HLA基因的DNA分型方法和试剂盒与流程
技术领域
本发明涉及应用大规模平行序列分析仪进行HLA基因的DNA分型的方法和试剂盒。
背景技术:
作为人主要组织相容性复合物(MHC)的人白细胞抗原(HLA)通过向T细胞呈递衍生自病原体等外来蛋白质的肽以及衍生自自身蛋白质的肽而深入地牵涉免疫应答的诱导,有6种抗原已知为主要的HLA。即,几乎在所有细胞中表达的I类分子(HLA-A、HLA-B、HLA-C)与主要在免疫系统细胞中表达的II类分子(HLA-DR、HLA-DQ、HLA-DP)。
HLA I类抗原由表现高度多态性的α链和几乎没有多态性的β2-微球蛋白组成,HLA II类抗原由存在高度多态的β链和多态性低的α链组成。I类分子的α链由HLA-A、HLA-B、HLA-C各基因编码,II类抗原的β链由HLA-DRB1、HLA-DQB1、HLA-DPB1基因编码,α链由HLA-DRA1、HLA-DQA1、HLA-DPA1基因编码。在基因水平,在HLA I类抗原中,编码α链的基因的外显子2和外显子3显示高度多态性,在HLA II类抗原中,编码β链的基因的外显子2显示高度多态性。
编码HLA的基因区域位于人6号染色体短臂6p21.3,从端粒侧至着丝粒侧,以I类区域(HLA-A、HLA-C、HLA-B等)、III类区域、II类区域(HLA-DRA、HLA-DRB1、HLA-DQA1、HLA-DQB1、HLA-DPA1、HLA-DPB1等)的顺序排列,许多基因以非常高的密度编码,这些基因与输血、移植和各种疾病的关联被报告。在III类区域中不存在HLA基因,存在补体成分、肿瘤坏死因子(TNF)等的基因。
在编码HLA-DR抗原的β链的HLA-DRB基因区域中,确认了5种结构多态性。在DR1型和DR10型中,在同一染色体上,除HLA-DRB1之外还定位HLA-DRB6和HLA-DRB9等假基因。在DR2型中,在同一染色体上,除HLA-DRB1之外还定位HLA-DRB5(DR51)基因以及HLA-DRB6和HLA-DRB9等假基因。在DR3、DR5以及DR6型中,除HLA-DRB1之外,在同一染色体上还定位HLA-DRB3(DR52)基因以及HLA-DRB2和HLA-DRB9等假基因。在DR4、DR7以及DR9型中,除HLA-DRB1之外,在同一染色体上还定位HLA-DRB4(DR53)基因以及HLA-DRB7、HLA-DRB8和HLA-DRB9等假基因。与这些相对,在DR8型中,在同一染色体上没有定位HLA-DRB1之外的HLA-DRB基因。
在各等位基因的外显子中,存在显示多态性的多个区域,在许多情况下,特定多态区域的碱基序列(氨基酸序列)在多个等位基因中是共同的。即,各HLA等位基因通过多个多态区域的组合而指定。在HLA I类抗原中,不仅外显子内的多态区域、而且具有同一碱基序列的外显子2或外显子3有时在多个等位基因中是共同的。
由于HLA中存在高度多态,已知等位基因的种类极多,它们的表示法也得到确定。也即,辨别血清学HLA型的第1领域(2位数(two-digit)水平)、辨别同一血清学HLA型内伴有氨基酸置换的等位基因的第2领域(4位数水平)、辨别具有不伴有氨基酸突变的碱基置换的等位基因的第3领域(6位数水平)、和辨别编码HLA分子的基因区域外(内含子)中伴有碱基置换的等位基因的第4领域(8位数水平)。
认为在骨髓移植时,如果希望移植者与供体的HLA型在4位数水平完全匹配,移植的成功率提高,重度GVHD频率降低。相反,如果HLA型在4位数水平不匹配,产生引起排斥反应等失败的风险增加。因此,准确且高精度地进行HLA分型在临床上是极端重要的。
作为HLA基因中的DNA分型法,基于聚合酶链式反应(PCR)的SBT(基于序列分型)法和SSO(序列特异性寡核苷酸)-Luminex法是主流。
这些常规的DNA分型法具有可以对多数样品迅速分型的优势,但是,有时不能准确确定多态区域和I类基因情况下外显子在染色体上的顺反位置关系,因此,产生相位模糊(phase ambiguity),有时难以进行高精度的HLA分型。
另外,常规方法是以各基因外显子区域为中心应用PCR的DNA分型法,因此,忽略了内含子区域和启动子区域中的碱基置换,其结果是,对基因结构与其它表达HLA基因一样但表达抑制的无效等位基因的检测有可能失败。
现有技术文献
专利文献
专利文献1 : 特开平11-216000号公报
非专利文献
非专利文献1 : Lind C.等,Human Immunology,第71卷,1033-1042页(2010年)。
技术实现要素:
发明要解决的課題
本发明的课题是,提供高精度的DNA分型方法和试剂盒,其排除了相位模糊引起的不明确。
解决课题的手段
本发明人基于新想法反复研究上述课题,从而完成本发明,所述新想法为,新设计能够特异性扩增I类HLA分子HLA-A、HLA-B和HLA-C以及II类HLA分子HLA-DRB1、HLA-DQA1、HLA-DQB1、HLA-DPA1和HLA-DPB1这些HLA基因的PCR引物,设定合适的PCR条件,应用大规模平行测序技术。
也即,本发明提供了包含以下步骤的HLA的DNA分型方法。
(1)制备对人基因组碱基序列中HLA-A、HLA-B、HLA-C、HLA-DQA1、HLA-DQB1、HLA-DPA1和HLA-DPB1各基因的上游区域和下游区域分别特异性退火的引物组以及对HLA-DRB1的外显子2和3'侧非翻译区域特异性退火的引物组的步骤;
(2)应用前述引物组对被测试样(DNA)进行PCR扩增的步骤;
(3)确定PCR扩增产物的碱基序列的步骤;和
(4)进行与数据库的同源性检索的步骤。
发明效果
本发明方法得到对来自1分子的HLA基因进行DNA分型所需的全部碱基序列,因此为排除了顺反位置关系不清楚的相位模糊的最终DNA分型法。通过该方法,实现了移植时希望移植者与供体候选者之间高精度的HLA匹配。
由于含有HLA基因的启动子区域、外显子区域、内含子区域等周边区域的基因全部碱基序列得到确定,可以检测出完全不表达或表达抑制的无效等位基因和新颖的等位基因。
附图说明
[图1] (a)示出HLA I类基因结构与分子结构的关联性的图。(b)示出HLA I类基因的启动子区域的结构的图。引用自Transplantation/transfusion Examination,Hidetoshi Inoko、Takehiko Sasazuki和Takeo Juuji编辑,Kodan-sha Scientific,2004年,第35页。
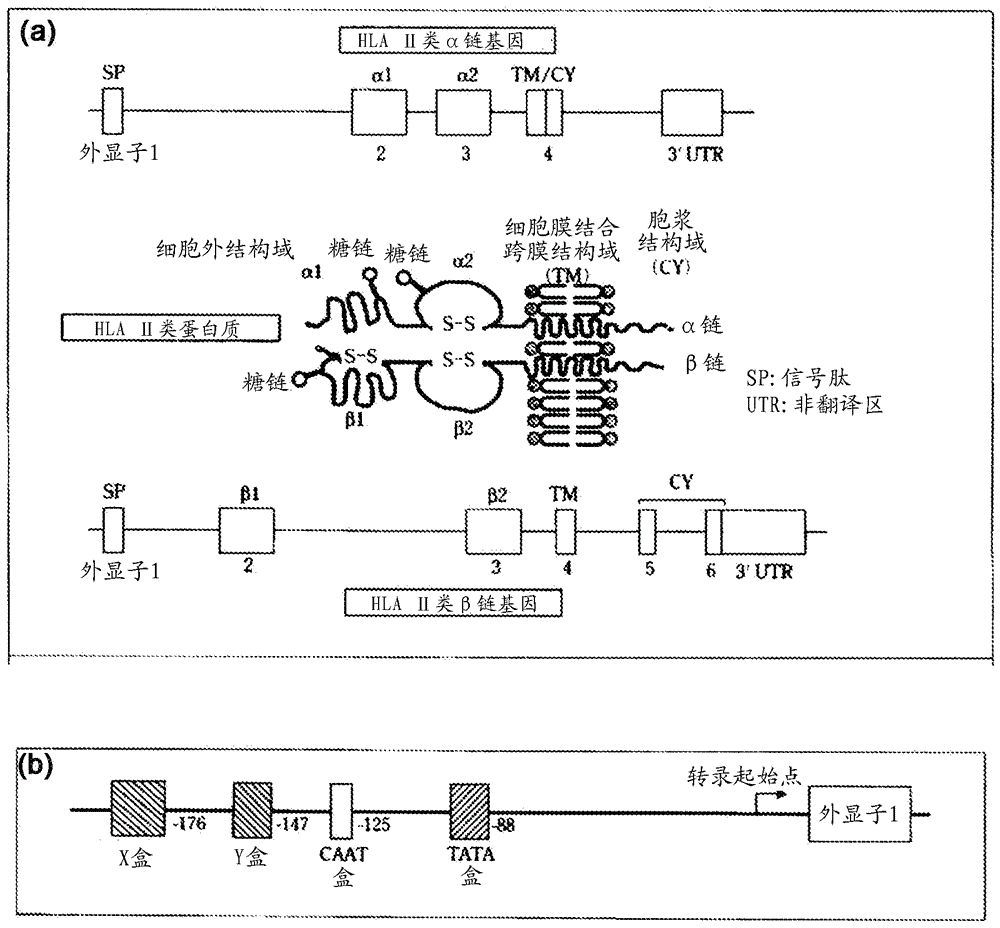
