有效抑制牦牛CAPN1基因表达的shRNA及其应用的制作方法
本发明涉及shRNA,尤其涉及能够有效抑制牦牛CAPN1基因表达的shRNA。
背景技术:
牦牛是分布在以青藏高原为中心及其毗邻的高山、亚高山地区的牛种,为牧民提供奶、肉、毛、役、燃料等生产和生活资料,具有“高原之舟”的美称。牦牛常年采食天然牧草,其肉的蛋白质含量高,脂肪含量低,且富含不饱和脂肪酸及特殊的风味物质,是符合现代生活要求的绿色食品(阎萍,2012),但是牦牛肉的嫩度等品质也制约了其市场接受度。因此,牦牛肉嫩度改良研究成为牦牛遗传育种领域研究的热点之一。
钙蛋白酶(calpain)是存在于脊椎动物细胞中的一种蛋白水解酶,其在各组织中广泛表达,主要参与神经发育、肌肉生长、信号转导、细胞凋亡及膜蛋白裂解等生物学通路。Calpain1和Calpain2是最早发现的两种钙蛋白酶的同型异构体,其中Calpain1是不均一的蛋白二聚体,大亚基由CAPN1基因编码。当大小亚基相结合时,钙蛋白酶不具有活性。Ca2+ 激活 CAPN1后,其大小亚基分离,因此认为小亚基有可能主要起调节的作用,大亚基起催化的作用。CAPN1的活性依赖于肌浆中的钙离子浓度,正常细胞中,游离的钙离子浓度很低,不能激活 CAPN1。当畜禽屠宰后,肌浆网和线粒体开始释放钙离子,从而促进肌动球蛋白的生成,使肌肉发生僵直。随着细胞内ATP耗尽和乳酸的累积,肌浆网被破坏,使大量的钙离子游离到肌浆中,从而激活CAPN1的活性,开始降解肌原纤维蛋白(Melody et al., 2004)。肌肉中CAPN1蛋白的上调可以促进肌联蛋白、肌腱线蛋白和粘着斑蛋白等肌原纤维蛋白的降解,从而提高肉的嫩度(Kemp et al., 2010)。CAST作为CAPN1抑制蛋白,与肉的嫩度负相关。
小发夹RNA(shRNA)是一种具有发夹状结构的小分子RNA,它通过RNAi途径使特定基因的表达沉默。与 siRNA 干扰作用的短暂性不同,shRNA 可构建成相应的载体,将载体导入细胞之后,就可以在其U6或H1启动子的作用下持续表达shRNA。目前shRNA已成为研究基因功能的最有效的工具之一。针对牦牛CAPN1基因设计特异性的shRNA序列,构建相应的慢病毒表达系统,为今后深入研究牦牛CAPN1基因的功能奠定了基础,可广泛应用于CAPN1基因相关的牦牛细胞,具有重要的应用前景和经济价值。
技术实现要素:
本发明公开了三种有效抑制牦牛CAPN1基因表达的shRNA,该shRNA为shCAPN1-1025、shCAPN1-1822和shCAPN1-1981,它们都包含21nt的siRNA正义链,7nt的loop环,21nt的siRNA反义链和终止信号。三条shRNA对CAPN1基因的mRNA抑制效率达80%以上。
本发明的第一个目的是提供有效抑制牦牛CAPN1基因表达的shRNA,所述shRNA为以下(1)-(3)中的任意一条,每一条shRNA分子由上下游两条DNA互补单链组成:
本发明的第二个目的是提供上述shRNA在有效抑制牦牛CAPN1基因表达中的应用。
作为优选,所述应用是将一条shRNA分子中的两条互补单链经退火形成双链的shRNA分子后,连接到慢病毒干扰载体上,构建得到shRNA慢病毒重组载体;然后将shRNA慢病毒重组载体与CAPN1表达质粒共转染293T细胞。
作为进一步优选,所述慢病毒干扰载体为miRZip慢病毒干扰载体。
作为优选,所述shRNA慢病毒重组载体的具体构建方法为:
(1)取100pmol的两条互补单链核苷酸各2μl,加入2μl 10×退火缓冲液和14μl灭菌超纯水,反应程序:95℃ 5min 72℃ 10min,在室温下放置 60min;然后取5ul加水95ul作为退火产物工作浓度;
(2)将miRZip慢病毒干扰载体经BamHI和EcoRI双酶切后回收线性化质粒,与步骤(1)得到的退火产物4℃过夜连接,将连接产物转化DH5a感受态细胞,用含氨苄青霉素100μg/μl的LB平板筛选,将筛选阳性克隆经测序正确后,提取纯化重组质粒。
作为优选,将shRNA慢病毒重组载体与CAPN1表达载体共转染293T细胞的具体方法为:
将shRNA慢病毒重组载体2μg与2μg的CAPN1表达质粒混合,加入生理盐水混匀,室温孵育5min,再加入6μl浓度为1mg/ml的聚乙烯亚胺,混匀后,室温孵育10min;最后加入293T细胞中进行细胞转染,充分的摇匀后放入37℃、5%CO2、95%相对湿度的培养箱中培养;感染6小时后,吸走孔内的培养基,换成新鲜的2ml含10%胎牛血清的 DMEM完全培养基,放入37℃、5%CO2、95%相对湿度的培养箱中培养;待细胞长满后,收集细胞。
