对话装置的制作方法
本公开涉及对话装置。
背景技术:
例如,在美国专利第9580028号公报中,公开了如下声音处理装置:使用声音辨识技术来确定说话者,说话者依照预先决定的设定控制后视镜以及座椅位置这样的车辆的装备。
上述声音处理装置虽然能够根据声音确定说话的个人并操作与个人对应的车辆的装备,但无法理解说话者发出的声音的内容,无法与说话者进行对话。另一方面,在与说话者进行对话的对话装置中使用人工智能(artificialintelligence:ai)的技术得到普及,但上述对话装置不论说话者处于何处都向预先决定的方向以预先决定的音量输出声音。因此,作为对话装置的对话对方的说话者有时难以听清从对话装置输出的声音。
技术实现要素:
本公开提供一种能够以使对话对方易于听清的方式输出声音的对话装置。
第1方案的对话装置具备:确定部,根据说话者发出的声音,确定所述说话者的方向;以及控制部,在向所述说话者输出声音的情况下,控制从扬声器输出的声音的指向性,以使向由所述确定部确定的方向的声音的指向性高于其它方向上的声音的指向性。
第1方案的对话装置能够提高从对话装置向说话者存在的方向输出的声音的指向性。因此,第1方案的对话装置能够以使对话对方易于听清的方式输出声音。
关于第2方案的对话装置,在第1方案中,所述确定部根据声音确定驾驶车辆的驾驶者的方向,所述控制部在从支援所述车辆的驾驶的驾驶支援装置取得与所述车辆的驾驶有关的信息的情况下,控制从扬声器输出的声音的指向性,以使通知所述信息的声音的指向性在由所述确定部确定的所述驾驶者存在的方向上比其它方向高。
第2方案的对话装置能够确定驾驶车辆的驾驶者的方向,提高向驾驶者的方向通知与车辆的驾驶有关的信息的声音的指向性。因此,第2方案记载的对话装置能够将与车辆的驾驶有关的信息易于听清地传递给驾驶者。
关于第3方案的对话装置,在第2方案中,所述驾驶支援装置是预先设置于所述车辆的车辆导航装置、或者具有车辆导航功能的便携型的信息设备。
第3方案的对话装置能够与预先设置于车辆的车辆导航装置、或者具备车辆导航功能的便携型的信息设备连接。因此,第3方案的对话装置能够不仅将从预先设置于车辆的车辆导航装置通知的与车辆的驾驶有关的信息易于听清地传递给驾驶者,而且还将从便携型的信息设备通知的与车辆的驾驶有关的信息易于听清地传递给驾驶者。
关于第4方案的对话装置,在第1方案中,所述确定部根据声音确定处于从扬声器输出的声音的到达范围内的多个人的方向,所述控制部在分别中继由所述确定部确定了方向的所述多个人中的至少2人的对话的情况下,控制从扬声器输出的声音的指向性,以使发出话语的所述说话者的声音的指向性在对话对方存在的方向上比其它方向高。
第4方案的对话装置通过声音确定各个对话对方的方向,将一方的对话对方发出的声音朝向另一方的对话对方中继。因此,第4方案的对话装置相比于与对话对方不经由对话装置进行对话的情况,对话对方的声音更易于听清。
关于第5方案的对话装置,在第4方案中,所述控制部进行如下控制:从受理包括指定对话对方的语句的声音至对话结束为止,中继各个对话对方的声音。
第5方案的对话装置能够理解在声音中是否包括指定对话对方的语句。因此,第5方案的对话装置能够根据话的内容掌握对话的开始而自主地开始声音的中继。
关于第6方案的对话装置,在第1方案~第5方案的任意一个中,所述控制部选择多个扬声器中的向由所述确定部确定的所述说话者存在的方向输出声音的扬声器,并进行从选择出的扬声器输出声音的控制。
第6方案的对话装置能够朝向说话者存在的方向输出声音。因此,第6方案的对话装置能够以使对话对方易于听清的方式输出声音。
关于第7方案的对话装置,在第1方案~第5方案的任意一个中,所述控制部控制多个扬声器中的各个扬声器的音量,以使所述多个扬声器中的向由所述确定部确定的所述说话者存在的方向输出声音的扬声器的音量大于朝向其它方向输出声音的扬声器的音量。
第7方案的对话装置使朝向说话者存在的方向输出声音的扬声器的音量大于向与说话者存在的方向不同的其它方向输出声音的扬声器的音量。因此,第7方案的对话装置能够以使对话对方易于听清的方式输出声音。
关于第8方案的对话装置,在第6方案或者第7方案中,所述控制部针对所述说话者的各个说话者收集易于听清的频带的信息,在从扬声器向所述说话者输出声音的情况下,进行根据所述说话者调制成为基准的预先决定的音质的控制,以使在所述频带中包含的声音强度大于具有所述预先决定的音质的声音的所述频带中包含的声音强度。
第8方案的对话装置在将从扬声器输出的声音的音质调制为说话者易于听清的音质之后,朝向说话者输出。因此,相比于针对对话对方以预先决定的音质输出声音的情况,能够输出易于听清的声音。
如以上说明,根据本公开,具有能够以使对话对方易于听清的方式输出声音这样的效果。
附图说明
将基于以下附图详细描述本发明的示例性实施例,其中:
图1是示出对话装置的外观例的图;
图2是示出第1实施方式所涉及的对话装置的结构例的图;
图3是示出第1实施方式以及第3实施方式所涉及的对话装置的电气系统的要部结构例的图;
图4是示出第1实施方式所涉及的对话装置中的对话处理的流程的一个例子的流程图;
图5是示出与音质的调制对应的对话处理的流程的一个例子的流程图;
图6是示出与音质的调制对应的对话处理的流程的一个例子的流程图;
图7是示出与音质的调制对应的对话处理的流程的一个例子的流程图;
图8是示出使用第2实施方式所涉及的对话装置的系统结构例的图;
图9是示出第2实施方式所涉及的对话装置的结构例的图;
图10是示出第2实施方式所涉及的对话装置的电气系统的要部结构例的图;
图11是示出第2实施方式所涉及的对话装置中的对话处理的流程的一个例子的流程图;
图12是示出第3实施方式所涉及的对话装置的结构例的图;
图13是示出映射制作处理的流程的一个例子的流程图;
图14是示出与中继模式对应的对话处理的流程的一个例子的流程图;以及
