一种蛋白质核酸适配体的筛选方法与流程
本发明涉及生物技术领域,具体涉及一种核酸适配体筛选方法,适用于以蛋白质为靶标的核酸适配体的筛选。
背景技术:
核酸适配体是一类能够形成特定三维结构的官能化寡核苷酸序列,其可高亲和力和高特异性的与蛋白质、肽、毒素、金属离子和细胞等结合。核酸适配体被称为“化学抗体”,相对于传统抗体,其分子量小、特异性强、稳定性高等特点使其成为极具潜力的配体。尤其对于难以制备抗体的蛋白质,适配体的筛选使这些蛋白高灵敏度检测成为可能。核酸适配体在生物传感器、生物药物和分子识别探针等许多领域的研究中亦具有广泛的应用。目前多种以蛋白质为靶标的适配体及其筛选技术已见报道。但这些方法都需要将适配体筛选库进行化学修饰,如结合链霉亲和素标记的磁珠或琼脂糖微球体,化学修饰可能会改变靶蛋白的固有结构,使得筛选得到的适配体富集效率低,得到的适配体的亲和力和特异性降低。因此,探索一种不用改变靶标结构,获得高亲和力适配体的筛选方法具有重要意义。
技术实现要素:
本发明所要解决的技术问题是针对现有技术的不足,提供一种新的、低成本的高富集率的蛋白质核酸适配体的筛选方法。该方法筛选得到的核酸适配体与其靶标蛋白能够高特异性和高亲和力结合,具有分子量小、稳定性高、可体外修饰、可化学合成、无免疫源性等优势。
本发明的目的是通过以下的技术方案来实现的。本发明是一种蛋白质核酸适配体的筛选方法,其特点是:将蛋白质包埋在聚苯乙烯96孔板或其它吸附蛋白质的器皿的表面;加入胰蛋白酶或蛋白酶消化降解蛋白质,使蛋白质与寡核苷酸结合复合物脱离容器表面,通过加热灭活蛋白酶并释放ssdna;与蛋白特异性接合的ssdna被富集,筛选得到亲和力高的适配体。
本发明所述的核酸适配体筛选方法,其进一步优选的技术方案是,其具体步骤如下:将蛋白分子包被在96孔聚苯乙烯板中,采用bsa或fbs封闭,再将寡核苷酸序列ssdna加到包被蛋白的板孔中孵育一定时间,用缓冲液将未结合的寡核苷酸序列去除后,用胰蛋白酶稀释液消化96孔聚苯乙烯板中的蛋白-寡核苷酸复合物,再将全部溶液体系在沸水中煮沸至使蛋白变性;通过12000g离心20min除去沉淀来去除蛋白残留;采用pcr富集次级文库,利用不对称pcr及变性聚丙烯酰胺凝胶切胶来制备和纯化寡核苷酸单链;循环以上步骤7-10次后可得到富集的核酸适配体。
本发明所述的核酸适配体筛选方法,其进一步优选的技术方案是,该筛选方法包括以下步骤:
(1)合成碱基长度在60-120nt的随机ssdna文库和20nt的两条引物;
随机文库:5’-aactacgctcagacagacac-(20-80)n-ctgtgatgcgactatctgag-3’;
5’引物:5’-aactacgctcagacagacac-3’
3’引物:5’-ctcagatagtcgcatcacag-3’
