类芽孢杆菌和芽孢杆菌属物种甘露聚糖酶的制作方法
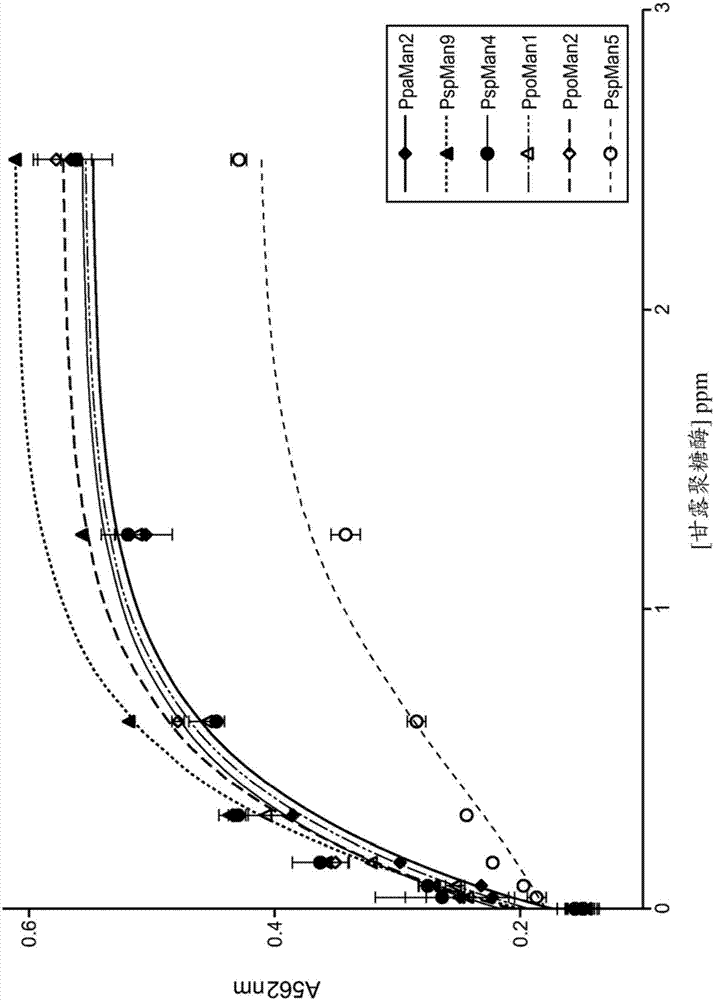
相关申请的交叉引用本专利申请要求2014年7月11日提交的国际申请pct/cn2014/082034的优先权,该国际申请的全部内容据此以引用方式并入本文。本公开涉及来自于类芽孢杆菌(paenibacillus)或芽孢杆菌属物种(bacillusspp)的内切-β-甘露聚糖酶,编码此类内切-β-甘露聚糖酶的多核苷酸,包含此类甘露聚糖酶的组合物,以及使用其的方法。包含此类内切-β-甘露聚糖酶的组合物适于用作洗涤剂以及清洁织物和硬质表面,以及多种其它工业应用。包括内切-β-甘露聚糖酶在内的甘露聚糖酶已用于洗涤剂清洁组合物中以通过水解甘露聚糖而除去胶渍。多种甘露聚糖是天然存在的,诸如例如线性甘露聚糖、葡甘露聚糖、半乳甘露聚糖和葡糖半乳甘露聚糖(glucogalactomannan)。每种此类甘露聚糖均由含有β-1,4-连接的甘露糖残基主链的多糖组成,这些残基中最多33%可被葡萄糖残基取代(yeoman等人,advapplmicrobiol,elsivier)。在半乳甘露聚糖或葡糖半乳甘露聚糖中,半乳糖残基以α-1,6-键连接至甘露聚糖主链(moreira和filho,applmicrobiolbiotechnol(《应用微生物学与生物技术》),79:165,2008)。因此,甘露聚糖水解成其组分糖需要内切-1,4-β-甘露聚糖酶,该酶水解主链键生成短链甘露寡糖,该甘露寡糖通过1,4-β-甘露糖苷酶进一步降解成单糖。尽管内切-β-甘露聚糖酶已在工业酶领域中已为人所知,但对于适于特定条件和用途的另外内切-β-甘露聚糖酶仍存在需要。具体地,本公开提供了包含重组多肽或其活性片段的ndl-clade。一个实施方案涉及包含本文所述的多肽或其片段、活性片段、或变体的ndl-clade。另一个实施方案涉及包含本文所述的重组多肽或其片段、活性片段、或变体的ndl-clade。在一些实施方案中,多肽或其片段、活性片段、或变体为内切-β-甘露聚糖酶。在一些实施方案中,重组多肽或其片段、活性片段、或变体为内切-β-甘露聚糖酶。在一个实施方案中,本文所述的多肽或其片段、活性片段、或变体包含asn33-asp-34-leu35(ndl),其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一些实施方案中,以上任一者的重组多肽或其活性片段包含asn33-asp-34-leu35(ndl),其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在另一个实施方案中,ndl-clade在第30-38位包含wxakndlxxai基序,其中xa为f或y并且x为任何氨基酸,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一些实施方案中,本文所述的多肽或其片段、活性片段、或变体在第30-38位包含wxakndlxbxcai基序,其中xa为f或y,xb为n、y或a,并且xc为a或t,并且其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一些实施方案中,本文所述的重组多肽或其片段、活性片段、或变体在第30-38位包含wxakndlxbxcai基序,其中xa为f或y,xb为n、y或a,并且xc为a或t,并且其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在另一个实施方案中,ndl-clade在第262-273位包含l262d263xxxgpxgxl272t273基序,其中x为任何氨基酸,并且其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在另一个实施方案中,ndl-clade在第262-273位包含l262d263m/lv/at/agpx1gx2l272t273基序,其中x1为n、a或s,并且x2为s、t或n,并且其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。另一个实施方案涉及在第262-273位包含ldm/latgpa/ngs/tlt基序的ndl-clade1,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。另一个实施方案涉及在第262-273位包含ldla/va/tgps/ngnlt基序的ndl-clade2,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。另一个实施方案涉及在第262-273位包含ldl/vs/at/ngpsgnlt基序的ndl-clade3,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在其它实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体与选自以下的氨基酸序列具有至少70%的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体与选自以下的氨基酸序列具有至少70%的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59和60。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体具有甘露聚糖酶活性,诸如对刺槐豆胶半乳甘露聚糖或魔芋葡甘露聚糖的活性。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体在表面活性剂存在下具有甘露聚糖酶活性。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体在4.5-9.0的ph范围内保留其最大甘露聚糖酶活性的至少70%。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体在40℃至70℃的温度范围内保留其最大甘露聚糖酶活性的至少70%。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体在洗涤剂组合物中具有清洁活性。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体在蛋白酶存在下具有甘露聚糖酶活性。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体能够水解选自瓜尔胶、刺槐豆胶以及它们的组合的底物。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体并未进一步包含糖类结合模块。另一个实施方案涉及包含至少一种前述段落的多肽的清洁组合物。本公开还提供了包含至少一种前述段落的重组多肽的清洁组合物。在一些实施方案中,该组合物还包含表面活性剂。在一些优选的实施方案中,表面活性剂为离子表面活性剂。在一些实施方案中,离子表面活性剂选自阴离子表面活性剂、阳离子表面活性剂、两性离子表面活性剂以及它们的组合。在一些优选的实施方案中,组合物还包含选自以下的酶:酰基转移酶、淀粉酶、α-淀粉酶、β-淀粉酶、α-半乳糖苷酶、阿拉伯聚糖酶、阿拉伯糖苷酶、芳基酯酶、β-半乳糖苷酶、β-葡聚糖酶、角叉菜多糖酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、软骨素酶、角质酶、内切-β-1,4-葡聚糖酶、内切-β-甘露聚糖酶、外切-β-甘露聚糖酶、酯酶、外切-甘露聚糖酶、半乳聚糖酶、葡萄糖淀粉酶、半纤维素酶、透明质酸酶、角蛋白酶、漆酶、乳糖酶、木质素酶、脂酶、脂解酶、脂氧合酶、甘露聚糖酶、金属蛋白酶、氧化酶、果胶酸裂解酶、果胶乙酰酯酶、果胶酶、戊聚糖酶、过水解酶、过氧化物酶、酚氧化酶、磷酸酶、磷脂酶、植酸酶、多聚半乳糖醛酸酶、蛋白酶、支链淀粉酶、还原酶、鼠李半乳糖醛酸酶、β-葡聚糖酶、鞣酸酶、转谷氨酰胺酶、木聚糖乙酰酯酶、木聚糖酶、木葡聚糖酶、木糖苷酶、以及它们的组合。