FAM78A基因的用途的制作方法
本发明属于生物医药领域,涉及FAM78A基因的用途,具体的涉及基因FAM78A在肺腺癌早期诊断和治疗中的用途。
背景技术:
随着人类生存环境的恶化,全世界癌症的发病率正在逐年升高,恶性肿瘤成为世界上致死率最高的疾病之一。而肺癌已成为最常见的恶性肿瘤,其发病率及致死率居所有恶性肿瘤之首。肺癌可以分为非小细胞肺癌(non small cell lung cancer,NSCLC)和小细胞肺癌(small cell lung cancer,SCLC),其中NSCLC约占肺癌总数的80%-85%,NSCLC中的肺腺癌占比逐年升高。在我国,肺癌的发病率及死亡率已跃居第一位,取代肝癌成为导致肿瘤患者死亡的主要疾病。据第三次全国疾病死因调查情况显示,近30年由于吸烟人群增加及环境污染加剧等因素,我国肺癌死亡率上升了465%,同时发病率也在逐步上升,对全社会人民的健康和生命造成了极大威胁。
肿瘤是一种分子水平的疾病,从基因蛋白水平进行肿瘤的研究是最终途径。近年在整体水平上以高通量分子扫描手段为基础的基因组学、蛋白质组学以及计算机辅助设计等技术的整合及相互关联的“技术链”的应用等为肿瘤的研究提供了新的契机,并且已经在乳腺癌、肺癌、胃癌、结肠癌、卵巢癌、黑色素瘤等的研究中取得了丰硕的成果。其中基因表达谱芯片是最典型的代表,通过基因表达谱芯片可以检测和筛选肿瘤组织与正常组织的差异基因以及癌基因、抑癌基因的变化及变化关系,从中寻找病因,为早期诊断及根治提供线索和依据。
目前治疗NSCLC的常规方法有手术治疗、铂二联化疗、放疗和靶向治疗等,但是这些常规治疗方法对中晚期肿瘤患者来说不能达到治愈的目的,因此,多数患者治疗后生存期仍很短,5年生存率不到15%。由于多数NSCLC患者早期无特异临床表现,在确诊时已至中晚期,多数患者已出现转移和局部侵犯。因此,探讨NSCLC的发病调控机制,早期干预肿瘤细胞的生长、侵袭和迁移能力,有助于提高NSCLC病人的生存率,降低其死亡率,为肺癌的基因诊断和靶向治疗提供更为可靠的依据。
技术实现要素:
为了弥补现有技术的不足,本发明的目的在于一种肺腺癌的生物标志物在肺腺癌早期诊断和治疗中的应用。
为了实现上述目的,本发明采用如下技术方案:
本发明提供了一种FAM78A基因的用途,用于制备早期诊断肺腺癌的产品。
进一步,所述产品包括:用RT-PCR、实时定量PCR、原位杂交或芯片诊断肺腺癌的产品。
进一步,所述用RT-PCR诊断肺腺癌的产品至少包括一对特异性扩增FAM78A基因的引物;所述用实时定量诊断肺腺癌的产品至少包括一对特异性扩增FAM78A基因的引物;所述用原位杂交诊断肺腺癌的产品包括与FAM78A基因的核酸序列杂交的探针;所述用芯片诊断肺腺癌的产品包括与FAM78A基因的核酸序列杂交的探针或与FAM78A蛋白特异性结合的抗体或配体。。
本发明提供了一种诊断肺腺癌的产品,所述产品能通过检测样本中FAM78A的表达水平来诊断肺腺癌。
进一步,所述的产品包括芯片、制剂、或试剂盒。
进一步,所述芯片可用于检测包括FAM78A基因在内的多个基因或其编码的蛋白(例如,与肺腺癌相关的多个基因)的表达水平;所述试剂盒可用于检测包括FAM78A基因在内的多个基因或其编码的蛋白(例如,与肺腺癌相关的多个基因)的表达水平。
本发明提供了一种FAM78A基因的用途,用于筛选预防或治疗肺腺癌的药物。
本发明提供了一种筛选预防或治疗肺腺癌药物的方法,所述方法包括:
用候选物质处理表达或含有FAM78A基因或其编码的蛋白的体系;和
检测所述体系中FAM78A基因或其编码的蛋白的表达或活性;
其中,所述候选物质可增加FAM78A的表达,则表明该候选物质是预防或治疗肺腺癌的潜在物质。
进一步,在测试组中,将候选物质加入到表达或含有FAM78A基因或其编码的蛋白的体系中;和/或检测测试组的体系中FAM78A基因或其编码的蛋白的表达或活性,并与对照组相对比,其中所述的对照组是不添加呢所述候选物质的表达或或含有FAM78A基因或其编码的蛋白的体系;如果测试组中FAM78A基因或其编码的蛋白的表达或活性高于对照组,即表明该候选物质是预防或治疗肺腺癌的潜在物质。
本发明提供了一种FAM78A基因的用途,用于制备预防或治疗肺腺癌的药物组合物。
进一步,所述药物组合物包括FAM78A基因、蛋白或其促进剂。
进一步,所述FAM78A蛋白包括全长FAM78A蛋白、成熟的FAM78A蛋白、FAM78A的与DNA结合的结构域、或含所述结构域的FAM78A活性片段;所述促进剂包括FAM78A基因表达产物、促进型miRNA、促进型转录调控因子、或促进型靶向小分子化合物。
进一步,所述药物组合物还包括药学上可接受的载体和/或辅料。
本发明的优点和有益效果:
本发明首次发现了FAM78A与肺腺癌的发生发展相关,可将其作为肺腺癌诊断用基因标志物,用来区分人早期肺腺癌。
