骤1013:将所述第一图像与所述第二图像进行拼接形成所述整合图像。
在本发明实施例中,监控系统将第一图像与降采样处理后的第二图像进行拼接,形成整合图像,其中,拼接的方式可以是第一图像和第二图像横向平行排列的方式拼接,也可以是第一图像和第二图像纵向平行拼接的方式拼接。
这里,以横向平行排列的拼接方式为例,因此,拼接后所得的整合图像的宽度等于第一图像的宽度(w,width),整合图像的高度等于第一图像的高度(h,high)与降采样后所得的图像(如第二图像)的高度h之和,其中,运算式如下所示:
整合图像的宽度:wtotal=wmax;
整合图像的高度:htotal=∑hi;
其中,wmax为第一图像的宽度,hi为第一图像和第二图像的高度之和,整合图像其他冗余部分赋值为0,冗余部分如图2中的图像(d)的右上角黑色部分。需要说明的是,1)所获得的整合图像中,每个相互平行的图像中只包含对应类目标检测物的标记信息,如图像(b)只包含行人的标记信息,图像(c)只包含面包车的标记信息;2)图像(b)实质为图像(a),图像(c)为图像(a)经过降采样处理后的压缩图像。
举例来说,监控系统使用降采样参数对图像(a)进行降采样处理,得到尺寸大小为size=(640×0.4)×(480×0.4)=256×192的图像之后,将图像(b)和图像(c)进行横向平行拼接,从而形成拼接后的整合图像,如图像(d)所示。
在一可选的实施例中,该多目标检测方法还包括在步骤1011之前,通过训练获取候选降采样参数。请参阅图7,为本发明实施例提供的一种获得候选降采样参数的流程示意图,所述获得候选降采样参数的方法步骤包括:
步骤1021:获取包含多类目标对象的第一样本图像;
步骤1022,将所述第一样本图像输入目标检测网络进行训练,所述目标检测网络包括卷积神经网络及与所述卷积神经网络的全连接层连接的降采样参数分支,所述降采样参数分支包括多个全连接层。
步骤1023:通过训练直至得到与所述多类目标对象达到不同目标比例时对应的候选降采样参数。
由于在传统的目标检测网络中,对单一进行目标检测时,对目标检测物的框定均采用标准化的包围盒,其中该标准化的包围盒的尺寸只需要与单一目标检测物的尺寸进行适配。而本申请实施例所提供的多目标检测方法中,对于一个场景中不同类型的目标检测物而言,当将包含多目标检测物的待检测原始图像进行特征提取时,标准化的包围盒并不能针对每个目标检测物的特征或大小进行框定,例如,对于场景中较小的目标检测物,标准化的包围盒可以保证该目标检测物的精准框定描述;但是相对于较大的目标检测物,标准化的包围盒可能无法完全覆盖该目标检测物,以至于丢失重要训练特征。
为了能够实现针对包含多目标检测物的待检测图像对多目标检测物的同时检测,本发明实施例根据一个场景或者不同场景中的多类目标检测物之间的不同大小比例,采用自适应方法来得到较大目标检测物的降采样参数。
请参阅图8,目标检测网络由卷积神经网络和降采样参数分支组成,其中,卷积神经网络包括卷积层、池化层和全连接层,降采样参数分支与全连接层连接。通过将样本图像输入目标检测网络进行训练,根据样本图像中所分别包含的目标对象的原始尺寸以及通过降采样后需要达到的不同目标比例,将样本图像中所包含的目标对象通过训练能够达到对应的目标比例时所采用的降采样参数确定候选降采样参数。以样本图像中包含的目标对象的原始尺寸为x,目标比例分别为s1为例,将样本图像输入目标检测网络进行训练,确定该样本图像中所包含的目标对象的原始尺寸x达到对应的目标比例s1时所采用的降采样参数确定为候选降采样参数。可以理解的,样本图像的数量、样本图像中所包含的目标对象的数量、目标对象的原始尺寸、以及目标比例均可以根据实际应用而进行调整。
目标检测网络由卷积神经网络和降采样参数分支组成,在需要获取降采样参数时,将第一样本图像输入目标检测网络中,将卷积神经网络的全连接层得到的特征图,经过包含多个全连接层的降采样参数分支(或多个全连接层)得到候选降采样参数(scale),如图8所示。在训练的过程中,通过设置不同的参考标准(groundtruth)值,获得不同的降采样参数(如0.3至0.7),如全连接层2后得到的scale,与全连接层1所得的参考值进行对比,得到对应该场景中不同目标检测物比例的最优降采样参数。需要说明的是,groundtruth可以是自动设置,也可以手动设置,本发明实施例中不做具体限定。