在一些实施方案中,组合物还包含蛋白酶和淀粉酶。在一些实施方案中,洗涤剂选自衣物洗涤剂、织物软化洗涤剂、餐具洗涤剂和硬质表面清洁剂。在一些实施方案中,该组合物为颗粒、粉末、固体、条棒、液体、片剂、凝胶、糊剂、泡沫、片或单位剂量组合物。在一些实施方案中,洗涤剂为选自液体、粉末、颗粒状固体和小片的形式。本公开还提供水解存在于表面上的污垢或污渍中的甘露聚糖底物的方法,该方法包括:使表面与洗涤剂组合物接触以产生清洁的表面。本公开还提供纺织物清洁的方法,该方法包括:使沾污的纺织物与洗涤剂组合物接触以产生清洁的纺织物。此外,本公开提供编码前述段落的多肽的核酸或分离的核酸。此外,本公开提供编码前述段落的重组多肽的核酸或分离的核酸。本公开还提供包含可操作地连接至调控序列的本文所述核酸的表达载体。本公开还提供包含与调控序列有效组合的本文所述分离的核酸的表达载体。另外,还提供包含本文所述表达载体的宿主细胞。另一个实施方案提供了包含编码本文所述重组多肽的核酸的宿主细胞。在一些实施方案中,宿主细胞为细菌细胞或真菌细胞。本公开还提供产生本发明的内切-β-甘露聚糖酶的方法,该方法包括:在适合产生包含本发明的内切-β-甘露聚糖酶的培养物的条件下在培养基中培养宿主细胞。在一些实施方案中,该方法还包括通过离心从培养物中移除宿主细胞,并通过过滤移除小于10kda的碎片以产生富含内切-β-甘露聚糖酶的上清液。本公开还提供水解多糖的方法,该方法包括:使包含甘露糖的多糖与上清液接触以产生包含甘露糖的寡糖。在一些实施方案中,多糖选自甘露聚糖、葡甘露聚糖、半乳甘露聚糖、半乳葡甘露聚糖以及它们的组合。通过以下说明,本发明的组合物和方法的这些及其它方面将显而易见。附图说明图1提供了p2jm-pspman4的质粒图谱。图2a-b示出类芽孢杆菌和芽孢杆菌属物种甘露聚糖酶在ph8下,20分钟内对刺槐豆胶(cs-73)的清洁性能。图3a-c示出包括bciman1、bciman3、bciman4、pamman2、ppaman2、ppoman1、ppoman2、pspman4、pspman5、pspman9和ptuman2的甘露聚糖酶的clustalw(1.83)多序列对比。图4示出包括bciman1、bciman3、bciman4、pamman2、ppaman2、ppoman1、ppoman2、pspman4、pspman5、pspman9和ptuman2的甘露聚糖酶的系统发育树,示出来自于其它甘露聚糖酶的ndl-clade甘露聚糖酶的分支以及ndl-clade1和ndl-clade2的分化。图5示出ndl-clade甘露聚糖酶在第30-38位的基序,其使用保守的线性序列编号。图6示出介于保守的leu262-asp263(ld)残基与保守的leu272-thr273(lt)残基之间的ndl-clade甘露聚糖酶(包括ndl-clade1和ndl-clade2甘露聚糖酶)的基序,其使用保守的线性序列编号。图7示出存在于ndl-clade甘露聚糖酶中的基序变化的可能结构结果。最接近的已知芽孢杆菌属jamb-602(1wky)的甘露聚糖酶结构被显示为黑色,而pspman4、pspman9和ppaman2的模型化结构被显示为灰色。缺失基序的位置用箭头予以突出。假定缺失基序影响其所处的环的结构。图8示出pamman3和基准甘露聚糖酶在ph7.2下,30分钟内对刺槐豆胶(cs-73)的清洁性能。图9a-9f示出用clustalw软件创建的成熟形式的各种甘露聚糖酶的多个序列的比对。图10示出用邻近相加的方法(neighborjoiningmethod)创建并用geneioustreebuilder程序显现的成熟形式的各种甘露聚糖酶的氨基酸序列的系统发育树。图11a-11c示出用clustalw软件创建的成熟形式的ndl-clade甘露聚糖酶的序列比对。本文描述了来自类芽孢杆菌或芽孢杆菌属物种的内切-β-甘露聚糖酶,编码此类内切-β-甘露聚糖酶的多核苷酸,包含此类甘露聚糖酶的组合物,以及使用其的方法。在一个实施方案中,本文所述的类芽孢杆菌和芽孢杆菌属物种内切-β-甘露聚糖酶在洗涤剂组合物存在下具有糖基水解酶活性。本文所述的内切-β-甘露聚糖酶的这一特征使其特别适用于多种清洁应用及其它工业应用,例如,在这些应用中所述酶可在存在于洗涤剂组合物中的表面活性剂和其它组分的存在下水解甘露聚糖。为清楚起见,定义了以下术语。未作定义的术语和缩写应赋予它们的在本领域中使用的普通含义。如本文所用,“甘露聚糖内切-1,4-β-甘露糖苷酶”、“内切-1,4-β-甘露聚糖酶”、“内切-β-1,4-甘露聚糖酶”、“β-甘露聚糖酶b”、“β-1,4-甘露聚糖4-甘露水解酶”、“内切-β-甘露聚糖酶”、“β-d-甘露聚糖酶”、“1,4-β-d-甘露聚糖甘露水解酶”或“内切-β-甘露聚糖酶”(ec3.2.1.78)是指能够随机水解甘露聚糖、半乳甘露聚糖和葡甘露聚糖中的1,4-β-d-甘露糖苷键的酶。内切-1,4-β-甘露聚糖酶是若干糖基水解酶家族(包括gh26和gh5)的成员。具体地,内切-β-甘露聚糖酶构成一组可降解甘露聚糖的多糖酶,并表示能够裂解含有甘露糖单元的多糖链(即,能够裂解甘露聚糖、葡甘露聚糖、半乳甘露聚糖和半乳葡甘露聚糖中的糖苷键)的酶。本发明的“内切-β-甘露聚糖酶”可具有另外的酶活性(例如内切-1,4-β-葡聚糖酶、1,4-β-甘露糖苷酶、纤维糊精酶活性等)。如本文所用,“甘露聚糖酶”、“甘露糖苷酶”、“甘露聚糖水解酶”、“甘露聚糖酶多肽”或“甘露聚糖酶蛋白”是指表现出甘露聚糖降解能力的酶、多肽或蛋白质。甘露聚糖酶可例如为内切-β-甘露聚糖酶、外切-β-甘露聚糖酶或糖基水解酶。如本文所用,可以根据本领域中已知的任何工序测定甘露聚糖酶活性(参见例如lever,anal.biochem,47:248,1972;美国专利6,602,842;和国际公布wo95/35362a1)。如本文所用,“甘露聚糖”为具有由β-1,4-连接的甘露糖组成的主链的多糖;“葡甘露聚糖”为具有或多或少规则交替的β-1,4-连接的甘露糖和葡萄糖的主链的多糖;“半乳甘露聚糖”和“半乳葡甘露聚糖”是有α-1,6连接的半乳糖侧支链的甘露聚糖和葡甘露聚糖。这些化合物可以乙酰化。半乳甘露聚糖和半乳葡甘露聚糖的降解通过完全或部分移除半乳糖侧枝而促进。另外,乙酰化甘露聚糖、葡甘露聚糖、半乳甘露聚糖和半乳葡甘露聚糖的降解通过完全或部分脱乙酰化而促进。乙酰基可通过碱或通过甘露聚糖乙酰酯酶而移除。从甘露聚糖酶或通过甘露聚糖酶和α-半乳糖苷酶和/或甘露聚糖乙酰酯酶的组合释放的低聚物可通过β-甘露糖苷酶和/或β-葡糖苷酶进一步降解以释放游离的麦芽糖。如本文所用,“催化活性”或“活性”定量描述给定底物在限定反应条件下的转化率。术语“残余活性”定义为酶在某一组条件下的催化活性与在一组不同条件下的催化活性的比率。术语“比活性”定量描述在限定反应条件下单位量的酶的催化活性。如本文所用,“ph稳定性”描述蛋白经受有限暴露于下述ph值的特性,所述ph值明显偏离于其稳定性最佳的ph(例如,高于或低于最佳ph的多于一个ph单位,而不会在其活性可测量的条件下丧失其活性)。如本文所用,短语“洗涤剂稳定性”是指所指定的洗涤剂组合物组分(如水解酶)在洗涤剂组合物混合物中的稳定性。如本文所用,“过水解酶”是能够催化下述反应的酶,所述反应导致形成适于诸如清洁、漂白和消毒的应用的过酸。如本文所用,在短语“水性组合物”和“水性环境”中使用的术语“水性”是指由至少50%的水构成的组合物。水性组合物可含有至少50%的水、至少60%的水、至少70%的水、至少80%的水、至少90%的水、至少95%的水、至少97%的水、至少99%的水或甚至至少99%的水。