重组人成纤维细胞生长因子21融合蛋白及其在制备治疗代谢疾病药物中的应用的制作方法
本发明涉及重组蛋白领域,尤其涉及一种重组人成纤维细胞生长因子21融合蛋白及其制备方法,本发明还涉及该重组人成纤维细胞生长因子21融合蛋白在制备治疗代谢疾病药物中的用途,属于成纤维细胞生长因子技术领域。
背景技术:
糖尿病(diabetes mellitus,DM),是一类由胰腺功能病变的慢性代谢类疾病,以高血糖为主要特征,是一种终身疾病。其发病机理是胰岛素抵抗或胰岛素分泌减少,导致机体糖脂代谢紊乱所致。随着世界人口的老龄化,糖尿病已成为一种常见病、多发病,现已成为继癌症和心脑血管病之后,第三大威胁人类生命的疾病(Nathan DM, et al. Medical management of hyperglycaemia in type 2 diabetes: a consensus algorithm for the initiation and adjustment of therapy. Diabetes Care 2009; 32: 193–203. Culy CR, Jarvis B. Repaglinide: a review of its therapeutic use in type 2 diabetes mellitus [J]. Drugs, 2001, 61(11): 1625)。
随着经济的日益发展,我国的糖尿病患者数量也呈上升趋势,据调查结果估计,现中国大约有1亿糖尿病患者。目前治疗糖尿病的药物大多数是以胰岛素为核心发挥作用,如胰岛素类制剂或其增敏剂类药物等,但这些药物对有些糖尿病患者特别是II型糖尿病的晚期患者效果仍然不够理想。由于没有可替代胰岛素的药物和更先进的治疗手段,尽管病人对胰岛素产生抵抗作用,导致上述药物无法奏效,胰岛素仍然是治疗II型糖尿病的首选药物。随着胰岛素抵抗作用的不断加剧,胰岛素的疗效逐渐减弱,血糖无法控制在正常水平。由于血糖长期维持在较高水平,从而导致很多严重的并发症,如失明、肾衰、心脑血管疾病和神经系统疾病等。因此II型糖尿病的临床治疗中一直迫切需要一种能取代胰岛素,解决胰岛素抵抗的新型药物。
成纤维细胞生长因子(FGF)21属于FGF家族中一名新成员,FGF21基因主要在肝脏和脂肪中表达,FGF21在体外能够促进HepG2细胞和3T3-L1脂肪细胞消耗葡萄糖,在动物体内具有降低血糖和甘油三酯等功能,并且不会产生低血糖和引起肿瘤发生等副作用(Kharitonenkov A, et al. FGF-21 as a novel metabolic regulator. J Clin Invest 2005; 115:1627–35. Kharitonenkov A, et al. The metabolic state of diabetic monkeys is regulated by fibroblast growth factor-21. Endocrinology 2007;148:774–81)。FGF21安全、有效以及不依赖胰岛素调节生物体内血糖水平的特点,使其有望成为治疗II型糖尿病的新型药物。然而,随着对FGF21的深入了解,我们发现野生型FGF21的生物学功能及临床应用受到了体内稳定性和自身免疫原性的制约(Huang Z, et al. A better anti-diabetic recombinant human fibroblast growth factor 21 (rhFGF21) modified with polyethylene glycol. PLoS One 2011;6:e20669. Ye X, et al. Enhancement of the pharmacological efficacy of FGF-21 by genetic modification and PEGylation. Curr Pharm Biotechnol 2014;14:1287–98.),故对FGF21进行改造和修饰将逐渐成为近年来研究的热点。
人血清白蛋白(HSA)是由585个氨基酸残基组成的单链无糖基化的球形蛋白质,是人体血清内含量最高的蛋白,分子量为66kDa,第356位的苏氨酸是可能存在O-糖基化位点(He, X.M. and D.C. Carter, Atomic structure and chemistry of human serum albumin. Nature, 1992. 358(6383): p. 209-15.),其在调节血液渗透压和促进伤口愈合等方面起着重要的作用,并且具有人体相容性好、分子量大、半衰期长及无酶活性和免疫原性等优点,这使得白蛋白融合技术在研制长效重组蛋白药物领域倍受关注(Nel, M.R., Human albumin administration in critically ill patients. Critical analysis of original studies has to take place. BMJ, 1998. 317(7162): p. 882.)。很多具有治疗功能的蛋白质,如干扰素、人生长激素和IL-2等,经过白蛋白融合技术的改造后,都可以开发成为具有药效更佳和注射次数减少等优点的重组蛋白药物。白蛋白融合技术的优势在于其不需要额外的化学修饰,生产工艺简单,产物均一,且质量控制相对容易,延长药物半衰期的效果可能要比化学修饰(如PEG修饰和乙酰化等)更有效(Muller, N., et al., Superior serum half life of albumin tagged TNF ligands. Biochemical and Biophysical Research Communications, 2010. 396(4): p. 793-799.)。但在白蛋融合蛋白的表达和储存过程中伴有降解和聚合现象,增加了纯化的难度和临床用药时出现免疫反应的风险(Yao, X.Q., et al., Degradation of HSA-AX15(R13K) when expressed in Pichia pastoris can be reduced via the disruption of YPS1 gene in this yeast. J Biotechnol, 2009. 139(2): p. 131-6. Cordes, A.A., et al., Selective domain stabilization as a strategy to reduce fusion protein aggregation. J Pharm Sci, 2012. 101(4): p. 1400-9. Cordes, A.A., J.F. Carpenter, and T.W. Randolph, Selective domain stabilization as a strategy to reduce human serum albumin-human granulocyte colony stimulating factor aggregation rate. J Pharm Sci, 2012. 101(6): p. 2009-2016.)。近来研究发现,HSA 第 381-585位氨基酸残基构成的第3结构域(3DHSA)是HSA与新生儿Fc受体(FcRn)结合的关键部位,在受体介导的胞吞保护作用下耐受蛋白酶的降解,从而保证HSA具有较长的半衰期(Andersen, J.T., J.D. Qian, and I. Sandlie, The conserved histidine 166 residue of the human neonatal Fc receptor heavy chain is critical for the pH-dependent binding to albumin. Eur J Immunol, 2006. 36(11): p. 3044-3051.)。基于对白蛋白长效机制的深入认识,Kenanova 等(Kenanova, V.E., et al., Tuning the serum persistence of human serum albumin domain III:diabody fusion proteins. Protein Eng Des Sel, 2010. 23(10): p. 789-98.)将3DHSA 作为融合伴侣,构建了一系列抗癌胚抗原双抗体与3DHSA的融合蛋白,证明了3DHSA作为融合伴侣延长蛋白药物半衰期的可行性。
蛋白稳定性的高低直接影响其在宿主细胞中的表达量,为了提高蛋白产量及稳定性,并在不影响蛋白原有活性的基础上,需要将FGF21进行适当的改造。本发明通过将FGF21与HSA或3DHSA连接成融合蛋白的形式来提高FGF21的稳定性,为以后FGF21的产业化提供了重要的技术帮助。
技术实现要素:
