抗TNF‑α醣抗体及其用途的制作方法
本发明主张以下优先权:美国临时申请案美国申请序号(USSN)62/003,908,申请于2014年5月28日、USSN 62/020,199,申请于2014年7月2日、USSN 62/110,338,申请于2015年1月30日。其内容各自以全文引用方式并入本文中。
背景技术:
Fc醣基化已成为治疗性单株抗体领域中的重要主题。Fc醣基化可显着改质Fc效应物功能(例如Fc受体结合及补体活化),且由此影响治疗抗体的活体内安全及功效特征。
基于基因改造的若干表达系统已报导会产生治疗性单株抗体。这些表达系统包含酵母(例如嗜甲醇酵母菌)、昆虫细胞系及甚至细菌。然而,这些表达系统具有诸多可不利地影响治疗抗体的效应物功能的缺陷。
大部分经批准生物药物是在哺乳动物细胞培养系统中产生以递送具有具有期望醣基化模式的蛋白质且由此确保减小的免疫原性及较高活体内功效及稳定性。非哺乳动物表达系统(例如CHO或NS0细胞)具有添加复杂人类型聚醣所需的机制。然而,这些系统中所产生的聚醣可不同于人类中所产生的聚醣。其醣基化机制通常添加不期望碳水化合物污染物,此可改变蛋白质折迭,诱导免疫原性,且减小药物的循环寿命。显而易见,呈N-乙酰基神经胺酸形式的唾液酸不能有效添加于大部分哺乳动物细胞中且6-链接在这些细胞中丢失。唾液酸转移所需的具有各种酶活性的改造细胞尚未成功提供醣型至蛋白质药物的人类样模式。迄今为止,需要将动物细胞或醣蛋白改造成尽可能类似于人类蛋白质的高度唾液酸化产物。
另外,哺乳动物细胞培养递送并不皆具有相同性质的醣基化模式的异质混合物。这些醣基化模式可影响诸如治疗性蛋白质的安全性、功效及血清半衰期等性质。
自体免疫性病症是重大且广泛的医学问题。TNFα(坏死因子α)是自体免疫性疾病(例如类风湿性关节炎、牛皮癣性关节炎、强直性脊柱炎、克罗恩氏病(Crohn's disease)及牛皮癣)中的发炎的主要促成者。
TNF在发炎中的重要性已藉由抗TNF抗体在控制类风湿性关节炎及其他发炎性病状中的疾病活性中的功效突出显示。当前存在4种批准用于治疗类风湿性关节炎的抗TNFα mAb,包含REMICADETM(英夫利昔单抗(Infliximab))、嵌合抗TNFα mAb、ENBRELTM(依那西普(Etanercept))、TNFR-Ig Fc融合蛋白、HUMIRATM(阿达木单抗(Adalimumab))、人类抗TNFα mAb及(赛妥珠单抗(Certolizumab pegol))、聚乙二醇化Fab片段。
阿达木单抗是藉由基因技术改造的人类源重组IgG1单株抗体。阿达木单抗结合至TNF-α但并不结合至TNF-β且具有大约2周的半衰期。其已在2002年12月31日批准用于RA患者。
阿达木单抗是在中国仓鼠卵巢(CHO)细胞中产生且在Fc结构域中的醣基化模式具有高度异质性。异质混合物中的每一IgG分子可能并不皆具有相同性质,且某些结合至治疗蛋白的N-连接寡醣可在患者中触发不期望效应,由此可视为安全问题。
技术实现要素:
因此,本揭示内容的一态样是关于抗TNFα醣抗体的组合物,其包括在每一Fc上具有相同N-聚醣的抗TNFα IgG分子的均质群体。本发明的抗TNFα醣抗体可自抗TNFα单株抗体由Fc醣改造产生。重要的是,与未醣改造的相应单株抗体相比,本文所阐述的抗TNFα醣抗体具有改良的治疗价值以及增加的TNFα结合亲和力。
在优选实施例中,N-聚醣连接至Fc区的Asn-297。
在一些实施例中,本文所阐述的抗TNFα醣抗体包括具有SEQ ID NO:1中所陈述氨基酸序列的重链及具有SEQ ID NO:2中所陈述氨基酸序列的轻链。在一优选实施例中,所述醣抗体包括阿达木单抗的轻链序列及重链序列。
本文揭示衍生自阿达木单抗的功能活性抗TNFα醣抗体。这些抗TNFα醣抗体与阿达木单抗相比展现类似或改良的TNFα结合亲和力。
在一些实施例中,本发明醣抗体中的N-聚醣具有双触角(biantennary)结构。在一些实施例中,N-聚醣包括二等分(bisecting)GlcNAc。
在一些实施例中,本文所阐述的N-聚醣包括至少一个α2-6末端唾液酸。在某些实施例中,N-聚醣包括一个α2-6末端唾液酸。在一优选实施例中,N-聚醣包括两个α2-6末端唾液酸。
在一些实施例中,本文所阐述的N-聚醣包括至少一个α2-3末端唾液酸。在某些实施例中,N-聚醣包括一个α2-3末端唾液酸。在一优选实施例中,N-聚醣包括两个α2-3末端唾液酸。
在一些实施例中,本文所阐述的N-聚醣包括至少一种半乳醣。在某些实施例中,N-聚醣包括一种半乳醣。在一优选实施例中,N-聚醣包括两种半乳醣。
在优选实施例中,N-聚醣发生岩藻醣基化。在一些实施例中,N-聚醣发生去岩藻醣基化。
在一些实施例中,N-聚醣具有选自由以下组成的群的聚醣序列:Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc2、Sia(α2-6)Gal2GlcNAc2Man3GlcNAc2、Sia(α2-6)GalGlcNAc2Man3GlcNAc2、Sia2(α2-6)Gal2GlcNAc3Man3GlcNAc2、Sia(α2-6)Gal2GlcNAc3Man3GlcNAc2、Sia(α2-6)GalGlcNAc3Man3GlcNAc2、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc2、Sia(α2-3)GalGlcNAc3Man3GlcNAc2、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc2、Sia(α2-3)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc2(F)、Sia(α2-6)Gal2GlcNAc2Man3GlcNAc2(F)、Sia(α2-6)GalGlcNAc2Man3GlcNAc2(F)、Sia2(α2-6)Gal2GlcNAc3Man3GlcNAc2(F)、Sia(α2-6)Gal2GlcNAc3Man3GlcNAc2(F)、Sia(α2-6)GalGlcNAc3Man3GlcNAc2(F)、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc2(F)、Sia(α2-3)Gal2GlcNAc3Man3GlcNAc2(F)、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc2(F)、Sia(α2-3)Gal2GlcNAc3Man3GlcNAc2(F)、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc2(F)、Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc2(F)、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc2(F)及Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc2(F)。
在优选实施例中,N-聚醣具有选自由以下组成的群的聚醣序列:Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc2、Sia(α2-6)GalGlcNAc2Man3GlcNAc2、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc2、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc2、Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc2(F)、Sia(α2-6)GalGlcNAc2Man3GlcNAc2(F)、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc2(F)、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc2(F)、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc2(F)及Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc2(F)。
本揭示内容的另一态样描述一种医药组合物,其包括本文所阐述的抗TNFα醣抗体的组合物及医药上可接受的载剂。
本揭示内容的医药组合物可用于治疗。本文所揭示者包含治疗人类患者的TNF介导的发炎性疾病的方法,所述方法包括向有需要的人类投与有效量的本文所阐述的医药组合物。
在一些实施例中,所述投与包括向所述人类经口投与所述医药组合物。TNF介导的发炎性疾病的实例包含但不限于发炎性肠病(包含溃疡性结肠炎及克罗恩氏病)、类风湿性关节炎、牛皮癣、牛皮癣性关节炎、强直性脊柱炎及幼年型特发性关节炎。
在一些实施例中,本文所阐述的治疗方法进一步包括向患者投与抗TNFα治疗剂。在一些实施例中,抗TNFα治疗剂是阿达木单抗、英夫利昔单抗或依那西普。
本发明的抗TNFα醣抗体可自在细胞中产生的抗TNFα单株抗体生成。在优选实施例中,抗TNFα单株抗体用于治疗应用。在一些实施例中,治疗性单株抗体市面有售或处于研发中。抗TNFα单株抗体可为人类化、人类或嵌合抗体。
可在活体外产生本文所阐述的抗TNFα醣抗体。可藉由Fc醣改造生成抗TNFα醣抗体。在某些实施例中,自在诸如哺乳动物细胞等细胞中产生的抗TNFα单株抗体以酶方式或以化学酶方式改造抗TNFα醣抗体。
本文阐述制备岩藻醣基化醣抗体的方法,所述方法包括以下步骤:(a)使单株抗体与至少一种醣苷内切酶接触,由此得到在Fc上具有二醣(GlcNAc-Fuc)的抗体,及(b)在适宜条件下将碳水化合物部分添加至二醣的GlcNAc中。
本文所阐述者亦包含制备去岩藻醣基化醣抗体的方法,所述方法包括以下步骤:(a)使单株抗体与α-岩藻醣苷酶及至少一种醣苷内切酶接触,由此得到在Fc上具有单醣(GlcNAc)的抗体,及(b)在适宜条件下将碳水化合物部分添加至GlcNAc中。
本发明方法中的单株抗体可为抗TNFα单株抗体。在一些实施例中,本发明方法中的抗TNFα单株抗体是阿达木单抗、英夫利昔单抗或依那西普。
在一些实施例中,碳水化合物部分是选自由以下组成的群:Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc、Sia(α2-6)GalGlcNAc2Man3GlcNAc、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc、Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc、Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc(F)、Sia(α2-6)GalGlcNAc2Man3GlcNAc(F)、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc(F)、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc(F)、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc(F)及Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc(F)。
可藉由转醣苷酶实施步骤(b)中的添加。转醣苷酶包含但不限于EndoS、EndoH、EndoA、EndoM、EndoF1、EndoF2及EndoF3。
在一些实施例中,本发明方法中的醣苷内切酶是EndoA、EndoF、EndoF1、EndoF2、EndoF3、EndoH、EndoM、EndoS或其变体。
在一些实施例中,α-岩藻醣苷酶包括具有与SEQ ID NO:5至少约90%、91%、92%、93%、94%、95%、96%、97%、98%、99%一致的氨基酸序列的多肽。
在某些实施例中,α-岩藻醣苷酶是重组类杆菌(Bacteroides)α-岩藻醣苷酶。
在一些实施例中,碳水化合物部分是醣恶唑啉。
本发明一或多个实施例的详细内容陈述于下文说明书中。根据下列图式及若干实施例的详细说明亦及随附申请专利范围,本发明的其他特征或优点将显而易见。
附图说明
图1.抗TNFα GAb 201及101(上图)以及GAb 200及401(下图)的SDS-PAGE分析。抗TNFα GAb 101(上图)及GAb 401(下图)的N-聚醣特征分析。
图2.展示TNFα与抗TNFα GAb 200、401及阿达木单抗的结合亲和力。
具体实施方式