如本文所用,术语“表面活性剂”是指任何在本领域中通常被认为具有表面活性性质的化合物。表面活性剂通常包括阴离子型、阳离子型、非离子型和两性离子型化合物,它们在下文中有进一步的描述。如本文所用,“表面性质”用于指静电荷,以及蛋白质的表面所展现的诸如疏水性和亲水性之类的性质。术语“氧化稳定性”是指本公开的内切-β-甘露聚糖酶在本文所公开的甘露糖苷水解、清洁或其它处理期间(例如当暴露于漂白剂或氧化剂或者与漂白剂或氧化剂接触时)常见的条件下,在给定时间段内保留规定量的酶活性。在一些实施方案中,内切-β-甘露聚糖酶在与漂白剂或氧化剂接触给定时间段(例如至少约1分钟、约3分钟、约5分钟、约8分钟、约12分钟、约16分钟、约20分钟等)后保留至少约50%、约60%、约70%、约75%、约80%、约85%、约90%、约92%、约95%、约96%、约97%、约98%或约99%的内切-β-甘露聚糖酶活性。术语“螯合剂稳定性”是指本公开的内切-β-甘露聚糖酶在本文所公开的甘露糖苷水解、清洁或其它处理期间(例如当暴露于螯合剂或者与螯合剂接触时)的常见条件下,在给定时间段内保留规定量的酶活性。在一些实施方案中,内切-β-甘露聚糖酶在与螯合剂接触给定时间段(例如至少约10分钟、约20分钟、约40分钟、约60分钟、约100分钟等)后保留至少约50%、约60%、约70%、约75%、约80%、约85%、约90%、约92%、约95%、约96%、约97%、约98%或约99%的内切-β-甘露聚糖酶活性。术语“热稳定性”和“热稳定的”是指本公开的内切-β-甘露聚糖酶在本文所公开的甘露糖苷水解、清洁或其它处理期间(例如当暴露于改变的温度时)常见的条件下暴露于确定的温度给定时间段后保留规定量的酶活性。改变的温度包括增加或降低的温度。在一些实施方案中,内切-β-甘露聚糖酶在暴露于改变的温度给定的时间段(例如至少约60分钟、约120分钟、约180分钟、约240分钟、约300分钟等)后保留至少约50%、约60%、约70%、约75%、约80%、约85%、约90%、约92%、约95%、约96%、约97%、约98%或约99%的内切-β-甘露聚糖酶活性。术语“清洁活性”是指在本文所公开的甘露糖苷水解、清洁或其它处理期间常见的条件下由内切-β-甘露聚糖酶实现的清洁性能。在一些实施方案中,关于由食品、家用试剂或个人护理产品产生的酶敏感的污渍,通过应用各种清洁测定法对清洁性能进行测定。某些这种污渍包括例如冰淇淋、番茄酱、烧烤酱、蛋黄酱、汤类、巧克力奶、巧克力布丁、冷冻甜点、洗发剂、爽身水、防晒产品、牙膏、刺槐豆胶或瓜尔胶,如在污渍经受标准洗涤条件后由各种色谱分析法、分光光度法或其它定量方法所测定。示例性测定法包括但不限于wo99/34011、美国专利6,605,458和美国专利6,566,114(它们均以引用方式并入本文)中所述的那些测定法,以及实施例中包括的那些方法。如本文所用,术语“清洁的表面”和“清洁的纺织物”分别指具有沾污表面或纺织物的至少10%,优选至少15%、20%、25%、30%、35%或40%的污渍去除百分比的表面或纺织物。术语内切-β-甘露聚糖酶的“清洁有效量”是指特定清洁组合物中实现所需水平酶活性的本文所述内切-β-甘露聚糖酶的量。此类有效量可由本领域普通技术人员容易地确定并且基于多种因素,例如所用的特定内切-β-甘露聚糖酶、清洁应用、清洁组合物的具体组成以及是需要液体组合物还是干燥(例如颗粒状、条状、粉末状、固体状、液体状、片剂、凝胶状、糊剂、泡沫状、片状或单位剂量)组合物等等。如本文所用,术语“清洁辅助材料”意指针对所需清洁组合物的特定类型和产品的形式(例如液体、颗粒、粉末、条、糊状物、喷雾、片剂、凝胶、单位剂量、片、或泡沫组合物)选择的任何液体、固体或气体材料,这些材料还优选与组合物中使用的内切-β-甘露聚糖酶相容。在一些实施方案中,颗粒组合物为“紧凑(compact)”形式,而在其它实施方案中,液体组合物为“浓缩”形式。如本文所用,“清洁组合物”和“清洁制剂”是指可用于从待清洁物品例如织物、器皿、接触镜片、其它固体表面、毛发、皮肤、牙齿等除去不期望的化合物(例如污垢或污渍)的化学成分的混合物。所述组合物或制剂可视待清洁的表面、物品或织物以及组合物或制剂的所需形式而呈液体、凝胶、颗粒、粉末、条、糊状物、喷雾、片剂、凝胶、单位剂量、片、或泡沫形式。如本文所用,术语“洗涤剂组合物”和“洗涤剂制剂”是指旨在用于供清洁沾污物体的洗涤介质中的化学成分的混合物。洗涤剂组合物/制剂一般包含至少一种表面活性剂,并且可任选地包含水解酶、氧化-还原酶、助洗剂、漂白剂、漂白活化剂、上蓝剂和荧光染料、抗结块剂、掩蔽剂、酶活化剂、抗氧化剂和增溶剂。如本文所用,“餐具洗涤组合物”是指用于清洁餐具(包括刀叉餐具)的所有形式的组合物,其包括但不限于颗粒和液体形式。在一些实施方案中,餐具洗涤组合物是可用于自动洗碗碟机中的“自动餐具洗涤”组合物。不旨在使本公开局限于任何特定类型或餐具洗涤组合物。实际上,本公开可用于清洁任何材料(包括但不限于陶瓷、塑料、金属、瓷器、玻璃、丙烯酸树脂等)的餐具(例如器皿,其包括但不限于盘子、杯子、玻璃杯、碗等)和刀具(例如刀叉餐具,包括但不限于匙、刀、叉、服务用具等)。术语“餐具”在本文指器皿和刀具二者。如本文所用,术语“漂白”是指在合适的ph和温度条件下处理材料(例如织物、衣物、浆料等)或表面足够长的时间以实现材料变亮(即,变白)和/或清洁。适于漂白的化学品的示例包括但不限于clo2、h2o2、过酸、no2等。如本文所用,变体内切-β-甘露聚糖酶的“洗涤性能”是指变体内切-β-甘露聚糖酶对洗涤的贡献,这种贡献向洗涤剂组合物提供另外的清洁性能。洗涤性能在相关的洗涤条件下进行比较。术语“相关的洗涤条件”在本文中用于指在盘碟和衣物洗涤剂细分市场中家居下实际使用的条件,尤其洗涤温度、时间、洗涤力学、泡沫浓度、洗涤剂类型和水硬度。如本文所用,术语“消毒”是指从表面去除污染物,以及抑制或杀死物品表面上的微生物。不旨在本公开局限于任何特定的表面、物品或待去除的污染物或微生物。本文的清洁组合物的“紧凑”形式最佳由密度反映,就组成来说,由无机填料盐的量反映。无机填料盐是呈粉末形式的洗涤剂组合物的常规成分。在常规洗涤剂组合物中,填料盐大量存在,通常占总组合物的约17重量%至约35重量%。相比之下,在致密型组合物中,填料盐以不超过总组合物的约15%的量存在。在一些实施方案中,填料盐以不超过组合物的约10重量%,或更优选不超过约5重量%的量存在。在一些实施方案中,无机填料盐选自碱金属和碱土金属硫酸盐和氯化物。在一些实施方案中,优选填料盐为硫酸钠。术语“纺织物”或“纺织材料”是指织造织物,以及适于转变成或用作纱线、机织材料、针织材料和非织造物的人造短纤维和细丝。该术语涵盖由天然以及合成(例如制造的)纤维制成的纱线。当核酸或多核苷酸从其它组分(包括但不限于例如其它蛋白质、核酸、细胞等)至少部分地或完全地分开时,该核酸或多核苷酸是“分离的”。相似地,当多肽、蛋白质或肽从其它组分(包括但不限于例如其它蛋白质、核酸、细胞等)至少部分地或完全地分开时,该多肽、蛋白质或肽是“分离的”。以摩尔浓度计,在组合物中,分离的物质的丰度比其它物质更高。例如,分离的物质可以占所有存在的大分子物质的至少约60%、约65%、约70%、约75%、约80%、约85%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或约100%(以摩尔浓度计)。优选地,目的物质被纯化为基本上均一的(即通过常规检测方法在组合物中检测不到污染物)。纯度和均一性可以使用本领域熟知的多种技术测定,例如对核酸或蛋白质样品分别进行琼脂糖或聚丙烯酰胺凝胶电泳,然后染色显示。如果需要,可采用高分辨率技术,例如高效液相色谱法(hplc)或类似的方法来纯化材料。应用于核酸或多肽的术语“纯化的”一般表示经本领域熟知的分析技术测定,核酸或多肽基本上不含其它组分(例如纯化的多肽或多核苷酸在电泳凝胶、色谱洗脱物和/或经密度梯度离心的介质中形成离散的条带)。