本发明解决的技术问题是提供了一种重组人成纤维细胞生长因子21融合蛋白及其制备方法,该重组人成纤维细胞生长因子21融合蛋白能够用于制备治疗糖尿病或肥胖症的药物或药物组合物。
本发明为解决上述技术问题采用如下技术方案,重组人成纤维细胞生长因子21融合蛋白,其特征在于是将人成纤维细胞生长因子21重组蛋白hFGF21与HSA或3DHSA连接而成的重组融合蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21,其中重组融合蛋白hFGF21-HSA的氨基酸序列如序列表中SEQ ID NO:5所示,重组融合蛋白HSA-hFGF21的氨基酸序列如序列表中SEQ ID NO:6所示,重组融合蛋白hFGF21-3DHSA的氨基酸序列如序列表中SEQ ID NO:7所示,重组融合蛋白3DHSA-hFGF21的氨基酸序列如序列表中SEQ ID NO:8所示。
本发明所述的重组人成纤维细胞生长因子21融合蛋白编码基因,其特征在于:所述的重组融合蛋白hFGF21-HSA编码基因的核苷酸序列如序列表中SEQ ID NO:1所示,重组融合蛋白HSA-hFGF21编码基因的核苷酸序列如序列表中SEQ ID NO:2所示,重组融合蛋白hFGF21-3DHSA编码基因的核苷酸序列如序列表中SEQ ID NO:3所示,重组融合蛋白3DHSA-hFGF21编码基因的核苷酸序列如序列表中SEQ ID NO:4所示。
本发明所述的重组人成纤维细胞生长因子21融合蛋白编码基因的表达载体及含有该表达载体的宿主细胞,其特征在于:所用的表达载体优选为pET30a(+),宿主细胞优选为Rossetta(DE3)。
本发明所述的重组人成纤维细胞生长因子21融合蛋白的制备方法,其特征在于具体步骤为:将重组人成纤维细胞生长因子21融合蛋白编码基因的核苷酸序列与表达载体相连接得到重组表达载体;再将该重组表达载体转化宿主细胞,然后筛选高表达阳性宿主细胞,培养细胞并诱导表达重组人成纤维细胞生长因子21融合蛋白,收集菌体、破碎、离心、澄清、纯化,得到目标产物重组人成纤维细胞生长因子21融合蛋白。
本发明所述的重组人成纤维细胞生长因子21融合蛋白在制备治疗代谢疾病药物中的应用,其中代谢疾病包括糖尿病、肥胖症和代谢综合症。
本发明所述的用于治疗糖尿病或肥胖症的药物组合物,其特征在于包括治疗上有效剂量的重组人成纤维细胞生长因子21融合蛋白和药学上可接受的载体或辅料。
本发明的细胞试验和动物学试验结果表明,重组人成纤维细胞生长因子21融合蛋白能够较好的控制血糖波动,稳定维持24小时血糖处于正常水平。特别是hFGF21与3DHSA连接的重组融合蛋白,其降糖效果更佳。本发明的重组融合蛋白可作为药物治疗糖尿病、肥胖症或代谢综合症等代谢疾病。
附图说明
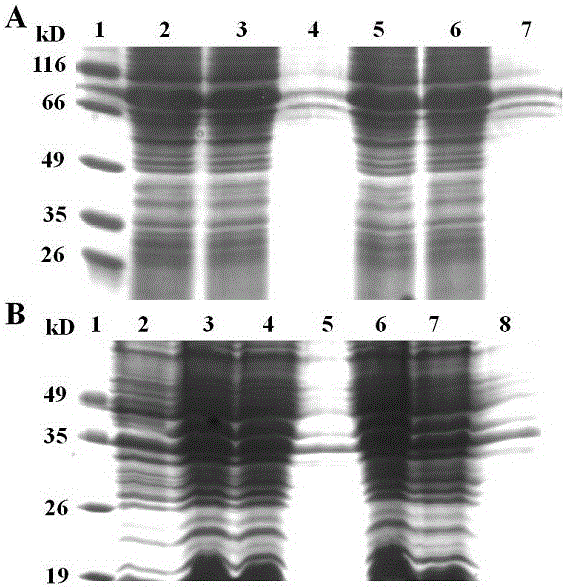
图1是重组融合蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21在大肠杆菌中表达量的SDS-PAGE电泳分析图;
图2是纯化后重组融合蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21的SDS-PAGE电泳分析图;
图3是5种蛋白的体内半衰期比较图;
图4是5种蛋白的体外细胞活性检测图;
图5是STZ诱导的I型糖尿病小鼠长期注射5种蛋白后每周血糖水平的变化曲线;
图6是STZ诱导的I型糖尿病小鼠注射不同蛋白8周后血糖、糖化血红蛋白及甘油三脂水平的变化曲线;
图7是II型糖尿病db/db小鼠长期注射5种蛋白后每周血糖水平的变化曲线;
图8是II型糖尿病db/db小鼠注射不同蛋白8周后血糖、糖化血红蛋白及甘油三脂水平的变化曲线。
具体实施方式
下面结合具体实施例来进一步描述本发明,本发明的优点和特点将会随着描述而更为清楚。但这些实施例仅是范例性的,并不对本发明的范围构成任何限制。本领域技术人员应该理解的是,在不偏离本发明的精神和范围下可以对本发明技术方案的细节和形式进行修改或替换,但这些修改和替换均落入本发明的保护范围内。
说明:本发明中涉及的基因的设计、合成和克隆、表达载体的构建、核酸提取、测序和鉴定,以及表达产物的分离和纯化等操作步骤,可按照本领域已知的技术进行(参见CURRENT PROTOCOLS IN MOLECULAR BIOLOGY)。若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。
实施例1
hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21表达载体的构建
根据大肠杆菌密码子偏好性,设计出4种基因,其核苷酸序列分别如序列表中SEQ ID NO:1(hFGF21-HSA)、SEQ ID NO:2(HSA-hFGF21)、SEQ ID NO:3(hFGF21-3DHSA)和SEQ ID NO:4(3DHSA-hFGF21)所示。将这4种基因送至上海捷瑞生物公司合成,同时在各基因两端设计NdeI与BamHI两酶切位点。
将4种合成的含有各自目的基因片段的载体和pET30a(+)分别用NdeI与Bam HI双酶切,酶切完毕后,胶回收各自需要的目标片段。使用T4 DNA连接酶将4种目的片段分别与原核表达载体pET30a(+)连接,连接反应体系为10µL,混匀,4℃连接过夜,然后各自转化至大肠杆菌DH5α中。挑取阳性克隆,经过酶切鉴定后,即分别构建得到4种重组质粒pET30a-hFGF21-HSA、pET30a-HSA-hFGF21、pET30a-hFGF21-3DHSA和pET30a-3DHSA-hFGF21。
实施例2
hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21四种融合蛋白的表达及纯化
(1)转化、培养并诱导表达
将含有正确序列的4种重组质粒pET30a-hFGF21-HSA、pET30a-HSA-hFGF21、pET30a-hFGF21-3DHSA和pET30a-3DHSA-hFGF21分别转化至表达菌株Rosseta(DE3)(北京全式金生物技术有限公司,目录号:CD801)。转化后的单菌落分别接种至20mL含Kan(50µg/mL)的LB培养基中,37℃培养8h,以体积比为1:100接种于另一20mL含Kan(50µg/mL)的LB培养基中,37℃培养,当A600在0.35左右时,加入IPTG至终浓度为0.25mmol/L进行诱导,诱导温度为30℃,5h后收获菌体,用Binding buffer(20mmol/L Na3PO4,pH 7.0) 重悬菌体,破碎菌体后离心,分别取上清和沉淀进行12wt% SDS-PAGE电泳分析。结果显示hFGF21与HSA或3DHSA连接后的融合蛋白大部分以可溶性形式表达,如图1所示,A图泳道1:蛋白标准分子量Marker;2、3、4:hFGF21-HSA全菌蛋白、菌体上清、菌体沉淀;5、6、7:HSA-hFGF21全菌蛋白、菌体上清、菌体沉淀;B图泳道1:蛋白标准分子量Marker;2:未诱导菌体;3、4、5:3DHSA-hFGF21全菌蛋白、菌体上清、菌体沉淀;6、7、8:hFGF21-3DHSA全菌蛋白、菌体上清、菌体沉淀。
(2)蛋白纯化
向菌体中加入一定浓度溶菌酶(1mg/mL),冰上放置30min,超声破碎菌体细胞(工作1s,间隔1s,4min/次,共3次循环)。破碎彻底后,12000rpm,4℃离心15min,收集上清。上清液过0.22μm滤膜澄清后,通过泵进入AKTA purifier 100系统,与2-3倍柱体积Binding buffer平衡好的Blue Sepharose 6FF柱(装于XK16/20空柱,柱高10cm,流速100cm/h)完全结合后,用4-5倍柱体积的binding buffer冲洗杂蛋白,当紫外曲线达到稳定的基线时,再用2-3倍柱体积Elution buffer(20mmol/L Na3PO4,2 mol/L NaCl,pH 7.0)洗脱目的蛋白,把结合在填料上的融合蛋白洗脱下来并收集到试管中。
把Superdex 75凝胶过滤柱(装于Column XK26/70空柱中,柱体积340mL,流速2mL/min)接到AKTA purifier 100系统中,先用2倍柱体积的蒸馏水替换其保护液(体积分数为20%乙醇),再用2倍柱体积的Desalting buffer(20mmol/L Na3PO4、150mmol/L NaCl,pH7.0)平衡柱子,然后将亲和层析洗脱液通过Superloop进样。收集各洗脱峰,并进行15wt% SDS-PAGE电泳分析,结果显示经纯化过后,四种融合蛋白纯度在95%以上,如图2所示,A图泳道1:蛋白标准分子量Marker;2:纯化后的hFGF21-HSA融合蛋白;3:纯化后的HSA-hFGF21融合蛋白;B图泳道1:蛋白标准分子量Marker;2:纯化后的hFGF21-3DHSA融合蛋白;3:纯化后的3DHSA-hFGF21融合蛋白。
实施例3
