一种谷氨酸棒杆菌重组菌及其构建方法与流程
本发明涉及一种谷氨酸棒杆菌重组菌及其构建方法,属于基因工程和酶工程技术领域。
背景技术:
nadph(还原型烟酰胺腺嘌呤二核苷酸磷酸)又称为还原型辅酶ⅱ,在很多生物体内的化学反应中起递氢体的作用,具有重要的生物学意义。它是烟酰胺腺嘌呤二核苷酸(nad+)中与腺嘌呤相连的核糖环系2'-位的磷酸化衍生物,nadph在细胞内分布广泛,通过参与800多个氧化还原反应来调节细胞内氧化还原水平并影响着众多基因表达、细胞功能、代谢途径和物质跨膜运输,参与多种合成代谢反应,如参与合成代谢,如氨基酸、脂类及核苷酸等细胞组成物质的合成均需nadph提供还原力,对细胞正常生长和代谢有重要影响nadph是nadp+的还原形式。并且是微生物代谢网络中含量最丰富的氧化还原辅酶之一。
微生物细胞内nadph主要通过中心碳代谢途径合成。其中,磷酸戊糖途径的不可逆氧化阶段是nadph的主要来源。依赖nadp+的6-磷酸葡萄糖脱氢酶和6-磷酸葡萄糖酸脱氢酶在氧化生成1mol6-磷酸葡萄糖酸和氧化脱羧生成1mol5-磷酸核酮糖过程中,分别产生1molnadph。微生物胞内nadph的消耗主要通过同化作用。同化作用利用中心碳代谢途径的中间代谢物,合成75~100个细胞原件、辅酶以及辅基,维持细胞正常生长代谢。此过程需消耗大量atp和nadph,如合成1g大肠杆菌干细胞需消耗41molatp和18molnadph。由此可见,胞内nadph的生成和消耗同胞内很多重要的代谢途径相关联,维持细胞内辅酶的平衡对于细胞生长、代谢以及产物的合成都非常关键。为了维持细胞正常生长和代谢,必须精确调控细胞内nadph的供应与需求。
nadph对c.glutamicumlyscfbr合成l-赖氨酸非常重要,合成1moll-赖氨酸需要消耗4molnadph。在l-赖氨酸生物合成途径中有四个反应涉及nadph的消耗。谷氨酸棒杆菌中nadph的代谢调控机制在不同的生理条件下通过13c代谢流分析得以阐明,这为建立nadph平衡具有重要作用。在谷氨酸棒杆菌中葡萄糖-6-磷酸脱氢酶、6-磷酸葡萄糖酸脱氢酶、苹果酸酶和异柠檬酸脱氢酶以nadp+为辅因子,参与nadph合成,这些nadph不仅要满足l-赖氨酸合成需求而且还要用于菌体生长。因为,增加1g菌体需要消耗16.4mmolnadph。谷氨酸棒杆菌中nadph的代谢是非常灵活的,它的消耗与合成很大程度上取决于菌体生长状态、碳源的供应以及菌体的遗传背景。目前许多基于nadph供给的调控策略无法调控和优化胞内nadph与中心碳代谢的特异性,为满足l-赖氨酸高效合成时对nadph的需求,理论上提高nadph的供给水平可显著增加l-赖氨酸产量。但一味强调提高辅因子nadph的合成量,不仅不利于l-赖氨酸的大量积累,还阻碍了菌体对糖的利用和降低菌体量,辅因子nadph水平与胞内微环境、代谢网络和目标代谢产物合成之间的关系还不明确。
技术实现要素:
为解决上述问题,本发明首次用来源于streptococcusmutans中的nad+-依赖型异柠檬酸脱氢酶替换c.glutamicumlyscfbr中的nadp+-依赖型异柠檬酸脱氢酶并同时敲除葡萄糖-6-磷酸脱氢酶和苹果酸酶编码基因,解决了不破坏三羧酸循环的情况下,阻断其nadph的合成。本发明的目的是:阻断胞内nadph的合成,实现菌株胞内nadph水平的精确调控。
本发明的第一个目的是提供一种谷氨酸棒杆菌重组菌,所述重组菌异源表达了nad+-依赖型异柠檬酸脱氢酶icdsm,并敲除了nadp+-依赖型异柠檬酸脱氢酶icdcg、葡萄糖-6-磷酸脱氢酶zwf和苹果酸酶male。
