一种高抗草甘膦EPSP合酶及其编码基因的应用的制作方法
本发明属于生物学领域,涉及一种微生物来源的5-烯醇丙酮酰莽草酸-3-磷酸合酶(5-enolpyruvylshikimate-3-phosphate Synthase,EPSP合酶)、其编码基因以及其在培育抗草甘膦植物中的应用。
背景技术:
草甘膦(glyphosate),是20世纪70年代初期,由美国孟山都公司的John E Franz最先发现合成。草甘膦具有高效、低毒、在环境中降解快、广谱灭生等优良特性,且制备工艺简单。由于草甘膦种种突出的特性,使其在几十年间迅速发展成为当今农业生产中生产量及销量最大,使用面积最广的一种除草剂。
草甘膦的作用机理主要是竞争性地抑制莽草酸途径中的催化PEP和S3P生成EPSP的EPSPS。草甘膦是PEP的结构类似物,其作为EPSPS的抑制因子,可以占据EPSPS与底物结合的活性位点导致莽草酸途径的受阻,进而使植物体内莽草酸大量积累,最终使植物产生草甘膦毒害(Steinrucken,H.C.,and Amrhein,N.(1980).The herbicide glyphosate is a potent inhibitor of 5-enolpyruvyl-shikimic acid-3-phosphate synthase.Biochem Biophys Res Commun 94,1207-1212)。
莽草酸途径只在植物和微生物中发现,尚未在哺乳动物中发现此途径存在的报道,莽草酸是很多化合物合成的前体,因此成为很多抗菌剂、活性移苗和除草剂的重要靶标。EPSPS作用于莽草酸途径中的第六步酶反应,是植物、微生物合成芳香族氨基酸及相关芳香族代谢物必不可少的关键酶。EPSPS由aroA基因编码,催化底物磷酸烯醇式丙酮酸(PEP)和莽草酸-3-磷酸(S3P)生成5-烯醇式丙酮酰莽草酸-3-磷酸(EPSP),在此过程中释放出1分子无机磷(Pi)。EPSPS在催化底物的过程中,首先与S3P结合成二元复合物,之后再通过切割C-O键与PEP相结合形成三元复合物,最终生成EPSP,介导莽草酸途径的正常进行(Boocock,M.R.,and Coggins,J.R.(1983).Kinetics of 5-enolpyruvylshikimate-3-phosphate synthase inhibition by glyphosate.FEBS Lett 154,127-133)。
EPSPS是广谱性除草剂草甘膦的作用靶标,草甘膦可以和EPSPS的底物PEP竞争性地抑制EPSPS的活性,导致植物莽草酸途径的受阻,使植物生长受到抑制甚至是死亡。来源于植物中的EPSPS编码基因,一般都不具有草甘膦抗性,低剂量的草甘膦就可以严重抑制EPSPS的酶活性(Funke,T.,Yang,Y.,Han,H.,et al.(2009).Structural basis of glyphosate resistance resulting from the double mutation Thr97->Ile and Pro101->Ser in5-enolpyruvylshikimate-3-phosphate synthase from Escherichia coli.J Biol Chem 284,9854-9860)。
为了增加植物EPSPS的草甘膦抗性能力,一般通过两种途径,可以增加其与底物PEP和S3P的亲和能力,或者增加对草甘膦的抑制常数。但由于PEP与草甘膦在结构上的高度相似,往往在增加EPSPS与PEP亲和能力的同时,对草甘膦的抑制常数也下降;另一方面,EPSPS对草甘膦结合能力下降的同时往往也伴随着对PEP亲和能力的下降(Zhou,M.,Xu,H.,Wei,X.,et al.(2006).Identification of a glyphosate-resistant mutant of rice5-enolpyruvylshikimate 3-phosphate synthase using a directed evolution strategy.Plant Physiol 140,184-195)。
生物体获得草甘膦抗性主要可通过以下几个途径进行:①草甘膦占据了EPSPS的活性位点,影响莽草酸途径的正常进行;莽草酸途径中增加EPSPS的含量就可以弥补因草甘膦的竞争而含量下降的EPSPS。②定向进化EPSPS是当前有关草甘膦抗性研究所做工作中最深入最广泛的。定向进化主要通过两个方面的策略来进行进化,第一是定点突变,第二是随机突变。③通过降解草甘膦也可以使生物体获得草甘膦抗性。草甘膦降解途径主要有两条,第一是C-P键断裂生成肌氨酸(Sarcosine),第二是C-N键断裂生成氨甲基膦酸(AMPA)。这两种代谢途径的中间代谢产物是很多微生物的碳源、氮源和磷源,为通过微生物代谢来研究草甘膦的降解过程提供了依据。④非靶向性的草甘膦抗性机理是指草甘膦并不直接作用于莽草酸途径中的EPSPS,草甘膦也没有通过降解途径被解毒,是多种因素综合而产生的草甘膦抗性。
生物技术在现代农业生产中所占的比重越来越大,转基因抗除草剂作物发展迅猛,草甘膦因其众多的优点使其成为培育抗除草剂转基因作物的首选。当前草甘膦抗性基因资源狭窄,需要挖掘一些新型的草甘膦抗性基因,这对培育转基因抗草甘膦植物有重大意义。
技术实现要素:
为了解决上述问题,本发明的目的在于提供一种具有草甘膦抗性的新的5-烯醇丙酮酰莽草酸-3-磷酸合酶(5-enolpyruvylshikimate-3-phosphate Synthase),简称EPSP合酶,以及其片段、类似物和衍生物,其具有较高的草甘膦抗性,可以用来培育抗草甘膦植物,其编码基因也可作为微生物和植物细胞培育中的筛选标记。
本发明的另一目的是提供编码上述EPSP合酶的基因。
本发明的再一目的是提供上述EPSP合酶及其编码基因的应用,尤其是在提高植物抗草甘膦能力方面的应用。
本发明解决其技术问题是采取以下技术方案实现的:
一种高抗草甘膦EPSP合酶,所述EPSP合酶是由SEQ ID NO.2氨基酸序列组成的蛋白、或多肽、或其保守性变异多肽、或其活性片段、或其活性衍生物;
SEQ ID NO.2
MKVTFSGRLTQNPTVIEVPGDKSISHRAVMLGSLAKGVTTVRKCLLAADVVSTIGMMRAMGVSIEIANGQVTITGAGESGLTRPNAELDAGNAGTAMRLMAGILAGQPFESVLVGDHSLSKRPMGRVATPLGQMGAQIQLSASGTAPMRITGTPKLRGITYDLPVASAQVKSAVLLAGLYADGATTVIERKPTRNYTETMVAAFGGNVSVNGQEIQVERSSLKGRDVVVPGDISSAAFFMVAAAINPGASITIRNVGINPTRTGIVDALRLMGARVELSDRRSSGGEEVADITVTGAELSGIELDADIAPRMIDEFPVFFIAAAFANGTTVVRGAEELRVKESDRIETMLVGLRQLGVVVESKPDGAVISGVGSRMLKGGVSIETAYDHRIGMAFAIASSRCEDGITVVDAEAIGTSFPGFGDLCAGCGLASSQ-