因此,仍需要使用改良的抗TNFα抗体来改良单株抗体疗法。醣基化模式的异质混合物中的少数特异性醣型已知会赋予期望生物功能。因此,极为关注生成含有充分定义的聚醣结构及序列作为用于治疗目的的期望醣型的治疗抗体。
本揭示内容是关于新颖种类的单株抗体(称为「醣抗体」)的研发。术语「醣抗体」是由发明者Dr.Chi-Huey Wong创造,其是指在Fc上具有单一均匀醣型的单株抗体(优选地治疗性单株抗体)的均质群体。构成均质群体的个别醣抗体相同,结合相同表位,且含有具有充分定义的聚醣结构及序列的相同Fc聚醣。
除非另外指示,否则本发明实践将采用熟习此项技术者熟知的分子生物学、微生物学、重组DNA及免疫学的习用技术。这些技术全面阐释于文献中。例如参见Molecular Cloning A Laboratory Manual,第2版,由Sambrook、Fritsch及Maniatis编辑(Cold Spring Harbor Laboratory Press,1989);DNA Cloning,第I及II卷(D.N.Glover编辑,1985);Culture Of Animal Cells(R.I.Freshney,Alan R.Liss公司,1987);Immobilized Cells And Enzymes(IRL Press,1986);B.Perbal,A Practical Guide To Molecular Cloning(1984);the treatise,Methods In Enzymology(Academic Press公司,N.Y.);Gene Transfer Vectors For Mammalian Cells(J.H.Miller及M.P.Calos编辑,1987,Cold Spring Harbor Laboratory);Methods In Enzymology,第154及155卷(Wu等人,编辑),Immunochemical Methods In Cell And Molecular Biology(Mayer及Walker编辑,Academic Press,London,1987);Antibodies:A Laboratory Manual,Harlow及Lanes(Cold Spring Harbor Laboratory Press,1988);及Handbook Of Experimental Immunology,第I-IV卷(D.M.Weir及C.C.Blackwell,编辑,1986)。
定义:
如本文中所使用,术语「抗TNFα醣抗体」(「anti-TNFα glycoantibodies,抗TNFα GAbs」)是指在Fc上具有相同醣型的抗TNFα IgG分子的均质群体。术语「抗TNFα醣抗体」(「anti-TNFα glycoantibody,抗TNFα GAb」)是指抗TNFα醣抗体(anti-TNFα glycoantibodies)中的个别IgG分子。
如本文中所使用,术语「聚醣」是指多醣、寡醣或单醣。聚醣可为醣残基的单体或聚合物且可为直链或具支链。聚醣可包含天然醣残基(例如葡萄醣、N-乙酰基葡醣胺、N-乙酰基神经胺酸、半乳醣、甘露醣、岩藻醣、己醣、阿拉伯醣、核醣、木醣等)及/或改质醣(例如2′-氟核醣、2′-脱氧核醣、磷酸甘露醣、6′硫N-乙酰基葡醣胺等)。如本文中所使用,术语「聚醣」是指多醣、寡醣或单醣。聚醣可为醣残基的单体或聚合物且可为直链或具支链。聚醣可包含天然醣残基(例如葡萄醣、N-乙酰基葡醣胺、N-乙酰基神经胺酸、半乳醣、甘露醣、岩藻醣、己醣、阿拉伯醣、核醣、木醣等)及/或改质醣(例如2′-氟核醣、2′-脱氧核醣、磷酸甘露醣、6′硫N-乙酰基葡醣胺等)。聚醣在本文中亦用于是指醣偶联物(例如醣蛋白、醣脂、醣肽、醣蛋白质组、肽多醣、脂多醣或蛋白聚醣)的碳水化合物部分。聚醣通常仅由单醣之间的O-醣苷链接组成。举例而言,纤维素是由β-1,4-连接D-葡萄醣构成的聚醣(或更具体而言葡聚醣),且甲壳质是由β-1,4-连接N-乙酰基-D-葡醣胺构成的聚醣。聚醣可为单醣残基的均聚物或异聚物,且可为直链或具支链。聚醣可发现连接至蛋白质,如在醣蛋白及蛋白聚醣中。其通常发现于细胞之外表面上。O-及N-连接聚醣极常见于真核细胞中,但亦可发现(但较不常见)于原核细胞中。N-连接聚醣发现连接至序列子中天门冬酰胺的R-基团氮(N)。序列子是Asn-X-Ser或Asn-X-Thr序列,其中X是除坚果醣外的任一氨基酸。
如本文中所使用,术语「岩藻醣」、「核心岩藻醣」及「核心岩藻醣残基」可互换使用且是指在α1,6-位连接至N-乙酰基葡醣胺的岩藻醣。
如本文中所使用,术语「岩藻醣基化」是指在Fc的N-聚醣中存在核心岩藻醣,而术语「去岩藻醣基化」是指在Fc的N-聚醣中不存在核心岩藻醣。
如本文中所使用,术语「N-聚醣」、「N-连接聚醣」、「N-连接醣基化」、「Fc聚醣」及「Fc醣基化」可互换使用且是指由连接至含Fc多肽中天门冬酰胺残基的酰胺氮的N-乙酰基葡醣胺(GlcNAc)连接的N-连接寡醣。术语「含Fc多肽」是指包括Fc区的多肽(例如抗体)。
如本文中所使用,术语「醣基化模式」及「醣基化特征」可互换使用且是指以酶方式或以化学方式自醣蛋白或抗体释放且然后(例如)使用LC-HPLC或MALDI-TOF MS及诸如此类分析碳水化合物结构的N-聚醣物质的特征性「指纹」。例如参见Current Analytical Chemistry,第1卷,第1期(2005),第28-57页中的综述;其全部内容以引用方式并入本文中。
如本文中所使用,术语「醣改造Fc」在本文中使用时是指Fc区上的N-聚醣以酶方式或以化学方式改变或改造。本文所用的术语「Fc醣改造」是指用于制备醣改造Fc的酶或化学制程。改造的方法实例阐述于(例如)Wong等人,USSN12/959,351中,其内容以引用方式并入本文中。在某些实施例中,聚醣可藉由使用内-GlcNACase及岩藻醣苷酶,然后藉由使用内-S突变体及聚醣恶唑啉制得。
本文所用的术语「效应物功能」是指源自抗体Fc区与Fc受体或配体的相互作用的生物化学事件。「效应物功能」实例包括C1q结合、补体依赖性细胞毒性、Fc受体结合、抗体依赖性细胞介导的细胞毒性(ADCC)、吞噬作用、细胞表面受体(例如B细胞受体、BCR)下调。可使用业内已知的各种分析法来分析这些效应物功能。
如本文中所使用,「抗体依赖性细胞介导的细胞毒性」或「ADCC」是指以下细胞毒性形式:其中与存在于某些细胞毒性细胞(例如自然杀手(NK)细胞、嗜中性球及巨噬球)上的Fc受体(FcR)结合的分泌Ig使这些细胞毒性效应细胞能够特异性结合带抗原靶细胞且随后利用细胞毒素杀死所述靶细胞。抗体「武装」这些细胞毒性细胞且为所述杀死过程绝对所需。用于介导ADCC的原代细胞(NK细胞)仅表达FcγRIII,而单核球表达FcγRI、FcγRII及FcγRIII。FcR于造血细胞上的表达汇总于Ravetch及Kinet,Annu.Rev.Immunol 9:457-92(1991)的第464页表3中。为评估所关注分子的ADCC活性,可实施活体外ADCC分析,例如阐述于美国专利第5,500,362号或美国专利第5,821,337号中者。可用于这些分析的效应细胞包含周边血单核细胞(PBMC)及自然杀手(NK)细胞。另一选择为或另外,可在活体内(例如在诸如揭示于Clynes等人,PNAS(USA)95:652-656(1998)中的动物模型中)评估所关注分子的ADCC活性。
本文所用的术语「补体依赖性细胞毒性」或「CDC」是指靶细胞在补体存在下的裂解。经典补体途径的活化是藉由补体系统的第一补体(C1q)与抗体(适当亚类)的结合来起始,这些抗体结合其同族抗原。为评估补体活化,可实施CDC分析,例如如Gazzano-Santoro等人,J.Immunol.Methods 202:163(1996)中所阐述。
「诱导细胞凋亡」的抗体是诱导计划性细胞死亡者,如藉由膜联蛋白V结合、DNA断裂、细胞收缩、内质网膨胀、细胞断裂及/或膜囊(称为凋亡小体)的形成所测定。优选地,细胞是感染细胞。各种方法可用于评估与细胞凋亡有关的细胞事件。举例而言,可藉由膜联蛋白结合量测磷脂酰丝胺酸(PS)异位;可经由DNA解链评估DNA断裂;且可藉由亚二倍体细胞的任何增加评估细胞核/染色质凝集以及DNA断裂。优选地,诱导细胞凋亡的抗体是在膜联蛋白结合分析中相对于未处理细胞产生约2至50倍、优选地约5至50倍及最佳地约10至50倍的膜联蛋白结合诱导者。
「嵌合」抗体(免疫球蛋白)中重链及/或轻链的一部分与衍生自特定物种或属于特定抗体种类或亚类的抗体的相应序列相同或同源,而所述(等)链的其余部分与衍生自另一物种或属于另一抗体种类或亚类的抗体的相应序列相同或同源;且包含这些抗体的片段,只要其展现期望生物活性即可(美国专利第4,816,567号;Morrison等人,Proc.Natl.Acad.Sci.USA,81:6851-6855(1984))。本文所用的人类化抗体是嵌合抗体的子组。
「人类化」形式的非人类(例如鼠类)抗体是含有最少量源自非人类免疫球蛋白的序列的嵌合抗体。在极大程度上,人类化抗体是如下人类免疫球蛋白(接受者或受体抗体):其中接受者的超变区残基由来自非人类物种(例如小鼠、大鼠、兔或非人类灵长类动物)的超变区(供体抗体)的具有期望特异性、亲和力及容量的残基所代替。在一些情况下,人类免疫球蛋白的Fv框架区(FR)残基由相应非人类残基代替。另外,人类化抗体可包括未在接受者抗体或供体抗体中发现的残基。作出这些改质以进一步改善抗体性能,例如结合亲和力。通常,人类化抗体将包括实质上全部的至少一个且通常两个可变结构域,其中全部或实质上全部超变环对应于非人类免疫球蛋白的彼等超变环,且全部或实质上全部FR区为人类免疫球蛋白序列的彼等FR区,但FR区可包含改良结合亲和力的一或多个氨基酸取代。FR中的这些氨基酸取代的数量通常在H链中不超过6,且在L链中不超过3。人类化抗体视情况亦包括通常人类免疫球蛋白的免疫球蛋白恒定区(Fc)的至少一部分。其他细节参见Jones等人,Nature 321:522-525(1986);Riechmann等人,Nature 332:323-329(1988);及Presta,Curr.Op.Struct.Biol.2:593-596(1992)。
治疗「(treating或treatment)」或「缓解」是指治疗性治疗及预防性(prophylactic或preventative)措施;其中目标是预防或减缓(减弱)靶定病理学病状或病症。彼等需要治疗者包含彼等已患有病症者以及彼等易于患有病症者或彼等拟预防病症者。若在接受治疗量的本发明方法的抗体之后,患者展示下列情形中的一或多者的可观察及/或可量测减小或不存在,则个体或哺乳动物成功「治疗」感染:减小感染细胞数量或不存在感染细胞;减小总感染细胞的百分比;及/或减轻(至一定程度)一或多种与特定感染有关的症状;减小发病率及死亡率;及改良生活质量问题。用于评估疾病的成功治疗及改良的上述参数可易于藉由医师熟知的常规程序量测。
与一或多种其他治疗剂「组合」投与包含以任一顺序同时(并行)及连续投与。
本文所用的「载剂」包含在所用剂量及浓度下对所暴露细胞或哺乳动物无毒的医药上可接受的载剂、赋形剂或稳定剂。通常,生理学上可接受的载剂是pH缓冲水溶液。生理学上可接受的载剂的实例包含缓冲剂,例如磷酸盐、柠檬酸盐及其他有机酸;抗氧化剂,包含抗坏血酸,低分子量(小于约10个残基)多肽;蛋白质,例如血清白蛋白、明胶或免疫球蛋白;亲水性聚合物,例如聚乙烯吡咯啶酮;氨基酸,例如甘胺酸、麸酰胺酸、天门冬酰胺、精胺酸或离胺酸;单醣、二醣及其他碳水化合物,包含葡萄醣、甘露醣或糊精;螯合剂,例如EDTA;醣醇,例如甘露醣醇或山梨醣醇;形成盐的抗衡离子,例如钠;及/或非离子型表面活性剂,例如TWEENTM、聚乙二醇(PEG)及PLURONICSTM。
术语「醣抗体」是由发明者Dr.Chi-Huey Wong创造,其是指具有结合Fc区的单一均匀醣型的单株抗体(优选地治疗性单株抗体)的均质群体。构成基本上均质群体的个别醣抗体相同,结合相同表位,且含有具有充分定义的聚醣结构及序列的相同Fc聚醣。
在Fc区醣基化特征背景中的术语「均质」、「均匀」、「均匀地」及「均质性」可互换使用且欲指由一种期望N-聚醣物质代表的单一醣基化模式,其中具有较少或并无痕量前体N-聚醣。在某些实施例中,前体N-聚醣的痕量是小于约2%。
「基本上纯」蛋白质意指基于组合物的总重量包括至少约90重量%(包含(例如)至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99重量%)的蛋白质的组合物。
「基本上均质」蛋白质意指基于组合物的总重量包括至少约98重量%的蛋白质(包含(例如)至少约98.5%、至少约99%)的组合物。在某些实施例中,蛋白质是抗体、结构变体及/或其抗原结合片段。
如本文中所使用,术语「IgG」、「IgG分子」、「单株抗体」、「免疫球蛋白」及「免疫球蛋白分子」可互换使用。