在一可选的实施例中,该多目标检测方法还包括在步骤101之前,通过训练获取训练后的神经网络模型。请参阅图9,图9为本发明实施例提供的一种获得训练后的神经网络模型的流程示意图,所述获得训练后的神经网络模型的方法步骤包括:
步骤1031:根据所述候选降采样参数对所述第一样本图像进行降采样,获得第二样本图样。
步骤1032:将所述第一样本图像与所述第二样本图像进行拼接形成样本拼接图像。
其中,对第一样本图像进行降采样处理获得第二样本图像与对第一图像进行降采样处理获得第二图像的方式相同;将第一样本图像与第二样本图像进行拼接形成样本拼接图像与将第一图像和第二图像进行拼接形成整合图像的方式相同,这里不再赘述。
步骤1033:将所述样本拼接图像输入初始的神经网络模型进行训练,所述初始的神经网络模型包括用于提取样本拼接图像特征的初始的卷积神经网络、用于将所述样本拼接图像特征分割成分别对应所述多类目标对象的特征的切分层及对所述多类目标对象的特征进行并行分支检测的初始的长短期神经网络。
步骤1034:通过训练直至所述长短期神经网络的损失函数满足收敛条件,得到训练后的神经网络模型。
这里,训练神经网络模型主要包括加载训练集和训练模型参数。加载训练集,即将基于样本拼接图像构造的训练集、以及样本拼接图像中所包括目标对象输入初始的神经网络模型进行迭代训练,通过前向传导、利用标注信息和代价函数来计算代价、通过反向传播代价函数梯度更新每一层中的参数,以调整初始的卷积神经网络、初始长短期神经网络的权重,直至所述长短期神经网络的损失函数分别满足收敛条件,得到训练后的神经网络模型。所述损失函数满足收敛条件包括:通过训练将损失函数中的参数进行调整或逼近,使损失函数在自变量趋近a,a∈(-∞,+∞)时,趋近于常数b,b为大于或等于0的数,对于b的具体取值,可以根据实际情况设定,本发明实施例中不做具体限定。
需要说明的是,步骤102中的神经网络模型为训练后的神经网络模型,通过训练后的神经网络模型可以进行本发明实施例中的目标检测。
训练时,不同目标对象的特征向量被输入各长短期记忆网络进行平行训练,由于不同目标对象的特性不同,平行训练为了达到最好的定制化效果,损失函数也需要在各长短期记忆网络进行定制化,以对训练结果进行优化调整。需要说明的是,各长短期记忆网络的损失函数依据不同目标进行定制,以期达到最好的训练效果。
请参阅图10,为了实现上述的多目标检测方法,本发明实施例提供了一种多目标检测装置,所述装置包括:
输入模块1001,用于将由第一图像和第二图像拼接而成的整合图像输入神经网络模型;其中,所述第一图像包含多类目标检测物,所述第二图像由第一图像经过降采样处理获得,所述神经网络模型用于提取整合图像特征、将所述整合图像特征分割成分别对应所述多类目标检测物的特征、并对所述多类目标检测物的特征进行并行分支检测;
第一获取模块1002,用于根据所述并行分支检测的结果获得多目标检测结果。
这里,所述神经网络模型包括第一神经网络、与所述第一神经网络进行级联的切分层及与所述切分层级联的多个第二神经网络;其中,所述第一神经网络以所述整合图像作为输入,提取所述整合图像特征作为输出;所述切分层以所述整合图像特征作为输入,分割成分别与所述多类目标检测物对应的特征向量作为输出;所述第二神经网络分别与所述多类目标检测物对应,所述第二神经网络分别以对应的目标检测物的特征向量作为输入,对所述目标检测物的特征向量进行并行分支判断分别获得所述目标检测物的判断结果作为输出。
这里,所述第一神经网络为卷积神经网络,所述第二神经网络为长短期记忆网络。
这里,所述切分层包括转置层,所述转置层与所述卷积神经网络的全连接层进行级联,用于对所述全连接层输出的整合图像特征进行转置。
这里,所述切分层还包括与所述转置层进行级联的剪切层,所述剪切层用于将所述转置层输出的转置结果中符合设定条件的数据进行删除;其中,所述符合设定条件的数据为所述卷积神经网络的卷积层进行卷积过程中,由同时覆盖所述第一图像和第二图像的区域的卷积核进行卷积处理所产生的数据。
这里,所述剪切层,还用于对所述转置层输出的转置结果根据所删除的数据的位置切分成分别对应所述多类目标检测物的多个特征向量,以作为所述长短期记忆网络的输入。