而且,所述由SEQ ID NO.2氨基酸序列组成的蛋白、或多肽、或其保守性变异多肽、或其活性片段、或其活性衍生物进一步为在SEQ ID NO.2氨基酸序列的基础上在C末端和/或N末端经取代、缺失或添加一个或几个氨基酸序列的变异形式序列组成的且具有草甘膦抗性和EPSP合酶活性的衍生蛋白、或多肽、或其保守性变异多肽、或其活性片段、或其活性衍生物。
而且,所述EPSP合酶是重组多肽、天然多肽、合成多肽;EPSP合酶是分离纯化的产物,或是化学合成的产物,或使用重组技术从原核或真核宿主中产生。
而且,所述EPSP合酶包括EPSP合酶的保守性变异多肽形式,这些变异形式为:同源序列、保守性变异体、等位变异体、天然突变体、诱导突变体、在高或低的严紧度条件下能与EPSPS DNA杂交的DNA所编码的蛋白、以及利用抗EPSP合酶的抗血清获得的多肽或蛋白;EPSP合酶保守性变异多肽是在SEQ ID No.2氨基酸序列基础上有至多10个氨基酸被性质相似或相近的氨基酸所替换而形成的多肽。
一种编码高抗草甘膦EPSP合酶的基因,所述编码基因的核苷酸序列为:SEQ ID NO.1。
SEQ ID NO.1
ATGAAGGTTACGTTTTCCGGCCGTCTGACCCAAAACCCGACAGTGATTGAGGTTCCTGGCGACAAGTCCATCTCTCACCGCGCGGTGATGCTCGGCTCTCTGGCTAAAGGGGTTACCACGGTTCGGAAGTGCTTGCTGGCAGCAGACGTGGTCAGCACCATCGGAATGATGCGAGCCATGGGAGTAAGCATTGAGATTGCGAACGGGCAGGTAACCATCACTGGGGCCGGCGAGAGTGGGCTCACGCGGCCAAATGCGGAACTGGACGCGGGCAACGCGGGTACTGCGATGAGGCTTATGGCCGGAATCTTGGCCGGGCAGCCCTTCGAAAGCGTGCTGGTTGGAGACCATTCTTTGTCGAAACGGCCGATGGGGCGTGTGGCGACCCCCCTTGGCCAAATGGGGGCGCAAATTCAGCTGTCAGCTTCCGGGACCGCTCCGATGAGGATCACCGGCACGCCAAAGCTTCGGGGCATCACTTACGATTTGCCCGTGGCCAGCGCCCAGGTGAAGTCGGCGGTACTGTTGGCCGGCCTCTATGCGGATGGAGCCACCACCGTGATAGAAAGGAAACCCACCCGCAACTACACGGAAACCATGGTGGCCGCCTTCGGAGGCAACGTCTCCGTCAACGGGCAAGAAATCCAAGTGGAGCGAAGCAGCCTGAAGGGCCGGGACGTTGTTGTTCCCGGCGACATATCGTCCGCAGCCTTTTTTATGGTGGCGGCTGCTATCAATCCTGGCGCCTCAATTACCATCAGGAACGTGGGAATAAATCCGACACGCACCGGCATTGTGGACGCACTGCGGCTCATGGGCGCGCGGGTAGAGCTTTCGGACCGCCGCAGCTCTGGTGGAGAGGAAGTCGCTGATATAACGGTCACCGGTGCCGAGCTGTCCGGAATCGAGCTCGACGCGGACATCGCGCCCCGGATGATCGACGAGTTCCCCGTGTTCTTTATTGCCGCGGCGTTTGCCAACGGGACCACTGTAGTGCGCGGAGCGGAGGAGCTCAGAGTTAAGGAAAGTGACCGTATTGAGACCATGCTCGTCGGGTTGCGCCAGCTTGGCGTAGTCGTCGAATCCAAGCCCGACGGCGCCGTGATATCGGGCGTGGGCAGTCGAATGCTCAAGGGCGGTGTCTCAATTGAGACGGCGTACGACCACCGAATCGGGATGGCTTTCGCCATCGCCAGCTCCCGCTGCGAAGACGGGATAACAGTCGTGGATGCGGAGGCGATCGGGACGTCGTTTCCGGGCTTTGGAGATCTGTGCGCCGGCTGCGGTCTGGCGAGCTCGCAATAA
而且,所述SEQ ID NO.1核苷酸序列的重组表达载体为p3301-121-sp-aroA818-2。
一种上述高抗草甘膦EPSP合酶的应用方法,该方法包括步骤如下:
(1)构建携带所述SEQ ID NO.1核苷酸序列的重组表达载体p3301-121-sp-aroA818-2的农杆菌;
(2)将植物细胞或组织或器官与步骤(1)中的农杆菌接触,使EPSP合酶编码基因转入细胞,并且整合到植物细胞的染色体上;
(3)选择出转入EPSP合酶编码基因的植物细胞或组织或器官;
(4)将步骤(3)中的植物细胞或组织或器官再生成高抗草甘膦植株,并将EPSP合酶编码基因作为微生物或植物转基因细胞培养的筛选标记。
而且,所述高抗草甘膦植株包括:玉米、水稻、小麦、大麦、高粱、棉花、大豆、烟草、杨树、甘薯、马铃薯、白菜、甘蓝及青椒。。
本发明的优点和积极效果是:
本发明提供了一种新的高抗草甘膦的EPSP合酶,为改变植物的草甘膦抗性提供了新的途径,具有巨大的应用前景。将本发明所述EPSP合酶编码基因导入植物并在其中表达后,所获得的转基因植物对草甘膦具有增强的耐受性,因此,可以通过在农作物中导入本发明所述EPSP合酶编码基因,改变现有优良农作物品种的草甘膦抗性,可获得抗草甘膦的玉米、水稻、小麦、大麦、高粱、棉花、大豆、烟草、杨树、甘薯、马铃薯、白菜、甘蓝、青椒或其它农作物品种,解决农业生产中存在的实际问题。
附图说明
图1为草甘膦抗性菌株的筛选鉴定图;
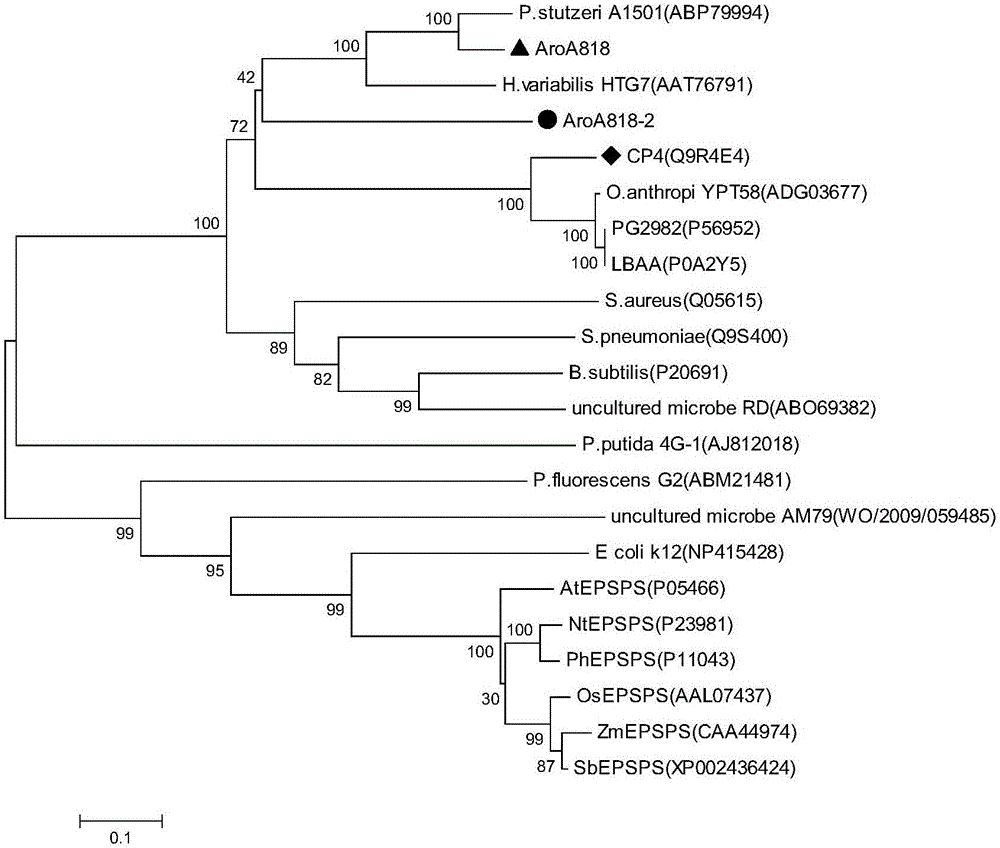
图2为AroA818-2与相关EPSPS序列构建系统进化树的示意图;
图3为含AroA818-2的重组菌株在草甘膦胁迫下的生长曲线鉴定图;
图4植物表达载体构建示意图。
具体实施方式
以下结合附图对本发明实施做进一步详述,以下实施例只是描述性的,不是限定性的,不能以此限定本发明的保护范围。
一种新的高耐受草甘膦的EPSP合酶,所述EPSP合酶为:
(1)SEQ ID NO.2所示的氨基酸序列组成的蛋白质;
(2)SEQ ID NO.2所示的氨基酸序列经取代、缺失或添加一个或几个氨基酸(较佳地1-20个)且具有草甘膦抗性和EPSP合酶活性的由(1)衍生的蛋白质。
