一种用于对不同银杏进行基因分型的SNP引物及检测方法与流程
技术领域:
本发明属于生物技术领域,具体涉及一种用于对不同银杏进行基因分型的snp引物及检测方法。
背景技术:
银杏(ginkgobilobal.)作为裸子植物银杏纲(ginkgopsida)现存唯一种,典型的中生代孑遗物种,素有“活化石”之美誉。银杏为落叶大乔木,树干高大,雌雄异株。树皮幼时浅绿色,老树呈灰褐色,深纵裂,粗糙;分枝繁茂,分长短枝。种子核果状,有臭味;中种皮骨质,白色,具2~3棱;内种皮膜质淡褐色,子叶2片;花期4~5月,9~10月种子成熟。银杏集材用、果用、叶用、园林绿化、观赏于一体,是一种全能的树种。银杏叶中含有大量的银杏黄酮类和银杏内酯类物质,对治疗神经病,骨髓病和脑病有独特的效用。银杏叶的非凡药用价值,已经使银杏叶制剂形成了一个巨大的产业。
单核苷酸多态性(singlenucleotidepolymorphisms,snp)是指单个核苷酸的变异引起的基因组水平上dna序列的多态性,其形式包括单碱基的插入、缺失、转换和颠换。在群体中,其等位基因频率大于1%,但有时也把cdna中频率小于1%的单碱基变异称之为snp。snp标记是继rflp和ssr之后发展起来的第三代分子标记,并广泛应用于植物遗传育种中,具有遗传稳定性高;密度高、分布广;二态性和等位基因性;富有代表性;易于实现高通量、自动化检测的特点。因此,snp被认为是应用前景最好的遗传标记之一。
随着测序技术的发展,测序质量的提高和成本的降低,挖掘snp位点并借此进行相关研究的例子越来越多。但该技术在植物中的应用多集中于农作物,在林木类方面的研究相对较少,且在银杏这一物种上的研究更是未见报道。随着时代的发展,野生资源的保护至关重要,对于孑遗树种古银杏保护不容忽视。因此,现急需一种快速、方便、可靠的银杏古树名木资源分子鉴定技术。利用dna分子标记方法绘制dna指纹图谱,能从本质上反映生物个体间的差异。常规的dna指纹图谱是采用第二代分子标记简单序列重复(ssr)进行的,但是第三代分子标记snp,无须基于凝胶电泳进行指纹图谱的检测,减少误差,省时,且高通量,准确性高。
技术实现要素:
发明目的:针对现有技术中存在的不足,本发明的目的是提供一种用于对不同银杏进行基因分型的snp引物,为84株古树名木建立指纹图谱。本发明的另一目的是提供上述snp引物的应用。
技术方案:为了实现上述发明目的,本发明采用的技术方案为:
一种用于对不同古银杏进行基因分型的snp引物,由22对引物组成,各引物的核苷酸序列如下表所示:
应用所述的snp引物构建银杏古树名木的指纹图谱,获得84个银杏古树名木对应的指纹图谱,如下表所示:
所述的应用snp引物构建银杏古树名木的指纹图谱,所使用的引物为11,名称分别:snp1,snp4,snp6,snp8,snp10,snp14,snp16,snp17,snp19,snp20,snp22。
所述snp引物在不同古银杏基因组dna的snp位点基因分型检测中的应用。
所述的应用,包括以下步骤:
1)待测银杏样品dna的提取;
2)使用相同反应体系及程序对银杏样本基因组dna进行pcr扩增,得到待测银杏的pcr产物;
3)对pcr扩增产物进行高分辨率溶解曲线分析确定snp位点的基因型;
4)sanger测序再次验证snp基因型。
步骤2)中,pcr反应体系10μl:25ng模板dna;1xforget-me-nottmqpcrmastermix;0.1μmol/lsnp引物;剩余ddh2o补齐。
步骤2)中,pcr反应程序:预变性95℃2min;95℃变性5s,45个循环;60℃复性30s。
步骤3)中,hrm的反应程序:95℃10s,60℃1min,95℃15s,60℃15s。
本发明通过实验证明:本发明的引物共22对,其中11对snp引物组合可以用于构建银杏古树名木的指纹图谱。本发明利用银杏转录组数据开发的snp引物能够对银杏进行基因分型,并且本发明操作方法简单,通量高,成本低。此外,本发明开发的11对snp引物构建了不同银杏古树名木的指纹图谱,验证的22个snp位点还可以用来分子标记辅助育种,遗传多样性研究,基于snp的关联分析,以及用于种质资源鉴定与分类等。