如本文中所使用,术语「Fc受体」或「FcR」阐述结合抗体的Fc区的受体。优选FcR是原始序列人类FcR。另外,优选FcR是结合IgG抗体者(γ受体)且包含FcγRI(CD64)、FcγRII(CD32)及FcγRIII(CD16)亚类的受体,包含这些受体的对偶基因变体及选择性剪接形式。FcγRII受体包含FcγRIIA(「活化型受体」)及FcγRIIB(「抑制型受体」),二者具有类似氨基酸序列,其主要差异在于其胞质结构域上。活化型受体FcγRIIA在其胞质结构域中含有免疫受体酪胺酸活化基序(ITAM)。抑制型受体FcγRIIB在其胞质结构域中含有免疫受体酪胺酸抑制基序(ITIM)。(参见M.inAnnu.Rev.Immunol.15:203-234(1997)中的综述)。在Ravetch及Kinet,Annu.Rev.Immunol 9:457-92(1991);Capel等人,Immunomethods 4:25-34(1994);及de Haas等人,J.Lab.Clin.Med.126:330-41(1995)中对FcR进行综述。本文的术语「FcR」涵盖其他FcR,包含彼等欲在将来鉴别者。所述术语亦包含新生儿受体(FcRn),所述受体负责将母体IgG转移至胎儿体内(Guyer等人,J.Immunol.117:587(1976)及Kim等人,J.Immunol.24:249(1994))。
如本文中所使用,术语「抗原」定义为任一能够诱发免疫反应的物质。如本文中所使用,术语「抗原特异性」是指特定抗原或抗原片段的供应产生特异性细胞增殖的细胞群体的性质。
如本文中所使用,术语「免疫原性」是指免疫原、抗原或疫苗刺激免疫反应的能力。
如本文中所使用,术语「表位」定义为抗原分子中接触抗体的抗原结合位点或T细胞受体的部分。
如本文中所使用,术语「特异性结合」是指结合对(例如抗体及抗原)的间的相互作用。在各种情况下,特异性结合可体现为亲和力常数为约10-6莫耳/公升、约10-7莫耳/公升或约10-8莫耳/公升或更小。
「分离」抗体是已经鉴定并自其天然环境组份中分离及/或回收的抗体。其天然环境的污染组份是会干扰抗体的研究、诊断或治疗用途的材料,且可包含酶、激素及其他蛋白质性溶质或非蛋白质性溶质。
本文所用的词组「实质上类似」、「实质上相同」、「等效」或「实质上等效」表示两个数值(例如一个值与分子有关且另一者与参考/对比分子有关)之间具有足够高相似度,从而熟习此项技术者会认为所述两个值之间的差异在藉由这些值(例如Kd值、抗病毒效应等)所量测生物特性的背景下具有较少或不具有生物及/或统计学显着性。所述两个值之间的差异是(例如)小于约50%、小于约40%、小于约30%、小于约20%及/或小于约10%,其随参考/对比分子的值而变化。
本文所用的词组「实质上减少」或「实质上不同」表示两个数值(通常一个值与分子有关且另一值与参考/对比分子有关)之间具有足够高差异度,从而熟习此项技术者会认为所述两个值之间的差异在藉由这些值(例如Kd值)所量测生物学特性的背景下具有统计学显着性。所述两个值之间的差异是(例如)大于约10%、大于约20%、大于约30%、大于约40%及/或大于约50%,其随参考/对比分子的值而变化。
「结合亲和力」通常是指分子(例如抗体)的单一结合位点与其结合配偶体(例如抗原)之间的非共价相互作用的总强度。除非另外指示,否则本文所用的「结合亲和力」是指固有结合亲和力,其反映结合对的成员(例如抗体及抗原)之间的1:1相互作用。分子X对于其配偶体Y的亲和力通常可表示为解离常数(Kd)。可藉由业内已知的常用方法(包含彼等阐述于本文中者)来量测亲和力。低亲和力抗体通常缓慢地结合抗原且往往易于解离,而高亲和力抗体通常较快结合抗原且往往较长时间保持结合。多种量测结合亲和力的方法为业内已知,其任一者皆可用于本发明目的。具体阐释性实施例阐述于下文中。
抗体的「可变区」或「可变结构域」是指抗体重链或轻链的胺基末端结构域。这些结构域通常是抗体的最可变部分且含有抗原结合位点。
术语「可变」是指如下事实:在抗体之间可变结构域的某些部分于序列上存在广泛差异且可用于实现每一特定抗体对其特定抗原的结合及特异性。然而,可变性在整个抗体可变结构域中并非均匀分布。在轻链及重链可变结构域二者中所述可变性均集中在三个称为互补决定区(CDR)或超变区的区段上。可变结构域的保守程度较高的部分称为框架(FR)。原始重链及轻链的可变结构域各自包括4个由三个CDR连结的主要采用β薄片构形的FR区,这些CDR形成连结且在一些情形下形成β薄片结构的一部分的环。每一链中的CDR藉助FR区保持紧密靠近,且与来自另一链的CDR一起促进形成抗体的抗原结合位点(参见Kabat等人,Sequences of Proteins of Immunological Interest,第5版,National Institutes of Health,Bethesda,Md(1991))。恒定结构域并不直接参与抗体与抗原的结合,但展现各种效应物功能,例如抗体参与抗体依赖性细胞毒性。
抗体的木瓜酶消化产生两个相同抗原结合片段,称为「Fab」片段,其各自具有单一抗原结合位点;及残余「Fc」片段,其名称反映其易于结晶的能力。经胃蛋白酶处理产生F(ab’)2片段,所述片段具有两个抗原组合位点且仍然能够交联抗原。
「Fv」是含有完全抗原识别及结合位点的最小抗体片段。在双链Fv物质中,此区域是由一个重链可变结构域与一个轻链可变结构域的紧密非共价结合二聚体组成。在单链Fv物质中,一个重链可变结构域及一个轻链可变结构域可藉由柔性肽连接体共价连接,从而这些轻链及重链可以与双链Fv物质中类似的「二聚体」结构来缔合。每一可变结构域的3个CDR以此构形相互作用以界定VH-VL二聚体的表面上的抗原结合位点。六个CDR共同赋予了所述抗体抗原结合特异性。然而,即使单一可变结构域(或Fv的一半,其仅包括三个对抗原具有特异性的CDR)亦具有识别并结合抗原的能力,但其亲和力低于完整结合位点。
Fab片段亦含有轻链恒定结构域及重链的第一恒定结构域(CH1)。Fab'片段与Fab片段的不同处在于在重链CH1结构域的羧基末端添加几个残基,包含一或多个来自抗体铰链区的半胱胺酸。在本文中,Fab'-SH是恒定结构域中的半胱胺酸残基具有游离硫醇基的Fab'的名称。F(ab')2抗体片段最初是作为在其间具有铰链半胱胺酸的Fab'片段对产生。亦已知抗体片段的其他化学偶合。
根据恒定结构域的氨基酸序列,可将来自任何脊椎动物物种的抗体(免疫球蛋白)的「轻链」指定为两种完全不同类型(称为卡帕(κ)及兰布达(λ))中的一种。
端视抗体(免疫球蛋白)重链中恒定结构域的氨基酸序列,可将抗体(免疫球蛋白)指定为不同种类。存在5大类抗体:IgA、IgD、IgE、IgG及IgM,且这些类别中的若干可进一步分成子类(同种型),例如IgG1、IgG2、IgG3、IgG4、IgA1及IgA2。对应于不同类别的免疫球蛋白的重链恒定结构域分别称为α、δ、ε、γ及μ。不同种类的免疫球蛋白的亚单位结构及三维构形已众所周知且通常阐述于(例如)Abbas等人,Cellular及Mol.Immunology,第4版(2000)中。抗体可为较大融合分子的一部分,其是藉由抗体与一或多种其他蛋白质或肽的共价或非共价缔合来形成。
术语「全长抗体」、「完整抗体」与「全抗体」在本文中可互换使用,其是指呈实质上完整形式的抗体,且不为如下文所定义的抗体片段。这些术语尤其是指重链含有Fc区的抗体。
「抗体片段」仅包括完整抗体的一部分,其中所述部分保留至少一种及(至多)大部分或所有通常在存在于完整抗体中时与所述部分有关的功能。在一实施例中,抗体片段包括完整抗体的抗原结合位点且由此保留结合抗原的能力。在另一实施例中,抗体片段(例如包括Fc区者)在存在于完整抗体中时保留通常与Fc区有关的至少一种生物功能,例如FcRn结合、抗体半衰期调变、ADCC功能及补体结合。在一实施例中,抗体片段是活体内半衰期实质上类似于完整抗体的单价抗体。举例而言,此一抗体片段可包括连接至能赋予片段活体内稳定性的Fc序列的抗原结合臂。
本文所用的术语「单株抗体」是指自实质上均质抗体的群体(亦即,构成所述群体的个别抗体除了可能少量存在的可能天然突变外,其余均相同)获得的抗体。因此,修饰语「单株」指示抗体的特征并非个别抗体的混合物。所述单株抗体通常包括一种包含会结合靶的多肽序列的抗体,其中所述靶结合多肽序列是藉由一种包含自多个多肽序列选择单一靶结合多肽序列的方法获得。举例而言,选拔方法可为自多个纯系(例如一组集合的杂交瘤纯系、噬菌体纯系或重组DNA纯系)选拔一个独特纯系。应理解,可进一步改变所选的靶结合序列,以例如改良对靶的亲和力、人类化所述靶结合序列、改良其在细胞培养中的生产、降低其活体内免疫原性、产生多特异性抗体,等等,且所述包括改变的靶结合序列的抗体亦是本发明的单株抗体。与通常包含针对不同决定基(表位)的不同抗体的多株抗体制剂相比,单株抗体制剂的每一单株抗体是针对抗原上的单一决定基。除特异性外,单株抗体制剂的优势在于其通常未经其他免疫球蛋白污染。修饰语「单株」指示抗体的特征是自实质上均质的抗体群体获得,且不应解释为需要藉由任一特定方法来产生所述抗体。举例而言,拟用于本发明的单株抗体可由各种技术制得,包括例如杂交瘤方法(例如Kohler等人,Nature,256:495(1975);Harlow等人,Antibodies:A Laboratory Manual,(Cold Spring Harbor Laboratory Press,第2版,1988);Hammerling等人,Monoclonal Antibodies and T-Cell hybridomas 563-681(Elsevier,N.Y.,1981))、重组DNA方法(参见例如美国专利第4,816,567号)、噬菌体展示技术(参见例如Clackson等人,Nature,352:624-628(1991);Marks等人,J.Mol.Biol.222:581-597(1992);Sidhu等人,J.Mol.Biol.338(2):299-310(2004);Lee等人,J.Mol.Biol.340(5):1073-1093(2004);Fellouse,Proc.Natl.Acad.Sci.USA 101(34):12467-12472(2004);及Lee等人,J.Immunol.Methods 284(1-2):119-132(2004)),及用于在具有一部分或所有编码人类免疫球蛋白序列的人类免疫球蛋白基因座或基因的动物中产生人类或人类样抗体的技术(参见例如WO98/24893;WO96/34096;WO96/33735;WO91/10741;Jakobovits等人,Proc.Natl.Acad.Sci.USA 90:2551(1993);Jakobovits等人,Nature 362:255-258(1993);Bruggemann等人,Year in Immunol.7:33(1993);美国专利第5,545,807号、第5,545,806号、第5,569,825号、第5,625,126号、第5,633,425号、第5,661,016号;Marks等人,Bio.Technology 10:779-783(1992);Lonberg等人,Nature 368:856-859(1994);Morrison,Nature 368:812-813(1994);Fishwild等人,Nature Biotechnol.14:845-851(1996);Neuberger,Nature Biotechnol.14:826(1996)及Lonberg及Huszar,Intern.Rev.Immunol.13:65-93(1995)。
具体而言,本文的单株抗体包含「嵌合」抗体,其中重链及/或轻链的一部分与衍生自特定物种或属于特定抗体种类或亚类的抗体的相应序列相同或同源,而所述(等)链的其余部分与衍生自另一物种或属于另一抗体种类或亚类的抗体的相应序列相同或同源;以及这些抗体的片段,只要其展现期望生物学活性即可(美国专利第4,816,567号;及Morrison等人,Proc.Natl.Acad.Sci.USA,81:6851-6855(1984))。
亦参见下列综述文件及其中所引用的参考文献:Vaswani及Hamilton,Ann.Allergy,Asthma&Immunol.1:105-115(1998);Harris,Biochem.Soc.Transactions 23:1035-1038(1995);Hurle及Gross,Curr.Op.Biotech.5:428-433(1994)。