[图2] (a)示出HLA II类基因结构与分子结构的关联性的图。(b)示出HLA II类基因的启动子区域的结构的图。引用自Transplantation/transfusion Examination,Hidetoshi Inoko、Takehiko Sasazuki和Takeo Juuji编辑,Kodan-sha Scientific,2004年,第46页至第47页。
[图3] 示出HLA-DR基因区域的图。引用自Transplantation/transfusion Examination,Hidetoshi Inoko、Takehiko Sasazuki和Takeo Juuji编辑,Kodan-sha Scientific,2004年,第48页。
[图4] 示出实施例1中扩增的PCR产物的扩增状况的琼脂糖凝胶电泳图。
[图5] 示出HLA基因的基因结构与设计PCR引物的位置的示意图(括号内指明在该区域设计的引物的序列编号)。
[图6] 示出实施例2中扩增的HLA基因的PCR扩增状况的琼脂糖凝胶电泳图。
[图7] 示出实施例3中3种DNA提取法得到的各PCR产物的琼脂糖凝胶电泳图。
具体实施方式
下文对本发明DNA分型方法按步骤详细说明。
(1)引物组制备步骤
在本发明的DNA分型方法中,首先,制备对人基因组碱基序列中HLA-A、HLA-B、HLA-C、HLA-DQA1、HLA-DQB1、HLA-DPA1和HLA-DPB1各基因的上游区域和下游区域分别特异性退火的引物组,以及对HLA-DRB1的外显子2和3'侧的非翻译区域特异性退火的引物组。
包含HLA基因存在的区域的人第6号染色体(6p21.3)的基因组碱基序列已经阐明,其基因结构与表达产物(HLA分子)的结构的关联也是已知的(参考图1和图2)。
也即,称为经典HLA I类分子的HLA-A、HLA-B和HLA-C的基因含有7个或8个外显子(图1(a)),外显子1的外侧有2种增强子和启动子区域调节表达(图1(b))。
进一步地,外显子2、3和4中存在多个多态区域也是已知的,因此,在常规的DNA分型方法中,应用尤其基于外显子2和3制备的引物进行PCR,随之产生如上述的相位模糊问题。
另外,称为经典的HLA II类分子的HLA-DR、HLA-DQ和HLA-DP由α链与β链构成,其各自基因包含5个或6个外显子(图2(a)),外显子1的外侧有启动子区域调节表达(图2(b))。
进一步地,外显子2和3中存在多个多态区域也是已知的,因此,在常规的DNA分型方法中,应用尤其基于外显子2制备的引物进行PCR,随之产生如上述的相位模糊问题。
本发明中,制备引物组,其能够PCR扩增经典的I类分子(HLA-A,HLA-B,HLA-C)以及经典的II类分子的HLA-DQA1、HLA-DQB1、HLA-DPA1和HLA-DPB1的基因区域的全部(不仅包含外显子,也包含内含子、5'侧与3'侧非翻译区域、启动子区域)、HLA-DRB1的含有外显子2至3'侧非翻译区域的基因区域,应用该引物组PCR扩增的PCR产物接受下述下一代测序(next-generation sequencing),因此能够排除相位模糊等的不确定性,也能够正确检测无效等位基因的有无。
具体地,制备下述表1至表4中列出的PCR引物组。
表1中序列编号1至3是特异性扩增作为MHC I类α链的HLA-A基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-A基因全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入(挟み込む)。
序列编号1具有相应于人基因组碱基序列(参考序列:hg19)中第29,909,487号至第29,909,514号的碱基序列。
序列编号2具有相应于人基因组碱基序列(参考序列:hg19)中第29,909,487号至第29,909,514号的碱基序列。
序列编号3具有与相应于人基因组碱基序列(参考序列:hg19)中第29,914,925号至第29,914,952号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,500个碱基(bp)。
表1中序列编号4至5是特异性扩增作为MHC I类α链的HLA-B基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-B基因全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号4具有与相应于人基因组碱基序列(参考序列:hg19)中第31,325,796号至第31,325,820号的碱基序列互补的碱基序列。
序列编号5具有相应于人基因组碱基序列(参考序列:hg19)中第31,321,212号至第31,321,235号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约4,600个碱基(bp)。
表1中序列编号6至8是特异性扩增作为MHC I类α链的HLA-C基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-C基因全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号6具有与相应于人基因组碱基序列(参考序列:hg19)中第31,240,868号至第31,240,892号的碱基序列互补的碱基序列。
序列编号7具有与相应于人基因组碱基序列(参考序列:hg19)中第31,240,868号至第31,240,892号的碱基序列互补的碱基序列。
序列编号8具有相应于人基因组碱基序列(参考序列:hg19)中第31,236,991号至第31,236,114号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约4,800个碱基(bp)。
[表1]
表2中序列编号9至11是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR1亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号9具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,131号至第32,552,156号的碱基序列互补的碱基序列。
序列编号10具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,131号至第32,552,156号的碱基序列互补的碱基序列。