图15是示出与中继模式对应的对话处理的流程的一个例子的流程图。
具体实施方式
以下,参照附图,详细说明本公开的实施例。此外,对相同的构成要素以及处理在所有附图中赋予相同的符号,省略重复的说明。
<第1实施方式>
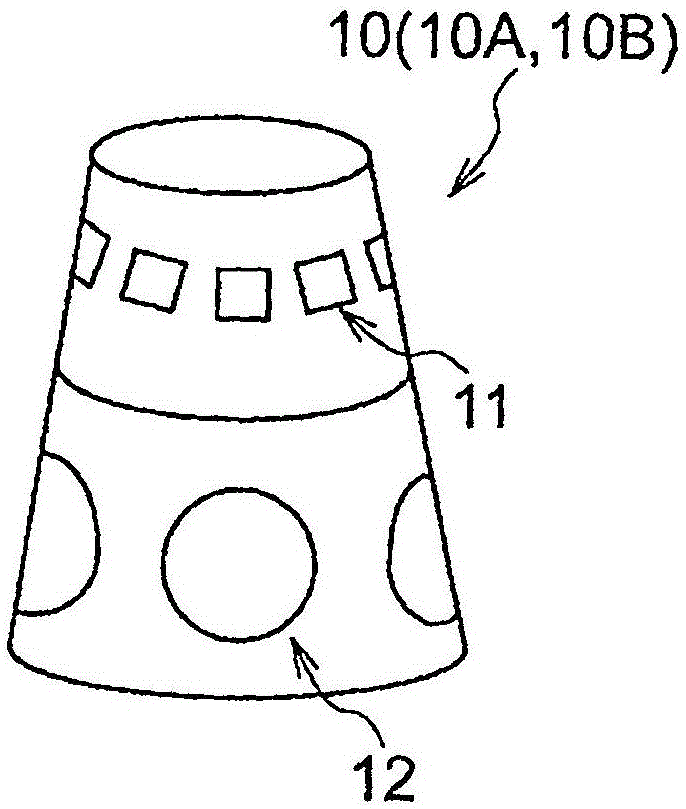
图1示出表示第1实施方式所涉及的对话装置10的外观例的图。对话装置10有时还被称为ai(artificialintelligence,人工智能)扬声器或者智能扬声器,如图1所示,在对话装置10的侧面,例如以包围对话装置10的方式,360度地配置有多个麦克风11以及多个扬声器12。
在图1的例子中,对话装置10的形状形成用与圆锥的高度方向相交的面将圆锥切下而成的形状,但对于对话装置10的形状无制约。另外,对话装置10的大小设为人可搬运的大小。
图2是示出对话装置10的功能性的结构例的结构图。对话装置10包括多个麦克风11、多个扬声器12、确定部13、生成部14、通信部15、输出部16以及控制部17。
将用麦克风11收集到的声音用各个麦克风11变换为声音信号,通知给确定部13。
确定部13根据从各个麦克风11通知的声音信号取得表示声音的大小的声音强度,确定声音是从哪个方向发出的。在该情况下,存在由朝向声音被发出的方向设置的麦克风11收集到的声音的声音强度变得最高的倾向,所以确定部13通过解析从各个麦克风11通知的声音信号的声音强度,能够确定发出的声音的方向。
因此,优选将指向性麦克风用作麦克风11,使用以使各个麦克风11的集音区域尽可能不重叠的方式,将麦克风11配置为沿着对话装置10的侧面包围对话装置10的对话装置10。
确定部13将确定的声音的方向通知给在后面说明的控制部17,并且例如将来自收集了确定的方向的声音的麦克风11的声音信号通知给生成部14。
生成部14解析用从确定部13通知的声音信号表示的声音的内容,生成与声音的内容对应的应答句子。具体而言,生成部14经由例如具备与因特网等通信线路30连接的通信协议的通信部15,与智能服务器31进行数据通信,生成适合于声音的内容的应答句子。
在智能服务器31中存储有各种信息,将从对话装置10请求的信息发送到对话装置10。此外,智能服务器31也可以构成为例如云计算。
例如生成部14在从确定部13受理具有“今天东京的天气如何?”这样的内容的声音信号的情况下,生成请求今天东京的天气的电文并针对智能服务器31发送。相对于此,在从智能服务器31受理“晴”这样的信息时,生成部14根据从确定部13受理的声音的内容和从智能服务器31受理的信息,使用预先决定的学习模型,生成例如“今天东京的天气晴”这样的应答句子。
生成部14在掌握从确定部13受理的声音的内容的情况下,有时也使用预先决定的学习模型。作为学习模型,利用使用例如教师信号和输入信号的组合来通过深度学习预先学习了神经元之间的加权等的多层神经网络。
生成部14在用公知的手法将从确定部13受理的声音的内容变换为句子之后,针对句子进行例如词素解析,将句子分割为词素。然后,生成部14通过将分割为词素的句子的各词素输入到学习模型,能够掌握句子的内容。
另外,生成部14例如通过将由从确定部13受理的声音表示的句子的词素、以及从智能服务器31受理的信息的各个输入到学习模型,能够生成针对由从确定部13受理的声音表示的句子的内容的回答。
这样,生成部14使用人工地实现了基于人类的知识的学习以及各种信息的人类的推理以及判断的人工智能,生成与由从确定部13受理的声音信号表示的声音的内容对应的应答句子。
生成部14将生成的应答句子通知给输出部16。
输出部16使用公知的声音合成处理,将由生成部14生成的应答句子变换为声音信号,将变换后的声音信号输出到扬声器12。由此,用麦克风11收集到的针对向对话装置10的指示以及提问这样的声音的应答作为声音从扬声器12输出。
输出部16在将应答句子变换为声音信号的情况下,使用具有成为基准的预先决定的音质的声音(以后称为“基准声音”)。即,从扬声器12输出的声音的高低以及说话速度这样的音质依照基准声音的音质。
此外,在输出部16中,关于声音的声音强度以及输出声音的扬声器的至少一方,依照来自控制部17的指示。
控制部17从确定部13、生成部14、通信部15以及输出部16的各功能部取得控制所需的信息,根据取得的信息控制各功能部的处理。
具体而言,控制部17从确定部13取得发出的声音的方向、即发出声音的人(以后称为“说话者”)的方向。另外,控制部17在用麦克风11收集到的声音中包含预先决定的种类的语句的情况下,从生成部14取得声音的内容的解析结果。另外,控制部17从通信部15取得在数据通信中有无通信障碍等信息。另外,控制部17从输出部16取得通知由输出部16从生成部14受理了应答句子的受理通知。
在图2中说明的对话装置10能够使用例如计算机来实现。图3是示出使用计算机20构成的对话装置10中的电气系统的要部结构例的图。
计算机20具备cpu(centralprocessingunit,中央处理单元)21、rom(readonlymemory,只读存储器)22、ram(randomaccessmemory,随机存取存储器)23、非易失性存储器24以及输入输出接口(i/o)25。另外,cpu21、rom22、ram23、非易失性存储器24以及i/o25经由总线26分别连接。此外,计算机20中使用的操作系统没有制约,可以使用任意的操作系统。
cpu21在对话装置10中作为确定部以及控制部发挥功能。在rom22中存储例如由cpu21执行的程序,ram23被用作临时地存储在cpu21的处理过程中生成的数据的工作区。
非易失性存储器24是即使切断供给到非易失性存储器24的电力但存储的信息也不会被消除而是被维持的存储装置的一个例子,使用例如半导体存储器,但也可以使用硬盘。
