一种免疫组库高通量测序文库的构建方法与流程
本发明属于生物医药服务领域,尤其是涉及一种免疫组库高通量测序文库的构建方法。
背景技术:
:免疫组库是指某个个体在任何特定时间点其循环系统中所有功能多样性B细胞和T细胞的总和。T细胞和B细胞分别介导机体的细胞免疫与体液免疫应答,分别通过其表面的细胞受体(TCR或BCR)来识别和结合抗原,进而发挥功能清除病原体或肿瘤细胞等。一个T或B淋巴细胞只表达一种TCR或BCR,每条TCR或BCR都由可变区和恒定区组成,不同克隆T、B细胞的恒定区可相同,但可变区不同,人体T、B细胞总数约1012,因而具有复杂的识别抗原受体的多样性。随着二代测序技术的问世,人们通过多重PCR或SMARTRACE法扩增TCR/BCR全长或CDR3区序列(主要是TCR的β链或BCR的重链),再结合高通量测序技术,可准确评估机体免疫组库的多样性及每种T、B细胞克隆组成及变化之间的关系。高通量测序技术(High-throughputsequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变,一次对几十万到几百万条核酸分子进行序列测定,因此在有些文献资料中称其为下一代测序技术,足见其划时代的改变,同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析称为可能,所以又被称为深度测序。现有多种文库构建方法,如基于多重PCR的文库构建方法,以DNA为模板,针对可变区(CDR3区域)设计许多对引物,扩增出CDR3区段,再连接高通测序相关接头,如中国专利201410398360.1公开了一种基因多态性区域测序文库及其制备方法,具体包括以下步骤:(1)根据基因多态性区域特征,设计引物,通过PCR扩增得到包含保守区域和多态性区域的DNA片段;(2)向PCR扩增所得DNA片段中加入核酸外切酶,控制核酸外切酶的浓度与反应时间或者控制核酸外切酶的反应温度与反应时间,水解DNA片段;(3)向步骤(2)所得DNA片段的水解产物中加入单链核酸酶,消化DNA突出单链,得到DNA混合片段。该发明制备基因多态性区域测序文库的方法特异性高、快速,可用于高度多态性区域的测序分型。但基于多重PCR的文库构建方法存在以下缺点,如因存在几十种引物扩增,扩增体系复杂;多重引物设计来自已知参考序列,不能充分捕捉到人类等位基因突变序列;多种引物扩增效率可能存在偏倚(bias),不能等效扩增;与RNA构建文库相比,DNA所需PCR反应体系较大。再如基于5'RACE的文库构建方法,以mRNA为模板,在恒定区设计引物逆转出TCR或BCR的全长序列,再经过2轮PCR富集这一目的序列,最后连接高通测序相关接头,如中国专利201510488029.3公开了一种检测血浆cfDNA中BCR和TCR免疫组库的方法,包括血浆cfDNA提取、BCRH链的全长多重PCR扩增和TCRβ链CDR3多重PCR扩增、两种扩增产物等体积混合后再进行一次PCR扩增、高通量测序、免疫组库精准信息分析,该发明方法能够同时检测血浆cfDNA中BCR和TCR,实现精准信息分析和免疫组库各亚克隆的精确定量,在无创检测领域具有广阔的应用前景。但基于5'RACE的文库构建方法也存在相应的缺点:文库构建中的PCR步骤及上机测序过程可能引入错误。本发明的目的在于克服上述现有技术的缺陷而提供一种高效率、高成功率的免疫组库高通量测序文库的构建方法。技术实现要素:本发明的目的在于克服现有技术的缺陷而提供一种高效率、高成功率的免疫组库高通量测序文库的构建方法。除非另外定义,本文中使用的所有技术和科学术语具有与本发明所属
技术领域:
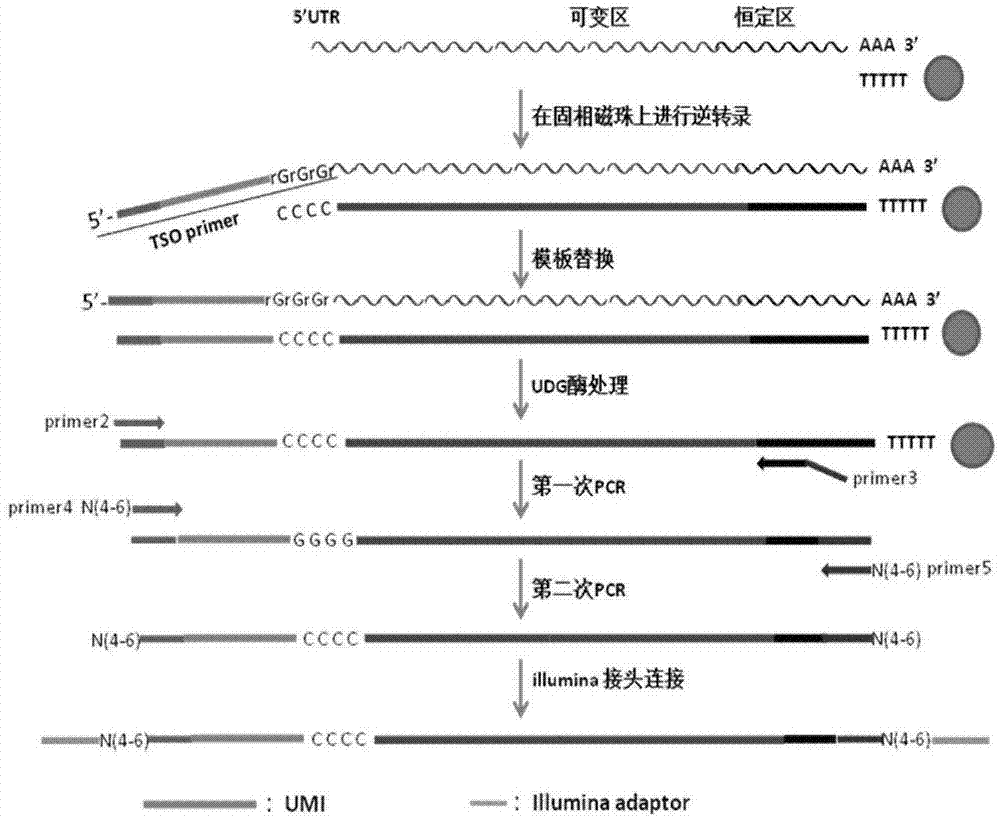
的普通技术人员通常理解的相同意义。术语:UMI全称为uniquemolecularidentifiers,由随机碱基组成,本发明设计的UMI的结构为UNNNNUNNNNUNNNNU,全长为15bp,为四个U碱基框架,两两之间包含四个随机碱基,其随机数目为412个,具有极好的随机性;引物TSO:此序列由一段UMI序列与一段通用序列组成;UDG酶:切割序列中的U碱基,TSO中的UMI序列包含U碱基,在完成逆转录后,加入UDG酶即可降解人工加入的包含UMI序列的TSO引物,避免干扰后续的扩增序列中UMI的技术;本发明是基于5'RACE的原理,同时引入UMI(分子条形码)的文库构建方案:在恒定区设计单引物进行逆转录,可等效扩增出所有类型TCR/BCRCDR全长序列,同时因引入UMI,可对后续的PCR或测序过程中引入的错误进行纠正。为实现上述目的,本发明采取的技术方案为:一种免疫组库高通量测序文库的构建方法。