免疫受体全长序列的检测方法及应用与流程
本发明涉及生物
技术领域:
,特别是涉及一种免疫受体全长序列的检测方法及应用。
背景技术:
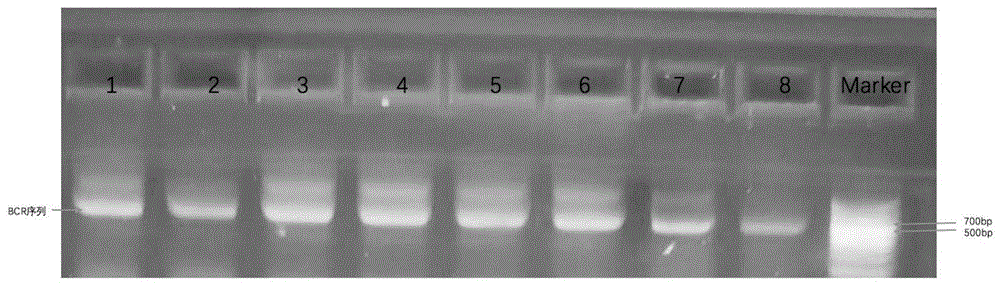
:b细胞受体(bcellreceptor,bcr)是动物体内的b细胞抗原识别决定性表面分子,bcr的重链(heavychain,h)由65~100种可变区(vh)、27种多变区(dh)、6种结合区(jh)和恒定区(ch)四部分基因片段组成;轻链(lightchain,l)由可变区、结合区和恒定区三部分基因片段组成。b淋巴细胞发育成熟过程中,通过v(d)j基因组合、连接多样性,以及体细胞高频突变、基因转换和类别转换等途径形成数量庞大且种类多样的b细胞受体(bcr)文库,其多样性可以多达1014种。bcr包含重链和轻链,人的bcr全长序列长度在700bp以上,获得全长序列能够帮助我们理解bcr的种类,丰度,来源等关键信息,用于评价各种免疫相关疾病和遗传性突变引起的某个物种所有b细胞或特定b细胞激活介导的细胞免疫反应中bcr基因重排碱基序列,以及各序列的丰度,用于研究不同b细胞克隆的转录情况和相互间关系,从而揭示更深层次的b细胞功能特异性,继而解释体液免疫应答耐受以及高频突变在b细胞应答识别抗原异常等相关生命现象。tcr即t细胞受体(tcellreceptor)为所有t细胞表面的特征性标志免疫受体,以非共价键与cd3结合,形成tcr—cd3复合物。tcr的作用是识别抗原。tcr是由两条不同肽链构成的异二聚体,由α、β两条肽链组成,每条肽链又可分为可变区(v区),恒定区(c区),跨膜区和胞质区等几部分;其特点是胞质区很短。tcr分子属于免疫球蛋白超家族,其抗原特异性存在于v区;v区(vα、vβ)又各有三个高变区cdr1、cdr2、cdr3,其中以cdr3变异最大,直接决定了tcr的抗原结合特异性。在tcr识别mhc-抗原肽复合体时,cdr1,cdr2识别和结合mhc分子抗原结合槽的侧壁,而cdr3直接与抗原肽相结合。免疫受体测序的应用方向包括:(1)孤立性iga缺乏症等原发性免疫缺陷病人体细胞突变筛查,(2)自身免疫病(sle,多发性硬化,i型糖尿病)治疗指导及其过程中病程监测,(3)感染性疾病,恶性肿瘤药物治疗效果和耐受性评估,(4)移植排斥(transplanttolerance)反应中耐受,排斥反应的预测和干预指导。现有的报道中,在检测bcr或tcr序列时,先进行逆转录(rt-pcr),然后对v(d)j区域进行pcr扩增,有些方法只是扩增并检测bcr或tcr中的cdr3序列。另外方法虽然对bcr或tcr全长进行pcr扩增,但序列长度达到500bp或以上,需要使用较长测序长度的测序仪,如illumina公司的miseq测序仪的pe300进行测序,测序的费用比较昂贵。目前,还没有一种技术能够对bcr或tcr全长序列进行片段化的短序列进行测序,并且进行短序列拼接的方法。技术实现要素:鉴于以上所述现有技术的缺点,本发明的目的在于提供一种免疫受体全长序列的检测方法及应用。本发明第一方面提供一种免疫受体全长序列的检测方法,至少包括如下步骤:1)获得免疫受体的全长,所述免疫受体的全长的一端连接有第一接头序列;不同的免疫受体的全长对应的第一接头序列不同;2)将步骤1)得到的序列进行片段化,获得片段化免疫受体;3)利用所述片段化免疫受体建立高通量测序文库;4)利用高通量测序仪对步骤3)获得的高通量测序文库进行高通量双端测序,所述高通量测序仪的读长不大于200bp;5)利用生物信息学拼接高通量测序数据,获得免疫受体全长的序列。本发明第二方面提供一种免疫受体全长序列的检测方法在以下一方面或多方面的用途:1)用于免疫受体的全长的序列鉴定;2)检测免疫受体多样性;3)鉴定免疫治疗新靶标;4)开发新型免疫治疗药物。如上所述,本发明的免疫受体的全长的序列鉴定方法及应用,具有以下有益效果:已报到的方法直接扩增短序列或者对全长序列进行测序,技术难点在于对短序列进行拼接的方法。主要原因是bcr或tcr上的短序列本身有重组和突变,无法直接与参考进行组进行比对。