4种蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21的体内半衰期检测
选取体重约2kg的家兔18只,随机分为6组。每组分别皮下注射6种蛋白hFGF21、hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21,剂量30nmol/kg,在给药后的0h、1h、3h、5h、7h、24 h,于耳缘静脉采血800μL左右。12000r/m离心10min,取上清保存于-20℃备用。
ELISA间接法测定6种蛋白的体内半衰期:用稀释好不同浓度的hFGF21、hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21蛋白(2μg/mL、0.2μg/mL、200ng/mL、20ng/mL和2ng/mL)分别建立蛋白浓度含量的标准曲线,将稀释后的标准蛋白和血清包被酶标板,应用ELISA间接法测定各血清中目标蛋白的含量,统计学分析并计算出6种蛋白的体内半衰期。体内半衰期t1/2=0.301*(t2-t1)/log(OD1/OD2),其中OD1和OD2分别表示t1和t2时取出血清所对应酶标板上的平均光吸收值。
结果如图3所示,经公式计算出融合蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA、3DHSA-hFGF21及野生型蛋白hFGF21的体内半衰期分别约为396min、402min、318min、331min和36min,说明了hFGF21蛋白经融合表达后体内半衰期显著增加。
实施例4
4种蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21的体外糖吸收活性检测
HepG2细胞培养:HepG2细胞(中国医学科学院基础所细胞库)为人肝癌细胞株,其生长条件为高糖DMEM培养基,其中加入10wt%新生牛血清NCS(Invitrogen Corporation)、青霉素100μg/mL、链霉素100μg/mL,在37℃、体积分数5% CO2、饱和湿度条件下培养。当细胞生长至高密度时,应进行传代,用0.25wt%胰蛋白酶液消化后,以体积比为1:3-1:5的比例将细胞接种于新的培养瓶内培养,取对数生长期的细胞用于实验。
HepG2细胞接种与处理:用质量浓度为0.25%胰蛋白酶消化液消化生长状态良好的HepG2细胞,离心收集细胞,按照2.5×104的密度将细胞接种于96孔板中继续培养,每孔中培养液体积为200μL。当细胞生长至均匀单层时,弃去上层培养液加入新鲜的无血清培养基继续培养12h后,即可加入待测蛋白检测活性。
加样HepG2细胞饥饿12h后,分别用不同浓度(10nmol/L、100nmol/L、1000nmol/L)的hFGF21、hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 5种蛋白刺激细胞24h,用GOD-POD法检测培养基中残留的葡萄糖含量。取培养基上清液2μL加入到200μL葡萄糖检测液中,每孔葡萄糖至少重复检测3次,37℃反应5-10min后,在500nm波长下测OD值。计算葡萄糖消耗率,并运用统计学分析实验结果。
培养液中残留的葡萄糖浓度和细胞葡萄糖消耗率的计算公式如下:
葡萄糖浓度(mmol/L)=OD样品/OD标准×5.55mmol/L
细胞葡萄糖消耗率(%)=[(C空白葡萄糖-C给药葡萄糖) / C空白葡萄糖] ×100%
数据分析结果如图4所示,结果显示,相对于hFGF21蛋白,hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21四种融合蛋白的体外细胞糖吸收活性也显著增加,且在低、中、高三种剂量下,差异都极显著(##p<0.01),说明4种融合蛋白的体外活性要显著优于hFGF21蛋白。其中3DHSA-hFGF21融合蛋白的体外活性最佳。
实施例6
4种蛋白hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21的体内药效检测
一、本发明4种融合蛋白在 I 型糖尿病动物模型上的活性检测
I 型糖尿病动物模型制备:雄性C57BL/6小鼠(购置于上海斯莱克实验动物有限责任公司,动物质量合格证号SCXK(沪)2012-0005)适应性饲喂至体重达到35g左右时开始实验。适应性喂养2周,选取体重25-30g小鼠60只随机分为6只正常对照组小鼠和52只造模组小鼠,准备开始造模。造模前小鼠需禁食不禁水12h,次日,造模组通过腹腔注射方式按体重比40mg/kg注射STZ注射液,恢复正常饮食,并给予1wt%的葡萄糖水饮用,间隔1d后再次禁食不禁水12h后,通过腹腔注射方式按体重比30mg/kg注射STZ注射液,间隔1d后第3次通过腹腔注射方式按体重比20mg/kg注射STZ注射液;对照组只注射柠檬酸-柠檬酸钠(pH 4.4)缓冲液。腹腔注射过程中,注意注射器针头插入的深度及角度,避免伤到小鼠内脏器官。STZ注射后,每隔7d检测一次小鼠空腹血糖和体重的变化。将注射4周后空腹血糖浓度>16.65mmol/L的小鼠判定为I型糖尿病动物模型。
分组,给药及指标检测:选取成模的血糖值低于25mmol/L的I型糖尿病小鼠36只,随机分为模型对照组、hFGF21组、hFGF21-HSA组、HSA-hFGF21组、hFGF21-3DHSA组和3DHSA-hFGF21组,每组6只。于每天早上8点半左右给予实验组相应的受试物一次,皮下注射,剂量50nmol/kg,模型对照组注射相同体积的生理盐水,连续给药8周。实验过程中自由饮食、饮水。
于每周第一天早上8点左右尾静脉采血测定各实验组小鼠血糖水平,给药8周后,各实验组小鼠处死(前夜禁食),眼球取血测定实验小鼠血糖(BG)、糖基化血红蛋白(GHb)和甘油三脂(TG)水平。所得实验数据进行统计学分析。
实验检测数据如图5、6所示,图5结果表明,相对于模型对照组,5种给药组小鼠血糖在给药1周后下降显著,且之后每周血糖变化趋势一致,但与hFGF21组相比,hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4组小鼠血糖水平下降迅速。hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4种融合蛋白在 I 型糖尿病小鼠上的长效降糖效果明显优于hFGF21,作用持续时间长,其中3DHSA-hFGF21组小鼠长期降糖效果最佳。
糖基化血红蛋白(GHb)测试通常可以反映患者近8-12周的血糖控制情况,故本实验检测给药8周后各实验组小鼠血糖和糖基化血红蛋白水平来比较6种蛋白控制血糖波动的能力。如图6所示,该结果进一步说明了hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4种融合蛋白对 I 型糖尿病小鼠的血糖水平具有长久持续的调控作用,且效果显著优于hFGF21。
给药8周后,各实验组小鼠血清甘油三脂水平结果如图6所示,相对于生理盐水组,5种蛋白都能显著降低TG含量。而与hFGF21相比,hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 四种蛋白在I型糖尿病小鼠的血脂水平上表现出更佳的改善效果。
二、本发明4种融合蛋白在 II 型糖尿病动物模型上的活性检测
分组、给药及指标检测:取SPF级9-11周龄雄性db/db小鼠(购自上海斯莱克实验动物有限责任公司,动物质量合格证号SCXK(沪)2012-0005)50只,预饲养1周后称重,次日禁食不禁水6h,尾静脉取血测定小鼠的空腹血糖,剔除体重异常,筛选血糖值相对接近均值的成模小鼠36只,随机分为模型对照组、hFGF21组、hFGF21-HSA组、HSA-hFGF21组、hFGF21-3DHSA组和3DHSA-hFGF21组,每组6只。于每天早上8点半左右给予实验组相应的受试物一次,皮下注射,剂量50nmol/kg,模型对照组注射相同体积的生理盐水,连续给药8周。实验过程中自由饮食、饮水。
于每周第一天早上8点左右尾静脉采血测定各实验组小鼠血糖水平,给药8周后,各实验组小鼠处死(前夜禁食),眼球取血测定实验小鼠血糖(BG)、糖基化血红蛋白(GHb)和甘油三脂(TG)水平。所得实验数据进行统计学分析。
实验检测数据如图7、8所示,图7结果表明,相对于模型对照组,5种给药组小鼠血糖在给药1周后下降显著,且之后每周血糖变化趋势一致,但与hFGF21组相比, hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4组小鼠血糖水平下降迅速。hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4种融合蛋白在II型糖尿病小鼠上的长效降糖效果明显优于hFGF21,作用持续时间长,其中3DHSA-hFGF21组小鼠长期降糖效果最佳。