本发明所提供的人肺腺癌基因标志物FAM78A,可以作为潜在药物靶点,应用于临床上肺腺癌的治疗。
附图说明
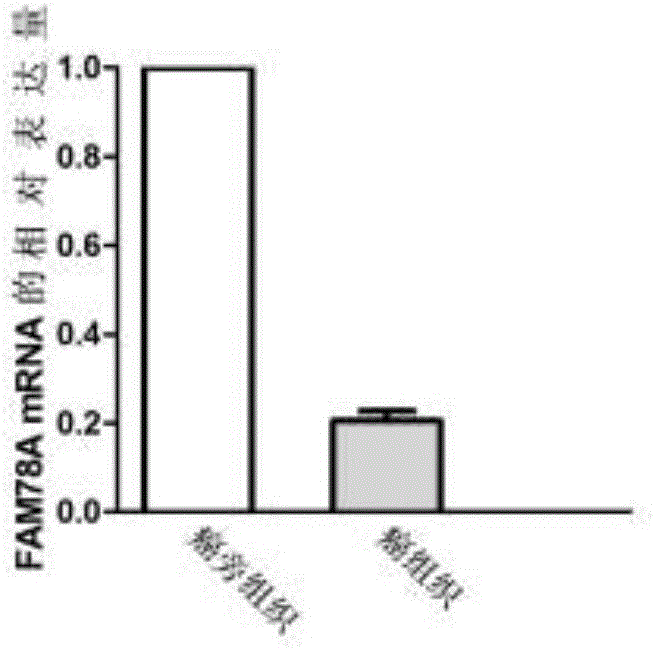
图1是利用QPCR检测FAM78A基因在肺腺癌组织中的表达情况图;
图2是利用QPCR检测FAM78A在肺腺癌细胞中的转染情况图;
图3是用CCK-8法检测FAM78A基因对肺腺癌细胞增殖的影响图;
图4是用流式细胞仪检测FAM78A基因对肺腺癌细胞凋亡的影响图;
图5是利用Transwell小室检测FAM78A对肺腺癌细胞迁移和侵袭的影响图;其中图A是FAM78A对肺腺癌细胞迁移的影响图;图B是FAM78A对肺腺癌细胞侵袭的影响图。
具体的实施方式
本发明经过广泛而深入的研究,通过高通量方法,采用目前覆盖数据库最广的基因芯片,检测肺腺癌标本中基因在肿瘤组织和癌旁组织的表达,发现其中具有明显表达差异的基因片段,探讨其与肺腺癌的发生之间的关系,从而为肺腺癌的早期检测及靶向治疗寻找更好的途径和方法。通过筛选,本发明首次发现了肺腺癌中FAM78A显著性下调。实验证明,通过增加FAM78A的表达水平,能够有效地抑制肺腺癌细胞的生长和侵袭,从而达到抑制肺腺癌的效果。
FAM78A基因
FAM78A基因是位于人9号染色体长臂3区4号带上,一种代表性的人FAM78A基因的核苷酸序列和氨基酸序列如SEQ ID NO.1和SEQ ID NO.2所示。本发明中的FAM78A包括野生型、突变型或其片段。
本发明的人FAM78A核苷酸全长序列或其片段通常可以用PCR扩增法、重组法或人工合成的方法获得。对于PCR扩增法,可根据已公开的有关核苷酸序列,尤其是开放阅读框序列来设计引物,并用市售的cDNA库或按本领域技术人员已知的常规方法所制备的cDNA库作为模板,扩增而得有关序列。当序列较长时,常常需要进行两次或多次PCR扩增,然后再将各次扩增出的片段按正确次序拼接在一起。
一旦获得了有关的序列,就可以用重组法来大批量地获得有关序列。这通常是将其克隆入载体,再转入细胞,然后通过常规方法从增殖后的宿主细胞中分离得到有关序列。此外,还可用人工合成的方法来合成有关序列,尤其是片段长度较短时。通常,通过先合成多个小片段,然后再进行连接可获得序列很长的片段。
应用PCR技术扩增DNA/RNA的方法被优选用于获得本发明的基因。用于PCR的引物可根据本文所公开的本发明的序列信息适当地选择,并可用常规方法合成。可用常规方法如通过凝胶电泳分离和纯化扩增的DNA/RNA片段。
本领域技术人员将认识到,本发明的实用性并不局限于对本发明的标志物基因的任何特定变体的基因表达进行定量。如果当核酸或其片段与其它核酸(或其互补链)最佳比对时(具有适当的核苷酸插入或缺失),在至少大约60%的核苷酸碱基、通常至少大约70%、更通常至少大约80%、优选至少大约90%、及更优选至少大约95-98%核苷酸碱基中存在核苷酸序列相同性,则这两个序列是“基本同源的”(或者基本相似的)。
或者,当核酸或其片段与另一核酸(或其互补链)、一条链或其互补序列在选择性杂交条件下杂交时,则其间存在基本同源或(相同性)。当杂交比特异性整体丧失发生更具选择性时,存在杂交选择性。典型地,当在至少大约14个核苷酸的一段序列存在至少大约55%相同性、优选至少大约65%、更优选至少大约75%及最优选至少大约90%相同性时,发生选择性杂交。如本文所述,同源对比的长度可以是较长的序列节段,在某些实施方案中通常为至少大约20个核苷酸,更通常为至少大约24个核苷酸,典型为至少大约28个核苷酸,更典型为至少大约32个核苷酸,及优选至少大约36或更多个核苷酸。
因此,本发明的多核苷酸与SEQ ID NO.1优选具有至少75%、更优选至少85%、更优选至少90%同源性。更优选地,存在至少95%、更优选至少98%同源性。
“FAM78A蛋白”包括FAM78A蛋白以及FAM78A蛋白的任何功能等同物。所述功能等同物包括FAM78A蛋白保守性变异蛋白质、或其活性片段,或其活性衍生物或其突变体。突变体包括等位变异体、天然突变体、诱导突变体、其氨基酸序列通过缺失、替代、增加和/或插入发生变异的突变体、在高或低的严紧条件下能与人FAM78A的DNA杂交的DNA所编码的蛋白质。
优选地,FAM78A蛋白是具有下列氨基酸序列的蛋白质:
(1)由序列表中SEQ ID NO.2所示的氨基酸序列组成的蛋白质;
(2)将SEQ ID NO.2所示的氨基酸序列经过一个或几个氨基酸残基的取代和/或缺失和/或添加且与SEQ ID NO.2所示的氨基酸序列具有相同功能的由SEQ ID NO.2所示的氨基酸序列衍生的蛋白质。取代、缺失或者添加的氨基酸的个数通常为1-50个,较佳地1-30个,更佳地1-20个,最佳地1-10个。