本发明的第三个目的是提供一种有效抑制牦牛CAPN1基因表达的方法,是将一条shRNA分子中的两条互补单链经退火形成双链的shRNA分子后,连接到慢病毒干扰载体上,构建得到shRNA慢病毒重组载体;然后将shRNA慢病毒重组载体与CAPN1表达质粒共转染293T细胞;作为优选,所述慢病毒干扰载体为miRZip慢病毒干扰载体。
作为优选,所述shRNA慢病毒重组载体的具体构建方法为:
(1)取100pmol的两条互补单链核苷酸各2μl,加入2μl 10×退火缓冲液和14μl灭菌超纯水,反应程序:95℃ 5min 72℃ 10min,在室温下放置 60min;然后取5ul加水95ul作为退火产物工作浓度;
(2)将miRZip慢病毒干扰载体经BamHI和EcoRI双酶切后回收线性化质粒,与步骤(1)得到的退火产物4℃过夜连接,将连接产物转化DH5a感受态细胞,用含氨苄青霉素100μg/μl的LB平板筛选,将筛选阳性克隆经测序正确后,提取纯化重组质粒。
作为优选,将shRNA慢病毒重组载体与CAPN1表达载体共转染293T细胞的具体方法为:
将shRNA慢病毒重组载体2μg与2μg的CAPN1表达质粒混合,加入生理盐水混匀,室温孵育5min,再加入6μl浓度为1mg/ml的聚乙烯亚胺,混匀后,室温孵育10min;最后加入293T细胞中进行细胞转染,充分的摇匀后放入37℃、5%CO2、95%相对湿度的培养箱中培养;感染6小时后,吸走孔内的培养基,换成新鲜的2ml含10%胎牛血清的 DMEM完全培养基,放入37℃、5%CO2、95%相对湿度的培养箱中培养;待细胞长满后,收集细胞。
本发明的有益效果为:本发明所述抑制牦牛CAPN1基因表达的shRNA能有效抑制牦牛CAPN1基因mRNA的表达量。将所述抑制牦牛CAPN1基因表达的shRNA构建于慢病毒载体上,得到的重组质粒既适合于体内研究,还适合于体外研究,因此,该重组质粒对于深入研究牦牛CAPN1基因的功能及分子育种均具有重要的科学意义及应用前景。同时,与人工合成的siRNA分子比较而言,CAPN1-shRNA慢病毒干扰载体在基因转移效率和基因沉默的持续性及稳定性上具有显著的优越性,彰显了该技术的进步。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为抑制牦牛CAPN1基因表达的shRNA慢病毒载体结构示意图。
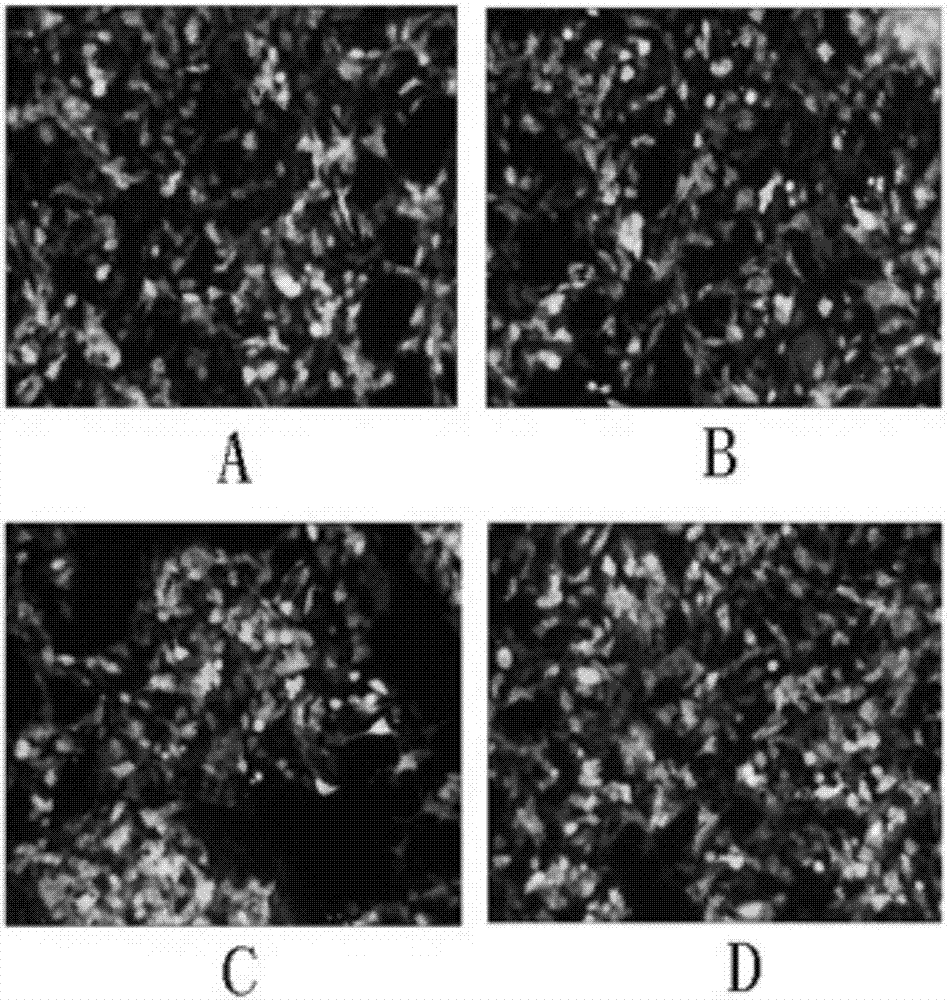
图2为靶质粒与干扰质粒共转染293T细胞48h后荧光观察结果图,图中:A:shCAPN1-1025干扰载体和PCDH-CMV-CAPN1-EF1-copGFP表达载体共转染293T细胞, B: shCAPN1-1822干扰载体和PCDH-CMV-CAPN1-EF1-copGFP表达载体共转染293T细胞,C: shCAPN1-1981干扰载体和PCDH-CMV-CAPN1-EF1-copGFP表达载体共转染293T细胞,D: 空载体和PCDH-CMV-CAPN1-EF1-copGFP表达载体共转染293T细胞。
图3 CAPN1-shRNA对CAPN1基因干扰的定量结果。
具体实施方式
以下的实施例便于更好地理解本发明,但并不限定本发明。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的试验材料,如无特殊说明,均为市售。
主要试剂和仪器、设备:
限制性内切酶;
T4连接酶(NEB);
DH5α感受态细胞;
shRNA慢病毒载体:miRZip(SBI公司);
pCDH-EF1-copGFP载体:全称pCDH-CMV-MCS-EF1-copGFP cDNA Cloning and Expression Vector(SBI公司);
DNA回收试剂盒(中美泰和);
质粒提取试剂盒(中美泰和);
DMEM完全培养基;
1×PBS;
Trypsin-EDTA ;
转染试剂Polyethylenimine(Polyscience, Cat # 23966);
样本(293T细胞 牛基因)-4个
BestarTM qPCR RT Kit:德国DBI公司;
Bestar® SybrGreen qPCR mastermix:德国DBI公司;
96孔板:美国life公司;
引物合成:美国life公司;
ABI7500荧光定量PCR仪(life technology公司);
TGL-16M低温冷冻离心机(湘仪);
SW-CJ-1D单人净化工作台(泸净净化);
HR40-Ⅱ A2生物安全柜(Haier);
Nanodrop2000超微量分光光度计:Thermo Scientific公司。
实施例1
本发明的方法步骤如下:
一、牦牛CAPN1基因表达载体的构建
