与TRAILR2和PSMA结合的双特异性抗体的制作方法
本发明涉及包含与肿瘤坏死因子相关凋亡诱导配体受体(tumornecrosisfactor-relatedapoptosisincludingligandreceptor2,trailr2)结合的抗原结合结构域和与前列腺特异性膜抗原(prostate-specificmembraneantigen,psma)结合的抗原结合结构域的双特异性抗体或该抗体片段、具有编码该抗体或该抗体片段的碱基序列的核酸、包含该核酸的重组载体、包含该重组载体的转化株、使用该转化株的该双特异性抗体或该抗体片段的制造方法、以及包含该双特异性抗体或该抗体片段的检测或测定试剂、诊断剂和治疗剂。
背景技术:
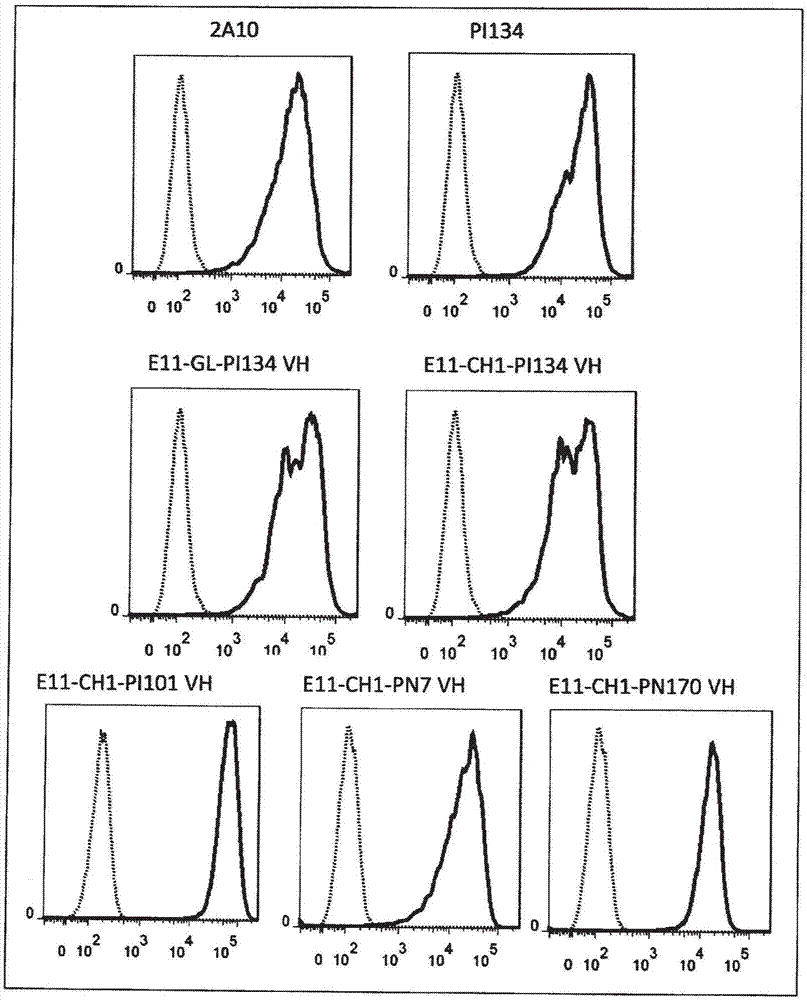
:抗体是存在于所有哺乳动物的血清、组织体液中的糖蛋白,在生物体内对外来抗原进行识别(非专利文献1)。抗体通过活化补体系统或结合于细胞表面上存在的受体(fcr)而活化fcr表达细胞的吞噬功能、抗体依赖性细胞毒潜能、介质的游离功能和抗原提呈功能等效应子功能,参与生物体防御。一分子的抗体由两条相同的轻链(l链)和两条相同的重链(h链)构成,具备两个抗原结合位点。抗体的类和亚类由h链决定,各类和亚类具有不同的固有功能。人的抗体存在5个不同的类,即,igg、iga、igm、igd和ige。igg进一步分类为igg1、igg2、igg3和igg4的亚类,iga进一步分类为iga1和iga2的亚类。多价抗体是在一分子内具备多个抗原结合位点的抗体。作为多价抗体的例子,首先有使用杂交-杂交瘤制作具有作为与不同抗原结合的多个不同的多肽链的h链和l链的多价抗体的报道(非专利文献3)。但是,该方法中,在一个细胞中表达两种不同的h链和l链,因此产生约10种抗体的h链与l链的组合。因此,具有所期望的h链与l链的组合的多价抗体的生成量低,并且也难以将这样的多价抗体选择地进行分离纯化,因此所期望的抗体的收量减少。为了克服该问题,报道了下述的尝试:通过将多个抗原结合位点连接起来作为单一多肽链进行表达而减少亚单位间的组合的变化,生产具有所期望的组合的抗体。作为一例,已知有包含将h链和l链的抗原结合位点连接为一个多肽而得到的单链fv(singlechainfv,scfv)的抗体(非专利文献4)。此外,还报道了使用igg1的h链恒定区的ch1结构域或该结构域的部分片段、以及l链恒定区或柔性连接子(gly-gly-gly-gly-ser)将两个抗原结合位点连接而成的抗体等(非专利文献5、专利文献1、专利文献2)。这些现有的多价抗体容易聚集,具有稳定性和生产率低的缺点。但另一方面,发现了在单一的h链多肽中具有多个抗原结合位点、抗原结合位点不相互接近的多价抗体稳定性高,生产率也良好(专利文献3)。在生物体内,由于正常细胞的世代交替而发生的生理性细胞死亡被称为凋亡,其区别于作为病理性细胞死亡的坏死(necrosis)(非专利文献6)。凋亡是在胚胎产生、淋巴细胞(t细胞和b细胞)的选择等过程中通常可见的现象(非专利文献7)。作为参与凋亡的分子,已鉴定出肿瘤坏死因子-α(tnf-α)、肿瘤坏死因子-β(tnf-β)、fas配体、cd40配体(cd154)等属于肿瘤坏死因子家族(tnf家族)的分子。tnf家族分子与细胞表面上的相应的特异性受体(tnf受体家族分子)结合,引起该受体的三聚体化,由此向细胞内转导信号,对各种细胞引起凋亡(非专利文献8-11)。tnf受体家族分子根据细胞外结构域的富半胱氨酸重复序列的存在来进行定义。其中,作为fas配体和tnf-α各自的受体的fas和tnfr1在细胞内具备被称为死亡结构域的、凋亡的信号转导所必需的区域。fas的活化会促进包含死亡结构域的接头分子fadd/mort1的缔合,引起结合于fadd/mort1上的半胱天冬酶-8(caspase-8)的活化。活化的caspase-8将下游的半胱天冬酶分子群依次活化,最后将细胞引向凋亡(非专利文献12)。通过将tnf受体家族分子的特异性抗体彼此交联(crosslink),也可向细胞内转导信号,因此,认为信号转导需要tnf受体家族分子的缔合(非专利文献13、14)。trail是由wiley等人发现的诱导凋亡的tnf家族分子,是tnf相关凋亡诱导配体的简称(非专利文献15)。该分子也被称为apo-2配体或apo-2l(非专利文献16)。不同于fas配体,trail在脾脏、肺、前列腺、胸腺、卵巢、小肠、大肠、外周血淋巴细胞、胎盘、肾脏等多种人的组织中以显著的水平被检测到,在若干种细胞株中恒定地表达。trail与trail受体结合,以与fas引起的死亡的信号转导类似的时间段,与tnf相比非常快速地诱导凋亡(非专利文献17)。作为trail受体(trailr),目前为止已鉴定出5种蛋白质。其中的两种受体trailr1(deathreceptor4,死亡受体4;也称为dr4)和trailr2(deathreceptor5,死亡受体5;也称为dr5)均在胞内区具有死亡结构域。trailr1的转录产物在包括脾脏、外周血白细胞、小肠、胸腺在内的人的多种组织中被确认到,trailr2的转录产物在脾脏、外周血淋巴细胞、卵巢等多种组织中被确认到(非专利文献18-20)。据报道,trailr2是通过选择性剪接(alternativesplicing)而具有两种形式的i型膜蛋白,在癌细胞中由440个氨基酸残基构成的形式的表达量多(非专利文献21、22)。另外,trailr2还通过trail的结合而三聚体化,经由自身的死亡结构域诱导细胞死亡信号,引起癌细胞的凋亡(非专利文献23)。包含trail的胞外区的重组人trail诱导各种癌细胞凋亡(非专利文献22),并且在使用人的大肠癌细胞和乳腺癌细胞的荷瘤小鼠模型中显示出显著的抗肿瘤效果(非专利文献25)。另外,trail与同样属于tnf家族且具有凋亡诱导活性的tnf-α或fas配体不同,不会对小鼠和食蟹猴的正常组织造成损伤(非专利文献26)。但是另一方面,已知重组人trail对于人正常肝实质细胞和人脑细胞也会诱导凋亡(非专利文献28、32)。据报道,抗trailr1和trailr2的单克隆抗体与上述重组人trail同样地对癌细胞诱导凋亡(非专利文献24、27、专利文献4)。这些抗体在使用人的大肠癌细胞等的荷瘤小鼠模型中也显示出抗肿瘤效果(非专利文献24、专利文献4)。总体来说,已经报道了:现有的抗trailr的抗体在体外实验中通过诱导细胞死亡而发挥抗肿瘤活性时需要进行抗体间的交联(非专利文献24、27)。作为抗体所产生的抗肿瘤活性的主要机制,可以列举:补体依赖性细胞毒作用(cdc)、抗体依赖性细胞毒作用(adcc)等利用宿主免疫系统进行的排除;和癌细胞上的靶分子所介导的直接的增殖抑制或细胞死亡诱导的引发这两种机制。例如,关于抗cd20抗体和抗her2/neu抗体,通过使用小鼠模型的实验暗示,在免疫活性细胞上表达的fc受体所介导的adcc承担抗体的抗肿瘤活性(非专利文献24)。此外,还报道了:抗cd20抗体的抗肿瘤活性在将抗体交联的情况下增强,带来癌细胞的增殖抑制效果(非专利文献24)。另一方面,psma是由3个结构域构成的由总计750个氨基酸残基构成的约110kda的ii型膜糖蛋白,上述3个结构域为由19个氨基酸残基构成的胞内结构域、由24个氨基酸残基构成的跨膜结构域和由707个氨基酸残基构成的胞外结构域。psma作为谷氨酸羧肽酶、n-乙酰化α连接酸性二肽酶和叶酸水解酶发挥功能(非专利文献29)。psma在生物体内表达于前列腺上皮细胞,其表达量在前列腺癌中上升,特别是在低分化型、转移性和激素抵抗性的腺癌中显著上升(非专利文献30、31)。另外,psma在小肠、唾液腺、十二指肠粘膜、近曲小管和脑中少量表达(非专利文献31)。此外,psma参与肿瘤的血管新生(非专利文献31),在大肠癌、乳腺癌、膀胱癌、胰腺癌、肾癌和黑色素瘤的与肿瘤相关的新生血管的上皮中也有表达(非专利文献32)。作为抗psma的抗体,已知有j591(atcc保藏号hb-12126)(专利文献5),并开发了利用177lu(钌)、89zr(锆)等的放射性标记物作为癌治疗剂和诊断剂。现有技术文献专利文献专利文献1:美国专利申请公开第2007/0071675号说明书专利文献2:国际公开第2001/077342号专利文献3:国际公开第2009/131239号专利文献4:国际公开第2002/094880号专利文献5:美国专利第5773292号说明书非专利文献非专利文献1:charlesa.j.et.al.,immunobiology,1997,currentbiologyltd/garlandpublishinginc.非专利文献2:emmanuellelaffyet.al.,humanantibodies14,33-55,2005非专利文献3:sureshet.al.,methodsenzymol.121,210-228,1986非专利文献4:kranzet.al.,j.hematotherimmunol.5,403-408,1995非专利文献5:wuet.al.,nat.biothech.25,1290-1297,2007非专利文献6:kerr,etal.,br.j.cancer26,239,1972非专利文献7:itoh,s.,etal.,cell66,233-243,1991非专利文献8:schmid,etal.,proc.natl.acad.sci.,83,1881,1986非专利文献9:dealtryetal.,eur.j.immunol.17,689,1987非专利文献10:krammer,etal.,curr.op.immunol.6,279-289,1994非专利文献11:nagata,etal.,science267,1449-1456,1995非专利文献12:nagataetal.,cell,88,355-365,1997非专利文献13:chuntharapaiaet.al.,j.immunol.166(8),4891,2001非专利文献14:ashkenaziaet.al.,natrevcancer2,420,2002非专利文献15:wileyetal.,immunity,3,673-682,1995非专利文献16:pitt,r.m.,etal.,j.biol.chem.271,12687-12690,1996非专利文献17:marsters,s.a.,etal.,curr.biol.6,750-752,1996非专利文献18:pan,g.,etal.,science276,111-113,1997非专利文献19:pan,g.,etal.,science277,815-818,1997非专利文献20:walczak,h.,etal.,emboj.,16,5386-5397,1997非专利文献21:screaton,g.r.,etal.,currbiol.,7,693-696,1997非专利文献22:arai,t.,etal.,cancerletters,133,197-204,1998非专利文献23:hymowitzs.g.etal.,molcell.,4,563-71,1999非专利文献24:griffith,t.s.,etal.,curr.opin.immunol.,10,559-563,1998非专利文献25:walczak,h.,etal.,naturemedicine5,2,157-163,1999非专利文献26:ashkenazi,a.,etal.,j.clin.invest.104,155-162,1999非专利文献27:mori,e.,etal,celldeathanddifferentiation,11,203-207,2004非专利文献28:jo,m.,etal.,naturemedicine,6,564-567,2000非专利文献29:elsasser-beileu.etal.,curr.drugtargets,10,118-125,2009非专利文献30:gregorakis,a.k.etal.,semin.urol.oncol.,16,2-12,1998非专利文献31:silver,d.a.,clin.cancerreseach,3,81-85,1997非专利文献32:chang,s.s.,curr.opin.invest.drugs,5,611-615,2004技术实现要素:发明所要解决的问题本发明所要解决的问题在于,提供包含与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域的双特异性抗体或该抗体片段、具有编码该抗体或该抗体片段的碱基序列的核酸、包含该核酸的重组载体、包含该重组载体的转化株、使用该转化株的该双特异性抗体或该抗体片段的制造方法、以及包含该双特异性抗体或该抗体片段的检测或测定试剂、诊断剂和治疗剂。用于解决问题的方法作为用于解决上述问题的方法,本发明提供包含与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域的双特异性抗体或该抗体片段。即,本发明涉及下述(1)~(30)。(1)一种双特异性抗体或该抗体片段,其包含与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域。(2)如(1)所述的双特异性抗体或该抗体片段,其仅在与trailr2和psma结合时使该trailr2活化。(3)如(1)或(2)所述的双特异性抗体或该抗体片段,其与trailr2和psma分别以二价进行结合。(4)如(1)~(3)中任一项所述的双特异性抗体或该抗体片段,其中,相比与psma结合的抗原结合结构域,与trailr2结合的抗原结合结构域的位置更靠n末端侧。(5)如(1)~(4)中任一项所述的双特异性抗体或该抗体片段,其中,与trailr2结合的抗原结合结构域为与trailr2结合的抗体的可变区(v区),并且与psma结合的抗原结合结构域为与psma结合的抗体的v区。(6)如(5)所述的双特异性抗体或该抗体片段,其中,与trailr2结合的单克隆抗体的重链可变区(heavychainvariableregion、以下记载为vh)的互补决定区(complementaritydeterminingregion;cdr)1~3的氨基酸序列分别包含序列号70~72所表示的氨基酸序列,并且轻链可变区(lightchainvariableregion、以下记载为vl)的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列。(7)如(5)或(6)所述的双特异性抗体或该抗体片段,其中,与trailr2结合的抗体的vh的氨基酸序列包含序列号118所表示的氨基酸序列,并且vl的氨基酸序列包含序列号119所表示的氨基酸序列。(8)如(5)~(7)中任一项所述的双特异性抗体或该抗体片段,其中,与psma结合的抗体的vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列,并且vh的cdr1~3的氨基酸序列包含选自由下述(a)~(d)组成的组中的任意一种氨基酸序列。(a)分别由序列号78、82和84表示的氨基酸序列、(b)分别由序列号78、79和80表示的氨基酸序列、(c)分别由序列号78、82和80表示的氨基酸序列、和(d)分别由序列号96~98表示的氨基酸序列。(9)如(5)~(8)中任一项所述的双特异性抗体或该抗体片段,其中,与psma结合的抗体的vl的氨基酸序列包含序列号119所表示的氨基酸序列,并且vh的氨基酸序列包含选自由下述(e)~(o)组成的组中的任意一种氨基酸序列。(e)序列号122所表示的氨基酸序列、(f)序列号120所表示的氨基酸序列、(g)序列号128所表示的氨基酸序列、(h)序列号123所表示的氨基酸序列、(i)序列号127所表示的氨基酸序列、(j)序列号124所表示的氨基酸序列、(k)序列号125所表示的氨基酸序列、(l)序列号129所表示的氨基酸序列、(m)序列号121所表示的氨基酸序列、(n)序列号126所表示的氨基酸序列、和(o)序列号130所表示的氨基酸序列。(10)如(5)~(9)中任一项所述的双特异性抗体或该抗体片段,其包含含有如下多肽的重链,所述多肽由与trailr2结合的抗体的vh和与psma结合的抗体的vh借助包含免疫球蛋白结构域或该结构域片段的连接子连接而成。(11)如(10)所述的双特异性抗体或该抗体片段,其中,连接子为来源于igg4或igm亚类的连接子。(12)如(10)或(11)所述的双特异性抗体或该抗体片段,其中,由与trailr2结合的抗体的vh、连接子和与psma结合的抗体的vh构成的多肽的氨基酸序列为选自由下述(a)~(m)组成的组中的任意一种氨基酸序列。(a)序列号131所表示的氨基酸序列、(b)序列号132所表示的氨基酸序列、(c)序列号133所表示的氨基酸序列、(d)序列号134所表示的氨基酸序列、(e)序列号135所表示的氨基酸序列、(f)序列号136所表示的氨基酸序列、(g)序列号137所表示的氨基酸序列、(h)序列号138所表示的氨基酸序列、(i)序列号139所表示的氨基酸序列、(j)序列号140所表示的氨基酸序列、(k)序列号141所表示的氨基酸序列、(l)序列号142所表示的氨基酸序列、和(m)序列号143所表示的氨基酸序列。(13)一种核酸,其具有编码(1)~(12)中任一项所述的双特异性抗体或该抗体片段的碱基序列。(14)一种重组载体,其含有(13)所述的核酸。(15)一种转化株,其包含(14)所述的重组载体。(16)一种(1)~(12)中任一项所述的双特异性抗体或该抗体片段的制造方法,包括:将(15)所述的转化株在培养基中中进行培养,从培养上清中收集双特异性抗体或该抗体片段。(17)一种用于检测或测定trailr2和psma中的至少一者的试剂,其包含(1)~(12)中任一项所述的双特异性抗体或该抗体片段。(18)一种trailr2和psma表达细胞相关疾病的诊断剂,其含有(1)~(12)中任一项所述的双特异性抗体或该抗体片段。(19)如(18)所述的诊断剂,其中,trailr2和psma表达细胞相关疾病为恶性肿瘤和癌症。(20)一种trailr2和psma表达细胞相关疾病的治疗剂,其含有(1)~(12)中任一项所述的双特异性抗体或该抗体片段作为有效成分。(21)如(20)所述的治疗剂,其中,trailr2和psma表达细胞相关疾病为恶性肿瘤和癌症。(22)一种检测或测定trailr2和psma中的至少一者的方法,其使用(1)~(12)中任一项所述的双特异性抗体或该抗体片段。(23)一种trailr2和psma表达细胞相关疾病的诊断方法,包括:使用(1)~(12)中任一项所述的双特异性抗体或该抗体片段来检测或测定trailr2和psma中的至少一者。(24)如(23)所述的诊断方法,其中,trailr2和psma表达细胞相关疾病为恶性肿瘤和癌症。(25)一种trailr2和psma表达细胞相关疾病的治疗方法,其使用(1)~(12)中任一项所述的双特异性抗体或该抗体片段。(26)如(25)所述的治疗方法,其中,trailr2和psma表达细胞相关疾病为恶性肿瘤和癌症。(27)(1)~(12)中任一项所述的双特异性抗体或该抗体片段在制造trailr2和psma表达细胞相关疾病的诊断剂中的应用。(28)如(27)所述的应用,其中,trailr2和psma表达细胞相关疾病为恶性肿瘤和癌症。(29)(1)~(12)中任一项所述的双特异性抗体或该抗体片段在制造trailr2和psma表达细胞相关疾病的治疗剂中的应用。(30)如(29)所述的应用,其中,trailr2和psma表达细胞相关疾病为恶性肿瘤和癌症。发明效果本发明的双特异性抗体或该抗体片段仅在与trailr2和psma结合时诱导与trailr2的活化相伴随的各种反应。因此,本发明的双特异性抗体或该抗体片段能够作为trailr2和psma表达细胞相关疾病的治疗剂和诊断剂使用。附图说明图1是示出本发明的双特异性抗体的结构的图。粗线表示将两个vh连接的连接子。图2是利用流式细胞仪分析抗hpsma单克隆抗体或htrailr2-hpsma双特异性抗体对hpsma/l929细胞的结合性而得到的结果。纵轴表示细胞数,横轴表示荧光强度。抗hpsma单克隆抗体使用2a10抗体或pi134抗体。htrailr2-hpsma双特异性抗体使用e11-gl-pi134vh抗体、e11-ch1-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体或e11-ch1-pnl70vh抗体。实线表示上述各抗体的结合性,虚线表示作为阴性对照使用的公知的抗dnp单克隆抗体的结合性。图3是利用流式细胞仪分析抗htrailr2单克隆抗体、抗hpsma单克隆抗体或htrailr2-hpsma双特异性抗体对htrailr2/l929细胞的结合性而得到的结果。纵轴表示细胞数,横轴表示荧光强度。抗htrailr2单克隆抗体使用e11抗体。抗hpsma单克隆抗体使用pi134抗体。htrailr2-hpsma双特异性抗体使用e11-ch1-pi101vh、e11-ch1-pn7vh抗体或e11-ch1-pn170vh抗体。实线表示上述各抗体的结合性,虚线表示作为阴性对照使用的抗dnp单克隆抗体的结合性。图4(a)和图4(b)是示出pc3细胞[图4(a)]和hpsma/pc3细胞[图4(b)]中的htrailr2或hpsma的表达量的图。纵轴表示细胞数,横轴表示荧光强度。各细胞利用抗htrailr2单克隆抗体e11抗体、抗hpsma单克隆抗体pi134抗体、trailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体或作为阴性对照的抗dnp单克隆抗体进行了染色。图5是示出lncap克隆fgc细胞中的htrailr2或hpsma的表达量的图。纵轴表示细胞数,横轴表示荧光强度。细胞利用抗htrailr2单克隆抗体e11抗体、抗hpsma单克隆抗体2a10抗体或作为阴性对照的抗dnp单克隆抗体进行了染色。图6是示出对于pc3细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、或者htrailr2-hpsma双特异性抗体e11-ch1-pi134vh抗体或e11-ch1-pi101vh抗体的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示抗体浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图7是示出对于pc3细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、或者htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体或e11-ch1-pn170vh抗体的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示抗体浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图8是示出对于hpsma/pc3细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、或者htrailr2-hpsma双特异性抗体e11-gl-pi134vh抗体或e11-ch1-pi134vh抗体的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示抗体浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图9是示出对于hpsma/pc3细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、或者htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体或e11-ch1-pn170vh抗体的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示抗体浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图10是示出对于hpsma/pc3细胞使用抗htrailr2激动型单克隆抗体kmda2抗体或htrailr2-hpsma双特异性抗体的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示抗体浓度(ng/ml)。htrailr2-hpsma双特异性抗体使用e11-ch1-pi101vh抗体、e11-ch1-pi105vh抗体、e11-ch1-pi108vh抗体、e11-ch1-p1115vh抗体、e11-ch1-pi118vh抗体、e11-ch1-pi127vh抗体、e11-ch1-pi143vh抗体或e11-ch1-pl223vh抗体。作为阴性对照,使用抗dnp单克隆抗体。图11是示出对于lncap克隆fgc细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、或者htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体或e11-ch1-pn170vh抗体的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示抗体浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图12(a)和图12(b)示出利用流式细胞术检测将htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体或trailr2配体trail/apo2添加到细胞中时的活化半胱天冬酶而得到的结果。纵轴表示细胞数,横轴表示荧光强度。图12(a)示出使用pc3细胞时的结果,图12(b)示出使用psma/pc3细胞时的结果。作为阴性对照,使用抗dnp单克隆抗体。图13是示出对于人正常肝细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体或trailr2配体trail/apo2的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示蛋白质浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图14是示出对于人正常肝细胞使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、htrailr2-hpsma双特异性抗体e11-ch1-pn7vh抗体或trailr2配体trail/apo2的细胞增殖性试验的结果的图。纵轴表示细胞的存活率(%),横轴表示蛋白质浓度(ng/ml)。作为阴性对照,使用抗dnp单克隆抗体。图15(a)~图15(d)示出htrailr2-hpsma双特异性抗体e11-ch1-pn7vh抗体[图15(a)]、htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2[图15(b)]和e11-ch1-pn7vhfab[图15(c)]、以及htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体[图15(d)]的结构。图15(a)~图15(c)的结构中的粗线表示连接子。图16示出对于pc3细胞使用各抗体或抗体片段的细胞增殖性试验的结果。纵轴表示吸光度,横轴表示抗体浓度(nm)。作为抗体或抗体片段,使用抗htrailr2激动型单克隆抗体kmda2抗体、htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体、htrailr2-hpsma双特异性抗体e11-ch1-pn7vh抗体、htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2或e11-ch1-pn7vhfab或者作为阴性对照的抗dnp单克隆抗体。图17示出对于hpsma/pc3细胞使用各抗体或抗体片段的细胞增殖性试验的结果。纵轴表示吸光度,横轴表示抗体浓度(nm)。作为抗体或抗体片段,使用抗htrailr2激动型单克隆抗体kmda2抗体、htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体、htrailr2-hpsma双特异性抗体e11-ch1-pn7vh抗体、htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2或e11-ch1-pn7vhfab或者作为阴性对照的抗dnp单克隆抗体。具体实施方式本发明涉及包含与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域的双特异性抗体或该抗体片段(以下,记载为本发明的双特异性抗体或该抗体片段)。本发明中,与trailr2或psma结合的抗原结合结构域只要特异性地识别并结合trailr2或psma,则可以为任何抗原结合结构域。例如,可以为抗体、配体、受体和天然存在的相互作用分子等能够利用基因重组技术进行制作的多肽、蛋白质分子及其片段、以及该蛋白质分子与低分子或天然物的结合体等任意形态。另外,作为抗原结合结构域,可以是利用抗体、配体和受体等已知的结合分子的结合结构域进行重组而得到的结合蛋白质,具体而言,可以列举包含与各抗原结合的抗体的cdr的重组蛋白质、包含cdr的抗体可变区、抗体可变区以及包含与各抗原结合的配体的结合结构域的重组蛋白质等。其中,本发明中,抗原结合结构域优选为抗体可变区。作为本发明的双特异性抗体或该抗体片段,可以列举仅在与trailr2和psma结合时将该trailr2活化的双特异性抗体或该抗体片段。本发明的双特异性抗体或该抗体片段通过与细胞上的trailr2和psma结合,使该trailr2三聚体化而活化,在trailr2表达细胞内引起死亡结构域所介导的接头分子fadd/mort1的缔合和半胱天冬酶8的活化等各种细胞反应。其结果,对于该细胞,诱导细胞增殖的抑制以及凋亡等细胞死亡等。即,作为本发明的双特异性抗体或该抗体片段,具体而言,可以列举仅在与trailr2和psma结合时产生选自由trailr2表达细胞内的fadd/mort1缔合、半胱天冬酶8活化、以及trailr2表达细胞的增殖抑制和细胞死亡诱导组成的组中的至少一种反应的双特异性抗体或该抗体片段等。本发明的双特异性抗体或该抗体片段可以与表达在同一细胞上的trailr2和psma结合,也可以与表达在不同细胞上的trailr2和psma结合。另外,本发明中,细胞死亡包含凋亡和坏死中的任意者,但优选为凋亡。本发明中的trailr2以与死亡受体5(deathreceptor5,dr5)、killer/dr5和trick2相同的含义使用。作为trailr2,可以列举例如包含ncbi(http://www.ncbi.nlm.nih.gov/)中ncbi登记号np_003833所示的氨基酸序列的人trailr2、和包含ncbi登记号np_064671所示的氨基酸序列的小鼠trailr2等。另外,可以列举例如由在ncbi登记号np_003833或ncbi登记号np_064671所示的氨基酸序列中缺失、置换或添加一个以上的氨基酸而成的氨基酸序列构成且具有trailr2的功能的多肽。包含与ncbi登记号np_003833或ncbi登记号np_064671所示的氨基酸序列具有70%以上、优选80%以上、进一步优选90%以上的同源性的氨基酸序列的多肽、由与ncbi登记号np_003833或ncbi登记号np_064671所示的氨基酸序列具有最优选95%、96%、97%、98%和99%以上的同源性的氨基酸序列构成且具有trailr2的功能的多肽也包含在本发明的trailr2中。具有在ncbi登记号np_003833或ncbi登记号np_064671所示的氨基酸序列中缺失、置换或添加一个以上的氨基酸而成的氨基酸序列的多肽可以通过使用定点诱变法[molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989);currentprotocolsinmolecularbiology(最新分子生物学实验方法汇编),约翰威利父子出版社(1987-1997);nucleicacidsresearch,10,6487(1982);proc.natl.acad.sci.usa,79,6409(1982);gene,34,315(1985);nucleicacidsresearch,13,4431(1985);proceedingofthenationalacademyofsciencesinusa,82,488(1985)]等,在例如编码ncbi登记号np_003833或ncbi登记号np_064671所示的氨基酸序列的dna中导入定点突变而得到。缺失、置换或添加的氨基酸的数量没有特别限定,优选为一个~几十个、例如1~20个、更优选为一个~几个、例如1~5个氨基酸。作为编码trailr2的基因,可以列举例如ncbi登记号nm_003842的第294位~第1616位所示的人trailr2的碱基序列、和ncbi登记号nm_020275所示的小鼠trailr2的碱基序列等。另外,例如包含由在ncbi登记号nm_003842的第294位~第1616位的碱基序列中缺失、置换或添加一个以上的碱基而成的碱基序列构成且编码具有trailr2的功能的多肽的dna的基因;包含由与ncbi登记号nm_003842的第294位~第1616位的碱基序列优选具有60%以上的同源性的碱基序列、更优选具有80%以上的同源性的碱基序列、进一步优选具有95%以上的同源性的碱基序列构成且编码具有trailr2的功能的多肽的dna的基因;以及包含由在严格条件下与ncbi登记号nm_003842的第294位~第1616位的dna杂交的dna构成且编码具有trailr2的功能的多肽的dna的基因等也包含在本发明的编码tailr2的基因中。作为在严格条件下杂交的dna,例如是指通过使用具有ncbi登记号nm_003842的第294位~第1616位所示的碱基序列的dna作为探针的菌落杂交法、噬菌斑杂交法、southern印记杂交法或dna微阵列法等得到的能够杂交的dna。具体而言,可以列举能够通过如下方法进行鉴定的dna:使用固定有来源于杂交的菌落或噬菌斑的dna或者具有该序列的pcr产物或寡聚dna的滤膜或载玻片,在0.7~1.0mol/l的氯化钠存在下在65℃下进行杂交[molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989);currentprotocolsinmolecularbiology(最新分子生物学实验方法汇编),约翰威利父子出版社(1987-1997);dnacloning1:coretechniques,apracticalapproach(dna克隆1:核心技术实用方法),第二版,牛津大学出版社(1995)]后,使用0.1~2倍浓度的ssc溶液(1倍浓度的ssc溶液的组成由150mmol/l氯化钠、15mmol/l柠檬酸钠构成),在65℃的条件下对滤膜或载玻片进行清洗。作为能够杂交的dna,可以列举例如与ncbi登记号nm_003842的第294位~第1616位所示的碱基序列优选具有60%以上的同源性的dna、更优选具有80%以上的同源性的dna、进一步优选具有95%以上的同源性的dna。编码真核生物的蛋白质的基因的碱基序列常常可以确认到基因的多态性。在本发明中使用的基因内由于这种多态性使碱基序列产生小规模突变而得到的基因也包含在本发明的编码trailr2的基因中。除了特别说明的情况以外,本发明中的同源性的数值可以是使用本领域技术人员公知的同源性检索程序算出的数值,对于碱基序列,可以列举使用blast[j.mol.biol.,215,403(1990)]中默认的参数算出的数值等,对于氨基酸序列,可以列举使用blast2[nucleicacidsresearch,25,3389(1997)、genomeresearch,7,649(1997)、http://www.ncbi.nlm.nih.gov/education/blastinfo/information3.html]中默认的参数算出的数值等。作为默认的参数,g(起始空位罚分,costtoopengap)在碱基序列的情况下为5、在氨基酸序列的情况下为11;-e(空位延伸罚分,costtoextendgap)在碱基序列的情况下为2、在氨基酸序列的情况下为1;-q(核苷酸错配罚分,penaltyfornucleotidemismatch)为-3;-r(核苷酸匹配得分,rewardfornucleotidematch)为1;-e(期望值,expectvalue)为10;-w(字长大小,wordsize)在碱基序列的情况下为11个残基、在氨基酸序列的情况下为3个残基;-y[非空位延伸下降的阈值,dropoff(x)forblastextensionsinbits)]在blastn的情况下为20、在blastn以外的程序中为7;-x(空位比对的下降阈值,xdropoffvalueforgappedalignmentinbits)为15;-z(最终空位比对的下降值,finalxdropoffvalueforgappedalignmentinbits)在blastn的情况下为50、在blastn以外的程序中为25(http://www.ncbi.nlm.nih.gov/blast/html/blastcgihelp.html)。由trailr2的氨基酸序列的部分序列构成的多肽可以通过本领域技术人员公知的方法来制作,例如,可以通过使编码ncbi登记号np_003833所示的氨基酸序列的dna的一部分缺失并对导入由包含上述dna的表达载体的转化体进行培养来制作。另外,可以基于上述方法中制作的多肽或dna,利用与上述同样的方法,得到具有例如在ncbi登记号np_003833所示的氨基酸序列的部分序列中缺失、置换或添加一个以上的氨基酸而成的氨基酸序列的多肽。此外,由trailr2的氨基酸序列的部分序列构成的多肽或者具有在trailr2的氨基酸序列的部分序列中缺失、置换或添加一个以上的氨基酸而成的氨基酸序列的多肽也可以通过芴甲氧羰基(fmoc)法和叔丁氧羰基(tboc)法等化学合成法来制造。作为本发明中的trailr2的胞外区,可以列举例如使用公知的跨膜区预测程序sosui(http://sosui.proteome.bio.tuat.ac.jp/sosuiframeo.html)、tmhmmver.2(http://www.cbs.dtu.dk/services/tmhmm-2.0/)或expasyproteomicsserver(http://ca.expasy.org/)等对ncbi登记号np_003833所示的人trailr2的氨基酸序列进行预测而得到的区域等。具体而言,可以列举ncbi登记号np_003833所示的氨基酸序列中的第54位至第212位的氨基酸序列。作为trailr2的功能,可以列举下述功能:trail(apo-2l)配体与trailr2结合时,形成trailr2的三聚体化,通过细胞内的死亡结构域促进接头分子fadd/mort1的缔合,引起与fadd/mort1结合的半胱天冬酶-8(caspase-8)的活化,结果对细胞诱导增殖抑制或凋亡。本发明中的psma以与叶酸水解酶(folatehydrolase,folh)、谷氨酸羧肽酶(glutamatecarboxypeptidaseii,gcp2)、前列腺特异性膜抗原(prostate-specificmembraneantigen,psm或psma)、n-乙酰化α连接酸性二肽酶(n-acetylatedalpha-linkedacidicdipeptidase1,naalad1)和naaladasei相同的含义来使用。作为psma,可以列举例如包含ncbi登记号np_004467或序列号112所示的氨基酸序列的人psma或包含ncbi登记号np_058050所示的氨基酸序列的小鼠psma等。另外,可以列举例如由在ncbi登记号np_004467、序列号112或ncbi登记号np_058050所示的氨基酸序列中缺失、置换或添加一个以上的氨基酸而成的氨基酸序列构成且具有psma的功能的多肽。包含与ncbi登记号np_004467、序列号112或ncbi登记号np_058050所示的氨基酸序列具有优选70%以上、更优选80%以上、进一步优选90%以上的同源性的氨基酸序列的多肽、由与ncbi登记号np_004467、序列号112或ncbi登记号np_058050所示的氨基酸序列具有最优选95%、96%、97%、98%和99%以上的同源性的氨基酸序列构成且具有psma的功能的多肽也包含在本发明的psma中。具有在ncbi登记号np_004467、序列号112或ncbi登记号np_058050所示的氨基酸序列中缺失、置换或添加一个以上的氨基酸而成的氨基酸序列的多肽可以通过使用上述的定点突变法等在编码例如ncbi登记号np_004467、序列号112或ncbi登记号np_058050所示的氨基酸序列的dna中导入定点突变而得到。缺失、置换或添加的氨基酸的数量没有特别限定,优选为1个~几十个、例如1~20个、更优选为1个~几个、例如1~5个氨基酸。作为本发明中的编码psma的基因,可以列举例如包含ncbi登记号nm_004476或序列号64所示的碱基序列的人psma的基因或包含ncbi登记号nm016770所示的碱基序列的小鼠psma的基因。另外,例如包含由在ncbi登记号nm_004476、序列号64或ncbi登记号nm016770所示的碱基序列中缺失、置换或添加一个以上的碱基而成的碱基序列构成且编码具有psma的功能的多肽的dna的基因;包含由与ncbi登记号nm_004476、序列号64或ncbi登记号nm016770所示的碱基序列具有60%以上的同源性的碱基序列、优选具有80%以上的同源性的碱基序列、进一步优选具有95%以上的同源性的碱基序列构成且编码具有psma的功能的多肽的dna的基因;以及包含由在严格条件下与ncbi登记号nm_004476、序列号64或ncbi登记号nm016770所示的dna杂交的dna构成且编码具有psma的功能的多肽的dna的基因等也作为本发明的编码psma的基因。作为psma的功能,可以列举作为谷氨酸羧肽酶、n-乙酰化α连接酸性二肽酶和叶酸水解酶发挥功能。本发明中,与trailr2结合是指识别trailr2的胞外区并且进行结合。另外,本发明中,与psma结合是指识别psma的胞外区并且进行结合。本发明中,抗体或该抗体片段与trailr2和psma中的至少一者结合这一点例如可以通过使用公知的免疫学检测法、优选荧光细胞染色法等对表达trailr2和psma中的至少一者的细胞与抗体的结合性进行确认的方法来确认。另外,也可以将公知的免疫学检测法[monoclonalantibodies-principlesandpractice(单克隆抗体原理与实践),第三版,学术出版社(1996);antibodies-alaboratorymanual(抗体实验室手册),冷泉港实验室(1988);单ク口一ン抗体実験マニユアル(单克隆抗体实验手册)、講談社サイエンテイフイツク(1987)]等组合使用。本发明中,抗体具有凋亡活性是指,通过抗体与细胞上的trailr2结合而诱导细胞死亡。本发明的双特异性抗体具有凋亡活性可以通过下述方法来确认。例如,将表达trailr2和psma的细胞接种到96孔板中,添加抗体并培养一定时期后,使wst-8试剂(dojindo公司制造)进行反应,利用酶标仪测定450nm的吸光度,由此测定细胞的存活率。抗体是来源于编码构成免疫球蛋白的重链的可变区和重链的恒定区、以及轻链的可变区和轻链的恒定区的全部或一部分的基因(称为“抗体基因”)的蛋白质。本发明的抗体也包含具有任意一种免疫球蛋白类和亚类的抗体或抗体片段。h链是指构成免疫球蛋白分子的两种多肽中分子量较大的多肽。重链决定抗体的类和亚类。iga、igd、ige、igg和igm分别具有α链、δ链、ε链、γ链和μ链作为重链,重链的恒定区利用不同的氨基酸序列来赋予特征。轻链(l链)是指构成免疫球蛋白分子的两种多肽中分子量较小的多肽。在人抗体的情况下,轻链存在κ链和λ链这两种。v区通常是指存在于免疫球蛋白的n末端侧的氨基酸序列内的富有多样性的区域。可变区以外的部分采取多样性少的结构,因此被称为恒定区(constantregion:c区)。重链和轻链的各可变区缔合而形成抗原结合位点,决定抗体对抗原的结合特性。在人的抗体的重链的情况下,可变区相当于kabat等人的eu索引(kabatet.al.,sequencesofproteinsofimmunologicalinterest,1991fifthedition)中的第1位至第117位的氨基酸序列,恒定区相当于第118位以后的氨基酸序列。在人的抗体的轻链的情况下,kabat等人提出的编号(kabatnumbering)中的第1位至第107位的氨基酸序列相当于可变区,第108位以后的氨基酸序列相当于恒定区。以下,将重链可变区或轻链可变区简记为vh或vl。抗原结合位点是抗体中识别抗原并与其结合的部位,是指形成与抗原决定簇(表位)互补的立体结构的部位。抗原结合位点与抗原决定簇之间产生强的分子间相互作用。抗原结合位点由包含至少3个cdr的vh和vl构成。在人抗体的情况下,vh和vl分别具有3个cdr。将这些cdr从n末端侧起依次分别称为cdr1、cdr2和cdr3。恒定区之中,重链恒定区或轻链恒定区分别表示为ch或cl。ch根据作为重链的亚类的α链、δ链、ε链、γ链和μ链进行分类。ch由从n末端侧起依次排列的ch1结构域、铰链结构域、ch2结构域、ch3结构域构成,将ch2结构域和ch3结构域合称为fc段。另一方面,cl分类为被称为cλ链和cκ链的2个亚类。本发明中,与trailr2结合的抗体是指识别trailr2的胞外区并且进行结合的单克隆抗体。另外,本发明中,与psma结合的抗体是指识别pmsa的胞外区并且进行结合的单克隆抗体。另外,本发明中,抗体也包含多克隆抗体和寡克隆抗体。单克隆抗体是保持单克隆性(monoclonality)的抗体产生细胞所分泌的抗体,其识别单一的表位(也称为抗原决定簇)。单克隆抗体分子彼此具有相同的氨基酸序列(一级结构),采取单一的结构。多克隆抗体是指不同克隆的抗体产生细胞所分泌的抗体分子的集合。寡克隆抗体是指混合有多种不同的单克隆抗体的抗体分子的集合。表位是指抗体所识别并结合的抗原的结构部位。作为表位,可以列举例如单克隆抗体所识别并结合的单一的氨基酸序列、由氨基酸序列构成的立体结构、结合有糖链的氨基酸序列和由结合有糖链的氨基酸序列构成的立体结构等。作为本发明中的单克隆抗体,可以列举由杂交瘤产生的抗体、和由利用包含抗体基因的表达载体进行了转化的转化体产生的基因重组抗体。杂交瘤例如可以通过制备抗原,由进行了该抗原的免疫的动物获取具有抗原特异性的抗体产生细胞,进而使该抗体产生细胞与骨髓瘤细胞融合来制备。通过对该杂交瘤进行培养、或者将该杂交瘤施用于动物而使该杂交瘤形成癌性腹水,并对该培养液或腹水进行分离、纯化,能够获取所期望的单克隆抗体。作为进行抗原免疫的动物,只要能够直至杂交瘤,则可以使用任何动物,优选使用小鼠、大鼠、仓鼠和兔等。另外,也可以由这种被免疫动物获取具有抗体产生能力的细胞,在体外对该细胞实施免疫后,与骨髓瘤细胞融合而制作杂交瘤。作为本发明中的基因重组抗体,可以列举例如重组小鼠抗体、重组大鼠抗体、重组仓鼠抗体、重组兔抗体、人型嵌合抗体(也称为嵌合抗体)、人源化抗体(也称为cdr移植抗体)和人抗体等利用基因重组技术制造的抗体。基因重组抗体中,可以根据作为对象的动物种类和目的来决定应用来自哪种动物种类的重链和轻链的可变区和恒定区。例如,在作为对象的动物种类为人的情况下,可以使可变区来源于人或小鼠等非人动物,使恒定区和连接子来源于人。嵌合抗体是指由人以外的动物(非人动物)的抗体的vh和vl与人抗体的ch和cl构成的抗体。作为非人动物,只要能够制作杂交瘤,可以使用小鼠、大鼠、仓鼠和兔等任何动物。嵌合抗体可以通过下述方法来制造:利用来源于生产单克隆抗体的非人动物的杂交瘤获取编码vh和vl的cdna,分别插入到具有编码人抗体的ch和cl的dna的动物细胞用表达载体中而构建嵌合抗体表达载体,导入动物细胞中进行表达。人源化抗体是指将非人动物抗体的vh和vl的cdr移植到人抗体的vh和vl的相应的cdr处而得到的抗体。vh和vl的cdr以外的区域被称为骨架区(以下表示为fr)。