一种RPA结合免疫荧光层析特异性检测H1甲流亚型的方法与流程
本发明属于分子生物学检测领域,具体地说,涉及一种rpa结合免疫荧光层析特异性检测h1甲流亚型的方法。
背景技术:
随着经济全球化的不断深入,国际贸易的不断发展,交通工具、货物、人员在国际间的流动日益频繁,国境口岸成为传播传染病及其媒介生物的重要途径。2009年甲流h1n1的流行给全球经济、人群健康造成重大危害,甲流防控经验提示,现有传统快速检测技术已经无法满足国境口岸检疫查验需求,因此亟待开发甲流的快速检测技术方法。
血细胞凝集抑制试验(hmagglutinationinhibition,hi)和神经氨酸酶抑制试验(neuraminidaseinhibition,ni)是当前流感病毒检测的标准方法,可应用与ha和na的分型。但由于参考血清供应的不足,这两种方法不能在全球被广泛应用,使用性受到一定的限制。而现在分子诊断技术已经成为新型病毒诊断方法的代表。核酸检测方法比传统方法更灵敏,更快速,也允许更广泛的病毒临床标本的检测。
常用的分子诊断技术包括快速抗原检测试验(rdts)和pcr/rt-pcr技术。
rdts简单、快速(10-15min),适合于床旁检测(poct)。然而,有大量的报道表示,rdts的灵敏度和特异性均非常有限,并且rdts的检测结果仍需要rt-pcr进行确认。
聚合酶链式反应(pcr)和实时荧光定量pcr技术(rt-pcr)是分子诊断的标准技术,其灵敏度高,特异性强。然而,要采用该方法进行检测,需将样本送往区域或中心实验室进行检测,不能随时随地进行检测,这主要是因为该检测方法需要专业的检测人员设备和复杂的操作过程,而且测试时间较长(50-90min),因此不适合床旁检测(poct)。
技术实现要素:
为了解决现有技术中存在的问题,本发明的目的是提供一种rpa结合免疫荧光层析特异性检测h1甲流亚型的方法。
为了实现本发明目的,本发明的技术方案如下:
第一方面,本发明提供一种特异性检测h1甲流亚型的引物,所述特异性引物包括:
正向引物:5’-agcaagttcgtggcccaatcatgaaacaaa-3’,
反向引物:5’-ttgctgagctttggatatgaatttcccttt-3’。
第二方面,本发明提供一种rpa结合免疫荧光层析特异性检测h1甲流亚型的方法,采用前述引物对待测样品的dna或rna进行rpa扩增。
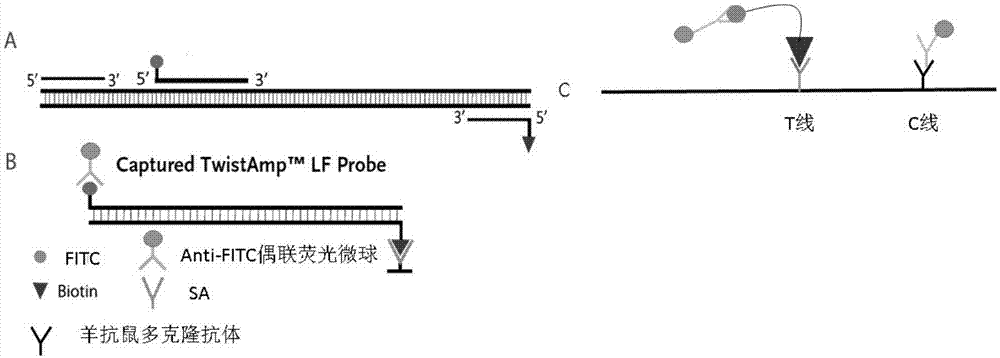
本发明所提供的rpa结合免疫荧光层析特异性检测h1甲流亚型的原理为:将荧光素fitc与生物素分别标记对特定基因特异且不会形成二聚体的引物进行标记,接下来用标记的引物进行rpa扩增,若体系中存在目标序列,将会得到同时携带生物素和fitc的扩增产物,将此扩增产物按一定比例与抗fitc单抗标记的荧光微球进行混合,从而得到同时携带生物素和荧光微球的扩增产物。将该扩增产物滴加到试纸条上,免疫复合物通过层析膜扩散,扩散到检测线时,生物素标记的扩增产物被生物素配体捕获,通过荧光检测仪器检测荧光微球的信号,检测线信号值越大则代表体系中目标基因得浓度越高(图1)。
因此,所述方法具体包括如下步骤:
(1)提取待测样本rna;
(2)以待测样本的rna为模板,反转录后,利用特异性引物进行rpa扩增,获得扩增产物;
所述特异性引物包括分别标记有荧光素fitc与生物素的以下引物:
正向引物:5’-agcaagttcgtggcccaatcatgaaacaaa-3’,
反向引物:5’-ttgctgagctttggatatgaatttcccttt-3’;
(3)利用生物素配体检测携带生物素标记的扩增产物;将抗fitc单抗标记的荧光微球与所述扩增产物混合,通过检测荧光微球的信号判断h1基因的浓度。
其中,所述rpa扩增的反应体系为:
将各种试剂混合均匀后,加入干粉试剂,最后加入2.5μl280mm醋酸镁充分混匀,置于37℃条件下反应20min。
所述rpa扩增的反应程序为:37℃条件下反应20min。
作为优选,以抗fitc单抗标记:荧光微球=1:10的质量比,利用抗fitc单抗标记荧光微球。
作为优选,将抗fitc单抗标记的荧光微球与所述扩增产物混合时,该抗fitc单抗标记的荧光微球的od值为0.02。
本发明经实验研究发现,100拷贝~500拷贝的模板,按照上述反应体系和反应程序进行扩增后,用od值在0.02左右的抗fitc单抗标记的荧光微球,采用罗氏实时荧光定量法检测,检测信号与可与扩增产物浓度呈良好的线性关系,如下表所示。
作为优选,在结合荧光微球前,将扩增产物稀释100倍,将稀释后的扩增产物与荧光微球以1:9的比例混合。
本发明涉及到的原料或试剂均为普通市售产品,涉及到的操作如无特殊说明均为本领域常规操作。
在符合本领域常识的基础上,上述各优选条件,可以相互组合,得到具体实施方式。
本发明的有益效果在于:
本发明针对现有技术中对甲流快速分型检测的不足,以甲流病毒的h1基因检测为切入点建立一套以恒温扩增技术为基础的免疫荧光层析技术。该项目可以在常温下进行等温扩增,只需将h1基因的特异引物分别进行修饰,便可实现1个试剂检测h1甲流亚型的需求。所构建的甲流检测技术平台可应用于口岸甲流快速筛检,控制甲流的传入传出,具有重要的应用推广价值。
附图说明
图1为rpa结合侧向流层析检测甲流分型的示意图;a.扩增反应;b.扩增产物;c.免疫层析检测示意图。
图2为免疫荧光层析检测rpa扩增产物校准曲线和免疫荧光层析检测rpa扩增产物线性范围。
图3为对h1基因进行特异性引物筛选时的电泳检测结果;a:以f1/r1为引物,h1/h5/h7/n1/n9为模板进行rpa扩增;b:以f2/r2为引物,h1/h5/h7/n1/n9为模板进行rpa扩增;c:以f3/r3为引物,h1/h5/h7/n1/n9为模板进行rpa扩增;d:以f4/r4为引物,h1/h5/h7/n1/n9为模板进行rpa扩增;e:以f5/r5为引物,h1/h5/h7/n1/n9为模板进行rpa扩增。
图4为h1特异性修饰引物验证。
图5为抗体量对标记活性的影响。
具体实施方式
下面结合实施例对本发明做进一步的解释说明。需要理解的是以下实施例的给出仅是为了起到说明的目的,并不是用于对本发明的范围进行限制。本领域的技术人员在不背离本发明的宗旨和精神的情况下,可以对本发明进行各种修改和替换。
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
实施例1
1、材料与方法
1.1材料
模板序列:于ncbi数据库中搜索凝集素基因:h1(s67220.1)、h5(ay854190.1)和h7(aj493472.1);神经氨酸酶基因:n1(ab539741.1)和n9(cy179917.1),将这五条基因序列送往生工生物工程(上海)股份有限公司进行合成。
普通引物设计:从ncbi数据库中搜索凝集素基因的17种变种(h1-h17)和神经氨酸酶基因10种变种(n1-n10)每一变种搜索6条,进行序列比对,找到变种之间的可变区域,变种之间再进行比对,找到变种内部的保守区域,然后以两个区域的交集为模板序列设计特异引物,每一基因设计5对引物,将设计好的引物送往生工生物工程(上海)股份有限公司进行合成。
表1甲流ha和na基因扩增引物
修饰引物:将筛选到的特异引物送往宝生物工程(大连)有限公司标记生物素和荧光素(fitc)。
其它材料:荧光微球,fitc单抗,羊抗鼠多克隆抗体,rpa试剂盒(
1.2方法
1.2.1反应体系
rpa扩增反应体系见表2。
表2rpa反应体系
按表2将各种试剂混合均匀后,加入干粉试剂,最后加入2.5μl280mm醋酸镁充分混匀,置于37℃条件下反应20min。
