用于进行甲基化检测测定的组合物和方法与流程
本申请要求2014年12月12日提交的美国临时申请序列号62/091,069的优先权,所述专利申请以引用方式并入本文。
发明领域
本文提供了涉及用于检测来自受试者的血液或血液制品中的上皮细胞特异性dna的组合物和方法的技术,其中血液或血液制品中上皮细胞dna的存在和量指示受试者体内的医疗状况的存在或量级。所述技术还涉及在诸如来自受试者的粪便或组织样品的样品中使用组织细胞特异性dna例如上皮细胞特异性dna作为甲基化测定的内部对照。
背景
已经研究了甲基化dna作为大多数肿瘤类型的组织中的一类潜在生物标记。在许多情况下,dna甲基转移酶在胞嘧啶-磷酸-鸟嘌呤(cpg)岛位点处向dna添加甲基作为对基因表达的表观遗传控制。在生物学上引人注目的机制中,肿瘤抑制基因启动子区中获得的甲基化事件被认为使表达沉默,从而有助于瘤形成。dna甲基化可能是比rna或蛋白质表达在化学上和生物学上更稳定的诊断工具(laird(2010)“principlesandchallengesofgenome-widednamethylationanalysis”natrevgenet11:191–203)。此外,在其它癌症如散发性结肠癌中,甲基化标记提供优异的特异性,并且比作为个体dna突变更具广泛的信息性和敏感性(zou等(2007)“highlymethylatedgenesincolorectalneoplasia:implicationsforscreening”cancerepidemiolbiomarkersprev16:2686–96)。
被分析与疾病或疾病风险相关的突变存在和/或甲基化状态的来自患者样品(例如血液、粪便和组织样品)的核酸通常在分析期间通过许多处理步骤。这些步骤可包括例如过滤、沉淀、捕获、洗涤、洗脱和/或化学修饰。为了分析dna以确定甲基化状态(例如测试dna的甲基化百分比),处理通常包括用亚硫酸氢盐处理以将未甲基化的dc碱基转化为du残基,使得它们更容易与被保护免于亚硫酸氢盐转化的甲基-c残基区分开来。
测试dna的精确定量(例如确定甲基化百分比、携带突变的dna的存在和量等)通常需要归一化成对照核酸,例如具有已知特征的内源性不变基因(例如,已知序列、已知的每细胞拷贝数)。归一化可能在例如样品处理、测定效率等中发生的样品-样品(sample-to-sample)变化的控制,并允许精确的样品-样品数据比较。
存在于循环癌细胞或复合物内的血液或血液制品中的癌症特异性标记dna或循环无细胞dna已被用于表征受试者体内的实体瘤,例如乳腺癌。然而,分析血液的特定癌症标记的效用仅限于评估已经针对那些标记表征的特定源肿瘤或癌症类型,并且受试者血液中特定标记的检测在检测其它病状或癌症中可能具有有限用途。
概述
本文提供了涉及表征样品例如血液样品、粪便样品等的不同种类核酸的存在或不存在和/或量的技术,所述不同种类核酸的存在或不存在和/或量例如可能与受试者的健康状态相关。例如,在一些实施方案中,所述技术涉及检测和测量与样品类型中的特定组织相关的dna,所述样品类型通常不含有来自此组织的dna。在优选的实施方案中,所述技术涉及检测和/或测量血液或血液制品样品中的上皮细胞和/或上皮细胞特异性dna。
在一些实施方案中,所述技术提供了用于监测受试者体内的疾病状态的方法,所述方法包括以下步骤:例如在第一时间点时从受试者获得第一血液制品样品;启动治疗方案,其中所述治疗方案包括治疗性干预;在第二时间点时从所述受试者获得第二血液制品样品,其中所述第二时间点是在所述治疗方案启动之后;以及测定所述第一血液制品样品和所述第二血液制品样品的上皮细胞特异性dna的量,其中所述第一血液制品样品与所述第二血液制品样品之间的上皮细胞特异性dna的量的差异指示所述受试者体内的所述疾病状态的变化。关于在测定第一和第二血液制品样品时,所述技术不受限制。例如,在一些实施方案中,在治疗方案开始之前测定第一血液制品样品,而在其它实施方案中,在治疗方案期间或在治疗方案之后或在治疗方案之后(例如在与第二血液制品样品相同的时间)测定第一血液制品样品。在优选的实施方案中,所述方法包括产生记录,例如患者记录诸如硬拷贝或电子医疗记录,其中记录报告测定结果,例如报告值(例如,比较样品中上皮细胞特异性dna的量或量变化)或基于值的诊断结果。
该方法不限于任何特定的治疗方案。在一些实施方案中,治疗方案可包括主动干预,例如可能是保持观察受试者的问题。在优选的实施方案中,其中所述治疗方案包括手术、药物疗法、化疗、免疫疗法、营养疗法、放射疗法、温度疗法和物理疗法中的一种或多种。
第一血液制品样品与第二血液制品样品之间的上皮细胞特异性dna的量的差异指示例如所述受试者体内的疾病状态的复发、进展或消退。在一些实施方案中,在收集第一样品之后不使用治疗方案,并且第一血液制品样品与第二血液制品样品之间的上皮细胞特异性dna的量的差异指示受试者体内的疾病状态的初始发生。在一些实施方案中,由血液或血液制品样品中上皮细胞特异性dna的存在所指示的疾病状态是癌症,例如转移性癌症。
在一些优选的实施方案中,上皮细胞特异性dna包括在上皮细胞中被甲基化并且在血细胞中未被甲基化的dna。在此类实施方案中,优选的方法包括用亚硫酸氢盐试剂处理来自血液制品样品的dna以产生转化的上皮细胞特异性dna。在优选的实施方案中,上皮细胞特异性dna包括zdhhc1dna,并且在特别优选的实施方案中,dna包含seqidno:26所示序列的至少一部分。
所述方法不限于任何特定形式的血液或血液制品样品,在某些优选的实施方案中,血液制品是血浆。
所述方法不限于测定样品的任何特定手段。在某些优选的实施方案中,测定包括使用聚合酶链式反应、核酸测序、质谱、甲基化特异性核酸酶、基于质量的分离或dna靶捕获。在特别优选的实施方案中,测定包括使用侧翼内切核酸酶测定。
在一些实施方案中,所述技术提供了与分析来自受试者的样品有关的组合物。例如,在一些实施方案中,所述组合物包含:包含seqidno:33的核苷酸序列的dna链和/或包含seqidno:27的核苷酸序列的dna链。在一些实施方案中,该组合物还包含检测探针寡核苷酸,其中所述检测探针寡核苷酸包含与所述dna链的一部分互补的区。在优选的实施方案中,检测探针寡核苷酸包含与seqidno:27的一部分和/或seqidno:33的一部分互补的区。在特别优选的实施方案中,检测探针寡核苷酸包含报道分子。报道分子不限于任何特定的可检测部分。在优选的实施方案中,报道分子包含荧光团。在一些实施方案中,检测探针包含侧翼序列。
在某些优选的实施方案中,该组合物还包含fret盒寡核苷酸、侧翼内切核酸酶(例如fen-1内切核酸酶)和/或dna聚合酶(例如热稳定性dna聚合酶)中的一种或多种。在优选的实施方案中,dna聚合酶是细菌dna聚合酶。在一些实施方案中,所述技术提供例如用于检测测定的反应混合物,所述反应混合物包含上述组合物的任何组合。
在一些实施方案中,所述技术涉及进行甲基化测定。特别地,在一些实施方案中,所述技术涉及用于甲基化测定的内部对照。
在一些实施方案中,所述技术提供了表征来自受试者的血液或血液制品样品的方法,所述方法包括测定所述样品以检测组织细胞特异性dna的存在,其中组织细胞特异性dna的存在指示血液或血液制品样品中组织细胞或来自组织细胞的dna的存在。组织细胞dna可存在于血液中的组织细胞内或其它复合物(例如核小体、附加体、免疫复合物、微粒等)内,或者其可为循环无细胞dna(ccfdna)的形式。在一些实施方案中,组织细胞特异性dna是上皮细胞特异性dna。在某些优选的实施方案中,血液制品样品是血浆样品。
在一些特别优选的实施方案中,组织细胞特异性dna是在上皮细胞中被甲基化并且在血细胞中未被甲基化的上皮细胞特异性dna,并且所述技术的应用优选包括用亚硫酸氢盐试剂处理来自样品的dna以产生转化的组织细胞特异性dna。在特别优选的实施方案中,如下文所述,上皮细胞特异性dna包括zdhhc1dna。
分析组织细胞特异性dna的方法不限于任何特定的dna分析方法。在一些实施方案中,测定包括使用聚合酶链式反应、核酸测序、质谱、甲基化特异性核酸酶、基于质量的分离和/或dna靶捕获。在优选的实施方案中,测定包括侧翼内切核酸酶测定。在一些优选的实施方案中,测定是侧翼内切核酸酶测定,例如quarts测定。
在一些实施方案中,所述技术提供可用于测定样品中总人dna输入的参考dna,作为测定样品中测试核酸的相对量(例如癌症标记基因的甲基化百分比)的手段。在某些优选的实施方案中,所述技术提供了具有类似于与其比较的标记dna的甲基化特征的参考dna,使得参考dna可与标记dna暴露于相同的制备步骤,并且将表现得像标记dna一样。
在一些实施方案中,所述技术提供对组织细胞(例如上皮细胞)特异性的对照或标记dna。在具体实施方案中,所述技术提供例如在组织细胞—例如正常和癌上皮细胞中被高度甲基化—但在血液中例如在淋巴细胞中未被甲基化的标记dna。这些标记dna具有许多应用。例如,在一些实施方案中,这些标记在定量可能还含有血细胞例如淋巴细胞的样品中的组织来源的dna方面用作对照或参考dna,其将在检测其它对照dna中产生本底,例如β-肌动蛋白。这些组织细胞特异性标记还可用于检测通常不存在组织细胞或组织dna的样品中(例如,血液中)的组织细胞,其中组织细胞或组织dna的存在可指示疾病(例如癌症转移)的存在。
例如,在一些实施方案中,所述技术提供了进行定量核酸检测测定的方法,包括测定来自受试者的样品的至少一种标记基因的量;测定相同样品的zdhhc1dna的量,并将样品中所述至少一个标记基因的量与zdhhc1dna的量进行比较,以确定所述样品中相对于zdhhc1dna的量的所述至少一种标记基因的量。在一些实施方案中,外部对照,例如校准标准可用来确定标记基因和/或zdhhc1dna的绝对定量。
在一些实施方案中,所述技术包括用亚硫酸氢盐试剂处理来自样品的dna,以产生转化的zdhhc1dna和至少一个转化的标记基因,使得测定标记基因和zdhhc1dna的量包括测定转化标记基因和转化zdhhc1dna的量。
上述测定核酸的方法不限于任何特定的方法。在一些实施方案中,测定包括使用聚合酶链式反应、核酸测序、质谱、甲基化特异性核酸酶、基于质量的分离或靶捕获中的一种或多种。在一些优选的实施方案中,标记dna的测定和zdhhc1dna的测定在单个反应中进行。在特别优选的实施方案中,测定是侧翼内切核酸酶测定,例如quarts测定。
在一些实施方案中,相对于转化的zdhhc1dna的量的转化的标记基因的量指示例如测试样品中标记的甲基化状态,并且甲基化状态包括相对于所述标记基因的正常甲基化状态的所述标记基因的增加或减少的甲基化。在某些优选的实施方案中,增加的甲基化百分比指示疾病状态。
另外的实施方案提供了检测血液或血液制品中的组织细胞的方法,包括:检测来自受试者的血液或血液制品样品中甲基化zdhhc1的存在,其中甲基化zdhhc1的存在指示血液中组织细胞例如上皮细胞的存在。在一些实施方案中,样品中组织细胞的存在指示受试者体内的转移性癌症。在一些实施方案中,血液制品是血浆。在一些实施方案中,测定包括使用聚合酶链式反应、核酸测序、质谱、甲基化特异性核酸酶、基于质量的分离或靶捕获。在一些实施方案中,测定是侧翼内切核酸酶测定,例如quarts测定。在一些实施方案中,癌症是结肠直肠癌。
另外的实施方案提供了检测来自受试者的血液或血液制品中的转移性癌症的方法,包括:检测来自受试者的血液或血液制品样品中甲基化zdhhc1的存在,其中甲基化zdhhc1的存在指示受试者体内的转移性癌症的存在。另一些实施方案提供试剂盒,所述试剂盒包含:a)至少一种寡核苷酸,其中所述寡核苷酸的至少一部分与zdhhc1特异性杂交;以及b)亚硫酸氢盐。在一些实施方案中,寡核苷酸选自例如捕获寡核苷酸、一对核酸引物、核酸探针或invader寡核苷酸中的一种或多种。在一些实施方案中,试剂盒还包含与一种或多种靶基因特异性杂交的一种或多种核酸。在一些实施方案中,试剂盒还包含固体支持物(例如磁珠)。在一些实施方案中,固体支持物包含一种或多种捕获试剂(例如,与zdhhc1和/或另外的靶基因互补的寡核苷酸)。
另外的实施方案提供组合物,所述组合物包含:zdhhc1核酸和至少一种寡核苷酸的复合物,其中所述寡核苷酸的至少一部分与所述zdhhc1核酸杂交。在一些实施方案中,组合物还包含一种或多种另外的反应混合物,所述一种或多种另外的反应混合物包含靶核酸和与一种或多种靶基因特异性杂交的一种或多种寡核苷酸的复合物。
另外的实施方案提供了筛选从受试者获得的样品中的瘤的方法,所述方法包括:a)测定来自受试者的样品的至少一种甲基化标记基因的量,所述至少一种甲基化标记基因选自由以下组成的组:从受试者获得的样品中的波形蛋白(vimentin)、胞裂蛋白9(septin9)、ndrg4和bmp3;测定样品的甲基化zdhhc1dna的量,并将样品中所述至少一种甲基化标记基因的量与甲基化zdhhc1dna的量进行比较,以确定样品中至少一种标记基因的甲基化状态。在一些实施方案中,至少一种标记是至少两种、三种、四种或所有标记。在一些实施方案中,测定还包括鉴定样品中的kras突变评分的步骤。在一些实施方案中,k-ras突变评分的测量通过定量等位基因特异性pcr来测量。在一些实施方案中,测定包括检测zdhhc1、bmp3、ndrg4的甲基化状态,并鉴定样品中的kras突变评分。在一些实施方案中,所述方法还包括确定样品中血红蛋白的存在的步骤。在一些实施方案中,患者患有炎性肠病。在某些优选的实施方案中,样品是粪便样品、组织样品、胰液样品、胰腺囊肿液样品、血液样品或尿液样品。瘤可包括例如胰腺瘤、结肠直肠瘤、胆管瘤、胃瘤、食道瘤或腺瘤。
一些实施方案提供试剂盒,所述试剂盒包含:a)至少一种寡核苷酸,其中寡核苷酸的至少一部分与zdhhc1特异性杂交;以及b)至少一种另外的寡核苷酸,其中寡核苷酸的至少一部分与选自波形蛋白、胞裂蛋白9、ndrg4和bmp3的标记特异性杂交。在一些实施方案中,试剂盒包含至少两种另外的寡核苷酸。在一些实施方案中,试剂盒还包含亚硫酸氢盐。在一些实施方案中,试剂盒还包含至少一种寡核苷酸,其中寡核苷酸的至少一部分与kras特异性杂交。在一些实施方案中,试剂盒还包含用于检测粪便样品中血红蛋白的存在的试剂。
某些实施方案提供组合物,所述组合物包含:a)zdhhc1核酸和至少一种寡核苷酸的复合物,其中寡核苷酸的至少一部分与zdhhc1核酸杂交;以及b)选自由波形蛋白、胞裂蛋白9、ndrg4和bmp组成的组的靶核酸和与靶核酸特异性杂交的一种或多种寡核苷酸的复合物。
附图简述
参考以下附图,本发明技术的这些和其它特征、方面和优点将变得更加容易理解:
图1a-2e提供了比较来自粪便、血液、细胞系和组织样品的β-肌动蛋白(btact)和亚硫酸氢盐转化的dna中的甲基化基因zdhhc1的存在的图。
