一种重组人源III型胶原蛋白及其生产方法与流程
本发明属于基因工程技术领域,涉及一种重组iii型人源胶原蛋白及其生产方法。
背景技术:
胶原蛋白是广泛存在于人体结缔组织一个重要的结构蛋白,约占人体总蛋白的1/3,占皮肤干重的3/4,在细胞质基质中起到支架作用,使皮肤保持弹性。iii型胶原蛋白主要存在于血管、皮肤和肠道中,其流失是导致皮肤衰老的主要原因。因此在目前的医美行业中,iii型胶原蛋白是主要的研究对象。
传统获得胶原蛋白的方法是从动物体中提取,处理过程涉及到酸碱酶解,容易使胶原蛋白失去其原本的生理活性,无法发挥其正常的生物学功能。且取自于动物体的蛋白,可能存在病毒隐患,也会导致人体的免疫排斥。
随着现代生物技术的发展,通过基因工程手段获得重组胶原蛋白成为一种可行的方法。且生产成本低,易于放大。以人体本身具有的胶原蛋基因为模板,也可有效避免免疫排斥现象。
技术实现要素:
人体天然iii型胶原蛋白三螺旋区域的基本氨基酸结构为(-gly-x-y-)n,其中x位氨基酸有28%为脯氨酸,y位氨基酸有42%为脯氨酸。脯氨酸羟基化是iii型胶原蛋白单链形成稳定三螺旋的基础,在此基础上胶原蛋白链才会进一步形成纤维,因此我们使用脯氨酸羟化酶基因进行共表达,使生产出的胶原蛋白形成类似于人体本身具有的iii型胶原蛋白的三螺旋结构。小球藻草履虫病毒1的脯氨酸羟化酶基因与人源脯氨酸羟化酶α亚基的基因序列相似,该酶易于表达且不限底物来源。我们在选择宿主方面决定用酿酒酵母表达系统,其不含内毒素且生产成本低,而共表达羟化酶刚好弥补其不具有羟化酶的缺陷。
本发明的目的是提供一种重组人源iii型胶原蛋白及其生产方法。
本发明的技术方案提供了一种重组人源胶原蛋白的生产方法,重组人源胶原蛋白利用小球藻草履虫病毒1的脯氨酸羟化酶基因共表达,弥补酵母系统缺乏脯氨酸羟化酶,使脯氨酸顺利羟基化,使单氨基酸链成功形成三螺旋结构。本发明提供的重组人源胶原蛋白是一种重组人源iii型胶原蛋白。
进一步的上述重组人源胶原蛋白的生产方法所使用了重组人源胶原蛋白dna序列,以ncbi数据库collageniiialpha-1链为模板,按酿酒酵母密码子优化,并规避基因工程操作中会涉及到的酶切位点,带基因工程所需酶切位点合成基因。上述的重组人源胶原蛋白dna的序列如seqidno.1:
5’-caatacgactcttacgacgttaagtctggtgttgctgttggtggtttggctggttacccaggtccagctggtccaccaggtccaccaggtccaccaggtacttctggtcacccaggttctccaggttctccaggttaccaaggtccaccaggtgaaccaggtcaagctggtccatctggtccaccaggtccaccaggtgctatcggtccatctggtccagctggtaaggacggtgaatctggtagaccaggtagaccaggtgaaagaggtttgccaggtccaccaggtatcaagggtccagcgggtataccaggcttcccaggtatgaagggtcacagaggtttcgacggtagaaacggtgaaaagggtgaaacaggtgcgccaggtctcaagggtgaaaatggtttgccaggtgaaaacggtgctccaggtccaatgggtccaagaggtgctccaggtgaaagaggtagaccaggtttgccaggtgctgctggtgctagaggtaacgacggtgctagaggttctgacggtcaaccaggtccaccaggtccaccaggtactgcgggcttcccaggttctccaggtgctaagggtgaagttggtccagctggttctccaggttctaacggtgctccaggtcaaagaggtgaaccaggtccacaaggtcacgctggtgctcaaggtccaccaggtccaccaggtatcaacggttctccaggtggtaagggtgaaatgggtccagctggtatcccaggtgcgccaggtctcatgggtgctcgtggtccaccaggtccagcgggtgctaacggtgcgccaggtctcagaggtggtgcgggtgaaccaggtaagaacggtgctaagggtgaaccaggtccaagaggtgaaagaggtgaagctggtatcccaggtgttccaggtgctaagggtgaagacggtaaggacggttctccaggtgaaccaggtgctaacggtttgccaggtgctgctggtgaaagaggtgctccaggtttcagaggtccagctggtccaaacggtatcccaggtgaaaagggtccagctggtgaaagaggtgctccaggtccagctggtccaagaggtgctgctggtgaaccaggtagagacggtgttccaggtggtccaggtatgagaggtatgccaggttctccaggtggtccaggttctgacggtaagccaggtccaccaggttctcaaggtgaatctggtagaccaggtccaccaggtccatctggtccaagaggtcaaccaggtgttatgggtttcccaggtccaaagggtaacgacggtgctccaggtaagaacggtgaaagaggtggtccaggtggtccaggtccacaaggtccaccaggtaagaacggtgaaactggtccacaaggtccaccaggtccaactggtccaggtggtgacaagggtgacactggtccaccaggtccacaaggtttgcaaggtttgccaggtactggtggtccaccaggtgaaaacggtaagccaggtgaaccaggtccaaagggtgacgctggtgctccaggtgctccaggtggtaagggtgacgctggtgctccaggtgaaagaggcccaccaggtctcgcgggtgcgccaggtctcagaggtggtgcgggtccaccaggtccagaaggtggtaagggtgctgctggtccaccaggtccaccaggtgctgcgggtactccaggtctccaaggtatgccaggtgaaagaggtggtttgggttctccaggtccaaagggtgacaagggtgaaccaggtggtccaggtgctgacggtgttccaggtaaggacggtccaagaggtccaactggtccaatcggtccaccaggtccagctggtcaaccaggtgacaagggtgaaggaggtgcgccaggtctcccaggtatcgcgggtccaagaggttctccaggtgaaagaggtgaaaccggtccaccaggtcccgctggcttcccaggtgctccaggtcaaaacggtgaaccaggtggtaagggtgaaagaggtgctccaggtgaaaagggtgaaggtggtccaccaggtgttgctggtccaccaggtggttctggtccagctggtccaccaggtccacaaggtgttaagggtgaaagaggttctccaggtggtccaggtgcggcgggcttcccaggtgcgcgtggtctcccaggtccaccaggttctaacggtaacccaggtccaccaggtccatctggttctccaggtaaggacggtccaccaggtccagctggtaacactggtgctccgggctctccaggtgtaagcggtccaaagggtgacgctggtcaaccaggtgaaaagggttctccaggtgctcaaggtccaccaggtgctccaggtccattgggtatcgctggtatcactggtgcgcgtggtctcgctggtccaccaggtatgccaggtccaagaggttctccaggtccacaaggtgttaagggtgaatctggtaagccaggtgctaacggtttgtctggtgaaagaggcccaccaggaccacaaggtctcccaggtttggcgggtactgctggtgaaccaggtagagacggtaacccaggttctgacggtttgccaggtagagacggttctccaggtggtaagggtgacagaggtgaaaacggttctccaggtgctccaggtgctccaggtcacccaggtccaccaggtccagttggtccagctggtaagtctggtgacagaggtgaatctggtccagctggtccagctggtgctccaggtccagctggttctagaggtgctccaggtccacaaggtccaagaggtgacaagggtgaaactggtgaaagaggtgctgctggtatcaagggtcacagaggtttcccaggtaacccaggtgctccaggttctccaggtccagctggtcaacaaggtgctatcggttctccaggtccagctggtccaagaggtccagttggtccatctggtccaccaggtaaggacggtacttctggtcacccaggtccaatcggtccaccaggtccaagaggtaacagaggtgaaagaggttctgaaggttctccaggtcacccaggtcaaccaggtccaccaggtccaccaggtgctccaggtccatgttgtggtggtgttggtgctgctgctatcgctggtatcggtggtgaaaaggctggtggtttcgctccatactacggt-3’