根据NCBI中公布的牦牛CAPN1基因mRNA[XM_005894060]序列,人工合成CDs区(为序列表SEQ ID No.1),并在序列5’和3’端分别引入XbaI和NotI酶切位点。
1、制备pUC57-CAPN1载体
生物公司在合成序列后,把合成序列连接在了pUC57载体上,得到pUC57-CAPN1载体。
2、pUC57-CAPN1载体及pCDH-EF1-copGFP载体双酶切
在2个无菌的0.2 ml EP反应管,分别取pUC57-CAPN1载体和pCDH-EF1-copGFP载体各15 µl,用XbaI和NotI内切酶在37℃双酶切3h,酶切体系如下:
10×Buffer 5 µl
载体/目的片段 15 µl
XbaI 1.5 µl
NotI 1.5 µl
ddH2O 27 µl
总体积 50 µl。
3、酶切产物回收
胶电泳检测酶切效果,切割在琼脂糖凝胶电泳胶中的目的基因片段条带和线性化的载体,回收纯化,具体步骤如下:
1) 酶切产物经1% 凝胶电泳后,在紫外灯下,用手术刀分别切取含目的片段和载体的凝胶条带至干净的1.5 ml EP管中,按100 mg凝胶对应100 µl溶液GB的比例向离心管中加入溶液GB;
2) 60℃水浴10 min至凝胶完全溶化,水浴期间振荡混合3次;
3) 将溶液转移至DNA纯化柱中,静置2 min,室温12 000 rpm离心1 min,弃滤液;
4) 向柱上加入600 µl溶液PW,室温12 000 rpm离心30 sec,弃滤液;
5) 重复上一操作一次;
6) 空柱12 000 rpm离心1 min以彻底去除纯化柱中残留的液体;
7) 将柱子置于新的1.5 ml EP管上,向柱中央加入35 µl 60℃预热的无菌水,13 400g离心1 min以洗脱出DNA。
4、目的片段与载体连接,得到PCDH-CAPN1-EF1-copGFP。
向0.2 ml EP管中加入以下试剂:T4 DNA Ligase酶,购于Thermo Fisher公司,具体反应体系如下:
酶切回收的载体 3μl
酶切回收的目的基因片段 2μl
10× T4 Buffer 2μl
T4 连接酶 0.5μl
ddH2O 12.5μl
总体积 20μl。
16℃连接过夜。
5、连接产物的转化
1) 冰浴中将10 µl连接产物分别加入至50 µl Top10感受态细胞中。轻轻旋转混匀,冰浴30 min;
2) 42℃水浴热休克90 s;
3) 快速将管转移至冰浴中,冰浴2 min;
4) 分别加入300 µl LB培养基,混匀, 37℃、200 rpm振荡培养1 h;
4) 于超净工作台中,将菌液均匀涂布于含Kan抗生素(100 μg/ml)的LB平板上,室温下放置,至液体吸收;
6) 倒置平板,转移入37℃生化培养箱过夜培养。
6、菌落PCR验证
挑取数个菌落,PCR检测。
7、阳性克隆测序验证
将菌落PCR鉴定得到的阳性克隆进行测序验证,测序完成后,软件比对测序结果,测序引物见表1。
表1 测序使用的引物
8、质粒小提,应用质粒提取试剂盒(中美泰和)按照说明书方法进行提取,具体步骤如下:
1) 用2 mL EP管收集3 µL经步骤7测序正确的菌液,12 000 rpm离心1 min,去上清;
2) 加入250 µL 溶液I/RNase A混合液,重悬菌体;
3) 加入250 µL溶液II,温和反复颠倒混匀6次,室温放置2 min;
4) 加入350 µL溶液III,温和反复颠倒混匀6次;
5) 13 000 rpm离心10 min,小心吸去上清至DNA纯化柱中,静置2 min;
6) 12 000 rpm离心1 min,弃滤液;
7) 加入500µL溶液W1至柱中,13000 rpm离心1 min,弃滤液;
8) 加入600µL溶液W2至柱中,12 000 rpm离心1 min,弃滤液。重复一次;
9) 空柱12 000 rpm离心2min;
10) 将柱取出置于新的1.5 ml EP管中,加入65 µl无菌水(60 °C预热),静置2 min,13 400 rpm离心1 min以洗脱出质粒。
9、酶切鉴定所提取质粒。其氨基酸序列为序列表中SEQ ID No.2。
二、牦牛CAPN1基因shRNA干扰载体的构建
1. 本发明针对CAPN1基因的ORF序列,人工设计合成并筛选到选择3个不同的靶位点作为靶序列(1105bp-1125bp,1822bp-1842bp和1981bp-2001bp),并将其设计为包含siRNA正义链、loop环(TCAAGAG)和siRNA反义链的shRNA结构,分别命名为shCAPN1-1105、shCAPN1-1822和shCAPN1-1981,在正义链模板的5’端添加了GATC,与BamH I酶切后形成的粘端互补;反义链模板的5’端添加了AATT,与EcoR I酶切后形成的粘端互补。具体序列为:
2. 取100pmol的两条互补单链核苷酸各2μl,加入2μl 10×退火缓冲液和14μl灭菌超纯水,反应程序:95℃ 5min 72℃ 10min,在室温下放置 60min。取5ul加水95ul作为退火产物工作浓度用。
3. 将miRZip慢病毒干扰载体经BamHI和EcoRI双酶切后回收线性化质粒,与步骤2得到的退火产物4℃过夜连接,连接产物转化DH5a感受态细胞,用LB平板氨苄青霉素100μg/μl进行筛选,将上游载体检测引物及下游shRNA寡核苷酸引物筛选阳性克隆并送上海生工测序鉴定序列正确后,提取纯化重组质粒用于转染。
三、shRNA干扰载体与CAPN1表达质粒共转染293T细胞
1. 293T细胞传代种板
1) 复苏293T经过一次传代后,待细胞状态较好时可用于转染;
2) 将10%血清的DMEM完全培养基、1×PBS和0.25%Trypsin-EDTA预先平衡至室温;
3) 吸去培养皿中的培养液,用1×PBS洗涤细胞2-3次,以去除残留的血清;
4) 吸去PBS,加入适量Trypsin-EDTA,轻轻旋转,使Trypsin-EDTA均匀覆盖培养器皿表面,消化1-2分钟,显微镜下可见细胞间隙增大,细胞变圆,用手轻拍培养皿的壁,立即加入2ml的DMEM完全培养基终止消化;
5) 用吸管吸取液体,轻轻吹打培养器皿表面,反复3-5次,使细胞彻底脱离瓶皿底壁,将细胞移入离心管中,再向培养瓶中加入1×PBS洗1次,并将洗液一并转移至离心管中,离心(250g,4分钟),吸去上清液;
6) 加入5ml的DMEM完全培养基重悬细胞沉淀,用吸管轻轻吹打收集的细胞悬液,取样计数;
7) 参照计数结果,取2×104cells/孔的密度接种至6孔板。
2. 质粒转染293T细胞
1) 待细胞完全贴壁后,长至60%左右密度即可进行转染;转染前,每孔细胞换成2ml新鲜的含10%胎牛血清的DMEM完全培养基,放置于培养箱孵育1h;
2) 将3条CAPN1-shRNA载体、shRNA空载体分别与CAPN1表达载体共转染293T细胞,三个干扰质粒、shRNA空载体分别各取2μg,与2μg的CAPN1表达质粒分别混合于1.5ml EP管中,加入200ul的生理盐水轻轻混匀,室温孵育5min,再加质粒6ul的转染试剂聚乙烯亚胺(Polyethylenimine) (1mg/ml),轻轻吹吸3-5次混匀,室温孵育10min。最后分别加入六孔板中进行细胞转染,充分的摇匀后放入37℃、5%CO2、95%相对湿度的培养箱中培养;
3) 感染6小时后,吸走孔内的培养基,换成新鲜的2ml含10%胎牛血清的 DMEM完全培养基,放入37℃、5%CO2、95%相对湿度的培养箱中培养;
4) 感染48小时后,于荧光显微镜下观察感染效果;
5) 待细胞长满后,即可收集进行QPCR检测。
四、shRNA对CAPN1基因转录水平抑制效果的评价
1、RNA的抽提
RNA 的提取按life technology公司提供的Triozol使用说明进行。程序如下:
1) 往细胞培养板中加入1ml TRIzol,反复吹打几次后吸出,置于1.5ml离心管;
2) 加入0.2ml氯仿,盖紧离心管管盖,上下颠倒混匀60s(请勿涡漩激烈振荡),室温静置3min,12,000g,4℃离心 15min,置于冰上;
3) 溶液分为三层,RNA溶解在水相中,小心吸取 500μl水相至另一个新的RNase free的EP管中;
4) 加入500μl异丙醇,-20度放置1h,12,000g,4℃离心10min,离心后管底出现RNA沉淀,弃上清;
5) 加入1ml 75%乙醇,用手轻轻颠倒,12,000g离心5min,去上清;
6) 超净工作台上吹干样品10min,加入适量DEPC水溶解RNA。 加入40μl DEPC水溶解沉淀。
2、RNA质量检测
用紫外分光光度计测定RNA浓度。
3、去基因组DNA和cDNA的合成
将RNA加入到gDNA吸附柱,室温10,000g离心1min,收集滤液即为去除基因组DNA的RNA。把RNA在65℃条件下热变性5分钟后,立即置于冰上冷却。然后进行逆转录。
逆转录反应试剂为:
5×RT Buffer 2ul
RT Enzyme Mix 0.5μl
Primer Mix 0.5μl
RNA 6μl
RNase-free Water 1μl
总体积 10μl。
反应条件:37℃ 15min,98℃ 5min,4℃ hold,反应结束后,-20℃保存。
4、实时荧光定量PCR
每个样本分别设置3个目的基因和3个内参基因的平行实验。
PCR反应体系为:
Bestar® SybrGreen qPCR mastermix 10μl