糖基化血红蛋白(GHb)测试通常可以反映患者近8-12周的血糖控制情况,故本实验检测给药8周后各实验组小鼠血糖和糖基化血红蛋白水平来比较5种蛋白控制血糖波动的能力。如图8所示,结果进一步说明了hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4种融合蛋白对II型糖尿病小鼠的血糖水平具有长久持续的调控作用,且效果显著优于hFGF21。
给药8周后,各实验组小鼠血清甘油三脂水平结果如图8所示,相对于生理盐水组,5种蛋白都能显著降低TG含量。而与hFGF21相比,hFGF21-HSA、HSA-hFGF21、hFGF21-3DHSA和3DHSA-hFGF21 4种融合蛋白在II型糖尿病小鼠的血脂水平上表现出更佳的改善效果。
SEQUENCE LISTING
<110> 河南师范大学
<120> 重组人成纤维细胞生长因子21融合蛋白及其在制备治疗代谢疾病药物中的应用
<160> 10
<170> PatentIn version 3.3
<210> SEQ ID NO:1
<211> 2352
<212> DNA
<213> 人工序列
<400> SEQ ID NO:1
gactcttctc cgctgctgca gttcggtggt caggttcgtc agcgttacct gtacaccgac 60
gacgctcagc agaccgaagc tcacctggaa atccgtgaag acggtaccgt tggtggtgct 120
gctgaccagt ctccggaatc tctgctgcag ctgaaagctc tgaaaccggg tgttatccag 180
atcctgggtg ttaaaacctc tcgtttcctg tgccagcgtc cggacggtgc tctgtacggt 240
tctctgcact tcgacccgga agcttgctct ttccgtgaac tgctgctgga agacggttac 300
aacgtttacc agtctgaagc tcacggtctg ccgctgcacc tgccgggtaa caaatctccg 360
caccgtgacc cggctccgcg tggtccggct cgtttcctgc cgctgccggg tctgccgccg 420
gctctgccgg aaccgccggg tatcctggct ccgcagccgc cggacgttgg ttcttctgac 480
ccgctgtcta tggttggtcc gtctcagggt cgttctccgt cttacacctc tggtggtggt 540
ggttctggtg gtggtggttc tggtggtggt ggttctagag gtgttttcag aagagacgct 600
cacaagtctg aagttgctca cagattcaag gacttgggtg aagaaaactt caaggctttg 660
gttttgatcg ctttcgctca atacttgcaa caatgtccat tcgaagacca cgttaagttg 720
gttaacgaag ttactgaatt tgctaagact tgtgttgctg acgaatctgc tgaaaactgt 780
gacaagtctt tgcacacttt gttcggtgac aagttgtgta ctgttgctac tttgagagaa 840
acttacggtg aaatggctga ctgttgtgct aagcaagaac cagaaagaaa cgaatgtttc 900
ttgcaacaca aggacgacaa cccaaacttg ccaagattgg ttagaccaga agttgacgtt 960
atgtgtactg ctttccacga caacgaagaa actttcttga agaagtactt gtacgaaatc 1020
gctagaagac acccatactt ctacgctcca gaattgttgt tcttcgctaa gagatacaag 1080
gctgctttca ctgaatgttg tcaagctgct gacaaggctg cttgtttgtt gccaaagttg 1140
gacgaattga gagacgaagg taaggcttct tctgctaagc aaagattgaa gtgtgcttct 1200
ttgcaaaagt tcggtgaaag agctttcaag gcttgggctg ttgctagatt gtctcaaaga 1260
ttcccaaagg ctgaatttgc tgaagtttct aagttggtta ctgacttgac taaggttcac 1320
actgaatgtt gtcacggtga cttgttggaa tgtgctgacg acagagctga cttggctaag 1380
tacatctgtg aaaaccaaga ctctatctct tctaagttga aggaatgttg tgaaaagcca 1440
ttgttggaaa agtctcactg tatcgctgaa gttgaaaacg acgaaatgcc agctgacttg 1500
ccatctttgg ctgctgactt cgttgaatct aaggacgttt gtaagaacta cgctgaagct 1560
aaggacgttt tcttgggtat gttcttgtac gaatacgcta gaagacaccc agactactct 1620
gttgttttgt tgttgagatt ggctaagact tacgaaacta ctttggaaaa gtgttgtgct 1680
gctgctgacc cacacgaatg ttacgctaag gttttcgacg aatttaagcc attggttgaa 1740
gaaccacaaa acttgatcaa gcaaaactgt gaattgttcg aacaattggg tgaatacaag 1800
ttccaaaacg ctttgttggt tagatacact aagaaggttc cacaagtttc tactccaact 1860
ttggttgaag tttctagaaa cttgggtaag gttggttcta agtgttgtaa gcacccagaa 1920
gctaagagaa tgccatgtgc tgaagactac ttgtctgttg ttttgaacca attgtgtgtt 1980
ttgcacgaaa agactccagt ttctgacaga gttactaagt gttgtactga atctttggtt 2040
aacagaagac catgtttctc tgctttggaa gttgacgaaa cttacgttcc aaaggaattt 2100
aacgctgaaa ctttcacttt ccacgctgac atctgtactt tgtctgaaaa ggaaagacaa 2160
atcaagaagc aaactgcttt ggttgaattg gttaagcaca agccaaaggc tactaaggaa 2220
caattgaagg ctgttatgga cgacttcgct gctttcgttg aaaagtgttg taaggctgac 2280
gacaaggaaa cttgtttcgc tgaagaaggt aagaagttgg ttgctgcttc tcaagctgct 2340
ttgggtttgt aa 2352
<210> SEQ ID NO:2
<211> 2352
<212> DNA
<213> 人工序列
<400> SEQ ID NO:2
agaggtgttt tcagaagaga cgctcacaag tctgaagttg ctcacagatt caaggacttg 60
ggtgaagaaa acttcaaggc tttggttttg atcgctttcg ctcaatactt gcaacaatgt 120
ccattcgaag accacgttaa gttggttaac gaagttactg aatttgctaa gacttgtgtt 180
gctgacgaat ctgctgaaaa ctgtgacaag tctttgcaca ctttgttcgg tgacaagttg 240
tgtactgttg ctactttgag agaaacttac ggtgaaatgg ctgactgttg tgctaagcaa 300
gaaccagaaa gaaacgaatg tttcttgcaa cacaaggacg acaacccaaa cttgccaaga 360
ttggttagac cagaagttga cgttatgtgt actgctttcc acgacaacga agaaactttc 420