进一步的上述重组人源胶原蛋白的生产方法中小球藻草履虫病毒1的脯氨酸羟化酶包括氨基酸209个,去除n端跨膜区,序列如seqidno.2:rregfetsdrpgvcdgkyyekidgflsdiecdvlinaaikkgliksevggatendpikldpksrnseqtwfmpgehevidkiqkktreflnskkhcidkynfedvqvarykpgqyyyhhydgddcddacpkdqrlatlmvylkapeeggggetdfptlktkikpkkgtsiffwvadpvtrklyketlhaglpvksgekiianqwiravk。
进一步的上述重组人源胶原蛋白的生产方法中小球藻草履虫病毒1的脯氨酸羟化酶dna序列,以ncbi数据库为模板,按酿酒酵母密码子优化,并规避基因工程操作中会涉及到的酶切位点,带基因工程所需酶切位点合成基因,序列如seqidno.3:
5’-agaagagaaggtttcgaaacttctgacagaccaggtgtttgtgacggtaagtactacgaaaagatcgacggtttcttgtctgacatcgaatgtgacgttttgatcaacgctgctatcaagaagggtttgatcaagtctgaagttggtggtgctactgaaaacgacccaatcaagttggacccaaagtctagaaactctgaacaaacttggttcatgccaggtgaacacgaagttatcgacaagatccaaaagaagactagagaatttttgaactctaagaagcactgtatcgacaagtacaacttcgaagacgttcaagttgctagatacaagccaggtcaatactactaccaccactacgacggtgacgactgtgacgacgcttgtccaaaggaccaacgtctcgctactctcatggtttacctcaaggctccagaagaaggtggtggtggtgaaactgacttcccaactttgaagactaagatcaagccaaagaagggtacttctatcttcttctgggttgctgacccagttactagaaagttgtacaaggaaactttgcacgctggtttgccagttaagtctggtgaaaagatcatcgctaaccaatggatcagagctgttaag-3’
进一步的上述重组人源胶原蛋白的生产方法中用含两个启动子的共表达载体pesc-ura分别克隆小球藻草履虫病毒1的脯氨酸羟化酶基因与人源iii型胶原蛋白基因,并转化到酿酒酵母中,经过酿酒酵母基因工程菌株的筛选、诱导表达并纯化得到重组人源iii型胶原蛋白。
进一步的上述重组人源胶原蛋白的生产方法中将上述两个基因的dna序列分别克隆在表达载体的两个mcs区,上述的基因序列seqidno.1克隆到纯化标签3’端,将基因重组后的共表达载体转化到酿酒酵母营养缺陷株中,筛选得到酿酒酵母基因工程菌。
进一步的上述重组人源胶原蛋白的生产方法中构建好的所述酿酒酵母基因工程菌株需要经过qpcr筛选表达量优势株。
进一步的上述重组人源胶原蛋白的生产方法中挑取优选后的所述酿酒酵母基因工程菌单菌落,至于5ml的sdcaa培养基中30℃培养过夜,将过夜培养的5ml菌液接种于500ml的sdcaa培养基中,30℃培养至od600达到2-3时,离心收集菌体,重悬于500ml的sgcaa培养基中,20℃诱导3天,离心收集菌体。
进一步的上述重组人源胶原蛋白的生产方法中将所述诱导表达后的菌体重悬于tris缓冲液中,高压匀浆破碎细胞,离心收集上清液。利用purkineanti-flag树脂从上清液中纯化得到重组人源iii型胶原蛋白,将纯化好的蛋白利用肠激酶切割n端纯化标签。
上述生产方法制的一种重组人源胶原蛋白,该重组人源胶原蛋白结构上还原了人体本身所具有的iii型胶原蛋白的三螺旋结构,蛋白质氨基酸序列与人体iii型胶原蛋白三螺旋区域一致,重组人源胶原蛋白生产方法利用小球藻草履虫病毒1的脯氨酸羟化酶基因共表达,弥补酵母系统缺乏脯氨酸羟化酶,使脯氨酸顺利羟基化,从而使单氨基酸链成功形成三螺旋结构。
本发明还有一些方案是通过以下技术方案实现的:
一种重组人源iii型胶原蛋白,结构为三螺旋,氨基酸序列还原人体iii型胶原蛋白alpha-1链,包括1068个氨基酸。碱基序列根据酿酒酵母密码子进行优化。
pbcv-1的脯氨酸羟化酶,包括209个氨基酸。碱基序列根据酿酒酵母密码子进行优化。
上述的重组人源iii型胶原蛋白的生产方法,包括如下步骤:
(1)酿酒酵母基因工程菌的构建和筛选;
(2)酿酒酵母基因工程菌的发酵培养及重组人源iii型胶原蛋白的诱导表达;
(3)重组人源iii型胶原蛋白的纯化。
步骤(1)中所述酿酒酵母基因工程菌的构建,步骤如下:(1)优化人源iii型胶原蛋白alpha-1链碱基并合成序列;(2)优化pbcv-1的脯氨酸羟化酶碱基并合成序列;(3)将两个目的基因分别克隆到表达载体的两个mcs区得到共表达载体,胶原蛋白基因克隆到纯化标签3’端;(4)将共表达载体转入营养缺陷型酿酒酵母中,筛选得到酿酒酵母基因工程菌株;(5)分别设计胶原蛋白和脯氨酸羟化酶qpcr引物,从rna水平筛选高表达株。
步骤(2)中所述的酿酒酵母基因工程菌的发酵培养,步骤如下:(1)挑取优选后的酿酒酵母基因工程菌单菌落,至于5ml的sdcaa培养基中30℃培养过夜。将过夜培养的5ml菌液接种于500ml的sdcaa培养基中,30℃培养至od600达到2-3时,离心收集菌体,重悬于500ml的sgcaa培养基中,20℃诱导3天,离心收集菌体。
步骤(3)中所述重组人源iii型胶原蛋白三螺旋的纯化,步骤如下:(1)用tris-hcl缓冲液重悬酵母,高压匀浆破碎细胞,离心收集上清液;(2)利用purkineanti-flag树脂从上清液中纯化得到重组人源iii型胶原蛋白。将纯化好的蛋白利用肠激酶切割n端纯化标签。
与现有技术相比,本发明具有以下特点:
(1)本发明利用脯氨酸羟基酶在体外实现胶原蛋白链形成三螺旋。
(2)采用酿酒酵母表达系统,适于大规模放大,且不含有内毒素,不需要后期去除,生产成本低,且合成基因经过酿酒酵母密码子优化,进一步提高蛋白表达量。
(3)本发明利用qpcr方法在rna水平筛选表达优势株。
(4)生产的重组人源iii型胶原蛋白具有良好的稳定性,其氨基酸组成几乎与天然胶原蛋白alpha-1链完全一致,应用于人体不会产生免疫排斥。且其生物相容性较好,可以广泛应用于外科医疗和医美行业。
附图说明
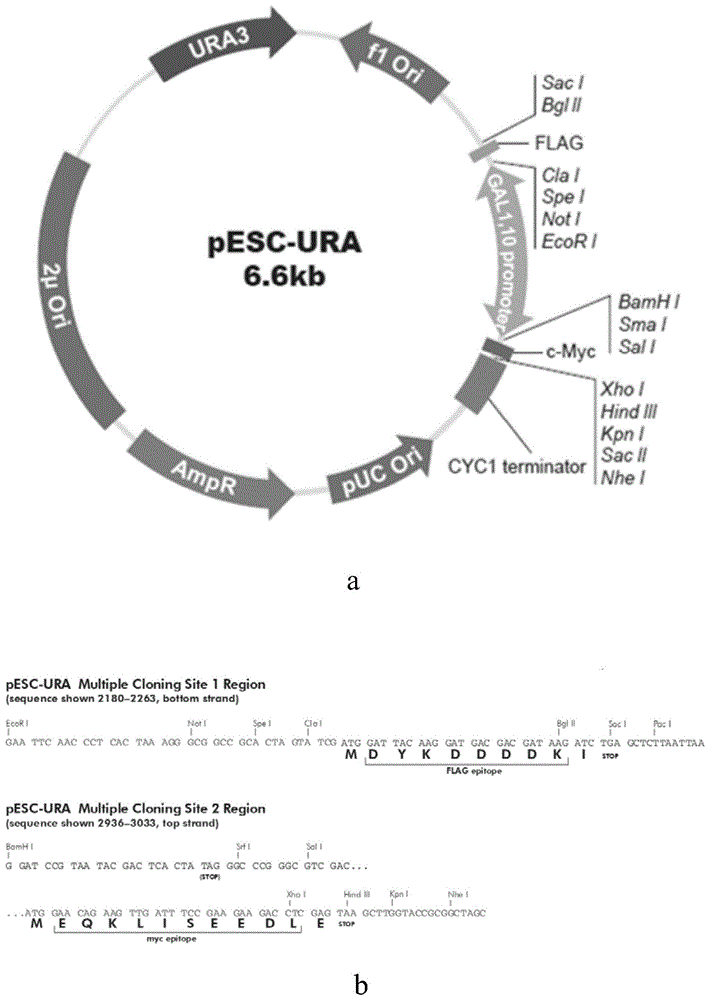
图1.a/b为本发明一实施例中的共表达载体pesc-ura的质粒图谱,其中将seqidno.1的dna序列5’和3’端分别添加bglii和saci的酶切位点序列及保护性碱基,克隆到表达载体的bglii和saci位点之间。saci酶切位点前后序列涵盖终止密码子,flag标签自带起始密码子,无需再添加。将seqidno.3的dna序列5’端添加bamhi酶切位点序列、保护性碱基和起始密码子;3’端添加终止密码子和sali酶切位点序列、保护性碱基,克隆到表达载体的bamhi和sali位点之间;
图2.为本发明一实施例几株胶原蛋白纯化后的westernblot图;
图3.为本发明一实施例几株胶原蛋白作为细胞外基质的生物相容性图。
具体实施方式
下述的实施例是为了进一步说明本发明的一些优选实施例,并非全部实施例。本领域专业人员在没有进行创造性劳动的前提下做出的基于本发明的其他实施例,都属于本发明的权利保护范围。下面将结合附图1~3对本发明作进一步的说明。
实施例中未注明具体条件的实验方法,通常按照本领域常规条件或按照设备、试剂制造厂商所建议的条件。
实施例1
人源胶原蛋白iii型基因与pbcv-1脯氨酸羟化酶共表达载体的构建:
在优化好的人源胶原蛋白iii型基因5’和3’端分别加bglii和saci酶切位点,基因合成,转化提取大量基因所在的质粒载体,用bglii和saci酶切,琼脂糖凝胶回收纯化。将pesc-ura质粒载体用同样的方法酶切回收纯化。将人源胶原蛋白iii型基因片段与pesc-ura质粒载体片段用t4dna连接酶16℃过夜连接,转化大肠杆菌dh5α,用氨苄lb平板筛选克隆,扩大培养后提取质粒双酶切鉴定(clai—saci),挑选成功的单克隆,扩大培养提取质粒作为载体,用bamhi和sali双酶切,琼脂糖凝胶回收纯化。将优化好的pbcv-1脯氨酸羟化酶基因5’和3’端分别加bamhi和sali酶切位点,基因合成,转化提取大量基因所在的质粒载体,用同样的方法酶切回收纯化。将pbcv-1脯氨酸羟化酶基因片段与已具有人源胶原蛋白iii型基因片段的pesc-ura质粒载体片段用t4dna连接酶16℃过夜连接,转化大肠杆菌dh5α,用氨苄lb平板筛选克隆,扩大培养后提取质粒双酶切鉴定(bamhi—hindiiii)。将鉴定成功的单克隆大量培养提取质粒。