图2a-2c提供比较如通过与粪便样品(2a)、细胞系(2b)和结肠直肠癌组织样品(2c)中所测量的对照基因btact或zdhhc1比较所确定的标记基因ndrg4的甲基化%的图。
图3a-3c提供比较通过与粪便样品(3a)、细胞系(3b)和结肠直肠癌组织样品(3c)中的对照基因btact或zdhhc1比较所确定的标记基因bmp3的甲基化%的图。
图4a-4e提供示出来自患有指定癌症的受试者和来自正常受试者的血浆样品中的zdhhc1标记水平的检测的表。
定义
为了有助于理解本发明技术,以下定义了许多术语和短语。另外的定义在整个详细描述中阐述。
如本文所用,“一个/种(a)”或“一个/种(an)”或“所述(the)”可意指一个/种或多于一个/种。例如,“一个/种”小部件可意指一个/种小部件或多个/种小部件。
如本文所用,术语“受试者”和“患者”是指任何动物,诸如狗、猫、鸟、家畜,并且特别是哺乳动物,优选为人。在某些情况下,受试者还是“用户”(并且因此用户还是受试者或患者)。
如本文所用,术语“样品”和“试样”可互换使用,并且在最广泛的意义上使用。在一定意义上,样品意在包括获自任何来源的试样或培养物,以及生物和环境样品。生物样品可获自动物(包括人),并且涵盖流体、固体、组织和气体。生物样品包括血液制品,诸如血浆、血清、粪便、尿液等。环境样品包括环境材料,诸如地表物质、土壤、水、泥、泥浆、生物膜、水、晶体和工业样品。然而,这些实例不能理解为限制适用于本发明的样品类型。
如本文所用,如在一些上下文中使用的“远程样品”涉及从样品的非细胞、组织或器官来源的位置间接收集的样品。例如,当在粪便样品(例如,不是从胰腺直接取得的样品)中评估源自胰腺的样品材料时,所述样品是远程样品。
当用于提及核酸捕获、检测或分析方法时,术语“靶”通常是指例如在疑似含有靶核酸的样品中具有特征(例如待检测或分析的特定核苷酸序列的核酸)的核酸。在一些实施方案中,靶是具有期望确定甲基化状态的特定序列的核酸。当用于提及聚合酶链式反应时,“靶”通常是指由用于聚合酶链式反应的引物所结合的核酸区。因此,寻求从可能存在于样品中的其它核酸序列中挑选出“靶”。“区段”被定义为靶序列内的核酸区。术语“样品模板”是指对于靶的存在而分析的源自样品的核酸。
如本文所用,术语“位点”是指核酸的限定区或区段内例如具有cpg二核苷酸的突变、多态性或c残基的特定位置,诸如染色体上的基因或任何其它表征的序列或rna分子。位点不限于任何特定的大小或长度,并且可以指染色体、基因、功能遗传元件的一部分或单核苷酸或碱基对。如本文在对可被甲基化的cpg位点的提及中所用,位点是指cpg二核苷酸中的c残基。
如本文所用,“捕获试剂”是指能够结合到分析物(例如靶)的任何药剂。优选地,“捕获试剂”是指能够特异性结合到分析物的任何药剂(例如与分析物具有比与任何其它部分更高的结合亲和性和/或特异性)。如果与分析物具有必要的结合亲和性和/或特异性,则任何部分诸如细胞、细胞器、无机分子、有机分子及其混合物或复合物均可用作捕获试剂。捕获试剂可以是肽、蛋白质(例如抗体或受体)、寡核苷酸、核酸、维生素、寡糖、碳水化合物、脂质、小分子或其复合物。包含核酸(例如寡核苷酸)的捕获试剂可以通过序列特异性杂交(例如,通过形成常规的沃森-克里克碱基对)或通过其它结合相互作用捕获核酸靶标。当捕获寡核苷酸与靶核酸杂交时,杂交可能涉及寡核苷酸的一部分或完整寡核苷酸序列,并且寡核苷酸可与完整靶核酸序列的一部分或完整靶核酸序列结合。
在核酸的上下文中,术语“扩增(amplifying)”或“扩增(amplification)”是指通常从少量的多核苷酸(例如单个多核苷酸分子)开始的多核苷酸或多核苷酸的一部分的多个拷贝的产生,其中扩增产物或扩增子通常是可检测的。多核苷酸的扩增涵盖各种化学和酶过程。在聚合酶链式反应(pcr)或连接酶链式反应(lcr;参见,例如美国专利号5,494,810;其以引用方式整体并入本文)过程中,由靶或模板dna分子的一个或几个拷贝产生多个dna拷贝是扩增形式。另外类型的扩增包括但不限于等位基因特异性pcr(参见,例如美国专利号5,639,611;其以引用方式整体并入本文)、组装pcr(参见,例如美国专利号5,965,408;其以引用方式整体并入本文)、解旋酶依赖性扩增(参见,例如美国专利号7,662,594;其以引用方式整体并入本文)、热启动pcr(参见,例如美国专利号5,773,258和5,338,671;每个所述专利均以引用方式整体并入本文)、序列间特异性pcr、反向pcr(参见,例如triglia,等(1988)nucleicacidsres.,16:8186;其以引用方式整体并入本文)、连接介导的pcr(参见,例如guilfoyle,r.等,nucleicacidsresearch,25:1854-1858(1997);美国专利号5,508,169;每个所述文献均以引用方式整体并入本文)、甲基化特异性pcr(参见,例如herman,等,(1996)pnas93(13)9821-9826;其以引用方式整体并入本文)、微引物pcr、多重连接依赖性探针扩增(参见,例如schouten,等,(2002)nucleicacidsresearch30(12):e57;其以引用方式整体并入本文)、多重pcr(参见,例如chamberlain,等,(1988)nucleicacidsresearch16(23)11141-11156;ballabio,等,(1990)humangenetics84(6)571-573;hayden,等,(2008)bmcgenetics9:80;每个所述文献均以引用方式整体并入本文)、嵌套式pcr、重叠延伸pcr(参见,例如higuchi,等,(1988)nucleicacidsresearch16(15)7351-7367);其以引用方式整体并入本文)、实时pcr(参见,例如,higuchi,等,(1992)biotechnology10:413-417;higuchi,等,(1993)biotechnology11:1026-1030;每个所述文献均以引用方式整体并入本文)、逆转录pcr(参见,例如bustin,s.a.(2000)j.molecularendocrinology25:169-193;其以引用方式整体并入本文)、固相pcr、热不对称交错pcr和touchdownpcr(参见,例如don,等,nucleicacidsresearch(1991)19(14)4008;roux,k.(1994)biotechniques16(5)812-814;hecker,等,(1996)biotechniques20(3)478-485;每个所述文献均以引用方式整体并入本文)。多核苷酸扩增还可以使用数字pcr来实现(参见,例如kalinina,等,nucleicacidsresearch.25;1999-2004,(1997);vogelstein和kinzler,procnatlacadsciusa.96;9236-41,(1999);国际专利公布号wo05023091a2;美国专利申请公布号20070202525;每个所述文献均以引用方式整体并入本文)。
术语“聚合酶链式反应”(“pcr”)是指描述了用于增加基因组或其它dna或rna的混合物中的靶序列的区段浓度而不进行克隆或纯化的方法的k.b.mullis美国专利号4,683,195、4,683,202和4,965,188的方法。用于扩增靶序列的这种方法包括将大量过量的两种寡核苷酸引物引入至含有所需靶序列的dna混合物,随后在dna聚合酶存在下进行精确的热循环序列。两种引物与其双链靶序列的相应链互补。为了实现扩增,将混合物变性,并且然后将引物退火至其靶分子内的互补序列。退火后,用聚合酶延伸引物,以便形成一对新的互补链。变性、引物退火和聚合酶延伸的步骤可以重复许多次(即,变性、退火和延伸构成一个“循环”;可存在许多“循环”)以获得高浓度的所需靶序列的扩增区段。所需靶序列的扩增区段的长度由引物相对于彼此的相对位置确定,并且因此此长度是可控参数。由于所述过程的重复方面,所述方法被称为“聚合酶链式反应”(“pcr”)。因为靶序列的所需扩增区段成为混合物中的主要序列(就浓度而言),所以它们据称是“pcr扩增的”,并且是“pcr产物”或“扩增子”。本领域技术人员将理解术语“pcr”涵盖使用例如实时pcr、嵌套式pcr、逆转录pcr(rt-pcr)、单引物和任意引物pcr(arbitrarilyprimedpcr)等的最初描述的方法的许多变型。
如本文所用,术语“核酸检测测定”是指确定目标核酸的核苷酸组成的任何方法。核酸检测测定包括但不限于dna测序方法、探针杂交方法、结构特异性切割测定(例如,invader测定(hologic,inc.),并且描述于例如美国专利号5,846,717、5,985,557、5,994,069、6,001,567、6,090,543和6,872,816;lyamichev等,nat.biotech.,17:292(1999)、hall等,pnas,usa,97:8272(2000)以及us2009/0253142中,每个所述文献均出于所有目的以引用方式整体并入本文);酶错配切割方法(例如,variagenics,美国专利号6,110,684、5,958,692、5,851,770,其以引用方式整体并入本文);以上所述的聚合酶链式反应(pcr);分支杂交方法(例如,chiron,美国专利号5,849,481、5,710,264、5,124,246和5,624,802,其以引用方式整体并入本文);滚环式复制(例如,美国专利号6,210,884、6,183,960和6,235,502,其以引用方式整体并入本文);nasba(例如,美国专利号5,409,818,其以引用方式整体并入本文);分子信标技术(例如,美国专利号6,150,097,其以引用方式整体并入本文);电子传感器技术(motorola,美国专利号6,248,229、6,221,583、6,013,170和6,063,573,其以引用方式整体并入本文);循环探针技术(例如美国专利号5,403,711、5,011,769和5,660,988,其以引用方式整体并入本文);dadebehring信号扩增方法(例如,美国专利号6,121,001、6,110,677、5,914,230、5,882,867和5,792,614,其以引用方式整体并入本文);连接酶链式反应(例如,baranayproc.natl.acad.sciusa88,189-93(1991));以及夹心杂交方法(例如,美国专利号5,288,609,其以引用方式整体并入本文)。
在一些实施方案中,扩增靶核酸(例如通过pcr),并使用侵入性切割测定同时检测扩增的核酸。被配置用于与扩增测定组合进行检测测定(例如侵入性切割测定)的测定在美国专利公布us20090253142a1(申请序列号12/404,240)中有所描述,所述申请出于所有目的以引用方式整体并入本文。称为quarts方法的另外的扩增加侵入性切割检测配置在美国专利号8,361,720;8,715,937;8,916,344和9,127,318中有所描述,所述专利出于所有目的以引用方式整体并入本文。如本文所用的术语“侵入性切割结构”是指包含以下的切割结构:i)靶核酸;ii)上游核酸(例如侵入性或“invader”寡核苷酸);以及iii)下游核酸(例如,探针),其中上游和下游核酸退火至靶核酸的连续区,并且其中重叠在上游核酸的3′部分与下游核酸与靶核酸之间形成的双链体之间形成。重叠在来自上游和下游核酸的一个或多个碱基相对于靶核酸碱基占据相同位置的情况下发生,无论上游核酸的重叠碱基是否与靶核酸互补,并且无论那些碱基是天然碱基还是非天然碱基。在一些实施方案中,例如如例如在美国专利号6,090,543中所公开的,与下游双链体重叠的上游核酸的3′部分是非碱性化学部分,诸如芳族环结构,所述专利以引用方式整体并入本文。在一些实施方案中,一个或多个核酸可例如通过共价键诸如核酸茎环或通过非核酸化学键(例如,多碳链)彼此附接。如本文所用,术语“侧翼内切核酸酶测定”包括如上所述的“invader”侵入性切割测定和quarts测定。
本文所用,用于提及多核苷酸(即,核苷酸序列)的术语“互补”或“互补性”是指与碱基配对规则有关的多核苷酸。例如,序列“5′-a-g-t-3′”与序列“3′-t-c-a-5′”互补。互补性可以是“部分的”,其中仅一些核酸碱基根据碱基配对规则来匹配。或者,在核酸之间可能存在“完全”或“总”互补性。核酸链之间的互补性程度对核酸链之间杂交的效率和强度具有显著影响。这在扩增反应以及依赖核酸间结合的检测方法中特别重要。
如本文所用,术语“引物”是指在置于诱导与核酸链互补的引物延伸产物合成的条件下时(例如,在核苷酸和诱导剂诸如生物催化剂(例如,dna聚合酶等)的存在下)能够充当合成的起始点的寡核苷酸(无论是当在纯化的限制性消化中时天然存在还是以合成方式产生)。为了扩增的最大效率,引物通常是单链的,但可以可替代地为部分或完全双链的。与模板核酸杂交的引物部分足够长以在诱导剂存在下引发延伸产物的合成。引物的确切长度将取决于很多因素,包括温度、引物来源和使用方法。引物可包括标记、标签、捕获部分等。
如本文所用,术语“核酸分子”是指含有核酸的分子,包括但不限于dna或rna。这个术语涵盖包含任何具有已知的dna和rna碱基类似物的序列,包括但不限于:4-乙酰胞嘧啶、8-羟基-n6-甲基腺苷、氮丙啶胞嘧啶、假异胞嘧啶、5-(羧羟基-甲基)尿嘧啶、5-氟尿嘧啶、5-溴尿嘧啶、5-羧甲基胺甲基-2-硫尿嘧啶、5-羧甲基-胺甲基尿嘧啶、二氢尿嘧啶、肌苷、n6-异戊烯基腺嘌呤、1-甲基腺嘌呤、1-甲基假尿嘧啶、1-甲基鸟嘌呤、1-甲基肌苷、2,2-二甲基鸟嘌呤、2-甲基腺嘌呤、2-甲基鸟嘌呤、3-甲基胞嘧啶、5-甲基胞嘧啶、n6-甲基腺嘌呤、7-甲基鸟嘌呤、5-甲氨基甲基尿嘧啶、5-甲氧基-氨基-甲基-2-硫尿嘧啶、β-d-甘露糖基q核苷(beta-d-mannosylqueosine)、5′-甲氧羰基甲基尿嘧啶、5-甲氧基尿嘧啶、2-甲硫基-n-异戊烯基腺嘌呤、尿嘧啶-5-氧基醋酸甲酯、尿嘧啶-5-氧基醋酸、氧基丁氧核苷(oxybutoxosine)、假尿嘧啶、q核苷、2-硫胞嘧啶、5-甲基-2-硫尿嘧啶、2-硫尿嘧啶、4-硫尿嘧啶、5-甲基尿嘧啶、n-尿嘧啶-5-氧基醋酸甲酯、尿嘧啶-5-氧基醋酸、假尿嘧啶、q核苷、2-硫胞嘧啶以及2,6-二氨基嘌呤。
如本文所用,术语“核碱基”与本领域中使用的其它术语同义,包括“核苷酸”、“脱氧核苷酸”、“核苷酸残基”、“脱氧核苷酸残基”、“核苷三磷酸(ntp)”或脱氧核苷酸三磷酸(dntp)。
