抗活性型GIP抗体的制作方法
本发明涉及一种与活性型gip特异性地反应的抗体其利用。
背景技术:
gip(肠抑胃肽(gastricinhibitorypolypeptide)或葡萄糖依赖性促胰岛素多肽(glucose-dependentinsulinotropicpolypeptide))为属于胰高血糖素(glucagon)-胰泌素(secretin)家族的消化道激素之一。gip与glp-1(胰高血糖素样肽1)一起称为肠促胰岛素(incretin),在脂质或糖质的摄食时由存在于小肠的k细胞分泌。
已知gip会促进胰岛β细胞的胰岛素分泌,并激发胰岛素存在下的脂肪细胞对葡萄糖的摄入。因此,也认为gip的作用成为肥胖的一个主要原因,实际上,有抑制gip的功能与抑制肥胖的报告(非专利文献1)。
进一步,报告有gip成为胰岛素抵抗性的原因之一(非专利文献1)。在胰岛素抵抗发病时,由胰岛素导致的糖的吸收作用降低,其结果,引起高胰岛素血症。高胰岛素血症也据说是与以肥胖为首的各种的生活习惯病的发病有关的根本原因,从生活习惯病的风险减轻的方面出发,胰岛素抵抗性的预防和改善也很重要。
另外,已知gip具有胃酸分泌抑制作用或胃运动抑制作(专利文献1~3),认为gip的上升抑制对饭后的消化促进或胃积食的改善有效。
因此,测定血液中的gip的浓度在这样的疾病或其治疗药的评价方面很重要。
但是,已知在gip中存在具有生理活性的活性型和不具有生理活性的非活性型。即,在人方面,前原gip(prepro-gip)由分布于胃、十二指肠、小肠上部的k细胞受到处理而成为活性型gip(也记为“gip(1-42)”),其后,通过由dpp-4将n末端的2个氨基酸切断而成为非活性型的gip(也记为“gip(3-42)”)。因此,生物体内gip的定量通过测定活性型和非活性型的总量,不能准确地得知治疗药的效果或生活习惯病的风险等。
一直以来,作为测定活性型gip的手段,市售有活性型gip定量试剂盒(ibl公司),但存在以下问题:1)饭后的血中活性型gip浓度高于该试剂盒的定量界限;2)稀释率不同的情况下的变动系数超过10%;3)稀释率越高,测定值越升高。另外,最近,报道有将由gip(1-42)的n末端侧6个氨基酸残基构成的肽作为免疫原制作的抗活性型gip单克隆抗体利用elisa法可以定量5~4000pg/ml浓度的活性型gip(非专利文献2)。另外,报道有将由gip(1-42)的n末端侧7个氨基酸残基构成的肽作为免疫原制作的抗活性型gip单克隆抗体利用elisa法定量7~500pg/ml浓度的活性型gip(专利文献4)。
(专利文献1)国际公开第01/87341号
(专利文献2)日本特表2006-213598号公报
(专利文献3)日本特开平5-95767号公报
(专利文献4)日本特开2013-138638号公报
(非专利文献1)miyawakik等,natmed.8(7):738-42,2002
(非专利文献2):jasons.troutt等,clinicalchemistry,57(6):849-855(2011)
技术实现要素:
本发明涉及以下的1)~3)。
1)一种抗体,其为结合于活性型gip且与非活性型gip实质上不结合的抗活性型gip抗体,其中,至少识别选自序列号5表示的氨基酸序列的第8~10号的氨基酸中的1个以上,且在h链上含有由下述(1)表示的氨基酸序列或其保守序列突变构成的区域。
emnpsdgrthfne(1)
2)一种活性型gip的检测或测定方法,其使用上述1)的抗体。
3)一种活性型gip的检测或测定试剂,其含有上述1)的抗体。
附图说明
图1是使用了本发明的抗活性型gip抗体的夹心elisa的标准曲线。
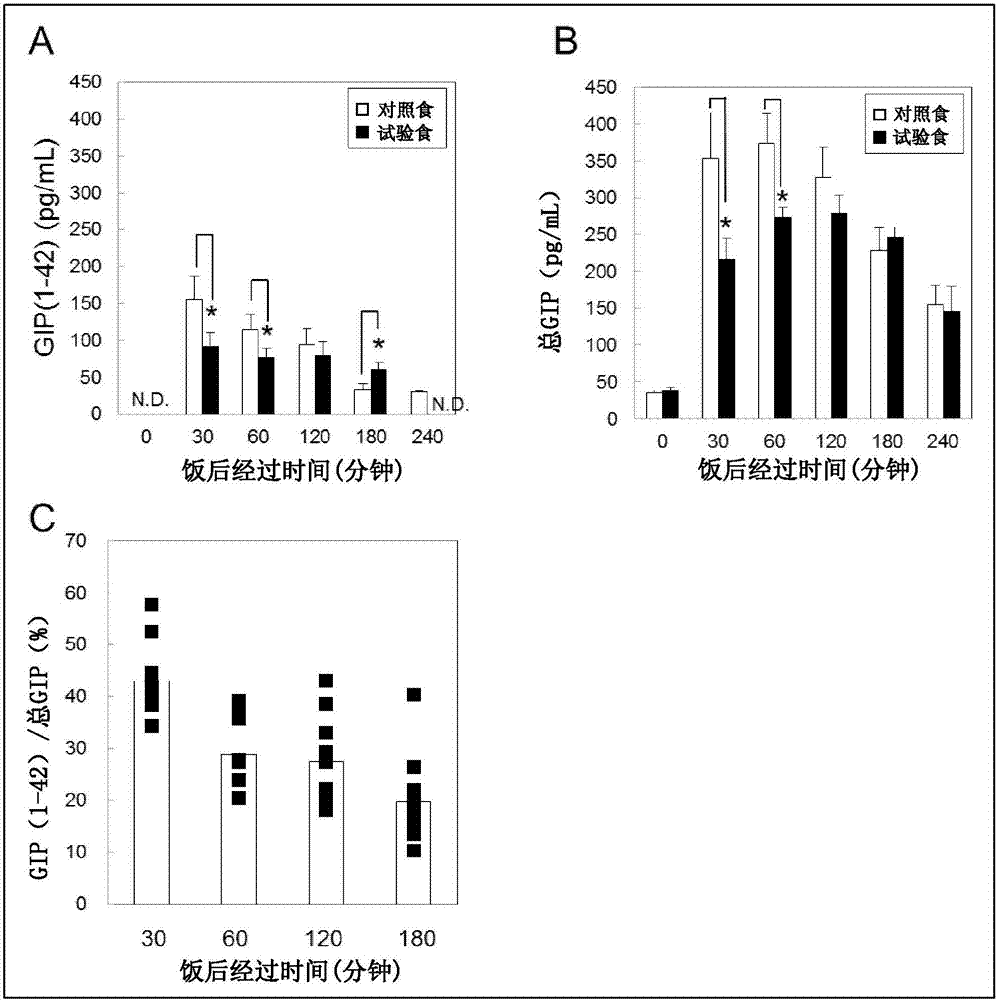
图2是使用了本发明的抗活性型gip抗体的健康人人血中活性型gip的定量。对照食及试验食摄取后的(a)血中gip(1-42)、(b)血中总gip值(n=5,同以被验者的交叉试验)。(c)饭后gip(1-42)相对于总gip的比例(%)
图3本发明抗活性型gip抗体的表位分析。
具体实施方式
本发明涉及提供一种能够高精度地检测活性型gip的抗活性型gip抗体。
本发明人等对特异性地识别活性型gip的抗体的获取进行了各种研究,其结果识别了与迄今为止的抗体不同的表位,并成功取得具有高特异性的新型的抗活性型gip抗体。
通过使用本发明的抗体,可以以高精度将活性型gip与非活性型gip区别从而进行检测。因此,根据本发明,可以进行生物体试样中的活性型gip的测定、活性型gip值的异常的检测、进而以活性型gip作为指标的治疗药的奏效性评价等。另外,通过计算活性型gip相对于总gip的比例,可以估计dpp-4活性。