当用于微量样品时,所述一种免疫组库高通量测序文库的构建方法包括以下步骤:1.cDNA模板的制备(1)细胞裂解将100-25000个淋巴细胞加入细胞裂解液中进行裂解,得到裂解物;(2)mRNA分离、逆转录、模板替换及UDG酶处理a、使用Dynabeads磁珠分离技术分离提纯步骤(1)得到的裂解物中的mRNA,获得纯化的mRNA;b、按照下表1配置逆转录反应体系A,并立即加入步骤(2)-a获得的纯化的mRNA,进行逆转录PCR,PCR程序为:50℃,1h;72℃,10min,得到PCR产物A;表1c、向步骤(2)-b得到的产物A中加入1uluracilDNAglycosylase,混合均匀后于PCR仪上继续进行逆转录反应,PCR反应程序为37℃,40min,得到PCR产物B;d、回收纯化产物B,即得到用于后续扩增的cDNA模板;2、第一次PCR反应(1)、PCR反应体系为:表2(2)、PCR反应程序为:表3:(3)、对第一次PCR反应的产物进行纯化,得到PCR产物C;3、第二次PCR(1)、PCR反应体系为:表4(2)、PCR反应程序为:表5(3)、对第二次PCR反应的产物进行纯化,得到PCR产物D;4、测序文库构建(1)、将步骤(3)得到的PCR产物D连接测序接头,得到测序文库样品;(2)、对测序文库样品筛选并质检;上述步骤(1)中所述的细胞裂解液选自分离mRNA的试剂盒DynabeadsmRNADIRECTMicroKit(TermoFisher)中带有的试剂;上述步骤(1)中每10000(细胞数量)淋巴细胞加入100μL的细胞裂解液;上述步骤(2)-c中每10μL反应物A中加入1μL的uracilDNAglycosylase;上述步骤(2)-d中tris-HCl的浓度为2-20mM;上述步骤(2)-d中所述的洗涤磁珠,为用tris-HCl反复洗涤磁珠2-5次;上述步骤1-(2)-b中所述的TSOprimer核苷酸序列下列核苷酸序列:当细胞受体为TCR时:TSOprimer的核苷酸序列包含或由SEQIDNO:1组成,其中末端的4个G为核糖核酸中的鸟嘌呤。当细胞受体为BCR时:TSOprimer的核苷酸序列包含或由SEQIDNO:2组成,其中末端的4个G为核糖核酸中的鸟嘌呤。上述步骤2-(1)中所述的Primer2核苷酸序列为下列核苷酸序列:当细胞受体为TCR时,primer2的核苷酸序列包含或由SEQIDNO:3组成;当细胞受体为BCR时,primer2的核苷酸序列包含或由SEQIDNO:4组成;上述步骤2-(1)中所述的Primer3核苷酸序列为下列核苷酸序列:当细胞受体为人类TCRbeta时,primer3的核苷酸序列包含或由SEQIDNO:5组成;当细胞受体为人类TCRalpha时,primer3的核苷酸序列包含或由SEQIDNO:6组成;当细胞受体为老鼠TCRbeta时,primer3的核苷酸序列包含或由SEQIDNO:7组成;当细胞受体为老鼠TCRalpha时,primer3的核苷酸序列包含或由SEQIDNO:8组成;当细胞受体为人类IgG/IgE重链时,primer3的核苷酸序列包含或由SEQIDNO:9组成;当细胞受体为人类IgA重链时,primer3的核苷酸序列包含或由SEQIDNO:10组成;当细胞受体为人类IgM重链时,primer3的核苷酸序列包含或由SEQIDNO:11组成;当细胞受体为人类IgD重链时,primer3的核苷酸序列包含或由SEQIDNO:12组成;当细胞受体为人类IgL轻链时,primer3的核苷酸序列包含或由SEQIDNO:13组成;当细胞受体为人类IgK轻链时,primer3的核苷酸序列包含或由SEQIDNO:14组成;当细胞受体为老鼠IgG1/IgG2重链时,primer3的核苷酸序列包含或由SEQIDNO:15组成;当细胞受体为老鼠IgG3重链时,primer3的核苷酸序列包含或由SEQIDNO:16组成;当细胞受体为老鼠IgA轻链时,primer3的核苷酸序列包含或由SEQIDNO:17组成;当细胞受体为老鼠IgM重链时,primer3的核苷酸序列包含或由SEQIDNO:18组成;受体为老鼠IgD重链时,primer3的核苷酸序列包含或由SEQIDNO:19组成;当细胞受体为老鼠IgE重链时,primer3的核苷酸序列包含或由SEQIDNO:20组成;当细胞受体为老鼠IgL轻链时,primer3的核苷酸序列包含或由SEQIDNO:21组成;当细胞受体为老鼠IgK轻链时,primer3的核苷酸序列包含或由SEQIDNO:22组成;上述步骤3-(1)中所述的Primer4核苷酸序列为下列核苷酸序列:当细胞受体为TCR时,primer4的核苷酸序列包含或由SEQIDNO:23组成;当细胞受体为BCR时,primer4的核苷酸序列包含或由SEQIDNO:24组成;上述步骤3-(1)中所述的Primer5核苷酸序列为下列核苷酸序列中的任意一条:当细胞受体为TCR时,primer5的核苷酸序列包含或由SEQIDNO:25组成;当细胞受体为BCR时,primer5的核苷酸序列包含或由SEQIDNO:26组成。