用于生产分泌蛋白质的哺乳动物细胞的制作方法
本发明涉及细胞培养技术领域。它涉及激活转录因子6β(atf6b)、或神经酰胺合酶2(cers2)和tbc1结构域家族成员20(tbc1d20)的组合的敲低(例如通过使用rna干扰)或基因敲除,所述蛋白质在细胞分泌途径中发挥作用。这种下调导致哺乳动物细胞中产生的生物药学相关产物的改善分泌。本发明特别涉及与对照细胞相比具有重组治疗蛋白质的增强分泌的哺乳动物细胞,产生所述哺乳动物细胞的方法,用于产生重组分泌性治疗蛋白质的方法,以及所述哺乳动物细胞用于增加重组分泌性治疗蛋白质的产率的用途。
背景技术
改善生产中治疗蛋白质的滴度,使得方法更有效,是工业中的明确目标。这可以导致供应用于临床研究和市场的蛋白质材料的成本降低和时间缩短。由于生产过程中的总产率由各个细胞的细胞比生产率以及过程中存在的活细胞数目决定,改善生产效率的策略通常旨在增加这两个参数中的任一个,而不会负面影响另一个。
存在通过增加细胞培养上清液中的蛋白质比生产率和/或总产率(即滴度或浓度)用于改善哺乳动物细胞中的重组蛋白质产生的需要,这是一般适用的并且不依赖于各个细胞系或待生产的蛋白质。
旨在改善治疗蛋白质滴度的改造策略可以集中于蛋白质分泌的不同阶段,例如蛋白质折叠、转录后调节和/或分泌。然而,与修改细胞的行为以获得用于产生重组蛋白质的有利表型相关的挑战之一是细胞内调节回路的复杂性质。靶向一种基因或蛋白质的表达是没有用的,除非它是关键途径中的限速因素或它是具有改变整组靶基因表达的潜力的转录因子。为此,作为整个基因网络的调节剂的微小rna用于产生蛋白质的细胞系中(wo2013/182553)。除非鉴定所有靶基因,否则靶向整个基因网络是不确定的过程。这些基因中的一些基调节也可能不利于蛋白质分泌或抵消其它基因的调节。本发明的目的是下调构成蛋白质分泌中的瓶颈的特定蛋白质,以便具有分泌性治疗蛋白质的更高产率。
重组治疗蛋白质的表达导致易位至内质网(er)用于进一步加工和后续分泌的总蛋白质量的增加。因此,er的蛋白质折叠能力是蛋白质生产的一个潜在瓶颈。
为此,一些研究涉及未折叠蛋白质应答(upr)中的改变,所述upr是使用er伴侣蛋白的适应性应激应答途径。通过upr相关转录因子如激活转录因子4(atf4)(ohyat等人,2008.biotechnologyandbioengineering.100(2):317-324)、x-box结合蛋白-1(xbp-1)(tiggesm等人,2006.metabolicengineering.8:264-272;beckere等人,2008.journalofbiotechnology.135:217-223)、或ccaat-增强子结合蛋白同源蛋白(chop)(nishimiyad等人,2013.applmicrobiolbiotechnol.97:2531-2539)的过表达获得重组生产细胞中治疗蛋白质的改善分泌。在2009年,bommiasamy等人显示不仅xbp-1的过表达,而且激活转录因子6α(atf6α)的组成型活性形式的表达增加了er的蛋白质折叠能力(bommiasamy等人,2009,journalofcellsciences.122:1626-1636)。
重组蛋白质分泌的另一个瓶颈是从er递送到高尔基体。小gtp酶rab1在er中已进行加工的蛋白质的囊泡转运中起关键作用。由于其牵涉调节分泌货物从er离开和copii囊泡束缚(haasa等人,2007.journalofcellscience.120:2997-3010),rab1活性中的增加可以有利于细胞的总蛋白质分泌。虽然rab1的过表达已描述为扩大高尔基体并且导致参与er至高尔基体转运的囊泡运输基因的上调,但其失活或耗尽导致er离开的阻断(haasa等人,2007.journalofcellscience.120:2997-3010;romeron等人,2013.mboc.24:617-632)。rab1被特异性gtp酶激活蛋白(gap)灭活,所述gap即tbc1结构域家族,成员20(tbc1d20)(haasa等人,2007.journalofcellscience.120:2997-3010)。
除er和er至高尔基体转运的蛋白质折叠能力中的限制之外,先前已显示在高尔基复合体处的蛋白质转运可以是重组蛋白质分泌中的进一步瓶颈(florinl等人,2009.journalofbiotechnology.141:84-90)。神经酰胺是二酰基甘油(dag)的来源,所述dag调节蛋白激酶d(pkd)的活性(haussera等人,2005.natcellbiol.7(9):880-886;fuchsyf等人,2009.traffic.10:858-867;baroncl和malhotrav.2002,science295(5553):325-8)。pkd对于通过神经酰胺转移蛋白(cert)将蛋白质从高尔基体转运到质膜至关重要(hanadak等人,2003.nature.426:803-809;florinl等人,2009.journalofbiotechnology.141:84-90;fugmannt等人,journalofcellbiology.178:15-22)。神经酰胺由六种不同的神经酰胺合酶同种型(cers1-6)合成。
然而,尚未鉴定出涉及upr或分泌途径的特定蛋白质,其在下调时松动上述瓶颈,且因此导致分泌蛋白质的增加产生。基因的下调可以具有技术优点。例如,敲除细胞对于该表型是稳定的,并且可以切除标记物基因。另外,rnai表达更容易控制,因为通常达到饱和水平并且表达水平对于蛋白质过表达不太关键。
技术实现要素:
在本发明中,显示敲低选择的靶基因增加了分泌蛋白质的产生,特别是降低atf6b活性,或降低cers2和tbc1d20活性,对分泌产物浓度、蛋白质生产率和活细胞密度发挥积极作用。这些结果提示靶向atf6b或cers2和tbc1d20的组合是用于改善治疗蛋白质包括抗体滴度的有效策略。
由于atf6b、cers2和tbc1d20蛋白活性的下调,目前能够改造哺乳动物细胞以改善其细胞生产率和/或细胞活力,特别是增加由细胞培养物分泌的蛋白质的量。本文提供的哺乳动物细胞、方法和用途允许分泌蛋白质的更有效和成本有效地产生,尤其是用于抗体产生。这可以加速药物开发,因为用于临床前研究的足够量的材料的生成对于总体开发时间轴是至关重要的。本发明的目的可以进一步用于生成一种或几种特定的分泌蛋白质,用于诊断目的、研究目的(靶识别、前导化合物鉴定和前导化合物优化)或者制造上市或处于临床开发中的治疗蛋白质。
在一个方面,本发明涉及具有重组治疗蛋白质的增强分泌的哺乳动物细胞,其包括(a)宿主细胞蛋白质tbc1结构域家族成员20(tbc1d20)和神经酰胺合酶2(cers2)的降低表达;或(b)宿主细胞蛋白质激活转录因子6β(atf6b)的降低表达;其中所述哺乳动物细胞进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
本发明的另一个方面涉及具有重组治疗蛋白质的增强分泌的哺乳动物细胞,其包括宿主细胞蛋白质tbc1d20和cers2的降低表达。任选地,哺乳动物细胞可以进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
在本发明的哺乳动物细胞中,(a)编码宿主细胞蛋白质的基因包含抑制所述宿主细胞蛋白质表达的遗传修饰,或(b)哺乳动物细胞包含通过rna干扰抑制编码所述宿主细胞蛋白质的基因表达的rna寡核苷酸,其中与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达降低。
在一个进一步方面,本发明涉及产生具有重组治疗蛋白质的增强分泌的哺乳动物细胞的方法,其包括(a)通过将(i)遗传修饰引入编码宿主细胞蛋白质的基因内,所述遗传修饰抑制所述宿主细胞蛋白质的表达,或将(ii)rna寡核苷酸引入哺乳动物细胞内,所述rna寡核苷酸通过rna干扰抑制编码所述宿主细胞蛋白质的基因的表达,来降低哺乳动物细胞中宿主细胞蛋白质tbc1d20和cers2或宿主细胞蛋白质atf6b的表达,和(b)引入编码重组分泌性治疗蛋白质的一种或多种基因。本发明的方法可以进一步包括下述步骤:(c)选择具有重组治疗蛋白质的增强分泌的细胞;和(d)任选地在允许编码重组分泌性治疗蛋白质的一种或多种基因表达的条件下,培养步骤(c)中获得的细胞。根据本发明的方法,与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达降低。
本发明的细胞或本发明的方法中的rna干扰可以通过小发夹rna(shrna)或短干扰rna(sirna)介导。优选地,用一种或多种表达载体转染哺乳动物细胞,所述表达载体包含编码所述sirna或shrna的核苷酸序列,更优选地,用编码所述sirna或shrna的一种或多种表达载体稳定转染哺乳动物细胞。如果靶向tbc1d20和/或cers2,则用于本发明的细胞或方法中的sirna可以是(a)sitbc1d20#1(seqidno:7)、或sicers2#1(seqidno:8)、或其组合;或者(b)如果靶向atf6b,则可以是siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10)和siatf6b#3(seqidno:11)中的一种或多种。如果靶向tbc1d20和/或cers2,则shrna可以包含(a)shtbc1d20#1(seqidno:12)、或shcers2#1(seqidno:13)和shcers2#2(seqidno:14)中的一种或多种、或其组合;或者(b)如果靶向atf6b,则可以包含shatf6b#1(seqidno:15)和shatf6b#2(seqidno:37)中的一种或多种。示例性sirna和shrna特别适用于仓鼠细胞,例如cho细胞。
编码宿主细胞蛋白质tbc1d20和cers2或atf6b的基因中的遗传修饰可以独立地是(a)基因缺失;或(b)抑制宿主细胞蛋白质表达的基因中,优选基因的编码区和/或基因的启动子或调节区中的突变。宿主细胞蛋白质tbc1d20优选与seqidno:4的氨基酸序列具有至少80%的序列同一性,宿主细胞蛋白质cers2优选与seqidno:5的氨基酸序列具有至少80%的序列同一性;并且宿主细胞蛋白质atf6b优选与seqidno:6的氨基酸序列具有至少80%的序列同一性。
根据本发明,重组分泌性治疗蛋白质可以是抗体,优选单克隆抗体、双特异性抗体或其片段。可替代地,重组分泌性治疗蛋白质也可以是fc融合蛋白。根据本发明的细胞或用于本发明的方法中的细胞优选是啮齿类动物或人细胞,优选啮齿类动物细胞,例如cho细胞。
在一个进一步方面,本发明还涉及用于在哺乳动物细胞中产生重组分泌性治疗蛋白质的方法,其包括(a)提供本发明的哺乳动物细胞,其中用重组分泌性治疗蛋白质转染细胞,或提供通过本发明的方法产生的哺乳动物细胞,(b)在允许重组分泌性治疗蛋白质产生的条件下,在细胞培养基中培养步骤(a)的哺乳动物细胞,(c)收获重组分泌性治疗蛋白质,和任选地(d)纯化重组分泌性治疗蛋白质。
在另外一个方面,本发明涉及本发明的哺乳动物细胞或通过本发明方法产生的哺乳动物细胞用于增加重组分泌性治疗蛋白质的产率的用途。
附图说明
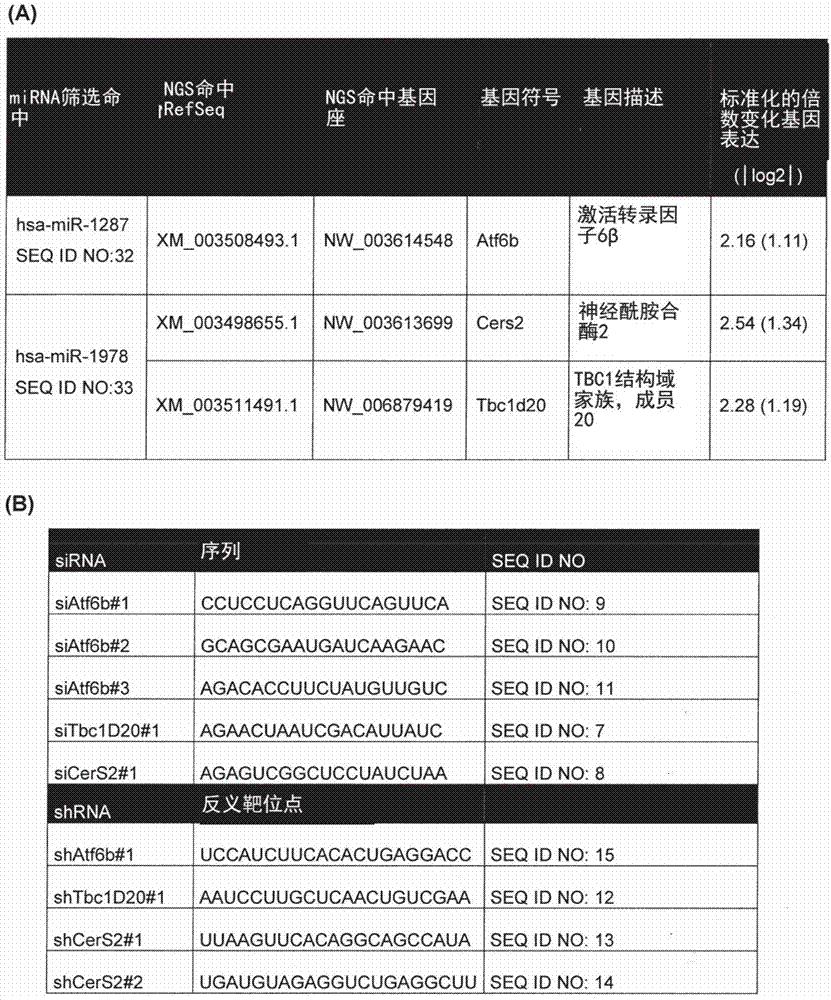
图1显示了通过下一代测序鉴定微生物的差异表达靶基因
小图(a)是显示用两种微小rnamir-1287和mir-1978中的每一种转染稳定分泌igg1抗体(mab1)的cho-dg44细胞(cho-mab1细胞)的表,所述微小rna对抗体产生和比生产率具有强烈作用。转染后12小时,通过下一代测序(ngs)的转录组概况分析用于鉴定两种mirna的直接靶基因。将具有|log2|倍变化>1(未转染的对照细胞(空白)中的基因表达超过2倍)的显著下调的基因定义为命中。选择mir-1287靶基因atf6b以及mir-1978靶基因cers2和tbc1d20用于进一步分析。显示了分别基因及其|log2|的表达(模拟相对于mirna转染)中的标准化倍数变化。首先通过sirna介导的基因敲低评价所选靶基因对抗体产生和比生产率的作用,随后为shrna介导的敲低以研究靶基因的长期耗尽。图(b)是列出本研究中使用的sirna和shrna的名称和序列的表。
图2显示了经由qpcr的靶基因验证
(a)和(b),用微小rnamir-c#1、mir-1287或mir-1978转染稳定分泌igg1抗体mab1的cho-dg44细胞。转染后一天,提取rna以通过qpcr定量atf6b、cers2和tbc1d20的mrna水平。(c)和(d),对于稳定分泌抗体mab1并且进一步稳定过表达mir-1287或mir-1978的cho-dg44细胞,定量这些靶基因的表达水平。通过对参考基因β肌动蛋白标准化来计算相对表达。小图(a)是条形图,显示与未转染的细胞(空白)相比,用mir-1287的瞬时转染导致atf6b的表达水平降低(n=3,误差条=一式三份的sem)。小图(b)是条形图,显示与未转染的细胞(空白)相比,用mirnamir-1978的瞬时转染导致cers2mrna和tbc1d20mrna的水平下降(n=3,误差条=一式三份的sem)。(c)-(d)用编码mir-1287或mir-1978的表达载体(pcdna6.2-gw/emgfp-mir1287-mir1287或pcdna6.2-gw/emgfp-mir1978-mir1978)、或阴性对照序列表达质粒(pcdna6.2-gw/emgfp-阴性对照)稳定转染稳定分泌igg抗体的cho-mab1细胞,并且通过facs富集gfp阳性细胞。小图(c)是条形图,显示与亲本cho-mab1细胞相比,稳定过表达mir-1287的cho-mab1细胞显示降低水平的atf6bmrna(n=3,误差条=一式三份的sem)。小图(d)是条形图,显示与亲本cho-mab1细胞相比,稳定过表达mir-1978的cho-mab1细胞显示降低水平的cers2和tbc1d20(n=2,误差条=一式两份的sem)。
图3显示了对于atf6b、cers2和tbc1d20特异性的sirna的敲低效率
稳定分泌igg1抗体mab1的cho-dg44细胞分别用对于atf6b或cers2和tbc1d20特异性的sirna转染,并且通过qpcr定量atf6b、cers2和tbc1d20的mrna水平。小图(a)是条形图,显示通过三种独立sirna(siaft6b#1、siaft6b#2和siaft6b#3)观察到atf6b的有效敲低(n=3,误差条=一式三份的sem)。小图(b)是条形图,显示通过同时用两种sirna(sitbc1d20#1和sicers2#1)的核转染观察到cers2和tbc1d20的组合敲低(n=2,误差条=一式两份的sem)。
图4显示了atf6b敲低对cho-mab1细胞生产率的作用
用对于atf6b特异性的三种独立sirna(siaft6b#1、siaft6b#2和siaft6b#3)中的每一种转染cho-mab1细胞。计算在第3天和第4天时的比生产率,并且对未转染的对照细胞(空白)标准化。atf6b的敲低导致在第4天改善的比生产率(n=3,误差条=一式三份的sem)。
图5显示了组合的cers2和tbc1d20敲低对cho-mab1细胞生产率的作用
用(a)(单独)和(b)组合的针对cers2和tbc1d20的sirna(sitbc1d20#1和sicers2#1)转染cho-mab1细胞。计算在第3天和第4天时的比生产率,并且对未转染的对照细胞(空白)标准化。小图(a)是条形图,显示cers2或tbc1d20的单个敲低在第4天略微增加比生产率(n=2,误差条=一式两份的sem)。小图(b)是条形图,显示cers2和tbc1d20的组合敲低导致在第3天和第4天比生产率中的进一步改善(n=3,误差条=一式三份的sem)。
图6显示了atf6b敲低对cho-mab2细胞生产率的作用
用对于atf6b特异性的三种独立sirna(siaft6b#1、siaft6b#2和siaft6b#3)中的每一种转染稳定分泌igg抗体mab2的进一步cho-dg44细胞克隆。计算在第3天和第4天时的比生产率,并且对未转染的对照细胞(空白)标准化。atf6b的敲低导致在第3天和第4天改善的比生产率(n=3,误差条=重复的sem)。
图7显示了组合的cers2和tbc1d20敲低对cho-mab2细胞生产率的作用
用组合的针对cers2和tbc1d20的sirna(sitbc1d20#1和sicers2#1)转染稳定分泌igg抗体mab2的cho-dg44细胞。计算在第3天和第4天时的比生产率,并且对未转染的对照细胞(空白)标准化。cers2和tbc1d20的组合敲低导致在第3天和第4天改善的比生产率(n=3,误差条=一式三份的sem)。
图8显示了通过流式细胞术定量测定抗体产生cho细胞中的稳定gfp表达
用含有gfp的表达载体稳定转染稳定分泌igg抗体mab2的cho-dg44细胞,所述表达载体进一步编码(如小图a中所示)对于atf6b特异性的shrna(pcdna6.2-gw/emgfp-shatf6b#1,其序列结构在小图b中示意性地表示),以及(如小图c中所示)对于cers2和tbc1d20特异性的shrna(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1或pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1,其序列结构在小图d中示意性地表示)。通过facs富集gfp阳性细胞,并且在分选后培养42天后通过流式细胞术分析分析活细胞(参见小图a和c)。作为阴性对照,使用没有gfp表达的未转染细胞(灰色)。
图9显示了通过qpcr定量在抗体产生cho细胞中的稳定敲低
用含有gfp的表达载体稳定转染稳定分泌igg抗体mab2的cho-dg44细胞,所述表达载体进一步编码(如小图a中所示)对于atf6b特异性的shrna(shatf6b#1)或(如小图b中所示)对于cers2和tbc1d20特异性的两种组合的shrna(shcers2#1-shtbc1d20#1、shcers2#2-shtbc1d20#1)。通过facs分选富集gfp阳性细胞,并且提取rna以通过qpcr分析分别测量atf6b或cers2和tbc1d20的mrna水平。通过对参考基因β肌动蛋白标准化来计算相对表达。
图10显示了在补料分批细胞培养中atf6b的稳定敲低的作用
用针对atf6b的shrna(pcdna6.2-gw/emgfp-shatf6b#1)或阴性对照序列表达质粒(pcdna6.2-gw/emgfp-阴性对照)稳定转染稳定分泌igg抗体mab2的cho-dg44细胞,并且通过facs分选富集gfp阳性细胞。在补料分批培养物中生长稳定的库(关于shatf6b#1的一个库和关于阴性对照质粒的两个独立库)。通过用台盼蓝排除的细胞计数和elisa分析,在第3-6天时测定上清液中的细胞密度和抗体浓度,并且计算比生产率。对于产物浓度(在小图a中)、在第6天的比生产率(在小图b中)和活细胞密度(在小图c中),显示了关于一个代表性实验的数据。
图11显示了在补料分批细胞培养中cers2和tbc1d20的稳定敲低的作用
用编码对于cers2和tbc1d20特异性的shrna(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1和pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)、或阴性对照序列(pcdna6.2-gw/emgfp-阴性对照)的表达载体稳定转染稳定分泌igg抗体mab2的cho-dg44细胞,并且通过facs分选富集gfp阳性细胞。在补料分批培养物中生长稳定的库(关于两个独立shrna组合中的每一个的一个库和关于阴性对照质粒的2个独立库)。通过用台盼蓝排除的细胞计数和elisa分析,在第3-11天时测定上清液中的细胞密度和抗体浓度,并且计算比生产率。对于产物浓度(在小图a中)、在第11天的比生产率(在小图b中)和活细胞密度(在小图c中),显示了关于一个代表性实验的数据。
图12显示了在补料分批条件下的抗体糖基化和聚集体形成的分析
用表达对于atf6b特异性的shrna(pcdna6.2-gw/emgfp-shatf6b#1)(在小图a、c中)、或对于cers2和tbc1d20特异性的shrna(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1和pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)(在小图b、d中)的表达载体稳定转染稳定分泌igg抗体mab2的cho-dg44细胞。作为对照,用阴性对照序列表达质粒(pcdna6.2-gw/emgfp-阴性对照)转染相同的抗体产生细胞。(a、b)使用基于微芯片的毛细管电泳(ce),在pngasef释放和荧光标记后分析igg抗体的fc-糖基化的组成。由色谱峰面积计算糖形的百分比,并且对于(在小图a中)表达shatf6b以及(在小图b中)表达shcers2和shtbc1d20的细胞进行显示。在右侧上的图例中的聚糖与每个条中的次序相反,即在底部处的man5,从底部第二的unk,等等。缩写:a2,双触角;g,半乳糖;f,岩藻糖;man,甘露糖;unk,未知;星号指示同种型。(c)稳定分泌igg抗体mab2并且稳定表达shatf6b#1、shatf6b#2或阴性对照序列的cho-dg44细胞在补料分批条件下培养7天。从上清液中纯化分泌的抗体并且通过hplc进行分析,并且在小图c中显示了分析的三个样品在一段时间内的吸收。(d)稳定表达shtbc1d20-shcers2#1、shcers#2-shtbc1d20或阴性对照序列的cho-mab2细胞在补料分批条件下培养11天。从上清液中纯化分泌的抗体,并且通过hplc进行分析,并且分析的三个样品在一段时间内的吸收显示于小图d中。
图13显示atf6b敲低对衣霉素治疗后的grp78、chop和herpud1表达的作用
用编码gfp盒加上包含特异性靶向atf6b的核苷酸序列的shrna序列的质粒(pcdna6.2-gw/emgfp-shatf6b#1或pcdna6.2-gw/emgfp-shatf6b#2)、或阴性对照构建体稳定转染稳定分泌igg抗体mab2的cho-dg44细胞。小图a是条形图,显示如通过qpcr定量的atf6b的mrna水平。值相对于对照给出。小图b提供了条形图,显示如通过qpcr定量的未处理细胞和衣霉素(tm)处理的细胞(2.5μg/mltm,6小时)中grp78、herpud1和chop的mrna水平,并且相对于在时间点0的阴性对照细胞显示。所有数据都显示为平均值+/-sem(n=3,**p<0.01,***p<0.001,单因素anova和tukeys多重比较检验),代表也如图13c的图例中所示的阴性对照(黑色条,左);shatf6b#1(灰色条,中间);和shatf6b#2(白色条,右)。(c)稳定分泌igg抗体mab2并且稳定表达shatf6b#1、shatf6b#2或阴性对照序列的cho-dg44细胞在补料分批条件下培养5天。在第5天,通过qpcr定量grp78/bip、herpud1和chop的mrna水平(如小图c中所示)。所有数据都显示为平均值+/-sem(n=3,**p<0.01,双因素anova和邦弗朗尼事后检验)。
图14显示了cers2和tbc1d20敲低对rab1活性和神经酰胺组成的作用
(a)用作为对照的非靶向sirna(nt)、sitbc1d20或sicers2/sitbc1d20转染稳定分泌igg抗体mab2的cho-dg44细胞。转染后三天,使用具有p115-gst融合蛋白的下拉测定在细胞匀浆物中检测活性rab1(如图a中所示)。通过用抗rab1抗体的免疫印迹检测结合的rab1。使用抗gst抗体作为上样对照检测p115-gst蛋白。裂解产物中的肌动蛋白检测验证蛋白质的相等加载(输入)。小图b是条形图,显示使用imagej软件定量活性rab1的条带强度。(n=3,平均值±sem)。小图c显示了在转染后第2天,通过qpcr确认敲低效率(n=3,平均值±sem)。(d)用ntsirna对照、sicers2或sitbc1d20/sicers2转染后三天,将细胞匀浆化,并且通过加入作为底物的c16-coa或c24-coa连同nbd标记的二氢鞘氨醇来测量神经酰胺合酶活性。通过薄层色谱法分离产物c16-二氢神经酰胺和c24-二氢神经酰胺,并且使用荧光扫描仪进行检测(如小图d中所示)。小图e是条形图,显示如使用imagej软件定量的c16-和c24-二氢神经酰胺的条带强度。用sirna对照转染的细胞中两种产物的强度设定为100%(n=3,平均值±sem)。小图f是条形图,显示通过qpcr确认sirna介导的敲低的效率(n=2,平均值±sem)。
图15显示了稳定敲低对下游靶的作用
(a)用编码对于cers2和tbc1d20特异性的shrna(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1和pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)、或阴性对照序列(pcdna6.2-gw/emgfp-阴性对照)的表达载体稳定转染稳定分泌igg抗体mab2的cho-dg44细胞,并且在荧光cers测定中分析,以检测cho-mab2细胞库中的神经酰胺合酶活性。在不同的反应中,c16-coa或c24-coa连同nbd标记的二氢鞘氨醇一起充当底物。通过薄层色谱法分离产物c16-神经酰胺和c24-神经酰胺,并且使用荧光扫描仪进行检测(如小图a中所示)。小图b显示了使用imagej软件定量的c16-和c24-神经酰胺的条带强度。阴性对照库中两种产物的强度均设定为100%。
具体实施方式
定义
一般实施方案“包含(comprising)”或“包含(comprised)”涵盖更具体的实施方案“由......组成”。此外,单数和复数形式不以限制方式使用。如本文使用的,单数形式“一个”、“一种”和“该/所述”指定单数和复数两者,除非明确指定仅单数。
如本文使用的,术语“核糖核酸”、“rna”或“rna寡核苷酸”描述了由核苷酸序列组成的分子,其由核碱基、核糖和磷酸基构成。rna通常是单链分子,并且可以发挥各种功能。术语核糖核酸特别涵盖信使rna(mrna)、转移rna(trna)、核糖体rna(rrna)、短干扰rna(sirna)、小发夹rna(shrna)和微小rna(mirna),其中每种都在生物细胞中起特异性作用。它包括小的非编码rna,例如微小rna(mirna)、短干扰rna(sirna)、小发夹rna(shrna)和piwi相互作用rna(pirna)。术语“非编码”意指rna分子不翻译成氨基酸序列。