本发明中“活性型gip”是指哺乳类的活性型gip,优选为人的活性型gip。人活性型gip为由42个的氨基酸构成的肽(“gip(1-42)”)(序列号5)。另一方面,“非活性型gip”是指活性型gip的n末端的2个氨基酸(ya)被切断后的肽(“gip(3-42)”)。
本发明中的抗活性型gip抗体为结合于活性型gip且与非活性型gip实质上不结合的抗体。
与非活性型gip实质上不结合可以通过使用蛋白质印迹(westernblotting)、免疫沉淀、免疫组织化学染色、及elisa等方法测定被验抗体和非活性型gip的结合来进行判断。具体而言,如果在将被验抗体相对于活性型gip的结合量设为100%的情况下,被验抗体相对于的非活性型gip的结合量至多为10%以下,优选5%以下,进一步优选1%以下,进一步更优选0.1%时,则可以认为其“与非活性型gip实质上不结合”。
另外,利用夹心elisa(sandwichelisa)的测定中,相对于非活性型gip溶液,可以使用例如抗总gip抗体作为捕捉抗体、生物素标记抗活性型gip单克隆抗体作为检测抗体来进行。
另外,本发明的抗体为识别活性型gip(序列号5)的n末端至第8号以后的氨基酸的抗体,为至少识别选自第8~10号(sdy)中的1个以上的氨基酸的抗体。
进一步,本发明的抗体在h链上含有由下述(1)表示的氨基酸序列或其保守序列突变构成的区域。
emnpsdgrthfne(1)
(1)中的字母文字是指氨基酸的一种文字标记,序列以从n末端至c末端方向的顺序记载。在此,i表示异亮氨酸,l表示亮氨酸,f表示苯基丙氨酸,v表示缬氨酸,a表示丙氨酸,t表示苏氨酸,d表示天门冬氨酸,q表示谷酰胺,e表示谷氨酸,m表示蛋氨酸,n表示天门冬酰胺,p表示脯氨酸,s表示丝氨酸,g表示甘氨酸,r表示精氨酸,h表示组氨酸。
在本发明中,“保守序列突变”是指对由突变前的氨基酸序列构成的抗体的反应性不产生显著的影响或不使其改变的氨基酸突变。这样的保守序列突变中包含1~多个,优选为1~3个,更优选1个的氨基酸的取代、加成及缺失。作为进行了该保守序列突变的氨基酸序列,可列举与突变前的氨基酸序列具有90%以上,优选为95%以上,进一步优选为98%以上的序列同一性的氨基酸序列。该突变可以利用部位特异的变异诱发及pcr介导变异诱发那样的本技术领域中公知的标准的技术而导入到本发明的抗体中。作为保守氨基酸取代,可举出将氨基酸残基取代为具有类似的侧链的氨基酸残基(氨基酸残基的家族)。该氨基酸残基的家族在本技术领域中被定义,包含具有碱基性侧链(例如赖氨酸、精氨酸、组氨酸)、酸性侧链(例如天门冬氨酸、谷氨酸)、非荷电极性侧链(例如甘氨酸、天门冬酰胺、谷酰氨、丝氨酸、苏氨酸、酪氨酸、半胱氨酸、色氨酸)、非极性侧链(例如丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯基丙氨酸、蛋氨酸)、β-分支侧链(例如苏氨酸、缬氨酸、异亮氨酸)、及芳香族侧链(例如酪氨酸、苯基丙氨酸、色氨酸、组氨酸)的氨基酸。
上述(1)表示的氨基酸序列编码由表示h链可变区的序列号2所示的氨基酸序列的第50~62号的13氨基酸残基构成的区域。
本发明的抗体只要具有上述反应性,也可以为被该抗体的片段、例如f(ab')2、f(ab')、单链fv(scfv)、vh及vl中的半胱氨酸残基取代的氨基酸残基经由二硫键而结合的二硫键fv(dsfv)或它们的聚合物、或scfv进行了二聚化后的二聚化v区域(双链抗体,diabody)。进而,只要具有上述反应性,则含有抗活性型gip抗体的一部分(即,具备构成抗体的氨基酸序列的一部分)且具有上述反应性的肽也包含于该抗体的碎片中。
另外,本发明抗体的免疫球蛋白类别没有特别限定,可以为igg、igm、iga、ige、igd、igy的任一种免疫球蛋白类别,优选为igg。另外,本发明的抗体也包含任一种同种型的抗体。
另外,本发明的抗体可以为非人动物的抗体、人型嵌合抗体、人源化抗体及人源抗体的任一种。作为非人动物的抗体,可以列举例如小鼠、大鼠、仓鼠、天竺鼠等的抗体,优选为小鼠的抗体。
在此,“人型嵌合抗体”为以将源自非人动物且与活性型gip特异性结合的抗体的恒定区域以具有与人的抗体相同的恒定区域的方式进行基因工程地突变的抗体,优选为人/小鼠嵌合抗体。另外,“人源化抗体”为将源自非人动物且与活性型gip特异性地结合的抗体的h链和l链的互补识别区域(cdr)以外的一级结构通过基因工程突变为对应于人的抗体的一级结构的抗体。另外,“人源抗体”是指作为完全源自人的抗体基因的表达产物的人源抗体。
作为本发明的抗体,进一步优选包含由序列号2表示的氨基酸序列或其保守序列突变构成的区域作为h链可变区。
而且,进一步优选包含由序列号2表示的氨基酸序列或其保守序列突变构成的区域作为h链可变区,且包含由序列号4表示的氨基酸序列或其保守序列突变构成的区域作为l链可变区。
在本发明中,作为另外一种方式,提供以下的1)及2)表示的抗体构成成分及其基因。特别是由序列号2表示的氨基酸序列或其保守序列突变构成的多肽(h链可变区)包含上述(1)表示的氨基酸序列,因此,优选作为担负本发明的抗体的功能的抗体片段。