(2)筛选:将蛋白用蛋白质包被液稀释并包被在96孔聚苯乙烯板中,37℃缓慢振荡2h,移出溶液并pbs洗涤3次,加入等体积的牛血清白蛋白封闭,37℃缓慢振荡1h,用pbs-t即含有0.05%(v/v)tween-20的pbs洗涤96孔聚苯乙烯板;将初始文库12000g离心5min后用结合ph7.6缓冲液稀释至50nm,95℃变性5min,冰上快速冷却15min;将上述处理的文库加入包被蛋白的96孔聚苯乙烯板中,37℃缓慢震荡孵育1h,用缓冲液清洗以去除未结合的寡核苷酸,再用胰蛋白酶稀释液将蛋白消化,胰蛋白酶:pbs=7:4(v/v),煮沸灭活胰蛋白酶,12000g离心20min去掉残留蛋白,通过醋酸钠与乙醇对得到的溶液去盐,得到能够与蛋白特异性结合的寡核苷酸;
(3)常规pcr扩增:将步骤(2)中得到的寡核苷酸作为模板进行常规pcr扩增,得到扩增产物;
(4)制备单链dna文库:将步骤(3)中得到的pcr产物作为模板进行不对称pcr扩增,将扩增产物通过变性聚丙烯酰胺凝胶电泳分离,切取目的条带并得到纯化产物,该纯化产物即为dna单链次级文库;
(5)重复筛选:将步骤(4)中的dna单链次级文库作为筛选库,进行步骤(2)中的筛选,并重复步骤(2)~(4)或干次;
(6)阴性筛选:在进行一轮筛选后,在第二轮筛选开始加入阴性筛选步骤,该筛选过程为,将步骤(4)得到的dna单链次级文库加入仅包被牛血清白蛋白的96孔聚苯乙烯板中孵育1h,将未结合的dna作为单链dna筛选库进行步骤(2)中的筛选;
(7)多轮筛选:在经过若干轮步骤(2)~(6)筛选后,将最后一轮筛选进行到步骤(3)后将产物进行测序。
上述筛选方法中,两次pcr的扩增条件优选为:94℃5min,94℃30s,53℃30s,72℃15s,经10轮循环后72℃5min(退火温度和循环数可在pcr前进行优化,选用无特异性扩增且条带明亮的条件)。不对称pcr的前向和后向引物比例优化也可在扩增之前进行,选出目的条带明显的引物比例。
本发胆将蛋白质包埋在聚苯乙烯96孔板或其它吸附蛋白质的器皿表面,加入ssdna文库孵育,洗去游离序列后,用胰蛋白酶消化蛋白-ssdna复合物,分离复合物,通过煮沸灭酶并释放ssdna。本方法可以大幅提高对核酸适配体富集。该方法能够保留更多与靶标蛋白结合的ssdna,提高了蛋白质核酸适配体筛选中适配体的富集量。
与现有技术相比,本发明的优点具体表现在:
(1)与传统蛋白质核酸适配体筛选方法相比,本筛选方法无需对筛选文库和pcr引物进行修饰,在节约成本的同时不会对靶标结构有任何改变,从而增加了筛选出的适配体的特异性;
(2)本筛选方法用胰蛋白酶实现蛋白质与其结合寡核苷酸的分离,相比于已见报道的用尿素的方法,该方法能够更好的实现核酸适配体的富集,让尽可能多的有亲和力的适配体得以保留。
(3)与传统抗体相比,本发明筛选出的适配体优点在于:无免疫源性、分子量小、可体外合成、稳定性高、易于保存。
(4)本发明可用于以蛋白为靶标的核酸适配体筛选,筛选得到的核酸适配体可以用于各类蛋白质的检测,筛选所得的核酸适配体的特异性高,亲和常数达到ng水平。
(5)本发明方法可以使与蛋白特异性接合的ssdna被富集,提高了筛选效率,筛选得到的适配体的亲和力高。用于以蛋白质为靶标的核酸适配体筛选。
