针对肾相关抗原1的抗体及其抗原结合片段的制作方法
发明领域
本发明涉及特异性地结合至肾相关抗原1(KAAG1)上的特异性抗体或抗原结合片段以及它们用于癌症的治疗、检测和诊断的用途。特别考虑了将治疗剂与这些抗体或抗原结合片段一起递送至细胞。
发明背景
在美国,在妇科恶性肿瘤中,卵巢癌占据女性中的最高肿瘤相关死亡率(杰玛(Jemal)等人,2005)。在美国,它是女性中癌相关死亡的第四大原因(梅农(Menon)等人,2005)。美国癌症协会估计在2005年总计22,220个新病例并且将16,210例死亡归因于该疾病(博纳姆(Bonome)等人,2005)。对于过去30年,统计数字大体上保持相同-产生卵巢癌的大多数女性将死于这种疾病(钱伯斯(Chambers)和范德尔海登(Vanderhyden),2006)。该疾病带来1:70的寿命风险以及>60%的死亡率(钱伯斯(Chambers)和范德尔海登(Vanderhyden),2006)。高死亡率是由于当恶性肿瘤已经扩散在卵巢以外时卵巢癌的早期检测的困难。实际上,>80%的患者被诊断为患有晚期疾病(III期或IV期)(博纳姆(Bonome)等人,2005)。这些患者有不良的预后,这反映为<45%的5年存活率,虽然80%至90%将最初对化疗有反应(贝雷克(Berek)等人,2000)。与较早时20%的5年存活率相比,这个增加的成就至少部分地是由于当肿瘤组织局限于卵巢时最佳地减小肿瘤组织的体积的能力,这是针对卵巢癌的重要的预后因素(布里斯托(Bristow R.E.),2000;布朗(Brown)等人,2004)。在被诊断患有早期疾病(I期)的患者中,5年存活率范围为>90(钱伯斯(Chambers)和范德尔海登(Vanderhyden),2006)。
卵巢癌包括从卵巢的表面上皮或从表面包涵体(surface inclusion)衍生的肿瘤的多相群。它们分为浆液性、粘液性、子宫内膜样性、透明细胞、以及布伦纳(过渡)类型,对应于女性生殖道器官中的不同类型的上皮(史(Shih)和库尔曼(Kurman),2005)。在这些类型中,浆液性肿瘤占诊断的卵巢癌病例的大约60%。每个组织学亚类进一步分为三组:良性的、中间的(交界性肿瘤或低恶性倾向(LMP))、和恶性的,反映它们的临床行为((塞德曼)Seidman等人,2002)。LMP表示10%至15%的被诊断为浆液性的肿瘤,并且是一个难题,因为它们展现非典型的核结构以及转移行为,然而它们与高级别(high-grade)浆液性肿瘤相比具有相当低的侵袭性。在相同的时期内,与晚期高级别疾病<45%的存活率不同,对于患有LMP肿瘤的患者的5年存活率是95%(贝雷克(Berek)等人,2000)。
目前,卵巢癌的诊断是部分地通过患者病史的常规分析、以及通过进行体格检查、超声检查和X射线检查、以及血液学筛查而完成的。已经报道用于血清生物标记的早期血液学检测的两种替代策略。一种方法是通过质谱法分析血清样品以便发现未知身份的蛋白质或蛋白质片段,从而检测癌症的存在或不存在(莫尔(Mor)等人,2005;科扎克(Kozak)等人,2003)。然而,这个策略是昂贵的并且不是广泛可用的。可替代地,是使用抗体微阵列、ELISA、或其他相似的方法检测在血清中的已知蛋白质/肽的存在或不存在。对于称为CA-125(癌抗原-125)的蛋白质生物标记的血清检测长期以来已被广泛地作为针对卵巢癌的标记而执行。然而,虽然卵巢癌细胞可以产生过量的这些蛋白质分子,仍有一些其他癌症(包括输卵管癌或子宫内膜癌(cancer of the lining of the uterus))、患有胰腺癌的人的60%、以及患有其他恶性肿瘤的人的20%-25%具有升高水平的CA-125。CA-125测试仅仅获得对于大约50%的I期卵巢癌患者的真实阳性结果,而具有获得来自II、III、和IV期卵巢癌患者的真实阳性结果的80%的可能性。其他20%的卵巢癌患者未显示CA-125浓度的任何增加。另外,升高的CA-125测试可以指示与癌症不相关的其他良性活动,例如月经、怀孕、或子宫内膜异位。因此,当早期疾病仍然是可治疗的、展现<10%的阳性预测值(PPV)时,这种测试对于该早期疾病的检测具有非常有限的临床应用。甚至在添加针对CA-125的超声筛查的情况下,PPV仅仅提高至大约20%(科扎克(Kozak)等人,2003)。因此,这个测试不是有效的筛查测试。
尽管疾病的病因学知识、侵袭性细胞减灭术、以及现代联合化疗的改进,但在死亡率上仅有很小的变化。不好的结果已经归因于(1)缺乏适当的用于早期疾病检测的与在这个阶段的症状的微弱表现相结合的筛查测试-诊断经常只是在进展到后期之后才作出的,在此时癌症的腹膜播散限制了有效治疗,以及(2)对标准化疗策略的抵抗的频繁产生,限制了患者的5年存活率的改进。用于卵巢癌的初始化疗方案包括卡铂(Paraplatin)和紫杉醇(taxol)的结合。多年的临床试验已经证明这种结合在有效手术之后是最有效的-减小了患有新诊断的卵巢癌的大约80%女性中的肿瘤体积,并且40%至50%将具有完全消退-但研究继续寻求改进患者反应的方法。最近的靶向难以到达的细胞的化疗剂的腹腔输注与静脉内递送结合已经增加了有效性。然而,严重的副作用常常导致不完全的疗程。一些其他的化疗剂包括多柔比星、顺铂、环磷酰胺、博来霉素、依托泊苷、长春碱、盐酸拓扑替康、异环磷酰胺、5-氟尿嘧啶以及美法仑。更为最近地,临床试验已经证明:与全身静脉化疗相比较,顺铂的腹膜内给药赋予了存活优势(卡尼斯特拉(Cannistra)和麦圭尔(McGuire),2007)。对于患有早期疾病接受化疗的女性而言,优异的存活率为开发改进卵巢癌检测的策略的研究工作提供了强的原理。此外,新的卵巢癌相关生物标记的发现将导致用于卵巢癌的未来治疗的、具有最小副作用而更有效的治疗策略的开发。
尽管这些在对于卵巢癌的理解和治疗方面的最近进展,化疗的使用常常与严重的不良反应相关,这些不良反应限制了它们的使用。因此,对于更具特异性的策略(例如,抗原组织特异性与单克隆抗体的选择性相结合)的需要将允许脱靶相关的副作用的显著减少。随着渐增数目的进行的临床试验,用于卵巢癌治疗的单克隆抗体的使用正开始出现(Oei等人,2008;尼哥底母(Nicodemus)和贝雷克(berek),2005)。这些试验中的大多数已经检验了与放射性同位素(例如钇-90)结合的单克隆抗体、或者靶向已经在其他癌类型中鉴定的肿瘤抗原的抗体的用途。对此的一个实例是贝伐单抗的使用,它靶向血管内皮生长因子(伯格(Burger),2007)。存在非常少的、当前作为用于单克隆抗体的治疗靶标而被研究的卵巢癌特异性抗原。一些实例包括称为B7-H4的蛋白质(西蒙(Simon)等人,2006)以及更近地叶酸受体-α(埃贝尔(Ebel)等人,2007)的使用,后者近来已经进入II期临床试验。
肾相关抗原1(KAAG1)是最初从衍生自组织相容性白细胞抗原-B7肾癌细胞系的cDNA文库克隆的,作为呈递至细胞毒性T淋巴细胞的抗原肽(Van den Eynde等人,1999;Genbank登录号Q9UBP8,SEQ ID NO.:28;29)。发现含有KAAG1的基因座编码转录在相对的DNA链上的两种基因。发现有义链编码一种转录物,该转录物编码称为DCDC2的蛋白质。由这些作者进行的表达研究发现,KAAG1反义转录物是肿瘤特异性的并且在正常组织中展现非常少的表达,而DCDC2有义转录物被广泛表达(Van den Eynde等人,1999)。在公开的专利申请号PCT/CA 2007/001134(其全部内容通过引用结合在此)中披露了在癌症中并且特别是在卵巢癌、肾癌、肺癌、结肠癌、乳腺癌以及黑色素瘤中的KAAG1转录物的表达。Van den Eynde等人还观察到在肾癌、结肠直肠癌、黑色素瘤、肉瘤、白血病、脑肿瘤、甲状腺瘤、乳腺癌、前列腺癌、食管癌、膀胱癌、肺癌、以及头颈肿瘤中的RNA表达。近来,通过连锁不平衡研究获得的强的遗传证据发现VMP/DCDC2/KAAG1基因座与诵读困难相关(舒马赫(Schumacher)等人,2006;科普(Cope)等人,2005)。这些报道之一指向作为诵读困难患者中的罪魁祸首(culprit)的DCDC2标记,因为在皮质神经元迁移中这种蛋白质的功能与常常展现异常的神经元迁移和成熟的这些患者的症状一致(舒马赫(Schumacher)等人,2006)。
发明概述
本发明涉及特异性抗-KAAG1抗体和抗原结合片段以及它们用于包含表达KAAG1或KAAG1变体的肿瘤细胞的癌症的治疗、检测和诊断的用途。这样的癌症的示例性实施例包括例如卵巢癌、皮肤癌、肾癌、结肠直肠癌、肉瘤、白血病、脑癌、甲状腺癌、乳腺癌、前列腺癌、食管癌、膀胱癌、肺癌以及头颈癌。
抗体或抗原结合片段在靶向在肿瘤细胞的表面上表达的KAAG1或KAAG1变体方面可以是特别有效的。
事实上,与例如在PCT/CA 2009/001586(其全部内容通过引用结合在此)中披露的3D3和3G10抗体相比较,本发明的抗体或抗原结合片段显现出具有改进的与表达KAAG1的肿瘤细胞结合的能力。这些抗体和抗原结合片段还被内化并且可以因此在将治疗剂递送至肿瘤细胞中是有用的。我们的结果表明,具有所希望特征(例如,改进的结合和内化)的抗体和抗原结合片段通常结合至KAAG1上的由氨基酸61至84界定的C端区域。然而,虽然3A4和3G10抗体两者都结合至相同的区域上,3A4抗体显现出比3G10抗体更有效地结合至肿瘤细胞的表面上。具体而言,在流式细胞术实验(一种测量抗体与细胞表面的直接结合的方法)中,表达KAAG1抗原的癌细胞需要比3G10大致少10倍的3A4。另外,在使用表面等离子体共振的结合实验中,发现3A4对KAAG1的亲和常数(KD)是在10皮摩尔以下,而抗体3D3和3G10展现出大于200皮摩尔的亲和常数(KD)(低20倍的亲和力)。因此,预期3A4在结合能力方面的这些增加转化为改进的治疗活性。
本发明在其一方面提供了一种分离的或基本上纯化的抗体或抗原结合片段,该抗体或抗原结合片段可以能够特异性地结合至一个序列,该序列与位于KAAG1(SEQ ID NO.:29)的氨基酸61至84之间的至少10个(例如10至20个或更多个)连续氨基酸是一致的。
本发明还提供了能够与在此所述的抗体或抗原结合片段竞争的分离的抗体或抗原结合片段。
在另一个方面,本发明涉及具有在此所述的氨基酸序列的特异性抗体或抗原结合片段。这样的抗体或抗原结合片段可以处于单克隆抗体、多克隆抗体、嵌合抗体、人源化抗体和人抗体(分离的)的形式,连同具有在此所述的特征的抗原结合片段。与此一道还包括这样的抗体或抗原结合片段:这些抗体或抗原结合片段包括在单克隆、嵌合、人源化或人抗体之间的轻链和/或重链的排列。
本发明的抗体或抗原结合片段可以因此包含人抗体的人恒定区和/或框架氨基酸。
术语“抗体”是指完整抗体、单克隆抗体或多克隆抗体。术语“抗体”还包括多特异性抗体,例如双特异性抗体。人抗体通常是由各自包含可变区和恒定区的两条轻链和两条重链组成。轻链可变区包含3个CDR,在此鉴定为侧翼是框架区的CDRL1或L1、CDRL2或L2以及CDRL3或L3。重链可变区包含3个CDR,在此鉴定为侧翼是框架区的CDRH1或H1、CDRH2或H2以及CDRH3或H3。已经使用卡巴特(Kabat)和肖蒂亚(Chotia)定义鉴定了本发明的人源化抗体的CDR(例如在SEQ ID NO.:56中列出的CDRH2)。然而,其他人(阿比南旦(Abhinandan)和马丁(Martin),2008)已经使用了宽松地基于Kabat和Chotia的改良的方法,得到较短的CDR(例如,在SEQ ID NO.:6中列出的CDRH2)的描述。
如在此使用的术语“抗原结合片段”是指保留与抗原(例如,KAAG1、KAAG1的分泌形式或其变体)结合的能力的抗体的一个或多个片段。已经显示抗体的抗原结合功能可以由完整抗体的片段执行。包含在术语抗体的“抗原结合片段”之内的结合片段的实例包括(i)Fab片段,由VL、VH、CL和CH1结构域组成的单价片段;(ii)F(ab')2片段,包含在铰链区由二硫桥连接的两个Fab片段的二价片段;(iii)Fd片段,由VH和CH1结构域组成;(iv)Fv片段,由抗体的单臂的VL和VH结构域组成,(v)dAb片段(华德(Ward)等人,(1989)《自然》(Nature)341:544-546),由VH结构域组成;以及(vi)分离的互补决定区(CDR)(例如,VH CDR3)。此外,虽然Fv片段的两个结构域VL和VH由独立的基因编码,可以使用重组方法通过使它们能够被制造为单一多肽链的合成接头而将它们结合,该单一多肽链中的VL和VH区配对以形成单价分子(称为单链Fv(scFv));参见例如伯德(Bird)等人(1988)《自然》(Science)242:423-426;以及赫斯顿(Huston)等人(1988)《美国国家科学院院刊》(Proc.Natl.Acad.Sci.USA)85:5879-5883)。这样的单链抗体还旨在被包含在术语抗体的“抗原结合片段”之内。此外,抗原结合片段包括结合域免疫球蛋白融合蛋白,这些结合域免疫球蛋白融合蛋白包含(i)与免疫球蛋白铰链区多肽融合的结合域多肽(例如重链可变区、轻链可变区、或经由接头肽而与轻链可变区融合的重链可变区),(ii)与铰链区融合的免疫球蛋白重链CH2恒定区,以及(iii)与CH2恒定区融合的免疫球蛋白重链CH3恒定区。铰链区可以通过将一个或多个半胱氨酸残基用丝氨酸残基替换而被修饰,从而防止二聚化。这样的结合域免疫球蛋白融合蛋白进一步披露于US 2003/0118592和US2003/0133939中。这些抗体片段是使用对于本领域的技术人员而言已知的常规技术而获得的,并且按照与完整抗体相同的方式对这些片段的效用进行了筛选。
术语“人源化抗体”包括全人源化抗体(即,框架是100%人源化的)以及部分人源化抗体(例如,至少一个可变结构域含有来自人抗体的一个或多个氨基酸,同时其他氨基酸是非人亲本抗体的氨基酸)。典型地,“人源化抗体”含有非人亲本抗体(例如,小鼠、大鼠、兔子、非人灵长类,等等)的CDR、以及与天然人抗体或人抗体共有序列的那些一致的框架。在这种情况下,那些“人源化抗体”表征为全人源化。“人源化抗体”还可以含有一种或多种氨基酸置换,这些置换不对应于人抗体或人抗体共有序列的那些。这样的置换包括例如可以保留抗体特征(例如,亲和力、特异性,等等)的回复突变(例如,非人氨基酸的再引入)。这样的置换通常是在框架区。“人源化抗体”任选地还包含:典型地为人抗体的恒定区(Fc)的至少一部分。典型地,“人源化抗体”的恒定区与人抗体的恒定区是一致的。
术语“天然人抗体”是指由人抗体谱(即,种系序列)编码的(可编码的)抗体。
术语“嵌合抗体”是指具有非人可变区和人恒定区的抗体。
术语“杂交抗体”是指这样一种抗体:包含来自某些类型的抗体(例如,人源化的)的它的重链或轻链可变区(它的重链或轻链)之一,而另一个重链或轻链可变区(重链或轻链)是来自另一种类型(例如,鼠,嵌合的)。
在一些实施例中,人源化抗体的重链和/或轻链框架区可以包含来自非人抗体(旨在被人源化)的从一至三十个氨基酸以及来自天然人抗体或人抗体共有序列的剩余部分。在一些情况下,人源化抗体可以包含从1至6个非人CDR并且六个CDR常常是非人的。
被选择用于非人亲本抗体的人源化的天然人抗体可以包含一个可变区,该可变区具有与非人亲本抗体的(模式化)可变区的三维结构(可重叠的)相似的三维结构。像这样,人源化抗体具有更大的具有与非人亲本抗体的三维结构相似的三维结构的可能性。
被选择用于人源化目的的天然人抗体的轻链可变区可以具有例如在整体上(在整个轻链可变区上)与非人亲本抗体的轻链可变区至少70%、75%、80%等的一致性。可替代地,被选择用于人源化目的的天然人抗体的轻链框架区可以具有例如与非人亲本抗体的轻链框架区至少70%、75%、80%、85%等的序列一致性。在一些实施例中,被选择用于人源化目的的天然人抗体在其轻链互补决定区中可以具有与非人亲本抗体的轻链互补决定区相同或基本上相同数目的氨基酸。
被选择用于人源化目的的天然人抗体的重链可变区可以具有例如在整体上(在整个重链可变区上)与非人亲本抗体的重链可变区至少60%、70%、75%、80%等的一致性。同样,根据本发明,人源化抗体重链的人框架区氨基酸残基可以来自天然人抗体重链框架区,该天然人抗体重链框架区具有与非人亲本抗体的重链框架区至少70%、75%、89%等的一致性。在一些实施例中,被选择用于人源化目的的天然人抗体在其重链互补决定区可以具有与非人亲本抗体的重链互补决定区相同或基本上相同数目的氨基酸。
被选择用于非人亲本抗体的人源化的天然人抗体可以包含一个可变区,该可变区具有与非人亲本抗体的(模式化)可变区的三维结构(可重叠的)相似的三维结构。像这样,人源化或杂交抗体具有更大的具有与非人亲本抗体的三维结构相似的三维结构的可能性。
例如,可以被选择用于人源化目的的天然人抗体重链可变区可以具有以下特征:a)与非人抗体重链的三维结构相似或相同的(可重叠的)三维结构,和/或b)具有与非人抗体的重链框架区至少70%一致的氨基酸序列的框架区。任选地,在重链CDR(例如,所有三个CDR)中的(许多个)氨基酸残基与非人重链CDR氨基酸残基相同或基本上相同。
可替代地,可以被选择用于人源化目的的天然人抗体轻链可变区可以具有以下特征:a)与非人抗体轻链的三维结构相似或相同的(可重叠的)三维结构,和/或b)具有与非人抗体的轻链框架区至少70%一致的氨基酸序列的框架区。任选地,在轻链CDR(例如,所有三个CDR)中的(许多个)氨基酸残基与非人轻链CDR氨基酸残基相同或基本上相同。
典型的抗原结合部位包含由轻链免疫球蛋白与重链免疫球蛋白配对形成的可变区。抗体可变区的结构是非常一致的并且展现非常相似的结构。这些可变区典型地包含相对同源的框架区(FR),这些框架区被三个称为互补决定区(CDR)的超变区间隔开。抗原结合片段的整体结合活性常常由CDR的序列决定。FR对于最优的抗原结合而言常常起着CDR的三维上的正确定位和比对的作用。
本发明的抗体和/或抗原结合片段可以例如源于小鼠、大鼠或任何其他哺乳动物或源于其他来源(例如,通过重组DNA技术)。
根据下文所给出的非限制性详细说明,本发明的进一步的范围、适用性和优势将变得清楚。然而,应当理解的是,这个详细说明在指示本发明的示例性实施例时仅仅是以举例的方式并参考附图而给出的。
附图简要说明
图1显示了来自ELISA的结果,ELISA将当与渐增浓度的重组人KAAG1一起孵育时3A4嵌合抗-KAAG1抗体的结合与对照抗体的结合进行了比较。3A4的结合曲线由较浅颜色的线显示。
图2显示了一个直方图,该直方图描述了来自ELISA分析的结果从而映射3A4抗-KAAG1抗体的表位特异性。结果显示3A4与包含在氨基酸61-84之间的KAAG1羧基端之内的氨基酸序列相互作用。将3A4与3C4、3D3、和3G10抗-KAAG1抗体的结合进行了比较,已知这些抗体分别与KAAG1的区域1-35、36-60、以及61-84相互作用。
图3A显示了用3A4抗-KAAG1抗体(颜色较深的线)与用对照IgG(颜色较浅的线)对SKOV-3和TOV-21G卵巢癌细胞进行的流式细胞术的比较结果。
图3B显示了用3A4抗-KAAG1抗体(颜色较深的线)与用对照IgG(颜色较浅的线)对293E人肾细胞进行的流式细胞术的比较结果。
图4表示通过流式细胞术用3A4抗-KAAG1抗体对SKOV-3细胞表面上的KAAG1抗原的检测。当细胞在37C被孵育时,荧光信号随着时间降低,表明当细胞与3A4一起孵育时,KAAG1/抗体复合物在孵育期间被内化。
图5显示了3A4抗-KAAG1的内化和它与LAMP1的共定位,LAMP1是一种与内体和溶酶体膜相关的蛋白质。
图6A和6B是表示暴露至不同的抗-KAAG1抗体的肿瘤细胞的FAC分析的图。
图7是代表在细胞膜中的KAAG1取向的2种可能的图示的原理图。
图8是鼠3A4可变结构域的分子模型(带状图)。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。
图9a是3A4可变结构域的人源化抗体Lh1Hh1(即,人源化轻链1和人源化重链1)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh1指定变体1的人源化轻链,而Hh1指定变体1的重链。
图9b是3A4可变结构域的人源化抗体Lh1Hh2(即,人源化轻链1和人源化重链2)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh1指定变体1的人源化轻链,而Hh2指定变体2的重链。
图9c是3A4可变结构域的人源化抗体Lh1Hh3(即,人源化轻链1和人源化重链3)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh1指定变体1的人源化轻链,而Hh3指定变体3的重链。
图9d是3A4可变结构域的人源化抗体Lh1Hh4(即,人源化轻链1和人源化重链4)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh1指定变体1的人源化轻链,而Hh4指定变体4的重链。
图9e是3A4可变结构域的人源化抗体Lh2Hh1(即,人源化轻链2和人源化重链1)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh2指定变体2的人源化轻链,而Hh1指定变体1的重链。
图9f是3A4可变结构域的人源化抗体Lh2Hh2(即,人源化轻链2和人源化重链2)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh2指定变体2的人源化轻链,而Hh2指定变体2的重链。
图9g是3A4可变结构域的人源化抗体Lh2Hh3(即,人源化轻链2和人源化重链3)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh2指定变体2的人源化轻链,而Hh3指定变体3的重链。
图9h是3A4可变结构域的人源化抗体Lh2Hh4(即,人源化轻链2和人源化重链4)的分子模型。CDR环着黑色,并且在轻链中用L1、L2和L3标记,而在重链中用H1、H2和H3标记。框架区显示为灰色。从鼠框架突变为人框架的残基的侧链描绘为球-和-棍图示。Lh2指定变体2的人源化轻链,而Hh4指定变体4的重链。
图10a是鼠和人源化轻链的3A4可变结构域的氨基酸序列比对。轻链具有两种人源化变体(Lh1和Lh2)。CDR显示为粗体,并且由CDRL1、CDRL2和CDRL3指示。在人源化序列中,是鼠氨基酸的、在人框架区内的回复突变加有下划线。
图10b是鼠和人源化重链的3A4可变结构域的氨基酸序列比对。重链具有四种人源化变体(Hh1至Hh4)。CDR显示为粗体,并且由CDRH1、CDRH2和CDRH3指示。在人源化序列中,是鼠氨基酸的、在人框架区内的回复突变加有下划线。
图11A是使用ClustalW2程序(拉金(Larkin M.A.),等人,(2007)ClustalW和ClustalX版本2.《生物信息学》(Bioinformatics)2007 23(21):2947-2948)的鼠3A4轻链可变区(SEQ ID NO.:4)与轻链可变区变体(SEQ ID NO.:33)的比对,其中“*”(星号)指示具有单个完全保守的残基的位置,其中“:”(冒号)指示在具有强相似特性的组之间的保守性(强相似特性即在Gonnet PAM 250矩阵中的得分>0.5),并且其中“。”(句点)指示在具有弱相似特性的组之间的保守性(弱相似特性即在Gonnet PAM250矩阵中的得分=<0.5)。
图11B是使用ClustalW2程序(拉金(Larkin M.A.),等人,(2007)ClustalW和ClustalX版本2.《生物信息学》(Bioinformatics)2007 23(21):2947-2948)的鼠3A4重链可变区(SEQ ID NO.:2)与轻链可变区变体(SEQ ID NO.:38)的比对,其中“*”(星号)指示具有单个完全保守的残基的位置,其中“:”(冒号)指示在具有强相似特性的组之间的保守性(强相似特性即在Gonnet PAM 250矩阵中的得分>0.5),并且其中“。”(句点)指示在具有弱相似特性的组之间的保守性(弱相似特性即在Gonnet PAM250矩阵中的得分=<0.5)。
图12a表示pKCR5-3A4-HC-变体1的质粒图谱。人源化3A4变体的重链以相同方式被克隆到pK-CR5的HindIII位点中。因此,所得质粒与pKCR5-3A4-HC变体1相同,除了重链免疫球蛋白可变结构域的序列之外。
图12b表示pMPG-CR5-3A4-LC-变体1的质粒图谱。3A4抗体的人源化变体1和2的轻链以相同方式被克隆到pMPG-CR5的BamHI位点中。因此,所得质粒与pMPG-CR5-3A4-LC-变体1相同,除了轻链免疫球蛋白可变结构域的序列之外。
图13表示在瞬时转染到CHO细胞之后抗体产生的分析。通过蛋白质印迹法来分析用人源化3A4抗体的轻链和重链的不同组合转染的CHOcTA细胞的上清液(转染后13天)。在上清液中产生的抗体的定量是在针对已知标准品(纯化的人类IgG抗体)的稀释物的蛋白质印迹的带扫描之后确定的。Mr分子量标记(kDa)。