上述步骤3-(1)中根据不同实验样品调整加入PCR产物C的比例,实验样品浓度与PCR产物C浓度的比值为:2-10:1;上述构建方法可以总结为:以细胞为起始样本,直接裂解细胞,使用带PolyT的磁珠捕获mRNA,然后以磁珠上的PolyT作为引物进行逆转录,当逆转录进行到mRNA5'UTR末端时逆转录酶会在cDNA分子的3'端加上几个“C”碱基,并与加入的模板转换引物TSO(此序列由一段UMI序列与一段通用序列组成)上的G碱基配对,继续以TSO引物为模板进行逆转录,从而引入UMI及通用序列;接着加入UDG酶降解加入的TSO引物,使用10mMtris–HC洗涤结合cDNA分子的磁珠3次,回收的磁珠全部作为PCR模板,以cDNA子3'端通用序列为上游引物及以TCR/BCR恒定区设计的下游引物(同时带上一段通用序列)进行第一次PCR反应;然后取一部分纯化后的第一次PCR产物作为模板,并以其两端的通用序列作为上下游引物进行第二次PCR反应,经过两轮PCR后得到TCR/BCR可变区的全长序列及引入的UMI序列,最后连接上illumina测序平台的接头序列,得到最终上机文库分子;当用于常规量样品时,所述的一种免疫组库高通量测序文库的构建方法包括以下步骤:1.cDNA模板的制备(1)总RNA提取将Trizol加入淋巴细胞中,提取总RNA,并质检;(2)逆转录、模板替换及UDG酶处理a、按照下表6配置反应体系B;并立即加入步骤1-(1)中提取的RNA;表6c、混匀步骤1-(2)反应体系B,瞬时离心后置于PCR仪上反应,反应程序为70℃,2min;42℃,1-3min,得到产物E;d、配置如表7逆转录反应体系C,并将逆转录反应体系C加入步骤1-(2-)-c中的反应液中;表7e、将配置的逆转录反应体系C加入反应体系B中,混合均匀得反应体系D,置于PCR仪上,反应程序为42℃,60min,得到反应产物F;f、向步骤1-(2)-e中的反应体系D中加入uracilDNAglycosylase,混合均匀后进行PCR反应,反应程序为37℃,40min,得产物G;g、回收纯化PCR产物G,即得到用于后续扩增的cDNA模板;2、第一次PCR反应(1)、PCR反应体系为:表8(2)、PCR反应程序为:表9:(3)、对第一次PCR反应的产物进行纯化,得到PCR产物H;3、第二次PCR(1)、PCR反应体系为:表10(2)、PCR反应程序为:表11(3)、对第二次PCR反应的产物进行纯化,得到PCR产物I;4、测序文库构建(1)、将步骤(3)得到的PCR产物I连接测序接头,得到测序文库样品;(2)、对测序文库样品筛选并质检;上述步骤1-(1)中按每107个细胞加入1mlTrizol的比例将Trizol加入淋巴细胞中;上述步骤1-(2)-f中每10μL反应物A中加入1μL的uracilDNAglycosylase;上述步骤1-(2)-d中所述的TSOprimer核苷酸序列为下列核苷酸序列中的任意一条:当细胞受体为TCR时:TSOprimer的核苷酸序列包含或由SEQIDNO:1组成,其中末端的4个G为核糖核酸中的鸟嘌呤。当细胞受体为BCR时:TSOprimer的核苷酸序列包含或由SEQIDNO:2组成,其中末端的4个G为核糖核酸中的鸟嘌呤。上述步骤1-(2)-a中所述的Primer1核苷酸序列为下列核苷酸序列:当细胞受体为人类TCRalpha时,primer1的核苷酸序列包含或由SEQIDNO:27组成;当细胞受体为人类TCRbeta时,primer1的核苷酸序列包含或由SEQIDNO:28组成;当细胞受体为老鼠TCRalpha时,primer1的核苷酸序列包含或由SEQIDNO:29组成;当细胞受体为老鼠TCRbeta时,primer1的核苷酸序列包含或由SEQIDNO:30组成;当细胞受体为人类BCRalpha时,primer1的核苷酸序列包含或由SEQIDNO:31组成;当细胞受体为人类BCRIgG重链时,primer1的核苷酸序列包含或由SEQIDNO:32组成;当细胞受体为人类BCRIgM重链时,primer1的核苷酸序列包含或由SEQIDNO:33组成;当细胞受体为人类BCRIgA重链时,primer1的核苷