1)以下的多肽及编码其的基因
(a)为由序列号2表示的氨基酸序列构成的多肽、或与该氨基酸序列具有90%以上,更优选为95%以上,进一步优选为98%以上的同一性的氨基酸序列的多肽,且该多肽担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能。
(b)为由序列号1表示的碱基序列构成的dna、或由与该碱基序列具有90%以上,更优选为95%以上,进一步优选为98%以上的同一性的碱基序列构成的dna,且该dna编码担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能的多肽。
2)以下的多肽及编码其的基因
(c)为由序列号4表示的氨基酸序列构成的多肽、或与该氨基酸序列具有90%以上,更优选95%以上,进一步优选98%以上的同一性的氨基酸序列的多肽,且该多肽担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能。
(d)为由序列号3表示的碱基序列构成的dna、或由与该碱基序列具有90%以上,更优选95%以上,进一步优选98%以上的同一性的碱基序列构成的dna,且该dna编码担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能的多肽。
作为由与上述的序列号1或3表示的碱基序列具有90%以上的同一性的碱基序列构成的dna,例如可举出在严格的条件下与序列号1或3表示的碱基序列进行杂交的dna。此时的杂交的条件可举出例如在6×ssc(0.9mnacl,0.09m柠檬酸三钠)或6×sspe(3mnacl,0,2mnah2po4,20mmedta·2na,ph7.4)中在42℃下进行杂交,之后在42℃下用0.5×ssc进行清洗的条件。
另外,在本发明中,氨基酸序列或碱基序列间的同一性是指在比对2个氨基酸序列或碱基序列时在两个序列中同样氨基酸残基或碱基存在的位置的数目相对于全长氨基酸残基数或碱基数的比例(%)。具体而言,例如可以通过利用李普曼-皮尔逊法(lipman-pearson法;science,227,1435,(1985))进行计算,并使用遗传信息处理软件genetyx-win(ver.5.1.1;软件开发)的同源性分析(searchhomology)程序,将比较的单位大小(unitsizetocompare)(ktup)设为2进行分析而算出。
作为包含由序列号2表示的氨基酸序列构成的区域作为h链可变区、且包含由序列号4表示的氨基酸序列构成的区域作为l链可变区的抗活性型gip抗体,可举出由后述实施例1所示的杂交瘤9b9h5-b9株产生的单克隆抗体。
本发明的抗活性型gip抗体可以使用公知的手段作为单克隆抗体得到。作为源自哺乳动物的单克隆抗体,包含由杂交瘤产生的抗体、以及设计抗体基因或抗体片段基因并使用公知的基因工程的方法生产的抗体。
作为基因工程的方法,可举出:通过制成将编码h链可变区的dna(例如由序列号1表示的碱基序列构成的dna)和编码l链可变区的dna(例如由序列号3表示的碱基序列构成的dna)分别插入于适当的载体的启动子下游后的重组体载体,由将其导入于宿主细胞的转化体制造h链及l链,将它们用具有可能性的肽连结;或通过将编码h链可变区的dna(由例如序列号1表示的碱基序列构成的dna)和编码l链可变区的dna(例如由序列号3表示的碱基序列构成的dna)用公知的编码接头的dna连接而制成插入于适当的载体的启动子下游的重组体载体,并将其在宿主细胞内进行表达等,从而生产具有抗原结合能力的单链的重组抗体蛋白质(scfv)。(参照maccfferty,j.etal.,nature,348,552-554,1990;timclacksonetal,nature,352,642-628,1991等)。另外,进一步,可以为生产将编码可变区的dna和编码恒定区域的dna结合而表达的蛋白质的方法。此时,恒定区域可以为与源自可变区的抗体同样的抗体,或可以为源自不同的抗体的抗体。
如上所述,用于制备功能上同等的多肽的氨基酸变异的导入例如可以使用部位特异的变异诱发法等来进行。
抗活性型gip抗体产生杂交瘤基本上可以使用公知技术如下地制作。
例如,可以根据需要通过将具有活性型gip或其n末端的氨基酸序列的肽(由序列号5的第1~15号的氨基酸序列构成的肽)与适当的载体蛋白质、例如钥孔血蓝蛋白(klh)或牛血清白蛋白等结合,通过进一步提高免疫原性,对非人哺乳动物进行免疫而制作。另外,用作致敏抗原(免疫源)的活性型gip或上述肽可以通过基因工程的方法或化学合成来制作。
作为用致敏抗原进行免疫的哺乳动物,没有特别地限定,优选考虑作为细胞融合中使用的母细胞的哺乳动物的骨髓瘤细胞的相容性而来选择,一般而言,可使用啮歯类的动物,例如小鼠、大鼠、仓鼠等。