本发明的bcr或tcr片段的拼接方法,使用新型的算法,能够实现对片段化的dna序列进行拼接,使得此方法能够获得原始的全长bcr序列。本发明对全长的bcr序列先进行片段化,然后进行pcr扩增,获得的序列长度为300左右,从而能够使用低成本的测序平台(如hiseq测序仪的pe150),从而降低90%以上的测序成本。通过对bcr全长序列进行定性和定量的检测,可以同时获得数以千万计的bcr免疫组库的序列,该项技术可以用于免疫学研究中的免疫组分分析,能够检测肿瘤病人免疫状态,而且可以用于其他免疫相关疾病的检测和治疗开发,如感染,器官移植,自身免疫,免疫性疾病等。本发明提供的一种基于片段化组装的高通量测序建库,来鉴定人的bcr全长序列(包含重链和轻链)的方法。该方法对bcr的rna进行逆转录和pcr扩增,文库构建和进行高通量测序,并进行序列比对和拼接,获得bcr全长序列。本发明改变了传统的建库方法,引入了dna片段化的步骤,减少测序文库长度,降低90%的测序成本;本发明开发了bcr的短片段拼接的分析方法,可以高效并且低成本地获得b细胞受体(bcr)的全长序列,基因重排碱基序列以及各种序列的丰度。在鉴定免疫治疗新靶标和开发新型免疫治疗药物领域,具有广阔的应用前景。附图说明图1是pcr两步法获取bcr全长序列。第1个到第8个孔分别代表不同肺癌患者的bcr文库样本,大小约700bp,第九个孔是100bpplusiidnaladder。图2是bcr文库序列的打断。第1个到第8个孔分别代表8个不同肺癌患者的bcr文库样本片段,大小在300bp-700bp之间,第9个孔是空白对照,第10个孔是100bpplusiidnaladder。图3是pcr扩增bcr文库并插入标签序列。第1个孔代表100bpplusiidnaladder,第2到第9个孔分别代表不同肺癌患者的bcr文库样本,大小在300bp-700bp。图4是pcr富集bcr文库。第1个到第8个孔分别代表不同肺癌患者的bcr文库样本,大小在300bp-700bp之间,第9个孔是100bpplusiidnaladder。图5是琼脂糖凝胶电泳纯化bcr文库。从第1个到第7个孔分别代表100bpplusiidnaladder和6个不同肺癌患者的bcr文库,切割范围300-700bp之间的条带。图6是随机打断reads组装示意图。图7是测序示意图。图8是read1进行一致性序列合并示意图。具体实施方式以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。此外应理解,本发明中提到的一个或多个方法步骤并不排斥在所述组合步骤前后还可以存在其他方法步骤或在这些明确提到的步骤之间还可以插入其他方法步骤,除非另有说明;还应理解,本发明中提到的一个或多个步骤之间的组合连接关系并不排斥在所述组合步骤前后还可以存在其他步骤或在这些明确提到的两个步骤之间还可以插入其他步骤,除非另有说明。而且,除非另有说明,各方法步骤的编号仅为鉴别各方法步骤的便利工具,而非为限制各方法步骤的排列次序或限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容的情况下,当亦视为本发明可实施的范畴。请参阅图1至图7。需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,虽图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。本发明实施例所述的一种免疫受体全长序列的检测方法,至少包括如下步骤:1)获得免疫受体的全长,所述免疫受体的全长的一端连接有第一接头序列;不同的免疫受体的全长对应的第一接头序列不同;2)将步骤1)得到的序列进行片段化,获得片段化免疫受体;3)利用所述片段化免疫受体建立高通量测序文库;4)利用高通量测序仪对步骤3)获得的高通量测序文库进行高通量双端测序,所述高通量测序仪的读长不大于200bp;5)利用生物信息学拼接高通量测序数据,获得免疫受体全长的序列。所述免疫受体选自bcr或tcr。所述免疫受体的全长的待测样本来源为人的rna样本。进一步的,所述待测样本为提取人外周血单核细胞获得的总rna。