(3)与SEQ ID NO.2所示的氨基酸序列具有至少80%同源性(又称为序列同一性),优选地,与SEQ ID NO.2所示的氨基酸序列至少约90%至95%的同源性,常为96%、97%、98%、99%同源性的氨基酸序列构成的多肽。
在本发明的具体实施方案中,所述FAM78A蛋白是具有SEQ ID NO.2所示的氨基酸序列的蛋白质。
通常,一个蛋白质中一个或多个氨基酸的修饰不会影响蛋白质的功能。本领域技术人员会认可改变单个氨基酸或小百分比的氨基酸或对氨基酸序列的个别添加、缺失、插入、替换是保守修饰,其中蛋白质的改变产生具有相似功能的蛋白质。提供功能相似的氨基酸的保守替换表是本领域公知的。
氨基酸序列的修饰可以源自自发突变或遗传后修饰,也可以人工诱导天然基因产生。通过添加一个氨基酸或多个氨基酸残基修饰的蛋白质的例子是PCSK1N蛋白的融合蛋白。对于与PCSK1N蛋白融合的肽或者蛋白质没有限制,只要所得的融合蛋白保留PCSK1N蛋白的生物学活性即可。
本发明可以利用本领域内已知的任何方法测定基因表达。本领域技术人员应当理解,测定基因表达的手段不是本发明的重要方面。可以在转录水平上检测生物标志物的表达水平。
芯片、试剂盒
本发明的所述的基因芯片包括:固相载体;以及有序固定在所述固相载体上的寡核苷酸探针,所述的寡核苷酸探针特异性地对应于FAM78A所示的部分或全部序列。
具体地,可根据本发明所述的基因,设计出适合的探针,固定在固相载体上,形成“寡核苷酸阵列”。所述的“寡核苷酸阵列”是指具有可寻址位置(即以区别性的,可访问的地址为特征的位置)的阵列,每个可寻址位置均含有一个与其相连的特征性寡核苷酸。根据需要,可将寡核苷酸阵列分成多个亚阵。
术语“探针”指能与另一分子的特定序列或亚序列或其它部分结合的分子。除非另有指出,术语“探针”通常指能通过互补碱基配对与另一多核苷酸(往往称为“靶多核苷酸”)结合的多核苷酸探针。根据杂交条件的严格性,探针能和与该探针缺乏完全序列互补性的靶多核苷酸结合。探针可作直接或间接的标记,其范围包括引物。杂交方式,包括,但不限于:溶液相、固相、混合相或原位杂交测定法。
本发明中针对FAM78A基因的寡核苷酸探针可以是DNA、RNA、DNA-RNA嵌合体、PNA或其它衍生物。所述探针的长度没有限制,只要完成特异性杂交、与目的核苷酸序列特异性结合,任何长度都可以。所述探针的长度可短至25、20、15、13或10个碱基长度。同样,所述探针的长度可长至60、80、100、150、300个碱基对或更长,甚至整个基因。由于不同的探针长度对杂交效率、信号特异性有不同的影响,所述探针的长度通常至少是14个碱基对,最长一般不超过30个碱基对,与目的核苷酸序列互补的长度以15-25个碱基对最佳。所述探针自身互补序列最好少于4个碱基对,以免影响杂交效率。
本发明中所述固相载体可采用基因芯片领域的各种常用材料,例如包括但不限于塑料制品、微颗粒、膜载体等。所述塑料制品可通过非共价或物理吸附机制与抗体或蛋白抗原相结合,最常用的塑料制品为聚苯乙烯制成的小试管、小珠和微量反应板;所述微颗粒是由高分子单体聚合成的微球或颗粒,其直径多为微米,由于带有能与蛋白质结合的功能团,易与抗体(抗原)形成化学偶联,结合容量大;所述膜载体包括硝酸纤维素膜、玻璃纤维素膜及尼龙膜等微孔滤膜。
所述的FAM78A芯片的制备可采用本领域已知的生物芯片的常规制造方法。例如,如果固相载体采用的是修饰玻片或硅片,探针的5’端含有氨基修饰的聚dT串,可将寡核苷酸探针配制成溶液,然后采用点样仪将其点在修饰玻片或硅片上,排列成预定的序列或阵列,然后通过放置过夜来固定,就可得到本发明的基因芯片。
本发明提供了一种试剂盒,所述试剂盒可用于检测FAM78A的表达。优选的,所述的制剂或试剂盒中还含有用于标记RNA样品的标记物,以及与所述标记物相对应的底物。此外,所述的试剂盒中还可包括用于提取RNA、PCR、杂交、显色等所需的各种试剂,包括但不限于:抽提液、扩增液、杂交液、酶、对照液、显色液、洗液等。此外,所述的试剂盒中还包括使用说明书和/或芯片图像分析软件。
促进剂和药物组合物
基于本发明的发现,本发明提供了一种药物组合物,所述药物组合物包含FAM78A的表达产物或FAM78A的促进剂。所述促进剂可以促进FAM78A基因或其编码的蛋白的表达和/或活性,从而抑制肺腺癌。所述FAM78A促进剂包括FAM78A基因表达产物、促进型miRNA、促进型转录调控因子、或促进型靶向小分子化合物。
通常,可将这些促进剂配制于无毒的、惰性的和药学上可接受的水性载体介质中,其中pH通常约为5-8,较佳地pH约为6-8,尽管pH值可随被配制物质的性质以及待治疗的病症而有所变化。配制好的药物组合物可以通过常规途径进行给药,其中包括(但并不限于):瘤内、肌内、腹膜内、静脉内、皮下、皮内、或局部给药。