附图说明
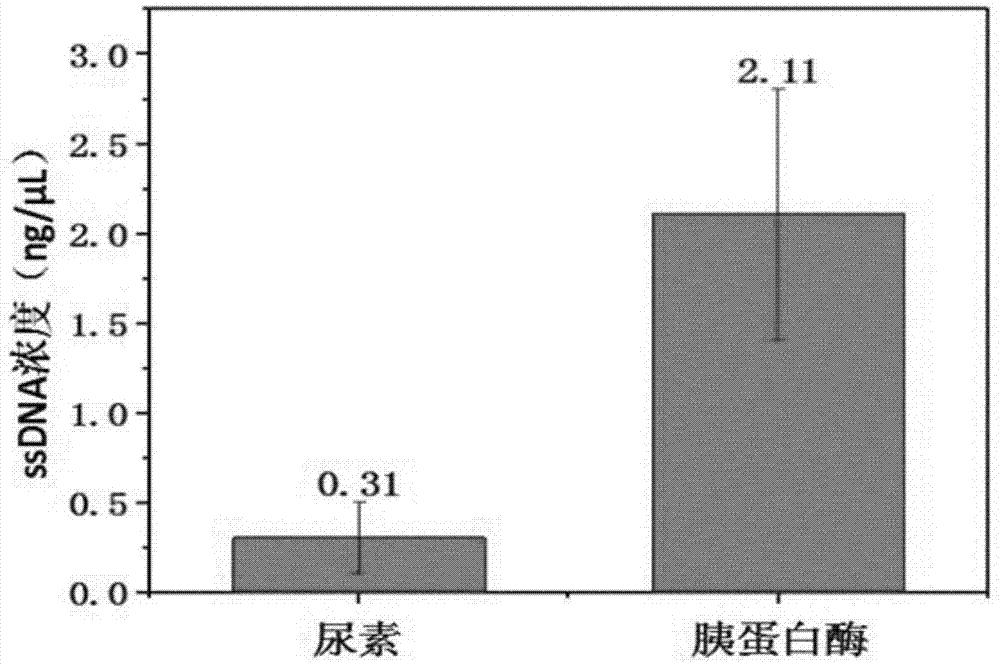
图1为本发明的实施例中胰蛋白酶与尿素对蛋白-寡核苷酸复合物分离数量对比图;
图2为本发明的实施例中以四种蛋白为靶标筛选的适配体测序结果中前五条序列富集所占比例分析图;
图3为本发明实施例中利用sigmaplot软件拟合的hp-ag的核酸适配体的亲和力检测结果;
图4为本发明实施例中利用sigmaplot软件拟合的cea的核酸适配体的亲和力检测结果;
图5为本发明实施例中利用sigmaplot软件拟合的ca199的核酸适配体的亲和力检测结果。
图6为本发明实施例中利用sigmaplot软件拟合的ca125的核酸适配体的亲和力检测结果;
图7为本发明实施例中利用idtoligonanlyzer3.1模拟的蛋白hp-ag的核酸适配体的二级结构;
图8为本发明实施例中利用idtoligonanlyzer3.1模拟的蛋白cea的核酸适配体的二级结构;
图9为本发明实施例中利用idtoligonanlyzer3.1模拟的蛋白ca199的核酸适配体的二级结构。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步的描述,但并不因此而限制本发明的保护范围。
实施例1:一种蛋白质核酸适配体的筛选方法:将蛋白质包埋在聚苯乙烯96孔板或其它吸附蛋白质的器皿的表面;加入胰蛋白酶或蛋白酶消化降解蛋白质,使蛋白质与寡核苷酸结合复合物脱离容器表面,通过加热灭活蛋白酶并释放ssdna;与蛋白特异性接合的ssdna被富集,筛选得到亲和力高的适配体。
实施例2:一种蛋白质核酸适配体的筛选方法:其具体步骤如下:将蛋白分子包被在96孔聚苯乙烯板中,采用bsa或fbs封闭,再将寡核苷酸序列ssdna加到包被蛋白的板孔中孵育一定时间,用缓冲液将未结合的寡核苷酸序列去除后,用胰蛋白酶稀释液消化96孔聚苯乙烯板中的蛋白-寡核苷酸复合物,再将全部溶液体系在沸水中煮沸至使蛋白变性;通过12000g离心20min除去沉淀来去除蛋白残留;采用pcr富集次级文库,利用不对称pcr及变性聚丙烯酰胺凝胶切胶来制备和纯化寡核苷酸单链;循环以上步骤7-10次后可得到富集的核酸适配体。
实施例3,蛋白质核酸适配体的筛选方法实验:
本实施例以幽门螺杆菌表面重组抗原hp-ag、癌胚天然抗原cea、肿瘤标志物ca125和ca199四种蛋白为靶标,用以下筛选方法进行核酸适配体筛选,具体步骤如下:
1合成80nt的随机单链dna文库和引物;
随机文库:5’-aactacgctcagacagacac-40n-ctgtgatgcgactatctgag-3’;
5’引物:5’-aactacgctcagacagacac-3’
3’引物:5’-ctcagatagtcgcatcacag-3’