术语“rna干扰”(rnai)指基因表达(蛋白质合成)的序列特异性或基因特异性抑制,而没有蛋白质合成的广泛压制。rnai可能涉及通过rna诱导的沉默复合物(risc)的信使rna(mrna)降解,阻止转录的mrna的翻译。由rnai引起的基因表达压制可能是瞬时的,或者它也可能更稳定的,甚至永久的。rnai可以由sirna或shrna介导。优选地,根据本发明的rnai是基因特异性的(仅靶向一个基因)。如果rna寡核苷酸包含与靶基因具有完全序列互补性的序列(即,小干扰rna的rna双链体的反义链和靶mrna之间的完美碱基配对),则rnai视为基因特异性的或对于其靶基因特异性的。基因特异性rnai可以由sirna或shrna介导。在一个优选实施方案中,rnai由sirna或shrna介导。在另一个优选实施方案中,rnai不由mirna介导。
术语“微小rna”或“mirna”在本文中可互换使用。微小rna是小的,约22个核苷酸长(通常长度在19到25个核苷酸之间)的非编码单链rna。mirna通常靶向超过一个基因。微小rna在真核细胞的基因组中编码,并且通常由rna聚合酶iii转录为长的初级转录物,然后首先在几个步骤中加工成约~70nt长的发夹环结构,随后加工成~22ntrna双链体。然后将活性成熟链加载到rna诱导的沉默复合物(risc)内,以便阻断靶蛋白的翻译或其分别mrna的降解。用mirna靶向允许错配,并且mrna翻译阻遏由不完全互补性(即,小干扰rna的rna双链体的反义链和靶mrna之间的不完全碱基配对)介导,而sirna和shrna由于完全序列互补性(即,小干扰rna的rna双链体的反义链和靶mrna之间的完美碱基配对)对于其靶是特异性的。通常,mirna在3′非翻译区(3′utr)中结合并且不是基因特异性的,而是靶向多重mrna。如本文使用的,术语“微小rna”涉及内源基因组哺乳动物mirna,例如人mirna。前缀“hsa”指示例如微小rna的人起源。可以使用包含基因组微小rna序列的表达载体将它们引入哺乳动物宿主细胞内,用于在哺乳动物宿主细胞中瞬时或稳定表达mirna。用于将基因组微小rna克隆到表达载体内的手段是本领域已知的。它们包括将具有大约300bp侧翼区的基因组mirna序列克隆到哺乳动物表达载体例如pbip-1内,所述哺乳动物表达载体与启动子可操作地连接。可替代地,一种或多种微小rna可以作为编码经改造的前体mirna序列(即短发夹)的多核苷酸克隆到哺乳动物表达载体内。例如,可以将成熟的mirna序列克隆到给定序列内,所述给定序列编码优化的发夹环序列以及例如衍生自鼠mirnamir-155的3′和5′侧翼区(lagos-quintana等人,2002.currbiol.30;12(9):735-9)。设计dna寡核苷酸,其编码mirna序列、所述环和分别的成熟mirna的反义序列,具有两个核苷酸消耗,以在发夹茎中产生内部环。此外,添加突出端用于在两个末端处克隆,以将dna寡核苷酸融合到3′和5′侧翼区。如本文使用的,mirna进一步包含非经典mirna。这些rna也可以衍生自‘持家’非编码rna(ncrna),包括核糖体rna(rrna)或转移rna(trna),并且以mirna样方式起作用。这些rna也可以源自哺乳动物线粒体ncrna,并且被称为线粒体基因组编码的小rna(mitosrna)。
如本文使用的,术语“小干扰”或“短干扰rna”或“sirna”指核苷酸的rna双链体,其靶向所需基因并且能够抑制它与之共享同源性的基因的表达。它由长双链rna(dsrna)或shrna形成。rna双链体通常包含19、20、21、22、23、24、25、26、27、28或29个核苷酸的两个互补的单链rna,其形成17、18、19、20、21、22、23、24、25、26或27个碱基对,并且具有2个核苷酸的3′突出端,优选地,rna双链体包含19-27个核苷酸的两个互补单链rna,其形成17-25个碱基对且具有2个核苷酸的3′突出端。sirna“靶向”基因,其中所述sirna的双链体部分的核苷酸序列与靶向基因的mrna的核苷酸序列互补。sirna或其前体始终外源地引入细胞内,例如直接地或通过具有编码所述sirna的序列的载体的转染,并且利用内源mirna途径用于sirna的正确加工和靶mrna的切割或降解。双链体rna可以由单个构建体在细胞中表达。
如本文使用的,术语“shrna”(小发夹rna)指rna双链体,其中sirna的一部分是发夹结构(shrna)的部分。shrna可以在细胞内加工成功能性sirna。除双链体部分之外,发夹结构可以含有位于形成双链体的两个序列之间的环部分。环可以在长度方面变化。在一些实施方案中,环为长度4、5、6、7、8、9、10、11、12、13或14个核苷酸。发夹结构还可以含有3′或5′突出端部分。在一些方面,突出端是长度为0、1、2、3、4或5个核苷酸的3′或5′突出端。在本发明的一个方面,载体中包含的核苷酸序列充当用于表达小发夹rna的模板,包含有义区、环区和反义区。在表达后,有义区和反义区形成双链体。shrna始终外源地引入,例如通过具有编码所述shrna的序列的载体的转染,并且利用内源mirna途径用于sirna的正确加工和靶mrna的切割或降解。具有编码shrna的序列的载体的使用具有超过使用化学合成的sirna的优点,因为靶基因的压制通常是长期和稳定的。
通常,sirna和shrna通过完全序列互补性(即,小干扰rna的rna双链体的反义链和靶mrna之间的完美碱基配对)介导mrna阻遏,并且因此对于其靶是特异性的。rna双链体的反义链也可以称为rna双链体的活性链。如本文使用的,完美碱基配对的完全序列互补性意指对于至少15个连续核苷酸、至少16个连续核苷酸、至少17个连续核苷酸、至少18个连续核苷酸、且优选至少19个连续核苷酸,小干扰rna的rna双链体的反义链与靶mrna具有至少89%的序列同一性,或者对于至少15个连续核苷酸、至少16个连续核苷酸、至少17个连续核苷酸、至少18个连续核苷酸、且优选至少19个连续核苷酸,优选与靶mrna至少93%的序列同一性。更优选地,对于至少15个连续核苷酸、至少16个连续核苷酸、至少17个连续核苷酸、至少18个连续核苷酸、且优选至少19个连续核苷酸,小干扰rna的rna双链体的反义链与靶mrna具有100%的序列同一性。
如本文使用的,术语“atf6b”指蛋白激活转录因子6β。它也被称为crebl1、camp应答元件结合蛋白相关蛋白、camp应答元件结合蛋白样1、camp依赖性转录因子atf-6β、camp应答元件结合蛋白样1、蛋白g13creb-rp、g13、环状amp依赖性转录因子atf-6β、creb相关蛋白、atf6-β。关于atf6b的外部id为:hgnc:2349;entrezgene:1388;ensembl:ensg00000213676;omim:600984;uniprotkb:q99941(http://www.genecards.org/cgiin/carddisp.pl?gene=atf6b&keywords=atf6b)。它包含具有seqidno:6的氨基酸序列或与seqidno:6具有至少80%序列同一性的氨基酸序列的蛋白质。
如本文使用的,术语“cers2”指蛋白质神经酰胺合酶2。它也称为lass2、长寿保障(lag1,酿酒酵母(s.cerevisiae))同系物2、肿瘤转移抑制基因1蛋白质、lag1同系物、神经酰胺合酶2、sp260、tmsg1、lag1长寿保障同系物2(酿酒酵母)、lag1长寿保障同系物2、lag1长寿保障2、l3。关于cers2的外部id为:hgnc:14076;entrezgene:29956;ensembl:ensg00000143418;omim:606920;uniprotkb:q96g23(http://www.genecards.org/cgi-bin/carddisp.pl?gene=cers2)。它包含具有seqidno:5的氨基酸序列或与seqidno:5具有至少80%序列同一性的氨基酸序列的蛋白质。
如本文使用的,术语“tbc1d20”指tbc1结构域家族成员20。它也称为c20orf140、warbm4和染色体20开放读码框140。关于tbc1d20的外部id为:hgnc:16133;entrezgene:128637;ensembl:ensg00000125875;omim:611663;uniprotkb:q96bz9(http://www.genecards.org/cgi-bin/carddisp.pl?gene=tbc1d20)。它包含具有seqidno:4的氨基酸序列或与seqidno:4具有至少80%序列同一性的氨基酸序列的蛋白质。
如本文使用的,通过rnai抑制tbc1d20、cers2或atf6b表达的rna寡核苷酸分别特异性地靶向编码tbc1d20、cers2或atf6b的rna。在一个优选实施方案中,rna寡核苷酸排除mirna。
术语“敲低”或“敲低技术”指基因沉默技术,其中与例如通过使用可以导致抑制靶基因产物的产生的sirna或shrna,通过rna干扰抑制靶基因表达的rna寡核苷酸引入之前的基因表达相比,靶基因或目的基因的表达降低。“双重敲低”是两个基因的敲低。
还可以通过使用“敲除”技术缺失基因来修饰基因。术语“敲除”指这样的细胞,其已经过遗传修饰,使得宿主细胞蛋白质aft6b或宿主细胞蛋白质tbc1d20和cers2的组合的表达被抑制,并且不产生相应的宿主细胞蛋白质(降低100%)。这可以使用本领域已知的各种技术来实现,所述技术包括crispr-cas9或锌指核酸酶技术。
可替代地,可以通过在基因中引入突变来改变基因,以抑制其蛋白质的表达。基因突变可以是基因的编码区或者启动子或调节区中的缺失、添加或取代。该基因突变可以在基因的一个或两个等位基因中。
如本文使用的,术语“降低(reduction)”、“降低(reduced)”或“降低(reduce)”一般意指与参考水平相比减少至少10%,例如与对照哺乳动物细胞相比减少至少约20%、或至少约30%、或至少约40%、或至少约50%、或至少约60%、或至少约70%、或至少约75%、或至少约80%、或至少约90%、或直到且包括100%减少、或10-100%之间的任何整数减少。与对照哺乳动物细胞相比,宿主细胞蛋白质tbc1d20和cers2或宿主细胞蛋白质atf6b的表达优选降低至少30%、至少40%、至少50%、至少75%或100%。
如本文使用的,术语“增强(enhancement)”、“增强(enhanced)”、“增强(enhanced)”、“增加(increase)”或“增加(increased)”一般意指与对照细胞相比增加至少10%,例如与对照细胞相比增加至少约20%、或至少约30%、或至少约40%、或至少约50%、或至少约75%、或至少约80%、或至少约90%、或至少约100%、或至少约200%、或至少约300%、或10-300%之间的任何整数减少。
如本文使用的,“对照细胞”或“对照哺乳动物细胞”是与它与之相比较的细胞相同的细胞,除了它没有宿主细胞蛋白质tbc1d20和cers2或atf6b的降低表达之外。对照哺乳动物细胞可以通过本发明的方法产生,但省略了降低宿主细胞蛋白质tbc1d20和cers2或宿主细胞蛋白质atf6b的表达的步骤。特别地,对照哺乳动物细胞缺乏抑制tbc1d20和cers2或atf6b表达的任何遗传修饰,并且缺乏通过rna干扰抑制基因tbc1d20和cers2或atf6b的任何经转染的rna寡核苷酸。
如本发明中使用的,术语“衍生物”或“同源物”意指多肽分子或核酸分子,其在序列中与原始序列或其互补序列至少70%相同。优选地,多肽分子或核酸分子在序列中与原始序列或其互补序列至少80%相同。更优选地,多肽分子或核酸分子在序列中与原始序列或其互补序列至少90%相同。还更优选地,多肽分子或核酸分子在序列中与原始序列或其互补序列至少95%相同。最优选地,多肽分子或核酸分子在序列中与原始序列或其互补序列至少98%相同。同源蛋白质进一步展示与原始序列相同或相似的蛋白质活性。
序列差异可以基于来自不同生物的同源序列中的差异,或者可以是天然存在的等位基因变异。它们也可以基于通过取代、插入或缺失一个或多个核苷酸或氨基酸,优选1、2、3、4、5、7、8、9或10个的序列靶向修饰。缺失、插入或取代突变体可以使用位点特异性诱变和/或基于pcr的诱变技术生成。
如本文使用的,术语“宿主细胞”是适合于产生分泌的重组治疗蛋白质的哺乳动物细胞系,并且因此也可以称为“哺乳动物细胞”。根据本发明的优选哺乳动物细胞是啮齿类动物细胞,例如仓鼠细胞。哺乳动物细胞是分离的细胞或细胞系。哺乳动物细胞优选是经转化的和/或永生化的细胞系。它们适于细胞培养中的连续传代,并且不包括其为器官结构的部分的原代非转化细胞。优选的哺乳动物细胞是bhk21、bhktk-、cho、cho-k1(如cho-dukx、cho-dukxb1)和cho-dg44细胞或此类细胞系中任一种的衍生物/后代。特别优选的是cho-dg44、cho-k1和bhk21,且甚至更优选的是cho-dg44和cho-k1细胞。最优选的是cho-dg44细胞。还涵盖了哺乳动物细胞,特别是cho-dg44和cho-k1细胞的谷氨酰胺合成酶(gs)缺陷衍生物。哺乳动物细胞可以进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。宿主细胞也可以是鼠细胞,例如鼠骨髓瘤细胞,例如ns0和sp2/0细胞,或此类细胞系中任一种的衍生物/后代。可以用于本发明的含义中的哺乳动物细胞的非限制性实例也概括于表1中。然而,这些细胞的衍生物/后代,其它哺乳动物细胞包括但不限于人、小鼠、大鼠、猴、和啮齿类动物细胞系也可以用于本发明中,特别是用于生物制药蛋白质的生产。
表1:哺乳动物生产细胞系
1cap(cevec的羊水细胞产生)细胞是基于原代人羊水细胞的永生化细胞系。它们通过用含有腺病毒5的功能e1和pix的载体转染这些原代细胞而生成。由于真实的人翻译后修饰,cap细胞允许具有优异生物活性和治疗功效的重组蛋白质的竞争性稳定产生。
当在无血清条件下且任选地在不含动物起源的任何蛋白质/肽的培养基中建立、适应和完全培养时,宿主细胞是最优选的。商购可得的培养基,例如ham′sf12(sigma,deisenhofen,德国)、rpmi-1640(sigma)、达尔贝科改良伊格尔培养基(dmem;sigma)、最低必需培养基(mem;sigma)、iscove′s改良达尔贝科培养基(imdm;sigma)、cd-cho(invitrogen,carlsbad,ca)、cho-s-invitrogen)、无血清cho培养基(sigma)和无蛋白cho培养基(sigma)是示例性的适当营养液。培养基中的任一种都可以根据需要补充有各种化合物,其中的非限制性实例是激素和/或其它生长因子(例如胰岛素、转铁蛋白、表皮生长因子、胰岛素样生长因子)、盐(例如氯化钠、钙、镁、磷酸盐)、缓冲剂(例如hepes)、核苷(例如腺苷、胸苷)、谷氨酰胺、葡萄糖或其它等价能源、抗生素和微量元素。任何其它必需的补充物还可以以本领域技术人员已知的适当浓度包括。在本发明中,优选使用无血清培养基,但补充有合适量血清的培养基也可以用于培养宿主细胞。对于表达可选择基因的遗传修饰细胞的生长和选择,将合适的选择剂加入培养基中。
术语“蛋白质”可与“氨基酸残基序列”或“多肽”互换使用,并且指任何长度的氨基酸聚合物。这些术语还包括通过反应进行翻译后修饰的蛋白质,所述反应包括但不限于糖基化、乙酰化、磷酸化或蛋白质加工。可以在多肽的结构中进行修饰和改变,例如与其它蛋白质融合,氨基酸序列取代、缺失或插入,同时分子维持其生物学功能活性。例如,某些氨基酸序列取代可以在多肽或其基础核酸编码序列中进行,并且可以获得具有相同性质的蛋白质。
术语“多肽”意指具有超过10个氨基酸的序列,并且术语“肽”意指长度最多10个氨基酸的序列。然而,这些术语可以互换使用。
本发明适合于生成用于生产生物药物或诊断性多肽/蛋白质的宿主细胞。本发明特别适合于通过显示增强的细胞生产率的细胞高产率表达大量不同目的基因。
“重组分泌性治疗蛋白质”指由任何长度的多核苷酸序列编码,适合于诊断或治疗用途,优选治疗用途的分泌性目的蛋白质,所述多核苷酸序列已引入宿主细胞内。编码蛋白质的所选序列可以是全长或截短的基因、融合或加上标签的基因,并且可以是cdna、基因组dna或dna片段,优选cdna。它可以是天然序列,即天然存在的形式,或者可以根据需要进行突变或以其它方式修饰。这些修饰包括密码子优化,以优化在所选宿主细胞中的密码子使用、人源化、融合或加上标签。“重组”蛋白质是由异源序列表达的蛋白质。
术语“宿主细胞蛋白质”一般涉及对于宿主细胞内源的所有蛋白质,但在本文中与宿主细胞蛋白质atf6b或两种宿主细胞蛋白质tbc1d20和cers2特异性相关使用。
如本文使用的,术语“生产”或“高度生产”、“产生”、“产生和/或分泌”、“生产”或“产生细胞”涉及重组分泌性治疗蛋白质的产生。“增加的产生和/或分泌”涉及重组分泌性治疗蛋白质的表达,并且意指比生产率中的增加、增加的滴度或两者。优选地,滴度或比生产率和滴度增加。如本文使用的,增加的滴度涉及相同体积中增加的浓度,即总产率中的增加。产生的重组分泌性治疗蛋白质可以是例如抗体,优选单克隆抗体、双特异性抗体或其片段,或融合蛋白,优选fc融合蛋白。
如本文使用的,术语“表达盒”指包含编码蛋白质(重组分泌性治疗蛋白质)的一种或多种基因和控制其表达的序列的载体部分。因此,它包含启动子序列、开放读码框和3′非翻译区,通常含有多腺苷酸化位点。优选地,载体是包含编码重组分泌性治疗蛋白质的一种或多种基因的表达载体。它可以是载体的部分,所述载体通常是表达载体,包括质粒或病毒载体。它也可以通过随机或靶向整合,例如通过同源重组在染色体中整合。表达盒使用克隆技术制备,并且因此不涉及天然存在的基因结构。
“载体”是可以用于将与其连接的另一种核酸(或“构建体”)引入细胞内的核酸。一种类型的载体是“质粒”,其指另外的核酸区段可以连接到其内的线性或环状双链dna分子。另一种类型的载体是病毒载体(例如,复制缺陷型逆转录病毒、腺病毒和腺伴随病毒),其中可以将另外的dna区段引入病毒基因组内。某些载体能够在它们引入其内的宿主细胞中自主复制(例如,包含细菌复制起点和附加型哺乳动物载体的细菌载体)。其它载体(例如,非附加型哺乳动物载体)在引入宿主细胞内且在选择压力下培养时整合到宿主细胞的基因组内,并且从而连同宿主基因组一起复制。载体可以用于指导所选多核苷酸在细胞中的表达。
术语“表达载体”意指具有赋予它与之可操作地连接的核酸片段在细胞中表达的能力的核酸。如本文使用的,表达载体可以是例如质粒、粘粒、病毒亚基因组或基因组片段,或能够在哺乳动物细胞中以可表达形式维持和/或复制异源dna的其它核酸。
术语“抗体”指由基本上由免疫球蛋白基因编码的一种或多种多肽组成的蛋白质。公认的免疫球蛋白基因包括κ、λ、α、γ、δ、ε和μ恒定区基因以及无数免疫球蛋白可变区基因。如本文使用的,术语“抗体”包括多克隆、单克隆、双特异性、多特异性、人、人源化或嵌合抗体。术语“抗体”和“免疫球蛋白”可互换使用,并且用于指示具有上文对于免疫球蛋白指出的结构特征的糖蛋白,但不限于其。
术语“抗体”在本文中以其最广泛的含义使用,并且涵盖单克隆抗体(包括全长单克隆抗体)、多克隆抗体、嵌合抗体、人源化抗体、人抗体、多特异性抗体(例如双特异性抗体)、单结构域抗体和抗体片段(例如fv、fab、fab′、f(ab)2或抗体的其它抗原结合子序列)。术语“抗体”还涵盖抗体缀合物和融合抗体。双特异性抗体包括
如本文使用的,术语“单克隆抗体”(mab)指基于氨基酸序列,从基本上同质的抗体群体获得的抗体。单克隆抗体是高度特异性的,针对单个抗原位点。此外,与通常包括针对不同决定簇(表位)的不同抗体的常规(多克隆)抗体制剂相反,每种mab针对抗原上的单一决定簇。除其特异性之外,mab的优点还在于它们可以通过未被其它免疫球蛋白污染的细胞培养物(杂交瘤、重组细胞等等)合成。本文的mab包括嵌合、人源化和人抗体。
“嵌合抗体”是这样的抗体,其中轻链和/或重链基因通常通过基因工程从不同物种(例如小鼠和人)的免疫球蛋白可变区和恒定区构建。或者可替代地,其重链基因属于特定抗体类别或亚类,而链的剩余部分来自相同或另一物种的另一个抗体类别或亚类。还覆盖了此类抗体的片段,优选含有或经修饰为含有至少一个ch2结构域的片段。例如,来自小鼠单克隆抗体的基因的可变区段可以连接到人恒定区段,例如γ1和γ3。通常的治疗性嵌合抗体因此是由来自小鼠抗体的可变结构域或抗原结合结构域和来自人抗体的恒定结构域或效应结构域组成的杂合蛋白(例如atcc登记号crl9688分泌抗tac嵌合抗体),尽管可以使用其它哺乳动物物种。
如本文使用的,术语“人源化抗体”指特异性嵌合抗体、免疫球蛋白链或其片段(例如fv、fab、fab′、f(ab)2或抗体的其它抗原结合子序列),其含有衍生自非人免疫球蛋白的最小序列。人源化抗体包含人构架区和来自非人(通常是小鼠或大鼠)抗体的一个或多个cdr。优选地,它们含有或经修饰为含有包含n联糖基化位点的重链免疫球蛋白恒定区的ch2结构域的至少一部分。在大多数情况下,人源化抗体是人免疫球蛋白(受体抗体),其中来自受体的互补决定区(cdr)的残基替换为来自非人物种(供体抗体)的cdr的残基,所述非人物种具有所需特异性、亲和力和能力的小鼠、大鼠或兔子。可能需要构架氨基酸中的调整,以保持结构域的抗原结合特异性、亲和力和/或结构。在一些情况下,人免疫球蛋白的fv构架残基替换为相应的非人残基。此外,人源化抗体可以包含既不在受体抗体中也不在输入的cdr或构架序列中发现的残基。进行这些修饰以进一步改进和最大化抗体性能。一般而言,人源化抗体将包含至少一个,且通常为两个可变结构域,其中cdr区的全部或基本上全部对应于非人免疫球蛋白的那些,并且构架区的全部或基本上全部是人免疫球蛋白共有序列的那些。优选地,人源化抗体还包含免疫球蛋白恒定区的至少一部分,通常是人免疫球蛋白的那种。
根据本发明的术语“ch2结构域”意欲描述包含n联糖基化位点的重链免疫球蛋白恒定区的ch2结构域。在定义免疫球蛋白ch2结构域时,一般参考免疫球蛋白,且特别参考通过kabat,e.a如应用于人igg1的免疫球蛋白的结构域结构(kabatea,1988.j.immunol.141:s25-s36;kabatea等人,1991.sequencesofproteinsofimmunologicalinterest.u.s.departmentofhealthandhumanservices,natl.inst.ofhealth,bethesda)。相应地,免疫球蛋白一般是约150kda的异四聚体糖蛋白,由两条相同的轻链和两条相同的重链组成。每条轻链通过一个共价二硫键与重链连接,而二硫键的数目在不同免疫球蛋白同种型的重链之间变化。每条重链和轻链还具有规则间隔的链内二硫桥。每条重链具有氨基末端可变结构域(vh),随后为羧基末端恒定结构域(ch)。每条轻链具有可变的n末端结构域(vl)和c末端恒定结构域(cl)。
取决于重链恒定结构域的氨基酸序列,可以将抗体分配到不同的类别。存在五个主要类别:iga、igd、ige、igg和igm。对应于不同类别抗体的重链恒定结构域分别称为α、δ、ε、γ和μ结构域。igm的μ链含有5个结构域(vh、chμ1、chμ2、chμ3和chμ4)。ige的重链也含有5个结构域,而iga的重链具有4个结构域。免疫球蛋白类可以进一步分成亚类(同种型),例如igg1、igg2、igg3、igg4、iga1和iga2。
不同类别的免疫球蛋白的亚基结构和三维构型是众所周知的。其中iga和igm是聚合的,并且每个亚基含有两条轻链和两条重链。igg的重链含有位于chγ1和chγ2结构域之间的多肽链,称为铰链区。iga的α链具有含有o联糖基化位点的铰链区。μ和ε链不具有与γ和α链的铰链区类似的序列,然而,它们在其它免疫球蛋白类别中含有缺少另一个的第四恒定域。
完整抗体的fc区通常包含两个ch2结构域和两个ch3结构域。根据本发明,ch2结构域优选是上述五个免疫球蛋白类别之一的ch2结构域。优选的是哺乳动物免疫球蛋白ch2结构域,例如灵长类动物或鼠免疫球蛋白,其中灵长类动物且尤其是人免疫球蛋白ch2结构域是优选的。免疫球蛋白ch2结构域的氨基酸序列是技术人员已知的或一般可获得的((kabatea等人,1991.sequencesofproteinsofimmunologicalinterest.u.s.departmentofhealthandhumanservices,natl.inst.ofhealth,bethesda)。在本发明的上下文中优选的免疫球蛋白ch2结构域是人igg,且优选igg1、igg2、igg3、igg4,更优选人igg1和igg3,且甚至更优选人igg1。使用edelman的编号系统(edelmangm等人,1969.proc.natl.acad.sci.63:78-85),免疫球蛋白ch2结构域优选始于与人igg1的谷氨酰胺233等价的氨基酸位置,并且延伸通过与赖氨酸340等价的氨基酸(ellisonj和hoodl,1982.proc.natl.acad.sci.79:1984-1988)。
关于人抗体分子,参考igg类别,其中n联寡糖附着至弯曲至fc区的ch2结构域的内表面的β-4的asn297的酰胺侧链。优选地,抗体或fc融合蛋白含有或经修饰为含有至少一个ch2结构域。ch2结构域是免疫球蛋白的ch2结构域,其具有人iggch2结构域的单个n联寡糖。ch2结构域优选是人igg1的ch2结构域。
“fc融合蛋白”定义为含有或经修饰为含有重链免疫球蛋白恒定区的ch2结构域的至少一部分的蛋白质,所述重链免疫球蛋白恒定区包含单个n联糖基化位点。根据kabateu命名法(kabatea等人,1991.sequencesofproteinsofimmunologicalinterest.u.s.departmentofhealthandhumanservices,natl.inst.ofhealth,bethesda),该n联糖基化位点在igg1、igg2、igg3或igg4抗体中的位置asn297处。融合蛋白的另一部分可以是天然或经修饰的异源蛋白质的完全序列或序列的任何部分,或者天然或经修饰的异源蛋白质的完全序列的组合物或序列的任何部分。fc融合蛋白可以通过基因工程方法构建,通过将包含n联糖基化位点的重链免疫球蛋白恒定区的ch2结构域引入另一种表达构建体内,所述表达构建体包含例如其它免疫球蛋白结构域、酶促活性蛋白质部分或效应结构域。因此,根据本发明的fc融合蛋白还包含与重链免疫球蛋白恒定区的ch2结构域连接的单链fv片段,所述重链免疫球蛋白恒定区包含例如n联糖基化位点。
此外,抗体片段包括例如“fab片段”(片段抗原结合=fab)。fab片段由两条链的可变区组成,其由相邻的恒定区保持在一起。这些可以通过例如用木瓜蛋白酶的蛋白酶消化由常规抗体形成,但类似的fab片段也可以通过基因工程产生。其它抗体片段包括f(ab′)2片段,其可以通过用胃蛋白酶的蛋白水解切割来制备。
根据定义,引入宿主细胞内的任何序列或基因就宿主细胞而言称为“异源序列”、“异源基因”、“异源rna”或“转基因”或“重组基因”,即使引入的序列、rna或基因与宿主细胞中的内源序列、rna或基因相同。“异源”或“重组”蛋白质或rna因此是由异源序列或基因表达的蛋白质或rna。在一个优选实施方案中,引入的序列、rna或基因与所讨论的宿主细胞的内源序列、rna或基因不相同,尽管其中它是相同的实施方案也与本发明结合加以考虑。
