一种适用于专用集成电路设计的交错匹配滤波方法与流程
本发明涉及一种适用于专用集成电路设计的交错匹配滤波方法,属于专用集成电路技术领域。
背景技术:
专用集成电路(asic)是为达到某种专门目的而设计的集成电路,在专用扩频基带信号处理芯片设计中,码相位的捕获和解扩解调均依赖于数字匹配滤波器的输出。asic设计成本和逻辑资源消耗密切相关,因此数字匹配滤波器的逻辑资源消耗是asic设计中一个关键的指标。
对于n倍chip速率过采样信号,如果用n个全流水结构和并行相乘相加的方法来完成匹配滤波,则会造成逻辑资源n倍的增长,这在asic设计中是无法接受的。而本发明提出的适用于asic设计的交错匹配滤波方法对延时后的信号进行奇偶交错匹配滤波,并用按位取反后补偿的操作替代乘法器完成数据的取反,显著减少逻辑资源的消耗,满足asic设计的要求。
技术实现要素:
为解决对扩频信号n倍chip速率采样后信号进行匹配滤波时消耗逻辑资源过大的问题,本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,采用对过采样信号延时后进行奇偶交错匹配滤波和按位取反后补偿的操作完全替代乘法器完成数据的取反的方式,完成对n倍chip速率过采样信号的匹配滤波,能够减少逻辑资源消耗和降低设计复杂度。
本发明是通过以下技术方案实现的。
本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,首先利用延时单元对扩频过采样信号进行延时;然后对延时后的数据进行判断处理,根据pn码相应位置的值对延时信号进行直接输出或者取反输出,其中的取反操作利用按位取反后补偿的方式来完成;最后利用一个流水线加法器树对判断处理后的数据进行逐级相加和寄存,最后一级加法运算的结果加上补偿值即为奇偶交错匹配滤波的输出结果,至此,完成对过采样信号的匹配滤波,能够减少逻辑资源消耗和降低设计复杂度。
本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,包括如下步骤:
步骤一、将m位的pn码写入m位的寄存器r,并统计pn码序列中“1”的总数为sadj,并对m倍扩频信号进行n倍chip速率过采样。
步骤二、对扩频信号进行多级延时。
将采样信号送入第一个延时单元,所述延时单元共有m个,且各个延时单元首尾相连,即前一个延时单元的数据输出与下一个延时单元的数据输入相连。每个延时单元中有n个延时器,每个延时器的延时周期是1个时钟周期。
步骤三、对延时数据进行判断处理。
在每个延时单元末尾处进行抽头,每个抽头后设置一个判断处理单元pi对延时单元输出数据进行判断处理。如果寄存器r的第i位数值为0,则pi对第i个抽头处的数据不进行处理并从pi输出;如果寄存器r的第i位数值为1,则pi对第i个抽头处的数据按位取反后从pi输出。其中i的取值为1,2,3,…,m。
步骤四、对判断处理后数据进行第1级加法运算并寄存。
将相邻两个判断处理单元pj和pj+1的输出送至第1级流水线加法器中进行加法运算,将运算结果通过非阻塞赋值存储至第1级寄存器。其中第1级流水线加法器和寄存器各有m/2个,j的取值为1,3,5…,m-1。
步骤五、对第1级加法运算结果进行逐级加法运算并寄存。
将第1级寄存器的结果通过第2级流水线加法器进行相加,并将结果存储至第2级寄存器,以此类推,直到第(log2m)级加法运算得到初步相加总和st。
步骤六、将s=st+sadj作为匹配滤波的一个结果输出。
步骤七、对步骤一所述的n倍chip速率过采样信号重复步骤二到步骤六的操作进行滤波,最终得到奇偶交错匹配滤波的全部输出;
至此,完成对n倍chip速率过采样信号的匹配滤波,能够减少逻辑资源消耗和降低设计复杂度。
有益效果:
1、本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,采用延时单元对过采样信号进行延时,并对延时后的数据进行交错匹配滤波,利用1个流水线加法器树就能够完成n倍chip速率过采样信号的匹配滤波,能够简化数字匹配滤波器设计结构,并显著减少逻辑资源消耗。