酸序列包含或由SEQIDNO:34组成;当细胞受体为人类BCRIgD重链时,primer1的核苷酸序列包含或由SEQIDNO:35组成;当细胞受体为人类BCRIgE重链时,primer1的核苷酸序列包含或由SEQIDNO:36组成;当细胞受体为人类BCRIgL重链时,primer1的核苷酸序列包含或由SEQIDNO:37组成;当细胞受体为老鼠BCRIgG1/IgG2重链时,primer1的核苷酸序列包含或由SEQIDNO:38组成;当细胞受体为老鼠BCRIgG3重链时,primer1的核苷酸序列包含或由SEQIDNO:39组成;当细胞受体为老鼠BCRIgA重链时,primer1的核苷酸序列包含或由SEQIDNO:40组成;当细胞受体为老鼠BCRIgM重链时,primer1的核苷酸序列包含或由SEQIDNO:41组成;当细胞受体为老鼠BCRIgD重链时,primer1的核苷酸序列包含或由SEQIDNO:42组成;当细胞受体为老鼠BCRIgE重链时,primer1的核苷酸序列包含或由SEQIDNO:43组成;当细胞受体为老鼠BCRIgL轻链时,primer1的核苷酸序列包含或由SEQIDNO:44组成;当细胞受体为老鼠BCRIgK轻链时,primer1的核苷酸序列包含或由SEQIDNO:45组成;上述步骤2-(1)中加入cDNA的量为步骤1-g制得的cDNA的1/5的量;上述步骤2-(1)中所述的Primer2核苷酸序列为下列核苷酸序列中的任意一条:当细胞受体为TCR时,primer2的核苷酸序列包含或由SEQIDNO:3组成;当细胞受体为BCR时,primer2的核苷酸序列包含或由SEQIDNO:4组成;上述步骤2-(1)中所述的Primer3核苷酸序列为下列核苷酸序列:当细胞受体为人类TCRbeta时,primer3的核苷酸序列包含或由SEQIDNO:5组成;当细胞受体为人类TCRalpha时,primer3的核苷酸序列包含或由SEQIDNO:6组成;当细胞受体为老鼠TCRbeta时,primer3的核苷酸序列包含或由SEQIDNO:7组成;当细胞受体为老鼠TCRalpha时,primer3的核苷酸序列包含或由SEQIDNO:8组成;当细胞受体为人类IgG/IgE重链时,primer3的核苷酸序列包含或由SEQIDNO:9组成;当细胞受体为人类IgA重链时,primer3的核苷酸序列包含或由SEQIDNO:10组成;当细胞受体为人类IgM重链时,primer3的核苷酸序列包含或由SEQIDNO:11组成;当细胞受体为人类IgD重链时,primer3的核苷酸序列包含或由SEQIDNO:12组成;当细胞受体为人类IgL轻链时,primer3的核苷酸序列包含或由SEQIDNO:13组成;当细胞受体为人类IgK轻链时,primer3的核苷酸序列包含或由SEQIDNO:14组成;当细胞受体为老鼠IgG1/IgG2重链时,primer3的核苷酸序列包含或由SEQIDNO:15组成;当细胞受体为老鼠IgG3重链时,primer3的核苷酸序列包含或由SEQIDNO:16组成;当细胞受体为老鼠IgA轻链时,primer3的核苷酸序列包含或由SEQIDNO:17组成;当细胞受体为老鼠IgM重链时,primer3的核苷酸序列包含或由SEQIDNO:18组成;当细胞受体为老鼠IgD重链时,primer3的核苷酸序列包含或由SEQIDNO:19组成;当细胞受体为老鼠IgE重链时,primer3的核苷酸序列包含或由SEQIDNO:20组成;当细胞受体为老鼠IgL轻链时,primer3的核苷酸序列包含或由SEQIDNO:21组成;当细胞受体为老鼠IgK轻链时,primer3的核苷酸序列包含或由SEQIDNO:22组成;上述步骤3-(1)中加入的PCR产物H为步骤2-(3)制得的PCR产物H的量的1/10;上述步骤3-(1)中所述的Primer4核苷酸序列为下列核苷酸序列中的任意一条:当细胞受体为TCR时,primer4的核苷酸序列包含或由SEQIDNO:23组成;当细胞受体为BCR时,primer4的核苷酸序列包含或由SEQIDNO:24组成;上述步骤3-(1)中所述的Primer5核苷酸序列为下列核苷酸序列中的任意一条:当细胞受体为TCR时,primer5的核苷酸序列包含或由SEQIDNO:25组成;当细胞受体为BCR时,primer5的核苷酸序列包含或由SEQIDNO:26组成。