“异源基因”或“异源序列”可以直接地(例如sirna)或通过使用“表达载体”,优选哺乳动物表达载体引入靶细胞内。用于构建载体的方法是本领域技术人员众所周知的,并且在各种出版物中描述。特别地,在(sambrookj等人,1989.molecularcloning:alaboratorymanual.coldspringharbor:coldspringharborlaboratorypress)和其中引用的参考文献中相当详细地综述了用于构建合适载体的技术,包括功能组分的描述,所述功能组分例如启动子、增强子、终止和多腺苷酸化信号、选择标记物、复制起点和剪接信号。载体可以包括但不限于质粒载体、噬菌粒、粘粒、人工/微型染色体(例如ace)、或病毒载体例如杆状病毒、逆转录病毒、腺病毒、腺伴随病毒、单纯疱疹病毒、逆转录病毒和细菌噬菌体。真核表达载体通常还含有原核序列,其促进载体在细菌中的繁殖,例如复制起点和用于在细菌中选择的抗生素抗性基因。包含多核苷酸可以可操作地连接到其内的克隆位点的各种真核表达载体是本领域众所周知的,并且一些从公司例如stratagene,lajolla,ca;invitrogen,carlsbad,ca;promega,madison,wi或bdbiosciencesclonetech,paloalto,ca商购可得。通常,表达载体还包含编码可选择标记物的表达盒,允许选择携带所述表达标记物的宿主细胞。
在本发明中,表达载体还用于将编码sirna或shrna的“异源序列”或“多核苷酸序列”引入宿主细胞内。此类表达载体可以包含sirna或shrna序列,用于在细胞中,特别是在哺乳动物细胞中,甚至更特别是在cho细胞中瞬时或稳定表达sirna或shrna。优选地,所述表达载体是哺乳动物表达载体。用于将编码sirna或shrna的核苷酸序列克隆到表达载体内的方法是本领域技术人员已知的。它们包括但不限于将包含侧翼区的sirna或shrna序列克隆到哺乳动物表达载体内,所述哺乳动物表达载体例如pcdna6.2,或本领域已知的任何其它载体,其可操作地连接于启动子,优选强启动子,例如cmv启动子或已知在宿主细胞中工作的任何其它强启动子。
如本文使用的,术语“表达”指异源核酸序列在宿主细胞内的转录和/或翻译。宿主细胞蛋白质如tbc1d20、cers2或atf6b在宿主细胞中的表达水平可以基于细胞中存在的相应mrna的量、或由如在呈现实例中的所选序列编码的多肽量来确定。例如,可以通过rna印迹杂交、核糖核酸酶rna保护、与细胞rna的原位杂交或通过pcr例如qpcr来定量由所选序列转录的mrna。由所选序列编码的蛋白质可以通过各种方法来定量,所述方法例如elisa、蛋白质印迹、放射性免疫测定、免疫沉淀、测定蛋白质的生物活性、蛋白质的免疫染色随后为facs分析、或均相时间分辨荧光(htrf)测定。非编码rna例如mirna的表达水平也可以通过pcr例如qpcr来定量。
如本文使用的,术语“转化(transformation)”或“转化(totransform)”、“转染(transfection)”或“转染(totransfect)”意指将任何遗传材料引入哺乳动物宿主细胞内,其中所述哺乳动物宿主细胞可以是瞬时转染或稳定转染的。遗传材料可以是包含目的基因(例如,重组分泌性治疗蛋白质)或者编码sirna或shrna的多核苷酸序列的表达载体。它还意指以对于分别病毒天然的方式引入病毒核酸序列。病毒核酸序列无需作为裸露核酸序列存在,而是可以包装在病毒蛋白质包膜中。
用多核苷酸或表达载体转染真核宿主细胞,导致遗传修饰的细胞或转基因细胞,可以通过本领域已知的任何方法进行(参见例如sambrookj等人,1989.molecularcloning:alaboratorymanual.coldspringharbor:coldspringharborlaboratorypress)。转染方法包括但不限于脂质体介导的转染、磷酸钙共沉淀、电穿孔、核转染、核穿化、微孔化、聚阳离子(例如deae-葡聚糖)介导的转染、原生质体融合、病毒感染和显微注射。转化可以导致宿主细胞的瞬时或稳定转化。优选地,转染是稳定转染。提供最佳转染频率和异源基因在特定宿主细胞系和类型中表达的转染方法是有利的。合适的方法可以通过常规程序来确定。对于稳定转染子,构建体或者整合到宿主细胞的基因组或者人工染色体/微型染色体内、或者游离地定位,以便在宿主细胞内稳定维持。因此,稳定转染的序列实际上保留在细胞及其子细胞的基因组中。通常,这涉及使用选择可标记物基因,并且目的基因或编码rna的多核苷酸序列连同可选择标记物基因整合在一起。在一些情况下,整个表达载体整合到细胞的基因组内,在其它情况下,仅表达载体的部分整合到细胞的基因组内。用编码所述重组分泌性治疗蛋白质的基因或用编码所述rna的多核苷酸序列稳定转染“稳定表达”重组分泌性治疗蛋白质或rna的细胞。因此,编码重组分泌性治疗蛋白质或rna的序列保留在细胞及其子细胞的基因组中。
本发明的表达载体可以进一步包含可选择标记物基因,例如抗生素抗性基因或可扩增标记物基因。可扩增的选择标记物基因可以与编码rna的多核苷酸序列可操作地连接。为了可操作地连接,编码rna的多核苷酸序列和可扩增的选择标记物基因可以位于同一载体上。通常,在本发明的表达载体中的重组分泌性治疗蛋白质和编码rna的多核苷酸序列与启动子和/或终止子可操作地连接。与启动子和/或终止子可操作地连接的重组分泌性治疗蛋白质或编码rna的多核苷酸序列也可称为表达盒。
“可选择标记物基因”或“选择标记物基因”是这样的基因,其编码可选择标记物,并且允许特异性选择含有该基因的细胞,通常通过向培养基中加入相应的“选择剂”。作为说明,抗生素抗性基因可以用作阳性可选择标记物。仅已用该基因转化的细胞能够在相应抗生素的存在下生长并且因此被选择。另一方面,未转化的细胞在这些选择条件下不能生长或存活。存在阳性、阴性和双功能可选择标记物。阳性可选择标记物允许通过赋予对选择剂的抗性或通过补偿宿主细胞中的代谢或分解代谢缺陷来选择并因此富集经转化的细胞。相比之下,已接受关于可选择标记物的基因的细胞可以通过阴性可选择标记物选择性地消除。其实例是单纯疱疹病毒的胸苷激酶基因,其在同时添加阿昔洛韦或更昔洛韦的细胞中的表达导致其消除。可用于本发明中的可选择标记物基因还包括可扩增的可选择标记物。文献描述了大量可选择标记物基因,包括双功能(阳性/阴性)标记物(参见例如wo92/08796和wo94/28143)。可用于本发明中的可选择标记物的实例包括但不限于氨基糖苷磷酸转移酶(aph)、潮霉素磷酸转移酶(hyg)、二氢叶酸还原酶(dhfr)、胸苷激酶(tk)、谷氨酰胺合成酶、天冬酰胺合成酶的基因,以及赋予对新霉素(g418/遗传霉素)、嘌呤霉素、组氨醇d、博来霉素、腐草霉素、杀稻瘟素和博莱霉素(zeocin)的抗性的基因。还包括遗传修饰的突变体和变体、片段、功能等价物、衍生物、同源物和与其它蛋白质或肽的融合,条件是可选择标记物保留其选择特性。此类衍生物在区域或结构域中的氨基酸序列中展示相当的同源性,其被认为是选择性的。
也可以通过荧光激活细胞分选(facs)进行选择,使用例如细胞表面标记物、细菌β-半乳糖苷酶或荧光蛋白(例如绿色荧光蛋白(gfp)及其来自维多利亚多管发光水母(aequoreavictoria)和海肾(renillareniformis)或其它物种的变体;红色荧光蛋白,荧光蛋白及其来自非生物发光物种(例如香菇珊瑚属物种(discosomasp.)、迎风海葵属物种(anemoniasp.)、羽珊瑚属物种(clavulariasp.)、钮扣珊瑚属物种(zoanthussp.))的变体,以选择重组细胞。
术语“选择剂”或“选择试剂”指干扰细胞生长或存活的物质,除非细胞中存在某种可选择标记物基因产物,其减轻选择试剂的效应。例如,为了在经转染的细胞中选择抗生素抗性基因如aph(氨基糖苷磷酸转移酶)的存在,使用抗生素遗传霉素(g418)。
术语“经修饰的新霉素磷酸转移酶(npt)”覆盖wo2004/050884中描述的所有突变体,特别是突变体d227g(asp227gly),其特征在于天冬氨酸(asp,d)取代在氨基酸位置227处的甘氨酸(gly,g),且特别优选突变体f240i(phe240ile),其特征在于苯丙氨酸(phe,f)取代在氨基酸位置240处的异亮氨酸(ile,i)。
“可扩增的可选择标记物基因”通常编码酶,其是在某些培养条件下的真核细胞生长所需的。例如,可扩增的可选择标记物基因可以编码二氢叶酸还原酶(dhfr)或谷氨酰胺合成酶(gs)。在这种情况下,如果用其转染的宿主细胞分别在选择剂氨甲蝶呤(mtx)或甲硫氨酸砜亚胺(msx)的存在下培养,则基因被扩增。与可扩增的可选择标记物基因连接的序列(即,与其物理接近的序列)连同可扩增的可选择标记物基因一起共扩增。可以将所述共扩增序列引入相同的表达载体或分开的载体上。
下表2给出了可扩增的可选择标记物基因和相关选择剂的非限制性实例,其可以根据本发明使用。合适的可扩增的可选择标记物基因也在通过kaufman的概述(kaufmanrj,1990.methodsenzymol.185:537-566)中描述。
表2:可扩增的可选择标记物基因
根据本发明,优选的可扩增的可选择标记物基因是编码具有gs或dhfr功能的多肽的基因。
本发明涉及哺乳动物细胞,其中编码宿主细胞蛋白质的至少一种基因包含抑制所述宿主细胞蛋白质表达的遗传修饰,或哺乳动物细胞包含通过rna干扰抑制编码宿主细胞蛋白质的基因表达的rna寡核苷酸,其中至少一种宿主细胞蛋白质是atf6b或tbc1d20和cers2。本发明还涉及制备所述哺乳动物细胞的方法和所述细胞在用于产生分泌性重组治疗蛋白质的方法中的用途。根据本发明,与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,宿主细胞蛋白质的表达降低意指在哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达是降低的。
在一个方面,本发明涉及具有重组治疗蛋白质的增强分泌的哺乳动物细胞,其包括宿主细胞蛋白质tbc1结构域家族成员20(tbc1d20)和神经酰胺合酶2(cers2)的降低表达;其中所述哺乳动物细胞任选进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
在另一个方面,本发明涉及具有重组治疗蛋白质的增强分泌的哺乳动物细胞,其包括宿主细胞蛋白质激活转录因子6β(atf6b)的降低表达,其中所述哺乳动物细胞进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
在本发明的一个实施方案中,具有重组治疗蛋白质的增强分泌的哺乳动物细胞包括宿主细胞蛋白质tbc1结构域家族成员20(tbc1d20)和神经酰胺合酶2(cers2)的降低表达;或宿主细胞蛋白质激活转录因子6β(atf6b)的降低表达,其中所述哺乳动物细胞进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
为了降低宿主细胞蛋白质在本发明的哺乳动物细胞中的表达,编码宿主细胞蛋白质的基因可以包含抑制所述宿主细胞蛋白质表达的遗传修饰,或哺乳动物细胞可以包含通过rna干扰抑制编码所述宿主细胞蛋白质的基因表达的rna寡核苷酸。与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,宿主细胞蛋白质的表达降低意指在哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达是降低的。在一个实施方案中,通过rna干扰抑制宿主细胞蛋白质的基因表达的rna寡核苷酸不是mirna。
本发明还涉及产生具有重组治疗蛋白质的增强分泌的哺乳动物细胞的方法,其包括(a)通过将(i)遗传修饰引入编码宿主细胞蛋白质的基因内,所述遗传修饰抑制所述宿主细胞蛋白质的表达,或
将(ii)rna寡核苷酸引入哺乳动物细胞内,所述rna寡核苷酸通过rna干扰抑制编码所述宿主细胞蛋白质的基因的表达,来降低哺乳动物细胞中宿主细胞蛋白质tbc1d20和cers2或宿主细胞蛋白质atf6b的表达,和(b)引入编码重组分泌性治疗蛋白质的一种或多种基因。该方法可以进一步包括步骤(c)选择具有重组治疗蛋白质的增强分泌的细胞。该方法可以进一步包括步骤(d)在允许编码重组分泌性治疗蛋白质的一种或多种基因表达的条件下,培养步骤(c)中获得的细胞。在步骤(b)中引入编码分泌性治疗蛋白质的一种或多种基因优选包括引入编码重组分泌性治疗剂的一个或多个表达盒。本发明方法的步骤(a)可以在步骤(b)之前或之后进行。因此,编码重组分泌蛋白质的一种或多种基因可以在遗传修饰或rna寡核苷酸(或包含编码所述rna寡核苷酸的核苷酸序列的表达载体)之前引入,导致宿主细胞蛋白质atf6b的降低表达或引入宿主细胞蛋白质tbc1d20和cers2。可替代地,编码重组分泌蛋白质的一种或多种基因可以在遗传修饰或rna寡核苷酸(或包含编码所述rna寡核苷酸的核苷酸序列的表达载体)之后引入,导致宿主细胞蛋白质atf6b的降低表达或引入宿主细胞蛋白质tbc1d20和cers2。本发明进一步涉及通过本发明的方法产生的哺乳动物细胞系。
哺乳动物细胞和通过本发明的方法产生的哺乳动物细胞可以进一步用于在哺乳动物细胞中产生重组分泌性治疗蛋白质的方法中。该方法包括(a)提供本发明的哺乳动物细胞,其中用重组分泌性治疗蛋白质转染细胞,或提供通过本发明的方法产生的哺乳动物细胞,(b)在允许重组分泌性治疗蛋白质产生的条件下,在细胞培养基中培养步骤(a)的哺乳动物细胞,和(c)收获重组分泌性治疗蛋白质。该方法可以进一步包括(d)纯化重组分泌性治疗蛋白质。
为了降低宿主细胞蛋白质在本发明的方法中的表达,编码宿主细胞蛋白质的基因可以包含抑制所述宿主细胞蛋白质表达的遗传修饰,或哺乳动物细胞可以包含通过rna干扰抑制编码所述宿主细胞蛋白质的基因表达的rna寡核苷酸。与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,宿主细胞蛋白质的表达降低意指在哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达是降低的。
哺乳动物细胞和通过本发明的方法产生的哺乳动物细胞可以进一步用于产生重组分泌性治疗蛋白质或增加重组分泌性治疗蛋白质的产率。本发明因此还涉及本发明的哺乳动物细胞或通过本发明的方法产生的哺乳动物细胞用于增加重组分泌性治疗蛋白质的产率的用途。它进一步涉及本发明的哺乳动物细胞或通过本发明的方法产生的哺乳动物细胞用于产生重组分泌性治疗蛋白质的用途。
由本发明的哺乳动物细胞或方法产生的重组分泌性治疗蛋白质优选为抗体,优选单克隆抗体、双特异性抗体或其片段、或fc融合蛋白。
宿主细胞蛋白质tbc1d20、cers2或atf6b的降低表达
宿主细胞蛋白质tbc1d20、cers2或atf6b的表达在根据本发明的哺乳动物细胞中降低,或者在本发明的方法中使用或产生。这意指与通过基因敲低或基因敲除不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,哺乳动物细胞中tbc1d20、cers2或atf6b的蛋白质表达降低。
在一个实施方案中,宿主细胞蛋白质tbc1d20和cers2的表达降低。宿主细胞蛋白质tbc1d20指在cho细胞中表达的仓鼠tbc1d20,例如由seqidno:1的cdna序列编码、或具有seqidno:4的氨基酸序列、或其任何同源物。如本文使用的,其同源物意指与seqidno:4的氨基酸序列具有至少80%,至少85%、至少90%、至少95%或至少98%的序列同一性的蛋白质。宿主细胞蛋白质cers2指在cho细胞中表达的仓鼠cers2,例如由seqidno:2的cdna序列编码、或具有seqidno:5的氨基酸序列、或其任何同源物。如本文使用的,其同源物意指与seqidno:5的氨基酸序列具有至少80%、至少85%、至少90%、至少95%或至少98%的序列同一性的蛋白质。
在另一个实施方案中,与对照细胞相比,atf6b的表达降低。宿主细胞蛋白质atf6b指在cho细胞中表达的仓鼠atf6b,例如由seqidno:3的cdna序列编码、或具有seqidno:6的氨基酸序列、或其任何同源物。如本文使用的,其同源物意指与seqidno:6的氨基酸序列具有至少80%、至少85%、至少90%、至少95%或至少98%的序列同一性的蛋白质。本领域技术人员将理解,宿主细胞蛋白质atf6b、tbc1d20和cers2的表达也可以降低。
术语“敲低”或“敲低技术”指基因沉默技术,其中与例如通过使用可以导致抑制靶基因产物的产生的sirna或shrna,通过rna干扰抑制靶基因表达的rna寡核苷酸引入之前的基因表达相比,靶基因或目的基因的表达降低。“双重敲低”是两个基因,例如编码tbc1d20和cers2的基因的敲低。
在一个实施方案中,哺乳动物细胞包含rna寡核苷酸,其通过rna干扰抑制编码所述宿主细胞蛋白质的基因的表达,其中所述宿主细胞蛋白质指atf6b或tbc1d20和cers2。技术人员将认识到rna寡核苷酸可以直接转染到细胞内,或者可以由细胞内的多核苷酸序列编码,例如通过使用表达载体。因此,表达载体包含编码所述rna寡核苷酸的多核苷酸序列。表达载体还可以包含编码第二rna寡核苷酸的多核苷酸序列。两种rna寡核苷酸可以由两个分开的表达盒编码,或者由例如通过ires序列分开的相同表达盒编码。靶向atf6b或tbc1d20和cers2的组合的sirna或shrna的过表达导致分泌的重组治疗蛋白质在哺乳动物表达系统中的增强产生和/或分泌。
优选地,rna寡核苷酸通过完全序列互补性(即,小干扰rna的rna双链体的反义链和靶mrna之间的完美碱基配对)介导mrna阻遏,并且因此对于其靶是特异性的。如本文使用的,完美碱基配对的完全序列互补性意指对于至少15个连续核苷酸、至少16个连续核苷酸、至少17个连续核苷酸、至少18个连续核苷酸、且优选至少19个连续核苷酸,小干扰rna的rna双链体的反义链与靶mrna具有至少89%的序列同一性,或者对于至少15个连续核苷酸、至少16个连续核苷酸、至少17个连续核苷酸、至少18个连续核苷酸、且优选至少19个连续核苷酸,优选与靶mrna至少93%的序列同一性。优选地,对于至少15个连续核苷酸、至少16个连续核苷酸、至少17个连续核苷酸、至少18个连续核苷酸、且优选至少19个连续核苷酸,小干扰rna的rna双链体的反义链与靶mrna具有100%的序列同一性。技术人员将理解mirna不通过完全序列互补性介导mrna阻遏,并且因此不是基因特异性的。因此,在一个实施方案中,rna寡核苷酸不是mirna。
优选地,rna干扰由小发夹rna(shrna)或短干扰rna(sirna)介导。可以用编码所述sirna或shrna的一种或多种表达载体转染哺乳动物细胞。优选地,用编码所述sirna或shrna的一种或多种表达载体稳定转染哺乳动物细胞。rna寡核苷酸可以是组成型表达或条件表达的。例如,rna寡核苷酸的表达在生长阶段期间可以是沉默的并且在蛋白质生产阶段期间开启。
用于敲低tbc1d20的示例性sirna是sitbc1d20#1(seqidno:7)。用于敲低cers2的示例性sirna是sicers2#1(seqidno:8)。优选地,具有seqidno:7或8的序列的sirna用于cho细胞中。这些sirna可以彼此独立地使用。因此,可以使用sitbc1d20#1或sicers2#1中的每一种,或者可以使用两种sirna。虽然根据本发明的方法或哺乳动物细胞降低tbc1d20和cers2两者的表达,但实现宿主细胞蛋白质降低的手段是彼此独立的。因此,可以通过使用sirna的基因敲低来降低宿主细胞蛋白质tbc1d20的表达,并且可以通过使用shrna的基因敲低来降低宿主细胞蛋白质cers2的表达,或反之亦然。可替代地,可以通过例如使用sirna的基因敲低来降低宿主细胞蛋白质tbc1d20的表达,并且可以通过基因敲除来降低宿主细胞蛋白质cers2的表达,或反之亦然。
用于敲低tbc1d20的示例性shrna包含shtbc1d20#1(seqidno:12);用于敲低cers2的示例性shrna包含shcers2#1(seqidno:13)、或shcers2#2(seqidno:14)、或所述shrna的组合。优选地,包含seqidno:12、13或14的序列的shrna用于cho细胞中。编码在本发明中适合用于敲低tbc1d20(seqidno:16和17)或cers2(seqidnos18-21)的shrna的示例性dna寡核苷酸显示于下文。优选地,编码靶向tbcd1d20的shrna的dna寡核苷酸包含seqidno:16的核苷酸序列6至26的序列(shtbc1d20#1寡核苷酸正向),且更优选seqidno:16的核苷酸序列6至26和46至64的序列(shtbc1d20#1寡核苷酸正向)。优选地,编码靶向cers2的shrna的dna寡核苷酸包含seqidno:18或20的核苷酸6至26的序列(shcers2#1或#2寡核苷酸正向),且更优选seqidno:18或20的核苷酸6至26和46至64的序列(shcers2#1或#2寡核苷酸正向)。
这些shrna可以彼此独立地使用。因此,可以使用shtbc1d20#1、shcers2#1或shcers2#2,或者可以使用shtbc1d20#1和shcers2#1或shcers2#2。虽然根据本发明的方法或哺乳动物细胞降低tbc1d20和cers2两者的表达,但实现宿主细胞蛋白质降低的手段是彼此独立的。因此,可以通过使用sirna的基因敲低来降低宿主细胞蛋白质tbc1d20的表达,并且可以通过使用shrna的基因敲低来降低宿主细胞蛋白质cers2的表达,或反之亦然。可替代地,可以通过例如使用shrna的基因敲低来降低宿主细胞蛋白质tbc1d20的表达,并且可以通过基因敲除来降低宿主细胞蛋白质cers2的表达,或反之亦然。
用于敲低atf6b的示例性sirna是siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10)、或siatf6b#3(seqidno:11)。优选地,根据本发明使用siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10)和siatf6b#3(seqidno:11)中的一种或多种,更优选使用siatf6b#1(seqidno:9)和siatf6b#2(seqidno:10)中的一种或多种。用于敲低atf6b的示例性shrna包含shatf6b#1(seqidno:15)或shatf6b#2(seqidno:37),优选shatf6b#1(seqidno:15)。优选地,具有seqidno:9、10或11的序列的sirna,或者包含seqidno:15或37的序列的shrna用于cho细胞中。编码在本发明中适合用于敲低atf6b的shrna的示例性dna寡核苷酸显示于下文(seqidno:22、23、35和36)。优选地,编码靶向atf6b的分别shrna的dna寡核苷酸包含seqidno:22或35的核苷酸6至26的序列(shatf6b#1或#2寡核苷酸正向),且更优选seqidno:22或35的核苷酸6至26和46至64的序列(shatf6b#1或#2寡核苷酸正向)。
在另一个实施方案中,编码宿主细胞蛋白质的至少一种基因包含抑制所述宿主细胞蛋白质表达的遗传修饰。编码宿主细胞蛋白质tbc1d20、cers2或atf6b的基因中的遗传修饰可以彼此独立地为基因缺失或抑制宿主细胞蛋白质表达的基因中的突变。突变可以是缺失、添加或取代。技术人员将知道突变可以在基因的编码区中和/或突变可以在基因的启动子或调节区中,只要基因表达降低。优选地,突变位于基因的启动子或调节区中。可以使用本领域已知的方法引入突变。技术人员将理解,使用具有降低的蛋白质活性的显性突变宿主细胞蛋白质的过表达可以实现相同的效应。可替代地,可以在哺乳动物细胞中缺失宿主细胞蛋白质基因,并且可以将在弱启动子控制下的编码所述宿主细胞蛋白质的表达盒引入哺乳动物细胞内,导致与对照细胞(即,不含有所述基因缺失的相同哺乳动物细胞)相比,宿主细胞蛋白质的总体表达降低。该基因突变可以在基因的一个或两个等位基因中。
通过与对照哺乳动物细胞,即不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,比较哺乳动物细胞中tbc1d20、cers2或atf6b的蛋白质表达,可以确定降低的宿主细胞蛋白质表达。优选地,与对照哺乳动物相比,宿主细胞蛋白质atf6b或宿主细胞蛋白质tbc1d20、cers2的表达降低至少30%、至少40%、至少50%、至少75%或100%。细胞。这可以在蛋白质水平上测量,例如通过elisa、通过蛋白质印迹、通过放射性免疫测定、免疫沉淀、测定蛋白质的生物活性、蛋白质的免疫染色随后为facs分析、或均相时间分辨荧光(htrf)测定、或本领域已知用于定量蛋白质的任何其它合适的方法。宿主细胞蛋白质atf6b或宿主细胞蛋白质tbc1d20、cers2的降低表达也可以在mrna水平上测定,例如通过定量pcr或本领域已知用于定量mrna的任何其它合适的方法。由所选序列转录的mrna可以通过rna印迹杂交、核糖核酸酶rna保护、与细胞rna的原位杂交或通过pcr进一步定量。
特别重要的是宿主细胞蛋白质表达在生产阶段期间降低。因此,只要宿主细胞蛋白质表达在大多数生产阶段期间降低,就能够在生长阶段之后或生产阶段早期诱导宿主细胞蛋白质表达的敲低。宿主细胞蛋白质表达应在培养结束前至少3天、培养结束前至少5天、培养结束前至少7天或培养结束前至少9天降低。优选地,宿主细胞蛋白质表达在细胞培养自始至终降低。
还可以通过使用“敲除”技术缺失基因来修饰基因。术语“敲除”指这样的细胞,其已经过遗传修饰,使得宿主细胞蛋白质aft6b或宿主细胞蛋白质tbc1d20和cers2的组合的表达被抑制,并且不产生相应的宿主细胞蛋白质(降低100%)。这可以使用本领域技术人员已知的各种技术来实现,所述技术包括crispr-cas9或锌指核酸酶技术。可替代地,可以通过在基因中引入突变来改变基因,以抑制其蛋白质的表达。基因突变可以是基因的编码区或者启动子或调节区中的核苷酸缺失、添加或取代。该基因突变可以在基因的一个或两个等位基因中。
重组治疗蛋白质的增强分泌
根据本发明的哺乳动物细胞中atf6b或tbc1d20和cers2的降低表达导致重组治疗蛋白质的增加分泌。通过改善的细胞密度或细胞活力可以增加蛋白质分泌。它也可以通过改善的比细胞生产率来增加。然而,技术人员将理解,在比细胞生产率基本上不受影响或甚至改善的情况下,具有改善的细胞密度或细胞活力仅增强分泌的重组治疗蛋白质的总产率。同样在细胞密度或细胞活力基本上不受影响或甚至改善的情况下,具有增加的比细胞生产率仅增强分泌的重组治疗蛋白质的总产率。重组治疗蛋白质的增强分泌因此指细胞培养中重组治疗蛋白质的总产率,通常作为浓度(滴度)例如mg/ml测量。与对照哺乳动物细胞,即不含有所述遗传修饰或rna寡核苷酸相比,根据本发明的重组治疗蛋白质的分泌增强至少10%、至少20%、至少30%、至少40%、至少50%、至少75%、至少100%或至少200%。在一个优选实施方案中,重组治疗蛋白质的分泌产率在收获时增强。