图14是重组KAAG1样品的Superdex G75凝胶过滤的曲线图。将KAAG1注入经过凝胶过滤,并且以0.4ml/min进行分离。最大的峰在15-19部分之间。
图15是列出了鼠3A4抗体和3A4抗体的人源化变体的速率常数和亲和常数的表格。
图16A是展示了人源化抗体的缔合速率(Ka)的直方图。
图16B是展示了人源化抗体的解离速率(Kd)的直方图。
图16C是展示了人源化抗体的亲和常数(KD)的直方图。
图17a展示了在ELISA中结合至KAAG1上的人源化3A4变体。这个图显示了3A4人源化抗体变体和鼠3A4的对比结合。与Lh1轻链变体组装的人源化重链(Hh1、Hh2、Hh3和Hh4)的浓度依赖性结合曲线。
图17b展示了在ELISA中结合至KAAG1上的人源化3A4变体。这个图显示了3A4人源化抗体变体和鼠3A4的对比结合。与Lh2轻链变体组装的人源化重链(Hh1、Hh2、Hh3和Hh4)的浓度依赖性结合曲线。
图18展示了结合至癌细胞表面上的KAAG1的人源化3A4变体。这个图解显示了人源化和鼠3A4抗体在未透性化的SKOV-3卵巢癌细胞上的对比结合活性。
发明详细说明
KAAG1在癌细胞中的表达和生物活性
本发明涉及抗体的用途,这些抗体靶向在不同癌类型(特别是卵巢癌)中发现的肿瘤。为了将抗体导向肿瘤,在癌细胞细胞表面表达的肿瘤特异性抗原的鉴定是必须进行的。有若干可供使用以鉴定肿瘤特异性抗原的技术,并且用于鉴定在卵巢肿瘤中的KAAG1的方法(即称为mRNA的基于转录的消减扩增(STAR)的创新发现平台)描述于公开的专利申请号PCT/CA2007/001134中,该申请号在2007年12月27日在WO/2007/147265号之下公开。
卵巢癌STAR文库的分析产生了许多编码分泌的和细胞表面的蛋白质的基因。这些中的之一,称为AB-0447,含有一个开放阅读框,该开放阅读框编码一种相应于SEQ ID NO.:29的84个氨基酸的多肽,SEQ ID NO.:29由一种885个碱基对的cDNA编码,该cDNA具有在SEQ ID NO.:28中显示的核苷酸序列。公开可用的数据库的研究揭示了AB-0447核苷酸序列与称为KAAG1的基因的核苷酸序列一致。生物信息学分析预测了将其功能结构域呈递至细胞外室的膜锚定蛋白。KAAG1是最初从肾癌文库作为细胞表面抗原而被克隆的,这是证实它的膜定位的一个结果。另外,我们的研究显示该蛋白质是在其氨基端被加工,这个结果与功能性信号肽在氨基酸30和34上或它们之间的裂解一致。此外,全长cDNA的瞬时表达导致在培养基中裂解的KAAG1的检测。这个最终发现指示这种膜锚定蛋白可以在以高水平表达时从细胞脱落。相比之下,KAAG1的氨基截短突变体的表达导致该蛋白质的细胞内保留。当前没有任何阐明它的功能的公开报道,并且如由本发明披露的卵巢癌中KAAG1的过度表达在以前从未有文件记录过。
因此我们已经研究了KAAG1是否可以用于基于抗体的诊断和治疗。
已经建立了若干基于卵巢癌细胞的模型,例如TOV-21G、TOV-112D、OV-90以及其他,并且这些模型对于本领域的技术人员来说是熟悉的。这些细胞是人卵巢癌细胞系的集合的一部分,这些人卵巢癌细胞系衍生自具有卵巢肿瘤或腹水液的患者。这些细胞系已经经历深入分析,包括在微阵列上的全基因表达谱,这些微阵列使这些细胞系成为优异的用于人卵巢癌的基于细胞的模型。生长特性、基因表达谱以及对化学治疗药的反应指示这些细胞系对于卵巢肿瘤体内行为是非常具有代表性的(贝诺特等人,2007)。从这些卵巢癌细胞系分离的总RNA的RT-PCR分析显示KAAG1转录物弱表达于从原发性肿瘤衍生的细胞系中。相比之下,源于腹水液的细胞系包含高水平的KAAG1表达。在来自腹水液的细胞中KAAG1的增加的表达表明细胞的环境影响KAAG1基因的调节。腹水细胞与晚期疾病相关,并且这种表达模式意味着增加的KAAG1水平与锚定非依赖性生长(anchorage-independent growth)相关。与这个后者的表明一致,发现当将这些细胞在3D培养下培养为球状体细胞时,在从原发性肿瘤衍生的细胞系中KAAG1表达显著增加。这些球状体细胞已经被广泛表征,并且发现其展示出许多与体内肿瘤相关的特性(科迪(Cody)等人,2008)。因此,发现在模拟肿瘤进展(特别是在卵巢癌的演化过程中)的模型中KAAG1的表达显著增加。
随着在卵巢癌细胞中KAAG1表达被调节的证明,在基于细胞的测定中检验了这种基因在卵巢癌细胞行为中的功能。为此目的,使用RNA干扰(RNAi)来敲低卵巢癌细胞系中的内源性KAAG1基因的表达,并且发现KAAG1的降低的表达导致如在标准细胞运动性测定中所确定的细胞迁移的显著减少,如由伤口愈合(或擦伤)分析所举例说明的。这种类型的分析测量了细胞填充一个融合单层中的裸露区的速度。KAAG1的表达降低导致卵巢癌细胞系的存活的降低,如通过克隆生成测定(例如集落存活分析)所测量的。本领域的技术人员可以使用其他方法来评估KAAG1在癌细胞(特别是卵巢癌细胞)的行为中的需要。
基于在大比例的卵巢肿瘤中KAAG1的表达、它在正常组织中的有限表达、以及在表达水平和增加的恶性之间的一致性、以及KAAG1在卵巢癌细胞系的行为中的假定的生物作用,将KAAG1选择作为治疗靶标,以用于开发用于卵巢癌的检测、预防、和治疗的抗体。KAAG1在除了卵巢癌之外的癌症中的表达还引导申请人对用于其他癌症适应症的治疗性或诊断性抗体进行评估。
因此本发明提供了抗-KAAG1抗体和其抗原结合片段,它们特异性地靶向KAAG1并且可以例如用作抗体-药物结合物。
这样的抗体和抗原结合片段包括例如单克隆抗体、多克隆抗体、嵌合抗体、人源化抗体、抗体片段、单链抗体、域抗体、以及具有抗原结合区的多肽。
结合至KAAG1上的抗体和抗原结合片段
最初将抗体针对它们对感兴趣抗原的特异性而从Fab文库分离。
在此所述的抗体或抗原结合片段的可变区可以与所希望的物种的恒定区融合,由此允许抗体由所希望的物种的效应细胞识别。恒定区可以例如源于IgG1、IgG2、IgG3、或IgG4亚型。克隆或合成框内恒定区与可变区在本领域的技术人员的范围之内,并且可以例如通过重组DNA技术来进行。因此,包含人抗体恒定区的抗体以及包含人抗体框架氨基酸的抗体或抗原结合片段也被本发明包括。
本发明因此提供了示例性实施例,包含一个轻链可变区的一种分离的抗体或抗原结合片段,该轻链可变区具有;
a.一个CDRL1序列,该CDRL1序列包含SEQ ID NO.:8或如在SEQID NO.:8中所列出的;
b.一个CDRL2序列,该CDRL2序列包含SEQ ID NO.:9或如在SEQID NO.:9中所列出的,或;
c.一个CDRL3序列,该CDRL3序列包含SEQ ID NO.:10或如在SEQID NO.:10中所列出的。
分离的抗体或抗原结合片段还可以包含一个重链可变区,该重链可变区具有;
a.一个CDRH1序列,该CDRH1序列包含SEQ ID NO.:5或如在SEQID NO.:5中所列出的;
b.一个CDRH2序列,该CDRH2序列包含SEQ ID NO.:6或如在SEQID NO.:6中所列出的,或;
c.一个CDRH3序列,该CDRH3序列包含SEQ ID NO.:7或如在SEQID NO.:7中所列出的。
在一个示例性实施例中,抗体或抗原结合片段可以包含轻链可变区的任何单独的CDR或者CDR1、CDR2和/或CDR3的组合。可以更具体地选择CDR3。组合可以包括例如CDRL1和CDRL3,CDRL1和CDRL2,CDRL2和CDRL3以及,CDRL1、CDRL2和CDRL3。
在另一个示例性实施例中,抗体或抗原结合片段可以包含重链可变区的任何单独的CDR或者CDR1、CDR2和/或CDR3的组合。可以更具体地选择CDR3。组合可以包括例如CDRH1和CDRH3,CDRH1和CDRH2,CDRH2和CDRH3以及,CDRH1、CDRH2和CDRH3。
根据本发明,抗体或抗原结合片段可以包含CDRL1、CDRL2或CDRL3中的至少两个CDR。
同样,根据本发明,抗体或抗原结合片段可以包含一个CDRL1、一个CDRL2和一个CDRL3。
进一步根据本发明,抗体或抗原结合片段可以包含:
a.CDRL1、CDRL2或CDRL3中的至少两个CDR以及;
b.一个CDRH1、一个CDRH2或一个CDRH3中的至少两个CDR。
抗体或抗原结合片段可以更优选地包含一个CDRL1、一个CDRL2和一个CDRL3。
抗体或抗原结合片段也可以更优选地包含一个CDRH1、一个CDRH2和一个CDRH3。
根据本发明,抗体或抗原结合片段可以包含一个CDRH1、一个CDRH2或一个CDRH3。
根据本发明,抗体或抗原结合片段也可以包含一个CDRH1、一个CDRH2和一个CDRH3。
当轻链可变区或重链可变区仅有一者可获得时,可以使用在本领域中已知的方法通过筛选互补可变区文库而重建抗体或抗原结合片段(波尔托拉诺(Portolano)等人《免疫学杂志》(The Journal of Immunology)(1993)150:880-887,克拉克森(Clarkson)等人,《自然》(Nature)(1991)352:624-628)。
本发明还包括含有在此处所述的CDR的至少一者中具有至少一个保守性氨基酸置换(与原始CDR相比较)的可变链的多肽或抗体。
本发明还包括含有在至少两个CDR中具有至少一个保守性氨基酸置换(与原始CDR相比较)的可变链的多肽或抗体。
本发明还包括含有在3个CDR中具有至少一个保守性氨基酸置换(与原始CDR相比较)的可变链的多肽或抗体。
本发明还包括含有在至少一个CDR中具有至少两个保守性氨基酸置换(与原始CDR相比较)的可变链的多肽或抗体。
本发明还包括含有在至少两个CDR中具有至少两个保守性氨基酸置换(与原始CDR相比较)的可变链的多肽或抗体。
本发明还包括含有在3个CDR中具有至少两个保守性氨基酸置换(与原始CDR相比较)的可变链的多肽或抗体。
在另一个方面,本发明涉及一种多肽、抗体或抗原结合片段,它们包含(在单一多肽链上或在多个分开的多肽链上)在此所述的抗体或抗原结合片段之一的轻链可变区的至少一个互补决定区以及重链可变区的至少一个互补决定区。
本发明在其另一个方面涉及抗-KAAG1抗体,这些抗-KAAG1抗体可以包含(在单一多肽链上或在多个分开的多肽链上)在此所述的抗体或抗原结合片段的所有六个互补决定区(CDR)。
变体抗体和抗原结合片段
本发明还包括在此所述的抗体或抗原结合片段的变体。所包括的变体抗体或抗原结合片段是具有在氨基酸序列中的变异的那些。例如,所包括的变体抗体或抗原结合片段是具有至少一个变体CDR(两个、三个、四个、五个或六个变体CDR或甚至12个变体CDR)、一个变体轻链可变区、一个变体重链可变区、一个变体轻链和/或一个变体重链的那些。包括在本发明中的变体抗体或抗原结合片段是具有例如与原始抗体或抗原结合片段相比较相似的或改进的结合亲和力的那些。
如在此使用的术语“变体”适用于在此所述的任何序列,并且包括例如变体CDR(CDRL1、CDRL2、CDRL3、CDRH1、CDRH2和/或CDRH3)、变体轻链可变区、变体重链可变区、变体轻链、变体重链、变体抗体、变体抗原片段以及KAAG1变体。
被本发明包括的变体抗体或抗原结合片段是可以包含插入、缺失或氨基酸置换(保守性或非保守性)的那些。这些变体在其氨基酸序列中的至少一个氨基酸残基可以被去除并且在其位置中插入一个不同的残基。
本发明的抗体或抗原结合片段可以具有如上所述的轻链可变区和/或重链可变区,并且可以进一步包含恒定区的氨基酸,例如人抗体恒定区的氨基酸。
在一个示例性实施例中,本发明的抗体或抗原结合片段可以包含例如人IgG1恒定区。
根据本发明的另一个示例性实施例,抗原结合片段可以是例如scFv、Fab、Fab'或(Fab')2。
用于置换诱变的感兴趣位点包括高变区(CDR),但是还考虑了在框架区中或甚至在恒定区中的修饰。可以通过将来自以下列出的组(1至6组)中之一的(CDR、可变链、抗体等的)氨基酸用相同组的另一个氨基酸交换而产生保守性置换。
保守性置换的其他示例性实施例示于表格1A中“优选的置换”标题之下。如果这样的置换导致所不希望的特性,则可以将在表1A中命名为“示例性置换”的、或如在下文进一步参考氨基酸类别所述的更多实质性改变引入,并且筛选产物。
本领域中已知的是变体可以通过置换诱变而产生,并且保留本发明的多肽的生物活性。这些变体在其氨基酸序列中的至少一个氨基酸残基被去除并且在其位置中插入一个不同的残基。例如,用于置换诱变的感兴趣的一个位点可以包括这样一个位点:在该位点中从不同物种获得的特定残基是相同的。被鉴定为“保守性置换”的置换的实例示于表1A中。如果这样的置换导致所不希望的改变,则可以将在表1A中命名为“示例性置换”的、或如在下文进一步参考氨基酸类别所述的其他类型的置换引入,并且筛选产物。
通过选择置换而完成在功能或免疫身份方面的实质性修饰,这些置换在它们对维持以下项的作用方面显著不同:(a)在置换区域中的多肽主链的结构,例如,如片层或螺旋构象。(b)分子在靶位点处的电荷或疏水性,或(c)侧链的体积。基于共同的侧链特性将天然存在的残基分组:
(1组)疏水性的:正亮氨酸、甲硫氨酸(Met)、丙氨酸(Ala)、缬氨酸(Val)、亮氨酸(Leu)、异亮氨酸(Ile)
(2组)中性亲水性的:半胱氨酸(Cys)、丝氨酸(Ser)、苏氨酸(Thr)
(3组)酸性的:天冬氨酸(Asp)、谷氨酸(Glu)
(4组)碱性的:天冬酰胺(Asn)、谷氨酰胺(Gln)、组氨酸(His)、赖氨酸(Lys)、精氨酸(Arg)
(5组)影响链取向的残基:甘氨酸(Gly)、脯氨酸(Pro);以及
(6组)芳香族的:色氨酸(Trp)、酪氨酸(Tyr)、苯丙氨酸(Phe)
非保守性置换将需要将这些类别之一的一个成员用另一个交换。
表1A.氨基酸置换
与原始抗体或抗原结合片段氨基酸序列相比,变体抗体或抗原结合片段可以在其氨基酸序列中具有实质上的序列相似性和/或序列一致性。在两种序列之间的相似性的程度是基于一致性(一致的氨基酸)和保守性置换的百分比。
通常,使用Blast 2序列程序(塔蒂阿娜A.达图索瓦(Tatiana A.Tatusova),托马斯L.马登(Thomas L.Madden)(1999),“Blast 2序列–一种新的用于比较蛋白质和核苷酸序列的工具”("Blast 2sequences-a new tool for comparing protein and nucleotide sequences"),FEMS微生物学快报(FEMS Microbiol Lett.)174:247-250)在此已经确定在可变链之间的相似性和一致性的程度,在该程序中使用默认设置(即,blastp程序,BLOSUM62矩阵(开放空位11以及延伸空位罚分1;gapx减少50,期望(expect)10.0,字号3))以及活化的过滤器。
因此一致性百分比将指示与原始肽相比较一致的、并且可以占据相同或相似位置的氨基酸。
相似性百分比将指示与在相同或相似位置处的原始肽相比较一致的氨基酸以及被保守性氨基酸置换替换的那些氨基酸。
因此,本发明的变体包含可以具有与原始序列或原始序列的一部分至少70%、75%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列一致性的那些变体。
变体的示例性实施例是具有与在此所述序列的至少81%的序列一致性并且具有与原始序列或原始序列的一部分81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列相似性的那些变体。
变体的其他示例性实施例是具有与在此所述序列的至少82%的序列一致性并且具有与原始序列或原始序列的一部分82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列相似性的那些变体。
变体的进一步的示例性实施例是具有与在此所述序列的至少85%的序列一致性并且具有与原始序列或原始序列的一部分85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列相似性的那些变体。
变体的其他示例性实施例是具有与在此所述序列的至少90%的序列一致性并且具有与原始序列或原始序列的一部分90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列相似性的那些变体。
变体的另外的示例性实施例是具有与在此所述序列的至少95%的序列一致性并且具有与原始序列或原始序列的一部分95%、96%、97%、98%、99%或100%的序列相似性的那些变体。
变体的又另外的示例性实施例是具有与在此所述序列的至少97%的序列一致性并且具有与原始序列或原始序列的一部分97%、98%、99%或100%的序列相似性的那些变体。
出于简明的目的,申请人在此提供了表1B,表1B展示了被本发明包括的并且包含指定的序列一致性%和序列相似性%的单独变体的示例性实施例。每个“X”应理解为定义一种给定的变体。
本发明包括含有与在此所述的序列至少80%的一致性的CDR、轻链可变区、重链可变区、轻链、重链、抗体和/或抗原结合片段。
本发明的抗体或抗原结合片段的示例性实施例是包含这样一种轻链可变区的那些:该轻链可变区包含与SEQ ID NO.:4至少70%、75%、80%一致的序列。
这些轻链可变区可以包含与SEQ ID NO.:8至少80%一致的CDRL1序列、与SEQ ID NO.:9至少80%一致的CDRL2序列以及与SEQ ID NO.:10至少80%一致的CDRL3序列。
在本发明的一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:8至少90%一致的CDRL1序列。
在本发明的另一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:8 100%一致的CDRL1序列。
在本发明的另一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:9至少90%一致的CDRL2序列。
在本发明的又另一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:9 100%一致的CDRL2序列。
在本发明的另一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:10至少90%一致的CDRL3序列。
在本发明的另外的示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:10 100%一致的CDRL3序列。
在一个示例性实施例中,抗体或抗原结合片段可以包含这样一种重链可变区:该重链可变区包含与SEQ ID NO.:2至少70%、75%、80%一致的序列。
这些重链可变区可以包含与SEQ ID NO.:5至少80%一致的CDRH1序列、与SEQ ID NO.:6至少80%一致的CDRH2序列以及与SEQ ID NO.:7至少80%一致的CDRH3序列。
在本发明的一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:5至少90%一致的CDRH1序列。
在本发明的另一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:5 100%一致的CDRH1序列。
在本发明的又另一个示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:6至少90%一致的CDRH2序列。
在本发明的一个另外的示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:6 100%一致的CDRH2序列。
在本发明的又另外的示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:7至少90%一致的CDRH3序列。
在本发明的另外的示例性实施例中,在此提供的任何抗体可以包含与SEQ ID NO.:7 100%一致的CDRH3序列。
在一些情况下,变体抗体重链可变区可以包含氨基酸缺失或添加(与或不与氨基酸置换组合)。常常可以容许1、2、3、4或5个氨基酸缺失或添加。
变体抗体或抗原结合片段的示例性实施例包括具有如在SEQ ID NO.:30中所列出的轻链可变区的那些:
SEQ ID NO.:30
DXVMTQTPLSLXVXXGXXASISCRSSQSLLHSNGNTYLEWYLQKPGQSPXLLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDXGVYYCFQGSHVPLTFGXGTXLEXK,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:4中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。氨基酸置换可以是例如在天然人抗体或人抗体共有序列的相应位置处发现的氨基酸。氨基酸置换可以是例如保守性的。
变体抗体或抗原结合片段的另一个示例性实施例包括具有如在SEQ ID NO.:31中所列出的轻链可变区的那些:
SEQ ID NO.:31
DXa1VMTQTPLSLXa2VXa3Xa4GXa5Xa6ASISCRSSQSLLHSNGNTYLEWYLQKPGQSPXa7LLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDXa8GVYYCFQGSHVPLTFGXa9GTXa10LEXa11K,
其中Xa1可以是疏水性氨基酸;
其中Xa2可以是A或P;
其中Xa3可以是中性亲水性氨基酸;
其中Xa4可以是L或P;
其中Xa5可以是酸性氨基酸;
其中Xa6可以是Q或P;
其中Xa7可以是碱性氨基酸;
其中Xa8可以是疏水性氨基酸;
其中Xa9可以是A或Q;
其中Xa10可以是碱性氨基酸;或
其中Xa11可以是疏水性氨基酸,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:4中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
变体抗体或抗原结合片段的另外的示例性实施例包括具有如在SEQ ID NO.:32中所列出的轻链可变区的那些:
SEQ ID NO.:32
DXA1VMTQTPLSLXAzVXA3XA4GXA5XA6ASISCRSSQSLLHSNGNTYLEWYLQKPGQSPXA7LLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDXA8GVYYCFQGSHVPLTFGXA9GTXA10LEXA11K
其中XA1可以是V或I
其中XA2可以是A或P
其中XA3可以是S或T
其中XA4可以是L或P
其中XA5可以是D或E
其中XA6可以是Q或P
其中XA7可以是K或Q
其中XA8可以是L或V
其中XA9可以是A或Q
其中XA10可以是R或K或
其中XA11可以是L或I,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:4中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
根据实施例,轻链可变结构域变体可以具有如在SEQ ID NO.:33或34中所列出的序列:
SEQ ID NO.:33
DIVMTQTPLSLPVTPGEPASISCRSSQSLLHSNGNTYLEWYLQKPGQSPQLLIYTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPLTFGQGTKLEIK。
SEQ ID NO.:34
DVVMTQTPLSLPVTPGEPASISCRSSQSLLHSNGNTYLEWYLQKPGQSPKLLIYTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPLTFGQGTKLEIK。
变体抗体或抗原结合片段的示例性实施例包括具有如在SEQ ID NO.:35中所列出的重链可变区的那些。
SEQ ID NO.:35
QXQLVQSGXEXXKPGASVKXSCKASGYTFTDDYMSWVXQXXGXXLEWXGDINPYNGDTNYNQKFKGXXXXTXDXSXSTAYMXLXSLXSEDXAVYYCARDPGAMDYWGQGTXVTVSS,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:2中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。氨基酸置换可以是例如在天然人抗体或人抗体共有序列的相应位置处发现的氨基酸。氨基酸置换可以是例如保守性的。
变体抗体或抗原结合片段的另一个示例性实施例包括具有如在SEQ ID NO.:36中所列出的重链可变区的那些:
SEQ ID NO.:36