用氯化钙和二硫苏糖醇(dtt)制作尿嘧啶缺陷型酿酒酵母感受态细胞,将共表达的质粒载体电转化入细胞,用sdcaa培养基筛选成功的转化株。
设计qpcr引物,从rna水平上分别鉴定胶原蛋白和脯氨酸羟化酶的表达情况,筛选几株不同表达水平的菌株进行诱导表达及纯化。挑取优选后的酿酒酵母基因工程菌单菌落,至于5ml的sdcaa培养基中30℃培养过夜。将过夜培养的5ml菌液接种于500ml的sdcaa培养基中(1:1000放大),30℃培养至od600达到2-3时,离心收集菌体,重悬于500ml的sgcaa培养基中,20℃诱导3天,离心收集菌体。
用tris-hcl缓冲液重悬基因工程酵母株(加蛋白酶抑制剂保护蛋白不被降解),高压匀浆破碎细胞,离心收集上清液,全程4℃操作。用rbs缓冲液清洗purkineanti-flag树脂,加平衡液平衡后,与收集的菌体破碎后上清混合,4℃轻摇过夜,此时含有flagepitope的胶原蛋白被吸附到树脂上。离心去除杂蛋白,用洗液清洗后,用洗脱液将含有标签的胶原蛋白洗脱下来,用带his标签的肠激酶切割n端纯化标签,利用分子筛得到成功结合成三螺旋结构的无纯化标签的胶原蛋白。
对纯化好的几株胶原蛋白进行westernblot鉴定,一抗使用collagenantibody(兔抗),抗靠近c-terminus(901-1200aa)
分析生产出的几株胶原蛋白的生物学活性,用人脐静脉内皮细胞(huvec),培养至一定密度后,分别加入不同株的纯化后的胶原蛋白,以其作为细胞外基质,检测细胞生存能力,观察细胞生存状态。以购买的商品化gelatin为细胞外基质的细胞密度为100%,量化不同株胶原蛋白作为细胞外基质的生物相容性。
上述的实施例是为了进一步说明本发明的一些优选实施例,并非全部实施例。本领域专业人员在没有进行创造性劳动的前提下做出的基于本发明的其他实施例,都属于本发明的权利保护范围。
序列表
<110>叶华
<120>一种重组人源iii型胶原蛋白及其生产方法
<141>2020-09-16
<160>3
<170>siposequencelisting1.0
<210>1
<211>3204
<212>dna
<213>artificialsequence
<400>1
caatacgactcttacgacgttaagtctggtgttgctgttggtggtttggctggttaccca60
ggtccagctggtccaccaggtccaccaggtccaccaggtacttctggtcacccaggttct120
ccaggttctccaggttaccaaggtccaccaggtgaaccaggtcaagctggtccatctggt180
ccaccaggtccaccaggtgctatcggtccatctggtccagctggtaaggacggtgaatct240
ggtagaccaggtagaccaggtgaaagaggtttgccaggtccaccaggtatcaagggtcca300
gcgggtataccaggcttcccaggtatgaagggtcacagaggtttcgacggtagaaacggt360
gaaaagggtgaaacaggtgcgccaggtctcaagggtgaaaatggtttgccaggtgaaaac420
ggtgctccaggtccaatgggtccaagaggtgctccaggtgaaagaggtagaccaggtttg480
ccaggtgctgctggtgctagaggtaacgacggtgctagaggttctgacggtcaaccaggt540
ccaccaggtccaccaggtactgcgggcttcccaggttctccaggtgctaagggtgaagtt600
ggtccagctggttctccaggttctaacggtgctccaggtcaaagaggtgaaccaggtcca660
caaggtcacgctggtgctcaaggtccaccaggtccaccaggtatcaacggttctccaggt720
ggtaagggtgaaatgggtccagctggtatcccaggtgcgccaggtctcatgggtgctcgt780
ggtccaccaggtccagcgggtgctaacggtgcgccaggtctcagaggtggtgcgggtgaa840
ccaggtaagaacggtgctaagggtgaaccaggtccaagaggtgaaagaggtgaagctggt900
atcccaggtgttccaggtgctaagggtgaagacggtaaggacggttctccaggtgaacca960