人源化抗体可以通过下述方法来制造:构建编码vh的氨基酸序列的cdna和编码vl的氨基酸序列的cdna,该vh的氨基酸序列由非人动物抗体的vh的cdr的氨基酸序列和任意的人抗体的vh的fr的氨基酸序列构成,该vl的氨基酸序列由非人动物抗体的vl的cdr的氨基酸序列和任意的人抗体的vl的fr的氨基酸序列构成,将上述cdna分别插入到具有编码人抗体的ch和cl的dna的动物细胞用表达载体中,构建人源化抗体表达载体,导入动物细胞中进行表达。人抗体原本是指天然存在于人体内的抗体,但也包含由利用最近的基因工程、细胞工程、发育工程的技术进步而制作的人抗体噬菌体文库和人抗体产生转基因动物得到的抗体等。天然存在于人体内的抗体例如可以通过下述方法来获取:使eb病毒等感染人外周血淋巴细胞而使其永生化,进行克隆,对产生该抗体的淋巴细胞进行培养,由该培养上清中纯化出该抗体。人抗体噬菌体文库是通过将从人b细胞制备的抗体基因插入到噬菌体基因中而使fab、scfv等抗体片段在噬菌体表面进行表达而得到的文库。可以以对于固定有抗原的底物的结合活性作为指标,由该文库中回收在表面表达有具有所期望的抗原结合活性的抗体片段的噬菌体。该抗体片段可以进一步利用基因工程的方法转变为由两条完全的h链和两条完全的l链构成的人抗体分子。人抗体产生转基因动物是指在细胞内整合有人抗体基因的动物。具体而言,例如,可以通过向小鼠es细胞中导入人抗体基因,将该es细胞移植到小鼠的早期胚胎中后,使其进行个体发育而制作产生人抗体的转基因小鼠。来源于产生人抗体的转基因动物的人抗体可以通过下述方法来制备:使用通常的在非人动物中进行的杂交瘤制作法获取杂交瘤,并进行培养,由此在培养上清中产生、蓄积抗体。作为基因重组抗体的ch,只要属于人免疫球蛋白则可以为任意ch,但优选人免疫球蛋白g(higg)类的ch。此外,可以使用属于higg类的higg1、higg2、higg3和higg4等亚类的任意一种。另外,作为基因重组抗体的cl,只要属于人免疫球蛋白则可以为任意cl,可以使用κ类或λ类的cl。本发明中,双特异性抗体是指具有特异性不同的两种抗原结合结构域的抗体。双特异性抗体的各个抗原结合结构域可以与单一抗原的不同表位结合,也可以与不同抗原结合。一分子的双特异性抗体对于单一抗原的不同表位或者各个不同抗原结合一个以上的抗原结合结构域,即分别以一价以上进行结合。例如,本发明中,在一分子的双特异性抗体具有与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域各两个的情况下,该双特异性抗体与trailr2和psma分别以二价进行结合。本发明中,每一分子的双特异性抗体可以与trailr2或psma以任何价进行结合,但优选与trailr2和psma至少分别以二价进行结合。另外,包含借助含有免疫球蛋白结构域或其片段的连接子等适当连接子进行了结合的多个抗原结合结构域的抗体也包含在本发明的双特异性抗体中。本发明的双特异性抗体中,与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域的位置可以适当选择。本发明的双特异性抗体可以利用现有的制作技术([natureprotocols,9,2450-2463(2014)]、国际公开第1998/050431号、国际公开第2001/7734号、国际公开第2002/002773号和国际公开第2009/131239号)等来制作。本发明的双特异性抗体中,和与psma结合的抗原结合结构域相比,与trailr2结合的抗原结合结构域可以位于更靠n末端侧的位置,也可以位于更靠c末端侧的位置,但优选位于更靠n末端侧的位置。作为本发明的双特异性抗体,可以使用抗体的v区作为抗原结合结构域,可以列举例如包含在一个重链中含有多个vh的重链的抗体、和包含两个含有一个vh的重链的抗体等。作为包含在一个重链中含有多个vh的重链的双特异性抗体,更具体而言,可以列举包含如下重链的抗体,所述重链含有使用包含免疫球蛋白结构域或其片段的连接子进行了结合的2个以上的vh。在使3个以上的vh结合的情况下,可以使用不同的免疫球蛋白结构域或其片段,也可以使用相同的免疫球蛋白结构域或其片段。另外,在使2个以上的vh连接的情况下,可以改变免疫球蛋白结构域或其片段的长度、种类,以使各vh能够特异性地与抗原结合。具体而言,本发明的双特异性抗体具有下述(a)~(e)所示的至少一个特征。(a)在一个重链多肽中包含多个(例如2~5个)不同的vh,vh相互隔开而不接近;(b)vh藉由10个氨基酸以上的多肽连接子串联(纵列)连接,更具体而言,vh使用例如包含免疫球蛋白结构域的全部或部分氨基酸序列的连接子进行连接;(c)轻链与重链缔合而形成抗原结合位点;(d)如图1所示具有由2条重链多肽和至少4条轻链多肽构成的结构,并且2条重链多肽间在铰链区利用二硫键进行连接,轻链多肽与重链多肽之间也利用二硫键进行连接;和(e)重链的恒定区例如由天然型抗体重链的恒定区的全部或一部分(例如ch1片段、ch1、ch2、ch3、ch1-铰链、ch1-铰链-ch2和ch1-铰链-ch2-ch3等)构成。本发明中,双特异性抗体中含有的与trailr2结合的抗体的vh和与psma结合的抗体的vh的位置可以适当选择。例如,对于图1所示结构的双特异性抗体而言,和与psma结合的抗体的vh相比,与trailr2结合的抗体的vh可以位于更靠n末端侧的位置,也可以位于更靠c末端侧的位置,但优选位于更靠n末端侧的位置。本发明中,双特异性抗体中含有的vl可以为相同的vl,也可以为不同的vl。作为具有相同的vl的双特异性抗体且能够与两个不同的抗原或相同抗原上的不同的两个表位结合的双特异性抗体的vh,只要是以各可变区能够与各特异性抗原或表位结合的方式进行了优化或改变的vh即可,例如,可以使用通过氨基酸改变进行的筛选或噬菌体展示等方法选择适当的vh。本发明中,连接子是指使多个抗原结合结构域结合的化学结构,优选为多肽。作为本发明的双特异性抗体中使用的连接子,可以列举例如包含免疫球蛋白结构域的全部或部分氨基酸序列的连接子、和包含由多个免疫球蛋白结构域构成的连接子的全部或部分氨基酸序列的连接子等。作为包含免疫球蛋白结构域的部分氨基酸序列的连接子,从免疫球蛋白中选择的氨基酸序列可以是断续的也可以是连续的,但优选连续的氨基酸序列。本发明中,免疫球蛋白结构域以具有与免疫球蛋白类似的氨基酸序列、由存在至少2个半胱氨酸残基的约100个氨基酸残基构成的肽作为最小单元。本发明中,免疫球蛋白结构域也包含含有多个上述最小单元的免疫球蛋白结构域的多肽。作为免疫球蛋白结构域,可以列举免疫球蛋白重链的vh、ch1、ch2和ch3、免疫球蛋白轻链的vl和cl等。免疫球蛋白的动物种类没有特别限定,优选为人。另外,免疫球蛋白重链的恒定区的亚类可以为igd、igm、igg1、igg2、igg3、igg4、iga1、iga2和ige中的任意一种,优选列举igg来源和igm来源。另外,免疫球蛋白轻链的恒定区的亚类可以为κ和λ中的任意一种。另外,免疫球蛋白结构域也存在于免疫球蛋白以外的蛋白质中,可以列举例如主要组织相容性抗原(mhc)、cd1、b7和t细胞受体(tcr)等属于免疫球蛋白超家族的蛋白质所包含的免疫球蛋白结构域。作为本发明的双特异性抗体中使用的免疫球蛋白结构域,可以应用任意一种免疫球蛋白结构域。在人抗体的情况下,ch1是指具有eu索引所示的第118位至第215位的氨基酸序列的区域。同样地,铰链区是指具有kabat等人的eu索引所示的第216位至第230位的氨基酸序列的区域,ch2是指具有kabat等人的eu索引所示的第231位至第340位的氨基酸序列的区域,ch3是指具有kabat等人的eu索引所示的第341位至第446位的氨基酸序列的区域。在ch1与ch2之间,存在称为铰链(hinge)区的富有柔软性的氨基酸区域。cl在人抗体的κ链的情况下是指具有kabat编号所示的第108位至第214位的氨基酸序列的区域,在λ链的情况下是指具有第108位至第215位的氨基酸序列的区域。作为本发明的双特异性抗体中使用的连接子,可以列举由在从n末端向c末端的方向上依次排列的ch1-铰链-ch2-ch3构成的免疫球蛋白结构域、由ch1-铰链-ch2构成的免疫球蛋白结构域、由ch1-铰链构成的免疫球蛋白结构域、由ch1构成的免疫球蛋白结构域、ch1的n末端侧的片段、由第14位的氨基酸残基为cys的14个氨基酸残基构成的ch1片段和由ch1的n末端起第1~14位的氨基酸残基构成的ch1片段、以及在这些免疫球蛋白结构域片段的氨基酸序列中改变了一个以上的氨基酸残基而成的片段,但并不限定于这些。另外,本发明中,作为连接子的一例,可以适当组合使用由抗体的ch1、铰链、ch2和ch3构成的氨基酸序列的全部或一部分片段。另外,也可以使这些氨基酸序列部分缺失或改变顺序来使用。另外,连接子所使用的抗体的亚类没有特别限定,优选为igm或igg4,更优选为igg4。本发明中,作为具体的连接子的例子,可以列举序列号11所表示的由igg4的ch1的n末端的第1~14位的14个氨基酸残基构成的连接子、序列号12所表示的由igm的ch1的n末端起第1~14位的氨基酸残基构成的连接子、和序列号93所表示的由igg4的ch1构成的连接子等,更优选为序列号93所表示的由igg4的ch1构成的连接子。在构成本发明的双特异性抗体或该抗体片段的氨基酸序列中缺失、添加、置换或插入一个以上的氨基酸残基、并且具有与上述抗体或其抗体片段同样的活性的抗体或其抗体片段也包含在本发明的双特异性抗体或其抗体片段中。缺失、置换、插入和/或添加的氨基酸的数量为一个以上,其数量没有特别限定,为利用molecularcloning(分子克隆),第二版,冷泉港实验室出版社(1989);currentprotocolsinmolecularbiology(最新分子生物学实验方法汇编),约翰威利父子出版社(1987-1997);nucleicacidsresearch,10,6487(1982);proc.natl.acad.sci.,usa,79,6409(1982);gene,34,315(1985);nucleicacidsresearch,13,4431(1985);proc.natl.acad.sciusa,82,488(1985)等中记载的定点突变法等公知的技术能够缺失、置换、插入或添加的程度的数量。例如为一个~几十个、优选为1~20个、更优选为1~10个、进一步优选为1~5个。上述的在本发明的双特异性抗体的氨基酸序列中缺失、置换、插入或添加一个以上的氨基酸残基表示下述情况。是指在相同序列中的任意、且一个或多个氨基酸序列中,存在一个或多个氨基酸残基的缺失、置换、插入或添加。另外,也存在同时发生缺失、置换、插入或添加的情况,置换、插入或添加的氨基酸残基可以为天然型和非天然型的任意情况。作为天然型氨基酸残基,可以列举例如l-丙氨酸、l-天冬酰胺、l-天冬氨酸、l-谷氨酰胺、l-谷氨酸、甘氨酸、l-组氨酸、l-异亮氨酸、l-亮氨酸、l-赖氨酸、l-精氨酸、l-蛋氨酸、l-苯丙氨酸、l-脯氨酸、l-丝氨酸、l-苏氨酸、l-色氨酸、l-酪氨酸、l-缬氨酸和l-半胱氨酸等。以下,示出能够相互置换的氨基酸残基的优选例。同一组中所含的氨基酸残基能够相互置换。a组:亮氨酸、异亮氨酸、正亮氨酸、缬氨酸、正缬氨酸、丙氨酸、2-氨基丁酸、蛋氨酸、o-甲基丝氨酸、叔丁基甘氨酸、叔丁基丙氨酸、环己基丙氨酸b组:天冬氨酸、谷氨酸、异天冬氨酸、异谷氨酸、2-氨基己二酸、2-氨基辛二酸c组:天冬酰胺、谷氨酰胺d组:赖氨酸、精氨酸、鸟氨酸、2,4-二氨基丁酸、2,3-二氨基丙酸e组:脯氨酸、3-羟基脯氨酸、4-羟基脯氨酸f组:丝氨酸、苏氨酸、高丝氨酸g组:苯丙氨酸、酪氨酸本发明的双特异性抗体或该抗体片段也包含含有进行了翻译后修饰的任意氨基酸残基的抗体。作为翻译后修饰,可以列举例如h链的c末端的赖氨酸残基的缺失[赖氨酸剪切(lysineclipping)]和多肽的n末端的谷氨酰胺残基向焦谷氨酰胺(puroglu)的转换等[becketal,analyticalchemistry,85,715-736(2013)]。作为本发明的双特异性抗体,具体而言,可以列举选自由下述(1)~(3)组成的组中的任意一种双特异性抗体等。(1)包含与trailr2结合的抗体的v区和与psma结合的抗体的v区的双特异性抗体,(2)包含与trailr2结合的抗体的vh的cdr1~3和vl的cdr1~3、以及与psma结合的抗体的vh的cdr1~3和vl的cdr1~3的双特异性抗体,和(3)包含与trailr2结合的抗体的vh和vl、以及与psma结合的抗体的vh和vl的双特异性抗体。上述(2)记载的双特异性抗体中,与trailr2结合的抗体的vl的cdr1~3和与psma结合的抗体的vl的cdr1~3可以分别相同,也可以不同,优选相同。另外,上述(3)记载的双特异性抗体中,与trailr2结合的抗体的vl和与psma结合的抗体的vl可以相同,也可以不同,优选相同。作为本发明的双特异性抗体,更具体而言,可以列举与trailr2结合的抗体的vh的cdr1~3的氨基酸序列分别包含序列号70~72所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的双特异性抗体。作为vh的cdr1~3的氨基酸序列分别包含序列号70~72所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的与trailr2结合的抗体的一个方式,可以列举抗人trailr2单克隆抗体e11抗体等。本发明的双特异性抗体也包含下述双特异性抗体:与trailr2结合的抗体的vh的cdr1~3的氨基酸序列和vl的cdr1~3的氨基酸序列分别与序列号70~72所表示的氨基酸序列和序列号74~76所表示的氨基酸序列至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少99%同源的双特异性抗体。另外,作为本发明的双特异性抗体的具体例,还可以列举与trailr2结合的抗体的vh的氨基酸序列包含序列号118所表示的氨基酸序列、并且vl的氨基酸序列包含序列号119所表示的氨基酸序列的双特异性抗体。作为vh的氨基酸序列包含序列号118所表示的氨基酸序列、并且vl的氨基酸序列包含序列号119所表示的氨基酸序列的与trailr2结合的抗体的一个方式,可以列举抗人trailr2单克隆抗体e11抗体等。本发明的双特异性抗体也包含下述双特异性抗体:与trailr2结合的抗体的vh和vl的氨基酸序列与序列号118所表示的vh的氨基酸序列和序列号119所表示的vl的氨基酸序列至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少99%同源的双特异性抗体。本发明中,作为与trailr2结合的抗体,也包含下述(1)~(3)中任一项所述的抗体。(1)在trailr2抗体单独的情况下,不显示出细胞增殖抑制活性和细胞死亡诱导活性中的至少一者,但在结合有针对其他抗原的结合结构域的双特异性抗体的情况下,才显示出细胞增殖抑制活性和细胞死亡诱导活性中的至少一者的抗体。(2)与包含分别由序列号70~72表示的vh的cdr1~3的氨基酸序列、并且包含分别由序列号74~76表示的vl的cdr1~3的氨基酸序列的抗体竞争地与trailr2结合的抗体。(3)与包含分别由序列号70~72表示的vh的cdr1~3的氨基酸序列、并且包含分别由序列号74~76表示的vl的cdr1~3的氨基酸序列的抗体结合相同表位的抗体。另外,作为本发明的双特异性抗体,可以列举与psma结合的抗体的vh的cdr1~3的氨基酸序列包含选自由下述(a)~(d)组成的组中的任意一种氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含由序列号74~76表示的氨基酸序列的双特异性抗体。(a)vh的cdr1~3的氨基酸序列分别包含由序列号78、82和84表示的氨基酸序列、(b)vh的cdr1~3的氨基酸序列分别包含由序列号78、79和80表示的氨基酸序列、(c)vh的cdr1~3的氨基酸序列分别包含由序列号78、82和80表示的氨基酸序列、和(d)vh的cdr1~3的氨基酸序列分别包含由序列号96~98表示的氨基酸序列。因此,作为本发明的双特异性抗体所具备的与psma结合的抗体的可变区,具体而言,可以列举选自由下述(a)~(d)组成的组中的任意一种vh、和cdr1~3分别包含序列号74~76所表示的氨基酸序列的vl。(a)包含序列号78、82和84所表示的氨基酸序列分别作为cdr1~3的vh、(b)包含序列号78、79和80所表示的氨基酸序列分别作为cdr1~3的vh、(c)包含序列号78、82和80所表示的氨基酸序列分别作为cdr1~3的vh、和(d)包含序列号96~98所表示的氨基酸序列分别作为cdr1~3的vh。作为包含cdr1~3分别包含序列号78、82和84所表示的氨基酸序列的vh和cdr1~3分别包含序列号74~76所表示的氨基酸序列的vl的、与psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pn7抗体等。作为包含cdr1~3分别包含序列号78、79和80所表示的氨基酸序列的vh和cdr1~3分别包含序列号74~76所表示的氨基酸序列的vl的、与psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi134抗体、pi143抗体、pi105抗体、pi127抗体、pi108抗体、pi115抗体和pl223抗体等。作为包含cdr1~3分别包含序列号78、82和80所表示的氨基酸序列的vh和cdr1~3分别包含序列号74~76所表示的氨基酸序列的vl的、与psma结合的抗体的一个方式可以列举抗人psma单克隆抗体pi101抗体和pi118抗体等。作为包含cdr1~3分别包含序列号96~98所表示的氨基酸序列的vh和cdr1~3分别包含序列号74~76所表示的氨基酸序列的vl的、与psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pn170抗体等。本发明的双特异性抗体也包含下述双特异性抗体,该双特异性抗体含有的vh以及vl所包含的氨基酸序列分别与作为与psma结合的抗体的vh的选自由上述(a)~(d)组成的组中的任意一种vh、以及cdr1~3分别包含序列号74~76所表示的氨基酸序列的vl的氨基酸序列至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少99%同源。另外,作为本发明的双特异性抗体所具备的与psma结合的抗体的可变区,具体而言,可以列举选自由下述(e)~(o)组成的组中的任意一种vh、和包含序列号119所表示的氨基酸序列的vl。(e)包含序列号122所表示的氨基酸序列的vh、(f)包含序列号120所表示的氨基酸序列的vh、(g)包含序列号128所表示的氨基酸序列的vh、(h)包含序列号123所表示的氨基酸序列的vh、(i)包含序列号127所表示的氨基酸序列的vh、(j)包含序列号124所表示的氨基酸序列的vh、(k)包含序列号125所表示的氨基酸序列的vh、(l)包含序列号129所表示的氨基酸序列的vh、(m)包含序列号121所表示的氨基酸序列的vh、(n)包含序列号126所表示的氨基酸序列的vh、和(o)包含序列号130所表示的氨基酸序列的vh。作为含有包含序列号122所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pn7抗体等。作为含有包含序列号120所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi134抗体等。作为含有包含序列号128所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi143抗体等。作为含有包含序列号123所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi105抗体等。作为含有包含序列号127所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi127抗体等。作为含有包含序列号124所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi108抗体等。作为含有包含序列号125所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi115抗体等。作为含有包含序列号129所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pl223抗体等。作为含有包含序列号121所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi101抗体等。作为含有包含序列号126所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pi118抗体等。作为含有包含序列号130所表示的氨基酸序列的vh和包含序列号119所表示的氨基酸序列的vl的、与人psma结合的抗体的一个方式,可以列举抗人psma单克隆抗体pn170抗体等。本发明的双特异性抗体也包含下述双特异性抗体,该双特异性抗体含有的vh以及vl所包含的氨基酸序列分别与作为与psma结合的抗体的vh的选自由上述(e)~(o)组成的组中的任意一种vh、以及包含序列号119所表示的氨基酸序列的vl的氨基酸序列至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少99%同源。另外,作为本发明的双特异性抗体中使用的抗psma抗体,也包含下述(1)或(2)所述的抗体等。(1)与vh的cdr1~3的氨基酸序列分别包含序列号78、82和84表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体;vh的cdr1~3的氨基酸序列分别包含序列号78、89和80所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体;vh的cdr1~3的氨基酸序列分别包含序列号78、82和80所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体;或vh的cdr1~3的氨基酸序列分别包含序列号96~98所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体竞争地与psma结合的抗体。(2)与vh的cdr1~3的氨基酸序列分别包含序列号78、82和84所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体;vh的cdr1~3的氨基酸序列分别包含序列号78、89和80所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体;vh的cdr1~3的氨基酸序列分别包含序列号78、82和80所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体;或vh的cdr1~3的氨基酸序列分别包含序列号96~98所表示的氨基酸序列、并且vl的cdr1~3的氨基酸序列分别包含序列号74~76所表示的氨基酸序列的抗体结合相同表位的抗体。本发明的双特异性抗体中,与trailr2结合的抗体的可变区相对于与psma结合的抗体的可变区,可以隔着连接子而位于n末端侧,也可以位于c末端侧,但优选隔着连接子而位于n末端侧。作为与trailr2结合的抗体的可变区相较于与psma结合的抗体的可变区位于n末端侧的双特异性抗体,可以列举由与trailr2结合的抗体的vh、连接子和与psma结合的抗体的vh构成的多肽的氨基酸序列为选自由下述(a)~(m)组成的组中的任意一种氨基酸序列的双特异性抗体。(a)序列号131所表示的氨基酸序列、(b)序列号132所表示的氨基酸序列、(c)序列号133所表示的氨基酸序列、(d)序列号134所表示的氨基酸序列、(e)序列号135所表示的氨基酸序列、(f)序列号136所表示的氨基酸序列、(g)序列号137所表示的氨基酸序列、(h)序列号138所表示的氨基酸序列、(i)序列号139所表示的氨基酸序列、(j)序列号140所表示的氨基酸序列、(k)序列号141所表示的氨基酸序列、(l)序列号142所表示的氨基酸序列、和(m)序列号143所表示的氨基酸序列。作为由与trailr2结合的抗体的vh、连接子和与psma结合的抗体的vh构成的多肽的氨基酸序列为上述(a)~(m)记载的氨基酸序列的、与trailr2和psma结合的双特异性抗体的一个方式,可以列举分别与人trailr2和人psma结合的双特异性抗体e11-ch1-pi134抗体、e11-ch1-pi101vh抗体、e11-ch1-pi105vh抗体、e11-ch1-pi108vh抗体、e11-ch1-pi115vh抗体、e11-ch1-pi118vh抗体、e11-ch1-pi127vh抗体、e11-ch1-pi143vh抗体、e11-ch1-pl223vh抗体、e11-ch1-pn7vh抗体、e11-ch1-pn170vh抗体、e11-gl-pi134vh抗体和e11-ml-pi101vh抗体等。本发明的双特异性抗体或该抗体片段也包含具有效应子活性的抗体或该抗体片段。效应子活性是指藉由抗体的fc段所引起的抗体依赖性的细胞毒活性,可以列举例如抗体依赖性细胞毒活性(antibody-dependentcellularcytotoxicityactivity;adcc活性)、补体依赖性细胞毒活性(complement-dependentcytotoxicityactivity;cdc活性)、由巨噬细胞、树突细胞等吞噬细胞产生的抗体依赖性吞噬活性(antibody-dependentcellularphagocytosisactivity;adcp活性)和调理素效应等。本发明中,adcc活性和cdc活性可以使用公知的测定方法[cancerimmunol.immunother.,36,373(1993)]进行测定。adcc活性是指,与靶细胞上的抗原结合的抗体通过藉由抗体的fc段与免疫细胞的fc受体结合而活化免疫细胞(自然杀伤细胞等)从而杀伤靶细胞的活性。fc受体(fcr)是与抗体的fc段结合的受体,通过抗体的结合而诱发各种各样的效应子活性。各fcr与抗体的亚类对应,igg、ige、iga、igm分别与fcγr、fcεr、fcαr、fcμr特异性结合。此外,fcγr中存在fcγri(cd64)、fcγrii(cd32)和fcγriii(cd16)的亚型,各亚型中存在fcγria、fcγrib、fcγric、fcγriia、fcγriib、fcγriic、fcγriiia和fcγriiib的同种型。这些不同的fcγr存在于不同的细胞上[annu.rev.immunol.9:457-492(1991)]。对于人而言,fcγriiib特异性地表达于中性粒细胞,fcγriiia表达于单核细胞、自然杀伤细胞(nk细胞)、巨噬细胞和一部分t细胞。通过抗体与fcγriiia的结合,诱发nk细胞依赖性的adcc活性。cdc活性是指,与靶细胞上的抗原结合的抗体使血液中的补体相关蛋白组所构成的一系列级联反应(补体活化经路)活化、从而杀伤靶细胞的活性。另外,通过由补体的活化产生的蛋白质片段,诱导免疫细胞的游走和活化。关于cdc活性的级联反应,首先c1q与fc段结合,接着与两种丝氨酸蛋白酶c1r和c1s结合,由此形成c1复合物而开始级联反应。本发明的双特异性抗体或该抗体片段对抗原表达细胞的cdc活性或adcc活性可以利用公知的测定方法[cancerimmunol.immunother.,36,373(1993)]进行评价。作为控制本发明的双特异性抗体的效应子活性的方法,已知有对结合于抗体的fc段(由ch2和ch3结构域构成的恒定区)的第297位的天冬酰胺(asn)的n-键合复合型糖链的还原末端上存在的n-乙酰葡糖胺(glcnac)上α-1,6键合的岩藻糖(也称为核心岩藻糖)的量进行控制的方法(国际公开第2005/035586号、国际公开第2002/31140号和国际公开第00/61739号);通过改变抗体的fc段的氨基酸残基而进行控制的方法(国际公开第00/42072号)等。通过控制添加至双特异性抗体上的岩藻糖的量,能够增加或降低抗体的adcc活性。例如,作为降低与抗体的fc结合的n-键合复合型糖链上结合的岩藻糖的含量的方法,可以使用α-1,6-岩藻糖转移酶基因缺失的宿主细胞来表达双特异性抗体,由此获得具有高adcc的双特异性抗体。另一方面,作为增加与双特异性抗体的fc结合的n-键合复合型糖链上结合的岩藻糖的含量的方法,可以使用导入有α-1,6-岩藻糖转移酶基因的宿主细胞来表达抗体,由此获取具有低adcc活性的双特异性抗体。另外,可以通过改变双特异性抗体的fc段的氨基酸残基而增加或降低adcc活性、cdc活性。例如,通过使用美国专利申请公开第2007/0148165号说明书中记载的fc段的氨基酸序列,能够增加双特异性抗体的cdc活性。另外,通过进行美国专利第6737056号说明书、美国专利第7297775号说明书或美国专利第7317091号说明书等中记载的氨基酸改变,既可以增加也可以降低adcc活性或cdc活性。此外,也可以通过将上述方法进行组合来获取效应子活性得到了控制的双特异性抗体。本发明的双特异性抗体的稳定性可以通过测定在纯化过程或在一定条件下保存后的样品中形成的聚集物(寡聚物)量来进行评价。即,将在相同条件下聚集物量降低的情况评价为抗体的稳定性提高。聚集物量可以通过使用包括凝胶过滤色谱在内的适当的色谱将聚集的抗体与未聚集的抗体分离来进行测定。本发明的双特异性抗体的生产率可以通过测定由抗体产生细胞产生至培养液中的抗体量来进行评价。更具体而言,可以通过利用hplc法、elisa法等适当的方法测定从培养液中除去产生细胞后的培养上清中含有的抗体的量来进行评价。本发明中,抗体片段是指包含与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域的具有抗原结合活性的抗体片段。本发明中,作为抗体片段,可以列举fab、fab’、f(ab’)2、scfv、双链抗体(diabody)、dsfv或包含cdr的肽等。fab是将igg抗体用作为蛋白分解酶的木瓜蛋白酶进行处理而得到的片段中(在h链的第224位的氨基酸残基处被切断)h链的n末端侧约一半与l链整体以二硫键(s-s键)结合而成的、分子量约5万的具有抗原结合活性的抗体片段。f(ab’)2是将igg用作为蛋白分解酶的胃蛋白酶进行处理而得到的片段中(在h链的第234位的氨基酸残基处被切断)比fab藉由铰链区的s-s键结合而得到的片段稍大的、分子量约10万的具有抗原结合活性的抗体片段。fab’是将上述f(ab’)2的铰链区的s-s键切断而得到的、分子量约5万的具有抗原结合活性的抗体片段。scfv是使用12个残基以上的适当的肽连接子(p)将1条vh和1条vl连接而得到的vh-p-vl或vl-p-vh多肽,是具有抗原结合活性的抗体片段。双链抗体(diabody)是抗原结合特异性相同或不同的scfv形成二聚体而得到的抗体片段,是对相同的抗原具有二价抗原结合活性、或对不同抗原分别具有特异性的抗原结合活性的抗体片段。dsfv是指将vh和vl中的各1个氨基酸残基置换为半胱氨酸残基、将所得的多肽藉由该半胱氨酸残基间的s-s键进行结合而得到的片段。包含cdr的肽包含vh或vl的cdr中的至少一个区域而构成。包含多个cdr的肽可以通过使cdr彼此直接结合或藉由适当的肽连接子结合而制作。包含cdr的肽可以通过构建编码本发明的双特异性抗体的vh和vl的cdr的dna、将该dna插入到原核生物用表达载体或真核生物用表达载体中并将该表达载体导入原核生物或真核生物来进行表达、制造。另外,包含cdr的肽也可以利用fmoc法或tboc法等化学合成法来制造。本发明的双特异性抗体的fc与抗体片段结合而成的融合蛋白、该fc与天然存在的配体或受体结合而成的fc融合蛋白(也称为免疫粘附素)、和使多个fc段融合而成的fc融合蛋白质等也包含在本发明中。另外,包含以抗体的效应子活性的增强或缺损、抗体的稳定化和血中半衰期的控制为目的而进行的氨基酸残基改变的fc段也可以用于本发明的双特异性抗体。作为本发明的双特异性抗体或抗体片段,包含利用化学或基因工程方法在本发明的双特异性抗体或其抗体片段上结合放射性同位素、低分子药剂、高分子药剂、蛋白质或抗体药物等而得到的抗体的衍生物。本发明中的抗体的衍生物可以通过利用化学方法[抗体工程入门、地人书馆(1994)]在本发明的双特异性抗体或其抗体片段的h链或l链的n末端侧或c末端侧、该抗体或其抗体片段中的适当的取代基或侧链上、以及该抗体或其抗体片段中的糖链等上结合放射性同位素、低分子药剂、高分子药剂、免疫激活剂、蛋白质或抗体药物等来制造。另外,本发明中的抗体的衍生物可以通过利用基因工程的方法将编码本发明的双特异性抗体或抗体片段的dna与编码所期望的蛋白质或抗体药物的dna连接,插入到表达载体中,将该表达载体导入适当的宿主细胞中进行表达来制造。作为放射性同位素,可以列举例如111in、131i、125i、90y、64cu、99tc、77lu或211at等。可以利用氯胺t法等使放射性同位素直接与抗体结合。另外,也可以在抗体上结合对放射性同位素进行螯合的物质。作为螯合剂,可以列举例如1-异硫氰酸苄酯基-3-甲基二亚乙基三胺五乙酸(mx-dtpa)等。作为低分子药剂,可以列举例如烷化剂、亚硝基脲剂、代谢拮抗剂、抗生素、植物生物碱、拓扑异构酶抑制剂、激素疗法剂、激素拮抗剂、芳香化酶抑制剂、p糖蛋白抑制剂、钼络合物衍生物、m期抑制剂或激酶抑制剂等抗癌剂[临床肿瘤学,癌症与化学疗法出版社(1996)]、氢化可的松或泼尼松龙等甾体剂,阿司匹林或吲哚美辛等非甾体剂,硫代苹果酸金或青霉胺等免疫调节剂,环磷酰胺或硫唑嘌呤等免疫抑制剂、马来酸氯苯那敏或氯马斯汀等抗组胺剂等抗炎剂[炎症与抗炎疗法,医齿药出版株式会社(1982)]等。作为抗癌剂,可以列举例如阿米福汀(氨磷汀)、顺铂、达卡巴嗪(dtic)、更生霉素、二氯甲基二乙胺(氮芥)、链脲霉素、环磷酰胺、异环磷酰胺、卡莫司汀(bcnu)、洛莫司汀(ccnu)、多柔比星(阿霉素)、表柔比星、吉西他滨(健择)、柔红霉素、丙卡巴肼、丝裂霉素、阿糖胞苷、依托泊苷、5-氟尿嘧啶、氟尿嘧啶、长春碱、长春新碱、博来霉素、道诺霉素、培洛霉素、雌莫司汀、紫杉醇(泰素)、多西紫杉醇(多西他奇)、阿地白介素、天冬酰胺酶、白消安、卡铂、奥沙利铂、奈达铂、克拉屈滨、喜树碱、10-羟基-7-乙基-喜树碱(sn38)、氟尿苷、氟达拉滨、羟基脲、伊达比星、美司那、依立替康(cpt-11)、拓扑替康、米托蒽醌、托泊替康、亮丙瑞林、甲地孕酮、美法仑、巯基嘌呤、羟基脲、普卡霉素、密妥坦、培门冬酶、喷司他丁、哌泊溴烷、链脲霉素、他莫昔芬、戈舍瑞林、亮丙瑞林、氟他胺、替尼泊苷、睾内酯、硫鸟嘌呤、塞替派、乌拉莫司汀、长春瑞滨、苯丁酸氮芥、氢化可的松、泼尼松龙、甲基泼尼松龙、长春地辛、尼莫司汀、司莫司汀、卡培他滨、雷替曲塞、氮胞苷、uft、奥沙利铂、吉非替尼(易瑞沙)、伊马替尼(sti571)、厄洛替尼、fms样酪氨酸激酶3(fms-liketyrosinekinase3;flt3)抑制剂、血管内皮生长因子受体(vegfr)抑制剂、成纤维细胞生长因子受体(fgfr)抑制剂、特罗凯等表皮生长因子受体(egfr)抑制剂、根赤壳菌素、17-烯丙基氨基-17-去甲氧基格尔德霉素、雷帕霉素、安吖啶、全反式维甲酸、沙利度胺、来那度胺、阿那曲唑、法曲唑、来曲唑、依西美坦、硫代苹果酸金、d-青霉胺、布西拉明、硫唑嘌呤、咪唑立宾、环孢素、雷帕霉素、氢化可的松、蓓萨罗丁(塔革雷汀)、他莫昔芬、地寒米松、孕激素类、雌激素类、阿那曲唑(瑞宁德)、利普安、阿司匹林、吲哚美辛、塞来昔布、硫唑嘌呤、青霉胺、硫代苹果酸金、马来酸氯苯那敏、氯苯那敏、氯马斯汀、维甲酸、蓓萨罗丁、砷、硼替佐米、别嘌呤醇、卡奇霉素、替伊莫单抗、塔革雷汀、奥唑米星、克拉霉素、瘤可维、酮康唑、氨鲁米特、苏拉明、甲氨蝶呤、类美登醇或其衍生物等。作为使低分子药剂与本发明的双特异性抗体结合的方法,可以列举例如通过戊二醛使药剂与该抗体的氨基间结合的方法、或通过水溶性碳二亚胺使药剂的氨基与该抗体的羧基结合的方法等。作为高分子药剂,可以列举聚乙二醇(peg)、白蛋白、右旋糖酐、聚环氧乙烷、苯乙烯马来酸共聚物、聚乙烯吡咯烷酮、吡喃共聚物或羟丙基甲基丙烯酰胺等。通过使这些高分子化合物与本发明的双特异性抗体或抗体片段结合,可以期待:(1)提高对化学性、物理性或生物性的各种因素的稳定性;(2)显著延长血中半衰期;或(3)抑制免疫原性的消失或抗体产生;等效果[生物结合药品、广川书店(1993)]。例如,作为使peg与本发明的双特异性抗体结合的方法,可以列举与peg化修饰试剂反应的方法等[生物结合药品、广川书店(1993)]。作为peg化修饰试剂,可以列举对赖氨酸的ε-氨基的修饰剂(日本特开昭61-178926号公报)、对天冬氨酸和谷氨酸的羧基的修饰剂(日本特开昭56-23587号公报)、或对精氨酸的胍基的修饰剂(日本特开平2-117920号公报)等。作为免疫激活剂,可以是作为免疫佐剂已知的天然物,作为具体例,使免疫亢进的药剂可以列举β(1→3)葡聚糖(例如香菇多糖或西佐糖)、或α-半乳糖神经酰胺(krn7000)等。作为蛋白质,可以列举例如使nk细胞、巨噬细胞或中性粒细胞等免疫活性细胞活化的细胞因子、增殖因子或毒素蛋白。作为细胞因子或增殖因子,可以列举例如干扰素(以下记作ifn)-α、ifn-β、ifn-γ、白细胞介素(以下记作il)-2、il-12、il-15、il-18、il-21、il-23、粒细胞集落刺激因子(g-csf)、粒细胞/巨噬细胞集落刺激因子(gm-csf)或巨噬细胞集落刺激因子(m-csf)等。作为毒素蛋白,可以列举例如蓖麻毒素、白喉毒素或ontak等,也包含为了调节毒性而向蛋白质中导入了突变的蛋白毒素。与蛋白质或抗体药物的融合抗体可以通过使编码蛋白质的cdna与编码本发明的双特异性抗体或抗体片段的cdna连接,构建编码融合抗体的dna,将该dna插入到原核生物或真核生物用表达载体中,将该表达载体导入原核生物或真核生物来进行表达、制造。在使用上述抗体的衍生物作为检测方法、定量方法、检测用试剂、定量用试剂或诊断剂的情况下,作为与本发明的双特异性抗体或其抗体片段结合的药剂,可以列举通常的免疫学检测或测定法中使用的标记物。作为标记物,可以列举例如碱性磷酸酶、过氧化物酶或荧光素酶等酶;吖啶酯或洛酚碱等发光物质;或者异硫氰酸荧光素(fitc)或四甲基罗丹明异硫氰酸盐(ritc)、alexa(注册商标)fluor488、r-藻红素(r-phycoerythrin,r-pe)等荧光物质等。本发明中包含具有cdc活性或adcc活性等细胞毒活性的双特异性抗体及其抗体片段。本发明的双特异性抗体或该抗体片段对抗原表达细胞的cdc活性或adcc活性可以利用公知的测定方法[cancerimmunol.immunother.,36,373(1993)]进行评价。另外,本发明涉及包含特异性地识别并结合trailr2和psma的双特异性抗体或其抗体片段的组合物、或含有该双特异性抗体或该抗体片段作为有效成分的trailr2和psma的表达细胞相关疾病的治疗剂。作为trailr2和psma的表达细胞相关疾病,例如只要是表达trailr2和psma的细胞相关的疾病则可以为任何疾病,可以列举例如恶性肿瘤和癌症等。本发明中,作为恶性肿瘤和癌症,可以列举例如大肠癌、结肠直肠癌、肺癌、乳腺癌、神经胶质瘤、恶性黑色素瘤(黑色素瘤)、甲状腺癌、肾细胞癌、白血病、淋巴瘤、t细胞淋巴瘤、胃癌、胰腺癌、子宫颈癌、子宫内膜癌、卵巢癌、食道癌、肝癌、头颈部鳞状细胞癌、皮肤癌、尿道癌、膀胱癌、前列腺癌、绒癌、咽癌、喉癌、间皮瘤、胸膜瘤、男性细胞瘤、子宫内膜增生、子宫内膜异位症、胚胎瘤、纤维肉瘤、卡波西氏肉瘤、血管瘤、海绵状血管瘤、成血管细胞瘤、视网膜母细胞瘤、星形细胞瘤、神经纤维瘤、少突胶质细胞瘤、髓母细胞瘤、神经母细胞瘤、神经胶质瘤、横纹肌肉瘤、胶质母细胞瘤、骨原性肉瘤、平滑肌肉瘤、甲状腺肉瘤和肾母细胞瘤等。含有本发明的双特异性抗体或该抗体片段或者它们的衍生物的治疗剂可以仅含有作为有效成分的该抗体或该抗体片段或者它们的衍生物,但通常优选以与药理学上可接受的一种以上的载体一起混合、利用制剂学
技术领域:
中公知的任意方法制造而成的药物制剂的形式提供。给药途径优选使用治疗时最有效的途径,可以列举例如经口给药或口腔内、呼吸道内、直肠内、皮下、肌肉内或静脉内等非经口给药。其中,优选静脉内给药。作为给药形态,可以列举例如喷雾剂、胶囊剂、片剂、散剂、颗粒剂、糖浆剂、乳剂、栓剂、注射剂、软膏或贴片剂等。给药量或给药次数根据目标治疗效果、给药方法、治疗期间、年龄和体重等而有所不同,通常成人每一天为10μg/kg~10mg/kg。此外,本发明涉及含有本发明的双特异性抗体或其抗体片段的trailr2和psma中的至少一者的免疫学检测用或测定用试剂、或trailr2和psma的表达细胞相关疾病的诊断剂。另外,本发明涉及使用本发明的双特异性抗体或其抗体片段的trailr2和psma中的至少一者的免疫学检测用或测定用方法、或trailr2和psma的表达细胞相关疾病的诊断方法。本发明中,作为检测或测定trailr2和psma中的至少一者的量的方法,可以列举任意公知的方法。可以列举例如免疫学检测或测定方法等。免疫学检测或测定方法是使用实施了标记的抗原或抗体对抗体量或抗原量进行检测或测定的方法。作为免疫学检测或测定方法,可以列举例如放射免疫测定法(ria)、酶免疫测定法(eia或elisa)、荧光免疫测定法(fia)、发光免疫测定法(luminescentimmunoassay)、蛋白免疫印记法或物理化学方法等。通过使用本发明的双特异性抗体或该抗体片段对表达trailr2和psma中的至少一者的细胞进行检测或测定,能够对trailr2和psma表达细胞相关的疾病进行诊断。表达trailr2和psma中的至少一种多肽的细胞的检测可以使用公知的免疫学检测法,可以列举例如免疫沉淀法、免疫细胞染色法、免疫组织染色法或荧光抗体染色法等。另外,还可以列举例如fmat8100hts系统(应用生物系统公司制造)等荧光抗体染色法等。本发明中,作为进行trailr2和psma中的至少一者的检测或测定的对象的生物体试样,只要是例如组织细胞、血液、血浆、血清、胰液、尿、粪便、组织液或培养液等可能包含表达trailr2和psma中的至少一者的细胞的试样,则没有特别限定。含有本发明的双特异性抗体或其抗体片段或者它们的衍生物的诊断剂可以根据目标诊断法含有用于进行抗原抗体反应的试剂、该反应的检测用试剂。作为用于进行抗原抗体反应的试剂,可以列举例如缓冲剂、盐等。作为检测用试剂,可以列举例如与上述双特异性抗体或其抗体片段或者它们的衍生物结合的被标记的二次抗体、或与标记对应的底物等通常的免疫学检测或测定法中使用的试剂。以下,具体地对本发明的双特异性抗体的制作方法、使用该抗体的trailr2和psma中的至少一者的测定方法、trailr2和psma表达细胞相关疾病的诊断方法和治疗方法进行记载。1.单克隆抗体的制作方法本发明中的单克隆抗体的制造方法包括下述操作步骤。即,(1)进行作为免疫原使用的抗原的纯化和在细胞表面过量表达抗原的细胞的制作中的至少一者;(2)将抗原对动物进行免疫后,采集血液检测其抗体效价,确定摘除脾脏等的时期,制备抗体产生细胞的步骤;(3)骨髓瘤细胞(骨髓瘤)的制备;(4)抗体产生细胞与骨髓瘤的细胞融合;(5)产生目标抗体的杂交瘤组的筛选;(6)从杂交瘤组中的单克隆(monoclonal)细胞的分离(克隆);(7)根据情况进行用于大量制造单克隆抗体的杂交瘤的培养、或移植了杂交瘤的动物的饲养;(8)如此制造的单克隆抗体的生理活性及其抗原结合特异性的研究、或作为标记试剂的特性的检测;等等。以下,沿着上述步骤对为了制作本发明中的与trailr2和psma结合的双特异性抗体而使用的、与trailr2结合的单克隆抗体和与psma结合的单克隆抗体的制作方法进行详述。该抗体的制作方法不限于此,例如也可以使用脾脏细胞以外的抗体产生细胞和骨髓瘤。(1)抗原的纯化表达trailr2和psma中的至少一者的细胞可以通过将包含编码trailr2和psma中的至少一者的全长或其部分长度的cdna的表达载体导入到大肠杆菌、酵母、昆虫细胞或动物细胞等中而得到。另外,可以从大量表达trailr2和psma中的至少一者的各种人肿瘤培养细胞或人组织等中纯化trailr2和psma中的至少一者,将其作为抗原使用。另外,也可以直接使用该肿瘤培养细胞或该组织等作为抗原。此外,也可以利用fmoe法或tboc法等化学合成法制备具有trailr2和psma中的至少一者的部分序列的合成肽,将其用于抗原。本发明中使用的trailr2和psma中的至少一者可以通过使用molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989);currentprotocolsinmolecularbiology(最新分子生物学实验方法汇编),约翰威利父子出版社(1987-1997)等中记载的方法等,利用例如下述的方法,使编码该trailr2和psma中的至少一者的dna在宿主细胞中进行表达来制造。将包含编码trailr2和psma中的至少一者的部分的全长cdna插入到适当的表达载体的启动子的下游,由此制作重组载体。也可以使用基于全长cdna而制备的包含编码多肽的部分的适当长度的dna片段来代替上述全长cdna。接着,将所得到的该重组载体导入适合该表达载体的宿主细胞中,由此能够得到生产trailr2和psma中的至少一者的转化体。作为表达载体,只要是能够在所使用的宿主细胞中自主复制或能够整合到染色体中、并且在能够转录编码trailr2和psma中的至少一者的dna的位置含有适当的启动子的表达载体,均可以使用。作为宿主细胞,只要是例如大肠杆菌等属于埃希氏菌属等的微生物、酵母、昆虫细胞或动物细胞等能够表达目的基因的宿主细胞,均可以使用。在使用大肠杆菌等原核生物作为宿主细胞的情况下,重组载体优选为能够在原核生物中自主复制、并且包含启动子、核糖体结合序列、包含编码trailr2和psma中的至少一者的部分的dna以及转录终止序列的载体。另外,该重组载体中未必需要具有转录终止序列,但优选紧挨在结构基因下配置转录终止序列。此外,该重组载体可以含有控制启动子的基因。作为该重组载体,优选使用将作为核糖体结合序列的夏因-达尔加诺序列与起始密码子之间调节为适当的距离(例如6~18个碱基)的质粒。另外,作为编码该trailr2和psma中的至少一者的dna的碱基序列,可以对碱基进行置换以形成最适于在宿主内表达的密码子,由此能够提高作为目标的trailr2和psma中的至少一者的生产率。作为表达载体,只要能够在所使用的宿主细胞中发挥功能则均可以使用,可以列举例如pbtrp2、pbtac1、pbtac2(以上为罗氏诊断公司制造)、pkk233-2(法玛西亚公司制造)、pse280(invitrogen公司制造)、pgemex-1(普洛麦格公司制造)、pqe-8(qiagen公司制造)、pkyp10(日本特开昭58-110600号公报)、pkyp200[agriculturalbiologicalchemistry,48,669(1984)]、plsa1[agric.biol.chem.,53,277(1989)]、pgel1[proc.natl.acad.sci.usa,82,4306(1985)]、pbluescriptiisk(-)(stratagene公司制造)、ptrs30[由大肠杆菌jm109/ptrs30(fermbp-5407)制备]、ptrs32[由大肠杆菌jm109/ptrs32(fermbp-5408)制备]、pgha2[由大肠杆菌igha2(fermbp-400)制备、日本特开昭60-221091号公报]、pgka2[由大肠杆菌igka2(fermbp-6798)制备、日本特开昭60-221091号公报]、pterm2(美国专利第4686191号说明书、美国专利第4939094号说明书、美国专利第5160735号说明书)、psupex、pub110、ptp5、pc194、peg400[j.bacteriol.,172,2392(1990)]、pgex(法玛西亚公司制造)、pet系统(novagen公司制造)或pme18sfl3(东洋纺公司制造)等。作为启动子,只要能够在所使用的宿主细胞中发挥功能,则可以为任何启动子。可以列举例如trp启动子(ptrp)、lac启动子、pl启动子、pr启动子或t7启动子等来源于大肠杆菌或噬菌体等的启动子。另外,还可以列举例如将两个ptrp串联而成的串联启动子、tac启动子、lact7启动子或leti启动子等进行了人工设计改变的启动子等。