基于三维子结构的药物分子比较方法与流程
本发明涉及药物分子的设计与筛选技术领域,特别是一种基于三维子结构的药物分子比较方法。
背景技术:
二维结构不相似的分子可能由于拥有相同或相似的子结构而具有相同或相似的生物活性。针对分子的二维子结构搜索,最大公用子结构算法gma(journalofchemicalinformationandcomputersciences,1996,36(1):25-34.)可以实现,得到以分子中原子序号标识的子结构原子序列;
药物分子的生物活性主要取决于其三维结构,一种基于加权高斯函数的分子叠合算法wega(journalofchemicalinformationandmodeling,2013,53(8):1967-1978.)可以实现分子的三维形状定量比较,每个加权高斯球对应一个原子,以所有加权高斯球体积的加和作为分子的体积,采用多个起始叠合情况,寻求全局最大叠合体积。
运用上述两种方法进行药物分子形状比较的主要缺陷是:gma算法只能进行二维子结构的检索,无法满足三维子结构检索和比较的需求;而wega算法没有考虑子结构部分对生物活性的重要性。
技术实现要素:
本发明所要解决的技术问题是如何提供一种基于三维子结构的药物分子比较方法,所述方法可以更有效地利用分子的结构信息。
为解决上述技术问题,本发明所采取的技术方案是:一种基于三维子结构的药物分子比较方法,其特征在于,所述方法包括如下步骤:
读入库分子的二维或三维结构信息,定义查询子结构,得到库分子的子结构匹配原子序列;
读入查询分子和库分子的三维结构信息,以及查询子结构的相关信息,分别计算查询分子、库分子各自子结构的自身重叠体积与各自边链的自身重叠体积;
计算查询分子和库分子多种叠合情况下的重叠体积;
根据查询分子子结构的自身重叠体积和边链的自身重叠体积,库分子子结构的自身重叠体积和边链的自身重叠体积和两分子的子结构及边链的叠合体积,分别计算查询分子和库分子子结构相似度,以及边链相似度,以子结构相似度和边链相似度作为两分子的综合相似度,当库分子匹配子结构有多个时,比较各个匹配子结构下两分子综合相似度,选择其中最大值作为两分子的综合相似度。
进一步的技术方案在于,所述的读入库分子的二维或三维结构信息,定义查询子结构,得到库分子的子结构匹配原子序列的方法如下:
由查询分子中定义子结构为查询子结构,定义的子结构为一个或多个,得到查询子结构原子序列;
读入查询子结构的结构信息,所述结构信息包括查询子结构中每个原子和键的类型;
读入库分子的二维或三维结构信息,所述二维或三维结构信息包括库分子中每个原子和键的类型;
使用gma算法得到库分子的子结构匹配原子序列。
进一步的技术方案在于:定义的查询子结构为多个时,且定义的查询子结构之间不允许有重叠,使用gma算法得到库分子的子结构匹配原子序列后,判断库分子多个子结构匹配原子序列中有无重复原子,舍弃有重复原子的序列,只保留相互无重复原子的多个子结构匹配序列;将相互无重复原子的多个子结构匹配序列合并为一个子结构序列,即视为一个子结构。
进一步的技术方案在于:当定义的查询子结构为一个时,再定义一个或多个外源子结构,且外源子结构即是不在查询分子中,但能与查询子结构有相似功能的子结构,使用gma算法得到库分子的与查询子结构或外源子结构对应的子结构匹配原子序列后,无需判断所有匹配原子序列中有无重复原子;外源子结构将视为单独的子结构,在相应的步骤中,将由外源子结构匹配得到的综合相似度与由查询子结构匹配的综合相似度比较得到综合相似度最好的结果。
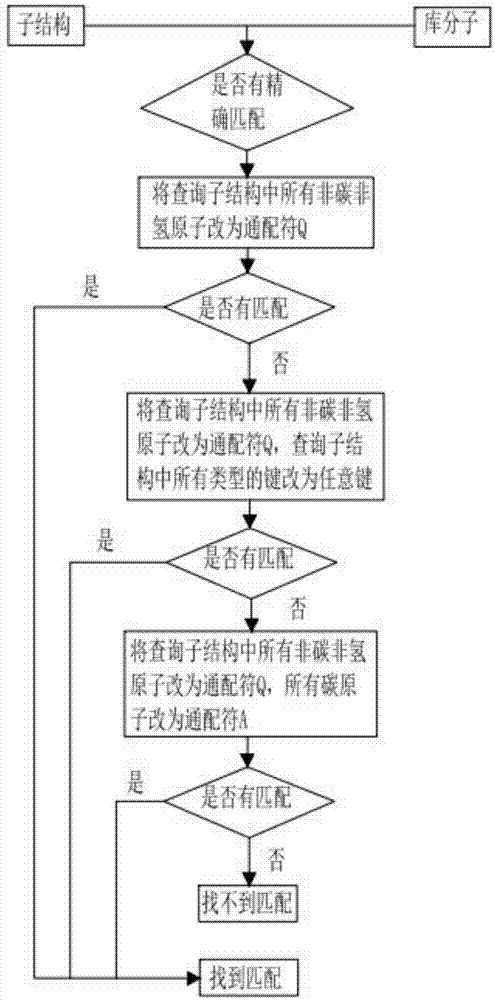
