一种II型糖尿病相关基因KCNIP1拷贝数变异的检测方法与应用与流程
本发明涉及人类疾病分子生物学检测领域,具体涉及一种检测
背景技术:
拷贝数变异(copynumbervariation,cnv)是基因组dna上一种亚显微水平的结构变异,涉及的基因组序列大小从1kb到多个mb,包括拷贝数增加(copynumbergain)和拷贝数减少(copynumberloss)。人类基因组中存在广泛的拷贝数变异,大部分cnv区域属于dna序列多态性范畴,是构成人类基础表型多样性的分子基础,有些cnv并不引起任何表型变化。然而,还有一些cnv能够扰乱功能基因的结构,影响基因表达,最终引起人类复杂疾病的发生。因此,鉴定出与疾病密切相关的cnv位点,对于疾病的筛查和诊断至关重要,具有重大的应用价值。
目前,cnv的检测技术主要包括:
糖尿病被认为是世界上第五大严重危害人类健康的疾病,其中90%为非胰岛素依赖型糖尿病,又称为
kv通道蛋白1(kcnip1)基因,是kcnip家族成员之一。kcnip1蛋白通过与下游靶基因的调控元件直接结合,进而调控其表达,在调控胰腺β细胞胰岛素分泌过程中发挥了重要作用。lee等研究发现敲除kcnip1基因能够影响β细胞的复极化,促进胰岛素分泌(leehs,moon,s,yun,jhetal.genome-widecopynumbervariationstudyrevealskcnip1asamodulatorofinsulinsecretion.genomics2014;104:113-120.)。由此可见,kcnip1基因可能与糖尿病的发生有关。高通量测序发现kcnip1基因序列中存在1854bp的拷贝数变异,我们推测该cnv可能造成个体间糖尿病的易感性差异。然而,目前尚未见kcnip1基因cnv影响
技术实现要素:
本发明的目的在于鉴定一种与
本发明解决其技术问题所采用的技术方案是:
一种ii型糖尿病相关基因kcnip1拷贝数变异的检测方法,以糖尿病患者和正常人的血液基因组dna为模板,以引物对p1(f1、r1)和p2(f2、r2)为引物,通过实时荧光定量pcr分别扩增kcnip1基因cnv区域和内参基因rnasep,根据定量结果分析kcnip1基因cnv在糖尿病患者和正常人中的分布差异,鉴定出该位点在糖尿病患者中的易感基因型。
本发明的所述与
本发明还提供用于检测与
表1实时荧光定量pcr的引物信息
本发明所述的用于实时荧光定量pcr检测的前述与
本发明还提供所述的kcnip1基因cnv标记在
前述的应用是通过以下技术方案来实现:
(1)提取待测
(2)以上述提取的基因组dna为模版,利用表1中的引物对进行实时荧光定量pcr检测kcnip1基因的cnv位点;
(3)以正常人为对照,根据log22−δδct值确定
步骤(2)中进行实时荧光定量pcr所用的扩增体系以20μl计为:50ng/μl模板dna1μl,10pmol/l的上、下游引物各1μl,2×sybrgreenqpcrmix10μl,去离子水7μl。
步骤(2)中进行实时荧光定量所用的pcr扩增的反应程序为:
所述的应用包括以下步骤:
(1)采用实时荧光定量pcr技术检测候选的kcnip1基因cnv位点在
(2)利用spss20.0软件将拷贝数变异类型与空腹血糖、糖化血红蛋白等
(3)根据拷贝数变异类型进行
本发明的实施案例中,以人kcnip1基因chr5q35.1:170062275–170064128区域为候选位点,通过实时荧光定量pcr技术检测该位点在
与现有技术相比,本发明提供的kcnip1基因拷贝数变异的检测方法操作简便、成本低廉、结果准确可靠,且不受检测dna模板量的限制,可对微量样品进行cnv检测。
kcnip1基因在调控胰岛素合成和分泌过程中发挥了至关重要的作用,将kcnip1基因的cnv位点与
附图说明
图1为本发明中采用实时荧光定量pcr检测kcnip1基因cnv在ii型糖尿病患者(t2d)和正常人(control)基因组中的分布情况。