本文所用的术语「超变区」、「HVR」或「HV」是指抗体可变结构域中序列超变及/或结构上形成所定义环的区域。通常,抗体包括6个超变区;3个位于VH中(H1、H2、H3),且3个位于VL中(L1、L2、L3)。本文使用且涵盖多个超变区的描述。Kabat互补决定区(CDR)是基于序列可变性且使用最为广泛(Kabat等人,Sequences of Proteins of Immunological Interest,第5版,Public Health Service,National Institutes of Health,Bethesda,Md.(1991))。而Chothia是指结构环的位置(Chothia及Lesk J.Mol.Biol.196:901-917(1987))。AbM超变区代表Kabat CDR与Chothia结构环之间的折衷方案且用于Oxford Molecular的AbM抗体建模软件中。「接触」超变区是基于对可获得复杂晶体结构的分析。来自这些超变区中每一者的残基如下所述。
Loop Kabat AbM Chothia Contact
L1 L24-L34 L24-L34 L26-L32 L30-L36
L2 L50-L56 L50-L56 L50-L52 L46-L55
L3 L89-L97 L89-L97 L91-L96 L89-L96
H1 H31-H35B H26-H35B H26-H32 H30-H35B
(Kabat编号)
H1 H31-H35 H26-H35 H26-H32 H30-H35
(Chothia编号)
H2 H50-H65 H50-H58 H53-H55 H47-H58
H3 H95-H102 H95-H102 H96-H101 H93-H101
超变区可包括如下「经延伸超变区」:VL中的24-36或24-34(L1)、46-56或50-56或49-56(L2)及89-97或89-96(L3)以及VH中的26-35(H1)、50-65或49-65(H2)及93-102、94-102或95-102(H3)。对于这些定义中的每一者,根据Kabat等人(见上文)对可变结构域残基编号。
「框架」或「FR」残基是彼等除如本文所定义超变区残基外的可变结构域残基。
术语「依Kabat中的可变结构域残基编号」或「依Kabat中的氨基酸位置编号」及其变化形式是指在Kabat等人,Sequences of Proteins of Immunological Interest,第5版,Public Health Service,National Institutes of Health,Bethesda,Md.(1991)中用于抗体编译的重链可变结构域或轻链可变结构域的编号系统。使用此编号系统,实际线性氨基酸序列可含有较少或额外的对应于可变结构域FR或HVR的缩短或插入的氨基酸。举例而言,重链可变结构域可包含在H2的残基52后的单氨基酸插入(根据Kabat编号的残基52a)及重链FR残基82后的插入残基(例如,根据Kabat编号的残基82a、82b及82c等)。可藉由将抗体序列的同源区与「标准」Kabat编号序列比对来确定所指定抗体残基的Kabat编号。
单链「Fv」或「scFv」抗体片段包括抗体的VH及VL结构域,其中这些结构域是以单一多肽链存在。通常,scFv多肽进一步包括VH结构域与VL结构域之间的多肽连接体,其使得scFv能够形成用于结合抗原的期望结构。关于scFv的综述,参见Pluckthun,The Pharmacology of Monoclonal Antibodies,第113卷,Rosenburg及Moore编辑,Springer-Verlag,New York,第269-315页(1994)。
术语「双价抗体」是指具有两个抗原结合位点的小抗体片段,这些片段包括在同一多肽链(VH-VL)中与轻链可变结构域(VL)链接的重链可变结构域(VH)。藉由使用过短而不容许在同一链上的两个结构域之间配对的连接体,迫使这些结构域与另一链的互补结构域配对并产生两个抗原结合位点。双价抗体更全面地阐述于(例如)EP 404,097;WO93/1161;及Hollinger等人,Proc.Natl.Acad.Sci.USA,90:6444-6448(1993)中。
「人类抗体」指其拥有的氨基酸序列是对应于由人类产生的抗体的氨基酸序列及/或是使用如本文所揭示制备人类抗体的任一技术所制备者。此人类抗体的定义明确排除包括非人类抗原结合残基的人类化抗体。
「亲和力成熟」抗体是在其一或多个HVR中存在一或多处改变的抗体,这些改变的结果会使这些抗体比没有彼等改变的亲代抗体更改良对抗原的亲和力。在一实施例中,亲和力成熟抗体对靶抗原具有毫微莫耳或甚至皮莫耳亲和力。亲和力成熟抗体是藉由业内已知程序产生。Marks等人,Bio/Technology 10:779-783(1992)阐述藉由VH及VL结构域改组达成亲和力成熟。CDR及/或框架残基的随机突变诱发阐述于以下文献中:Barbas等人,Proc Nat.Acad.Sci.USA 91:3809-3813(1994);Schier等人,Gene 169:147-155(1995);Yelton等人,J.Immunol.155:1994-2004(1995);Jackson等人,J.Immunol.154(7):3310-9(1995);及Hawkins等人,J.Mol.Biol.226:889-896(1992)。
「阻断性」抗体或「拮抗剂」抗体是抑制或降低所结合抗原的生物活性的抗体。某些阻断性抗体或拮抗剂抗体实质上或完全地抑制抗原的生物活性。
本文所用的「激动剂抗体」是模拟所关注多肽的功能活性中的至少一者的抗体。
「病症」是任一受益于本发明抗体的治疗的病状。此包含慢性及急性病症或疾病,包含使哺乳动物易患所讨论病症的彼等病理学病状。本文拟治疗病症的非限制性实例包含癌症。
术语「细胞增殖性病症」及「增殖性病症」是指与一定程度的异常细胞增殖有关的病症。在一实施例中,细胞增殖性病症是癌症。
本文所用的「肿瘤」是指所有肿瘤性细胞生长及增殖(无论是恶性的抑还是良性的)以及所有癌前期及癌性细胞及组织。本文中所提及的术语「癌症」、「癌性」、「细胞增殖性病症」、「增殖性病症」及「肿瘤」并不相互排斥。
术语「癌症」及「癌性」通常是指或阐述哺乳动物的特征通常在于细胞生长/增殖失调的生理学病状。癌症的实例包含但不限于癌瘤、淋巴瘤(例如何杰金氏淋巴瘤(Hodgkin’s lymphoma)及非何杰金氏淋巴瘤(non-Hodgkin's lymphoma))、母细胞瘤、肉瘤及白血病。这些癌症的更特定实例包含鳞状细胞癌、小细胞肺癌、非小细胞肺癌、肺腺癌、肺鳞状癌瘤、腹膜癌、肝细胞癌、胃肠癌、胰脏癌、胶质母细胞瘤、宫颈癌、卵巢癌、肝癌、膀胱癌、肝细胞瘤、乳癌、结肠癌、结肠直肠癌、子宫内膜或子宫癌瘤、唾液腺癌瘤、肾癌、肝癌、前列腺癌、外阴癌、甲状腺癌、肝癌瘤、白血病及其他淋巴组织增殖性病症及各种类型的头颈癌。
如本文中所使用,术语「抗原」定义为任一能够诱发免疫反应的物质。
如本文中所使用,术语「抗原特异性」是指供应特定抗原或抗原片段造成特异性细胞增殖的一种细胞群体的性质。
如本文中所使用,「治疗」是指试图改变所治疗个体或细胞的自然过程的临床介入,且可用于预防或在临床病理学过程期间实施。治疗的期望效应包含防止疾病发生或复发、缓解症状、减少疾病的任何直接或间接病理结果、防止或降低发炎及/或组织/器官损害、降低疾病进展速率、改善或缓和疾病状态,及缓解或改良预后。在一些实施例中,使用本发明抗体来延迟疾病或病症的发生。
「个体(individual或subject)」是脊椎动物。在某些实施例中,脊椎动物是哺乳动物。哺乳动物包含(但不限于)农场动物(例如牛)、运动动物、宠物(例如猫、狗及马)、灵长类动物、小鼠及大鼠。在某些实施例中,脊椎动物是人类。
用于治疗目的的「哺乳动物」是指任何归类为哺乳动物的动物,包含人类、家畜及农场动物,以及动物园动物、运动动物或宠物(例如狗、马、猫、牛等)。在某些实施例中,哺乳动物是人类。
「有效量」是指在所需剂量及时间段内有效达成期望治疗或预防结果的量。
本发明的物质/分子的「治疗有效量」可根据诸如以下因素而变化:个体的疾病状态、年龄、性别及体重,以及物质/分子于所述个体内引发期望反应的能力。治疗有效量亦为物质/分子的治疗有益效应胜过其任何毒性或有害效应的量。「预防有效量」是指在所需剂量及时间段内有效达成期望预防结果的量。通常(但未必),因预防剂量是在患病之前或患病早期用于个体中,故预防有效量会小于治疗有效量。
本文所用的术语「细胞毒性剂」是指抑制或阻止细胞功能及/或引起细胞破坏的物质。所述术语意欲包含放射性同位素(例如At211、I131、I125、Y90、Re186、Re188、Sm153、Bi212、P32、Pb212及Lu的放射性同位素);化学治疗剂(例如胺甲蝶呤(methotrexate)、阿霉素(adriamicin)、长春花生物碱(长春新碱(vincristine)、长春碱(vinblastine)、依托泊苷(etoposide))、多柔比星(doxorubicin)、美法仑(melphalan)、丝裂霉素C(mitomycin C)、苯丁酸氮芥(chlorambucil)、道诺霉素(daunorubicin)或其他嵌入剂);酶及其片段,例如溶核酶;抗生素;及毒素,例如细菌、真菌、植物或动物来源的小分子毒素或酶活性毒素,包含其片段及/或变体;及下文所揭示的各种抗肿瘤剂或抗癌剂。其他细胞毒性剂阐述于下文中。杀肿瘤剂引起肿瘤细胞破坏。
「化学治疗剂」是可用于治疗癌症的化学化合物。化学治疗剂的实例包含烷基化剂,例如噻替哌(thiotepa)及(环磷酰胺(cyclosphosphamide));磺酸烷基酯,例如白消安(busulfan)、英丙舒凡(improsulfan)及哌泊舒凡(piposulfan);氮杂环丙烷,例如苯得哌(benzodopa)、卡波醌(carboquone)、米得哌(meturedopa)及乌得哌(uredopa);伸乙基亚胺及甲基蜜胺,包含六甲蜜胺(altretamine)、三伸乙基嘧胺、三伸乙基磷酰胺、三伸乙基硫代磷酰胺及三羟甲基嘧胺;多聚乙酰(尤其布拉他辛(bullatacin)及布拉他辛酮(bullatacinone));δ-9-四氢大麻酚(屈大麻酚(dronabinol)、);β-拉帕醌(lapachone);拉帕醇(lapachol);秋水仙碱(colchicine);桦木酸;喜树碱(camptothecin)(包含合成类似物托泊替康(topotecan)CPT-11(伊立替康(irinotecan),)、乙酰基喜树碱(acetylcamptothecin)、莨菪素及9-胺基喜树碱);苔藓虫素(bryostatin);卡利司他汀(callystatin);CC-1065(包含其阿多来新(adozelesin)、卡折来新(carzelesin)及比折来新(bizelesin)合成类似物);鬼臼毒素(podophyllotoxin);鬼臼酸;替尼泊苷(teniposide);念珠藻素(cryptophycin)(尤其念珠藻素1及念珠藻素8);多拉司他汀(dolastatin);多卡米星(duocarmycin)(包含合成类似物KW-2189及CB1-TM1);艾榴素(eleutherobin);水鬼蕉碱(pancratistatin);匍枝珊瑚醇(sarcodictyin);海绵抑制素(spongistatin);氮芥,例如苯丁酸氮芥、萘氮芥(chlomaphazine)、氯磷酰胺(cholophosphamide)、雌莫司汀(estramustine)、异环磷酰胺(ifosfamide)、氮芥(mechlorethamine)、盐酸氧氮芥、美法仑、新氮芥(novembichin)、苯乙酸氮芥胆甾醇酯(phenesterine)、泼尼氮芥(prednimustine)、曲磷胺(trofosfamide)、尿嘧啶氮芥;亚硝基脲,例如卡莫司汀(carmustine)、氯脲菌素(chlorozotocin)、福莫司汀(fotemustine)、洛莫司汀(lomustine)、尼莫司汀(nimustine)及雷莫司汀(ranimnustine);抗生素,例如烯二炔抗生素(例如卡奇霉素(calicheamicin),尤其卡奇霉素γ1I及卡奇霉素ωI 1(例如参见Agnew,Chem.Intl.Ed.Engl.,33:183-186(1994));达内霉素(dynemicin),包含达内霉素A;埃斯波霉素(esperamicin);以及新制癌菌素发色团(neocarzinostatin