“寡核苷酸”是指包含至少两个核酸单体单元(例如核苷酸),通常多于三个单体单元,并且更通常大于十个单体单元的核酸。寡核苷酸的确切大小通常取决于各种因素,包括寡核苷酸的最终功能或用途。为了进一步说明,寡核苷酸通常小于200个残基长(例如,介于15个与100个之间),然而,如本文所用,所述术语还旨在涵盖更长的多核苷酸链。寡核苷酸常常以其长度来提及。例如,24个残基寡核苷酸被称为“24聚体”。通常,核苷单体通过磷酸二酯键或其类似物(包括硫代磷酸酯、二硫代磷酸酯、硒代磷酸酯、二硒代磷酸酯、硫代磷酰苯胺(phosphoroanilothioate)、酰基苯胺磷酸酯(phosphoranilidate)、氨基磷酸酯等,包括相关的抗衡离子例如h+、nh4+、na+等(如果此类抗衡离子存在))连接。此外,寡核苷酸通常是单链的。寡核苷酸任选地通过任何合适方法制备,所述任何合适方法包括但不限于由诸如以下的方法进行的现有或天然序列的分离、dna复制或扩增、逆转录、适当序列的克隆和限制性消化或直接化学合成:narang等(1979)methenzymol.68:90-99的磷酸三酯法;brown等(1979)methenzymol.68:109-151的磷酸二酯法;beaucage等(1981)tetrahedronlett.22:1859-1862的二乙基亚磷酰胺法;matteucci等(1981)jamchemsoc.103:3185-3191的三酯法;自动化合成法;或1984年7月3日授予caruthers等的题为“用于制备多核苷酸的方法”的美国专利号4,458,066的固体支持物法;或本领域技术人员已知的其它方法。所有这些参考文献均以引用方式并入。
生物聚合物的“序列”是指生物聚合物中单体单元(例如核苷酸、氨基酸等)的顺序和特性。通常在5′至3′方向上读取核酸的序列(例如,碱基序列)。
如本文所用,术语“基因”是指包含产生多肽、前体或rna(例如,非编码rna诸如核糖体rna、转移rna、剪接体rna、微小rna)所需的编码序列的核酸(例如dna)序列。多肽或非编码rna可由全长编码序列或编码序列的任何部分来编码,只要全长或片段多肽的所需活性或功能性质(例如,酶活性、配体结合、信号转导、免疫原性等)得以保留。此术语也涵盖结构基因的编码区以及与编码区相邻位于5′和3′末端上、在任一个末端上达约1kb或更长的距离的序列,以使得基因对应于全长mrna的长度。位于编码区的5′并且存在于mrna上的序列被称为5′非翻译序列。位于编码区的3′或下游并且存在于mrna上的序列被称为3′非翻译序列。术语“基因”涵盖基因的cdna和基因组形式。基因的基因组形式或克隆含有以被称为“内含子”或“插入区”或“插入序列”的非编码序列间断的编码区。内含子是转录至核rna(例如,hnrna)中的基因区段;内含子可含有调控元件(例如增强子)。内含子从核或初级转录物中去除或“剪除”;因此,内含子不存在于信使rna(mrna)转录物中。mrna在翻译期间起作用以指定新生多肽中的氨基酸的序列或顺序。
除了含有内含子以外,基因的基因组形式还可包括位于rna转录物上存在的5′和3′末端序列上的序列。这些序列被称为“旁侧”序列或区(这些侧接序列位于存在于mrna转录物上的非翻译序列5′或3′)。5′旁侧区可含有控制或影响基因转录的调控序列,诸如启动子和增强子。3′旁侧区可含有引导转录终止、转录后切割和聚腺苷酸化的序列。
当提及基因时,术语“野生型”是指具有从天然存在的来源分离的基因特征的基因。当提及基因产物时,术语“野生型”是指具有从天然存在的来源分离的基因产物特征的基因产物。如用于对象的术语“天然存在的”是指对象可在自然界中被发现的事实。例如,可从自然中的来源分离并且不通过人在实验室中有意修饰的存在于生物(包括病毒)中的多肽或多核苷酸序列为天然存在的。野生型基因常常是在群体中最频繁观察到的基因或等位基因,并且因此任意设计成基因的“正常”或“野生型”形式。相比之下,术语“修饰的”或“突变体”在提及基因或基因产物时分别指在与野生型基因或基因产物相比时显示序列和/或功能性质的修饰(例如,改变的特征)的基因或基因产物。应注意,天然存在的突变体可被分离;这些突变体通过以下事实来鉴定:在与野生型基因或基因产物相比时,它们具有改变的特征。
术语“等位基因”是指基因的变化;变化包括但不限于变体和突变体、多态性基因座和单核苷酸多态性基因座、移码和剪接突变。等位基因可天然存在于群体中,或者可能在群体的任何特定个体的生命期期间出现。
因此,当用于提及核苷酸序列时,术语“变体”和“突变体”是指与另一个通常相关的核苷酸酸序列不同之处在于的一个或多个核苷酸的核酸序列。“变化”是两个不同核苷酸序列之间的差异;通常,一个序列是参考序列。
如本文所用的术语“固体支持物”包括其上可固定靶(例如dna)的所有材料。可以或可以不被化学修饰的天然或合成材料可用作固体支持物,特别是聚合物诸如聚氯乙烯、聚乙烯、聚苯乙烯、聚丙烯酸酯或聚酰胺,或基于乙烯基芳族单体的共聚物、不饱和羧酸的酯、偏二氯乙烯、二烯或具有腈官能团的化合物(丙烯腈);氯乙烯和丙烯的聚合物、氯乙烯和乙酸乙烯酯的聚合物;基于苯乙烯或苯乙烯的取代衍生物的共聚物;合成纤维,诸如尼龙;无机材料,诸如二氧化硅、玻璃、陶瓷或石英;乳胶、磁性颗粒;金属衍生物。另外的实例包括但不限于微量滴定板、片、锥体、管、孔、珠子(例如,磁珠)、颗粒等,或平坦支撑物诸如二氧化硅或硅晶片。
如本文所用,术语“磁性颗粒”和“磁珠”可互换使用,并且是指响应于磁场的颗粒或珠子。通常,磁性颗粒包含没有磁场但是当暴露于磁场时形成磁偶极子的材料,例如在存在磁场的情况下能够被磁化但是在不存在这种场的情况下本身不是磁性的材料。如在此上下文中所用的术语“磁性”包括作为顺磁性材料或超顺磁性材料的材料。如本文所用,术语“磁性”还涵盖临时磁性材料,诸如具有低居里温度的铁磁性或亚铁磁性材料,条件是所述暂时磁性材料在根据本发明方法使用含有所述材料的二氧化硅磁性颗粒来分离生物材料的温度范围内是顺磁性的。如在对颗粒或珠子的提及中所用的术语“可混合的”是指例如在柱中呈游离形式(即不固定)但可添加至样品并通过混合作用(例如涡旋、搅拌、振荡、反复移液等)分布于样品液中的颗粒。
术语“探针”是指能够与另一种目标寡核苷酸杂交的无论是当在纯化的限制性消化中时天然存在还是以合成方式、以重组方式或通过pcr扩增产生的寡核苷酸(例如,核苷酸序列)。探针可以是单链或双链的。探针可用于特定基因序列的检测、鉴定和分离(例如,“捕获探针”)。预期了在一些实施方案中,本发明中使用的任何探针可以用任何“报道分子”标记,使得可在任何检测系统中检测到,所述任何检测系统包括但不限于酶(例如,elisa以及基于酶的组织化学测定)、荧光、放射性和发光系统。不希望本发明限于任何特定的检测系统或标记。
如本文所用,“甲基化”是指胞嘧啶的位置c5或n4处的胞嘧啶甲基化、腺嘌呤的n6位置或其它类型的核酸甲基化。体外扩增的dna通常是未甲基化的,因为典型的体外dna扩增方法未保留扩增模板的甲基化模式。然而,“未甲基化dna”或“甲基化dna”还可指原始模板分别为未甲基化或甲基化的扩增dna。
因此,如本文所用,“甲基化核苷酸”或“甲基化核苷酸碱基”是指在核苷酸碱基上存在甲基部分,其中甲基部分不存在于公认的典型核苷酸碱基中。例如,胞嘧啶在其嘧啶环上不含有甲基部分,但是5-甲基胞嘧啶在其嘧啶环的位置5处含有甲基部分。因此,胞嘧啶不是甲基化核苷酸,并且5-甲基胞嘧啶是甲基化核苷酸。在另一个实例中,胸腺嘧啶在其嘧啶环的位置5处含有甲基部分;然而,出于本文的目的,当存在于dna中时胸腺嘧啶被认为不是甲基化核苷酸,因为胸腺嘧啶是dna的典型核苷酸碱基。
如本文所用,“甲基化核酸分子”是指含有一个或多个甲基化核苷酸的核酸分子。
如本文所用,核酸分子的“甲基化状态”、“甲基化谱”和“甲基化状态”是指核酸分子中一个或多个甲基化核苷酸碱基的存在或不存在。例如,含有甲基化胞嘧啶的核酸分子被认为是甲基化的(例如,核酸分子的甲基化状态是甲基化的)。不含任何甲基化核苷酸的核酸分子被认为是未甲基化的。
特定核酸序列(例如,如本文所述的基因标记或dna区)的甲基化状态可指示序列中每个碱基的甲基化状态,或者可指示序列内碱基的(例如,一个或多个胞嘧啶的)子集的甲基化状态,或者可指示关于序列内的区甲基化密度的信息,而提供或不提供序列内发生甲基化的位置的精确信息。
核酸分子中核苷酸位点的甲基化状态是指核酸分子中特定位点处甲基化核苷酸的存在或不存在。例如,当核酸分子中第7个核苷酸处存在的核苷酸是5-甲基胞嘧啶时,核酸分子中第7个核苷酸处的胞嘧啶的甲基化状态是甲基化的。类似地,当核酸分子中第7个核苷酸处存在的核苷酸是胞嘧啶(且非5-甲基胞嘧啶)时,核酸分子中第7个核苷酸处的胞嘧啶的甲基化状态是未甲基化的。
甲基化状态可任选地由“甲基化值”表示或指示(例如,表示甲基化频率、分数、比率、百分比等)。甲基化值可例如通过在用甲基化依赖性限制酶进行限制性消化之后定量存在的完整核酸的量或通过在亚硫酸氢盐反应后比较扩增谱或通过比较亚硫酸氢盐处理的核酸和未处理核酸的序列来产生。因此,值(例如甲基化值)代表甲基化状态,并且因此可用作位点的多个拷贝内的甲基化状态的定量指标。当希望将样品中序列的甲基化状态与阈值或参考值进行比较时,这是特别有用的。
如本文所用,“甲基化频率”或“甲基化百分比(%)”是指相对于分子或位点未被甲基化的情况的数目的分子或位点被甲基化的情况的数目。
因此,甲基化状态描述了核酸(例如,基因组序列)的甲基化状态。此外,甲基化状态是指与甲基化相关的特定基因组位点处的核酸区段的特征。无论此dna序列内的任何胞嘧啶(c)残基是否被甲基化,所述特征包括但不限于:甲基化c残基的位置、整个核酸的任何特定区内的甲基化c的频率或百分比,以及由于例如等位基因起源的差异所引起的等位基因的甲基化差异。术语“甲基化状态”、“甲基化谱”和“甲基化状态”还指生物样品中整个核酸的任何特定区内的甲基化c或未甲基化c的相对浓度、绝对浓度或模式。例如,如果核酸序列内的胞嘧啶(c)残基被甲基化,则其可被称为“超甲基化的”或具有“增加的甲基化”,而如果dna序列内的胞嘧啶(c)残基序列未被甲基化,则其可被称为“低甲基化的”或具有“减少的甲基化”。同样地,如果与另一个核酸序列(例如,来自不同区或不同个体等)相比,核酸序列内的胞嘧啶(c)残基被甲基化,则与另一个核酸序列相比,所述序列被认为是超甲基化的或具有增加的甲基化。可替代地,如果与另一个核酸序列(例如,来自不同区或不同个体等)相比,dna序列内的胞嘧啶(c)残基被甲基化,则与另一个核酸序列相比,所述序列被认为是低甲基化的或具有减少的甲基化。另外,如本文所用的术语“甲基化模式”是指核酸区上的甲基化和未甲基化核苷酸的集合位点。当甲基化和未甲基化核苷酸的数目在整个区内相同或相似,但是甲基化和未甲基化核苷酸的位置不同时,两个核酸可具有相同或相似的甲基化频率或甲基化百分比,但是具有不同的甲基化模式。序列在它们的甲基化的程度(例如,相对于另一个序列,一个序列具有增加或减少的甲基化)、频率或模式不同时据称是“差异甲基化的”或具有“甲基化差异”或“不同甲基化状态”。术语“差异甲基化”是指癌症阳性样品中核酸甲基化的水平或模式与癌症阴性样品中核酸甲基化的水平或模式相比的差异。它还可指手术后癌症复发的患者与没有复发的患者之间的水平或模式的差异。差异甲基化和dna甲基化的特定水平或模式是预后和预测性生物标记,例如一旦界定了正确的截止或预测性特征。
甲基化状态频率可用于描述个体群体或来自单个个体的样品。例如,甲基化状态频率为50%的核苷酸位点在50%情况下是甲基化的,并且在50%情况下是未甲基化的。这种频率可用于例如描述个体群体或核酸集合中核苷酸位点或核酸区被甲基化的程度。因此,当第一群体或核酸分子汇集物中的甲基化与第二群体或核酸分子汇集物中的甲基化不同时,第一群体或汇集物的甲基化状态频率将与第二群体或汇集物的甲基化状态频率不同。这种频率还可用于例如描述单个个体中核苷酸位点或核酸区被甲基化的程度。例如,这种频率可用于描述来自组织样品的一组细胞在核苷酸位点或核酸区处被甲基化或未被甲基化的程度。
术语“高度甲基化的”是指特定位点(例如,cpg二核苷酸或一组二核苷酸或富含cpg的区)以一定速率以特定样品类型或组织类型甲基化的核酸,所述速率在可测量程度上大于对于另一种组织或样品类型中同一dna中的可比较位点所观察到的速率。“高度甲基化的”可以指单个特定c残基或区中多个c内的平均甲基化速率,作为所测定样品中所述位点的拷贝的分数。在一些实施方案中,在不使所述术语限于任何特定的甲基化水平的情况下,超甲基化位点可>10%甲基化,优选地>20%至40%,更优选地>50%至75%,仍更优选地介于75%与100%之间。
如本文所用,“核苷酸位点”是指核酸分子中核苷酸的位置。甲基化核苷酸的核苷酸位点是指核酸分子中甲基化核苷酸的位置。
通常,人dna的甲基化发生在包含相邻的鸟嘌呤和胞嘧啶的二核苷酸序列(也称为cpg二核苷酸序列)上,在所述二核苷酸序列中胞嘧啶位于鸟嘌呤的5′处。cpg二核苷酸内的大多数胞嘧啶在人基因组中是甲基化的,然而一些在特定的cpg二核苷酸富集基因组区(称为cpg岛)中保持未甲基化(参见,例如antequera等(1990)cell62:503–514)。
如本文所用,“cpg岛”是指相对于总基因组dna含有的cpg二核苷酸数目增加的基因组dna的富含g:c的区。cpg岛的长度可为至少100个、200个或更多个碱基对,其中所述区的g:c含量为至少50%,并且观察到的cpg频率相对于预期频率的比率为0.6;在一些情况下,cpg岛的长度可为至少500个碱基对,其中所述区的g:c含量为至少55%),并且观察到的cpg频率相对于预期频率的比率为0.65。相对于预期频率的观察到的cpg频率可根据gardiner-garden等(1987)j.mol.biol.196:261–281中提供的方法来计算。例如,相对于预期频率的观察到的cpg频率可根据式r=(a×b)/(c×d)来计算,其中r是观察到的cpg频率相对于预期频率的比率,a是分析序列中cpg二核苷酸的数目,b是分析序列中核苷酸的总数,c是分析序列中c核苷酸的总数,d是分析序列中g核苷酸的总数。甲基化状态通常在cpg岛中(例如在启动子区处)确定。将理解,人基因组中的其它序列倾向于dna甲基化,诸如cpa和cpt(参见,ramsahoye(2000)proc.natl.acad.sci.usa97:5237–5242;salmon和kaye(1970)biochim.biophys.acta.204:340–351;grafstrom(1985)nucleicacidsres.13:2827–2842;nyce(1986)nucleicacidsres.14:4353–4367;woodcock(1987)biochem.biophys.res.commun.145:888-894)。
如本文所用,术语“组织细胞”是指身体(例如人或动物身体)中的任何组织细胞,包括例如上皮细胞、肌肉细胞、神经细胞和骨细胞。组织细胞不包括血细胞。如本文所用,血液通常包含血浆、红细胞、白细胞(包括白血球和淋巴细胞)和血小板。白细胞包括嗜中性粒细胞(neutophil)、单核细胞、嗜酸性粒细胞和嗜碱性粒细胞,并且淋巴细胞包括t细胞、b细胞和自然杀伤细胞。