对计算机20的i/o25连接例如多个麦克风11、多个扬声器12以及通信单元27。
通信单元27是实现与通信部15对应的功能的装置,作为与通信线路30的连接方式,安装有多个通信协议以能够应对有线或者无线中的任意方式。进而,也可以在通信单元27中安装例如像蓝牙(注册商标)那样用于与处于约100m以内的近距离的信息设备进行通信的通信协议、以及像nfc(nearfieldcommunication,近场通信)那样用于与处于约10cm以内的极近距离的信息设备进行通信的通信协议。
此外,i/o25所连接的单元不限于图3所示的各单元,根据需要连接各种装置。例如,也可以对i/o25连接将针对对话装置10的用户的操作变换为电信号而通知给cpu21的按钮及触摸面板、以及与外部的信息设备的输出端子连接而将外部的信息设备的输出通知给cpu21的输入单元。另外,也可以对i/o25连接将由cpu21处理后的信息通知给用户的液晶显示器或者有机el(electroluminescence,电致发光)显示器等显示单元。
接下来,参照图4,说明第1实施方式所涉及的对话装置10的动作。图4是示出在例如对话装置10的电源被接通的情况下,由cpu21执行的对话处理的流程的一个例子的流程图。
规定对话处理的对话程序例如预先存储于对话装置10的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
首先,在步骤s10中,cpu21判定是否从有多个的麦克风11中的至少1个麦克风11接收到声音。在从任意一个麦克风11都未接收到声音的情况下,反复执行步骤s10,监视声音的接收。
另一方面,在从至少1个麦克风11接收到声音的情况下,转移到步骤s20。
在步骤s20中,cpu21针对在步骤s10中接收到声音的每个麦克风11取得声音的声音强度,确定声音从哪个方向发出,从而确定说话者的方向。
具体而言,收集到在从对话装置10观察时声音强度最大的声音的麦克风11所配置的方向成为说话者的方向。确定的说话者的方向被存储到例如ram23。
在步骤s30中,cpu21如上述说明那样使用学习模型来解析在步骤s10中接收到的声音的内容,与智能服务器31协作地生成与接收到的声音的内容对应的应答句子。
在步骤s40中,cpu21选择朝向在步骤s20中确定的说话者的方向输出声音的扬声器12。
具体而言,对多个麦克风11以及多个扬声器12分别分配唯一地识别麦克风11以及扬声器12的识别编号,在非易失性存储器24中预先存储有将麦克风11的识别编号、和朝向该麦克风11的配置位置的方向输出声音的扬声器12的识别编号对应关联的配置表格。
因此,cpu21参照配置表格,取得与收集到声音强度最大的声音的麦克风11的识别编号对应的扬声器12的识别编号。用取得的识别编号表示的扬声器12成为朝向说话者的方向输出声音的扬声器12。
此外,将在步骤s20中存储到ram23的说话者的方向也存储为收集到声音强度最大的声音的麦克风11的识别编号。
在步骤s50中,cpu21使用公知的声音合成处理,将在步骤s30中生成的应答句子变换为声音信号,将变换后的声音信号输出到在步骤s40中选择出的扬声器12。由此,从在步骤s40中选择出的扬声器12输出针对说话者向对话装置10的提问的应答。在该情况下,从在步骤s40中选择出的扬声器12以外的扬声器12不输出声音。
在步骤s40中选择出的扬声器12是朝向说话者的方向输出声音的扬声器12,在步骤s40中未选择的扬声器12是朝向与说话者的方向不同的方向输出声音的扬声器12。因此,相比于假设从对话装置10的多个的扬声器12中的、在步骤s40中选择出的扬声器12以外的扬声器12输出应答的情况,说话者易于听清来自对话装置10的应答。
即,对话装置10能够控制从扬声器12输出的声音的指向性,以使向对话对方的方向的声音的指向性比其它方向上的声音的指向性高。通过以上,结束图4所示的对话处理。
此外,在图4所示的对话处理中,通过仅从朝向对话对方的方向的扬声器12输出声音来控制从扬声器12输出的声音的指向性,但使向对话对方的方向的声音的指向性高于其它方向上的声音的指向性的控制方法不限于此。
例如,cpu21也可以在控制各个扬声器12的音量,以使在步骤s40中选择出的扬声器12的音量大于在步骤s40中未选择的扬声器12的音量之后,从各个扬声器12输出针对说话者向对话装置10的提问的应答。相比于其它方向,向说话者的方向输出的声音的音量更大,所以从对话装置10向对话对方的方向输出的声音比向其它方向输出的声音更易于听清。
这样,第1实施方式所涉及的对话装置10根据说话者发出的声音的方向确定说话者的方向,控制从扬声器12输出的声音的指向性,以使向说话者存在的方向的声音的指向性高于其它方向上的声音的指向性。因此,相比于不控制声音的指向性而从扬声器12输出应答的情况,对对话装置10提问的说话者更易于听清来自对话装置10的应答。
<第1实施方式的变形例>
在第1实施方式所涉及的对话装置10中,控制从扬声器输出的声音的指向性,对于与对话装置10的对话对方而言,易于听清来自对话装置10的应答。在此,说明通过从扬声器12输出说话者易于听清的频带的声音,使来自对话装置10的应答更易于听清的对话装置10。
此外,在该变形例中,作为一个例子,说明相同说话者与对话装置10进行对话的状况。
图5是示出由cpu21执行的与音质的变更指示对应的对话处理的流程的一个例子的流程图。规定在图5所示的流程图中表示的对话处理的对话程序例如预先存储于对话装置10的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
图5所示的流程图与图4不同的点是追加有步骤s22、s24以及s26,其它处理与在图4中说明的对话处理相同。
在步骤s20中,在确定针对对话装置10的说话者的方向之后,执行步骤s22。
