用于HLA基因高分辨率分型的引物、试剂盒及方法与流程
本发明涉及基因工程技术领域,具体涉及hla基因高分辨率分型的引物、试剂盒及方法。
背景技术:
人类白细胞抗原(humanleukemiaantigen,hla)基因即人类的主要组织相容性复合体mhc,hla基因位于第六号染色体短臂,是调控人体特异性免疫应答和决定疾病易感性个体差异的主要系统,与异基因造血干细胞移植及器官移植的排斥反应密切相关。异基因造血干细胞移植是治疗白血病、再生障碍性贫血、骨髓异常增生综合征等恶性血液病的主要疗法之一,hla基因型的匹配程度是决定移植物长期存活的主要因素,因此在移植前需要对供患者进行hla分型。
hla具有高度多态性的特点,截至2016年,已发现超过14,000个不同的hla等位基因。hla基因分型分为“低分辨分型”和“高分辨分型”,高分辨分型是指将hla基因区分到一组编码同一蛋白的等位基因,如“hla-a*01:01”。sbt(sequencingbasedtyping)法是hla分型的金标准。sbt法分为一代测序和二代测序(nextgenerationsequencing,ngs)。一代测序方法自1977年诞生至今已经是一个很成熟的方法,二代测序相对于一代测序进行hla分型具有高通量、易自动化、减少模棱两可结果等特点。近年来国际上已有不少机构对ngs进行hla分型进行了研究,并且已有部分研究用试剂盒,如onelambda公司的nxtype产品、illumina公司的trusighthla产品、gendx公司的ngsgo产品。然而,由于测序仪的随机测序误差以及生物信息分析时比对、组装等步骤产生的误差,上述产品和技术都存在一定的错误率。
技术实现要素:
本发明针对现有技术中存在的上述缺陷,提供了一种用于hla基因的高分辨率分型方法,该方法具有高通量、高分辨率和高准确性的优点。
为此,本发明一方面提供了一种用于hla基因高分辨率分型的引物组合,其由seqidno.1-10所示的引物组成。
在本发明优选的实施方案中,该引物组合进一步由第1-5组引物组成,其中第1组由seqidno.1-2所示的引物组成,第2组由seqidno.3-4所示的引物组成,第3组由seqidno.5-6所示的引物组成,第4组由seqidno.7-8所示的引物组成,第5组由seqidno.9-10所示的引物组成。
所述hla基因高分辨率分型引物分别为hla-a-f、hla-a-r、hla-b-f、hla-b-r、hla-c-f、hla-c-r、hla-dqb1-f、hla-dqb1-r、hla-drb1-f和hla-db1-r。其中引物组hla-a-f和hla-a-r扩增hla的a基因的1号~8号外显子,引物组hla-b-f和hla-b-r扩增hla的b基因的1号~7号外显子,引物组hla-c-f和hla-c-r扩增hla的c基因的1号~7号外显子,引物组hla-dqb1-f和hla-dqb1-r扩增hla的dqb1基因的2号~3号外显子,引物组hla-drb1-f和hla-drb1-r扩增hla的drb1基因的1号内含子~4号外显子。
本发明设计的具体引物情况如表1所示。
表1、本发明用于hla基因高分辨率分型的引物情况表
在本发明进一步优选的实施方案中,每条引物的浓度均为0.4μm。
本发明另一方面提供了一种用于hla基因分型的试剂盒,其包含本发明所述的引物组合。
本发明另一方面提供了本发明所述的引物组合在制备hla基因高分辨率分型试剂盒中的应用。
本发明再一方面提供了一种本发明所述的引物组合或者本发明所述的试剂盒在hla基因高分辨率分型中的应用。
本发明最后一方面提供了一种hla基因高分辨率分型方法,其包含以下步骤:
1、获取待测样品dna;
2、采用本发明所述的引物组合或采用本发明所述的试剂盒,以步骤1中获取的dna为模板,进行pcr扩增;
3、对所述pcr扩增产物进行序列测定;
4、对测序结果进行数据比对分析。
在本发明进一步优选的实施方案中,步骤2进一步包括以下步骤:
(1)样本dna提取:采用qiaampdnabloodminikit试剂盒,获取样本dna。
(2)扩增:以样本dna为模板,采用引物组hla-a-f/hla-a-r、hla-b-f/hla-b-r、hla-c-f/hla-c-r、hla-dr-f/hla-dr-r和引物组hla-dq-f/hla-dq-r分别进行扩增反应。扩增反应体系为25μl:2.5μl10×vazyme