“组织细胞特异性对照dna”和“组织细胞特异性dna是指可检测组织或来自组织的无细胞dna的存在,并且在血液或正常的血液组分(例如,如上所列的血浆、白细胞等)中可最低限度地检测或不可检测的dna。如本文所用,仅在组织中甲基化并且在血液中未被类似地甲基化的dna(或反之亦然)可以是关于甲基化状态的组织细胞特异性dna,即使dna的一级序列在两种细胞类型中是相同的。“上皮特异性对照dna”是指检测上皮细胞中发现的dna的组织特异性对照dna。
如本文所用,根据核酸分子的甲基化状态修饰核酸分子的核苷酸的试剂或甲基化特异性试剂是指可以反映核酸分子的甲基化状态的方式改变核酸分子的核苷酸序列的化合物或组合物或其它药剂。用这种试剂处理核酸分子的方法可包括使核酸分子与试剂接触,用另外的步骤偶联(如果需要),以实现所需的核苷酸序列变化。核酸分子核苷酸序列的这种变化可产生每个甲基化核苷酸被修饰成不同核苷酸的核酸分子。核酸核苷酸序列的这种变化可产生每个未甲基化核苷酸被修饰成不同核苷酸的核酸分子。核酸核苷酸序列的这种变化可产生未甲基化的所选核苷酸中的每个(例如,每个未甲基化胞嘧啶)被修饰成不同核苷酸的核酸分子。使用这种试剂来改变核酸核苷酸序列可产生作为甲基化核苷酸的每个核苷酸(例如,每个甲基化胞嘧啶)被修饰成不同核苷酸的核酸分子。如本文所用,修饰所选核苷酸的试剂的使用是指修饰核酸分子中的四种通常存在的核苷酸(对于dna,c、g、t和a;并且对于rna,c、g、u和a)中的一种核苷酸的试剂,使得试剂修饰一种核苷酸而不修饰其它三种核苷酸。在一个示例性实施方案中,这种试剂修饰未甲基化的所选核苷酸以产生不同的核苷酸。在另一个示例性实施方案中,这种试剂可使未甲基化胞嘧啶核苷酸脱氨基。示例性试剂是亚硫酸氢盐。
如本文所用,术语“亚硫酸氢盐试剂”是指在一些实施方案中包含亚硫酸氢盐(bisulfite)、亚硫酸氢盐(disulfite)、亚硫酸氢盐(hydrogensulfite)或其组合以区分例如cpg二核苷酸序列中的甲基化胞苷和未甲基化胞苷的试剂。
术语“甲基化测定”是指用于测定核酸序列内的一个或多个cpg二核苷酸序列的甲基化状态的任何测定。
术语“msap-pcr”(甲基化敏感性任意引物聚合酶链式反应)是指允许使用富含cg的引物进行基因组的全局扫描以集中于最可能含有cpg二核苷酸的区的本领域公认的技术,并且所述本领域公认的技术由gonzalgo等(1997)cancerresearch57:594–599加以描述。
术语“methylighttm”是指由eads等(1999)cancerres.59:2302–2306描述的本领域公认的基于荧光的实时pcr技术。
术语“heavymethyltm”是指覆盖扩增引物之间或由扩增引物覆盖的cpg位置的甲基化特异性阻断探针(在本文中还被称为阻断剂)使得能够进行核酸样品的甲基化特异性选择性扩增的测定。
术语“heavymethyltmmethylighttm”测定是指heavymethyltmmethylighttm测定,其为methylighttm测定的变化,其中methylighttm测定与覆盖扩增引物之间的cpg位置的甲基化特异性阻断探针组合。
术语“ms-snupe”(甲基化敏感性单核苷酸引物延伸)是指由gonzalgo和jones(1997)nucleicacidsres.25:2529–2531描述的本领域公认的测定。
术语“msp”(甲基化特异性pcr)是指由herman等(1996)proc.natl.acad.sci.usa93:9821–9826以及由美国专利号5,786,146描述的本领域公认的甲基化测定。
术语“cobra”(组合亚硫酸氢盐限制性分析)是指由xiong和laird(1997)nucleicacidsres.25:2532–2534描述的本领域公认的甲基化测定。
术语“mca”(甲基化cpg岛扩增)是指由toyota等(1999)cancerres.59:2307–12以及wo00/26401a1中描述的甲基化测定。
如本文所用,术语“试剂盒”是指递送材料的任何递送系统。在核酸纯化系统和反应测定的上下文中,所述递送系统包括允许将试剂和装置(例如适当容器中的抑制剂吸附剂、颗粒、变性剂、寡核苷酸、旋转过滤器等)和/或支持材料(例如,缓冲液、用于执行程序的书面说明书等)从一个位置存储、运输或递送至另一个位置的系统。例如,试剂盒包括一个或多个套罩(例如,盒),其含有相关反应试剂和/或支持材料。如本文所用,术语“分段试剂盒”是指包括各自含有总试剂盒组分的子部分的两个或更多个单独容器的递送系统。所述容器可共同或单独输送至预定接受者。例如,第一容器可含有用于样品收集的材料和缓冲液,而第二容器含有捕获寡核苷酸和变性剂。术语“分段试剂盒”旨在涵盖含有根据联邦食品、药物和化妆品法(federalfood,drug,andcosmeticact)的第520节(e)款来管理的分析物特异性试剂(asr)的试剂盒,但不限于此。事实上,包含各自含有总试剂盒组分的子部分的两个或更多个单独容器的任何递送系统包括于术语“分段试剂盒”中。相比之下,“组合试剂盒”是指含有单一容器(例如,容纳每个所需组分的单一盒)中的反应测定的所有组分的递送系统。术语“试剂盒”包括分段试剂盒和组合试剂盒。
如本文所用的术语“系统”是指用于出于特定目的使用的物品的集合。在一些实施方案中,所述物品包括作为例如物品上、纸上或可记录介质(例如,磁盘、cd、闪存驱动器等)上提供的信息的使用说明书。在一些实施方案中,说明书将用户引导至在线位置,例如网站。
如本文所用,术语“信息”是指任何事实或数据的集合。在对使用计算机系统(包括但不限于互联网)存储或处理的信息的提及中,所述术语是指以任何格式(例如,模拟、数字、光学等)存储的任何数据。如本文所用,术语“与受试者有关的信息”是指关于受试者(例如人、植物或动物)的事实或数据。术语“基因组信息”是指关于基因组的信息,包括但不限于核酸序列、基因、甲基化百分比、等位基因频率、rna表达水平、蛋白质表达、与基因型相关的表型等。“等位基因频率信息“是指关于等位基因频率的事实或数据,包括但不限于等位基因特性、等位基因的存在与受试者(例如,人受试者)的特征之间的统计学相关性、个体或群体中等位基因的存在或不存在、等位基因存在于具有一个或多个特定特征的个体中的可能性百分比等。
详述
本文提供涉及进行用于检测和定量dna(例如,甲基化dna)的测定的技术。特别地,所述技术涉及用于所述甲基化测定的内部对照。
本公开的实施方案提供用作甲基化标记和内部对照的称为“zdhhc1”的标记。在本公开实施方案的开发期间进行的实验证实,在正常血液样品(例如,获自无病个体)中发现很少或没有甲基化zdhhc1。与通常使用的内部对照dna(例如β-肌动蛋白)相反,zdhhc1产生例如来自存在于组织或粪便样品中的血液的非常低的本底信号。在本发明技术的开发期间,发现在示例性甲基化测定(例如侧翼内切核酸酶测定,诸如quarts测定)中用zdhhc1替代actb内部对照增加了测定的灵敏度和特异性。
另外的实验证实,zdhhc1用作可用于检测血液中的上皮组织细胞的标记(例如,作为转移性癌症的标记)。本文描述了示例性实施方案。
尽管本文的公开内容是指某些说明的实施方案,但是应理解,这些实施方案通过举例而不是通过限制的方式呈现。
i.组织细胞特异性标记
在检测和定量已经进行亚硫酸氢盐转化的甲基化富含cpg的dna的测定中,典型的是还检测存在于相同样品中的对照基因,所述对照基因验证测定中的dna输入,不管来源(例如,癌症、正常、粪便、组织)如何。这种对照基因用于例如归一化跨越不同样品的测定中获得的dna拷贝数数据,以精确地显示样品-样品的较高或较低的疾病相关的标记水平。
对于归一化基因以最佳地运作的甲基化测定,其应满足若干标准。理想的归一化基因,例如:1)应相等地存在于正常组织和患病组织中;2)应与被测定的测试基因/标记(例如超甲基化是疾病状态的指标的dna标记)具有大约相同的gc含量;3)应与测试基因/标记以相同的方式反应,以进行预定量(pre-pcr)样品处理,诸如亚硫酸氢盐转化;以及4)应具有与所测定的测试基因/标记的pcr扩增效率类似的pcr扩增效率。
β-肌动蛋白基因(通常用作用于检测甲基化标记dna的归一化基因的基因)不与疾病诸如癌症和腺瘤等相关的甲基化标记(例如,波形蛋白、胞裂蛋白9、ndrg4、bmp3)具有相同的gc含量和cpg甲基化,因此其在pre-pcr亚硫酸氢盐转化或pcr扩增中表现得不像所述标记dna一样。在本技术的发展中,已经发现使用满足上述标准的归一化基因代替actb提高了测定灵敏度和特异性。在本技术的开发中,进一步发现使用在正常组织和患病组织中被高度甲基化但在血液中未被甲基化的标记基因提供了对组织细胞(例如上皮细胞)特异性并且在血液中的存在低的标记。所述对照dna的使用减少来自样品(例如粪便或组织样品)中存在的任何血液的本底,并且还可用于检测可能例如在肿瘤转移期间发生的血液中的所述组织细胞的异常存在。
在本文中描述的实验鉴定了在正常和癌组织中高度甲基化的基因(例如,zdhhc1)。这些基因在血液中未高度甲基化,并且除了如实施例6所述,与转移性癌症相关联之外,它们在血液中被甲基化的程度未根据疾病状态而变化。这允许仅反映组织且不依赖于样品中血液含量的更好和更精确的甲基化计算。本文描述的基因用于归一化患者与样品之间的标记水平。
zdhhc1、zfand3、zmym4、odz2和trio被鉴定为候选甲基化标记。选择在血沉棕黄层中具有低甲基化的归一化基因允许更敏感地检测目标标记的甲基化(例如,用于归一化信号的分母低,并且因此目标标记的甲基化%变得更大并且更易于区分)。
本文所述的归一化基因在组织(癌症和正常)中被高度甲基化,并且在血液中未被高度甲基化,并且提供优于现有标记的若干优点:
1-gc含量和cpg甲基化和亚硫酸氢盐反应性与所研究的dna标记更类似。
2-它们显示与所测量的标记dna的pcr扩增效率更类似的pcr扩增效率。
3-血沉棕黄层中的低甲基化状态允许在血液中或在血液存在下的目标标记的更高甲基化百分比检测。
ii.甲基化检测测定
本文所述的标记(例如,特别是zdhhc1)可在各种甲基化检测测定用作归一化试剂和疾病状态的指标。
用于分析核酸的5-甲基胞嘧啶存在的最常用方法是基于由frommer等描述用于检测dna中的5-甲基胞嘧啶的亚硫酸氢盐法(frommer等(1992)proc.natl.acad.sci.usa89:1827–31,其出于所有目的以引用方式整体明确地并入本文)或其变化。映射5-甲基胞嘧啶的亚硫酸氢盐法是基于观察到的胞嘧啶而非5-甲基胞嘧啶与亚硫酸氢盐离子(也称为亚硫酸氢盐)的反应。所述反应通常根据以下步骤进行:首先,胞嘧啶与亚硫酸氢盐反应形成磺化胞嘧啶。接着,磺化反应中间体的自发脱氨基产生磺化尿嘧啶。最后,磺化尿嘧啶在碱性条件下脱磺酸化形成尿嘧啶。检测是可能的,因为尿嘧啶碱基与腺嘌呤配对(因此表现得像胸腺嘧啶一样),而5-甲基胞嘧啶碱基与鸟嘌呤配对(因此表现得像胞嘧啶一样)。这使得可以通过例如亚硫酸氢盐基因组测序(griggg和clarks,bioessays(1994)16:431–36;griggg,dnaseq.(1996)6:189–98)、例如美国专利号5,786,146所公开的甲基化特异性pcr(msp)或使用比较序列特异性探针切割的测定(例如quarts侧翼内切核酸酶测定)(参见,例如zou等(2010)“sensitivequantificationofmethylatedmarkerswithanovelmethylationspecifictechnology”clinchem56:a199;美国专利8,361,720以及美国专利申请序列号;12/946,745;12/946,752和61/705,603)来将甲基化胞嘧啶与非甲基化胞嘧啶鉴别开来。
一些常规技术涉及包括以下的方法:在琼脂糖基质中封闭待分析的dna,从而防止dna的扩散和复性(亚硫酸氢盐仅与单链dna反应),以及用快速透析替代沉淀和纯化步骤(oleka,等(1996)“amodifiedandimprovedmethodforbisulfitebasedcytosinemethylationanalysis”nucleicacidsres.24:5064-6)。因此,可以分析单个细胞的甲基化状态,从而说明所述方法的效用和灵敏度。用于检测5-甲基胞嘧啶的常规方法的综述由rein,t.,等(1998)nucleicacidsres.26:2255提供。
亚硫酸氢盐技术通常包括在亚硫酸氢盐处理之后扩增已知核酸的短的特异性片段,然后通过测序(olek和walter(1997)nat.genet.17:275–6)或引物延伸反应(gonzalgo和jones(1997)nucleicacidsres.25:2529–31;wo95/00669;美国专利号6,251,594)测定产物以分析单个胞嘧啶位置。一些方法使用酶消化(xiong和laird(1997)nucleicacidsres.25:2532–4)。通过杂交进行的检测也已经在本领域中有所描述(olek等,wo99/28498)。另外,已经描述了使用亚硫酸氢盐技术以进行关于单个基因的甲基化检测(grigg和clark(1994)bioessays16:431–6;zeschnigk等(1997)hummolgenet.6:387–95;feil等(1994)nucleicacidsres.22:695;martin等(1995)gene157:261–4;wo9746705;wo9515373)。
各种甲基化测定程序可根据本发明技术与亚硫酸氢盐处理联合使用。这些测定允许测定核酸序列内一个或多个cpg二核苷酸(例如,cpg岛)的甲基化状态。除了其它技术之外,所述测定还涉及亚硫酸氢盐处理的核酸的测序、pcr(用于序列特异性扩增)、southern印迹分析和甲基化敏感性限制酶的使用。
例如,已经通过使用亚硫酸氢盐处理来简化基因组测序以分析甲基化模式和5-甲基胞嘧啶分布(frommer等(1992)proc.natl.acad.sci.usa89:1827–1831)。另外,例如如由sadri和hornsby(1997)nucl.acidsres.24:5058–5059所述或如被称为cobra(组合亚硫酸氢盐限制性分析)(xiong和laird(1997)nucleicacidsres.25:2532–2534)的方法所体现,由亚硫酸氢盐转化的dna扩增的pcr产物的限制酶消化可用于评估甲基化状态。