例如,在电泳凝胶中产生基本上一个条带的核酸或多肽是“纯化的”。纯化的核酸或多肽的纯度为至少约50%,通常纯度为至少约60%、约65%、约70%、约75%、约80%、约85%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%、约99.5%、约99.6%、约99.7%、约99.8%,或更大(例如以摩尔浓度计的重量%)。在相关意义上,在应用纯化或富集技术后某分子的浓度有实质性增加时,则对组合物富集了该分子。术语“富集的”是指以高于初始组合物的相对或绝对浓度存在于组合物中的化合物、多肽、细胞、核酸、氨基酸或其它指定材料或组分。如本文所用,“多肽”是指包含多个通过肽键连接的氨基酸的分子。术语“多肽”、“肽”和“蛋白质”可互换使用。蛋白质可任选经过修饰(例如糖基化、磷酸化、酰化、法尼基化、异戊烯化、磺酸化等)以增加功能性。当此类氨基酸序列展现活性时,其可称为“酶”。使用氨基酸残基的常规单字母或三字母代码,其中氨基酸序列是以标准的氨基末端至羧基末端取向(即n→c)示出。术语“多核苷酸”涵盖dna、rna、异源双链体和能编码多肽的合成分子。核酸可为单链或双链的,并且可以具有化学修饰。术语“核酸”与“多核苷酸”可互换使用。由于遗传密码具有简并性,故可以使用多于一个密码子来编码特定氨基酸,并且本发明组合物和方法涵盖编码特定氨基酸序列的核苷酸序列。除非另外说明,否则核酸序列是以5'至3'取向提供。如本文所用,术语“野生型”和“天然的”是指自然界中存在的多肽或多核苷酸。关于多肽的术语“野生型”、“亲本”或“参考”是指不在一个或多个氨基酸位置处包括人为制造的置换、插入或缺失的天然存在的多肽。类似地,关于多核苷酸的术语“野生型”、“亲本”或“参考”是指不包括人为制造的核苷改变的天然存在的多核苷酸。然而,应注意,编码野生型多肽、亲本多肽或参考多肽的多核苷酸不局限于天然存在的多核苷酸,而涵盖任何编码野生型多肽、亲本多肽或参考多肽的多核苷酸。如本文所用,“变体多肽”是指通过置换、添加或缺失一个或多个氨基酸,通常利用重组dna技术,从亲本(或参考)多肽衍生的多肽。变体多肽与亲本多肽可能有少数氨基酸残基不同,并且可通过其与亲本多肽一级氨基酸序列的同源性/同一性水平来限定。优选地,变体多肽与亲本多肽具有至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或甚至至少99%的氨基酸序列同一性。可以使用诸如blast、align和clustal之类的已知程序,使用标准参数确定序列同一性。(参见例如altschul等人,[1990]j.mol.biol.215:403-410;henikoff等人[1989]proc.natl.acad.sci.usa89:10915;karin等人[1993]proc.natl.acad.sciusa90:5873;以及higgins等人[1988]gene73:237-244)。用于进行blast分析的软件通过国家生物技术信息中心(nationalcenterforbiotechnologyinformation)公开获得。也可用fasta(pearson等人[1988]proc.natl.acad.sci.usa85:2444-2448)来搜索数据库。两个多肽实质上相同的一个指示是第一多肽与第二多肽是免疫交叉反应性的。通常,差别在于保守氨基酸置换的多肽是免疫交叉反应性的。因此,例如,在两个多肽仅相差保守置换的情况下,一种多肽与第二多肽实质上相同。如本文所用,“变体多核苷酸”编码变体多肽;与亲本多核苷酸具有指定程度的同源性/同一性;或在严格条件下与亲本多核苷酸或其互补序列杂交。优选地,变体多核苷酸与亲本多核苷酸具有至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或甚至至少99%的核苷酸序列同一性。测定同一性百分比的方法是本领域已知的并且上文刚进行描述。术语“源自”涵盖术语“来源于”、“从...获得”、“可由...获得”、“分离自”和“由...产生”,并且通常是指一种指定材料在另一指定材料中找到其起源或者具有可参照另一指定材料而描述的特征。如本文所用,术语“杂交”是指用于使一条核酸链通过本领域已知的碱基配对与互补链接合的方法。如本文所用,短语“杂交条件”是指进行杂交反应的条件。这些条件通常根据测量杂交的条件的“严格性”程度来分类。严格性程度可例如基于核酸结合复合物或探针的解链温度(tm)。例如,“最高严格性”通常在约tm-5℃(比探针的tm低5°)下发生;“高严格性”通常在比tm低约5-10°下发生;“中等严格性”通常在比探针的tm低约10-20°下发生;并且“低严格性”通常在比tm低约20-25°下发生。另选地或除此之外,杂交条件可基于杂交的盐或离子强度条件和/或一种或多种严格性洗涤,例如:6xssc=极低的严格性;3xssc=较低至中等的严格性;1xssc=中等的严格性;和0.5xssc=较高的严格性。在功能上,可以使用最高严格性条件来鉴别与杂交探针具有严格的同一性或接近严格的同一性的核酸序列;而高严格性条件用于鉴别与探针具有约80%或更高序列同一性的核酸序列。对于需要高选择性的应用,通常需要使用相对严格的条件来形成杂交物(例如,使用相对较低的盐和/或高温条件)。如本文所用,严格条件定义为50℃和0.2xssc(1xssc=0.15mnacl、0.015m柠檬酸钠,ph7.0)。在关于至少两条核酸或多肽的上下文中,短语“基本上相似”和“基本上相同”意指,多核苷酸或多肽包含与亲本或参考序列具有至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或甚至至少约99%的同一性,或者不包括在不增加功能性的情况下仅为避开本描述所作的氨基酸置换、插入、缺失或修饰的序列。如本文所用,“表达载体”是指dna构建体,其含有编码指定多肽且可操作地连接至能够实现该多肽在合适的宿主中表达的合适控制序列的dna序列。这种控制序列包括实现转录的启动子、控制这种转录的任选的操纵子序列、编码合适的mrna核糖体结合位点的序列和控制转录和翻译终止的序列。载体可以是质粒、噬菌体颗粒或仅仅是潜在基因组插入物。一旦转化进适合宿主中,载体就可独立于宿主基因组复制和发挥作用,或者在一些情况下可整合进基因组本身中。术语“重组”是指例如通过使编码序列突变以产生改变的多肽、将编码序列与另一基因的编码序列融合、使基因处于不同启动子控制下、在异源生物体中表达基因、以降低或升高的水平表达基因、以不同于基因的天然表达谱的方式有条件地或组成地表达基因等,对遗传物质(即,核酸、核酸编码的多肽以及包含这些多核苷酸的载体和细胞)进行修饰以改变其序列或表达特征。一般说讲,重组核酸、多肽和基于它们的细胞已通过人进行操纵使得其与自然界中存在的相关核酸、多肽和细胞不相同。“信号序列”是指结合至多肽的n端部分,并且促进成熟形式的蛋白质从细胞分泌的氨基酸序列。细胞外蛋白质的成熟形式没有信号序列,其在分泌过程期间被切除。术语“选择标记”或“可选择标记”是指能够在宿主细胞中表达使得易于选择含有所引入的核酸或载体的宿主的基因。可选标记的示例包括但不限于抗微生物物质(例如潮霉素、博来霉素或氯霉素)和/或赋予宿主细胞代谢益处(如营养益处)的基因。如本文所用,术语“可选标记”或“可选基因产物”是指编码酶活性的基因的使用,该酶活性给表达该选择性标记的细胞赋予抗生素或药物抗性。如本文所用,术语“调控元件”是指控制核酸序列表达的某一方面的遗传元件。举例来说,启动子是促进可操作地连接的编码区的转录起始的调控元件。另外的调控元件包括剪接信号、聚腺苷酸化信号和终止信号。如本文所用,“宿主细胞”一般为以使用本领域已知的重组dna技术构建的载体转化或转染的原核或真核宿主。转化的宿主细胞能够复制编码蛋白质变体的载体或者表达所需的蛋白质变体。在载体编码蛋白质变体的前蛋白或原蛋白形式的情况下,这些变体在表达时通常由宿主细胞分泌到宿主细胞培养基中。