2、本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,利用按位取反后补偿的操作代替乘法器实现对数据的取反操作,优化逻辑时序,节省逻辑资源。
3、本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,通过加法器和寄存器实现每级加法流水线先相加后寄存的操作,缩短时序路径,能够满足更高的时序要求。
4、本发明公开的一种适用于专用集成电路设计的交错匹配滤波方法,对n倍chip速率过采样信号进行顺序的奇偶交错匹配滤波后,输出结果仍是顺序的各路采样值匹配滤波结果,更有易于进行后续信号处理。
附图说明
图1是具体实施方式中适用于asic设计的交错匹配滤波结构示意图。
图2是具体实施方式中适用于asic设计的交错匹配滤波方法流程图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明和详细描述。
实施例1:
本实施例公开的一种适用于专用集成电路设计的交错匹配滤波方法,用于某一直接序列扩频系统,该系统扩频比为1024。
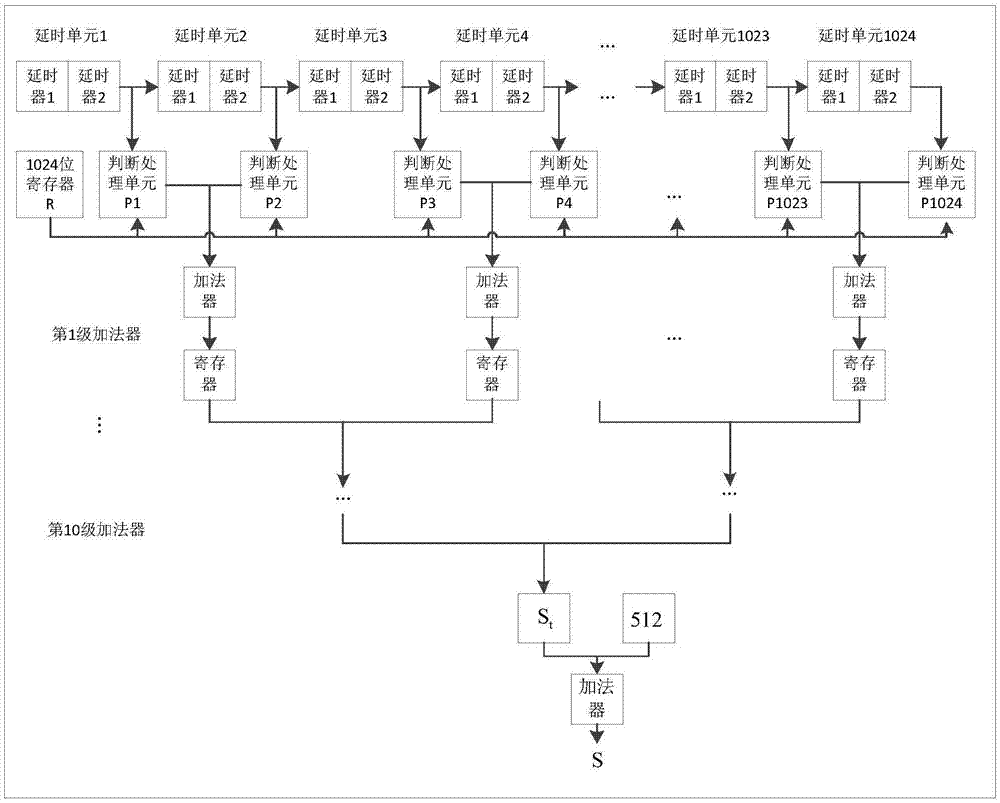
图1所示为具体实施方式中适用于asic设计的交错匹配滤波结构示意图,
图2所示为具体实施方式中适用于asic设计的交错匹配滤波方法流程图,本实施例公开的一种适用于专用集成电路设计的交错匹配滤波方法,具体实施步骤如下:
步骤一、将1024位的pn码写入1024位的寄存器r,统计pn码序列中“1”的总数为512,并对1024倍扩频信号进行2倍chip速率过采样。
步骤二、对扩频信号进行多级延时。
将采样信号送入第一个延时单元,所述延时单元共有1024个,且各个延时单元首尾相连,即前一个延时单元的数据输出与下一个延时单元的数据输入相连。每个延时单元中有2个延时器,每个延时器的延时周期是一个时钟周期。
步骤三、对延时数据进行判断处理。
在每个延时单元末尾处进行抽头,每个抽头后设置一个判断处理单元pi对延时单元输出数据进行判断处理。如果寄存器r的第i位数值为0,则pi对第i个抽头处的数据不进行处理并从pi输出;如果寄存器r的第i位数值为1,则pi对第i个抽头处的数据按位取反后从pi输出。其中i的取值为1,2,3,…,1024。
步骤四、对判断处理后数据进行第1级加法运算并寄存。
将相邻两个判断处理单元pj和pj+1的输出送至第1级流水线加法器中进行加法运算,将运算结果通过非阻塞赋值存储至第1级寄存器。其中第1级流水线加法器和寄存器各有512个,j的取值为1,3,5…,1023。
步骤五、对第1级加法运算结果进行逐级加法运算。
将第1级寄存器的结果通过第2级流水线加法器进行相加,并将结果存储至第2级寄存器,以此类推,直到第10级加法运算得到初步相加总和st。
步骤六、将s=st+512作为匹配滤波的一个结果输出。
步骤七、对步骤一所述的2倍chip速率过采样信号重复步骤二到步骤六的操作进行滤波,最终得到奇偶交错匹配滤波的全部输出。
本实施例中利用1个10级流水线加法器树就可以完成对2倍chip速率过采样信号的奇偶交错匹配滤波,显著减少逻辑资源消耗。
判断处理单元采用按位取反后补偿的操作替代乘法器完成对数据的取反工作,优化逻辑时序,减少资源消耗。
采用10级相加后寄存的流水线方式完成1024个数据的相加过程,缩短逐级相加过程中的时序路径,可以满足更高的时序要求。
本实施例方法输出的匹配滤波结果是顺序的第1路和第2路采样信号匹配滤波的结果,更方便对数据做后续的信号处理。
以上所述为本发明的较佳实施例而已,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化和变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!