作为宿主细胞,可以列举例如大肠杆菌xl1-blue、大肠杆菌xl2-blue、大肠杆菌dh1、大肠杆菌mc1000、大肠杆菌ky3276、大肠杆菌w1485、大肠杆菌jm109、大肠杆菌hb101、大肠杆菌no.49、大肠杆菌w3110、大肠杆菌ny49或大肠杆菌dh5α等。作为将重组载体导入到宿主细胞中的方法,只要是将dna导入到所使用的宿主细胞中的方法,则均可以使用,可以列举例如使用钙离子的方法[proc.natl.acad.sci.usa,69,2110(1972)、gene,17,107(1982)、molecular&generalgenetics,168,111(1979)]。在使用动物细胞作为宿主的情况下,作为表达载体,只要是能够在动物细胞中发挥功能的表达载体则均可以使用,可以列举例如pcdnai(invitrogen公司制造)、pcdm8(funakoshi公司制造)、page107[日本特开平3-22979号公报;cytotechnology,3,133(1990)]、pas3-3(日本特开平2-227075号公报)、pcdm8[nature,329,840(1987)]、pcdnai/amp(invitrogen公司制造)、pcdna3.1(invitrogen公司制造)、prep4(invitrogen公司制造)、page103[j.biochemistry,101,1307(1987)]、page210、pme18sfl3或pkantex93(国际公开第97/10354号)等。作为启动子,只要是能够在动物细胞中发挥功能的启动子则均可以使用,可以列举例如巨细胞病毒(cmv)的即刻早期(ie)基因的启动子、sv40的早期启动子、逆转录病毒的启动子、金属硫蛋白启动子、热休克启动子、srα启动子或莫洛尼小鼠白血病病毒的启动子或增强子。另外,也可以将人cmv的ie基因的增强子与启动子共同使用。作为宿主细胞,可以列举例如人伯基特氏淋巴瘤细胞那马瓦(namalwa)、来源于非洲绿猴肾脏的细胞cos、来源于中国仓鼠卵巢的细胞cho或人白血病细胞hbt5637(日本特开昭63-000299号公报)等。作为将重组载体导入到宿主细胞中的方法,只要是将dna导入到动物细胞中的方法则均可以使用,可以列举例如电穿孔法[cytotechnology,3,133(1990)]、磷酸钙法(日本特开平2-227075号公报)或脂质体转染法[proc.natl.acad.sci.usa,84,7413(1987)]等。将如上得到的来源于包含整合有编码trailr2和psma中的至少一者的dna的重组载体的微生物或动物细胞等的转化体在培养基中进行培养,使该trailr2和psma中的至少一者在培养物中生成并蓄积,从该培养物中进行收集,由此能够制造trailr2和psma中的至少一者。将该转化体在培养基中进行培养的方法可以按照宿主培养中使用的通常的方法来进行。在来源于真核生物的细胞中进行表达的情况下,能够得到附加有糖或糖链的trailr2和psma中的至少一者。在对利用使用了诱导性启动子的重组载体进行了转化的微生物进行培养时,可以根据需要向培养基中添加诱导剂。例如,在对利用使用了lac启动子的重组载体进行了转化的微生物进行培养的情况下,可以在各培养基中添加异丙基-β-d-硫代吡喃半乳糖苷等,在对利用使用了trp启动子的重组载体进行了转化的微生物进行培养的情况下,可以在各培养基中添加吲哚丙烯酸等。作为对以动物细胞为宿主而得到的转化体进行培养的培养基,可以列举例如通常使用的rpmi1640培养基[thejournaloftheamericanmedicalassociation,199,519(1967)]、伊格尔(eagle)的mem培养基[science,122,501(1952)]、杜氏改良mem培养基[virology,8,396(1959)]、199培养基[proc.soc.exp.biol.med.,73,1(1950)]、伊思考夫(iscove)改良的杜氏培养基(imdm)培养基、或者在这些培养基中添加胎牛血清(fbs)等而得到的培养基等。培养通常在ph6~8、30~40℃、5%co2存在下等条件下进行1~7天。另外,培养中可以根据需要向培养基中添加卡那霉素、青霉素等抗生素。作为编码trailr2和psma中的至少一者的基因的表达方法,除了直接表达以外,还可以使用分泌生产或融合蛋白表达等方法[molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989)]。作为trailr2和psma中的至少一者的生产方法,可以列举例如在宿主细胞内进行生产的方法、分泌到宿主细胞外的方法、或在宿主细胞外膜上进行生产的方法,可以通过改变所使用的宿主细胞或所生产的trailr2和/psma的至少一者的结构来选择适当的方法。例如,制作在编码胞外区的氨基酸序列的dna上连接编码抗体的fc段的dna、编码谷胱甘肽s-转移酶(gst)的dna、或者编码flag标签的dna或编码组氨酸标签的dna等而得到的dna并进行表达、纯化,由此能够制作抗原融合蛋白。具体而言,可以列举例如使trailr2和psma中的至少一者的胞外区与人igg的fc段结合而得到的fc融合蛋白、trailr2和psma中的至少一者的胞外区与谷胱甘肽s-转移酶(gst)的融合蛋白。在trailr和psma中的至少一者在宿主细胞内或宿主细胞外膜上进行生产的情况下,通过使用鲍尔森等人的方法[j.biol.chem.,264,17619(1989)]、罗等人的方法[proc.natl.acad.sci.,usa,86,8227(1989)、genesdevelop.,4,1288(1990)]、日本特开平05-336963号公报或国际公开第94/23021号等记载的方法,能够使trailr2和psma中的至少一者主动地分泌至宿主细胞外。另外,也可以利用使用了二氢叶酸还原酶基因等的基因扩增系统(日本特开平2-227075号公报)来提高trailr2和psma中的至少一者的产量。所生产的trailr2和psma中的至少一者例如可以如下进行分离、纯化。在trailr2和psma中的至少一者在细胞内以溶解状态表达的情况下,在培养结束后通过离心分离回收细胞,悬浮于水系缓冲液中后,利用超声波破碎机、法式压滤壶、manton-gaulin匀浆器或卧式砂磨机等将细胞破碎,得到无细胞提取液。从将该无细胞提取液离心分离而得到的上清中利用通常的蛋白质分离纯化法,即,单独使用或者组合使用溶剂提取法、利用硫酸铵等的盐析法、脱盐法、利用有机溶剂的沉淀法、使用二乙氨基乙基(deae)-琼脂糖、diaionhpa-75(三菱化学公司制造)等树脂的阴离子交换色谱法、使用s-琼脂糖ff(法玛西亚公司制造)等树脂的阳离子交换色谱法、使用丁基琼脂糖、苯基琼脂糖等树脂的疏水性色谱法、使用分子筛的凝胶过滤法、亲和色谱法、色谱聚焦法或等电点电泳等电泳法等方法,由此能够得到纯化蛋白质。在trailr2和psma中的至少一者在细胞内形成不溶体而进行表达的情况下,与上述同样地回收细胞后将其破碎,进行离心分离,由此作为沉淀级分回收该trailr2和psma中的至少一者的不溶体。将回收的该trailr2和psma中的至少一者的不溶体用蛋白改性剂进行可溶化。对该可溶化液进行稀释或透析,由此使该trailr2和psma中的至少一者恢复至正常的立体结构后,利用与上述同样的分离纯化法能够得到多肽的纯化蛋白质。在trailr2和psma中的至少一者或其糖修饰体等衍生物被分泌至细胞外的情况下,可以在培养上清中回收该trailr2和psma中的至少一者或其糖修饰体等衍生物。与上述同样地使用离心分离等方法对该培养上清进行处理,由此获取可溶性级分,使用与上述同样的分离纯化法,能够从该可溶性级分中得到纯化蛋白质。另外,本发明中使用的trailr2和psma中的至少一者也可以利用fmoc法或tboc法等化学合成法来制造。具体而言,可以利用例如advancedchemtech公司制造、珀金埃尔默公司制造、法玛西亚公司制造、proteintechnologyinstrument公司制造、synthecell-vega公司制造、perceptive公司制造、或岛津制作所公司制造等的肽合成仪进行化学合成。(2)抗体产生细胞的制备步骤对3~20周龄的小鼠、大鼠或仓鼠等动物进行(1)中得到的抗原的免疫,采集该动物的脾脏、淋巴结或外周血中的抗体产生细胞。另外,作为动物,可以列举例如富塚等人的文献[tomizuka.etal.,procnatlacadsciusa.,97、722,(2000)]中记载的产生来源于人的抗体的转基因小鼠、为了提高免疫原性而进行了trailr2或psma的条件性基因敲除的小鼠等作为被免疫动物。免疫通过将抗原与弗氏完全佐剂、氢氧化铝凝胶、百日咳菌疫苗等适当的佐剂一起给药来进行。小鼠免疫时的免疫原给药法可以为皮下注射、腹腔内注射、静脉内注射、皮内注射、肌肉内注射或足底注射等中的任意一种,优选腹腔内注射、足底注射或静脉内注射。在抗原为部分肽的情况下,制作与bsa(牛血清白蛋白)或钥孔血蓝蛋白(keyholelimpethemocyanin,klh)等载体蛋白的结合体,将其用作免疫原。抗原的给药在第一次给药后每隔1~2周进行5~10次。在各给药后第3~7天从眼底静脉丛采血,使用酶免疫测定法[antibodies-alaboratorymanual(抗体实验室手册),冷泉港实验室(1988)]等测定其血清的抗体效价。若使用上述血清对免疫所用的抗原显示出充分的抗体效价的动物作为融合用抗体的产生细胞的供给源,则能够提高后续操作的效果。在抗原的最终给药后第3~7天,从免疫后的动物体内摘除脾脏等包含抗体产生细胞的组织,采集抗体产生细胞。抗体产生细胞是作为浆细胞及其前体细胞的淋巴细胞,其可以从个体的任意部位获得,通常可以从脾脏、淋巴结、骨髓、扁桃体、外周血或它们的适当组合等而得到,但最普遍使用脾脏细胞。在使用脾脏细胞的情况下,将脾脏细切、打散后离心分离,进而除去红细胞,由此获取融合用抗体产生细胞。(3)骨髓瘤的制备步骤作为骨髓瘤,可以使用来源于小鼠、大鼠、豚鼠、仓鼠、兔或人等哺乳动物的自身不具有抗体产生能力的细胞,通常使用由小鼠得到的细胞株,例如8-氮杂鸟嘌呤抗性小鼠(来源于balb/c)骨髓瘤细胞株p3-x63ag8-u1(p3-u1)[currenttopicsinmicrobiologyandimmunology,18,1(1978)]、p3-ns1/1-ag41(ns-1)[europeanj.immunology,6,511(1976)]、sp2/0-ag14(sp-2)[nature,276,269(1978)]、p3-x63-ag8653(653)[j.immunology,123,1548(1979)]或p3-x63-ag8(x63)[nature,256,495(1975)]等。该细胞株可以在适当的培养基例如8-氮杂鸟嘌呤培养基[添加有谷氨酰胺、2-巯基乙醇、庆大霉素、fcs和8-氮杂鸟嘌呤的rpmi-1640培养基]、伊思考夫改良杜氏培养基(iscove’smodifieddulbecco’smedium;以下称为“imdm”)或杜氏改良伊格尔培养基(dulbecco’smodifiedeaglemedium;以下称为“dmem”)等培养基中进行传代培养。在细胞融合的3~4天前,将上述细胞株在正常培养基(例如含有10%fcs的dmem培养基)中传代培养,在进行融合的当天确保2×107个以上的细胞数。(4)细胞融合将(2)中得到的融合用抗体产生细胞和(3)中得到的骨髓瘤细胞用最低必需培养基(mem)或pbs(磷酸氢二钠1.83g、磷酸二氢钾0.21g、氯化钠7.65g、蒸馏水1升、ph7.2)充分清洗,按照融合用抗体产生细胞∶骨髓瘤细胞=5∶1~10∶1的方式混合,离心分离后,除去上清。将沉淀的细胞团块充分打散后,在37℃下一边搅拌一边加入聚乙二醇-1000(peg-1000)、mem培养基和二甲亚砜的混合液。进一步,每1~2分钟添加mem培养基1~2ml,添加数次后,加入mem培养基使总量为50ml。离心分离后,除去上清,将沉淀的细胞团块轻轻打散后,将细胞轻柔地悬浮于hat培养基[添加有次黄嘌呤、胸腺嘧啶和氨基蝶呤的正常培养基]中。将该悬浮液在5%co2温箱中在37℃下培养7~14天。另外,也可以利用下述方法进行细胞融合。将脾脏细胞和骨髓瘤细胞用无血清培养基(例如dmem)或磷酸缓冲生理盐溶液(以下称为“磷酸缓冲液”)充分清洗,按照脾脏细胞与骨髓瘤细胞的细胞数之比为约5∶1~约10∶1的方式混合,并进行离心分离。除去上清,将沉淀的细胞团块充分打散后,在搅拌的同时滴加1ml含有50%(w/v)聚乙二醇(分子量1000~4000)的无血清培养基。然后,缓慢加入10ml的无血清培养基后,进行离心分离。再次弃去上清,将沉淀的细胞悬浮于含有适量的次黄嘌呤-氨基喋呤-胸腺嘧啶(hat)液和人白细胞介素-2(il-2)的正常培养基(以下称为hat培养基)中,分注到培养用板(以下称为板)的各孔中,在5%二氧化碳存在下在37℃下培养约2周。中途适当补充hat培养基。(5)杂交瘤组的选择在融合所用的骨髓瘤细胞为8-氮杂鸟嘌呤抗性株的情况下、即为次黄嘌呤-鸟嘌呤磷酸核苷转移酶(hgprt)缺陷株的情况下,未融合的骨髓瘤细胞和骨髓瘤细胞彼此的融合细胞无法在hat培养基中存活。另一方面,抗体产生细胞彼此的融合细胞和抗体产生细胞与骨髓瘤细胞的杂交瘤能够在hat培养基中存活,但抗体产生细胞彼此的融合细胞的寿命仍是有限的。因此,通过在hat培养基中继续进行培养,仅抗体产生细胞与骨髓瘤细胞的杂交瘤存活下来,结果能够获取杂交瘤。对于以集落状生长的杂交瘤,进行从hat培养基向除去氨基蝶呤后的培养基(以下称为ht培养基)的培养基更换。然后,采集一部分培养上清,使用后述的抗体效价测定法选择出产生抗体的杂交瘤。作为抗体效价的测定方法,可以列举例如放射性同位素免疫定量法(ria法)、固相酶联免疫定量法(elisa法)、荧光抗体法和被动血细胞凝集反应法等各种公知技术,从检测灵敏度、快速性、准确性和操作自动化的可能性等观点出发,优选ria法或elisa法。将通过测定抗体效价判断出产生所期望的抗体的杂交瘤转移到另一板中进行克隆。作为该克隆法,可以列举例如以使板的1个孔中含有1个细胞的方式稀释后进行培养的有限稀释法、在软琼脂培养基中进行培养并回收集落的软琼脂法、利用显微操纵器分离出1个细胞的方法、利用细胞分选仪分离出1个细胞的方法等。对于确认了抗体效价的孔,重复2~4次例如利用有限稀释法进行的克隆,选择出稳定地确认到抗体效价的杂交瘤株作为产生针对人trailr2或psma的单克隆抗体的杂交瘤株。(6)单克隆抗体的制备对姥鲛烷处理[腹腔内给药2,6,10,14-四甲基十五碳烷(姥鲛烷)0.5ml,饲养2周]后的8~10周龄的小鼠或裸鼠腹腔内注射(5)中得到的单克隆抗体产生杂交瘤。在10~21天杂交瘤形成癌性腹水。从该小鼠采集腹水,离心分离而除去固体成分后,用40~50%硫酸铵进行盐析,利用辛酸沉淀法、deae-琼脂糖柱、蛋白a柱或凝胶过滤柱进行纯化,收集igg或igm级分,制成纯化单克隆抗体。另外,使该杂交瘤在同系小鼠(例如balb/c)或nu/nu小鼠、大鼠、豚鼠、仓鼠或兔等的腹腔内增殖,由此能够得到大量含有与trailr2或psma结合的单克隆抗体的腹水。将(5)中得到的单克隆抗体产生杂交瘤在添加有10%fbs的rpmi1640培养基等中进行培养后,通过离心分离除去上清,悬浮于git培养基或添加有5%daigogf21的杂交瘤sfm培养基等中,通过烧瓶培养、摇床培养或袋培养等培养3~7天。对所得到的细胞悬浮液进行离心分离,利用蛋白a柱或蛋白g柱从所得到的上清中进行纯化,收集igg级分,也能够得到纯化单克隆抗体。作为纯化的简便方法,也可以利用市售的单克隆抗体纯化试剂盒(例如,mabtrapgii试剂盒;amershampharmaciabiotech公司制造)等。抗体亚类的确定使用亚类分型试剂盒通过酶免疫测定法来进行。蛋白量的定量可以通过劳里法和由280nm处的吸光度[1.4(od280)=免疫球蛋白1mg/ml]进行计算的方法来进行。(7)单克隆抗体对trailr2或psma的结合分析单克隆抗体对trailr2或psma的结合活性可以利用双向免疫扩散(ouchterlony)法、elisa法、ria法、流式细胞术(fcm)或表面等离子体共振法(spr)等结合分析系统来进行测定。双向免疫扩散法简便,但在抗体的浓度低的情况下,需要进行浓缩操作。另一方面,在使用elisa法或ria法的情况下,通过使培养上清直接与抗原吸附固相反应,进而使用与各种免疫球蛋白同种型、亚类对应的抗体作为二次抗体,能够鉴定抗体的同种型、亚类,并且能够测定抗体的结合活性。作为步骤的具体例,使纯化或部分纯化的重组trailr2和psma中的至少一者吸附于elisa用96孔板等固相表面,进而利用与抗原无关的蛋白、例如牛血清白蛋白(bsa)对未吸附有抗原的固相表面进行封闭。将elisa板用含有磷酸缓冲盐溶液(pbs)和0.05%tween20的pbs(tween-pbs)等进行清洗后,使连续稀释的第一抗体(例如小鼠血清、培养上清等)进行反应,使抗体结合到固定于板上的抗原上。接着,分注利用生物素、酶(辣根过氧化物酶,horseradishperoxidase,hrp;碱性磷酸酶,alkalinephosphatase,alp等)、化学发光物质或放射线化合物等进行了标记的抗免疫球蛋白抗体作为第二抗体,使第二抗体与结合于板上的第一抗体反应。用tween-pbs充分清洗后,进行与第二抗体的标记物质对应的反应,选择出对靶抗原特异性地发生反应的单克隆抗体。fcm法的情况下,能够测定抗体对抗原表达细胞的结合活性[cancerimmunol.immunother.,36,373(1993)]。抗体与表达在细胞膜上的膜蛋白抗原结合是指,该抗体识别并结合天然存在的抗原的立体结构。作为spr法,可以列举利用biacore进行的动力学分析。例如,使用biacoret100,测定抗原与被测物之间的结合的动力学,使用设备附带的分析软件对其结果进行分析。作为步骤的具体例,通过胺偶联法将抗小鼠igg抗体固定于传感器芯片cm5上,然后使杂交瘤培养上清或纯化单克隆抗体等被测物质流过,使其以适当量结合,进而使浓度已知的多个浓度的抗原流过,测定结合和解离。接着,使用设备附带的软件利用1∶1结合模型对所得到的数据进行动力学分析,获取各种参数。或者,通过例如胺偶联法将trailr2和psma中的至少一者固定于传感器芯片上,然后使浓度已知的多个浓度的纯化单克隆抗体流过,测定结合和解离。使用设备附带的软件利用双价结合模型对所得到的数据进行动力学分析,获取各种参数。另外,本发明中,与抗trailr2或psma的抗体竞争地与trailr2或psma结合的抗体可以通过使被测抗体共存于上述的结合分析系统中并进行反应来进行选择。即,通过筛选在添加有被测抗体时与抗原的结合受到抑制的抗体,能够得到在与trailr2或psma的结合中与上述获取的抗体竞争的抗体。(8)抗trailr2或psma的单克隆抗体的表位的鉴定本发明中,抗体所识别并结合的表位的鉴定可以如下进行。例如,制作抗原的部分缺陷体、改变了在种间不同的氨基酸残基而得到的突变体、或改变了特定结构域而得到的突变体,若抗体对该缺陷体或突变体的反应性降低,则表明缺陷部位或氨基酸改变部位为该抗体的表位。这种抗原的部分缺陷体和突变体可以使用适当的宿主细胞例如大肠杆菌、酵母、植物细胞或哺乳动物细胞等以分泌蛋白的形式获得,也可以在宿主细胞的细胞膜上表达而以抗原表达细胞的形式制备。在膜型抗原的情况下,为了在保持抗原的立体结构的状态下进行表达,优选在宿主细胞的膜上表达。另外,也可以制作模仿抗原的一级结构或立体结构的合成肽来确认抗体的反应性。关于合成肽,可以列举使用公知的肽合成技术制作该分子的各种部分肽的方法等。例如,对于人和小鼠的trailr2或psma的胞外区,可以通过制作将构成各区域的结构域适当组合而得到的嵌合蛋白并确认抗体对该蛋白质的反应性来鉴定抗体的表位。然后,可以通过使用本领域技术人员公知的寡肽合成技术进一步详细地合成各种其对应部分的寡肽或该肽的突变体等并确认抗体对该肽的反应性来限定表位。作为用于得到多种寡肽的简便的方法,也可以利用市售的试剂盒[例如,spots试剂盒(genosysbiotechnologies公司制造)、使用多针合成法的一系列多针肽合成试剂盒(chiron公司制造)等]。结合在和与trailr2或psma结合的抗体所结合的表位相同的表位上的抗体可以通过如下方法获取:对利用上述结合分析系统得到的抗体的表位进行鉴定,制作该表位的部分合成肽、模拟表位的立体结构的合成肽或该表位的重组体等,进行免疫。例如,若表位为膜蛋白,则通过制作使全部胞外区或一部分胞外结构域与适当的标签例如flag标签、组氨酸标签、gst蛋白或抗体fc段等连接而成的重组融合蛋白并用该重组蛋白进行免疫,能够更高效地制作该表位特异性的抗体。2.基因重组抗体的制作作为基因重组抗体的制作例,在p.j.delves.,antibodyproductionessentialtechniques.(抗体制作基础技术),1997;wiley、p.shepherdandc.dean.monoclonalantibodies.(单克隆抗体),2000,牛津大学出版社;和j.w.goding.,monoclonalantibodies:principlesandpractice.(单克隆抗体原理与实践),1993,学术出版社等中进行了概述,以下示出嵌合抗体、人源化抗体和人抗体的制作方法。另外,对于基因重组小鼠抗体、大鼠抗体、仓鼠抗体和兔抗体,也可以利用同样的方法进行制作。(1)由杂交瘤获取编码单克隆抗体的v区的cdna编码单克隆抗体的vh和vl的cdna的获取例如可以如下进行。首先,由产生单克隆抗体的杂交瘤提取mrna,合成cdna。接着,将所合成的cdna克隆到噬菌体或质粒等载体中,制作cdna文库。使用编码抗体的c区部分或v区部分的dna作为探针,从该文库中分别分离出具有编码vh或vl的cdna的重组噬菌体或重组质粒。确定所分离出的重组噬菌体或重组质粒内的vh或vl的全部碱基序列,由该碱基序列推定vh或vl的全部氨基酸序列。作为杂交瘤的制作中使用的非人动物,使用小鼠、大鼠、仓鼠或兔等,但只要能够制作杂交瘤,任何动物均可以使用。由杂交瘤制备总rna时,使用异硫氰酸胍-三氟乙酸铯法[methodsinenzymol.,154,3(1987)]、或rnaeasy试剂盒(qiagen公司制造)等试剂盒等。由总rna制备mrna时,使用固定有寡聚(dt)的纤维素柱法[molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989)]、或oligo-dt30<super>mrna纯化试剂盒(宝生物公司制造)等试剂盒等。另外,也可以使用fasttrackmrna分离试剂盒(invitrogen公司制造)或quickprepmrna纯化试剂盒(法玛西亚公司制造)等试剂盒来制备mrna。cdna的合成和cdna文库的制作使用公知的方法[molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989);currentprotocolsinmolecularbiology(最新分子生物学实验方法汇编),附录1,约翰威利父子出版社(1987-1997)]或用于cdna合成和质粒克隆的superscript质粒系统(invitrogen公司制造)或zap-cdna合成试剂盒(stratagene公司制造)等试剂盒等。制作cdna文库时,作为整合以由杂交瘤提取的mrna为模板而合成的cdna的载体,只要是可整合该cdna的载体,则任何载体均可以使用。例如使用zapexpress[strategies,5,58(1992)]、pbluescriptiisk(+)[nucleicacidsresearch,17,9494(1989)]、λzapii(stratagene公司制造)、λgt10、λgt11[dnacloning:apracticalapproach(dna克隆实用方法),i,49(1985)]、lambdabluemid(clontech公司制造)、λexcell、pt7t3-18u(法玛西亚公司制造)、pcd2[mol.cell.biol.,3,280(1983)]或puc18[gene,33,103(1985)]等。对于导入利用噬菌体或质粒载体构建的cdna文库的大肠杆菌,只要能够导入、表达和维持该cdna文库,则可以使用任何大肠杆菌。例如,使用xl1-bluemrf’[strategies,5,81(1992)]、c600[genetics,39,440(1954)]、y1088、y1090[science,222,778(1983)]、nm522[j.mol.biol.,166,1(1983)]、k802[j.mol.biol.,16,118(1966)]或jm105[gene,38,275(1985)]等。从cdna文库中选择编码非人抗体的vh或vl的cdna克隆时,使用利用同位素或荧光标记的探针的集落杂交法或噬菌斑杂交法[molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989)]等。另外,也可以通过制备引物,以由mrna合成的cdna或cdna文库作为模板,进行聚合酶链式反应法[以下表示为pcr法;molecularcloning,alaboratorymanual(分子克隆实验指南),第二版,冷泉港实验室出版社(1989);currentprotocolsinmolecularbiology(最新分子生物学实验方法汇编),附录1,约翰威利父子出版社(1987-1997)]来制备编码vh或vl的cdna。将所选择的cdna用适当的限制酶等切割后,克隆到pbluescriptsk(-)(stratagene公司制造)等质粒中,利用通常使用的碱基序列分析方法等确定该cdna的碱基序列。例如,进行双脱氧法[proc.natl.acad.sci.usa,74,5463(1977)]等反应后,使用a.l.f.dna测序仪(法玛西亚公司制造)等碱基序列自动分析装置等进行分析。根据所确定的全部碱基序列分别推定vh和vl的全部氨基酸序列,与已知抗体的vh和vl的全部氨基酸序列[sequencesofproteinsofimmunologicalinterest,usdept.healthandhumanservices(1991)]进行比较,由此确认所获取的cdna是否编码包含分泌信号序列的抗体的vh和vl各自的完整氨基酸序列。关于包含分泌信号序列的抗体的vh和vl各自的完整氨基酸序列,通过与已知抗体的vh和vl的全部氨基酸序列[sequencesofproteinsofimmunologicalinterest,usdept.healthandhumanservices(1991)]进行比较,能够推定分泌信号序列的长度和n末端氨基酸序列,进而能够鉴定出它们所属的亚类。另外,vh和vl的各cdr的氨基酸序列可以通过与已知抗体的vh和vl的氨基酸序列[sequencesofproteinsofimmunologicalinterest,usdept.healthandhumanservices(1991)]进行比较来推定。另外,通过使用例如swiss-prot或pir-protein等任意的数据库对所得到的vh和vl的完整氨基酸序列进行利用blast法[j.mol.biol.,215,403(1990)]等的同源性检索,能够确认该vh和vl的完整氨基酸序列是否为新序列。(2)基因重组抗体表达用载体的构建基因重组抗体表达用载体可以通过将编码人抗体的ch和cl的至少一者的dna克隆到动物细胞用表达载体中来构建。作为人抗体的c区域,可以使用任意的人抗体的ch和cl,可以使用例如人抗体的γ1亚类的ch和κ类的cl等。作为编码人抗体的ch和cl的dna,使用cdna,但也可以使用由外显子和内含子构成的染色体dna。作为动物细胞用表达载体,只要能够整合编码人抗体的c区的基因并进行表达,则可以使用任何表达载体,可以使用例如page107[cytotechnol.,3,133(1990)]、page103[j.biochem.,101,1307(1987)]、phsg274[gene,27,223(1984)]、pkcr[proc.natl.acad.sci.usa,78,1527(1981)]、psg1bd2-4[cytotechnol.,4,173(1990)]、或pse1uk1sed1-3[cytotechnol.,13,79(1993)]、inpep4(biogen-idec公司制造)、n5kg1val(美国专利第6001358号说明书)、转座子载体(国际公开第2010/143698号)等。作为动物细胞用表达载体的启动子和增强子,可以使用sv40的早期启动子[j.biochem.,101,1307(1987)]、莫洛尼小鼠白血病病毒ltr[biochem.biophys.res.commun.,149,960(1987)]、cmv启动子(美国专利第5168062号说明书)或免疫球蛋白h链的启动子[cell,41,479(1985)]和增强子[cell,33,717(1983)]等。从载体构建的容易度、向动物细胞中导入的容易度、抗体h链和l链在细胞内的表达量的均衡性等观点出发,基因重组抗体的表达使用搭载有抗体h链和l链这两者的基因的载体(串联型载体)[j.immunol.methods,167,271(1994)],但也可以将分别搭载有抗体h链和l链的各基因的多个载体(分离型载体)组合使用。作为串联型的基因重组抗体表达用载体,使用pkantex93(国际公开第97/10354号)、pee18[hybridoma,17,559(1998)]、n5kg1val(美国专利第6001358号说明书)、tol2转座子载体(国际公开第2010/143698号)等。(3)嵌合抗体表达载体的构建将(1)中得到的编码非人抗体的vh或vl的cdna分别克隆到(2)中得到的基因重组抗体表达用载体内的编码人抗体的ch或cl的基因的各自的上游,由此能够构建嵌合抗体表达载体。首先,为了使编码非人抗体的vh或vl的cdna的3’末端侧与人抗体的ch或cl的5’末端侧连接,制作以如下方式设计的vh和vl的cdna:连接部分的碱基序列编码适当的氨基酸且成为适当的限制酶识别序列。接着,将所制作的vh和vl的cdna分别克隆到(2)中得到的基因重组抗体表达用载体内的编码人抗体的ch或cl的基因的各自的上游,以使它们以适当的形式进行表达,从而构建嵌合抗体表达载体。另外,也可以使用在两端具有适当的限制酶的识别序列的合成dna,利用pcr法对编码非人抗体的vh或vl的cdna分别进行扩增,将它们克隆到(2)中得到的基因重组抗体表达用载体中,由此构建嵌合抗体表达载体。(4)编码人源化抗体的v区的cdna的制作编码人源化抗体的vh或vl的cdna可以如下制作。首先,分别选择出移植(1)中得到的非人抗体的vh或vl的cdr的氨基酸序列的人抗体的vh或vl的骨架区(以下表示为fr)的氨基酸序列。所选择的fr的氨基酸序列只要是来源于人抗体的氨基酸序列,则均可以使用。例如,使用蛋白数据库(proteindatabank)等数据库中登记的人抗体的fr的氨基酸序列或人抗体的fr的各亚类的共有氨基酸序列[sequencesofproteinsofimmunologicalinterest,usdept.healthandhumanservices(1991)]等。为了抑制抗体的结合活性的降低,选择与原来的非人抗体的vh或vl的fr的氨基酸序列具有尽量高的同源性(60%以上)的人fr的氨基酸序列。接着,向选择好的人抗体的vh或vl的fr的氨基酸序列中分别移植原来的非人抗体的cdr的氨基酸序列,分别设计出人源化抗体的vh或vl的氨基酸序列。通过考虑在抗体基因的碱基序列中出现的密码子的使用频率[sequencesofproteinsofimmunologicalinterest,usdept.healthandhumanservices(1991)]而将所设计的氨基酸序列转换成dna序列,分别设计出人源化抗体的vh或vl的cdna序列。基于设计好的dna序列,合成多条由约100~150个碱基的长度构成的合成dna,使用这些合成dna进行pcr反应。这种情况下,从pcr反应中的反应效率和能够合成的dna的长度的观点出发,优选对于h链和l链各自设计4~6条合成dna。另外,也可以合成可变区全长的合成dna来使用。此外,通过在位于两端的合成dna的5’末端导入适当的限制酶的识别序列,能够容易地将编码人源化抗体的vh或vl的cdna克隆到(2)中得到的基因重组抗体表达用载体中。pcr反应后,将扩增产物分别克隆到pbluescriptsk(-)(stratagene公司制造)等质粒中,通过与(1)中记载的方法同样的方法来确定碱基序列,从而获取具有编码所期望的人源化抗体的vh或vl的氨基酸序列的dna序列的质粒。(5)人源化抗体的v区的氨基酸序列的改变对于人源化抗体而言,仅将非人抗体的vh和vl的cdr移植到人抗体的vh和vl的fr中时,其抗原结合活性与原来的非人抗体相比降低[bio/technology,9,266(1991)]。因此,鉴定出人抗体的vh和vl的fr的氨基酸序列中直接与抗原的结合相关的氨基酸残基、与cdr的氨基酸残基相互作用的氨基酸残基、以及维持抗体的立体结构而间接与抗原的结合相关的氨基酸残基,并将这些氨基酸残基置换为原来的非人抗体的氨基酸残基,由此能够使降低的人源化抗体的抗原结合活性升高。为了鉴定出与抗原结合活性相关的fr的氨基酸残基,可以通过使用x射线晶体分析[j.mol.biol.,112,535(1977)]或计算机建模[proteinengineering,7,1501(1994)]等来进行抗体的立体结构的构建和分析。另外,通过针对各个抗体制作多种改变体并反复研究与各自的抗原结合活性的相关性来进行各种尝试,能够获取具有所需要的抗原结合活性的改变人源化抗体。人抗体的vh和vl的fr的氨基酸残基可以通过使用改变用合成dna进行(4)中记载的pcr反应来进行改变。对于pcr反应后的扩增产物,通过(1)中记载的方法来确定碱基序列,从而确认已实施了目标改变。(6)人源化抗体表达载体的构建将所构建的编码人源化抗体的vh或vl的cdna分别克隆到(2)中得到的基因重组抗体表达用载体的编码人抗体的ch或cl的各基因的上游,能够构建人源化抗体表达载体。例如,通过向(4)和(5)中得到的构建人源化抗体的vh或vl时使用的合成dna中位于两端的合成dna的5’末端导入适当的限制酶的识别序列,将所构建的vh或vl的cdna分别克隆到(2)中得到的基因重组抗体表达用载体内的编码人抗体的ch或cl的各基因的上游,以使它们以适当的形式进行表达。(7)人抗体表达载体的构建在使用产生人抗体的动物作为被免疫动物来建立产生单克隆抗体的杂交瘤的情况下,在(1)中能够得到人抗体的vh和vl的氨基酸序列和cdna序列。因此,通过将(1)中得到的编码人抗体的vh或vl的基因分别克隆到(2)中得到的基因重组抗体表达用载体的编码人抗体的ch或cl的各基因的上游,能够构建人抗体表达载体。(8)基因重组抗体的瞬时表达使用(3)、(6)和(7)中得到的基因重组抗体表达载体、或对它们进行改变而得到的表达载体,瞬时地表达基因重组抗体,从而能够有效地评价所得到的多种基因重组抗体的抗原结合活性。用于导入表达载体的宿主细胞只要是能够表达基因重组抗体的宿主细胞,则可以使用任何细胞,例如使用cos-7细胞[美国典型培养物保藏中心(atcc)编号:crl1651]。向cos-7细胞中导入表达载体时,使用deae-右旋糖酐法[methodsinnucleicacidsres.,crc出版社(1991)]或脂质体转染法[proc.natl.acad.sci.usa,84,7413(1987)]等。导入表达载体后,使用酶免疫抗体法[monoclonalantibodies-principlesandpractice(单克隆抗体原理与实践),第三版,学术出版社(1996);antibodies-alaboratorymanual(抗体实验室手册),冷泉港实验室(1988);单克隆抗体实验手册、讲谈社scientific(1987)]等测定培养上清中的基因重组抗体的表达量和抗原结合活性。(9)基因重组抗体的稳定表达株的获取和基因重组抗体的制备通过将(3)、(6)和(7)中得到的基因重组抗体表达载体导入到适当的宿主细胞中,能够得到稳定表达基因重组抗体的转化株。作为表达载体向宿主细胞中的导入,可以列举例如电穿孔法[日本特开平2-257891号公报;cytotechnology,3,133(1990)]、钙离子法、电穿孔法、原生质体法、醋酸锂法、磷酸钙法、脂质体转染法等。另外,作为向后述的动物中导入基因的方法,可以列举例如显微注射法、使用电穿孔或脂质体转染法将基因导入es细胞中的方法和核移植法等。作为导入基因重组抗体表达载体的宿主细胞。只要是能够表达基因重组抗体的宿主细胞,则可以使用任何细胞。例如使用小鼠sp2/0-ag14细胞(atcccrl1581)、小鼠p3x63-ag8.653细胞(atcccrl1580)、中国仓鼠cho-k1细胞(atccccl-61)、dukxb11(atccccl-9096)、pro-5细胞(atccccl-1781)、cho-s细胞(lifetechnologies、目录号11619)、二氢叶酸还原酶基因(dhfr)缺陷的cho细胞(cho/dg44细胞)[proc.natl.acad.sci.usa,77,4216(1980)]、获得了凝集素抗性的lec13细胞[somaticcellandmoleculargenetics,12,55(1986)]、α-1,6-岩藻糖转移酶基因缺陷的cho细胞(国际公开第2005/035586号、国际公开第02/31140号)、大鼠yb2/3hl.p2.g11.16ag.20细胞(atcc编号:crl1662)等。另外,也可以使用与细胞内糖核苷酸gdp-岩藻糖的合成相关的酶等蛋白质、与在n-糖苷键复合型糖链的还原末端的n-乙酰葡糖胺的6位上使岩藻糖的1位进行α连接的糖链修饰相关的酶等蛋白质、或者与细胞内糖核苷酸gdp-岩藻糖向高尔基体的转运相关的蛋白质等的活性降低或缺失的宿主细胞,例如α-1,6-岩藻糖转移酶基因缺陷的cho细胞(国际公开第2005/035586号、国际公开第02/31140号)等。导入表达载体后,将稳定表达基因重组抗体的转化株在含有g418硫酸盐(以下表示为g418)等药剂的动物细胞培养用培养基中进行培养,由此进行选择(日本特开平2-257891号公报)。动物细胞培养用培养基使用rpmi1640培养基(invitrogen公司制造)、git培养基(日本制药公司制造)、ex-cell301培养基(jrh公司制造)、ex-cell302培养基(jrh公司制造)、ex-cell325培养基(jrh公司制造)、imdm培养基(invitrogen公司制造)或hybridoma-sfm培养基(invitrogen公司制造)、或者在这些培养基中添加有fbs等各种添加物的培养基等。通过将所得到的转化株在培养基中进行培养,使基因重组抗体在培养上清中表达、蓄积。培养上清中的基因重组抗体的表达量和抗原结合活性可以利用elisa法等进行测定。另外,可以利用dhfr扩增系统(日本特开平2-257891号公报)等使转化株所产生的基因重组抗体的表达量升高。基因重组抗体可以使用蛋白a柱从转化株的培养上清中进行纯化[monoclonalantibodies-principlesandpractice(单克隆抗体原理与实践),第三版,学术出版社(1996);antibodies-alaboratorymanual(抗体实验室手册),冷泉港实验室(1988)]。另外,也可以将凝胶过滤、离子交换色谱和超滤等蛋白质的纯化中使用的方法组合来进行纯化。纯化后的基因重组抗体的h链、l链或整个抗体分子的分子量可以使用聚丙烯酰胺凝胶电泳法[nature,227,680(1970)]、或蛋白免疫印迹法[monoclonalantibodies-principlesandpractice(单克隆抗体原理与实践),第三版,学术出版社(1996);antibodies-alaboratorymanual(抗体实验室手册),冷泉港实验室(1988)]等进行测定。3.双特异性抗体的制作本发明的双特异性抗体例如可以通过下述方法来制作:首先,使用上述1.记载的方法获取与不同表位结合的多种单克隆抗体,接着,使用上述2.记载的方法确定各抗体的vh和vl的cdna序列,设计出将各抗体的抗原结合位点连接而成的抗体。具体而言,可以通过下述方法来制作:合成将各抗体的抗原结合位点和连接子适当组合而成的dna,整合到上述2.(2)记载的基因重组抗体表达载体中,使其表达该双特异性抗体。更具体而言,可以通过下述方法来制作:合成编码藉由连接子将各抗体的vh连接而成的多肽的dna,并且合成编码各抗体的vl的dna,将这些dna整合到上述2.(2)记载的基因重组抗体表达载体中,使其表达该双特异性抗体。抗原结合位点除了可以使用上述1.记载的杂交瘤的方法来分离、获取以外,还可以利用噬菌体展示法、酵母展示法等技术来分离、获取[emmanuellelaffyet.al.,humanantibodies14,33-55,(2005)]。连接子是将某一抗原结合结构域与另一抗原结合结构域之间连接起来的肽,通常由10个氨基酸残基以上的多肽构成。本发明中,作为连接子的一例,可以将由抗体的ch1、铰链、ch2和ch3构成的氨基酸序列的全部或部分片段适当组合来使用。另外,也可以使这些氨基酸序列部分缺失或改变顺序来使用。用于连接子的抗体的动物种类没有特别限定,优选为人。另外,用于连接子的抗体的亚类没有特别限定,优选为igm或igg4,更优选为igg4。本发明中,作为具体的连接子的例子,可以列举由序列号11所表示的igg4的ch1的n末端至第14位的14个氨基酸残基构成的连接子、由序列号12所表示的igm的ch1的n末端至第14位的氨基酸残基构成的连接子、和由序列号93所表示的igg4的ch1构成的连接子等,优选为由序列号93所表示的igg4的ch1构成的连接子。另外,在制作由多个vh和单个vl构成的双特异性抗体的情况下,以双特异性抗体中含有的各抗原结合位点与各自的特异性抗原反应的方式使用噬菌体展示法等进行筛选,选择出最适合单个vl的各个vh。具体而言,首先,使用上述1.记载的方法,使用第一抗原对动物进行免疫,由其脾脏制作杂交瘤,克隆出编码第一抗原结合位点的dna序列。接着,使用第二抗原对动物进行免疫,由其脾脏制备cdna文库,利用pcr由该文库获取编码vh的氨基酸序列的dna。接着,制作表达将通过第二抗原的免疫得到的vh与第一抗原结合位点的vl连接而成的scfv的噬菌体文库,通过使用该噬菌体文库的筛选(panning),选择出展示有与第二抗原特异性地结合的scfv的噬菌体。由所选择的噬菌体克隆出编码第二抗原结合位点的vh的氨基酸序列的dna序列。进而,设计出编码藉由上述连接子将第一抗原结合位点的vh与第二抗原结合位点的vh连接而成的多肽的氨基酸序列的dna序列,将该dna序列和编码单个vl的氨基酸序列的dna序列插入到例如上述2.(2)记载的基因重组抗体表达载体中,由此能够构建本发明的双特异性抗体的表达载体。4.本发明的双特异性抗体或其抗体片段的活性评价纯化的抗体或其抗体片段的活性评价可以如下进行。本发明的双特异性抗体对表达trailr2和psma中的至少一者的细胞株的结合活性可以使用上述1.(7)记载的结合分析系统来测定。对于表达trailr2和psma中的至少一者的细胞的cdc活性或adcc活性可以利用公知的测定方法[cancerimmunol.immunother.,36,373(1993)]来测定。本发明的双特异性抗体的细胞死亡诱导活性可以利用下述方法来测定。例如,将细胞接种到96孔板中,添加抗体并培养一定期间后,使wst-8试剂(dojindo公司制造)进行反应,利用酶标仪测定450nm的吸光度,由此测定细胞的存活率。5.使用本发明的双特异性抗体或其抗体片段的疾病的治疗方法本发明的双特异性抗体或其抗体片段能够用于trailr2和psma表达细胞相关疾病的治疗。作为trailr2和psma相关的疾病,可以列举例如恶性肿瘤和癌症等。作为恶性肿瘤和癌症,可以列举例如大肠癌、结肠直肠癌、肺癌、乳腺癌、神经胶质瘤、恶性黑色素瘤(黑色素瘤)、甲状腺癌、肾细胞癌、白血病、淋巴瘤、t细胞淋巴瘤、胃癌、胰腺癌、子宫颈癌、子宫内膜癌、卵巢癌、食道癌、肝癌、头颈部鳞状细胞癌、皮肤癌、尿道癌、膀胱癌、前列腺癌、绒癌、咽癌、喉癌、胸膜瘤、男性细胞瘤、子宫内膜增生、子宫内膜异位症、胚胎瘤、纤维肉瘤、卡波西氏肉瘤、血管瘤、海绵状血管瘤、成血管细胞瘤、视网膜母细胞瘤、星形细胞瘤、神经纤维瘤、少突胶质细胞瘤、髓母细胞瘤、神经母细胞瘤、神经胶质瘤、横纹肌肉瘤、胶质母细胞瘤、骨原性肉瘤、平滑肌肉瘤、甲状腺肉瘤和肾母细胞瘤等。含有本发明的双特异性抗体或该抗体片段或者它们的衍生物的治疗剂可以仅含有作为有效成分的该抗体或该抗体片段或者它们的衍生物,但通常优选以与药理学上可接受的一种以上的载体一起混合、利用制剂学
技术领域:
中公知的方法制造而成的药物制剂的形式提供。作为给药途径,可以列举例如经口给药或口腔内、呼吸道内、直肠内、皮下、肌肉内或静脉内等非经口给药。作为给药形态,可以列举例如喷雾剂、胶囊剂、片剂、散剂、颗粒剂、糖浆剂、乳剂、栓剂、注射剂、软膏或贴片剂等。各种制剂可以使用通常所用的赋形剂、增量剂、粘结剂、浸润剂、崩解剂、表面活性剂、润滑剂、分散剂、缓冲剂、防腐剂、增溶剂、防腐剂、着色料、香味剂和稳定剂等通过常规方法来制造。作为赋形剂,可以列举例如乳糖、果糖、葡萄糖、玉米淀粉、山梨醇、结晶纤维素、无菌水、乙醇、甘油、生理盐水和缓冲液等。作为崩解剂,可以列举例如淀粉、海藻酸钠、明胶、碳酸钙、柠檬酸钙、糊精、碳酸镁和合成硅酸镁等。作为粘结剂,可以列举例如甲基纤维素或其盐、乙基纤维素、阿拉伯胶、明胶、羟丙基纤维素和聚乙烯基吡咯烷酮等。作为润滑剂,可以列举例如滑石、硬脂酸镁、聚乙二醇和氢化植物油等。作为稳定剂,可以列举例如精氨酸、组氨酸、赖氨酸、蛋氨酸等氨基酸、人血清白蛋白、明胶、葡聚糖40、甲基纤维素、亚硫酸钠、偏亚硫酸钠等。作为其他添加剂,可以列举例如糖浆、凡士林、甘油、乙醇、丙二醇、柠檬酸、氯化钠、亚硝酸钠及磷酸钠等。作为适合于经口给药的制剂,可以列举例如乳剂、糖浆剂、胶囊剂、片剂、散剂或颗粒剂等。乳剂或糖浆剂这样的液体制备物使用水、蔗糖、山梨醇或果糖等糖类、聚乙二醇或聚丙二醇等二醇类、芝麻油、橄榄油或大豆油等油类,对羟基苯甲酸酯类等防腐剂、或者草莓香料或薄荷等香料类等作为添加剂来制造。胶囊剂、片剂、散剂或颗粒剂等使用乳糖、葡萄糖、蔗糖或甘露醇等赋形剂、淀粉或海藻酸钠等崩解剂、硬脂酸镁或滑石等润滑剂、聚乙烯醇、羟丙基纤维素或明胶等粘结剂、脂肪酸酯等表面活性剂或甘油等增塑剂等作为添加剂来制造。作为适合非经口给药的制剂,可以列举例如注射剂、栓剂或喷雾剂等。注射剂使用由盐溶液、葡萄糖溶液或该两者的混合物构成的载体等来制造。栓剂使用可可脂、氢化脂肪或羧酸等载体来制造。喷雾剂使用不刺激接受者的口腔和呼吸道粘膜并且使本发明的单克隆抗体或其抗体片段以微细粒子的形式分散从而容易吸收的载体等来制造。作为载体,可以列举例如乳糖或甘油等。另外,也可以以气溶胶或干粉的形式制造。此外,上述非经口剂中也可以添加在适合经口给药的制剂中作为添加剂所例示的成分。关于以本发明的双特异性抗体的有效量与适当的稀释剂和药理学上可使用的载体的组合进行给药的有效量,每1次每1kg体重为0.0001mg~100mg,以2天至8周的间隔进行给药。6.使用本发明的双特异性抗体或其抗体片段的疾病的诊断方法通过使用本发明的双特异性抗体或该抗体片段来检测或测定表达trailr2和psma中的至少一者的细胞,能够对trailr2和psma表达细胞相关的疾病进行诊断。作为trailr2和psma表达细胞相关疾病的恶性肿瘤或癌的诊断例如可以如下地检测或测定trailr2和psma中的至少一者来进行。首先,对于从多名健康人的生物体内采集的生物试样,使用本发明的双特异性抗体或该抗体片段或者它们的衍生物,利用下述免疫学方法进行trailr2和psma中的至少一者的检测或测定,考察健康人的生物体试样中的trailr2和psma中的至少一者的存在量。接着,对受试者的生物体试样中也同样地考察trailr2和psma中的至少一者的存在量,将其存在量与健康人的存在量进行比较。在受试者的trailr2和psma中的至少一者的存在量与健康人相比增加的情况下,将该受试者诊断为癌症。对于其他的trailr2和psma表达细胞相关疾病的诊断,也可以使用同样的方法进行诊断。免疫学方法是使用实施了标记的抗原或抗体来检测或测定抗体量或抗原量的方法。可以列举例如放射性物质标记免疫抗体法、酶联免疫测定法、荧光免疫测定法、发光免疫测定法、蛋白免疫印迹法或物理化学方法等。作为放射性物质标记免疫抗体法,可以列举例如使本发明的双特异性抗体或该抗体片段与抗原或表达抗原的细胞等反应,进而使实施了放射性标记的抗免疫球蛋白抗体或结合片段进行反应,然后利用闪烁计数仪等进行测定的方法。作为酶联免疫测定法,可以列举例如使本发明的双特异性抗体或该抗体片段与抗原或表达抗原的细胞等反应,进而使实施了标记的抗免疫球蛋白抗体或结合片段进行反应,然后利用吸光光度计测定显色色素的方法。可以列举例如夹心elisa法等。作为酶联免疫测定法中使用的标记物,可以使用公知的酶标记[酶免疫测定法、医学书院(1987)]。可以使用例如碱性磷酸酶标记、过氧化物酶标记、荧光素酶标记或生物素标记等。夹心elisa法是使抗体结合于固相上后、使其捕获作为检测或测定对象的抗原并使第二抗体与被捕获的抗原反应的方法。该elisa法中,准备作为与要检测或测定的抗原结合的抗体或抗体片段的、抗原结合位点不同的两种抗体,预先使其中的第一抗体或抗体片段吸附到板(例如96孔板)上,接着将第二抗体或抗体片段预先用fitc等荧光物质、过氧化物酶等酶或生物素等进行标记。在吸附有上述抗体的板上使从生物体内分离的细胞或其破碎液、组织或其破碎液、细胞培养上清、血清、胸水、腹水或眼液等进行反应,然后使标记的抗体或抗体片段进行反应,并进行与标记物质对应的检测反应。利用将浓度已知的抗原进行连续稀释而制作的标准曲线,算出受试样品中的抗原浓度。作为夹心elisa法中使用的抗体,可以使用多克隆抗体或单克隆抗体中的任何一种,也可以使用fab、fab’或f(ab)2等抗体片段。作为夹心elisa法中使用的两种抗体的组合,可以是与不同表位结合的单克隆抗体或该抗体片段的组合,也可以是多克隆抗体与单克隆抗体或其抗体片段的组合。作为荧光免疫测定法,例如利用文献[monoclonalantibodies-principlesandpractice(单克隆抗体原理与实践),第三版,学术出版社(1996);单克隆抗体实验手册、讲谈社scientific(1987)]等中记载的方法进行测定。作为荧光免疫测定法中使用的标记物,可以使用公知的荧光标记[荧光抗体法、softscience公司(1983)]。例如可以使用fitc或ritc等。作为发光免疫测定法,例如利用文献[生物发光与化学发光、临床检查42、广川书店(1998)]等中记载的方法进行测定。作为发光免疫测定法中使用的标记物,可以列举公知的发光体标记,例如使用吖啶酯或洛酚碱等。作为蛋白免疫印记法,将抗原或表达抗原的细胞等利用sds(十二烷基硫酸钠)-page[antibodies-alaboratorymanual(抗体实验室手册),冷泉港实验室(1988)]分级后,将该凝胶印迹到聚偏二氟乙烯(pvdf)膜或硝酸纤维素膜上,使与抗原结合的抗体或抗体片段与该膜进行反应,进而使实施了fitc等荧光物质、过氧化物酶等酶标记或生物素标记等的抗igg抗体或其抗体片段进行反应,然后使该标记可见化,由此进行测定。以下示出一例。首先,将表达具有所期望的氨基酸序列的多肽的细胞或组织溶解,在还原条件下使每个泳道的蛋白量为0.1~30μg,利用sds-page法进行电泳。接着,将电泳后的蛋白转印到pvdf膜上,在含有1~10%bsa的pbs(以下表示为bsa-pbs)中在室温下反应30分钟,进行封闭操作。在此,使本发明的双特异性抗体进行反应,用含有0.05~0.1%的tween-20的pbs(tween-pbs)进行清洗,并使过氧化物酶标记的山羊抗小鼠igg在室温下反应2小时。用tween-pbs进行清洗,使用ecl蛋白免疫印迹检测试剂(安玛西亚公司制造)等对结合有该抗体的条带进行检测,由此对抗原进行检测。作为利用蛋白免疫印迹法的检测中使用的抗体,使用能够与未保持天然型立体结构的多肽结合的抗体。作为物理化学方法,例如,使作为抗原的trailr2和psma中的至少一者与本发明的双特异性抗体或其抗体片段结合,由此形成聚集物,对聚集物进行检测。此外,作为物理化学方法,还可以使用毛细管法、单向免疫扩散法、免疫比浊法或乳胶免疫比浊法[临床检查法提要、金原出版(1998)]等。乳胶免疫比浊法中,使用以抗体或抗原致敏的粒径约0.1μm~约1μm的聚苯乙烯乳胶等载体,利用对应的抗原或抗体引起抗原抗体反应时,反应液中的散射光增加,透射光减少。以吸光度或积分球浊度的形式检测该变化,由此测定受试样品中的抗原浓度等。另一方面,表达trailr2和psma中的至少一者的细胞的检测或测定可以使用公知的免疫学检测法,优选使用免疫沉淀法、免疫细胞染色法、免疫组织染色法或荧光抗体染色法等。作为免疫沉淀法,使表达trailr2和psma中的至少一者的细胞等与本发明的双特异性抗体或其抗体片段反应后,加入对蛋白g琼脂糖等免疫球蛋白具有特异性结合能力的载体,使抗原抗体复合物沉淀。或者,也可以利用下述方法来进行。首先,使本发明的双特异性抗体或其抗体片段固相化于elisa用96孔板上,然后利用bsa-pbs进行封闭。接着,弃去bsa-pbs并用pbs充分清洗后,使表达trailr2和psma中的至少一者的细胞或组织的溶解液进行反应。用sds-page用样品缓冲液从充分清洗后的板上提取免疫沉淀物,通过上述蛋白免疫印迹法进行检测。免疫细胞染色法或免疫组织染色法为下述方法:将表达抗原的细胞或组织等根据情况用表面活性剂或甲醇等进行处理以使抗体的透过性良好,然后与本发明的双特异性抗体进行反应,进而与实施了fitc等荧光标记、过氧化物酶等酶标记或生物素标记等的抗免疫球蛋白抗体或其结合片段进行反应,然后使该标记可见化并利用显微镜进行显微观察。另外,可以通过使细胞与荧光标记的抗体反应并利用流式细胞仪进行分析的荧光抗体染色法[monoclonalantibodies-principlesandpractice(单克隆抗体原理与实践),第三版,学术出版社(1996);单克隆抗体实验手册、讲谈社scientific(1987)]来进行检测。特别地,本发明的双特异性抗体或其抗体片段可以利用荧光抗体染色法来检测表达在细胞膜上的trailr2和psma中的至少一者。另外,荧光抗体染色法中,在使用fmat8100hts系统(应用生物系统公司制造)等的情况下,可以在不对形成的抗体-抗原复合物与未参与抗体-抗原复合物形成的游离抗体或抗原进行分离的情况下测定抗原量或抗体量。以下,利用实施例更具体地对本发明进行说明,但本发明不受下述实施例的限定。实施例[实施例1]抗htrailr2激动型单克隆抗体kmda2抗体的表达质粒载体的构建作为抗人trailr2(htrailr2)抗体的阳性对照抗体,基于国际公开第2002/094880号记载的0304克隆的重链可变区(vh)、轻链可变区(vl)的氨基酸序列制作了抗htrailr2激动型单克隆抗体kmda2抗体。将kmda2抗体的vh的全部碱基序列示于序列号1,将由该序列推定的包含信号序列的vh的全部氨基酸序列示于序列号7,将从序列号7所示的氨基酸序列中除去信号序列后的氨基酸序列示于序列号114。另外,将kmda2抗体的vl的全部碱基序列示于序列号2,将由该序列推定的包含信号序列的vl的全部氨基酸序列示于序列号8,将从序列号8所示的氨基酸序列中除去信号序列后的氨基酸序列示于序列号115。通过以下记载的方法构建kmda2抗体的表达质粒载体。以kmda2抗体的l链cdna作为模板,使用以在vl的末端添加限制酶识别位点的方式设计的序列号3和序列号4所表示的引物,通过pcr对该l链的前导序列和可变区进行扩增。通过乙醇沉淀回收该pcr片段后,利用限制酶bglii和bsiwi进行消化,得到约400bp的dna片段。另一方面,将质粒载体n5kg4pe(记载于国际公开第2002/088186号)用限制酶bglii和bsiwi消化后,利用碱性磷酸酶(e.colic75)(宝酒造公司制造)进行脱磷酸化处理,得到稍小于约9kb的dna片段。利用t4dna连接酶将这两个dna片段连接,得到质粒n5kg4pe-kmda2l。接着,将n5kg4pe-kmda2l用限制酶nhei和sali消化而进行脱磷酸化,得到约9.3kb的dna片段。另一方面,以kmda2抗体的h链cdna作为模板,使用序列号5和序列号6所表示的引物,通过pcr对kmda2的h链的前导序列和可变区进行扩增。将该pcr片段用限制酶nhei和sali消化,得到约450bp的dna片段。将这两个dna片段进行连接,制作抗htrailr2激动型单克隆抗体kmda2抗体的表达质粒载体n5kg4pe_kmda2。通过上述方法扩增的h链pcr片段由h链的5’非翻译区、信号序列、可变区(vh)和恒定区的一部分构成。同样地,l链的pcr扩增片段由l链的5’非翻译区、前导序列、可变区(vl)和恒定区的一部分构成。前导序列是抗体的分泌信号序列,是被从成熟抗体蛋白质上切去的氨基酸序列。[实施例2]抗htrailr2单克隆抗体e11抗体的表达质粒载体的构建为了用于后述的与htrailr2和hpsma结合的双特异性抗体的制作,制作了抗htrailr2单克隆抗体e11抗体。e11抗体基于国际公开第2002/094880号记载的e-11-13克隆的vh和vl的氨基酸序列进行制作。将e11抗体的序列信息示于表1。表1中将编码抗体的vh或vl的氨基酸序列的全部碱基序列记载为编码vh或vl(包含信号序列)的碱基序列,将由该碱基序列推定的氨基酸序列记载为vh或vl(包含信号序列)的氨基酸序列,并且将由该氨基酸序列除去信号序列后的氨基酸序列记载为vh或vl(除外信号序列)的氨基酸序列。另外,将抗体的重链或轻链的cdr1~3的氨基酸序列分别记载为hcdr1~3或lcdr1~3的氨基酸序列。将编码e11抗体的vh和vl的氨基酸序列的碱基序列插入到质粒载体n5kg1(记载于美国专利第6001358号说明书)或n5kg4pe[r409k](记载于国际公开第2002/088186号)中,得到作为人igg1型抗htrailr2单克隆抗体的e11抗体的表达质粒载体n5kg1_e11和作为突变人igg4(恒定区包含s228p、l235e和r409k的氨基酸改变的人igg4)型抗htrailr2单克隆抗体的e11抗体的表达质粒载体n5kg4pe[r409k]_e11。[表1]抗htrailr2单克隆抗体e11抗体的序列信息编码vh(包含信号序列)的碱基序列序列号9vh(包含信号序列)的氨基酸序列序列号69vh(除外信号序列)的氨基酸序列序列号118hcdr1的氨基酸序列序列号70hcdr2的氨基酸序列序列号71hcdr3的氨基酸序列序列号72编码vl(包含信号序列)的碱基序列序列号10vl(包含信号序列)的氨基酸序列序列号73vl(除外信号序列)的氨基酸序列序列号119lcdr1的氨基酸序列序列号74lcdr2的氨基酸序列序列号75lcdr3的氨基酸序列序列号76[实施例3]抗hpsma单克隆抗体的获取(1)具有与抗htrailr2单克隆抗体e11抗体相同的vl的氨基酸序列的抗hpsma单克隆抗体的获取和该抗体的表达质粒载体的制作通过如下记载的方法获取具有与抗htrailr2单克隆抗体e11抗体相同的vl的氨基酸序列的抗hpsma单克隆抗体。对人抗体产生小鼠[ishida&lonberg,ibc’s11thantibodyengineering,abstract2000;ishida,i.etal.,cloning&stemcells4,85-96(2002);石田功(2002)、实验医学20、6、846-851]腹腔内给药作为免疫原的后述的实施例5的flag-psma与西格玛佐剂系统(sigmaadjuvantsystem,sigma-aldrich公司制造)的混合物,进行免疫。利用外科方法从免疫后的小鼠体内摘除脾脏,将脾脏放置于细胞滤网(falcon公司制造)上,用硅棒轻轻研碎的同时将细胞转移至管中,离心分离使细胞沉淀后,在冰中与红细胞去除试剂反应3分钟,进一步进行离心分离。使用isogen(日本基因公司制造)从所得到的脾脏细胞中提取rna,利用smarterracecdna扩增试剂盒(clontech公司制造)对cdna进行扩增,进而利用pcr对vh基因片段进行扩增。将vh基因片段和表1中记载的e11的vl基因分别插入到噬菌粒pcantab5e(amershampharmacia公司制造)中,转化大肠杆菌tg1(lucigen公司制造),得到质粒。使所得到的质粒感染m13ko7辅助噬菌体(invitrogen公司制造),由此得到将vh基因文库化而成的人抗体m13噬菌体文库。使用该人抗体m13噬菌体文库和下述的噬菌体展示法,获取具有与抗htrailr2单克隆抗体e11抗体相同的vl的氨基酸序列的抗hpsma单克隆抗体。使将后述的实施例5的flag-psma固相化、并使用superblock封闭缓冲液(thermo公司制造)对未结合flag-psma的部位进行了封闭的maxisorpstartube(nunc公司制造)与人抗体m13噬菌体文库在室温下反应1小时,用pbs清洗5次后,使用0.1m的gly-hcl(ph2.2)将噬菌体洗脱。使洗脱的噬菌体感染tg1感受态细胞,使噬菌体扩增。然后,再次使固相化于maxisorpstartube上flag-psma进行反应,并实施清洗和洗脱。将该操作重复2次或3次,将展示与flag-psma特异性结合的scfv的噬菌体浓缩。将浓缩后的噬菌体单克隆化,利用elisa选择出与flag-psma具有结合性的克隆。elisa中,使用将后述实施例5的flag-psma固相化、并使用superblock封闭缓冲液(thermo公司制造)对未结合flag-psma的部位进行封闭后的maxisorp(nunc公司制造)。向各孔中添加各噬菌体克隆,在室温下反应30分钟后,用含有0.1%tween20的pbs(以下记载为pbs-t)将各孔清洗3次。接着,用含有10%blockace(大日本制药株式会社制造)的pbs-t将以辣根过氧化物酶标记的抗m13抗体(gehealthcare公司制造)稀释5000倍,向各孔中各添加该稀释后的溶液50μl,在室温下孵育30分钟。用pbs-t将微孔板清洗3次后,向各孔中加入tmb显色底物液(dako公司制造)各50μl,在室温下孵育10分钟。最后,向各孔中加入0.5m硫酸(50μl/孔),使显色反应终止,利用酶标仪(1420arvo多标记计数仪:wallac公司制造)测定波长450nm(参比波长570nm)下的吸光度。对于与flag-psma结合的克隆,进行序列分析,获取了具有与表1所示的抗htrailr2单克隆抗体e11抗体相同的vl的氨基酸序列的抗hpsma单克隆抗体pi134抗体、pi101抗体、pn7抗体、pi105抗体、pi108抗体、pi115抗体、pi118抗体、pi127抗体、pi143抗体、pl223抗体和pn170抗体。利用与表1同样的表示方法将各hpsma单克隆抗体的重链的序列信息示于表2中。[表2]抗hpsma单克隆抗体的重链的序列信息合成编码pi134抗体、pi101抗体、pi105抗体、pi108抗体、pi115抗体、pi118抗体、pi127抗体、pi143抗体、pl223抗体和pn170抗体的各vh和vl的氨基酸序列的碱基序列,利用与实施例1同样的方法制作插入到质粒载体n5kg1中而得到的表达质粒载体,分别命名为n5kg1_e11vl_pi134、n5kg1_e11vl_pi101、n5kg1_e11vl_pi105、n5kg1_e11vl_pi108、n5kg1_e11vl_pi115、n5kg1_e11vl_pi118、n5kg1_e11vl_pi127、n5kg1_e11vl_pi143、n5kg1_e11vl_pl223和n5kg1_e11vl_pn170。另外,合成编码pn7抗体的vh和vl的氨基酸序列的碱基序列,利用与实施例1同样的方法制作插入到质粒载体n5kg4pe[r409k](记载于国际公开第2002/088186号)中而得到的表达质粒载体,命名为n5kg4pe[r409k]_e11vl_pn7。(2)抗hpsma单克隆抗体2a10抗体的表达质粒载体的制作作为抗hpsma单克隆抗体的阳性对照抗体,制作了国际公开第2006/089230号中记载的抗hpsma单克隆抗体2a10抗体。将2a10抗体的vh的全部碱基序列示于序列号23,将由该序列推定的包含信号序列的vh的全部氨基酸序列示于序列号24,将从序列号24所示的氨基酸序列中除去信号序列后的氨基酸序列示于序列号116。另外,将2a10抗体的vl的全部碱基序列示于序列号25,将由该序列推定的包含信号序列的vl的全部氨基酸序列示于序列号26,将从序列号26所示的氨基酸序列中除去信号序列后的氨基酸序列示于序列号117。利用以下记载的方法制作2a10抗体的表达质粒载体。合成编码2a10抗体的vl的氨基酸序列的基因,亚克隆到质粒载体n5kg1的bglii-bsiwi位点,得到n5kg1_2a10vl。接着,合成编码2a10的vh的基因作为模板,使用序列号27和序列号28所表示的引物以及kodplusdna聚合酶(东洋纺公司制造),通过pcr对vh区的基因片段进行扩增。pcr中,将由94℃下30秒、58℃下30秒、68℃下45秒构成的反应实施25个循环。以所得到的vh区的基因片段作为模板,使用序列号29和序列号28所表示的引物以及kod聚合酶,通过pcr扩增出在vh区连接有信号序列的基因片段。pcr中,将由94℃下30秒、58℃下30秒、68℃下90秒构成的反应实施25个循环。将所得到的基因片段插入到n5kg1_2a10vl载体的sali-nhei位点,得到抗hpsma单克隆抗体2a10抗体的表达质粒载体n5kg1_2a10。[实施例4]与htrailr2和hpsma结合的双特异性抗体的表达载体的构建利用下述方法制作具有图1记载的结构的、与htrailr2和hpsma结合的双特异性抗体(以下记载为htrailr2-hpsma双特异性抗体或仅记载为双特异性抗体)。该双特异性抗体的重链从图1的n末端侧起依次包含抗htrailr2单克隆抗体e11抗体的vh、连接子和抗hpsma单克隆抗体的vh的氨基酸序列,该抗体的4个轻链均包含e11抗体的vl的氨基酸序列。将该双特异性抗体这样的不同的两个抗原结合位点的vl共同的抗体称为轻链共通型双特异性抗体。将htrailr2-hpsma双特异性抗体的名称、该抗体的制作中使用的抗trailr2单克隆抗体的克隆名、连接子的结构、抗hpsma单克隆抗体的克隆名和该双特异性抗体的表达质粒载体的名称示于表3。另外,关于该双特异性抗体,将由e11抗体的vh、连接子和抗hpsma单克隆抗体的vh(以下也仅记载为vh-连接子-vh)构成的多肽的氨基酸序列和编码该氨基酸序列的碱基序列示于表4。[表3][表4](1)具有人igg4的ch1作为连接子的htrailr2-hpsma双特异性抗体的表达质粒载体的制作关于表3和表4所记载的双特异性抗体中具有人igg4的ch1作为连接子的双特异性抗体,利用下述方法制作表达质粒载体。将该连接子的氨基酸序列示于序列号93。以人igg4的恒定区的碱基序列作为模板,使用序列号30和序列号31所表示的引物以及kodplusdna聚合酶(东洋纺公司制造),通过pcr对连接子部分的基因片段进行扩增。另一方面,使用表5所示的vh扩增用模板载体、vh扩增用引物和kod聚合酶,通过pcr对各抗hpsma单克隆抗体的vh区的基因片段进行扩增。pcr中,均将由94℃下30秒、58℃下30秒、68℃下45秒构成的反应实施25个循环。接着,以上述连接子部分和各抗hpsma单克隆抗体的vh区的各基因片段作为模板,使用表5所示的vh-连接子结合用引物和kod聚合酶,通过pcr扩增出连接子部分与各抗hpsma单克隆抗体的vh区连接而成的基因片段。pcr中,将由94℃下30秒、58℃下30秒、68℃下90秒构成的反应实施25个循环。将扩增出的基因片段与利用nhei断开的n5kg1_e11或n5kg4pe[r409k]_e11连接,由此得到表5所示的各htrailr2-hpsma双特异性抗体的表达质粒载体。[表5](2)具有人igg4的ch1的n末端至第14位的氨基酸序列作为连接子(gl连接子)的htrailr2-hpsma双特异性抗体的表达质粒载体的制作利用以下记载的方法制作表3和表4所示的htrailr2-hpsma双特异性抗体e11-gl-pi1134vh抗体的表达质粒载体。该双特异性抗体的连接子是序列号11所表示的人igg4的ch1的n末端至第14位的氨基酸序列。以质粒载体n5kg1_e11vl_pi134作为模板,使用序列号57和序列号33所表示的引物以及kod聚合酶,通过pcr对抗hpsma单克隆抗体pi134抗体的vh区的基因片段进行扩增。pcr中,将94℃下30秒、58℃下30秒、68℃下45秒的反应实施25个循环。将该基因片段与利用限制酶nhei断开的n5kg1_e11连接,由此制作htrailr2-hpsma双特异性抗体e11-gl-pi1134vh抗体的表达质粒载体n5kg1_e11vl_e11-gl-pi134vh。(3)具有人igm的ch1的n末端至第14位的氨基酸序列作为连接子(ml连接子)的htrailr2-hpsma双特异性抗体的表达质粒载体的制作利用以下记载的方法制作表3和表4所示的htrailr2-hpsma双特异性抗体e11-ml-pi101vh抗体的表达质粒载体。该双特异性抗体的连接子是序列号12所表示的人igm的ch1的n末端至第14位的氨基酸序列。以n5kg1_e11作为模板,使用序列号59和序列号60所表示的引物以及kod聚合酶,通过pcr对抗htrailr2单克隆抗体e11抗体的vh区的基因片段进行扩增。pcr中,将94℃下30秒、58℃下30秒、68℃下45秒的反应实施25个循环。另一方面,以n5kg1_e11vl_pi101作为模板,使用序列号61和序列号62所表示的引物以及kod聚合酶,通过pcr对抗hpsma单克隆抗体pi101抗体的vh区的基因片段进行扩增。pcr中,将94℃下30秒、58℃下30秒、68℃下45秒的反应实施25个循环。接着,将上述的e11抗体的vh区和pi101抗体的vh区的基因片段插入到利用限制酶sali和nhei断开的n5kg1中,制作htrailr2-hpsma双特异性抗体e11-ml-pi101vh抗体的表达质粒载体n5kg1_e11vl_e11-ml-pi101vh。[实施例5]可溶性hpsma抗原的制备作为人前列腺特异性膜抗原(hpsma)的可溶性抗原,利用以下记载的方法制作在n末端添加有flag标签的hpsma的细胞外结构域蛋白质。将编码hpsma的氨基酸序列的碱基序列示于序列号64,将由该碱基序列推定的氨基酸序列示于序列号112。合成hpsma的细胞外结构域的基因序列,插入到插入有flag标签的n5(idec公司制造)载体的spei-bamhi位点,由此制作表达在n末侧添加有flag标签的hpsma的细胞外结构域的质粒载体n5/flag-hpsma。将flag-hpsma的碱基序列示于序列号92,将由该碱基序列推定的氨基酸序列示于序列号113。使用freestyle(商标)293表达系统(invitrogen公司制造)将n5/flag-hpsma导入到悬浮性293细胞中并进行培养,在瞬时表达系统中使蛋白进行表达。载体导入7天后,回收培养上清,用孔径0.22μm的膜滤器(millipore公司制造)进行过滤。将该培养上清装填至flag融合蛋白质纯化用anti-flagm2affinitygel(柱体积2ml)(sigmaaldrich公司制造)上,用pbs(-)清洗后,利用洗脱液[20mm柠檬酸、50mmnacl(ph3.4)]进行洗脱,回收到含有1m磷酸钠缓冲液(ph7.0)的管中。接着,通过使用vivaspin(sartriusstealin公司制造)的超滤将洗脱液的溶剂置换为pbs后,使用孔径0.22μm的膜滤器(millex-gv、millipore公司制造)进行过滤灭菌,得到flag融合蛋白质溶液。纯化flag-hpsma融合蛋白质的浓度通过280nm的吸光度进行测定。[实施例6]膜型hpsma的表达质粒载体的制作利用以下记载的方法,使用延伸pcr,制作在hpsma的n末端侧添加有信号序列和膜结合位点的膜型hpsma表达质粒载体。以hpsma基因(序列号64)的合成dna作为模板,使用序列号65和序列号66所表示的引物以及kod聚合酶,将94℃下30秒、58℃下30秒、68℃下3分钟的反应实施25个循环,由此进行pcr扩增。以该pcr产物作为模板,使用序列号67和序列号66所表示的引物以及kod聚合酶,将94℃下30秒、58℃下30秒、68℃下3分钟的反应实施25个循环,由此进行pcr扩增。进而,以该pcr产物作为模板,使用序列号68和序列号66所表示的引物以及kod聚合酶,将94℃下30秒、58℃下30秒、68℃下3分钟的反应实施25个循环,由此进行pcr扩增。使用pef6/v5-histopota表达试剂盒(invitrogen公司制造)对该扩增产物进行topo克隆,选择出正确地插入了hpsma基因的克隆,由此得到膜型hpsma的表达质粒载体pef6-hpsmafull。[实施例7]抗htrailr2单克隆抗体、抗hpsma单克隆抗体和htrailr2-hpsma双特异性抗体的制备利用freestyle(商标)293表达系统(invitrogen公司制造)将实施例1至实施例4中制作的各种抗体的表达质粒载体基因导入到悬浮性293细胞中,在瞬时表达系统中使抗体进行表达。在载体的导入起7天后,回收培养上清,用孔径0.22μm的膜滤器(millipore公司制造)过滤后,使用蛋白a树脂(mabselect、gehealthcarebioscience公司制造)将抗体进行亲和纯化。作为清洗液,使用磷酸缓冲液。利用洗脱液[20mm柠檬酸钠、50mmnacl缓冲液(ph3.4)]将吸附于蛋白a上的抗体进行洗脱,回收到含有1m磷酸钠缓冲液(ph7.0)的管中。接着,通过使用vivaspin(sartriusstealin公司制造)的超滤将洗脱液的溶剂置换为pbs。进而,利用aktafplc(gehealthcare公司制造),使用superdex高性能柱(gehealthcare公司制造)由该抗体溶液分离得到单体级分,用孔径0.22μm的膜滤器(millex-gv、millipore公司制造)进行过滤灭菌。使用akta系统孔径0.22μm的膜滤器(millex-gv、millipore公司制造)进行过滤灭菌,由此得到目标纯化抗体溶液。测定抗体溶液的280nm的吸光度,将浓度1mg/ml换算为1.40光密度,由此算出纯化抗体的浓度。[实施例8]表达hpsma的l929和pc3的制备使用hilymax(同仁化学公司制造)将实施例6中得到的膜型hpsma的表达质粒载体导入到小鼠结缔组织来源的成纤维细胞l929[美国典型培养物保藏中心(atcc)编号:ccl-1]和人前列腺癌细胞pc3[atcc编号:crl-1435]细胞中。利用抗生素杀稻瘟菌素(invitrogen公司制造)对基因导入后的细胞进行筛选,然后利用有限稀释法进行克隆,得到在细胞表面表达hpsma的l929细胞(以下简记为hpsma/l929)和pc3细胞(以下简记为hpsma/pc3)。[实施例9]利用流式细胞仪的htrailr2-hpsma双特异性抗体对htrailr2和hpsma的结合性的评价利用流式细胞术,按照下述步骤对实施例7中得到的各种htrailr2-hpsma双特异性抗体对htrailr2和hpsma的结合性进行评价。使用实施例7中得到的各种htrailr2-hpsma双特异性抗体、抗hpsma单克隆抗体或抗htrailr2单克隆抗体,利用facs分析对htrailr2/l929细胞(记载于国际公开第2002/094880号)和实施例8中得到的hpsma/l929细胞的结合性。将细胞以1×106细胞/ml的浓度悬浮于染色缓冲液[含有0.1%nan3、1%fbs的pbs]中,以100μl/孔分注到96孔圆底板(bd公司制造)中。离心分离(2000rpm、4℃、2分钟)后,除去上清,向所得到的沉淀物中添加实施例7中得到的各抗体并悬浮,然后在冰温下静置30分钟。进一步进行离心分离(2000rpm、4℃、2分钟),除去上清,将所得到的沉淀物用200μl/孔的染色缓冲液清洗2次后,以50μl/孔添加1μg/ml的rpe荧光标记小鼠抗人抗体(铰链区)克隆4e3抗体(southernbioblot公司制造),在冰温下孵育30分钟。用染色缓冲液清洗2次后,悬浮于200μl/孔的染色缓冲液中,利用流式细胞仪facscantoii(bd公司制造)测定各细胞的荧光强度。将所得到的结果示于图2和图3。细胞使用htrailr2/l929细胞(记载于国际公开第2002/094880号)和实施例8中得到的hpsma/l929细胞。htrailr2/l929细胞使用抗hpsma单克隆抗体2a10抗体或pi134抗体、或者htrailr2-hpsma双特异性抗体e11-gl-pi134vh抗体、e11-ch1-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体或e11-ch1-pn170vh抗体进行了染色。将所得到的结果示于图3。hpsma/l929细胞使用抗trailr2单克隆抗体e11抗体、抗hpsma单克隆抗体pi134抗体、或者htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体或e11-ch1-pn170vh抗体进行了染色。将所得到的结果示于图2。如图3所示,对于htrailr2/l929细胞,抗htrailr2单克隆抗体e11抗体、以及htrialr2-hpsma双特异性抗体el1-ch1-pi101vh抗体、e11-ch1-pn7vh抗体和e11-ch1-pn170vh抗体进行了结合,另一方面,抗hpsma单克隆抗体pi134抗体未进行结合。由此表明,htrailr2/l929细胞表达htrailr2而不表达hpsma。另外表明,作为htrialr2-hpsma双特异性抗体的e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体和e11-ch1-pn170vh抗体对htrailr2具有结合性。如图2所示,对于hpsma/l929细胞,作为抗hpsma单克隆抗体的2a10抗体和pi134抗体、以及htrailr2-hpsma双特异性抗体e11-ch1-pi134vh抗体、e11-gl-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体和e11-ch1-pn170vh抗体全部进行了结合。由此表明,hpsma/l929细胞表达hpsma,htrailr2-hpsma双特异性抗体e11-ch1-pi134vh抗体、e11-gl-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体和e1l-ch1-pn170vh抗体对hpsma具有结合性。关于表3所示的其他htrailr2-hpsma双特异性抗体,利用与上述同样的方法确认了其与pc3细胞(表达trailr2)和实施例8中制作的hpsma/pc3细胞(表达hpsma、trailr2这两者)这两者结合(未公开数据)。hpsma/pc3细胞的psma的表达量高于trailr2的表达量,对于任意一种抗体来说,hpsma/pc3细胞中的荧光强度均高于pc3细胞中的荧光强度。由以上表明,本发明的htrailr2-hpsma双特异性抗体与htrailr2和hpsma中的任意一者均结合。[实施例10]利用流式细胞仪的pc3细胞、hpsma/pc3细胞和lncap克隆fgc细胞的抗原表达分析按照下述步骤,利用facs法评价pc3细胞、实施例8中制作的hpsma/pc3细胞和人前列腺癌细胞株lncap克隆fgc(crl-1740)中的htrailr2或hpsma的表达的有无。将pc3细胞、hpsma/pc3细胞或lncap克隆fgc细胞以1×106细胞/ml的浓度悬浮于染色缓冲液(含有0.1%nan3和1%fbs的pbs)中,以100μl/孔分注到96孔圆底板(bd公司制造)中。离心分离(2000rpm、4℃、2分钟)后,除去上清,向所得到的沉淀物中添加实施例7中得到的各抗体并悬浮,然后在冰温下静置30分钟。进一步进行离心分离(2000rpm、4℃、2分钟),除去上清,将所得到的沉淀物用200μl/孔的染色缓冲液清洗2次后,以50μl/孔添加1μg/ml的rpe荧光标记小鼠抗人抗体(铰链区)克隆4e3(southernbioblot公司制造),在冰温下孵育30分钟。用染色缓冲液清洗2次后,悬浮于200μl/孔的染色缓冲液中,利用流式细胞仪facscantoii(bd公司制造)测定各细胞的荧光强度。抗体使用抗htrailr2单克隆抗体e11抗体、抗hpsma单克隆抗体2a10抗体或pi134抗体、htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体或作为阴性对照的公知的抗dnp单克隆抗体。将所得到的结果示于图4(a)和图4(b)、以及图5。如图4(a)所示,对于pc3细胞,抗htrailr2单克隆抗体e11抗体和双特异性抗体e11-ch1-pi101vh抗体进行了结合,抗hpsma单克隆抗体pi134抗体未进行结合。如图4(b)所示,对于hpsma/pc3细胞,e11抗体、e11-ch1-pi101vh抗体和pi134抗体进行了结合。此外还表明,与e11抗体相比,pi134抗体和e11-ch1-pi101vh抗体具有更强的结合活性。由该结果表明,pc3细胞不表达hpsma而仅表达htrailr2,hpsma/pc3细胞表达htrailr2和hpsma这两种抗原。如图5所示,对于lncap克隆fgc,抗htrailr2单克隆抗体e11抗体和抗hpsma单克隆抗体2a10抗体进行了结合。由该结果表明,lncap克隆fgc表达htrailr2和hpsma这两种抗原。[实施例11]使用htrailr2-hpsma双特异性抗体的pc3细胞和hpsma/pc3细胞的增殖性试验使用实施例7中得到的各种抗体,如下评价pc3细胞和实施例8中得到的hpsma/pc3细胞的增殖性。由此能够确认实施例7中得到的抗体对于上述细胞是否抑制细胞增殖和/或是否诱导细胞死亡。在实施例10中确认了,pc3细胞是表达htrailr2而不表达hpsma的细胞,hpsma/pc3细胞是表达htrailr2和hpsma的细胞。抗体使用抗htrailr2单克隆抗体e11抗体、抗htrailr2激动型单克隆抗体kmda2抗体、htrailr2-hpsma双特异性抗体e11-ch1-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体、e11-ch1-pn170vh抗体、e11-gl-pi134vh、e11-ch1-pi105vh抗体、e11-ch1-pi108vh抗体、e11-ch1-pi115vh抗体、e11-ch1-pi118vh抗体、e11-ch1-pi127vh抗体、e11-ch1-pi143vh抗体、e11-ch1-pl223vh抗体、或作为阴性对照抗体的公知的抗dnp单克隆抗体。将2~10×104细胞/ml的细胞以50μl/孔接种到平底96孔板中,在37℃、5.0%二氧化碳下培养16小时。添加调节为各种浓度的上述抗体并使总量为100μl/孔,在37℃、5.0%二氧化碳下培养72小时后,向各孔中添加细胞计数试剂盒-8(wst-8)(同仁化学公司制造)各10μl。在各条件下使用4个独立的孔进行评价。进一步在37℃、5.0%二氧化碳下培养4小时后,添加0.1mhcl使反应停止,利用酶标仪(1420arvo多标记计数仪:wallac公司制造)测定波长450nm(参比波长630nm)下的吸光度。利用下式算出各孔的细胞的存活率。存活率(%)=100×(a-b)/(c-b)(式中,a表示被测孔的吸光度,b表示无细胞孔的吸光度,c表示无抗体添加孔的吸光度)。将所得到的结果示于图6~10。将对于pc3细胞的结果示于图6和图7,将对于hpsma/pc3细胞的结果示于图8~10。如图7和图9所示,抗htrailr2单克隆抗体e11抗体对于任意一种细胞均与抗dnp单克隆抗体同等地未使细胞的存活率降低。另一方面,如图6~图10所示,与抗dnp单克隆抗体相比,抗trailr2激动型单克隆抗体kmda2抗体对于任意一种细胞均使细胞的存活率降低。如图6和图7所示,htrailr2-hpsma双特异性抗体e11-ch1-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体和e11-ch1-pn170vh抗体对于pc3细胞与抗dnp单克隆抗体同等地未使细胞的存活率降低。另一方面,如图8~图10所示,对于hpsma/pc3细胞,与抗dnp单克隆抗体相比,htrailr2-hpsma双特异性抗体e11-gl-pi134vh抗体、e11-ch1-pi134vh抗体、e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体、e11-ch1-pn170vh抗体、e11-ch1-pi105vh抗体、e11-ch1-pi108vh抗体、e11-ch1-pi115vh抗体、e11-ch1-pi118vh抗体、e11-ch1-pi127vh抗体、e11-ch1-pi143vh抗体和e11-ch1-pl223vh抗体均使细胞的存活率降低。另外,单独的抗hpsma单克隆抗体2a10抗体、pi134抗体、pn7抗体对于任意一种细胞均与抗dnp单克隆抗体同等地未使细胞的存活率降低(数据未公开)。即,本发明的htrailr2-hpsma双特异性抗体对于表达htrailr2而不表达hpsma的细胞不使细胞的存活率降低,对于表达htrailr2和hpsma这两者的细胞使细胞的存活率降低。因此表明,本发明的htrailr2-hpsma双特异性抗体仅与htrailr2结合时不抑制细胞增殖和/或诱导细胞死亡,在与htrailr2和hpsma结合时才诱导上述反应。另外表明,作为本发明的htrailr2-hpsma双特异性抗体的亲本抗体的抗htrailr2单克隆抗体e11抗体对于表达htrail2而不表达hpsma的细胞、以及表达htrailr2和hpsma的细胞均不使细胞的存活率降低。因此表明,本发明中使用的抗trailr2单克隆抗体通过制成与针对psma的结合结构域结合的双特异性抗体后,才抑制细胞增殖和/或诱导细胞死亡。[实施例12]使用htrailr2-hpsma双特异性抗体的癌细胞的增殖性试验使用实施例7中得到的各种抗体,如下评价lncap克隆fgc细胞(atcc、crl_1740)的增殖性。抗体使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体、或e11-ch1-pn170vh抗体、或者作为阴性对照抗体的公知的抗dnp单克隆抗体。在实施例10中确认了lncap克隆fgc细胞表达htrailr2和hpsma这两者。将4×104细胞/ml的lncap克隆fgc细胞以50μl/孔接种到平底96孔板中,在37℃、5.0%二氧化碳下培养16小时。添加调节为各种浓度的上述抗体并使总量为100μl/孔,在37℃、5.0%二氧化碳下培养72小时后,向各孔中添加细胞计数试剂盒-8(wst-8)(同仁化学公司制造)各10μl。对于各条件,使用4个独立的孔进行评价。进一步在37℃、5.0%二氧化碳下培养4小时后,添加0.1mhcl使反应停止,利用酶标仪(1420arvo多标记计数仪:wallac公司制造)测定波长450nm(参比波长630nm)下的吸光度。利用下式算出各孔的细胞的存活率。存活率(%)=100×(a-b)/(c-b)(式中,a表示被测孔的吸光度,b表示无细胞孔的吸光度,c表示无抗体添加的孔的吸光度)。将所得到的结果示于图11。如图11所示,对于lncap克隆fgc细胞,抗htrailr2单克隆抗体e11抗体与抗dnp单克隆抗体同等地未使细胞的存活率降低。另一方面,与抗dnp单克隆抗体相比,抗htrailr2激动型单克隆抗体kmda2抗体以及htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体、e11-ch1-pn7vh抗体和e11-ch1-pn170vh抗体使lncap克隆fgc细胞的存活率降低。由该结果表明,即使是并非强制表达株的通常的细胞株,只要是表达htrailr2和hpsma的细胞,本发明的htrailr2-hpsma双特异性抗体对该细胞也会抑制细胞增殖和/或诱导细胞死亡。[实施例13]利用流式细胞仪的半胱天冬酶的检测通过以如下记载的方式使用流式细胞仪和fam-flica级联反应检测试剂盒(immunochemistry公司制造)对活化半胱天冬酶进行检测来确认实施例7中得到的htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体对pc3细胞和hpsma/pc3细胞是否诱导凋亡。在实施例10中,确认了pc3细胞是表达htrailr2而不表达hpsma的细胞,hpsma/pc3细胞是不表达htrailr2和hpsma的细胞。将pc3细胞或hpsma/pc3细胞以5×104细胞/孔分注到96孔圆底板(bd公司制造)中。离心分离(2000rpm、4℃、2分钟)后,除去上清,向所得到的沉淀物中添加用培养基稀释为终浓度1μg/ml的阴性对照抗体(抗dnp单克隆抗体)、e11-ch1-pi101vh抗体或trailr2配体trail/apo2(r&dsystems公司制造),在37℃下孵育6小时。进行离心分离(2000rpm、4℃、2分钟),除去上清后,添加用培养基稀释的试剂盒附带的flica各50μl/ml,在37℃下孵育30分钟。然后,使用试剂盒附带的凋亡清洗缓冲液清洗4次后,以100μl/孔的凋亡清洗缓冲液进行悬浮,使用流式细胞仪facscantoii(bd公司制造)测定各细胞的荧光强度。将所得到的结果示于图12(a)和图12(b)。如图12(a)所示,在pc3细胞中,活化半胱天冬酶在添加e11-ch1-pi101vh抗体时未被检测到,仅在添加trail时被检测到。另一方面,如图12(b)所示,在hpsma/pc3细胞中,在添加e11-ch1-pi101vh抗体和trail中任意一种时均在细胞内检测到活化半胱天冬酶。由该结果表明,e11-ch1-pi101vh抗体对于表达htrailr2而不表达hpsma的细胞不诱导凋亡,对于表达htrailr2和hpsma这两者的细胞特异性地诱导凋亡。另外,在向hpsma/pc3细胞中添加e11-ch1-pi101vh抗体时,与添加trailr2配体trail时同样地检测到活化半胱天冬酶。因此表明,本发明的htrailr2-hpsma双特异性抗体在仅与htrailr2结合时不诱导凋亡,在与htrailr2和hpsma结合时诱导凋亡。另外表明,该凋亡是trailr2介导的。[实施例14]基于正常肝细胞的增殖性试验的htrailr2-hpsma双特异性抗体的安全性评价使用实施例7中得到的各种抗体,如下评价正常肝细胞(celsisivt公司、ivt-m00995-p)的增殖性。由此,可以确认实施例7中得到的各种抗体对于正常肝细胞是否诱导细胞增殖抑制和细胞死亡中的至少一者。抗体使用抗htrailr2激动型单克隆抗体kmda2抗体、抗htrailr2单克隆抗体e11抗体、htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体或e11-ch1-pn7vh抗体、或作为阴性对照抗体的公知的抗dnp单克隆抗体。另外,作为阳性对照,还使用trailr2配体trail/apo2来代替抗体。将2×104细胞/ml的正常肝细胞以50μl/孔接种到平底96孔板中,在37℃、5.0%二氧化碳下培养16小时。添加调节为各种浓度的上述抗体并使总量为100μl/孔,在37℃、5.0%二氧化碳下培养72小时后,向各孔中添加细胞计数试剂盒-8(wst-8)(同仁化学公司制造)各10μl。对于各条件,使用4个独立的孔进行评价。进一步在37℃、5.0%二氧化碳下培养4小时后,添加0.1mhcl使反应停止,利用酶标仪(1420arvo多标记计数仪:wallac公司制造)测定波长450nm(参比波长630nm)下的吸光度。利用下式算出各孔的细胞的存活率。存活率(%)=100×(a-b)/(c-b)(式中,a表示被测孔的吸光度,b表示无细胞孔的吸光度,c表示无抗体添加的孔的吸光度)。将所得到的结果示于图13和图14。如图13和图14所示,与抗dnp单克隆抗体相比,抗htrailr2激动型单克隆抗体kmda2抗体和trilr2配体trail/apo2使正常肝细胞的存活率降低,与此相对,抗htrailr2单克隆抗体e11抗体、以及htrailr2-hpsma双特异性抗体e11-ch1-pi101vh抗体和e11-ch1-pn7vh抗体与抗dnp单克隆抗体同等地未使正常肝细胞的存活率降低。由该结果表明,本发明的htrailr2-hpsma双特异性抗体对于正常肝细胞不抑制细胞增殖和/或诱导细胞死亡。因此表明,本发明的htrailr2-hpsma双特异性抗体使由抗trailr2激动型单克隆抗体或trail/apo2引起的对正常肝细胞的毒性大幅降低。[实施例15]htrailr2-hpsma双特异性抗体或该抗体片段的表达质粒载体的构建为了考察实施例11中测定的htrailr2-hpsma双特异性抗体所具有的细胞增殖抑制活性和细胞死亡诱导活性中的至少一者与双特异性抗体的结构的关系,制作图15(b)~图15(d)中分别所示的htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2和e11-ch1-pn7vhfab以及htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体,对其细胞增殖抑制活性和细胞死亡诱导活性中的至少一者进行评价。(1)htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2的表达质粒载体的构建e11-ch1-pn7vhf(ab’)2是使实施例4和7中制作的htrailr2-hpsma双特异性抗体e11-ch1-pn7vh的ch2和ch3缺失而得到的双特异性抗体片段[图15(b)]。利用下述方法制作htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2的表达质粒载体。该双特异性抗体片段的重链从n末端侧起依次包含抗htrailr2单克隆抗体e11抗体的vh、连接子(人igg4的ch1区域)和抗hpsma单克隆抗体pn7抗体的vh的氨基酸序列,在c末端包含作为纯化用的标签的flag标签和his标签。此外,该双特异性抗体片段的轻链均包含e11抗体的vl的氨基酸序列。e11-ch1-pn7vhf(ab’)2通过铰链区内的半胱氨酸形成二聚体,对htrailr2和hpsma分别以二价进行结合[图15(b)]。以人igg4的恒定区的碱基序列作为模板,使用引物33(序列号144)和引物34(序列号145)以及kodplusdna聚合酶(东洋纺公司制造),通过pcr对连接子部分的基因片段进行扩增。另外,以实施例3中记载的n5kg4pe[r409k]_e11vl_pn7载体作为模板,使用引物35(序列号146)和引物36(序列号147)以及kodplusdna聚合酶(东洋纺公司制造),通过pcr对pn7抗体的vh区的基因片段进行扩增。此外,以人igg4的恒定区的碱基序列作为模板,使用引物37(序列号148)和引物38(序列号149)以及kod聚合酶,通过pcr对ch1和铰链区部分的基因片段进行扩增。将通过pcr反应扩增出的该基因片段与使用限制酶nhei和bamhi断开的实施例2记载的n5kg1_e11载体连接,由此制作htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2的表达质粒载体n5kg_e11vl_e11-ch1-pn7vhf(ab’)2。将e11-ch1-pn7vhf(ab’)2的除去重链的信号序列后的碱基序列示于序列号150,将由该碱基序列推定的氨基酸序列示于序列号151。(2)htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhfab的表达质粒载体的构建利用下述方法制作htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhfab的表达质粒载体。e11-ch1-pn7vhfab是与(1)中记载的e11-ch1-pn7vhf(ab’)2相比缺失了铰链区的结构,对htrailr2和hpsma分别以一价进行结合[图15(c)]。以人igg4的恒定区的碱基序列作为模板,使用引物33(序列号144)和引物34(序列号145)以及kodplusdna聚合酶(东洋纺公司制造),通过pcr对连接子部分的基因片段进行扩增。