一种DNA甲基化测序数据计算解读方法与流程
本发明涉及基因测序技术,具体涉及一种dna甲基化测序数据计算解读方法。
背景技术:
近年来,随着下一代测序技术(nextgenerationsequence,ngs)的广泛应用,基因测序的成本迅速下降,基因测序技术得以在更加广泛的生物、医疗、健康、刑侦、农业等等许多领域被推广应用。其中,基于ngs的脱氧核糖核酸(deoxyribo-nucleicacid,dna)甲基化测序是一个非常有应用价值的分支领域,受到广泛的关注。
甲基化(methylation)是指从活性甲基化合物(如s-腺苷基甲硫氨酸)上将甲基催化转移到其他化合物的过程。甲基化是表观遗传学(epigenetics)的重要研究内容之一。最常见的甲基化修饰有dna甲基化和组蛋白甲基化。脊椎动物的dna甲基化一般发生在cpg位点(sites),即dna序列中的胞嘧啶(cytosine)-磷酸(phosphoricacid)-鸟嘌呤(guanine)位点,经dna甲基转移酶催化胞嘧啶转化为5-甲基胞嘧啶。人类基因中约80%-90%的cpg位点已被甲基化,1%-2%人类基因组是cpg群,并且cpg甲基化与转录活性成反比。dna甲基化能引起染色质结构、dna构象、dna稳定性及dna与蛋白质相互作用方式的改变,能关闭某些基因的活性,去甲基化则诱导了基因的重新活化和表达。例如,已有的研究表明,人的dna甲基化与癌症、衰老、老年痴呆等许多疾病密切相关,异常的甲基化往往是许多疾病的起因。因此,dna甲基化检测对于生物研究、医疗诊断、法医生物学等多个领域具有非常大的应用价值。
近年来,科学家们将传统的甲基化检测技术与目标基因组捕获技术以及ngs高通量测序技术相结合,定量测定人及其它物种基因组中甲基化的技术已经进入实用阶段。目前最为常用的是亚硫酸盐测序法(bisulfitesequencing,bs-seq),即用亚硫酸盐处理基因组dna,则未发生甲基化的胞嘧啶被转化为尿嘧啶(uracil),而甲基化的胞嘧啶不变。随后设计bsp(bisulfitesequencingpcr)引物进行聚合酶链式反应(polymerasechainreaction,pcr),在扩增过程中尿嘧啶全部转化为胸腺嘧啶(thymine),最后对pcr产物进行测序就可以判断cpg位点是否发生甲基化。
基于ngs的dna甲基化测序的数据处理流程包括数据计算和数据解读两大步骤,其中数据计算步骤完成参考基因组的预处理和原始测序数据的去伪、比对、去重等计算任务,以便数据解读时使用;数据解读步骤对数据计算处理后的数据在生物学、医学、健康保健等领域的科学含义进行分析、揭示和解释。
目前,基于ngs的dna甲基化测序技术在应用上存在两个方面的瓶颈:
一个瓶颈是测序数据产出能力远远大于测序数据处理能力。例如,在基于ngs的dna甲基化测序中比较常用的测序数据计算解读软件methy-pipe,对典型的、包含300m个读长为75碱基对(basepair,bp)的短测序片段(reads)的单样本数据,在12核intel至强(xeon)处理器上进行整个计算解读流程中的一个任务——比对(alignment),就耗时大约5小时,而illumina公司的hiseq4000测序仪在5个小时之内能够产出200m个读长为300bp的reads。因此,一方面,测序生成的原始数据每年3到5倍的增加速度已经远超摩尔定律,而测序数据的计算解读又是高输入/输出密集和高计算密集型任务,对测序数据进行实时的、准确的计算解读和传送变得非常困难,面临着巨大的挑战。另一方面,目前典型的测序数据计算解读方法仍然主要是依托高性能的中央处理器(centralprocessingunit,简称cpu),运用基于多线程技术的软件进行处理。但是,在保证准确性的前提下,它能获得的计算解读加速性能仍然无法满足上述挑战的需求。所以,这种方法已经缺乏持续性。