可将所述待测样本rna进行反转录获得待测样本的cdna。然后连接第一接头序列。步骤1)中,所述第一接头序列包括umi片段。umi即uniquemolecularidentifier,不同的免疫受体对应的umi片段不同;即为每个rna分子加入的特有的碱基序列。在一种实施方式中,所述第一接头序列的核苷酸序列如seqidno:1所示。可选的,利用多重pcr反应引物对待测样本的dna进行多重pcr扩增,获得免疫受体的全长;多重pcr反应引物包括上游引物和下游引物,所述上游引物为包括用于扩增第一接头序列的核苷酸片段。在一种实施方式中,所述上游引物的核苷酸序列如seqidno:2所示,下游引物由第一引物组和第二引物组构成,所述第一引物组包括的核苷酸序列如seqidno:3-8所示,所述第二引物组包括的核苷酸序列如seqidno:9-13所示。步骤2)中,利用限制性内切酶进行片段化。步骤3)中,建立高通量测序文库的方法为:31)给所述片段化免疫受体装载第二接头和标签,同时进行扩增;32)利用pcr富集引物进行富集,获得高通量测序文库。步骤1)中,利用多重pcr反应引物对待测样本的dna进行多重pcr扩增,获得免疫受体全长;步骤31)中,扩增用的pcr上游引物与所述多重pcr反应引物中的上游引物一致,下游引物为适用于测序平台的index引物。所述第二接头序列与pcr反应引物的下游引物index互补,所述下游引物index的5’端包括标签序列,所述标签序列为由6~8个核苷酸序列组成的序列条码,其中,所述序列条码之间至少有一个核苷酸不同。在一种实施方式中,步骤31)中,所述第二接头序列选自核苷酸序列如seqidno:14-15所示。在一种实施方式中,步骤32)中,所述pcr富集引物包括核苷酸序列如seqidno:16所示的上游引物,和核苷酸序列如seqidno:17所示的下游引物。步骤4)中,测序为双端测序,所述高通量测序仪的读长不大于200bp。例如为200bp,150bp,100bp等。在一种实施方式中,可以采用pe150长度的测序仪。例如可以为hiseq的pe150长度的测序仪。如图7所示,步骤4)中,双端测序的正向测序获得的序列为read1(左侧箭头),反向测序获得的序列为read2(右侧箭头)。其中,read1中含有第一接头序列。因此,在打断时(打x的位置代表打断的位置),可以根据第一接头序列将read1固定,read2为可变区域。步骤5)中,高通量测序数据的拼接方法可以为:51)将第一接头序列相同的测序序列分为同一组;52)若同一组中,两条测序序列的read2满足以下条件:i)有重叠区域,且属于首尾重叠;ii)重叠区域≥15bp;iii)read1序列一致;则两条测序序列可拼接;53)在同一组中,将满足步骤52)中的条件的测序序列组装成重叠群,对重叠群中的序列进行合并,得到read2的一致性序列;54)在同一组中,对所有read1进行一致性序列合并,将合并后获得的read1的一致性序列与步骤53)获得的read2的一致性序列进行拼接,从而得到免疫受体的全长的序列。步骤51)中,含有相同umi序列的测序序列来自同一打断前的rna分子。通过对相同umi的短序列进行拼装组合即可还原初始的rna序列。在进行拼接之前,可以将高通量测序数据进行质量控制。具体的,测序结果的fastq文件,使用fastqc和trimmomatic进行质量控制;使用trimmomatic去除adaptor序列和低碱基质量序列,剩余序列需满足全长4mer滑动窗口区域平均碱基质量均满足一定阈值。例如,剩余序列平均碱基质量大于30(sanger/illumina1.9encoding),4mer滑动窗口平均质量大于20。步骤52)中,所述首尾重叠是指,例如,测序序列a与测序序列b存在重叠区域,若测序序列a的重叠区域在测序序列a的首端,则测序序列b的重叠区域在测序序列b的尾端;若测序序列a的重叠区域在测序序列a的尾端,则测序序列b的重叠区域在测序序列b的首端。步骤52)中,所述重叠区域允许自定义错配的阈值。例如每20bp允许1错配(图6)。所述read1序列一致,允许错配。具体是指两条测序序列的read1完全一致或超过99%一致或超过98%的序列一致或超过97%的序列一致、或超过96%的序列一致、或超过95%的序列一致。