蛋白质atf6b涉及未折叠蛋白质应答(upr)。先前已描述仅“atf6α,而不是atf6β和atf4,具有触发er扩增的能力”(bommiasamy等人,2009,journalofcellsciences.122:1626-1636),并且仅atf6a负责er伴侣蛋白的转录诱导(yamamoto等人,2007,cell.13:365-376)。进一步报道,与atf6a相比,atf6b是er应激应答(ersr)基因的非常弱的转录激活因子(thuerauf等人,2007,thejournalofbiologicalchemistry.282(31):22865-22878)。不受理论束缚,我们因此认为生产细胞系中atf6b的耗尽可能增加atf6a的转录活性,并且因此通过触发er伴侣蛋白的表达来增加er的蛋白质折叠能力。
不同链长的神经酰胺由er中六种不同的神经酰胺合酶同种型(cers1-6)合成。cers2催化非常长链的神经酰胺(c20-c26)的合成,并且其在小鼠中的耗尽已显示减少非常长链的神经酰胺(>c22),同时诱导c16-c18神经酰胺的补偿性增加(
小gtp酶rab1在er中已进行加工的蛋白质的囊泡转运中起关键作用。需要gtp结合的rab1来维持高尔基体(haasa等人,2007.journalofcellscience.120:2997-3010)。tbc1d20是gtp酶激活蛋白(gap)。它催化活性、gtp结合的rab1转变成无活性的gdp结合状态。因此,不受理论束缚,tbc1d20的耗尽可以导致rab1的组成型活性形式,正面影响囊泡蛋白转运过程。
tbc1d20和cers2两者均涉及在高尔基体处的蛋白质转运。tbc1d20和cers2表达的降低因此看起来协同作用,与单独降低所述蛋白质中的每一种相比,导致增加的重组蛋白质分泌。
分泌的重组治疗蛋白质
在本发明的哺乳动物细胞中产生的分泌的重组治疗蛋白质包括但不限于抗体或融合蛋白,例如fc融合蛋白。其它分泌的重组治疗蛋白质可以是例如酶、细胞因子、淋巴因子、粘附分子、受体和衍生物或其片段、以及可以充当激动剂或拮抗剂和/或具有治疗或诊断用途的任何其它多肽和支架。
其它目的重组蛋白质是例如但不限于胰岛素,胰岛素样生长因子,hgh,tpa,细胞因子,例如白细胞介素(il),例如il-1、il-2、il-3、il-4、il-5、il-6、il-7、il-8、il-9、il-10、il-11、il-12、il-13、il-14、il-15、il-16、il-17、il-18,干扰素(ifn)α,ifnβ,ifnγ,ifnω或ifnτ,肿瘤坏死因子(tnf),例如tnfα和tnfβ,tnfγ,trail;g-csf,gm-csf,m-csf,mcp-1和vegf。还包括促红细胞生成素或任何其它激素生长因子以及可以充当激动剂或拮抗剂和/或具有治疗或诊断用途的任何其它多肽的产生。
优选的重组分泌性治疗蛋白质是抗体或其片段或衍生物。因此,本发明可以有利地用于产生抗体,例如单克隆抗体、多特异性抗体或其片段,优选单克隆抗体、双特异性抗体或其片段。此外,根据本发明用于产生重组分泌性治疗蛋白质的方法可以有利地用于产生抗体,例如单克隆抗体、多特异性抗体或其片段,优选单克隆抗体、双特异性抗体或其片段。在本发明的范围内的示例性抗体包括但不限于抗cd2、抗cd3、抗cd20、抗cd22、抗cd30、抗cd33、抗cd37、抗cd40、抗cd44、抗cd44v6、抗cd49d、抗cd52、抗egfr1(her1)、抗egfr2(her2)、抗gd3、抗igf、抗vegf、抗tnfα、抗il2、抗il-5r或抗ige抗体,并且优选选自抗cd20、抗cd33、抗cd37、抗cd40、抗cd44、抗cd52、抗her2/neu(erbb2)、抗egfr、抗igf、抗vegf、抗tnfα、抗il2和抗ige抗体。
抗体片段包括例如“fab片段”(片段抗原结合=fab)。fab片段由两条链的可变区组成,其由相邻的恒定区保持在一起。这些可以通过例如用木瓜蛋白酶的蛋白酶消化由常规抗体形成,但类似的fab片段也可以通过基因工程产生。其它抗体片段包括f(ab′)2片段,其可以通过用胃蛋白酶的蛋白水解切割来制备。
使用基因工程方法,能够产生缩短的抗体片段,其仅由重链(vh)和轻链(vl)的可变区组成。这些被称为fv片段(片段可变=可变部分的片段)。因为这些fv片段缺乏通过恒定链的半胱氨酸的两条链的共价键合,所以fv片段经常是稳定的。通过例如10至30个氨基酸,优选15个氨基酸的短肽片段,将重链和轻链的可变区连接是有利的。以这种方式,获得通过肽接头连接、由vh和vl组成的单条肽链。这种抗体蛋白质称为单链-fv(scfv)。scfv-抗体蛋白的实例是本领域技术人员已知的。
近年来,已开发了各种策略用于制备作为多聚体衍生物的scfv。这预期特别导致具有改善的药代动力学和生物分布性质以及增加的结合亲合力的重组抗体。为了实现scfv的多聚化,将scfv制备为具有多聚化结构域的融合蛋白。多聚化结构域可以是例如igg的ch3区或卷曲螺旋结构(螺旋结构)如亮氨酸拉链结构域。然而,还存在这样的策略,其中scfv的vh/vl区之间的相互作用用于多聚化(例如,双抗体、三抗体和五抗体)。通过双抗体,技术人员意指二价同源二聚体scfv衍生物。将scfv分子中的接头缩短至5-10个氨基酸导致形成同源二聚体,其中发生链间vh/vl-叠加。另外通过掺入二硫桥可以稳定双抗体。双抗体-抗体蛋白的实例是本领域技术人员已知的。
根据本发明的优选的分泌性重组治疗性抗体是双特异性抗体。双特异性抗体通常在一个分子中组合对于靶细胞(例如恶性b细胞)和效应细胞(例如t细胞、nk细胞或巨噬细胞)的抗原结合特异性。示例性双特异性抗体是双抗体、bite(双特异性t细胞衔接物)形式和dart(双重亲和性重新靶向)形式,但不限于其。双抗体形式在两条分开的多肽链上分离具有两种抗原结合特异性的重链和轻链的同源可变结构域,其中两条多肽链是非共价结合的。dart形式基于双抗体形式,但它通过c末端二硫桥提供另外的稳定。
通过三抗体,体技术人员意指三价同源三聚体scfv衍生物。在所述scfv衍生物中,vh-vl结构域直接融合而无需接头序列,这导致三聚体的形成。本领域技术人员还熟悉具有二价、三价或四价结构并衍生自scfv的所谓的微型抗体。多聚化通过二聚体、三聚体或四聚体卷曲螺旋结构进行。
在本发明的上下文中还预期了微型抗体。通过微型抗体,技术人员意指二价同源二聚体scfv衍生物。它由融合蛋白组成,所述融合蛋白含有免疫球蛋白,优选igg,最优选igg1的ch3区作为二聚化区域,其经由铰链区(例如也来自igg1)和接头区与scfv连接。微型抗体-抗体蛋白的实例是本领域技术人员已知的。
另一种优选的重组分泌治疗蛋白是融合蛋白,例如fc融合蛋白。因此,本发明可以有利地用于产生融合蛋白,例如fc融合蛋白。此外,根据本发明用于生产分泌性重组治疗蛋白质的方法可以有利地用于生产融合蛋白,例如fc融合蛋白。
融合蛋白的效应部分可以是天然或经修饰的异源蛋白质的完全序列或序列的任何部分,或者天然或经修饰的异源蛋白质的完全序列的组合物或序列的任何部分。免疫球蛋白恒定结构域序列可以得自任何免疫球蛋白亚型,例如igg1、igg2、igg3、igg4、iga1或iga2亚型,或者类别例如iga、ige、igd或igm。优选地,它们衍生自人免疫球蛋白,更优选人igg,且甚至更优选人igg1和igg3。fc融合蛋白的非限制性实例是mcp1-fc、icam-fc、epo-fc和scfv片段等等,其与包含n联糖基化位点的重链免疫球蛋白恒定区的ch2结构域偶联。fc融合蛋白可以通过基因工程方法构建,通过将包含n联糖基化位点的重链免疫球蛋白恒定区的ch2结构域引入另一种表达构建体内,所述表达构建体包含例如其它免疫球蛋白结构域、酶促活性蛋白质部分或效应结构域。因此,根据本发明的fc融合蛋白还包含与重链免疫球蛋白恒定区的ch2结构域连接的单链fv片段,所述重链免疫球蛋白恒定区包含例如n联糖基化位点。
重组分泌性治疗蛋白质,尤其是抗体、抗体片段或fc融合蛋白优选作为分泌多肽从培养基中回收/分离。必须从其它重组蛋白质和宿主细胞蛋白质中纯化重组分泌性治疗蛋白质,以获得重组分泌性治疗蛋白质的基本上同质的制剂。作为第一步,从培养基或裂解产物中去除细胞和/或微粒细胞碎片。此外,例如通过在免疫亲和性或离子交换柱上分级、乙醇沉淀、反相hplc、sephadex色谱法、以及在二氧化硅或阳离子交换树脂如deae上的色谱法,从污染性可溶蛋白质、多肽和核酸中纯化重组分泌性治疗蛋白质。用于纯化由宿主细胞表达的异源蛋白质的方法是本领域已知的。
在一个实施方案中,重组分泌性治疗蛋白质由编码分泌的一个或多个表达盒编码。
在一些实施方案中,可以将分泌性治疗蛋白质置于可扩增的遗传选择标记物,例如二氢叶酸还原酶(dhfr)、谷氨酰胺合成酶(gs)的控制下。可扩增的选择标记物基因可以与分泌性治疗蛋白质表达盒在相同的表达载体上。可替代地,可扩增的选择标记物基因和分泌性治疗蛋白质表达盒可以在不同的表达载体上,但是紧密接近地整合到宿主细胞的基因组内。例如,同时共转染的两种或更多种载体经常紧密接近地整合到宿主细胞的基因组内。然后通过将扩增试剂(例如,用于dhfr的mtx或用于gs的msx)加入培养基内,介导含有分泌性治疗蛋白质表达盒的遗传区域的扩增。
例如,通过将编码分泌性治疗蛋白质的多核苷酸的多重拷贝克隆到表达载体内,也可以实现宿主细胞或生产细胞中足够高稳定水平的分泌性治疗蛋白质。可以进一步组合将编码分泌性治疗蛋白质的多核苷酸的多重拷贝克隆到表达载体内,且如上所述扩增分泌性治疗蛋白质表达盒。
抗体生产
为了产生重组抗体,将编码全长轻链和重链或其片段的dna分子插入表达载体内,使得序列与转录和翻译控制序列可操作地连接。可替代地,可以使用本文提供的序列信息化学合成编码轻链可变区和重链可变区的dna分子。合成的dna分子可以与其它适当的核苷酸序列包括例如恒定区编码序列和表达控制序列连接,以产生编码所需抗体的常规基因表达构建体。为了制造本发明的抗体,技术人员可以从本领域众所周知的广泛多样的表达系统中选择,例如,由kipriyanow和legall,2004.molecularbiotechnology.26:39-60综述的那些。表达载体包括质粒、逆转录病毒、粘粒、ebv衍生的附加体等等。术语“表达载体”包含适合于表达外来dna的任何载体。此类表达载体的实例是病毒载体,例如腺病毒、牛痘病毒、杆状病毒和腺伴随病毒载体。在这方面,表述“病毒载体”应理解为意指dna和病毒颗粒两者。噬菌体或粘粒载体的实例包括pwe15、m13、λembl3、λembl4、λfixii、λdashii、λzapii、λgt10、λgt11、charon4a和charon21a。质粒载体的实例包括pbr、puc、pbluescriptii、pgem、ptz和pet组。可以使用各种穿梭载体,例如可以在多种宿主微生物如大肠杆菌(e.coli)和假单胞菌属物种(pseudomonassp)中自主复制的载体。另外,人工染色体载体被视为表达载体。表达载体和表达控制序列选择为与宿主细胞相容。哺乳动物表达载体的实例包括但不限于可从invitrogen获得的pcdna3、pcdna3.1(+/-)、pgl3、pzeosv2(/-)、psectag2、pdisplay、pef/myc/cyto、pcmv/myc/cyto、pcr3.1、psinreps、dh26s、dhbb、pnmt1、pnmt41、pnmt81,可从promega获得的pci,可从stratagene获得的pmbac、ppbac、pbk-rsv和pbk-cmv,可从clontech获得的ptres及其衍生物。
可以将抗体轻链基因和抗体重链基因插入分开的载体内。在某些实施方案中,将两种dna序列插入相同的表达载体内。方便的载体是编码功能完整的人ch或cl免疫球蛋白序列的那些,其中改造适当的限制性位点,使得任何vh或vl序列可以容易地插入且表达,如上所述,其中ch1和/或上铰链区包含于本发明的至少一种氨基酸修饰。恒定链通常是关于抗体轻链的κ或λ。重组表达载体还可以编码促进抗体链从宿主细胞中分泌的信号肽。可以将编码抗体链的dna克隆到载体内,使得信号肽与成熟抗体链dna的氨基末端在框内连接。信号肽可以是免疫球蛋白信号肽或来自非免疫球蛋白的异源肽。可替代地,编码抗体链的dna序列可以已经含有信号肽序列。除编码抗体链的dna序列之外,重组表达载体还携带调节序列,包括启动子、增强子、终止和多腺苷酸化信号、以及控制宿主细胞中的抗体链表达的其它表达控制元件。关于启动子序列的实例(对于在哺乳动物细胞中的表达例示的)是衍生自(cmv)的启动子和/或增强子(例如cmv猿猴病毒40(sv40)(例如sv40启动子/增强子)、腺病毒(例如腺病毒主要晚期启动子(admlp)、多瘤和强哺乳动物启动子如天然免疫球蛋白和肌动蛋白启动子。关于多腺苷酸化信号的实例是bgh多聚a、sv40晚期或早期多聚a;可替代地,可以使用免疫球蛋白基因的3′utr等。
重组表达载体还可以携带调节载体在宿主细胞中的复制的序列(例如复制起点)和可选择标记物基因。根据本领域众所周知的转染方法,包括脂质体介导的转染、聚阳离子介导的转染、原生质体融合、显微注射、磷酸钙沉淀、电穿孔或通过病毒载体的转移,编码本发明抗体的重链或其抗原结合部分和/或轻链或其抗原结合部分的核酸分子、以及包含这些dna分子的载体可以引入宿主细胞,例如细菌细胞或高等真核细胞,例如哺乳动物细胞内。
从单个表达载体或两种分开的表达载体表达重链和轻链在本领域的普通技术内。优选地,编码重链和轻链的dna分子存在于两种载体上,所述两种载体共转染到宿主细胞,优选哺乳动物细胞内。
可用作表达的宿主的哺乳动物细胞系是本领域众所周知的,并且尤其包括中国仓鼠卵巢(cho、cho-dg44、cho-k1)细胞、nso、sp2/0细胞、hela细胞、hek293细胞、幼仓鼠肾(bhk)细胞、猴肾细胞(cos)、人癌细胞(例如hepg2)、a549细胞、3t3细胞或任何此类细胞系的衍生物/后代。可以使用其它哺乳动物细胞,包括但不限于人、小鼠、大鼠、猴和啮齿类动物细胞系,或其它真核细胞,包括但不限于酵母、昆虫和植物细胞,或原核细胞如细菌。通过将宿主细胞培养足以允许抗体分子在宿主细胞中表达的时间段来产生本发明的抗体分子。在表达后,完整抗体(或抗体的抗原结合片段)可以使用本领域众所周知的技术收获且纯化,例如蛋白a、蛋白g、亲和标签例如谷胱甘肽-s-转移酶(gst)和组氨酸标签。
蛋白质纯化
重组分泌性治疗蛋白质优选作为分泌的多肽从培养基中回收。必须使用用于重组蛋白质的标准蛋白质纯化方法纯化重组分泌性治疗蛋白质,其方式是获得基本上同质的蛋白质制剂。例如,作为第一步,可用于获得本发明的重组分泌性治疗蛋白质的现有技术纯化方法包括从培养基或裂解产物中去除细胞和/或微粒细胞碎片。然后例如通过在免疫亲和性或离子交换柱上分级、乙醇沉淀、反相hplc、sephadex色谱法、在二氧化硅或阳离子交换树脂上的色谱法,从污染性可溶蛋白质、多肽和核酸中纯化重组分泌性治疗蛋白质。例如可以通过标准蛋白a色谱法,例如使用蛋白a旋转柱(gehealthcare),来纯化抗体或fc融合蛋白。可以通过还原型sdspage来验证蛋白质纯度。重组分泌性治疗蛋白质浓度可以通过测量在280nm处的吸光度并利用蛋白质比消光系数来确定。作为用于获得重组分泌性治疗蛋白质制剂的方法中的最后一步,如下文对于治疗应用所述,可以将纯化的重组分泌性治疗蛋白质干燥,例如冻干。
药物组合物
为了在治疗中使用,可以将重组分泌性治疗蛋白质配制成适于促进对动物或人施用的药物组合物。含有重组分泌性治疗蛋白质的药物组合物可以以剂量单位形式呈现,并且可以通过任何合适的方法制备。重组分泌性治疗蛋白质的典型制剂可以通过将蛋白质与生理学上可接受的载体、赋形剂或稳定剂以冻干或以其它方式干燥的制剂或者水溶液或者水性或非水性悬浮液的形式混合来制备。载体、赋形剂、改性剂或稳定剂在所采用的剂量和浓度下是无毒的。它们包括缓冲系统,例如磷酸盐、柠檬酸盐、乙酸盐和其它无机酸或有机酸及其盐;抗氧化剂,包括抗坏血酸和甲硫氨酸;防腐剂(例如十八烷基二甲基苄基氯化铵;氯化六甲双铵;苯扎氯铵、苄索氯铵;苯酚、丁基或苯甲醇;对羟基苯甲酸烷基酯,例如对羟基苯甲酸甲酯或对羟基苯甲酸丙酯;儿茶酚;间苯二酚;环己醇;3-戊醇;和间甲酚);蛋白质,例如血清白蛋白、明胶或免疫球蛋白;亲水性聚合物,例如聚乙烯吡咯烷酮或聚乙二醇(peg);氨基酸,例如甘氨酸、谷氨酰胺、天冬酰胺、组氨酸、精氨酸或赖氨酸;单糖、二糖、寡糖或多糖和其它碳水化合物,包括葡萄糖、甘露糖、蔗糖、海藻糖、糊精或葡聚糖;螯合剂,例如edta;糖醇,例如甘露醇或山梨糖醇;成盐抗衡离子,例如钠;金属络合物(例如锌-蛋白质络合物);和/或离子或非离子型表面活性剂,例如tween(tm)(聚山梨醇酯)、pluronics(tm)或脂肪酸酯、脂肪酸醚或糖酯。有机溶剂也可以包含在重组分泌性治疗蛋白质制剂中,例如乙醇或异丙醇。赋形剂还可以具有释放修饰或吸收修饰功能。
重组分泌性治疗蛋白质也可以干燥(冷冻干燥、喷雾干燥、喷雾冷冻干燥、通过近临界或超临界气体干燥、真空干燥、空气干燥)、沉淀或结晶或包埋在制备的微胶囊中,例如通过凝聚技术或通过界面聚合,在胶体药物递送系统(例如脂质体、白蛋白微球体、微乳剂、纳米颗粒和纳米胶囊)中分别使用例如羟甲基纤维素或明胶和聚(甲基丙烯酸甲酯),在粗乳剂中,或者例如通过pcmc技术(蛋白质涂布的微晶体)沉淀或固定在载体或表面上。这些技术公开于remington:thescienceandpracticeofpharmacy,第21版,hendricksonr.ed中。
天然地,用于体内施用的制剂必须是无菌的;灭菌可以通过常规技术,例如通过经由无菌滤膜过滤来完成。
增加抗体浓度以达到所谓的高浓度液体制剂(hclf)可能是有用的;生成此类hclf的各种方法已得到描述。
重组分泌性治疗蛋白质也可以包含在缓释制剂中。此外,重组分泌性治疗蛋白质可以以其它施加形式掺入,例如分散体、悬浮液或脂质体、片剂、胶囊、粉末、喷雾剂、使用或不使用渗透增强装置的透皮或皮内贴剂或乳膏、晶片、鼻、颊或肺部制剂,或者可以通过植入细胞或-在基因治疗后-由个体的自身细胞产生。
重组分泌性治疗蛋白质也可以用化学基团衍生化,所述化学基团例如聚乙二醇(peg)、甲基或乙基、或碳水化合物基团。这些基团可用于改善抗体的生物特征,例如增加血清半衰期或增加组织结合。
优选的施加模式是肠胃外,通过输注或注射(静脉内、肌内、皮下、腹膜内、皮内),但也可以应用其它施加模式,例如通过吸入、透皮、鼻内、经颊、经口。
为了预防或治疗疾病,重组分泌性治疗蛋白质的适当剂量将取决于待治疗的疾病类型、疾病的严重程度和过程、重组分泌性治疗蛋白质是施用用于预防还是治疗目的、先前治疗、患者的临床病史和对重组分泌治疗蛋白的应答、以及主治医师的判断。重组分泌性治疗蛋白质适合于一次或在一系列治疗中施用于患者。
材料和方法
表3:实施例中使用的细胞系
悬浮细胞的细胞培养
产生mab的cho-dg44细胞的悬浮培养物(urlaubg等人,1986.somaticcellandmoleculargenetics.12(6):555-566)及其稳定转染子在化学成分确定的无血清培养基中温育。种子培养物每2-3天进行传代培养,其中接种密度分别为3×105-2×105个细胞/ml。细胞在t-烧瓶(greiner)中生长。将t-烧瓶在增湿的培养箱(varolab)中在37℃和5%co2下温育。使用计数室通过台盼蓝排除来测定细胞浓度和活力。
补料分批培养
将细胞以3x105个细胞/ml接种到125ml摇瓶(corning)中的30ml化学成分确定的不含抗生素或mtx的无血清培养基中。将培养物在37℃和5%co2中在minitron培养箱(infors)中以120rpm搅动,在第3天后将其降低至2%。从第3天开始每天添加进料溶液,并且使用离线葡萄糖分析装置“labotrace”(traceanalytics)测量葡萄糖。在浓度低于3g/l时,将葡萄糖(#g8769,sigma-aldrich)调整至5g/l。使用“countess2fl自动细胞计数器”(lifetechnologies),通过台盼蓝排除来测定细胞密度和活力。累积比生产率计算为在给定日通过elisa分析的产物浓度除以直至该时间点的“活细胞积分”(ivc)。
抗体生产细胞的生成
用编码igg1抗体mab1(具有根据seqidno:24的序列的重链和根据seqidno:25的轻链序列)的表达质粒稳定转染cho-dg44细胞(urlaubg等人,1983.cell.33:405-412),并且在本文中称为cho-mab1。通过在次黄嘌呤和胸苷的不存在下,以及在分别的选择试剂的存在下,培养经转染的细胞来进行选择,关于选择试剂的抗性盒由表达质粒编码。在选择约3周后,获得稳定的细胞群体,并且根据标准的原种培养方案进一步培养,伴随每2至3天的传代培养。逐步添加增加浓度的甲氨蝶呤,以增加mab1基因表达。在下一步中,进行稳定转染的细胞群体的基于facs的单细胞克隆,以生成单克隆细胞系。
可替代地用编码igg1抗体mab2(具有根据seqidno:26的序列的重链和根据seqidno:27的轻链序列)的表达质粒稳定转染cho-dg44细胞(urlaubg等人,1983.cell.33:405-412),并且在本文中称为cho-mab2。通过在次黄嘌呤和胸苷的不存在下,以及在分别的选择试剂的存在下,培养经转染的细胞来进行选择,关于选择试剂的抗性盒由表达质粒编码。在选择约3周后,获得稳定的细胞群体,并且根据标准的原种培养方案进一步培养,伴随每2至3天的传代培养。逐步添加增加浓度的甲氨蝶呤,以增加mab2基因表达。在下一步中,进行稳定转染的细胞群体的基于clonepixfl的单细胞克隆,以生成单克隆细胞系。
稳定转染的cho-mab1或cho-mab2细胞在补充有g418(gibco,lifetechnologies)的化学成分确定的无血清培养基(boehringer-ingelheim)中培养。cho-mab1细胞培养基补充有400nmmtx,并且cho-mab2细胞培养基补充有100nmmtx(sigma-aldrich,德国)。细胞每2或3天进行传代培养,其中接种密度为3x105个细胞/ml或2x105个细胞/ml。
人微小rna在cho生产细胞中的瞬时表达
稳定分泌igg1抗体(mab1)的cho-dg44细胞在补充有g418(gibco,lifetechnologies)和400nmmtx(sigma-aldrich,德国)的化学成分确定的无血清培养基(boehringer-ingelheim)中培养,并且每2或3天进行传代培养,其中接种密度为3x105个细胞/ml或2x105个细胞/ml。
根据制造商的说明书,使用amaxa96孔shuttledevice(lonza)和程序96-dt-133,在含有1μmmirna的96孔nucleofector试剂盒sg(lonza)中,在传代培养后一天经由核转染(4x105个细胞/样品)转染细胞。对于瞬时转染,使用阴性对照mirnamir-c#1(miridian微小rna模拟阴性对照#1,dharmacon)。然后将细胞以3x105个细胞/ml的密度接种到24孔平底板(greiner)内。转染后一天,通过加入新鲜培养基使培养基的体积加倍。转染后两天,使用rneasyplusminikit(qiagen)提取总rna,并且如下所述通过qpcr测定靶基因的mrna水平。
下一代测序
如上所述,使用amaxa96孔shuttledevice(lonza)和程序96-dt-133,在含有1μmmirna(mir-c#1、hsa-mir-1287或hsa-mir-1978)的96孔nucleofector试剂盒sg(lonza)中,在传代培养后一天经由核转染(4x105个细胞/样品)转染稳定分泌igg1抗体(mab1)的cho-dg44细胞。转染后12小时,根据制造商的说明书,使用rneasyplusminikit(qiagen)提取总rna,并且使用rna6000nanokit,用2100bioanalyzer(agilent)分析质量和数量。随后,根据制造商的说明书,使用truseqrnasampleprepkitv2(illumina),用200ngrna生成cdna文库。简言之,富集多聚a+rna,随后为多聚a+rna(100-500bp)的随机片段化,不含链特异性的dscdna合成,条形码标记的衔接子/样品的连接和不对称连接的片段的扩增。使用dna1000kit,用2100bioanalyzer(agilent)分析质量和数量。在hiseq2000测序仪器(illumina)上,cdna文库在全流动室上加载有9pmol/泳道,具有单读模式和60个循环的片段测序加上7个循环的条形码测序。将序列读段/样品用tophat软件针对来自灰仓鼠(cricetulusgriseus)的参考基因组(组装″crigri_1.0″https://www.ncbi.nlm.nih.gov/assembly/309608)进行作图。根据mortazavi等人(naturemethods-5,621-628(2008))进行定量。因此,转录物丰度计算为rpkm(=每百万映射读段的每千碱基外显子模型的读段)。
人sirna在cho生产细胞中的瞬时表达
cho-mab1细胞和cho-mab2细胞在化学成分确定的无血清培养基(boehringer-ingelheim)中培养,所述培养基分别补充有400nmmtx(sigma-aldrich,德国)和100nmmtx,以及g418(gibco,lifetechnologies)。细胞每2或3天进行传代培养,其中接种密度为3x105个细胞/ml或2x105个细胞/ml。
根据制造商的说明书,使用amaxa96孔shuttledevice(lonza)和程序96-dt-133,在含有2μmsirna的96孔nucleofector试剂盒sg(lonza)中,在传代培养后一天经由核转染(4x105个细胞/样品)转染细胞。然后将细胞以3x105个细胞/ml的密度接种到24孔平底板(greiner)内。转染后一天,通过加入新鲜培养基使培养基的体积加倍。转染后两天,使用rneasyplusminikit(qiagen)提取总rna,并且如下所述通过qpcr测定靶基因atf6b、cers2和tbc1d20的mrna水平。上清液在转染后第1-4天收集,并且贮存于-20℃下直至通过elisa的抗体测量。用水代替sirna(模拟对照)或用具有下述序列的非靶向阴性对照库(ntsirna)转染阴性对照细胞:ugguuuacaugucgacuaa、ugguuuacauguuguguga、ugguuuacauguuuucuga和ugguuuacauguuuuccua(分别为seqidno:38-41)(dharmacon,#d-001810-10)。
通过qpcr分析的atf6b、cers2、tbc1d20、grp78、chop和herpud1rna表达测量
使用rneasyplusminikit(qiagen)提取2x105至2x106个细胞的总rna。根据制造商的说明书,使用quantitectreversetranscriptionkit(qiagen),用100ngrna生成cdna。使用cfx96装置(biorad),在白色96孔pcr平板(biorad)中,用dynamocolorflashsybrgreenqpcrkit(thermoscientific)进行qpcr。β肌动蛋白用作参考基因。用单阈值方法完成计算,并且计算δδcq值(bio-radcfx管理器软件2.1)。
表4:qpcr分析中使用的引物
重组抗体浓度的测定