在将核酸序列插入细胞的语境中,术语“引入”意指转化、转导或转染。转化的手段包括本领域已知的原生质体转化法、氯化钙沉淀法、电穿孔法、裸dna法等。(参见chang和cohen[1979]mol.gen.genet(《当代遗传学》),168:111-115;smith等人[1986]appl.env.microbiol.51:634;以及ferrari等人在harwood,bacillus,plenumpublishingcorporation,第57-72页,1989中的综述文章)。其它科技术语的含义与本发明所属领域普通技术人员通常所理解的相同(参见例如singleton和sainsbury,dictionaryofmicrobiologyandmolecularbiology(微生物学与分子生物学词典),第2版,johnwileyandsons,ny1994;以及hale和marham,theharpercollinsdictionaryofbiology(哈普柯林斯生物学词典),harperperennial,ny1991)。除非文中另外明确说明,否则单数术语“一个”、“一种”和“所述”包括复数含义。如本文结合数值所用,术语“约”是指数值的-10%至+10%范围。例如,短语“约6的ph值”是指5.4至6.6的ph值。提供的小标题是出于便利的目的,不应解释为限制。在一个小标题下包括的描述可适用于本说明书整体。类芽孢杆菌和芽孢杆菌属物种多肽一个实施方案涉及包含本文所述的多肽或其片段、活性片段、或变体的ndl-clade。另一个实施方案涉及包含本文所述的重组多肽或其片段、活性片段、或变体的ndl-clade。在一些实施方案中,多肽或重组多肽或其片段、活性片段、或变体为内切-β-甘露聚糖酶。在一些实施方案中,本文所述的多肽或重组多肽或其片段、活性片段、或变体包含asn33-asp-34-leu35(ndl),其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一个方面,本文所述的组合物或方法包括ndl-clade中的多肽或重组多肽或其片段、活性片段、或变体。在另一方面,本文所述的多肽或重组多肽或其片段、活性片段、或变体用于本文所述的方法或组合物。在一个方面,本发明的组合物和方法提供了ndl-clade中的重组内切-β-甘露聚糖酶多肽或其片段、活性片段、或变体。在另一个方面,本发明的组合物和方法包括ndl-clade中的重组内切-β-甘露聚糖酶多肽或其片段、活性片段、或变体。在另一个方面,本发明的组合物和方法包括ndl-clade中的内切-β-甘露聚糖酶多肽或其片段、活性片段、或变体。另一个方面涉及ndl-clade中的多肽或重组多肽内切-β-甘露聚糖酶、或其片段、活性片段、或变体。一个实施方案涉及内切-β-甘露聚糖酶的ndl-clade。另一个实施方案涉及内切-β-甘露聚糖酶的ndl-clade1。另一个实施方案涉及内切-β-甘露聚糖酶的ndl-clade2。另一个实施方案涉及内切-β-甘露聚糖酶的ndl-clade3。在一些实施方案中,ndl-clade包含asn33-asp-34-leu35,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列相对应来编号并且是基于保守的线性序列编号的。在另一个实施方案中,ndl-clade在第30-38位包含wxakndlxxai基序,其中xa为f或y并且x为任何氨基酸,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列相对应来编号并且是基于保守的线性序列编号的。在一些实施方案中,ndl-clade在第30-38位包含wxakndlxbxcai基序,其中xa为f或y,xb为n、y或a,并且xc为a或t,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列相对应来编号并且是基于保守的线性序列编号的。在另一个实施方案中,ndl-clade在第262-273位包含l262d263xxxgpxgxl272t273基序,其中x为任何氨基酸,并且其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在另一个实施方案中,ndl-clade在第262-273位包含l262d263m/lv/at/agpx1gx2l272t273基序,其中x1为n、a或s,并且x2为s、t或n,并且其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一些实施方案中,ndl-clade1在第262-273位包含ldm/latgpn/ags/tlt,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一些实施方案中,ndl-clade2在第262-273位包含ldla/va/tgps/ngnlt,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在其它实施方案中,ndl-clade3在第262-273位包含ldl/vs/at/ngpsgnlt,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号并且是基于保守的线性序列编号的。在一个方面,本发明的组合物和方法提供了本文所述的类芽孢杆菌和芽孢杆菌属物种的内切-β-甘露聚糖酶多肽或其片段、活性片段、或变体。示例性类芽孢杆菌或芽孢杆菌属物种多肽包括从环状芽孢杆菌(b.circulans)k-1分离的bciman1(seqidno:2)、从环状芽孢杆菌196分离的bciman3(seqidno:4)、从环状芽孢杆菌cgmcc1554分离的bciman4(seqidno:6)、从多粘类芽孢杆菌(paenibacilluspolymyxa)e681分离的ppoman1(seqidno:8)、从多粘类芽孢杆菌sc2分离的ppoman2(seqidno:10)、从类芽孢杆菌属a1分离的pspman4(seqidno:12)、从类芽孢杆菌属ch-3分离的pspman5(seqidno:14)、从解淀粉类芽孢杆菌(paenibacillusamylolyticus)分离的pamman2(前体蛋白为seqidno:16并且成熟蛋白为seqidno:17)、从类芽孢杆菌属n021菌株分离的pamman3(seqidno:63)、从饲料类芽孢杆菌(paenibacilluspabuli)分离的ppaman2(前体蛋白为seqidno:19)、从类芽孢杆菌属fel05分离的pspman9(前体蛋白为seqidno:21)、以及从paenibacillustundrae分离的ptuman2(前体蛋白为seqidno:23并且成熟蛋白为seqidno:24)。本发明组合物和方法涵盖这些及其它分离的pspman4多肽。另一个实施方案涉及本文所述的多肽或重组多肽或其片段、活性片段、或变体,其包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。另一个实施方案涉及本文所述的重组多肽或其片段、活性片段、或变体,其包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59和60。在另一个实施方案中,ndl-clade多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade1重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在另一个实施方案中,ndl-clade1多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在甚至另一个实施方案中,ndl-clade2多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在另一个实施方案中,ndl-clade2重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在甚至另一个实施方案中,ndl-clade3多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:74和81。