这里,所述装置还包括:采集模块1003、降采样模块1004和拼接模块1005;其中,
采集模块1003,用于在将由第一图像和第二图像拼接而成的整合图像输入神经网络模型之前,获取所述第一图像,根据所述第一图像中所述目标检测物的显示参数确定降采样参数;
降采样模块1004,用于根据所述降采样参数对所述第一图像进行降采样处理,获得所述第二图像;
拼接模块1005,用于将所述第一图像与所述第二图像进行拼接形成所述整合图像。
这里,所述装置还包括:判断模块1006;其中,
判断模块1006,用于在根据所述并行分支检测的结果获得多目标检测结果之前,判断所述多个目标检测物是否被遮挡;
所述第一获取模块1002,具体用于:
当所述多个目标检测物未被遮挡时,将所述多个目标检测物的特征与对应的标准模型进行相似判断,根据判断的结果获得多目标检测结果;
当所述多个目标检测物中至少一个被遮挡时,调整被遮挡的目标检测物对应的相似阈值,对所述多个目标检测物的特征与对应的所述标准模型进行相似判断,根据判断的结果获得多目标检测结果。
这里,所述第一获取模块1002,具体用于:
根据设定的相似阈值对并行分支检测的结果进行相似判断,获得相似判断结果;
对所述第二图像进行升采样;
确定所述相似判断结果对应的目标检测物位于所述升采样后的第二图像的位置信息;
生成包含所述位置信息和所述相似判断结果的目标检测结果。
这里,所述装置还包括:第二获取模块1007;其中,
第二获取模块1007,用于在将由第一图像和第二图像拼接而成的整合图像输入神经网络模型之前,获取包含多类目标对象的第一样本图像;将所述第一样本图像输入目标检测网络进行训练,所述目标检测网络包括卷积神经网络及与所述卷积神经网络的全连接层连接的降采样参数分支,所述降采样参数分支包括多个全连接层;
通过训练直至得到与所述多类目标对象达到不同目标比例时对应的候选降采样参数。
这里,第二获取模块1007,还用于在通过训练直至得到与所述多类目标对象达到不同目标比例时对应的候选降采样参数之后,根据所述候选降采样参数对所述第一样本图像进行降采样,获得第二样本图样;
拼接模块1005,还用于将所述第一样本图像与所述第二样本图像进行拼接形成样本拼接图像;
输入模块1001,还用于将所述样本拼接图像输入初始的神经网络模型进行训练,所述初始的神经网络模型包括用于提取样本拼接图像特征的初始的卷积神经网络、用于将所述样本拼接图像特征分割成分别对应所述多类目标对象的特征的切分层及对所述多类目标对象的特征进行并行分支检测的初始的长短期神经网络;
通过训练直至所述长短期神经网络的损失函数满足收敛条件,得到训练后的神经网络模型。
参阅图11,为本发明实施例提供的一种多目标检测装置的结构示意图,多目标检测装置1100可以是监控设备或监控系统等,其结构可以包括:至少一个处理器1110、存储器1120、至少一个网络接口1130和至少一个用户接口1140。多目标检测装置1100中的各个组件通过总线系统1150耦合在一起。可理解,总线系统1150用于实现这些组件之间的连接通信总线系统1150除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图9中将各种总线都标为总线系统1150。
其中,用户接口1140可以是显示器、鼠标或键盘等,其中,该显示器可以是触摸屏显示器。
存储器1120可以是易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者,本发明实施例描述的存储器1120旨在包括但不限于这些和任意其它适合类型的存储器。
本发明实施例中的存储器1120用于存储各种类型的数据以支持多目标检测装置1100的操作。这些数据的示例包括:用于在多目标检测装置1100上操作的任何计算机程序,如操作系统1121和应用程序1122。
其中,操作系统1121包含各种系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务。应用程序1122可以包含各种应用程序,实现本发明实施例提供的多目标检测方法的程序可以包含在应用程序1122中作为一个功能模块,当然也可以提供为专门用于多目标检测方法的应用程序。
本发明实施例提供的多目标检测方法可以应用于处理器1110中,或者由处理器1110实现,基于纯硬件的方式实施,或者基于软件和硬件结合的方式实施。