进一步的技术方案在于:在匹配的过程中默认的是子结构精确匹配,当库分子中没有精确匹配的子结构时,选择继续进行泛匹配,得到更多的子结构匹配序列;泛匹配规则如下:将查询子结构中所有非碳非氢原子改为通配符q;若库分子仍无匹配,将查询子结构中所有非碳非氢原子改为通配符q,查询子结构中所有类型的键改为任意键;若库分子仍无匹配,将查询子结构中所有非碳非氢原子改为通配符q,所有碳原子改为通配符a。
进一步的技术方案在于,所述读入查询分子和库分子的三维结构信息,以及查询子结构的相关信息,分别计算查询分子、库分子各自子结构的自身重叠体积与各自边链的自身重叠体积的方法如下:
读入查询分子的三维结构信息,所述三维结构信息包括查询分子中每个原子的类型及其坐标数值;
读入查询子结构的相关信息,所述相关信息为每个查询子结构的原子个数以及原子序列;
计算查询分子中子结构原子的叠合权重wc,查询分子中边链原子的权重为ws;
计算查询分子子结构的自身重叠体积和边链的自身重叠体积,
读入库分子的三维结构信息,所述三维结构信息包括库分子中每个原子的类型及其坐标数值;
计算库分子中子结构原子的叠合权重w′c,库分子中边链原子的权重为w′s;
计算库分子子结构的自身重叠体积和边链的自身重叠体积,
进一步的技术方案在于,计算查询分子中子结构原子的叠合权重wc的计算公式为:
库分子中子结构原子的叠合权重w′c的计算公式为:
进一步的技术方案在于,所述的计算查询分子和库分子多种叠合情况下的重叠体积vc的方法如下:
进一步的技术方案在于,将查询分子的子结构重心和库分子子结构的重心作为叠合中心,将两分子进行起始叠合,计算查询分子和库分子在多种叠合情况下的重叠体积。
进一步的技术方案在于,所述的综合相似度比较规则如下:设定某一阈值,在两个子结构相似度之差大于该阈值时,选择较大的子结构相似度与其对应的边链相似度;在两个子结构相似度之差不大于该阈值时,选择较大的边链相似度与其对应的子结构相似度,将此得到的综合相似度
采用上述技术方案所产生的有益效果在于:本发明所述方法能提高分子形状比较的灵活性,更利于先导化合物的发现,可应用于药物分子的虚拟筛选。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为通配符匹配流程图;
图2为只定义一个查询子结构时两分子综合相似度的比较流程图;
图3为定义多个查询子结构时两分子综合相似度的比较流程图;
图4为定义一个查询子结构以及一个或多个外源子结构时分子综合相似度的比较流程图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细的说明。
本发明提出的一种基于三维子结构的药物分子比较方法能提高分子形状比较的灵活性,可以更有效地利用分子的结构信息。对于wega算法中提出的加权高斯球计算方法保持不变,对子结构部分的各原子赋予相应的叠合权重因子,使得两分子叠合过程中,子结构部分得到较大的叠合。本发明提出以下方法计算权重:
实施例一:只定义一个查询子结构时两分子综合相似度的比较
如图1所示,本发明所述方法包括如下步骤:
步骤(1),读入库分子的二维或三维结构信息,定义查询子结构,得到库分子的子结构匹配原子序列,具体包括:
由查询分子中定义子结构为查询子结构,定义的子结构可以为一个或多个,得到查询子结构原子序列;
读入查询子结构的结构信息,所述结构信息包括查询子结构中每个原子和键的类型;
读入库分子的二维或三维结构信息,所述二维或三维结构信息包括库分子中每个原子和键的类型;
使用gma算法得到库分子的子结构匹配原子序列。
默认的是子结构精确匹配,当库分子中没有精确匹配的子结构时,可选择继续进行泛匹配,得到更多的子结构匹配序列。泛匹配规则如下:将查询子结构中所有非碳非氢原子改为通配符q;若库分子仍无匹配,将查询子结构中所有非碳非氢原子改为通配符q,查询子结构中所有类型的键改为任意键;若库分子仍无匹配,将查询子结构中所有非碳非氢原子改为通配符q,所有碳原子改为通配符a;