另一个瓶颈是测序数据解读的深度、广度无法满足科研人员的需求,与此同时其可读性又无法满足普通大众的需求。目前测序数据解读的典型方法是基于一个参考基因组,然而,当前使用的参考基因组本身就是基于有限的样本,既不足以代表整个相关物种的多样性,又不完备,因此在数据计算解读时会导致偏差,而且缺乏与其它生物、医学信息的广泛地、深度交叉分析,难以满足专业科研人员深入研究的需求。此外,测序数据解读还基本停留在专业领域,面向非专业的大众,又缺乏可读性,即缺乏对测序数据直接的生物意义和间接的健康影响的通俗易懂、形式多样的解读。
目前,信息处理领域常见的处理器类型有中央处理器(centralprocessingunit,简称cpu)、现场可编程门阵列(fieldprogrammablegatearray,简称fpga)、图形处理器(graphicsprocessingunit,简称gpu)和数字信号处理器(digitalsignalprocessor,简称dsp)。高性能cpu通常都包括多个处理器核(processorcore),从硬件上支持多线程,但是其设计目标还是面向通用应用程序,而相对于特殊的计算,通用应用程序的并行性较小,需要较复杂的控制和较低的性能目标。因此,cpu片上的硬件资源主要还是用于实现复杂的控制而不是计算,没有为特殊功能包含专门的硬件,能够支持的计算并行度不高。fpga是一种半定制电路,优点有:基于fpga进行系统开发,设计周期短、开发费用低;功耗低;生产后可重新修改配置,设计灵活性高,设计风险小。缺点是:实现同样的功能,fpga一般来说比专用集成电路(applicationspecificintegratedcircuit,asic)的速度要慢,比asic电路面积要大。随着技术的发展和演进,fpga向更高密度、更大容量、更低功耗和集成更多硬核知识产权(intellectualproperty,ip)的方向发展,fpga的缺点在缩小,而优点在放大。相比于cpu,fpga可以用硬件描述语言来定制实现、修改和增加并行计算。gpu最初是一种专门用于图像处理的微处理器,能够从硬件上支持纹理映射和多边形着色等图形计算基本任务。由于图形学计算涉及一些通用数学计算,比如矩阵和向量运算,而gpu拥有高度并行化的架构,因此,随着相关软硬件技术的发展,gpu计算技术日益兴起,即gpu不再局限于图形处理,还被开发用于线性代数、信号处理、数值仿真等并行计算,可以提供数十倍乃至于上百倍于cpu的性能。但是目前的gpu存在2个问题:一是,受限于gpu的硬件结构特性,很多并行算法不能在gpu上有效地执行;二是,gpu运行中会产生大量热量,能耗较高。dsp是一种用数字方法对各种信号进行快速分析、变换、滤波、检测、调制、解调等运算处理的微处理器。为此,dsp在芯片内部结构上做了特殊的优化,比如硬件实现高速、高精度的乘法等。随着数字时代的到来,dsp广泛应用于智能设备、资源勘探、数字控制、生物医学、航天航空等各个领域,具有功耗低、精度高、可进行二维与多维处理等特点。综上所述,以上四种计算器件各有特点,又各有局限性。
针对前述基于ngs的dna甲基化测序技术应用发展存在的两个方面的瓶颈,如何利用上述处理器来实现海量测序数据的快速实时、精准深入、通俗易懂、形式多样的计算解读,则已经成为一项亟待解决的关键技术问题。
技术实现要素:
本发明要解决的技术问题:针对现有技术的上述问题,提供一种快速实时、精准深入、通俗易懂、形式多样的dna甲基化测序数据计算解读方法。
为了解决上述技术问题,本发明采用的技术方案为:
一种dna甲基化测序数据计算解读方法,实施步骤包括:
1)对用于dna甲基化测序的参考基因组数据和原始的测序样本数据进行预处理;
2)通过cpu调用fpga上硬件实现的比对器将预处理后的测序样本数据和参考基因组进行比对;