在将致敏抗原对动物进行免疫中,可按照公知的方法进行。例如,可通过将致敏抗原注射于哺乳动物的腹腔内、或皮下来进行。具体而言,将致敏抗原用pbs(磷酸盐缓冲盐水,phosphate-bufferedsaline)或生理盐水等稀释为适当量,将悬浮的物质根据所期望适量混合通常的佐剂(例如费氏完全佐剂),乳化后,给药于动物的皮下、皮内、腹腔等而暂时刺激后,根据需要重复进行同样的操作。抗原的给药量根据给药途径、动物种类来适当决定,但优选通常的给药量为每次10μg~1mg左右。这样进行免疫,并确认到血清中所期望的抗体水平上升之后,从抗体水平上升后的哺乳动物中取出免疫细胞,进行细胞融合。作为进行细胞融合时的优选免疫细胞,特别地列举脾细胞。
作为与上述免疫细胞融合的另一个母细胞的哺乳动物的骨髓瘤细胞可以适当使用已经公知的各种细胞株、例如p3x63、ns-1、mpc-11、sp2/0等。
上述免疫细胞和骨髓瘤细胞的细胞融合可以按照公知的方法,例如科勒等的方法(kohleretal.,nature,vol,256,p495-497(1975))等来进行。即,通过在聚乙二醇(平均分子量1000~6000的peg,30~60%浓度)、仙台病毒(hvj)等的细胞融合促进剂的存在下,根据期望添加二甲基亚砜等辅助剂,在rpmi1640培养液、mem培养液等营养培养液中将免疫细胞和骨髓瘤细胞进行混合,从而形成融合细胞(杂交瘤)。
将通过融合而形成的杂交瘤在含有次黄嘌呤、胸甙及氨基蝶呤的培养基(hat培养基)等选择培养基上培养1天~7天,与未融合细胞进行分离。将得到的杂交瘤进一步从其产生的抗体(结合于活性型gip、且与非活性型gip实质上不结合的抗体)中选择出来。
按照公知的有限稀释法将选择的杂交瘤进行单一克隆化,确立作为单一克隆性抗体产生杂交瘤。
检测杂交瘤所产生的抗体的活性的方法可以使用公知的方法。例如可举出elisa法、凝集反应法、放射免疫分析法。
为了从得到的杂交瘤取得单克隆抗体,可采用:按照通常的方法培养该杂交瘤,作为其培养上清液而得到的方法;或将杂交瘤给药于与其具有相容性的哺乳动物而使其增殖,作为其腹水而得到的方法等。
抗体的精制可以使用盐析法、凝胶过滤法、离子交换色谱法或亲和色谱法等公知的精制手段来进行。
通过将本发明的抗活性型gip抗体用于任意的免疫学的测定方法,可以特异性地检测或测定检测体中的活性型gip。即,使本发明的抗活性型gip抗体与检测体接触,并检测对该抗体的结合从而在免疫学上测定活性型gip的水平,由此可以检测或测定生物体试样或生物体内的活性型gip。
由此,可以进行生物体试样中的活性型gip的测定、活性型gip值的异常的检测、进而进行以活性型gip作为指标的治疗药的奏效性评价等。
在此,作为免疫学的测定法,没有特别地限制,作为定性的分析,可以列举免疫组织染色法、荧光抗体法、吸附法、以及中和法,作为定量分析,可以列举elisa法、放射免疫分析法、及蛋白质印迹法等。其中,从简便性的观点考虑,优选使用elisa法。在elisa法、放射免疫分析法中,有竞争法、夹心法、直接吸附法。
竞争法为使抗活性型gip抗体与分析用板结合,向其中与小牛肠碱性磷酸酶(ciap)、辣根过氧化物酶等酶或用放射性同位素等标记了的一定浓度的活性型gip一起添加试样。试样中的活性型gip和标记了的活性型gip围绕对抗活性型gip抗体的结合而竞争,根据试样中的活性型gip的浓度,标记活性型gip与抗活性型gip抗体结合,因此,可以根据对该标记活性型gip的抗体的结合量推定试样中的活性型gip的浓度。
夹心法为使用抗gip抗体和标记抗活性型gip抗体的方法,作为抗gip抗体,优选与抗活性型gip抗体表位不同的抗体,作为这样的抗体,可举出抗总gip抗体。另外,优选使用固定化抗gip抗体和标记抗活性型gip抗体的方法。
作为固定化抗gip抗体,优选将抗体固定化于聚苯乙烯板、胶乳颗粒、磁性颗粒、玻璃纤维膜、尼龙膜、硝基纤维素膜、醋酸纤维素膜等不溶性支撑体上的抗体。
另外,作为标记抗活性型gip抗体的标记,例如可以使用放射性同位体(例如32p、35s、3h)、酶(例如过氧化物酶、碱性磷酸酶、荧光素酶)、蛋白(例如抗生物素蛋白)、低分子化合物(例如生物素)、荧光物质(例如fitc)、化学发光物质(例如阿地尼亚(aclidinium))、胶乳颗粒(例如着色胶乳颗粒、荧光胶乳颗粒)、金属(例如金、银、铂等贵金属)胶体颗粒、碳原子等。
另外,直接吸附法(直接法)为使抗原吸附于固相,从而使之与标记抗活性型gip抗体反应的方法。