SEQ ID NO.2:
MKVTFSGRLTQNPTVIEVPGDKSISHRAVMLGSLAKGVTTVRKCLLAADVVSTIGMMRAMGVSIEIANGQVTITGAGESGLTRPNAELDAGNAGTAMRLMAGILAGQPFESVLVGDHSLSKRPMGRVATPLGQMGAQIQLSASGTAPMRITGTPKLRGITYDLPVASAQVKSAVLLAGLYADGATTVIERKPTRNYTETMVAAFGGNVSVNGQEIQVERSSLKGRDVVVPGDISSAAFFMVAAAINPGASITIRNVGINPTRTGIVDALRLMGARVELSDRRSSGGEEVADITVTGAELSGIELDADIAPRMIDEFPVFFIAAAFANGTTVVRGAEELRVKESDRIETMLVGLRQLGVVVESKPDGAVISGVGSRMLKGGVSIETAYDHRIGMAFAIASSRCEDGITVVDAEAIGTSFPGFGDLCAGCGLASSQ-
经系统进化树分析,所述EPSP合酶属于II型EPSP合酶。
本发明中,术语“EPSP合酶”、“EPSPS多肽”、“EPSPS”或“5-烯醇丙酮酰莽草酸-3-磷酸合酶”可互换使用,都指具有SEQ ID No.2所示的氨基酸序列的蛋白、或多肽、或其保守性变异多肽、或其活性片段、或其活性衍生物。它们包括含有或不含有起始甲硫氨酸的EPSP合酶。
本发明中,“分离的”是指物质从其原始环境中分离出来(如果是天然的物质,原始环境即是天然环境)。如活体细胞内的天然状态下的多聚核苷酸和多肽是没有分离纯化的,但同样的多聚核苷酸或多肽如从天然状态中同存在的其他物质中分开,则为分离纯化的。
本发明中,“分离的EPSP合酶或EPSPS多肽”是指EPSPS多肽基本上不含天然的其它蛋白、脂类、糖类或其它物质。本领域的技术人员能用标准的蛋白质纯化技术纯化EPSP合酶。
本发明的EPSPS多肽可以是重组多肽、天然多肽、合成多肽,优选为重组多肽。本发明的EPSPS多肽可以是分离纯化的产物,或是化学合成的产物,或使用重组技术从原核或真核宿主(例如,细菌、酵母、高等植物、昆虫和哺乳动物细胞)中产生。根据重组生产方案所用的宿主,本发明的EPSPS多肽可以是糖基化的,或可以是非糖基化的。本发明的EPSPS多肽还可包括或不包括起始的甲硫氨酸残基。
本发明还包括EPSP合酶的片段、衍生物和类似物。如本文所用,术语“片段”、“衍生物”和“类似物”是指基本上保持本发明的天然EPSP合酶相同的生物学功能或活性的多肽。本发明的多肽片段、衍生物或类似物可以是(i)有一个或多个保守或非保守性氨基酸残基(优选保守性氨基酸残基)被取代的多肽,而这样的取代的氨基酸残基可以是也可以不是由遗传密码编码的,或(ii)在一个或多个氨基酸残基中具有取代基团的多肽,或(iiii)成熟多肽与另一个化合物融合所形成的多肽,或(iv)附加的氨基酸序列融合到此多肽序列而形成的多肽(如前导序列或分泌序列或用来纯化此多肽的序列)。根据本发明的记载,这些片段、衍生物和类似物属于本领域熟练技术人员公知的范围。
在本发明中,术语“EPSPS多肽”还包括具有与EPSP合酶相同功能的、SEQ ID No.2所示的氨基酸序列的变异形式。这些变异形式包括(但并不限于):若干个(通常为1-50个,较佳地1-30个,更佳地1-20个,最佳地1-10个)氨基酸的缺失、插入和/或取代,以及在C末端和/或N末端添加一个或数个(通常为20个以内,较佳地为10个以内,更佳地为5个以内)氨基酸。例如,在本领域中,用性能相近或相似的氨基酸进行取代时,通常不会改变蛋白质的功能。又比如,在C末端和/或N末端添加一个或数个氨基酸通常也不会改变蛋白质的功能。该术语还包括EPSP合酶的活性片段和活性衍生物。
所述“EPSPS多肽”的变异形式包括:同源序列、保守性变异体、等位变异体、天然突变体、诱导突变体、在高或低的严紧度条件下能与EPSPS DNA杂交的DNA所编码的蛋白、以及利用抗EPSPS多肽的抗血清获得的多肽或蛋白。本发明还提供了其它多肽,如包含EPSPS多肽或其片段的融合蛋白。除了几乎全长的多肽外,本发明还包括了EPSPS多肽的可溶性片段。通常,该片段具有EPSPS多肽序列的至少约10个连续氨基酸,通常至少约30个连续氨基酸,较佳地至少约50个连续氨基酸,更佳地至少约80个连续氨基酸,最佳地至少约100个连续氨基酸。
本发明还提供了EPSP合酶或EPSPS多肽的类似物。这些类似物与天然EPSPS多肽的差别可以是氨基酸序列上的差异,也可以是不影响序列的修饰形式上的差异,或者兼而有之。这些多肽包括天然或诱导的遗传变异体。诱导变异体可以通过各种技术得到。
在本发明中,“EPSP合酶保守性变异多肽”指与SEQ ID No.2所示的氨基酸序列相比,有至多10个,较佳地至多8个,更佳地至多5个,最佳地至多3个氨基酸被性质相似或相近的氨基酸所替换而形成多肽。这些保守性变异多肽优选为根据表1进行氨基酸替换而产生。
表1氨基酸替换表
本发明还提供了编码所述EPSP合酶的基因。所述基因的核苷酸序列为:(a)编码上述EPSP合酶的多核苷酸;(b)与多核苷酸(a)互补的多核苷酸。
优选地,所述基因编码具有SEQ ID NO.2所示氨基酸序列的多肽。更优选地,所述基因具有SEQ ID NO.1所示的核苷酸序列或具有SEQ ID NO.1所示的核苷酸序列中1-1302位的序列。
SEQ ID NO.1:
ATGAAGGTTACGTTTTCCGGCCGTCTGACCCAAAACCCGACAGTGATTGAGGTTCCTGGCGACAAGTCCATCTCTCACCGCGCGGTGATGCTCGGCTCTCTGGCTAAAGGGGTTACCACGGTTCGGAAGTGCTTGCTGGCAGCAGACGTGGTCAGCACCATCGGAATGATGCGAGCCATGGGAGTAAGCATTGAGATTGCGAACGGGCAGGTAACCATCACTGGGGCCGGCGAGAGTGGGCTCACGCGGCCAAATGCGGAACTGGACGCGGGCAACGCGGGTACTGCGATGAGGCTTATGGCCGGAATCTTGGCCGGGCAGCCCTTCGAAAGCGTGCTGGTTGGAGACCATTCTTTGTCGAAACGGCCGATGGGGCGTGTGGCGACCCCCCTTGGCCAAATGGGGGCGCAAATTCAGCTGTCAGCTTCCGGGACCGCTCCGATGAGGATCACCGGCACGCCAAAGCTTCGGGGCATCACTTACGATTTGCCCGTGGCCAGCGCCCAGGTGAAGTCGGCGGTACTGTTGGCCGGCCTCTATGCGGATGGAGCCACCACCGTGATAGAAAGGAAACCCACCCGCAACTACACGGAAACCATGGTGGCCGCCTTCGGAGGCAACGTCTCCGTCAACGGGCAAGAAATCCAAGTGGAGCGAAGCAGCCTGAAGGGCCGGGACGTTGTTGTTCCCGGCGACATATCGTCCGCAGCCTTTTTTATGGTGGCGGCTGCTATCAATCCTGGCGCCTCAATTACCATCAGGAACGTGGGAATAAATCCGACACGCACCGGCATTGTGGACGCACTGCGGCTCATGGGCGCGCGGGTAGAGCTTTCGGACCGCCGCAGCTCTGGTGGAGAGGAAGTCGCTGATATAACGGTCACCGGTGCCGAGCTGTCCGGAATCGAGCTCGACGCGGACATCGCGCCCCGGATGATCGACGAGTTCCCCGTGTTCTTTATTGCCGCGGCGTTTGCCAACGGGACCACTGTAGTGCGCGGAGCGGAGGAGCTCAGAGTTAAGGAAAGTGACCGTATTGAGACCATGCTCGTCGGGTTGCGCCAGCTTGGCGTAGTCGTCGAATCCAAGCCCGACGGCGCCGTGATATCGGGCGTGGGCAGTCGAATGCTCAAGGGCGGTGTCTCAATTGAGACGGCGTACGACCACCGAATCGGGATGGCTTTCGCCATCGCCAGCTCCCGCTGCGAAGACGGGATAACAGTCGTGGATGCGGAGGCGATCGGGACGTCGTTTCCGGGCTTTGGAGATCTGTGCGCCGGCTGCGGTCTGGCGAGCTCGCAATAA
本发明中,编码EPSP合酶的多核苷酸可以是DNA形式或RNA形式。DNA形式包括cDNA,基因组DNA或人工合成的DNA。DNA可以是单链的或是双链的。DNA可以是编码链或非编码链。编码成熟多肽的编码区序列可以与SEQ ID NO.1所示的编码区序列相同或者是简并的变异体。如本文所用,“简并的变异体”在本发明中是指编码具有SEQ ID NO.2所示的氨基酸序列的蛋白质,但与SEQ ID NO.1所示的编码区序列有差别的核酸序列。
编码SEQ ID NO.2所示的氨基酸序列的成熟多肽的多核苷酸包括:只编码成熟多肽的编码序列;成熟多肽的编码序列和各种附加编码序列;成熟多肽的编码序列(和任选的附加编码序列)以及非编码序列。
术语“编码EPSPS多肽的多核苷酸”可以是包括编码此多肽的多核苷酸,也可以是还包括附加编码和/或非编码序列的多核苷酸。
本发明还涉及上述多核苷酸的变异体,其编码与本发明有相同的氨基酸序列的多肽或多肽的片段、类似物和衍生物。此多核苷酸的变异体可以是天然发生的等位变异体或非天然发生的变异体。这些核苷酸变异体包括取代变异体、缺失变异体和插入变异体。如本领域所知的,等位变异体是一个多核苷酸的替换形式,它可能是一个或多个核苷酸的取代、缺失或插入,但不会从实质上改变其编码的多肽的功能。
本发明还涉及与上述的序列杂交且两个序列之间具有至少50%,较佳地至少70%,更佳地至少80%相同性的多核苷酸。本发明特别涉及在严格条件下与本发明所述多核苷酸可杂交的多核苷酸。在本发明中,“严格条件”是指:(1)在较低离子强度和较高温度下的杂交和洗脱,如0.2×SSC,0.1%SDS,600℃;或(2)杂交时加有变性剂,如50%(v/v)甲酰胺,0.1%小牛血清/0.1%Ficoll,42℃等;或(3)仅在两条序列之间的相同性至少在90%以上,更好是95%以上时才发生杂交。并且,可杂交的多核苷酸编码的多肽与SEQ ID NO.2所示的成熟多肽有相同的生物学功能和活性。
本发明还涉及与上述的序列杂交的核酸片段。如本文所用,“核酸片段”的长度至少含15个核苷酸,较好是至少30个核苷酸,更好是至少50个核苷酸,最好是至少100个核苷酸以上。核酸片段可用于核酸的扩增技术(如PCR)以确定和/或分离编码EPSP合酶的多聚核苷酸。
本发明中的多肽和多核苷酸优选以分离的形式提供,更佳地被纯化至均质。
本发明的编码所述EPSP合酶基因的全长序列或其片段通常可以用人工合成、PCR扩增法、或重组法的方法获得。例如首先根据SEQ ID NO.1的序列进行全序列合成。
对于PCR扩增法,可根据本发明所公开的有关核苷酸序列,尤其是开放阅读框序列来设计引物,并用人工合成的EPSP合酶编码基因全长序列或其片段作为模板,扩增而得有关序列。
一旦获得了有关序列,就可以用重组法来大批量地获得有关序列。这通常是将其克隆入载体,再转入细胞,然后通过常规方法从增殖后的宿主细胞中分离得到有关序列。
此外,还可用人工合成的方法来合成有关序列,尤其是片段长度较短时。通常,通过先合成多个小片段,然后再进行连接可获得序列很长的片段。
目前,已经可以完全通过化学合成来得到编码本发明EPSP合酶蛋白(或其片段和衍生物)的基因。然后可将该基因引入本领域中已知的各种现有的DNA分子(或如载体)和细胞中。此外,还可通过化学合成将突变引入本发明蛋白序列中。
发明人经过广泛而深入的研究,从草甘膦重度污染土壤中筛选得到草甘膦抗性微生物P818,通过Tail-PCR的方法(获得aroA818)及测序方法(获得aroA818-2)获得了EPSP合酶的两个拷贝基因(其中aroA818已经申请专利,专利号:ZL201310376641.2;证书号:第1695432号),标记为并且通过实验验证了它具有高抗草甘膦的能力,并且转入植物后,可导致植物抗草甘膦能力提高。
本发明所述草甘膦抗性微生物P818:假单胞菌(Pseudomonas sp.)P818,现已保藏于中国微生物菌种保藏管理委员会普通微生物中心,地址:北京市朝阳区北辰西路1号院3号,中国科学院微生物研究所,邮编100101,保藏日期2013年8月12日,保藏号CGMCC No.7989。
本发明还提供了含有上述编码EPSP合酶基因的载体。优选地,所述载体为重组表达载体。
本发明中,EPSP合酶的编码基因可插入到重组表达载体中。术语“重组表达载体”指本领域熟知的细菌质粒、噬菌体、酵母质粒、植物细胞病毒、哺乳动物细胞病毒或其他载体。总之,只要能在宿主体内复制和稳定,任何质粒和载体都可以用。重组表达载体的一个重要特征是通常含有复制起点、启动子、标记基因和翻译控制元件。
本领域的技术人员熟知的方法能用于构建含EPSP合酶编码基因和合适的转录/翻译控制信号的表达载体。这些方法包括体外重组DNA技术、DNA合成技术、体内重组技术等。所述的基因可有效连接到表达载体中的适当启动子上,以指导mRNA合成。表达载体还包括翻译起始用的核糖体结合位点和转录终止子。
此外,表达载体优选地包含一个或多个选择性标记基因,以提供用于选择转化的宿主细胞的表型性状,如真核细胞培养用的二氢叶酸还原酶、新霉素抗性以及绿色荧光蛋白(GFP),或用于大肠杆菌的四环素或氨节青霉素抗性。