有益效果:与现有技术相比,本发明具有以下的技术优势:
1)结果高度准确、可靠:利用本发明进行检测与鉴定,检测结果100%准确,检测结果提供了高度的可靠性,为银杏古树名木提供指纹图谱,对野生资源的保护意义重大。
2)操作快速简便:进行不同个体间的样本检测,一般整个试验过程只需几小时即可完成,与传统的测序技术相比,省时省力,可以实现高通量。
3)无需基于凝胶电泳进行,减少试剂和耗材的使用,更佳环保,同时节省人力和减少人工误差。
4)检测结果灵敏度高:对待检测样品仅需提供模板dna25ng即可准确进行鉴定。
附图说明
图1是从银杏转录组测序数据中鉴定出的snp及其变异类型和数目结果图;
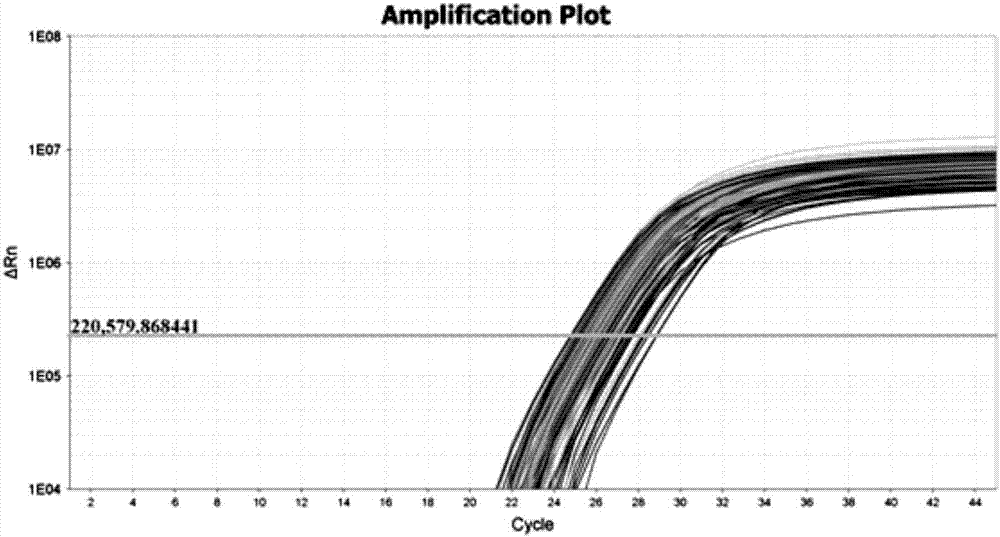
图2是以引物snp18为例,在不同古银杏个体表现出的扩增曲线图;
图3是以引物snp18为例,利用高分辨率溶解曲线分析后,不同古银杏个体表现出不同的溶解曲线峰图;
图4是以引物snp18为例,根据不同古银杏个体表现出的差异溶解曲线峰,对其进行基因分型结果的溶解曲线,红色为cc,蓝色为ct,绿色为tt。
具体实施方式
下面结合具体实施例对本发明做进一步的说明。
实施例1
1、初步筛选对银杏进行基因分型的snp引物
1)转录组数据的获得
根据制造商的说明书使用rneasyplantminikit(qiagen,hilde,germany)进行银杏总rna提取。提取后,在1.0%的琼脂糖凝胶上检测rna的降解和污染。使用
每个样品的总量为3μgrna用作rna样品制备的输入材料。按照制造商的说明书,使用
fastq格式的原始数据(rawreads)首先通过内部perl脚本进行处理。在此步骤中,通过删除包含适配器的读取,包含poly-n的读取以及从原始数据读取的低质量来获取干净的数据(cleanreads)。同时,计算了cleandata的q20,q30,gc含量和序列重复水平。所有的下游分析都是以高质量的cleandata为基础。然后,将所有库/样本中的左文件(read1files)合并到一个大的left.fq文件中,将正确的文件(read2files)合并到一个大的right.fq文件中。基于left.fq和right.fq使用trinity(grabherretal.,2011)完成转录组组装,默认情况下min_kmer_cov设置为2,其他所有参数设置为默认值。选择具有最长长度的每个基因的转录本作为unigenes。
2)snp的识别
本实施例通过使用picard-toolsv1.41和samtoolsv0.1.18来排序,删除重复读取,对齐合并获得每个样本的bam结果。采用gatk2v3.2软件用于执行snpcalling(mckennaetal,2010)。原始的vcf文件使用gatk标准方法过滤(参数为clusterwindowsize:10;mq0>=4and(mq0/(1.0*dp))>0.1;qual<10;qual<30.0orqd<5.0orhrun>5),最后仅保留距离大于5的snp。通过该方法鉴定出65535个snp,snp变异的形式有多种,但类型主要有转换和颠换,转换是颠换的2倍左右,如图1所示。
3)snp引物的设计
根据转录组unigenes序列,挑选60个snp位点,利用oligo6.0软件设计60对snp引物。设计的方法如下:首先确定snp位点所在序列的位置,然后在snp位点的上下游分别设计正向引物和反向引物,引物设计的参数为引物长度18-23bp;tm60℃左右,尽可能保证上下游引物的tm值一致,一般不超过2℃;gc含量在40-60%(45-55%最佳);pcr产物大小为100-300bp;其它还应注意引物3'端不应出现超过3个的连续g或c;引物不能形成发夹结构,即不能有4bp以上的回文序列;引物自身、引物之间尽量不能有连续4个以上的碱基互补,尤其避免3'端的互补。