检测体(生物体试样)中的活性型gip的检测通过使试样中的活性型gip与固定化抗gip抗体反应来进行,例如在利用夹心法的情况下,可以通过使试样含有液和固定化抗gip抗体反应然后使上述标记抗体反应、或者使固定化抗gip抗体和标记抗体同时反应来进行。反应结束后,如果测定由试样中的活性型gip、固定化抗gip抗体以标记抗体形成的复合体中的标记量,则可以测定试样中的活性型gip量。标记量的测定可以用对应于标记体的种类的方法来进行。例如,在使用酶作为标记的情况下,反应后,加入基质,并测定酶活性。另外,在使用荧光(包括荧光胶乳颗粒)或化学发光物质作为标记的情况下,在不引起消光的条件下测定信号。着色胶乳颗粒、金属胶体颗粒、以及碳颗粒等通过目视或反射光等来测定信号。
含有本发明的抗活性型gip抗体的检测或测定试剂(试剂盒)是在使用本发明的抗活性型gip抗体测定或检测检测体中的活性型gip的方法中使用,是用于定性、定量或半定量地检测或测定从被验者采集的生物体试样(例如组织、血液、血浆、血清、淋巴液等)或生物体内的活性型gip的试剂。
含有该抗活性型gip抗体的检测或测定试剂,优选为在被标记化的本发明的抗活性型gip抗体之外,还含有例如检体用稀释液、固定化抗gip抗体、反应基质、根据需要的显色试剂、反应停止用试剂、标准抗原试剂、样品前处理用试剂、阻断试剂等而构成。另外,抗活性型gip抗体可以包含或固定于树脂、膜、薄膜、容器等中,或溶解于溶剂中。
关于上述的实施方式,在本发明中,公开有以下的方式。
<1>一种抗体,其为结合于活性型gip且与非活性型gip实质上不结合的抗活性型gip抗体,其中,至少识别选自序列号5表示的氨基酸序列的第8~10号氨基酸中的1个以上,且在h链上含有由下述(1)表示的氨基酸序列或其保守序列突变构成的区域。
emnpsdgrthfne(1)
<2>根据<1>的抗体,其包含由序列号2表示的氨基酸序列或其保守序列突变构成的区域作为h链可变区。
<3>根据<2>的抗体,其中,保守序列突变后的氨基酸序列与序列号2表示的氨基酸序列具有90%以上的同一性。
<4>根据<1>或<2>的抗体,其包含由序列号2表示的氨基酸序列或其保守序列突变构成的区域作为h链可变区,且包含由序列号4表示的氨基酸序列或其保守序列突变构成的区域作为l链可变区。
<5>根据<4>的抗体,其中,相对于序列号2表示的氨基酸序列进行了保守序列突变的氨基酸序列与序列号2表示的氨基酸序列具有90%以上的同一性,相对于序列号4表示的氨基酸序列进行了保守序列突变的氨基酸序列与序列号4表示的氨基酸序列具有90%以上的同一性。
<6>一种活性型gip的检测或测定方法,其使用<1>~<5>中任一项的抗体。
<7>一种试样中的活性型gip的检测或测定方法,其包含以下的1)~2)的工序。
1)使固定化抗gip抗体和被标记了的<1>~<5>中任一项的抗体一起或分别与试样含有液接触的工序;
2)测定由试样中的活性型gip、上述固定化抗gip抗体以及标记抗体形成的复合体中的标记量的工序。
<8>一种活性型gip的检测或测定试剂,其包含<1>~<5>中任一项的抗体。
<9>以下的多肽及编码其的基因
(a)为由序列号2表示的氨基酸序列构成的多肽、或与该氨基酸序列具有90%以上,更优选为95%以上,进一步优选为98%以上的同一性的氨基酸序列的多肽,且该多肽担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能。
(b)为由序列号1表示的碱基序列构成的dna、或由与该碱基序列具有90%以上,更优选为95%以上,进一步优选为98%以上的同一性的碱基序列构成的dna,且该dna编码担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能的多肽。
<10>以下的多肽及编码其的基因
(c)为由序列号4表示的氨基酸序列构成的多肽、或与该氨基酸序列具有90%以上,更优选为95%以上,进一步优选为98%以上的同一性的氨基酸序列的多肽,且该多肽担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能。
(d)由序列号3表示的碱基序列构成的dna、或由与该碱基序列具有90%以上,更优选为95%以上,进一步优选为98%以上的同一性的碱基序列构成的dna,且该dna编码担负作为结合于活性型gip且与非活性型gip实质上不结合的抗体的功能的多肽。
实施例
实施例1抗体的制作
1)免疫用肽的合成
将活性型gip的n末端15氨基酸(gip(1-15))peg化后,使klh化学性地结合,制作klh结合peg化gip(1-15),作为免疫抗原。将对活性型gip的n末端15氨基酸(gip(1-15))进行了peg化后的物质作为测定用抗原(1),将对非活性型gip的n末端13氨基酸(gip(3-15))进行了peg化后的物质作为测定用抗原(2)。
2)免疫
使用balb/c小鼠3只,在背部皮下进行了免疫。在初次的免疫中,给药将上述中制作的抗原和完全费氏佐剂进行了混合后的乳胶。从初次免疫开始每2周使用将抗原和不完全费氏佐剂进行了混合后的乳剂实施追加免疫。一次性免疫的抗原量在0.1~0.2mg的范围内进行。实施初次免疫7周后,使用从小鼠采集的血清实施抗体值测定,确认了抗体值的上升。