chromophore)及有关色蛋白烯二炔抗生素发色团)、阿克拉霉素(aclacinomysin)、放线菌素(actinomycin)、安曲霉素(authramycin)、偶氮丝胺酸、博来霉素(bleomycin)、放线菌素c(cactinomycin)、卡拉比星(carabicin)、洋红霉素(carminomycin)、嗜癌霉素(carzinophilin)、色霉素(chromomycin)、更生霉素(dactinomycin)、道诺霉素、地托比星(detorubicin)、6-重氮基-5-侧氧基-L-正白胺基、多柔比星(包含吗啉基-多柔比星、氰基吗啉基-多柔比星、2-吡咯啉并-多柔比星及脱氧阿霉素)、泛艾霉素(epirubicin)、依索比星(esorubicin)、埃达霉素(idarubicin)、麻西罗霉素(marcellomycm)、丝裂霉素(例如丝裂霉素C)、霉酚酸、诺加霉素(nogalamycin)、橄榄霉素(olivomycin)、培洛霉素(peplomycin)、波弗霉素(potfiromycin)、嘌呤霉素(puromycin)、三铁阿霉素(quelamycin)、罗多比星(rodorubicin)、链黑菌素(streptonigrin)、链脲菌素(streptozocin)、杀结核菌素(tubercidin)、乌苯美司(ubenimex)、净司他汀(zinostatin)、佐柔比星(zorubicin);抗代谢剂,例如胺甲蝶呤及5-氟尿嘧啶(5-FU);叶酸类似物,例如二甲叶酸(denopterin)、胺甲蝶呤、蝶罗呤(pteropterin)、三甲曲沙(trimetrexate);嘌呤类似物,例如氟达拉滨(fludarabine)、6-巯嘌呤、硫咪嘌呤(thiamiprine)、硫鸟嘌呤;嘧啶类似物,例如安西他滨(ancitabine)、阿扎胞苷(azacitidine)、6-阿扎尿苷(azauridine)、卡莫氟(carmofur)、阿醣胞苷(cytarabine)、二脱氧尿苷、脱氧氟尿苷、依诺他滨(enocitabine)、氟尿苷(floxuridine);雄激素,例如卡普睪酮(calusterone)、丙酸甲雄烷酮(dromostanolone propionate)、环硫雄醇(epitiostanol)、美雄烷(mepitiostane)、睪内酯(testolactone);抗肾上腺剂,例如胺鲁米特(aminoglutethimide)、米托坦(mitotane)、曲洛司坦(trilostane);叶酸补充剂,例如亚叶酸;醋葡醛内酯;醛磷酰胺醣苷;胺基酮戊酸;恩尿嘧啶(eniluracil);安吖啶(amsacrine);贝斯特布西(bestrabucil);比生群(bisantrene);依达曲沙(edatraxate);地磷酰胺(defofamine);秋水仙胺(demecolcine);地吖醌(diaziquone);依氟鸟胺酸(elfornithine);依利乙铵(elliptinium acetate);埃坡霉素(epothilone);依托格鲁(etoglucid);硝酸镓;羟基脲;香菇多醣;氯尼达明(lonidamine);类美坦辛(maytansinoids),例如美坦辛(maytansine)及安丝菌素(ansamitocin);米托胍腙(mitoguazone);米托蒽醌(mitoxantrone);美得眠(mopidanmol);硝基胺;喷司他汀(pentostatin);蛋胺氮芥(phenamet);吡柔比星(pirarubicin);洛索蒽醌(losoxantrone);2-乙基酰肼;丙卡巴肼(procarbazine);多醣复合物(JHS Natural Products,Eugene,Oreg.);雷佐生(razoxane);根霉素(rhizoxin);西佐喃(sizofuran);锗螺胺(spirogermanium);替奴佐酸(tenuazonic acid);三亚胺醌(triaziquone);2,2′,2″-三氯三乙胺;单端孢霉烯(trichothecene)(尤其T-2毒素、疣孢菌素A(verracurin A)、杆孢菌素A(roridin A)及蛇形菌索(anguidine));乌拉坦(urethan);长春地辛(vindesine)达卡巴嗪(dacarbazine);甘露氮芥(mannomustine);二溴甘露醇(mitobronitol);二溴卫矛醇(mitolactol);哌泊溴烷(pipobroman);加赛特辛(gacytosine);阿醣胞苷(arabinoside)(「Ara-C」);噻替哌(thiotepa);类紫杉醇(taxoid),例如太平洋紫杉醇(paclitaxel)(Bristol-Myers Squibb Oncology,Princeton,N.J.)、太平洋紫杉醇的无克列莫佛(Cremophor)、经白蛋白改造的奈米颗粒调配物(ABRAXANETM)(American Pharmaceutical Partners,Schaumberg,Ill.)及多西紫杉醇(doxetaxel)(-Poulenc Rorer,Antony,France);苯丁酸氮芥;吉西他滨(gemcitabine)6-硫鸟嘌呤;巯嘌呤;胺甲蝶呤;铂类似物,例如顺铂(cisplatin)及卡铂(carboplatin);长春碱铂;依托泊苷(VP-16);异环磷酰胺;米托蒽醌;长春新碱奥沙利铂(oxaliplatin);醛氢叶酸;长春瑞滨(vinorelbine)诺肖林(novantrone);依达曲沙(edatrexate);道诺霉素(daunomycin);胺基蝶呤(aminopterin);伊班膦酸盐(ibandronate);拓扑异构酶抑制剂RFS 2000;二氟甲基鸟胺酸(DMFO);类视色素,例如视黄酸;卡培他滨(capecitabine)上述药剂中任一者的医药上可接受的盐、酸或衍生物;以及上述药剂中的两者或更多者的组合,例如环磷酰胺、多柔比星、长春新碱及泼尼松龙(prednisolone)的组合疗法的缩写CHOP及利用与5-FU及醛氢叶酸组合的奥沙利铂(ELOXATINTM)的治疗方案的缩写FOLFOX。
如本文中所使用,「治疗」是指试图改变所治疗个体或细胞的自然过程的临床介入,且可用于预防或在临床病理学过程期间实施。治疗的期望效应包含防止疾病发生或复发、缓解症状、减少疾病的任何直接或间接病理结果、防止或降低发炎及/或组织/器官损害、降低疾病进展速率、改善或缓和疾病状态及缓解或改良预后。在一些实施例中,使用本发明抗体来延迟疾病或病症的发生。
「个体(individual或subject)」是脊椎动物。在某些实施例中,脊椎动物是哺乳动物。哺乳动物包含(但不限于)农场动物(例如牛)、运动动物、宠物(例如猫、狗及马)、灵长类动物、小鼠及大鼠。在某些实施例中,脊椎动物是人类。
用于治疗目的的「哺乳动物」是指任何归类为哺乳动物的动物,包含人类、家畜及农场动物,以及动物园动物、运动动物或宠物(例如狗、马、猫、牛等)。在某些实施例中,哺乳动物是人类。
「有效量」是指在所需剂量及时间段内有效达成期望治疗或预防结果的量。
本发明的物质/分子的「治疗有效量」可根据诸如以下因素而变化:个体的疾病状态、年龄、性别及体重,以及物质/分子于所述个体内引发期望反应的能力。治疗有效量亦为物质/分子的治疗有益效应胜过其任何毒性或有害效应的量。「预防有效量」是指在所需剂量及时间段内有效达成期望预防结果的量。通常(但未必),因预防剂量是在患病之前或患病早期用于个体中,故预防有效量会小于治疗有效量。
本文所用的术语「细胞毒性剂」是指抑制或阻止细胞功能及/或引起细胞破坏的物质。所述术语意欲包含放射性同位素(例如At211、I131、I125、Y90、Re186、Re188、Sm153、Bi212、P32、Pb212及Lu的放射性同位素);化学治疗剂(例如胺甲蝶呤、阿霉素、长春花生物碱(长春新碱、长春碱、依托泊苷)、多柔比星、美法仑、丝裂霉素C、苯丁酸氮芥、道诺霉素或其他嵌入剂);酶及其片段,例如溶核酶;抗生素;及毒素,例如来自细菌、真菌、植物或动物来源的小分子毒素或酶活性毒素,包含其片段及/或变体;及下文所揭示的各种抗肿瘤剂或抗癌剂。其他细胞毒性剂阐述于下文中。杀肿瘤剂引起肿瘤细胞破坏。
与一或多种其他治疗剂「组合」投与包含以任一顺序同时(并行)及连续投与。
醣抗体
自培养物中的哺乳动物细胞所产生重组蛋白的醣基化是确保有效使用治疗抗体的重要过程(Goochee等人,1991;Jenkins及Curling,1994)。哺乳动物细胞培养递送并不皆具有相同性质的醣基化模式的异质混合物。这些醣基化模式可影响诸如治疗性蛋白质的安全性、功效及血清半衰期等性质。已藉由研发新颖种类的单株抗体(称为「醣抗体」)来成功解决醣型异质性问题。
术语「醣抗体」是由发明者Dr.Chi-Huey Wong创造,其是指在Fc上具有单一均匀醣型的单株抗体(优选地治疗性单株抗体)的均质群体。构成均质群体的个别醣抗体相同,结合相同表位,且含有具有充分定义的聚醣结构及序列的相同Fc聚醣。
可自在细胞中产生的单株抗体、优选地治疗性单株抗体生成醣抗体。醣抗体可市面有售或处于研发中。用于治疗性应用的单株抗体可为人类化、人类或嵌合单株抗体。用于治疗应用的经批准单株抗体的实例包含但不限于莫罗单抗(Muromomab)、阿昔单抗(Abciximab)、利妥昔单抗(Rituximab)、达克珠单抗(Daclizumab)、巴利昔单抗(Basiliximab)、帕利珠单抗(Palivizumab)、英夫利昔单抗、曲妥珠单抗(Trastuzumab)、依那西普、吉姆单抗(Gemtuzumab)、阿来组单抗(Alemtuzumab)、伊布莫单抗(Ibritomomab)、阿达木单抗、阿来塞普(Alefacept)、奥马珠单抗(Omalizumab)、依法珠单抗(Efalizumab)、西妥昔单抗(Cetuximab)、贝伐珠单抗(Bevacizumab)、那他珠单抗(Natalizumab)、兰尼单抗(Ranibizumab)、帕尼单抗(Panitumumab)、艾库珠单抗(Eculizumab)及赛妥珠单抗。
本文阐述藉由Fc醣改造衍生自治疗性单株抗体的功能活性醣抗体。具有优化醣型的醣抗体与治疗性单株抗体相比展现类似或优选的活性。具有优化醣型的醣抗体预计可提供用于治疗性应用的替代方式。
抗TNFα醣抗体
单核球及巨噬球因应于内毒素或其他刺激分泌称为肿瘤坏死因子-α(TNFα)及肿瘤坏死因子-β(TNFβ)的细胞介素。TNFα是17kD蛋白质亚单位的可溶性同源三聚体(Smith,等人,J.Biol.Chem.262:6951-6954(1987))。亦存在膜结合26kD前体形式的TNF(Kriegler等人,Cell 53:45-53(1988))。TNF-α是发炎性反应的强力诱导剂,是先天免疫性的关键调控剂且在调控针对细胞内细菌及某些病毒感染的Th1免疫反应中发挥重要作用。然而,失调TNF亦可有助于诸多病理学情况。这些病理性情况包含免疫介导的发炎性疾病(IMID),包含类风湿性关节炎、克罗恩氏病(Crohn's disease)、牛皮癣性关节炎、强直性脊柱炎、溃疡性结肠炎及严重慢性斑块状牛皮癣。
本揭示内容描述新颖种类的抗TNFα单株抗体,称为「抗TNFα醣抗体」(「抗TNFα GAb」)。抗TNFα醣抗体可自抗TNFα单株抗体(「亲代抗体」)由Fc醣改造生成。本文所用的术语「亲代抗体」是指用于产生抗TNFα醣抗体的抗TNFα单株抗体。构成均质群体的个别抗TNFα醣抗体相同且含有具有充分定义的聚醣结构及序列的相同Fc聚醣。本发明的抗TNFα醣抗体可结合人类TNFα抗原的相同表位作为其亲代抗体。
亲代抗体可在诸如哺乳动物细胞、嗜甲醇酵母菌或昆虫细胞等细胞中产生。优选地,亲代抗体是在哺乳动物细胞中产生。亲代抗体可为FDA批准或正处于研发中。经批准或处于研发中的抗TNFα单株抗体包含英夫利昔单抗、阿达木单抗、戈利木单抗(Golimumab)、CDP870(赛妥珠单抗)、TNF-TeAb及CDP571。
本发明的抗TNFα醣抗体可包括具有SEQ ID NO:1中所陈述氨基酸序列的重链及具有SEQ ID NO:2中所陈述氨基酸序列的轻链。本发明的抗TNFα醣抗体可包括阿达木单抗的轻链序列及重链序列。
下表1展示阿达木单抗的重链及轻链序列
表1.
如本文所阐述,N-聚醣可连接至Fc区的Asn-297。
本发明的N-聚醣具有Man3GlcNAc2的共有五醣核心,其亦称为「三甘露醣核心」或「五醣核心」,其中「Man」是指甘露醣,「Glc」是指葡萄醣,「NAc」是指N-乙酰基,且GlcNAc是指N-乙酰基葡醣胺。
本文所阐述的N-聚醣可具有双触角结构。
N-聚醣可具有链内取代,包括「二等分(bisecting)」GlcNAc。在聚醣于三甘露醣核心上包括二等分GlcNAc时,所述结构表示为Man3GlcNAc3。在聚醣包括连接至三甘露醣核心的核心岩藻醣时,所述结构表示为Man3GlcNAc2(F)。N-聚醣可包括一或多个末端唾液酸(例如N-乙酰基神经胺酸)。表示为「Sia」的结构是指末端唾液酸。唾液酸化可发生于双触角结构的α1-3或α1-6臂上。
本文所阐述的N-聚醣可包括至少一个α2–6末端唾液酸。在一些实施例中,N-聚醣包括一个α2-6末端唾液酸。在一优选实施例中,N-聚醣包括两个α2-6末端唾液酸。
N-聚醣可包括至少一个α2–3末端唾液酸。在某些实施例中,N-聚醣包括一个α2-3末端唾液酸。在一优选实施例中,N-聚醣包括两个α2-3末端唾液酸。
N-聚醣可包括至少一种半乳醣。在某些实施例中,N-聚醣包括一种半乳醣。在一优选实施例中,N-聚醣包括两种半乳醣。
N-聚醣可发生岩藻醣基化或去岩藻醣基化。优选地,N-聚醣发生岩藻醣基化。
表2列示抗TNFα醣抗体中的实例性N-聚醣。本揭示内容实施例可包含或不包含本文所列示的任一N-聚醣。
表2.