为了评价经转染的细胞中的重组抗体产生,在给定时间点从细胞培养物中收集上清液。然后通过酶联免疫吸附测定(elisa)分析产物浓度。首先,高结合96孔微板(greiner)用针对人iggfc片段的抗体(jacksonimmunoresearchlaboratories)以1∶480稀释度在4℃下包被过夜。在用pbs(ph7.4)中的0.15%tween20洗涤三次后,平板与封闭缓冲液(pbs中的1%bsa,ph7.4)在室温下温育1小时,随后为三个洗涤步骤。上清液在稀释缓冲液(0.5%bsa,pbs中的0.01%tween80,ph7.4)中稀释至标准曲线范围内(1-50ng/μl或1-100ng/μl)的适当浓度。作为标准,mab1抗体以0-100ng/μl的连续稀释度使用。将稀释的样品和标准在室温下温育1.5小时。在反复洗涤后,将样品以1∶5000稀释度与针对人κ轻链的hrp-缀合的抗体(sigma)在室温下一起温育,随后为三个洗涤步骤。用0.1m甘氨酸、1mmzncl2和1mmmgcl2(ph10.4)以1mg/ml的浓度新鲜制备底物对硝基苯磷酸盐(sigmaaldrich),并且在黑暗中温育20分钟。通过加入3mnaoh终止反应,并且使用infinitem200pro多模式阅读器(tecan),测量在405nm和492nm的参考波长处的吸收。
微小rnamir-1287和mir-1978的稳定过表达
block-ittmpo1iimirrnai表达载体试剂盒(pcdna6.2-gw/emgfp-mirna表达系统试剂盒)用于稳定表达mirna。将编码特定微小rna的两个拷贝的dna寡核苷酸作为短发夹克隆到哺乳动物表达载体pcdna6.2内。为此,如手册中所述设计编码相应mirna的dna寡核苷酸。简言之,将成熟mirna序列包埋在给定序列中,所述给定序列包括优化的发夹环序列以及衍生自鼠mirnamir-155的3′和5′侧翼区(lagos-quintana等人,2002)。侧翼区存在于载体上,并且设计dna寡核苷酸,其编码mirna序列、所述环和分别的成熟mirna的反义序列,具有2个核苷酸消耗,以在发夹茎中产生内部环。此外,添加突出端用于在两个末端处克隆。可以使用在线工具mfold(m.zuker.mfoldwebserverfornucleicacidfoldingandhybridizationprediction.nucleicacidsres.31(13),3406-3415,2003)分析发夹结构。如通过制造商描述的,将dna链退火并且连接到emeraldgfp报告蛋白基因的3′-utr内。用于将mirna克隆到载体主链内的寡核苷酸序列如下:
hsa-mir-1287寡核苷酸正向:
tgctgtgctggatcagtggttcgagtcgttttggccactgactgacgactcgaaccacatccagca(seqidno:28)
hsa-mir-1287寡核苷酸反向:
cctgtgctggatgtggttcgagtcgtcagtcagtggccaaaacgactcgaaccactgatccagcac(seqidno:29)
hsa-mir-1978寡核苷酸正向:
tgctgggtttggtcctagcctttctagttttggccactgactgactagaaaggctaaccaaacc(seqidno:30)
hsa-mir-1978寡核苷酸反向:
cctgggtttggttagcctttctagtcagtcagtggccaaaactagaaaggctaggaccaaaccc(seqidno:31)
施加链接技术生成含有超过一个mirna的载体。对于具有两个拷贝的一个mirna,如通过制造商描述的,特定微小rna(例如由pcdna6.2-gw/emgfp-mir1287-mir1287或pcdna6.2-gw/emgfp-mir1978-mir1978指示的hsa-mir1287或mir-1978)的两个拷贝作为dna寡核苷酸克隆到哺乳动物表达载体pcdna6.2-gw/emgfp-mirna((block-ittmpoliimirrnai表达载体试剂盒,来自lifetechnologies的k4936-00)内,所述dna寡核苷酸编码作为短发夹的所述mirna。简言之,用酶bamhi和xhoi切除mirna盒。用酶bglii和xhoi打开已经含有一个mirna的载体。将dna与橙色上样缓冲液混合,并且在用tae缓冲液制备的1%琼脂糖凝胶中分离,用溴化乙锭显现条带,并且从凝胶中切下适当大小的条带。用dna梯验证尺寸。用凝胶提取试剂盒洗脱dna。根据制造商的说明书,使用t4dna连接酶,将dna插入物连接到载体内。随后,用dna转化感受态大肠杆菌,并且在含有壮观霉素的琼脂平板上铺平板。挑取菌落,并且用dna纯化试剂盒提取dna,通过首先用bamhi和bglii的对照消化随后为测序进行检查。
为了生成稳定的细胞库,如通过制造商描述的,使用具有pcdna6.2-gw/emgfp-mir-1287-1287或pcdna6.2-gw/emgfp-mi-1978-1978的优化方案,用lipofectamine2000和plus试剂(invitrogen)转染cho-mab1,并且用10μg/ml杀稻瘟素s(lifetechnologies)选择细胞,并且通过facs(facsdiva)富集gfp阳性细胞。作为对照载体,如所述的稳定转染表达gfp的阴性对照mirna表达载体(pcdna6.2-gw/emgfp-阴性对照mirna,由试剂盒提供)。阴性对照mirna具有下述序列:gaaauguacugcgcguggagac(seqidno:34)
稳定的shrna介导的atf6b、cers2和tbc1d20的敲低
block-ittmpo1iimirrnai表达载体试剂盒(pcdna6.2-gw/emgfp-mirna表达系统试剂盒)用于稳定表达shrna。将编码特定shrna的dna寡核苷酸作为短发夹克隆到哺乳动物表达载体pcdna6.2内。为此,如上文对于mirna克隆描述的,设计编码分别shrna的dna寡核苷酸,并且克隆到整合载体内。用于将shrna克隆到载体主链内的寡核苷酸序列如下,其中下划线指示反义靶位点及其互补序列,分别具有两个核苷酸的缺失,与环序列连接:
shtbc1d20#1寡核苷酸正向:
tgctgaatccttgctcaactgtcgaagttttggccactgactgacttcgacaggagcaaggatt(seqidno:16)
shtbc1d20#1寡核苷酸反向:
cctgaatccttgctcctgtcgaagtcagtcagtggccaaaacttcgacagttgagcaaggattc(seqidno:17)
shcers2#1寡核苷酸正向:
tgctgttaagttcacaggcagccatagttttggccactgactgactatggctgtgtgaacttaa(seqidno:18)
shcers2#1寡核苷酸反向:
cctgttaagttcacacagccatagtcagtcagtggccaaaactatggctgcctgtgaacttaac(seqidno:19)
shcers2#2寡核苷酸正向:
tgctgtgatgtagaggtctgaggcttgttttggccactgactgacaagcctcacctctacatca(seqidno:20)
shcers2#2寡核苷酸反向:
cctgtgatgtagaggtgaggcttgtcagtcagtggccaaaacaagcctcagacctctacatcac(seqidno:21)
shatf6b#1寡核苷酸正向:
tgctgtccatcttcacactgaggaccgttttggccactgactgacggtcctcagtgaagatgga(seqidno:22)
shatf6b#1寡核苷酸反向:
cctgtccatcttcactgaggaccgtcagtcagtggccaaaacggtcctcagtgtgaagatggac(seqidno:23)
shatf6b#2寡核苷酸正向:
tgctgttcacttccagaacctcctctgttttggccactgactgacagaggaggctggaagtgaa
(seqidno:35)
shatf6b#2寡核苷酸反向:
cctgttcacttccagcctcctctgtcagtcagtggccaaaacagaggaggttctggaagtgaac
(seqidno:36)
作为对照载体,如所述的稳定转染表达gfp的阴性对照mirna(seqidno:34)表达载体(pcdna6.2-gw/emgfp-阴性对照mirna,由试剂盒提供)。
如上所述施加链接技术生成含有超过一种shrna(pcdna6.2-gw/emgfp-shtbc1d20-shcers2#1和pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20)的载体。
为了生成稳定的细胞库,根据制造商的说明书,用celllinenucleofectorkitv(lonza),经由核转染在传代培养后一天转染cho-mab2细胞。简言之,将5x106个细胞/样品重悬浮于含有5μg质粒dna的100μl溶液v(lonza)中,并且使用celllinenucleofectordevice(lonza)和程序h14,在比色杯中进行核转染。然后将细胞用5ml预热的化学成分确定的不含抗生素的无血清培养基接种到t25烧瓶内。转染72小时后,将培养基更换为化学成分确定的含有1μg/ml杀稻瘟素s(lifetechnologies)的无血清培养基用于选择。转染后14天,细胞通过facs(bdfacsariaiii)富集细胞的gfp阳性细胞。如前所述通过qpcr监测atf6b、cers2和tbc1d20的有效敲低,并且在培养42天后,通过流式细胞术(miltenyimacsquant)分析细胞的gfp表达。
atf6b、cers2和tbc1d20的敲除
为了生成耗尽atf6b、cers2或tbc1d20的敲除细胞,施加crispr/cas9技术。对于grna设计,目的基因组基因座中的靶位点选择在分别基因的所有转录物变体中存在的第一外显子中的原型间隔物相邻基序(pam)的上游。对于每个靶基因,设计三个grna序列并且克隆到
抗体纯化
使用在移液机械臂上运行的填充有mabselect树脂(gehealthcare)的robocolumns(atoll),从无细胞细胞培养上清液中纯化抗体。用1mtris将用于洗脱的低ph中和至ph5.5,以阻止抗体变性。当氨基干扰糖基化分析时,使用10kdamwcopesvivaspin500500过滤单元(sartorius)通过超滤将缓冲液更换为纯水。使用nanodrop2000c光学分光计(photospectrometer)(thermoscientific)测定最终蛋白质浓度。
糖基化模式的分析
为了阐明在实施例10和11中描述的表达shrna的cho-mab2细胞库中产生的igg的fc-糖基化的结构和组成,在通过用pngasef酶促消化还原后,从纯化的抗体中释放出聚糖。根据制造商的方案,在labghipgxii仪器(perkinelmer)上,使用具有profilerproglycanprofiling系统的基于微芯片的毛细管电泳(ce),在pngasef释放和荧光标记后分析igg抗体的fc-糖基化的组成。通过labchipgx软件分析电泳图,以鉴定且定量各个糖结构。由色谱峰面积计算糖形的百分比。将所有值标准化为100%总糖结构/样品。
实施例
实施例1:通过下一代测序(ngs)的转录组概况分析
cho细胞通常用于生产治疗蛋白质。基因工程方法已尝试通过表达特异性cdna来优化这些细胞的生产率。天然存在的非编码rna通过调节整组靶蛋白的表达来调节细胞命运,当在cho生产细胞中过表达时,这可以导致超分泌表型。为了利用非编码rna的能力并鉴定正面影响异源治疗蛋白质的分泌的那些,用人微小rna文库转染cho-mab1细胞。基于该全基因组功能性微小rna(mirna)筛选,以鉴定增强cho-mab1细胞的抗体生产率的mirna,对抗体产生和比生产率具有强烈作用的两个mirna筛选命中mir-1287(seqidno:32)和mir-1978(seqidno:33)选择用于进一步分析(图1)。为了鉴定负责对cho细胞生产率的正面作用的直接mirna靶基因,用两种mirna中的每一种瞬时转染cho-mab1细胞。如上所述,在96孔nucleofectorkitsg(lonza)中,在传代培养后一天经由核转染(4x105个细胞/样品)转染细胞。然后将细胞以3x105个细胞/ml的密度接种到24孔板(greiner)内。转染后12小时,如上所述,使用下一代测序(ngs)通过转录组概况分析来分析细胞。
将具有其表达倍数变化的|log2|>1(在未转染细胞中表达超过2倍)的显著下调的基因定义为命中。然后参考关于相关途径的现有知识选择候选mirna靶基因用于进一步分析。选择atf6b作为mir-1287的靶基因,假设其下调触发未折叠蛋白应答(upr)。选择cers2和tbc1d20两者作为mir-1978的靶基因,分别涉及囊泡和非囊泡蛋白分泌的调节。首先通过sirna介导的基因敲低来评价其对抗体产生和比生产率的作用。在瞬时方法中重现对比生产率的正面作用,通过shrna获得靶基因的长期耗尽。sirna和shrna的名称和序列在图1b中列出。
实施例2:通过qpcr分析验证选择的ngs命中
为了验证分别作为mirnamir-1287和mir-1978的直接靶基因的ngs命中atf6b和cers2/tbc1d20,通过qpcr分析它们的表达水平。如上所述,用两种微小rna中的每一种转染cho-mab1细胞。转染后一天,如上所述提取rna,以通过qpcr分析(图2a和b)测量atf6b、cers2或tbc1d20的mrna水平。通过对参考基因β肌动蛋白标准化来计算相对表达。另外,在稳定过表达分别mirna的cho-mab1细胞中,通过qpcr分析目的基因表达水平中的变化。通过用含有gfp的表达载体转染cho-mab1细胞生成这些细胞库,所述表达载体进一步编码mir-1287或mir-1978(pcdna6.2-gw/emgfp-mir-1287-1287和pcdna6.2-gw/emgfp-mir-1978-1978)(图2c和d)。瞬时和稳定表达mir-1287的cho-mab1细胞两者均显示atf6b的表达水平降低,指示通过mirna的直接靶向。瞬时表达mir-1978的cho-mab1细胞以及具有稳定的mir-1978过表达的细胞库显示cers2和tbc1d20的mrna水平减少。因此,所有三种ngs命中都验证为分别mirna的直接靶基因。
实施例3:有效的sirna介导atf6b、cers2和tbc1d20的敲低
mir-1287和mir-1978的表达强烈改善表达重组抗体的cho细胞系(cho-mab1)的比生产率。为了调查经验证的mir-1287靶基因atf6b以及经验证的mir-1978靶cers2和tbc1d20的耗尽是否也正面影响产生重组抗体的cho细胞的比生产率,用对于分别的靶mrna特异性的sirna转染cho-mab1细胞。分别地,三种独立sirna用于下调atf6b并且两种sirna用于下调cers2和tbc1d20。转染一天后,提取rna并且通过qpcr分析定量atf6b、cers2和tbc1d20的mrna水平。通过对参考基因β肌动蛋白标准化来计算相对表达(图3)。与未转染的对照细胞相比(并且与在分开实验中用非靶向对照sirna转染的细胞相比,数据未显示),用对于atf6b特异性的sirna瞬时转染的cho-mab1细胞具有强烈降低的atf6bmrna水平。敲低效率对于所有三种独立sirna是相似的。与未转染的对照细胞相比(并且与在分开实验中用非靶向对照sirna转染的细胞相比,数据未显示),用对于cers2特异性的sirna和对于tbc1d20特异性的sirna瞬时转染cho-mab1细胞导致cers2和tbc1d20的表达降低。因此,对于atf6b和cers2以及tbc1d20的所有sirna都诱导分别靶基因的有效敲低。
实施例4:sirna介导的atf6b敲低增加了cho-mab1细胞的比生产率
为了调查atf6b的敲低是否改善cho-mab1细胞的比生产率,用对于atf6b特异性的三种独立sirna(siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10)和siatf6b#3(seqidno:11))转染稳定表达mab1抗体的细胞。细胞在1ml的总体积中(24孔形式)用一式三份样品培养4天。如上所述,通过elisa在转染后第3天和第4天时,测定经转染的细胞的上清液中的抗体浓度。另外,如上所述每天测定细胞密度和活力,使得能够计算比生产率。与未转染的对照细胞相比(并且与在分开实验中用非靶向对照sirna转染的细胞相比,数据未显示),atf6b的敲低导致在第4天改善的比生产率(图4)。
实施例5:组合的sirna介导的cers2和tbc1d20敲低使cho-mab1细胞的比生产率增加至多1.5倍
为了探究两种mir-1978靶cers2和tbc1d20的敲低是否对cho-mab1细胞的比生产率具有正面影响,首先用对于cers2或tbc1d20的特异性sirna转染这些细胞,并且在第二次实验中用两种sirna一起转染细胞。如实施例4中所述进行实验。在第3天和第4天的比生产率测定揭示cers2或tbc1d20的单一敲低仅略微改善比生产率,而两种靶基因的组合敲低使比生产率增加至多1.5倍(图5)。
实施例6:对于atf6b的三种独立sirna改善了cho-mab2细胞的比生产率
为了探究增加的比生产率是否对于产生mab1的cho细胞是特异性的,或者同样可以在另一种产生igg的cho细胞系中观察到,用对于atf6b特异性的三种独立sirna(siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10),siatf6b#3(seqidno:11))中的每一种瞬时转染cho-mab2细胞。如实施例4中所述进行实验。值得注意的是,所有三种sirna在转染后第3天和第4天都使比生产率增加1.2-1.6倍(图6)。
实施例7:cers2和tbc1d20的组合敲低改善了cho-mab2细胞的比生产率
此外,我们感兴趣的是cers2和tbc1d20的组合敲低是否也导致cho-mab2细胞的比生产率增加。如实施例4中所述,使用对于tbc1d20特异性的sirna,sitbc1d20#1(seqidno:7)和对于cers2特异性的sirna,sicers2#1(seqidno:8)进行实验。类似于稳定表达mab1抗体的cho细胞,与模拟转染的对照细胞相比,比生产率增加至多1.5倍(图7),提供通过瞬时下调cers2和tbc1d20的这种改善不依赖于细胞克隆、培养基和产生的抗体的证据。
对于稳定表达人血清白蛋白的cho-dg44细胞,也观察到比生产率中的类似增加(数据未显示)。
实施例8:通过流式细胞术分析cho-mab2细胞中的shrna表达
用编码gfp盒加上shrna序列的质粒稳定转染cho-mab2细胞,所述shrna序列包含特异性靶向atf6b的核苷酸序列(shatf6b#1;seqidno:15)、或包含特异性靶向cers2(shcers2#1;seqidno:13和shcers2#2;seqidno:14)和tbc1d20(shtbc1d20#1;seqidno:12)的序列的两个个别shrna序列的组合(pcdna6.2-gw/emgfp-shatf6b#1、pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1和pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)。在用杀稻瘟素s选择后(杀稻瘟素抗性基因由pcdna6.2-gw/emgfp载体编码),基于其gfp荧光分选细胞。对照细胞是未转染的亲代细胞。为了验证稳定转染的shrna的表达,通过流式细胞术分析细胞的gfp表达,其与shrna表达相关联,并且检测gfp阳性群体至少42天(图8)。这显示cho细胞能够稳定过表达shrna至少6周。
实施例9:通过定量pcr分析稳定转染的产生igg的cho细胞中的shrna表达
如上所述,用编码gfp盒加上shrna序列的质粒稳定转染cho-mab2细胞,所述shrna序列包含特异性靶向atf6b的核苷酸序列、或包含特异性靶向cers2和tbc1d20的序列的两个个别shrna序列的组合pcdna6.2-gw/emgfp-shatf6b#1、pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1或pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)。在用杀稻瘟素s选择后(抗性基因在pcdna6.2-gw/emgfp载体上编码),基于其gfp荧光分选细胞。稳定表达对照载体(pcdna6.2-gw/emgfp-阴性对照)的细胞库和未转染的亲代细胞充当阴性对照。为了验证稳定转染的shrna的表达,如上所述,我们从所有细胞中分离rna,并且分别进行atf6b、cers2和tbc1d20mrna水平的qpcr分析。与对照载体转染的细胞和亲代细胞相比,用编码shrna的质粒转染的细胞具有降低的atf6bmrna水平或降低的cers2和tbc1d20mrna水平(图9)。这证实质粒编码的shrna的稳定基因组整合导致cho细胞中分别靶基因的水平减少。
实施例10:稳定表达关于atf6b的shrna的cho-mab2细胞的补料分批培养
用含有shrna序列的表达载体稳定转染cho-mab2细胞,所述shrna序列包含特异性靶向atf6b的核苷酸序列(pcdna6.2-gw/emgfp-shatf6b#1),并且如上所述,基于其gfp表达分选细胞。在补料分批培养期间,使用表达靶向atf6b的shrna序列的一个细胞库和用阴性对照载体转染的两个独立细胞库。如上所述,分别通过用台盼蓝排除的细胞计数和elisa分析,在第3-6天时测定细胞密度、活力和产物形成(μg/ml)。计算比生产率。有趣的是,与用阴性对照载体转染的细胞相比,表达对于atf6b特异性的shrna的细胞显示改善的抗体滴度、改善的比生产率和增加的活细胞密度(图10)。此外,细胞活力未改变(数据未显示)。这证明了耗尽atf6b的稳定的cho细胞库在补料分批培养期间具有增加的生产能力,而不损害活细胞密度和活力。
实施例11:稳定表达对于cers2和tbc1d20特异性的shrna组合的cho-mab2细胞的补料分批培养
如上所述,用含有shrna序列的表达载体稳定转染cho-mab2细胞,所述shrna序列包含特异性靶向cers2和tbc1d20的序列(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1或pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1),并且基于其gfp表达分选细胞。在两次独立实验中,在补料分批培养期间,使用靶向cers2和tbc1d20mrna的两种独立的shrna组合和用阴性对照载体转染的两个独立细胞库。如上所述,分别通过用台盼蓝排除的细胞计数和elisa分析,在第3-11天时测定细胞密度、活力和产物形成。计算比生产率。与用阴性对照载体转染的细胞库相比,表达针对cers2和tbc1d20的shrna的两个细胞库均显示改善的抗体表达和比生产率(图11)。这证明了耗尽cers2和tbc1d20的稳定的cho细胞库具有增加的滴度和比生产能力。
实施例12:抗体糖基化和抗体聚集体形成的分析
为了分析产物质量,我们首先分析了在上文实施例10和11中描述的表达shrna的cho-mab2细胞库中产生的igg的fc-糖基化的结构和组成。在通过用pngasef酶促消化还原后,从纯化的抗体中释放出聚糖。根据制造商的方案,在labghipgxii仪器(perkinelmer)上,使用具有profilerproglycanprofiling系统的基于微芯片的毛细管电泳(ce),在pngasef释放和荧光标记后分析igg抗体的fc-糖基化的组成。通过labchipgx软件分析电泳图,以鉴定且定量各个糖结构。由色谱峰面积计算糖形的百分比。将所有值标准化为100%总糖结构/样品。图12中的结果显示atf6b(图12a)、cers2和tbc1d20(图12b)的耗尽不影响mab2抗体的糖基化。除从表达shatf6b#1的细胞纯化的抗体之外,在从表达shatf6b#2的细胞纯化的抗体中未观察到抗体糖基化中的变化(数据未显示)。
为了进一步证明产物质量得到维持,在补料分批运行结束时,通过hplc分析聚集体的形成。稳定表达shatf6b#1或shatf6b#2(pcdna6.2-gw/emgfp-shatf6b#1或pcdna6.2-gw/emgfp-shatf6b#2)或阴性对照序列的cho-mab2细胞在补料分批条件下培养7天。从上清液中纯化分泌的抗体并且通过hplc进行分析。图12c显示了来自不同细胞(表达shatf6b#1或shatf6b#2的细胞以及阴性对照)的抗体制剂是非常相似的,其中聚集体的比例小于1.5%。
稳定表达shtbc1d20-shcers2#1(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1)和shcers#2-shtbc1d20(pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)或阴性对照序列的第二细胞库在补料分批条件下培养11天。从上清液中纯化分泌的抗体并且通过hplc进行分析。图12d显示了来自不同细胞(表达shtbc1d20-shcers2#1或shcers#2-shtbc1d20的细胞以及阴性对照)的抗体制剂是非常相似的,其中聚集体的比例小于1.5%。
实施例13:葡萄糖调节蛋白78(grp78/bip)、chop和er相关降解(erad)组分herpud1的表达在atf6b敲低中是增加的
由于atf6在er应激期间充当转录因子,我们探究了atf6b敲低是否导致upr相关基因的任何变化。分析三种真正的upr标记物-葡萄糖调节蛋白78(grp78)、具有泛素样结构域1的同型半胱氨酸诱导型er蛋白(herpud1)、以及ccaat-增强子-结合蛋白同源蛋白(chop或ddit3,ncbi参考序列xm_007648092.1)的mrna水平-在用er应激诱导试剂衣霉素(tm)处理后。
如实施例8中所述产生稳定转染的细胞。简言之,用编码gfp盒加上shrna序列的质粒稳定转染cho-mab2细胞,所述shrna序列包含特异性靶向atf6b的核苷酸序列(pcdna6.2-gw/emgfp-shatf6b#1或pcdna6.2-gw/emgfp-shatf6b#2),编码包含seqidno:15(uccaucuucacacugaggacc)的序列的shatf6b#1和包含seqidno:37(uucacuuccagaaccuccucu)的序列的shatf6b#2。稳定表达对照载体(pcdna6.2-gw/emgfp-阴性对照)的细胞库充当阴性对照。为了验证稳定转染的shrna的表达,如上所述,分离rna并且进行atf6bmrna水平的qpcr分析。与阴性对照相比,用编码shrna的质粒转染的细胞具有降低的atf6bmrna水平(图13a)。这再次证实靶向atf6b的质粒编码的shrna的稳定基因组整合导致cho细胞中分别靶基因的表达减少。