上述构建方法可以总结为:以RNA为起始样本,在TCR/BCR地区设计引物进行逆转录,当逆转录进行到mRNA5'UTR末端时逆转录酶会在cDNA分子的3'端加上几个“C”碱基,并与加入的模板转换引物TSO(此序列由一段UMI序列与一段通用序列组成)上的G碱基配对,继续以TSO引物为模板进行逆转录,从而引入UMI及通用序列;接着加入UDG酶降解加入的TSO引物,使用PCR产物回收试剂盒纯化回收cDNA产物;取一部分cDNA为模板,以cDNA子3'端通用序列为上游引物及接近TCR/BCR可变区的恒定区设计的下游引物(同时带上一段通用序列)进行第一次PCR反应;然后取一部分纯化后的第一次PCR产物作为模板,并以其两端的通用序列作为上下游引物进行第二次PCR反应,经过两轮PCR后得到TCR/BCR可变区的全长序列及引入的UMI序列,最后连接上illumina测序平台的接头序列,得到最终上机文库分子。本发明的有益效果:(1)本发明是基于5'RACE的原理,同时引入UMI(分子条形码)的文库构建方法:在恒定区设计单引物进行逆转录,可等效扩增出所有类型TCR/BCRCDR全长序列,同时因引入UMI,可对后续的PCR或测序过程中引入的错误进行纠正;(2)在逆转录这一环节设计了针对微量样品(低至100个细胞)的实验流程即通过PolyT磁珠捕获mRNA,并以磁珠上的PolyT为逆转引物合成cDNA并纯化回收cDNA,较常规方法可大大提高效率,保证了微量样品的实验成功率;(3)本发明可满足微量样品(低至100个细胞)建库的实验要求;(4)本发明可等效扩增出TCR/BCR的CDR全长序列;附图说明图1为微量RNA起始时文库构建流程图。图2为常规量RNA起始时文库构建流程图。图3为实施例1中样品A的质检结果图。图4为实施例1中样品B的质检结果图。图5为实施例2中样品1的质检结果图。图6为实施例2中样品2的质检结果图。图7为实施例2中样品3的质检结果图。具体实施方式以下实施例的说明只是用于帮助理解本发明的方法及其核心思想,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。对所公开的实施例的下述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例中,而是可以应用于符合与本文所公开的原理和新颖特点相一致的更宽的范围。实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件(例如参考J.萨姆布鲁克等著,黄培堂等译的《分子克隆实验指南》,第三版,科学出版社)或者按照产品说明书进行。实施例1微量起始样本的免疫组库高通量测序文库的构建方法样本处理:使用淋巴细胞分离液分离健康人外周血单个核细胞,并进行计数(2×106个/ml),取20000个细胞进行后续BCR文库构建实验;1、cDNA模板的制备(1)细胞裂解将10000个淋巴细胞加入100ul细胞裂解液中进行裂解,得到裂解液;(2)mRNA分离、逆转录、模板替换及UDG酶处理1)、使用试剂盒DynabeadsmRNADIRECTMicroKit(TermoFisher)对已裂解的细胞样品进行mRNA分离,操作按说明书进行;2)、按表12所示,配置逆转录体系,并立即加入至第一步中已捕获mRNA的磁珠中,重悬磁珠,转移至PCR小管中,PCR反应程序为50℃1h,72℃10min;表123)、向上述反应体系中加入1uluracilDNAglycosylase(5U/μl)及2.3ul反应buffer,混合均匀后于PCR仪上:37℃,40min;4)、使用10mMtris–HCl磁珠进行洗涤3次,回收的磁珠即为用于后续扩增的cDNA模板;其中,TSOprimer的核苷酸序列为SEQIDNO:1所示,其中末端的4个G为核糖核酸中的鸟嘌呤。2、第一次PCR(1)、在PCR管中配置如表13所示反应体系;表13(2)、将以上反应体系重悬步骤1中回收的磁珠,用移液器混合均匀置于PCR仪上进行如下表14所示反应程序;表14(3)、使用1.8倍AmpureXP磁珠对PCR产物进行纯化,最终用16ul洗脱;其中,primer2的核苷酸序列为SEQIDNO:1所示,其中末端的4个G为核糖核酸中的鸟嘌呤。其中,primer3的核苷酸序列为SEQIDNO:6所示。