在本发明的一种实施方式中,所述的nad+-依赖型异柠檬酸脱氢酶来源于变形链球菌streptococcusmutans。
在本发明的一种实施方式中,所述nad+-依赖型异柠檬酸脱氢酶的核苷酸序列如seqidno.1所示。
在本发明的一种实施方式中,所述nadp+-依赖型异柠檬酸脱氢酶的核苷酸序列如seqidno.2所示。
在本发明的一种实施方式中,所述的葡萄糖-6-磷酸脱氢酶的核苷酸序列如seqidno.3所示。
在本发明的一种实施方式中,所述的苹果酸酶的核苷酸序列如seqidno.4所示。
在本发明的一种实施方式中,所述重组菌的宿主为谷氨酸棒杆菌c.glutamicumlyscfbr。
在本发明的一种实施方式中,所述重组菌以pk18mobsacb作为表达载体。
本发明的第二个目的是提供一种所述重组菌的构建方法,包括如下步骤:
(1)分别构建重组自杀型质粒pk18mobsacb-δicdcg::icdsm、pk18mobsacb-△zwf和pk18mobsacb-△male;
(2)重组菌株c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm的构建:分别将步骤(1)的三种重组自杀型质粒转化到宿主谷氨酸棒杆菌c.glutamicumlyscfbr中,筛选得到所述的重组菌。
本发明的第三个目的是提供重组菌在饲料工业、医药工业或食品工业中的应用。
本发明的有益效果是:本发明通过利用菌株c.glutamicumlyscfbr(基因lysc编码酶ak解除反馈抑制作用)为出发菌株,该菌株为遗传背景清晰的l-赖氨酸产生菌,利用基因工程手段敲除参与胞内nadph合成途径中的关键酶基因zwf(葡萄糖-6-磷酸脱氢酶)、male(苹果酸酶),并将自身nadp+-依赖型异柠檬酸脱氢酶(编码基因icdcg)替换成streptococcusmutansnad+-依赖型异柠檬酸脱氢酶(编码基因icdsm),获得基因工程菌株c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm,重组菌经lbg液体培养基摇瓶实验,重组菌胞内nadh含量由出发菌的1.97μmol(gdcw)-1增加到2.73μmol(gdcw)-1,胞内nadph含量降低至0.15μmol(gdcw)-1,明显低于出发菌胞内nadph含量1.43μmol(gdcw)-1。此发明成功阻断了谷氨酸棒杆菌中nadph合成的相关途径,可精确调控胞内nadph水平的菌株提供崭新的思路。
附图说明
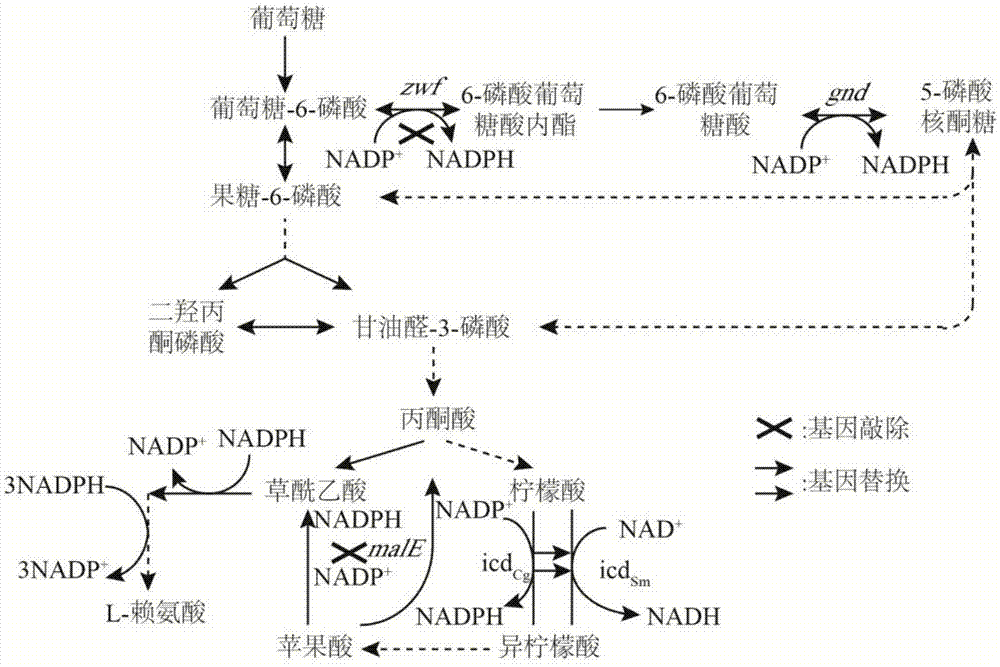
图1:谷氨酸棒杆菌l-赖氨酸合成中nadph的生成途径;
注:编码基因:zwf葡萄糖-6-磷酸脱氢酶,gnd6-磷酸葡萄糖酸脱氢酶,male苹果酸酶;icd异柠檬酸脱氢酶。
图2:验证基因zwf、male敲除和基因icd替换pcr产物电泳图;
泳道说明:m泳道为dnamarker/ladder;1号泳道为以c.glutamicumlyscfbrδzwf基因组为模板,zwf-f和zwf-r为引物的pcr产物;2号泳道为以c.glutamicumlyscfbrδzwfδmale基因组为模板,male-f和male-r为引物的pcr产物;3号泳道为以c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm基因组为模板,icd-f和icd-r为引物的pcr产物;
图3:重组菌和出发菌胞内腺嘌呤核苷酸(atp、adp和amp)的测定;