另外,以实施例3中记载的n5kg4pe[r409k]_e11vl_pn7载体作为模板,使用引物35(序列号146)和引物36(序列号147)以及kodplusdna聚合酶(东洋纺公司制造),通过pcr对抗hpsma单克隆抗体pn7抗体的vh区的基因片段进行扩增。此外,以人igg4的恒定区的碱基序列作为模板,使用引物37(序列号148)和引物39(序列号152)以及kod聚合酶,通过pcr对ch1部分的基因片段进行扩增。将通过pcr反应扩增出的该基因片段与使用限制酶nhei和bamhi断开的n5kg1_e11载体连接,由此制作htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhfab的表达质粒载体n5kg_e11vl_e11-ch1-pn7vhfab。将e11-ch1-pn7vhfab的除去重链的信号序列后的碱基序列示于序列号153,将由该碱基序列推定的氨基酸序列示于序列号154。(3)htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体的表达质粒载体的构建利用下述方法制作htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体的表达质粒载体。该双特异性抗体是包含抗htrailr2单克隆抗体e11抗体的vh的重链与包含抗体hpsma单克隆抗体pn7抗体的vh的重链形成杂合二聚体、对htrailr2和hpsma分别以一价进行结合的抗体。该双特异性抗体的一个重链为由e11抗体的vh的氨基酸序列和导入有k409r的氨基酸突变的人igg1的恒定区的氨基酸序列构成的重链(以下记载为e11k409r),另一个重链为由pn7抗体的vh的氨基酸序列和导入有f405l的氨基酸突变的人igg1的恒定区的氨基酸序列构成的重链(以下记载为pn7f405l)。e11k409r和pn7f405l分别包含k409r和f405l的氨基酸突变,由此促进这些重链间的杂合二聚体的形成[natureprotocols,9,2450-2463(2014)][图15(d)]。另外,该抗体的vl[图15(d)的e11vl和pn7vl]均相同,包含序列号119所表示的氨基酸序列。e11_pn7hetero抗体的制作方法在实施例16中详述,首先,分别制作重链为e11k409r、轻链包含e11抗体的vl的氨基酸序列的抗htrailr2单克隆抗体;和重链为pn7f405l、轻链包含e11抗体的vl的氨基酸序列的抗hpsma单克隆抗体。接着,将这两种抗体混合,进行还原反应,由此可以制作各抗体的重链e11k409r和pn7f405l形成了杂合二聚体的e11_pn7hetero抗体。重链为e11k409r、轻链包含e11的vl的氨基酸序列的抗htrailr2抗体的表达质粒载体n5kg1_e11vl_e11vhk409r通过将导入有k409r的氨基酸突变的人iggl重链恒定区基因片段与使用限制酶nhei和bamhi断开的人igg1型抗htrailr2单克隆抗体e11抗体的表达质粒载体n5kg1_e11连接而制作。重链为pn7f405l、轻链包含e11抗体的vl的氨基酸序列的抗hpsma单克隆抗体的表达质粒载体n5kg1_e11vl_pn7vhf405l通过将导入有f405l的氨基酸突变的人igg1重链恒定区基因片段与使用限制酶nhei和bamhi断开的突变人igg4型抗hpsma单克隆抗体pn7抗体的表达质粒载体n5kg4pe[r409k]_e11vl_pn7连接而制作。将除去e11k409r的信号序列后的碱基序列示于序列号155,将由该碱基序列推定的氨基酸序列示于序列号156。将除去pn7f405l的信号序列后的碱基序列示于序列号157,将由该碱基序列推定的氨基酸序列示于序列号158。[实施例16]htrailr2-hpsma双特异性抗体或该抗体片段的制备(1)htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2和e11-ch1-pn7vhfab的制备利用expi293(注册商标)表达系统(thermofisherscientific公司制造)将实施例15中制作的htrailr2-hpsma双特异性抗体片段的表达质粒载体n5kg_e11vl_e11-ch1-pn7vhf(ab’)2或n5kg_e11vl_e11-ch1-pn7vhfab基因导入到悬浮性expi293f(注册商标)细胞中,使e11-ch1-pn7vhf(ab’)2或e11-ch1-pn7vhfab进行瞬时表达。在基因导入起第4天后,回收培养上清,使用孔径0.22μm的膜滤器(thermoscientific公司制造)进行过滤。将该培养上清装填至flag融合蛋白质纯化用的anti-flagm2affinitygel(柱体积2ml)(sigmaaldrich公司制造)上,用pbs(-)清洗后,利用洗脱缓冲液[20mm柠檬酸、50mmnacl(ph3.4)]进行洗脱,回收到含有200mm磷酸钠缓冲液(ph7.0)的管中。接着,利用vivaspin(sartriusstealin公司制造)对该洗脱液进行浓缩,利用nap(注册商标)柱(gehealthcarebioscience公司制造)将溶剂置换为pbs。进而,利用aktaexplore(gehealthcare公司制造),使用superdex高性能柱(gehealthcarebioscience公司制造),由该洗脱液分离得到与e11-ch1-pn7vhf(ab’)2或e11-ch1-pn7vhfab的分子量相当的级分,使用孔径0.22μm的膜滤器(millex-gv、millipore公司制造)进行过滤灭菌,由此得到含有htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2或e11-ch1-pn7vhfab的抗体溶液。通过sds-page法确认了所得到的抗体溶液中的e11-ch1-pn7vhf(ab’)2或e11-ch1-pn7vhfab均为95%以上的纯度。利用流式细胞术确认了该双特异性抗体片段对htrailr2和hpsma均具有结合活性。(2)htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体的制备利用expi293(注册商标)expressionsystem(thermofisherscientific公司制造)将实施例15中制作的表达质粒载体n5kg1_e11vl_e11vhk409r基因导入到悬浮性expi293f(注册商标)细胞中,使重链为e11k409r、轻链包含e11抗体的vl的氨基酸序列的抗htrailr2单克隆抗体进行瞬时表达。实施例15中制作的表达质粒载体n5kg1_e11vl_pn7vhf405l也通过同样的方法基因导入到悬浮性expi293f(注册商标)细胞中,使重链为pn7f405l、轻链包含e11抗体的vl的氨基酸序列的抗hpsma单克隆抗体进行瞬时表达。对于各基因导入细胞,在基因导入起第4天后回收培养上清,使用孔径0.22μm的膜滤器(thermoscientific公司制造)进行过滤,使用蛋白a树脂(mabselect、gehealthcarebioscience公司制造)对抗体进行亲和纯化。作为清洗液,使用磷酸缓冲液。利用洗脱缓冲液[20mm柠檬酸钠、50mmnacl缓冲液(ph3.4)]将吸附于蛋白a上的抗体洗脱,回收到含有200m磷酸钠缓冲液(ph7.0)的管中。接着,利用vivaspin(sartriusstealin公司制造)将洗脱液浓缩,利用nap(商标)柱(gehealthcarebioscience公司制造)将溶剂置换为pbs。由此,得到含有重链为e11k409r、轻链包含e11抗体的vl的氨基酸序列的抗htrailr2单克隆抗体或重链为pn7f405l、轻链包含e11抗体的vl的氨基酸序列的抗hpsma单克隆抗体的抗体溶液。接着,使用上述两种抗体溶液,依据natureprotocols,9,2450-2463(2014)进行下述反应,制作htrailr2-hpsma杂合双特异性抗体he11_pn7hetero抗体。将上述的抗htrailr2单克隆抗体溶液和抗hpsma单克隆抗体溶液混合,在75mm2-mea、pbs中进行90分钟还原反应。利用nap(注册商标)柱(gehealthcarebioscience公司制造)将所得到的反应溶液的溶剂置换为pbs,在4℃下孵育16小时。由此,各抗体的重链e11k409r和pn7f405l形成杂合二聚体。进而,利用aktaexplore(gehealthcare公司制造),使用superdex高性能柱(gehealthcarebioscience公司制造),由反应溶液分离得到与e11_pn7hetero相当的级分,使用孔径0.22μm的膜滤器(millex-gv、millipore公司制造)进行过滤灭菌,由此得到含有htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体的抗体溶液。通过sds-page法确认了所得到的抗体溶液中的e11_pn7hetero抗体为95%以上的纯度。另外,利用流式细胞术确认了e11_pn7hetero抗体对htrailr2和hpsma具有结合活性。[实施例17]使用htrailr2-hpsma双特异性抗体的pc3细胞和hpsma/pc3细胞的增殖性试验使用实施例7中制作的htrailr2-hpsma双特异性抗体e11-ch1-pn7vh抗体、实施例16中制作的htrailr2-hpsma双特异性抗体片段e11-ch1-pn7vhf(ab’)2和e11-ch1-pn7vhfab、以及htrailr2-hpsma杂合双特异性抗体e11_pn7hetero抗体,如下评价pc3细胞和实施例8中得到的hpsma/pc3细胞的增殖性。由此,可以确认上述抗体对于pc3细胞和hpsma/pc3细胞是否抑制细胞增殖和/或诱导细胞死亡。另外,作为阴性对照,使用公知的抗dnp单克隆抗体。在实施例10中确认了pc3细胞表达htrailr2而不表达hpsma,hpsma/pc3细胞表达htrailr2和hpsma。将2~10×104细胞/ml的细胞以50μl/孔接种到平底96孔板中,在37℃、5.0%二氧化碳下培养16小时。添加调节为各种浓度的抗体并使总量为100μl/孔と,在37℃、5.0%二氧化碳下培养72小时后,向各孔中添加细胞计数试剂盒-8(wst-8)(同仁化学公司制造)各10μl。对于各条件,使用4个独立的孔进行评价。进一步在37℃、5.0%二氧化碳下培养4小时后,添加0.1mhcl使反应停止,利用酶标仪(1420arvo多标记计数仪:wallac公司制造)测定波长450nm(参比波长630nm)下的吸光度。将所得到的结果示于图16和17。抗体浓度统一为摩尔浓度。所得到的吸光度的值反映各孔中的细胞数。将对于pc3细胞的结果示于图16,将对于hpsma/pc3细胞的结果示于图17。如图16和图17所示,在添加了10nm的抗htrailr2激动型单克隆抗体kmda2抗体的孔中,对于任意一种细胞而言,与添加了抗dnp单克隆抗体的孔相比,细胞数均略微降低。在添加了其他抗体或抗体片段的孔中,对于pc3细胞而言,均显示出与添加了抗dnp单克隆抗体的孔同等的细胞数。对于hpsma/pc3细胞,在添加了e11-ch1-pn7vh抗体或e11-ch1-pn7vhf(ab’)2的孔中,与添加了kmda2抗体的孔相比细胞数降低。另一方面,在添加了e11-ch1-pn7vhfab和e11_pn7hetero抗体的孔中,显示出与添加了抗dnp单克隆抗体的孔同等的细胞数。由此表明,e11-ch1-pn7vh抗体和e11-ch1-pn7vhf(ab’)2对于表达htrailr2而不表达hpsma的细胞不抑制细胞增殖和/或诱导细胞死亡,对于表达htrailr2和hpsma的细胞抑制细胞增殖和/或诱导细胞死亡。另一方面表明,e11-ch1-pn7vhfab和e11_pn7hetero抗体即使在表达htrailr2和hpsma的细胞中也不诱导上述反应。e11-ch1-pn7vh抗体、e11-ch1-pn7vhf(ab’)2、e11-ch1-pn7vhfab和e11_pn7hetero抗体都是使用相同的抗htrailr2单克隆抗体e11抗体和抗hpsma单克隆抗体pn7抗体的可变区而制作的,但就各抗体或抗体片段的结构而言,e11-ch1-pn7vh抗体和e11-ch1-pn7vhf(ab’)2与htrailr2和hpsma分别以二价进行结合,e11-ch1-pn7vhfab和e11_pn7hetero抗体与htrailr2和hpsma分别以一价进行结合。由以上表明,本发明的htrailr2-hpsma双特异性抗体或该抗体片段在与htrailr2和hpsma分别以二价结合时,抑制细胞增殖和/或诱导细胞死亡,在与各抗原分别以一价结合时,不产生上述反应。产业上的可利用性根据本发明,能够提供包含与trailr2结合的抗原结合结构域和与psma结合的抗原结合结构域的双特异性抗体或该抗体片段、具有编码该抗体或该抗体片段的碱基序列的核酸、包含该核酸的重组载体、包含该重组载体的转化株、使用该转化细胞的该双特异性抗体或该抗体片段的制造方法、以及包含该双特异性抗体或该抗体片段的检测或测定试剂、诊断剂和治疗剂。使用特定的方式详细地对本发明进行了说明,但对于本领域技术人员而言显而易见的是,可以在不脱离本发明的意图和范围的情况下进行各种变更和变形。需要说明的是,本申请基于2015年1月8日提交的美国临时申请(62/101042号),通过引用将其全部内容援引于此。序列表自由文本序列号1-人工序列的说明:kmda2的vh的碱基序列序列号2-人工序列的说明:kmda2的vl的碱基序列序列号3-人工序列的说明:引物1的碱基序列序列号4-人工序列的说明:引物2的碱基序列序列号5-人工序列的说明:引物3的碱基序列序列号6-人工序列的说明:引物4的碱基序列序列号7-人工序列的说明:kmda2的vh的氨基酸序列序列号8-人工序列的说明:kmda2的vl的氨基酸序列序列号9-人工序列的说明:e11的vh的碱基序列序列号10-人工序列的说明:e1l的vl的碱基序列序列号11-人工序列的说明:gl连接子的氨基酸序列序列号12-人工序列的说明:ml连接子的氨基酸序列序列号13-人工序列的说明:pi134的vh的碱基序列序列号14-人工序列的说明:pi101的vh的碱基序列序列号15-人工序列的说明:pn7的vh的碱基序列序列号16-人工序列的说明:pi105的vh的碱基序列序列号17-人工序列的说明:pi108的vh的碱基序列序列号18-人工序列的说明:pi115的vh的碱基序列序列号19-人工序列的说明:pi118的vh的碱基序列序列号20-人工序列的说明:pi127的vh的碱基序列序列号21-人工序列的说明:pi143的vh的碱基序列序列号22-人工序列的说明:pl223的vh的碱基序列序列号23-人工序列的说明:2a10的vh的碱基序列序列号24-人工序列的说明:2a10的vh的氨基酸序列序列号25-人工序列的说明:2a10的vl的碱基序列序列号26-人工序列的说明:2a10的vl的氨基酸序列序列号27-人工序列的说明:引物5的碱基序列序列号28-人工序列的说明:引物6的碱基序列序列号29-人工序列的说明:引物7的碱基序列序列号30-人工序列的说明:引物8的碱基序列序列号31-人工序列的说明:引物9的碱基序列序列号32-人工序列的说明:引物10的碱基序列序列号33-人工序列的说明:引物11的碱基序列序列号34-人工序列的说明:e11_vh-ch1-pi134_vh的碱基序列序列号35-人工序列的说明:引物12的碱基序列序列号36-人工序列的说明:e11_vh-ch1-pi101_vh的碱基序列序列号37-人工序列的说明:引物13的碱基序列序列号38-人工序列的说明:引物14的碱基序列序列号39-人工序列的说明:e11_vh-ch1-pi105_vh的碱基序列序列号40-人工序列的说明:e11_vh-ch1-pi108_vh的碱基序列序列号41-人工序列的说明:e11_vh-ch1-pi115_vh的碱基序列序列号42-人工序列的说明:引物15的碱基序列序列号43-人工序列的说明:e11_vh-ch1-pi118_vh的碱基序列序列号44-人工序列的说明:引物16的碱基序列序列号45-人工序列的说明:e11_vh-ch1-pi127_vh的碱基序列序列号46-人工序列的说明:引物17的碱基序列序列号47-人工序列的说明:引物18的碱基序列序列号48-人工序列的说明:e11_vh-ch1-pi143_vh的碱基序列序列号49-人工序列的说明:引物19的碱基序列序列号50-人工序列的说明:引物20的碱基序列序列号51-人工序列的说明:e11_vh-ch1-pl223_vh的碱基序列序列号52-人工序列的说明:引物21的碱基序列序列号53-人工序列的说明:e11_vh-ch1-pn7_vh的碱基序列序列号54-人工序列的说明:引物22的碱基序列序列号55-人工序列的说明:引物23的碱基序列序列号56-人工序列的说明:e11_vh-ch1-pn170_vh的碱基序列序列号57-人工序列的说明:引物24的碱基序列序列号58-人工序列的说明:e11_vh-gl-pi134_vh的碱基序列序列号59-人工序列的说明:引物25的碱基序列序列号60-人工序列的说明:引物26的碱基序列序列号61-人工序列的说明:引物27的碱基序列序列号62-人工序列的说明:引物28的碱基序列序列号63-人工序列的说明:e11_vh-ml-pi101_vh的碱基序列序列号65-人工序列的说明:引物29的碱基序列序列号66-人工序列的说明:引物30的碱基序列序列号67-人工序列的说明:引物31的碱基序列序列号68-人工序列的说明:引物32的碱基序列序列号69-人工序列的说明:e11的vh的氨基酸序列序列号70-人工序列的说明:e11的hcdr1的氨基酸序列序列号71-人工序列的说明:e11的hcdr2的氨基酸序列序列号72-人工序列的说明:e11的hcdr3的氨基酸序列序列号73-人工序列的说明:e11的vl的氨基酸序列序列号74-人工序列的说明:e11的lcdr1的氨基酸序列序列号75-人工序列的说明:e11的lcdr2的氨基酸序列序列号76-人工序列的说明:e11的lcdr3的氨基酸序列序列号77-人工序列的说明:pi134的vh的氨基酸序列序列号78-人工序列的说明:pi134、pi143、pi105、pi127、pi108、pi115、pl223、pn7、pi101、pi118的hcdr1的氨基酸序列序列号79-人工序列的说明:pi134、pi143、pi105、pi127、pi108、pi115、pl223的hcdr2的氨基酸序列序列号80-人工序列的说明:pi134、pi143、pi105、pi127、pi108、pi115、pl223、pi101、pi118的hcdr3的氨基酸序列序列号81-人工序列的说明:pi101的vh的氨基酸序列序列号82-人工序列的说明:pi101、pn7、pi118的hcdr2的氨基酸序列序列号83-人工序列的说明:pn7的vh的氨基酸序列序列号84-人工序列的说明:pn7的hcdr3的氨基酸序列序列号85-人工序列的说明:pi105的vh的氨基酸序列序列号86-人工序列的说明:pi108的vh的氨基酸序列序列号87-人工序列的说明:pi115的vh的氨基酸序列序列号88-人工序列的说明:pi118的vh的氨基酸序列序列号89-人工序列的说明:pi127的vh的氨基酸序列序列号90-人工序列的说明:pi143的vh的氨基酸序列序列号91-人工序列的说明:pl223的vh的氨基酸序列序列号92-人工序列的说明:n末端flag融合psma细胞外结构域的碱基序列序列号93-人工序列的说明:igg4ch1连接子的氨基酸序列序列号94-人工序列的说明:pn170的vh的碱基序列序列号95-人工序列的说明:pn170的vh的氨基酸序列序列号96-人工序列的说明:pn170的hcdr1的氨基酸序列序列号97-人工序列的说明:pn170的hcdr2的氨基酸序列序列号98-人工序列的说明:pn170的hcdr3的氨基酸序列序列号99-人工序列的说明:e11_vh-ch1-pi134_vh的氨基酸序列序列号100-人工序列的说明:e11_vh-ch1-pi101_vh的氨基酸序列序列号101-人工序列的说明:e11_vh-ch1-pi105_vh的氨基酸序列序列号102-人工序列的说明:e11_vh-ch1-pi108_vh的氨基酸序列序列号103-人工序列的说明:e11_vh-ch1-pi115_vh的氨基酸序列序列号104-人工序列的说明:e11_vh-ch1-pi118_vh的氨基酸序列序列号105-人工序列的说明:e11_vh-ch1-pi127_vh的氨基酸序列序列号106-人工序列的说明:e11_vh-ch1-pi143_vh的氨基酸序列序列号107-人工序列的说明:e11_vh-ch1-pl223_vh的氨基酸序列序列号108-人工序列的说明:e11_vh-ch1-pn7_vh的氨基酸序列序列号109-人工序列的说明:e11_vh-ch1-pn170_vh的氨基酸序列序列号110-人工序列的说明:e11_vh-gl-pi134_vh的氨基酸序列序列号111-人工序列的说明:e11_vh-ml-pi101_vh的氨基酸序列序列号113-人工序列的说明:n末端flag融合psma细胞外结构域的氨基酸序列序列号114-人工序列的说明:kmda2的vh的除去信号序列后的氨基酸序列序列号115-人工序列的说明:kmda2的vl的除去信号序列后的氨基酸序列序列号116-人工序列的说明:2a10的vh的除去信号序列后的氨基酸序列序列号117-人工序列的说明:2a10的vl的除去信号序列后的氨基酸序列序列号118-人工序列的说明:e11的vh的除去信号序列后的氨基酸序列序列号119-人工序列的说明:e11的vl的除去信号序列后的氨基酸序列序列号120-人工序列的说明:pi134的vh的除去信号序列后的氨基酸序列序列号121-人工序列的说明:pi101的vh的除去信号序列后的氨基酸序列序列号122-人工序列的说明:pn7的vh的除去信号序列后的氨基酸序列序列号123-人工序列的说明:pi105的vh的除去信号序列后的氨基酸序列序列号124-人工序列的说明:pi108的vh的除去信号序列后的氨基酸序列序列号125-人工序列的说明:pi115的vh的除去信号序列后的氨基酸序列序列号126-人工序列的说明:pi118的vh的除去信号序列后的氨基酸序列序列号127-人工序列的说明:pi127的vh的除去信号序列后的氨基酸序列序列号128-人工序列的说明:pi143的vh的除去信号序列后的氨基酸序列序列号129-人工序列的说明:pl223的vh的除去信号序列后的氨基酸序列序列号130-人工序列的说明:pn170的vh的除去信号序列后的氨基酸序列序列号131-人工序列的说明:e11_vh-ch1-pi134_vh的除去信号序列后的氨基酸序列序列号132-人工序列的说明:e11_vh-ch1-pi101_vh的除去信号序列后的氨基酸序列序列号133-人工序列的说明:e11_vh-ch1-pi105_vh的除去信号序列后的氨基酸序列序列号134-人工序列的说明:e11_vh-ch1-pi108_vh的除去信号序列后的氨基酸序列序列号135-人工序列的说明:e11_vh-ch1-pi115_vh的除去信号序列后的氨基酸序列序列号136-人工序列的说明:e11_vh-ch1-pi118_vh的除去信号序列后的氨基酸序列序列号137-人工序列的说明:e11_vh-ch1-pi127_vh的除去信号序列后的氨基酸序列序列号138-人工序列的说明:e11_vh-ch1-pi143_vh的除去信号序列后的氨基酸序列序列号139-人工序列的说明:e11_vh-ch1-pl223_vh的除去信号序列后的氨基酸序列序列号140-人工序列的说明:e11_vh-ch1-pn7_vh的除去信号序列后的氨基酸序列序列号141-人工序列的说明:e11_vh-ch1-pn170_vh的除去信号序列后的氨基酸序列序列号142-人工序列的说明:e11_vh-gl-pi134_vh的除去信号序列后的氨基酸序列序列号143-人工序列的说明:e11_vh-ml-pi101_vh的除去信号序列后的氨基酸序列序列号144-人工序列的说明:引物33序列号145-人工序列的说明:引物34的碱基序列序列号146-人工序列的说明:引物35的碱基序列序列号147-人工序列的说明:引物36的碱基序列序列号148-人工序列的说明:引物37的碱基序列序列号149-人工序列的说明:引物38的碱基序列序列号150-人工序列的说明:e11-ch1-pn7vhf(ab’)2的碱基序列序列号151-人工序列的说明:合成构建体的氨基酸序列序列号152-人工序列的说明:引物39的碱基序列序列号153-人工序列的说明:e11-ch1-pn7vhfab的碱基序列序列号154-人工序列的说明:合成构建体的氨基酸序列序列号155-人工序列的说明:e11k409r的碱基序列序列号156-人工序列的说明:合成构建体的氨基酸序列序列号157-人工序列的说明:pn7f405l的碱基序列序列号158-人工序列的说明:合成构建体的氨基酸序列序列表<110>协和发酵麒麟株式会社(kyowahakkokirinco.,ltd.)<120>与trailr2和psma结合的双特异性抗体(bispecificantibodybindingtotrailr2andpsma)<130>w519750<150>us62/101,042<151>2015-01-08<160>158<170>patentinversion3.3<210>1<211>435<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofkmda2_vh<400>1atggactggacctggaggatcctcttcttggtggcagcagctacaagtgcccactcccag60gtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccagttataaaattaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacagtggtaacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagatcctatggt360tcggggagttattatagagactattactacggtatggacgtctggggccaagggaccacg420gtcaccgtctcctca435<210>2<211>381<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofkmda2_vl<400>2atggaagccccagctcagcttctcttcctcctgctactctggctcccagataccaccgga60gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccacc120ctctcctgcagggccagtcagagtgttagcagctacttagcctggtaccaacagaaacct180ggccaggctcccaggctcctcatctatgatgcatccaacagggccactggcatcccagcc240aggttcagtggcagtgggtctgggacagacttcactctcaccatcagcagcctagagcct300gaagattttgcagtttattactgtcagcagcgtagcaactggccgctcactttcggcgga360gggaccaaggtggagatcaaa381<210>3<211>41<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer1<400>3atcacagatctctcaccatggaagccccagctcagcttctc41<210>4<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer2<400>4ggtgcagccaccgtacgtttgatctccaccttg33<210>5<211>38<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer3<400>5gcgactaagtcgacaccatggactggacctggaggatc38<210>6<211>32<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer4<400>6agagagagaggctagctgaggagacggtgacc32<210>7<211>145<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofkmda2_vh<400>7metasptrpthrtrpargileleupheleuvalalaalaalathrser151015alahisserglnvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrsertyrlysileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnserglyasnthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileser859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargsertyrglyserglysertyrtyrargasptyr115120125tyrtyrglymetaspvaltrpglyglnglythrthrvalthrvalser130135140ser145<210>8<211>127<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofkmda2_vl<400>8metglualaproalaglnleuleupheleuleuleuleutrpleupro151015aspthrthrglygluilevalleuthrglnserproalathrleuser202530leuserproglygluargalathrleusercysargalaserglnser354045valsersertyrleualatrptyrglnglnlysproglyglnalapro505560argleuleuiletyraspalaserasnargalathrglyileproala65707580argpheserglyserglyserglythraspphethrleuthrileser859095serleugluprogluaspphealavaltyrtyrcysglnglnargser100105110asntrpproleuthrpheglyglyglythrlysvalgluilelys115120125<210>9<211>432<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh<400>9atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctca432<210>10<211>384<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vl<400>10atggaagccccagctcagcttctcttcctcctgctactctggctcccagataccaccgga60gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccacc120ctctcctgcagggccagtcagagtgttagcagcttcttagcctggtaccaacagaaacct180ggccaggctcccaggctcctcatctatgatgcatccaacagggccactggcatcccagcc240aggttcagtggcagtgggtctgggacagacttcactctcaccatcagcagcctagagcct300gaagattttgcagtttattactgtcagcagcgtagcaactggcctctcactttcggccct360gggaccaaagtggatatcaaacgt384<210>11<211>14<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofgllinker<400>11alaserthrlysglyproservalpheproleualaprocys1510<210>12<211>14<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofmllinker<400>12glyseralaseralaprothrleupheproleuvalsercys1510<210>13<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi134_vh<400>13atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactcccag60gtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccctggtcaccgtctcctca414<210>14<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi101_vh<400>14atggggtcaaccgccatcctcgccctcctcctggctgttctccaaggagtctgttccgag60gtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatataatctcgccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacagtggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccagggacacctccataaacacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccctggtcaccgtctcctca414<210>15<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpn7_vh<400>15atggagtttgggctgagctgggttttccttgttgctattttaaaaggtgtccagtgtgaa60gtgcagctggtgcagtccggagctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggttacacctttaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacagtggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccagggacacctccataagcacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgcggacgaactgg360gaatcctggtacttcgatctctggggccgtggaaccctggtcaccgtctcctca414<210>16<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi105_vh<400>16atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactccgag60gtccagctggtacagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccacg180ggacaagggcttgagtggctgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataggcacagcctacatg300gagctgaacagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccctggtcactgtctcctca414<210>17<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi108_vh<400>17atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactcccag60gtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatg300gagctgaccagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccctggtcactgtctcctca414<210>18<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi115_vh<400>18atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactccgag60gtgcagctggtgcagtccggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccctggtcaccgtctcctca414<210>19<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi118_vh<400>19atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactcccag60gtgcagctggtgcaatctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatataatctcaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacagtggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccatagacacagcctacatg300gagctgagcaacctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggaaccctggtcaccgtctcctca414<210>20<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi127_vh<400>20atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactcccaa60gtccagctggtacagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccacg180ggacaagggcttgagtggctgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataggcacagcctacatg300gagctgaacagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccctggtcactgtctcctca414<210>21<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpi143_vh<400>21atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactcccag60gtccagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccacggtcaccgtctcctca414<210>22<211>414<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpl223_vh<400>22atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactccgaa60gtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacaatggttacacaggctatgca240cagaagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgg360gtctactggtacttcgatctctggggccgtggcaccatggtcaccgtctcttca414<210>23<211>435<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceof2a10_vh<400>23atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcggaggtgcagctggtgcagtctggagcagaggtgaaaaagccc120ggggagtctctgaagatctcctgtaagggttctggatacagctttaccagtaactggatc180ggctgggtgcgccagatgcccgggaaaggcctggagtggatggggatcatctatcctggt240gactctgataccagatacagcccgtccttccaaggccaggtcaccatctcagccgacaag300tccatcagcaccgcctacctgcagtggagcagcctgaaggcctcggacaccgccatgtat360tactgtgcgaggcaaactggtttcctctggtcctccgatctctggggccgtggcaccctg420gtcactgtctcctca435<210>24<211>145<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceof2a10_vh<400>24metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleusergluvalglnleuvalgln202530serglyalagluvallyslysproglygluserleulysilesercys354045lysglyserglytyrserphethrserasntrpileglytrpvalarg505560glnmetproglylysglyleuglutrpmetglyileiletyrprogly65707580aspseraspthrargtyrserproserpheglnglyglnvalthrile859095seralaasplysserileserthralatyrleuglntrpserserleu100105110lysalaseraspthralamettyrtyrcysalaargglnthrglyphe115120125leutrpserseraspleutrpglyargglythrleuvalthrvalser130135140ser145<210>25<211>387<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceof2a10_vl<400>25atggacatgagggtccccgctcagctcctggggcttctgctgctctggctcccaggtgcc60agatgtgccatccagttgacccagtctccatcctccctgtctgcatctgtaggagacaga120gtcaccatcacttgccgggcaagtcaggacattagcagtgctttagcctggtatcaacag180aaaccagggaaagctcctaagctcctgatctatgatgcctccagtttggaaagtggggtc240ccatcaaggttcagcggctatggatctgggacagatttcactctcaccatcaacagcctg300cagcctgaagattttgcaacttattactgtcaacagtttaatagttacccgctcactttc360ggcggagggaccaaggtggagatcaaa387<210>26<211>129<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceof2a10_vl<400>26metaspmetargvalproalaglnleuleuglyleuleuleuleutrp151015leuproglyalaargcysalaileglnleuthrglnserproserser202530leuseralaservalglyaspargvalthrilethrcysargalaser354045glnaspileserseralaleualatrptyrglnglnlysproglylys505560alaprolysleuleuiletyraspalaserserleugluserglyval65707580proserargpheserglytyrglyserglythraspphethrleuthr859095ileasnserleuglnprogluaspphealathrtyrtyrcysglngln100105110pheasnsertyrproleuthrpheglyglyglythrlysvalgluile115120125lys<210>27<211>68<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer5<400>27ctgtggttcttcctcctgctggtggcggctcccagatgggtcctgtcggaggtgcagctg60gtgcagtc68<210>28<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer6<400>28ggtgctagctgaggagacagtgaccagggtgcc33<210>29<211>65<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer7<400>29gacccgtcgacgctatggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcc60tgctg65<210>30<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer8<400>30gtcaccgtctcctcagctagcaccaaggggcca33<210>31<211>20<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer9<400>31aactctcttgtccaccttgg20<210>32<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer10<400>32aaggtggacaagagagttcaggtgcagctggtgcag36<210>33<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer11<400>33gcccttggtgctagctgaggagacggtgaccag33<210>34<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi134_vh<400>34atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttcaggtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataagcaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccctggtcaccgtctcc1080tca1083<210