3、第二次PCR(1)、在PCR管中配置如表15反应体系;表15(2)、将以上反应体系混合均匀,瞬时离心,置于PCR仪上,PCR反应程序如表16所示:表16(3)、使用1.2倍AmpureXP磁珠对PCR产物进行纯化;(4)、使用Qubit对纯化的PCR产物进行定量;其中,primer4的核苷酸序列为:(N)4–6(ACCTG)CAGTGGTATCAACGCAGAG;其中,primer5的核苷酸序列为:(N)4-6(CGTAA)ATTGGGCAGCCCTGATT;4、测序文库构建(1)、使用NEBDNA建库试剂盒将上述PCR产物连接适用于illumina平台的接头;(2)、使用AmpureXP磁珠对最终文库进行片段筛选并质检,结果如表17所示,样品A和样品B的质检结果分别如图3和图4所示;表17实施例2常规量起始样本的免疫组库高通量测序文库的构建方法本实施例样本以健康人外周血为样本,具体实施步骤如下:1、cDNA模板的制备(1)总RNA提取1)、淋巴细胞分离;2)、按每107个细胞加入1mlTrizol的比例将Trizol加入至分离的淋巴细胞中,提取总RNA;3)、将提取出的RNA进行agilent2100质检;(2)逆转录、模板替换及UDG酶处理(常规起始量样品)1)、在PCR管中准备如表14所示的反应体系(mix1);表182)、用移液器或轻弹管壁混匀以上反应体系,瞬时离心后置于PCR仪上反应:70℃,2min;42℃,1min至配好以下逆转录体系;3)、在PCR管中配置逆转录体系(mix2),PCR反应体系如表15所示;表194)、将配置的12ulmix2加入至mix1中,混合均匀,置于PCR仪上:PCR反应程序为42℃,60min;5)、向上述反应体系中加入1uluracilDNAglycosylase(5U/μL),混合均匀后于PCR仪上:PCR反应程序为37℃,40min;6)、使用试剂盒MinElutePCRPurifcationKit(Qiagen)对合成的cDNA进行纯化;其中,primer1的核苷酸序列为SEQIDNO:27所示。2、第一次PCR(1)、在PCR管中配置如表20所示的反应体系;表20(2)、将以上反应体系混合均匀,瞬时离心,置于PCR仪上,PCR反应程序如表21所示:表21(3)、使用试剂盒QIAquickPCRPurifcationKi对PCR产物进行纯化;其中,priemer2的核苷酸序列为SEQIDNO:3所示;其中,primer3的核苷酸序列为SEQIDNO:5所示。3、第二次PCR(1)、在PCR管中配置如表22所示反应体系;表22(2)、将以上反应体系混合均匀,瞬时离心,置于PCR仪上,PCR反应程序为表23所示;表23(3)、使用试剂盒QIAquickPCRPurifcationKit对PCR产物进行纯化;(4)、使用Qubit对纯化的PCR产物进行定量;其中,primer4的核苷酸序列为:(N)4–6(ACTGG)CAGTGGTATCAACGCAGAG;其中,primer5的核苷酸序列为:(N)4-6(TACGA)ATTGGGCAGCCCTGATT;4、测序文库构建(1)、使用NEBDNA建库试剂盒将上述PCR产物连接适用于illumina平台的接头了;(2)、使用AmpureXP磁珠对最终文库进行片段筛选并质检,结果如表24所示,样品1、样品2和样品3的质检结果分别如图5、图6和图7所示;表24样品名起始量第二次PCR产量最终文库浓度样品1900ng10.4ng/ul,30ul65ng/ul,30ul样品21ug13.1ng/ul,30ul73ng/ul,30ul样品31ug13.9ng/ul,30ul52ng/ul,30ul实施例3通过比较更正前UMI的种类数目和UMI自身纠错后的种类数去评估对测序准确度的影响,且同一个UMI测到的多条reads可以互相纠正,提高reads序列的准确度,测试用20个文库的数据情况如表25所示:表25可以看到有70%以上的UMI种类得到了校正,说明本发明对数据准确率有极大的提高,另外也有相当多的UMI对应的reads数目是大于2的,可以对这部分的reads互相校正,去除PCR和测序错误,提高数据的准确度。序列表<110>广州华银医学检验中心有限公司<120>一种免疫组库高通量测序文库的构建方法<130>20180704<160>45<170>SIPOSequenceListing1.0<210>1<211>45<212>DNA<213>人工序列(rengongxulie)<220><221>misc_feature<222>(24)..(27)<223>nisa,c,g,toru<220><221>misc_feature<222>(29)..(32)<223>nisa,c,g,toru<220><221>misc_feature<222>(34)..(37)<223>nisa,c,g,toru<400>1aagcaguggtaucaacgcagagunnnnunnnnunnnnucttgggg45<210>2<211>45<212>DNA<213>人工序列(rengongxulie)<220><221>misc_feature<222>(24)..