3)通过cpu调用gpu上编程实现的识别器、fpga上硬件实现的深度学习模型基于比对结果进行甲基化识别;
4)对结果数据进行可视化,通过cpu调用fpga上硬件实现的深度学习模型对结果数据反映的甲基化功能进行挖掘和分析,且cpu调用gpu上编程处理分析挖掘相关的视频、动画和显示任务,cpu调用dsp上编程处理和分析挖掘相关的图形、图像和音频任务。
优选地,步骤1)对参考基因组数据进行预处理的详细步骤包括:对参考基因组数据进行针对甲基化的生信转换,通过cpu调用fpga上硬件实现的索引生成器为生信转换后的参考基因组数据生成用于后续比对任务的索引,输出生信转换后的参考基因组数据及其索引。
优选地,步骤1)对原始的测序样本数据进行预处理的详细步骤包括:对原始的测序样本数据进行数据质量控制得到可靠样本数据,所述数据质量控制包括修剪dna甲基化测序原始样本数据,移除reads上的接头序列和低质量的碱基,对可靠样本数据进行针对甲基化的生信转换,输出生信转换后的dna甲基化的测序可靠样本数据。
优选地,步骤1)中对用于dna甲基化测序的参考基因组数据和原始的测序样本数据进行预处理是在cpu上基于不同的线程并发执行的。
优选地,步骤2)的详细步骤包括:
2.1)读取上述生信转换后的参考基因组数据及其索引;读取上述修剪后的dna甲基化测序可靠样本数据和生信转换后的dna甲基化测序可靠样本数据;
2.2)根据上述生信转换后的参考基因组数据的索引,通过cpu调用fpga上硬件实现的比对器将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行精确比对,建立上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据之间的映射关系;
2.3)判断dna甲基化测序样本数据是否为双端reads,如果是双端reads,则跳转执行步骤2.4);否则为单端reads,跳转执行步骤2.5);不明确的reads则直接移除;
2.4)对于双端reads,在不匹配数受控以及双端reads之间的读距受控条件下,根据上述生信转换后的参考基因组数据的索引,再次通过cpu调用fpga上硬件实现的比对器将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行比对,增加建立上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据之间的映射关系;跳转执行步骤2.6);
2.5)对于单端reads,在不匹配数受控的条件下,根据上述生信转换后的参考基因组数据的索引,再次通过cpu调用fpga上硬件实现的比对器将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行比对,增加建立上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据之间的映射关系;
2.6)根据上述比对结果,移除重复的reads;
2.7)根据上述比对结果,生成基本的统计信息,所述基本的统计信息包括比对率统计、甲基化密度水平统计的至少一种;
2.8)输出上述数据比对结果和基本统计信息。
优选地,步骤3)的详细步骤包括:
3.1)读取上述生信转换后的参考基因组数据及其索引;读取上述修剪后的dna甲基化测序可靠样本数据和生信转换后的dna甲基化测序可靠样本数据;读取上述数据比对的结果信息;读取上述基本统计结果信息;
3.2)识别每个有效的甲基化位点;
3.3)进行各种指定的特殊甲基化区的识别;
3.4)通过cpu调用fpga上硬件实现的深度学习模型负责并行执行asms识别;
3.5)输出甲基化识别结果信息。