>35<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer12<400>35aaggtggacaagagagttgaggtgcagctggtgcag36<210>36<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi101_vh<400>36atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttgaggtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatataatctcgccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacagtggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccagggacacctccataaacaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccctggtcaccgtctcc1080tca1083<210>37<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer13<400>37aaggtggacaagagagttgaagtgcagctggtgcag36<210>38<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer14<400>38gcccttggtgctagctgaggagacagtgaccag33<210>39<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi105_vh<400>39atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttgaggtccagctggtacagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccacgggacaagggcttgagtggctgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataggcaca960gcctacatggagctgaacagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccctggtcactgtctcc1080tca1083<210>40<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi108_vh<400>40atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttcaggtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataagcaca960gcctacatggagctgaccagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccctggtcactgtctcc1080tca1083<210>41<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi115_vh<400>41atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttgaggtgcagctggtgcagtccggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataagcaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccctggtcaccgtctcc1080tca1083<210>42<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer15<400>42aaggtggacaagagagttcaggtgcagctggtgcaa36<210>43<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi118_vh<400>43atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttcaggtgcagctggtgcaatctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatataatctcaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacagtggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccatagacaca960gcctacatggagctgagcaacctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggaaccctggtcaccgtctcc1080tca1083<210>44<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer16<400>44aaggtggacaagagagttcaagtccagctggtacag36<210>45<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi127_vh<400>45atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttcaagtccagctggtacagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccacgggacaagggcttgagtggctgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataggcaca960gcctacatggagctgaacagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccctggtcactgtctcc1080tca1083<210>46<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer17<400>46aaggtggacaagagagttcaggtccagctggtgcag36<210>47<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer18<400>47gcccttggtgctagctgaggagacggtgaccgt33<210>48<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pi143_vh<400>48atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttcaggtccagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataagcaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccacggtcaccgtctcc1080tca1083<210>49<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer19<400>49aaggtggacaagagagttgaagtgcagctggtgcag36<210>50<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer20<400>50gcccttggtgctagctgaagagacggtgaccat33<210>51<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1_pl223_vh<400>51atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttgaagtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccttcaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacaatggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccaggaacacctccataagcaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgaga1020actaactgggtctactggtacttcgatctctggggccgtggcaccatggtcaccgtctct1080tca1083<210>52<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer21<400>52aaggtggacaagagagttgaagtgcagctggtgcag36<210>53<211>1083<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pn7_vh<400>53atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgctccagg480agcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccg540gtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtc600ctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcagcttg660ggcacgaagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaag720agagttgaagtgcagctggtgcagtccggagctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggttacacctttaccacttatgatatcaactgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacagtggttacaca900ggctatgcacagaagttccagggcagagtcaccatgaccagggacacctccataagcaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgcgg1020acgaactgggaatcctggtacttcgatctctggggccgtggaaccctggtcaccgtctcc1080tca1083<210>54<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer22<400>54aaggtggacaagagagttgaggtccagctggtacag36<210>55<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer23<400>55gcccttggtgctagctgaggagacagtgaccag33<210>56<211>1089<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ch1-pn170_vh<400>56atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaaaggaccttctgtatttcctcttgcgccatgctctcgc480tctacgtcagaatcaactgccgctctggggtgcctggttaaagactacttcccggagcct540gtgacagtgagttggaactccggcgccctgacatcaggagtgcatacatttcccgccgtg600cttcagagcagcggactttatagcctcagcagtgtggtgaccgtgccatcttccagcctg660gggaccaagacctacacctgtaacgtggaccacaaacccagcaacaccaaggttgataag720agggtcgaggtccagctggtacagtctggggctgaggtgaagaagcctggggcctcagtg780aaggtctcctgcaaggcttctggatacaccctcaccagttatgatatcaattgggtgcga840caggccactggacaagggcttgagtggatgggatggatgaaccctaacagtggttacaca900ggctatgcacagaagttccaggacagagtcaccatgaccaggaacaccgccataaacaca960gcctacatggagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgaga1020gaggcgggttacgatggtatctggtacttcgatctctggggccgtggcaccctggtcact1080gtctcctca1089<210>57<211>75<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer24<400>57gtcaccgtctcctcagctagcaccaaggggccatccgtcttccccctggcgccctgccag60gtgcagctggtgcag75<210>58<211>831<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-gl-pi134_vh<400>58atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagctagcaccaagggcccatccgtcttccccctggcgccctgccaggtg480cagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcctgc540aaggcttctggatacaccttcaccacttatgatatcaactgggtgcgacaggccactgga600caagggcttgagtggatgggatggatgaaccctaacaatggttacacaggctatgcacag660aagttccagggcagagtcaccatgaccaggaacacctccataagcacagcctacatggag720ctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgggtc780tactggtacttcgatctctggggccgtggcaccctggtcaccgtctcctca831<210>59<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer25<400>59agacccgtcgacgtcatggatctcatgtgcaag33<210>60<211>35<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer26<400>60ggggcggatgcgctccctgaggagacggtgaccag35<210>61<211>78<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer27<400>61ctggtcaccgtctcctcagggagcgcatccgccccaacccttttccccctcgtctcctgt60gaggtgcagctggtgcag78<210>62<211>39<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer28<400>62cccttggtgctagctgaggagacggtgaccagggtgcca39<210>63<211>831<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11_vh-ml-pi101_vh<400>63atggatctcatgtgcaagaaaatgaagcacctgtggttcttcctcctgctggtggcggct60cccagatgggtcctgtcccagctgcagctgcaggagtcgggcccaggactggtgaagcct120tcggagaccctgtccctcacctgcactgtctctggtggctccatcatcagtaaaagttcc180tactggggctggatccgccagcccccagggaaggggctggagtggattgggagtatctat240tatagtgggagtaccttctacaacccgtccctcaagagtcgagtcaccatatccgtagac300acgtccaagaaccagttctccctgaagctgagctctgtgaccgccgcagacacggctgtg360tattactgtgcgagactgacagtggctgagtttgactactggggccagggaaccctggtc420accgtctcctcagggagcgcatccgccccaacccttttccccctcgtctcctgtgaggtg480cagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcctgc540aaggcttctggatataatctcgccacttatgatatcaactgggtgcgacaggccactgga600caagggcttgagtggatgggatggatgaaccctaacagtggttacacaggctatgcacag660aagttccagggcagagtcaccatgaccagggacacctccataaacacagcctacatggag720ctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagaactaactgggtc780tactggtacttcgatctctggggccgtggcaccctggtcaccgtctcctca831<210>64<211>2253<212>dna<213>homosapiens<400>64atgtggaatctccttcacgaaaccgactcggctgtggccaccgcgcgccgcccgcgctgg60ctgtgcgctggggcgctggtgctggcgggtggcttctttctcctcggcttcctcttcggg120tggtttataaaatcctccaatgaagctactaacattactccaaagcataatatgaaagca180tttttggatgaattgaaagctgagaacatcaagaagttcttatataattttacacagata240ccacatttagcaggaacagaacaaaactttcagcttgcaaagcaaattcaatcccagtgg300aaagaatttggcctggattctgttgagctagcacattatgatgtcctgttgtcctaccca360aataagactcatcccaactacatctcaataattaatgaagatggaaatgagattttcaac420acatcattatttgaaccacctcctccaggatatgaaaatgtttcggatattgtaccacct480ttcagtgctttctctcctcaaggaatgccagagggcgatctagtgtatgttaactatgca540cgaactgaagacttctttaaattggaacgggacatgaaaatcaattgctctgggaaaatt600gtaattgccagatatgggaaagttttcagaggaaataaggttaaaaatgcccagctggca660ggggccaaaggagtcattctctactccgaccctgctgactactttgctcctggggtgaag720tcctatccagatggttggaatcttcctggaggtggtgtccagcgtggaaatatcctaaat780ctgaatggtgcaggagaccctctcacaccaggttacccagcaaatgaatatgcttatagg840cgtggaattgcagaggctgttggtcttccaagtattcctgttcatccaattggatactat900gatgcacagaagctcctagaaaaaatgggtggctcagcaccaccagatagcagctggaga960ggaagtctcaaagtgccctacaatgttggacctggctttactggaaacttttctacacaa1020aaagtcaagatgcacatccactctaccaatgaagtgacaagaatttacaatgtgataggt1080actctcagaggagcagtggaaccagacagatatgtcattctgggaggtcaccgggactca1140tgggtgtttggtggtattgaccctcagagtggagcagctgttgttcatgaaattgtgagg1200agctttggaacactgaaaaaggaagggtggagacctagaagaacaattttgtttgcaagc1260tgggatgcagaagaatttggtcttcttggttctactgagtgggcagaggagaattcaaga1320ctccttcaagagcgtggcgtggcttatattaatgctgactcatctatagaaggaaactac1380actctgagagttgattgtacaccgctgatgtacagcttggtacacaacctaacaaaagag1440ctgaaaagccctgatgaaggctttgaaggcaaatctctttatgaaagttggactaaaaaa1500agtccttccccagagttcagtggcatgcccaggataagcaaattgggatctggaaatgat1560tttgaggtgttcttccaacgacttggaattgcttcaggcagagcacggtatactaaaaat1620tgggaaacaaacaaattcagcggctatccactgtatcacagtgtctatgaaacatatgag1680ttggtggaaaagttttatgatccaatgtttaaatatcacctcactgtggcccaggttcga1740ggagggatggtgtttgagctagccaattccatagtgctcccttttgattgtcgagattat1800gctgtagttttaagaaagtatgctgacaaaatctacagtatttctatgaaacatccacag1860gaaatgaagacatacagtgtatcatttgattcacttttttctgcagtaaagaattttaca1920gaaattgcttccaagttcagtgagagactccaggactttgacaaaagcaacccaatagta1980ttaagaatgatgaatgatcaactcatgtttctggaaagagcatttattgatccattaggg2040ttaccagacaggcctttttataggcatgtcatctatgctccaagcagccacaacaagtat2100gcaggggagtcattcccaggaatttatgatgctctgtttgatattgaaagcaaagtggac2160ccttccaaggcctggggagaagtgaagagacagatttatgttgcagccttcacagtgcag2220gcagctgcagagactttgagtgaagtagcctaa2253<210>65<211>80<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer29<400>65ggggcgctggtgctggcgggtggcttctttctcctcggcttcctcttcgggtggtttata60aaatcctccaatgaagctac80<210>66<211>28<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer30<400>66gcggccgcttaggctacttcactcaaag28<210>67<211>60<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer31<400>67ggctgtggccaccgcgcgccgcccgcgctggctgtgcgctggggcgctggtgctggcggg60<210>68<211>59<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer32<400>68actagtcgtcatgtggaatctccttcacgaaaccgactcggctgtggccaccgcgcgcc59<210>69<211>144<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh<400>69metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140<210>70<211>7<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_hcdr1<400>70serlyssersertyrtrpgly15<210>71<211>16<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_hcdr2<400>71seriletyrtyrserglyserthrphetyrasnproserleulysser151015<210>72<211>8<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_hcdr3<400>72leuthrvalalaglupheasptyr15<210>73<211>128<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vl<400>73metglualaproalaglnleuleupheleuleuleuleutrpleupro151015aspthrthrglygluilevalleuthrglnserproalathrleuser202530leuserproglygluargalathrleusercysargalaserglnser354045valserserpheleualatrptyrglnglnlysproglyglnalapro505560argleuleuiletyraspalaserasnargalathrglyileproala65707580argpheserglyserglyserglythraspphethrleuthrileser859095serleugluprogluaspphealavaltyrtyrcysglnglnargser100105110asntrpproleuthrpheglyproglythrlysvalaspilelysarg115120125<210>74<211>11<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_lcdr1<400>74argalaserglnservalserserpheleuala1510<210>75<211>7<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_lcdr2<400>75aspalaserasnargalathr15<210>76<211>9<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_lcdr3<400>76glnglnargserasntrpproleuthr15<210>77<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi134_vh<400>77metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahisserglnvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnasnglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileser859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>78<211>5<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi134pi143pi105pi127pi108pi115pl223pn7pi101pi118_hcdr1<400>78thrtyraspileasn15<210>79<211>17<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi134pi143pi105pi127pi108pi115pl223_hcdr2<400>79trpmetasnproasnasnglytyrthrglytyralaglnlysphegln151015gly<210>80<211>10<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi134pi143pi105pi127pi108pi115pl223pi101pi118_hcdr3<400>80thrasntrpvaltyrtrptyrpheaspleu1510<210>81<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi101_vh<400>81metglyserthralaileleualaleuleuleualavalleuglngly151015valcyssergluvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrasnleu354045alathrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnserglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargaspthrserileasn859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>82<211>17<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi101pn7pi118_hcdr2<400>82trpmetasnproasnserglytyrthrglytyralaglnlysphegln151015gly<210>83<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn7_vh<400>83metglupheglyleusertrpvalpheleuvalalaileleulysgly151015valglncysgluvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnserglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargaspthrserileser859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpglusertrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>84<211>10<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn7_hcdr3<400>84thrasntrpglusertrptyrpheaspleu1510<210>85<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi105_vh<400>85metglyserthralaileleualaleuleuleualavalleuglngly151015valcyssergluvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrasnleu354045alathrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnserglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargaspthrserileasn859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>86<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi108_vh<400>86metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahisserglnvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnasnglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileser859095thralatyrmetgluleuthrserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>87<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi115_vh<400>87metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahissergluvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnasnglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileser859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>88<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi118_vh<400>88metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahisserglnvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrasnleu354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnserglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileasp859095thralatyrmetgluleuserasnleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>89<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi127_vh<400>89metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahisserglnvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpleuglytrpmetasnproasnasnglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserilegly859095thralatyrmetgluleuasnserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrleuvalthrvalserser130135<210>90<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi143_vh<400>90metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahisserglnvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnasnglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileser859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrthrvalthrvalserser130135<210>91<211>138<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpl223_vh<400>91metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahissergluvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrphe354045thrthrtyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnasnglytyrthrglytyrala65707580glnlyspheglnglyargvalthrmetthrargasnthrserileser859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrp115120125glyargglythrmetvalthrvalserser130135<210>92<211>2214<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofn_flag-psma_ecd<400>92atgagggtccccgctcagctcctggggctcctgctgctctggctcccaggtgcacgatgt60gactacaaggacgacgatgacaagactagtaaatcctccaatgaagctactaacattact120ccaaagcataatatgaaagcatttttggatgaattgaaagctgagaacatcaagaagttc180ttatataattttacacagataccacatttagcaggaacagaacaaaactttcagcttgca240aagcaaattcaatcccagtggaaagaatttggcctggattctgttgagctagcacattat300gatgtcctgttgtcctacccaaataagactcatcccaactacatctcaataattaatgaa360gatggaaatgagattttcaacacatcattatttgaaccacctcctccaggatatgaaaat420gtttcggatattgtaccacctttcagtgctttctctcctcaaggaatgccagagggcgat480ctagtgtatgttaactatgcacgaactgaagacttctttaaattggaacgggacatgaaa540atcaattgctctgggaaaattgtaattgccagatatgggaaagttttcagaggaaataag600gttaaaaatgcccagctggcaggggccaaaggagtcattctctactccgaccctgctgac660tactttgctcctggggtgaagtcctatccagatggttggaatcttcctggaggtggtgtc720cagcgtggaaatatcctaaatctgaatggtgcaggagaccctctcacaccaggttaccca780gcaaatgaatatgcttataggcgtggaattgcagaggctgttggtcttccaagtattcct840gttcatccaattggatactatgatgcacagaagctcctagaaaaaatgggtggctcagca900ccaccagatagcagctggagaggaagtctcaaagtgccctacaatgttggacctggcttt960actggaaacttttctacacaaaaagtcaagatgcacatccactctaccaatgaagtgaca1020agaatttacaatgtgataggtactctcagaggagcagtggaaccagacagatatgtcatt1080ctgggaggtcaccgggactcatgggtgtttggtggtattgaccctcagagtggagcagct1140gttgttcatgaaattgtgaggagctttggaacactgaaaaaggaagggtggagacctaga1200agaacaattttgtttgcaagctgggatgcagaagaatttggtcttcttggttctactgag1260tgggcagaggagaattcaagactccttcaagagcgtggcgtggcttatattaatgctgac1320tcatctatagaaggaaactacactctgagagttgattgtacaccgctgatgtacagcttg1380gtacacaacctaacaaaagagctgaaaagccctgatgaaggctttgaaggcaaatctctt1440tatgaaagttggactaaaaaaagtccttccccagagttcagtggcatgcccaggataagc1500aaattgggatctggaaatgattttgaggtgttcttccaacgacttggaattgcttcaggc1560agagcacggtatactaaaaattgggaaacaaacaaattcagcggctatccactgtatcac1620agtgtctatgaaacatatgagttggtggaaaagttttatgatccaatgtttaaatatcac1680ctcactgtggcccaggttcgaggagggatggtgtttgagctagccaattccatagtgctc1740ccttttgattgtcgagattatgctgtagttttaagaaagtatgctgacaaaatctacagt1800atttctatgaaacatccacaggaaatgaagacatacagtgtatcatttgattcacttttt1860tctgcagtaaagaattttacagaaattgcttccaagttcagtgagagactccaggacttt1920gacaaaagcaacccaatagtattaagaatgatgaatgatcaactcatgtttctggaaaga1980gcatttattgatccattagggttaccagacaggcctttttataggcatgtcatctatgct2040ccaagcagccacaacaagtatgcaggggagtcattcccaggaatttatgatgctctgttt2100gatattgaaagcaaagtggacccttccaaggcctggggagaagtgaagagacagatttat2160gttgcagccttcacagtgcaggcagctgcagagactttgagtgaagtagcctaa2214<210>93<211>98<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofigg4_ch1_linker<400>93alaserthrlysglyproservalpheproleualaprocysserarg151015serthrsergluserthralaalaleuglycysleuvallysasptyr202530pheprogluprovalthrvalsertrpasnserglyalaleuthrser354045glyvalhisthrpheproalavalleuglnserserglyleutyrser505560leuserservalvalthrvalproserserserleuglythrlysthr65707580tyrthrcysasnvalasphislysproserasnthrlysvalasplys859095argval<210>94<211>420<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpn170_vh<400>94atggactggacctggaggatcctcttcttggtggcagcagccacaggtgcccactccgag60gtccagctggtacagtctggggctgaggtgaagaagcctggggcctcagtgaaggtctcc120tgcaaggcttctggatacaccctcaccagttatgatatcaattgggtgcgacaggccact180ggacaagggcttgagtggatgggatggatgaaccctaacagtggttacacaggctatgca240cagaagttccaggacagagtcaccatgaccaggaacaccgccataaacacagcctacatg300gagctgagcagcctgagatctgaggacacggccgtgtattactgtgcgagagaggcgggt360tacgatggtatctggtacttcgatctctggggccgtggcaccctggtcactgtctcctca420<210>95<211>140<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn170_vh<400>95metasptrpthrtrpargileleupheleuvalalaalaalathrgly151015alahissergluvalglnleuvalglnserglyalagluvallyslys202530proglyalaservallysvalsercyslysalaserglytyrthrleu354045thrsertyraspileasntrpvalargglnalathrglyglnglyleu505560glutrpmetglytrpmetasnproasnserglytyrthrglytyrala65707580glnlyspheglnaspargvalthrmetthrargasnthralaileasn859095thralatyrmetgluleuserserleuargsergluaspthralaval100105110tyrtyrcysalaargglualaglytyraspglyiletrptyrpheasp115120125leutrpglyargglythrleuvalthrvalserser130135140<210>96<211>5<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn170_hcdr1<400>96sertyraspileasn15<210>97<211>17<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn170_hcdr2<400>97trpmetasnproasnserglytyrthrglytyralaglnlysphegln151015asp<210>98<211>12<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn170_hcdr3<400>98glualaglytyraspglyiletrptyrpheaspleu1510<210>99<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi134_vh<400>99metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalglnvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileserthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>100<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi101_vh<400>100metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalgluvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrasnleuala260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnserglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargaspthrserileasnthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>101<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi105_vh<400>101metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalgluvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpleuglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileglythr305310315320alatyrmetgluleuasnserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>102<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi108_vh<400>102metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalglnvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileserthr305310315320alatyrmetgluleuthrserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>103<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi115_vh<400>103metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalgluvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileserthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>104<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi118_vh<400>104metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalglnvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrasnleuthr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnserglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileaspthr305310315320alatyrmetgluleuserasnleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>105<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi127_vh<400>105metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalglnvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpleuglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileglythr305310315320alatyrmetgluleuasnserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>106<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi143_vh<400>106metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalglnvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileserthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrthrvalthrvalserser355360<210>107<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pl223_vh<400>107metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalgluvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnasnglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargasnthrserileserthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpvaltyrtrptyrpheaspleutrpgly340345350argglythrmetvalthrvalserser355360<210>108<211>361<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pn7_vh<400>108metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalgluvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrphethr260265270thrtyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnserglytyrthrglytyralagln290295300lyspheglnglyargvalthrmetthrargaspthrserileserthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargthrasntrpglusertrptyrpheaspleutrpgly340345350argglythrleuvalthrvalserser355360<210>109<211>363<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pn170_vh<400>109metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysserarg145150155160serthrsergluserthralaalaleuglycysleuvallysasptyr165170175pheprogluprovalthrvalsertrpasnserglyalaleuthrser180185190glyvalhisthrpheproalavalleuglnserserglyleutyrser195200205leuserservalvalthrvalproserserserleuglythrlysthr210215220tyrthrcysasnvalasphislysproserasnthrlysvalasplys225230235240argvalgluvalglnleuvalglnserglyalagluvallyslyspro245250255glyalaservallysvalsercyslysalaserglytyrthrleuthr260265270sertyraspileasntrpvalargglnalathrglyglnglyleuglu275280285trpmetglytrpmetasnproasnserglytyrthrglytyralagln290295300lyspheglnaspargvalthrmetthrargasnthralaileasnthr305310315320alatyrmetgluleuserserleuargsergluaspthralavaltyr325330335tyrcysalaargglualaglytyraspglyiletrptyrpheaspleu340345350trpglyargglythrleuvalthrvalserser355360<210>110<211>277<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-gl-pi134_vh<400>110metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140alaserthrlysglyproservalpheproleualaprocysglnval145150155160glnleuvalglnserglyalagluvallyslysproglyalaserval165170175lysvalsercyslysalaserglytyrthrphethrthrtyraspile180185190asntrpvalargglnalathrglyglnglyleuglutrpmetglytrp195200205metasnproasnasnglytyrthrglytyralaglnlyspheglngly210215220argvalthrmetthrargasnthrserileserthralatyrmetglu225230235240leuserserleuargsergluaspthralavaltyrtyrcysalaarg245250255thrasntrpvaltyrtrptyrpheaspleutrpglyargglythrleu260265270valthrvalserser275<210>111<211>277<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ml-pi101_vh<400>111metaspleumetcyslyslysmetlyshisleutrpphepheleuleu151015leuvalalaalaproargtrpvalleuserglnleuglnleuglnglu202530serglyproglyleuvallysprosergluthrleuserleuthrcys354045thrvalserglyglyserileileserlyssersertyrtrpglytrp505560ileargglnproproglylysglyleuglutrpileglyseriletyr65707580tyrserglyserthrphetyrasnproserleulysserargvalthr859095ileservalaspthrserlysasnglnpheserleulysleuserser100105110valthralaalaaspthralavaltyrtyrcysalaargleuthrval115120125alaglupheasptyrtrpglyglnglythrleuvalthrvalserser130135140glyseralaseralaprothrleupheproleuvalsercysgluval145150155160glnleuvalglnserglyalagluvallyslysproglyalaserval165170175lysvalsercyslysalaserglytyrasnleualathrtyraspile180185190asntrpvalargglnalathrglyglnglyleuglutrpmetglytrp195200205metasnproasnserglytyrthrglytyralaglnlyspheglngly210215220argvalthrmetthrargaspthrserileasnthralatyrmetglu225230235240leuserserleuargsergluaspthralavaltyrtyrcysalaarg245250255thrasntrpvaltyrtrptyrpheaspleutrpglyargglythrleu260265270valthrvalserser275<210>112<211>750<212>prt<213>homosapiens<400>112mettrpasnleuleuhisgluthraspseralavalalathralaarg151015argproargtrpleucysalaglyalaleuvalleualaglyglyphe202530pheleuleuglypheleupheglytrppheilelysserserasnglu354045alathrasnilethrprolyshisasnmetlysalapheleuaspglu505560leulysalagluasnilelyslyspheleutyrasnphethrglnile65707580prohisleualaglythrgluglnasnpheglnleualalysglnile859095glnserglntrplysglupheglyleuaspservalgluleualahis100105110tyraspvalleuleusertyrproasnlysthrhisproasntyrile115120125serileileasngluaspglyasngluilepheasnthrserleuphe130135140gluproproproproglytyrgluasnvalseraspilevalpropro145150155160pheseralapheserproglnglymetprogluglyaspleuvaltyr165170175valasntyralaargthrgluaspphephelysleugluargaspmet180185190lysileasncysserglylysilevalilealaargtyrglylysval195200205pheargglyasnlysvallysasnalaglnleualaglyalalysgly210215220valileleutyrseraspproalaasptyrphealaproglyvallys225230235240sertyrproaspglytrpasnleuproglyglyglyvalglnarggly245250255asnileleuasnleuasnglyalaglyaspproleuthrproglytyr260265270proalaasnglutyralatyrargargglyilealaglualavalgly275280285leuproserileprovalhisproileglytyrtyraspalaglnlys290295300leuleuglulysmetglyglyseralaproproaspsersertrparg305310315320glyserleulysvalprotyrasnvalglyproglyphethrglyasn325330335pheserthrglnlysvallysmethisilehisserthrasngluval340345350thrargiletyrasnvalileglythrleuargglyalavalglupro355360365aspargtyrvalileleuglyglyhisargaspsertrpvalphegly370375380glyileaspproglnserglyalaalavalvalhisgluilevalarg385390395400serpheglythrleulyslysgluglytrpargproargargthrile405410415leuphealasertrpaspalagluglupheglyleuleuglyserthr420425430glutrpalaglugluasnserargleuleuglngluargglyvalala435440445tyrileasnalaaspserserilegluglyasntyrthrleuargval450455460aspcysthrproleumettyrserleuvalhisasnleuthrlysglu465470475480leulysserproaspgluglyphegluglylysserleutyrgluser485490495trpthrlyslysserproserproglupheserglymetproargile500505510serlysleuglyserglyasnaspphegluvalphepheglnargleu515520525glyilealaserglyargalaargtyrthrlysasntrpgluthrasn530535540lyspheserglytyrproleutyrhisservaltyrgluthrtyrglu545550555560leuvalglulysphetyraspprometphelystyrhisleuthrval565570575alaglnvalargglyglymetvalphegluleualaasnserileval580585590leupropheaspcysargasptyralavalvalleuarglystyrala595600605asplysiletyrserilesermetlyshisproglnglumetlysthr610615620tyrservalserpheaspserleupheseralavallysasnphethr625630635640gluilealaserlysphesergluargleuglnasppheasplysser645650655asnproilevalleuargmetmetasnaspglnleumetpheleuglu660665670argalapheileaspproleuglyleuproaspargprophetyrarg675680685hisvaliletyralaproserserhisasnlystyralaglygluser690695700pheproglyiletyraspalaleupheaspilegluserlysvalasp705710715720proserlysalatrpglygluvallysargglniletyrvalalaala725730735phethrvalglnalaalaalagluthrleusergluvalala740745750<210>113<211>737<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofn_flag-hpsma_ecd<400>113metargvalproalaglnleuleuglyleuleuleuleutrpleupro151015glyalaargcysasptyrlysaspaspaspasplysthrserlysser202530serasnglualathrasnilethrprolyshisasnmetlysalaphe354045leuaspgluleulysalagluasnilelyslyspheleutyrasnphe505560thrglnileprohisleualaglythrgluglnasnpheglnleuala65707580lysglnileglnserglntrplysglupheglyleuaspservalglu859095leualahistyraspvalleuleusertyrproasnlysthrhispro100105110asntyrileserileileasngluaspglyasngluilepheasnthr115120125serleuphegluproproproproglytyrgluasnvalseraspile130135140valpropropheseralapheserproglnglymetprogluglyasp145150155160leuvaltyrvalasntyralaargthrgluaspphephelysleuglu165170175argaspmetlysileasncysserglylysilevalilealaargtyr180185190glylysvalpheargglyasnlysvallysasnalaglnleualagly195200205alalysglyvalileleutyrseraspproalaasptyrphealapro210215220glyvallyssertyrproaspglytrpasnleuproglyglyglyval225230235240glnargglyasnileleuasnleuasnglyalaglyaspproleuthr245250255proglytyrproalaasnglutyralatyrargargglyilealaglu260265270alavalglyleuproserileprovalhisproileglytyrtyrasp275280285alaglnlysleuleuglulysmetglyglyseralaproproaspser290295300sertrpargglyserleulysvalprotyrasnvalglyproglyphe305310315320thrglyasnpheserthrglnlysvallysmethisilehisserthr325330335asngluvalthrargiletyrasnvalileglythrleuargglyala340345350valgluproaspargtyrvalileleuglyglyhisargaspsertrp355360365valpheglyglyileaspproglnserglyalaalavalvalhisglu370375380ilevalargserpheglythrleulyslysgluglytrpargproarg385390395400argthrileleuphealasertrpaspalagluglupheglyleuleu405410415glyserthrglutrpalaglugluasnserargleuleuglngluarg420425430glyvalalatyrileasnalaaspserserilegluglyasntyrthr435440445leuargvalaspcysthrproleumettyrserleuvalhisasnleu450455460thrlysgluleulysserproaspgluglyphegluglylysserleu465470475480tyrglusertrpthrlyslysserproserproglupheserglymet485490495proargileserlysleuglyserglyasnaspphegluvalphephe500505510glnargleuglyilealaserglyargalaargtyrthrlysasntrp515520525gluthrasnlyspheserglytyrproleutyrhisservaltyrglu530535540thrtyrgluleuvalglulysphetyraspprometphelystyrhis545550555560leuthrvalalaglnvalargglyglymetvalphegluleualaasn565570575serilevalleupropheaspcysargasptyralavalvalleuarg580585590lystyralaasplysiletyrserilesermetlyshisproglnglu595600605metlysthrtyrservalserpheaspserleupheseralavallys610615620asnphethrgluilealaserlysphesergluargleuglnaspphe625630635640asplysserasnproilevalleuargmetmetasnaspglnleumet645650655pheleugluargalapheileaspproleuglyleuproaspargpro660665670phetyrarghisvaliletyralaproserserhisasnlystyrala675680685glygluserpheproglyiletyraspalaleupheaspilegluser690695700lysvalaspproserlysalatrpglygluvallysargglniletyr705710715720valalaalaphethrvalglnalaalaalagluthrleusergluval725730735ala<210>114<211>126<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofkmda2_vhexcludingsignalsequence<400>114glnvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrsertyr202530lysileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglyasnthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargsertyrglyserglysertyrtyrargasptyrtyrtyrgly100105110metaspvaltrpglyglnglythrthrvalthrvalserser115120125<210>115<211>107<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofkmda2_vlexcludingsignalsequence<400>115gluilevalleuthrglnserproalathrleuserleuserprogly151015gluargalathrleusercysargalaserglnservalsersertyr202530leualatrptyrglnglnlysproglyglnalaproargleuleuile354045tyraspalaserasnargalathrglyileproalaargphesergly505560serglyserglythraspphethrleuthrileserserleuglupro65707580gluaspphealavaltyrtyrcysglnglnargserasntrpproleu859095thrpheglyglyglythrlysvalgluilelys100105<210>116<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceof2a10_vhexcludingsignalsequence<400>116gluvalglnleuvalglnserglyalagluvallyslysproglyglu151015serleulysilesercyslysglyserglytyrserphethrserasn202530trpileglytrpvalargglnmetproglylysglyleuglutrpmet354045glyileiletyrproglyaspseraspthrargtyrserproserphe505560glnglyglnvalthrileseralaasplysserileserthralatyr65707580leuglntrpserserleulysalaseraspthralamettyrtyrcys859095alaargglnthrglypheleutrpserseraspleutrpglyarggly100105110thrleuvalthrvalserser115<210>117<211>106<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceof2a10_vlexcludingsignalsequence<400>117ileglnleuthrglnserproserserleuseralaservalglyasp151015argvalthrilethrcysargalaserglnaspileserseralaleu202530alatrptyrglnglnlysproglylysalaprolysleuleuiletyr354045aspalaserserleugluserglyvalproserargpheserglytyr505560glyserglythraspphethrleuthrileasnserleuglnproglu65707580aspphealathrtyrtyrcysglnglnpheasnsertyrproleuthr859095pheglyglyglythrlysvalgluilelys100105<210>118<211>118<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vhexcludingsignalsequence<400>118glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserser115<210>119<211>108<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vlexcludingsignalsequence<400>119gluilevalleuthrglnserproalathrleuserleuserprogly151015gluargalathrleusercysargalaserglnservalserserphe202530leualatrptyrglnglnlysproglyglnalaproargleuleuile354045tyraspalaserasnargalathrglyileproalaargphesergly505560serglyserglythraspphethrleuthrileserserleuglupro65707580gluaspphealavaltyrtyrcysglnglnargserasntrpproleu859095thrpheglyproglythrlysvalaspilelysarg100105<210>120<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi134_vhexcludingsignalsequence<400>120glnvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnasnglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>121<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi101_vhexcludingsignalsequence<400>121gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrasnleualathrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargaspthrserileasnthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>122<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn7_vhexcludingsignalsequence<400>122gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargaspthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpglusertrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>123<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi105_vhexcludingsignalsequence<400>123gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrasnleualathrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargaspthrserileasnthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>124<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi108_vhexcludingsignalsequence<400>124glnvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnasnglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileserthralatyr65707580metgluleuthrserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>125<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi115_vhexcludingsignalsequence<400>125gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnasnglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>126<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi118_vhexcludingsignalsequence<400>126glnvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrasnleuthrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileaspthralatyr65707580metgluleuserasnleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>127<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi127_vhexcludingsignalsequence<400>127glnvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpleu354045glytrpmetasnproasnasnglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileglythralatyr65707580metgluleuasnserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserser115<210>128<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpi143_vhexcludingsignalsequence<400>128glnvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnasnglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrthrvalthrvalserser115<210>129<211>119<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpl223_vhexcludingsignalsequence<400>129gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnasnglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargasnthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpvaltyrtrptyrpheaspleutrpglyarggly100105110thrmetvalthrvalserser115<210>130<211>121<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofpn170_vhexcludingsignalsequence<400>130gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrleuthrsertyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560glnaspargvalthrmetthrargasnthralaileasnthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargglualaglytyraspglyiletrptyrpheaspleutrpgly100105110argglythrleuvalthrvalserser115120<210>131<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi134_vhexcludingsignalsequence<400>131glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalglnvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>132<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi101_vhexcludingsignalsequence<400>132glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrasnleualathrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285aspthrserileasnthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>133<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi105_vhexcludingsignalsequence<400>133glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpleuglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileglythralatyrmetgluleuasnserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>134<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi108_vhexcludingsignalsequence<400>134glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalglnvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileserthralatyrmetgluleuthrserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>135<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi115_vhexcludingsignalsequence<400>135glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>136<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi118_vhexcludingsignalsequence<400>136glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalglnvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrasnleuthrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileaspthralatyrmetgluleuserasnleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>137<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi127_vhexcludingsignalsequence<400>137glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalglnvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpleuglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileglythralatyrmetgluleuasnserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>138<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pi143_vhexcludingsignalsequence<400>138glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalglnvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrthrvalthrvalserser325330335<210>139<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pl223_vhexcludingsignalsequence<400>139glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnasngly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285asnthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpvaltyrtrp305310315320tyrpheaspleutrpglyargglythrmetvalthrvalserser325330335<210>140<211>335<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pn7_vhexcludingsignalsequence<400>140glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285aspthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpglusertrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserser325330335<210>141<211>337<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ch1-pn170_vhexcludingsignalsequence<400>141glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrleuthrsertyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tyrthrglytyralaglnlyspheglnaspargvalthrmetthrarg275280285asnthralaileasnthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargglualaglytyraspgly305310315320iletrptyrpheaspleutrpglyargglythrleuvalthrvalser325330335ser<210>142<211>251<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-gl-pi134_vhexcludingsignalsequence<400>142glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysglnvalglnleuvalglnserglyalagluvallys130135140lysproglyalaservallysvalsercyslysalaserglytyrthr145150155160phethrthrtyraspileasntrpvalargglnalathrglyglngly165170175leuglutrpmetglytrpmetasnproasnasnglytyrthrglytyr180185190alaglnlyspheglnglyargvalthrmetthrargasnthrserile195200205serthralatyrmetgluleuserserleuargsergluaspthrala210215220valtyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleu225230235240trpglyargglythrleuvalthrvalserser245250<210>143<211>251<212>prt<213>artificial<220><223>descriptionoftheartificialsequence;aminoacidsequenceofe11_vh-ml-pi101_vhexcludingsignalsequence<400>143glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserserglyseralaseralaprothrleuphepro115120125leuvalsercysgluvalglnleuvalglnserglyalagluvallys130135140lysproglyalaservallysvalsercyslysalaserglytyrasn145150155160leualathrtyraspileasntrpvalargglnalathrglyglngly165170175leuglutrpmetglytrpmetasnproasnserglytyrthrglytyr180185190alaglnlyspheglnglyargvalthrmetthrargaspthrserile195200205asnthralatyrmetgluleuserserleuargsergluaspthrala210215220valtyrtyrcysalaargthrasntrpvaltyrtrptyrpheaspleu225230235240trpglyargglythrleuvalthrvalserser245250<210>144<211>37<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer33<400>144tcaccgtctcctcagctagcaccaaaggaccttctgt37<210>145<211>24<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer34<400>145gaccctcttatcaaccttggtgtt24<210>146<211>36<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer35<400>146aaggttgataagagggtcgaagtgcagctggtgcag36<210>147<211>34<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer36<400>147gccccttggtgctagctgaggagacggtgaccag34<210>148<211>33<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer37<400>148cgtctcctcagctagcaccaaggggccatccgt33<210>149<211>79<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer38<400>149aaccgttaacggatcctcagtggtggtggtggtgatgcttatcatcgtcgtctttgtaat60ccggacatggtggacaagg79<210>150<211>1380<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11-ch1-pn7vhf(ab')2<220><221>cds<222>(1)..