3)细胞融合
从抗体值上升了的小鼠中摘除脾脏,得到了脾细胞。将得到的脾细胞和小鼠骨髓瘤细胞株p3u1利用peg法融合。其后,播种于20张96孔板(1×105cells/孔)。
4)筛选
将测定用抗原(1)及(2)以成为1μg/ml的方式用pbs(-)稀释从而在板上固相化,通过使用了进行了hrp标记后的抗小鼠ig抗体作为二级抗体的elisa法评价杂交瘤培养上清液和抗原(1)及(2)的反应,选择在抗原(1)中显示阳性且在抗原(2)中显示阴性的杂交瘤作为抗活性型gip单克隆抗体产生杂交瘤。
5)克隆
利用有限稀释法将上述得到的杂交瘤以可得到单一的菌落的方式进行培养,由此进行抗体产生杂交瘤的克隆,再次elisa测定单一菌落形成孔,确立产生对抗原(1)显示阳性且对抗原(2)显示阴性的抗体的9b9h5-b9株。
对于所得到的抗体产生杂交瘤的保存,培养该杂交瘤并在对数增殖期回收之后,用含fbs的细胞冻结液调制成细胞浓度成为1×106cells/ml之后,以成为1×106cells/管的方式分注于冻存管,在冷冻杯(bicell)中在-80℃下保存。
6)抗体生产
将得到的产生抗体杂交瘤的冻结冷冻杯解冻,对hybridoma-sfm进行无血清驯化。扩大培养后,在2个滚瓶(500ml×2个,1l)中进行培养,回收培养上清液。使用回收的培养上清液进行proteina精制,精制了单克隆抗体。
实施例2与利用elisa法的活性型gip的反应性
利用elisa法确认了实施例1中得到的单克隆抗体与活性型gip的反应性。在nh2基生物素标记试剂盒(dojindo公司制)中进行抗活性型gip单克隆抗体的氨基的生物素标记。在人(总)胃抑素(gip)elisa测定试剂盒(millipore公司制)中作为附属的检测抗体“gipdetectionantibody”(生物素标记抗总gip单克隆抗体)的替代,使用1μg/ml制作的生物素标记抗活性型gip单克隆抗体进行elisa。制作将gip(1-42)或gip(3-42)的2000pg/ml溶液至6个阶段做成最高浓度的4倍稀释系列(8.2~2000pg/ml),通过利用抗总gip单克隆抗体(附属于millipore公司制的人(总)胃抑素(gip)elisa测定试剂盒)作为捕捉抗体;用生物素标记抗活性型gip单克隆抗体作为检测抗体;并在检测中使用了过氧化物酶-链霉亲和素结合物的夹心elisa体系,制作了将gip浓度作为x轴,将吸光度450nm~590nm作为y轴的标准曲线(图1)。
如图1所示,在gip(3-42)中,在高浓度域中吸光度也不上升,仅在gip(1-42)中吸光度依赖于浓度地上升,因此确认了本elisa体系在gip(3-42)中没有交叉性,能够特异性地检测gip(1-42)。
实施例3人活性型gip的测定
为了评价是否可以将实施例2中构建的gip(1-42)elisa法在实际上用于人血中gip(1-42)测定,使用了人血浆样品进行了探讨。
相对于健康人,将摄取了对照食(标准食)、或试验食(gip减少食)之后的各时间的血中gip(1-42)值示于图2a,将作为比较测定的血中总gip值示于图2b。血中gip(1-42)值在饭后30分钟值处观察到峰值(图2a),但与至饭后120分钟值都维持高值的总gip(图2b)相比,显示在早期血中浓度减少。在对照食和试验食的比较中,在饭后30分钟值及60分钟值处,试验食相对于对照食可看到显著的血中gip(1-42)值的减少(图2a),并可看到与总gip值(图2b)同样的倾向。另外,求出gip(1-42)相对于饭后的总gip的比例(图2c)。在饭后30、60、120及180分钟时,各时间的平均值为43%、28%、27%、及19%,显示在饭后早期活性型gip的比例高,其后经时地减少。
实施例4活性型gip单克隆抗体的表位分析
为了特定实施例1中制作的单克隆抗体的表位,制作下述的合成肽。
(1)gip(1-10):nh2-yaegtfisdy-cooh
(2)gip(1-9):nh2-yaegtfisd-cooh
(3)gip(1-8):nh2-yaegtfis-cooh
(4)gip(1-7):nh2-yaegtfi-cooh
(5)gip(1-6):nh2-yaegtf-cooh
(6)gip(1-6)+gip非特异的4aa(随机4aa):nh2-yaegtfvnlv-cooh
将合成的6种肽以成为1μg/ml的方式用pbs(-)进行稀释并在96孔板上固相化,使用生物素标记抗活性型gip单克隆抗体,并在检测中使用过氧化物酶-链霉亲和素结合物进行elisa。将结果示于图3。
由图3可知:必须以gip(1-8)以上、即从n末端8个氨基酸以上的长度的活性型gip肽作为抗活性型gip单克隆抗体的识别部位。
实施例5h链及l链可变区的氨基酸序列的分析
(1)序列决定