(27)<223>nisa,c,g,toru<220><221>misc_feature<222>(29)..(32)<223>nisa,c,g,toru<220><221>misc_feature<222>(34)..(37)<223>nisa,c,g,toru<400>2aagcaguggtaucaacgcagagunnnnunnnnunnnnucttgggg45<210>3<211>19<212>DNA<213>人工序列(rengongxulie)<400>3aagcagtggtatcaacgca19<210>4<211>19<212>DNA<213>人工序列(rengongxulie)<400>4aagcagtggtatcaacgca19<210>5<211>36<212>DNA<213>人工序列(rengongxulie)<400>5attgggcagccctgattacacsttkttcaggtcctc36<210>6<211>36<212>DNA<213>人工序列(rengongxulie)<400>6attgggcagccctgattgggtcagggttctggatat36<210>7<211>39<212>DNA<213>人工序列(rengongxulie)<400>7attgggcagccctgattggagtcacatttctcagatcct39<210>8<211>38<212>DNA<213>人工序列(rengongxulie)<400>8attgggcagccctgattcaggttctgggttctggatgt38<210>9<211>33<212>DNA<213>人工序列(rengongxulie)<400>9attgggcagccctgattarggggaagacsgatg33<210>10<211>33<212>DNA<213>人工序列(rengongxulie)<400>10attgggcagccctgattcagcgggaagaccttg33<210>11<211>33<212>DNA<213>人工序列(rengongxulie)<400>11attgggcagccctgattagggggaaaagggttg33<210>12<211>33<212>DNA<213>人工序列(rengongxulie)<400>12attgggcagccctgattatatgatggggaacac33<210>13<211>33<212>DNA<213>人工序列(rengongxulie)<400>13attgggcagccctgattgygggaacagagtgac33<210>14<211>33<212>DNA<213>人工序列(rengongxulie)<400>14attgggcagccctgattgatggtgcagccacag33<210>15<211>33<212>DNA<213>人工序列(rengongxulie)<400>15attgggcagccctgattagtggatagacmgatg33<210>16<211>33<212>DNA<213>人工序列(rengongxulie)<400>16attgggcagccctgattaagggatagacagatg33<210>17<211>34<212>DNA<213>人工序列(rengongxulie)<400>17attgggcagccctgatttcagtgggtagatggtg34<210>18<211>33<212>DNA<213>人工序列(rengongxulie)<400>18attgggcagccctgattgggggaagacatttgg33<210>19<211>33<212>DNA<213>人工序列(rengongxulie)<400>19attgggcagccctgattctctgagaggaggaac33<210>20<211>33<212>DNA<213>人工序列(rengongxulie)<400>20attgggcagccctgattaaggggtagagctgag33<210>21<211>33<212>DNA<213>人工序列(rengongxulie)<400>21attgggcagccctgattagrggaaggtggaaac33<210>22<211>33<212>DNA<213>人工序列(rengongxulie)<400>22attgggcagccctgattggatggtgggaagatg33<210>23<211>19<212>DNA<213>人工序列(rengongxulie)<400>23cagtggtatcaacgcagag19<210>24<211>19<212>