(1380)<400>150cagctgcagctgcaggagtcgggcccaggactggtgaagccttcggag48glnleuglnleuglngluserglyproglyleuvallysproserglu151015accctgtccctcacctgcactgtctctggtggctccatcatcagtaaa96thrleuserleuthrcysthrvalserglyglyserileileserlys202530agttcctactggggctggattcgccagcccccagggaaggggctggag144sersertyrtrpglytrpileargglnproproglylysglyleuglu354045tggattgggagtatctattatagtgggagtaccttctacaacccgtcc192trpileglyseriletyrtyrserglyserthrphetyrasnproser505560ctcaagagtcgagtcaccatatccgtagacacgtccaagaaccagttc240leulysserargvalthrileservalaspthrserlysasnglnphe65707580tccctgaagctgagctctgtgaccgccgcagacacggctgtgtattac288serleulysleuserservalthralaalaaspthralavaltyrtyr859095tgtgcgagactgacagtggctgagtttgactactggggccagggaacc336cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110ctggtcaccgtctcctcagctagcaccaaaggaccgtctgtatttcct384leuvalthrvalserseralaserthrlysglyproservalphepro115120125cttgcgccatgctctcgctctacgtcagaatcaactgccgctctgggg432leualaprocysserargserthrsergluserthralaalaleugly130135140tgcctggttaaagactacttcccggagcctgtgacagtgagttggaac480cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160tccggcgccctgacatcaggagtgcatacatttcccgccgtgcttcag528serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175agcagcggactttatagcctcagcagtgtggtgaccgtgccatcttcc576serserglyleutyrserleuserservalvalthrvalproserser180185190agcctggggaccaagacctacacctgtaacgtggaccacaaacccagc624serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205aacaccaaggttgataagagggtcgaagtgcagctggtgcagtccgga672asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220gctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggct720alagluvallyslysproglyalaservallysvalsercyslysala225230235240tctggttacacctttaccacttatgatatcaactgggtgcgacaggcc768serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255actggacaagggcttgagtggatgggatggatgaaccctaacagtggt816thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tacacaggctatgcacagaagttccagggcagagtcaccatgaccagg864tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285gacacctccataagcacagcctacatggagctgagcagcctgagatct912aspthrserileserthralatyrmetgluleuserserleuargser290295300gaggacacggccgtgtattactgtgcgcggacgaactgggaatcctgg960gluaspthralavaltyrtyrcysalaargthrasntrpglusertrp305310315320tacttcgatctctggggccgtggaaccctggtcaccgtctcctcagct1008tyrpheaspleutrpglyargglythrleuvalthrvalserserala325330335agcaccaaggggccatccgtgttccctcttgccccatgctctaggtct1056serthrlysglyproservalpheproleualaprocysserargser340345350accagcgaatctactgccgctcttggttgtcttgtcaaagactacttc1104thrsergluserthralaalaleuglycysleuvallysasptyrphe355360365ccggaacctgtcacagtcagctggaatagtggcgctttgacctctggt1152progluprovalthrvalsertrpasnserglyalaleuthrsergly370375380gtccacacttttcccgcggttctgcagtcctcaggcctgtatagcctg1200valhisthrpheproalavalleuglnserserglyleutyrserleu385390395400agttccgtggtgaccgttccttcttctagcctggggacgaaaacgtac1248serservalvalthrvalproserserserleuglythrlysthrtyr405410415acctgtaatgtggatcacaaacccagcaatacaaaggttgacaagcgc1296thrcysasnvalasphislysproserasnthrlysvalasplysarg420425430gtagagagtaagtatggacctccttgtccaccatgtccggattacaaa1344valgluserlystyrglyproprocysproprocysproasptyrlys435440445gacgacgatgataagcatcaccaccaccaccactga1380aspaspaspasplyshishishishishishis450455<210>151<211>459<212>prt<213>artificial<220><223>syntheticconstruct<400>151glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285aspthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpglusertrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserserala325330335serthrlysglyproservalpheproleualaprocysserargser340345350thrsergluserthralaalaleuglycysleuvallysasptyrphe355360365progluprovalthrvalsertrpasnserglyalaleuthrsergly370375380valhisthrpheproalavalleuglnserserglyleutyrserleu385390395400serservalvalthrvalproserserserleuglythrlysthrtyr405410415thrcysasnvalasphislysproserasnthrlysvalasplysarg420425430valgluserlystyrglyproprocysproprocysproasptyrlys435440445aspaspaspasplyshishishishishishis450455<210>152<211>79<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;primer39<400>152aaccgttaacggatcctcagtggtggtggtggtggtgtttgtcgtcgtcgtctttgtagt60caactctcttgtccacctt79<210>153<211>1344<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11-ch1-pn7vhfab<220><221>cds<222>(1)..(1344)<400>153cagctgcagctgcaggagtcgggcccaggactggtgaagccttcggag48glnleuglnleuglngluserglyproglyleuvallysproserglu151015accctgtccctcacctgcactgtctctggtggctccatcatcagtaaa96thrleuserleuthrcysthrvalserglyglyserileileserlys202530agttcctactggggctggattcgccagcccccagggaaggggctggag144sersertyrtrpglytrpileargglnproproglylysglyleuglu354045tggattgggagtatctattatagtgggagtaccttctacaacccgtcc192trpileglyseriletyrtyrserglyserthrphetyrasnproser505560ctcaagagtcgagtcaccatatccgtagacacgtccaagaaccagttc240leulysserargvalthrileservalaspthrserlysasnglnphe65707580tccctgaagctgagctctgtgaccgccgcagacacggctgtgtattac288serleulysleuserservalthralaalaaspthralavaltyrtyr859095tgtgcgagactgacagtggctgagtttgactactggggccagggaacc336cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110ctggtcaccgtctcctcagctagcaccaaaggaccttctgtatttcct384leuvalthrvalserseralaserthrlysglyproservalphepro115120125cttgcgccatgctctcgctctacgtcagaatcaactgccgctctgggg432leualaprocysserargserthrsergluserthralaalaleugly130135140tgcctggttaaagactacttcccggagcctgtgacagtgagttggaac480cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160tccggcgccctgacatcaggagtgcatacatttcccgccgtgcttcag528serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175agcagcggactttatagcctcagcagtgtggtgaccgtgccatcttcc576serserglyleutyrserleuserservalvalthrvalproserser180185190agcctggggaccaagacctacacctgtaacgtggaccacaaacccagc624serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205aacaccaaggttgataagagggtcgaagtgcagctggtgcagtccgga672asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220gctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggct720alagluvallyslysproglyalaservallysvalsercyslysala225230235240tctggttacacctttaccacttatgatatcaactgggtgcgacaggcc768serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255actggacaagggcttgagtggatgggatggatgaaccctaacagtggt816thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tacacaggctatgcacagaagttccagggcagagtcaccatgaccagg864tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285gacacctccataagcacagcctacatggagctgagcagcctgagatct912aspthrserileserthralatyrmetgluleuserserleuargser290295300gaggacacggccgtgtattactgtgcgcggacgaactgggaatcctgg960gluaspthralavaltyrtyrcysalaargthrasntrpglusertrp305310315320tacttcgatctctggggccgtggaaccctggtcaccgtctcctcagct1008tyrpheaspleutrpglyargglythrleuvalthrvalserserala325330335agcaccaaggggccatccgtcttccccctggcgccctgctccaggagc1056serthrlysglyproservalpheproleualaprocysserargser340345350acctccgagagcacagccgccctgggctgcctggtcaaggactacttc1104thrsergluserthralaalaleuglycysleuvallysasptyrphe355360365cccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggc1152progluprovalthrvalsertrpasnserglyalaleuthrsergly370375380gtgcacaccttcccggctgtcctacagtcctcaggactctactccctc1200valhisthrpheproalavalleuglnserserglyleutyrserleu385390395400agcagcgtggtgaccgtgccctccagcagcttgggcacgaagacctac1248serservalvalthrvalproserserserleuglythrlysthrtyr405410415acctgcaacgtagatcacaagcccagcaacaccaaggtggacaagaga1296thrcysasnvalasphislysproserasnthrlysvalasplysarg420425430gttgactacaaagacgacgacgacaaacaccaccaccaccaccactga1344valasptyrlysaspaspaspasplyshishishishishishis435440445<210>154<211>447<212>prt<213>artificial<220><223>syntheticconstruct<400>154glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaprocysserargserthrsergluserthralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrlysthrtyrthrcysasnvalasphislysproser195200205asnthrlysvalasplysargvalgluvalglnleuvalglnsergly210215220alagluvallyslysproglyalaservallysvalsercyslysala225230235240serglytyrthrphethrthrtyraspileasntrpvalargglnala245250255thrglyglnglyleuglutrpmetglytrpmetasnproasnsergly260265270tyrthrglytyralaglnlyspheglnglyargvalthrmetthrarg275280285aspthrserileserthralatyrmetgluleuserserleuargser290295300gluaspthralavaltyrtyrcysalaargthrasntrpglusertrp305310315320tyrpheaspleutrpglyargglythrleuvalthrvalserserala325330335serthrlysglyproservalpheproleualaprocysserargser340345350thrsergluserthralaalaleuglycysleuvallysasptyrphe355360365progluprovalthrvalsertrpasnserglyalaleuthrsergly370375380valhisthrpheproalavalleuglnserserglyleutyrserleu385390395400serservalvalthrvalproserserserleuglythrlysthrtyr405410415thrcysasnvalasphislysproserasnthrlysvalasplysarg420425430valasptyrlysaspaspaspasplyshishishishishishis435440445<210>155<211>1347<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofe11k409r<220><221>cds<222>(1)..(1347)<400>155cagctgcagctgcaggagtcgggcccaggactggtgaagccttcggag48glnleuglnleuglngluserglyproglyleuvallysproserglu151015accctgtccctcacctgcactgtctctggtggctccatcatcagtaaa96thrleuserleuthrcysthrvalserglyglyserileileserlys202530agttcctactggggctggattcgccagcccccagggaaggggctggag144sersertyrtrpglytrpileargglnproproglylysglyleuglu354045tggattgggagtatctattatagtgggagtaccttctacaacccgtcc192trpileglyseriletyrtyrserglyserthrphetyrasnproser505560ctcaagagtcgagtcaccatatccgtagacacgtccaagaaccagttc240leulysserargvalthrileservalaspthrserlysasnglnphe65707580tccctgaagctgagctctgtgaccgccgcagacacggctgtgtattac288serleulysleuserservalthralaalaaspthralavaltyrtyr859095tgtgcgagactgacagtggctgagtttgactactggggccagggaacc336cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110ctggtcaccgtctcctcagctagcaccaagggcccatcggtcttcccc384leuvalthrvalserseralaserthrlysglyproservalphepro115120125ctggcaccctcctccaagagcacctctgggggcacagcggccctgggc432leualaproserserlysserthrserglyglythralaalaleugly130135140tgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaac480cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160tcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacag528serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175tcctcaggactctactccctcagcagcgtggtgaccgtgccctccagc576serserglyleutyrserleuserservalvalthrvalproserser180185190agcttgggcacccagacctacatctgcaacgtgaatcacaagcccagc624serleuglythrglnthrtyrilecysasnvalasnhislysproser195200205aacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaact672asnthrlysvalasplyslysvalgluprolyssercysasplysthr210215220cacacatgcccaccgtgcccagcacctgaactcctggggggaccgtca720histhrcysproprocysproalaprogluleuleuglyglyproser225230235240gtcttcctcttccccccaaaacccaaggacaccctcatgatctcccgg768valpheleupheproprolysprolysaspthrleumetileserarg245250255acccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccct816thrprogluvalthrcysvalvalvalaspvalserhisgluasppro260265270gaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgcc864gluvallyspheasntrptyrvalaspglyvalgluvalhisasnala275280285aagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtc912lysthrlysproargglugluglntyrasnserthrtyrargvalval290295300agcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtac960servalleuthrvalleuhisglnasptrpleuasnglylysglutyr305310315320aagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaacc1008lyscyslysvalserasnlysalaleuproalaproileglulysthr325330335atctccaaagccaaagggcagccccgagaaccacaggtgtacaccctg1056ileserlysalalysglyglnproarggluproglnvaltyrthrleu340345350cccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgc1104proproserargaspgluleuthrlysasnglnvalserleuthrcys355360365ctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagc1152leuvallysglyphetyrproseraspilealavalglutrpgluser370375380aatgggcagccggagaacaactacaagaccacgcctcccgtgctggac1200asnglyglnprogluasnasntyrlysthrthrproprovalleuasp385390395400tccgacggctccttcttcctctacagcaggctcaccgtggacaagagc1248seraspglyserphepheleutyrserargleuthrvalasplysser405410415aggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggct1296argtrpglnglnglyasnvalphesercysservalmethisgluala420425430ctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa1344leuhisasnhistyrthrglnlysserleuserleuserproglylys435440445tga1347<210>156<211>448<212>prt<213>artificial<220><223>syntheticconstruct<400>156glnleuglnleuglngluserglyproglyleuvallysproserglu151015thrleuserleuthrcysthrvalserglyglyserileileserlys202530sersertyrtrpglytrpileargglnproproglylysglyleuglu354045trpileglyseriletyrtyrserglyserthrphetyrasnproser505560leulysserargvalthrileservalaspthrserlysasnglnphe65707580serleulysleuserservalthralaalaaspthralavaltyrtyr859095cysalaargleuthrvalalaglupheasptyrtrpglyglnglythr100105110leuvalthrvalserseralaserthrlysglyproservalphepro115120125leualaproserserlysserthrserglyglythralaalaleugly130135140cysleuvallysasptyrpheprogluprovalthrvalsertrpasn145150155160serglyalaleuthrserglyvalhisthrpheproalavalleugln165170175serserglyleutyrserleuserservalvalthrvalproserser180185190serleuglythrglnthrtyrilecysasnvalasnhislysproser195200205asnthrlysvalasplyslysvalgluprolyssercysasplysthr210215220histhrcysproprocysproalaprogluleuleuglyglyproser225230235240valpheleupheproprolysprolysaspthrleumetileserarg245250255thrprogluvalthrcysvalvalvalaspvalserhisgluasppro260265270gluvallyspheasntrptyrvalaspglyvalgluvalhisasnala275280285lysthrlysproargglugluglntyrasnserthrtyrargvalval290295300servalleuthrvalleuhisglnasptrpleuasnglylysglutyr305310315320lyscyslysvalserasnlysalaleuproalaproileglulysthr325330335ileserlysalalysglyglnproarggluproglnvaltyrthrleu340345350proproserargaspgluleuthrlysasnglnvalserleuthrcys355360365leuvallysglyphetyrproseraspilealavalglutrpgluser370375380asnglyglnprogluasnasntyrlysthrthrproprovalleuasp385390395400seraspglyserphepheleutyrserargleuthrvalasplysser405410415argtrpglnglnglyasnvalphesercysservalmethisgluala420425430leuhisasnhistyrthrglnlysserleuserleuserproglylys435440445<210>157<211>1350<212>dna<213>artificial<220><223>descriptionoftheartificialsequence;nucleotidesequenceofpn7f405l<220><221>cds<222>(1)..(1350)<400>157gaagtgcagctggtgcagtccggagctgaggtgaagaagcctggggcc48gluvalglnleuvalglnserglyalagluvallyslysproglyala151015tcagtgaaggtctcctgcaaggcttctggttacacctttaccacttat96servallysvalsercyslysalaserglytyrthrphethrthrtyr202530gatatcaactgggtgcgacaggccactggacaagggcttgagtggatg144aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045ggatggatgaaccctaacagtggttacacaggctatgcacagaagttc192glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560cagggcagagtcaccatgaccagggacacctccataagcacagcctac240glnglyargvalthrmetthrargaspthrserileserthralatyr65707580atggagctgagcagcctgagatctgaggacacggccgtgtattactgt288metgluleuserserleuargsergluaspthralavaltyrtyrcys859095gcgcggacgaactgggaatcctggtacttcgatctctggggccgtgga336alaargthrasntrpglusertrptyrpheaspleutrpglyarggly100105110accctggtcaccgtctcctcagctagcaccaagggcccatcggtcttc384thrleuvalthrvalserseralaserthrlysglyproservalphe115120125cccctggcaccctcctccaagagcacctctgggggcacagcggccctg432proleualaproserserlysserthrserglyglythralaalaleu130135140ggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtgg480glycysleuvallysasptyrpheprogluprovalthrvalsertrp145150155160aactcaggcgccctgaccagcggcgtgcacaccttcccggctgtccta528asnserglyalaleuthrserglyvalhisthrpheproalavalleu165170175cagtcctcaggactctactccctcagcagcgtggtgaccgtgccctcc576glnserserglyleutyrserleuserservalvalthrvalproser180185190agcagcttgggcacccagacctacatctgcaacgtgaatcacaagccc624serserleuglythrglnthrtyrilecysasnvalasnhislyspro195200205agcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaa672serasnthrlysvalasplyslysvalgluprolyssercysasplys210215220actcacacatgcccaccgtgcccagcacctgaactcctggggggaccg720thrhisthrcysproprocysproalaprogluleuleuglyglypro225230235240tcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcc768servalpheleupheproprolysprolysaspthrleumetileser245250255cggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagac816argthrprogluvalthrcysvalvalvalaspvalserhisgluasp260265270cctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataat864progluvallyspheasntrptyrvalaspglyvalgluvalhisasn275280285gccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtg912alalysthrlysproargglugluglntyrasnserthrtyrargval290295300gtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggag960valservalleuthrvalleuhisglnasptrpleuasnglylysglu305310315320tacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaa1008tyrlyscyslysvalserasnlysalaleuproalaproileglulys325330335accatctccaaagccaaagggcagccccgagaaccacaggtgtacacc1056thrileserlysalalysglyglnproarggluproglnvaltyrthr340345350ctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacc1104leuproproserargaspgluleuthrlysasnglnvalserleuthr355360365tgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggag1152cysleuvallysglyphetyrproseraspilealavalglutrpglu370375380agcaatgggcagccggagaacaactacaagaccacgcctcccgtgctg1200serasnglyglnprogluasnasntyrlysthrthrproprovalleu385390395400gactccgacggctccttcttgctctacagcaagctcaccgtggacaag1248aspseraspglyserpheleuleutyrserlysleuthrvalasplys405410415agcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgag1296serargtrpglnglnglyasnvalphesercysservalmethisglu420425430gctctgcacaaccactacacgcagaagagcctctccctgtctccgggt1344alaleuhisasnhistyrthrglnlysserleuserleuserprogly435440445aaatga1350lys<210>158<211>449<212>prt<213>artificial<220><223>syntheticconstruct<400>158gluvalglnleuvalglnserglyalagluvallyslysproglyala151015servallysvalsercyslysalaserglytyrthrphethrthrtyr202530aspileasntrpvalargglnalathrglyglnglyleuglutrpmet354045glytrpmetasnproasnserglytyrthrglytyralaglnlysphe505560glnglyargvalthrmetthrargaspthrserileserthralatyr65707580metgluleuserserleuargsergluaspthralavaltyrtyrcys859095alaargthrasntrpglusertrptyrpheaspleutrpglyarggly100105110thrleuvalthrvalserseralaserthrlysglyproservalphe115120125proleualaproserserlysserthrserglyglythralaalaleu130135140glycysleuvallysasptyrpheprogluprovalthrvalsertrp145150155160asnserglyalaleuthrserglyvalhisthrpheproalavalleu165170175glnserserglyleutyrserleuserservalvalthrvalproser180185190serserleuglythrglnthrtyrilecysasnvalasnhislyspro195200205serasnthrlysvalasplyslysvalgluprolyssercysasplys210215220thrhisthrcysproprocysproalaprogluleuleuglyglypro225230235240servalpheleupheproprolysprolysaspthrleumetileser245250255argthrprogluvalthrcysvalvalvalaspvalserhisgluasp260265270progluvallyspheasntrptyrvalaspglyvalgluvalhisasn275280285alalysthrlysproargglugluglntyrasnserthrtyrargval290295300valservalleuthrvalleuhisglnasptrpleuasnglylysglu305310315320tyrlyscyslysvalserasnlysalaleuproalaproileglulys325330335thrileserlysalalysglyglnproarggluproglnvaltyrthr340345350leuproproserargaspgluleuthrlysasnglnvalserleuthr355360365cysleuvallysglyphetyrproseraspilealavalglutrpglu370375380serasnglyglnprogluasnasntyrlysthrthrproprovalleu385390395400aspseraspglyserpheleuleutyrserlysleuthrvalasplys405410415serargtrpglnglnglyasnvalphesercysservalmethisglu420425430alaleuhisasnhistyrthrglnlysserleuserleuserprogly435440445lys当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 用于治疗HBV感染和相关病症的三特异性结合分子的制造方法与工艺
- 对磺胺类药物具有特异性的固相微萃取纤维的制备方法与流程
- 一种检测猪初乳中抗PEDV特异性IgA抗体的夹心ELISA试剂盒的制造方法与工艺
- 用于施用CD19xCD3双特异性抗体的给药方案的制造方法与工艺
- 双特异性抗‑VEGF/抗‑ANG‑2抗体及其在治疗眼血管疾病中的应用的制造方法与工艺
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 双特异性四价抗体及其制造和使用方法与制造工艺
- 利用特异性挥发物筛选昆虫相关嗅觉蛋白的方法与制造工艺
- 使用与表面偶联的单特异性四聚抗体复合物组合物从样品中分离出靶实体的方法与制造工艺
- 抗-WT1/HLA双特异性抗体的制造方法与工艺
- 与CD56分子特异性结合的多肽及其应用的制造方法与工艺
- 用于治疗HBV感染和相关病症的三特异性结合分子的制造方法与工艺
- 对磺胺类药物具有特异性的固相微萃取纤维的制备方法与流程
- 避免信号干扰的肌原纤维蛋白丝氨酸磷酸化水平的测定方法与流程
- 一种检测猪初乳中抗PEDV特异性IgA抗体的夹心ELISA试剂盒的制造方法与工艺
- 用于施用CD19xCD3双特异性抗体的给药方案的制造方法与工艺
- 双特异性抗‑VEGF/抗‑ANG‑2抗体及其在治疗眼血管疾病中的应用的制造方法与工艺
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 活化人CD40的抗体和针对人PD‑L1的抗体的组合疗法的制造方法与工艺
- 双特异性四价抗体及其制造和使用方法与制造工艺