4)snp引物的有效性验证
提取银杏基因组dna,以银杏基因组dna为模板,采用待检测snp引物进行pcr扩增,获得pcr扩增产物;反应结束后,取3μl的pcr产物加入4μlloadingbuffer,再加3μlddh2o,利用8%聚丙烯酰胺凝胶进行电泳,然后采用银染方法对pcr扩增产物进行检测。能检测到目的条带且无其它杂带和引物二聚体的,该待检测引物即为有效引物。
10μl的pcr反应体系中包括:10×buffer;0.2mmol/ldntps;2.5mmol/lmg2+;0.2μmol/lsnp引物;1utaqdna聚合酶和40ngdna模版;剩余ddh2o补齐。
pcr的反应程序为:预变性94℃5min;30循环的94℃30s,最佳tm55℃30s,72℃30s;延伸72℃3min,最终4℃保存。
结果表明:挑选的60对snp引物中,有45对引物能够扩增出条带,说明引物设计的方法较好,但其中的18对引物扩增出的条带不单一,可能存在多个snp位点,暂不考虑进行hrm分析,另外27对引物扩增条带单一且产物大小与预期一致,暂为有效snp引物,用于hrm分析。1对引物对应1个目标snp位点,1对引物的扩增产物为含有对应snp位点的dna片段。
2、再次筛选对银杏进行基因分型的snp引物
1)pcr扩增及高分辨率溶解曲线(hrm)分析进行基因分型
以90个银杏个体(其中6个银杏个体为转录组测序的银杏;84棵银杏古树名木,分别来自3个群体,贵州盘县28株,浙江天目山28株和湖北安陆28株)的基因组dna为模板,分别采用上述27对snp有效性引物进行pcr扩增,得到每个个体的27个引物对应的pcr扩增产物,每个引物对的pcr扩增产物为含有某个snp位点的dna片段。
pcr反应体系10μl:25ng模板dna;1×forget-me-nottmqpcrmastermix;0.1μmol/lsnp引物;剩余ddh2o补齐。采用viia7中的highresolutionmelt进行pcr及基因分型。第一步,10μl的pcr反应程序:预变性95℃2min;45个循环的95℃变性5s,60℃复性30s;第二步,hrm的反应程序:95℃10s,60℃1min,95℃15s,60℃15s。
结果表明:有22对引物能够进行基因分型,其余5对引物(snp23,snp24,snp25,snp26,snp27)因有杂峰或基因分型时可信度不高,所以被淘汰。采用applied
图2为以snp18为例,在不同银杏个体表现出的扩增曲线;图3为以snp18为例,利用高分辨率溶解曲线分析后,不同银杏个体表现出不同的溶解曲线峰;图4为以snp18为例,根据不同银杏个体表现出的差异溶解曲线峰,对其进行基因分型结果的溶解曲线,红色为cc,蓝色为ct,绿色为tt。22对snp引物对90个银杏个体的基因分型结果如下表所示:
其中,11对snp引物组合(snp1,snp4,snp6,snp8,snp10,snp14,snp16,snp17,snp19,snp20,snp22)构建银杏古树名木指纹代码,获得84个银杏古树名木对应的指纹图谱,序号1-28为贵州盘县这个群体的28株古银杏,序号29-56为浙江天目山这个群体的28株古银杏,序号57-84为湖北安陆这个群体的28株古银杏,如下表所示:
2)高分辨率溶解曲线分析结果的验证
通过对pcr产物测序对高分辨率溶解曲线分析得到的基因分型的结果进行验证。具体步骤如下:挑选snp的不同分型的pcr产物10μl,进行sanger测序,根据测序峰图和等位基因出现的频率确定基因型,并与hrm技术的snp基因分型结果进行比较,以验证引物基因分型的准确性。
经过sanger测序验证本发明的引物通过hmr分析对银杏进行基因分型的结果100%正确,结果可靠。
- 还没有人留言评论。精彩留言会获得点赞!