在步骤s22中,cpu21使用学习模型来解析在步骤s10中接收到的声音的内容,判定在接收到的声音中是否包括例如“想要改变音质”这样的表示音质的变更指示的表达。也可以根据用接收到的声音表示的表达是否与例如在非易失性存储器24中预先存储的表示音质的变更指示的表达一致,判定在接收到的声音中是否包括音质的变更指示。或者,也可以将用接收到的声音表示的句子的词素输入到学习模型,依照学习模型的输出结果,判定在cpu21接收到的声音中是否包括音质的变更指示。在该情况下,例如即使在未将“改变音质”作为表示音质的变更指示的表达存储于非易失性存储器24的情况下,cpu21也能够将“改变音质”自主地判定为是音质的变更指示。
在步骤s22的判定处理是否定判定的情况下、即在步骤s10中接收到的声音中不包括表示音质的变更指示的表达的情况下,转移到步骤s30,以后执行与图4所示的对话处理相同的处理。
另一方面,在步骤s22的判定处理是肯定判定的情况下、即在步骤s10中接收到的声音中包括表示音质的变更指示的表达的情况下,转移到步骤s24。
在步骤s24中,cpu21从预先决定的多个频带选择1个频带,生成由在选择出的频带中包含的频率构成的音作为测定音。
在步骤s26中,cpu21起动测定定时器,测定从起动测定定时器起的累计时间。测定定时器利用例如内置于cpu21的定时器功能即可。
之后,cpu21执行已经说明的步骤s40以及s50,从向说话者的方向输出声音的扬声器12输出在步骤s24中生成的测定音。此外,cpu21控制扬声器12的音量,以使得例如以最小音量从扬声器12输出测定音,随着时间经过使测定音的音量变大。
通过以上,从对话装置10朝向说话者输出在步骤s24中选择出的频带的测定音。
相对于此,听到测定音的说话者在听到测定音的阶段将表示听到测定音的测定音可听应答送到对话装置10。作为一个例子,听到测定音的说话者向对话装置10说出例如“听到”。“听到”是测定音可听应答的一个例子。
图6是示出在从说话者受理音质的变更指示并从对话装置10输出测定音之后由cpu21执行的与测定音可听应答对应的对话处理的流程的一个例子的流程图。规定在图6所示的流程图中表示的对话处理的对话程序例如预先存储于对话装置10的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
在步骤s100中,cpu21与图4的步骤s10同样地,判定是否从至少1个麦克风11接收到声音。在未接收到声音的情况下,转移到在后面说明的步骤s130。另一方面,在接收到某种声音的情况下,转移到步骤s110。
在步骤s110中,cpu21通过与图4的步骤s20同样的方法确定说话者的方向。
在步骤s120中,cpu21使用学习模型来解析在步骤s100中接收到的声音的内容,判定在接收到的声音中是否包括例如“听到”这样的测定音可听应答。在步骤s100中接收到的声音中未包括测定音可听应答的情况下,转移到步骤s130。
在步骤s130中,cpu21判定在图5的步骤s26中起动的测定定时器的定时器值是否为阈值t0以上。阈值t0是在是否听到测定音的判定中使用的值,通过例如利用对话装置10的真机的实验、基于对话装置10的设计规格的计算机仿真等预先求出,预先存储到非易失性存储器24。
在测定定时器的定时器值小于阈值t0的情况下,cpu21判定为残留有从说话者发出测定音可听应答的可能性。因此,转移到步骤s100,cpu21监视声音的接收。另一方面,在测定定时器的定时器值是阈值t0以上的情况下、以及在步骤s120中cpu21判定为在步骤s100中接收到的声音中包括测定音可听应答的情况下,转移到步骤s140。
在步骤s140中,cpu21将从扬声器12输出的测定音的频带和测定定时器的定时器值对应关联,记录到存储于ram23的可听范围表格。记录到可听范围表格的测定定时器的定时器值表示测定音可听应答时间,该测定音可听应答时间表示从输出测定音至说话者应答听到测定音的期间。因此,测定音可听应答时间越短,表示说话者越易于听清与测定音对应的频带的音。
在步骤s150中,cpu21判定是否已针对预先决定的多个频带,输出与所有频带对应的测定音。在存在尚未生成测定音的频带的情况下,转移到步骤s160。
在步骤s160中,cpu21在预先决定的多个频带中选择1个尚未选择的频带,生成由在选择出的频带中包含的频率构成的音,作为测定音。
在步骤s170中,cpu21进行与图4的步骤s40同样的处理,选择朝向在步骤s110中确定的说话者的方向输出声音的扬声器12。
在步骤s180中,cpu21从在步骤s170中选择出的扬声器12输出在步骤s160中生成的测定音。在该情况下,cpu21也控制扬声器12的音量,以使得例如以最小音量从扬声器12输出测定音,随着时间经过使测定音的音量变大。
在步骤s190中,cpu21使测定定时器的定时器值返回到“0”,执行再次开始测定定时器的时间测量的测定定时器的再起动。然后,转移到步骤s100,cpu21监视从扬声器12输出的、针对与新的频带对应的测定音的来自说话者的测定音可听应答。
cpu21反复执行以上的处理,直至从扬声器12输出与预先决定的多个频带的各个频带对应的测定音为止。在步骤s150的判定处理中判定为输出了与所有频带对应的测定音的情况下,转移到步骤s200。
在步骤s200中,cpu21参照可听范围表格中的每个频带的测定音可听应答时间,将进行音质的变更指示的说话者最易于听清的频带(以后,称为“最佳频带”)存储到例如非易失性存储器24。
通过以上,结束与图6所示的测定音可听应答对应的对话处理。
图7是示出在进行与图6所示的测定音可听应答对应的对话处理之后,由cpu21执行的对话处理的流程的一个例子的流程图。
规定在图7所示的流程图中表示的对话处理的对话程序例如预先存储于对话装置10的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