ttgaagaagt acttgtacga aatcgctaga agacacccat acttctacgc tccagaattg 480
ttgttcttcg ctaagagata caaggctgct ttcactgaat gttgtcaagc tgctgacaag 540
gctgcttgtt tgttgccaaa gttggacgaa ttgagagacg aaggtaaggc ttcttctgct 600
aagcaaagat tgaagtgtgc ttctttgcaa aagttcggtg aaagagcttt caaggcttgg 660
gctgttgcta gattgtctca aagattccca aaggctgaat ttgctgaagt ttctaagttg 720
gttactgact tgactaaggt tcacactgaa tgttgtcacg gtgacttgtt ggaatgtgct 780
gacgacagag ctgacttggc taagtacatc tgtgaaaacc aagactctat ctcttctaag 840
ttgaaggaat gttgtgaaaa gccattgttg gaaaagtctc actgtatcgc tgaagttgaa 900
aacgacgaaa tgccagctga cttgccatct ttggctgctg acttcgttga atctaaggac 960
gtttgtaaga actacgctga agctaaggac gttttcttgg gtatgttctt gtacgaatac 1020
gctagaagac acccagacta ctctgttgtt ttgttgttga gattggctaa gacttacgaa 1080
actactttgg aaaagtgttg tgctgctgct gacccacacg aatgttacgc taaggttttc 1140
gacgaattta agccattggt tgaagaacca caaaacttga tcaagcaaaa ctgtgaattg 1200
ttcgaacaat tgggtgaata caagttccaa aacgctttgt tggttagata cactaagaag 1260
gttccacaag tttctactcc aactttggtt gaagtttcta gaaacttggg taaggttggt 1320
tctaagtgtt gtaagcaccc agaagctaag agaatgccat gtgctgaaga ctacttgtct 1380
gttgttttga accaattgtg tgttttgcac gaaaagactc cagtttctga cagagttact 1440
aagtgttgta ctgaatcttt ggttaacaga agaccatgtt tctctgcttt ggaagttgac 1500
gaaacttacg ttccaaagga atttaacgct gaaactttca ctttccacgc tgacatctgt 1560
actttgtctg aaaaggaaag acaaatcaag aagcaaactg ctttggttga attggttaag 1620
cacaagccaa aggctactaa ggaacaattg aaggctgtta tggacgactt cgctgctttc 1680
gttgaaaagt gttgtaaggc tgacgacaag gaaacttgtt tcgctgaaga aggtaagaag 1740
ttggttgctg cttctcaagc tgctttgggt ttgggtggtg gtggttctgg tggtggtggt 1800
tctggtggtg gtggttctga ctcttctccg ctgctgcagt tcggtggtca ggttcgtcag 1860
cgttacctgt acaccgacga cgctcagcag accgaagctc acctggaaat ccgtgaagac 1920
ggtaccgttg gtggtgctgc tgaccagtct ccggaatctc tgctgcagct gaaagctctg 1980
aaaccgggtg ttatccagat cctgggtgtt aaaacctctc gtttcctgtg ccagcgtccg 2040
gacggtgctc tgtacggttc tctgcacttc gacccggaag cttgctcttt ccgtgaactg 2100
ctgctggaag acggttacaa cgtttaccag tctgaagctc acggtctgcc gctgcacctg 2160
ccgggtaaca aatctccgca ccgtgacccg gctccgcgtg gtccggctcg tttcctgccg 2220
ctgccgggtc tgccgccggc tctgccggaa ccgccgggta tcctggctcc gcagccgccg 2280
gacgttggtt cttctgaccc gctgtctatg gttggtccgt ctcagggtcg ttctccgtct 2340
tacacctctt aa 2352
<210> SEQ ID NO:3
<211>1194
<212> DNA
<213> 人工序列
<400> SEQ ID NO:3
gactcttctc cgctgctgca gttcggtggt caggttcgtc agcgttacct gtacaccgac 60
gacgctcagc agaccgaagc tcacctggaa atccgtgaag acggtaccgt tggtggtgct 120
gctgaccagt ctccggaatc tctgctgcag ctgaaagctc tgaaaccggg tgttatccag 180
atcctgggtg ttaaaacctc tcgtttcctg tgccagcgtc cggacggtgc tctgtacggt 240
tctctgcact tcgacccgga agcttgctct ttccgtgaac tgctgctgga agacggttac 300
aacgtttacc agtctgaagc tcacggtctg ccgctgcacc tgccgggtaa caaatctccg 360
caccgtgacc cggctccgcg tggtccggct cgtttcctgc cgctgccggg tctgccgccg 420
gctctgccgg aaccgccggg tatcctggct ccgcagccgc cggacgttgg ttcttctgac 480
ccgctgtcta tggttggtcc gtctcagggt cgttctccgt cttacacctc tggtggtggt 540
ggttctggtg gtggtggttc tggtggtggt ggttctgttg aagaaccaca aaacttgatc 600
aagcaaaact gtgaattgtt cgaacaattg ggtgaataca agttccaaaa cgctttgttg 660
gttagataca ctaagaaggt tccacaagtt tctactccaa ctttggttga agtttctaga 720
aacttgggta aggttggttc taagtgttgt aagcacccag aagctaagag aatgccatgt 780
gctgaagact acttgtctgt tgttttgaac caattgtgtg ttttgcacga aaagactcca 840
gtttctgaca gagttactaa gtgttgtact gaatctttgg ttaacagaag accatgtttc 900
tctgctttgg aagttgacga aacttacgtt ccaaaggaat tcaacgctga aactttcact 960
ttccacgctg acatctgtac tttgtctgaa aaggaaagac aaatcaagaa gcaaactgct 1020
ttggttgaat tggttaagca caagccaaag gctactaagg aacaattgaa ggctgttatg 1080
gacgacttcg ctgctttcgt tgaaaagtgt tgtaaggctg acgacaagga aacttgtttc 1140
gctgaagaag gtaagaagtt ggttgctgct tctcaagctg ctttgggttt gtaa 1194
<210> SEQ ID NO:4
<211> 1194
<212> DNA
<213> 人工序列
<400> SEQ ID NO:4
gttgaagaac cacaaaactt gatcaagcaa aactgtgaat tgttcgaaca attgggtgaa 60