在本发明进一步优选的实施方案中,步骤3进一步包括以下步骤:
(1)利用nexteraxt试剂盒对所述pcr扩增子进行二代测序建库:
(a)标记基因组dna:将10μltd和5μl标准化的dna在孔板里混匀,加入5μlatm后混匀,在20℃下以280×g的转速离心1分钟,然后在pcr仪上运行以下程序:预热盖,55℃5min,10℃保存。运行完毕后加入5μlnt后混匀,在20℃下以280×g的转速离心1分钟,最后在室温下孵育5分钟。
(b)扩增标记后的dna:在上一步得到的产物中分别加入5μl标签1引物(n7xx)和标签2引物(n5xx)后混匀,注意两个不同的样本不可以使用完全相同的两个标签引物,将15μlnpm添加到含有标签接头的每个样本中并混匀,在20℃下以280×g的转速离心1分钟,然后在pcr仪上运行以下程序:72℃3min;95℃30s;再依次按照以下程序运行9个循环,95℃10s,55℃30s,72℃30s;10℃保存。
(c)纯化扩增后的dna:将上一步得到的产物在20℃下以280×g的转速离心1分钟,将50μlpcr产物转移至新midi孔板中,加入30μlampurexp(beckmancoulter公司)磁珠并用移液枪轻柔混匀。将混合物在室温下静置孵育5分钟后置于磁力架(thermofisher公司)上直至混合物变得清澈(约2-5分钟),用移液枪移除上清液并按以下方式清洗两次:向每个孔中加入200μl新制备的浓度为80%的乙醇,在磁力架上孵育5分钟,用移液枪移除上清液。清洗过后使用20μl移液器小心移除每个孔中残余的80%乙醇,在磁力架上风干15分钟后加入52.5μlrsb并用移液枪混匀,在室温下孵育2分钟后置于磁力架上直至混合物变得清澈(约2-5分钟),用移液枪转移50μl上层清液至新的孔板中。
(d)混合文库:使用qubittm对纯化后的样本进行浓度测定,并将所有样本稀释至同一浓度,然后将所有样本等量混合于低吸附离心管中并混匀。
(2)文库构建完毕后,在illuminamiseq或illuminanextseq500测序平台进行测序:
(a)在illuminamiseq平台进行测序:将构建好的文库稀释至4nm,取5μl稀释后文库与5μl新制备的0.2mnaoh溶液充分混合均匀,室温下变性5分钟,再加入990μl提前解冻并预冷的ht1溶液,用移液枪轻柔混合均匀,再从中取375μl与225μl提前解冻并预冷的ht1混合,用移液枪轻柔混合均匀,制成上机文库。
将300-cyclemiseqreagentkitv2上机试剂盒提前取出置于常温水浴中解冻,使用illuminaexperimentmanager软件按照格式设置好文库信息的samplesheet,将制备好的上机文库用移液枪转移至试剂盒固定孔内,洗涤仪器后按照illuminamiseq上机提示步骤进行测序前设置,导入samplesheet并开始测序。
(b)在illuminanextseq500平台进行测序:将构建好的文库稀释至4nm,取5μl稀释后文库与5μl新制备的0.2mnaoh溶液充分混合均匀,室温下变性5分钟,加入5μlph为7.0的tris-hcl,再加入985μl提前解冻并预冷的ht1溶液,用移液枪轻柔混合均匀,再从中取104μl与1196μl提前解冻并预冷的ht1混合,用移液枪轻柔混合均匀,制成上机文库。
将300-cyclemidoutputkit上机试剂盒提前取出置于常温水浴中解冻,将制备好的上机文库用移液枪转移至试剂盒固定孔内,洗涤仪器后按照illuminanextseq500上机提示步骤进行测序前设置并开始测序。
在本发明进一步优选的实施方案中,步骤4进一步包括以下步骤:
(1)根据建库时加入的index序列信息,将不同样本的reads分开为不同序列文件。
(2)对每个样本reads进行数据校正,去除引物区域、去除duplicatereads、去除低质量区域,得到高质量的reads。
(3)将校正后reads通过bwa软件与hla-a、b、c、drb1、dqb1参考序列进行比对,并进行碱基校正,输出比对后的序列。
(4)截取各位点外显子部分序列,与imgt/hla型别数据库进行比对,序列一致则将数据库中等位基因型别赋予该样本,最终得到hla-a、b、c、drb1、dqb1五个位点基因型。
由上述描述可知,与现有技术相比,本发明具备如下优点。