1.2.2电泳检测
使用1%琼脂糖凝胶于80ma电流下进行电泳检测,上样量:4μl扩增产物+4μl水+2μl10×loadingbuffer(含0.1%goldview),dl2000dnamarker:4μldl2000dnamarker+1μl10×loadingbuffer(含0.1%goldview),使用凝胶成像系统对电泳结果进行成像并分析。
1.2.3荧光微球偶联fitc单抗的制备
采用的荧光微球为外购原料,表面修饰有羧基官能团,通过化学键偶连上fitc单克隆抗体。取适量体积的荧光微球(200nm)溶液,采用离心的方式进行洗涤,置于磁力搅拌器上室温匀速搅拌,按照cooh数量加入一定量的edc(0.1mg/1mg荧光微球)活化剂进行活化15min,之后,按照最佳蛋白标记量(0.1mg/1mg荧光微球)加入fitc单抗,匀速搅拌反应2h,然后加入封闭剂(终止剂),反应30min,最后进行纯化得到微球-抗体复合物。通过2-3次离心洗涤的方式分离出微球-抗体复合物,用保存液将复合物分散到一定固含量,4℃保存。
1.2.4检测卡的制备
t线包被液:10mmpb+3%甲醇(ph6.0)。
c线包被液:10mmpbs+2%海藻糖+0.1%pc-300(ph7.4)。
用t线包被液将亲和素稀释至2mg/ml;用c线包被液将羊抗鼠多克隆抗体稀释至1mg/ml。最后使用划膜仪将亲和素、羊抗鼠多克隆抗体分别划在t线和c线(喷量为1μl/cm),水印消失后,置于42℃干燥2d,切条装卡。
1.2.5免疫荧光层析检测扩增产物
稀释液:10mmpbs(含0.1%tween)。
配置反应液:稀释液将抗fitc抗体标记荧光微球稀释至od=0.02。
用纯水将扩增产物稀释100倍,20μl扩增产物加入180μl反应液中,充分混匀后吸取90μl混合液,滴加到测试卡的加样孔中,室温下放置15min,将测试卡插入免疫荧光检测仪的承载孔中,仪器将自动对测试卡进行扫描计算结果。
2、实验效果
2.1空白限
使用免疫荧光层析检测卡重复20次测量阴性对照扩增产物,根据空白限计算公式:空白线=平均值(20次检测值)+2*sd,结果见表3,表明当信号值≤31.4时为阴性。
表3阴性对照扩增产物检测信号值
2.2灵敏度
使用免疫荧光层析技术对反应体系h1总模板量为0拷贝、10拷贝、20拷贝、40拷贝、60拷贝、80拷贝和100拷贝的扩增产物进行检测,结果见表4。表明,该检测方法的最低检出限为100拷贝。
表4h1基因模板不同拷贝数扩增产物信号值
2.3特异性
使用免疫荧光层析技术对反应体系h1、h5、h7、n1、n9总模板量为500拷贝的扩增产物进行检测,结果见表5。表明本试剂盒能够特异性的检测甲流h1分型,h5、h7、n1和n9等甲流分型均保持良好的阴性结果。
表5试剂盒特异性验证
2.4校准曲线
使用免疫荧光层析技术对反应体系h1总模板量为0拷贝、100拷贝、200拷贝、500拷贝、1000拷贝、2000拷贝和5000拷贝的扩增产物进行检测,结果见表6和图2。表明该检测方法在拷贝数100-500的范围,拷贝数与信号值线性相关,相关系数r2=0.9662。
表6h1基因不同拷贝数扩增产物免疫荧光层析检测信号值
3、试验过程中筛选试验数据
3.1h1基因特异引物筛选
以h1、h5、h7、n1和n9基因的质粒为模板,分别以五对引物(表1)按前述“1.2方法”进行rpa扩增,扩增产物同样按照前述方法进行电泳检测,结果见图3,表明五对引物中,只有f2/r2对于h1基因是特异的,可用于特异检测h1基因。
3.2h1基因特异修饰引物验证
为确定f2/r2经修饰后是否对扩增反应有影响,采用按前述“1.2方法”进行rpa扩增,扩增产物同样按照前述方法进行电泳检测,结果见图4,表明引物修饰后对扩增无明显影响,可进行免疫荧光层析检测。