在甚至另一个实施方案中,ndl-clade3重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大同一性的氨基酸序列:seqidno:74和81。在其它实施方案中,以上任一种的多肽或重组多肽或其片段、活性片段、或变体与选自以下的氨基酸序列具有至少70%的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade多肽或重组多肽或其片段、活性片段、或变体包含与选自以下的氨基酸序列具有至少70%同一性的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade1多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少70%同一性的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在另一个实施方案中,ndl-clade2多肽或重组多肽或其片段、活性片段、或变体包含与选自以下的氨基酸序列具有至少70%同一性的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在甚至另一个实施方案中,ndl-clade3多肽或重组多肽或其片段、活性片段、或变体包含与选自以下的氨基酸序列具有至少70%同一性的氨基酸序列:seqidno:74和81。在其它实施方案中,以上任一种的多肽或重组多肽或其片段、活性片段、或变体与选自以下的氨基酸序列具有至少80%的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少80%同一性的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade1多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少80%同一性的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在另一个实施方案中,ndl-clade2多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少80%同一性的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在甚至另一个实施方案中,ndl-clade3多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少80%同一性的氨基酸序列:seqidno:74和81。在其它实施方案中,以上任一种的多肽或重组多肽或其片段、活性片段、或变体与选自以下的氨基酸序列具有至少90%的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少90%同一性的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade1多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少90%同一性的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在另一个实施方案中,ndl-clade2多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少90%同一性的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在甚至另一个实施方案中,ndl-clade3多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少90%同一性的氨基酸序列:seqidno:74和81。在其它实施方案中,以上任一种的多肽或重组多肽或其片段、活性片段、或变体与选自以下的氨基酸序列具有至少95%的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少95%同一性的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,ndl-clade1多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少95%同一性的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在另一个实施方案中,ndl-clade2多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少95%同一性的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在甚至另一个实施方案中,ndl-clade3多肽或重组多肽或其片段、活性片段、或变体还包含与选自以下的氨基酸序列具有至少95%同一性的氨基酸序列:seqidno:74和81。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其包含选自以下的氨基酸序列:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59和60。在另一个实施方案中,本发明为上述实施方案中任一项的多肽或重组多肽或其片段、活性片段、或变体,其包含选自以下的氨基酸序列:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,本发明为ndl-clade多肽或重组多肽或其片段、活性片段、或变体,其包含选自以下的氨基酸序列:seqidno:4、6、8、10、12、14、16、17、19、21、23、24、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在另一个实施方案中,本发明为ndl-clade1多肽或重组多肽或其片段、活性片段、或变体,其包含选自以下的氨基酸序列:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71。在另一个实施方案中,本发明为ndl-clade2多肽或重组多肽或其片段、活性片段、或变体,其包含选自以下的氨基酸序列:seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73。在甚至另一个实施方案中,本发明为ndl-clade3多肽或重组多肽或其片段、活性片段、或变体,其包含选自以下的氨基酸序列:seqidno:74和81。序列同一性可例如使用诸如blast、align或clustal之类的程序(如本文中所述)通过氨基酸序列比对来测定。在一些实施方案中,本发明的多肽为分离的多肽。在一个实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽具有甘露聚糖酶活性。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽具有甘露聚糖酶活性。在一些实施方案中,甘露聚糖酶活性是对甘露聚糖树胶的活性。在一些实施方案中,甘露聚糖酶活性是对刺槐豆胶半乳甘露聚糖的活性。在一些实施方案中,甘露聚糖酶活性是对魔芋葡甘露聚糖的活性。