按照常规方法,进行从9b9h5-b9杂交瘤的总rna的提取,将其作为模板制备cdna。使用表1所示的引物,在表2所示的条件下进行pcr,将含有h链及l链的可变区的pcr产物进行扩增。
即,将得到的cdna(利用h链特异的引物合成)作为模板,将小鼠抗体(igg)h链特异的引物作为反向引物(reverseprimer)、将表1所示的通用引物(universalprimer)作为正向引物(forwardprimer)进行racepcr反应。同样地,以cdna(利用l链特异的引物合成)为模板,使用l链特异的引物进行racepcr反应。在pcr酶中使用primestargxl。将得到的pcr产物在cloningplasmidpmd20-t中进行连接,通过常规方法的转化,从而每pcr产物取得48个克隆。
[表1]
※h-pcr中将标记的两个序列每个等摩尔地混合使用
[表2]
取得的克隆使用引物m13-47(cgccagggttttcccagtcacgac;序列号10),从plasmid区域的一侧进行分析。使用bigdyeterminatorsv3.1cyclesequencingkit(abi公司),按照附属的实验计划进行测序,并决定序列。决定了的序列中,对由源自实验试样的碱基序列推定的氨基酸序列,利用blast(http://blast.ncbi.nlm.nih.gov/blast.cgi)进行相似性检索,确定推定为编码h链及l链的可变区的碱基序列(起始密码子以后)、及氨基酸序列(序列号1~4)。在此,序列号1及2表示编码单克隆抗体的h链可变区的碱基序列及氨基酸序列,序列号3及4表示编码单克隆抗体的l链可变区的碱基序列及氨基酸序列。
另外,对于h链可变区的氨基酸序列,用blast(http://blast.ncbi.nlm.nih.gov/blast.cgi)进行相似性的检索,结果,关于距离其n末端第50~62号的氨基酸残基“emnpsdgrthfne”,没有发现具有与其具有90%以上的同一性的氨基酸序列的多肽。
序列表
<110>花王株式会社
<120>抗活性型gip抗体
<130>ks1415
<150>jp2014-258849
<151>2014-12-22
<160>10
<170>patentinversion3.5
<210>1
<211>339
<212>dna
<213>小鼠
<220>
<221>cds
<222>(1)..(339)
<400>1
caggtccaactgcagcagcctggggctgaactggtgaagcctggggcc48
glnvalglnleuglnglnproglyalagluleuvallysproglyala
151015
tcagtgaagctgtcctgcaaggcttctggctacaccttcaccagcttc96
servallysleusercyslysalaserglytyrthrphethrserphe
202530
tggatgcactgggtgattcagaggcctggacaaggccttgagtggatt144
trpmethistrpvalileglnargproglyglnglyleuglutrpile
354045
ggagagatgaatcctagcgacggtcgtactcacttcaatgaaaagttc192
glyglumetasnproseraspglyargthrhispheasnglulysphe
505560
aagaccaaggccacactgactatagacacatcctccaacacagcctac240
lysthrlysalathrleuthrileaspthrserserasnthralatyr
65707580
atggaactcaacagcctgacatctgaggactctgcggtctattactgt288
metgluleuasnserleuthrsergluaspseralavaltyrtyrcys
859095
gcaagaaggatggaggactggggccaagggactctggtcactgtttct336
alaargargmetgluasptrpglyglnglythrleuvalthrvalser
100105110
gca339
ala
<210>2
<211>113
<212>prt
<213>小鼠
<400>2
glnvalglnleuglnglnproglyalagluleuvallysproglyala
151015
servallysleusercyslysalaserglytyrthrphethrserphe
202530
trpmethistrpvalileglnargproglyglnglyleuglutrpile
354045
glyglumetasnproseraspglyargthrhispheasnglulysphe
505560