序列编号11具有相应于人基因组碱基序列(参考序列:hg19)中第32,546,609号至第32,546,629号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,200个碱基(bp)。
表2中序列编号31、32是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR1、HLA-DR4、HLA-DR6(DR13)、HLA-DR10亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号31具有与相应于人基因组碱基序列(参考序列:hg19)中第32,558,110号至第32,558,133号的碱基序列互补的碱基序列。
序列编号32具有相应于人基因组碱基序列(参考序列:hg19)中第32,551,974号至第32,551,999号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是HLA-DR1亚型约6,100个碱基(bp)、HLA-DR4亚型约9,100个碱基(bp)、HLA-DR6(DR13)亚型约8,900个碱基(bp)、HLA-DR10亚型约8,900个碱基(bp)。
表2中序列编号11和12是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR2亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号11如上述。
序列编号12具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,130号至第32,552,151号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,500个碱基(bp)。
表3中序列编号31和33是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR2(DR15)亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号31如上述。
序列编号33具有相应于人基因组碱基序列(参考序列:hg19)中第32,551,974号至第32,551,999号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约6,100个碱基(bp)。
表2中序列编号13和14是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR3、HLA-DR5、HLA-DR6、HLA-DR8亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号13具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,137号至第32,552,160号的碱基序列互补的碱基序列。
序列编号14具有相应于人基因组碱基序列(参考序列:hg19)中第32,546,609号至第32,546,629号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,100个碱基(bp)。
表2中序列编号34和32是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR3亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号34具有与相应于人基因组碱基序列(参考序列:hg19)中第32,558,110号至第32,558,133号的碱基序列互补的碱基序列。
序列编号32如上述。
应用这些引物组得到的PCR产物的预测长度是约8,900个碱基(bp)。
表2中序列编号15和16是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR4亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号15具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,131号至第32,552,157号的碱基序列互补的碱基序列。
序列编号16具有相应于人基因组碱基序列(参考序列:hg19)中第32,546,609号至第32,546,629号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约6,200个碱基(bp)。
表2中序列编号31和35是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR5(DR11)亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号31如上述。
序列编号35具有相应于人基因组碱基序列(参考序列:hg19)中第32,551,974号至第32,551,999号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约8,900个碱基(bp)。
表2中序列编号31和36是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR5(DR12)亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号31如上述。
序列编号36具有相应于人基因组碱基序列(参考序列:hg19)中第32,551,974号至第32,551,999号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约8,900个碱基(bp)。
[表2]
表3中序列编号31和37是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR6(DR14)亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号31如上述。
序列编号37具有相应于人基因组碱基序列(参考序列:hg19)中第32,551,974号至第32,551,999号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约8,900个碱基(bp)。