在一个实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中甘露聚糖酶活性处于表面活性剂存在的情况中。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其活性片段,其中甘露聚糖酶活性处于表面活性剂存在的情况中。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在4.5-9.0的ph范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在4.5-9.0的ph范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在5.5-8.5的ph范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在5.5-8.5的ph范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在6.0-7.5的ph范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在6.0-7.5的ph范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在高于3.0、3.5、4.0或4.5的ph下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在高于3.0、3.5、4.0或4.5的ph下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在低于10.0、9.5或9.0的ph下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在低于10.0、9.5或9.0的ph下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在40℃至70℃的温度范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在45℃至65℃的温度范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在50℃至60℃的温度范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在高于20℃、25℃、30℃、35℃、或40℃的温度下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在低于90℃、85℃、80℃、75℃、或70℃的温度下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在40℃至70℃的温度范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在45℃至65℃的温度范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在50℃至60℃的温度范围内保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在高于20℃、25℃、30℃、35℃、或40℃的温度下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在低于90℃、85℃、80℃、75℃、或70℃的温度下保留其最大蛋白酶活性的至少70%。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在洗涤剂组合物中具有清洁活性。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在洗涤剂组合物中具有清洁活性。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在洗涤剂组合物中具有清洁活性。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽在蛋白酶存在下具有甘露聚糖酶活性。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽能够水解选自瓜尔胶、刺槐豆胶以及它们的组合的底物。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在洗涤剂组合物中具有清洁活性。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽在蛋白酶存在下具有甘露聚糖酶活性。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽能够水解选自瓜尔胶、刺槐豆胶以及它们的组合的底物。在一些实施方案中,本发明为上述实施方案中任一项的多肽或其片段、活性片段、或变体,其中所述多肽并未进一步包含糖类结合模块。在一些实施方案中,本发明为上述实施方案中任一项的重组多肽或其片段、活性片段、或变体,其中所述多肽并未进一步包含糖类结合模块。在某些实施方案中,本发明的多肽通过重组方式产生,而在其它实施方案中,本发明的多肽通过合成方式产生,或从天然来源中纯化而得。在某些其它实施方案中,本发明的多肽包含不会实质上影响多肽的结构和/或功能的置换。示例性的置换是保守突变,如表i中所概述的。表i:氨基酸置换涉及天然存在的氨基酸的置换一般是通过使编码本发明重组多肽的核酸突变,然后在生物体中表达变体多肽来进行。涉及非天然存在的氨基酸的置换或氨基酸的化学修饰一般是在由生物体合成本发明重组多肽后通过以化学方式对所述多肽进行修饰来实现。在一些实施方案中,本发明的分离的变体多肽与seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59或60基本上相同,这意指其不包含不会显著影响多肽的结构、功能或表达的氨基酸置换、插入或缺失。在一些实施方案中,本发明的分离的变体多肽与seqidno:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81基本上相同,这意指其不包含不会显著影响多肽的结构、功能或表达的氨基酸置换、插入或缺失。在一些实施方案中,本发明的分离的变体多肽与seqidno:seqidno:seqidno:6、12、14、16、17、19、21、23、24、34、35、36、38、39、40、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70和71基本上相同,这意指其不包含不会显著影响多肽的结构、功能或表达的氨基酸置换、插入或缺失。在一些实施方案中,本发明的分离的变体多肽与seqidno:4、8、10、30、31、32、42、43、44、46、47、48、72和73基本上相同,这意指其不包含不会显著影响多肽的结构、功能或表达的氨基酸置换、插入或缺失。在一些实施方案中,本发明的分离的变体多肽与seqidno:74和81基本上相同,这意指其不包含不会显著影响多肽的结构、功能或表达的氨基酸置换、插入或缺失。本发明的此类分离的变体多肽包括仅设计用于避开本描述的多肽。在一些实施方案中,本发明的多肽(包括其变体)具有1,4-β-d-甘露糖苷水解酶活性,其包括甘露聚糖酶、内切-1,4-β-d-甘露聚糖酶、外切-1,4-β-d-甘露聚糖酶半乳甘露聚糖酶和/或葡甘聚糖酶活性。1,4-β-d-甘露糖苷水解酶活性可使用本文所述的测定法或通过本领域已知的其它测定法来测定和测量。在一些实施方案中,本发明的多肽在洗涤剂组合物的存在下具有活性。本发明的多肽包括“全长”多肽的保留1,4-β-d-甘露糖苷水解酶活性的片段。这些片段优选保留全长多肽的活性位点,但可具有非关键性氨基酸残基的缺失。