实例性抗TNFα醣抗体的制备
本发明的抗TNFα醣抗体可自抗TNFα单株抗体(「亲代抗体」)由Fc醣改造产生。在一些实施例中,亲代抗体是阿达木单抗
本文阐述制备岩藻醣基化醣抗体的方法,所述方法包括以下步骤:(a)使单株抗体与至少一种醣苷内切酶接触,由此得到在Fc上具有二醣(GlcNAc-Fuc)的抗体,及(b)在适宜条件下将碳水化合物部分添加至二醣的GlcNAc中。
本发明方法中的单株抗体可为抗TNFα单株抗体。在一些实施例中,抗TNFα单株抗体是阿达木单抗、英夫利昔单抗或依那西普。
本发明方法中所使用的醣苷内切酶可为EndoA、EndoF、EndoF1、EndoF2、EndoF3、EndoH、EndoM、EndoS或其变体。
在本发明方法中,藉由向GlcNAc中添加碳水化合物部分以延伸醣链来实施步骤(b)中使用转醣苷酶之后续酶介导的醣基化。转醣苷酶的实例包含(但不限于)EndoA、EndoF、EndoF1、EndoF2、EndoF3、EndoH、EndoM、EndoS及其变体。
业内众所周知,使用醣恶唑啉作为醣供体进行醣基化可用于合成寡醣,因为醣基化反应是加成反应且其进行并不伴随任何酸、水或诸如此类的去除(Fujita等人,Biochim.Biophys.Acta 2001,1528,9–14)。
在一些实施例中,碳水化合物部分是醣恶唑啉。
在一些实施例中,碳水化合物部分是选自由以下组成的群:Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc、Sia(α2-6)GalGlcNAc2Man3Glc NAc、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc、Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc、Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc(F)、Sia(α2-6)GalGlcNAc2Man3GlcNAc(F)、Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc(F)、Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc(F)、Sia2(α2-3/α2-6)Gal2GlcNAc3Man3GlcNAc(F)及Sia2(α2-6/α2-3)Gal2GlcNAc3Man3GlcNAc(F)。
本文所述者亦包含制备去岩藻醣基化醣抗体的改良方法,所述方法包括以下步骤:(a)使单株抗体与α-岩藻醣苷酶及至少一种醣苷内切酶接触,由此得到在Fc上具有单醣(GlcNAc)的抗体,及(b)在适宜条件下将碳水化合物部分添加至GlcNAc中。
本发明改良方法中的单株抗体可为抗TNFα单株抗体。在一些实施例中,抗TNFα单株抗体是阿达木单抗。
本发明改良方法的α-岩藻醣苷酶包括含有与SEQ ID NO:5的序列具有至少85%一致性的氨基酸序列的多肽、其功能变体。
α-岩藻醣苷酶可包括含有与SEQ ID NO:5的序列(列示于表3中)具有至少约90%、91%、92%、93%、94%、95%、96%、97%、98%、99%一致性的氨基酸序列的多肽、其变体或片段。在某些实施例中,α-岩藻醣苷酶是重组类杆菌α-岩藻醣苷酶。
应理解,本发明的α-岩藻醣苷酶的多肽可进行衍生或改质以有助于其分离或纯化。因此,在本发明的一实施例中,藉由添加能够直接及特异性结合分离构件的配体来衍生或改质用于本发明的多肽。另一选择为,藉由添加结合对的一个成员来衍生或改质多肽且分离构件包括藉由添加结合对的另一成员来衍生或改质的试剂。可使用任何适宜结合对。在藉由添加结合对的一个成员来衍生或改质用于本发明的多肽的一优选实施例中,多肽优选地加组胺酸卷标或加生物素卷标。通常,在基因层面上包含组胺酸或生物素卷标的氨基酸编码序列且蛋白质重组表达于大肠杆菌(E.coli.)中。组胺酸或生物素标签通常存在于多肽的一端(在N-末端或C-末端处)。组胺酸标签通常是由6个组胺酸残基组成,但其可长于此长度(通常长达7、8、9、10或20个氨基酸)或较短(例如5、4、3、2或1个氨基酸)。另外,组胺酸标签可含有一或多种氨基酸取代、优选地如上文所定义的保守取代。
如本文所阐述的变体多肽是彼等氨基酸序列自SEQ ID NO:5中的氨基酸序列有所变化者,但与包括具有SEQ ID NO:5的氨基酸序列的多肽的酶展现相同或类似功能。
如本文中所使用,关于序列的序列一致性百分比(%)定义为在比对序列且引入间隙(若需要)以达成最大百分比序列之后,候选多肽序列中与参考多肽序列中的氨基酸残基相同的氨基酸残基的一致性百分比。出于确定序列一致性百分比的目的,比对可以熟习此项技术者所熟知的多种方式来达成,例如使用可公开获得的计算机软件,例如BLAST、ALIGN或Megalign(DNASTAR)软件。彼等熟习此项技术者可测定用于量测比对的适当参数,包含在所比较序列的全长范围内达成最大比对所需要的任何算法。
本发明的一些优选实施例显示于实例中。
医药组合物及调配物
在制备如本文所阐述的抗TNFα GAb之后,可产生「预冻干调配物」。用于制备调配物的抗TNFα GAb优选地基本上纯且期望地基本上均质(亦即不含污染蛋白质等)。「基本上纯」蛋白质意指基于组合物的总重量包括至少约90重量%蛋白质、优选地至少约95重量%的组合物。「基本上均质」蛋白质意指基于组合物的总重量包括至少约99重量%蛋白质的组合物。在某些实施例中,蛋白质是抗体。
考虑期望剂量体积、投与模式等来确定预冻干调配物中的抗TNFα GAb量。在所选蛋白质是完整抗体(全长抗体)的情形下,约2mg/mL至约50mg/mL、优选地约5mg/mL至约40mg/mL及最佳地约20-30mg/mL是实例性起始蛋白质浓度。蛋白质通常存在于溶液中。举例而言,蛋白质可存在于pH为约4-8及优选地约5-7的pH缓冲溶液中。实例性缓冲剂包含组胺酸、磷酸盐、Tris、柠檬酸盐、琥珀酸盐及其他有机酸。缓冲剂浓度可为约1mM至约20mM或约3mM至约15mM,此端视(例如)缓冲剂及调配物(例如复原调配物)的期望等渗性而定。优选缓冲剂是组胺酸,其中如下文所显示此可具有冻干保护性质。经证实,琥珀酸盐为另一有用缓冲剂。
将冻干保护剂添加至预冻干调配物中。在优选实施例中,冻干保护剂是非还原醣,例如蔗醣或海藻醣。预冻干调配物中冻干保护剂的量通常应使得在复原后所得调配物等渗。然而,高渗复原调配物亦可适宜。此外,冻干保护剂的量不应过低而使蛋白质在冻干后发生不可接受的程度的降解/聚集。在冻干保护剂是醣(例如蔗醣或海藻醣)且蛋白质是抗体的情形下,预冻干调配物中的实例性冻干保护剂浓度为约10mM至约400mM及优选地约30mM至约300mM及最佳地约50mM至约100mM。
选择用于每一蛋白质及冻干保护剂的蛋白质对冻干保护剂的组合比率。在使用抗体作为所选蛋白质且使用醣(例如蔗醣或海藻醣)作为冻干保护剂以用于生成具有高蛋白质浓度的等渗复原调配物的情形下,冻干保护剂对抗体的莫耳比率可为约100莫耳至约1500莫耳冻干保护剂对1莫耳抗体及优选地约200莫耳至约1000莫耳冻干保护剂对1莫耳抗体、例如约200莫耳至约600莫耳冻干保护剂对1莫耳抗体。
在本发明的优选实施例中,已发现期望将表面活性剂添加至预冻干调配物中。另一选择为,或此外,可将表面活性剂添加至冻干调配物及/或复原调配物中。实例性表面活性剂包含非离子型表面活性剂,例如聚山梨醇酯(例如聚山梨醇酯20或80);泊洛沙姆(poloxamer)(例如泊洛沙姆188);曲拉通(Triton);十二烷基硫酸钠(SDS);月桂基硫酸钠;辛基醣苷钠;月桂基-、肉豆蔻基-、亚麻油基-或硬脂酰基-磺基甜菜碱;月桂基-、肉豆蔻基-、亚麻油基-或硬脂酰基-肌胺酸;亚麻油基-、肉豆蔻基-或鲸蜡基-甜菜碱;月桂酰胺基丙基-、椰子酰胺基丙基-、亚麻油酰胺基丙基-、肉豆蔻酰胺基丙基-、棕榈油酰胺基丙基-或异硬脂酰胺基丙基-甜菜碱(例如月桂酰胺基丙基);肉豆蔻酰胺基丙基-、棕榈油酰胺基丙基-或异硬脂酰胺基丙基-二甲胺;甲基椰油基牛黄酸钠或甲基油基牛磺酸二钠;及MONAQUAT系列(Mona Industries公司,Paterson,N.J.)、聚乙二醇、聚丙二醇及乙二醇与丙二醇的共聚物(例如Pluronics、PF68等)。所添加表面活性剂的量应可减少复原蛋白质的聚集并使在复原后微粒的形成最小化。举例而言,表面活性剂可以约0.001-0.5%及优选地约0.005-0.05%的量存在于预冻干调配物中。
在本发明的某些实施例中,在制备预冻干调配物时使用冻干保护剂(例如蔗醣或海藻醣)及增积剂(例如甘露醇或甘胺酸)的混合物。增积剂可使得产生均匀冻干饼状物且其中并无过量气穴等。
其他医药上可接受的载剂、赋形剂或稳定剂(例如彼等阐述于Remington's Pharmaceutical Sciences第16版,Osol,A.编辑(1980)中者)可包含于预冻干调配物(及/或冻干调配物及/或复原调配物)中,前提是其不会不利地影响调配物的期望特性。可接受的载剂、赋形剂或稳定剂在所用剂量及浓度下对接受者无毒且包含:额外缓冲剂;防腐剂;共溶剂;抗氧化剂,包含抗坏血酸及甲硫胺酸;螯合剂,例如EDTA;金属错合物(例如Zn-蛋白质错合物);生物可降解聚合物,例如聚酯;及/或成盐抗衡离子,例如钠。
本文所阐述的医药组合物及调配物优选地较为稳定。「稳定」调配物/组合物是以下物质:其中抗体在储存后基本上保持其物理及化学稳定性及完整性。用于量测蛋白质稳定性的各种分析技术在业内可获得且综述于Peptide and Protein Drug Delivery,247-301,Vincent Lee编辑,Marcel Dekker公司,New York,N.Y.,Pubs.(1991)及Jones,A.Adv.Drug Delivery Rev.10:29-90(1993)中。可于所选时间段的所选温度下量测稳定性。
用于活体内投与的调配物必须无菌。此易于藉由过滤经由无菌过滤膜在冻干及复原之前或之后达成。另一选择为,举例而言,可藉由在约120℃下对除蛋白质外的成份实施高压灭菌约30分钟来达成整个混合物的无菌性。
在将蛋白质、冻干保护剂及其他可选组份混合至一起之后,将调配物冻干。许多不同冻干剂可用于此目的,例如(Hull,USA)或(Leybold-Heraeus,Germany)冻干剂。冷冻-干燥是藉由冷冻调配物且随后使来自冷冻内容物的冰在适于初级干燥的温度下升华来达成。在此条件下,产物温度低于调配物的共熔点或陷缩温度。通常,在通常介于约50毫托至250毫托之间的适宜压力下,用于初级干燥的搁板温度将介于约-30℃至25℃之间(前提是产物在初级干燥期间保持冷冻)。容纳试样的容器(例如玻璃小瓶)的调配物、大小及类型以及液体体积主要取决于干燥所需之时间,其可介于几小时至数天(例如40-60hr)之间。二级干燥阶段可在约0-40℃下实施,其主要取决于容器的类型及大小及所采用蛋白质的类型。然而,在本文中发现,二级干燥步骤可能未必需要。举例而言,冻干的整个除水期中的搁板温度可介于约15℃-30℃(例如约20℃)之间。二级干燥所需的时间及压力将使得产生适宜冻干饼状物,此端视(例如)温度及其他参数而定。二级干燥时间取决于产物中的期望残余水分含量,且通常持续至少约5小时(例如10-15小时)。压力可与初级干燥步骤期间所采用的压力相同。冷冻-干燥条件可端视调配物及小瓶大小而变化。
在一些情况下,可期望在容器中冻干蛋白质调配物,其中复原蛋白质以避免转移步骤。此情况下的容器可为(例如)3、5、10、20、50或100cc小瓶。作为一般主张,冻干将得到冻干调配物,其中其水分含量小于约5%及优选地小于约3%。
在期望阶段、通常在向患者投与蛋白质时,可使用稀释剂复原冻干调配物,从而复原调配物中的蛋白质浓度为至少50mg/mL、例如约50mg/mL至约400mg/mL、更佳地约80mg/mL至约300mg/mL及最佳地约90mg/mL至约150mg/mL。复原调配物中的这些高蛋白质浓度可视为尤其可用于预期皮下递送复原调配物的情形。然而,对于其他投与途径(例如静脉内投与)而言,可能期望复原调配物中的蛋白质浓度较低(例如在复原调配物中约5-50mg/mL或约10-40mg/mL蛋白质)。在某些实施例中,复原调配物中的蛋白质浓度显着高于预冻干调配物。举例而言,复原调配物中的蛋白质浓度可为预冻干调配物的约2-40倍、优选地3-10倍及最佳地3-6倍(例如至少三倍或至少四倍)。
此外,本揭示内容亦提供适于单一疗法或组合疗法的组合医药组合物,其包括本文所阐述的实质上均质醣抗体及其他抗体及/或其他治疗剂。医药组合物可以共同调配物形式投与或以共同投与治疗方案使用。
通常在约25℃的温度下进行复原,以确保完全水合,但可视需要采用其他温度。复原所需的时间将端视(例如)稀释剂的类型、赋形剂及蛋白质的量而定。稀释剂实例包含无菌水、注射用抑菌水(BWFI)、pH缓冲溶液(例如磷酸盐缓冲盐水)、无菌盐水溶液、林格氏溶液(Ringer's solution)或右旋糖溶液。稀释剂视情况含有防腐剂。防腐剂实例已在上文中加以阐述,且诸如苄醇或酚醇等芳族醇为优选防腐剂。藉由评估不同防腐剂浓度与蛋白质及防腐剂功效测试的兼容性来决定所采用防腐剂的量。举例而言,若防腐剂是芳族醇(例如苄醇),则其可以约0.1%-2.0%及优选地约0.5%-1.5%但最佳地约1.0%-1.2%的量存在。优选地,复原调配物具有小于6000个颗粒/小瓶,这些颗粒的大小>10μm。
免疫偶联物
在另一态样中,本发明提供免疫偶联物或抗体-药物偶联物(ADC),其包括偶联至细胞毒性剂(例如化学治疗剂)、药物、生长抑制剂、毒素(例如细菌、真菌、植物或动物来源的酶活性毒素或其片段)或放射性同位素(亦即放射性偶联物)的抗体。