1、高通量:相比于传统的sbt和sso等方法,使用二代测序的方法对hla进行分型具有高通量的特点,每个样本在pcr扩增后单独进行文库构建,并在最终上机测序时混合在一起。测序反应每次最多可以同时测定480个样本,每个样本从dna提取到测序结束,全部流程可短至2天,效率远高于传统的sbt和sso等方法。
2、高分辨率:所述方法得到的hla分型结果包含低分辨率和高分辨率分型结果。例如b*15:01,其中b代表基因座位,15为1区等位基因组即低分辨型别,01为2区特异性hla蛋白即高分辨型别。
3、高准确性:使用本发明中所用的方法对3000份随机样本进行了hla分型检测,分型准确率可达100%。
附图说明
图1:采用本发明扩增引物组hla-a-f/hla-a-r、hla-b-f/hla-b-r、hla-c-f/hla-c-r、hla-dr-f/hla-dr-r和hla-dq-f/hla-dq-r分别扩增得到的电泳谱图。
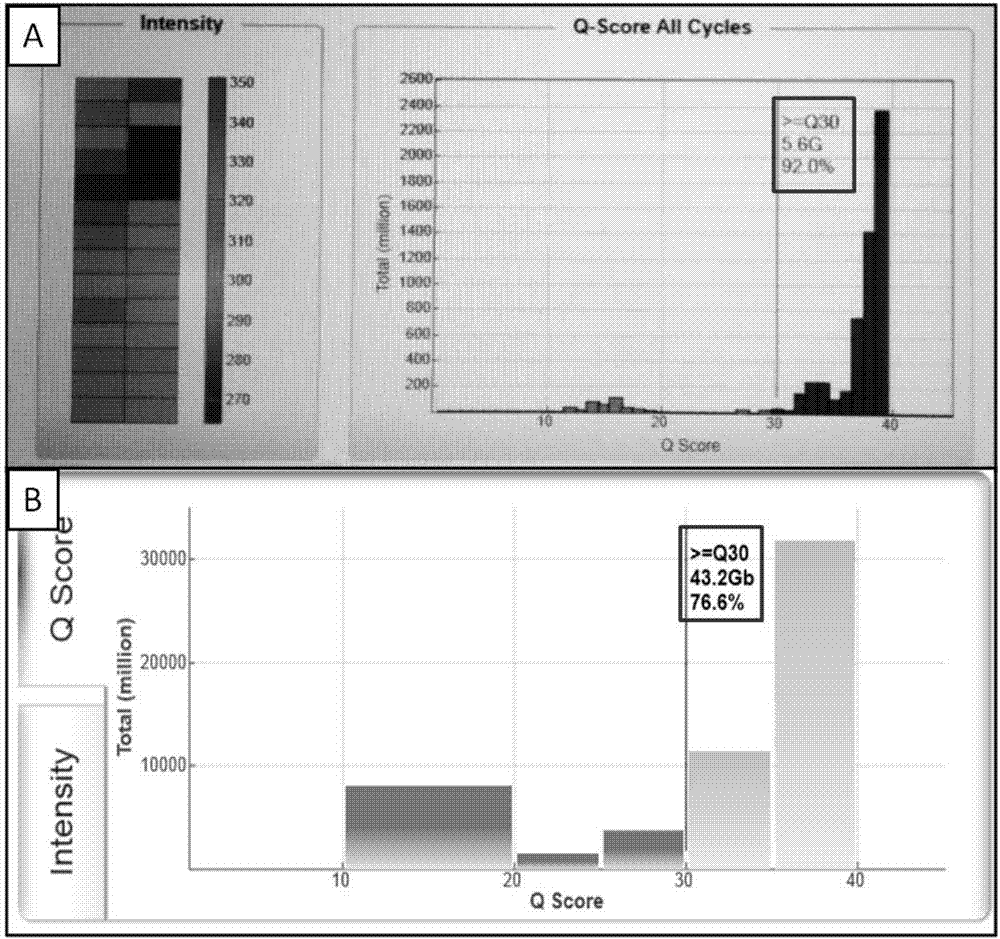
图2:illuminamiseq测序平台与illuminanextseq500测序平台结果数据比较图。
图2a:illuminamiseq测序结果图;
图2b:illuminanextseq500测序结果图。
图3:本发明获得的低分辨率和高分辨率分型结果示例图。
图4:illuminamiseq上机关键程序设置图。
图5:illuminanextseq500上机关键程序设置图。
具体实施方式
下面通过实施例对本发明作进一步的详细说明,旨在用于说明本发明而非限定本发明。应当指出,对于本领域技术人员而言,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也同样落入本发明的保护范围之内。
实施例1:引物的设计、合成
在本实施例中,pcr引物设计所需要的hla外显子序列来源imgt/hladatabase,网址:http://www.ebi.nc.uk/ipd/imgt/hla/。引物设计采用primerpremier6.0软件,设计的引物在imgt数据库中进行比对,确认该组引物能特异性地对所需片段进行扩增或测序。
所述引物由上海英骏生物技术有限公司合成,具体序列如前所述。
实施例2:扩增引物的筛选
1、随机选取96份dna样本(包含一个阴性对照),对hla基因外显子进行扩增,通过琼脂糖凝胶电泳初步判断引物组的扩增效率和特异性。
(1)dna提取按照qiaampdnabloodminikit试剂盒进行,随后采用dnase-freeddh2o稀释到10ng/μl备用。
(2)采用25μl的扩增体系:2.5μl10×vazyme
(3)针对引物组hla-a-f/hla-a-r、hla-b-f/hla-b-r和hla-c-f/hla-c-r的扩增反应,反应条件为95℃2min;再依次按照以下程序运行35个循环,93℃30s,60℃30s,72℃180s;15℃保存。针对引物组hla-dr-f/hla-dr-r和引物组hla-dq-f/hla-dq-r的扩增反应,反应条件为95℃2min;再依次按照以下程序运行35个循环,93℃30s,60℃30s,68℃210s;15℃保存。
(4)pcr产物经2%琼脂糖电泳130v,30min后进行检测,根据电泳得到的条带判断引物组的扩增效率和特异性。
采用本发明扩增引物组hla-a-f/hla-a-r、hla-b-f/hla-b-r、hla-c-f/hla-c-r、hla-dr-f/hla-dr-r和hla-dq-f/hla-dq-r分别扩增得到的电泳谱图如附图1所示。
2、随机选取96份dna样本(包含一个阴性对照),使用经过琼脂糖凝胶电泳检测后获得的具有良好扩增效率和特异性的引物组对其hla基因外显子进行扩增,使用nexteraxt试剂盒对所述pcr扩增子进行二代测序建库,文库构建完毕后,在illuminamiseq或illuminanextseq500测序平台进行测序。对测序结果进行分析,判断引物组的特异性和分型准确性。
illuminamiseq测序平台与illuminanextseq500测序平台结果数据比较图分别如附图2a和2b所示。
经过检测分析,最终确定的5组扩增引物为hla-a-f/hla-a-r、hla-b-f/hla-b-r、hla-c-f/hla-c-r、hla-dr-f/hla-dr-r和hla-dq-f/hla-dq-r,分别对hla基因的五个基因座的相应外显子进行扩增。
实施例3:illuminamiseq和illuminanextseq500上机关键程序设置