作为本发明的一种优选方式,所述的FAM78A的促进剂是一种含有FAM78A的表达载体。所述的表达载体通常还含有启动子、复制起点和/或标记基因等。
本领域的技术人员熟知的方法能用于构建本发明所需的表达载体。这些方法包括体外重组DNA技术、DNA合成技术、体内重组技术等。所述的表达载体优选地包含一个或多个选择性标记基因,以提供用于选择转化的宿主细胞的表型性状,如卡拉霉素、庆大霉素、潮霉素、氨苄青霉素抗性。
在本发明中,是本领域已知的各种载体,如市售的载体、包括质粒、粘粒、噬菌体、病毒等。表达载体向宿主细胞中的导入可以使用电穿孔法、磷酸钙法、脂质体法、DEAE葡聚糖法、显微注射、病毒感染、脂质体转染、与细胞膜透过性肽的结合等周知的方法。
在本发明中,“宿主细胞”胞可以是原核细胞,如细菌细胞;或是低等真核细胞,如酵母细胞;或是高等真核细胞,如哺乳动物细胞。代表性例子有:大肠杆菌,链霉菌属的细菌细胞;真菌细胞如酵母;植物细胞;果蝇S2或Sf9的昆虫细胞;CHO、COS、或293细胞的动物细胞等。
用重组DNA转化宿主细胞可用本领域技术人员熟知的常规技术进行。当宿主为原核生物如大肠杆菌时,能吸收DNA的感受态细胞可在指数生长期后收获,用CaCl2法处理,所用的步骤在本领域众所周知。另一种方法是使用MgCl2。如果需要,转化也可用电穿孔的方法进行。当宿主是真核生物,可选用如下的DNA转染方法:磷酸钙共沉淀法,常规机械方法如显微注射、电穿孔、脂质体包装等。
本发明中的药物组合物包括安全有效量的FAM78A蛋白或其促进剂、和/或与所述促进剂配伍的其他药类以及药学上可接受的载体和/或辅料。
术语“有效量”是指可对人和/或动物产生功能或活性的且可被人和/或动物所接受的量。“药学上可接受的载体”指用于治疗剂给药的载体,包括各种赋形剂和稀释剂。该术语指这样一些药剂载体:它们本身并不是必要的活性成分,且施用后没有过分的毒性。合适的载体是本领域普通技术人员所熟知的。在组合物中药学上可接受的载体可含有液体,如水、盐水、缓冲液。另外,这些载体中还可能存在辅助性的物质,如填充剂、润滑剂、助流剂、润湿剂或乳化剂、pH缓冲物质等。所述的载体中还可以含有细胞转染试剂。
本发明中,可以采用本领域熟知的多种方法来将所述的促进剂或其编码基因、或其药物组合物给药于哺乳动物。包括但不限于:皮下注射、肌肉注射、经皮给予、局部给予、植入、缓释给予等;优选的,所述给药方式是非肠道给予的。
优选的,可采用基因治疗的手段进行。比如,可直接将FAM78A的促进剂通过诸如注射等方法给药于受试者;或者,可通过一定的途径将携带FAM78A的促进调剂的表达单位(比如表达载体或病毒等)递送到靶点上,具体情况需视所述的促进剂的类型而定,这些均是本领域技术人员所熟知的。
本发明所述的FAM78A的促进剂的有效量可随给药的模式和待治疗的疾病的严重程度等而变化。优选的有效量的选择可以由本领域普通技术人员根据各种因素来确定(例如通过临床试验)。所述的因素包括但不限于:所述的FAM78A的促进剂的药代动力学参数例如生物利用率、代谢、半衰期等;患者所要治疗的疾病的严重程度、患者的体重、患者的免疫状况、给药的途径等。例如,由治疗状况的迫切要求,可每天给予若干次分开的剂量,或将剂量按比例地减少。
本发明的药物组合物还可与其他治疗肺腺癌的药物联用,其他治疗性化合物可以与主要的活性成分同时给药,甚至在同一组合物中同时给药。
本发明的药物组合物还可以以单独的组合物或与主要的活性成分不同的剂量形式单独给予其它治疗性化合物。主要成分的部分剂量可以与其它治疗性化合物同时给药,而其它剂量可以单独给药。在治疗过程中,可以根据症状的严重程度、复发的频率和治疗方案的生理应答,调整本发明药物组合物的剂量。
药物筛选
本发明提供了一种筛选预防或治疗肺腺癌药物的方法,即:
在实验组中,向细胞培养体系中加入待测化合物,并测定FAM78A的表达水平;在对照组中,向同样的培养体系中不加入待测化合物,并测定FAM78A的表达水平;其中,如果实验组中FAM78A的表达水平大于对照组,则说明该候选化合物为FAM78A的促进剂。
在本发明中,所述的方法还包括步骤:对上面步骤获得的候选化合物进一步测试其抑制肝癌的效果,若测试化合物对肺腺癌有显著的抑制效果,则说明该化合物为FAM78A促进剂。
本发明中,术语“样本”以其最广泛的含义使用。在一种含义中,意在包括从任何来源获得的标本或培养物,以及生物和环境样本。生物样本可获自动物(包括人)并涵盖液体、固体、组织和气体。生物样本包括血液制品,诸如血浆、血清等。然而,此类样本不应解释为限制适用于本发明的样本类型。