优选地,步骤3.3)进行各种指定的特殊甲基化区的识别时包括2个并发执行的子任务:子任务①:进行甲基化密度低、基因表达量高的dna区的低甲基化区识别,以及甲基化密度高、基因表达量低的dna区的高甲基化区识别;子任务②:通过cpu进行在多种样本中基因组里甲基化状态不相同的区域的差异甲基化区识别,以及通过cpu调用基于gpu上编程实现的识别器负责并行执行dmrs识别来实现个体间dmrs的识别,其中差异甲基化区被看作为可能参与基因转录水平调控的功能性区域。
优选地,步骤4)的详细步骤包括:
4.1)读取上述基本统计结果信息、甲基化识别结果信息;
4.2)通过cpu调用gpu和dsp将基本统计结果信息和甲基化识别结果信息进行可视化处理,且cpu调用gpu上编程处理分析挖掘相关的视频、动画和显示任务,cpu调用dsp上编程处理和分析挖掘相关的图形、图像和音频任务;
4.3)通过cpu调用fpga上硬件实现的深度学习模型负责并行执行甲基化功能分析和挖掘;且cpu调用gpu上编程处理分析挖掘相关的视频、动画和显示任务,cpu调用dsp上编程处理和分析挖掘相关的图形、图像和音频任务;
4.4)输出上述各种分析数据和深度解读报告。
本发明dna甲基化测序数据计算解读方法具有下述优点:
1、对于dna甲基化测序数据计算解读流程中的每个耗时瓶颈,基于任务本身的算法或模型并行性,结合cpu、fpga、gpu和dsp这四种处理器的特点,分别进行了有针对性的并行加速,提高了dna甲基化测序数据计算解读的实时性。
2、对于dna甲基化测序数据计算解读流程中的甲基化识别和甲基化功能分析与挖掘,基于任务本身的目标,结合cpu、fpga、gpu和dsp这四种处理器的特点,引入深度学习模型,加快和丰富了深度学习源数据的处理,提高了dna甲基化测序数据计算解读的深度和广度。
3、对于dna甲基化测序数据计算解读流程中的数据可视化,结合cpu、gpu和dsp这三种处理器的特点,配合完成可视化处理,提高了dna甲基化测序数据可视化的实时性,丰富了dna甲基化测序数据可视化的多样性。
附图说明
图1为本发明实施例dna甲基化测序数据计算解读的总流程示意图。
图2为本发明实施例dna甲基化测序数据计算解读的预处理流程示意图。
图3为本发明实施例dna甲基化测序数据计算解读的数据比对流程示意图。
图4为本发明实施例dna甲基化测序数据计算解读的甲基化识别流程示意图。
图5为本发明实施例dna甲基化测序数据计算解读的识别数据可视化和甲基化功能分析挖掘流程示意图。
具体实施方式
如图1所示,本实施例的dna甲基化测序数据计算解读方法的实施步骤包括:
1)对用于dna甲基化测序的参考基因组数据和原始的测序样本数据进行预处理;
2)通过cpu调用fpga上硬件实现的比对器将预处理后的测序样本数据和参考基因组进行比对(alignment);这个步骤需要使用cpu和fpga这两种处理器;
3)通过cpu调用gpu上编程实现的识别器、fpga上硬件实现的深度学习(deeplearning,dl)模型基于比对结果进行甲基化识别;这个步骤需要使用cpu、fpga和gpu这三种处理器;
4)对结果数据进行可视化,通过cpu调用fpga上硬件实现的深度学习模型对结果数据反映的甲基化功能进行挖掘和分析,且cpu调用gpu上编程处理分析挖掘相关的视频、动画和显示任务,cpu调用dsp上编程处理和分析挖掘相关的图形、图像和音频任务。这个步骤需要使用cpu、fpga、gpu和dsp这四种处理器。
如图1所示,本实施例中步骤1)和2)完成dna甲基化测序数据的计算任务;步骤3)和4)完成dna甲基化测序数据的解读任务。以下详细步骤描述中,如果未加特殊说明,缺省使用的是cpu。
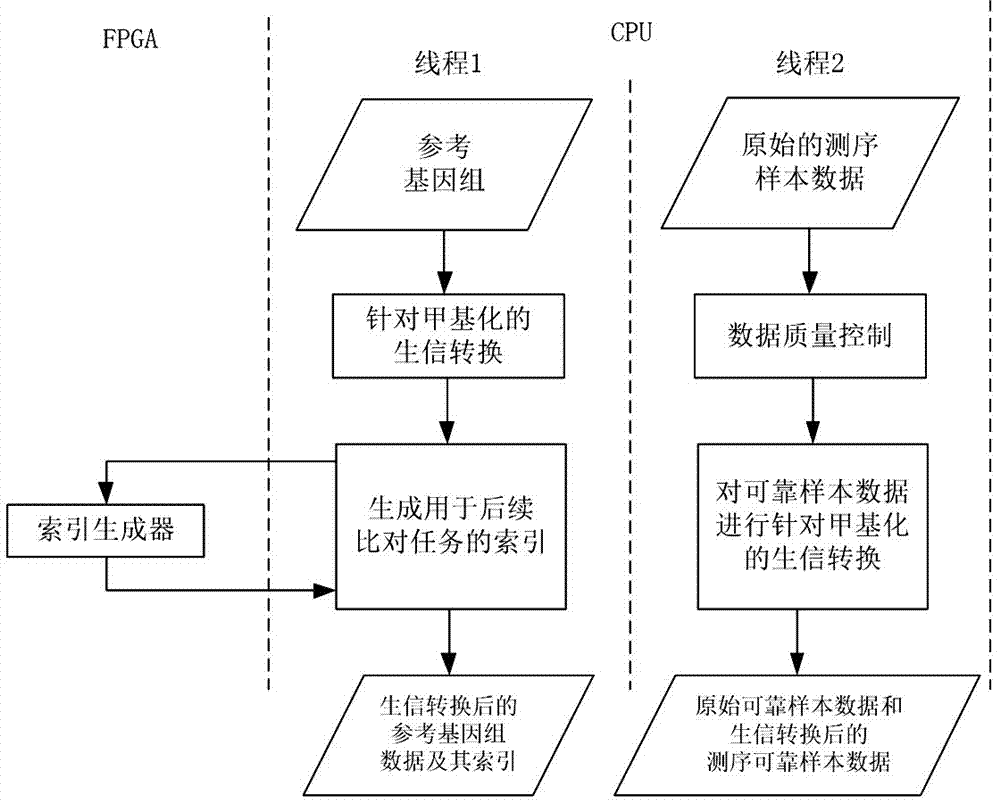