图4:重组菌和出发菌胞内吡啶核苷酸(nad+、nadh、nadp+和nadph)的测定。
具体实施方式
以下通过具体实施案例来进一步说明本发明内容,以使本领域的技术人员可以更好地理解本发明并能予以实施,但是这些实施案例不构成对本发明的限制。
表1.pcr扩增所需引物序列(下划线为酶切位点)
实施例1:敲除c.glutamicumlyscfbr中zwf编码基因
以c.glutamicumatcc13032基因组为模板,分别以zwf-l-f/zwf-l-r和zwf-r-f/zwf-r-r为引物pcr(表1),获得分别在3’端和5’端有相同限制性内切酶的pcr产物。将以上述pcr产物分别与线性化并与重组自杀型质粒pk18mobsacb酶连构建重组质粒pk18mobsacb-δzwf。
将验证正确的质粒pk18mobsacb-△zwf电击转化c.glutamicumlyscfbr,经含有50μg·ml-1卡那霉素的lbg固体培养基于30℃培养筛选获得第一次同源重组转化子。再将经一次重组的转化子接入含100g·l-1蔗糖的lbgs液体培养基于30℃培养,培养基中含蔗糖会导致含sacb基因的线性化整合基因片段与基因组dna中目的基因进行第二次同源重组,lbgs培养的菌液在lbg平板上划线分离,在平板上长出的菌落可能是回复野生型也可能是基因敲除型,菌落pcr验证单菌落,提取转化子染色体,以目标基因icd的上下游引物进行pcr并对pcr产物进行测序鉴定,最终获得目的重组菌株c.glutamicumlyscfbrδzwf。
实施例2:敲除c.glutamicumlyscfbrδzwf中male编码基因
以c.glutamicumatcc13032基因组为模板,分别以male-l-f/male-l-r和male-r-f/male-r-r为引物pcr(表1),获得分别在3’端和5’端有相同限制性内切酶的pcr产物。将以上述pcr产物分别与线性化并与重组自杀型质粒pk18mobsacb酶连构建重组质粒pk18mobsacb-δmale。
将验证正确的质粒pk18mobsacb-δmale电击转化c.glutamicumlyscfbrδzwf,经含有50μg·ml-1卡那霉素的lbg固体培养基于30℃培养筛选获得第一次同源重组转化子。再将经一次重组的转化子接入含100g·l-1蔗糖的lbgs液体培养基于30℃培养,培养基中含蔗糖会导致含sacb基因的线性化整合基因片段与基因组dna中目的基因进行第二次同源重组,lbgs培养的菌液在lbg平板上划线分离,在平板上长出的菌落可能是回复野生型也可能是基因敲除型,菌落pcr验证单菌落,提取转化子染色体,以目标基因male的上下游引物进行pcr并对pcr产物进行测序鉴定,最终获得目的重组菌株c.glutamicumlyscfbrδzwfδmale。
实施例3:streptococcusmutansjh1005编码基因icdsm表达框的获得
根据genbank中streptococcusmutansjh1005全基因组核酸序列中的icd基因序列,在其基因上下游分别加入限制性内切酶ecori和xhoi酶切位点序列并在上游加入谷氨酸棒杆菌sd识别序列gaaaggagatatacc(seqidno.5),并将组合好的序列提交给通用生物系统(安徽)有限公司进行合成,获得含有目的基因的重组质粒puc57-icdsm。随后,采用限制性内切酶ecori和xhoi酶切重组质粒puc57-icdsm。随后采用胶回收试剂盒回收icdsm片段。将icdsm片段与经相同限制性内切酶酶切后的c.glutamicum-e.coli穿梭表达质粒pdxw-8相连构建重组质粒pdxw-8-icdsm。最后,以pdxw-8-icdsm为模板,以ptac-f/ptac-r为引物进行pcr(表1),获得ptac-icdsm-rrnbt1t2表达框。