QXb1QLVQSGXb2EXb3Xb4KPGASVKXb5SCKASGYTFTDDYMSWVXb6QXb7Xb8GXb9Xb10LEWXb11GDINPYNGDTNYNQKFKGXb12Xb13Xb14Xb15TXb16DXb17SXb18STAYMXb19LXb20SLXb21SEDXb22AVYYCARDPGAMDYWGQGTXb23VTVSS,
其中Xb1可以是疏水性氨基酸;
其中Xb2可以是P或A;
其中Xb3可以是疏水性氨基酸;
其中Xb4可以是V或K;
其中Xb5可以是疏水性氨基酸;
其中Xb6可以是碱性氨基酸;
其中Xb7可以是S或A;
其中Xb8可以是H或P;
其中Xb9可以是碱性氨基酸;
其中Xb10可以是S或G;
其中Xb11可以是疏水性氨基酸;
其中Xb12可以是碱性氨基酸;
其中Xb13可以是疏水性氨基酸;
其中Xb14可以是I或T;
其中Xb15可以是疏水性氨基酸;
其中Xb16可以是疏水性氨基酸;
其中Xb17可以是K或T;
其中Xb18可以是中性亲水性氨基酸;
其中Xb19可以是Q或E;
其中Xb20可以是N或S;
其中Xb21可以是T或R;
其中Xb22可以是中性亲水性氨基酸;或
其中Xb23可以是S或L,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:2中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
变体抗体或抗原结合片段的另外的示例性实施例包括具有如在SEQ ID NO.:37中所列出的重链可变区的那些:
SEQ ID NO.:37
QXB1QLVQSGXB2EXB3XB4KPGASVKXB5SCKASGYTFTDDYMSWVXB6QXB7XB8GXB9XB10LEWXB11GDINPYNGDTNYNQKFKGXB12XB13XB14XB15TXB16DXB17SXB18STAYMXB19LXB20SLXB21SEDXB22AVYYCARDPGAMDYWGQGTXB23VTVSS
其中XB1可以是I或V;
其中XB2可以是P或A;
其中XB3可以是M或V;
其中XB4可以是V或K;
其中XB5可以是M或V;
其中XB6可以是K或R;
其中XB7可以是S或A;
其中XB8可以是H或P;
其中XB9可以是K或Q;
其中XB10可以是S或G;
其中XB11可以是I或M;
其中XB12可以是K或R;
其中XB13可以是A或V;
其中XB14可以是I或T;
其中XB15可以是L或I,
其中XB16可以是V或A;
其中XB17可以是K或T;
其中XB18可以是S或T;
其中XB19可以是Q或E;
其中XB20可以是N或S;
其中XB21可以是T或R;
其中XB22可以是S或T;或
其中XB23是S或L,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:2中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
根据实施例,重链可变结构域变体可以具有如在SEQ ID NO.38至41中任一个所列出的序列:
SEQ ID NO.:38
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWMGDINPYNGDTNYNQKFKGRVTITADTSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS。
SEQ ID NO.:39
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWMGDINPYNGDTNYNQKFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS。
SEQ ID NO.:40
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWIGDINPYNGDTNYNQKFKGRATLTVDKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS。
SEQ ID NO.:41
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVKQAPGQGLEWIGDINPYNGDTNYNQKFKGKATLTVDKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS。
抗体在细胞中的产生
可以通过对于本领域的技术人员熟悉的多种方法制造在此披露的抗-KAAG1抗体,例如,杂交瘤方法或通过重组DNA方法。
在本发明的一个示例性实施例中,可以通过常规的杂交瘤技术产生抗-KAAG1抗体(例如,可以与一并披露的抗体竞争的抗体),其中将小鼠用抗原免疫,将脾细胞分离,并且将其与缺乏HGPRT表达的骨髓瘤细胞融合,并且通过含有次黄嘌呤、氨基喋呤和胸腺嘧啶(HAT)的培养基来选择杂交细胞。
在本发明的另外的示例性实施例中,可以通过重组DNA方法产生抗-KAAG1抗体。
为了表达抗-KAAG1抗体,可以将能够编码在此所述的轻和重免疫球蛋白链的任何一者或任何其他核苷酸序列插入表达载体(即,含有用于在特定宿主中的插入编码序列的转录和翻译控制的元件的载体)中。这些元件可以包含调节序列,例如增强子、组成型和诱导型启动子、以及5′和3′非翻译区。可以使用本领域的技术人员熟知的方法来构建这样的表达载体。这些方法包括体外重组DNA技术、合成技术、以及体内基因重组。
可以利用本领域的技术人员已知的多种表达载体/宿主细胞系统来表达从能够编码在此所述的轻和重免疫球蛋白链中的任何一者的核苷酸序列衍生的多肽或RNA。这些包括但不限于微生物,例如用重组噬菌体、质粒、或粘粒DNA表达载体转化的细菌;用酵母表达载体转化的酵母;用杆状病毒载体感染的昆虫细胞系统;用病毒或细菌表达载体转化的植物细胞系统;或动物细胞系统。为了重组蛋白在哺乳动物系统中的长期产生,在细胞系中稳定的表达可能受到影响。例如,可以使用表达载体(该表达载体可以含有病毒复制起点和/或内源性表达元件、以及在相同或分开的载体上的可选择或可见的标记基因)将能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列转化到细胞系中。本发明并不限制于所采用的载体或宿主细胞。在本发明的某些实施例中,可以将能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列各自连接至分开的表达载体中,并且将每个链单独地表达。在另一个实施例中,可以将能够编码在此所述的轻和重免疫球蛋白链的任何一者的轻和重链两者连接至单一表达载体中,并且将它们同时表达。
可替代地,可以分别使用体外转录系统或偶联的体外转录/翻译系统从一种载体表达RNA和/或多肽,该载体包含能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列。
一般而言,可以通过本领域的技术人员已知的多种程序来鉴定包含能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列的和/或表达由能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列所编码的多肽或其一部分的宿主细胞。这些程序包括但不限于:DNA/DNA或DNA/RNA杂交、PCR扩增、和蛋白质生物测定或免疫测定技术(包括用于核酸或氨基酸序列的检测和/或定量的基于膜、溶液、或芯片的技术)。使用特异性多克隆或多克隆抗体用于行检测和测量多肽的表达的免疫方法在本领域中是已知的。此类技术的实例包括酶联免疫吸附测定(ELISA)、放射免疫测定(RIA)、以及荧光激活细胞分选(FACS)。本领域的技术人员可以容易地使这些方法适应于本发明。
因此,可以将包含能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列的宿主细胞在用于转录相应RNA(mRNA,等等)和/或从细胞培养物表达多肽的条件下进行培养。取决于所使用的序列和/或载体,由细胞产生的多肽可以分泌或可以保留在细胞内。在一个示例性实施例中,可以将包含能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列的表达载体设计为包含信号序列,这些信号序列指导多肽穿过原核或真核细胞膜的分泌。
由于遗传码的固有的简并性,可以产生并使用编码相同的、基本上相同的或功能相当的氨基酸序列的其他DNA序列,例如,以便表达由能够编码在此所述的轻和重免疫球蛋白链的任何一者的核苷酸序列所编码的多肽。可以使用本领域中通常已知的方法将本发明的核苷酸序列工程化,以便出于多种目的而改变核苷酸序列,这些目的包括但不限于基因产物的克隆、加工、和/或表达的修饰。可以使用通过随机断裂以及基因片段和合成寡核苷酸的再组装PCR的DNA改组而将核苷酸序列工程化。例如,寡核苷酸介导的定点诱变可以用于引入创造新的限制酶切位点的突变、改变糖基化模式、改变密码子偏爱性、产生剪接变体,等等。
另外,可以针对其调节插入序列的表达或以所希望的方式加工所表达的多肽的能力而选择宿主细胞株。这样的多肽修饰包括但不限于乙酰化、羧基化、糖基化、磷酸化、脂化、以及酰化。在一个示例性实施例中,包含特定糖基化结构或模式的抗-KAAG1抗体可以是所希望的。切割多肽的“前体原”(“prepro”)形式的翻译后加工还可以用于指定蛋白质靶向、折叠、和/或活性。具有用于翻译后活性的细胞机器和特征性机理的不同宿主细胞(例如,CHO、海拉细胞(Hela)、MDCK、HEK293、和W138)是可商购的,并且来自美国典型培养物保藏中心(ATCC),并且可以被选择为确保所表达多肽的正确修饰和加工。
本领域的技术人员将易于理解的是,可以将天然的、修饰的、或重组的核酸序列连接至异源序列,导致含有在以上提及的任何宿主系统中的异源多肽部分的融合多肽的翻译。这样的异源多肽部分可以通过使用可商购的亲和基质而促进融合多肽的纯化。这样的部分包括但不限于谷胱甘肽S转移酶(GST)、麦芽糖结合蛋白、硫氧还蛋白、钙调蛋白结合肽、6-His(His)、FLAG、c-myc、血球凝集素(HA)、以及抗体表位(例如单克隆抗体表位)。
在又另外的方面,本发明涉及可以包含编码融合蛋白的核苷酸序列的多核苷酸。融合蛋白可以包含融合配偶体(例如,HA、Fc,等等),该融合配偶体与在此所述的多肽(例如,完整轻链、完整重链、可变区、CDR,等等)融合。
本领域的技术人员还将容易地认识到,可以使用本领域中熟知的化学或酶学方法而全部或部分地合成核酸和多肽序列。例如,可以使用不同的固相技术进行肽合成,并且可以将机器(例如ABI 431A肽合成仪(PE Biosystems))用于自动合成。如果希望的话,可以在合成期间改变氨基酸序列和/或将氨基酸序列与来自其他蛋白质的序列结合,从而产生变体蛋白质。
抗体结合物
本发明的抗体或抗原结合片段可以与可检测部分(即,用于检测或诊断目的)结合或与治疗部分(用于治疗目的)结合。
“可检测部分”是通过光谱的、光化学的、生物化学的、免疫化学的、化学的和/或其他物理学手段可检测的部分。可以使用本领域中熟知的方法,将可检测部分直接地和/或间接地(例如经由一个连接,如但不限于DOTA或NHS连接)连接至本发明的抗体和其抗原结合片段。可以使用多种多样的可检测部分,其中取决于所要求的灵敏度、结合的容易、稳定性要求和可供使用的仪器而选择。适合的可检测部分包括但不限于:荧光标记、放射性标记(例如而不限于125I、In111、Tc99、I131,并且包括用于PET扫描仪的正电子发射同位素等等)、核磁共振活性标记、发光标记、化学发光标记、生色团标记、酶标记(例如并且不限于辣根过氧化物酶、碱性磷酸酯酶,等等)、量子点和/或纳米颗粒。可检测部分可以引起和/或产生可检测信号,由此允许来自可检测部分的信号被检测到。
在本发明的另一个示例性实施例中,抗体或其抗原结合片段可以与治疗部分(例如,药物、细胞毒性部分、抗癌剂)连接(修饰)。
在一个示例性实施例中,抗-KAAG1抗体和抗原结合片段可以包含化疗剂、细胞毒性剂或抗癌药(例如,小分子)。这样的化疗剂或细胞毒性剂包括但不限于钇-90、钪-47、铼-186、碘-131、碘-125、以及许多由本领域的技术人员公认的其他药剂(例如,镥(如Lu177)、铋(例如Bi213)、铜(例如Cu67))。在其他情况下,除了本领域的技术人员已知的其他之外,化疗剂、细胞毒性剂或抗癌药还可以包括5-氟尿嘧啶、阿霉素、伊立替康、紫杉烷、假单胞杆菌内毒素、蓖麻毒蛋白、奥莉丝汀(auristatin)(例如,单甲基奥莉丝汀E、单甲基奥莉丝汀F)、美登醇(例如,美登素)以及其他毒素。
可替代地,为了进行本发明的方法,并且如在本领域中已知的,可以将本发明的抗体或抗原结合片段与一种第二分子(例如,第二抗体,等等)组合使用,该第二分子能够特异性地结合至本发明的抗体或抗原结合片段上并且可以携带一个所希望的可检测的、诊断性或治疗性的部分。
抗体的药物组合物和它们的用途
本发明还包括抗-KAAG1抗体或抗原结合片段(结合的或未结合的)的药物组合物。该药物组合物可以包含抗-KAAG1抗体或抗原结合片段,并且还可以包含药学上可接受的载体。
本发明的其他方面涉及一种组合物,该组合物可以包含在此所述的抗体或抗原结合片段以及一种载体。
本发明还涉及一种药物组合物,该药物组合物可以包含在此所述的抗体或抗原结合片段以及一种药学上可接受的载体。
除了活性成分之外,药物组合物还可以包含药学上可接受的载体(这些载体包括水、PBS、盐溶液、明胶、油、醇类、和其他赋形剂)以及促进将活性化合物加工为药学上可使用的制剂的助剂。在其他情况下,这样的制剂可以是灭菌的。
如在此使用的“药物组合物”表示治疗有效量的药剂连同药学上可接受的稀释剂、防腐剂、增溶剂、乳化剂、佐剂和/或载体。如在此使用的“治疗有效量”是指对于给定病症和给药方案而言提供治疗效果的量。这样的组合物是液体或冻干的或另外地是干燥的制剂,并且包含:具有不同的缓冲内容物(例如,Tris-HCl、乙酸盐、磷酸盐)、pH和离子强度的稀释剂,添加剂(例如白蛋白或明胶,以预防吸附至表面),洗涤剂(例如,吐温20、吐温80、普朗尼克F68、胆汁酸盐)。增溶剂(例如甘油、聚乙三醇)、抗氧化剂(例如,抗坏血酸、焦亚硫酸钠)、防腐剂(例如硫柳汞、苯甲醇、对羟基苯甲酸酯)、増量物质或张度调节剂(例如乳糖、甘露醇)、聚合物(例如聚乙二醇)与蛋白质的共价附接、与金属离子的络合、或材料的结合(该材料结合在聚合化合物,例如聚乳酸、聚乙醇酸、水溶胶等的微粒制剂中或微粒制剂上或结合在脂质体、微乳液、胶束、单层或多层囊泡、红细胞血影、或原生质球上)。这样的组合物将影响物理状态、溶解度、稳定性、体内释放速率以及体内清除速率。控制释放或持续释放组合物包括在亲脂性储库(例如,脂肪酸、蜡、油)中的制剂。还被本发明包括的是用聚合物(例如,泊洛沙姆或泊洛沙胺)包衣的微粒组合物。本发明的组合物的其他实施例结合微粒形式保护性包衣、蛋白酶抑制剂或渗透促进剂,以用于不同的给药途径,包括经肠胃外、肺、鼻、口、阴道、直肠的途径。在一个实施例中,药物组合物是经肠胃外、癌旁、经粘膜、透皮、肌内、静脉内、皮内、皮下、腹膜内、心室内、颅内、和瘤内给予的。
另外,如在此使用的“药学上可接受的载体”或“药用载体”在本领域中是已知的,并且包括但不限于0.01M-0.1M或0.05M磷酸盐缓冲液或0.8%盐水。另外,这样的药学上可接受的载体可以是水性的或非水性的溶液、悬浮液、和乳液。非水性溶剂的实例是丙二醇、聚乙二醇、植物油(例如橄榄油)、以及注射用有机酯(例如油酸乙酯)。水性载体包括水、醇/水性溶液、乳液或悬浮液,包括盐水和缓冲介质。肠胃外媒介物包括氯化钠溶液、林格氏葡萄糖、葡萄糖和氯化钠、乳酸化林格氏液或固定油。静脉内媒介物包括流体和营养补充剂、电解质补充剂,例如基于林格氏葡萄糖的那些,等等。还可以存在防腐剂和其他添加剂,例如,如抗微生物剂、抗氧化剂、整理剂(collating agent)、惰性气体,等等。
对于任何化合物,可以初步在细胞培养测定或动物模型(例如小鼠、大鼠、兔、狗、或猪)中估算治疗有效剂量。还可以使用动物模型来确定浓度范围和给药途径。这种信息可以进而用来确定对于在人类中给药有用的剂量和途径。这些技术对于本领域的技术人员是熟知的,并且治疗有效剂量是指改善症状或病症的活性成分的量。可以通过在细胞培养物中或用实验动物的标准药学程序确定治疗效力和毒性,例如通过计算和比较ED50(在50%的群体中治疗有效的剂量)和LD50(对50%的群体致死的剂量)统计量。可以将以上所述的任何治疗组合物应用至对这种治疗有需要的任何受试者,包括但不限于哺乳动物,例如狗、猫、牛、马、兔、猴子、和人。
可以通过任何数目的途径给予在此发明中利用的药物组合物,包括但不局限于:口服、静脉内、动脉内、髓内、鞘内、心室内、经皮、皮下、腹膜内、鼻内、肠内、局部、舌下、或直肠的方式。
用于本披露的目的的术语“治疗”是指治疗性治疗和预防性或防止性措施,其中目的是减慢(减轻)目标病理性病症或失调。对治疗有需要的那些包括已经患有失调的那些连同易于患有失调的那些或者其中失调有待预防的那些。具体而言,有需要的受试者包括具有升高水平的一种或多种癌症标记的受试者。
抗-KAAG1抗体和其抗原结合片段可以在不同癌症类型的治疗中具有治疗用途,例如卵巢癌、肾癌、结肠癌、肺癌、黑色素瘤,等等。在一个示例性实施例中,抗体和片段在卵巢癌中具有治疗用途。在一个更具体的实施例中,受试者可以具有例如复发的卵巢癌。在又另一个实施例中,受试者可以具有例如转移癌。
在某些例子中,抗-KAAG1抗体和片段可以阻断KAAG1与其蛋白质伴侣的相互作用。本发明的抗-KAAG1抗体可以特别地用来将治疗部分递送至表达KAAG1的细胞。
抗-KAAG1抗体和其抗原结合片段可以在不同类型的卵巢癌的治疗中具有治疗用途。若干不同的细胞类型可以产生不同的卵巢癌组织型。卵巢癌的最常见形式包括源于卵巢或输卵管的上皮细胞层的肿瘤。此类上皮性卵巢癌包括浆液性肿瘤、卵巢子宫内膜样瘤(endometroid tumor)、粘液性肿瘤、透明细胞瘤、以及交界性肿瘤。在其他实施例中,抗-KAAG1抗体和其抗原结合片段具有在其他类型的卵巢癌的治疗中的用途,例如种系和性索卵巢癌。
在某些情况下,可以同步地联合针对相同病症给予的其他治疗而给予抗-KAAG1抗体和其抗原结合片段。像这样,可以将抗体与抗有丝分裂物质(例如,紫杉烷)、基于铂的药剂(例如,顺铂)、DNA损伤剂(例如阿霉素)以及其他对于本领域的技术人员已知的抗癌疗法一起给予。在其他情况下,可以将抗-KAAG1抗体和其抗原结合片段与其他治疗性抗体一起给予。这些包括但不限于靶向EGFR、CD-20、和Her2的抗体。
本发明在其另外的方面中涉及一种用于抑制表达KAAG1细胞的生长的方法,该方法可以包括使这种细胞与有效量的在此所述的抗体或抗原结合片段接触。
本发明还包括在哺乳动物中治疗癌症或抑制表达KAAG1的细胞的生长的方法,该方法可以包括将例如与在此所述的治疗部分结合的抗体或抗原结合片段给予至有需要的受试者。
在另外的方面,本发明提供了使用本发明的抗体或抗原结合片段的治疗方法、诊断方法、和检测方法,以及这些抗体或抗原结合片段在用于这种目的的药物组合物或药物的制造中的用途。
因此,本发明涉及在此所述的分离的抗体或抗原结合片段在癌症的治疗中(在用于癌症的治疗的药物组合物的制造中)的用途。
抗体或抗原结合片段可以更特别地可应用于恶性肿瘤,包括例如具有转移能力的恶性肿瘤和/或由锚定非依赖性生长所表征的肿瘤细胞。
本发明的抗体或抗原结合片段还可以用于癌症的诊断中。可以通过将本发明的抗体或抗原结合片段给予至患有或疑似患有癌症的哺乳动物而体内进行癌症的诊断。还可以通过使从哺乳动物获得的样品与抗体或抗原结合片段接触、并且确定表达KAAG1或KAAG1变体的细胞(肿瘤细胞)的存在或不存在而离体进行诊断。
因此,本发明还包括在哺乳动物中检测癌症或检测表达KAAG1的细胞的方法,该方法可以包括将在此所述的抗体或抗原结合片段给予至有需要的受试者。
本发明在其另一方面涉及用于检测表达KAAG1或KAAG1变体的细胞的方法,该方法可以包括使这种细胞与在此所述的抗体或抗原结合片段接触,并且检测由抗体和表达KAAG1或KAAG1变体的细胞形成的复合物。在检测方法中使用的抗体或抗原结合片段的示例性实施例是能够结合至KAAG1的细胞外区的那些。
在检测方法中使用的抗体或抗原结合片段的其他示例性实施例是结合至在肿瘤细胞表面上表达的KAAG1或KAAG1变体的那些。
将会从在此所述的治疗、检测或诊断方法受益的有需要的受试者是那些患有或疑似患有癌症(例如,卵巢癌(例如,浆液性、子宫内膜样、透明细胞或粘液性的)、皮肤癌(例如,黑色素瘤、鳞状细胞癌)、肾癌(例如,乳头状细胞癌、透明细胞癌)、结肠直肠癌症(例如,结肠直肠癌)、肉瘤、白血病、脑肿瘤、甲状腺瘤、乳癌(例如,乳腺癌)、前列腺癌症(例如,前列腺癌)、食管肿瘤、膀胱肿瘤、肺肿瘤(例如,肺癌)或头颈部肿瘤,并且尤其是当癌症表征为恶性时和/或当表达KAAG1或KAAG1变体的细胞表征为锚定非依赖性生长时)的受试者。
可以通过成像、组织活检、基因检测来鉴定患有癌症的受试者。可替代地,可以使用标准测定(例如,ELISA等等)通过在他们体液中的癌症标记的存在而鉴定患有癌症的患者。
特别地被本发明包括的是患有或倾向于患有卵巢癌(例如,浆液性、子宫内膜样、透明细胞或粘液性的)、皮肤癌(例如黑色素瘤、鳞状细胞癌)或肾癌(例如,乳头状细胞癌)并且尤其是当癌症表征为是恶性的和/或当表达KAAG1或KAAG1变体的细胞表征为锚定非依赖性生长时的患者。
本发明的另一方面涉及用于检测KAAG1(SEQ ID NO.:29)、具有与SEQ ID NO.:29至少80%序列一致性的KAAG1变体、或者KAAG1或KAAG1变体的循环形式的分泌形式的方法,该方法可以包括使表达KAAG1或KAAG1变体的细胞或包含或疑似包含KAAG1或KAAG1变体的样品(活检、血清、血浆、尿液,等等)与在此所述的抗体或抗原结合片段接触,并且对结合进行测量。样品可以源于可能患有癌症(例如,卵巢癌、转移癌)或可能疑似患有癌症(例如,卵巢癌、转移癌)的哺乳动物(例如,人类)。样品可以是从哺乳动物或细胞培养上清获得的组织样品。
根据本发明,样品可以是从哺乳动物获得的血清样品、血浆样品、血液样品、精液或腹水液。在此所述的抗体或抗原结合片段可以有利地检测KAAG1的分泌或循环形式(在血液中循环)。
该方法可以包括将结合至KAAG1或KAAG1变体的抗体或抗原结合片段所形成的复合物进行定量。
抗体结合至抗原将引起预期的抗原的分子量的增加。因此,在抗体或抗原结合片段与抗原结合后发生物理变化。
可以使用例如电泳,随后为蛋白质印迹以及凝胶或印迹的着色,连接计算机的质谱、HPLC,FACS或其他方式来检测这样的变化。能够计算分子量的移位的装置在本领域中是已知的,并且包括例如PhosphorimagerTM。
当抗体包括例如可检测标记时,可以通过由标记发射的荧光、标记的辐射发射、与其底物一起提供的标记的酶活性或其他方式而检测抗原-抗体复合物。
可以通过本领域中已知的不同方法进行在抗体或抗原结合片段与抗原之间的结合的检测和/或测量。可以用能够检测由可检测标记(辐射发射、荧光、颜色变化等等)发射的信号的装置来监测在抗体或抗原结合片段与抗原之间的结合。这种装置提供了指示如所发生的结合的数据,并且还提供了关于结合至抗原的抗体的量的指示。装置(通常与计算机连接)可能还能够计算在背景信号(例如,在不存在抗原-抗体结合的情况下获得的信号)或背景噪声与在特异性的抗体-抗原结合后获得的信号之间的差。因此这样的装置可以给用户提供关于抗原是否已经被检测的指示和结论。
本发明的另外的方面涉及试剂盒,这些试剂盒可以包含一个或多个容器,这些容器包含在此所述的一种或多种抗体或抗原结合片段。
核酸、载体和细胞
抗体通常是在允许表达轻链和重链的细胞中产生的,该轻链和重链是从一种或多种载体表达的,该一种或多种载体包含编码轻链和/或重链的核酸序列。
因此本发明包括能够编码在此所述的CDR、轻链可变区、重链可变区、轻链、重链中任何一个的核酸。
因此本发明在另外的方面涉及编码能够特异性地结合至KAAG1的抗体的轻链可变区和/或重链可变区的核酸。
本发明的核酸的示例性实施例包括编码轻链可变区的核酸,该轻链可变区包含:
a.一个CDRL1,该CDRL1如在SEQID NO.:8中所列出的或包含SEQ ID NO.:8;
b.一个CDRL2,该CDRL2如在SEQID NO.:9中所列出的或包含SEQ ID NO.:9,或;
c.一个CDRL3序列,该CDRL3序列如在SEQID NO.:10中所列出的或包含SEQ ID NO.:10。
根据本发明,该核酸可以编码可以包含CDRL1、CDRL2或CDRL3中的至少两个CDR的轻链可变区。
同样,根据本发明,该核酸可以编码可以包含一个CDRL1、一个CDRL2和一个CDRL3的轻链可变区。
本发明还涉及编码重链可变区的核酸,该重链可变区包含:
a.一个CDRH1序列,该CDRH1如在SEQ ID NO.:5中所列出的或包含SEQ ID NO.:5;
b.一个CDRH2序列,该CDRH2序列如在SEQID NO.:6中所列出的或包含SEQ ID NO.:6,或;