Forward Primer(20μM) 0.25μl
Reverse Primer(20μM) 0.25 μl
50×ROX 0.04μl
cDNA 5μl
ddH2O 4.46μl
反应条件为:95℃ 2min;95℃ 10s,60℃ 34s,72℃ 30s,45个循环;循环结束后从60℃升高到98℃获取熔解曲线。
使用的引物参见表2。
表2
在进行定量PCR试验前,应先进行预试验检测cDNA样品的质量。对cDNA样品使用内参基因ACTB进行Real-time PCR试验,根据Ct值,评价cDNA样品质量。18<Ct<25的可直接进行后期试验;若Ct≥30说明cDNA样品浓度偏低,需重新进行反转录;若无扩增结果,则cDNA质量存在问题,需重新进行反转录。
将cDNA模板从10倍到105倍梯度稀释,并以此为模板,对每对探针进行荧光定量PCR反应。以内参基因ACTB的五个梯度反应制作标准曲线,将其他各对引物的曲线斜率和R2与内参基因进行比较,保证扩增效率一致。
5、荧光定量PCR数据统计分析
所述的荧光定量PCR数据标准化统计分析为以ACTB基因为内参基因校正不同样品初始模板量以及反转录效率的差异,每次反应,每个样本的目的基因和内参基因各重复三次,获得平均Ct值,利用Excel软件计算样品ΔΔCt值,用法计算得到目的基因的相对表达量和各shRNA片段抑制效率。干扰效率(%)=[(表达对照组表达量-shRNA组表达量)/表达对照组表达量]×100%。本发明的三条shRNA均对CAPN1有较好的抑制作用,其中,shRNA1105的抑制效率为85%,shRNA1822的抑制效率为92%,shRNA1981的抑制效率最高,达98%。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
序列表
<110> 中国农业科学院兰州畜牧与兽药研究所
<120> 有效抑制牦牛CAPN1基因表达的shRNA及其应用
<170> PatentIn version 3.5
<210> 1
<211> 2151
<212> DNA
<213> CAPN1基因CDs区序列
<400> 1
atggccgagg agttcatcac tccggtgtac tgcaccgggg tgtctgcaca agtgcagaag 60
cagcgggcca aggagctggg cctgggccgc catgaaaatg ccatcaagta cctgggccag 120
gattacgagc agctgcgggt tcactgcctg caaagagggg cccttttccg tgacgaggct 180
ttccccccag tgccccagag cctgggcttc aaggagctgg gccccaactc ctccaaaacc 240
tatggcatca agtggaagcg tcccacggag ctgttctcaa acccccagtt catcgtggat 300
ggagccaccc gcacggacat ctgccagggc gcactggggg actgttggct cctggctgcc 360
atcgcctccc ttaccctcaa tgacaccctc ctgcaccgag tagttccaca tggccaaagc 420
ttccaggatg gctacgctgg catcttccat ttccagctgt ggcagtttgg tgagtgggtg 480
gatgtggtgg tggatgacct gctgcccacc aaggacggga agctggtgtt tgtgcactct 540
gcccaaggca acgagttctg gagcgccctg ctggagaagg cctatgccaa ggtgaacggc 600
agctacgagg ccctctcagg aggcagcacg tctgagggct ttgaggactt caccggcgga 660
gtcaccgagt ggtacgagct gcggaaggcg cccagcgacc tctacaacat catcctcaag 720
gccctggagc gtggctccct gctgggctgc tccatcgata tctccagcat tctggacatg 780
gaggctgtca ccttcaagaa gctagtgaag ggccacgcct actctgtgac cggggccaag 840
caggtgaact accagggcca gatggtgaac ctgatccgga tgcggaaccc ctggggcgag 900