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,例如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring HarborLaboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。
实施例1筛选与肺腺癌相关的基因标志物
1、样品收集
各收集8例肺腺癌癌旁组织和肺腺癌组织样本。肺腺癌肿瘤组织标本取材部位为主要肿瘤区域,位于肿瘤肿块中外1/3与正常组织交接处,排除肿瘤中心明显坏死、钙化部分以及肿瘤外围正常肺组织;癌旁正常肺组织标本取自肿瘤边缘5cm以上的部位,肉眼观察无明显变化。上述所有标本的取得均通过组织伦理委员会的同意。
2、RNA样品的制备(利用E.Z.N.A.miRNA kit进行操作)
在研钵中导入液氮,取上述获得的组织放入研钵中,在液氮中剪碎并研磨成粉末,剪碎后投入液氮中并研磨至粉末状,随后转入玻璃匀浆器中;组织匀浆在玻璃匀浆器中加入Trizol试剂,在冰上研磨组织。将匀浆后组织匀浆液转入无RNA酶的EP管中,室温下静置5min。按照试剂盒中的说明书提取分离RNA。具体如下:
1)RNA的分离:
在EP管中加入0.2m1氯仿,盖紧EP管盖,手动剧烈振荡15s,使其充分混匀。室温下孵化5min。然后在4℃下以14000g离心15min。离心后样品分为三层,RNA存在于上层水相中。
2)RNA沉淀
将分离得的水相取450μl移至新的无RNA酶的EP管中,按照1:1的比例加入450μl异丙醇,上下颠倒混匀后在室温下孵化10min,4℃14000g离心10min。
3)RNA洗脱
离心后小心移去上清,加入1ml 75%乙醇(灭酶处理,现用现配并在冰上预冷)冲洗RNA,随后4℃7500g离心5min。
4)RNA再溶解
小心移去洗涤之后的上清,在超净工作台中打开EP管管盖,在室温下放置RNA样本5-10min,晾干。加入无RNA酶处理水20-50μl,55-60℃水浴箱中水浴10min。
5)RNA样品的质量分析
分光光度计检测:
NanoDrop1000分光光度计检测RNA样品,RNA-seq测序的样品要求:OD260/OD280为1.8-2.2。
琼脂糖凝胶电泳检测:
将上述提取的RNA进行琼脂糖凝胶电泳,Agilent Technologies 2100Bioanalyzer检测RNA样品质量,观察28S rRNA和18S rRNA主带明显、无降解、RNA完整性指数合格、浓度达到要求,可以用于芯片的基因表达谱及筛选实验。
3、逆转录和标记
用Low RNA Input Linear Amplification Kit将mRNA逆转录成cDNA,同时用Cy3分别标记实验组和对照组。
4、杂交
基因芯片采用Aglient公司的人全基因组表达谱芯片。按芯片使用说明书的步骤进行。
5、数据分析
利用Agilent GeneSpring软件对芯片结果进行分析,筛选表达量具有显著性差异(标准为该基因在癌与癌旁的表达量相差2倍以上,而且p<0.05)的基因。
6、结果
结果显示,FAM78A在肺腺癌组织中的表达量显著低于癌旁组织中的表达量。
实施例2 QPCR测序验证FAM78A基因的差异表达
1、对FAM78A基因差异表达进行大样本QPCR验证。按照实施例1中的样本收集方式选择肺腺癌癌旁组织和肺腺癌组织各50例。
2、RNA提取步骤如实施例1所述。
3、逆转录
1)反应体系:
RNA模板1μl,随机引物1μl,双蒸水加至12μl,混匀,低转速离心,65℃5min,然后放在冰上冷却。
继续在12μl反应液中加入下列成分:
5×反应缓冲液4μl,RNA酶抑制剂(20U/μl)1μl,10mM dNTP混合液2μl,AMV反转录酶(200U/μl)1μl;充分混匀并进行离心处理;
2)逆转录反应条件
25℃5min,42℃60min,70℃5min。
3)聚合酶链反应
引物设计:
根据Genebank中FAM78A基因和GAPDH基因的编码序列设计QPCR扩增引物,由博迈德生物公司合成。具体引物序列如下:
FAM78A基因:
正向引物为5’-TCAGCATGAATGACAACT-3’(SEQ ID NO.3);
反向引物为5’-CGGTAGATATTGGTGAGC-3’(SEQ ID NO.4)。
GAPDH基因:
正向引物为5’-AATCCCATCACCATCTTCCAG-3’(SEQ ID NO.5);
反向引物为5’-GAGCCCCAGCCTTCTCCAT-3’(SEQ ID NO.6)。
配制PCR反应体系:
2×qPCR混合液12.5μl,基因引物2.0μl,反转录产物2.5μl,ddH2O 8.0μl。
PCR反应条件:95℃10min,(95℃15s,60℃60s)×40个循环,60℃5min延伸反应。75℃至95℃,每20s升温1℃,绘制溶解曲线。以SYBR Green作为荧光标记物,在Light Cycler荧光定量PCR仪上进行PCR反应,通过融解曲线分析和电泳确定目的条带,ΔΔCT法进行相对定量。