表3中序列编号17和18是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR7亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号17具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,137号至第32,552,160号的碱基序列互补的碱基序列。
序列编号18具有相应于人基因组碱基序列(参考序列:hg19)中第32,546,606号至第32,546,629号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,100个碱基(bp)。
表3中序列编号38和36是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR7、HLA-DR9亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号38具有相应于人基因组碱基序列(参考序列:hg19)中第32,558,110号至第32,558,133号的互补的碱基序列。
序列编号36如上述。
应用这些引物组得到的PCR产物的预测长度是约11,400个碱基(bp)。
表3中序列编号31和39是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR8亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号31如上述。
序列编号39具有相应于人基因组碱基序列(参考序列:hg19)中第32,551,974号至第32,551,999号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约8,900个碱基(bp)。
表3中序列编号19和20是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR9亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号19具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,137号至第32,552,160号的碱基序列互补的碱基序列。
序列编号20具有相应于人基因组碱基序列(参考序列:hg19)中第32,546,609号至第32,546,629号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,100个碱基(bp)。
表3中序列编号21和22是特异性扩增作为MHC II类β链的HLA-DRB1基因的HLA-DR10亚型基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DRB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号21具有与相应于人基因组碱基序列(参考序列:hg19)中第32,552,137号至第32,552,159号的碱基序列互补的碱基序列。
序列编号22具有相应于人基因组碱基序列(参考序列:hg19)中第32,546,403号至第32,546,435号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,400个碱基(bp)。
[表3]
表4中序列编号23和24是特异性扩增作为MHC II类α链的HLA-DPA1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DPA1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号23具有与相应于人基因组碱基序列(参考序列:hg19)中第33,041,478号至第33,041,502号的碱基序列互补的碱基序列。
序列编号24具有相应于人基因组碱基序列(参考序列:hg19)中第33,031,888号至第33,031,911号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约9,600个碱基(bp)。
表4中序列编号40和41是特异性扩增作为MHC II类α链的HLA-DPA1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DPA1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号40具有与相应于人基因组碱基序列(参考序列:hg19)中第33,041,573号至第33,041,596号的碱基序列互补的碱基序列。
序列编号41具有相应于人基因组碱基序列(参考序列:hg19)中第33,031,888号至第33,031,912号的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约9,600个碱基(bp)。
表4中序列编号25和26是特异性扩增作为MHC II类β链的HLA-DPB1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DPB1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号25具有相应于人基因组碱基序列(参考序列:hg19)中第33,043,056号至第33,043,079号的碱基序列。
序列编号26具有与相应于人基因组碱基序列(参考序列:hg19)中第33,055,476号至第33,055,499号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约12,400个碱基(bp)。
表4中序列编号42和43是特异性扩增作为MHC II类β链的HLA-DPB1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DPB1基因的5'非翻译区域至外显子2从上游侧和下游侧夹入。
序列编号42具有相应于人基因组碱基序列(参考序列:hg19)中第33,043,168号至第33,043,191号的碱基序列。
序列编号43具有与相应于人基因组碱基序列(参考序列:hg19)中第33,049,084号至第33,049,107号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约5,900个碱基(bp)。
表4中序列编号44和45是特异性扩增作为MHC II类β链的HLA-DPB1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DPB1基因的外显子2至3'非翻译区域从上游侧和下游侧夹入。