gtggagtgga caggagcctg gagtgacggc tcctcggagt ggaacggcgt ggacccttac 960
atgcgggagc agctccgggt caagatggag gatggggagt tctggatgtc attccgagac 1020
ttcatgcgtg aattcacccg cctggagatc tgcaacctga cacccgatgc gctcaagagc 1080
cagaggttcc gcaactggaa caccaccctg tacgagggca cctggcggcg ggggagcacc 1140
gcggggggct gccgcaacta cccagccact ttctgggtga acccccagtt caagatccgg 1200
ctggaggaga cggatgaccc ggaccccgac aactacgggg gtcgcgagtc aggctgcagc 1260
ttcctgctcg ccctcatgca gaagcaccgc cgtcgggagc gccgtttcgg ccgtgacatg 1320
gagaccatag gcttcgctgt ctacgaggtc cctccggagc tggtgggcca gccagccgtg 1380
catctgaagc gggacttctt cctgtccaac gcctcccggg cccggtccga gcagttcatc 1440
aacctgcggg aggtcagcac ccgcttccgc ctgccgcctg gggagtatgt ggtggtgccc 1500
tccacctttg agcccaacaa ggaaggtgac tttgtgctgc gtttcttctc agagaagagc 1560
gcagggaccc aagagctgga tgaccaggtc caggccaatc tccccgacga gcaagtgctc 1620
tcagaagagg agattgatga gaacttcaag tccctcttca gacaactggc aggggaggac 1680
atggagatca gcgtcaagga gctgcggacc atcctcaaca ggatcatcag caaacacaaa 1740
gacctgcgga ccacgggctt cagcctggag tcctgccgca gcatggtcaa cctcatggat 1800
cgcgacggca atggcaaact gggcctggtg gagttcaaca tcctatggaa ccggatccgg 1860
aattacctgt ccatcttccg gaagtttgac ctggacaagt cgggcagcat gagtgcctat 1920
gaaatgcgga tggccattga gtttgcaggc ttcaagctca acaagaagct gtacgagctc 1980
attatcaccc gctactcgga gcccgacctg gccgtggact tcgacaactt cgtgtgctgc 2040
ctggtgcggc tggagaccat gttccggttt ttcaaaactc tggacactga tctggatgga 2100
gtggtgacct ttgacttgtt taagtggtta cagctgacca tgtttgcatg a 2151
<210> 2
<211> 716
<212> PRT
<213> 人工蛋白
<400> 2
Met Ala Glu Glu Phe Ile Thr Pro Val Tyr Cys Thr Gly Val Ser Ala
1 5 10 15
Gln Val Gln Lys Gln Arg Ala Lys Glu Leu Gly Leu Gly Arg His Glu
20 25 30
Asn Ala Ile Lys Tyr Leu Gly Gln Asp Tyr Glu Gln Leu Arg Val His
35 40 45
Cys Leu Gln Arg Gly Ala Leu Phe Arg Asp Glu Ala Phe Pro Pro Val
50 55 60
Pro Gln Ser Leu Gly Phe Lys Glu Leu Gly Pro Asn Ser Ser Lys Thr
65 70 75 80
Tyr Gly Ile Lys Trp Lys Arg Pro Thr Glu Leu Phe Ser Asn Pro Gln
85 90 95
Phe Ile Val Asp Gly Ala Thr Arg Thr Asp Ile Cys Gln Gly Ala Leu