步骤53)中,所述重叠区域即为覆盖度(overlap)。read2的覆盖度(overlap)可采用以下方法进行优化计算:应用c++代码经单指令流多数据流(simd)优化对所有反向(read2)序列进行覆盖度(overlap)计算。步骤54)中,在read1进行一致性序列合并时,对于一组组read1中某个位置的碱基冲突,选取占比最高的碱基作为一致性序列相应的位置中的碱基。具体的,步骤54)的示意图如图8所示。一种read1共有14条,其中,在14条序列中,虚线a、b、c、d部分表示该位置的碱基冲突,其中虚线内的不同颜色的方块表示不同的碱基,在虚线a中,有10条序列有浅色色块,4条没有,则最后合并时,该位置选择浅色色块代表的碱基;同理,在虚线b中,有5条序列有深色色块,9条没有,则最后合并时,该位置选择无深色色块代表的碱基;在虚线c和d中,分别选择无浅色色块代表的碱基;……最终得到能够代表大多数read1的一条一致性序列。在一种实施方式中,所述免疫受体的全长的序列的鉴定方法,还包括以下步骤:6)将步骤5)中获得的序列进行注释。具体的,使用igblast工具对组装后的bcr序列进行注释,并使用自主研发的脚本程序对注释结果进行解析,得到bcr序列对应的germline的vdj基因,以及其中的framework序列和cdr1,2,3。所述免疫受体的全长的序列鉴定方法,还包括以下步骤:7)二次序列拼接:对于组装出cdr3,但未组装出完整vh/vl序列的情况,将cdr3相同的测序序列分为同一组,重复步骤52)-54),得到免疫受体的全长的序列。本发明一实施例提供前述免疫受体全长序列的检测方法在以下一方面或多方面的用途:1)用于免疫受体的全长的序列鉴定;2)检测免疫受体多样性;3)鉴定免疫治疗新靶标;4)开发新型免疫治疗药物。实施例材料及试剂说明:trizoltmreagent(赛默飞:货号15596018)氯仿(上海凌峰化学试剂有限公司:货号67-66-3)异丙醇(生工:货号67-63-0)无水乙醇(生工生物:货号64-17-6)1mtris-hcl溶液(ph8.0,invitrogen,cas:1862815)edta(diamond,cas:6381-92-6)nacl(生工生物,cas:7647-14-5)depc水(生工生物,cas:7732-18-5)sds(bbilifesciences,cas:151-21-3)lymphopreptm(stemcelltechnologiesinc.货号07801)smarterracecdnaamplificationkit(货号:634859)q5高保真聚合酶(neb,货号:m0491l)dntp(neb,货号:n0447l)ultratmiifsdnamodule(neb,货号e7810s/l)t4dnaligase(neb,货号:m0202l)琼脂糖凝胶回收试剂盒(qiagen,货号:28606)magicpuresizeselectiondnabeads(全式金,货号:ec401)dna裂解液具体步骤如下:(一)分离人血中的外周血单核细胞(pbmcs)1.收集肺癌患者的新鲜血样;2.使用lymphopreptm试剂盒,按说明书操作,获得高纯度的的pbmcs(二)从外周血单核细胞中提取核糖核酸rna1.在生物安全柜中,向分离获得的外周血单核细胞(pbmcs)中加入1mltrizoltm试剂,充分吹打混匀,室温静置5min,以保证trizol试剂充分裂解细胞并释放其中的rna;2.加入0.2ml三氯甲烷,剧烈震摇20s,室温静置5分钟后在离心机中进行离心,离心条件是4℃,12000rpm,15min;3.取离心获得的400μl上清液,加入等体积异丙醇,轻轻上下颠倒混匀,静置10min,后进行离心分离,4℃,10000rpm,10min,离心后弃上清液;4.在沉淀中加入1ml75%冰乙醇,轻轻上下颠倒混匀,然后进行离心,条件为4℃,7500rpm,5min,离心后弃上清,即获得沉淀的rna,室温晾干10min;5.加入20uldepc水溶解rna沉淀,获得rna溶液。6.