图7所示的流程图与图4不同的点是步骤s50被置换为步骤s50a,其它处理与在图4中说明的对话处理相同。
在步骤s50a中,cpu21使用公知的声音合成处理,将在步骤s30中生成的应答句子变换为声音信号,将变换后的声音信号输出到在步骤s40中选择出的扬声器12。在该情况下,cpu21从非易失性存储器24取得在图6的步骤s200中存储的说话者的最佳频带,以使最佳频带中的声音的声音强度高于基准声音的方式调制基准声音的音质,从选择出的扬声器12输出。
由此,相比于其它频带的声音,最佳频带的声音被强调,所以相比于从扬声器12用基准声音输出应答的情况,说话者更易于听清来自对话装置10的应答。通过以上,结束图7所示的对话处理。
此外,在图6的流程图中,cpu21也可以执行在步骤s100中接收到的声音的频率分析,将声音的频率分析结果和最佳频带对应关联地存储到非易失性存储器24。
在该情况下,在图7的对话处理中,cpu21针对在步骤s10中接收到的声音进行频率分析,从非易失性存储器24取得对应关联了与得到的频率分析结果最接近的频率分析结果的最佳频带。然后,cpu21也可以在步骤s50a中,使用根据频率分析结果从非易失性存储器24取得的最佳频带,调制基准声音的音质。由此,对话装置10能够针对每个说话者调制基准声音的音质。
因此,通过将说话者的语音的频率分析结果和最佳频带对应关联地存储到非易失性存储器24,能够针对向对话装置10提问的每个说话者,以比基准声音更易于听清的声音通知应答。
<第2实施方式>
在第1实施方式中,关于利用对话装置10的场所,未特别设置制约,但在第2实施方式中,说明在车辆40中利用的对话装置10a。
图8是示出使用第2实施方式所涉及的对话装置10a的系统结构例的图。
如图8所示,对话装置10a被带入到车辆40内,与设置于例如车内的仪表盘等预先决定的位置的车辆导航装置8连接。另外,对话装置10a通过进行无线通信的通信协议,经由通信线路30与智能服务器31连接。
此外,车辆40中的对话装置10a的连接目的地不限于车辆导航装置8,也可以与控制搭载于车辆40的电子设备的ecu(electroniccontrolunit,电子控制单元)等其它装置连接。车辆导航装置8以及ecu是驾驶支援装置的一个例子。
图9是示出对话装置10a的功能性的结构例的结构图。图9所示的对话装置10a的结构与图2所示的第1实施方式所涉及的对话装置10的结构不同的点在于,追加了输入部18,生成部14以及控制部17被分别置换为生成部14a以及控制部17a。
输入部18受理从车辆导航装置8输出的、支援车辆40的驾驶的支援信息。作为支援信息,包括例如车辆40的行进方向、车辆40的行进方向的变更位置、车辆40的当前位置以及车辆40的速度等。
输入部18对控制部17a通知从车辆导航装置8受理的支援信息。
控制部17a除了对话装置10中的控制部17的处理以外,在从输入部18受理支援信息时,为了确定车辆40的驾驶者在从对话装置10a观察时处于哪个方向,控制生成部14a以生成呼叫驾驶者的句子。另外,控制部17a对生成部14a通知从输入部18受理的支援信息。
生成部14a除了对话装置10中的生成部14的处理以外,在从控制部17a被指示呼叫驾驶者的句子的生成时,生成呼叫驾驶者的句子,通知给输出部16。另外,生成部14a在从控制部17a受理支援信息时,根据支援信息的内容,生成传递与支援信息关联的信息的句子、或者生成将支援信息的内容传递给驾驶者的句子。
具体而言,在例如对话装置10a受理车辆40的当前位置作为支援信息的情况下,生成部14a从智能服务器31取得包括车辆40的当前位置的地图,如果在从车辆40的当前位置起预先决定的范围内有学校,则制作“请注意速度”这样的句子。另外,在对话装置10a受理车辆40的当前位置以及车辆40的燃料的剩余量作为支援信息的情况下、并且受理的燃料的剩余量小于预先决定的剩余量的情况下,生成部14a从智能服务器31取得处于最接近车辆40的当前位置的场所的加油站,制作例如“请在前方1km的加油站加油”这样的句子。另外,在对话装置10a受理例如“在前方100m右拐”这样的与车辆40的行进方向有关的信息作为支援信息的情况下,生成部14a将与行进方向有关的信息放入句子,生成例如“请在前方100m的交叉路口右拐”这样的驾驶者易于理解的句子。此时,在从智能服务器31得到前方100m的交叉路口相比于其它交叉路口是事故多发的交叉路口这样的信息的情况下,也可以添加“事故多发的交叉路口。请注意”这样的句子。
这样,将根据支援信息的内容由生成部14a生成的句子称为“驾驶支援句子”。
在图9中说明的对话装置10a能够使用例如计算机来实现。图10是示出使用计算机20构成的对话装置10a中的电气系统的要部结构例的图。
图10所示的要部结构例与图3所示的第1实施方式所涉及的对话装置10的要部结构例不同的点在于,经由连接器以有线方式连接受理来自车辆导航装置8等的支援信息的输入单元28,其它结构与图3相同。此外,在从车辆导航装置8等以无线方式发送支援信息的情况下,代替输入单元28而用通信单元27受理支援信息。
接下来,说明第2实施方式所涉及的对话装置10a的动作。
图11是示出在例如对话装置10a的电源被接通的情况下,由cpu21执行的对话处理的流程的一个例子的流程图。
规定在图11所示的流程图中表示的对话处理的对话程序例如预先存储于对话装置10a的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
首先,在步骤s300中,cpu21判定是否从车辆导航装置8接收到支援信息。在未接收到支援信息的情况下,反复执行步骤s300的处理,监视支援信息的接收。
另一方面,在接收到支援信息的情况下,转移到步骤s310。