使用抗体-药物偶联物局部递送细胞毒性剂或细胞生长抑制剂(亦即在癌症治疗中杀死或抑制肿瘤细胞的药物)(Syrigos及Epenetos(1999)Anticancer Research 19:605-614;Niculescu-Duvaz及Springer(1997)Adv.Drg Del.Rev.26:151-172;美国专利第4,975,278号)容许药物部分体靶向递送至肿瘤且累积在细胞内,而全身性投与这些未偶联药物药剂则可能对正常细胞及欲消除的肿瘤细胞产生不可接受程度的毒性(Baldwin等人(1986)Lancet(Mar.15,1986):第603-05页;Thorpe,(1985)「Antibody Carriers Of Cytotoxic Agents In Cancer Therapy:A Review」,Monoclonal Antibodies'84:Biological And Clinical Applications,A.Pinchera等人(编辑),第475-506页)。由此寻求具有最小毒性的最大功效。已报导多株抗体及单株抗体二者均可用于这些策略中(Rowland等人(1986)Cancer Immunol.Immunother.,21:183-87)。这些方法中所使用的药物包含道诺霉素、多柔比星、胺甲喋呤及长春地辛(Rowland等人(1986),见上文)。抗体-毒素偶联物中所使用的毒素包含细菌毒素(例如白喉毒素(diphtheria toxin))、植物毒素(例如蓖麻毒素)、小分子毒素(例如格尔德霉素(geldanamycin)(Mandler等人(2000)Jour.of the Nat.Cancer Inst.92(19):1573-1581;Mandler等人(2000)Bioorganic&Med.Chem.Letters 10:1025-1028;Mandler等人(2002)Bioconjugate Chem.13:786-791)、类美登素(maytansinoid)(EP 1391213;Liu等人(1996)Proc.Natl.Acad.Sci.USA 93:8618-8623))及卡奇霉素(calicheamicin)(Lode等人(1998)Cancer Res.58:2928;Hinman等人(1993)Cancer Res.53:3336-3342)。毒素可藉由包含微管蛋白结合、DNA结合或拓扑异构酶抑制的机制来实现其细胞毒性及细胞生长抑制效应。当偶联至大抗体或蛋白质受体配体时,一些细胞毒性药物倾向为无活性或具有较小活性。
抗体衍生物
可进一步改质本发明抗体以含有业内已知且易于获得的其他非蛋白质性部分。在一实施例中,适于衍生抗体的部分是水溶性聚合物。水溶性聚合物的非限制性实例包含但不限于聚乙二醇(PEG)、乙二醇/丙二醇的共聚物、羧甲基纤维素、右旋糖酐、聚乙烯醇、聚乙烯基吡咯啶酮、聚-1,3-二氧杂环戊烷、聚-1,3,6-三恶烷、乙烯/马来酸酐共聚物、聚氨基酸(均聚物或无规共聚物)及右旋糖酐或聚(n-乙烯基吡咯啶酮)聚乙二醇、聚丙二醇均聚物、聚环氧丙烷/环氧乙烷共聚物、聚氧乙基化多元醇(例如甘油)、聚乙烯醇及其混合物。聚乙二醇丙醛可因其在水中具有稳定性而在制造方面具有优势。聚合物可具有任何分子量,且可为具支链或不具支链。连接至抗体的聚合物的数量可有所变化,且若连接一个以上的聚合物,则聚合物可为相同或不同分子。通常,用于衍生的聚合物的数量及/或类型可基于包含但不限于以下在内的考虑因素来确定:欲改良抗体的特定性质或功能、抗体衍生物是否将用于界定条件下的疗法等。
在另一实施例中,提供抗体与非蛋白质性部分的偶联物,其可藉由暴露于辐射来选择性加热。在一实施例中,非蛋白质性部分是碳奈米管(Kam等人,Proc.Natl.Acad.Sci.102:11600-11605(2005))。辐射可具有任一波长,且包含但不限于如下波长的辐射:其不会危害正常细胞,但将非蛋白质性部分加热至可将毗邻抗体-非蛋白质性部分的细胞杀死的温度。
治疗应用
自体免疫性病症是重大且广泛的医学问题。举例而言,类风湿性关节炎(RA)是在美国影响200万以上人的自体免疫性疾病。RA引起关节的慢性发炎且通常是可引起关节破坏及功能失能的进展性病况。类风湿性关节炎的病因未知,但基因诱因、感染剂及环境因素皆与疾病的病因有关。在活动性RA中,症状可包含疲乏、食欲缺乏、低热、肌肉及关节疼痛与僵硬。另外,在疾病发作期间,因滑膜发炎,关节通常变得发红、肿胀、疼痛及触痛。另外,因RA是全身性疾病,故发炎可影响身体中除关节外的器官及区域,包含眼睛及口腔的腺、肺内衬、心包及血管。
肿瘤坏死因子α(TNF-α)是藉由诸多细胞类型(包含单核球及巨噬球)产生的细胞介素,其最初是基于其诱导某些小鼠肿瘤的坏死的能力来鉴别。随后,称为恶病质素的因子(与恶病质有关)展示与TNF-α相同。TNF-α与诸多其他人类疾病及病症(包含休克、败血症、感染、自体免疫性疾病、RA、克罗恩氏病、移植排斥及移植物抗宿主病)的病理生理学有关。
本揭示内容提供治疗人类的TNF介导的发炎性疾病的方法,所述方法包括向有需要的人类投与发炎有效量的实例性抗TNFα醣抗体或其抗原结合片段及本文所阐述的其医药调配物/组合物。
本发明方法的实例性发炎性疾病可选自以下群:发炎性肠病(包含溃疡性结肠炎及克罗恩氏病)、类风湿性关节炎、牛皮癣、牛皮癣性关节炎、强直性脊柱炎及幼年型特发性关节炎。
本发明一或多个实施例的详细内容陈述于下文说明书中。根据下列图式及若干实施例的详细说明亦及随附申请专利范围,本发明的其他特征或优点将显而易见。
本发明包含下列实例以证明本发明的优选实施例。彼等熟习此项技术者应了解,下列实例中揭示的技术代表本发明者发现在实践本发明中运行良好的技术,且因此可认为构成其实践的优选方式。然而,彼等熟习此项技术者借助于本揭示内容应了解,可对所揭示特定实施例作出多种改变且仍获得相同或类似结果,此并不背离本发明的精神及范围。
实例
实例1:用于分析抗TNFα的N-醣基化的一般程序
研发质谱方法以藉由施加至醣肽前体的碰撞诱导解离(CID)能量监测寡醣源片段离子(水合氢离子)的产率。水合氢离子的多反应监测(MRM)方法可达成对未来生物类似治疗剂的常规质量控制分析的规章性要求。
将5ug阿达木单抗(购自Abbvie)溶于25ul 2M胍-HCl中,且添加二硫苏醣醇(DTT)至最终浓度为5mM。在110℃培育10分钟之后,将经还原半胱胺酸残基在37℃下于10mM碘乙酰胺(IAA)中实施烷基化1小时。添加5mM DTT以在室温下淬灭过量IAA 10分钟。将产物在50mM碳酸氢铵中稀释15次,然后使用旋转管柱进行微量离心(10kDa蛋白质截留MW)。使用1:25(w/w)的酶:蛋白质比率在37℃下实施胰蛋白酶消化4小时。将试样在-20℃下冷冻以用于LC-MS/MS分析。
仪器
藉由m/z 204水合氢离子(HexNAc)监测使用具有Aglient 1200 HPLC系统的4000QTrap三相四极柱质谱仪(AB Sciex)实施醣肽量化。为相对量化醣肽微异质性,在计算机上获得前体离子m/z,其涵盖所有可能聚醣组合物,且监测每一前体离子的单一定量转变(Q3m/z=204)。
MS数据分析
使用Analyst 1.5(AB Sciex)处理所获取原始数据。将每一转变的质量层析图且藉由峰面积进行量化。针对所有组合组份的总和来计算每一组份的百分比组成。
实例2:实例性抗TNFα GAb的生成
抗TNFα GAb301
藉助PNGase F自阿达木单抗的Fc区完全去除Asn297处的N-连接聚醣,且使用4-12%Bis-Tris NeuPAGE及来自经改质及未改质IgG的胰蛋白酶醣肽的LC-MS/MS分析进行评估。使用胰蛋白酶醣肽的分子量测定每一天门冬酰胺酸处的N-连接醣基化的潜在位点且有助于阐明主要聚醣的物质。
抗TNFα GAb200
将存于磷酸钠缓冲剂(50mM,pH 7.0,1.25mL)中的阿达木单抗(2.5mg)与Endo S(125μg)在37℃下一起培育5h以得到阿达木单抗(抗TNFα GAb200)的Fc上的二醣(GlcNAc-Fuc)。在使用磷酸钠缓冲剂(20mM,pH 7.0)预平衡的蛋白质A-琼脂树脂(1mL)的管柱上对反应混合物实施亲和层析。使用磷酸钠缓冲剂(20mM,pH 7.0,10mL)洗涤管柱。使用甘胺酸-HCl(50mM,pH 3.0,10mL)释放结合的IgG,且立即使用Tris-Cl缓冲剂(1.0M,pH 8.3)中和洗脱部分。合并含有Fc片段的部分且藉由离心过滤(Amicon Ultra离心过滤器,Millipore,Billerica,MA)浓缩以得到抗TNFα GAb201。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽TKPREEQYNSTYR及EEQYNSTYR以证实GAb200的醣基化模式。抗TNFα GAb200的N-聚醣特征分析的结果展示于图1中。
抗TNFα GAb201
将存于磷酸钠缓冲剂(50mM,pH 7.0,1.25mL)中的阿达木单抗(2.5mg)与Endo S(125μg)及重组类杆菌α-L-岩藻醣苷酶(2.5mg)的混合物在37℃下一起培育5h以得到阿达木单抗(抗TNFα GAb201)的Fc上的单醣(GlcNAc)。在使用磷酸钠缓冲剂(20mM,pH 7.0)预平衡的蛋白质A-琼脂树脂(1mL)的管柱上对反应混合物实施亲和层析。使用磷酸钠缓冲剂(20mM,pH 7.0,10mL)洗涤管柱。使用甘胺酸-HCl(50mM,pH 3.0,10mL)释放结合的IgG,且立即使用Tris-Cl缓冲剂(1.0M,pH 8.3)中和洗脱部分。合并含有Fc片段的部分且藉由离心过滤(Amicon Ultra离心过滤器,Millipore,Billerica,MA)浓缩以得到抗TNFα GAb201。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb201的醣基化模式。
抗TNFα GAb101
根据公开方法自鸡蛋黄分离唾液酸醣肽(SGP)。简言之,离心鸡蛋黄的酚提取物,过滤,且藉由层析管柱(包含Sephadex G-50、Sephadex G-25、DEAE-Toyoperarl 650M、CM-Sephadex C-25及Sephadex G-25)纯化。将存于磷酸钠缓冲剂(50mM,pH 6.0,5mM)中的唾液酸醣肽(SGP)(52mg)的溶液与Endo M(53μg)在37℃下一起培育。在7小时之后,在藉由水洗脱的Sephadex G-25管柱上对反应混合物实施凝胶过滤层析。合并含有产物的部分且冻干以得到白色粉末产物(聚醣-101)(30mg,产率为82%)。
将存于水中的聚醣-101(Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(62.7mg)及Et3N(89μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-101)且冻干以得到白色粉末。
将聚醣恶唑啉-101添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及Gab 201的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb101。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb101的醣基化模式。
抗TNFα GAb104
将存于水中的聚醣-104(Sia2(α2-6)Gal2GlcNAc3Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(64mg)及Et3N(95μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-104)且冻干以得到白色粉末。
将聚醣恶唑啉-104添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及GAb201的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb104。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb104的醣基化模式。
抗TNFα GAb107
将存于水中的聚醣-107(Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(62.7mg)及Et3N(89μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-107)且冻干以得到白色粉末。
将聚醣恶唑啉-107添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及GAb201的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb107。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb107的醣基化模式。
抗TNFα GAb109
将存于水中的聚醣-109(Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(64mg)及Et3N(95μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-109)且冻干以得到白色粉末。
将聚醣恶唑啉-109添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及GAb201的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb109。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb109的醣基化模式。
抗TNFα GAb401