利用nano-100检测rna的浓度及纯度。使用e-gelex的琼脂糖凝胶电泳(2%agarose,invitrogen,g402002)鉴定rna质量。7.所得的总rna产物溶液在-80℃贮存。(三)反转录获取rna转录本使用smarterracecdnaamplificationkit试剂盒,将所得总rna反转录成cdna,步骤如下:步骤1.在冰上配制反应体系mix1:rna1ugdtoligo(0.5ug/ul)1uldepc水补至10ulmix1混匀后简单离心;在pcr仪中进行反应,程序为:72℃,3min;42℃,2min。其中oligo序列为ttttttttttttttttttn(seqidno:18)步骤2.在冰上配制反应混合体系:待步骤1反应结束后,将mix1加入到反应混合体系中,充分混匀,42℃,90min;70℃,10min;置于4℃保存。其中rnaoligonucleotide的序列为ccctacacgacgctcttccgatctnnnnnnnnnnnngcggg(seqidno:1)。其中,序列最后的三个碱基ggg(字体加粗)为rna核苷酸。(四)分离法纯化rna反转录产物1.将步骤(三)中的反转录产物加入到400uldna裂解液中,室温混匀,加入等体积酚:氯仿:异戊醇(1:1:1),上下颠倒混匀,静置5min;2.使用12000rpm,15min离心,保留上清液,加入等体积异丙醇混匀,在室温静置10min;3.使用12000rpm,10min,离心,弃去上清液,加入新鲜1ml75%乙醇洗涤沉淀。重复一次;4.室温自然晾干10min;5.加入20uldnase/rnase-free的蒸馏水进行溶解,使用nano-100仪器测定cdna的浓度及纯度。(五)pcr两步法获取bcr基因全长序列1.配制第一轮pcr反应体系,体系组成如下:5xq5reactionbuffer40ulclone-seq-f2(10um)2ul混合引物1(12um)2uldntp(2.5mm)4ulq5聚合酶(2u/ul)2ul模板dna1ugdnase/rnase-free蒸馏水补至200ul其中模板dna为步骤(四)中纯化的cdna,clone-seq-f2为上游引物,混合引物1为下游引物,由human-vdjc-r1-1:7七个引物组成;pcr程序如下:具体引物序列信息如下:2.配制第二轮pcr反应体系,反应体系组成如下:5xq5reactionbuffer20ulclone-seq-f22ul混合引物2(12um)2uldntp(2.5mm)2ulq5聚合酶(2u/ul)1ul模板dna2uldnase/rnase-free蒸馏水补至100ul其中模板dna为步骤(五)第一轮的pcr反应产物,clone-seq-f2为上游引物,混合引物2是下游引物,也是由human-vdjc-r2-1~5的五个引物组成。pcr反应程序如下:具体引物信息如下:引物名称序列序列号human-vdjc-r2-1aagtagcccgtggccaggcaseqidno:9human-vdjc-r2-2aagtagtccttgaccaggcaseqidno:10human-vdjc-r2-3tggtacccagttatcaagcaseqidno:11human-vdjc-r2-4aagaagccctggaccaggcaseqidno:12human-vdjc-r2-5aggaagtcctgtgcgaggcaseqidno:133.使用e-gelex2%琼脂糖凝胶电泳鉴定pcr产物,大小约700bp(图1),(六)纯化bcr全长序列1.按照magicpuresizeselectiondnabeads的操作步骤纯化bcr文库;2.使用nano-100仪器测定cdna的浓度及纯度。(七)bcr文库序列打断1.利用ultratmiifsdnamodule试剂盒,将bcr全长序列进行片段化,反应体系如下:其中模板dna是步骤(六)纯化所得dna2.反应程序:32℃,90s;65℃,30min;3.e-gelex2%agarose鉴定:可获得300-700bp大小不同的bcr断序(图2)。(八)磁珠纯化bcr基因序列片段1.