lysthrlysalathrleuthrileaspthrserserasnthralatyr
65707580
metgluleuasnserleuthrsergluaspseralavaltyrtyrcys
859095
alaargargmetgluasptrpglyglnglythrleuvalthrvalser
100105110
ala
<210>3
<211>324
<212>dna
<213>小鼠
<220>
<221>cds
<222>(1)..(324)
<400>3
gacatcaagatgacccagtctccatcttccatgtatgcatctctagga48
aspilelysmetthrglnserprosersermettyralaserleugly
151015
gagagagtcactatcacttgcaaggcgagtcaggacattaatagctat96
gluargvalthrilethrcyslysalaserglnaspileasnsertyr
202530
ttaggctggttccagcagaaaccagggaaatctcctaagaccctgata144
leuglytrppheglnglnlysproglylysserprolysthrleuile
354045
tatggtgcaaacagattggtagatggggtcccatcaaggttcagtggc192
tyrglyalaasnargleuvalaspglyvalproserargphesergly
505560
agtggatctgggcaagattactctctcaccatcagcagcctggagtat240
serglyserglyglnasptyrserleuthrileserserleuglutyr
65707580
gacgatatgggaatatattattgtctacagtatgatgagtttccgctc288
aspaspmetglyiletyrtyrcysleuglntyraspglupheproleu
859095
accttcggtgctgggaccaagctggagctgaaacgg324
thrpheglyalaglythrlysleugluleulysarg
100105
<210>4
<211>108
<212>prt
<213>小鼠
<400>4
aspilelysmetthrglnserprosersermettyralaserleugly
151015
gluargvalthrilethrcyslysalaserglnaspileasnsertyr
202530
leuglytrppheglnglnlysproglylysserprolysthrleuile
354045
tyrglyalaasnargleuvalaspglyvalproserargphesergly
505560
serglyserglyglnasptyrserleuthrileserserleuglutyr
65707580
aspaspmetglyiletyrtyrcysleuglntyraspglupheproleu
859095
thrpheglyalaglythrlysleugluleulysarg
100105
<210>5
<211>42
<212>prt
<213>智人
<400>5
tyralagluglythrpheileserasptyrserilealametasplys
151015
ilehisglnglnaspphevalasntrpleuleualaglnlysglylys
202530
lysasnasptrplyshisasnilethrgln
3540
<210>6
<211>67
<212>dna
<213>人工序列
<220>
<223>合成寡核甘酸
<400>6
ctaatacgactcactatagggcaagcagtggtatcaacgcagagtctaatacgactcact60
atagggc67
<210>7
<211>23
<212>dna
<213>人工序列
<220>
<223>合成寡核甘酸
<400>7
gggaartarcccttgaccaggca23
<210>8
<211>23
<212>dna
<213>人工序列
<220>
<223>合成寡核甘酸
<400>8
gggaartagcctttgacaaggca23
<210>9
<211>26
<212>dna
<213>人工序列
<220>
<223>合成寡核甘酸
<400>9
cactgccatcaatcttccacttgaca26
<210>10
<211>24
<212>dna
<213>人工序列
<220>
<223>合成寡核甘酸
<400>10
cgccagggttttcccagtcacgac24
- 还没有人留言评论。精彩留言会获得点赞!