实施例4:c.glutamicumlyscfbr中icd编码基因icdcg替换为streptococcusmutansjh1005icd编码基因icdsm
以c.glutamicumatcc13032基因组为模板,分别以icd-l-f/icd-l-r和icd-r-f/icd-r-r为引物pcr(表1),获得分别在3’端和5’端有相同限制性内切酶的pcr产物。将以上述pcr产物分别与线性化并与重组自杀型质粒pk18mobsacb酶连构建重组质粒pk18mobsacb-δicdcg;将将纯化后的pcr产物ptac-icdsm-rrnbt1t2与pk18mobsacb-δicdcg连接,二者同时用sali酶切,酶切产物通过粘性末端连接,获得重组质粒pk18mobsacb-δicdcg::icdsm。
将验证正确的质粒pk18mobsacb-δicdcg::icdsm电击转化c.glutamicumlyscfbrδzwfδmale,经含有50μg·ml-1卡那霉素的lbg固体培养基于30℃培养筛选获得第一次同源重组转化子。再将经一次重组的转化子接入含100g·l-1蔗糖的lbgs液体培养基于30℃培养,培养基中含蔗糖会导致含sacb基因的线性化整合基因片段与基因组dna中目的基因进行第二次同源重组,lbgs培养的菌液在lbg平板上划线分离,在平板上长出的菌落可能是回复野生型也可能是基因敲除型,菌落pcr验证单菌落,提取转化子染色体,以目标基因icd的上下游引物进行pcr并对pcr产物进行测序鉴定,最终获得目的重组菌株c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm。
实施例5:重组菌c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm和出发菌c.glutamicumlyscfbr胞内辅酶ⅰnad(h)和辅酶ⅱnadp(h)的测定
辅酶ⅰnad(h)的测定:收集500万细菌,加入0.5ml酸性(碱性)提取液,超声破碎1min(强度20%或200w,超声2s,停1s),盖紧后煮沸5min,冰浴中冷却后,10000g4℃离心10min,取上清液200μl至另一新的离心管中,加入等体积的碱性(酸性)提取液使之中和,10000g4℃离心10min,取上清。随后,以试剂盒nad/nadhquantificationcolorimeterickit特异性检测nad+和nadh,并计算nadh/nad+。
辅酶ⅱnadp(h)的测定:收集400-500万细菌,加入0.9ml酸性(碱性)提取液,超声破碎1min(强度20%或200w,超声2s,停1s),盖紧后煮沸5min,冰浴中冷却后,10000g4℃离心10min,取上清液200μl至另一新的离心管中,加入等体积的碱性(酸性)提取液使之中和,10000g4℃离心10min,取上清。随后,以试剂盒nadp/nadphquantificationcolorimeterickit特异性检测nadp+和nadph,并计算nadph/nadp+。
表2为重组菌和出发菌胞内吡啶核苷酸(nad+、nadh、nadp+和nadph)的含量,从表中可以看出,胞内nadph含量降低至0.15μmol(gdcw)-1,明显低于出发菌胞内nadph含量1.43μmol(gdcw)-1。
表2.重组菌和出发菌胞内吡啶核苷酸含量
a:单位是μmol(gdcw)-1.