100 105 110
Gly Asp Cys Trp Leu Leu Ala Ala Ile Ala Ser Leu Thr Leu Asn Asp
115 120 125
Thr Leu Leu His Arg Val Val Pro His Gly Gln Ser Phe Gln Asp Gly
130 135 140
Tyr Ala Gly Ile Phe His Phe Gln Leu Trp Gln Phe Gly Glu Trp Val
145 150 155 160
Asp Val Val Val Asp Asp Leu Leu Pro Thr Lys Asp Gly Lys Leu Val
165 170 175
Phe Val His Ser Ala Gln Gly Asn Glu Phe Trp Ser Ala Leu Leu Glu
180 185 190
Lys Ala Tyr Ala Lys Val Asn Gly Ser Tyr Glu Ala Leu Ser Gly Gly
195 200 205
Ser Thr Ser Glu Gly Phe Glu Asp Phe Thr Gly Gly Val Thr Glu Trp
210 215 220
Tyr Glu Leu Arg Lys Ala Pro Ser Asp Leu Tyr Asn Ile Ile Leu Lys
225 230 235 240
Ala Leu Glu Arg Gly Ser Leu Leu Gly Cys Ser Ile Asp Ile Ser Ser
245 250 255
Ile Leu Asp Met Glu Ala Val Thr Phe Lys Lys Leu Val Lys Gly His
260 265 270
Ala Tyr Ser Val Thr Gly Ala Lys Gln Val Asn Tyr Gln Gly Gln Met
275 280 285
Val Asn Leu Ile Arg Met Arg Asn Pro Trp Gly Glu Val Glu Trp Thr
290 295 300
Gly Ala Trp Ser Asp Gly Ser Ser Glu Trp Asn Gly Val Asp Pro Tyr
305 310 315 320
Met Arg Glu Gln Leu Arg Val Lys Met Glu Asp Gly Glu Phe Trp Met
325 330 335
Ser Phe Arg Asp Phe Met Arg Glu Phe Thr Arg Leu Glu Ile Cys Asn
340 345 350
Leu Thr Pro Asp Ala Leu Lys Ser Gln Arg Phe Arg Asn Trp Asn Thr
355 360 365
Thr Leu Tyr Glu Gly Thr Trp Arg Arg Gly Ser Thr Ala Gly Gly Cys
370 375 380
Arg Asn Tyr Pro Ala Thr Phe Trp Val Asn Pro Gln Phe Lys Ile Arg
385 390 395 400
Leu Glu Glu Thr Asp Asp Pro Asp Pro Asp Asn Tyr Gly Gly Arg Glu
405 410 415
Ser Gly Cys Ser Phe Leu Leu Ala Leu Met Gln Lys His Arg Arg Arg
420 425 430
Glu Arg Arg Phe Gly Arg Asp Met Glu Thr Ile Gly Phe Ala Val Tyr
435 440 445
Glu Val Pro Pro Glu Leu Val Gly Gln Pro Ala Val His Leu Lys Arg
450 455 460
Asp Phe Phe Leu Ser Asn Ala Ser Arg Ala Arg Ser Glu Gln Phe Ile
465 470 475 480
Asn Leu Arg Glu Val Ser Thr Arg Phe Arg Leu Pro Pro Gly Glu Tyr
485 490 495
Val Val Val Pro Ser Thr Phe Glu Pro Asn Lys Glu Gly Asp Phe Val
500 505 510
Leu Arg Phe Phe Ser Glu Lys Ser Ala Gly Thr Gln Glu Leu Asp Asp
515 520 525