tacaagttcc aaaacgcttt gttggttaga tacactaaga aggttccaca agtttctact 120
ccaactttgg ttgaagtttc tagaaacttg ggtaaggttg gttctaagtg ttgtaagcac 180
ccagaagcta agagaatgcc atgtgctgaa gactacttgt ctgttgtttt gaaccaattg 240
tgtgttttgc acgaaaagac tccagtttct gacagagtta ctaagtgttg tactgaatct 300
ttggttaaca gaagaccatg tttctctgct ttggaagttg acgaaactta cgttccaaag 360
gaattcaacg ctgaaacttt cactttccac gctgacatct gtactttgtc tgaaaaggaa 420
agacaaatca agaagcaaac tgctttggtt gaattggtta agcacaagcc aaaggctact 480
aaggaacaat tgaaggctgt tatggacgac ttcgctgctt tcgttgaaaa gtgttgtaag 540
gctgacgaca aggaaacttg tttcgctgaa gaaggtaaga agttggttgc tgcttctcaa 600
gctgctttgg gtttgggtgg tggtggttct ggtggtggtg gttctggtgg tggtggttct 660
gactcttctc cgctgctgca gttcggtggt caggttcgtc agcgttacct gtacaccgac 720
gacgctcagc agaccgaagc tcacctggaa atccgtgaag acggtaccgt tggtggtgct 780
gctgaccagt ctccggaatc tctgctgcag ctgaaagctc tgaaaccggg tgttatccag 840
atcctgggtg ttaaaacctc tcgtttcctg tgccagcgtc cggacggtgc tctgtacggt 900
tctctgcact tcgacccgga agcttgctct ttccgtgaac tgctgctgga agacggttac 960
aacgtttacc agtctgaagc tcacggtctg ccgctgcacc tgccgggtaa caaatctccg 1020
caccgtgacc cggctccgcg tggtccggct cgtttcctgc cgctgccggg tctgccgccg 1080
gctctgccgg aaccgccggg tatcctggct ccgcagccgc cggacgttgg ttcttctgac 1140
ccgctgtcta tggttggtcc gtctcagggt cgttctccgt cttacacctc ttaa 1194
<210> SEQ ID NO:5
<211> 783
<212> PRT
<213> 人工序列
<400> SEQ ID NO:5
Asp Ser Ser Pro Leu Leu Gln Phe Gly Gly Gln Val Arg Gln Arg Tyr Leu Tyr Thr Asp 20
Asp Ala Gln Gln Thr Glu Ala His Leu Glu Ile Arg Glu Asp Gly Thr Val Gly Gly Ala 40
Ala Asp Gln Ser Pro Glu Ser Leu Leu Gln Leu Lys Ala Leu Lys Pro Gly Val Ile Gln 60
Ile Leu Gly Val Lys Thr Ser Arg Phe Leu Cys Gln Arg Pro Asp Gly Ala Leu Tyr Gly 80
Ser Leu His Phe Asp Pro Glu Ala Cys Ser Phe Arg Glu Leu Leu Leu Glu Asp Gly Tyr 100
Asn Val Tyr Gln Ser Glu Ala His Gly Leu Pro Leu His Leu Pro Gly Asn Lys Ser Pro 120
His Arg Asp Pro Ala Pro Arg Gly Pro Ala Arg Phe Leu Pro Leu Pro Gly Leu Pro Pro 140
Ala Leu Pro Glu Pro Pro Gly Ile Leu Ala Pro Gln Pro Pro Asp Val Gly Ser Ser Asp 160
Pro Leu Ser Met Val Gly Pro Ser Gln Gly Arg Ser Pro Ser Tyr Thr Ser Gly Gly Gly 180
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Gly Val Phe Arg Arg Asp Ala 200
His Lys Ser Glu Val Ala His Arg Phe Lys Asp Leu Gly Glu Glu Asn Phe Lys Ala Leu 220
Val Leu Ile Ala Phe Ala Gln Tyr Leu Gln Gln Cys Pro Phe Glu Asp His Val Lys Leu 240
Val Asn Glu Val Thr Glu Phe Ala Lys Thr Cys Val Ala Asp Glu Ser Ala Glu Asn Cys 260
Asp Lys Ser Leu His Thr Leu Phe Gly Asp Lys Leu Cys Thr Val Ala Thr Leu Arg Glu 280
Thr Tyr Gly Glu Met Ala Asp Cys Cys Ala Lys Gln Glu Pro Glu Arg Asn Glu Cys Phe 300
Leu Gln His Lys Asp Asp Asn Pro Asn Leu Pro Arg Leu Val Arg Pro Glu Val Asp Val 320
Met Cys Thr Ala Phe His Asp Asn Glu Glu Thr Phe Leu Lys Lys Tyr Leu Tyr Glu Ile 340
Ala Arg Arg His Pro Tyr Phe Tyr Ala Pro Glu Leu Leu Phe Phe Ala Lys Arg Tyr Lys 360
Ala Ala Phe Thr Glu Cys Cys Gln Ala Ala Asp Lys Ala Ala Cys Leu Leu Pro Lys Leu 380
Asp Glu Leu Arg Asp Glu Gly Lys Ala Ser Ser Ala Lys Gln Arg Leu Lys Cys Ala Ser 400
Leu Gln Lys Phe Gly Glu Arg Ala Phe Lys Ala Trp Ala Val Ala Arg Leu Ser Gln Arg 420
Phe Pro Lys Ala Glu Phe Ala Glu Val Ser Lys Leu Val Thr Asp Leu Thr Lys Val His 440
Thr Glu Cys Cys His Gly Asp Leu Leu Glu Cys Ala Asp Asp Arg Ala Asp Leu Ala Lys 460
Tyr Ile Cys Glu Asn Gln Asp Ser Ile Ser Ser Lys Leu Lys Glu Cys Cys Glu Lys Pro 480
Leu Leu Glu Lys Ser His Cys Ile Ala Glu Val Glu Asn Asp Glu Met Pro Ala Asp Leu 500
Pro Ser Leu Ala Ala Asp Phe Val Glu Ser Lys Asp Val Cys Lys Asn Tyr Ala Glu Ala 520
Lys Asp Val Phe Leu Gly Met Phe Leu Tyr Glu Tyr Ala Arg Arg His Pro Asp Tyr Ser 540
Val Val Leu Leu Leu Arg Leu Ala Lys Thr Tyr Glu Thr Thr Leu Glu Lys Cys Cys Ala 560
Ala Ala Asp Pro His Glu Cys Tyr Ala Lys Val Phe Asp Glu Phe Lys Pro Leu Val Glu 580