根据公开方法自鸡蛋黄分离唾液酸醣肽(SGP)。简言之,离心鸡蛋黄的酚提取物,过滤,且藉由层析管柱(包含Sephadex G-50、Sephadex G-25、DEAE-Toyoperarl 650M、CM-Sephadex C-25及Sephadex G-25)纯化。将存于磷酸钠缓冲剂(50mM,pH 6.0,5mM)中的唾液酸醣肽(SGP)(52mg)的溶液与Endo M(53μg)在37℃下一起培育。在7小时之后,在藉由水洗脱的Sephadex G-25管柱上对反应混合物实施凝胶过滤层析。合并含有产物的部分且冻干以得到白色粉末产物(聚醣-101)(30mg,产率为82%)。
将存于水中的聚醣-101(Sia2(α2-6)Gal2GlcNAc2Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(62.7mg)及Et3N(89μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-401)且冻干以得到白色粉末。
将聚醣恶唑啉-401添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及GAb 200的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb401。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb401的醣基化模式。N-聚醣特征分析的结果展示于图1中。
抗TNFα GAb404
将存于水中的聚醣-104(Sia2(α2-6)Gal2GlcNAc3Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(64mg)及Et3N(95μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-404)且冻干以得到白色粉末。
将聚醣恶唑啉-404添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及GAb200的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb404。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb404的醣基化模式。
抗TNFα GAb407
将存于水中的聚醣-107(Sia2(α2-3)Gal2GlcNAc2Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(62.7mg)及Et3N(89μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-407)且冻干以得到白色粉末。
将聚醣恶唑啉-407添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及Gab 200的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb407。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb407的醣基化模式。
抗TNFα GAb409
将存于水中的聚醣-109(Sia2(α2-3)Gal2GlcNAc3Man3GlcNAc)(30mg)、2-氯-1,3-二甲基咪唑啉鎓氯化物(DMC)(64mg)及Et3N(95μL)的溶液在4℃下搅拌1h。在Sephadex G-25管柱上对反应混合物实施凝胶过滤层析且藉由0.05%Et3N水溶液洗脱。合并含有产物的部分(聚醣恶唑啉-409)且冻干以得到白色粉末。
将聚醣恶唑啉-409添加至存于50mM Tris缓冲剂(pH 7.8)中的醣苷内切酶及Gab 200的混合物中且在室温下培育一小时。使用蛋白质A亲和力管柱纯化反应混合物,随后使用阴离子交换管柱capto Q纯化以收集期望产物抗TNFα GAb409。产物经过胰蛋白酶处理,且使用奈米喷雾LC/MS分析醣肽、TKPREEQYNSTYR及EEQYNSTYR以证实GAb409的醣基化模式。
实例3:实例性抗TNFα GAb的结合亲和力
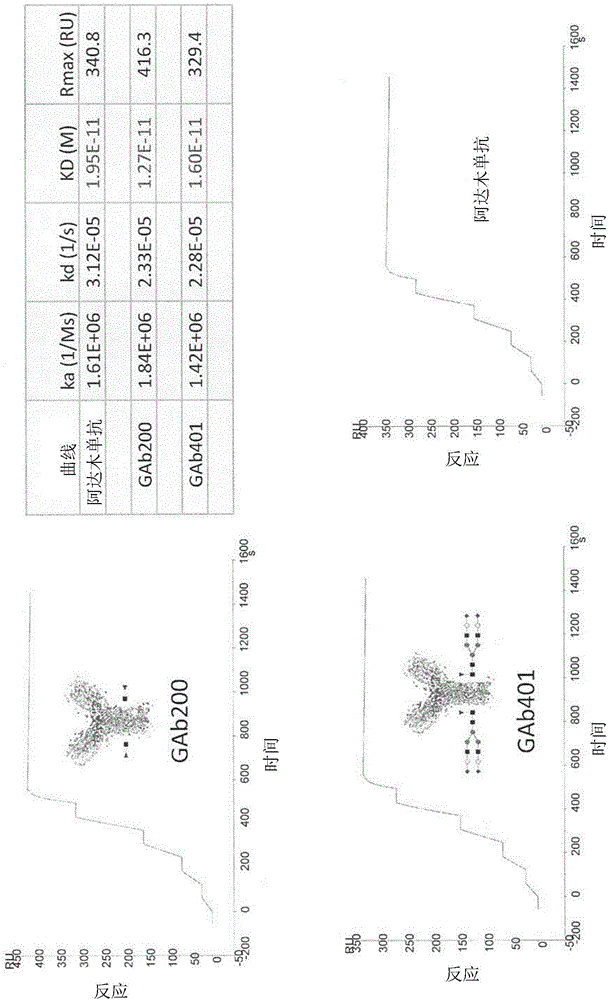
在大肠杆菌(PROSPEC)中产生含有158个氨基酸的人类重组TNF-α(MW=17.5kDa)且纯化。滴定重组人类TNF-α蛋白质且在HBS-EP缓冲剂中制备50nM、25nM、12.5nM、6.25nM及3.125nM的连续稀释液。将阿达木单抗及抗TNFα GAb 200及401在HBS-EP缓冲剂中稀释至10μg/ml的浓度,且然后捕获至预固定抗人类Fc结构域抗体的CM5芯片上。然后以30μl/min的流速注入连续浓度的重组人类TNF-α作为分析物且结合至芯片上的所捕获抗体。在结合之后,藉由再生缓冲剂10mM pH1.5甘胺酸-HCl以50μl/min的流速洗涤抗体-分析物复合物。将CM5芯片在4℃下维持于pH7.4PBS中以共进一步使用。使用Biacore T200评估软件将单一循环动力学数据拟合至1:1结合模型以量测平衡常数(Ka/Kd)。图2中的结果展示,GAb200、GAb401及阿达木单抗的结合亲和力常数相当且介于1.27至1.95E-11M之间。
实例4:实例性抗TNFα GAb与FcγRIIIA的结合亲和力
自经转染HEK-293细胞系纯化FcγRIIIA重组蛋白,且然后以0.5ug/mL在ELISA涂覆缓冲剂(50mM Na2CO3,50mM NaHCO3,pH10)中制备。将抗TNFα GAb在2%BSA/PBST中自150nM 5倍滴定至1.54*10-5nM,且然后施加至预固定重组FcγRIIIA的ELISA板上。在室温下培育1小时之后,使用抗人类IgG-HRP在室温下于2%BSA/TBST中将板处理0.5hr。在使用TBST洗涤3次之后,添加色原体以产生颜色且然后藉由添加2.5N H2SO4终止。在OD450下读取吸亮度,且藉由软件SoftMax Pro 6.0获得EC50。表4中之结果展示,抗TNFα GAb101及GAb401与Humira相比在EC50及最大结合程度方面展现较强FcγRIIIA结合亲和力。
表4.
·相对于Humira的增加倍数。
实例性实施例中的Fc受体结合增加至少约1.35倍、1.5倍、1.75倍、2倍、2.5倍、3倍或更高。
序列表
<110> 中央研究院
<120> 抗TNF-α醣抗体及其用途
<130> G2112-00902
<140> PCT/US2015/032737
<141> 2015-05-27
<150> 62/110,338
<151> 2015-01-30
<150> 62/020,199
<151> 2014-07-02
<150> 62/003,908
<151> 2014-05-28
<160> 6
<170> PatentIn 版本 3.5
<210> 1
<211> 224
<212> PRT
<213> 人工序列
<220>
<223> 人工序列描述:合成多肽
<400> 1
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Thr Trp Asn Ser Gly His Ile Asp Tyr Ala Asp Ser Val
50 55 60
Glu Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Val Ser Tyr Leu Ser Thr Ala Ser Ser Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
<210> 2
<211> 248
<212> PRT
<213> 人工序列
<220>
<223> 人工序列描述:合成多肽
<400> 2
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Arg Tyr Asn Arg Ala Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
210 215 220
Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
225 230 235 240
Lys Ser Phe Asn Arg Gly Glu Cys
245
<210> 3
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> 人工序列描述:合成肽
<400> 3
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
1 5 10
<210> 4
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 人工序列描述:合成肽
<400> 4
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
1 5
<210> 5
<211> 414
<212> PRT
<213> 人工序列
<220>
<223> 人工序列描述:合成多肽
<400> 5
Gln Gln Lys Tyr Gln Pro Thr Glu Ala Asn Leu Lys Ala Arg Ser Glu
1 5 10 15
Phe Gln Asp Asn Lys Phe Gly Ile Phe Leu His Trp Gly Leu Tyr Ala
20 25 30
Met Leu Ala Thr Gly Glu Trp Thr Met Thr Asn Asn Asn Leu Asn Tyr
35 40 45
Lys Glu Tyr Ala Lys Leu Ala Gly Gly Phe Tyr Pro Ser Lys Phe Asp
50 55 60
Ala Asp Lys Trp Val Ala Ala Ile Lys Ala Ser Gly Ala Lys Tyr Ile
65 70 75 80
Cys Phe Thr Thr Arg His His Glu Gly Phe Ser Met Phe Asp Thr Lys
85 90 95
Tyr Ser Asp Tyr Asn Ile Val Lys Ala Thr Pro Phe Lys Arg Asp Val
100 105 110
Val Lys Glu Leu Ala Asp Ala Cys Ala Lys His Gly Ile Lys Leu His
115 120 125
Phe Tyr Tyr Ser His Ile Asp Trp Tyr Arg Glu Asp Ala Pro Gln Gly
130 135 140
Arg Thr Gly Arg Arg Thr Gly Arg Pro Asn Pro Lys Gly Asp Trp Lys
145 150 155 160
Ser Tyr Tyr Gln Phe Met Asn Asn Gln Leu Thr Glu Leu Leu Thr Asn
165 170 175
Tyr Gly Pro Ile Gly Ala Ile Trp Phe Asp Gly Trp Trp Asp Gln Asp
180 185 190
Ile Asn Pro Asp Phe Asp Trp Glu Leu Pro Glu Gln Tyr Ala Leu Ile
195 200 205
His Arg Leu Gln Pro Ala Cys Leu Val Gly Asn Asn His His Gln Thr
210 215 220
Pro Phe Ala Gly Glu Asp Ile Gln Ile Phe Glu Arg Asp Leu Pro Gly
225 230 235 240
Glu Asn Thr Ala Gly Leu Ser Gly Gln Ser Val Ser His Leu Pro Leu
245 250 255
Glu Thr Cys Glu Thr Met Asn Gly Met Trp Gly Tyr Lys Ile Thr Asp
260 265 270
Gln Asn Tyr Lys Ser Thr Lys Thr Leu Ile His Tyr Leu Val Lys Ala
275 280 285
Ala Gly Lys Asp Ala Asn Leu Leu Met Asn Ile Gly Pro Gln Pro Asp
290 295 300
Gly Glu Leu Pro Glu Val Ala Val Gln Arg Leu Lys Glu Val Gly Glu
305 310 315 320
Trp Met Ser Lys Tyr Gly Glu Thr Ile Tyr Gly Thr Arg Gly Gly Leu
325 330 335
Val Ala Pro His Asp Trp Gly Val Thr Thr Gln Lys Gly Asn Lys Leu
340 345 350
Tyr Val His Ile Leu Asn Leu Gln Asp Lys Ala Leu Phe Leu Pro Ile
355 360 365
Val Asp Lys Lys Val Lys Lys Ala Val Val Phe Ala Asp Lys Thr Pro
370 375 380
Val Arg Phe Thr Lys Asn Lys Glu Gly Ile Val Leu Glu Leu Ala Lys
385 390 395 400
Val Pro Thr Asp Val Asp Tyr Val Val Glu Leu Thr Ile Asp
405 410
<210> 6
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 人工序列描述:合成 6xHis 标记
<220>
<223> 取代及优选态样的详细描述见申请时说明书
<400> 6
His His His His His His
1 5
- 还没有人留言评论。精彩留言会获得点赞!