DNA<213>人工序列(rengongxulie)<400>24cagtggtatcaacgcagag19<210>25<211>17<212>DNA<213>人工序列(rengongxulie)<400>25attgggcagccctgatt17<210>26<211>17<212>DNA<213>人工序列(rengongxulie)<400>26attgggcagccctgatt17<210>27<211>22<212>DNA<213>人工序列(rengongxulie)<400>27acacatcagaatccttactttg22<210>28<211>19<212>DNA<213>人工序列(rengongxulie)<400>28cagtatctggagtcattga19<210>29<211>18<212>DNA<213>人工序列(rengongxulie)<400>29tttcggcacattgatttg18<210>30<211>18<212>DNA<213>人工序列(rengongxulie)<400>30caatctctgcttttgatg18<210>31<211>22<212>DNA<213>人工序列(rengongxulie)<400>31acacatcagaatccttactttg22<210>32<211>21<212>DNA<213>人工序列(rengongxulie)<400>32gaagtagtccttgaccaggca21<210>33<211>21<212>DNA<213>人工序列(rengongxulie)<400>33gtgatggagtcgggaaggaag21<210>34<211>21<212>DNA<213>人工序列(rengongxulie)<400>34gcgacgaccacgttcccatct21<210>35<211>19<212>DNA<213>人工序列(rengongxulie)<400>35ggaccacagggctgttatc19<210>36<211>19<212>DNA<213>人工序列(rengongxulie)<400>36agtcacggaggtggcattg19<210>37<211>16<212>DNA<213>人工序列(rengongxulie)<400>37gctcccgggtagaagt16<210>38<211>19<212>DNA<213>人工序列(rengongxulie)<400>38kkacagtcactgagctgct19<210>39<211>19<212>DNA<213>人工序列(rengongxulie)<400>39gtacagtcaccaagctgct19<210>40<211>19<212>DNA<213>人工序列(rengongxulie)<400>40ccaggtcacattcatcgtg19<210>41<211>20<212>DNA<213>人工序列(rengongxulie)<400>41ctggatgacttcagtgttgt20<210>42<211>20<212>DNA<213>人工序列(rengongxulie)<400>42gccatttctcatttcagagg20<210>43<211>19<212>DNA<213>人工序列(rengongxulie)<400>43gttcacagtgctcatgttc19<210>44<211>19<212>DNA<213>人工序列(rengongxulie)<400>44tgtaccatytgccttccag19<210>45<211>19<212>DNA<213>人工序列(rengongxulie)<400>45actgccatcaatcttccac19当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 一种构建Hi‑C高通量测序文库的方法与制造工艺
- 桑葚病原菌高通量鉴定及种属分类方法及其应用与制造工艺
- 基于高通量测序技术检测乳腺癌/卵巢癌易感基因的多重PCR特异性引物、试剂盒及方法与制造工艺
- 基于高通量测序检测人EGFR基因变异的质控方法及试剂盒与制造工艺
- 基于高通量测序技术的小麦病原微生物检测方法及其应用与制造工艺
- 一种基于二代高通量测序技术的地中海贫血症的基因检测试剂盒的制造方法与工艺
- 一种基于集群的高通量数据分析方法与制造工艺
- 高通量双折射干涉成像光谱仪装置及其成像方法与制造工艺
- 高通量测序检测人循环肿瘤DNA EGFR基因的捕获探针及试剂盒的制造方法与工艺
- 一种高通量测序检测无创亲子鉴定的方法与制造工艺