进一步优选地,所述重组表达载体为p3301-121-sp-aroA818-2,所述重组表达载体p3301-121-sp-aroA818-2的构建方法包括如下步骤:
(1)设计上游引物5'-AGGATCCATGAAGGTTACGTTTTCC-3',5'端引入BamHI酶切位点(GGATCC);下游引物5'-GAGCTCTTATACCCATACGATGTTCCAGATTACGCTTTGCGAGCTCGCCAGA-3',5'端引入SacI酶切位点(GAGCTC);
(2)提取草甘膦抗性微生物P818的基因组总DNA,以步骤(1)设计的上游引物和下游引物为引导进行PCR反应,扩增EPSP合酶基因;
(3)将扩增得到的PCR产物克隆至pEASY T1 simple载体上,测序,得载体T-p818-2-3301;
(4)用HindIII和EcoRI酶切质粒pBI121,回收35S-GUS-NOS片段;用HindIII和EcoRI酶切载体pCAMBIA3301,回收载体片段,连接,得到质粒pCAMBIA3301-121;
(5)用BamHI和SacI酶切含EPSP合酶基因的载体T-p818-2-3301,电泳并回收EPSP合酶基因片段;同样用SacI和BamH1酶切pCAMBIA3301-121载体,电泳并回收载体片段;连接,得到载体p3301-121-aroA818-2;
(6)将来源于豌豆的叶绿体定位信号肽(signal peptide,Accession number:X00806.1),在5'端和3'端分别添加XbaI和BamHI酶切位点,通过酶切连接方法,亚克隆至载体p3301-121-aroA818-2的BamHI和XbaI酶切位点,得到重组表达载体p3301-121-sp-aroA818-2。
其中,步骤(2)中,PCR反应体系:
PCR反应程序:98℃5分钟;98℃30秒,55℃30秒,72℃45秒,35个循环;72℃10分钟;4℃保温;
本发明还提供了含有上述EPSP合酶编码基因或含EPSP合酶编码基因的重组表达载体的宿主细胞。所述宿主细胞为被所述EPSP合酶编码基因直接转化或转导的宿主细胞或被含EPSP合酶编码基因的重组表达载体转化或转导的宿主细胞。
宿主细胞可以是原核细胞,如细菌细胞;或是低等真核细胞,如酵母细胞;或是高等真核细胞,如植物细胞。代表性例子有:大肠杆菌,链霉菌属、农杆菌;真菌细胞如酵母;植物细胞;昆虫细胞等。
本发明的EPSP合酶编码基因在高等真核细胞中表达时,如果在载体中插入增强子序列时将会使转录得到增强。增强子是DNA的顺式作用因子,通常大约有10到300个碱基对,作用于启动子以增强基因的转录。
本领域一般技术人员都清楚如何选择适当的载体、启动子、增强子和宿主细胞。
用重组DNA转化宿主细胞可用本领域技术人员熟知的常规技术进行。当宿主为原核生物如大肠杆菌时,能吸收DNA的感受态细胞可在指数生长期后收获,用CaCl2法处理,所用的步骤在本领域众所周知。另一种方法是使用MgCl2。如果需要,转化也可用电穿孔的方法进行。当宿主是真核生物,可选用如下的DNA转染方法:磷酸钙共沉淀法,常规机械方法如显微注射、电穿孔、脂质体包装等。转化植物也可使用农杆菌转化或基因枪转化等方法,例如叶盘法。对于转化的植物细胞、组织或器官可以用常规方法再生成植株,从而获得抗草甘膦抗性提高的植物。
包含所述EPSP合酶编码基因以及适当启动子或者控制序列的载体,可以用于转化适当的宿主细胞,以使其能够表达蛋白质。
本发明还提供了一种制备具有草甘膦抗性和EPSP合酶活性的多肽的方法,该方法包括:(a)在适合表达的条件下,培养上述被转化或转导的宿主细胞;(b)从培养物中分离出具有所述活性的多肽。
通过常规的重组DNA技术,利用本发明的EPSP合酶编码基因可用来表达或生产重组的EPSPS多肽。一般来说有以下步骤:
(1)将本发明的EPSP合酶编码基因(或变异体),或将含有所述EPSP合酶编码基因的重组表达载体转化或转导合适的宿主细胞;
(2)在合适的培养基中培养所述宿主细胞;
(3)从培养基或细胞中分离、纯化所述EPSPS多肽。
获得的转化子可以用常规方法培养,表达本发明的基因所编码的多肽。根据所用的宿主细胞,培养中所用的培养基可选自各种常规培养基。在适于宿主细胞生长的条件下进行培养。当宿主细胞生长到适当的细胞密度后,用合适的方法(如温度转换或化学诱导)诱导选择的启动子,将细胞再培养一段时间。
在上面的方法中的重组多肽可在细胞内、或在细胞膜上表达、或分泌到细胞外。如果需要,可利用其物理的、化学的和其它特性通过各种分离方法分离和纯化重组的蛋白。这些方法是本领域技术人员所熟知的。这些方法的例子包括但并不限于:常规的复性处理、用蛋白沉淀剂处理(盐析方法)、离心、渗透破菌、超处理、超离心、分子筛层析(凝胶过滤)、吸附层析、离子交换层析、高效液相层析(HPLC)和其它各种液相层析技术及这些方法的结合。
本发明还提供了一种提高植物草甘膦抗性的方法,所述方法包括如下步骤:
(1)构建携带含上述EPSP合酶编码基因的重组表达载体的农杆菌;
(2)将植物细胞或组织或器官与步骤(1)中的农杆菌接触,使EPSP合酶编码基因转入细胞,并且整合到植物细胞的染色体上;
(3)选择出转入EPSP合酶编码基因的植物细胞或组织或器官;
(4)将步骤(3)中的植物细胞或组织或器官再生成植株。
优选地,所述植株为玉米、水稻、小麦、大麦、高粱、棉花、大豆、烟草、杨树、甘薯、马铃薯、白菜、甘蓝、青椒或其它农作物品种。
本发明还提供了能够与上述EPSP合酶特异性结合的抗体,包括多克隆抗体和单克隆抗体。也就是说,本发明还提供了对上述EPSP合酶编码基因或是其片段编码的多肽具有特异性的多克隆抗体和单克隆抗体,尤其是单克隆抗体。较佳地,指那些能与EPSP合酶编码基因产物或片段结合但不识别和结合于其它非相关抗原分子的抗体。本发明中抗体包括那些能够结合并抑制EPSP合酶的分子,也包括那些并不影响EPSP合酶功能的抗体。本发明还包括那些能与修饰或未经修饰形式的EPSP合酶编码基因产物结合的抗体。
本发明不仅包括完整的单克隆或多克隆抗体,而且还包括具有免疫活性的抗体片段、或嵌合抗体。
本发明的抗体可以通过本领域内技术人员已知的各种技术进行制备。例如纯化的EPSP合酶编码基因产物或者其具有抗原性的片段,可被施用于动物以诱导多克隆抗体的产生。与之相似的,表达EPSP合酶或其具有抗原性的片段的细胞可用来免疫动物来生产抗体。此类单克隆抗体可以利用杂交瘤技术来制备。本发明的各类抗体可以利用EPSP合酶编码基因产物的片段或功能区,通过常规免疫技术获得。这些片段或功能区可以利用重组方法制备或利用多肽合成仪合成。与EPSP合酶编码基因产物的未修饰形式结合的抗体可以用原核细胞(例如E.coli)中生产的基因产物来免疫动物而产生;与翻译后修饰形式结合的抗体(如糖基化或磷酸化的蛋白或多肽),可以用真核细胞(例如酵母或昆虫细胞)中产生的基因产物来免疫动物而获得。抗EPSP合酶的抗体可用于检测样品中的EPSP合酶。