3.3灵敏度
3.3.1标记抗体用量筛选
为提高检测灵敏度,参照前述“1.2方法”标记不同量抗体(0.05mg/1mg荧光微球、0.1mg/1mg荧光微球、0.2mg/1mg荧光微球和0.4mg/1mg荧光微球),标记抗体按前述“1.2方法”进行活性验证,结果见图5,表明最佳标记抗体用量为0.1mg/1mg荧光微球。
3.3.2荧光微球粒径筛选
除增加抗体用量外,还可通过增加抗体结合位点,提高微球结合抗体量,按前述“1.2方法”标记不同粒径荧光微球(200nm和300nm),结果表明粒径对检测信号无影响,结果见表7。
表7荧光微球粒径对标记活性的影响
3.4扩增产物稀释倍数筛选
扩增体系中含有大量保护蛋白和集凝试剂,这些成分均会影响检测信号,本方法与荧光微球混合前,使用纯水对阴性扩增产物(0拷贝)和100拷贝扩增产物进行梯度稀释(1/10、1/100、1/200、1/400),并按前述“1.2方法”进行层析检测,结果表明,稀释100倍既能保证扩增体系中保护蛋白和集凝试剂的干扰,也能保证检测具有较高的检测灵敏度检测结果见表8。
表8扩增产物稀释倍数对检测结果的影响
虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
序列表
<110>迈克生物股份有限公司
<120>一种rpa结合免疫荧光层析特异性检测h1甲流亚型的方法
<141>2018-08-30
<160>10
<170>siposequencelisting1.0
<210>1
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>1
agcaagttcgtggcccaatcatgaaacaaa30
<210>2
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>2
ttgctgagctttggatatgaatttcccttt30
<210>3
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>3
caagttcgtggcccaatcatgaaacaaacg30
<210>4
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>4
ttgctgagctttggatatgaatttcccttt30
<210>5
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>5
ttcgtggcccaatcatgaaacaaacggagg30
<210>6
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>6
atttgctgagctttggatatgaatttccct30
<210>7
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>7
cgtggcccaatcatgaaacaaacggaggtg30
<210>8
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>8
atttgctgagctttggatatgaatttccct30
<210>9
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>9
ttcgtggcccaatcatgaaacaaacggagg30
<210>10
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>10
taggatttgctgagctttggatatgaattt30
- 还没有人留言评论。精彩留言会获得点赞!