序列编号44具有相应于人基因组碱基序列(参考序列:hg19)中第33,048,182号至第33,048,207号的碱基序列。
序列编号45具有与相应于人基因组碱基序列(参考序列:hg19)中第33,055,428号至第33,055,453号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约7,200个碱基(bp)。
表4中序列编号27和28是特异性扩增作为MHC II类α链的HLA-DQA1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DQA1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号27具有相应于人基因组碱基序列(参考序列:hg19)中第32,604,318号至第32,604,338号的碱基序列。
序列编号28具有与相应于人基因组碱基序列(参考序列:hg19)中第32,611,681号至第32,611,701号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约7,400个碱基(bp)。
表4中序列编号46和47是特异性扩增作为MHC II类α链的HLA-DQA1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DQA1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号46具有相应于人基因组碱基序列(参考序列:hg19)中第32,604,469号至第32,604,488号的碱基序列。
序列编号47具有与相应于人基因组碱基序列(参考序列:hg19)中第32,611,936号至第32,611,956号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约7,400个碱基(bp)。
表4中序列编号29和30是特异性扩增作为MHC II类β链的HLA-DQB1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DQB1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号29具有相应于人基因组碱基序列(参考序列:hg19)中第32,626,545号至第32,626,568号的碱基序列。
序列编号30具有与相应于人基因组碱基序列(参考序列:hg19)中第32,635,612号至第32,635,637号的碱基序列互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约9,100个碱基(bp)。
表4中序列编号29、30、48-50是特异性扩增作为MHC II类β链的HLA-DQB1基因的PCR引物组。这些引物组是在下列位置存在的碱基序列,其将人基因组碱基序列(参考序列:hg19)中HLA-DQB1基因的全部区域(包含启动子、外显子和内含子)从上游侧和下游侧夹入。
序列编号29和48具有相应于人基因组碱基序列(参考序列:hg19)中第32,626,545号至第32,626,568号的碱基序列。
序列编号30、49、50具有相应于人基因组碱基序列(参考序列:hg19)中第32,635,612号至第32,635,637号的互补的碱基序列。
应用这些引物组得到的PCR产物的预测长度是约9,100个碱基(bp)。
[表4]
这些引物可以用本领域常用的方法制备。另外,表1和表2中记载的引物组是最优选的例子,在本发明的方法中,可以使用任何引物组,只要是可以在将HLA的各基因全部区域从上游侧和下游侧夹入的位置退火的正向引物和反向引物的组。
(2)PCR扩增步骤
在本发明的方法中,应用前述步骤(1)中制备的引物组,对被测试样(DNA)进行PCR扩增。
PCR扩增反应按照通常的方案实施。具体如下。
1.取决于被测试样的形式,从该试样提取DNA。
2.对提取的DNA定量,设定合适引物浓度并配制反应液。
3.设定反应条件进行PCR反应。
例如:热变性步骤(通常92至97℃)
退火步骤(通常55至72℃)
延伸步骤(通常65至80℃)
在本发明的方法中,在除HLA-DRB1的HLA基因的情况下,优选前述退火步骤的温度设为约60℃。由于在约60℃退火,可以等比率(均一地)生成等位基因。另外,对于HLA-DRB1,优选前述退火步骤的温度设为约70℃。由于在约70℃退火,可以特异性地仅产生目的DR亚型。
4.纯化得到的PCR产物,进行随后的碱基序列确定步骤。
(3)碱基序列确定步骤。
随后,确定前述步骤(2)中生成的PCR产物(扩增DNA)的碱基序列。该步骤优选应用称为下一代测序(或超高速测序)的方法进行。关于下一代测序,参考例如Experimental Medicine, Vol. 27, No. 1, 2009 (Yodo-sha)等。
在本说明书中,应用Roche的基因组序列分析仪FLX系统基于焦磷酸测序的序列确定方法在下文记载。
1.前述步骤(2)中得到的PCR产物通过雾化器片段化成约500个碱基左右。
2.在该片段化的DNA片段的末端附加DNA衔接子。
3.将附加了DNA衔接子的DNA片段制成单链DNA片段后,将其通过衔接子与珠子结合,将得到的珠子包埋入油包水型乳剂(形成1个珠子结合1个DNA片段的微反应器环境)。
4.实施乳剂PCR反应,在各珠子上形成各DNA片段的拷贝(各DNA片段在各微反应器内克隆扩增,因此能够不与其他序列竞争地、同时平行地实施多数片段的扩增)。随后,破坏乳剂并且回收具有扩增的DNA片段的珠子。
5.浓缩珠子,将珠子装载在picotiter板中(1个孔的尺寸为放入1个珠子)。
6.对各珠子,通过萤光素酶的荧光反应检测聚合酶在酶反应时产生的焦磷酸,根据发光的强度和模式确定DNA的碱基序列。以一定顺序加入4种核酸(A、C、G、T),记录相应于添加的核酸的化学发光模式,基于其信号强度与位置信息的组合确定碱基序列。
(4)DNA分型步骤
然后,将前述步骤(3)中得到的碱基序列与已知的HLA等位基因的碱基序列数据库的数据进行比较,从而确定被测试样中包含的DNA的等位基因型(直至8位数)。
本发明方法以前述表1中记载的引物组作为代表例。其特征是,在夹入HLA I类和除HLA-DRB1之外的HLA II类的各基因全部区域、以及HLA-DRB1的外显子2至3'非翻译区域的位置设定引物,确定跨越几乎全部区域扩增的DNA的序列,从而排除相位模糊(不确定性),能够获得与无效等位基因相关的信息。