多克隆抗体的生产可用EPSP合酶或多肽免疫动物,如家兔,小鼠,大鼠等。多种佐剂可用于增强免疫反应,包括但不限于弗氏佐剂等。
本发明还涉及定量和定位检测EPSP合酶水平的测试方法。这些试验是本领域所熟知的,且包括FISH测定和放射免疫测定。
一种检测样品中是否存在EPSP合酶的方法是利用EPSP合酶的特异性抗体进行检测,它包括:将样品与EPSP合酶特异性抗体接触;观察是否形成抗体复合物,形成了抗体复合物就表示样品中存在EPSP合酶。
本发明还提供了所述EPSP合酶编码基因在微生物或植物转基因细胞培养中作为筛选标记分子的应用。
本发明的EPSP合酶编码基因的一部分或全部可作为探针固定在微阵列(microarray)或DNA芯片(又称为“基因芯片”)上,用于基因的表达分析。用EPSP合酶特异的引物进行RNA-聚合酶链反应(RT-PCR)体外扩增也可检测EPSP合酶的转录产物。
在本发明的一个实例中,提供了一种分离的多核苷酸,它编码具有SEQ ID NO.2所示氨基酸序列的多肽。本发明的多核苷酸是从采用免培养技术构建的群落水平DNA库中分离、并人工全合成的。其核苷酸序列如SEQ ID NO.1所示,它包含的多核苷酸序列全长为1305个碱基,编码全长为434个氨基酸的EPSP合酶(SEQ ID NO.2)。
实施例1抗性菌株的筛选鉴定
草甘膦重度污染土壤样品用液体M9培养基进行梯度稀释,将稀释倍数为106的土壤悬液涂布于含有300mM草甘膦的M9固体培养基上,37℃进行培养。由于M9培养基为营养缺陷型,能够存活和生长的细菌为草甘膦抗性菌株。将获得的纯合菌株摇菌后用不含草甘膦的液体M9培养基重悬菌体,之后吸取2Μl重悬菌液点于含有350mM草甘膦的固体M9培养基平板上,37℃倒置培养,观察菌体的生长状况,最终鉴定能够耐受高浓度草甘膦胁迫的菌株。
本发明经过筛选得到一株草甘膦抗性菌株,命名为818(图1),它能在含300mM草甘膦的M9培养基中生长。
本发明通过PCR方法获得了菌株818的16SrDNA序列。提取菌株818的基因组总DNA,以如下正向引物和反向引物为引导进行PCR反应。通过PCR扩增从细菌818的基因组DNA中扩增其16SrDNA序列。
正向引物序列:5'-AGAGTTTGATCATGGCTCAG-3',反向引物序列:5'-TACGGTTACCTTGTTACGACTT-3'。
PCR反应体系:
PCR反应程序:98℃5分钟;98℃30秒,55℃30秒,72℃45秒,共35个循环;72℃10分钟;4℃保温。
将扩增得到的PCR产物克隆至pEASY T1 simple载体上,用通用引物M13(F)和M13(R)进行测序,将获得的结果在NCBI上进行序列比对,结果显示其与假单胞菌Pseudomonas mendocina ymp、Pseudomonas mendocina strain NS2等都有99%左右的同一性,因此推测该菌株是一类假单胞菌Pseudomonas sp,将其命名为P818。
本发明所述草甘膦抗性微生物P818:假单胞菌(Pseudomonas sp.)P818,现已保藏于中国微生物菌种保藏管理委员会普通微生物中心,地址:北京市朝阳区北辰西路1号院3号,中国科学院微生物研究所,邮编100101,保藏日期2013年8月12日,保藏号CGMCC No.7989。
实施例2 P818EPSP合酶与其它已知草甘膦抗性EPSP合酶的相似性
在已有研究基础上,通过全基因组测序(由北京基因组研究所完成),获得了假单胞菌P818的EPSPS编码基因的第二个拷贝,命名为aroA818-2。aroA818-2全长1305bp,编码434个氨基酸。搜集有一定研究基础的典型的部分EPSPS序列采用Neighbor-Joining算法构建系统进化发育树(MEGA6.0),自展值1000次。
系统进化分析显示AroA818-2属于II型的EPSPS,它与盐单胞菌HTG7EPSPS及CP4的EPSPS同源关系最近(图2)。
实施例3含AroA818-2的重组菌株在草甘膦胁迫下的生长曲线鉴定
利用原核表达载体PUC18的BamHI和SalI酶切位点,将aroA818,maroA818(基于CP4序列第97位特异的A,对AroA818进行G/A的点突变,具有较高草甘膦抗性)及aroA818-2分别构建至PUC18的BamHI和SalI酶切位点上,转化aroA缺陷型菌株ER2799,重组菌株用含有200mM glyphosate的液体M9培养基进行培养,测定重组菌株的生长曲线。
载体构建方法采用HD Cloning Kit(clontech),所用引物为,正向:5’-CGGTACCCGGGGATCCGATGAAGGTTACGTTTTCC-3’,反向:5’-ATGCCTGCAGGTCGACTTATTGCGAGCTCGCCAGA-3‘。
PCR反应体系:
PCR反应程序:98℃5分钟;98℃30秒,55℃30秒,72℃45秒,共35个循环;72℃10分钟;4℃保温。
In-fusion反应体系为:
50℃反应15min,之后转化DH5α,筛选阳性克隆,并测序鉴定,获得重组质粒。重组质粒转化大肠杆菌aroA缺陷型菌株ER2799进行草甘膦抗性鉴定,以质粒PUC18,PUC-aroA818,PUC-MaroA818为对照。
结果表明(图3),含有aroA818-2(标注为1305)的重组菌株具有一定的草甘膦抗性,aroA818-2可以赋予重组菌株抵抗高浓度的草甘膦的胁迫,aroA818-2具有培育遗传修饰植物的潜力。
实施例4植物表达载体的构建及转基因烟草和拟南芥的获得
1、基因克隆
根据完整的aroA818-2基因的序列,设计特异性引物。同时在基因的终止密码子前端添加HA标签序列,利于后期检测基因的翻译情况。设计上游引物5'-AGGATCCATGAAGGTTACGTTTTCC-3',5'端引入BamHI酶切位点(GGATCC),下游引物5'-GAGCTCTTATACCCATACGATGTTCCAGATTACGCTTTGCGAGCTCGCCAGA-3',5'端引入SacI酶切位点(GAGCTC)。以细菌P818的基因组DNA为模板,以上游引物和下游引物为引导进行PCR反应。
PCR反应体系:
PCR反应程序:98℃5分钟;98℃30秒,55℃30秒,72℃45秒,35个循环;72℃10分钟;4℃保温。
将扩增得到的PCR产物克隆至pEASY T1 simple载体上,用通用引物M13(F)5‘-TGTAAAACGACGGCCAGT-3’和M13(R)5’-CAGGAAACAGCTATGACC-3’进行测序,测序结果显示克隆正确,载体命名为T-p818-2-3301。