c.一个CDRH3序列,该CDRH3序列如在SEQID NO.:7中所列出的或包含SEQ ID NO.:7。
根据本发明,该核酸可以编码可以包含CDRH1、CDRH2或CDRH3中的至少两个CDR的重链可变区。
根据本发明,该核酸可以编码可以包含一个CDRH1、一个CDRH2和一个CDRH3的重链可变区。
还被本发明包括的是编码具有至少一个保守性氨基酸置换的抗体变体的核酸。
根据本发明,该核酸可以编码包含至少一个保守性氨基酸置换的CDR。
根据本发明,该核酸可以编码包含在这些CDR的至少两个中的至少一个保守性氨基酸置换的CDR。
根据本发明,该核酸可以编码包含在3个CDR中的至少一个保守性氨基酸置换的CDR。
根据本发明,该核酸可以编码包含在至少一个CDR中的至少两个保守性氨基酸置换的CDR。
根据本发明,该核酸可以编码包含在这些CDR的至少两个中的至少两个保守性氨基酸置换的CDR。
根据本发明,该核酸可以编码包含在3个CDR中的至少两个保守性氨基酸置换的CDR。
本发明的其他方面涉及编码具有与SEQ ID NO.:4至少70%、75%、80%的序列一致性的轻链可变区的核酸。
本发明的又其他方面涉及编码具有与SEQ ID NO.:2至少70%、75%、80%的序列一致性的重链可变区的核酸。
在又另一方面,本发明涉及包含在此所述的核酸的载体。
根据本发明,该载体可以是表达载体。
包含用于在特定宿主中的插入编码序列的转录和翻译控制的元件的载体在本领域中是已知的。这些元件可以包含调节序列,例如增强子、组成型和诱导型启动子、以及5'和3'非翻译区。可以使用本领域的技术人员熟知的方法来构建这样的表达载体。这些方法包括体外重组DNA技术、合成技术、以及体内基因重组。
在另一方面,本发明涉及分离的细胞,这种分离的细胞可以包含在此所述的核酸、抗体或抗原结合片段。
这种分离的细胞可以包含在分开的载体上或在相同的载体上的、编码轻链可变区的核酸以及编码重链可变区的核酸。这种分离的细胞还可以包含在分离的载体上或在相同的载体上的、编码轻链的核酸以及编码重链的核酸。
根据本发明,这种细胞可以能够表达、组装和/或分泌一种抗体或其抗原结合片段。
在另一方面,本发明提供了可以包含和/或可以表达在此所述的抗体的细胞。
根据本发明,这种细胞可以包含编码一个轻链可变区的一种核酸、以及编码一个重链可变区的一种核酸。
这种细胞可以能够表达、组装和/或分泌一种抗体或其抗原结合片段。
呈现了以下实例以进一步概述本发明的细节。
实例
实例1
这个实例描述了抗体3A4结合至KAAG1。
结合KAAG1的抗体是使用Alere噬菌体展示技术而产生的。用于产生这些抗体的技术和方法的详细说明可以在美国专利号6,057,098中找到。另外,产生针对KAAG1的抗体的详细说明可以在PCT/CA 2009/001586中找到。简言之,该技术利用了展示抗原结合片段(Fab)的噬菌体文库的严格筛选(stringent panning)。在几轮的筛选之后,获得称为Omniclonal的文库,将该文库针对重组Fab进行富集,该Fab含有轻链和重链可变区,这些轻链和重链可变区以非常高的亲和力和特异性结合至KAAG1。根据这个文库(更精确地指定为Omniclonal AL0003A2ZB),从大肠杆菌制备96个单独的重组单克隆Fab,并且测试KAAG1结合。单克隆指定的3A4基于它对重组KAAG1的高结合活性以及它对卵巢癌细胞表面上的KAAG1的亲和力而衍生自单克隆抗体的这个96孔板。
重链和轻链免疫球蛋白链的可变区的核苷酸序列分别显示在SEQ ID NO.:1和3中,而重链和轻链免疫球蛋白链的可变区的多肽序列分别显示在SEQ ID NO.:2和4中。3A4重链免疫球蛋白的互补决定区(CDR)分别显示在SEQ ID NO.:5、6和7中,而3A4轻链免疫球蛋白的CDR分别显示在SEQ ID NO.:8、9和10中。
除了进行Fab单克隆与KAAG1蛋白之间的相互作用研究的可能性以外,Fab的用途在关于有意义的体外和体内研究以确认抗原的生物功能的方面受限制。因此,有必要的是将包含在3A4Fab中的轻链和重链可变区转移至全抗体支架,从而产生小鼠-人嵌合IgG1。构建用于轻和重免疫球蛋白链两者的表达载体,使得i)Fab表达载体的原始细菌信号肽序列上游替换为哺乳动物信号肽,并且ii)在小鼠抗体中的轻链和重链恒定区替换为人恒定区。完成这个转移的方法利用了本领域的技术人员熟悉的标准分子生物学技术。在此描述了该方法的简要概述。
轻链表达载体-将目前的哺乳动物表达质粒(称为pTTVH8G(Durocher等人,2002),被设计为在293E瞬时转染系统中使用)进行修饰以适应小鼠轻链可变区。所得的小鼠-人嵌合轻链包含小鼠可变区、之后为人κ恒定结构域。通过用引物OGS1773和OGS1774(分别为SEQ ID NO:11和12)的PCR来扩增编码人κ恒定结构域的cDNA序列。人κ恒定区的核苷酸序列和相应的氨基酸序列分别显示在SEQ ID NO:13和14中。将所得321个碱基对的PCR产物连接到pTTVH8G中,使其刚好在人VEGF A(NM_003376)的信号肽序列的下游。这个克隆步骤还定位了独特的限制性内切核酸酶位点,这些限制性内切核酸酶位点容许编码小鼠轻链可变区的cDNA的精确定位。最终的表达质粒(称为pTTVK1)的序列,显示在SEQ ID NO.:15中。基于在SEQ ID NO.:3中显示的3A4轻链可变序列,将对于轻链可变区具有特异性的PCR引物设计为在其5’-端掺入与VEGF A信号肽的最后20个碱基对一致的序列。这个引物的序列显示在SEQ ID NO:16中。反向引物(SEQ ID NO.:17)在其3’-端掺入与人κ恒定结构域的前面的20个碱基对一致的序列。将PCR片段和消化的pTTVK1两者用T4DNA聚合酶的3’-5’核酸外切酶活性处理,产生经由退火连接的互补末端。将退火反应转化到感受态的大肠杆菌中,并且通过测序来验证表达质粒以确保小鼠轻链可变区被适当地插入pTTVK1表达载体中。
重链表达载体-按照与以上所述的用于产生轻链免疫球蛋白的pTTVK1相似的方式设计产生3A4重链免疫球蛋白的表达载体。通过连接编码人恒定CH1区的cDNA序列将包含人IgGK信号肽序列连同IgG1的人Fc结构域的CH2和CH3区的质粒pYD11(迪罗谢(Durocher)等人,2002)进行修饰。将被设计为包含独特的限制性内切核酸酶位点的PCR引物OGS1769和OGS1770(SEQ ID NO:18和19)用于扩增人IgG1CH1区,该人IgG1CH1区包含在SEQ ID NO:20和21中显示的核苷酸序列和相应的氨基酸序列。在将人CH1的309个碱基对片段刚好连接在IgGK信号肽序列的下游之后,修饰的质粒(SEQ ID NO.:22)指定为pYD15。当将选择的重链可变区连接到这个载体时,所得的质粒编码具有人恒定区的全IgG1重链免疫球蛋白。将对于抗体3A4的重链可变区(SEQ ID NO:1)具有特异性的PCR引物设计为在其5’-端掺入一个与IgGK信号肽的最后20个碱基对一致的序列。这个引物的序列显示在SEQ ID NO:23中。反向引物(SEQ ID NO.:24)在其3’-端掺入与人CH1恒定结构域的前面的20个碱基对一致的序列。将PCR片段和消化的pYD15两者用T4DNA聚合酶的3’-5’外切核酸酶活性处理,产生经由退火连接的互补末端。将退火反应转化到感受态的大肠杆菌中,并且通过测序来验证表达质粒以确保小鼠重链可变区被适当地插入pYD15表达载体中。
人3A4嵌合IgG1在293E细胞中的表达–使用瞬时转染系统(迪罗谢(Durocher)等人,2002)将以上制备的编码轻链和重链免疫球蛋白的表达载体在293E细胞中表达。将轻链与重链的比率进行优化以便实现在组织培养基中抗体的最大产率,并且发现它是9:1(L:H)。
嵌合3A4结合至KAAG1-为了测量3A4单克隆抗体的相对结合,使用大规模的瞬时转染技术(迪罗谢(Durocher)等人,2002;迪罗谢(Durocher),2004)使重组人KAAG1在293E细胞中产生。作为Fc融合蛋白的人重组KAAG1的表达和纯化发现于PCT/CA2009/001586中。为了进行Fc-KAAG1与抗体制剂的结合,将Fc-KAAG1用NHS-生物素(Pierce公司,罗克福德(Rockford),伊利诺伊州(IL))进行生物素酰化,并且将10ng/孔在室温下包被在链霉亲和素96孔板中持续1小时。将纯化的嵌合3A4以渐增的浓度添加,并且在室温下孵育30分钟。在TMB液体底物(加拿大西格玛-奥德里奇有限公司(Sigma-Aldrich Canada Ltd.),奥克维尔(Oakville),安大略省(ON))的存在下,将结合的抗体用HRP结合的人抗-κ轻链抗体进行检测,并且在酶标仪(microtiter plate reader)中在450nm下进行读取。如在图1中所示,3A4与固定的KAAG1蛋白是以剂量依赖性方式进行相互作用。当将无关IgG对照与重组KAAG1一起孵育时,甚至在非常最高的浓度下,没有观察到结合活性。这个结果证明3A4结合至人KAAG1上。将3A4的结合与具有不同表位特异性的嵌合3D3的结合进行比较(描述于特伦布莱(Tremblay)和菲利翁(Filion)(2009)中)(参见实例2)。在这个类型的测定中,3A4的结合活性非常类似于3D3(参见图1)。
实例2
这个实例描述了表位作图研究,以便确定3A4抗体结合至KAAG1的哪个区。
为了进一步描绘被3A4抗体结合的KAAG1的区域,使KAAG1的截短突变体表达并且将其用于ELISA中。关于全长KAAG1,将截短形式通过PCR进行扩增,并且将其连接进BamHI/HindIII消化的pYD5中。所使用的引物组合了具有在SEQ ID NO.:25中显示的序列的正向寡核苷酸与SEQ ID NO:26和27的引物,从而产生分别在KAAG1的氨基酸数60和35处结束的Fc融合的片段。如以上针对全长Fc-KAAG1所述的,进行这些重组突变体的表达,并且用蛋白-A进行纯化。
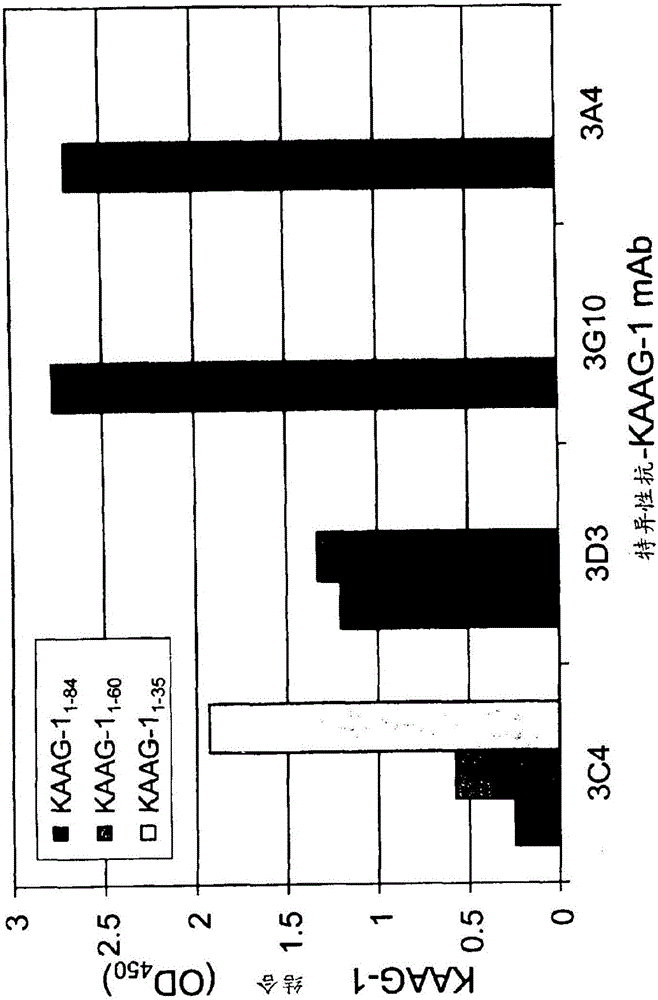
基于特伦布莱(Tremblay)和菲利翁(Filion)(2009)的传授,已知的是其他抗体与重组KAAG1的特异性区域相互作用。因此,抗-KAAG1抗体3C4、3D3、和3G10分别与KAAG1的1-35、36-60、和61-84区相互作用。这些结合结果复现并示于图2中。为了确定由3A4抗体结合的KAAG1中的区域,根据在实例1中所述的相似方案,使用KAAG1截短的Fc融合体进行ELISA。仅有的改变是使用了不同的生物素酰化的Fc-KAAG1截短突变体。结果显示3A4的结合特异性与3G10相似。在不具有超过氨基酸60的氨基酸序列的KAAG1突变体中,3A4与KAAG1不发生结合。这指示3A4与由人KAAG1的氨基酸61-84所描绘的区域相互作用。3A4和3D3具有如由ELISA所测量的几乎相同的结合活性(实例1)但具有非常不同的表位特异性的观察表明3A4的结合特性与3D3是相当不同的。
实例3
这个实例描述了3A4结合至在癌细胞系的表面上的KAAG1的能力。
使用流式细胞术来检测在细胞系表面上的KAAG1。基于使用KAAG1mRNA特异性引物的RT-PCR表达分析,预期所选择的的癌细胞系表达KAAG1蛋白。为了验证这一点,卵巢癌细胞(SKOV-3和TOV-21G)和显示非常少的KAAG1表达的对照细胞系(293E)。使用5mM EDTA将细胞收获,用血细胞计数器进行计数,并且以2×106个细胞/ml的细胞密度重悬浮于FCM缓冲液(1×PBS中的0.5%BSA、10μg/ml山羊血清)中。将嵌合3A4或对照IgG以5μg/ml的终浓度添加至100μl的细胞,并且在冰上孵育2小时。将细胞在冷PBS中进行洗涤以去除未结合的抗体,将其重悬浮于包含与FITC结合的抗-人IgG(作为第二抗体)(以1:200稀释)的100μl FCM缓冲液中,并且在冰上孵育持续45分钟。在冷PBS中的另一个洗涤步骤之后,将细胞重悬浮于250μl FCM缓冲液中,并且用流式细胞仪进行分析。来自这个实验的结果显示在图3A和3B中。细胞系与对照抗体的孵育导致相应于典型地在抗体从细胞略去时获得的信号的频率曲线(histogram)。这确立了这些FCM值的背景信号(图3A和3B)。相比之下,SKOV-3、TOV-21G与3A4嵌合抗体的孵育导致强的荧光信号(图3A)。这指示抗体有效地检测在这些癌细胞表面上的KAAG1。293E细胞,即人肾细胞系,预期显示非常少的KAAG1表达,并且事实上,FCM频率曲线显示与对照抗体相比较几乎没有偏移(参见图3B)。因此,3A4特异性地检测在癌细胞表面上的KAAG1。将3A4的活性与3D3(在特伦布莱(Tremblay)和菲利翁(Filion)(2009)的传授内容中所描述的一种抗-KAAG1抗体)进行比较。基于此专利申请,已知的是,如通过FCM所测量的,3D3可以检测在癌细胞表面上的KAAG1。这在将3D3在SKOV-3和TOV-21G细胞的存在下孵育时被证实(参见图3A)。该荧光信号与3A4相比较不是那么高,指示3A4具有检测在卵巢癌细胞表面上的KAAG1的不同的并且增强的能力。在我们实验室获得的其他结果表明,在3D3未在这个测定中展现活性(结果未显示)的条件下,3A4可以检测在癌细胞表面上的KAAG1。综上所述,在与3D3比较时3A4在表位特异性方面的这些观察和差异表明这些抗体具有不同的抗-KAAG1特性。
实例4
用于使用3A4抗-KAAG1抗体作为抗体结合物的方法
如上所证明,使用流式细胞术在癌细胞表面上通过3A4检测KAAG1抗原。有一些不同的分子事件,这些事件可以在抗体结合至其在细胞表面上的靶标后发生。这些包括i)阻滞对另一个细胞表面抗原/受体或配体的可及性,ii)形成相对稳定的抗体-抗原复合物,从而允许细胞经由ADCC或CDC而被靶向,iii)信号转导事件可以如由激动性抗体所例示而发生,iv)该复合物可以被内化,或v)该复合物可以从细胞表面脱落。为了解决这个问题,我们希望检查3A4抗体-KAAG1复合物在细胞表面上的行为。将SKOV-3细胞铺板、洗涤、并且与5μg/ml的如在实例3中所述的嵌合3A4抗体一起孵育。在洗涤之后,添加OSE完全培养基,并且将细胞置于37℃,持续高达90分钟。将细胞在指示的时间处移出(参见图4),快速冷却,进行制备以用于使用FITC-结合的抗-人IgG的细胞计量术,并且结果表达为剩余的平均荧光强度的百分比(平均荧光强度,%)。如在图4中所展示,荧光信号在30-45分钟的时期内快速降低。这个结果指示3A4/KAAG1复合物从细胞消失,这指示复合物的内化可能发生。解释造成在细胞表面荧光中这个降低的机理的初级研究已经揭示该复合物似乎被内化。
通过在活细胞上进行免疫荧光法以判断这种内化是否可以用显微镜观察而进一步证实这些发现。将SKOV-3细胞接种在全培养基(OSE培养基(Wisent),含有10%FBS、2mM谷氨酰胺、1mM丙酮酸钠、1×非必需氨基酸、以及抗生素)中的盖玻片上。一旦细胞适当地附着,添加新鲜的包含10ug/ml的3A4抗-KAAG1嵌合抗体的培养基,并且在37℃孵育4小时。将细胞在PBS中洗涤,然后固定在4%多聚甲醛(在PBS中)中持续20分钟。在洗涤之后,将细胞用在PBS中的0.1%Triton X-100进行透性化,持续5分钟。用在PBS中的1.5%奶粉进行封闭,持续1小时。通过在PBS中的1.5%奶中与抗-LAMP1(圣克鲁兹,sc-18821,以1:100稀释)孵育2小时而检测溶酶体相关膜蛋白1(LAMP1,常(Chang)等人,2002)。在PBS中洗涤之后,将第二抗体一起添加在1.5%的奶中,并且孵育1小时。对于抗-KAAG1嵌合抗体,第二抗体是以1:300稀释的、罗丹明红-X结合的驴抗-人IgG(H+L)。对于抗-LAMP1抗体,第二抗体是以1:300稀释的、DyLight488结合的山羊抗-小鼠IgG(H+L)。两种第二抗体都来自杰克逊免疫研究公司(Jackson ImmunoResearch)。将盖玻片在PBS中洗涤,并且封固在具有DAPI的ProLong Gold抗荧光衰减封片剂(antifade reagent)中。如在图5A中所见,在37℃在SKOV-3卵巢癌细胞的存在下孵育4小时之后,能够在其主要位于核周区域附近的复合物中检测到3A4抗体(箭头,参见在图5A中的左图中的红色染色),这是典型的基于内体-溶酶体的内化途径。当溶酶体标记LAMP1被可视化并且被发现也在这些区域中表达时进一步证实了这个观察(箭头,参见在图5A的中间图中的绿色染色)。重要的是,两个图像的合并导致黄橙色结构的出现,指示3A4和抗-LAMP1抗体存在于相同的结构中(箭头,参见在图5A的右图中的黄色染色)。3A4(与癌细胞表面上的KAAG1结合)与LAMP1(晚期内体/溶酶体的标记)的共定位显示抗体/抗原复合物被内化,并且它遵循适合于将要结合至3A4抗体上的有效载荷的释放的一种途径。在另一个细胞系TOV-21G中观察到了相同的结果(参见图5B)。
综上所述,这些研究证明了对于KAAG1具有特异性的抗体(例如3A4)可以具有作为抗体-药物结合物(ADC)的用途。因此,KAAG1的高水平卵巢癌特异性连同这个靶标被内化到细胞中的能力将支持作为ADC应用的开发。
实例5
在癌细胞表面上的KAAG1的优先检测。
虽然开发了与KAAG1蛋白的不同表位相互作用的若干抗体,当KAAG1表达在完整癌细胞的表面上时这些表位的可及性未被完全阐明。KAAG1的氨基酸一级结构(在人蛋白质中的氨基酸总数是84)的生物信息学分析未揭示可以相应于跨膜结构域的任何明显的序列,并且因此KAAG1如何锚定至细胞膜是不完全清楚的。
发现针对KAAG1产生的抗体结合至KAAG1蛋白中的三个不同区域上(参见PCT/CA2009/001586)。大多数抗体与KAAG1蛋白中的氨基酸35-60相互作用,并且在本申请中由抗体3D3和3G12举例说明。与KAAG1的在氨基酸61-84之间的羧基端相互作用的抗体是由抗体3A4来举例说明。最后,如由3C4所举例说明的,与蛋白质的氨基端区域相互作用的抗体显示对于表达KAAG1的细胞的非常少的结合。
本申请表明,当KAAG1表达在细胞中时,羧基端区域(氨基酸61-84)暴露于细胞外空间,并且靶向这个区域的抗体在KAAG1-阳性细胞的检测和潜在的处理上是最有效的。结合至KAAG1的中间区(氨基酸35-60)的抗体还可以检测在细胞表面上的KAAG1,但与和羧基端相互作用的抗体相比达到较低的程度。
卵巢癌细胞系,例如SKOV-3,对于KAAG1表达是阳性的。使用这些细胞以通过流式细胞术检测表达KAAG1,流式细胞术是一种允许细胞表面蛋白的检测的方法并且为本领域的技术人员所熟知。简言之,对于每个样品,将100,000个细胞与在1μg/ml浓度下的第一抗体(抗-KAAG1、或对照抗体)在冰上孵育1小时。在用冰冷的PBS洗涤几次之后,将染色细胞与结合至荧光染料(FITC)上的第二抗体一起孵育,检测结合至这些细胞的第一抗体的存在。在几次另外的洗涤之后,将细胞用流式细胞仪进行分析。在图6中表达的结果显示Y轴和X轴,Y轴代表计数数目(细胞),而X轴表示荧光的数量(荧光信号)。当将SKOV-3细胞与3A4抗体孵育时,观察到大的荧光移位,指示在细胞的表面上有丰富的KAAG1蛋白(图6A)并且它被这种抗体有效地识别。在相同条件下,与KAAG1的中间区相互作用的抗体3G12和3D3(图6A)对于检测KAAG1而言显著更不有效。当将细胞与增加浓度的3G12或3D3孵育时,可以在细胞表面上检测到KAAG1(未显示)。当将细胞与对照IgG(图6A)或3C4(一种针对KAAG1氨基端的抗体)(图6A)孵育时,没有观察到信号。这些结果指示与KAAG1的羧基端相互作用的抗体可以比针对KAAG1的其他区域的抗体更有效地检测在癌细胞表面上的抗原。这隐含了KAAG1的羧基端暴露于细胞的细胞外(外部)空间。针对其他表达KAAG1的癌细胞系获得了相似的结果。
还在SKOV-3细胞中进行了实验,这些细胞是用Triton X-100进行了透性化的。Triton X-100典型地用于透性化细胞膜并且释放膜蛋白。当透性化的细胞与3A4孵育并在流式细胞仪中测量时(参见图6B),该信号类似于在完整细胞中获得的信号。引人注目地,当透性化细胞与结合至KAAG1中间区上的3G12抗体孵育时(图6B),该信号与3A4的一样强。这些结果指示KAAG1的中间区可能存在于细胞膜中或细胞内部。用3D3抗体(另一个中间区结合剂)获得了相似的结果(图6B),但针对3D3获得的信号不是那么强。如前,在这个测定中,IgG对照未显示任何可检测的信号(图6B)。有趣的是,细胞与结合至KAAG1氨基区上的3C4抗体的孵育未导致任何可检测的信号(图6B)。这个最终结果表明KAAG1的氨基区可能在蛋白质转运至细胞膜过程中被切掉。
总体上,这些实验提供了KAAG1抗原在表达在癌细胞表面上时它的结构和取向的许多深入的了解。基于这些数据,提出两种针对在细胞表面处KAAG1结构的模型(图7)。在第一个模型中(图7,模型A),数据表明中间部分实际上是KAAG1的跨膜区,该跨膜区仅部分地暴露于细胞外空间。这将使得KAAG1的羧基端可容易地检测,而使得中间区更难以结合。在第二个模型中(图7,模型B),KAAG1通过另一种其自身埋入细胞膜中的蛋白质而锚定至膜上。再者,羧基端将是由抗体(例如3A4)易于接近的,但在KAAG1与蛋白质伴侣之间的相互作用将使得难于进入中间区。显示由羧基端结合剂(如由3A4举例说明的)和中间区结合剂(如由3G12和3D3举例说明的)两者组成的抗体在透性化细胞的存在下测试的结果与两种模型一致。3C4抗体不能结合至完整的或透性化细胞中的KAAG1上很可能是由于缺乏包含在KAAG1的成熟加工膜形式的氨基端中的氨基酸,并且两种模型均与此一致。
这些结果隐含了靶向癌细胞中KAAG1的羧基端(具体而言是由氨基酸61-84跨过的区域)的抗体最适合于用作治疗表达KAAG1的癌的治疗剂的抗体的开发。此外,结合至羧基端区域上的KAAG1抗体的其他用途包括用于检测表达KAAG1的癌的诊断试剂。
根据本领域中已知的方法,可以通过用KAAG1的C-端部分免疫一种动物而产生或分离具有与3A4抗体相似的结合特异性的抗体或抗原结合片段,这些方法包括杂交瘤技术、通过用KAAG1的C-端部分筛选抗体或抗原结合片段的文库和/或用在此所述的3A4抗体对分离的抗体或抗原结合片段进行竞争测定。
实例6
通过3A4小鼠单克隆抗体的设计而人源化
小鼠3A4单克隆抗体的可变区的3D建模
这项任务是通过同源建模而完成的。与轻链和重链的鼠3A4可变区序列(SEQ ID NO:4和2)最相似的模板结构是通过针对PDB的BLAST检索而鉴定的。为了建立小鼠3A4可变区的初始模型,使用了以下模板结构(PDB码):对于轻链为2IPU(L链),而对于重链为1F11(B链)。其他适合的模板,针对轻链而言可以在PDB入口2DDQ中找到,针对重链而言可以在PDB入口3IY3、1KTR、2VXT、1A6T和1IGI中找到。在这些根据鼠3A4序列的模板结构上操作所需要的突变:在2IPU轻链中7个突变,而在1F11重链中17个突变加3-残基缺失。通过将对应的模板结构的重链和轻链进行叠加将相应于鼠3A4可变区的重链和轻链的突变结构组装为二链抗体结构。将组装的3A4可变区的所得结构首先通过用AMBER力场的能量最低化和约束的逐步释放(范围为从首先松弛的CDR环至框架区的主链重原子(只有在最后阶段才完全松弛))而细化。然后将在每个抗体可变区结构中的CDR-H3环通过蒙特卡罗最小化(Monte-Carlo-minimization,MCM)构象采样(其中在每个MCM循环中对CDR-H3区中的二面角进行采样,随后为预定义区的能量最低化,该预定义区在CDR-H3环的初始构象周围处延伸)而细化。小鼠3A4抗体的模型化可变区的表示给出在图8中。与每个3A4可变序列最相似的人或人源化可变序列的结构也是从PDB鉴定的,并且然后将其叠加在鼠3A4可变区的模型化结构上。这些结构包括针对轻链的PDB入口3QCT、3AAZ、1WT5和3M8O以及针对重链的PDB入口1I9R、3NFP、1T04、1ZA6、3HC4、2D7T和1WT5。这些结构用于辅助在框架区中的突变的建模,以便建立起始于模型化鼠3D结构的人源化3D结构。
小鼠3A4氨基酸序列和模型化结构的表征
进行这个步骤以估算人源化指数(humanness index)、抗原接触倾向指数,以描绘CDR、规范残基、链间包装(VH/VL界面残基)、可变-/恒定-区包装(VH/CH和VL/CL界面残基)、特殊的框架残基、潜在的N-和O-糖基化位点、隐蔽残基、Vernier区残基、以及与CDR的靠近。互联网可获得的资源和本地软件可以用来评定这些特性。
针对小鼠CDR的最好的人轻链和重链框架的选择
这是通过针对人种系数据库(VBASE)的局部拷贝、针对其他序列文库(Genbank和SwissProt)的标准序列同源性比较、连同人框架共有序列的集合而进行的。进行BLAST检索以检索仅在框架区中具有最高同源性的序列匹配(因此排除CDR)同时匹配CDR环长度的序列。经鉴定用于3A4抗体的轻链和重链的人框架分别相应于k2和h1类别。对于这些类别,除了人共有序列之外,还保留了与3A4框架序列最相似的若干人种系框架序列。