在步骤s310中,cpu21使用学习模型,解析在步骤s300中接收到的支援信息的内容,根据支援信息的内容,生成驾驶支援句子。
在步骤s320中,cpu21从对话装置10a的各个扬声器12输出例如“司机先生”那样对车辆40的驾驶者提问的句子。在该情况下,cpu21使用预先存储于非易失性存储器24的、与对驾驶者提问的句子对应的声音信号即可。
期待驾驶者针对向驾驶者的提问例如应答“是”,所以在步骤s330中,cpu21与图4的步骤s10同样地,判定是否从至少1个麦克风11接收到声音。
在接收到声音的情况下,在步骤s340中,cpu21利用与图4的步骤s20同样的方法,确定声音被发出的方向,从而确定车辆40中的驾驶者的方向。
在步骤s350中,cpu21与图4的步骤s40同样地,选择朝向在步骤s340中确定的驾驶者的方向输出声音的扬声器12。
在步骤s360中,cpu21与图4的步骤s50同样地,使用公知的声音合成处理,将在步骤s310中生成的驾驶支援句子变换为声音信号,从在步骤s350中选择出的扬声器12输出变换后的声音信号。
通过以上,结束图11所示的对话处理。
这样,根据第2实施方式所涉及的对话装置10a,通过从对话装置10a向车辆40的驾驶者提问,自主地掌握驾驶者的位置,从朝向驾驶者输出声音的扬声器12输出驾驶支援句子,以使驾驶者易于听清。对话装置10a每当从车辆导航装置8受理支援信息时更新驾驶者的位置,所以例如即使对话装置10a的位置被车辆40的同乘者变更,也能够朝向驾驶者通知驾驶支援句子。
此外,在未变更车辆40中的对话装置10a的位置的情况下,对话装置10a无需每当从车辆导航装置8受理支援信息时更新驾驶者的位置。因此,对话装置10a也可以在对话装置10a的电源被接通之后,在将图11的步骤s320至步骤s340的处理执行1次而掌握驾驶者的位置之后,执行从图11的流程图删除步骤s320至步骤s340的处理后的对话处理。在该情况下,相比于每当从车辆导航装置8受理支援信息时更新驾驶者的位置的情况,对话装置10a能够抑制从对话装置10a向驾驶者进行提问的次数。
另外,如果对话装置10a的位置未频繁地变更,则对话装置10a也可以不每当从车辆导航装置8受理支援信息时更新驾驶者的位置,而例如以10分钟等预先决定的间隔执行图11的步骤s320至步骤s340的处理,更新驾驶者的位置。在该情况下,相比于每当从车辆导航装置8受理支援信息时更新驾驶者的位置的情况,对话装置10a能够更新驾驶者的位置,并且抑制从对话装置10a向驾驶者的提问。
在图11的流程图中,在从对话装置10a向驾驶者输出声音的情况下,通过仅从朝向驾驶者的方向的扬声器12输出声音,控制从扬声器12输出的声音的指向性。但是,相比于其它方向使声音更易于到达驾驶者的方向的控制方法不限于此。
例如,如在第1实施方式中说明的那样,cpu21也可以控制各个扬声器12的音量,以使朝向驾驶者的方向的扬声器12的音量大于其它扬声器12的音量。
在第2实施方式中,使用对话装置10a从预先设置于车辆40的车辆导航装置8以及ecu取得支援信息的例子,说明了对话装置10a的动作,但支援信息的取得目的地不限于此。对话装置10a也可以从如安装有实现车辆导航功能的应用的智能手机那样的便携型的信息设备取得支援信息。便携型的信息设备与车辆导航装置8不同,并非预先设置于车辆40,而是乘坐车辆40的人带入到车辆40的信息设备。
<第3实施方式>
在第1实施方式以及第2实施方式中,说明了对话装置10或者对话装置10a与说话者进行对话的例子。然而,例如在车内驾驶者和在后部座席乘坐的同乘者进行对话的情况下,有时由于周围的噪音而难以听清对话对方的话。
因此,在第3实施方式中,说明具备中继对话以使对话对方的话易于听清的中继模式的对话装置10b。
图12是示出对话装置10b的功能性的结构例的结构图。图12所示的对话装置10b的结构与图2所示的第1实施方式所涉及的对话装置10的结构不同的点在于,生成部14以及控制部17被分别置换为生成部14b以及控制部17b。其它结构与第1实施方式所涉及的对话装置10的结构相同。
对话装置10b能够使用例如计算机20来实现。使用计算机20构成的对话装置10b中的电气系统的要部结构例成为与图3所示的第1实施方式所涉及的对话装置10中的电气系统的要部结构例相同的结构。
接下来,参照图13、图14以及图15,说明第3实施方式所涉及的对话装置10b的动作。
图13是示出在例如针对对话装置10b进行了映射的制作指示的情况下,由cpu21执行的映射制作处理的流程的一个例子的流程图。
映射是指,将确定处于从对话装置10b的扬声器12输出的声音的到达范围内并且参加对话的说话者的信息、和从对话装置10b观察的说话者的方向对应关联的表格。
此外,通过任意说话者对对话装置10b发出具有委托映射的制作的意图的发言、例如“制作映射”这样提问,进行映射的制作指示。
规定映射制作处理的映射制作程序例如预先存储于对话装置10b的rom22。cpu21读入在rom22中存储的映射制作程序来执行映射制作处理。
在步骤s400中,cpu21与图4的步骤s10同样地,判定是否从至少1个麦克风11接收到声音。在未接收到声音的情况下,反复执行步骤s400,监视声音的接收。
另一方面,在接收到某种声音的情况下,转移到步骤s410。
在步骤s410中,cpu21通过利用与图4的步骤s20同样的方法,确定声音被发出的方向,确定说话者的方向。
在步骤s420中,cpu21判定在步骤s400中接收到的声音中是否包括结束映射的制作的结束指示。
在接收到的声音中包括映射的结束指示的情况下,结束图13所示的映射制作处理。另一方面,在接收到的声音中未包括映射的结束指示的情况下,转移到步骤s430。
此外,通过任意说话者对对话装置10b发出具有委托映射的制作结束的意图的发言、例如“结束映射的制作”这样提问,进行映射的结束指示。