在bcr序列的片段化反应体系中加入去离子水补充至50ul2.按照magicpuresizeselectiondnabeads的操作步骤纯化bcr基因序列片段3.使用nano-100仪器测定cdna的浓度及纯度,获得的同体积bcr断序的浓度应大于原来浓度1.5~2.5倍,否则不符合片段化的要求。(九)装载接头(adaptor)将adaptor连接至cdna序列5‘端,具体步骤如下:1.生成接头的反应体系adaptorprimerf(100um)1uladaptorprimerr(100um)1uldnase/rnase-free蒸馏水8ul反应程序:95℃反应2min,冷却后置于4℃保存。2.接头连接反应adaptor5ult4dnaligase2ult4ligasebuffer5ul模板dna所有纯化的cdnadnase/rnase-free蒸馏水补至50ul其中模板dna为步骤(八)纯化的cdna。反应程序:室温反应1h,65℃反应10min终止连接。接头adaptor序列序列信息如下:adaptorfp-gatcggaagagcacacgtctgaactccagtcacseqidno:14adaptorrgtgactggagttcagacgtgtgctcttccgatctseqidno:15(十)磁珠纯化插入接头(adaptor)后的bcr文库1.按照magicpuresizeselectiondnabeads试剂盒的操作步骤纯化cdna2.利用nano-100仪器测定cdna的浓度及纯度(十一)扩增并插入标签序列1.配制pcr反应体系如下:5xq5reactionbuffer20ulclone-seq-f2(10um)3ulindex引物(10um)3uldntp(2.5mm)2ulq5聚合酶(2u/ul)1ul模板dna100ngdnase/rnase-free蒸馏水补至100ul模板dna为步骤(十)磁珠纯化的产物,clone-seq-f2为上游引物,index引物为下游引物,含有标签序列,不同样品使用不同的index不同。index引物序列为illumina标准index序列。2.pcr反应程序如下:3.e-gelex2%agarose鉴定:可获得序列大小不同的bcr文库片段,范围在300-700bp之间(图3)。(十二)pcr富集bcr文库1.配制pcr反应体系:5xq5reactionbuffer20ulcri-3rd-f(10um)2ulcri-3rd-r(10um)2uldntp(2.5mm)2ulq5聚合酶(2u/ul)1ul模板dna2uldnase/rnase-free蒸馏水补至100ul其中模板dna是步骤(十一)中的pcr产物,cri-3rd-f是上游引物,cri-3rd-r是下游引物。2.pcr反应程序如下:3.e-gelex2%agarose鉴定:可获得序列大小不同的bcr文库片段,大小范围在300-700bp之间(图4)。具体引物信息如下:(十三)纯化bcr测序文库1.配制1%琼脂糖凝胶,使用110v,30min条件的电泳来分离目的片段;2.切胶回收300-700bp之间的目的条带(图5),按照琼脂糖凝胶回收试剂盒操作说明纯化cdna;(十四)按照invitrogenqubittmdsdnahsassaykit适合的操作步骤测定样品浓度。然后混合不同的样本,使用hiseq的双端150bp长度进行高通量测序。上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属
技术领域:
中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。序列表<110>上海寻百会生物科技有限公司<120>免疫受体全长序列的检测方法及应用<160>18<170>siposequencelisting1.0<210>1<211>41<212>dna<213>人工序列(artificialsequence)<400>1ccctacacgacgctcttccgatctnnnnnnnnnnnngcggg41<210>2<211>58<212>dna<213>人工序列(artificialsequence)<400>2aatgatacggcgaccaccgagatctacactctttccctacacgacgctcttccgatct58<210>3<211>20<212>dna<213>人工序列(artificialsequence)<400>3caggacaaagtgatggagtc20<210>4<211>20<212>dna<213>人工序列(artificialsequence)<400>4cacgacaccgtcaccggttc20<210>5<211>20<212>dna<213>人工序列(artificialsequence)<400>5caggtgacagtcacggacgt20<210>6<211>20<212>dna<213>人工序列(artificialsequence)<400>6caggagaaagtgatggagtc20<210>7<211>20<212>dna<213>人工序列(artificialsequence)<400>7caggtcacactgagtggctc20<210>8<211>20<212>dna<213>人工序列(artificialsequence)<400>8caggtcaccatcaccggctc20<210>9<211>20<212>dna<213>人工序列(artificialsequence)<400>9aagtagcccgtggccaggca20<210>10<211>20<212>dna<213>人工序列(artificialsequence)<400>10aagtagtccttgaccaggca20<210>11<211>20<212>dna<213>人工序列(artificialsequence)<400>11tggtacccagttatcaagca20<210>12<211>20<212>dna<213>人工序列(artificialsequence)<400>12aagaagccctggaccaggca20<210>13<211>20<212>dna<213>人工序列(artificialsequence)<400>13aggaagtcctgtgcgaggca20<210>14<211>33<212>dna<213>人工序列(artificialsequence)<400>14gatcggaagagcacacgtctgaactccagtcac33<210>15<211>34<212>dna<213>人工序列(artificialsequence)<400>15gtgactggagttcagacgtgtgctcttccgatct34<210>16<211>20<212>dna<213>人工序列(artificialsequence)<400>16aatgatacggcgaccaccga20<210>17<211>21<212>dna<213>人工序列(artificialsequence)<400>17caagcagaagacggcatacga21<210>18<211>19<212>dna<213>人工序列(artificialsequence)<400>18ttttttttttttttttttn19当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 金黄色葡萄球菌肠毒素C2的核酸适配体C203及其筛选方法和应用与制造工艺
- 一种全人源化EGFRvIII嵌合抗原受体T细胞及其制备方法与制造工艺
- 嵌合抗原受体及制备方法与制造工艺
- 检测外周血CAR‑T细胞的TaqMan实时荧光定量PCR试剂盒的制造方法与工艺
- CD20特异性嵌合抗原受体及其应用的制造方法与工艺
- 一种用于辣根过氧化物酶染色的染色剂及其制备方法、染色组合、应用及标记酶染色试剂盒与制造工艺
- 对SSEA4抗原具有特异性的嵌合抗原受体的制造方法与工艺
- 具有针对CD79和CD22的特异性的分子的制造方法与工艺
- 具有针对CD45和CD79的特异性的分子的制造方法与工艺
- 一种检测嵌合抗原受体T细胞对肝癌细胞抑制作用的模型和方法与制造工艺