ggtgctaacggtttgccaggtgctgctggtgaaagaggtgctccaggtttcagaggtcca1020
gctggtccaaacggtatcccaggtgaaaagggtccagctggtgaaagaggtgctccaggt1080
ccagctggtccaagaggtgctgctggtgaaccaggtagagacggtgttccaggtggtcca1140
ggtatgagaggtatgccaggttctccaggtggtccaggttctgacggtaagccaggtcca1200
ccaggttctcaaggtgaatctggtagaccaggtccaccaggtccatctggtccaagaggt1260
caaccaggtgttatgggtttcccaggtccaaagggtaacgacggtgctccaggtaagaac1320
ggtgaaagaggtggtccaggtggtccaggtccacaaggtccaccaggtaagaacggtgaa1380
actggtccacaaggtccaccaggtccaactggtccaggtggtgacaagggtgacactggt1440
ccaccaggtccacaaggtttgcaaggtttgccaggtactggtggtccaccaggtgaaaac1500
ggtaagccaggtgaaccaggtccaaagggtgacgctggtgctccaggtgctccaggtggt1560
aagggtgacgctggtgctccaggtgaaagaggcccaccaggtctcgcgggtgcgccaggt1620
ctcagaggtggtgcgggtccaccaggtccagaaggtggtaagggtgctgctggtccacca1680
ggtccaccaggtgctgcgggtactccaggtctccaaggtatgccaggtgaaagaggtggt1740
ttgggttctccaggtccaaagggtgacaagggtgaaccaggtggtccaggtgctgacggt1800
gttccaggtaaggacggtccaagaggtccaactggtccaatcggtccaccaggtccagct1860
ggtcaaccaggtgacaagggtgaaggaggtgcgccaggtctcccaggtatcgcgggtcca1920
agaggttctccaggtgaaagaggtgaaaccggtccaccaggtcccgctggcttcccaggt1980
gctccaggtcaaaacggtgaaccaggtggtaagggtgaaagaggtgctccaggtgaaaag2040
ggtgaaggtggtccaccaggtgttgctggtccaccaggtggttctggtccagctggtcca2100
ccaggtccacaaggtgttaagggtgaaagaggttctccaggtggtccaggtgcggcgggc2160
ttcccaggtgcgcgtggtctcccaggtccaccaggttctaacggtaacccaggtccacca2220
ggtccatctggttctccaggtaaggacggtccaccaggtccagctggtaacactggtgct2280
ccgggctctccaggtgtaagcggtccaaagggtgacgctggtcaaccaggtgaaaagggt2340
tctccaggtgctcaaggtccaccaggtgctccaggtccattgggtatcgctggtatcact2400
ggtgcgcgtggtctcgctggtccaccaggtatgccaggtccaagaggttctccaggtcca2460
caaggtgttaagggtgaatctggtaagccaggtgctaacggtttgtctggtgaaagaggc2520
ccaccaggaccacaaggtctcccaggtttggcgggtactgctggtgaaccaggtagagac2580
ggtaacccaggttctgacggtttgccaggtagagacggttctccaggtggtaagggtgac2640
agaggtgaaaacggttctccaggtgctccaggtgctccaggtcacccaggtccaccaggt2700
ccagttggtccagctggtaagtctggtgacagaggtgaatctggtccagctggtccagct2760
ggtgctccaggtccagctggttctagaggtgctccaggtccacaaggtccaagaggtgac2820