cobratm分析是用于确定少量基因组dna中特定基因座处的dna甲基化水平的定量甲基化测定(xiong和laird,nucleicacidsres.25:2532-2534,1997)。简言之,限制酶消化用于揭示亚硫酸氢钠处理的dna的pcr产物的甲基化依赖性序列差异。首先通过根据由frommer等(proc.natl.acad.sci.usa89:1827-1831,1992)所述的程序通过标准亚硫酸氢盐处理将甲基化依赖性序列差异引入基因组dna中。然后使用对目标cpg岛特异性的引物进行亚硫酸氢盐转化的dna的pcr扩增,随后进行限制性内切酶消化、凝胶电泳以及使用特异性标记的杂交探针进行的检测。原始dna样品中的甲基化水平以跨广谱的dna甲基化水平的线性定量方式由消化和未消化pcr产物的相对量表示。此外,此技术可以可靠地应用于获自显微切割石蜡包埋组织样品的dna。
用于cobratm分析的典型试剂(例如,其可在典型的基于cobratm的试剂盒中发现)可包括但不限于:用于特定基因座(例如特异性基因、标记、基因区、标记区、亚硫酸氢盐处理的dna序列、cpg岛等)的pcr引物;限制酶和适当的缓冲液;基因杂交寡核苷酸;对照杂交寡核苷酸;用于寡核苷酸探针的激酶标记试剂盒;以及标记的核苷酸。另外,亚硫酸氢盐转化试剂可包括:dna变性缓冲液;磺化缓冲液;dna回收试剂或试剂盒(例如沉淀、超滤、亲和柱);脱磺酸化缓冲液;以及dna回收组分。
诸如“methylighttm”(基于荧光的实时pcr技术)(eads等,cancerres.59:2302-2306,1999)、ms-snupetm(甲基化敏感性单核苷酸引物延伸)反应(gonzalgo和jones,nucleicacidsres.25:2529-2531,1997)、甲基化特异性pcr(“msp”;herman等,proc.natl.acad.sci.usa93:9821-9826,1996;美国专利号5,786,146)和甲基化cpg岛扩增(“mca”;toyota等,cancerres.59:2307-12,1999)的测定被单独使用或与这些方法中的一种或多种组合使用。
“heavymethyltm”测定、技术是用于基于亚硫酸氢盐处理的dna的甲基化特异性扩增来评估甲基化差异的定量方法。覆盖扩增引物之间或由扩增引物覆盖的cpg位置的甲基化特异性阻断探针(“阻断剂”)使得能够进行核酸样品的甲基化特异性选择性扩增。
术语“heavymethyltmmethylighttm”测定是指heavymethyltmmethylighttm测定,其为methylighttm测定的变化,其中methylighttm测定与覆盖扩增引物之间的cpg位置的甲基化特异性阻断探针组合。heavymethyltm测定还可与甲基化特异性扩增引物组合使用。
用于heavymethyltm分析的典型试剂(例如,其可在典型的基于methylighttm的试剂盒中发现)可包括但不限于:用于特定位点(例如特异性基因、标记、基因区、标记区、亚硫酸氢盐处理的dna序列、cpg岛,或亚硫酸氢盐处理的dna序列或cpg岛等)的pcr引物;阻断寡核苷酸;优化的pcr缓冲液和脱氧核苷酸;以及taq聚合酶。
msp(甲基化特异性pcr)允许评估cpg岛内几乎任何一组cpg位点的甲基化状态,而不依赖于使用甲基化敏感性限制酶无关(herman等proc.natl.acad.sci.usa93:9821-9826,1996;美国专利号5,786,146)。简言之,dna由亚硫酸氢钠修饰,所述亚硫酸氢钠将未甲基化胞嘧啶而非甲基化胞嘧啶转化成尿嘧啶,并且随后用对甲基化dna与未甲基化dna特异性的引物扩增产物。msp仅需要少量dna,对给定cpg岛位点的0.1%甲基化等位基因敏感,并且可对提取自石蜡包埋样品的dna进行。用于msp分析的典型试剂(例如,其可在典型的基于msp的试剂盒中发现)可包括但不限于:用于特定基因座(例如特异性基因、标记、基因区、标记区、亚硫酸氢盐处理的dna序列、cpg岛等)的甲基化和未甲基化pcr引物;优化的pcr缓冲液和脱氧核苷酸以及特异性探针。
methylighttm测定是利用基于荧光的实时pcr(例如
methylighttm测定用作用于核酸例如基因组dna样品中的甲基化模式的定量测试,其中序列鉴别在探针杂交水平上发生。在定量版本中,pcr反应在与特定推定的甲基化位点重叠的荧光探针存在下提供甲基化特异性扩增。对于输入dna量的无偏倚控制通过引物和探针都不覆盖任何cpg二核苷酸的反应来提供。可替代地,通过用不覆盖已知甲基化位点的对照寡核苷酸(例如,heavymethyltm的基于荧光的版本和msp技术)或用覆盖潜在甲基化位点的寡核苷酸探测偏倚pcr汇集物来实现基因组甲基化的定性测试。
methylighttm方法与任何合适的探针(例如
用于methylighttm分析的典型试剂(例如,其可在典型的基于methylighttm的试剂盒中发现)可包括但不限于:用于特定基因座(例如特异性基因、标记、基因区、标记区、亚硫酸氢盐处理的dna序列、cpg岛等)的pcr引物;
qmtm(定量甲基化)测定是用于基因组dna样品中的甲基化模式的替代性定量测试,其中序列鉴别在探针杂交水平上发生。在此定量版本中,pcr反应在与特定推定的甲基化位点重叠的荧光探针存在下提供无偏倚扩增。对于输入dna量的无偏倚控制通过引物和探针都不覆盖任何cpg二核苷酸的反应来提供。可替代地,通过用不覆盖已知甲基化位点的对照寡核苷酸(heavymethyltm的基于荧光的版本和msp技术)或用覆盖潜在甲基化位点的寡核苷酸探测偏倚pcr汇集物来实现基因组甲基化的定性测试。
在扩增过程中,qmtm方法可与任何合适的探针例如
ms-snupetm技术是用于基于亚硫酸氢盐处理dna评估特定cpg位点处的甲基化差异,随后进行单核苷酸引物延伸的定量方法(gonzalgo和jones,nucleicacidsres.25:2529-2531,1997)。简言之,基因组dna与亚硫酸氢钠反应以将未甲基化的胞嘧啶转化成尿嘧啶,同时使5-甲基胞嘧啶不变。然后使用对亚硫酸氢盐转化的dna特异性的pcr引物进行所需靶序列的扩增,并且将所得产物分离并用作用于目标cpg位点处的甲基化分析的模板。可对少量的dna(例如,显微切割的病理切片)进行分析,并其避免利用限制酶以确定cpg位点处的甲基化状态。
用于ms-snupetm分析的典型试剂(例如,其可在典型的基于ms-snupetm的试剂盒中发现)可包括但不限于:用于特定基因座(例如特异性基因、标记、基因区、标记区、亚硫酸氢盐处理的dna序列、cpg岛等)的pcr引物;优化的pcr缓冲液和脱氧核苷酸;凝胶提取试剂盒;阳性对照引物;用于特定基因座的ms-snupetm引物;反应缓冲液(用于ms-snupe反应);以及标记的核苷酸。另外,亚硫酸氢盐转化试剂可包括:dna变性缓冲液;磺化缓冲液;dna回收试剂或试剂盒(例如沉淀、超滤、亲和柱);脱磺酸化缓冲液;以及dna回收组分。
约化表示亚硫酸氢盐测序(rrbs)以对核酸的亚硫酸氢盐处理开始,以将所有未甲基化胞嘧啶转化成尿嘧啶,随后进行限制酶消化(例如,通过识别包括cg序列的位点的酶,诸如mspi),并且偶联至衔接子配体之后进行片段的完整测序。限制酶的选择丰富了cpg致密区的片段,减少了可能在分析过程中映射到多基因位置的冗余序列的数目。因此,rrbs通过选择用于测序的限制性片段的子集(例如,通过使用制备性凝胶电泳的大小选择)来降低核酸样品的复杂性。与全基因组亚硫酸氢盐测序相反,由限制酶消化产生的每个片段均含有至少一个cpg二核苷酸的dna甲基化信息。因此,rrbs丰富了在这些区中具有高频限制酶切位点的启动子、cpg岛和其它基因组特征的样品,并且因此提供了评估一个或多个基因组基因座的甲基化状态的测定。
用于rrbs的典型方案包括以下步骤:用限制酶诸如mspi消化核酸样品、补齐突出端和a加尾、连接衔接子、亚硫酸氢盐转化以及pcr。参见,例如等(2005)“genome-scalednamethylationmappingofclinicalsamplesatsingle-nucleotideresolution”natmethods7:133–6;meissner等(2005)“reducedrepresentationbisulfitesequencingforcomparativehigh-resolutiondnamethylationanalysis”nucleicacidsres.33:5868–77。
在一些实施方案中,定量等位基因特异性实时靶标和信号扩增(quarts)测定用于评估甲基化状态。在每个quarts测定中依次发生三种反应,包括在初级反应中的扩增(反应1)和靶探针切割(反应2);以及次级反应中的fret切割和荧光信号产生(反应3)。当用特异性引物扩增靶核酸时,具有侧翼序列的特异性检测探针与扩增子松散结合。靶结合位点处的特异性侵入性寡核苷酸的存在致使5′核酸酶例如fen-1内切核酸酶通过在检测探针与侧翼序列之间切割来释放侧翼序列。侧翼序列与对应的fret盒的非发夹部分互补。因此,侧翼序列在fret盒上用作侵入性寡核苷酸,并且实现fret盒荧光团与猝灭剂之间的切割,这产生了荧光信号。切割反应可切割每个靶点的多个探针,并且因此释放每个侧翼的多个荧光团,从而提供指数信号扩增。quarts可通过使用fret盒用不同的染料来检测单个反应孔中的多个靶。参见,例如zou等(2010)“sensitivequantificationofmethylatedmarkerswithanovelmethylationspecifictechnology”clinchem56:a199)中。
术语“亚硫酸氢盐试剂”是指如本文所公开用于区分甲基化cpg二核苷酸序列和未甲基化cpg二核苷酸序列的包含亚硫酸氢盐(bisulfite)、亚硫酸氢盐(disulfite)、亚硫酸氢盐(hydrogensulfite)或其组合的试剂。所述处理的方法是本领域已知的(例如,pct/ep2004/011715和wo2013/116375,每个所述专利均以引用方式整体并入)。在一些实施方案中,亚硫酸氢盐处理在诸如但不限于正烷撑二醇(n-alkylenglycol)或二乙二醇二甲醚(dme)的变性溶剂存在下或在二氧杂环己烷或二氧杂环己烷衍生物存在下进行。在一些实施方案中,变性溶剂以1%与35%(v/v)之间的浓度使用。在一些实施方案中,亚硫酸氢盐反应在诸如但不限于苯并二氢吡喃衍生物(例如6-羟-2,5,7,8,-四甲基苯并二氢吡喃2-羧酸)或三羟基苯甲酸(trihydroxybenzoneacid)及其衍生物(例如没食子酸)的清除剂存在下进行(参见:pct/ep2004/011715,其以引用方式整体并入)。在某些优选的实施方案中,亚硫酸氢盐反应包括例如如wo2013/116375所述的用亚硫酸氢铵进行的处理。
在一些实施方案中,在定量之前纯化亚硫酸氢盐处理的dna。这可通过本领域已知的任何手段进行,所述任何手段诸如但不限于例如通过microcontm柱(由milliporetm制造)进行的超滤。纯化根据改进的制造商方案来进行(参见,例如pct/ep2004/011715,其以引用方式整体并入)。在一些实施方案中,亚硫酸氢盐处理的dna与固体支持物(例如磁珠)结合,并且在dna与支持物结合时发生脱磺酸化和洗涤。例如在wo2013/116375中提供了所述实施方案的实例。在某些优选的实施方案中,在于支持物上脱磺酸化和洗涤之后,支持物结合的dna立即准备用于甲基化测定。在一些实施方案中,脱磺酸化dna在测定之前从支持物上洗脱。
在一些实施方案中,使用根据本发明的多组引物寡核苷酸(例如,参见表2)和扩增酶来扩增处理的dna的片段。若干dna区段的扩增可在同一个反应容器中同时进行。通常,使用聚合酶链式反应(pcr)进行扩增。
在所述方法的另一个实施方案中,通过使用甲基化特异性引物寡核苷酸来检测标记内或附近的cpg位置的甲基化状态。此技术(msp)已在授予herman的美国专利号6,265,171中有所描述。用于扩增亚硫酸氢盐处理的dna的甲基化状态特异性引物的使用允许甲基化核酸与未甲基化核酸之间的分化。msp引物对含有至少一种与亚硫酸氢盐处理的cpg二核苷酸杂交的引物。因此,所述引物的序列包含至少一个cpg二核苷酸。对未甲基化dna特异性的msp引物在cpg中的c位置的位置处含有“t”。通过扩增获得的片段可携带可直接或间接检测的标记。在一些实施方案中,标记是荧光标记、放射性核素或可在质谱仪中检测到的具有典型质量的可拆分分子片段。当所述标记是质量标记时,一些实施方案提供了具有单个正或负净电荷的标记扩增子,从而允许在质谱仪中具有更好的可检测性(delectability)。检测可通过例如基质辅助激光解吸/电离质谱(maldi)或使用电子喷雾质谱(esi)来进行和可视化。
适于这些测定技术的分离dna的方法是本领域已知的。特别地,一些实施方案包括如美国专利申请序列号13/470,251(“核酸分离”,以us2012/0288868出版)所述的核酸分离,所述专利以引用方式整体并入本文。
在一些实施方案中,本文所述的标记用于对粪便样品进行的quarts测定。在一些实施方案中,提供了用于生产dna样品的方法,特别是用于生产以下dna样品的方法,所述dna样品包含小体积(例如小于100、小于60微升)的高度纯化的低丰度核酸,并且基本上和/或实际上不含抑制用于测试dna样品的测定(例如,pcr、invader、quarts测定等)的物质。所述dna样品可用于诊断测定中,所述诊断测定定性地检测存在于取自患者的样品中的基因、基因变体(例如,等位基因)或基因修饰(例如,甲基化)的存在或定量地测量其活性、表达或量。例如,一些癌症与特定突变等位基因或特定甲基化状态的存在相关,因此检测和/或定量所述突变等位基因或甲基化状态在癌症的诊断和治疗中具有预测价值。
许多有价值的遗传标记以极低的量存在于样品中,并且产生所述标记的许多事件是罕见的。因此,甚至灵敏的检测方法诸如pcr也需要大量的dna来提供足够的低丰度靶以满足或取代测定的检测阈值。此外,甚至低量抑制性物质的存在也损害了涉及检测所述低量靶的这些测定的精确度和精密度。因此,本文提供了提供体积和浓度的必要管理以产生所述dna样品的方法。
一些生物样品,诸如粪便样品,含有多种对pcr抑制性的多种多样的不同化合物。因此,dna提取程序包括去除和/或灭活pcr抑制剂的方法。因此,在一些实施方案中,在实施例1中描述了处理和制备样品,以及特别地但不排他地用于从包含核酸的样品中去除测定抑制剂的方法、系统和试剂盒。
在一些实施方案中,样品包括血液、血清、血浆、胃分泌物、胰液、胃肠道活检样品、来自胃肠道活检的显微切割细胞、脱落到肠胃道腔中的胃肠道细胞和/或从粪便中回收的胃肠道细胞。在一些实施方案中,受试者是人。这些样品可源自上消化道、下胃肠道,或者包括来自上胃肠道和下胃肠道的细胞、组织和/或分泌物。样品可包括来自肝、胆管、胰腺、胃、结肠、直肠、食道、小肠、阑尾、十二指肠、息肉、胆囊、肛门和/或腹膜的细胞、分泌物或组织。在一些实施方案中,样品包括细胞液、腹水、尿液、排泄物、胰液、内窥镜检查期间获得的液体、血液、粘液或唾液。在一些实施方案中,样品是粪便样品。