实施例6:重组菌c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm和出发菌c.glutamicumlyscfbr胞内atp、adp、amp的测定
利用0.6mol·l-1高氯酸(pca)抽提重组菌c.glutamicumlyscfbrδzwfδmaleδicdcg::icdsm和出发菌c.glutamicumlyscfbr胞内atp、adp和amp。随后,采用hplc技术对抽提液进行分析,测定胞内atp、adp和amp的浓度。将50ml细胞样品从培养物中取出,立即在液氮中冷冻60s,并储存在-20℃。通过hplc(agilent1100系列,thermoelectroncorporation,ma,usa)测量细胞内atp的浓度。为了提取atp,将10ml的0.6mhclo4加入到细胞沉淀中并混合用磁力搅拌器彻底搅拌10分钟。将混合物以10,000×g离心10分钟以收集上清液。将另外10ml的0.6mhclo4加入到沉淀中,充分混合10分钟,离心后收集上清液。将两部分上清液在25ml容量瓶中混合并用0.6mhclo4补足至25ml。取10毫升所制备的溶液,并用0.8m氢氧化钾将ph调节至7.0。在4℃保持30分钟后,通过过滤从孔中除去晶体kclo4(孔径=0.22μm),然后在应用hplc柱之前用磷酸盐缓冲液(ph7.0)稀释至25ml。hplc分析的进样量为10μl。使用80%10mmkh2po4(ph7.0)和20%甲醇的混合物作为流动相,流速为1.2mlmin-1。紫外检测器的波长设置为260nm,柱温控制在25℃。
表3为重组菌和出发菌胞内腺嘌呤核苷酸(atp、adp和amp)的含量,从表中可以看出,重组菌胞内atp含量降低,而adp、amp含量略微升高。
表3.重组菌和出发菌胞内腺嘌呤核苷酸的含量
a:单位是μmol(gdcw)-1.
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
序列表
<110>江南大学
<120>一种谷氨酸棒杆菌重组菌及其构建方法
<160>25
<170>siposequencelisting1.0
<210>1
<211>1182
<212>dna
<213>(人工序列)
<400>1
atggcagaaaaagtaagttttgaagaagggaaattacaggtgcctgataagcccgtcatt60
ccttacattgaaggagatggtgttggtcaggatatttggaagaatgcgcaaatcgttttt120
gataaagccattgctaaagtttatggaggtcacaagcaggttatttggcgggaggtttta180
gctggtaaaaaagcttataaggaaacaggcaactggctgcctaatgagactttagaaatt240
atcaagacgcatttacttgctattaaaggtccattggaaactcctgttggaggtggtatt300
cgttccttaaatgttgccctgcgtcaagaattggatctctttgcttgcgtgcgtccagtg360
cgttatttcaaaggtgtccctagtccacttaagcatcctgaaaaaacggctattactatt420
tttcgagaaaatactgaagatatttacgcaggtatcgaatggaatgcgggtacagcagaa480
gttcaaaaggtcatcaactttttacaagatgatatgcaggttaagaaaattcgttttcca540
aaaagcagcagtatagggattaaacctatttcaattgaaggcagccaacgtttgattcgt600
gcagctatcgaatatgctctggccaacaatctgaccaaggtaactttggttcataaagga660
aatattcaaaaattcactgaaggtggctttagaaaatggggctatgaattagcaaaacgt720
gagtatgctgccgaacttgccagtggtcaattggtagttgatgatattattgctgacaat780
ttcttgcaacaaattctgctcaagcctgagcgttttgatgtagttgccttaacgaatctc840
aatggggactatgccagcgatgccttagcagcacaagttggcggtattggtatttcgcca900
ggagctaatattaactatcaaacgggacatgctatttttgaagcaacccatggaacggct960
ccagatattgcaggtcaagacttggccaacccatcttctgttttattatcaggctgcatg1020
ctttttgactatattggttggtcaaaagtctcagatttaatcatgaaagctgttgaaaaa1080
gctattgcaaatggtcaagttaccattgattttgccaaggaactaggggttgaagcattg1140
acaacctgtcagttttctgaagttctattgacttatttatag1182
<210>2
<211>2217
<212>dna
<213>(人工序列)
<400>2