用于回复突变的框架残基的鉴定以及多重人源化变体的设计
这是标记应当特别谨慎地突变为相应的人序列的氨基酸残基的重要步骤。这些残基代表在亲和力丢失的情况下用于回复突变为小鼠序列的主要候选者。它是最困难的并且不可预测的经设计的人源化步骤,特别是在不存在抗体-抗原复合物的实验结构的情况下。它依赖于在以下类别的一项或多相中的残基的鉴定:规范CDR-H3、Vernier区,特殊的靠近CDR的(在之内)链间包装、以及糖基化位点残基。这样的残基可能直接或间接地影响抗原结合部位和亲和力。在人种系数据库中在每个位置处的抗原接触倾向性指数连同氨基酸发生在决定是否某些残基可以安全地从小鼠序列突变为人序列中也是极其重要的。3A4抗体轻链可变区的人源化涉及11个突变,突变为其建议的人源化框架,以用于100%的框架人源化。3A4抗体重链可变区的人源化涉及23个突变,突变为其建议的人源化框架,以用于100%的框架人源化。这些100%人源化可变区序列分别为标记的Lvh1和Hvh1(SEQ ID NO:33和38)。另外的人源化序列还被设计为:其中将若干来自3A4小鼠序列的残基基于谨慎的结构和比较序列分析而保留,这些分析指示如果在这些位置将突变引入则有高的改变抗原结合亲和力的概率。可变区的这些序列是标记的Lvh2、Hvh2、Hvh3和Hvh4(SEQ ID NO:34、39、40和41)。
两种人源化轻链变体(包括恒定区)在此被鉴定为Lh1(SEQ ID NO.:43)和Lh2(SEQ ID NO.:44)。四种人源化重链变体(包括恒定区_)在此被鉴定为Hh1(SEQ ID NO.:46)、Hh2(SEQ ID NO.:47)、Hh3(SEQ ID NO.:48)和Hh4(SEQ ID NO.:49)。两种人源化轻链和4种人源化重链可以组装为8种人源化抗体(Lh1Hh1、Lh1Hh2、Lh1Hh3、Lh1Hh4、Lh2Hh1、Lh2Hh2、Lh2Hh3、和Lh2Hh4)。对于所有的这些组合的分子模型是通过起始于鼠3A4可变区的3D模型的同源建模而构建的,并且它们描绘于图9a-9h中。
在3A4轻链人源化序列Lvh2(SEQ ID NO:34)的情况下,来自小鼠序列的框架残基Val-L2和Lys-L45被保留,这是因为残基L2是半隐蔽的、与CDR-L1和CDR-L3两者接触,并且具有抗原接触倾向,而残基L45接近重链。我们注意到这些鼠残基两者均可以出现在人框架中。在3A4重链人源化序列Hvh2(SEQ ID NO:39)的情况下,来自小鼠序列的框架残基Ile-H2和Lys-L73被保留,这是因为残基H2是半隐蔽的、与CDR-H1和CDR-H3两者接触,并且具有抗原接触倾向,而残基H73属于支持CDR-H2的Vernier区,并且这些鼠残基两者均可以出现在人框架中。在3A4重链人源化序列Hvh3(SEQ ID NO:40)的情况下,Ile-H2和Lys-L73回复突变被保留,并且除了这些之外还保留了来自小鼠序列的框架残基Ile-H48、Ala-H67、Leu-H69和Val-H71,这是因为所有这些另外的鼠残基是隐蔽的残基,并且属于支持CDR-H2的Vernier区,并且鼠残基H71也可以出现在人框架中。在3A4重链人源化序列Hvh4(SEQ ID NO:41)的情况下,包括Hvh3人源化变体的所有的6个回复突变加上另外的两个小鼠框架残基Lys-H38和Lys-H66(这是因为它们代表接近于CDR-H2的半隐蔽残基)。所得的鼠和人源化链的氨基酸序列列于表1中。鼠和人源化轻链可变区的比对显示在图10a中,并且鼠和人源化重链可变区的比对显示在图10b中。
图11a和11b分别是鼠轻链可变区与100%人源化轻链可变区的比对、以及鼠重链可变区与100%人源化重链可变区的比对。这个图展示了保留的氨基酸以及已经被选择用于置换的那些氨基酸。
实例7
3A4人源化变体抗体的组装和表达
这些研究的目的是确定抗-凝聚素抗体的动力学参数。具体而言,是为了确定3A4抗-KAAG1单克隆抗体的人源化是否影响它与人KAAG1结合的动力学参数。为此,使用来自BioRad的ProteOn XPR36仪器开发动力学分析方法。将人KAAG1固定在传感器芯片上。注入全长抗体或Fab片段并且允许其与固定的KAAG1相互作用。
编码3A4的嵌合(鼠)重链和轻链的质粒的构建
使用以下寡核苷酸引物对将嵌合抗体的重链和轻链通过PCR从原始鼠免疫球蛋白链扩增:重链,由SEQ ID NO:50编码的5’-寡核苷酸和由SEQ ID NO:51编码的3’-寡核苷酸;轻链,由SEQ ID NO:52编码的5’-寡核苷酸和由SEQ ID NO:53编码的3’-寡核苷酸。将所得的PCR产物通过Hind III消化,并且克隆道预先用Hind III消化的pK-CR5(SEQ ID NO:21)中。
编码人源化重链3A4变体1、2、3和4的质粒的构建
编码抗体3A4的人源化重链区(Hh1、Hh2、Hh3和Hh4)的片段订购自GenScript(皮斯卡塔韦(Piscataway),美国)。将包含kozak序列和终止密码子序列的DNA片段用HindIII消化,并且克隆到质粒pK-CR5的HindIII位点中,该质粒被预先用小牛肠碱性磷酸酶(NEB)脱磷酸化以防止重新环化。图12a显示了质粒pK-CR5-3A4-HC-变体1的图谱。将人源化3A4的所有重链变体以相似的方式进行构建。
编码人源化轻链3A4变体1和2的质粒的构建
编码抗体3A4的人轻链区(Lh1和Lh2)的片段订购自GenScript。将包含kozak序列和终止密码子序列的DNA片段用BamHI消化,并且克隆到质粒pMPG-CR5(SEQ ID NO:55)的BamHI位点中,该质粒被预先用小牛肠碱性磷酸酶(NEB)脱磷酸化以防止重新环化。图12b显示了质粒pMPG-CR5-3A4-LC-变体1的图谱。将人源化3A4的所有轻链变体以相似的方式进行构建。
瞬时转染研究
使用Mini-Prep试剂盒(凯杰(Qiagen)公司,米西索加(Mississauga),安大略省(ON)),根据制造商的建议,将质粒DNA从大肠杆菌的少量培养物分离。简言之,将含有100μg/ml氨苄西林的2ml LB培养基用在连接和转化之后挑出的单一菌落接种。将培养物在37℃在伴随剧烈震荡(250RPM)下培养过夜。然后使用由试剂盒提供的方案、缓冲液、以及柱子将质粒从1.5ml的培养物分离。使用50μl的无菌水将DNA洗脱。使用Plasmid Plus Maxi试剂盒(凯杰(Qiagen)公司,米西索加(Mississauga),安大略省(ON)),根据制造商的建议,将质粒DNA从大肠杆菌的大量培养物分离。将含有100μg/mL氨苄西林的200mL LB培养基用大肠杆菌的单一新鲜菌落接种,并且在37℃在剧烈震荡(250RPM)下培养过夜。使细菌(针对重链为130mL培养物,而针对轻链为180mL培养物)通过在6000×g、在4℃离心持续15分钟而沉淀,并且使用由试剂盒提供的方案、缓冲液和柱子将质粒分离。将纯的质粒重悬浮于无菌50mM Tris(pH 8)中,并且通过测量在260nm下的光密度值而定量。在转染之前,将纯化的质粒通过用苯酚/氯仿抽提而灭菌,随后进行乙醇沉淀。将质粒重悬浮于无菌50mM Tris(pH 8)中,并且通过在260nm下的光密度值而定量。
在转染之前,将细胞(CHO-cTA)用PBS进行洗涤,并且将其以4.0×106个细胞/ml的浓度重悬浮于不含硫酸葡聚糖的生长培养基(CD-CHO,英杰公司(Invitrogen))中,在悬浮培养中持续3小时。对于每个质粒组合,通过缓慢添加补充有10μg/ml各质粒以及50μg/ml聚乙烯亚胺(PEI Max;Polysciences)的5ml CDCHO培养基而使45ml的细胞被转染。终浓度是:各个质粒为1μg/ml,并且PEI为5μg/m1。在2小时之后,在30℃转移细胞。接下来的几天,将50μg/mL的硫酸葡聚糖和3.75ml的各个补充物(高效进料A和B,英杰公司(Efficient Feed A and B Invitrogen))添加至细胞,并且将它们在30℃培养13天。在4、6、8和11天添加2.5ml的进料A和2.5ml的进料B。在13天时,将上清液经过离心和通过0.22μM过滤器过滤进行澄清。
将CHO细胞(CHOcTA)用编码3A4抗体的人源化重链和轻链的不同变体的质粒进行转染,这些质粒由CR5启动子调节。进行用轻链和重链的不同组合的转染。作为对照,还用编码嵌合/鼠抗体的质粒转染细胞。
抗体的纯化
通过在1500rpm下使用Amicon Ultra(Ultacell-50k)盒离心将来自CHO细胞转染的15ml上清液浓缩。根据制造商的建议,使用Nab spin试剂盒蛋白A加(赛默科学),将浓缩抗体(550μl)纯化。然后使用PBS以及浓缩Amicon Ultra(Ultracel-10K)盒在2500rpm下将纯化抗体脱盐至250μl的终体积。通过使用Nanodrop分光光度计读取OD280而将纯化抗体定量,并且将其保持在-20℃的冷冻下。将纯化抗体的等分部分重悬浮于等体积的Laemmli 2X中,并且将其在95℃加热5分钟,并在冰上冷却。使用已知量的从人骨髓瘤血浆纯化的人IgG1κ(Athens Research)制作标准曲线。将样品在聚丙烯酰胺Novex 10%Tris-甘氨酸凝胶(加拿大英杰公司(Invitrogen Canada Inc.),伯灵顿(Burlington),安大略省(ON))上进行分离,并且将其转移至Hybond-N硝酸纤维素膜(阿莫仙生物科学公司(Amersham Bioscience Corp.),Baie d’Urfée,魁北克省(QC))上在275mA下持续1小时。将膜在PBS中的0.15%吐温20、5%脱脂乳中封闭1小时,并且用结合至Cy5的山羊抗-人IgG(H+L)(杰克逊公司(Jackson),目录号109-176-099)孵育1小时。通过用Typhoon Trio+扫描仪(通用医疗(GE Healthcare))扫描来对信号进行揭示和定量。如在图13中所示,在CHO细胞中表达3A4人源化抗体变体的所有组合。
实例8
鼠和人源化3A4抗体的动力学分析
辅助材料
GLM传感器芯片、Biorad ProteOn胺偶联试剂盒(EDC,sNHS和乙醇胺),以及10mM乙酸钠缓冲液是从Bio-Rad实验室(米西索加(Mississauga),安大略省(ON))购买的。HEPES缓冲液、EDTA、和NaCl是从西格玛奥德里奇(奥克维尔(Oakville),安大略省(ON))购买的。10%的吐温20溶液是从Teknova(霍利斯特(Hollister),加利福尼亚州(CA))购买的。山羊抗-人IgG Fc片段特异性抗体是从杰克逊免疫研究公司(Jackson ImmunoResearch)购买的。凝胶过滤柱Superdex 75 10/300GL是从通用医疗(GE Healthcare)购买的。
凝胶过滤
将在3.114mg/ml浓度和220μL体积的KAAG1蛋白注入Superdex G75柱。在不含吐温20的HBST电泳缓冲液(参见下文)中以0.4ml/min进行分离。所收集的部分的体积是500μL。使用5500的延伸系数(extension coefficient)和8969的MW通过OD280确定在每个部分中KAAG1的浓度。图14代表KAAG1的凝胶过滤的曲线。潜在聚集体的小峰是在11ml左右处洗脱出。将在13ml处洗脱的蛋白质用作SPR测定的分析物(部分15-19)。
SPR生物传感器测定
使用BioRad ProteOn XPR36仪器(Bio-Rad实验室有限公司,米西索加(Mississauga),安大略省(ON)),在25℃的温度下,用HBST电泳缓冲液(10mM HEPES,150mM NaCl,3.4mM EDTA,以及0.05%吐温20,pH 7.4)进行所有的表面等离子体共振测定。使用GLM传感器芯片产生抗-小鼠Fc捕获表面,该传感器芯片用在分析物(水平)方向上以30μL/min注入(持续300秒)的1:5稀释度的标准BioRad sNHS/EDC溶液活化。在刚好活化之后,将在10mM NaOAc(pH 4.5)中的13μg/mL的特异性抗-人IgG Fc片段溶液在分析物方向上以25μL/min的流速注入,直到大致8000个共振单位(RU)被固定。将剩余的活性基团通过在分析物方向上以30μL/min注入1M乙醇胺(持续300秒)进行淬灭,并且这还确保产生用于空白对比的模拟活化的中间点(mock-activated interspot)。用于结合至KAAG1的3A4变体的筛选以两步进行:在配体方向(垂直)上将来自细胞上清液的3A4变体间接地捕获在抗-人IgG Fc片段特异性表面上,随后在分析物方向上注入KAAG1。首先,在配体方向上,将一种缓冲液以100uL/min注入持续30秒,用于稳定基线。对于每个3A4捕获物,将在细胞培养基中未纯化的3A4变体在HBST中稀释至4%,或大致使用在HBST中的1.25μg/mL的纯化3A4。将四至五种3A4变体连同野生型3A4一起同时以25μL/min流量注入单独的配体通道中,持续240秒。这导致在抗-人IgG Fc片段特异性表面上大致400RU-700RU的饱和3A4捕获物。将第一配体通道留空以用作空白对照(如果需要的话)。3A4捕获步骤之后立即进行在分析物方向上的两次缓冲液注入,以稳定基线,并且然后将凝胶过滤纯化的KAAG1注入。对于典型的筛选,将五个KAAG1浓度(8、2.66、0.89、0.29、和0.098nM)和缓冲液对照以50μL/min同时注入单独的分析物通道中持续120秒,具有600秒的解离相,导致一组结合传感图,其中针对每个捕获3A4变体具有缓冲液参照。通过0.85%的磷酸以100μL/min持续18秒的18秒脉冲而再生特异性抗-人IgG Fc片段-3A4复合物,以便制备用于下一个注入循环的抗-人IgG Fc片段特异性表面。将传感图进行比对并且使用缓冲液空白注射和中间点(interspot)进行双重参照,并且使用ProteOn Manager软件v3.0分析所得的传感图。使用局部Rmax,通过将参照的传感图拟合为1:1朗缪尔结合模型来确定动力学和亲和力值,并且从所得的速率常数(kd s-1/ka M-1s-1)导出亲和常数(KD M)。
速率常数和亲和常数的确定
图15概述了针对KAAG1与纯化的鼠3A4、瞬时表达为嵌合变体和瞬时表达为人源化变体的鼠3A4相互作用的缔合速率常数(ka,1/Ms)和解离速率常数(kd,1/s)以及亲和常数(KD,M)。这些常数图解地表示于图16中。针对纯化的亲本、嵌合的和人源化的3A4变体而言,缔合速率常数是非常相似的(图16a)。与纯的亲本3A4相比,针对瞬时表达嵌合体的解离速率常数是相似的,这表明转染程序未改变KAAG1与抗体的相互作用的参数(图16b)。然而,所有的人源化变体似乎具有略微改变的解离速率(off rate),即较快的解离速率(dissociation rate)(图16b)。这反映在亲和常数上(图16c)。总之,在人源化变体的结合常数(logKD)与在亲本抗体(LcHc)中制得的回复突变的数目之间存在着线性相关,其中当突变数目增加时,结合亲和力下降。然而,在没有保留小鼠残基的较差的变体(H1L1,0.47nM)与保留了10个小鼠残基的最佳变体(H4L2,0.1nM)之间在结合亲和力方面的差异仅差4倍。最后,发现所有变体针对KAAG1的结合亲和力是纳摩尔之下的,并且最佳变体(H4L2,0.1nM)展现出比鼠(LcHc,0.057nM)大约弱6倍的亲和力。总体上,这些结果表明,当所有变体展示出针对KAAG1的非常高的亲和力时人源化是成功的。
实例9
在ELISA中3A4人源化变体结合至KAAG1
还使用ELISA方法来比较人源化3A4变体的结合活性与鼠3A4抗体的结合活性。将重组人KAAG1隔夜(O/N)包被在96-孔板中,洗涤,并且在室温下与渐增量的鼠的或人源化的3A4变体孵育1小时。在另一轮的洗涤步骤之后,将结合至HRP的抗-人抗体添加至孔中,并且将结合的3A4抗体在Abs450下进行量热式测量。如在图17A中所示,当与鼠3A4(LcHc)比较时,人源化变体(Lh1Hh1、Lh1Hh2、Lh1Hh3和Lh1Hh4)展示出与KAAG1的非常相似的结合这个结果表明,当与人源化轻链的L1变体组装时,所有四种人源化重链变体相对原始的h3A4重链而言是相当的。图17B显示了当重链变体与3A4人源化轻链的Lh2变体组装时的结果。在这种情况下,变体的结合有差异。例如,Lh2hh4是与鼠3A4相比较具有最接近的曲线的变体。这与SPR数据一致(参见实例3),显示重链的变体4对于KAAG1具有最高亲和力。综上所述,这些结合结果显示,在这个测定中,所有人源化变体均与人KAAG1相互作用。虽然有细微差异,但ELISA的结合SPR结果相符。
实例10
在癌细胞表面上3A4人源化变体的结合
使用流式细胞术来评估人源化3A4变体与在癌细胞表面上表达的KAAG1相互作用的能力。为此,将SKOV-3卵巢癌细胞(先前我们已经通过流式细胞术显示这些卵巢癌细胞有效地被3A4结合)与八种人源化变体以及原始鼠抗体孵育。简言之,用EDTA使SKOV-3细胞从板脱离,并且将其与3.0mg/ml、0.3mg/ml或0.3mg/ml的抗体在冰上孵育持续1小时。在三次洗涤步骤之后,将细胞与第二抗体(结合至FITC的抗-人IgG)在冰上孵育1小时。在流式细胞仪中测量细胞表面荧光,并且将这些值显示在图18的直方图中。如所描绘的,所有变体可以检测在未透性化时的表面上的KAAG1,并且最强的信号是在3A4抗体的最高浓度下(3mg/ml)获得的,并且随着抗体浓度降低而降低。在不同的变体之间,具有最多的鼠回复突变的变体(图18,参见Lh1Hh4和Lh2Hh4)与在细胞表面上的KAAG1以最高的活性相互作用。事实上,与鼠3A4抗体(LcHc)相比较,Lh1Hh4和Lh2hh4表现为略微改进的与KAAG1的细胞表面结合。
出版物(其内容特此通过引用结合)
-杰玛(Jemal A),默里(Murray T),沃德(Ward E),塞缪尔斯(Samuels A),蒂瓦里(Tiwari RC),加富尔(Ghafoor A),福伊尔(Feuer EJ)和图恩(Thun MJ).癌症统计学(Cancer statistics),2005.《临床医师肿瘤杂志》(CA Cancer J Clin)2005;55:10-30。
-梅农(Menon U),斯凯特(Skates SJ),路易斯(Lewis S),罗森塔尔(Rosenthal AN),拉福德(Rufford B),西布莉(Sibley K),麦克唐纳(Macdonald N),道内(Dawnay A),耶拉伊(Jeyarajah A),巴斯特(Bast RC Jr),奥拉姆(Oram D)和雅各布斯(Jacobs IJ).使用卵巢癌算法风险筛选卵巢癌的前瞻性研究(Prospective study using the risk of ovarian cancer algorithm to screen for ovarian cancer).《临床肿瘤学杂志》(J Clin Oncol).2005;23(31):7919-26。
-博纳姆(Bonome T),李(Lee JY),帕克(Park DC),里登维克(Radonovich M),派斯-麦迪逊(Pise-Masison C),布雷迪(Brady J),加德纳(Gardner GJ),郝(Hao K),王(Wong WH),巴雷特(Barrett JC),陆(Lu KH),苏德(Sood AK),格申森(Gershenson DM),莫克(Mok SC)和比雷(Birrer MJ).卵巢的浆液性低恶性倾向、低级、和高级肿瘤的表达谱(Expression profiling of serous low malignancy potential,low grade,and high-grade tumors of the ovary).《癌症研究》(Cancer Res)2005;65:10602-10612。
-钱伯斯(Chambers,A)和Vanderhyden,B.在尿液中的卵巢癌生物标记(Ovarian Cancer Biomarkers in Urine).《临床癌症研究》(Clin Cancer Res)2006;12(2):323-327。
-贝雷克(Berek)等人.《癌症医学》(Cancer Medicine).第5版,伦敦:B.C.Decker公司;2000.1687-1720页。
-布里斯托(Bristow R.E).卵巢癌管理中的外科标准(Surgical standards in the management of ovarian cancer).《当代肿瘤学观点》(Curr Opin Oncol)2000;12:474-480。
-布朗(Brown E),斯图尔特(Stewart M),Rye T,Al-Nafussi A,威廉斯(Williams AR),布拉德伯恩(Bradburn M),史密斯(Smyth J)和加布拉(Gabra H).卵巢的癌肉瘤:来自单中心的19年前瞻性数据(Carcinosarcoma of the ovary:19years of prospective data from a single center).《癌症》(Cancer)2004;100:2148-2153。
-史(Shih L-M)和库尔曼(Kurman RJ).卵巢交界瘤的分子发病机制:新的观点和旧的挑战(Molecular Pathogenesis of Ovarian Borderline Tumors:New Insights and Old Challenges).《临床癌症研究》(Clin Cancer Res)2005;11(20):7273-7279。
-塞德曼(Seidman JD),拉塞尔(Russell P),库尔曼(Kurman RJ).卵巢的表面上皮肿瘤(Surface epithelial tumors of the ovary).在库尔曼(Kurman RJ)编的女性生殖道的布劳斯汀病理学(Blaustein’s pathology of the female genital tract).第5版.纽约施普林格(New York:Springer-Verlag);2002.791-904页中。
-卡尼斯特拉(Cannistra SA)和麦圭尔(McGuire WP).在妇科癌症管理中的进展(Progress in the management of gynecologic cancer).《临床肿瘤学杂志》(J.Clin.Oncol).2007;25(20):2865-2866。
-Oei AL,斯维普(Sweep FC),托马斯(Thomas CM),博尔曼(Boerman OC),马萨格尔(Massuger LF).用于治疗上皮性卵巢癌的单克隆抗体的用途(The use of monoclonal antibodies for the treatment of epithelial ovarian cancer).《肿瘤学国际杂志》(Int.J.Oncol).2008;32(6):1145-1157。
-尼哥底母(Nicodemus CF)和贝雷克(Berek JS).卵巢癌的单克隆抗体疗法(Monoclonal antibody therapy of ovarian cancer).《抗癌疗法专家评论》(Expert Rev.Anticancer Ther).2005;5(1):87-96。
-博格(Burger RA).用贝伐单抗在管理上皮性卵巢癌中的经验(Experience with bevacizumab in the management of epithelial ovarian cancer).《临床肿瘤学杂志》(J.Clin.Oncol).2007;25(20):2902-2908。
-西蒙(Simon I),卓(Zhuo S),科瑞尔(Corral L),迪亚曼迪斯(Diamandis EP),萨诺(Sarno MJ),沃尔弗特(Wolfert RL),金(Kim NW).B7-H4是针对卵巢癌的新颖的膜结合蛋白和候选血清和组织生物标记(B7-H4is a novel membrane-bound protein and a candidate serum and tissue biomerker for ovarian cancer).《癌症研究》(Cancer Res).2006;66(3):1570-1575
-埃贝尔(Ebel W),鲁蒂埃(Routhier EL),福利(Foley B),雅各布(Jacob S),麦克多诺(McDonough JM),帕特尔(Patel RK),图尔钦(Turchin HA),朝(Chao Q),克兰(Kline JB),欧德(Old LJ),菲利普斯(Phillips MD),尼古拉德斯(Nicolaides NC),萨斯(Sass PM),格拉索(Grasso L).一种拮抗叶酸受体-α的人源化单克隆抗体MORab-003的临床前评估(Preclinical evaluation of MORab-003,a humanized monoclonal antibody antagonizing folate receptor-alpha).《癌症免疫学》(Cancer Immun).2007;7:6-13。