2、载体构建及向农杆菌的转化
用HindIII和EcoRI酶切质粒pBI121回收35S-GUS-NOS片段,连接到用HindIII和EcoRI酶切的pCAMBIA3301上,构建质粒pCAMBIA3301-121。用BamHI和SacI酶切含aroA818-2基因的载体T-p818-2-3301,酶切产物跑琼脂糖凝胶电泳,分别回收约1.3k的片段。同样用SacI和BamH1酶切pCAMBIA3301-121载体,电泳并回收11kb片段。将回收的基因片段和载体片段用T4DNA连接酶连接,使aroA818-2基因片段取代该载体上的来源于pBI121的GUS片段,载体命名为p3301-121-aroA818-2。为使aroA818-2基因更好地作用于叶绿体中,在aroA818-2因前端,利用XbaI和BamHI酶切位点,亚克隆一来源于豌豆的叶绿体定位信号肽(signal peptide,Accession number:X00806.1),在叶绿体定位信号肽5’端和3’端通过PCR克隆的方法添加XbaI和BamHI酶切位点,通过酶切连接方法,亚克隆至载体p3301-121-aroA818-2的BamHI和XbaI酶切位点,得到重组载体p3301-121-sp-aroA818-2。载体构建策略见(图4)。
3、转基因植株的获得
取200μL农杆菌EHA105感受态细胞,加入lμg载体p3301-121-sp-aroA818-2的DNA,液氮中速冻1分钟,37℃水浴5分钟,然后加入lmL空白YEB培养基,28℃慢速振荡培养4小时;l000rpm离心30秒,弃上清,加入0.lmLYEB培养基重新悬浮细胞,涂布于含有100μg/mL卡那霉素和50μg/mL利福平的YEB平板上,28℃培养约48小时。挑取平板上长出的单菌落,接种于YEB液体培养液中,28℃振荡培养过夜;小量提取质粒DNA,以质粒DNA为模板进行PCR扩增鉴定。
烟草转化方法:将含有植物表达载体p3301-121-sp-aroA818-2的农杆菌接种于YEB液体培养液(含有100μg/mL卡那霉素和50μg/mL利福平)中,28℃振荡培养至OD600为0.6-0.8。4000rpm,室温离心10分钟,用MS盐溶液(PH7.0)重新悬浮菌体,使用时采用MS盐溶液稀释至OD600=0.3左右。无菌的烟草叶片切去边缘和主要叶脉,在上述农杆菌菌液中浸泡10分钟;用滤纸吸干植物材料表面的菌液,转入上铺一层滤纸的MS基本培养基,28℃暗培养三天后。将材料转到含有抗生素的分化培养基(MS+3mg/L 6-BA+0.2mg/L NAA+20mg/L Basta+250μg/mL塞孢霉素)。待抗性芽生长至2-3cm高时,切下小芽转入生根培养基中(MS基本培养基+20mg/L Basta),进一步培养得到转基因阳性苗,提取DNA进行PCR鉴定。
拟南芥转化方法:将含有植物表达载体p3301-121-sp-aroA818-2的农杆菌在固体YEB平板上培养2-3天后,用涂布器刮取菌层至一小烧瓶中,用30mL YEB液体重悬。重悬后的菌液OD值为2.0左右。
另外准备120mL含有0.03%Silwet L-77的浓度为5%的蔗糖溶液。将以上两种溶液混合得到每次转化所用的转化液。将装着拟南芥的小花托倾斜,使拟南芥植株的花序能够完全浸泡在农杆菌转化液中30秒。将植株套入一个塑料PE手套中,然后将花托平放,并在苗子上盖一个盖子,使苗子避光水平放置16-24小时后置于光下正常培养。将收取的T0代转基因植株的种子放入无菌水中4℃纯化三天,之后用移液器转移均匀铺于含有蛭石:营养土(3:1)的小花盆中,并覆膜保湿,25℃,16hr光照/8hr黑暗条件下培养,待幼苗长至10天左右时,喷施1:1000倍稀释的Basta,存活下来的苗为转基因阳性苗,提取DNA进行PCR鉴定。
SEQUENCE LISTING
<110> 天津农学院
<120> 一种高抗草甘膦EPSP合酶及其编码基因的应用
<130> 2017-01-06
<160> 2
<170> PatentIn version 3.3
<210> 1
<211> 1305
<212> DNA
<213> SEQ ID NO.1
<400> 1
atgaaggtta cgttttccgg ccgtctgacc caaaacccga cagtgattga ggttcctggc 60
gacaagtcca tctctcaccg cgcggtgatg ctcggctctc tggctaaagg ggttaccacg 120
gttcggaagt gcttgctggc agcagacgtg gtcagcacca tcggaatgat gcgagccatg 180
ggagtaagca ttgagattgc gaacgggcag gtaaccatca ctggggccgg cgagagtggg 240
ctcacgcggc caaatgcgga actggacgcg ggcaacgcgg gtactgcgat gaggcttatg 300
gccggaatct tggccgggca gcccttcgaa agcgtgctgg ttggagacca ttctttgtcg 360
aaacggccga tggggcgtgt ggcgaccccc cttggccaaa tgggggcgca aattcagctg 420
tcagcttccg ggaccgctcc gatgaggatc accggcacgc caaagcttcg gggcatcact 480
tacgatttgc ccgtggccag cgcccaggtg aagtcggcgg tactgttggc cggcctctat 540
gcggatggag ccaccaccgt gatagaaagg aaacccaccc gcaactacac ggaaaccatg 600
gtggccgcct tcggaggcaa cgtctccgtc aacgggcaag aaatccaagt ggagcgaagc 660
agcctgaagg gccgggacgt tgttgttccc ggcgacatat cgtccgcagc cttttttatg 720
gtggcggctg ctatcaatcc tggcgcctca attaccatca ggaacgtggg aataaatccg 780
acacgcaccg gcattgtgga cgcactgcgg ctcatgggcg cgcgggtaga gctttcggac 840
cgccgcagct ctggtggaga ggaagtcgct gatataacgg tcaccggtgc cgagctgtcc 900
ggaatcgagc tcgacgcgga catcgcgccc cggatgatcg acgagttccc cgtgttcttt 960