步骤1)包括2个并发执行的子任务:参考基因组的预处理和dna甲基化测序原始样本数据的预处理。如图2所示,本实施例中步骤1)中对用于dna甲基化测序的参考基因组数据和原始的测序样本数据进行预处理是在cpu上基于不同的线程(线程1和线程2)并发执行的。
参见图2,步骤1)对参考基因组数据进行预处理的详细步骤包括:对参考基因组数据进行针对甲基化的生信(insilico)转换,通过cpu调用fpga上硬件实现的索引生成器为生信转换后的参考基因组数据生成用于后续比对任务的索引,输出生信转换后的参考基因组数据及其索引。这个步骤需要使用cpu和fpga这两种处理器;对参考基因组数据进行针对甲基化的生信(insilico)转换时,如果采用的是bs-seq测序技术,需要将参考基因组数据中所有代表未发生甲基化胞嘧啶(cytosine)的c转换为代表胸腺嘧啶(thymine)的t。若dna为双链(watsonandcrickstrands),则2条链都需要进行转换。为生信转换后的参考基因组数据生成用于后续比对任务的索引时,cpu负责索引生成的流程控制,fpga上硬件实现的索引生成器负责并行生成索引,cpu和fpga之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入fpga,能够并行加速完成其中的计算密集任务。虽然在一段时间内,特定的参考基因组数据相对固定,可以生成索引一次,再在同类应用中反复使用,但是,一旦参考基因组数据有了更新,必须重新生成新索引。
参见图2,步骤1)对原始的测序样本数据进行预处理的详细步骤包括:对原始的测序样本数据进行数据质量控制得到可靠样本数据(cleandatas),所述数据质量控制包括修剪dna甲基化测序原始样本数据,移除reads上的接头序列(theadaptersequence)和低质量的碱基(bases),对可靠样本数据进行针对甲基化的生信转换,输出生信转换后的dna甲基化的测序可靠样本数据。对经过上述修剪后得到的dna甲基化测序可靠样本数据进行针对甲基化的生信转换时,如果采用的是bs-seq测序技术,需要将dna甲基化测序可靠样本数据中所有代表胞嘧啶(cytosine)的c转换为代表胸腺嘧啶(thymine)的t。
如图3所示,步骤2)的详细步骤包括:
2.1)读取上述生信转换后的参考基因组数据及其索引;读取上述修剪后的dna甲基化测序可靠样本数据和生信转换后的dna甲基化测序可靠样本数据;
2.2)根据上述生信转换后的参考基因组数据的索引,通过cpu调用fpga上硬件实现的比对器1将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行精确比对,建立上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据之间的映射关系;通过cpu调用fpga上硬件实现的比对器1进行比对时,cpu负责数据精确比对的流程控制,fpga上硬件实现的比对器1负责并行执行数据精确比对,cpu和fpga之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,本实施例通过加入fpga上硬件实现的比对器1,能够并行加速完成其中的计算密集任务。
2.3)判断dna甲基化测序样本数据是否为双端(paired-end)reads,如果是双端reads,则跳转执行步骤2.4);否则为单端(single-end)reads,跳转执行步骤2.5);不明确(ambiguous)的reads则直接移除;