2筛选:将四种蛋白质分别用蛋白包被液稀释并包被在96孔聚苯乙烯板中,37℃缓慢振荡2h,移出溶液并用pbs洗涤,加入等体积的1mg/ml牛血清白蛋白,37℃缓慢振荡1h后倒掉蛋白液并用pbs-t洗涤96孔聚苯乙烯板3次。将初始文库12000g离心5min后用结合缓冲液(ph7.6)稀释至50nm,95℃变性5min,冰上冷却15min。将上述处理的文库加入包被蛋白的96孔聚苯乙烯板中,37℃缓慢震荡孵育1h(随筛选轮数增加相应减少孵育时间),用结合缓冲液,pbs和水分别清洗去除未结合的寡核苷酸。ca125和ca199蛋白用胰蛋白酶在37℃下反应3~5min将蛋白消化,煮沸3min使蛋白酶变性,12000g离心20min吸取上清液来去掉残留蛋白酶。hp-ag和cea蛋白则用7m的尿素缓冲液在37℃反应30min将核酸变性。通过醇沉法对得到的寡核苷酸脱盐(加1/10体积的醋酸钠与900μl无水乙醇,-20℃放置1h后12000g离心20min,去上清并加400μl70%的乙醇将沉淀重悬后12000g离心10min,去上清并在离心浓缩机中30℃浓缩1h至试管干燥,加入20μl超纯水将寡核苷酸重溶)得到较纯的能够与蛋白特异性结合的寡核苷酸。
3常规pcr扩增:将步骤(2)中得到的寡核苷酸作为模板进行常规pcr扩增,扩增条件为94℃5min,94℃30s,53℃30s,72℃15s,经10轮循环后72℃5min得到扩增产物;
4制备单链dna文库:将步骤(3)中得到的pcr产物作为模板进行不对称pcr扩增,前后向引物量比例为1:100,将扩增产物跑变性聚丙烯酰胺凝胶电泳,切取目的条带并得到纯化产物,该纯化产物即为dna单链次级文库。
5重复筛选:将步骤4中的dna单链次级文库作为筛选库,进行步骤2中的筛选,并重复步骤2~4多次;
6阴性筛选:在进行一轮筛选后,在第二轮筛选开始加入阴性筛选步骤,该筛选过程为,将步骤4得到的dna单链次级文库加入仅包被1mg/ml的牛血清白蛋白的96孔聚苯乙烯板中孵育1h,将未结合的dna作为单链dna筛选库进行步骤2中的筛选。
7多轮筛选:在筛选的整个过程中,阳性筛选的孵育时间随筛选轮数的增加递减(60min,50min,40min,30min,20min,20min,20min),阴性筛选的孵育时间则递增(20min,30min,40min,50min,60min,60min)。在经过多轮步骤2~6筛选后,最后一轮筛选进行到步骤3后将产物进行测序。
8测序结果分析:对四种蛋白质对应的核酸适配体测序结果进行统计,各列出前5条序列如表1所示。
表1:不同靶蛋白筛选所得适配体中前5条的富集量
根据统计结果可知,以ca125、ca199为靶标的适配体富集比率达到6.77%~8.24%,明显高于hp-ag和cea筛选所得适配体的富集比率(0.15%~0.21%)。
考察1:超微量分光光度计检测本实施例中胰蛋白酶与尿素对蛋白-寡核苷酸复合物分离的分离效果。