就纯硬件的实施方式来说,处理器1110可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,本发明实施例提供的多目标检测方法的各步骤可以通过处理器1110中的硬件的集成逻辑电路完成,例如在示例性实施例中,多目标检测装置1100可以内建有用于实现本发明实施例提供的多目标检测方法的硬件译码处理器实施,例如,专用集成电路(asic,applicationspecificintegratedcircuit)、复杂可编程逻辑器件(cpld,complexprogrammablelogicdevice)、现场可编程门阵列(fpga,field-programmablegatearray)等实现。
就软硬件结合的实施方式来说,上述的处理器1110可以是通用处理器及软件模块组合执行完成。软件模块可以位于存储介质中,该存储介质位于存储器1120,其中,存储介质存储能够在处理器1110上运行的计算机程序,处理器1110在读取并运行储器1120中的计算机程序时,完成本发明实施例提供的多目标检测方法。
作为一示例,请参阅图12,为本发明实施例提供的另一种多目标检测方法的流程示意图,所述方法包括:
步骤1251:采集第一图像。
本发明实施例中,监控系统对行人和车辆进行训练和检测,第一图像为监控场景视频中的一帧图像,其尺寸大小为640×480。对于连续的视频来说,相邻两帧图像中的目标检测物的分布差别很小,因此,可以每隔一定帧数,如15帧选取一张图像执行一次检测。
步骤1252:生成拼接的整合图。
在第一图像中,由于车辆的显示尺寸相对于行人的显示尺寸过大,对第一图像进行降采样,其中,假设降采样参数scale=0.4,那么,对第一图像进行降采样后得到尺寸为256×192的第二图像。
获得第二图像之后,将第一图像和第二图像进行拼接,形成整合图像,其尺寸大小为640×672,如图2所示,其中,第一图像中包围盒框定的为行人,第二图像中包围盒框定的是车辆,而右上角冗余部分赋值为0。
步骤1253:通过卷积神经网络和切分层处理,得到特征向量。
这里,卷积神经网络可以是googlenet。
将整合图像作为训练数据输入神经网络模型,其中,神经网络模型包括卷积神经网络、切分层和长短期记忆网络,卷积神经网络可以采用googlenet。
输入的整合图像通过卷积神经网络,得到n×c×w×h特征向量,通过googlenet中的自定义函数generate_intermediate_layers(net),将n×c×w×h的特征转置为(n×w×h)×c×1×1的特征向量,以符合googlenet后续的卷积操作,其中n是批次大小,c是通道数量,w是网格宽度,h是网格高度。
然后,将(n×w×h)×c×1×1的特征向量经过googlenet中的卷积层convolution,googlenet的最后一个卷积层inception_5b/output为输入,卷积层的参数为:
param_lr_mults=[1.,2.],param_decay_mults=[0.,0.],num_output=1024,kernel_dim=(1,1),weight_filler=filler(“gaussian”,0.005),bias_filler=filler(“constant”,0.)),全连接层的输出变量为post_fc7_conv。
可选的,post_fc7_conv经过googlenet的power层,,假设取参数为scale=0.01,power层的输出变量用lstm_fc7_conv表示,那么,power层的输出为20×21×1024特征向量v0,如图5所示。
那么,power层对每个输入的特征x计算其(shift+scale*x)power值,将其作为lstm_fc7_conv的输出值,其中,当shift为0,scale为0.01时,经过power层的目的是对输入的特征x进行压缩处理。
lstm_fc7_conv再输入转置层,将20×21×1024特征向量v0转置为420×1024的特征向量vt,其中,该特征向量vt包含了车辆以及行人特征信息,并作为切分层的输入,输入用lstm_input表示。