通配符匹配流程如图2所示;
步骤(2),系统读入查询分子和库分子的三维结构信息,以及查询子结构的相关信息,分别计算查询分子、库分子各自子结构的自身重叠体积与各自边链的自身重叠体积,具体包括:
读入查询分子的三维结构信息,所述三维结构信息包括查询分子中每个原子的类型及其坐标数值;
读入查询子结构的相关信息,所述相关信息为每个查询子结构的原子个数以及原子序列;
计算查询分子中子结构原子的叠合权重wc,边链原子(除子结构外的其他原子)的权重为ws;
查询分子子结构叠合权重的计算方式为:
计算查询分子子结构的自身重叠体积和边链的自身重叠体积,
读入库分子的三维结构信息,所述三维结构信息包括库分子中每个原子的类型及其坐标数值;
计算库分子中子结构原子的叠合权重w′c,边链原子(除子结构外的其他原子)的权重为w′s;
库分子子结构叠合权重的计算方式为:
计算库分子子结构的自身重叠体积和边链的自身重叠体积,
步骤(3),将查询分子的子结构重心和库分子子结构的重心(子结构各原子的平均位置)作为叠合中心,将两分子进行起始叠合,计算查询分子和库分子在wega算法所述的多种叠合情况下的重叠体积,其中两子结构的重叠体积计算如下:所述的计算查询分子和库分子多种叠合情况下的重叠体积vc的方法如下:
步骤(4),根据查询分子子结构的自身重叠体积和边链的自身重叠体积,库分子子结构的自身重叠体积和边链的自身重叠体积和两分子的子结构及边链的最大叠合体积,分别计算查询分子和库分子子结构相似度,以及边链相似度;以子结构相似度和边链相似度作为两分子的综合相似度;
当库分子匹配子结构有多个时,比较各个匹配子结构下两分子综合相似度,选择其中最大值作为两分子的综合相似度;
设定某一阈值(默认为0.03,可根据实际需要自由设定),在两个子结构相似度之差大于该阈值时,选择较大的子结构相似度与其对应的边链相似度;在两个子结构相似度之差不大于该阈值时,选择较大的边链相似度与其对应的子结构相似度。将此得到的综合相似度
阈值可根据具体需求而加以设定,子结构相似度相差越大,子结构在分子中的重要性应越小。
实施例二:定义多个查询子结构时两分子综合相似度的比较,如图3所示。
定义的查询子结构为多个时,在定义时多个查询子结构间不能重叠。使用gma算法得到库分子的子结构匹配原子序列后,判断库分子多个子结构匹配原子序列中有无重复原子,舍弃有重复原子的序列,只保留相互无重复原子的多个子结构匹配序列;将相互无重复原子的多个子结构匹配序列合并为一个子结构序列,即视为一个子结构,采用实施例一的方式找到库分子所有符合的子结构匹配原子序列,计算两分子各自子结构的自身重叠体积与各自边链的自身重叠体积以及两分子最大重叠体积,最后进行综合相似度比较。
实施例三:定义一个查询子结构以及一个或多个外源子结构时分子综合相似度的比较,如图4所示。
当定义的查询子结构为一个时,可再定义一个或多个外源子结构(外源子结构即是不在查询分子中,但能与查询子结构有相似功能的子结构),使用gma算法得到库分子的与查询子结构或外源子结构对应的子结构匹配原子序列后,无需判断所有匹配原子序列中有无重复原子。外源子结构将视为单独的子结构,采用实施例一的方式继续进行库分子子结构匹配,采用实施例一的方式找到库分子所有符合的子结构匹配原子序列,计算两分子各自子结构的自身重叠体积与各自边链的自身重叠体积以及两分子最大重叠体积,将由外源子结构匹配得到的综合相似度与由查询子结构匹配的综合相似度比较得到综合相似度最好的结果。
- 还没有人留言评论。精彩留言会获得点赞!