为了调查下游upr相关基因的表达是否受到影响,用或不用衣霉素(tm)处理表达阴性对照序列或对于atf6b特异性的shrna的cho-mab2细胞。通过qpcr定量未处理细胞和tm处理细胞中grp78、herpud1和chop的mrna水平(图13b)。与表达阴性对照构建体的细胞库(黑色条)相比,用对于atf6b特异性的shrna稳定转染的细胞中grp78和herpud1两者的表达显著增强,而chop表达仅略微增强。这些结果指示转录因子atf6b的敲低在转录水平下触发upr。
我们进一步分析了下游upr相关基因的表达在补料分批培养中是否也受到影响。稳定表达atf6b特异性shrna或阴性对照构建体的cho-mab2细胞在摇瓶中培养,伴随每天进料。在第5天时,分析了upr相关基因grp78/bip、chop和herpud1的mrna水平。根据种子原种培养中获得的结果,当与对照细胞相比时,在表达shatf6b的细胞中upr相关基因grp78/bip和herpud1的mrna水平升高(图13c)。此外,与阴性对照相比(数据未显示),shatf6b#1和shatf6b#2转染的细胞显示在第7天在上清液中增加的抗体浓度(1.36倍)和增加的活细胞密度,而活力直到第7天不变。并且糖基化模式未改变(数据未显示)。
实施例14:tbc1d20敲低增强rab1活性,并且cers2敲低改变重组cho细胞中的神经酰胺组成。
tbc1d20是用于小gtp酶rab1的gtp酶激活蛋白(gap)。我们因此使用gst下拉测定调查cho-mab2细胞中的tbc1d20敲低是否导致增强的活性rab1水平。
p115-gst表达构建体的克隆
为了生成p115-gst融合蛋白,分别使用kpni与bamhi以及sali与noti,将p115(如brandon等人2006;mol.biol.cell.,17(7):2996-3008中所述,衍生自pegfp-n2-p115)亚克隆到载体pgex-6p-1(gehealthcare)内。通过sanger测序(gatcbiotechag)验证构建体的完整性。
蛋白质表达和提取
p115-gst融合蛋白在大肠杆菌中表达,随后为蛋白质提取。简言之,在具有100μg/ml氨苄青霉素的luriabroth(lb)培养基中选择转化体,并且当培养物达到0.8-1.0的od600时,通过添加0.3mm异丙基-β-d-硫代半乳糖吡喃糖苷(iptg)来刺激表达。通过离心收获细菌,并且将团块在干冰上冷冻30分钟。将团块重悬浮于裂解缓冲液(以ph7.5的50mmtris-hcl、1mmedta、1mmdtt和完全蛋白酶抑制剂(roche))中,并且加入0.1μg/ml溶菌酶。在冰上伴随温和振荡温育30分钟后,在冰上再加入5mmmgcl2和20ng/mldna酶30分钟,随后以3000g离心30分钟。然后将蛋白质提取上清液与1ml50%谷胱甘肽珠(gehealthcare)一起温育(1小时,4℃)。将珠形成团块(在500g、4℃下5分钟),用4ml洗涤缓冲液(裂解缓冲液加上100mmnacl)洗涤三次,重悬浮于4ml重悬浮缓冲液(不含edta的洗涤缓冲液)中,形成团块(在500g、4℃下5分钟),再洗涤一次,并且最后重悬浮于0.5ml重悬浮缓冲液中,得到1mlgst-p115-珠的50%浆料。
gst下拉测定
cht-igg细胞用组合的sitbc1d20、sicers2和sitbc1d20或nt对照经由核转染进行转染。转染72小时后,1x106个细胞在1ml匀浆缓冲液(10mmhepesph7,4、150mmnacl、5mmmgcl2、1%triton-x-100、1mmdtt、5%甘油、磷酸酶抑制剂混合物和完全蛋白酶抑制剂混合物(roche))中进行裂解,并且在冰上温育10分钟。将每种裂解产物与25μl50%gst-p115-珠混合,并在4℃下伴随温和振荡温育1小时。将珠形成团块,并且用均化缓冲液洗涤三次。将珠重悬浮于具有10μl凝胶上样缓冲液的20μl匀浆缓冲液中,在95℃下温育5分钟,短暂涡旋并形成团块。将蛋白质在12%丙烯酰胺凝胶上分离,转移到硝酸纤维素膜,并且用抗rab1抗体(抗体-online.com)检测。用抗gst抗体(gehealthcare)检测融合蛋白。还使用抗肌动蛋白抗体(sigma-aldrich)通过免疫印迹分析细胞裂解产物(输入)的等分试样,以确认相等的蛋白质量已经受下拉测定。
转染后三天,使用具有p115-gst融合蛋白的下拉测定,从细胞匀浆物中提取活性rab1,利用其与融合至gst的rab1效应蛋白p115的结合亲和力。用单独或与sicers2组合的sitbc1d20转染的cho-mab2细胞显示增加量的活性rab1(图14a)。使用imagej软件的定量确认,rab1活性在用单独或与sicers2组合的sitbc1d20转染的细胞中增加2倍(图14b)。在转染后第2天的敲低对照(qpcr)揭示,在用单独或与sicers2组合的sitbc1d20转染的细胞中50%的tbc1d20mrna降低(图14c)。这些发现确认rab1gaptbc1d20的敲低扩增了cho-mab2细胞中的rab1活性。
我们进一步分析了在用单独或与sicers2组合的sitbc1d20转染的细胞中的神经酰胺组成。在er处的神经酰胺合成及其随后转运至高尔基复合体是分泌途径中的必要步骤。cers2是哺乳动物细胞中表达的六种神经酰胺合酶同种型之一。每种同种型使用脂肪酰基-coa的有限子集作为用于神经酰胺合成的底物。cers2优先生成非常长链的神经酰胺,特别是c22和c24-神经酰胺。由于其在分泌途径中的关键作用,可设想er膜的改变的神经酰胺组成可以影响货物蛋白质的分选和运输。
为了调查神经酰胺组成在cers2敲低细胞中是否改变,用单独的sicers2#1(seqidno:8)、与tbc1d20#1(seqidno:7)组合的sicers2#1、或作为对照的非靶向sirna库(sirnant-对照,seqidno:38至41)转染cho-mab2细胞,并且使用荧光神经酰胺合酶活性测定进行分析。
荧光神经酰胺合酶活性测定
在核转染后第3天,将1.5x106个细胞形成团块,重悬浮于1ml裂解缓冲液(以ph7.4的20mmhepes、25mmkcl、2mmmgcl2、250mm蔗糖和完全蛋白酶抑制剂混合物(roche))中,并且使用26g针(terumo)进行机械裂解。使用二辛可宁酸(bca)测定(biorad)来测定蛋白质浓度。为了测量神经酰胺合酶活性,如通过kim等人(kim等人,2012)所述进行荧光测定,伴随较少修改。简言之,50μg匀浆蛋白在反应缓冲液(20mmhepes,ph7.4,25mmkcl,2mmmgcl2,0.5mmdtt,0.1%(w/v)无脂肪酸bsa,10μmnbd-二氢鞘氨醇,50μm脂肪酸-coa和250mm蔗糖)中伴随振荡在35℃下温育30分钟(对于c16-神经酰胺定量)和120分钟(对于c24-神经酰胺定量)。用250μl氯仿/甲醇(2∶1)终止反应,涡旋,离心且将下层相转移到5ml玻璃管。如所述的再次提取上层水相,并且合并两个有机相,且在氮蒸汽下干燥,随后重悬浮于100μl甲醇中。将2x2μl的每种反应施加到铝背衬的silicagel60tlc板上,并且通过色谱法(氯仿/甲醇/水,8∶1∶0.1v/v/v)分离。使用typhoontrio+scanner(gehealthcare)检测产物的荧光。通过薄层色谱法分离产物c16-二氢神经酰胺和c24-二氢神经酰胺,并且使用荧光扫描仪进行检测(图14d)。使用imagej软件定量c16-和c24-二氢神经酰胺的条带强度(图14e)。
与对照相比,cers2的敲低以及cers2和tbc1d20的组合敲低导致减少水平的c24-神经酰胺和增加量的c16-神经酰胺(图14d和e)。定量揭示c24-神经酰胺的级分在cers2敲低后平均降低67.6%,并且在cers2和tbc1d20的组合敲低后降低68.8%。c16-神经酰胺在用sicers2转染的细胞中增加73.0%,并且在用sicers2和sitbc1d20转染的细胞中增加19.1%。因为c24-神经酰胺的降低明显强于c16-神经酰胺的增强,因此更多的lc神经酰胺(例如c14-或c18-神经酰胺)另外受到影响是可能的。如上所述,通过qpcr确认sirna介导的敲低的效率(图14f)。因此,cers2的敲低导致改变的神经酰胺组成,具有c16-神经酰胺/c24-神经酰胺的比率增加。
实施例15:cers2的稳定敲低改变了重组cho细胞中的神经酰胺组成。
如实施例11中所述,用含有shrna序列的表达载体稳定转染cho-mab2细胞,所述shrna序列包含特异性靶向cers2和tbc1d20的序列(pcdna6.2-gw/emgfp-shtbc1d20#1-shcers2#1或pcdna6.2-gw/emgfp-shcers2#2-shtbc1d20#1)。细胞在传代培养后一天进行裂解,并且如实施例14中所述,使用荧光神经酰胺合酶活性分析神经酰胺组成。
与对照细胞相比,通过两种独立shrna组合的cers2和tbc1d20的双重敲低导致c24-神经酰胺的强烈减少(shtbc1d20#1-shcers2#1:51.7%,shcers2#2-shtbc1d20#152.1%)。同时,c16-神经酰胺的量急剧增加了97.7%(shtbc1d20#1-shcers2#1)和74.5%(shcers2#2-shtbc1d20#1),确认了在瞬时实验中获得的结果(图14d和e)。
实施例16:在cho-mab2细胞中crispr/cas9介导的atf6b敲除
迄今为止,我们可以显示与未转染的细胞或用阴性对照质粒转染的细胞相比,在cho-mab2细胞中atf6b的瞬时和稳定敲低增强了抗体分泌。为了调查atf6b蛋白的总耗尽是否可以进一步改善生产率,通过突变atf6b基因以获得转录的过早停止并因此阻止atf6b蛋白形成来生成敲除细胞。应用crispr/cas9系统,使用靶向atf6b基因的三个独立的grna序列,以生成稳定耗尽atf6b的cho细胞克隆。通过鉴定两种atf6b转录物变体中存在的前两个外显子中的原型间隔物相邻基序(pam)来选择靶位点。设计三种引导rna,其中每种与pam位点上游的序列具有20个互补核苷酸。将每个grna克隆到
实施例17:在cho-mab2细胞中crispr/cas9介导的cers2和tbc1d20的组合敲除
我们先前可以显示与未转染的细胞或用阴性对照质粒转染的细胞相比,在cho-mab2细胞中cers2和tbc1d20的瞬时和稳定敲低增强了抗体分泌。为了调查cers2和tbc1d20蛋白的总耗尽是否可以进一步改善生产率,通过突变cers2和tbc1d20基因以获得转录的过早停止并因此阻止cers2和tbc1d20蛋白形成来生成敲除细胞系。应用crispr/cas9技术,靶向cers2的三个独立的grna和靶向tbc1d20的三个独立的grna用于突变分别的基因。通过鉴定所有六种cers2转录物变体或两种tbc1d20转录物变体中分别存在的前两个外显子中的原型间隔物相邻基序(pam)来选择靶位点。对于每个基因设计三种引导rna,其与pam位点上游的序列具有20个互补核苷酸。如上所述,将每个grna克隆到
本发明通过下述项目涵盖:
1.一种具有重组治疗蛋白质的增强分泌的哺乳动物细胞,其包括
(a)宿主细胞蛋白质tbc1结构域家族成员20(tbc1d20)和神经酰胺合酶2(cers2)的降低表达;或
(b)宿主细胞蛋白质激活转录因子6β(atf6b)的降低表达,
其中所述哺乳动物细胞进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
2.项目1的哺乳动物细胞,其具有降低的atf6b蛋白表达,并且进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
3.项目1或2的哺乳动物细胞,其中与对照哺乳动物细胞相比,所述宿主细胞蛋白质tbc1d20和cers2或所述宿主细胞蛋白质atf6b的表达降低至少30%、至少40%、至少50%、至少75%或100%。
4.项目1至3中任一项的哺乳动物细胞,其中与对照哺乳动物细胞相比,所述重组治疗蛋白质的分泌增强至少10%、至少20%、至少30%、至少40%、至少50%、至少75%、至少100%或至少200%。
5.前述项目中任一项的哺乳动物细胞,其中
(a)编码所述宿主细胞蛋白质的基因包含抑制所述宿主细胞蛋白质表达的遗传修饰,或
(b)所述哺乳动物细胞包含通过rna干扰抑制编码所述宿主细胞蛋白质的基因表达的rna寡核苷酸,和
其中与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,所述哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达降低。
6.项目5的哺乳动物细胞,其中所述rna干扰由小发夹rna(shrna)或短干扰rna(sirna)介导。
7.项目6的哺乳动物细胞,其中所述哺乳动物细胞已用一种或多种表达载体转染,所述表达载体包含编码所述sirna或shrna的核苷酸序列。
8.项目7的哺乳动物细胞,其中所述哺乳动物细胞用一种或多种表达载体稳定转染,所述表达载体包含编码所述sirna或shrna的核苷酸序列。
9.项目6至8中任一项的哺乳动物细胞,其中所述sirna是
(a)sitbc1d20#1(seqidno:7)、或sicers2#1(seqidno:8)、或其组合;或
(b)siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10)和siatf6b#3(seqidno:11)中的一种或多种。
10.项目6至8中任一项的哺乳动物细胞,其中所述shrna包含
(a)shtbc1d20#1(seqidno:12)、或shcers2#1(seqidno:13)和shcers2#2(seqidno:14)中的一种或多种、或其组合;或
(b)shatf6b#1(seqidno:15)和shatf6b#2(seqidno:37)中的一种或多种,优选shatf6b#1(seqidno:15)。
11.项目5的哺乳动物细胞,其中编码所述宿主细胞蛋白质tbc1d20、cers2或atf6b的基因中的遗传修饰独立地是
(a)基因缺失;或
(b)抑制所述宿主细胞蛋白质表达的基因中的突变。
12.项目11的哺乳动物细胞,其中所述突变是缺失、添加或取代。
13.项目12的哺乳动物细胞,其中
(a)所述突变位于所述基因的编码区中;和/或
(b)所述突变位于所述基因的启动子或调节区中。
14.前述项目中任一项的哺乳动物细胞,其中
(a)所述宿主细胞蛋白质tbc1d20与seqidno:4的氨基酸序列具有至少80%的序列同一性,并且所述宿主细胞蛋白质cers2与seqidno:5的氨基酸序列具有至少80%的序列同一性;或
(b)所述宿主细胞蛋白质atf6b与seqidno:6的氨基酸序列具有至少80%的序列同一性。
15.项目14的哺乳动物细胞,其中
(a)所述宿主细胞蛋白质tbc1d20具有seqidno:4的氨基酸序列,并且所述宿主细胞蛋白质cers2具有seqidno:5的氨基酸序列;或
(b)所述宿主细胞蛋白质atf6b具有seqidno:6的氨基酸序列。
16.一种具有重组治疗蛋白质的增强分泌的哺乳动物细胞,其包括所述宿主细胞蛋白质tbc1d20和cers2的降低表达。
17.项目16的哺乳动物细胞,其进一步包含编码重组分泌性治疗蛋白质的一个或多个表达盒。
18.项目17的哺乳动物细胞,其中与对照哺乳动物细胞相比,所述重组治疗蛋白质的分泌增强至少10%、至少20%、至少30%、至少40%、至少50%、至少75%、至少100%或至少200%。
19.项目16至18的哺乳动物细胞,其中与对照哺乳动物细胞相比,所述宿主细胞蛋白质tbc1d20和cers2的表达降低至少30%、至少40%、至少50%、至少75%或100%。
20.项目16至19中任一项的哺乳动物细胞,其中
(a)编码所述宿主细胞蛋白质的基因包含抑制所述宿主细胞蛋白质表达的遗传修饰,或
(b)所述哺乳动物细胞包含通过rna干扰抑制编码所述宿主细胞蛋白质的基因表达的rna寡核苷酸,和
其中与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,所述哺乳动物细胞中tbc1d20和cers2的蛋白质表达降低。
21.项目20的哺乳动物细胞,其中所述rna干扰由小发夹rna(shrna)或短干扰rna(sirna)介导。
22.项目21的哺乳动物细胞,其中所述哺乳动物细胞已用一种或多种表达载体转染,所述表达载体包含编码所述sirna或shrna的核苷酸序列。
23.项目22的哺乳动物细胞,其中所述哺乳动物细胞已用一种或多种表达载体稳定转染,所述表达载体包含编码所述sirna或shrna的核苷酸序列。
24.项目21至23中任一项的哺乳动物细胞,其中所述sirna是sitbc1d20#1(seqidno:7)、或sicers2#1(seqidno:8)、或其组合。
25.项目21至23中任一项的哺乳动物细胞,其中所述shrna包含shtbc1d20#1(seqidno:12)、或shcers2#1(seqidno:13)和shcers2#2(seqidno:14)中的一种或多种、或其组合。
26.项目20的哺乳动物细胞,其中编码所述宿主细胞蛋白质tbc1d20和cers2的基因中的遗传修饰独立地是
(a)基因缺失;或
(b)抑制所述宿主细胞蛋白质表达的基因中的突变。
27.项目26的哺乳动物细胞,其中所述突变是缺失、添加或取代。
28.项目27的哺乳动物细胞,其中
(a)所述突变位于所述基因的编码区中;和/或
(b)所述突变位于所述基因的启动子或调节区中。
29.项目16至28中任一项的哺乳动物细胞,其中所述宿主细胞蛋白质tbc1d20与seqidno:4的氨基酸序列具有至少80%的序列同一性,并且所述宿主细胞蛋白质cers2与seqidno:5的氨基酸序列具有至少80%的序列同一性。
30.项目16至29中任一项的哺乳动物细胞,其中所述宿主细胞蛋白质tbc1d20具有seqidno:4的氨基酸序列,并且所述宿主细胞蛋白质cers2具有seqidno:5的氨基酸序列。
31.前述项目中任一项的哺乳动物细胞,其中所述重组分泌性治疗蛋白质是
(a)抗体,优选单克隆抗体、双特异性抗体或其片段,或
(b)fc融合蛋白。
32.前述项目中任一项的哺乳动物细胞,其中所述细胞是啮齿类动物或人细胞。
33.项目32的哺乳动物细胞,其中所述啮齿类动物细胞是仓鼠细胞。
34.项目33的哺乳动物细胞,其中所述仓鼠细胞是cho细胞,优选cho-dg44细胞、cho-k1细胞或其谷氨酰胺合成酶(gs)缺陷衍生物。
35.一种产生具有重组治疗蛋白质的增强分泌的哺乳动物细胞的方法,其包括:
(a)通过以下降低所述哺乳动物细胞中宿主细胞蛋白质tbc1d20和cers2或宿主细胞蛋白质atf6b的表达
(i)将遗传修饰引入编码所述宿主细胞蛋白质的基因内,所述遗传修饰抑制所述宿主细胞蛋白质的表达,或
(ii)将rna寡核苷酸引入所述哺乳动物细胞内,所述rna寡核苷酸通过rna干扰抑制编码所述宿主细胞蛋白质的基因的表达,和
(b)引入编码重组分泌性治疗蛋白质的一种或多种基因。
36.项目35的方法,其进一步包括下述步骤:
(c)选择具有重组治疗蛋白质的增强分泌的细胞;和
(d)任选地在允许编码重组分泌性治疗蛋白质的一种或多种基因表达的条件下,培养步骤(c)中获得的所述细胞。
37.项目35或36的方法,其中与不含有所述遗传修饰或rna寡核苷酸的相同哺乳动物细胞相比,所述哺乳动物细胞中tbc1d20和cers2的蛋白质表达或atf6b的蛋白质表达降低。
38.项目35或37中任一项的方法,其包括降低所述哺乳动物细胞中的tbc1d20和cers2蛋白质表达。
39.项目35或37中任一项的方法,其包括降低所述哺乳动物细胞中的atf6b蛋白质表达。
40.项目35至39中任一项的方法,其中所述rna干扰由小发夹rna(shrna)或短干扰rna(sirna)介导。
41.项目40的方法,其包括用一种或多种表达载体转染所述哺乳动物细胞,所述表达载体包含编码所述sirna或shrna的核苷酸序列。
42.项目41的方法,其中所述哺乳动物细胞用一种或多种表达载体稳定转染,所述表达载体包含编码所述sirna或shrna的核苷酸序列。
43.项目40至42中任一项的方法,其中sirna是
(a)sitbc1d20#1(seqidno:7)、或sicers2#1(seqidno:8)、或其组合;或
(b)siatf6b#1(seqidno:9)、siatf6b#2(seqidno:10)和siatf6b#3(seqidno:11)中的一种或多种。
44.项目40至42中任一项的方法,其中所述shrna包含
(a)shtbc1d20#1(seqidno:12)、或shcers2#1(seqidno:13)和shcers2#2(seqidno:14)中的一种或多种、或其组合;或
(b)shatf6b#1(seqidno:15)和shatf6b#2(seqidno:37)中的一种或多种,优选shatf6b#1(seqidno:15)。
45.项目35的方法,其中编码所述宿主细胞蛋白质tbc1d20和cers2或atf6b的基因中的遗传修饰独立地是
(a)基因缺失;或
(b)抑制所述宿主细胞蛋白质表达的基因中的突变。
46.项目45的方法,其中所述突变是缺失、添加或取代。
47.项目46的方法,其中
(a)所述突变位于所述基因的编码区中;和/或
(b)所述突变位于所述基因的启动子或调节区中。
48.项目35至47中任一项的方法,其中
(a)所述宿主细胞蛋白质tbc1d20与seqidno:4的氨基酸序列具有至少80%的序列同一性,并且所述宿主细胞蛋白质cers2与seqidno:5的氨基酸序列具有至少80%的序列同一性;或
(b)所述宿主细胞蛋白质atf6b与seqidno:6的氨基酸序列具有至少80%的序列同一性。
49.项目35至48中任一项的方法,其中,
(a)所述宿主细胞蛋白质tbc1d20具有seqidno:4的氨基酸序列,并且所述宿主细胞蛋白质cers2具有seqidno:5的氨基酸序列;或
(b)所述宿主细胞蛋白质atf6b具有seqidno:6的氨基酸序列。
50.项目35至49中任一项的方法,其中所述重组分泌性治疗蛋白质是
(a)抗体,优选单克隆抗体、双特异性抗体或其片段,或
(b)fc融合蛋白。
51.项目35至50中任一项的方法,其中所述细胞是啮齿类动物或人细胞。
52.项目51的方法,其中所述啮齿类动物细胞是仓鼠细胞。
53.项目52的方法,其中所述仓鼠细胞是cho细胞,优选cho-dg44细胞、cho-k1细胞或其谷氨酰胺合成酶(gs)缺陷衍生物。
54.项目35至53中任一项的方法,其中步骤(a)可在步骤(b)之前或之后进行。
55.项目35至54中任一项的方法,其中步骤(c)的选择步骤在选择剂的存在下进行。
56.项目35至55中任一项的方法,其进一步包括扩增步骤(b′),其包括将步骤(b)中引入的一种或多种基因连同可扩增的可选择标记物基因一起扩增,并且在允许所述可扩增的可选择标记物基因扩增的试剂的存在下,培养所述哺乳动物细胞。
57.项目56的方法,其中所述可扩增的可选择标记物基因编码可扩增的可选择标记物二氢叶酸还原酶或谷氨酰胺合成酶。
58.项目35至57中任一项的方法,其中与使用相同原材料通过项目35至56中任一项的方法,但省略步骤(a)生产的哺乳动物细胞相比,所述宿主细胞蛋白质tbc1d20和cers2或所述宿主细胞蛋白质atf6b的表达降低至少30%、至少40%、至少50%、至少75%或100%。
59.项目35至58中任一项的方法,其中与使用相同原材料通过项目35至58中任一项的方法,但省略步骤(a)生产的哺乳动物细胞相比,所述重组治疗蛋白质的分泌增强至少10%、至少20%、至少30%、至少40%、至少50%、至少75%、至少100%或至少200%。
60.一种用于在哺乳动物细胞中产生重组分泌性治疗蛋白质的方法,其包括:
(a)提供项目1至34中任一项的哺乳动物细胞,其中用重组分泌性治疗蛋白质转染所述细胞,或提供通过项目35至59中任一项的方法产生的哺乳动物细胞,
(b)在允许所述重组分泌性治疗蛋白质产生的条件下,在细胞培养基中培养步骤(a)的所述哺乳动物细胞,
(c)收获所述重组分泌性治疗蛋白质,和任选地
(d)纯化所述重组分泌性治疗蛋白质。
61.项目1至34中任一项的哺乳动物细胞或通过项目35至59的方法产生的哺乳动物细胞用于增加重组分泌性治疗蛋白质的产率的用途。
62.项目61的用途,其中所述重组分泌性治疗蛋白质是
(a)抗体,优选单克隆抗体、双特异性抗体或其片段,或
(b)fc融合蛋白。
序列表
seqidno1:tbc1d20中国仓鼠cdna
seqidno2:cers2中国仓鼠cdna
seqidno3:atf6b中国仓鼠cdna
seqidno4:tbc1d20中国仓鼠蛋白质
seqidno5:cers2中国仓鼠蛋白质
seqidno6:atf6b中国仓鼠蛋白质
seqidno7:sitbc1d20#1
seqidno8:sicers2#1
seqidno9:siatf6b#1
seqidno10:siatf6b#2
seqidno11:siatf6b#3
seqidno12:shtbc1d20#1
seqidno13:shcers2#1
seqidno14:shcers2#2
seqidno15:shatf6b#1
seqidno16:shtbc1d20#1_寡核苷酸_正向
seqidno17:shtbc1d20#1_寡核苷酸_反向
seqidno18:shcers2#1_寡核苷酸_正向
seqidno19:shcers2#1_寡核苷酸_反向
seqidno20:shcers2#2_寡核苷酸_正向
seqidno21:shcers2#2_寡核苷酸_反向
seqidno22:shatf6b#1_寡核苷酸_正向
seqidno23:shatf6b#1_寡核苷酸_反向
seqidno24:mab1igg1重链
seqidno25:mab1igg1轻链
seqidno26:mab2igg1重链
seqidno27:mab2igg1轻链
seqidno28:hsa-mir-1287_寡核苷酸_正向
seqidno29:hsa-mir-1287_寡核苷酸_反向
seqidno30:hsa-mir-1978_寡核苷酸_正向
seqidno31:hsa-mir-1978_寡核苷酸_反向
seqidno32:hsa-mir-1287
seqidno33:hsa-mir-1978
seqidno:34:阴性对照
seqidno35:shatf6b#2_寡核苷酸_正向
seqidno36:shatf6b#2_寡核苷酸_反向
seqidno37:shatf6b#2
seqidno38:sirnant-对照#1