-Van den Eynde BJ,高格勒(Gaugler B),普罗布斯特-凯珀(Probst-Kepper M),米肖(Michaux L),德维伊斯特(Devuyst O),洛奇(Lorge F),韦南茨(Weynants P),伯恩(Boon T).在人肾肿瘤上由细胞毒T淋巴细胞识别的新抗原来源于反向链转录(A new antigen recognized by cytotoxic T lymphocytes on a human kidney tumor results from reverse strand transcription).《实验医学杂志》(J.Exp.Med.)1999;190(12):1793-1799。
-苏克楠(Sooknanan R),特伦布莱(Tremblay GB),菲利翁(Filion M).癌症中涉及的多核苷酸和多肽序列(Polynucleotides and polypeptide sequences involved in cancer).2007;在2007年12月27日在WO/2007/147265号下公开的PCT/CA2007/001134。
-舒马赫(Schumacher J),安东尼(Anthoni H),达赫杜赫(Dahdouh F),IR,希尔默(Hillmer AM),克拉克(Kluck N),曼泰(Manthey M),普卢姆(Plume E),沃恩克(Warnke A),雷姆沙伊德(Remschmidt H),Hülsmann J,齐雄(Cichon S),林格伦(Lindgren CM),普若平(Propping P),祖凯利(Zucchelli M),齐格勒(Ziegler A),佩拉尔-扬维德(Peyrard-Janvid M),Schulte-G,MM,凯雷(Kere J).DCDC2作为阅读困难的易患基因的有力遗传证据(Strong genetic evidence of DCDC2as a susceptibility gene for dyslexia).《美国人类遗传学杂志》(Am.J.Hum.Genet.)2006;78:52-62。
-科普(Cope N),哈罗德(Harold D),希尔(Hill G),莫斯克维娜(Moskvina V),史蒂文森(Stevenson J),霍尔曼斯(Holmans P),欧文(Owen MJ),O'Donovan MC,威廉斯(Williams J).在染色体6p上的KIAA0319是发育性阅读困难的易患基因的有力证据(Strong evidence that KIAA0319on chromosome 6p is a susceptibility gene for developmental dyslexia).《美国人类遗传学杂志》(Am.J.Hum.Genet.)2005;76:581-591。
-莫尔(Mor G),维辛廷(Visintin I),来(Lai Y),赵(Zhao H),施瓦兹(Schwartz P),卢瑟福(Rutherford T),岳(Yue L),布雷-沃德(Bray-Ward P)和沃德(Ward DC)用于卵巢癌早期检测的血清蛋白标记(Serum protein markers for early detection of ovarian cancer).《美国科学院院刊》(PNAS)2005;102:7677-7682。
-科扎克(Kozak KR),阿姆内乌斯(Amneus MW),蒲赛(Pusey SM),苏(Su F),梁(Luong MN),梁(Luong SA),雷迪(Reddy ST)和法里亚斯-艾斯纳(Farias-Eisner R).使用强的阴离子交换蛋白芯片针对卵巢癌的生物标记的鉴定:在诊断和预后中的潜在用途(Identification of biomarkers for ovarian cancer using strong anion-exchange ProteinChips:potential use in diagnosis and prognosis).《美国科学院院刊》(PNAS)2003;100:12343-12348。
-MH,哈得森(Hudson TJ),梅尔(Maire G),斯夸尔(Squire JA),阿坎德(Arcand SL),普罗文彻(Provencher D),马斯-马森(Mes-Masson AM),托尼恩(Tonin PN).染色体X基因在正常的卵巢表面上皮细胞和上皮性卵巢癌细胞系的原始培养物中表达的全局分析(Global analysis of chromosome X gene expression in primary cultures of normal ovarian surface epithelial cells and epithelial ovarian cancer cell lines).《国际肿瘤学杂志》(Int.J.Oncol.)2007;30(1):5-17。
-科迪(Cody NA),Zietarska M,Filali-Mouhim A,普罗文彻(Provencher DM),马斯-马森(Mes-Masson AM),托尼恩(Tonin PN).单层、球状体、和肿瘤生长条件对致瘤性上皮性卵巢癌细胞系中的染色体3基因表达的影响(Influence of monolayer,spheroid,and tumor growth conditions on chromosome 3gene expression in tumorigenic epithelial ovarian cancer cell lines).《BMC药物基因组学》(BMC Med.Genomics)2008;1(1):34。
-比希勒(Buechler J),瓦克斯(Valkirs G),格雷(Gray J).多价展示文库(Polyvalent display libraries).2000;U.S.6,057,098。
-迪罗谢(Durocher Y),卡门(Kamen A),佩雷特(Perret S),彭(Pham PL).通过悬浮生长的哺乳动物细胞的瞬时转染增强重组蛋白的生产(Enhanced production of recombinant proteins by transient transfection of suspension-growing mammalian cells).2002;加拿大专利申请号CA2446185。
-迪罗谢(Durocher Y).用于增强的瞬时基因表达的表达载体以及表达它们的哺乳动物细胞(Expression vectors for enhanced transient gene expression and mammalian cells expressing them).2004;美国专利申请号60/662,392。
-特伦布莱(Tremblay GB),菲利翁(Filion M).特异性阻断肿瘤抗原生物活性的抗体(Antibodies that specifically block the biological activity of a tumor antigen).2009;PCT/CA2009/001586。
-迪罗谢(Durocher Y),卡门(Kamen A),佩雷特(Perret S),彭(Pham PL).通过悬浮生长的哺乳动物细胞的瞬时转染增强重组蛋白的生产(Enhanced production of recombinant proteins by transient transfection of suspension-growing mammalian cells).2002;加拿大专利申请号CA2446185。
-迪罗谢(Durocher Y).用于增强的瞬时基因表达的表达载体以及表达它们的哺乳动物细胞(Expression vectors for enhanced transient gene expression and mammalian cells expressing them).2004;美国专利申请号60/662,392。
-常(Chang MH),卡拉乔格斯(Karageorgos LE),梅克勒(Meikle PJ).CD107a(LAMP-1)与CD107b(LAMP-2).2002;《生物调节基因与体内平衡物杂志》(J Biol Regul Homeost Agents).16:147-51。
-阿比南当(Abhinandan,KR)和马丁(Martin,ACR).针对Kabat的分析和改进以及抗体可变结构域的在结构上正确的编号(Analysis and improvements to Kabat and structurally correct numbering of antibody variable domains).2008;《分子免疫学》(Mol Immunol),45,3832-3839。
在说明书中引用的序列
SEQ ID NO.:1-3A4重链可变区核苷酸序列
CAGATCCAGTTGGTGCAATCTGGACCTGAGATGGTGAAGCCTGGGGCTTCAGTGAAGATGTCCTGTAAGGCTTCTGGATACACATTCACTGACGACTACATGAGCTGGGTGAAACAGAGCCATGGAAAGAGCCTTGAGTGGATTGGAGATATTAATCCTTACAACGGTGATACTAACTACAACCAGAAGTTCAAGGGCAAGGCCATATTGACTGTAGACAAATCCTCCAGCACAGCCTACATGCAGCTCAACAGCCTGACATCGGAAGACTCAGCAGTCTATTACTGTGCAAGAGACCCGGGGGCTATGGACTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCA
SEQ ID NO.:2-3A4重链可变区多肽序列
QIQLVQSGPEMVKPGASVKMSCKASGYTFTDDYMSWVKQSHGKSLEWIGDINPYNGDTNYNQKFKGKAILTVDKSSSTAYMQLNSLTSEDSAVYYCARDPGAMDYWGQGTSVTVSS
SEQ ID NO.:3-3A4轻链可变区核苷酸序列
GATGTTGTGATGACCCAAACTCCACTCTCCCTGGCTGTCAGTCTTGGAGATCAAGCCTCCATCTCTTGCAGATCTAGTCAGAGCCTTCTACATAGTAATGGAAACACCTATTTAGAATGGTACCTTCAGAAACCAGGCCAGTCTCCAAAGCTCCTGATCCACACAGTTTCCAACCGATTTTCTGGGGTCCCAGACAGATTCAGTGGCAGTGGATCAGGGACAGATTTCACACTCAAGATCAGCAGAGTGGAGGCTGAGGATCTGGGAGTTTATTACTGCTTTCAAGGTTCACATGTTCCGCTCACGTTCGGTGCTGGGACCAGGCTGGAGCTGAAA
SEQ ID NO.:4-3A4轻链可变区多肽序列
DVVMTQTPLSLAVSLGDQASISCRSSQSLLHSNGNTYLEWYLQKPGQSPRLLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDLGVYYCFQGSHVPLTFGAGTRLELK
SEQ ID NO.:5-3A4重链CDR1多肽序列
GYTFTDDYMS
SEQ ID NO.:6-3A4重链CDR2多肽序列
DINPYNGDTN
SEQ ID NO.:7-3A4重链CDR3多肽序列
DPGAMDY
SEQ ID NO.:8-3A4轻链CDR1多肽序列
RSSQSLLHSNGNTYLE
SEQ ID NO.:9-3A4轻链CDR2多肽序列
TVSNRFS
SEQ ID NO.:10-3A4轻链CDR3多肽序列
FQGSHVPLT
SEQ ID NO.:11-OGS1773
GTAAGCAGCGCTGTGGCTGCACCATCTGTCTTC
SEQ ID NO.:12-OGS1774
GTAAGCGCTAGCCTAACACTCTCCCCTGTTGAAGC
SEQ ID NO.:13-人κ恒定核苷酸序列
GCTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG
SEQ ID NO.:14-人κ恒定多肽序列
AVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO.:15
CTTGAGCCGGCGGATGGTCGAGGTGAGGTGTGGCAGGCTTGAGATCCAGCTGTTGGGGTGAGTACTCCCTCTCAAAAGCGGGCATTACTTCTGCGCTAAGATTGTCAGTTTCCAAAAACGAGGAGCATTTGATATTCACCTGGCCCGATCTGGCCATACACTTGAGTGACAATGACATCCACTTTGCCTTTCTCTCCACAGGTGTCCACTCCCAGGTCCAAGTTTAAACGGATCTCTAGCGAATTCATGAACTTTCTGCTGTCTTGGGTGCATTGGAGCCTTGCCTTGCTGCTCTACCTCCACCATGCCAAGTGGTCCCAGGCTTGAGACGGAGCTTACAGCGCTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAGGGTACCGCGGCCGCTTCGAATGAGATCCCCCGACCTCGACCTCTGGCTAATAAAGGAAATTTATTTTCATTGCAATAGTGTGTTGGAATTTTTTGTGTCTCTCACTCGGAAGGACATATGGGAGGGCAAATCATTTGGTCGAGATCCCTCGGAGATCTCTAGCTAGAGCCCCGCCGCCGGACGAACTAAACCTGACTACGGCATCTCTGCCCCTTCTTCGCGGGGCAGTGCATGTAATCCCTTCAGTTGGTTGGTACAACTTGCCAACTGGGCCCTGTTCCACATGTGACACGGGGGGGGACCAAACACAAAGGGGTTCTCTGACTGTAGTTGACATCCTTATAAATGGATGTGCACATTTGCCAACACTGAGTGGCTTTCATCCTGGAGCAGACTTTGCAGTCTGTGGACTGCAACACAACATTGCCTTTATGTGTAACTCTTGGCTGAAGCTCTTACACCAATGCTGGGGGACATGTACCTCCCAGGGGCCCAGGAAGACTACGGGAGGCTACACCAACGTCAATCAGAGGGGCCTGTGTAGCTACCGATAAGCGGACCCTCAAGAGGGCATTAGCAATAGTGTTTATAAGGCCCCCTTGTTAACCCTAAACGGGTAGCATATGCTTCCCGGGTAGTAGTATATACTATCCAGACTAACCCTAATTCAATAGCATATGTTACCCAACGGGAAGCATATGCTATCGAATTAGGGTTAGTAAAAGGGTCCTAAGGAACAGCGATATCTCCCACCCCATGAGCTGTCACGGTTTTATTTACATGGGGTCAGGATTCCACGAGGGTAGTGAACCATTTTAGTCACAAGGGCAGTGGCTGAAGATCAAGGAGCGGGCAGTGAACTCTCCTGAATCTTCGCCTGCTTCTTCATTCTCCTTCGTTTAGCTAATAGAATAACTGCTGAGTTGTGAACAGTAAGGTGTATGTGAGGTGCTCGAAAACAAGGTTTCAGGTGACGCCCCCAGAATAAAATTTGGACGGGGGGTTCAGTGGTGGCATTGTGCTATGACACCAATATAACCCTCACAAACCCCTTGGGCAATAAATACTAGTGTAGGAATGAAACATTCTGAATATCTTTAACAATAGAAATCCATGGGGTGGGGACAAGCCGTAAAGACTGGATGTCCATCTCACACGAATTTATGGCTATGGGCAACACATAATCCTAGTGCAATATGATACTGGGGTTATTAAGATGTGTCCCAGGCAGGGACCAAGACAGGTGAACCATGTTGTTACACTCTATTTGTAACAAGGGGAAAGAGAGTGGACGCCGACAGCAGCGGACTCCACTGGTTGTCTCTAACACCCCCGAAAATTAAACGGGGCTCCACGCCAATGGGGCCCATAAACAAAGACAAGTGGCCACTCTTTTTTTTGAAATTGTGGAGTGGGGGCACGCGTCAGCCCCCACACGCCGCCCTGCGGTTTTGGACTGTAAAATAAGGGTGTAATAACTTGGCTGATTGTAACCCCGCTAACCACTGCGGTCAAACCACTTGCCCACAAAACCACTAATGGCACCCCGGGGAATACCTGCATAAGTAGGTGGGCGGGCCAAGATAGGGGCGCGATTGCTGCGATCTGGAGGACAAATTACACACACTTGCGCCTGAGCGCCAAGCACAGGGTTGTTGGTCCTCATATTCACGAGGTCGCTGAGAGCACGGTGGGCTAATGTTGCCATGGGTAGCATATACTACCCAAATATCTGGATAGCATATGCTATCCTAATCTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATTTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATCTGTATCCGGGTAGCATATGCTATCCTAATAGAGATTAGGGTAGTATATGCTATCCTAATTTATATCTGGGTAGCATATACTACCCAAATATCTGGATAGCATATGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATTTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATCTGTATCCGGGTAGCATATGCTATCCTCACGATGATAAGCTGTCAAACATGAGAATTAATTCTTGAAGACGAAAGGGCCTCGTGATACGCCTATTTTTATAGGTTAATGTCATGATAATAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTCGCCCTTATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTGGTGAAAGTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGATCTCAACAGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGCACTTTTAAAGTTCTGCTATGTGGCGCGGTATTATCCCGTGTTGACGCCGGGCAAGAGCAACTCGGTCGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAAAAGCATCTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGTGATAACACTGCGGCCAACTTACTTCTGACAACGATCGGAGGACCGAAGGAGCTAACCGCTTTTTTGCACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAATGAAGCCATACCAAACGACGAGCGTGACACCACGATGCCTGCAGCAATGGCAACAACGTTGCGCAAACTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGGATGGAGGCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTTATTGCTGATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGGCCAGATGGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATGGATGAACGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTAACTGTCAGACCAAGTTTACTCATATATACTTTAGATTGATTTAAAACTTCATTTTTAATTTAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCATTGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGCTCGCCGCAGCCGAACGACCGAGCGCAGCGAGTCAGTGAGCGAGGAAGCGGAAGAGCGCCCAATACGCAAACCGCCTCTCCCCGCGCGTTGGCCGATTCATTAATGCAGCTGGCACGACAGGTTTCCCGACTGGAAAGCGGGCAGTGAGCGCAACGCAATTAATGTGAGTTAGCTCACTCATTAGGCACCCCAGGCTTTACACTTTATGCTTCCGGCTCGTATGTTGTGTGGAATTGTGAGCGGATAACAATTTCACACAGGAAACAGCTATGACCATGATTACGCCAAGCTCTAGCTAGAGGTCGACCAATTCTCATGTTTGACAGCTTATCATCGCAGATCCGGGCAACGTTGTTGCATTGCTGCAGGCGCAGAACTGGTAGGTATGGCAGATCTATACATTGAATCAATATTGGCAATTAGCCATATTAGTCATTGGTTATATAGCATAAATCAATATTGGCTATTGGCCATTGCATACGTTGTATCTATATCATAATATGTACATTTATATTGGCTCATGTCCAATATGACCGCCATGTTGACATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGCCCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTCCGCCCCCTATTGACGTCAATGACGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTACGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTGATGCGGTTTTGGCAGTACACCAATGGGCGTGGATAGCGGTTTGACTCACGGGGATTTCCAAGTCTCCACCCCATTGACGTCAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCAAAATGTCGTAATAACCCCGCCCCGTTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAAGCAGAGCTCGTTTAGTGAACCGTCAGATCCTCACTCTCTTCCGCATCGCTGTCTGCGAGGGCCAGCTGTTGGGCTCGCGGTTGAGGACAAACTCTTCGCGGTCTTTCCAGTACTCTTGGATCGGAAACCCGTCGGCCTCCGAACGGTACTCCGCCACCGAGGGACCTGAGCGAGTCCGCATCGACCGGATCGGAAAACCTCTCGAGAAAGGCGTCTAACCAGTCACAGTCGCAAGGTAGGCTGAGCACCGTGGCGGGCGGCAGCGGGTGGCGGTCGGGGTTGTTTCTGGCGGAGGTGCTGCTGATGATGTAATTAAAGTAGGCGGT
SEQ ID NO.:16-OGS18500
ATGCCAAGTGGTCCCAGGCTGATGTTGTGATGACCCAAACTCC
SEQ ID NO:.17-OGS2084
GGGAAGATGAAGACAGATGGTGCAGCCACAGTCCG
SEQ ID NO.:18-OGS1769
GTAAGCGCTAGCGCCTCAACGAAGGGCCCATCTGTCTTTCCCCTGGCCCC
SEQ ID NO.:19-OGS1770