5、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,癌与癌旁组织的配对比较采用t检验,认为当P<0.05时具有统计学意义。
6、结果
结果如图1所示,与肺腺癌癌旁组织相比,FAM78A在肺腺癌组织中表达下调,差异具有统计学意义(P<0.05),同芯片检测结果一致。
实施例3 FAM78A过表达
1、细胞培养
人肺腺癌细胞株A549,以含10%胎牛血清和1%P/S的RPMI1640培养基在37℃、5%CO2、相对湿度为90%的培养箱中培养。2-3天换液1次,使用0.25%含EDTA的胰蛋白酶常规消化传代。
将培养瓶中的细胞用胰酶进行消化并接种在6孔板中,保证细胞数为2-8×105个/孔,加入细胞培养基。过夜,第二天观察细胞密度,细胞密度为70%以上可进行转染。
2、基因过表达载体的构建
根据FAM78A的cDNA序列(如SEQ ID NO.1所示)合成特异的PCR扩增引物,引物序列如下:
正向引物:5’-CCGAAGCTTGCCACCATGCCTGGTTTTTTCTGTGA-3’(SEQ ID NO.7)
反向引物:5’-CGGCTCGAGCCGGTGCTTGGGCGGGATCACCACC-3’(SEQ ID NO.8)
从成人胎脑的cDNA文库(clontech公司,货号:638831)中扩增全长的GDPD2基因的编码序列,上述cDNA序列经限制性内切酶HindIII和XhoI双酶切后插入到经限制性内切酶HindIII和XhoI双酶切的真核细胞表达载体pcDNA3.1中,连接获得的重组载体pcDNA3.1-1用于后续实验。
3、转染
将肺腺癌细胞分为3组,分别为对照组(A549)、空白对照组(转染pcDNA3.1-NC)、实验组(转染pcDNA3.1-1)。使用脂质体2000进行载体的转染,具体转染方法按照说明书的指示进行。pcDNA3.1空载体和pcDNA3.1-1的转染浓度均为0.5μg/ml。
4、QPCR检测FAM78A基因的转录水平
4.1细胞总RNA的提取
1)将6孔板中的细胞培养液倒掉,用PBS冲洗两次,各孔加入1ml Trizol试剂,室温放置5min。
2)加入0.2m1氯仿,剧烈震荡15s,4℃,12000g离心15min。
3)水相转移到新管中,加入4.5m1异丙醇,室温放置10min;4℃,10000g离心10min。
4)倒掉液体,用l ml的75%乙醇洗EP管壁。4℃,7500g,离心5min。
5)倒掉清洗后的75%乙醇,室温晾置5-10min。
6)加入25μ1无RNA酶的DEPC水,-70℃保存。
4.2逆转录步骤同实施例2。
4.3QPCR扩增步骤同实施例2。
5、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,FAM78A基因过表达组与对照组之间的差异采用t检验,认为当P<0.05时具有统计学意义。
6、结果
结果如图2显示,与非转染组和转染空白质粒组相比,转染FAM78A组中过表达FAM78A,差异具有统计学意义(P<0.05)。
实施例4 FAM78A基因对肺腺癌细胞增殖的影响
采用CCK-8实验检测FAM78A基因对肺腺癌细胞增殖能力影响。
1、细胞培养与转染步骤同实施例3。
2、第二天将细胞取出,显微镜下观察细胞生长情况,1ml/孔加入含EDTA的胰酶,进行细胞消化,待消化完成后去除胰酶,加入细胞培养基混匀使细胞悬浮,然后进行细胞计数。
3、将细胞悬液浓度稀释为1.5×104个/ml,之后往96孔板中进行接种,每孔加入细胞悬液200μ1,细胞控制在3000个左右,接种8个复孔。设置pcDNA3.1-1实验组和pcDNA3.1-NC对照组。共铺4块96孔板分别用于24h、48h、72h、96h4个检测时间点。
4、24h后,将第一块96孔板取出,每孔中加入10μ1的CCK-8检测液,将96孔板继续放入细胞培养箱中孵育4h左右,用酶标仪检测各孔在450nm波长处的吸光度值并记录数据。
5、在48h、72h、96h后分别重复步骤4中的操作,最后统计出各时间点的吸光度值,作出生长曲线图。
6、统计学分析
实验都是按照重复3次来完成的,采用SPSS18.0统计软件来进行统计分析,两者之间的差异采用t检验,认为当P<0.05时具有统计学意义。
7、结果
结果如图3所示,与对照相比,实验组在转染pcDNA3.1-1后,细胞的增殖明显受到了抑制,差异具有统计学意义(P<0.05)说明FAM78A具有抑制细胞增殖的作用。
实施例5 FAM78A基因对肺腺癌细胞凋亡的影响
使用流式细胞仪检测FAM78A基因对细胞凋亡的影响。