Glu Pro Gln Asn Leu Ile Lys Gln Asn Cys Glu Leu Phe Glu Gln Leu Gly Glu Tyr Lys 600
Phe Gln Asn Ala Leu Leu Val Arg Tyr Thr Lys Lys Val Pro Gln Val Ser Thr Pro Thr 620
Leu Val Glu Val Ser Arg Asn Leu Gly Lys Val Gly Ser Lys Cys Cys Lys His Pro Glu 640
Ala Lys Arg Met Pro Cys Ala Glu Asp Tyr Leu Ser Val Val Leu Asn Gln Leu Cys Val 660
Leu His Glu Lys Thr Pro Val Ser Asp Arg Val Thr Lys Cys Cys Thr Glu Ser Leu Val 680
Asn Arg Arg Pro Cys Phe Ser Ala Leu Glu Val Asp Glu Thr Tyr Val Pro Lys Glu Phe 700
Asn Ala Glu Thr Phe Thr Phe His Ala Asp Ile Cys Thr Leu Ser Glu Lys Glu Arg Gln 720
Ile Lys Lys Gln Thr Ala Leu Val Glu Leu Val Lys His Lys Pro Lys Ala Thr Lys Glu 740
Gln Leu Lys Ala Val Met Asp Asp Phe Ala Ala Phe Val Glu Lys Cys Cys Lys Ala Asp 760
Asp Lys Glu Thr Cys Phe Ala Glu Glu Gly Lys Lys Leu Val Ala Ala Ser Gln Ala Ala 780
Leu Gly Leu *** 783
<210> SEQ ID NO:6
<211> 783
<212> PRT
<213> 人工序列
<400> SEQ ID NO:6
Arg Gly Val Phe Arg Arg Asp Ala His Lys Ser Glu Val Ala His Arg Phe Lys Asp Leu 20
Gly Glu Glu Asn Phe Lys Ala Leu Val Leu Ile Ala Phe Ala Gln Tyr Leu Gln Gln Cys 40
Pro Phe Glu Asp His Val Lys Leu Val Asn Glu Val Thr Glu Phe Ala Lys Thr Cys Val 60
Ala Asp Glu Ser Ala Glu Asn Cys Asp Lys Ser Leu His Thr Leu Phe Gly Asp Lys Leu 80
Cys Thr Val Ala Thr Leu Arg Glu Thr Tyr Gly Glu Met Ala Asp Cys Cys Ala Lys Gln 100
Glu Pro Glu Arg Asn Glu Cys Phe Leu Gln His Lys Asp Asp Asn Pro Asn Leu Pro Arg 120
Leu Val Arg Pro Glu Val Asp Val Met Cys Thr Ala Phe His Asp Asn Glu Glu Thr Phe 140
Leu Lys Lys Tyr Leu Tyr Glu Ile Ala Arg Arg His Pro Tyr Phe Tyr Ala Pro Glu Leu 160
Leu Phe Phe Ala Lys Arg Tyr Lys Ala Ala Phe Thr Glu Cys Cys Gln Ala Ala Asp Lys 180
Ala Ala Cys Leu Leu Pro Lys Leu Asp Glu Leu Arg Asp Glu Gly Lys Ala Ser Ser Ala 200
Lys Gln Arg Leu Lys Cys Ala Ser Leu Gln Lys Phe Gly Glu Arg Ala Phe Lys Ala Trp 220
Ala Val Ala Arg Leu Ser Gln Arg Phe Pro Lys Ala Glu Phe Ala Glu Val Ser Lys Leu 240
Val Thr Asp Leu Thr Lys Val His Thr Glu Cys Cys His Gly Asp Leu Leu Glu Cys Ala 260
Asp Asp Arg Ala Asp Leu Ala Lys Tyr Ile Cys Glu Asn Gln Asp Ser Ile Ser Ser Lys 280
Leu Lys Glu Cys Cys Glu Lys Pro Leu Leu Glu Lys Ser His Cys Ile Ala Glu Val Glu 300
Asn Asp Glu Met Pro Ala Asp Leu Pro Ser Leu Ala Ala Asp Phe Val Glu Ser Lys Asp 320
Val Cys Lys Asn Tyr Ala Glu Ala Lys Asp Val Phe Leu Gly Met Phe Leu Tyr Glu Tyr 340
Ala Arg Arg His Pro Asp Tyr Ser Val Val Leu Leu Leu Arg Leu Ala Lys Thr Tyr Glu 360
Thr Thr Leu Glu Lys Cys Cys Ala Ala Ala Asp Pro His Glu Cys Tyr Ala Lys Val Phe 380
Asp Glu Phe Lys Pro Leu Val Glu Glu Pro Gln Asn Leu Ile Lys Gln Asn Cys Glu Leu 400
Phe Glu Gln Leu Gly Glu Tyr Lys Phe Gln Asn Ala Leu Leu Val Arg Tyr Thr Lys Lys 420
Val Pro Gln Val Ser Thr Pro Thr Leu Val Glu Val Ser Arg Asn Leu Gly Lys Val Gly 440
Ser Lys Cys Cys Lys His Pro Glu Ala Lys Arg Met Pro Cys Ala Glu Asp Tyr Leu Ser 460
Val Val Leu Asn Gln Leu Cys Val Leu His Glu Lys Thr Pro Val Ser Asp Arg Val Thr 480
Lys Cys Cys Thr Glu Ser Leu Val Asn Arg Arg Pro Cys Phe Ser Ala Leu Glu Val Asp 500
Glu Thr Tyr Val Pro Lys Glu Phe Asn Ala Glu Thr Phe Thr Phe His Ala Asp Ile Cys 520
Thr Leu Ser Glu Lys Glu Arg Gln Ile Lys Lys Gln Thr Ala Leu Val Glu Leu Val Lys 540
His Lys Pro Lys Ala Thr Lys Glu Gln Leu Lys Ala Val Met Asp Asp Phe Ala Ala Phe 560
Val Glu Lys Cys Cys Lys Ala Asp Asp Lys Glu Thr Cys Phe Ala Glu Glu Gly Lys Lys 580
Leu Val Ala Ala Ser Gln Ala Ala Leu Gly Leu Gly Gly Gly Gly Ser Gly Gly Gly Gly 600
Ser Gly Gly Gly Gly Ser Asp Ser Ser Pro Leu Leu Gln Phe Gly Gly Gln Val Arg Gln 620
Arg Tyr Leu Tyr Thr Asp Asp Ala Gln Gln Thr Glu Ala His Leu Glu Ile Arg Glu Asp 640
Gly Thr Val Gly Gly Ala Ala Asp Gln Ser Pro Glu Ser Leu Leu Gln Leu Lys Ala Leu 660
Lys Pro Gly Val Ile Gln Ile Leu Gly Val Lys Thr Ser Arg Phe Leu Cys Gln Arg Pro 680
Asp Gly Ala Leu Tyr Gly Ser Leu His Phe Asp Pro Glu Ala Cys Ser Phe Arg Glu Leu 700