在制作映射的情况下,需要确定在步骤s400中接收到的声音的说话者是谁,所以在步骤s430中,cpu21判定在接收到的声音中是否包括说话者的名字。通过用学习模型解析接收到的声音,得到在接收到的声音中是否包括说话者的名字的判定结果。
在步骤s430的判定处理中判定为在接收到的声音中不包括说话者的名字的情况下,转移到步骤s440。
在步骤s440中,cpu21为了取得在步骤s400中接收到的声音的说话者是谁,生成例如“你是谁?”这样的询问说话者的名字的问句。
在步骤s450中,cpu21进行与图4的步骤s40同样的处理,选择朝向在步骤s410中确定的说话者的方向输出声音的扬声器12。
在步骤s460中,cpu21进行与图4的步骤s50同样的处理,从在步骤s450中选择出的扬声器12输出在步骤s440中生成的问句。由此,针对不知道名字的说话者进行名字的提问。
cpu21在执行步骤s460之后,使控制转移到步骤s400,监视任意声音的接收。
从对话装置10b被询问名字的说话者例如如“我是山田”这样说出自己的名字,所以在步骤s400中,接收到包括名字的声音。因此,在步骤s430中,cpu21判定为在接收到的声音中包括说话者的名字,转移到步骤s470。
在步骤s470中,cpu21从在步骤s400中接收到的声音取得说话者的名字。在步骤s400中接收到“我是山田”这样的声音的情况下,cpu21取得与说话者的名字相当的“山田”。此外,为了从接收到的声音取得说话者的名字,cpu21使用从声音解析话语的意思的学习模型即可。
在步骤s480中,cpu21使用例如快速傅立叶变换等公知的频率分析手法,执行在步骤s400中接收到的声音的频率分析。由此,得到说话者的语音的特征。
在步骤s490中,cpu21制作将在步骤s410中确定的说话者的方向、在步骤s470中取得的说话者的名字、以及在步骤s480中取得的说话者发出的语音的频率分析结果分别对应关联的映射,将制作出的映射存储到ram23。
在步骤s500中,cpu21为了确认是否还残留有尚未说出名字的说话者,生成例如如“还有谁?”这样向处于对话装置10b的周围的说话者提问的问句。然后,cpu21从对话装置10b的各个扬声器12输出生成的问句,使控制转移到步骤s400。
如果还残留有针对来自对话装置10b的提问尚未说出名字的说话者,则由于期待未说出名字的说话者向对话装置10b说话,所以cpu21针对接收到的声音反复执行步骤s400~s500的处理,直至在步骤s420中受理映射的结束指示为止。由此,cpu21能够制作将在从对话装置10b观察时在哪里有具有何种声质的说话者对应关联的映射。
图14是示出在图13所示的映射制作处理结束之后由cpu21执行的对话处理的流程的一个例子的流程图。
规定对话处理的对话程序例如预先存储于对话装置10b的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
图14所示的流程图与图4所示的第1实施方式所涉及的对话装置10的流程图不同的点在于,追加有步骤s21以及步骤s60~s70的处理。
在此作为一个例子,对话开始的契机设为从例如如“嗨,山田”那样,说话者叫出对话对方的名字开始。
在步骤s21中,cpu21判定是否在步骤s10中接收到的声音中包括对话对方的名字的基础之上,包括呼叫对话对方的表达。通过用从声音解析话语的意思的学习模型,解析接收到的声音,得到在接收到的声音中是否包括对话对方的名字以及呼叫对话对方的表达的判定结果。
在接收到的声音中未包括对话对方的名字以及呼叫对话对方的表达的情况下,cpu21判定为人彼此未开始对话,接收到的声音是向对话装置10b的提问,使执行目的地转移到步骤s30。以后,通过cpu21执行已经说明的步骤s30、s40以及s50的处理,对话装置10b进行与从扬声器12朝向向对话装置10b提问的说话者的方向输出针对向对话装置10b的提问的应答的第1实施方式所涉及的对话装置10相同的动作。
另一方面,在步骤s21的判定处理中判定为在接收到的声音中包括对话对方的名字以及呼叫对话对方的表达的情况下,转移到步骤s60。此外,cpu21将在接收到的声音中包含的对话对方的名字存储到ram23。
在步骤s60中,cpu21通过将例如在ram23中存储的表示动作模式的变量的值设定为表示中继模式的值,设定为使对话装置10b的动作以中继模式动作。
在步骤s62中,cpu21参照映射,确定处于在步骤s20中确定的方向的说话者是谁、确定说话者的名字。即,cpu21确定开始对话的说话者的名字。
然后,cpu21将确定的说话者的名字和在步骤s21中存储到ram23的对话对方的名字分别对应关联,作为对话表格存储到ram23。由此,进行对话的成员的信息被存储到ram23。此外,在说话者例如如“嘿,山田和田中”那样叫多个人的情况下,将被说话者叫到的各个人作为说话者的对话对方存储到对话表格。
在步骤s64中,cpu21参照映射,确定在步骤s21中将名字存储到ram23的对话对方在从对话装置10b观察时处于哪个方向。
在步骤s66中,cpu21选择朝向在步骤s64中确定的对话对方存在的方向输出声音的扬声器12。
在步骤s68中,cpu21从在步骤s66中选择出的扬声器12输出在步骤s10中接收到的开始对话的说话者发出的声音。由此,相比于从向与对话对方存在的方向不同的方向输出声音的扬声器12输出开始对话的说话者发出的声音的情况,说话者发出的声音更易于听清地通知给对话对方。
在步骤s70中,cpu21起动对话定时器。对话定时器利用例如内置于cpu21的定时器功能即可。
在此“对话定时器”是指,用于判定开始的对话是否结束的定时器。对话装置10b将在说话者说出某种发言之后直至经过预先决定的时间为止谁也未应答的情况规定为对话的结束。将规定对话的结束的预先决定的时间设为阈值t1(t1>0),存储到例如非易失性存储器24。此外,对话定时器未起动的情况下的对话定时器的定时器值表示“0”。