1、细胞培养步骤同实施例3。
2、细胞转染步骤同实施例3。
3、步骤
1)将3m1 10×上样缓冲液用27m1蒸馏水稀释。
2)收集细胞样本并用预冷的PBS清洗。
3)将细胞加入lml 1×上样缓冲液,300g离心10min,吸出缓冲液。
4)再次加入lml 1×上样缓冲液,将细胞悬液中细胞浓度调整为1×106个/ml。
5)将细胞悬液取出100μ1,加入EP管中。
6)将5μl的Annexin V FITC加入EP管中,混匀EP管中的液体,在室温下避光孵育10min。
7)向EP管中加入5μ1PI染液,在室温下避光5min。
8)在EP管中加入500μl的PBS溶液,轻轻混匀,1h内上流式细胞仪进行检测。
3、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS13.0统计软件来进行统计分析的,两者之间的差异采用的t检验,认为当P<0.05时具有统计学意义。
4、结果:
结果如图4所示,实验组与对照组相比,细胞凋亡率具有显著的变化(P<0.05),该结果说明,FAM78A的低表达降低了细胞的凋亡率。
实施例6细胞迁移及侵袭实验
1、Transwell小室制备
无菌条件下Matrigel冰浴融化,用PBS进行20倍稀释,以50μl/孔的体积铺在Transwell小室的聚碳酸酯膜上。37℃放置4h,待Matrigel胶聚合成凝胶后取出,轻轻吸出上层析出液。每孔中加入50μl的含BSA的无血清培养液对基底膜进行水化处理,37℃放置30min。
2、配置细胞悬液
细胞撤血清饥饿处理12-24h,对细胞进行消化处理,终止消化后进行离心,去除上层培养液。用PBS对沉淀细胞进行清洗,加入含有BSA的无血清培养基对其进行重悬。调整细胞的密度至5×l05个/ml。
3、细胞接种
取细胞悬液200μ1(迁移实验为100μ1,侵袭实验为200μ1)加入到Transwell小室中。在24孔板下室加入500μ1含FBS的1640培养基。把细胞放入细胞培养箱中培养24h。
4、染色
细胞在培养结束后使用DAPI染色。把小室细胞先用PBS漂洗2遍,放入DAPI工作液中室温染色5-20min。用PBS漂洗2遍,放入荧光显微镜下观察并计数。
5、结果
结果如图5所示,在肺腺癌细胞转染质粒之后,与对照组相比,实验组的迁移及侵袭能力均有明显下降,结果说明FAM78A能够抑制肺腺癌细胞的迁移及侵袭。
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
SEQUENCE LISTING
<110> 北京泱深生物信息技术有限公司
<120> FAM78A基因的用途
<160> 8
<170> PatentIn version 3.5
<210> 1
<211> 852
<212> DNA
<213> 人源
<400> 1
atgcctggtt ttttctgtga ctgctggcct tccctggaga tcagagcgct cctgtatgcc 60
atgggctgta ttcagagcat cggaggcaaa gccagagtct tccgggaagg gatcacggtg 120
attgatgtga aagcctccat cgaccccgtc cccactagca tcgatgagtc ctccagcgtg 180
gtgctccgct accggacacc ccacttccgg gcctcggccc aggtggtcat gccgcccatc 240
cccaagaagg agacttgggt agttggctgg atccaggcgt gcagccacat ggagttctac 300
aaccagtacg gcgagcaggg catgtccagc tgggagctcc ccgacctcca ggagggcaag 360
atccaagcca tcagcgactc ggatggggtg aactacccct ggtacggcaa caccacagag 420
acctgcacca tcgtgggccc caccaagagg gactccaagt tcatcatcag catgaatgac 480
aacttttacc ccagcgtcac atgggccgtg cccgtcagcg agagcaacgt ggccaagctc 540
accaatatct accgggacca gagcttcacc acctggctgg tggccaccaa cacctccacc 600
aacgacatga tcatcctgca gacgctgcac tggcgcatgc agctcagcat cgaggtgaac 660
cccaaccggc ccctgggcca gcgcgcccgg ctgcgggagc ccatcgccca ggaccagccc 720