如图5所示,lstm_input作为切分层的输入,切分层将该特征向量vt切分成车辆部分与行人部分,车辆部分为48×1024大小的特征向量vp,输出为lstm_car_input,行人部分为300×1024大小的特征向量vc,输出为lstm_ped_input,分别对应原特征向量v0中的8×6×1024和20×15×1024部分。
通过切分层之后,分别将车辆部分与行人部分的特征向量传递给长短期记忆网络中。
步骤1254:通过长短期记忆网络,对车辆部分与行人部分的特征向量分别进行处理。
在一个可选的具体实施例中,提供一种长短期记忆网络的生成方法,主要包括如下步骤。首先,通过数组(numpydata)层初始化各个长短期记忆网络的第一层输入,其中,第一层输入为隐藏状态种子(lstm_hidden_seed)和记忆状态种子(lstm_mem_seed)的格式。
然后,根据初始参数生成长短期记忆网络单元及连接单元的各门限,之前的隐藏状态为当前单元输入,运行当前时间步长后输出的隐藏状态为丢失内容。其中,门限即是指让信息选择性通过的方式,用于输出0~1之间的数字,描述一个神经元有多少信息应该被通过,如输出“0”意味着“全都不能通过”,输出“1”意味着“让所有都通过”。以本申请实施例中包含车辆和形成的第一图像的检测为例,这里根据初始参数,行人与车辆的长短期记忆网络长度都为max_len=5,输出丢失率为p=0.2,每个输出都服从二项伯努利分布b(1-p),则大约认为训练时只使用了(1-p)比例的输出,剩下的作为输出隐藏状态。
最后,经过全连接内积层得到包围盒ip_bbox和置信度ip_soft_conf。
可选的,所述长短期记忆网络的生成方式方法还包括定制损失函数的步骤,包括:
s1:在生成长短期记忆网络的输入种子前,生成groundtruth层,自定义函数generate_ground_truth_layers(net,box_flags,boxes)借用numpydata层转换包围盒信息格式,在每个长短期记忆网络单元中编码每个包围盒,包围盒相当于一个多维数组,如numpy格式的数组,其中包含x、y中心坐标以及宽和高,5该包围盒的大小可以具体表示为boxes=centerx[n]+centery[n]+width[n]+height[n]。
s2:在长短期记忆网络后生成损失函数层,即定制损失函数,这里用到softmax损失函数和hungarian损失函数。
s3:softmax损失函数可以是目前已知的神经网络的内置函数,其具体表0达式在此不再赘述。对于hungarian损失函数,在长短期记忆网络每个迭代中,输出目标包围盒b={bpos,bc}、bpos=(bx,by,bw,bh)∈r4是x、y中心坐标相对位置和宽高信息的集合,bc∈[0,1]是置信度。定义groundtruth包围盒集合为g={bi|i=1,…,m},模型产生备选包围盒集合为
损失函数(lossfunction)是神经网络优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程,损失函数值越小,对应预测的结果和真实结果的值就越接近。可以理解的是,关于长短期记忆网络所对应的损失函数并不限于上述softmax损失函数和hungarian损失函数,具体实施时,针对训练不同目标检测物的不同长短期记忆网络,其所对应的损失函数也可以采用已知的其它损失函数,如对数损失函数、交叉熵损失函数等。
步骤1255:根据长短期记忆网络处理结果获得多目标检测的结果。
由于目标检测物的类别不同,或者监控场景不同,目标检测物检测的难易程度可能存在差异,因此,对不同的场景下不同类别的目标检测物的检测,可采用不同的相似阈值,以该多目标检测方法应用于不同场景下获得的图像作为第一图像为例:
场景1:某公园路口摄像头的监控场景。
第一图像为某公园路口摄像头的监控场景的图像,具体如图13所示,目标检测物体为车辆和行人,设置车辆的相似阈值为0.5,行人的相似阈值为0.3,那么,1)当长短期记忆网络输出的针对车辆特征的相似度大于或等于0.5时,则检测出该车辆特征的类别为车辆;当长短期记忆网络输出的针对行人特征的相似度大于或等于0.3时,则检测出该行人特征的类别为行人。2)当长短期记忆网络输出的针对车辆特征的相似度小于0.5时,则无法确定该车辆特征所归属的类别,即本次对车辆的检测失败;当长短期记忆网络输出的针对行人特征的相似度小于0.3时,则无法确定该行人特征所归属的类别,即本次对行人的检测失败。