atggctaagatcatctggacccgcaccgacgaagcaccgctgctcgcgacctactcgctg60
aagccggtcgtcgaggcatttgctgctaccgcgggcattgaggtcgagacccgggacatt120
tcactcgctggacgcatcctcgcccagttcccagagcgcctcaccgaagatcagaaggta180
ggcaacgcactcgcagaactcggcgagcttgctaagactcctgaagcaaacatcattaag240
cttccaaacatctccgcttctgttccacagctcaaggctgctattaaggaactgcaggac300
cagggctacgacatcccagaactgcctgataacgccaccaccgacgaggaaaaagacatc360
ctcgcacgctacaacgctgttaagggttccgctgtgaacccagtgctgcgtgaaggcaac420
tctgaccgccgcgcaccaatcgctgtcaagaactttgttaagaagttcccacaccgcatg480
ggcgagtggtctgcagattccaagaccaacgttgcaaccatggatgcaaacgacttccgc540
cacaacgagaagtccatcatcctcgacgctgctgatgaagttcagatcaagcacatcgca600
gctgacggcaccgagaccatcctcaaggacagcctcaagcttcttgaaggcgaagttcta660
gacggaaccgttctgtccgcaaaggcactggacgcattccttctcgagcaggtcgctcgc720
gcaaaggcagaaggtatcctcttctccgcacacctgaaggccaccatgatgaaggtctcc780
gacccaatcatcttcggccacgttgtgcgcgcttacttcgcagacgttttcgcacagtac840
ggtgagcagctgctcgcagctggcctcaacggcgaaaacggcctcgctgcaatcctctcc900
ggcttggagtccctggacaacggcgaagaaatcaaggctgcattcgagaagggcttggaa960
gacggcccagacctggccatggttaactccgctcgcggcatcaccaacctgcatgtccct1020
tccgatgtcatcgtggacgcttccatgccagcaatgattcgtacctccggccacatgtgg1080
aacaaagacgaccaggagcaggacaccctggcaatcatcccagactcctcctacgctggc1140
gtctaccagaccgttatcgaagactgccgcaagaacggcgcattcgatccaaccaccatg1200
ggtaccgtccctaacgttggtctgatggctcagaaggctgaagagtacggctcccatgac1260
aagaccttccgcatcgaagcagacggtgtggttcaggttgtttcctccaacggcgacgtt1320
ctcatcgagcacgacgttgaggcaaatgacatctggcgtgcatgccaggtcaaggatgcc1380
ccaatccaggattgggtaaagcttgctgtcacccgctcccgtctctccggaatgcctgca1440
gtgttctggttggatccagagcgcgcacacgaccgcaacctggcttccctcgttgagaag1500
tacctggctgaccacgacaccgagggcctggacatccagatcctctcccctgttgaggca1560
acccagctctccatcgaccgcatccgccgtggcgaggacaccatctctgtcaccggtaac1620
gttctgcgtgactacaacaccgacctcttcccaatcctggagctgggcacctctgcaaag1680
atgctgtctgtcgttcctttgatggctggcggcggactgttcgagaccggtgctggtgga1740
tctgctcctaagcacgtccagcaggttcaggaagaaaaccacctgcgttgggattccctc1800
ggtgagttcctcgcactggctgagtccttccgccacgagctcaacaacaacggcaacacc1860
aaggccggcgttctggctgacgctctggacaaggcaactgagaagctgctgaacgaagag1920
aagtccccatcccgcaaggttggcgagatcgacaaccgtggctcccacttctggctgacc1980
aagttctgggctgacgagctcgctgctcagaccgaggacgcagatctggctgctaccttc2040
gcaccagtcgcagaagcactgaacacaggcgctgcagacatcgatgctgcactgctcgca2100
gttcagggtggagcaactgaccttggtggctactactcccctaacgaggagaagctcacc2160