实施例
下文举出具体例对本发明进行更详细地说明,但本发明不限于这些实施例。
(实施例1)
[实验方法]
1.以已提取的基因组DNA作为模板,应用各HLA I类基因特异性引物组(参考表1:序列编号1至8)进行PCR反应。具体顺序如下。
(1)PCR扩增应用Prime STAR GXL聚合酶(TaKaRa)。即,在50 ng的基因组DNA溶液中,加入4 μL的5 × PrimeSTAR GXL缓冲液、1.6 μL的dNTP溶液、各4μL(1pmol/μL)的PCR引物、0.8μL的Prime STAR GXL聚合酶,用灭菌水将反应液总量调整至20μL。
(2)在94度保温2分钟后,随后将98度10秒、60度20秒、68度5分钟的3步骤作为1个工序重复30次。另外,该PCR扩增中应用GeneAmp PCR System 9700 (Applied Biosystems)。PCR后,通过琼脂糖凝胶电泳确认PCR产物的扩增情况。其电泳图示于图4。
2.确定PCR产物的碱基序列。具体地,如下进行。
(1)将PCR产物按照QIAquick PCR Purification Kit(QIAGEN)的标准方案纯化。
(2)按照PicoGreen dsDNA Quantitation Kit(Invitrogen)的标准方案测定浓度。
(3)将纯化的PCR产物调整至500ng/100μL的浓度,按照Genome Sequencer(GS)Junior(Roche)的标准方案进行快速文库(rapid library)的制备、乳剂PCR、测序,获得1个样品1万个读出(reads)的碱基序列。
(4)通过GS de novo Assembler(Roche)组合和编辑这些序列,之后通过与DNA数据库上已知碱基序列的同源性检索,鉴定HLA基因的等位基因。
[讨论]
在HLA-A、HLA-B以及HLA-C中,设计分别特异性扩增5.5kb、4.6kb以及4.8kb的PCR引物。根据PCR条件的研究以及这些PCR产物的琼脂糖凝胶电泳,对各HLA I类基因得到PCR产物,同时在目的分子量位置得到单一的扩增产物(图4)。另外,通过Sanger法确定PCR产物的碱基序列,结果得到与已知不矛盾的HLA等位基因,因此确认本PCR系统能够用于HLA分型。
应用3个样本的HLA-B*40:02纯合子以及17个样本的包含在常规DNA分型法中观察到的相位模糊的等位基因的组合(B*40和B*55)的HLA-B*40:02杂合子,通过GS Junior对来自HLA-B基因的PCR产物进行HLA分型,结果从所有样本检测出HLA-B*40:02:01:01,在17个样本的杂合子中,除15种已知等位基因,还检测出2种新的等位基因。尤其是,对于观察到相位模糊的等位基因的组合(B*40和B*55)的1个样本,能够分型为HLA-B*40:02:01:01和HLA-B*55:02:01:01。因此本发明方法能够无相位模糊地在8位数水平进行HLA分型,同时是用于高效检测作为无效等位基因的原因的启动子和内含子内的碱基置换、插入和缺失的良好手段。
(实施例2)
[实验方法]
1.以已提取的基因组DNA作为模板,应用HLA I类和HLA II类各基因特异性引物组(参考表1至4:序列编号1至8、9至22、31至50)进行PCR反应。具体顺序如下。
(1)PCR扩增应用Prime STAR GXL聚合酶(TaKaRa)。即,在50 ng的基因组DNA溶液中,加入4 μL的5 × PrimeSTAR GXL缓冲液、1.6 μL的dNTP溶液、1至7 μL(4 pmol/μL)的PCR引物、0.8 μL的Prime STAR GXL聚合酶,用灭菌水将反应液总量调整至20μL。
(2)在94度保温2分钟后,随后将98度10秒、70度5分钟的2步骤作为1个工序重复30次。另外,该PCR扩增中应用GeneAmp PCR System 9700 (Applied Biosystems)。PCR后,通过琼脂糖凝胶电泳确认PCR产物的扩增情况。其电泳图示于图6。
2.确定PCR产物的碱基序列。具体地,如下进行。
(1)将PCR产物按照QIAquick PCR Purification Kit(QIAGEN)的标准方案纯化。
(2)按照PicoGreen dsDNA Quantitation Kit(Invitrogen)的标准方案测定浓度。
(3)将纯化的PCR产物调整至100 ng的浓度,按照Ion Personal Genome Machine(Ion PGM)(LifeTechnologies)的标准方案进行片段库的制备、乳剂PCR、测序,获得1个样品30万个读出的碱基序列。
(4)通过GS De Novo Assembler(Roche)组合和编辑这些序列,之后通过与DNA数据库上已知碱基序列的同源性检索,鉴定HLA基因的等位基因。
[结果和讨论]
1.在HLA-A、HLA-B、HLA-C、HLA-DRB1的5'非翻译区域至外显子2,HLA-DRB1的外显子2至3'非翻译区域,HLA-DQB1、HLA-DPB1的5'非翻译区域至外显子2和HLA-DPB1的外显子2至3'非翻译区域,设计特异性扩增各自4kb至12kb的PCR引物。根据PCR条件的研究以及这些PCR产物的琼脂糖凝胶电泳,对HLA I类和HLA II类的各基因得到PCR产物,同时在目的分子量位置得到单一的扩增产物(图6)。另外,通过Sanger法确定PCR产物的碱基序列,结果得到与已知不矛盾的HLA等位基因,因此再次确认本PCR系统能够用于HLA分型。
2.应用包含在常规DNA分型法中观察到相位模糊的等位基因的组合的4个样本,通过Ion PGM对来自HLA-A、HLA-B、HLA-C、HLA-DRB1的5'非翻译区域至外显子2,HLA-DRB1的外显子2至3'非翻译区域,HLA-DQB1、HLA-DPB1的5'非翻译区域至外显子2和HLA-DPB1的外显子2至3'非翻译区域的各基因的PCR产物进行HLA分型,结果对于HLA-A、HLA-B、HLA-C、HLA-DRB1、HLA-DQB1,可以进行全部基因区域的分型。对于HLA-DPB1,可以进行仅外显子部分的分型。进一步地,对于HLA-B、HLA-C、HLA-DRB1、HLA-DQB1的各基因,检测出新的等位基因。因此本发明方法能够无相位模糊地在8位数水平进行HLA分型,同时是用于高效检测作为无效等位基因的原因的启动子和内含子内的碱基置换、插入和缺失的良好手段。
(实施例3)
[实验方法]
1.应用Buccal Cell DNA Extraction Kit,BuccalQuick(TRIMGEN)提取基因组DNA。