此外,在检测到较大的目标检测物后,再次定位其包围框所在区域,判断该目标检测物是否有其它物体在此区域中重叠或覆盖,如果有,则降低被重叠或覆盖的目标检测物的判断阈值。例如,若检测到较大的目标检测物为车辆,重新判断该车辆的包围盒位置内是否有其它的包围盒,如果有其它的包围盒,则降低车辆阈值为t,0.1<t<0.5,使用降低后的车辆阈值t重新进行检测;若检测到较大的目标检测物为为行人,重新判断该车辆的包围盒位置内是否有其它的包围盒,如果有其它的包围盒,则降低行人阈值为s,0.1<s<0.3,使用降低后的车辆阈值s重新进行检测,从而提高目标检测物的准确率和效率。
场景2:a市路口摄像头的监控场景。
第一图像为a市路口摄像头的监控场景,具体如图14所示,目标检测物体为车辆和行人,设置车辆和行人的相似阈值为0.5,那么,1)当长短期记忆网络输出的针对车辆特征的相似度大于或等于0.5时,则检测出该车辆特征的类别为车辆;当长短期记忆网络输出的针对行人特征的相似度大于或等于0.5时,则检测出该行人特征的类别为行人。2)当长短期记忆网络输出的针对车辆特征的相似度小于0.5时,则无法确定该车辆特征所归属的类别,即本次对车辆的检测失败;当长短期记忆网络输出的针对行人特征的相似度小于0.5时,则无法确定该行人特征所归属的类别,即本次对行人的检测失败。
此外,在检测到较大的目标检测物后,需要再次定位其包围框所在区域,判断该目标检测物是否有其它物体在此区域中重叠或覆盖,如果有,则降低被重叠或覆盖的目标检测物的判断阈值。例如,若检测到较大的目标检测物为车辆,重新判断该车辆的包围盒位置内是否有其它的包围盒,如果有其它的包围盒,则降低车辆阈值为t,0.1<t<0.5,使用降低后的车辆阈值t重新进行检测;若检测到较大的目标检测物为为行人,重新判断该车辆的包围盒位置内是否有其它的包围盒,如果有其它的包围盒,则降低行人阈值为s,0.1<s<0.5,使用降低后的车辆阈值s重新进行检测,从而确定图像中车辆和行人的类别。
场景3:b市路口摄像头的监控场景。
第一图像为a市路口摄像头的监控场景,具体如图15所示,目标检测物体为车辆和行人,设置车辆和行人的相似阈值为0.4,那么,1)当长短期记忆网络输出的针对车辆特征的相似度大于或等于0.4时,则检测出该车辆特征的类别为车辆;当长短期记忆网络输出的针对行人特征的相似度大于或等于0.4时,则检测出该行人特征的类别为行人。2)当长短期记忆网络输出的针对车辆特征的相似度小于0.4时,则无法确定该车辆特征所归属的类别,即本次对车辆的检测失败;当长短期记忆网络输出的针对行人特征的相似度小于0.4时,则无法确定该行人特征所归属的类别,即本次对行人的检测失败。
此外,在检测到较大的目标检测物后,需要再次定位其包围框所在区域,判断该目标检测物是否有其它物体在此区域中重叠或覆盖,如果有,则降低被重叠或覆盖的目标检测物的判断阈值。例如,若检测到较大的目标检测物为车辆,重新判断该车辆的包围盒位置内是否有其它的包围盒,如果有其它的包围盒,则降低车辆阈值为t,0.1<t<0.4,使用降低后的车辆阈值t重新进行检测;若检测到较大的目标检测物为为行人,重新判断该车辆的包围盒位置内是否有其它的包围盒,如果有其它的包围盒,则降低行人阈值为s,0.1<s<0.4,使用降低后的车辆阈值s重新进行检测,从而确定图像中车辆和行人的类别。
当检测出车辆和行人的类别之后,对车辆和行人的特征进行升采样、整合,得到场景中车辆和行人在密集分布场景中的清晰检测结果。
本发明实施例还提供一种存储介质,存储有计算机程序,所述计算机程序被处理器执行时用于实现本发明任一实施例提供的多目标检测方法,例如,如图1、图6、图7、图9和图12中所示实施例的多目标检测方法;存储介质包括易挥发性随机存取存储器(ram)、只读存储器(rom)、电可擦可编程只读存储器(eeprom)、闪存或其他存储器技术、只读光盘(cd-rom)、数字通用盘(dvd)或其它被访问的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。本发明的保护范围应以所述权利要求的保护范围以准。
- 还没有人留言评论。精彩留言会获得点赞!