2.4)对于双端reads,在不匹配(mismatches)数受控(例如不超过2个)以及双端reads之间的读距受控(例如在50到600个bases之间)条件下,根据上述生信转换后的参考基因组数据的索引,再次通过cpu调用fpga上硬件实现的比对器2将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行比对,增加建立上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据之间的映射关系;跳转执行步骤2.6);本实施例中将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行比对时,cpu负责数据比对的流程控制,fpga上硬件实现的比对器2负责并行执行数据比对,cpu和fpga之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入fpga,能够并行加速完成其中的计算密集任务;
2.5)对于单端reads,在不匹配(mismatches)数受控(通常不超过2个)的条件下,根据上述生信转换后的参考基因组数据的索引,再次通过cpu调用fpga上硬件实现的比对器2将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行比对,增加建立上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据之间的映射关系;通过cpu调用fpga上硬件实现的比对器2将上述生信转换后的dna甲基化测序可靠样本数据和上述生信转换后的参考基因组数据进行比对时,cpu负责数据比对的流程控制,fpga上硬件实现的比对器2负责并行执行数据比对,cpu和fpga之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入fpga,能够并行加速完成其中的计算密集任务;
2.6)根据上述比对结果,移除重复(duplicate)的reads;
2.7)根据上述比对结果,生成基本的统计信息,所述基本的统计信息包括比对率(alignmentrate)统计,甲基化密度水平(methylationdensitylevel)统计的至少一种;
2.8)输出上述数据比对结果和基本统计信息。
本实施例中,步骤3)基于比对结果进行甲基化识别需要使用cpu、fpga和gpu这三种处理器;如图4所示,步骤3)的详细步骤包括:
3.1)读取上述生信转换后的参考基因组数据及其索引;读取上述修剪后的dna甲基化测序可靠样本数据和生信转换后的dna甲基化测序可靠样本数据;读取上述数据比对的结果信息;读取上述基本统计结果信息;
3.2)识别每个有效的甲基化位点;例如,dna甲基化主要形成5-甲基胞嘧啶(5-mc)和少量的n6-甲基腺嘌呤(n6-ma)及7-甲基鸟嘌呤(7-mg)。在真核生物中,5-mc主要出现在cpg序列、cpxpg、cca/tgg和gatc中;
3.3)进行各种指定的特殊甲基化区的识别;
3.4)通过cpu调用fpga上硬件实现的深度学习模型负责并行执行asms(allele-specificmethylatedregions,等位基因特异性甲基化区)识别;在asms识别时,cpu负责asms识别的流程控制,fpga上硬件实现的深度学习模型负责并行执行asms识别,cpu和fpga之间有数据和指令交互。使用深度学习方法进行asms识别,可以支持基于大数据的统计学模型,能够实现更加准确的asms分类和预测。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入fpga,硬件实现深度学习模型,能够并行加速完成深度学习任务;
3.5)输出甲基化识别结果信息。