aaaatcctga gcaagaatga gcccatcccg cccagcgccc tggtcaagcc caatgccaac 780
gatgcccagg tcctcatgtg gcggcccaag tacgggcagc cgctggtggt gatcccgccc 840
aagcaccggt ga 852
<210> 2
<211> 283
<212> PRT
<213> 人源
<400> 2
Met Pro Gly Phe Phe Cys Asp Cys Trp Pro Ser Leu Glu Ile Arg Ala
1 5 10 15
Leu Leu Tyr Ala Met Gly Cys Ile Gln Ser Ile Gly Gly Lys Ala Arg
20 25 30
Val Phe Arg Glu Gly Ile Thr Val Ile Asp Val Lys Ala Ser Ile Asp
35 40 45
Pro Val Pro Thr Ser Ile Asp Glu Ser Ser Ser Val Val Leu Arg Tyr
50 55 60
Arg Thr Pro His Phe Arg Ala Ser Ala Gln Val Val Met Pro Pro Ile
65 70 75 80
Pro Lys Lys Glu Thr Trp Val Val Gly Trp Ile Gln Ala Cys Ser His
85 90 95
Met Glu Phe Tyr Asn Gln Tyr Gly Glu Gln Gly Met Ser Ser Trp Glu
100 105 110
Leu Pro Asp Leu Gln Glu Gly Lys Ile Gln Ala Ile Ser Asp Ser Asp
115 120 125
Gly Val Asn Tyr Pro Trp Tyr Gly Asn Thr Thr Glu Thr Cys Thr Ile
130 135 140
Val Gly Pro Thr Lys Arg Asp Ser Lys Phe Ile Ile Ser Met Asn Asp
145 150 155 160
Asn Phe Tyr Pro Ser Val Thr Trp Ala Val Pro Val Ser Glu Ser Asn
165 170 175
Val Ala Lys Leu Thr Asn Ile Tyr Arg Asp Gln Ser Phe Thr Thr Trp
180 185 190
Leu Val Ala Thr Asn Thr Ser Thr Asn Asp Met Ile Ile Leu Gln Thr
195 200 205
Leu His Trp Arg Met Gln Leu Ser Ile Glu Val Asn Pro Asn Arg Pro
210 215 220
Leu Gly Gln Arg Ala Arg Leu Arg Glu Pro Ile Ala Gln Asp Gln Pro
225 230 235 240
Lys Ile Leu Ser Lys Asn Glu Pro Ile Pro Pro Ser Ala Leu Val Lys
245 250 255
Pro Asn Ala Asn Asp Ala Gln Val Leu Met Trp Arg Pro Lys Tyr Gly
260 265 270
Gln Pro Leu Val Val Ile Pro Pro Lys His Arg
275 280
<210> 3
<211> 18
<212> DNA
<213> 人工序列
<400> 3
tcagcatgaa tgacaact 18
<210> 4
<211> 18
<212> DNA
<213> 人工序列
<400> 4
cggtagatat tggtgagc 18
<210> 5
<211> 21
<212> DNA
<213> 人工序列
<400> 5
aatcccatca ccatcttcca g 21
<210> 6
<211> 19
<212> DNA
<213> 人工序列
<400> 6
gagccccagc cttctccat 19
<210> 7
<211> 35
<212> DNA
<213> 人工序列
<400> 7
ccgaagcttg ccaccatgcc tggttttttc tgtga 35
<210> 8
<211> 34
<212> DNA
<213> 人工序列
<400> 8
cggctcgagc cggtgcttgg gcgggatcac cacc 34
- 还没有人留言评论。精彩留言会获得点赞!