将本实施例中hp-ag蛋白包被在96孔聚苯乙烯板,用1mg/ml牛血清白蛋白封闭间隙。将1μm的初始文库95℃变性5min后冰上快速冷却15min。将上述处理的文库加入包被蛋白的96孔聚苯乙烯板中,37℃缓慢震荡孵育1h后用结合缓冲液,pbs和水分别清洗去除未结合的寡核苷酸。ca125和ca199蛋白用胰蛋白酶在37℃下反应3~5min后煮沸3min使蛋白酶变性,通过12000g离心20min吸取上清液来去掉残留胰蛋白酶。hp-ag和cea蛋白则用7m的尿素缓冲液在37℃反应30min使核酸变性。通过醇沉法对得到的寡核苷酸脱盐,得到较纯的能够与蛋白特异性结合的寡核苷酸。(设置四组不加dna的蛋白板为对照,处理条件分别对应hp-ag、cea、ca125和ca199。)用超微量分光光度计检测醇沉之后的核酸含量,检测结果如图1所示,检测结果表明,胰蛋白酶能够更好的将与蛋白结合的寡核苷酸洗脱下来。
考察2:本实施例中以四种蛋白为靶标筛选的适配体测序结果中前五条序列富集所占比例的比较。
对本实施例中以四种蛋白为靶标筛选的适配体测序结果进行统计,并对四种适配体中前五条序列富集所占比例进行比较,结果如图2所示。检测结果表明:用胰蛋白酶来消化蛋白质的方法能够使适配体的富集效果更好。
考察3:用全波长多功能微孔板检测仪检测并用sigmaplot软件分析拟合本实施例中四种蛋白对应的核酸适配体的解离常数。
分别将本实施例中四种蛋白靶标的出现次数最多的四条适配体进行合成,并在5’端添加fam荧光标签,稀释为不同浓度(25nm,50nm,75nm,100nm,125nm,150nm,175nm,200nm,225nm,250nm)与相同浓度的各自的靶蛋白在37℃孵育20min后洗去未结合的序列,加7m的尿素缓冲液使适配体悬浮,在全波长多功能微孔板检测仪中检测适配体在490nm激发光下530nm处的发射值。用sigmaplot软件对数据进行拟合。结果如图3-6所示。检测结果表明,用胰蛋白酶来消化蛋白质的方法能够使适配体的亲和力提高。
考察4:利用idtoligonanlyzer3.1预测本实施例中筛选得到的四种核酸适配体的二级结构。
利用idtoligonanlyzer3.1对本实施例中筛选得到的四种核酸适配体的二级结构进行预测。部分结构图参照图7-9。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种舌癌细胞的核酸适配体及试剂盒的制造方法与工艺
- 金黄色葡萄球菌肠毒素C2的核酸适配体C203及其筛选方法和应用与制造工艺
- 胰岛素核酸适体INS5及其制备方法与制造工艺
- 一种高亲和力兴奋剂核酸适体EPO4及其制备方法与制造工艺
- 一种邻苯二甲酸酯类增塑剂单链DNA核酸适配体及其筛选与表征方法及电化学传感器与制造工艺
- 基于高特异性核酸适体荧光探针INS1胰岛素试剂盒及其检测方法与制造工艺
- 运用核酸适配体与溶菌酶特异性识别并形成G四链体进行荧光显现潜指纹的方法与制造工艺
- 基于快速识别核酸适体荧光探针INS2胰岛素试剂盒及其检测方法与制造工艺
- 一种用于检测沙门氏菌的增敏型核酸适配体试纸条及其制备方法
- 几种识别灭草松的核酸适配体序列及其衍生物的制作方法