所述样品可通过本领域已知(诸如对技术人员将是显而易见)的任何数目的手段获得。例如,可以容易地获得尿液和粪便样品,而例如可通过使用针头和注射器来以肠胃外方式获得血液、腹水、血清或胰液样品。可通过使样品经受本领域技术人员已知的各种技术来获得无细胞或基本上无细胞的样品,所述各种技术包括但不限于离心和过滤。虽然通常优选不使用侵入性技术来获得样品,但是仍可优选获得诸如组织匀浆、组织切片和活检试样的样品。所述技术不限于用于制备样品并提供用于测试的核酸的方法。例如,在一些实施方案中,例如如美国专利号8,808,990和9,169,511以及wo2012/155072所详述或通过相关方法使用直接基因捕获来从粪便样品或从血液或从血浆样品中分离dna。
标记的分析可单独进行或与一个测试样品内的另外标记同时进行。例如,若干标记可组合成用于有效处理多个样品并且潜在地提供更大的诊断和/或预后精确度的一个测试。此外,本领域技术人员将认识到测试来自相同受试者的多个样品的值(例如,在连续的时间点时)。序列样品的所述测试可允许鉴定标记甲基化状态随时间推移的变化。甲基化状态的变化以及甲基化状态变化的不存在可提供关于疾病状态的有用信息,所述有用信息包括但不限于确定事件开始的大约时间、可救治组织的存在和量、药物疗法的适当性、各种疗法的有效性以及确定受试者结果(包括未来事件的风险)。
生物标记的分析可以各种物理形式进行。例如,微量滴定板或自动化的使用可用来促进大量测试样品的处理。可替代地,可开发单一样品格式来例如在流动运输或急诊室环境中及时地促进即时治疗和诊断。
预期所述技术的实施方案以试剂盒的形式提供。试剂盒包含本文所述的组合物、装置、仪器等的实施方案以及试剂盒的使用说明书。所述说明书描述了用于由样品制备分析物(例如用于收集样品并由样品制备核酸)的适当方法。试剂盒的单独组分包装在适当容器和包装(例如,小瓶、盒子、泡罩包装、安瓿、罐子、瓶子、管子等)中,并且组分在适当容器(例如,一个盒子或多个盒子)中包装在一起,以便试剂盒的用户方便地存储、运送和/或使用。应当理解,液体组分(例如,缓冲液)可以冻干形式提供以由使用者重构。试剂盒可包括用于评估、验证和/或确保试剂盒性能的对照或参考。例如,用于测定村子存在于样品中的核酸的量的试剂盒可包括包含用于比较的已知浓度的相同或另一种核酸的对照,并且在一些实施方案中包括对于对照核酸特异性的检测试剂(例如,引物)。所述试剂盒适于在临床环境中使用,并且在一些实施方案中适于在用户的家中使用。在一些实施方案中,试剂盒的组分提供用于由样品制备核酸溶液的系统的功能性。在一些实施方案中,系统的某些组分由用户提供。
iii.其它应用
在一些实施方案中,诊断测定鉴定个体中疾病或病状的存在。在一些实施方案中,所述疾病是癌症(例如,胃肠道系统的癌症)。
本公开不限于特定标记。在一些实施方案中,利用异常甲基化与胃肠道瘤相关的标记(例如,波形蛋白、胞裂蛋白9、ndrg4中的一种或多种;还参见2014年12月12日提交的美国临时专利申请号62/091,053,所述专利申请出于所有目的以引用方式整体并入本文)。在一些实施方案中,测定还包括检测突变的kras基因(参见,例如实施例1)。在一些实施方案中,测定还包括检测粪便样品中的血红蛋白(参见,例如实施例1)。
在一些实施方案中,所述技术涉及用于治疗患者(例如,患有胃肠道癌的患者、患有早期胃肠道癌的患者或可能发展胃肠道癌的患者)的方法,所述方法包括测定如本文所提供的一种或多种标记的甲基化状态,以及基于测定甲基化状态的结果向患者施用治疗。治疗可以是施用药物化合物、疫苗、进行手术、对患者进行成像、进行另一个测试。优选地,所述用途是临床筛选的方法、预后评估的方法、监测疗法结果的方法、鉴定最可能响应于特定治疗性治疗的患者的方法、对患者或受试者进行成像的方法,以及用于药物筛选和开发的方法。
在所述技术的一些实施方案中,提供了用于诊断受试者体内的胃肠道癌的方法。如本文所用的术语“诊断(diagnosing)”和“诊断(diagnosis)”是指技术人员可估计并且甚至确定受试者是否患有给定疾病或病状或可能在将来发展给定疾病或病状的方法。技术人员常常基于一种或多种诊断指标例如像生物标记(例如本文所述的那些生物标记)进行诊断,所述生物标记的甲基化状态指示病状的存在、严重性或不存在。
临床癌症预后连同诊断涉及确定癌症的侵袭性和肿瘤复发的可能性以规划最有效的疗法。如果可进行更精确的预后,或者甚至可评估发展癌症的潜在风险,则可为患者选择适当的疗法,并且在一些情况下选择不太苛刻的疗法。癌症生物标记的评估(例如,确定甲基化状态)可用于分离具有良好预后和/或低的发展癌症风险的受试者,与可能受益于更密集的治疗的更可能发展癌症或遭受癌症复发的那些受试者相比,所述受试者将不需要疗法或需要有限疗法。
因此,如本文所用,“进行诊断”或“诊断”还包括确定发展癌症的风险或确定预后,其可基于本文所公开的诊断生物标记(例如,本文所述的那些生物标记)的测量来提供预测临床结果(具有或没有医学治疗)、选择适当的治疗(或治疗是否将有效)或监测当前治疗以及潜在地改变治疗。此外,在目前公开的主题的一些实施方案中,可随时间推移进行生物标记的多次测定以促进诊断和/或预后。生物标记的暂时变化可用来预测临床结果、监测胃肠道癌的进展和/或监测针对癌症的适当疗法的功效。在这种实施方案中,例如,可能期望在有效疗法过程期间随时间推移在生物样品中看到本文公开的一种或多种生物标记(以及潜在的一种或多种另外生物标记(如果被监测))的甲基化状态的变化。
目前公开的主题在一些实施方案中还提供了用于确定是否启动或继续预防或治疗受试者体内的癌症的方法。在一些实施方案中,所述方法包括在一段时间周期内由受试者提供一系列生物样品;分析所述系列生物样品以确定每种生物样品中的本文公开的至少一种生物标记的甲基化状态;以及比较每种生物样品中的一种或多种生物标记的甲基化状态的任何可测量的变化。所述时间周期内生物标记甲基化状态的任何变化均可用于预测发展癌症的风险、预测临床结果、确定是否启动或继续预防或治疗癌症以及当前疗法是否有效地治疗癌症。例如,可在启动治疗之前选择第一时间点,并且可在启动治疗之后的一段时间时选择第二时间点。甲基化状态可在取自不同时间点的每个样品中测量,并记录定性和/或定量差异。来自不同样品的生物标记水平的甲基化状态的变化可与胃肠道癌风险、预后、确定治疗功效和/或受试者的癌症进展相关。
在优选的实施方案中,本发明的方法和组合物用于治疗或诊断早期例如疾病症状出现之前的疾病。在一些实施方案中,本发明的方法和组合物用于治疗或诊断临床期疾病。
如上所述,在一些实施方案中,可进行一种或多种诊断或预后生物标记的多种测定,并且可使用标记的暂时变化来确定诊断或预后。例如,诊断标记可在初始时间时测定,并且在第二时间时再次测定。在此类实施方案中,初始时间至第二时间的标记增加可以是癌症的特定类型或严重性或给定预后的诊断。同样地,初始时间至第二时间的标记减少可指示癌症的特定类型或严重性或给定预后。此外,一个或多个标记的变化程度可与癌症的严重性和未来的不良事件有关。技术人员将理解,虽然在某些实施方案中,可在多个时间点进行相同生物标记的比较测量,但是还可在一个时间点时测量给定生物标记,并且在第二时间点时测量第二生物标记,并且这些标记的比较可提供诊断信息。
如本文所用,短语“确定预后”是指技术人员可预测受试者体内的病状的过程或结果的方法。术语“预后”不是指以100%精确度预测病状的过程或结果的能力,或者甚至给定过程或结果可预测地或多或少可能基于生物标记的甲基化状态发生。相反,技术人员将理解,术语“预后”是指将发生某种过程或结果的可能性增加;也就是说,当与未展现病状的那些个体相比时,过程或结果更可能在展现给定病状的受试者中发生。例如,在未展现病状的个体(例如,具有一个或多个靶基因的正常甲基化状态)的个体中,给定结果(例如,患有胃肠道癌)的机会可能非常低。
在一些实施方案中,统计学分析将预后指标与不利结果的倾向相关联。例如,在一些实施方案中,如由统计学显著性水平所确定,与获自未患有癌症的患者的正常对照样品中甲基化状态不同的甲基化状态可表明,受试者比具有更类似于对照样品中甲基化状态的水平的受试者更可能患有癌症。此外,甲基化状态从基线(例如“正常”)水平的变化可反映患者预后,并且甲基化状态的变化程度可与不良事件的严重性有关。统计学显著性常常通过比较两个或更多个群体并确定置信区间和/或p值来确定。参见,例如dowdy和wearden,statisticsforresearch,johnwiley&sons,newyork,1983,其以引用方式整体并入本文。本主题的示例性置信区间为90%、95%、97.5%、98%、99%、99.5%、99.9%和99.99%,而示例性p值为0.1、0.05、0.025、0.02、0.01、0.005、0.001和0.0001。
在其它实施方案中,可建立本文公开的预后性或诊断性生物标记的甲基化状态的阈值变化程度,并将生物样品中生物标记的甲基化状态的变化程度简单地与甲基化状态的阈值变化程度相比较。本文提供的生物标记的甲基化状态的优选阈值变化为约5%、约10%、约15%、约20%、约25%、约30%、约50%、约75%、约100%和约150%。在另一些实施方案中,可建立“诺模图”,通过所述“诺模图”,预测性或诊断性指标(生物标记或生物标记组合)的甲基化状态直接与给定结果的相关处置有关。技术人员熟悉所述诺模图的使用以使两个数值相关联,认识到此测量值的不确定性与标记浓度的不确定性相同,因为引用了单独样品测量值,而不是群体平均值。
在一些实施方案中,对照样品与生物样品同时分析,使得获自生物样品的结果可与获自对照样品的结果相比较。另外,预期可提供标准曲线,生物样品的测定结果可与所述标准曲线相比较。如果使用荧光标记,则此类标准曲线呈现作为测定单位(例如荧光信号强度)的函数的生物标记甲基化状态。使用取自多个供体的样品,可提供正常组织中一种或多种生物标记的对照甲基化状态的标准曲线,以及取自患有化生的供体或患有胃肠道癌的供体的组织中的一种或多种生物标记的“处于风险中”水平的标准曲线。在所述方法的某些实施方案中,在鉴定获自受试者的生物样品中的本文提供的一种或多种标记的异常甲基化状态时,将受试者鉴定为患有化生。在所述方法的其它实施方案中,获自受试者的生物样品中一种或多种所述生物标记的异常甲基化状态的检测致使可将受试者鉴定为患有癌症。
在一些实施方案中,如果当与对照甲基化状态相比时,存在样品中至少一种生物标记的甲基化状态的可测量差异,则将所述受试者诊断为患有胃肠道癌。相反,当在生物样品中未鉴定到甲基化状态的变化时,则可将受试者鉴定为不患有胃肠道癌、不处于癌症风险中或具有低的癌症风险。在此方面,患有癌症或具有其风险的受试者可与患有低至基本上无癌症或具有其风险的受试者区分开来。具有发展胃肠道癌风险的那些受试者可置于更密集和/或定期筛选方案(包括内窥镜监视)中。另一方面,具有低至基本上无风险的那些受试者可避免进行内窥镜检查直至未来筛选的时间,例如根据本发明技术进行的筛选指示胃肠道癌的风险已经出现在那些受试者中。
如上所述,根据本发明技术方法的实施方案,检测一种或多种生物标记的甲基化状态的变化可以是定性测定,或者可以是定量测定。因此,将受试者诊断为患有胃肠道癌或处于发展胃肠道癌风险中的步骤指示,进行某些阈值测量,例如生物样品中的一种或多种生物标记的甲基化状态不同于预定的对照甲基化变化。在所述方法的一些实施方案中,对照甲基化状态是任何可检测的生物标记甲基化状态。在与生物样品同时测试对照样品的方法的其它实施方案中,预定甲基化状态是对照样品的甲基化状态。在所述方法的其它实施方案中,预定甲基化状态基于标准曲线和/或通过标准曲线来鉴定。在所述方法的其它实施方案中,预定甲基化状态具体地是状态或状态范围。因此,预定甲基化状态可部分基于所实践的方法的实施方案和所需特异性等在将对本领域技术人员显而易见的容许极限内来选择。
此外,关于诊断方法,优选的受试者是脊椎动物受试者。优选的脊椎动物是温血的;优选的温血脊椎动物是哺乳动物。优选的哺乳动物最优选地是人。如本文所用,术语“受试者”包括人和动物受试者。因此,本文提供了兽医治疗性用途。因此,本发明技术提供了对哺乳动物的诊断,所述哺乳动物诸如人以及由于濒危而具有重要性的那些哺乳动物,诸如西伯利亚虎;具有经济重要性的那些哺乳动物,诸如在养殖场养殖以供人消费的动物;和/或对人具有社会重要性的动物,诸如作为宠物或在动物园饲养的动物。此类动物的实例包括但不限于:食肉动物诸如猫和狗;猪,包括家猪、阉猪(hog)和野猪;反刍动物和/或有蹄类动物,诸如家牛、公牛、绵羊、长颈鹿、鹿、山羊、野牛和骆驼;鳍足类和马。因此,还提供了家畜的诊断和治疗,所述家畜包括但不限于驯养的猪、反刍动物、有蹄类动物、马(包括赛马)等。目前公开的主题还包括用于诊断受试者的胃肠道癌的系统。所述系统可例如作为商业试剂盒提供,所述商业试剂盒可用来在生物样品已经收集自的受试者中筛选胃肠道癌的风险或诊断胃肠道癌。根据本发明技术提供的示例性系统包括评估本文所述标记的甲基化状态。
近年来,已经显而易见的是,可在许多癌症患者的血液中检测到代表转移性肿瘤细胞的循环上皮细胞。稀有细胞的分子谱在生物和临床研究中是重要的。应用的范围为用于疾病预后的癌症患者外周血中循环上皮细胞(cepc)的表征以及个性化治疗(参见,例如,cristofanillim,等(2004)nengljmed351:781–791;hayesdf,等(2006)clincancerres12:4218–4224;buddgt,等(2006)clincancerres12:6403–6409;morenojg,等(2005)urology65:713–718;pantel等,(2008)natrev8:329–340;以及cohensj,等(2008)jclinoncol26:3213–3221)。
在本公开的实施方案的发展过程中进行的实验确定了以下意外的结果:血液或血浆中甲基化zdhhc1在的存在与转移性癌症患者中的血液中上皮细胞的存在相关。因此,本公开的实施方案提供了用于通过鉴定血浆或全血中甲基化zdhhc1的存在来检测受试者体内的转移性癌症的存在的组合物和方法。使用任何合适的方法(例如本文所述的那些方法)鉴定甲基化zdhhc1的存在。
实验实施例
实施例1
dna分离方法和quarts测定
以下提供了诸如可根据所述技术的实施方案使用的分析之前的dna分离的示例性方法以及示例性quarts测定。在此实施例中描述了将quarts技术应用于来自粪便和各种组织样品的dna,但是所述技术容易地应用于例如如其它实施例所示的其它核酸样品。
从粪便样品中收集靶dna.