2.将应用Buccal Cell DNA Extraction Kit,BuccalQuick(TRIMGEN)提取的基因组DNA进一步通过异丙醇和乙醇纯化。
3.应用QIAamp DNA Blood Mini Kit(QIAGEN)提取基因组DNA。
4.应用第1至3项中提取的基因组DNA各3个样本,通过与实施例1和实施例2同样的实验方法,应用HLA-A、HLA-B、HLA-C、HLA-DQB1特异性引物组(参考表1和表4:序列编号1至8、29、30、48至50)进行PCR反应。PCR后,通过琼脂糖凝胶电泳确认PCR产物的扩增情况。其电泳图示于图7。
[实验结果和讨论]
图7的泳道1至3显示用实验方法1提取的情况下PCR产物的扩增情况,泳道4至6显示用实验方法2提取的情况下PCR产物的扩增情况,泳道7至9显示用实验方法3提取的情况下PCR产物的扩增情况。对于任一基因,以用实验方法1提取的基因组DNA作为模板的PCR扩增都与用实验方法3提取的基因组DNA等价地得到目的PCR产物。实验方法3中伴随采血,但实验方法1中可从口腔粘膜采取细胞,因此证明,如果应用本发明方法,在不可能采血的情况下也可以充分地进行HLA分型。
序列表
<110> TOKAI University Educational System
<120> Method and Kit for DNA typing of HLA genes
<130> PC0879GDP
<150> JP 2011-159832
<151> 2011-07-21
<160> 30
<170> Patent In version 3.1
<210> 1
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 1
AACTC AGAGC TAAGG AATGA TGGCA AAT 28
<210> 2
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 2
AACTC AGAGC TATGG AATGA TGGTA AAT 28
<210> 3
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 3
ATATA ACCAT CATCG TGTCC CAAGG TTC 28
<210> 4
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 4
CCCGG TTGCA ATAGA CAGTA ACAAA 25
<210> 5
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 5
GGGTC CAATT TCACA GACAA ATGT 24
<210> 6
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 6
TGCTT AGATG TGCAT AGTTC ACGAA 25
<210> 7
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 7
TGCTT AGATG TGCAT AGTTC CGGAA 25
<210> 8
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 8
TGGAC CCAAT TTTAC AAACA AATA 24
<210> 9
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 9
GCACG TTTCT TGTGG CAGCT TAAGT T 26
<210> 10
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 10
GCACG TTTCT TGTGG CAGCT AAAGT T 26
<210> 11
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 11
ATGCA CGGGA GGCCA TACGG T 21
<210> 12
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 12
TTTCC TGTGG CAGCC TAAGA GG 22
<210> 13
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 13
CACAG CACGT TTCTT GGAGT ACTC 24
<210> 14
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 14
ATGCA CAGGA GGCCA TAGGG T 21
<210> 15
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 15
AGCAC GTTTC TTGGA GCAGG TTAAA CA 27
<210> 16
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 16
ATGCA TGGGA GGCAG GAAGC A 21
<210> 17
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 17
CACAG CACGT TTCCT GTGGC AGGG 24
<210> 18
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 18
CAGAT GCATG GGAGG CAGGA AGCG 24
<210> 19
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 19
CACAG CACGT TTCTT GAAGC AGGA 24
<210> 20
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 20
ATGCA TGGGA GGCAG GAAGC G 21
<210> 21
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 21
ACAGC ACGTT TCTTG GAGGA GGT 23
<210> 22
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 22