通过以上,对话装置10b的动作被切换到中继模式。
此外,在图14的步骤s62中,使用在步骤s20中确定的说话者的方向,确定开始对话的说话者的名字。然而,在映射中包括说话者的语音的频率分析结果。因此,在步骤s62中,cpu21也可以在执行在步骤s10中接收到的声音的频率分析之后,参照映射,将具有与得到的频率分析结果最接近的频率分析结果的人确定为开始对话的说话者。在该情况下,即使在说话者的位置与映射的制作时的位置变化的情况下,相比于根据说话者发出的语音的方向确定说话者是谁的情况,也能够更高精度地确定说话者。
图15是示出由cpu21执行的、与中继模式对应的对话处理的流程的一个例子的流程图。
规定对话处理的对话程序例如预先存储于对话装置10b的rom22。cpu21读入在rom22中存储的对话程序而执行对话处理。
在已经说明的步骤s10以及s20中,在由cpu21根据由各个麦克风11收集到的声音的声音强度确定说话者的方向之后,执行步骤s23。
在步骤s23中,cpu21判定对话定时器的定时器值是否为t1以上。在对话定时器的定时器值是t1以上的情况下,转移到步骤s25。
该情况表示从上次的说话者的发言起不说话状态持续t1以上,能够视为在进行对话的成员之间对话暂时结束。因此,在步骤s25中,cpu21将例如在ram23中存储的表示动作模式的变量的值从表示中继模式的值变更为其它值,解除中继模式。
另一方面,在步骤s23中判定为对话定时器的定时器值小于t1的情况下、或者执行了步骤s25的情况下,转移到步骤s27。
在步骤s27中,cpu21判定对话装置10b的动作模式是否为中继模式。在对话装置10b的动作模式并非中继模式的情况下,转移到步骤s29。
在步骤s29中,cpu21停止对话定时器,使对话定时器的定时器值返回到“0”。
在该情况下,对话装置10b的动作模式并非中继模式,所以cpu21掌握在步骤s10中接收到的声音是针对对话装置10b发出的提问。因此,cpu21执行已经说明的步骤s30、s40以及s50,进行从扬声器12朝向对对话装置10b提问的说话者的方向输出针对向对话装置10b的提问的应答的与第1实施方式所涉及的对话装置10相同的动作。
另一方面,在步骤s27的判定处理中判定为对话装置10b的动作模式是中继模式的情况下,转移到步骤s80。
在步骤s80中,cpu21参照映射,确定处于在步骤s20中确定的方向的说话者是谁、确定说话者。即,cpu21确定说话的说话者的名字。
在步骤s82中,cpu21参照在图14的步骤s62中制作出的对话表格,确定在步骤s80中确定的说话者的对话对方。
进而,cpu21参照映射,确定说话者的对话对方存在的方向。
在步骤s84中,cpu21选择朝向在步骤s82中确定的对话对方存在的方向输出声音的扬声器12。
在步骤s86中,cpu21从在步骤s84中选择出的扬声器12输出在步骤s10中接收到的说话者发出的声音。通过以上,结束图15所示的对话处理。
此外,在图15的步骤s80中,cpu21使用在步骤s20中确定的说话者的方向确定说话者。然而,在映射中包括说话者的语音的频率分析结果。因此,在步骤s80中,cpu21也可以在执行在步骤s10中接收到的声音的频率分析之后,参照映射,将具有与得到的频率分析结果最接近的频率分析结果的人确定为说话者。在该情况下,即使在说话者的位置在对话的途中变化的情况下,相比于根据说话者发出的语音的方向确定说话者是谁的情况,也能够更高精度地确定说话者。
这样,根据第3实施方式所涉及的对话装置10b,自主地判定成员之间的对话的开始,将对话装置10b设定为中继模式,从扬声器12朝向对话对方存在的方向输出说话者发出的语音,从而进行语音的中继。因此,相比于不确定对话对方存在的方向而从扬声器12向与对话对方存在的方向不同的方向输出说话者发出的声音的情况,说话者发出的声音更易于听清地通知给对话对方。
此外,在图13~图15的各流程图中,在从对话装置10b向说话者或者对话对方输出声音的情况下,通过仅从朝向说话者或者对话对方的方向的扬声器12输出声音,控制从扬声器12输出的声音的指向性。但是,相比于其它方向使声音更易于到达说话者以及对话对方的方向的控制方法不限于此。
例如,如在第1实施方式中说明的那样,cpu21也可以控制各个扬声器12的音量,以使朝向说话者或者对话对方的方向的扬声器12的音量大于其它扬声器12的音量。
以上,使用各实施方式说明了本公开,但本公开不限定于各实施方式记载的范围。能够在不脱离本公开的要旨的范围内对各实施方式施加各种变更或者改良,施加该变更或者改良而得到的方式也包含于本公开的技术范围。例如,也可以在不脱离本公开的要旨的范围内变更处理的顺序。
另外,在各实施方式中,作为一个例子,说明了用软件实现各处理的方式,但也可以将与图4~图7、图11以及图13~图15所示的流程图等同的处理安装到例如asic(applicationspecificintegratedcircuit,专用集成电路),用硬件处理。在该情况下,相比于用软件实现各处理的情况,能够期待处理的高速化。
另外,在上述各实施方式中,说明了各程序安装于rom22的方式,但不限定于此。本公开所涉及的各程序还能够以记录到计算机可读取的存储介质的方式提供。例如,也可以以记录到cd(compactdisc,光盘)-rom或者dvd(digitalversatiledisc,数字多功能光盘)-rom等光盘的方式提供本公开所涉及的各程序。另外,也可以以记录到usb(universalserialbus,通用串行总线)存储器以及闪存存储器等半导体存储器的方式提供本公开所涉及的各程序。进而,对话装置10、10a、10b也可以从与通信线路30连接的存储装置下载本公开所涉及的各程序。
- 还没有人留言评论。精彩留言会获得点赞!