将全部粪便收集在塑料桶中。例如以每克粪便约4ml,将防腐缓冲液例如150mmedta、500mmtris-cl和10mmnacl(ph9.0)添加至粪便中,并且可将缓冲的粪便直接使用或在–80℃下保存。
从粪便样品中分离靶核酸的示例性程序:
1.例如用缓冲液将粪便样品匀化,以形成粪便匀浆。例如通过离心或过滤处理匀浆以将残留固体与液体分离,以产生“粪便上清液”。
2.将粪便上清液处理以去除测定抑制剂(例如,如美国专利号8,993,341所述用聚乙烯吡咯烷酮,所述专利以引用方式整体并入本文),产生“澄清上清液”。
3.将十毫升澄清上清液(代表约4克粪便的当量)与硫氰酸胍(gtc)混合至2.4m的终浓度;
4.然后将混合物在90℃水浴中加热10分钟以使存在于粪便中的dna(和蛋白质)变性。
5.将含有与目标靶序列(“目标特异性捕获探针”)互补的共价附接(偶联)寡核苷酸的顺磁性颗粒添加至样品中。然后将样品孵育(例如,在约22℃-25℃的环境温度下)一个小时,以使靶dna与磁性颗粒上的捕获探针杂交。
6.将澄清上清液、gtc和颗粒的混合物暴露于磁场以将颗粒(现在含有与捕获探针杂交的靶dna)与粪便上清液/gtc混合物分离,将所述粪便上清液/gtc混合物转移至新管中。参见,例如美国专利申请序列号13/089,116,其以引用方式并入本文。
可将变性/杂交/分离循环(步骤4-6)重复例如至少四次或更多次,以从相同粪便上清液样品中连续提取不同的靶dna。
ffpe组织dna
使用qiaampdnaffpe组织试剂盒(qiagensciences,germantown,md)分离来自福尔马林固定石蜡包埋(ffpe)组织的dna。
从细胞和血浆中分离dna
对于细胞系,可使用例如“
用于从4ml血浆样品中分离dna的示例性程序如下:
·向4ml血浆样品中添加300μl蛋白酶k(20mg/ml)并混合。
·将3μl的1μg/μl鱼dna添加至血浆蛋白酶k混合物中。
·将2ml血浆裂解缓冲液添加至血浆中。
血浆裂解缓冲液为:
-4.3m硫氰酸胍
-10%igepalca-630(支链的辛基苯氧基聚(乙烯氧基)乙醇)
(与45ml的4.8m硫氰酸胍合并的5.3g的igepalca-630)
·在以500rpm振荡的情况下将混合物在55℃下孵育1小时。
·添加3ml血浆裂解缓冲液并混合。
·添加200μl磁性二氧化硅结合珠[16μg珠子/μl],并再次混合。
·添加2ml100%异丙醇并混合。
·在以500rpm振荡情况下在30℃下孵育30分钟。
·将管置于磁体上,并使珠子收集。将上清液抽出并丢弃。
·将750μlguhcl-etoh添加至含有结合珠的容器中并混合。
guhcl-etoh洗涤缓冲液为:
-3mguhcl
-57%etoh。
·以400rpm振荡1分钟。
·将样品转移至深孔板或2ml微量离心管中。
·将管置于磁体上,并使珠子收集10分钟。将上清液抽出并丢弃。
·将1000μl洗涤缓冲液(10mmtrishcl、80%etoh)添加至珠子,并在振荡情况下在30℃下孵育3分钟。
·将管置于磁体上,并使珠子收集。将上清液抽出并丢弃。
·将500μl洗涤缓冲液添加至珠子,并在振荡情况下在30℃下孵育3分钟。
·将管置于磁体上,并使珠子收集。将上清液抽出并丢弃。
·添加250μl洗涤缓冲液,并在振荡情况下在30℃下孵育3分钟。
·将管置于磁体上,并使珠子收集。将剩余缓冲液抽出并丢弃。
·添加250μl洗涤缓冲液,并在振荡情况下在30℃下孵育3分钟。
·将管置于磁体上,并使珠子收集。将剩余缓冲液抽出并丢弃。
·在振荡情况下在70℃下将珠子干燥15分钟。
·将125μl洗脱缓冲液(10mmtrishcl,ph8.0,0.1mmedta)添加至珠子,并在振荡情况下在65℃下孵育25分钟。
·将管置于磁体上,并使珠子收集10分钟。
·将含有dna的上清液抽出并转移至新的容器或管中。
quarts测定
quarts技术将基于聚合酶的靶dna扩增过程与基于侵入性切割的信号扩增过程组合。所述技术例如在美国专利8,361,720;美国专利号8,715,937;美国专利号8,916,344;以及美国专利申请序列号14/036,649中有所描述,每个所述专利均以引用方式并入本文。以类似于实时pcr的方式监测由quarts反应产生的荧光信号,并允许定量样品中靶核酸的量。
示例性quarts反应通常包括约400-600nmol/l(例如,500nmol/l)的每种引物和检测探针、约100nmol/l的侵入性寡核苷酸、约600-700nmol/l的每种fret盒(fam,例如由hologic,inc.商业提供;hex,例如由biosearchtechnologies,idt商业提供;以及quasar670,例如由biosearchtechnologies商业提供)、6.675ng/μlfen-1内切核酸酶(例如,
对于粪便dna测试,如上所述,通常如上所述使用捕获探针以从澄清上清液中捕获靶核酸片段。捕获探针的实例如下所示,且通常包含5′-6碳氨基修饰的键(integrateddnatechnology,coralville,ia):
对于ndrg4:
/5ammc6/tccctcgcgcgtggcttccgccttctgcgcggctggggtgcccggtgg-3′(seqidno:1)
对于bmp3:
/5ammc6/gcgggacactccgaaggcgcaaggag-3′(seqidno:2)
对于kras:
/5ammc6/ggcctgctgaaaatgactgaatataaacttgtggtagttggagc-3′(seqidno:3)以及
/5ammc6/ctctattgttggatcatattcgtccacaaaatgattctgaattagc-3′(seqidno:4)
用亚硫酸氢盐使用例如ez-96dna甲基化试剂盒(zymoresearch,irvineca)或使用亚硫酸氢铵如wo2013/116375中所述处理用于甲基化测试的捕获dna,所述专利以引用方式并入本文。通常将转化的样品在50微升10mmtris、0.1mmedtaph8.0中以20纳克/微升trna(sigma)洗脱;将10微升亚硫酸氢盐处理的dna用quarts方法以30微升反应体积在96孔pcr板上测定。将pcr板在lightcycler480(roche)中循环。
quarts测定可涉及单独标记或标记的复用组合,并且通常另外包含用于检测参考核酸例如β-肌动蛋白的寡核苷酸,或以下本发明的实施方案中讨论的标记。
在此实施方案中,对于以下每种靶标,引物和探针(integrateddnatechnology,coralville,ia)如下:
对于ndrg4:
引物5′-cggttttcgttcgttttttcg-3′,(seqidno:5)
引物5′-gtaacttccgccttctacgc-3′,(seqidno:6)
探针5′-cgccgagggttcgtttatcg/3′c6/(seqidno:7)
对于bmp3:
引物5′-gtttaattttcggtttcgtcgtc-3′(seqidno:8)
引物5′-ctcccgacgtcgctacg-3′(seqidno:9)
探针5′-cgccgaggcggttttttgcg/3′c6/(seqidno:10)
对于亚硫酸氢盐处理的β-肌动蛋白:
引物5′-tttgtttttttgattaggtgtttaaga-3′(seqidno:52)
引物5′-caccaacctcataaccttatc-3′(seqidno:59)
探针5′-ccacggacgatagtgttgtgg/3′c6/(seqidno:60)
例如测定板中的每次测定均包括亚硫酸氢盐处理的dna样品、标准曲线样品、阳性对照和阴性对照。可使用例如以300至1000个链从工程化质粒切割的靶链制成标准曲线。将亚硫酸氢盐处理的cpgenome通用甲基化dna(millipore,billerica,ma)和人基因组dna(merck,germany)用作阳性对照和阴性对照。通过将靶基因的cp与相关测定的标准曲线比较来确定dna链数。通过将甲基化基因的链数除以对照dna(例如,β-肌动蛋白或本文提供的候选对照标记)链数并乘以100来确定每种标记的甲基化百分比。
kras突变
使用quarts测定来评价kras基因的密码子12/13处的7个突变。将每个突变测定设计为单重测定。kras突变特异性正向引物和探针为:
对于g12s突变:
引物5′-cttgtggtagttggagcaa-3′(seqidno:11)
探针5′-gcgcgtccagtggcgtaggc/3′c6/(seqidno:12);
对于g12c突变
引物5′-aaacttgtggtagttggacctt-3′(seqidno:13)
探针5′-gcgcgtcctgtggcgtaggc/3′c6/(seqidno:14);
对于g12r突变
引物5′-tataaacttgtggtagttggacctc-3′(seqidno:15)
探针5′-gcgcgtcccgtggcgtaggc/3′c6/(seqidno:16);
对于g12d突变
引物5′-acttgtggtagttggagctca-3′(seqidno:17)
探针5′-gcgcgtccatggcgtaggca/3′c6/(seqidno:18);
对于g12v突变
引物5′-acttgtggtagttggagctct-3′(seqidno:19)
探针5′-gcgcgtccttggcgtaggca/3′c6/(seqidno:20);
对于g12a突变
引物5′-aacttgtggtagttggagatgc-3′(seqidno:21)
探针5′-gcgcgtccctggcgtaggca/3′c6/(seqidno:22);
对于g13d突变
引物5′-ggtagttggagctggtca-3′(seqidno:23)
探针5′-gcgcgtccacgtaggcaaga/3′c6/(seqidno:24)
对于所有kras突变体,所用的反向引物为
5′-ctattgttggatcatattcgtc-3′(seqidno:25)
kras的quarts循环条件和试剂浓度与甲基化测定中的那些相同。每个板含有由工程化质粒、阳性对照和阴性对照以及水空白制成的标准物,并在lightcycler480(roche)或abi7500(thermoscientific)中运行。通过将靶基因的cp或ct与此测定的标准曲线比较来确定dna链数。基于500倍稀释因子和1.95的扩增效率计算50微升kras中每种突变标记的浓度。将此值除以甲基化测定中的β-肌动蛋白浓度或zdhh,然后乘以100以确定突变百分比。
在以下所讨论的测定中,“btact”是指甲基化测定中β-肌动蛋白的表征,并且“act”或“actb”是指突变测定中β-肌动蛋白的表征。
实施例2
候选对照基因的鉴定和测试
如上所述,在某些实施方案中,根据甲基化状态选择所述技术的对照基因。在第一步中,选择在正常和癌症上皮组织细胞两者中被高度甲基化的基因作为候选对照基因。作为第二步,筛选所选候选基因以鉴定以下基因,在所述基因中基因的甲基化形式在血液和血液级分中最低限度地存在。在优选的实施方案中,可进一步分析候选基因以选择与待分析的一种或多种标记基因具有相似gc含量和cpg甲基化含量的基因,使得亚硫酸氢盐反应性和pcr扩增行为类似于待分析的标记基因。
zdhhc1、zfand3、zmym4、odz2和trio被鉴定为可能适于用作对照的甲基化基因。
这些候选标记具有以下基因座(参考grch37/hg19组装):
zdhhc1足迹:chr16,67428559-67428628
zmym4足迹:chr1,35877002-35877078
zfand3足迹:chr6,37841985-37842061
odz2足迹:chr5,167285650-167285775
trio足迹:chr5,14461291-14461417
将zdhhc1、zfand3和zmym4基因选择用于进一步分析,并使用quarts技术来测定以比较正常样品和癌症样品中基因的甲基化,并评估血液(例如血清)中标记的存在。测定中所用的寡核苷酸如下以图解方式所示。术语“野生型”用于指不存在亚硫酸氢盐转化情况下的基因序列,所述基因序列不受甲基化状态影响。
zdhhc1-锌指,含dhhc型的1
未处理靶序列:
5'-ggggccggggccgacagcccacgctggcgcggcaggcgcgtgcgcccgccgttttcgtgagcccgagcag-3'(seqidno:26)
亚硫酸氢盐处理的靶序列:
5'-ggggucggggucgauaguuuacgutggcgcgguaggcgcgtgcguucgucgttttcgtgaguucgaguag-3'
(seqidno:33)
亚硫酸氢盐处理的复制靶序列:
5’-ggggtcggggtcgatagtttacgttggcgcggtaggcgcgtgcgttcgtcgttttcgtgagttcgagtag-3’(seqidno:27)
quarts测定寡核苷酸(所有示出5’至3’):
zfand3-锌指,an1型结构域3
未处理靶序列:
5′-tctctgtgtactaatttccctttttggccggacgtggtggctcacgcctgtaatcccagcactttgggaggccaaag-3'(seqidno:37)
亚硫酸氢盐处理的靶序列:
5′-tttttgtstattaatttttttttttggtcggacgtggtggtttacgtttgtaattttagtattttgggaggttaaag-3′(seqidno:38)
quarts测定寡核苷酸(所有示出5’至3’):
____________________________________________________________________
zmym4-锌指,mym型4
未处理靶序列:
5'-
ccatctatagaaaaatggattagggccgggcacagtggctcacgcctgtaatcccagcactttgggaggccgaggca-3′(seqidno:44)
亚硫酸氢盐处理的靶序列:
5'-
ttatttatagaaaaatggattagggtcgggtatagtggtttacgtttgtaattttagtattttgggaggtcgaggta-3′(seqidno:45)
quarts测定寡核苷酸(所有示出5’至3’):
quasar670a3fret盒:
5′dq670-tct(i-bhq2)agccggttttccggctgagactccgcgtc-c63′(seqidno:51)
[fp=正向引物;rp=反向引物;3′c6=3′己烷;5amm6=5′氨基;cp=捕获探针;q670=
使用上述寡核苷酸组合,使用β-肌动蛋白(btact)(用于归一化)或使用三种候选对照基因(zdhhc1、zmym和zfand)中的一种对各种不同样品类型(血液、血浆和两种人结肠直肠癌细胞系ht29和ht116)进行癌症标记ndrg4和bmp3的甲基化分析。如实施例1所述一式两份进行测定。表1示出重复的平均值:
表1
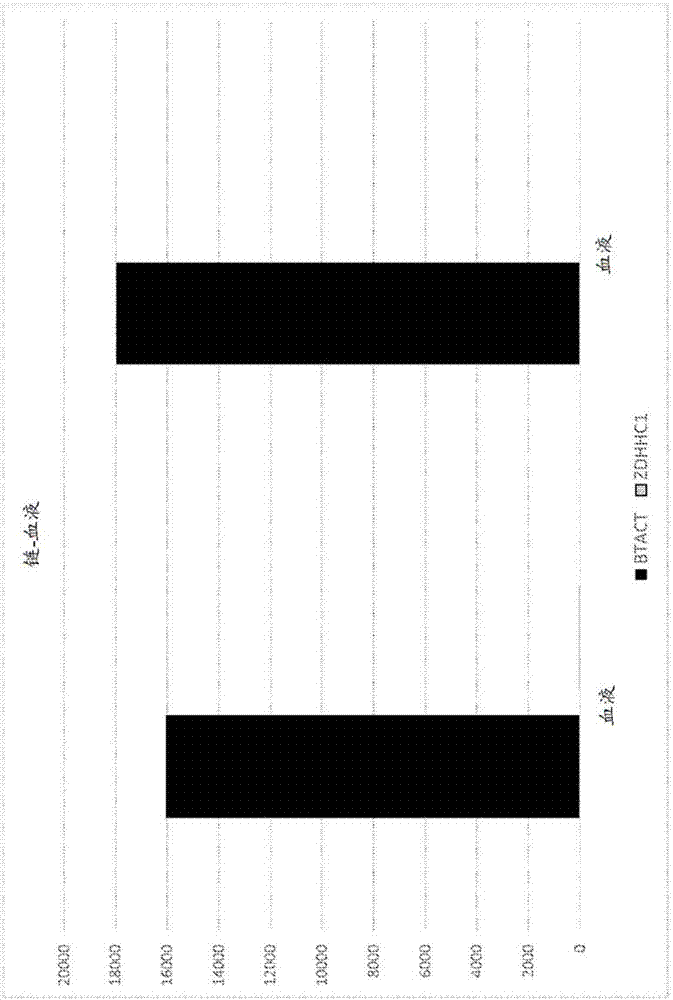
从这些数据可以看出,所有三种候选标记均如btact一样在癌细胞系ht29和ht116中显示出强阳性信号。然而,zfand3和zmym4v2两者均如btact一样在血液样品中显示显著信号,诸如可在具有存在的一定量血液的样品(例如组织或粪便样品)中产生不期望的本底。
此实施例显示,zdhhc1在血液和血浆中具有较低的本底信号,并且容易在上皮细胞系中检测到。选择zdhhc1以进行进一步分析。
实施例3
比较β-肌动蛋白和zdhhc1以归一化癌症标记测定
与btact平行测试zdhhc1标记,以比较作为对照的这些dna以确定ndrg4和bmp3标记基因的甲基化%。将从福尔马林固定石蜡包埋的组织样品中分离的dna表征,将测定信号归一化为β-肌动蛋白或zdhhc1。结果示于下表3中。
这些数据显示,ndrg4和bmp3标记相对于zdhhc1的甲基化%与相同标记相对于β-肌动蛋白的甲基化%相当,显示出可使用zdhhc1代替β-肌动蛋白以进行归一化。
表3
如表3所示,使用zdhhc1测定的甲基化%值与使用btact测定的甲基化%值的比较显示,这些对照在这些组织样品上的表现相当,并且可在测量癌症标记基因的甲基化中使用zdhhc1代替btact。
实施例4
正常组织样品和癌组织样品中的zdhhc1和β-肌动蛋白dna
此实施例描述了不同的癌组织样品和正常组织样品的延伸取样中的zdhhc1和β-肌动蛋白链的数目的比较。测试来自正常和异常组织类型(包括胆管、结肠、食管、头、肺、胰腺、小肠和胃)的dna。
将从福尔马林固定石蜡包埋的组织样品中分离的dna用下表4所示的β-肌动蛋白(actb)和zdhhc1的中值测定信号来表征。
表4
这些数据证实,在所测试的所有组织类型、以及正常组织类型和非正常(例如,腺瘤、癌、化生)组织类型中均检测到甲基化zdhhc1对照。结果显示癌组织与正常组织之间的zdhhc1甲基化水平相等。
实施例5
zdhhc1对在复杂样品中归一化癌症标记测定的影响
对使用zdhhc1作为测定中的归一化标记进行进一步的实验来检测更复杂样品(例如粪便,血液等)以及正常组织样品和结肠直肠癌组织样品中的癌症。表5a示出了ndrg4甲基化标记和两个对照dna的检测到的链,并示出了如使用各对照dna所测定的ndrg4的甲基化%。相同测定反应中检测到的bmp3标记的数据示于表5b中。
表5a
表5b
这些数据显示甲基化的zdhhc1对照dna存在在来自正常和结肠直肠癌阳性受试者的粪便样品中是基本上均匀的,并证实在血液样品中基本上不存在标记。这些数据还证实zdhhc1存在基本上等同于不含血液(例如细胞系)的β-肌动蛋白dna样品。
实施例6
患有转移性癌症的受试者的血浆样品中的zdhhc1
此实施例描述了转移性癌症患者的血浆样品中zdhhc1的检测。
将1至2毫升的正常、晚期腺瘤(aa)和腺癌(aca)、患者血浆样品用于quarts测定。使用qiagen循环核酸试剂盒处理来自结肠癌受试者和正常受试者的血浆样品。血浆的起始体积的范围为0.75-2.0ml。对dna进行亚硫酸氢盐转化,并用zdhhc1和btact寡核苷酸混合物测试。结果显示,具有肝转移的iv期癌症样品中的zdhhc1链水平较高。