GTAAGCGAATTCACAAGATTTGGGCTCAACTTTCTTG
SEQ ID NO.:20-人免疫球蛋白CH1区核苷酸序列
GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCAGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGT
SEQ ID NO.:21-人免疫球蛋白CH1区多肽序列
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSC
SEQ ID NO.:22
CTTGAGCCGGCGGATGGTCGAGGTGAGGTGTGGCAGGCTTGAGATCCAGCTGTTGGGGTGAGTACTCCC
TCTCAAAAGCGGGCATTACTTCTGCGCTAAGATTGTCAGTTTCCAAAAACGAGGAGGATTTGATATTCACCTGGCCCGATCTGGCCATACACTTGAGTGACAATGACATCCACTTTGCCTTTCTCTCCACAGGTGTCCACTCCCAGGTCCAAGTTTGCCGCCACCATGGAGACAGACACACTCCTGCTATGGGTACTGCTGCTCTGGGTTCCAGGTTCCACTGGCGGAGACGGAGCTTACGGGCCCATCTGTCTTTCCCCTGGCCCCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGAATTCACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGATGAGCTGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCCGGGAAATGATCCCCCGACCTCGACCTCTGGCTAATAAAGGAAATTTATTTTCATTGCAATAGTGTGTTGGAATTTTTTGTGTCTCTCACTCGGAAGGACATATGGGAGGGCAAATCATTTGGTCGAGATCCCTCGGAGATCTCTAGCTAGAGCCCCGCCGCCGGACGAACTAAACCTGACTACGGCATCTCTGCCCCTTCTTCGCGGGGCAGTGCATGTAATCCCTTCAGTTGGTTGGTACAACTTGCCAACTGAACCCTAAACGGGTAGCATATGCTTCCCGGGTAGTAGTATATACTATCCAGACTAACCCTAATTCAATAGCATATGTTACCCAACGGGAAGCATATGCTATCGAATTAGGGTTAGTAAAAGGGTCCTAAGGAACAGCGATGTAGGTGGGCGGGCCAAGATAGGGGCGCGATTGCTGCGATCTGGAGGACAAATTACACACACTTGCGCCTGAGCGCCAAGCACAGGGTTGTTGGTCCTCATATTCACGAGGTCGCTGAGAGCACGGTGGGCTAATGTTGCCATGGGTAGCATATACTACCCAAATATCTGGATAGCATATGCTATCCTAATCTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATTTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATCTGTATCCGGGTAGCATATGCTATCCTAATAGAGATTAGGGTAGTATATGCTATCCTAATTTATATCTGGGTAGCATATACTACCCAAATATCTGGATAGCATATGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATTTATATCTGGGTAGCATAGGCTATCCTAATCTATATCTGGGTAGCATATGCTATCCTAATCTATATCTGGGTAGTATATGCTATCCTAATCTGTATCCGGGTAGCATATGCTATCCTCACGATGATAAGCTGTCAAACATGAGAATTAATTCTTGAAGACGAAAGGGCCTCGTGATACGCCTATTTTTATAGGTTAATGTCATGATAATAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTCGCCCTTATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTGGTGAAAGTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGATCTCAACAGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGCACTTTTAAAGTTCTGCTATGTGGCGCGGTATTATCCCGTGTTGACGCCGGGCAAGAGCAACTCGGTCGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAAAAGCATCTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGTGATAACACTGCGGCCAACTTACTTCTGACAACGATCGGAGGACCGAAGGAGCTAACCGCTTTTTTGCACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAATGAAGCCATACCAAACGACGAGCGTGACACCACGATGCCTGCAGCAATGGCAACAACGTTGCGCAAACTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGGATGGAGGCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTTATTGCTGATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGGCCAGATGGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATGGATGAACGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTAACTGTCAGACCAAGTTTACTCATATATACTTTAGATTGATTTAAAACTTCATTTTTAATTTAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCATTGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGCTCGCCGCAGCCGAACGACCGAGCGCAGCGAGTCAGTGAGCGAGGAAGCGTACATTTATATTGGCTCATGTCCAATATGACCGCCATGTTGACATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGCCCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTCCGCCCCCTATTGACGTCAATGACGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTACGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTGATGCGGTTTTGGCAGTACACCAATGGGCGTGGATAGCGGTTTGACTCACGGGGATTTCCAAGTCTCCACCCCATTGACGTCAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCAAAATGTCGTAATAACCCCGCCCCGTTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAAGCAGAGCTCGTTTAGTGAACCGTCAGATCCTCACTCTCTTCCGCATCGCTGTCTGCGAGGGCCAGCTGTTGGGCTCGCGGTTGAGGACAAACTCTTCGCGGTCTTTCCAGTACTCTTGGATCGGAAACCCGTCGGCCTCCGAACGGTACTCCGCCACCGAGGGACCTGAGCGAGTCCGCATCGACCGGATCGGAAAACCTCTCGAGAAAGGCGTCTAACCAGTCACAGTCGCAAGGTAGGCTGAGCACCGTGGCGGGCGGCAGCGGGTGGCGGTCGGGGTTGTTTCTGGCGGAGGTGCTGCTGATGATGTAATTAAAGTAGGCGGT
SEQ ID NO.:23-OGS1879
GGGTTCCAGGTTCCACTGGCCAGATCCAGTTGGTGCAATCTGG
SEQ ID NO.:24-OGS1810
GGGGCCAGGGGAAAGACAGATGGGCCCTTCGTTGAGGC
SEQID NO.:25
GTAAGCGGATCCATGGATGACGACGCGGCGCCC
SEQ ID NO.:26
GTAAGCAAGCTTAGGCCGCTGGGACAGCGGAGGTGC
SEQ ID NO.:27
GTAAGCAAGCTTGGCAGCAGCGCCAGGTCCAGC
SEQ ID NO.:28
GAGGGGCATCAATCACACCGAGAAGTCACAGCCCCTCAACCACTGAGGTGTGGGGGGGTAGGGATCTGCATTTCTTCATATCAACCCCACACTATAGGGCACCTAAATGGGTGGGCGGTGGGGGAGACCGACTCACTTGAGTTTCTTGAAGGCTTCCTGGCCTCCAGCCACGTAATTGCCCCCGCTCTGGATCTGGTCTAGCTTCCGGATTCGGTGGCCAGTCCGCGGGGTGTAGATGTTCCTGACGGCCCCAAAGGGTGCCTGAACGCCGCCGGTCACCTCCTTCAGGAAGACTTCGAAGCTGGACACCTTCTTCTCATGGATGACGACGCGGCGCCCCGCGTAGAAGGGGTCCCCGTTGCGGTACACAAGCACGCTCTTCACGACGGGCTGAGACAGGTGGCTGGACCTGGCGCTGCTGCCGCTCATCTTCCCCGCTGGCCGCCGCCTCAGCTCGCTGCTTCGCGTCGGGAGGCACCTCCGCTGTCCCAGCGGCCTCACCGCACCCAGGGCGCGGGATCGCCTCCTGAAACGAACGAGAAACTGACGAATCCACAGGTGAAAGAGAAGTAACGGCCGTGCGCCTAGGCGTCCACCCAGAGGAGACACTAGGAGCTTGCAGGACTCGGAGTAGACGCTCAAGTTTTTCACCGTGGCGTGCACAGCCAATCAGGACCCGCAGTGCGCGCACCACACCAGGTTCACCTGCTACGGGCAGAATCAAGGTGGACAGCTTCTGAGCAGGAGCCGGAAACGCGCGGGGCCTTCAAACAGGCACGCCTAGTGAGGGCAGGAGAGAGGAGGACGCACACACACACACACACACAAATATGGTGAAACCCAATTTCTTACATCATATCTGTGCTACCCTTTCCAAACAGCCTA
SEQ ID NO.:29
MDDDAAPRVEGVPVAVHKHALHDGLRQVAGPGAAAAHLPRWPPPQLAASRREAPPLSQRPHRTQGAGSPPETNEKLTNPQVKEK
SEQ ID NO.:30(变体轻链可变区)
DXVMTQTPLSLXVXXGXXASISCRSSQSLLHSNGNTYLEWYLQKPGQSPXLLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDXGVYYCFQGSHVPLTFGXGTXLEXK
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:4中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。氨基酸置换可以是例如保守性的。
SEQ ID NO.:31(变体轻链可变区)
DXa1VMTQTPLSLXa2VXa3Xa4GXa5Xa6ASISCRSSQSLLHSNGNTYLEWYLQKPGQSPXa7LLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDXa8GVYYCFQGSHVPLTFGXa9GTXa10LEXa11K
其中Xa1可以是疏水性氨基酸;
其中Xa2可以是A或P;
其中Xa3可以是中性亲水性氨基酸;
其中Xa4可以是L或P;
其中Xa5可以是酸性氨基酸;
其中Xa6可以是Q或P;
其中Xa7可以是碱性氨基酸;
其中Xa8可以是疏水性氨基酸;
其中Xa9可以是A或Q;
其中Xa10可以是碱性氨基酸;或
其中Xa11可以是疏水性氨基酸,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:4中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
SEQ ID NO.:32(变体轻链可变区)
DXA1VMTQTPLSLXA2VXA3XA4GXA5XA6ASISCRSSQSLLHSNGNTYLEWYLQKPGQSPXA7LLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDXA8GVYYCFQGSHVPLTFGXA9GTXA10LEXA11K
其中XA1可以是V或I
其中XA2可以是A或P
其中XA3可以是S或T
其中XA4可以是L或P
其中XA5可以是D或E
其中XA6可以是Q或P;
其中XA7可以是K或Q
其中XA8可以是L或V
其中XA9可以是A或Q
其中XA10可以是R或K,或
其中XA11可以是L或I,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:4中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
SEQ ID NO.:33(变体1轻链可变区:Lvh1)
DIVMTQTPLSLPVTPGEPASISCRSSQSLLHSNGNTYLEWYLQKPGQSPQLLIYTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPLTFGQGTKLEIK
SEQ ID NO.:34(变体2轻链可变区:Lvh2)
DVVMTQTPLSLPVTPGEPASISCRSSQSLLHSNGNTYLEWYLQKPGQSPKLLIYTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPLTFGQGTKLEIK
SEQ ID NO.:35(变体重链可变区)
QXQLVQSGXEXXKPGASVKXSCKASGYTFTDDYMSVVVXQXXGXXLEWXGDINPYNGDTNYNQKFKGXXXXTXDXSXSTAYMXLXSLXSEDXAVYYCARDPGAMDYWGQGTXVTVSS
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:2中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。氨基酸置换可以是例如保守性的。
SEQ ID NO.:36(变体重链可变区)
QXb1QLVQSGXb2EXb3Xb4KPGASVKXb5SCKASGYTFTDDYMSWVXb6QXb7Xb8GXb9Xb10LEWXb11GDINPYNGDTNYNQKFKGXb12Xb13Xb14Xb15TXb16DXb17SXb18STAYMXb19LXb20SLXb21SEDXb22AVYYCARDPGAMDYWGQGTXb23VTVSS
其中Xb1可以是疏水性氨基酸;
其中Xb2可以是P或A;
其中Xb3可以是疏水性氨基酸;
其中Xb4可以是V或K;
其中Xb5可以是疏水性氨基酸;
其中Xb6可以是碱性氨基酸;
其中Xb7可以是S或A;
其中Xb8可以是H或P;
其中Xb9可以是碱性氨基酸;
其中Xb10可以是S或G;
其中Xb11可以是疏水性氨基酸;
其中Xb12可以是碱性氨基酸;
其中Xb13可以是疏水性氨基酸;
其中Xb14可以是I或T;
其中Xb15可以是疏水性氨基酸;
其中Xb16可以是疏水性氨基酸;
其中Xb17可以是K或T;
其中Xb18可以是中性亲水性氨基酸;
其中Xb19可以是Q或E;
其中Xb20可以是N或S;
其中Xb21可以是T或R;
其中Xb22可以是中性亲水性氨基酸;或
其中Xb23可以是S或L,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:2中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
SEQ ID NO.:37(变体重链可变区)
QXB1QLVQSGXB2EXB3XB4KPGASVKXB5SCKASGYTFTDDYMSWVXB6QXB7XB8GXB9XB10LEWXB11GDINPYNGDTNYNQKFKGXB12XB13XB14XB15TXB16DXB17SXB18STAYMXB19LXB20SLXB21SEDXB22AVYYCARDPGAMDYWGQGTXB23VTVSS
其中XB1可以是I或V;
其中XB2可以是P或A;
其中XB3可以是M或V;
其中XB4可以是V或K;
其中XB5可以是M或V;
其中XB6可以是K或R;
其中XB7可以是S或A;
其中XB8可以是H或P;
其中XB9可以是K或Q;
其中XB10可以是S或G;
其中XB11可以是I或M;
其中XB12可以是K或R;
其中XB13可以是A或V;
其中XB14可以是I或T;
其中XB15可以是L或I,
其中XB16可以是V或A;
其中XB17可以是K或T;
其中XB18可以是S或T
其中XB19可以是Q或E;
其中XB20可以是N或S;
其中XB21可以是T或R;
其中XB22可以是S或T;或
其中XB23可以是S或L,
其中,由X确定的氨基酸的至少一个是与在SEQ ID NO.:2中列出的多肽中的相应氨基酸相比较的氨基酸置换(保守性或非保守性)。
SEQ ID NO.:38(变体1重链可变区:Hvh1)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWMGDINPYNGDTNYNQKFKGRVTITADTSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS
SEQ ID NO.:39(变体2重链可变区:Hvh2)
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWMGDINPYNGDTNYNQKFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS
SEQ ID NO.:40(变体3重链可变区:Hvh3)
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWIGDINPYNGDTNYNQKFKGRATLTVDKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS
SEQ ID NO.:41(变体4重链可变区:Hvh4)
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVKQAPGQGLEWIGDINPYNGDTNYNQKFKGKATLTVDKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSS
SEQ ID NO:42 3A4鼠轻(κ)链
DVVMTQTPLSLAVSLGDQASISCRSSQSLLHSNGNTYLEWYLQKPGQSPKLLIHTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDLGVYYCFQGSHVPLTFGAGTRLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:43 3A4人源化轻(κ)链变体1;Lh1
DIVMTQTPLSLPVTPGEPASISCRSSQSLLHSNGNTYLEWYLQKPGQSPQLLIYTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:44 3A4人源化轻(κ)链变体2;Lh2
DVVMTQTPLSLPVTPGEPASISCRSSQSLLHSNGNTYLEWYLQKPGQSPKLLIYTVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:45 3A4鼠重(Igg1)链
QIQLVQSGPEMVKPGASVKMSCKASGYTFTDDYMSWVKQSHGKSLEWIGDINPYNGDTNYNQKFKGKAILTVDKSSSTAYMQLNSLTSEDSAVYYCARDPGAMDYWGQGTSVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:46 3A4人源化重(Igg1)链变体1;Hh1
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWMGDINPYNGDTNYNQKFKGRVTITADTSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:47 3A4人源化重(Igg1)链变体2;Hh2
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWMGDINPYNGDTNYNQKFKGRVTITADKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:48 3A4人源化重(Igg1)链变体3;Hh3
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVRQAPGQGLEWIGDINPYNGDTNYNQKFKGRATLTVDKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:49 3A4人源化重(Igg1)链变体4:Hh4
QIQLVQSGAEVKKPGASVKVSCKASGYTFTDDYMSWVKQAPGQGLEWIGDINPYNGDTNYNQKFKGKATLTVDKSTSTAYMELSSLRSEDTAVYYCARDPGAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:50
ATACCCAAGCTTGCCACCATGGAGAGAGACACAC
SEQ ID NO:51
ATACCCAAGCTTCATTTCCCGGGAGACAGGGAG
SEQ ID NO:52
ATACCCAAGCTTGGGCCACCATGAACTTTCTGCTGTCTTGG
SEQ ID NO:53
ATACCCAAGCTTCTAACACTCTCCCCTGTTGAAG
SEQ ID NO:54pK-CR5