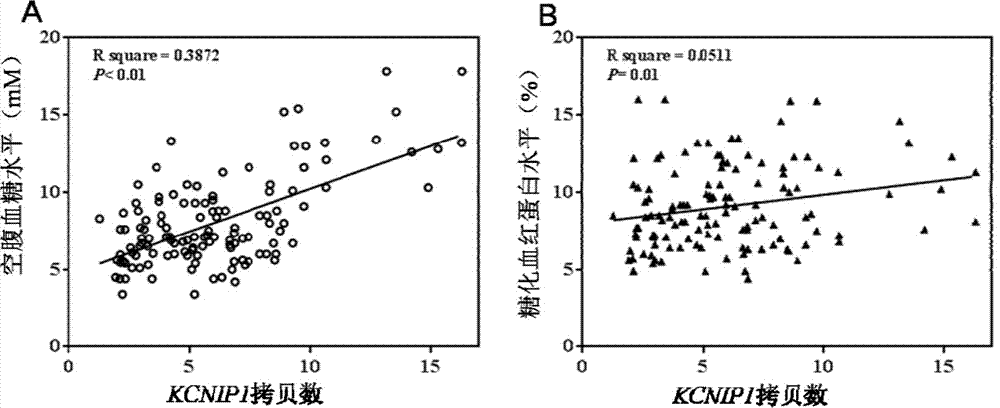
图2为kcnip1基因拷贝数与糖尿病患者空腹血糖、糖化血红蛋白的相关性分析。
图3为kcnip1基因3种拷贝数变异型与ogtt实验中的血糖、胰岛素水平的比较分析。
具体实施方式
下面对本发明做进一步的详细说明,所述是对本发明的解释而不是限定。若未特别指明,均按照常规的实验条件或按照制造厂商说明书建议的条件。
一种ii型糖尿病相关基因kcnip1拷贝数变异的检测方法,以糖尿病患者和正常人的血液基因组dna为模板,以引物对p1(f1、r1)和p2(f2、r2)为引物,通过实时荧光定量pcr分别扩增kcnip1基因cnv区域和内参基因rnasep,根据定量结果分析kcnip1基因cnv在糖尿病患者和正常人中的分布差异,鉴定出该位点在糖尿病患者中的易感基因型。
其中所述的cnv标记是指人kcnip1基因(genbank:nc_000005.9)候选区域chr5q35.1:170062275–170064128的拷贝数变异;所述的拷贝数变异位点根据log22−δδct值可分为3种基因型:插入型(log22−δδct>0.5);缺失型(log22−δδct<-0.5);正常型(log22−δδct≤|±0.5|);所述的实时荧光定量pcr试剂包括2×sybrgreenqpcrmix和去离子水;所述的实时荧光定量pcr引物对p1和p2序列信息见表1:
表1实时荧光定量pcr的引物信息
本发明检测方法中kcnip1基因cnv位点作为分子标记,应用于ii型糖尿病的筛查和诊断时,具体包括以下步骤:
(1)提取ii型糖尿病患者和正常人的血液基因组dna;
(2)以上述基因组dna为模版,利用权利要求4中的引物对进行实时荧光定量pcr检测kcnip1基因cnv;
(3)根据kcnip1基因cnv的检测结果,如果拷贝数为插入型,则待测个体对糖尿病更易感,患病症状更严重,而缺失型个体则相反。
其中,所述步骤(2)中进行实时荧光定量pcr所用的扩增体系为20μl,包含50ng/μl模板dna1μl,10pmol/l的上、下游引物各1μl,2×sybrgreenqpcrmix10μl,去离子水7μl。
其中,所述步骤(2)中进行实时荧光定量pcr所用的反应程序为:
本发明利用实时荧光定量pcr对ii型糖尿病相关基因kcnip1的cnv进行检测时步骤如下:
1、血液样本采集
本发明具体以ii型糖尿病患者和正常个体作为检测对象,126个ii型糖尿病患者的血液样本采自武汉科技大学附属天佑医院内分泌科,100个正常人血液样本采自武汉大学校医院体检科。本实验内容是经过武汉科技大学附属天佑医院医学伦理委员会批准。
2、基因组dna的分离、提取、纯化
参考文献sambrocketal(2002)方法。
3、cnv序列及参考序列的扩增
以ncbi数据库(http://www.ncbi.nlm.nih.gov/)公布的人kcnip1基因序列(genbankaccessionnc_000005.9)为参考序列,利用primer5.0设计实时荧光定量pcr引物检测kcnip1基因拷贝数变异,扩增片段大小为101bp。内参序列为已知的不存在拷贝数变异的序列,即rnasep基因中的一段122bp的序列。引物对序列信息如表1所示。
其中,进行实时荧光定量pcr所用的扩增体系以20μl计为:50ng/μl模板dna1μl,10pmol/l的上、下游引物各1μl,2×sybrgreenqpcrmix10μl,去离子水7μl。
pcr扩增的反应程序为:
4、拷贝数变异分析
每个待测样品分别用目标序列和参考序列的引物进行扩增,并且每个扩增反应做3个重复。根据2−δδct方法进行拷贝数变异分析。其中δδct=(ct目的基因-ct内参基因)实验组-(ct目的基因-ct内参基因)对照组。实验组即为待检测有无cnv的样本,对照组即为已知无拷贝数变异的样本。2−δδct表示的是实验组目标序列的拷贝数相对与对照组的倍数。然后将基因的拷贝丰度进行对数转化(以2为底2−δδct的对数)使之符合正态分布,进行方差齐性检验后,统计检验各组间的差异。