除了一个之外,所有样品均没有zdhhc1标记链。在血浆中显示大量的zdhhc1标记链的一个样品是iv期转移。这些数据支持使用zdhhc1作为转移的一般标记来检测血液/血浆中的上皮细胞。结果汇总于表6中:
表6
*包括一个为由阶段表征的样品。
在两个aa样品的另外研究中,8个aca样品中的两个被分类为具有观察到的转移的iv期,并且在34个正常样品中的一个中检测到iv期,显示zdhhc1/btact比率显著升高(41%),并且一个样品似乎具有正常的zdhhc1/btact比率(4.3%)。其它样品均未显示升高的zdhhc1/btact比率。
实施例7
患有癌症的受试者的血浆样品中的zdhhc1
如附图4a-4e所详述,在包括来自癌症患者的57个样品和52个正常样品的另外一组患者样品中测量zdhhc1的血浆水平。将dna从4ml血浆中提取并进行亚硫酸氢盐转化。将zdhhc1dna预扩增10个循环,然后如实施例1所述使用quarts侧翼测定、使用实施例2中所述的引物和探针来检测。结果示于图4a-4e中的表中,并且各样品类型的平均数据如下:
实施例8
检测zdhhc1以监测疾病状态和/或进展
可分析患者样品(例如血液制品样品,诸如血浆样品)的上皮细胞或上皮细胞dna的存在,作为监测疾病状态(例如发生、进展、对疗法的应答、术后、缓解、复发等)的手段。在一些实施方案中,在多个时间点时从患者获取样品,并且在各时间点时测量存在的zdhhc1dna(无论是游离的,还是处于循环细胞或复合物中)的量,并且比较在不同时间点时获取的样品中zdhhc1dna的量,以评估疾病状态的变化。
在第一时间点时,从患者获取血液样品,并制备血浆样品。
在第二时间点时,从患者获取第二血液样品,并制备第二血浆样品。
测试整个血液样品的zdhhc1dna或进一步处理样品以产生血浆级分。
例如使用如以上实施例1和6中所述的方法测试每个血浆样品的zdhhc1dna的存在和量。预期在一些实施方案中,不立即测试第一样品(例如,将血液或血浆或从其中分离的dna存储以进行稍后的测试),并且同时测试第一样品和第二样品。在其它实施方案中,在收集第二血液样品之前测试第一血浆样品,并将结果存储以进行稍后的比较。
所述技术不限于在第一时间点与第二时间点之间发生的特定事件或行动过程。例如,第一时间点可以是在不存在对疾病的怀疑的时间,例如,第一测定可能是建立基线,以期望监测受试者的未来疾病发生。可替代地,可在以下点时获取第一时间点,在所述点时,在受试者中可能存在病状或疾病,但疾病状态是监测优于主动治疗性干预而优选作为行动过程的疾病状态,例如可监测疾病状态的变化,诸如转移。在其它情况下,可在两个时间点之间向受试者施用主动疗法,例如手术、药物疗法等,并且可使用血液中上皮细胞dna的测量来监测疗法的功效。
以上说明书中所提及的所有出版物和专利均出于所有目的以引用方式整体并入本文。本技术的所描述的组合物、方法和用途的各种修改和变化对于本领域技术人员是显而易知的,而不背离所描述的技术的范围和精神。虽然已结合具体的示例性实施方案描述了本技术,但应理解的是,要求保护的本发明不应不适当地局限于此类具体的实施方案。事实上,对药理学、生物化学、医学科学或相关领域的技术人员来说显而易见的用于进行本发明的所述模式的各种修改旨在处于以下权利要求的范围内。
序列表
<110>精密科学公司
<120>用于进行甲基化检测测定的组合物和方法
<130>exct-33905/wo-1/ord
<150>us62/091,069
<151>2014-12-12
<160>62
<170>patentin3.5版
<210>1
<211>48
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>1
tccctcgcgcgtggcttccgccttctgcgcggctggggtgcccggtgg48
<210>2
<211>26
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>2
gcgggacactccgaaggcgcaaggag26
<210>3
<211>44
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>3
ggcctgctgaaaatgactgaatataaacttgtggtagttggagc44
<210>4
<211>46
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>4
ctctattgttggatcatattcgtccacaaaatgattctgaattagc46
<210>5
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>5
cggttttcgttcgttttttcg21
<210>6
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>6
gtaacttccgccttctacgc20
<210>7
<211>18
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>7
cgccgagggttcgtttat18
<210>8
<211>23
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>8
gtttaattttcggtttcgtcgtc23
<210>9
<211>17
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>9
ctcccgacgtcgctacg17
<210>10
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>10
cgccgaggcggttttttgcg20
<210>11
<211>18
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>11
cttgtggtagttggagca18
<210>12
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>12
gcgcgtccagtggcgtaggc20
<210>13
<211>22
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>13
aaacttgtggtagttggacctt22
<210>14
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>14
gcgcgtcctgtggcgtaggc20
<210>15
<211>25
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>15
tataaacttgtggtagttggacctc25
<210>16
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>16
gcgcgtcccgtggcgtaggc20
<210>17
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>17
acttgtggtagttggagctca21
<210>18
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>18
gcgcgtccatggcgtaggca20
<210>19
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>19
acttgtggtagttggagctct21
<210>20
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>20
gcgcgtccttggcgtaggca20
<210>21
<211>22
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>21
aacttgtggtagttggagatgc22
<210>22
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>22
gcgcgtccctggcgtaggca20
<210>23
<211>18
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>23
ggtagttggagctggtca18
<210>24
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>24
gcgcgtccacgtaggcaaga20
<210>25
<211>22
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>25
ctattgttggatcatattcgtc22
<210>26
<211>70
<212>dna
<213>智人
<400>26
ggggccggggccgacagcccacgctggcgcggcaggcgcgtgcgcccgccgttttcgtga60
gcccgagcag70
<210>27
<211>70
<212>dna
<213>智人
<400>27
ggggtcggggtcgatagtttacgttggcgcggtaggcgcgtgcgttcgtcgttttcgtga60
gttcgagtag70
<210>28
<211>12
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>28
gttggcgcggta12
<210>29
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>29
gtcggggtcgatagtttacg20
<210>30
<211>20
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>30
cgaactcacgaaaacgacga20
<210>31
<211>12
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>31
gacgaacgcacg12
<210>32
<211>19
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>32
actcgaactcacgaaaacg19
<210>33
<211>70
<212>dna
<213>智人
<400>33
ggggucggggucgauaguuuacgutggcgcgguaggcgcgtgcguucgucgttttcgtga60
guucgaguag70
<210>34
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>34
gacgcggaggttggcgcggta21
<210>35
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>35
gacgcggaggacgaacgcacg21
<210>36
<211>28
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>36
ctcgggctcacgaaaacggcgggcgcac28
<210>37
<211>77
<212>dna
<213>智人
<400>37
tctctgtgtactaatttccctttttggccggacgtggtggctcacgcctgtaatcccagc60
actttgggaggccaaag77
<210>38
<211>77
<212>dna
<213>智人
<400>38
tttttgtgtattaatttttttttttggtcggacgtggtggtttacgtttgtaattttagt60
attttgggaggttaaag77
<210>39
<211>12
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>39
acgtggtggttt12
<210>40
<211>28
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>40
tgtgtattaatttttttttttggtcgga28
<210>41
<211>28
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>41
cctcccaaaatactaaaattacaaacgt28
<210>42
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>42
gacgcggagacgtggtggttt21
<210>43
<211>35
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>43
gtgctgggattacaggcgtgagccaccacgtccgg35
<210>44
<211>77
<212>dna
<213>智人
<400>44
ccatctatagaaaaatggattagggccgggcacagtggctcacgcctgtaatcccagcac60
tttgggaggccgaggca77
<210>45
<211>77
<212>dna
<213>智人
<400>45
ttatttatagaaaaatggattagggtcgggtatagtggtttacgtttgtaattttagtat60
tttgggaggtcgaggta77
<210>46
<211>12
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>46
aacgtaaaccac12
<210>47
<211>22
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>47
gaaaaatggattagggtcgggt22
<210>48
<211>28
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>48
tcgacctcccaaaatactaaaattacaa28
<210>49
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>49
gacgcggagaacgtaaaccac21
<210>50
<211>36
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>50
cggcctcccaaagtgctgggattacaggcgtgagcc36
<210>51
<211>29
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>51
agccggttttccggctgagactccgcgtc29
<210>52
<211>27
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>52
tttgtttttttgattaggtgtttaaga27
<210>53
<211>0
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>53
000
<210>54
<211>0
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>54
000
<210>55
<211>0
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>55
000
<210>56
<211>0
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>56
000
<210>57
<211>0
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>57
000
<210>58
<211>0
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>58
000
<210>59
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>59
caccaacctcataaccttatc21
<210>60
<211>21
<212>dna
<213>人工序列
<220>
<223>dna引物/探针
<400>60
ccacggacgatagtgttgtgg21
<210>61
<211>166
<212>dna
<213>智人
<400>61
ctctgcaggttctatttgctttttcccagatgagctctttttctggtgtttgtctctctg60
actaggtgtctaagacagtgttgtgggtgtaggtactaacactggctcgtgtgacaaggc120
catgaggctggtgtaaagcggccttggagtgtgtattaagtaggtg166
<210>62
<211>166
<212>dna
<213>智人
<400>62
ttttgtaggttttatttgtttttttttagatgagttttttttttggtgtttgtttttttg60
attaggtgtttaagatagtgttgtgggtgtaggtattaatattggtttgtgtgataaggt120
tatgaggttggtgtaaagtggttttggagtgtgtattaagtaggtg166
- 还没有人留言评论。精彩留言会获得点赞!