Gln Val Gln Ala Asn Leu Pro Asp Glu Gln Val Leu Ser Glu Glu Glu
530 535 540
Ile Asp Glu Asn Phe Lys Ser Leu Phe Arg Gln Leu Ala Gly Glu Asp
545 550 555 560
Met Glu Ile Ser Val Lys Glu Leu Arg Thr Ile Leu Asn Arg Ile Ile
565 570 575
Ser Lys His Lys Asp Leu Arg Thr Thr Gly Phe Ser Leu Glu Ser Cys
580 585 590
Arg Ser Met Val Asn Leu Met Asp Arg Asp Gly Asn Gly Lys Leu Gly
595 600 605
Leu Val Glu Phe Asn Ile Leu Trp Asn Arg Ile Arg Asn Tyr Leu Ser
610 615 620
Ile Phe Arg Lys Phe Asp Leu Asp Lys Ser Gly Ser Met Ser Ala Tyr
625 630 635 640
Glu Met Arg Met Ala Ile Glu Phe Ala Gly Phe Lys Leu Asn Lys Lys
645 650 655
Leu Tyr Glu Leu Ile Ile Thr Arg Tyr Ser Glu Pro Asp Leu Ala Val
660 665 670
Asp Phe Asp Asn Phe Val Cys Cys Leu Val Arg Leu Glu Thr Met Phe
675 680 685
Arg Phe Phe Lys Thr Leu Asp Thr Asp Leu Asp Gly Val Val Thr Phe
690 695 700
Asp Leu Phe Lys Trp Leu Gln Leu Thr Met Phe Ala
705 710 715
<210> 3
<211> 58
<212> DNA
<213> CAPN1sh1上游序列
<400> 3
gatcggatgt cattccgaga cttcatcaag agtgaagtct cggaatgaca tccttttt 58
<210> 4
<211> 58
<212> DNA
<213> CAPN1sh1下游序列
<400> 4
aattaaaaag gatgtcattc cgagacttca ctcttgatga agtctcggaa tgacatcc 58
<210> 5
<211> 58
<212> DNA
<213> CAPN1sh2上游序列
<400> 5
gatcggatca tcagcaaaca caaagtcaag agctttgtgt ttgctgatga tccttttt 58
<210> 6
<211> 58
<212> DNA
<213> CAPN1sh2下游序列
<400> 6
aattaaaaag gatcatcagc aaacacaaag ctcttgactt tgtgtttgct gatgatcc 58
<210> 7
<211> 58
<212> DNA
<213> CAPN1sh3上游序列
<400> 7
gatcggaagt ttgacctgga caagttcaag agacttgtcc aggtcaaact tccttttt 58
<210> 8
<211> 58
<212> DNA
<213> CAPN1sh3下游序列
<400> 8
aattaaaaag gaagtttgac ctggacaagt ctcttgaact tgtccaggtc aaacttcc 58
- 还没有人留言评论。精彩留言会获得点赞!
- 一种利用短单链DNA抑制昆虫基因表达的方法与流程
- 特异性抑制Eya2基因表达的siRNA及其重组载体和应用的制作方法与工艺
- 抑制罗汉果CAS基因表达的方法与流程
- 特异性抑制CLDN8基因表达的siRNA及其重组载体和应用的制作方法与工艺
- 抑制小鼠促性腺激素抑制激素基因表达的siRNA及其应用的制作方法与工艺
- 一种抑制梨种子赤霉素合成基因表达的方法与流程
- KPNA2基因的应用和抑制KPNA2基因表达的siRNA的应用的制造方法与工艺
- 特异性抑制PADI2基因表达的siRNA及其重组载体和应用的制造方法与工艺
- 一种高效表达小鼠促性腺激素抑制激素基因的慢病毒载体及其应用的制造方法与工艺
- 一种抑制人黑色素瘤RBM3基因表达的siRNA及其质粒载体的制造方法与工艺