1、illuminamiseqsamplesheet设置
参照附图4,打开illuminaexperimentmanager软件,依次填写reagentcartridgebarcode,选择sampleprepkit为“nexteraitv2”,选择indexreads为“2”,填写experimentname,选择readtype为“pairedend”,填写cycleread1和cycleread2为151,右边界面选择“useadaptertrimming”,点击next。
在samplesheetwizard-sampleselection界面内,按照实际情况为每个样本添加index信息,添加完毕后点击finish。
2、illuminanextseq500上机关键程序设置
参照附图5,按照上机提示操作至runsetup步骤,依次输入runname,libraryid,选择“pairedend”,在readlength里自左向右依次填入“151”、“151”、“8”、“8”,点击next并按照后续提示操作。
实施例4:样品检测分析
随机选取3000份样本,使用所述引物对hla基因进行pcr扩增,使用nexteraxt试剂盒对所述pcr扩增子进行二代测序建库,文库构建完毕后,分别在illuminamiseq或illuminanextseq500测序平台进行测序。illuminamiseq测序平台选用
本发明获得的不同样本低分辨率和高分辨率分型结果示例图如附图3所示。
经过检测分析,illuminamiseq的分型率为98.5%,准确率为100%,单次测序通量为24个样本,q30为大于90%;illuminanextseq500的分型率为91.7%,准确率为100%,单次测序通量为480个样本,q30为大于75%。由此可知,illuminamiseq的q30较高,数据质量较好,分型率较高;illuminanextseq的通量较高。
序列表
<110>上海荻硕贝肯医学检验所有限公司
上海荻硕贝肯生物科技有限公司
深圳荻硕贝肯精准医学有限公司
上海荻硕贝肯生物技术有限公司
<120>用于hla基因高分辨率分型的引物、试剂盒及方法
<160>10
<170>siposequencelisting1.0
<210>2
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>2
gtatggattggggagtcccagcc23
<210>10
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>10
gagcacaggtcagcgtgggaaga23
<210>4
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>4
acccacccggactcarartctcct24
<210>4
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>4
cactctagaccccaagaatctcacctttt29
<210>5
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>5
gcgtcgggtccttcttcctga21
<210>6
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>6
ccacccccgaccacttcagct21
<210>7
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>7
cgcgggctgttccacagctcc21
<210>8
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>8
tcagccccagcacgaagcctccaa24
<210>9
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>9
agctcctgcytrgaggtctccagaac26
<210>10
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>10
cttgctctgtgcagattcagaccgtgc27
- 还没有人留言评论。精彩留言会获得点赞!