aagggtgaaactggtgaaagaggtgctgctggtatcaagggtcacagaggtttcccaggt2880
aacccaggtgctccaggttctccaggtccagctggtcaacaaggtgctatcggttctcca2940
ggtccagctggtccaagaggtccagttggtccatctggtccaccaggtaaggacggtact3000
tctggtcacccaggtccaatcggtccaccaggtccaagaggtaacagaggtgaaagaggt3060
tctgaaggttctccaggtcacccaggtcaaccaggtccaccaggtccaccaggtgctcca3120
ggtccatgttgtggtggtgttggtgctgctgctatcgctggtatcggtggtgaaaaggct3180
ggtggtttcgctccatactacggt3204
<210>2
<211>209
<212>prt
<213>artificialsequence
<400>2
argarggluglyphegluthrseraspargproglyvalcysaspgly
151015
lystyrtyrglulysileaspglypheleuseraspileglucysasp
202530
valleuileasnalaalailelyslysglyleuilelyssergluval
354045
glyglyalathrgluasnaspproilelysleuaspprolysserarg
505560
asnsergluglnthrtrpphemetproglygluhisgluvalileasp
65707580
lysileglnlyslysthrargglupheleuasnserlyslyshiscys
859095
ileasplystyrasnphegluaspvalglnvalalaargtyrlyspro
100105110
glyglntyrtyrtyrhishistyraspglyaspaspcysaspaspala
115120125
cysprolysaspglnargleualathrleumetvaltyrleulysala
130135140
proglugluglyglyglyglygluthrasppheprothrleulysthr
145150155160
lysilelysprolyslysglythrserilephephetrpvalalaasp
165170175
provalthrarglysleutyrlysgluthrleuhisalaglyleupro
180185190
vallysserglyglulysileilealaasnglntrpileargalaval
195200205
lys
<210>3
<211>627
<212>dna
<213>artificialsequence
<400>3
agaagagaaggtttcgaaacttctgacagaccaggtgtttgtgacggtaagtactacgaa60
aagatcgacggtttcttgtctgacatcgaatgtgacgttttgatcaacgctgctatcaag120
aagggtttgatcaagtctgaagttggtggtgctactgaaaacgacccaatcaagttggac180
ccaaagtctagaaactctgaacaaacttggttcatgccaggtgaacacgaagttatcgac240
aagatccaaaagaagactagagaatttttgaactctaagaagcactgtatcgacaagtac300
aacttcgaagacgttcaagttgctagatacaagccaggtcaatactactaccaccactac360
gacggtgacgactgtgacgacgcttgtccaaaggaccaacgtctcgctactctcatggtt420
tacctcaaggctccagaagaaggtggtggtggtgaaactgacttcccaactttgaagact480
aagatcaagccaaagaagggtacttctatcttcttctgggttgctgacccagttactaga540
aagttgtacaaggaaactttgcacgctggtttgccagttaagtctggtgaaaagatcatc600
gctaaccaatggatcagagctgttaag627
- 还没有人留言评论。精彩留言会获得点赞!