seqidno39:sirnant-对照#2
seqidno40:sirnant-对照#3
seqidno41:sirnant-对照#4
seqidno42:qpcr引物(atf6b)正向
seqidno43:qpcr引物(atf6b)反向
seqidno44:qpcr引物(tbc1d20)正向
seqidno45:qpcr引物(tbc1d20)反向
seqidno46:qpcr引物(cers2)正向
seqidno47:qpcr引物(cers2)反向
seqidno48:qpcr引物(chop)正向
seqidno49:qpcr引物(chop)反向
seqidno50:qpcr引物(grp78)正向
seqidno51:qpcr引物(grp78)反向
seqidno52:qpcr引物(herpud1)正向
seqidno53:qpcr引物(herpud1)反向
序列表
<110>勃林格殷格翰国际公司
<120>用于生产分泌蛋白质的哺乳动物细胞
<130>boe16575pct
<150>ep16161253.6
<151>2016-03-18
<160>53
<170>bissap1.3.6
<210>1
<211>3330
<212>dna
<213>灰仓鼠
<220>
<223>tbc1d20cdna
<400>1
cgcgcctgcgcgtcgcaggccgacagagaccagcctgtcccggccgcagtggggttacac60
ccgcggtggaagccgcgtctcaggctccgccgccagccggggctcgggctggggcccggg120
cccccggggatggccctccggccctcacagggcgacggctccgcgggccgctggaactgt180
ggcttgggaaaggcagactttaatgccaaaaggaaaaagaaggtggcggaaatacaccag240
gccctgaacagtgatcccaccgacgtggctgcccttcgacgaatggcgatcagtgaggga300
gggctcctgactgatgagatcaggtgccaggtgtggcccaagctcctcaatgtcaacacc360
tgtgagccaccgcctgtgtcaaggaaggatcttcgacagttgagcaaggattaccagcaa420
gtactgctggatgtcaggcggtctcttcggcgcttccctcctggcatgccagatgagcag480
agagaagggcttcaggaagaactaatcgacattatcctcctcatcttggatcgcaaccct540
cagctccactactaccagggctaccatgacatcgtggtcacctttctgctggtggtgggc600
gagaggctggcaacatccttggtagaaaaattatctacccatcacctcagggatttcatg660
gatcccacaatggacaataccaagcacattctaaattatctgatgcccatcattgaccaa720
gtgaacccagaactccatgacttcatgcagagtgctgaggtggggaccatctttgccctc780
agctggcttatcacctggtttgggcacgtcctgtcagacttcaggcacgttgtgcggtta840
tacgacttcttcctggcctgccacccactcatgcccatttactttgcagctgtgattgtg900
ctgtaccgggagcaggaagtcctggactgtgactgtgacatggcctctgtccaccacctg960
ttgtctcagatccctcaggacctgccctatgagacgctcatcagcagagcaggagacctc1020
tttgttcagttccccccttctgaacttgcaagggaggcagctgcacagcaagaggctgaa1080
agaacggcagcctctactttcaaagactttgagctggcatcagcccagcagaggccagat1140
atggtgctgcggcagcggtttcggggacttctgcggcctgagactcgaacaaaagatgtc1200
ctgaccaaaccaaggaccaaccgctttgtgaaactggcagtgatggggctaacggtggca1260
cttggagcagcagcactagcagtggtgaagagtgccctggagtgggcccctaagttccag1320
ctgcagctgttcccctgaactcagccccaggagccacttccgtacccagtgcaccaagct1380
ctccccattcccagaaaggcactagagggtgggattgctgtcattaaagggttcctgtca1440
ggggtgttctgttctgccacccttggcagcttgtcttttggctttgtggctaatggcaac1500
actgcctgacactgggtttagtggacctgagtgctctgtgctcctcaactgctgcaagtg1560
gctgtggtgcccctggctacccaattcactgcctagaagaaagttgggcccgaagatgcc1620
ctccttaccgcaccacgtgtcctgcatctcctagacaaagcaggcaggagctgccaacaa1680
agtctagccttgggatgaaagcgaggggagaggactgtagcttgggggccagttggttag1740
agacaggcatgagctgggttctagttaaattttatgatcccagcctagagatcacttgca1800
gaggaatgttaacccccctgaacggtgttgcctgtgtctccctatttctctacaagccac1860
atgacattacctataaagacatttttaatactatttttatgattgtatactacaccaaac1920
atagcgagtattctcacttaagaaaaatgacttatatatgtatgcaggtgtccacagagg1980
ccagaagtggacttgagatttcatggagcctggtgtgggtgctggtatctgagtgctggt2040
cctctactaaagctcaagcaggaagtgctctcaactgttgagccatctctccggcctcct2100
cactcacacagttccttcatggagaagctatcagtgatgagcttatattggcctgacatt2160
tgtttccttttttggaggggaatagaacccagggccttgtacatgtgaggcaagtgttct2220
accactgagtagtaccaaactttttagtagtttttatttttgagacagggtctatttaag2280
ttacccaggctagccttgaacttttgatcctcctgcctcagctcccgattatctgggagg2340
acagggttgcacctgagatatattccctgctcagtttagccaaagttgctttgtgaacag2400
ccccacgccccagtgtcgcccccatctcactttctgatttcccactcatcacccacttgg2460
cctgtgtattgatctcctcagctgctggtctcaggctgggaatgtccttggaaacttgcc2520
agcatgtagacaggttttggcaggaatcccataccaccagcctcgcttacccctgggctc2580
ctccaggagggcacatgggatccatgggatcactcggtcttcctaggatggctttgttaa2640
aagcaaggccaggtttgttttgaagagactctggcttgaaaacaaaagtgccttttgctg2700
ctctaaagagtgtatagtaggaagcatctgcatgcctccatctcctgatcattcctgggc2760
actcttctccagtcataccatgtccagacccagtgtgtccctgtgcccgccgcatgccgt2820
ggacactctgtgtgctgggcagccacaagccagagcacatagaaggtgtccaggctgaat2880
cacacaaagcactttaaccaaatcaagctggagtggttaagtcattctccacacaggagc2940
cctgcctagagtgagtgattcacagggattagttcaggacaaaggaggattttccaggat3000
ccagagtgataaggtgacaaatactgtttagtctcccacaggagcttgtcatctgtacct3060
ctagcaagcatacttgaagagctgtaggaagtgtgctggctgaggggaggggcatgggcc3120
cagggtccaagccacaattctgcatccaaacaagcaggtggcactggcttgtgctgagct3180
gaagagtggtgtgtgcccataccaggactcccctgctactaagaagcgttgtcaatttac3240
cttcaggtacttacttaactctgtaaagatatgtgtagatgttttgtacagagccctgta3300
tgaaataaacacccttatgtggttcctaat3330
<210>2
<211>1305
<212>dna
<213>灰仓鼠
<220>
<223>cers2cdna
<400>2
gcgtggccagctctgggagcagcagctggtgaaactagctttacgggcgggcggtaactt60
gctaattactggctcagaggccctcgagctagcttgctccctgcaggatgctgcagacct120
tgtatgaccacttctggtgggaccgactatggctgcctgtgaacttaacctgggctgatc180
tagaagacagagatggacgtgtctatgccaaagcctcagacctctacatcacacttcccc240
tggccttggtctttcttgtcattcgatacttctttgagctttatgtggctacacccctgg300
ctgccctcctgaatgttaaggagaaaacccgactacgagcacctcccaatgtcaccttag360
aacatttctacctgaccaacggcaagcagcccaagcaggtggaggttgagcttttgtctc420
ggcagagtgggctctctggccgccagatagaacgctggttccgccgccgccgcaaccagg480
acaggcccagccttctcaagaagttccgagaagccagttggagattcacattttacctga540
ttgcctttgttgcgggcatggctgtcattgtggataaaccctggttctatgacttgagga600
aagtttgggagggctatcccatacagagcatcgtcccttctcagtattggtactacatga660
ttgaactctccttctactggtccctgctcttcagcattgcttctgatgtcaagcgaaagg720
attttaaggaacagatcatccaccacgtggccaccatcattctcctcagcttctcctggt780
ttgccaattatgtccgagcagggactctcatcatggctctgcatgactcttctgactacc840
tgctggagtccgccaagatgtttaactacgcgggatggaaaaacacctgcaataacatct900
tcattgtcttcgccatcgttttcatcattactcgactggttatcatgcctttctggatcc960
tacactgcacgctggtatacccactggagctctaccctgccttctttggctattacttct1020
tcaacatcatgatggcagtgctacagatgctgcatatcttctgggcctacttcattttgc1080
gcatggcccacaagttcataactggaaagctggtagaagatgaacgcagtgaccgagaag1140
aaacagagagctcagagggggaggaggctgcagctggggcaggagcaaagagtcggctcc1200
tatctaatggccaccccatcctcaataacaatcatcctaagaatgactgaaccattgtcc1260
tagctgcctcccacattaatacacgaagccaagaaactagccaac1305
<210>3
<211>2172
<212>dna
<213>灰仓鼠
<220>
<223>atf6bcdna
<400>3
cacaggttcctggagtaggggaggtcctcagtgtgaagatggagtccttagcacctccac60
tctgcctgctgggagacgatccagcatccccatttgaaacggtccaaatcaccgtgggtt120
ctgtcgctgatgacccctcagatatccagaccaaggtagaacccgcctctccatcttctt180
ctgtcaactccgaggcctccctgctctcagcagactctcccagccaggcttttataggag240
aggaggttctggaagtgaagacggagtccccatctcctccggggtgcctcctgtgggatg300
tcccagctccttcacttggagctgtccagatcagcatgggcccatcacctgttagttcct360
cagggaaagctccagccactcggaagcctccactgcagcccaagcctgtggtgctaacca420
cagttcaggtgccacctagagctgggcctcccagcactactgtccttttgcagcccctcg480
tccagcagcccgcagtgtccccagttgtcctcatccaaggtgctattcgagtccagcctg540
aagggccagcccctgcagttccacggcccgaaaggaagagcattgtccctgctcctctgc600
ctgggaactcctgccctcctgaagtggacgcaaagctgctgaagcgtcagcagcgaatga660
tcaagaacagagagtcggcctgccagtcccgccggaagaagaaagagtatctgcagggac720
tggaggccagactgcaggctgtgctggcagacaaccagcaactgcgcagggagaatgctg780
ccctccggcggcggctggagaccctgctgacagagaacagtgagctcaagctgggctctg840
ggaacaggaaagttgtctgcatcatggtcttccttctcttcattgccttcaactttggac900
ctgtgagcattagtgagccacctccagctcccatctctcctcggatgagcagggaggaag960
ctcgacccaggagacacctgctggagttctccgagcaggggccagctcatggtgttgaac1020
ccctccagaaagctgcccggggcccagaggagcggcagcccagccctgcaggcaggccca1080
gcttcagaaacctgacagccttccctggcggggccaaggagctgctgctgagagacctgg1140
accagctcttcctcgcctctgactgccgccacttcaaccgcacggagtccctgaggcttg1200
ctgatgagctgagtggctgggtgcagcgtcaccagagaggtcgacggaggatgcctcaca1260
gggcccaggagagacagaagtctcagctacggaagaagtcaccgccagtgaaaccagtcc1320
ccacccaacctccaggacctcctgagagggaccctgtggggcagctgcagctctaccgcc1380
acccaggccgttcgcagcctgagtttctagatgcaatcgaccggcgggaagacaccttct1440
atgttgtctccttccgaagggaccacttgctgctcccggccatcagccacaacaagacgt1500
ccagacccaagatgtccctggtgatgccagccatggcccccaatgagaccgtgtcaggcc1560
gggggcccccaggggactatgaggagatgatgcagatcgagtgtgaggtcatggacacca1620
gggtgattcacatcaagacctccacggtgcccccctcactccggaagcagccatccccaa1680
ccccaggcaataccacaggtggccccctgccagcttctgcagccagtcaggccagtcagg1740
cctcccaccagcccctctacctcaaccacccctgacctctgcagctcacgttggcttaga1800
actggtttgggggagcctggtccttgaacttgggggtaattggtaaaggaaagcagggtg1860
tatgggatccagcacttaatgggagtagggtgggtggctcacctctccttacctcttcag1920
aatatagggctcctctccttcctgcaaacccccaggccccctctttctctgagagaacct1980
cctcaggttcagttcagggtgggtagcttcccatagcctctttgttctttggtttatcta2040
ttcaggagtagaggtgggactttggtccccaggtgggacaagagatgctcttgggtggtg2100
gaagtcagtctgtgtgtgtattatcttttttattattactaaataaataacccagaggga2160
gctaaaggaatg2172
<210>4
<211>402
<212>prt
<213>灰仓鼠
<220>
<223>tbc1d20
<400>4
metalaleuargproserglnglyaspglyseralaglyargtrpasn
151015
cysglyleuglylysalaasppheasnalalysarglyslyslysval
202530
alagluilehisglnalaleuasnseraspprothraspvalalaala
354045
leuargargmetalailesergluglyglyleuleuthraspgluile
505560
argcysglnvaltrpprolysleuleuasnvalasnthrcysglupro
65707580
proprovalserarglysaspleuargglnleuserlysasptyrgln
859095
glnvalleuleuaspvalargargserleuargargpheproprogly
100105110
metproaspgluglnarggluglyleuglnglugluleuileaspile
115120125
ileleuleuileleuaspargasnproglnleuhistyrtyrglngly
130135140
tyrhisaspilevalvalthrpheleuleuvalvalglygluargleu
145150155160
alathrserleuvalglulysleuserthrhishisleuargaspphe
165170175
metaspprothrmetaspasnthrlyshisileleuasntyrleumet
180185190
proileileaspglnvalasnprogluleuhisaspphemetglnser
195200205
alagluvalglythrilephealaleusertrpleuilethrtrpphe
210215220
glyhisvalleuseraspphearghisvalvalargleutyraspphe
225230235240
pheleualacyshisproleumetproiletyrphealaalavalile
245250255
valleutyrarggluglngluvalleuaspcysaspcysaspmetala
260265270
servalhishisleuleuserglnileproglnaspleuprotyrglu
275280285
thrleuileserargalaglyaspleuphevalglnpheproproser
290295300
gluleualaargglualaalaalaglnglnglualagluargthrala
305310315320
alaserthrphelysaspphegluleualaseralaglnglnargpro
325330335
aspmetvalleuargglnargpheargglyleuleuargprogluthr
340345350
argthrlysaspvalleuthrlysproargthrasnargphevallys
355360365
leualavalmetglyleuthrvalalaleuglyalaalaalaleuala
370375380
valvallysseralaleuglutrpalaprolyspheglnleuglnleu
385390395400
phepro
<210>5
<211>380
<212>prt
<213>灰仓鼠
<220>
<223>cers2
<400>5
metleuglnthrleutyrasphisphetrptrpaspargleutrpleu
151015
provalasnleuthrtrpalaaspleugluaspargaspglyargval
202530
tyralalysalaseraspleutyrilethrleuproleualaleuval
354045
pheleuvalileargtyrphephegluleutyrvalalathrproleu
505560
alaalaleuleuasnvallysglulysthrargleuargalapropro
65707580
asnvalthrleugluhisphetyrleuthrasnglylysglnprolys
859095
glnvalgluvalgluleuleuserargglnserglyleuserglyarg
100105110
glnilegluargtrppheargargargargasnglnaspargproser
115120125
leuleulyslyspheargglualasertrpargphethrphetyrleu
130135140
ilealaphevalalaglymetalavalilevalasplysprotrpphe
145150155160
tyraspleuarglysvaltrpgluglytyrproileglnserileval
165170175
proserglntyrtrptyrtyrmetilegluleuserphetyrtrpser
180185190
leuleupheserilealaseraspvallysarglysaspphelysglu
195200205
glnileilehishisvalalathrileileleuleuserphesertrp
210215220
phealaasntyrvalargalaglythrleuilemetalaleuhisasp
225230235240
serserasptyrleuleugluseralalysmetpheasntyralagly
245250255
trplysasnthrcysasnasnilepheilevalphealailevalphe
260265270
ileilethrargleuvalilemetprophetrpileleuhiscysthr
275280285
leuvaltyrproleugluleutyrproalaphepheglytyrtyrphe
290295300
pheasnilemetmetalavalleuglnmetleuhisilephetrpala
305310315320
tyrpheileleuargmetalahislyspheilethrglylysleuval
325330335
gluaspgluargseraspargglugluthrglusersergluglyglu
340345350
glualaalaalaglyalaglyalalysserargleuleuserasngly
355360365
hisproileleuasnasnasnhisprolysasnasp
370375380
<210>6
<211>578
<212>prt
<213>灰仓鼠
<220>
<223>atf6b
<400>6
metgluserleualaproproleucysleuleuglyaspaspproala
151015
serprophegluthrvalglnilethrvalglyservalalaaspasp
202530
proseraspileglnthrlysvalgluproalaserproserserser
354045
valasnserglualaserleuleuseralaaspserproserglnala
505560
pheileglyglugluvalleugluvallysthrgluserproserpro
65707580
proglycysleuleutrpaspvalproalaproserleuglyalaval
859095
glnilesermetglyproserprovalserserserglylysalapro
100105110
alathrarglysproproleuglnprolysprovalvalleuthrthr
115120125
valglnvalproproargalaglyproproserthrthrvalleuleu
130135140
glnproleuvalglnglnproalavalserprovalvalleuilegln
145150155160
glyalaileargvalglnprogluglyproalaproalavalproarg
165170175
progluarglysserilevalproalaproleuproglyasnsercys