本实施例中,步骤3.3)进行各种指定的特殊甲基化区的识别时包括2个并发执行的子任务:子任务①:进行甲基化密度低、基因表达量高的dna区的低甲基化区(hypo-methylatedregions)识别,以及甲基化密度高、基因表达量低的dna区的高甲基化区(hyper-methylatedregions)识别;子任务②:通过cpu进行在多种样本中基因组里甲基化状态不相同的区域的差异甲基化区识别,以及通过cpu调用基于gpu上编程实现的识别器负责并行执行dmrs(differentiallymethylatedregions,dmrs,差异甲基化区)识别来实现个体间dmrs(inter-dmrs)的识别,其中差异甲基化区被看作为可能参与基因转录水平调控的功能性区域。子任务②通过cpu进行在多种样本中基因组里甲基化状态不相同的区域的差异甲基化区识别,以及通过cpu调用基于gpu上编程实现的识别器负责并行执行dmrs识别时,cpu负责dmrs识别的流程控制,gpu上编程实现的识别器负责并行执行dmrs的识别,cpu和gpu之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入gpu,能够并行加速完成其中的计算密集任务;
如图5所示,步骤4)的详细步骤包括:
4.1)读取上述基本统计结果信息、甲基化识别结果信息;
4.2)通过cpu调用gpu和dsp将基本统计结果信息和甲基化识别结果信息进行可视化处理,且cpu调用gpu上编程处理分析挖掘相关的视频、动画和显示任务,cpu调用dsp上编程处理和分析挖掘相关的图形、图像和音频任务;进行可视化处理,能够以各种科学、直观、生动的方式表现数据的含义。例如:各种甲基化位点的分布及比例,不同甲基化区的分布及比例,等等。本实施例中通过cpu调用gpu和dsp将基本统计结果信息和甲基化识别结果信息进行可视化处理时,cpu负责可视化的流程控制;gpu上编程处理视频、动画和显示等任务,cpu和gpu之间有数据和指令交互;dsp上编程处理图形、图像和音频等任务,cpu和dsp之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入gpu和dsp,它们和cpu相互配合,能够并行加速完成多媒体处理任务;
4.3)通过cpu调用fpga上硬件实现的深度学习模型负责并行执行甲基化功能分析和挖掘;且cpu调用gpu上编程处理分析挖掘相关的视频、动画和显示任务,cpu调用dsp上编程处理和分析挖掘相关的图形、图像和音频任务;
甲基化功能分析和挖掘,即基于上述分析数据,进一步深入分析相关的甲基化功能,并扩大外延,在已知的知识之外,再挖掘未知的关联。例如:已知甲基化和癌症存在关联,这一步骤就进一步深入分析各种甲基化模式在癌症中的作用,更进一步深入分析各种甲基化模式在各种细分癌症中的作用;挖掘甲基化和其它疾病之间是否存在关联,等等。
本实施例中通过cpu调用fpga上硬件实现的深度学习模型负责并行执行甲基化功能分析和挖掘时,cpu负责分析和挖掘的流程控制;fpga上硬件实现的深度学习模型负责并行执行分析和挖掘,cpu和fpga之间有数据和指令交互。使用深度学习方法进行分析和挖掘,可以支持基于大数据的统计学模型,能够实现更加准确的分析和挖掘;gpu上编程处理分析挖掘相关的视频、动画和显示等任务,cpu和gpu之间有数据和指令交互;dsp上编程处理和分析挖掘相关的图形、图像和音频等任务,cpu和dsp之间有数据和指令交互。只使用cpu时,这一步骤是整个dna甲基化测序数据计算解读流程中的耗时瓶颈之一,加入fpga、gpu和dsp,它们和cpu相互配合,能够并行加速完成深度学习及相关多媒体处理任务;
4.4)输出上述各种分析数据和深度解读报告。
综上所述,本实施例的dna甲基化测序数据计算解读方法能够满足测序数据计算解读的快速实时、精准深入、通俗易懂、形式多样的要求,为dna甲基化测序技术的应用推广助力。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!