Leu Leu Glu Asp Gly Tyr Asn Val Tyr Gln Ser Glu Ala His Gly Leu Pro Leu His Leu 720
Pro Gly Asn Lys Ser Pro His Arg Asp Pro Ala Pro Arg Gly Pro Ala Arg Phe Leu Pro 740
Leu Pro Gly Leu Pro Pro Ala Leu Pro Glu Pro Pro Gly Ile Leu Ala Pro Gln Pro Pro 760
Asp Val Gly Ser Ser Asp Pro Leu Ser Met Val Gly Pro Ser Gln Gly Arg Ser Pro Ser 780
Tyr Thr Ser *** 783
<210> SEQ ID NO:7
<211> 397
<212> PRT
<213> 人工序列
<400> SEQ ID NO:7
Asp Ser Ser Pro Leu Leu Gln Phe Gly Gly Gln Val Arg Gln Arg Tyr Leu Tyr Thr Asp 20
Asp Ala Gln Gln Thr Glu Ala His Leu Glu Ile Arg Glu Asp Gly Thr Val Gly Gly Ala 40
Ala Asp Gln Ser Pro Glu Ser Leu Leu Gln Leu Lys Ala Leu Lys Pro Gly Val Ile Gln 60
Ile Leu Gly Val Lys Thr Ser Arg Phe Leu Cys Gln Arg Pro Asp Gly Ala Leu Tyr Gly 80
Ser Leu His Phe Asp Pro Glu Ala Cys Ser Phe Arg Glu Leu Leu Leu Glu Asp Gly Tyr 100
Asn Val Tyr Gln Ser Glu Ala His Gly Leu Pro Leu His Leu Pro Gly Asn Lys Ser Pro 120
His Arg Asp Pro Ala Pro Arg Gly Pro Ala Arg Phe Leu Pro Leu Pro Gly Leu Pro Pro 140
Ala Leu Pro Glu Pro Pro Gly Ile Leu Ala Pro Gln Pro Pro Asp Val Gly Ser Ser Asp 160
Pro Leu Ser Met Val Gly Pro Ser Gln Gly Arg Ser Pro Ser Tyr Thr Ser Gly Gly Gly 180
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Val Glu Glu Pro Gln Asn Leu Ile 200
Lys Gln Asn Cys Glu Leu Phe Glu Gln Leu Gly Glu Tyr Lys Phe Gln Asn Ala Leu Leu 220
Val Arg Tyr Thr Lys Lys Val Pro Gln Val Ser Thr Pro Thr Leu Val Glu Val Ser Arg 240
Asn Leu Gly Lys Val Gly Ser Lys Cys Cys Lys His Pro Glu Ala Lys Arg Met Pro Cys 260
Ala Glu Asp Tyr Leu Ser Val Val Leu Asn Gln Leu Cys Val Leu His Glu Lys Thr Pro 280
Val Ser Asp Arg Val Thr Lys Cys Cys Thr Glu Ser Leu Val Asn Arg Arg Pro Cys Phe 300
Ser Ala Leu Glu Val Asp Glu Thr Tyr Val Pro Lys Glu Phe Asn Ala Glu Thr Phe Thr 320
Phe His Ala Asp Ile Cys Thr Leu Ser Glu Lys Glu Arg Gln Ile Lys Lys Gln Thr Ala 340
Leu Val Glu Leu Val Lys His Lys Pro Lys Ala Thr Lys Glu Gln Leu Lys Ala Val Met 360
Asp Asp Phe Ala Ala Phe Val Glu Lys Cys Cys Lys Ala Asp Asp Lys Glu Thr Cys Phe 380
Ala Glu Glu Gly Lys Lys Leu Val Ala Ala Ser Gln Ala Ala Leu Gly Leu *** 397
<210> SEQ ID NO:8
<211> 397
<212> PRT
<213> 人工序列
<400> SEQ ID NO:8
Val Glu Glu Pro Gln Asn Leu Ile Lys Gln Asn Cys Glu Leu Phe Glu Gln Leu Gly Glu 20
Tyr Lys Phe Gln Asn Ala Leu Leu Val Arg Tyr Thr Lys Lys Val Pro Gln Val Ser Thr 40
Pro Thr Leu Val Glu Val Ser Arg Asn Leu Gly Lys Val Gly Ser Lys Cys Cys Lys His 60
Pro Glu Ala Lys Arg Met Pro Cys Ala Glu Asp Tyr Leu Ser Val Val Leu Asn Gln Leu 80
Cys Val Leu His Glu Lys Thr Pro Val Ser Asp Arg Val Thr Lys Cys Cys Thr Glu Ser 100
Leu Val Asn Arg Arg Pro Cys Phe Ser Ala Leu Glu Val Asp Glu Thr Tyr Val Pro Lys 120
Glu Phe Asn Ala Glu Thr Phe Thr Phe His Ala Asp Ile Cys Thr Leu Ser Glu Lys Glu 140
Arg Gln Ile Lys Lys Gln Thr Ala Leu Val Glu Leu Val Lys His Lys Pro Lys Ala Thr 160
Lys Glu Gln Leu Lys Ala Val Met Asp Asp Phe Ala Ala Phe Val Glu Lys Cys Cys Lys 180
Ala Asp Asp Lys Glu Thr Cys Phe Ala Glu Glu Gly Lys Lys Leu Val Ala Ala Ser Gln 200
Ala Ala Leu Gly Leu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser 220
Asp Ser Ser Pro Leu Leu Gln Phe Gly Gly Gln Val Arg Gln Arg Tyr Leu Tyr Thr Asp 240
Asp Ala Gln Gln Thr Glu Ala His Leu Glu Ile Arg Glu Asp Gly Thr Val Gly Gly Ala 260
Ala Asp Gln Ser Pro Glu Ser Leu Leu Gln Leu Lys Ala Leu Lys Pro Gly Val Ile Gln 280
Ile Leu Gly Val Lys Thr Ser Arg Phe Leu Cys Gln Arg Pro Asp Gly Ala Leu Tyr Gly 300
Ser Leu His Phe Asp Pro Glu Ala Cys Ser Phe Arg Glu Leu Leu Leu Glu Asp Gly Tyr 320
Asn Val Tyr Gln Ser Glu Ala His Gly Leu Pro Leu His Leu Pro Gly Asn Lys Ser Pro 340
His Arg Asp Pro Ala Pro Arg Gly Pro Ala Arg Phe Leu Pro Leu Pro Gly Leu Pro Pro 360
Ala Leu Pro Glu Pro Pro Gly Ile Leu Ala Pro Gln Pro Pro Asp Val Gly Ser Ser Asp 380
Pro Leu Ser Met Val Gly Pro Ser Gln Gly Arg Ser Pro Ser Tyr Thr Ser *** 397
- 还没有人留言评论。精彩留言会获得点赞!