180185190
proprogluvalaspalalysleuleulysargglnglnargmetile
195200205
lysasnarggluseralacysglnserargarglyslyslysglutyr
210215220
leuglnglyleuglualaargleuglnalavalleualaaspasngln
225230235240
glnleuargarggluasnalaalaleuargargargleugluthrleu
245250255
leuthrgluasnsergluleulysleuglyserglyasnarglysval
260265270
valcysilemetvalpheleuleupheilealapheasnpheglypro
275280285
valserilesergluproproproalaproileserproargmetser
290295300
arggluglualaargproargarghisleuleuglupheserglugln
305310315320
glyproalahisglyvalgluproleuglnlysalaalaargglypro
325330335
glugluargglnproserproalaglyargproserpheargasnleu
340345350
thralapheproglyglyalalysgluleuleuleuargaspleuasp
355360365
glnleupheleualaseraspcysarghispheasnargthrgluser
370375380
leuargleualaaspgluleuserglytrpvalglnarghisglnarg
385390395400
glyargargargmetprohisargalaglngluargglnlyssergln
405410415
leuarglyslysserproprovallysprovalprothrglnpropro
420425430
glyproprogluargaspprovalglyglnleuglnleutyrarghis
435440445
proglyargserglnproglupheleuaspalaileaspargargglu
450455460
aspthrphetyrvalvalserpheargargasphisleuleuleupro
465470475480
alaileserhisasnlysthrserargprolysmetserleuvalmet
485490495
proalametalaproasngluthrvalserglyargglyproprogly
500505510
asptyrgluglumetmetglnileglucysgluvalmetaspthrarg
515520525
valilehisilelysthrserthrvalproproserleuarglysgln
530535540
proserprothrproglyasnthrthrglyglyproleuproalaser
545550555560
alaalaserglnalaserglnalaserhisglnproleutyrleuasn
565570575
hispro
<210>7
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnasitbc1d20#1
<400>7
agaacuaaucgacauuauc19
<210>8
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnasicers2#1
<400>8
agagucggcuccuaucuaa19
<210>9
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnasiartf6b#1
<400>9
ccuccucagguucaguuca19
<210>10
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnasiatf6b#2
<400>10
gcagcgaaugaucaagaac19
<210>11
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnasiatf6b#3
<400>11
agacaccuucuauguuguc19
<210>12
<211>21
<212>rna
<213>人工序列
<220>
<223>shrnashtbc1d20#1
<400>12
aauccuugcucaacugucgaa21
<210>13
<211>21
<212>rna
<213>人工序列
<220>
<223>shrnashcers2#1
<400>13
uuaaguucacaggcagccaua21
<210>14
<211>21
<212>rna
<213>人工序列
<220>
<223>shrnashcers2#2
<400>14
ugauguagaggucugaggcuu21
<210>15
<211>21
<212>rna
<213>人工序列
<220>
<223>shrnashatf6b#1
<400>15
uccaucuucacacugaggacc21
<210>16
<211>64
<212>dna
<213>人工序列
<220>
<223>shtbc1d20#1_寡核苷酸_正向
<400>16
tgctgaatccttgctcaactgtcgaagttttggccactgactgacttcgacaggagcaag60
gatt64
<210>17
<211>64
<212>dna
<213>人工序列
<220>
<223>shtbc1f20#1_寡核苷酸_反向
<400>17
cctgaatccttgctcctgtcgaagtcagtcagtggccaaaacttcgacagttgagcaagg60
attc64
<210>18
<211>64
<212>dna
<213>人工序列
<220>
<223>shcers2#1_寡核苷酸_正向
<400>18
tgctgttaagttcacaggcagccatagttttggccactgactgactatggctgtgtgaac60
ttaa64
<210>19
<211>64
<212>dna
<213>人工序列
<220>
<223>shcers2#1_寡核苷酸_反向
<400>19
cctgttaagttcacacagccatagtcagtcagtggccaaaactatggctgcctgtgaact60
taac64
<210>20
<211>64
<212>dna
<213>人工序列
<220>
<223>shcers2#2_寡核苷酸_正向
<400>20
tgctgtgatgtagaggtctgaggcttgttttggccactgactgacaagcctcacctctac60
atca64
<210>21
<211>64
<212>dna
<213>人工序列
<220>
<223>shcers2#2_寡核苷酸_反向
<400>21
cctgtgatgtagaggtgaggcttgtcagtcagtggccaaaacaagcctcagacctctaca60
tcac64
<210>22
<211>64
<212>dna
<213>人工序列
<220>
<223>shatf6b#1_寡核苷酸_正向
<400>22
tgctgtccatcttcacactgaggaccgttttggccactgactgacggtcctcagtgaaga60
tgga64
<210>23
<211>64
<212>dna
<213>人工序列
<220>
<223>shatf6b#1_寡核苷酸_反向
<400>23
cctgtccatcttcactgaggaccgtcagtcagtggccaaaacggtcctcagtgtgaagat60
ggac64
<210>24
<211>463
<212>prt
<213>人工序列
<220>
<223>mab1重链
<400>24
metglupheglyleusertrpleupheleuvalalaileleulysgly
151015
valglncysgluvalglnleuvalgluserglyglyglyleuvallys
202530
proglyglyserleuargleusercysalaalaserglyphethrphe
354045
sersertyraspmetsertrpvalargglnalaproglylysglyleu
505560
glutrpvalserthrileserserglyglysertyrthrtyrtyrleu
65707580
aspserilelysglyargphethrileserargaspasnalalysasn
859095
serleutyrleuglnmetasnserleuargalagluaspthralaval
100105110
tyrtyrcysalaargglnglyleuasptyrtrpglyargglythrleu
115120125
valthrvalserseralaserthrlysglyproservalpheproleu
130135140
alaproserserlysserthrserglyglythralaalaleuglycys
145150155160
leuvallysasptyrpheprogluprovalthrvalsertrpasnser
165170175
glyalaleuthrserglyvalhisthrpheproalavalleuglnser
180185190
serglyleutyrserleuserservalvalthrvalproserserser
195200205
leuglythrglnthrtyrilecysasnvalasnhislysproserasn
210215220
thrlysvalasplyslysvalgluprolyssercysasplysthrhis
225230235240
thrcysproprocysproalaprogluleuleuglyglyproserval
245250255
pheleupheproprolysprolysaspthrleumetileserargthr
260265270
progluvalthrcysvalvalvalaspvalserhisgluaspproglu
275280285
vallyspheasntrptyrvalaspglyvalgluvalhisasnalalys
290295300
thrlysproargglugluglntyrasnserthrtyrargvalvalser
305310315320
valleuthrvalleuhisglnasptrpleuasnglylysglutyrlys
325330335
cyslysvalserasnlysalaleuproalaproileglulysthrile
340345350
serlysalalysglyglnproarggluproglnvaltyrthrleupro
355360365
proserargaspgluleuthrlysasnglnvalserleuthrcysleu
370375380
vallysglyphetyrproseraspilealavalglutrpgluserasn
385390395400
glyglnprogluasnasntyrlysthrthrproprovalleuaspser
405410415
aspglyserphepheleutyrserlysleuthrvalasplysserarg
420425430
trpglnglnglyasnvalphesercysservalmethisglualaleu
435440445
hisasnhistyrthrglnlysserleuserleuserproglylys
450455460
<210>25
<211>233
<212>prt
<213>人工序列
<220>
<223>mab1轻链
<400>25
metglualaproalaglnleuleupheleuleuleuleutrpleupro
151015
aspthrthrglygluilevalleuthrglnserproalathrleuser
202530
leuserproglygluargalathrleusercysseralaserserser
354045
ileasntyriletyrtrptyrglnglnlysproglyglnalaproarg
505560
leuleuiletyrleuthrserasnleualaserglyvalproalaarg
65707580
pheserglyserglyserglythraspphethrleuthrileserser
859095
leugluprogluaspphealavaltyrtyrcysleuglntrpserser
100105110
asnproleuthrpheglyglyglythrlysvalgluilelysargthr
115120125
valalaalaproservalpheilepheproproseraspgluglnleu
130135140
lysserglythralaservalvalcysleuleuasnasnphetyrpro
145150155160
argglualalysvalglntrplysvalaspasnalaleuglnsergly
165170175
asnserglngluservalthrgluglnaspserlysaspserthrtyr
180185190
serleuserserthrleuthrleuserlysalaasptyrglulyshis
195200205
lysvaltyralacysgluvalthrhisglnglyleuserserproval
210215220
thrlysserpheasnargglyglucys
225230
<210>26
<211>470
<212>prt
<213>人工序列
<220>
<223>mab2重链
<400>26
metglytrpsercysileileleupheleuvalalathralathrgly
151015
valhissergluvalglnleuvalgluserglyglyglyleuvalgln
202530
proglyglyserleuargleusercysalavalserglytyrserile
354045
thrserglytyrsertrpasntrpileargglnalaproglylysgly
505560
leuglutrpvalalaserilethrtyraspglyserthrasntyrasn
65707580
proservallysglyargilethrileserargaspaspserlysasn
859095
thrphetyrleuglnmetasnserleuargalagluaspthralaval
100105110
tyrtyrcysalaargglyserhistyrpheglyhistrphispheala
115120125
valtrpglyglnglythrleuvalthrvalserseralaserthrlys
130135140
glyproservalpheproleualaproserserlysserthrsergly
145150155160
glythralaalaleuglycysleuvallysasptyrpheproglupro
165170175
valthrvalsertrpasnserglyalaleuthrserglyvalhisthr
180185190
pheproalavalleuglnserserglyleutyrserleuserserval
195200205
valthrvalproserserserleuglythrglnthrtyrilecysasn
210215220
valasnhislysproserasnthrlysvalasplyslysvalglupro
225230235240
lyssercysasplysthrhisthrcysproprocysproalaproglu
245250255
leuleuglyglyproservalpheleupheproprolysprolysasp
260265270
thrleumetileserargthrprogluvalthrcysvalvalvalasp
275280285
valserhisgluaspprogluvallyspheasntrptyrvalaspgly
290295300
valgluvalhisasnalalysthrlysproargglugluglntyrasn
305310315320
serthrtyrargvalvalservalleuthrvalleuhisglnasptrp
325330335
leuasnglylysglutyrlyscyslysvalserasnlysalaleupro
340345350
alaproileglulysthrileserlysalalysglyglnproargglu
355360365
proglnvaltyrthrleuproproserarggluglumetthrlysasn
370375380
glnvalserleuthrcysleuvallysglyphetyrproseraspile
385390395400
alavalglutrpgluserasnglyglnprogluasnasntyrlysthr
405410415
thrproprovalleuaspseraspglyserphepheleutyrserlys
420425430
leuthrvalasplysserargtrpglnglnglyasnvalphesercys
435440445
servalmethisglualaleuhisasnhistyrthrglnlysserleu
450455460
serleuserproglylys
465470
<210>27
<211>237
<212>prt
<213>人工序列
<220>
<223>mab2轻链
<400>27
metglytrpsercysileileleupheleuvalalathralathrgly
151015
valhisseraspileglnleuthrglnserproserserleuserala
202530
servalglyaspargvalthrilethrcysargalaserglnserval
354045
asptyraspglyaspsertyrmetasntrptyrglnglnlysprogly
505560
lysalaprolysleuleuiletyralaalasertyrleuglusergly
65707580
valproserargpheserglyserglyserglythraspphethrleu
859095
thrileserserleuglnprogluaspphealathrtyrtyrcysgln
100105110
glnserhisgluaspprotyrthrpheglyglnglythrlysvalglu
115120125
ilelysargthrvalalaalaproservalpheilepheproproser
130135140
aspgluglnleulysserglythralaservalvalcysleuleuasn
145150155160
asnphetyrproargglualalysvalglntrplysvalaspasnala
165170175
leuglnserglyasnserglngluservalthrgluglnaspserlys
180185190
aspserthrtyrserleuserserthrleuthrleuserlysalaasp
195200205
tyrglulyshislysvaltyralacysgluvalthrhisglnglyleu
210215220
serserprovalthrlysserpheasnargglyglucys
225230235
<210>28
<211>66
<212>dna
<213>人工序列
<220>
<223>hsa-mirna-1287_寡核苷酸_正向
<400>28
tgctgtgctggatcagtggttcgagtcgttttggccactgactgacgactcgaaccacat60
ccagca66
<210>29
<211>66
<212>dna
<213>人工序列
<220>
<223>hsa-mir-1287_寡核苷酸_反向
<400>29
cctgtgctggatgtggttcgagtcgtcagtcagtggccaaaacgactcgaaccactgatc60
cagcac66
<210>30
<211>64
<212>dna
<213>人工序列
<220>
<223>hsa-mirna-1978_寡核苷酸_正向
<400>30
tgctgggtttggtcctagcctttctagttttggccactgactgactagaaaggctaacca60
aacc64
<210>31
<211>64
<212>dna
<213>人工序列
<220>
<223>hsa-mir-1978_寡核苷酸_反向
<400>31
cctgggtttggttagcctttctagtcagtcagtggccaaaactagaaaggctaggaccaa60
accc64
<210>32
<211>22
<212>rna
<213>人类
<220>
<223>hsa-mirna-1287
<400>32
ugcuggaucagugguucgaguc22
<210>33
<211>21
<212>rna
<213>人类
<220>
<223>hsa-mirna-1978
<400>33
gguuugguccuagccuuucua21
<210>34
<211>22
<212>rna
<213>人工序列
<220>
<223>阴性对照mirna
<400>34
gaaauguacugcgcguggagac22
<210>35
<211>64
<212>dna
<213>人工序列
<220>
<223>shatf6b#2_寡核苷酸_正向
<400>35
tgctgttcacttccagaacctcctctgttttggccactgactgacagaggaggctggaag60
tgaa64
<210>36
<211>64
<212>dna
<213>人工序列
<220>
<223>shatf6b#2_寡核苷酸_反向
<400>36
cctgttcacttccagcctcctctgtcagtcagtggccaaaacagaggaggttctggaagt60
gaac64
<210>37
<211>21
<212>rna
<213>人工序列
<220>
<223>shatf6b#2
<400>37
uucacuuccagaaccuccucu21
<210>38
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnant-对照#1
<400>38
ugguuuacaugucgacuaa19
<210>39
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnant-对照#2
<400>39
ugguuuacauguuguguga19
<210>40
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnant-对照#3
<400>40
ugguuuacauguuuucuga19
<210>41
<211>19
<212>rna
<213>人工序列
<220>
<223>sirnant-对照#4
<400>41
ugguuuacauguuuuccua19
<210>42
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(atf6b)正向
<400>42
gagcaggatgtcccgtttga20
<210>43
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(atf6b)反向
<400>43
agctcagggaggaggaagag20
<210>44
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(tbc1d20)正向
<400>44
ccctgaacagtgatcccacc20
<210>45
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(tbc1d20)反向
<400>45
atccttccttgacacaggcg20
<210>46
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(cers2)正向
<400>46
cccatacagagcatcgtccc20
<210>47
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(cers2)反向
<400>47
ggcaaaccaggagaagctga20
<210>48
<211>22
<212>dna
<213>人工序列
<220>
<223>qpcr引物(chop)正向
<400>48
gaccctgtttctttcccttcag22
<210>49
<211>21
<212>dna
<213>人工序列
<220>
<223>qpcr引物(chop)反向
<400>49
ggactgggttctgctttcagg21
<210>50
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(grp78)正向
<400>50
accacctattcctgcgttgg20
<210>51
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(grp78)反向
<400>51
agaccgtgttctcgggattg20
<210>52
<211>20
<212>dna
<213>人工序列
<220>
<223>qpcr引物(herpud1)正向
<400>52
gaagagtcccaaccagcgtc20
<210>53
<211>21
<212>dna
<213>人工序列
<220>
<223>qpcr引物(herpud1)反向
<400>53
atgtcgcttttcctgctttgg21
- 还没有人留言评论。精彩留言会获得点赞!