aacatcatgcgcccagtcgcacagttcaacgagatcgttgacgcactgaagaagtaa2217
<210>3
<211>1545
<212>dna
<213>(人工序列)
<400>3
gtgagcacaaacacgaccccctccagctggacaaacccactgcgcgacccgcaggataaa60
cgactcccccgcatcgctggcccttccggcatggtgatcttcggtgtcactggcgacttg120
gctcgaaagaagctgctccccgccatttatgatctagcaaaccgcggattgctgccccca180
ggattctcgttggtaggttacggccgccgcgaatggtccaaagaagactttgaaaaatac240
gtacgcgatgccgcaagtgctggtgctcgtacggaattccgtgaaaatgtttgggagcgc300
ctcgccgagggtatggaatttgttcgcggcaactttgatgatgatgcagctttcgacaac360
ctcgctgcaacactcaagcgcatcgacaaaacccgcggcaccgccggcaactgggcttac420
tacctgtccattccaccagattccttcacagcggtctgccaccagctggagcgttccggc480
atggctgaatccaccgaagaagcatggcgccgcgtgatcatcgagaagcctttcggccac540
aacctcgaatccgcacacgagctcaaccagctggtcaacgcagtcttcccagaatcttct600
gtgttccgcatcgaccactatttgggcaaggaaacagttcaaaacatcctggctctgcgt660
tttgctaaccagctgtttgagccactgtggaactccaactacgttgaccacgtccagatc720
accatggctgaagatattggcttgggtggacgtgctggttactacgacggcatcggcgca780
gcccgcgacgtcatccagaaccacctgatccagctcttggctctggttgccatggaagaa840
ccaatttctttcgtgccagcgcagctgcaggcagaaaagatcaaggtgctctctgcgaca900
aagccgtgctacccattggataaaacctccgctcgtggtcagtacgctgccggttggcag960
ggctctgagttagtcaagggacttcgcgaagaagatggcttcaaccctgagtccaccact1020
gagacttttgcggcttgtaccttagagatcacgtctcgtcgctgggctggtgtgccgttc1080
tacctgcgcaccggtaagcgtcttggtcgccgtgttactgagattgccgtggtgtttaaa1140
gacgcaccacaccagcctttcgacggcgacatgactgtatcccttggccaaaacgccatc1200
gtgattcgcgtgcagcctgatgaaggtgtgctcatccgcttcggttccaaggttccaggt1260
tctgccatggaagtccgtgacgtcaacatggacttctcctactcagaatccttcactgaa1320
gaatcacctgaagcatacgagcgcctcattttggatgcgctgttagatgaatccagcctc1380
ttccctaccaacgaggaagtggaactgagctggaagattctggatccaattcttgaagca1440
tgggatgccgatggagaaccagaggattacccagcgggtacgtggggtccaaagagcgct1500
gatgaaatgctttcccgcaacggtcacacctggcgcaggccataa1545
<210>4
<211>1179
<212>dna
<213>(人工序列)
<400>4
atgaccatcgacctgcagcgttccacccaaaacctcacccatgaggaaatcttcgaggca60
cacgagggcggaaagctctccattagttccactcgtccgctccgcgacatgcgcgatctt120
tcccttgcttacacccctggtgttgctcaggtttgtgaagcaatcaaggaagatccagag180
gttgcgcgcacccacacgggcattggaaacaccgtcgcggttatttccgacggcaccgct240
gttcttggccttggcgatatcggacctcaggcctcccttcccgtcatggagggcaaggct300
cagctgtttagctctttcgctggcctgaaggctatccctatcgttttggacgttcacgat360
gttgacgctttggttgagaccatcgcagccatcgcgccttctttcggtgctatcaacttg420
gaggacatctccgctcctcgttgcttcgaggtggagcgccgcctcatcgagcgtctcgat480