attgccgcgg cgtttgccaa cgggaccact gtagtgcgcg gagcggagga gctcagagtt 1020
aaggaaagtg accgtattga gaccatgctc gtcgggttgc gccagcttgg cgtagtcgtc 1080
gaatccaagc ccgacggcgc cgtgatatcg ggcgtgggca gtcgaatgct caagggcggt 1140
gtctcaattg agacggcgta cgaccaccga atcgggatgg ctttcgccat cgccagctcc 1200
cgctgcgaag acgggataac agtcgtggat gcggaggcga tcgggacgtc gtttccgggc 1260
tttggagatc tgtgcgccgg ctgcggtctg gcgagctcgc aataa 1305
<210> 2
<211> 434
<212> PRT
<213> SEQ ID NO.2
<400> 2
Met Lys Val Thr Phe Ser Gly Arg Leu Thr Gln Asn Pro Thr Val Ile
1 5 10 15
Glu Val Pro Gly Asp Lys Ser Ile Ser His Arg Ala Val Met Leu Gly
20 25 30
Ser Leu Ala Lys Gly Val Thr Thr Val Arg Lys Cys Leu Leu Ala Ala
35 40 45
Asp Val Val Ser Thr Ile Gly Met Met Arg Ala Met Gly Val Ser Ile
50 55 60
Glu Ile Ala Asn Gly Gln Val Thr Ile Thr Gly Ala Gly Glu Ser Gly
65 70 75 80
Leu Thr Arg Pro Asn Ala Glu Leu Asp Ala Gly Asn Ala Gly Thr Ala
85 90 95
Met Arg Leu Met Ala Gly Ile Leu Ala Gly Gln Pro Phe Glu Ser Val
100 105 110
Leu Val Gly Asp His Ser Leu Ser Lys Arg Pro Met Gly Arg Val Ala
115 120 125
Thr Pro Leu Gly Gln Met Gly Ala Gln Ile Gln Leu Ser Ala Ser Gly
130 135 140
Thr Ala Pro Met Arg Ile Thr Gly Thr Pro Lys Leu Arg Gly Ile Thr
145 150 155 160
Tyr Asp Leu Pro Val Ala Ser Ala Gln Val Lys Ser Ala Val Leu Leu
165 170 175
Ala Gly Leu Tyr Ala Asp Gly Ala Thr Thr Val Ile Glu Arg Lys Pro
180 185 190
Thr Arg Asn Tyr Thr Glu Thr Met Val Ala Ala Phe Gly Gly Asn Val
195 200 205
Ser Val Asn Gly Gln Glu Ile Gln Val Glu Arg Ser Ser Leu Lys Gly
210 215 220
Arg Asp Val Val Val Pro Gly Asp Ile Ser Ser Ala Ala Phe Phe Met
225 230 235 240
Val Ala Ala Ala Ile Asn Pro Gly Ala Ser Ile Thr Ile Arg Asn Val
245 250 255
Gly Ile Asn Pro Thr Arg Thr Gly Ile Val Asp Ala Leu Arg Leu Met
260 265 270
Gly Ala Arg Val Glu Leu Ser Asp Arg Arg Ser Ser Gly Gly Glu Glu
275 280 285
Val Ala Asp Ile Thr Val Thr Gly Ala Glu Leu Ser Gly Ile Glu Leu
290 295 300
Asp Ala Asp Ile Ala Pro Arg Met Ile Asp Glu Phe Pro Val Phe Phe
305 310 315 320
Ile Ala Ala Ala Phe Ala Asn Gly Thr Thr Val Val Arg Gly Ala Glu
325 330 335
Glu Leu Arg Val Lys Glu Ser Asp Arg Ile Glu Thr Met Leu Val Gly
340 345 350
Leu Arg Gln Leu Gly Val Val Val Glu Ser Lys Pro Asp Gly Ala Val
355 360 365
Ile Ser Gly Val Gly Ser Arg Met Leu Lys Gly Gly Val Ser Ile Glu
370 375 380
Thr Ala Tyr Asp His Arg Ile Gly Met Ala Phe Ala Ile Ala Ser Ser
385 390 395 400
Arg Cys Glu Asp Gly Ile Thr Val Val Asp Ala Glu Ala Ile Gly Thr
405 410 415
Ser Phe Pro Gly Phe Gly Asp Leu Cys Ala Gly Cys Gly Leu Ala Ser
420 425 430
Ser Gln
- 还没有人留言评论。精彩留言会获得点赞!
- 5-烯醇丙酮莽草酸-3-磷酸合酶抗体的免疫原及其制备方法与应用的制作方法
- 一种便于使用的抗草甘膦转基因大豆pcr-elisa检测试剂盒的制作方法
- 一种快速检测抗草甘膦g2-epsps蛋白的金标试剂盒的制作方法
- 一种以基因优化方法获得的抗草甘膦基因及其表达载体的制作方法
- 一种双甘膦废水套用制备草甘膦中间体双甘膦的工艺的制作方法
- 草甘膦降解酶基因和含该基因的载体的制作方法
- 草甘膦抗性基因及含该基因的载体和转化子的制作方法
- 分离自土壤的高抗草甘膦epsp合酶及其编码序列的制备和用途的制作方法
- 一种抗草甘膦EPSP合成酶GmEPSPS-2及其编码基因与应用的制作方法
- 一种抗草甘膦EPSP合成酶GmEPSPS及其编码基因与应用的制作方法