CTAAATTGTAAGCGTTAATATTTTGTTAAAATTCGCGTTAAATTTTTGTTAAATCAGCTCATTTTTTAACCAATAGGCCGAAATCGGCAAAATCCCTTATAAATCAAAAGAATAGACCGAGATAGGGTTGAGTGTTGTTCCAGTTTGGAACAAGAGTCCACTATTAAAGAACGTGGACTCCAACGTCAAAGGGCGAAAAACCGTCTATCAGGGCGATGGCCCACTACGTGAACCATCACCCTAATCAAGTTTTTTGGGGTCGAGGTGCCGTAAAGCACTAAATCGGAACCCTAAAGGGAGCCCCCGATTTAGAGCTTGACGGGGAAAGCCGGCGAACGTGGCGAGAAAGGAAGGGAAGAAAGCGAAAGGAGCGGGCGCTAGGGCGCTGGCAAGTGTAGCGGTCACGCTGCGCGTAACCACCACACCCGCCGCGCTTAATGCGCCGCTACAGGGCGCGTCCCATTCGCCATTCAGGCTGCGCAACTGTTGGGAAGGGCGATCGGTGCGGGCCTCTTCGCTATTACGCCAGCTGGCGAAAGGGGGATGTGCTGCAAGGCGATTAAGTTGGGTAACGCCAGGGTTTTCCCAGTCACGACGTTGTAAAACGACGGCCAGTGAGCGCGCGTAATACGACTCACTATAGGGCGAATTGGAGCTCCACCGCGGTGGCGGCCGCTCTAGAACTAGTGGATCCACATCGGCGCGCCAAATGATTTGCCCTCCCATATGTCCTTCCGAGTGAGAGACACAAAAAATTCCAACACACTATTGCAATGAAAATAAATTTCCTTTATTAGCCAGAGGTCGAGATTTAAATAAGCTTGCTAGCAGATCTTTGGACCTGGGAGTGGACACCTGTGGAGAGAAAGGCAAAGTGGATGTCATTGTCACTCAAGTGTATGGCCAGATCGGGCCAGGTGAATATCAAATCCTCCTCGTTTTTGGAAACTGACAATCTTAGCGCAGAAGTAATGCCCGCTTTTGAGAGGGAGTACTCACCCCAACAGCTGGATCTCAAGCCTGCCACACCTCACCTCGACCATCCGCCGTCTCAAGACCGCCTACTTTAATTACATCATCAGCAGCACCTCCGCCAGAAACAACCCCGACCGCCACCCGCTGCCGCCCGCCACGGTGCTCAGCCTACCTTGCGACTGTGACTGGTTAGACGCCTTTCTCGAGAGGTTTTCCGATCCGGTCGATGCGGACTCGCTCAGGTCCCTCGGTGGCGGAGTACCGTTCGGAGGCCGACGGGTTTCCGATCCAAGAGTACTGGAAAGACCGCGAAGAGTTTGTCCTCAACCGCGAGCCCAACAGCTGGCCCTCGCAGACAGCGATGCGGAAGAGAGTGACCGCGGAGGCTGGATCGGTCCCGGTGTCTTCTATGGAGGTCAAAACAGCGTGGATGGCGTCTCCAGGCGATCTGACGGTTCACTAAACGAGCTCTGCTTATATAGGCCTCCCACCGTACACGCCTACCTCGACCCGGGTACCAATCTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTAAGGTTGTCGAGTGAAGACGAAAGGGTTCATTAAGGCGCGCCGTCGACCTCGAGGGGGGGCCCGGTACCCAGCTTTTGTTCCCTTTAGTGAGGGTTAATTGCGCGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTACAGGCATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCACTCATGGTTATGGCAGCACTGCATAATTCTCTTACTGTCATGCCATCCGTAAGATGCTTTTCTGTGACTGGTGAGTACTCAACCAAGTCATTCTGAGAATAGTGTATGCGGCGACCGAGTTGCTCTTGCCCGGCGTCAATACGGGATAATACCGCGCCACATAGCAGAACTTTAAAAGTGCTCATCATTGGAAAACGTTCTTCGGGGCGAAAACTCTCAAGGATCTTACCGCTGTTGAGATCCAGTTCGATGTAACCCACTCGTGCACCCAACTGATCTTCAGCATCTTTTACTTTCACCAGCGTTTCTGGGTGAGCAAAAACAGGAAGGCAAAATGCCGCAAAAAAGGGAATAAGGGCGACACGGAAATGTTGAATACTCATACTCTTCCTTTTTCAATATTATTGAAGCATTTATCAGGGTTATTGTCTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGGGGTTCCGCGCACATTTCCCCGAAAAGTGCCAC
SEQ ID NO:55pMPG-CR5
GTCGACGATACCGTGCACTTAATTAAGCGCGCTCGACCAAATGATTTGCCCTCCCATATGTCCTTCCGAGTGAGAGACACAAAAAATTCCAACACACTATTGCAATGAAAATAAATTTCCTTTATTAGCCAGAGGTCGAGGTCGGGGGATCCGTTTAAACTTGGACCTGGGAGTGGACACCTGTGGAGAGAAAGGCAAAGTGGATGTCATTGTCACTCAAGTGTATGGCCAGATCGGGCCAGGTGAATATCAAATCCTCCTCGTTTTTGGAAACTGACAATCTTAGCGCAGAAGTAATGCCCGCTTTTGAGAGGGAGTACTCACCCCAACAGCTGGATCTCAAGCCTGCCACACCTCACCTCGACCATCCGCCGTCTCAAGACCGCCTACTTTAATTACATCATCAGCAGCACCTCCGCCAGAAACAACCCCGACCGCCACCCGCTGCCGCCCGCCACGGTGCTCAGCCTACCTTGCGACTGTGACTGGTTAGACGCCTTTCTCGAGAGGTTTTCCGATCCGGTCGATGCGGACTCGCTCAGGTCCCTCGGTGGCGGAGTACCGTTCGGAGGCCGACGGGTTTCCGATCCAAGAGTACTGGAAAGACCGCGAAGAGTTTGTCCTCAACCGCGAGCCCAACAGCTGGCCCTCGCAGACAGCGATGCGGAAGAGAGTGACCGCGGAGGCTGGATCGGTCCCGGTGTCTTCTATGGAGGTCAAAACAGCGTGGATGGCGTCTCCAGGCGATCTGACGGTTCACTAAACGAGCTCTGCTTATATAGGCCTCCCACCGTACACGCCTACCTCGACCCGGGTACCAATCTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTATAATACAAACAGACCAGATTGTCTGTTTGTTAAGGTTGTCGAGTGAAGACGAAAGGGTTAATTAAGGCGCGCCGTCGACTAGCTTGGCACGCCAGAAATCCGCGCGGTGGTTTTTGGGGGTCGGGGGTGTTTGGCAGCCACAGACGCCCGGTGTTCGTGTCGCGCCAGTACATGCGGTCCATGCCCAGGCCATCCAAAAACCATGGGTCTGTCTGCTCAGTCCAGTCGTGGACCAGACCCCACGCAACGCCCAAAATAATAACCCCCACGAACCATAAACCATTCCCCATGGGGGACCCCGTCCCTAACCCACGGGGCCAGTGGCTATGGCAGGGCCTGCCGCCCCGACGTTGGCTGCGAGCCCTGGGCCTTCACCCGAACTTGGGGGGTGGGGTGGGGAAAAGGAAGAAACGCGGGCGTATTGGCCCCAATGGGGTCTCGGTGGGGTATCGACAGAGTGCCAGCCCTGGGACCGAACCCCGCGTTTATGAACAAACGACCCAACACCCGTGCGTTTTATTCTGTCTTTTTATTGCCGTCATAGCGCGGGTTCCTTCCGGTATTGTCTCCTTCCGTGTTTCAGTTAGCCTCCCCCATCTCCCCTATTCCTTTGCCCTCGGACGAGTGCTGGGGCGTCGGTTTCCACTATCGGCGAGTACTTCTACACAGCCATCGGTCCAGACGGCCGCGCTTCTGCGGGCGATTTGTGTACGCCCGACAGTCCCGGCTCCGGATCGGACGATTGCGTCGCATCGACCCTGCGCCCAAGCTGCATCATCGAAATTGCCGTCAACCAAGCTCTGATAGAGTTGGTCAAGACCAATGCGGAGCATATACGCCCGGAGCCGCGGCGATCCTGCAAGCTCCGGATGCCTCCGCTCGAAGTAGCGCGTCTGCTGCTCCATACAAGCCAACCACGGCCTCCAGAAGAAGATGTTGGCGACCTCGTATTGGGAATCCCCGAACATCGCCTCGCTCCAGTCAATGACCGCTGTTATGCGGCCATTGTCCGTCAGGACATTGTTGGAGCCGAAATCCGCGTGCACGAGGTGCCGGACTTCGGGGCAGTCCTCGGCCCAAAGCATCAGCTCATCGAGAGCCTGCGCGACGGACGCACTGACGGTGTCGTCCATCACAGTTTGCCAGTGATACACATGGGGATCAGCAATCGCGCATATGAAATCACGCCATGTAGTGTATTGACCGATTCCTTGCGGTCCGAATGGGCCGAACCCGCTCGTCTGGCTAAGATCGGCCGCAGCGATCGCATCCATGGCCTCCGCGACCGGCTGCAGAACAGCGGGCAGTTCGGTTTCAGGCAGGTCTTGCAACGTGACACCCTGTGCACGGCGGGAGATGCAATAGGTCAGGCTCTCGCTGAATTCCCCAATGTCAAGCACTTCCGGAATCGGGAGCGCGGCCGATGCAAAGTGCCGATAAACATAACGATCTTTGTAGAAACCATCGGCGCAGCTATTTACCCGCAGGACATATCCACGCCCTCCTACATCGAAGCTGAAAGCACGAGATTCTTCGCCCTCCGAGAGCTGCATCAGGTCGGAGACGCTGTCGAACTTTTCGATCAGAAACTTCTCGACAGACGTCGCGGTGAGTTCAGGCTTTTTCATATCTCATTGCCCGGGATCTGCGGCACGCTGTTGACGCTGTTAAGCGGGTCGCTGCAGGGTCGCTCGGTGTTCGAGGCCACACGCGTCACCTTAATATGCGAAGTGGACCTGGGACCGCGCCGCCCCGACTGCATCTGCGTGTTCGAATTCGCCAATGACAAGACGCTGGGCGGGGTTTGTGTCATCATAGAACTAAAGACATGCAAATATATTTCTTCCGGGGACACCGCCAGCAAACGCGAGCAACGGGCCACGGGGATGAAGCAGGGCATGGCGGCCGACGCGCTGGGCTACGTCTTGCTGGCGTTCGCGACGCGAGGCTGGATGGCCTTCCCCATTATGATTCTTCTCGCTTCCGGCGGCATCGGGATGCCCGCGTTGCAGGCCATGCTGTCCAGGCAGGTAGATGACGACCATCAGGGACAGCTTCAAGGATCGCTCGCGGCTCTTACCAGCCTAACTTCGATCACTGGACCGCTGATCGTCACGGCGATTTATGCCGCCTCGGCGAGCACATGGAACGGGTTGGCATGGATTGTAGGCGCCGCCCTATACCTTGTCTGCCTCCCCGCGTTGCGTCGCGGTGCATGGAGCCGGGCCACCTCGACCTGAATGGAAGCCGGCGGCACCTCGCTAACGGATTCACCACTCCAAGAATTGGAGCCAATCAATTCTTGCGGAGAACTGTGAATGCGCAAACCAACCCTTGGCAGAACATATCCATCGCGTCCGCCATCTCCAGCAGCCGCACGCGGCGCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTGCAGGCATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCACTCATGGTTATGGCAGCACTGCATAATTCTCTTACTGTCATGCCATCCGTAAGATGCTTTTCTGTGACTGGTGAGTACTCAACCAAGTCATTCTGAGAATAGTGTATGCGGCGACCGAGTTGCTCTTGCCCGGCGTCAACACGGGATAATACCGCGCCACATAGCAGAACTTTAAAAGTGCTCATCATTGGAAAACGTTCTTCGGGGCGAAAACTCTCAAGGATCTTACCGCTGTTGAGATCCAGTTCGATGTAACCCACTCGTGCACCCAACTGATCTTCAGCATCTTTTACTTTCACCAGCGTTTCTGGGTGAGCAAAAACAGGAAGGCAAAATGCCGCAAAAAAGGGAATAAGGGCGACACGGAAATGTTGAATACTCATACTCTTCCTTTTTCAATATTATTGAAGCATTTATCAGGGTTATTGTCTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGGGGTTCCGCGCACATTTCCCCGAAAAGTGCCACCTGACGTCTAAGAAACCATTATTATCATGACATTAACCTATAAAAATAGGCGTATCACGAGGCCCTTTCGTCTTCAAGAATTCTCATGTTTGACAGCTTATCTCTAGCAGATCCGGAATTCCCCTCCCCAATTTAAATGAGGACCTAACCTGTGGAAATCTACTGATGTGGGAGGCTGTAACTGTACAAACAGAGGTTATTGGAATAACTAGCATGCTTAACCTTCATGCAGGGTCACAAAAAGTGCATGACGATGGTGGAGGAAAACCTATTCAAGGCAGTAATTTCCACTTCTTTGCTGTTGGTGGAGACCCCTTGGAAATGCAGGGAGTGCTAATGAATTACAGGACAAAGTACCCAGATGGTACTATAACCCCTAAAAACCCAACAGCCCAGTCCCAGGTAATGAATACTGACCATAAGGCCTATTTGGACAAAAACAATGCTTATCCAGTTGAGTGCTGGGTTCCTGATCCTAGTAGAAATGAAAATACTAGGTATTTTGGGACTTTCACAGGAGGGGAAAATGTTCCCCCAGTACTTCATGTGACCAACACAGCTACCACAGTGTTGCTAGATGAACAGGGTGTGGGGCCTCTTTGTAAAGCTGATAGCCTGTATGTTTCAGCTGCTGATATTTGTGGCCTGTTTACTAACAGCTCTGGAACACAACAGTGGAGAGGCCTTGCAAGATATTTTAAGATCCGCCTGAGAAAAAGATCTGTAAAGAATCCTTACCTAATTTCCTTTTTGCTAAGTGACCTTATAAACAGGAGAACCCAGAGAGTGGATGGGCAGCCTATGTATGGTATGGAATCCCAGGTAGAAGAGGTTAGGGTGTTTGATGGCACAGAAAGACTTCCAGGGGACCCAGATATGATAAGATATATTGACAAACAGGGACAATTGCAAACCAAAATGCTTTAAACAGGTGCTTTTATTGTACATATACATTTAATAAATGCTGCTTTTGTATAAGCCACTTTTAAGCTTGTGTTATTTTGGGGGTGGTGTTTTAGGCCTTTTAAAACACTGAAAGCCTTTACACAAATGCAACTCTTGACTATGGGGG TCTGACCTTTGGGAATGTTCAGCAGGGGCTGAAGTATCTGAGACTTGGGAAGAGCATTGTGATTGGGATTCAGTGCTTGATCCATGTCCAGAGTCTTCAGTTTCTGAATCCTCTTCTCTTGTAATATCAAGAATACATTTCCCCATGCATATATTATATTTCATCCTTGAAAAAGTATACATACTTATCTCAGAATCCAGCCTTTCCTTCCATTCAACAATTCTAGAAGTTAAAACTGGGGTAGATGCTATTACAGAGGTAGAATGCTTCCTAAACCCAGAAATGGGGGATCTGC
SEQ ID NO.:56-3A4人源化重链CDR2多肽序列
DINPYNGDTNYNQKFKG
本发明的一些实施方案如下:
1.一种抗体或其抗原结合片段,该抗体或其抗原结合片段能够特异性地结合至肾相关抗原1(KAAG1)上,这种肾相关抗原1具有与SEQ ID NO.:4至少70%一致的一个轻链可变区和/或与SEQ ID NO.:2至少70%一致的一个重链可变区,其中所述抗体或其抗原结合片段与SEQ ID NO.:4或SEQ ID NO.:2相比包含至少一个氨基酸置换,并且其中所述氨基酸置换是在一个互补决定区(CDR)之外。
2.如实施方案1所述的抗体或抗原结合片段,其中该轻链可变区与SEQ ID NO.:4是至少80%一致的。
3.如实施方案1所述的抗体或抗原结合片段,其中该轻链可变区与SEQ ID NO.:4是至少90%一致的。
4.如实施方案1至3中任一项所述的抗体或抗原结合片段,其中该重链可变区与SEQ ID NO.:2是至少80%一致的。
5.如实施方案4所述的抗体或抗原结合片段,其中该重链可变区与SEQ ID NO.:2是至少90%一致的。
6.如实施方案1至5中任一项所述的抗体或抗原结合片段,其中该至少一个氨基酸置换是在该轻链可变区之内。
7.如实施方案1至6中任一项所述的抗体或抗原结合片段,其中该至少一个氨基酸置换是在该重链可变区之内。
8.如实施方案1至7中任一项所述的抗体或抗原结合片段,其中这些重链CDR包含在SEQ ID NO.:5、SEQ ID NO.:6和SEQ ID NO.:7中列出的这些氨基酸。
9.如实施方案1至8中任一项所述的抗体或抗原结合片段,其中这些轻链CDR包含在SEQ ID NO.:8、SEQ ID NO.:9和SEQ ID NO.:10中列出的这些氨基酸。
10.如实施方案1至9中任一项所述的抗体或抗原结合片段,其中该抗体是一种单克隆抗体、一种嵌合抗体、一种杂交抗体、一种人源化抗体或一种人抗体、或它们的一种抗原结合片段。
11.如实施方案1至10中任一项所述的抗体或抗原结合片段,其中该轻链可变区是如在SEQ ID NO.:30中所列出的。
12.如实施方案11所述的抗体或抗原结合片段,其中该轻链可变区是如在SEQ ID NO.:32中所列出的。
13.如实施方案12所述的抗体或抗原结合片段,其中该轻链可变区是如在SEQ ID NO.:33中或在SEQ ID NO.:34中所列出的。
14.如实施方案1至13中任一项所述的抗体或抗原结合片段,其中该重链可变区是如在SEQ ID NO.:35中所列出的。
15.如实施方案14所述的抗体或抗原结合片段,其中该重链可变区是如在SEQ ID NO.:36中所列出的。
16.如实施方案15所述的抗体或抗原结合片段,其中该重链可变区是如在SEQ ID NO.:37中所列出的。
17.如实施方案16所述的抗体或抗原结合片段,其中该重链可变区是如在SEQ ID NO.:38、SEQ ID NO.:39、SEQ ID NO.:40或SEQ ID NO.:41中所列出的。
18.一种抗体或抗原结合片段,该抗体或抗原结合片段能够与如实施方案1至17中任一项所述的抗体或抗原结合片段竞争并且具有少1nM的亲和力。
19.如实施方案1至17中任一项所述的抗体或抗原结合片段,该抗体或抗原结合片段与一种治疗部分相结合。
20.如实施方案1至17中任一项所述的抗体或抗原结合片段,该抗体或抗原结合片段与一种可检测部分相结合。
21.一种核酸,该核酸编码如实施方案1至17中任一项所述的抗体或抗原结合片段的一个轻链可变区和/或一个重链可变区。
22.一种载体,该载体包含如实施方案21所述的核酸。
23.如实施方案22所述的载体,其中所述载体是一种表达载体。
24.一种分离的细胞,这种分离的细胞包含如实施方案21所述的核酸。
25.如实施方案24所述的分离的细胞,其中所述细胞包含编码一个轻链可变区的一种核酸、以及编码一个重链可变区的一种核酸。
26.如实施方案25所述的分离的细胞,其中所述细胞能够表达、组装和/或分泌一种抗体或其抗原结合片段。
27.一种分离的细胞,这种分离的细胞包含或表达如实施方案1至20中任一项所述的抗体或抗原结合片段。
28.如实施方案27所述的分离的细胞,其中所述细胞包含编码一个轻链可变区的一种核酸、以及编码一个重链可变区的一种核酸。
29.如实施方案28所述的分离的细胞,其中所述细胞能够表达、组装和/或分泌一种抗体或其抗原结合片段。
30.一种药物组合物,该药物组合物包含如实施方案1至20中任一项所述的抗体或抗原结合片段、以及一种药学上可接受的载体。
31.一种组合物,该组合物包含如实施方案1至20中任一项所述的抗体或抗原结合片段、以及一种载体。
32.一种治疗癌症的方法,该癌症包含表达KAAG1或一种KAAG1变体的细胞,该方法包括将如实施方案1至20中任一项所述的抗体或抗原结合片段给予至有需要的受试者。
33.如实施方案32所述的方法,其中该癌症选自下组,该组由以下各项组成:卵巢癌、皮肤癌、肾癌、结肠直肠癌、肉瘤、白血病、脑肿瘤、甲状腺瘤、乳腺癌、前列腺癌、食管肿瘤、膀胱肿瘤、肺肿瘤以及头颈部肿瘤。
34.如实施方案33所述的方法,其中该癌症是卵巢癌。
35.如实施方案34所述的方法,其中该癌症是复发性卵巢癌。
36.如实施方案32至35中任一项所述的方法,其中该癌症是转移性的。
37.一种检测肿瘤的方法,该肿瘤包含表达KAAG1或一种KAAG1变体的细胞,该方法包括将如实施方案1至20中任一项所述的抗体或抗原结合片段给予至有需要的受试者。
38.如实施方案37所述的方法,其中有需要的受试者患有一种选自下组的癌症,该组由以下各项组成:卵巢癌、皮肤癌、肾癌、结肠直肠癌、肉瘤、白血病、脑癌、甲状腺癌、乳腺癌、前列腺癌、食管癌、膀胱癌、肺癌以及头颈癌。
39.一种用于检测KAAG1或KAAG1变体的方法,该方法包括使一种表达KAAG1或KAAG1变体的细胞或一种包含或疑似包含KAAG1或该KAAG1变体的样品与如实施方案1至20中任一项所述的抗体或抗原结合片段接触,并且对结合进行测量。
40.如实施方案39所述的方法,其中受试者患有或疑似患有癌症。
41.如实施方案40所述的方法,其中该癌症是转移性的。
42.如实施方案39至41中任一项所述的方法,其中该样品是从一种哺乳动物获得的一种血清样品、一种血浆样品或一种血液样品。
43.如实施方案39至41中任一项所述的方法,其中该样品是从一种哺乳动物获得的一种组织样品。
44.如实施方案39至41所述的方法,其中该样品是一种细胞培养物或一种上清液。
45.如实施方案39至44中任一项所述的方法,该方法包括将结合至KAAG1或该KAAG1变体上的抗体的量进行定量。
46.一种试剂盒,该试剂盒包含如实施方案1至20中任一项所述的抗体或抗原结合片段。
47.如实施方案1至20中任一项所述的抗体或抗原结合片段在一种药剂的制造中的用途,该药剂用于治疗癌症,该癌症包含表达KAAG1或一种KAAG1变体的细胞。
48.如实施方案47所述的用途,其中该癌症选自下组,该组由以下各项组成:卵巢癌、皮肤癌、肾癌、结肠直肠癌、肉瘤、白血病、脑癌、甲状腺癌、乳腺癌、前列腺癌、食管癌、膀胱癌、肺癌以及头颈癌。
49.如实施方案48所述的用途,其中该癌症是卵巢癌。
50.如实施方案49所述的用途,其中该癌症是复发性卵巢癌。
51.如实施方案47至50中任一项所述的用途,其中该癌症是转移性的。
52.如实施方案1至20中任一项所述的抗体或抗原结合片段在包含表达KAAG1或一种KAAG1变体的细胞的癌症的诊断中的用途,或在表达KAAG1或一种KAAG1变体的细胞的检测中的用途。
53.如实施方案52所述的用途,其中该癌症选自下组,该组由以下各项组成:卵巢癌、皮肤癌、肾癌、结肠直肠癌、肉瘤、白血病、脑癌、甲状腺癌、乳腺癌、前列腺癌、食管癌、膀胱癌、肺癌以及头颈癌。
54.如实施方案53所述的用途,其中该癌症是卵巢癌。
55.如实施方案54所述的用途,其中该癌症是复发性卵巢癌。
56.如实施方案52至55中任一项所述的用途,其中该癌症是转移性的。
57.一种用于获得抗体或其抗原结合片段的方法,该抗体或其抗原结合片段适合于用作一种治疗癌症的抗体-药物结合物,该癌症包含表达KAAG1或一种KAAG1变体的细胞,该方法包括:
a.提供特异性地结合至一种表位的一种抗体或一种抗原结合片段,该表位被包含在KAAG1或一种KAAG1变体的氨基酸61与84之间;
b.对该抗体或抗原结合片段在表达KAAG1或一种KAAG1变体的一种细胞之内的内化进行测试;并且
c.对被内化的一种抗体或一种抗原结合片段进行分离。
- 还没有人留言评论。精彩留言会获得点赞!