attccagttatgcacgatgaccagcacggcaccgctgtggttatcctcgctgcgctgcgc540
aactccctgaagctgctggatcgcaagatcgaagacctcaagattgttatttccggcgca600
ggcgcagcgggcgttgcagctgtagatatgctgaccaacgctggagcaaccgacatcgtg660
gttcttgattcccgaggcatcatccacgacagccgtgaggatctttccccagttaaggct720
gctcttgcagagaagaccaaccctcgtggcatcagcggtggcatcaatgaggctttcacc780
ggcgcggacctgttcattggcgtgtccggcggcaacatcggcgaggacgctctcaaactc840
atggccccggagccaatcctgttcaccctggcgaacccaaccccagagatcgatcctgag900
ctgtctcagaagtacggcgccatcgtcgcgaccggccgctctgacctgcctaaccagatc960
aacaacgtgctcgcgttcccaggaattttcgccggcgctctcgcagccaaggctaagaag1020
atcacccccgagatgaagctcgccgctgcagaggcaatcgccgacatcgcagctgaggac1080
ctcgaggtcggccgcatcgtgcctaccgccctggatccccgcgtcgccccagcagtcaag1140
gcagctgtccaggccgtcgccgaagcgcaaaacgcttaa1179
<210>5
<211>15
<212>dna
<213>(人工序列)
<400>5
gaaaggagatatacc15
<210>6
<211>30
<212>dna
<213>(人工序列)
<400>6
acgcgtcgacgctgtcctacggctgtgcag30
<210>7
<211>29
<212>dna
<213>(人工序列)
<400>7
acgcgtcgacgcctggcggcagtagcgcg29
<210>8
<211>30
<212>dna
<213>(人工序列)
<400>8
cccaagcttatgatgtctttggcttcgtcg30
<210>9
<211>31
<212>dna
<213>(人工序列)
<400>9
acgcgtcgacgagttcctcgcactggctgag31
<210>10
<211>31
<212>dna
<213>(人工序列)
<400>10
acgcgtcgacgaggatgtctttttcctcgtc31
<210>11
<211>29
<212>dna
<213>(人工序列)
<400>11
cggaattcgatcttggcaggcgatgaaac29
<210>12
<211>17
<212>dna
<213>(人工序列)
<400>12
atggctaagatcatctg17
<210>13
<211>16
<212>dna
<213>(人工序列)
<400>13
ttacttcttcagtgcg16
<210>14
<211>30
<212>dna
<213>(人工序列)
<400>14
cccaagcttgctgcgtggaagtgttcacac30
<210>15
<211>31
<212>dna
<213>(人工序列)
<400>15
acgcgtcgactgagccttgccctccatgacg31
<210>16
<211>31
<212>dna
<213>(人工序列)
<400>16
acgcgtcgacccagagatcgatcctgagctg31
<210>17
<211>29
<212>dna
<213>(人工序列)
<400>17
gctctagactgaacacttgtggcgcggcg29
<210>18
<211>19
<212>dna
<213>(人工序列)
<400>18
atgaccatcgacctgcagc19
<210>19
<211>19
<212>dna
<213>(人工序列)
<400>19
aaatattggcgcctcgacg19
<210>20
<211>28
<212>dna
<213>(人工序列)
<400>20
cgggatcctgaggctttggctctgcgcg28
<210>21
<211>27
<212>dna
<213>(人工序列)
<400>21
gctctagagctgtgaaggaatctggtg27
<210>22
<211>28
<212>dna
<213>(人工序列)
<400>22
gctctagattggtcgccgtgttactgag28
<210>23
<211>28
<212>dna
<213>(人工序列)
<400>23
cccaagcttgggtgatccaatgaggagg28
<210>24
<211>32
<212>dna
<213>(人工序列)
<400>24
gaaaggagatataccgtgagcacaaacacgac32
<210>25
<211>21
<212>dna
<213>(人工序列)
<400>25
ttatggcctgcgccaggtgtg21
- 还没有人留言评论。精彩留言会获得点赞!