当cnv位点为正常型时,根据log22−δδct计算出归一化值接近0,即log22−δδct≤|±0.5|;当cnv为缺失型时,log22−δδct计算出归一化值log22−δδct<-0.5;当cnv为插入型时,log22−δδct计算出归一化值log22−δδct>0.5。
kcnip1基因拷贝数在ii型糖尿病患者(t2d,n=126)和正常个体(control,n=100)中的分布情况如图1所示,该cnv在两个群体中分布呈极显著差异(p<0.01),拷贝数插入型在ii型糖尿病患者中属于优势基因型,而拷贝数正常型在正常人中属于优势基因型。
5、kcnip1基因cnv位点与ii型糖尿病临床指标的关联分析
(1)kcnip1基因不同拷贝数与空腹血糖、糖化血红蛋白相关性分析
首先,确定ii型糖尿病患者的kcnip1基因cnv位点的拷贝数目,将拷贝数的变化与对应的空腹血糖、糖化血红蛋白水平进行皮尔逊相关性分析,结果如图2所示,kcnip1基因的拷贝数与空腹血糖、糖化血红蛋白水平均呈正相关(p<0.05),拷贝数越大,其临床症状越明显。
(2)kcnip1基因cnv位点与血糖、胰岛素水平的关联分析
临床数据:ogtt实验中血糖和胰岛素水平。
关联分析模型:先对数据进行描述分析,确定是否存在离群值,再利用最小二乘分析对数据校正;根据数据特征,应用spss20.0软件分析各基因型间的生产性状效应。在对基因型效应进行分析时采用了固定模型:
yij=μ+cnvi+eij,
其中:yij为性状观察值,μ为总体均值,cnvi为第i个拷贝数变异类型的固定效应,eij为随机误差。各组数据间的差异性采用lsd多重比较进行检验,试验结果以mean±se形式表示。
ogtt实验的关联分析结果表明(见图3),kcnip1基因cnv位点可显著影响60-min、120-min和180-min的血糖和胰岛素水平,其中,拷贝数插入型(copynumbergain)的血糖水平显著高于缺失型(copynumberloss),相反地,拷贝数缺失型(copynumberloss)的胰岛素水平显著高于插入型(copynumbergain)。由此可见,kcnip1基因该cnv位点不同基因型与ii型糖尿病的临床指标显著相关。
6、上述cnv标记在ii型糖尿病临床筛查和诊断中的应用
鉴定的kcnip1基因chr5q35.1:170062275–170064128位点的拷贝数变异可作为重要的分子遗传标记,其中,拷贝数插入型为
核苷酸序列表
<110>武汉科技大学
<120>一种ii型糖尿病相关基因kcnip1拷贝数变异的检测方法与应用
<160>3
<210>1
<211>1854
<212>dna
<213>人(human)
<220>
<400>1
ctgcctgcctcggcctcccaaagtgttgagattacaggagtgagccatcacgcccggccaagaagaccttttaaagtagatgttctaagagtctctttcagttctgaatctctttgttatcttacatgttaccccctcagagatgccttccctcactcccctgtccaaggtagctctccacccaagtcagcagtcatcacagaaccatcacaacctgaagccctgtgcatgttgctgtttatttcctgtttacatcacaacctgaagccctgtgcatgtagctgtatactaaccctagagttagtatagcttagttaaactttcatttattgctaaaggtttatcactgctgtctctatcagcctccctgcactgtaagggacaagggggcaggtccagtttctgtcttgtttcaggttttgtctccagccaagataagtatctttgcaaggctctgtttttattctgaaaggaaattaggagctattggagggtatggagtggaaggggacagtcttctgccttggatgtataaaagggatgctgggccacgctgatgggctagaccatggcaggcagagaaaacaggcaggaggccaggcaggggctgccagtgcccagacacaggccgggaggtgcaggtggcagtggcaggcagtggccaggccctgggtatattttgaaggtcaagccaacaggacttgccagtgggctgggtatgggcatgagacaggcaagttctcccagatgtgactccgatgtgacattttggagactccctcaacacccacctggggaagacagaccagttgggaggaaatatctggagtctcattttattaattctgagagtttgttgtattagacagtgaagcggaaatgtcaggaagtcagctggaaataggagtctggagttggggggaaagcctagccagagacaggaattgtggcgtcattggcgtagagacagcgtttaaagctgtgacgctagatgggttcaccaggggaatgagagtcgaaagagaagagcagagcagagctgagccctgaggggggcagaaaggcacacagggacagtggaggcaggaggcagaaggcagagggtggcgggccaacagctctgaaggtcagtgctctatcacaggggggtggccgaggaggggcccgaggctggaaccaggaggcactatcccaggcctgccttctcatgccagcagcagtgatctatcctcaaggagaatattgattgagcacctactgcatgcagagacctcatcaatggctcaatcaatatgacacggccacgcttcctgatccgagccctctgagcaggtattttccatcctggacttatccctgtttctcaggagagggatggacccaagagacaaatagttcccccaagatcgcacagcaagccagtgtaaaacaagcatagaaaccagcttttagggggctcaaggtgggggtcagaaaatgaggtgagagcaagcatttactgagcacctcctgtaaatatctcctacatacgaagtgctctacccacattactgaccacccaataaaggcaggtcctgtaattcccaatttgcagatggataagcagaggcttaggggtgtgaaacaacctcctcaaggtcatggcttctaagtggtggagccaggcctgcaaaccaggctgtctgaatccaaaatccacctccaagtccacagtgggttggccccacccccaacccatccccatcaccaacaggacggtggtcagagtccactgaatgaaagcatgcgtgcattcaaaatagacagccaatcagcagccttccatcagaaatgtcatctttatgacaacagcat1854
<210>2
<211>20
<212>dna
<213>人工序列
<220>
<223>上游引物f1
<400>2
aatatgacacggccacgctt20
<210>3
<211>19
<212>dna
<213>人工序列
<220>
<223>下游引物r1
<400>3
tgtctcttgggtccatccct20
<210>4
<211>20
<212>dna
<213>人工序列
<220>
<223>上游引物f2
<400>4
tctctcgtgtaccctcccag20
<210>5
<211>20
<212>dna
<213>人工序列
<220>
<223>下游引物r2
<400>5
ttgccagtgctgatgtctca20
- 还没有人留言评论。精彩留言会获得点赞!