TGGAA TGTCT AAAGC AAGCT ATTTA ACATA TGT 33
<210> 23
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 23
TGATT TCTCT GATAG GTGAA TCCCA 25
<210> 24
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 24
TTGGC CTCTT GGCTA TACCT CTTT 24
<210> 25
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 25
ATTGA AGACA AGGAA TCGAA GTCC 24
<210> 26
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 26
TCCCC CGATG GAAGA TATTA TTTG 24
<210> 27
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 27
GCAAA GGTAT TGCTT GGGCT A 21
<210> 28
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 28
CAGAC TGCGC CTCTA TTCAG G 21
<210> 29
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 29
AAGAA ACAAA CTGCC CCTTA CACC 24
<210> 30
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 30
TAGTA TTGCC CCTAG TCACT GTCAA G 26
<210> 31
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 31
CTGCT GCTCC TTGAG GCATC CACA 24
<210> 32
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 32
CTTCT GGCTG TTCCA GTACT CGGCA T 26
<210> 33
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 33
CTTCT GGCTG TTCCA GTACT CAGCG T 26
<210> 34
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 34
CTGCT GCTCC CTGAG GCATC CACA 24
<210> 35
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 35
CTTCT GGCTG TTCCA GTACT CCTCA T 26
<210> 36
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 36
CTTCT GGCTG TTCCA GGACT CGGCG A 26
<210> 37
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 37
CTTCT GGCTG TTCCA GTGCT CCGCA G 26
<210> 38
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 38
CTGCT ACTCC TTGAG GCATC CACA 24
<210> 39
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 39
CTTCT GGCTG TTCCA GTACT CGGCG C 26
<210> 40
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 40
CTCTC TTGAC CACGC TGGTA CCTA 24
<210> 41
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 41
TTGGC CTCTT GGCTA TACCT CTTTT 25
<210> 42
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 42
CCTCC TGACC CTGAT GACAG TCCT 24
<210> 43
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 43
CCATC TGCCC CTCAA GCACC TCAA 24
<210> 44
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 44
CTCAG TGCTC GCCCC TCCCT AGTGA T 26
<210> 45
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 45
GCACA GTAGC TTTCG GGAAT TGACC A 26
<210> 46
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 46
GCCAG GGAGG GAAAT CAACT 20
<210> 47
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 47
ATCCA GTGGA GGACA CAGCA C 21
<210> 48
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 48
AAGAA ACAAA CTGCC CCTTA TACC 24
<210> 49
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 49
TAGTA CTGCC CCTAG TCACT GCCAA G 26
<210> 50
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 50
TAGTA CTGTC CCTAG TCACT GCCAA G 26
- 还没有人留言评论。精彩留言会获得点赞!