这些片段的活性可使用本文所述的测定法或通过本领域已知的其它测定法容易地测定。在一些实施方案中,本发明多肽的片段在洗涤剂组合物的存在下保留1,4-β-d-甘露糖苷水解酶活性。在一些实施方案中,本发明多肽的氨基酸序列和衍生物作为n和/或c端融合蛋白而产生,例如以有助于提取、检测和/或纯化和/或向本发明多肽增加功能性质。融合蛋白伴侣的示例包括但不限于谷胱甘肽s-转移酶(gst)、6xhis、gal4(dna结合和/或转录激活结构域)、flag、myc、bce103(wo2010/044786)或本领域技术人员熟知的其它标签。在一些实施方案中,在融合蛋白伴侣与所关注的蛋白质序列之间提供蛋白水解裂解位点,以允许移除融合蛋白序列。优选地,融合蛋白不阻碍本发明多肽的活性。在一些实施方案中,将本发明的多肽融合至功能结构域,其包括前导肽、前肽、一个或多个结合结构域(模块)和/或催化结构域。合适的结合结构域包括但不限于各种特异性的糖类结合模块(例如cbm),从而在应用本发明多肽的过程中向存在的碳水化合物组分提供增强的亲和力。如本文所述,本发明多肽的cbm和催化结构域可操作地连接。糖类结合模块(cbm)被定义为碳水化合物活性酶内的连续氨基酸序列,其含有具有碳水化合物结合活性的分立折叠(discreetfold)。几个例外是纤维小体支架蛋白(cellulosomalscaffoldinprotein)中的cbm以及极少数的独立推定cbm(independentputativecbm)。cbm需要作为模块存在于较大的酶内使这类碳水化合物结合蛋白与其它非催化性糖结合蛋白如凝集素和糖转运蛋白区分开来。cbm之前根据最初发现若干结合纤维素的模块而被分类为纤维素结合结构域(cbd)(tomme等人,eurjbiochem,170:575-581,1988;以及gilkes等人,jbiolchem,263:10401-10407,1988)。然而,碳水化合物活性酶中结合碳水化合物而非纤维素但满足cbm标准的另外模块被持续发现,因此需要使用更加包容性的术语将这些多肽重新分类。之前对纤维素结合结构域的分类基于氨基酸相似性。cbd的分组称为“型”并用罗马数字进行编号(例如i型cbd或ii型cbd)。为了与糖苷水解酶分类一致,现在将这些分组称为家族并用阿拉伯数字进行编号。家族1至13与i至xiii型相同(tomme等人,载于enzymaticdegradationofinsolublepolysaccharides(saddler,j.n.&penner,m.编辑),cellulose-bindingdomains:classificationandproperties.第142-163页,americanchemicalsociety,washington,1995)。对cbm的结构和结合模式的详细综述可见于(boraston等人,biochemj,382:769-81,2004)。预计cbm的家族分类:有助于鉴别cbm,在一些情况下预测结合特异性,有助于鉴别功能残基,揭示进化关系并可能可预测多肽折叠。由于蛋白质的折叠比它们的序列更保守,因此可将一些cbm家族分成超家族或部族(clan)。当前的cbm家族为1-63。cbm/cbd还作为非水解型多糖结合蛋白存在于藻类,例如红藻紫红紫菜(porphyrapurpurea)中。然而,大多数cbd来自纤维素酶和木聚糖酶。cbd存在于蛋白的n端和c端或在内部。酶杂合体是本领域已知的(参见例如wo90/00609和wo95/16782)并可通过以下方法制备:将包含连接(通过或不通过接头)到编码所公开的本发明多肽的dna序列的编码纤维素结合结构域的dna片段的dna构建体转化进宿主细胞,然后使宿主细胞生长以表达融合基因。酶杂合体可由下式表示:cbm-mr-x或x-mr-cbm在上式中,cbm为对应于至少糖类结合模块的氨基酸序列的n-端或c-端区域;mr为中间区域(接头),并且可为键或短连接基团,其优选具有约2至约100个碳原子,更优选2至40个碳原子;或优选为约2至约100个氨基酸,更优选为2至40个氨基酸;并且x为本发明的具有甘露聚糖酶催化活性的多肽的n-端或c-端区域。此外,甘露聚糖酶可包含多于一个cbm或其它无糖分解功能的模块/结构域。术语“模块”和“结构域”在本公开中可互换使用。合适的酶活性结构域具有支持本发明多肽在产生所需产物中的作用的活性。催化结构域的非限制性示例包括:纤维素酶、半纤维素酶(诸如木聚糖酶)、外切-甘露聚糖酶、葡聚糖酶、阿拉伯聚糖酶、半乳糖苷酶、果胶酶和/或其它活性如蛋白酶、脂肪酶、酸性磷酸酶和/或其它酶或其功能片段。融合蛋白任选通过接头序列连接至本发明多肽,该接头序列只是接合本发明多肽和融合结构域而不显著影响任一组分的性质,或者接头任选地针对预期应用具有功能重要性。另选地,将本文所述的本发明多肽与一种或多种所关注的另外的蛋白质结合使用。目标蛋白质的非限制性示例包括:酰基转移酶、淀粉酶、α-淀粉酶、β-淀粉酶、α-半乳糖苷酶、阿拉伯聚糖酶、阿拉伯糖苷酶、芳基酯酶、β-半乳糖苷酶、β-葡聚糖酶、角叉菜多糖酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、软骨素酶、角质酶、内切-β-1,4-葡聚糖酶、内切-β-甘露聚糖酶、外切-β-甘露聚糖酶、酯酶、外切-甘露聚糖酶、半乳聚糖酶、葡萄糖淀粉酶、半纤维素酶、透明质酸酶、角蛋白酶、漆酶、乳糖酶、木质素酶、脂酶、脂解酶、脂氧合酶、甘露聚糖酶、氧化酶、果胶酸裂解酶、果胶乙酰酯酶、果胶酶、戊聚糖酶、过氧化物酶、酚氧化酶、磷酸酶、磷脂酶、植酸酶、多聚半乳糖醛酸酶、蛋白酶、支链淀粉酶、还原酶、鼠李半乳糖醛酸酶、β-葡聚糖酶、鞣酸酶、转谷氨酰胺酶、木聚糖乙酰酯酶、木聚糖酶、木葡聚糖酶、木糖苷酶、金属蛋白酶和/或其它酶。在其它实施方案中,本发明多肽与引导本发明多肽的细胞外分泌的信号肽融合。例如,在某些实施方案中,信号肽为本发明多肽的天然信号肽。在其它实施方案中,信号肽为非天然信号肽,诸如枯草芽孢杆菌(b.subtilis)apre信号肽。在一些实施方案中,本发明多肽在成熟形式与信号肽之间具有ala-gly-lys的n端延伸。在一些实施方案中,本发明的多肽是在异源生物体(即,除类芽孢杆菌和芽孢杆菌属物种之外的生物体)中表达。示例性的异源生物体是革兰氏阳性细菌,如枯草芽孢杆菌(bacillussubtilis)、地衣芽孢杆菌(bacilluslicheniformis)、迟缓芽孢杆菌(bacilluslentus)、短芽孢杆菌(bacillusbrevis)、嗜热脂肪地芽胞杆菌(geobacillusstearothermophilus)(以前称为嗜热脂肪芽胞杆菌(bacillusstearothermophilus))、嗜碱芽孢杆菌(bacillusalkalophilus)、解淀粉芽孢杆菌(bacillusamyloliquefaciens)、凝结芽孢杆菌(bacilluscoagulans)、环状芽胞杆菌(bacilluscirculans)、灿烂芽孢杆菌((bacilluslautus)、巨大芽孢杆菌(bacillusmegaterium)、苏云金芽胞杆菌(bacillusthuringiensis)、变铅青链霉菌(streptomyceslividans)或鼠灰链霉菌(streptomycesmurinus);革兰氏阴性细菌,如大肠杆菌(escherichiacoli);酵母,如酵母菌属(saccharomycesspp.)或裂殖酵母属(schizosaccharomycesspp.),例如酿酒酵母(saccharomycescerevisiae);和丝状真菌,如曲霉菌属(aspergillusspp.),例如米曲霉(aspergillusoryzae)或黑曲霉(aspergillusniger)和里氏木霉(trichodermareesei)。将核酸转化进这些生物体中的方法是本领域熟知的。适用于转化曲霉菌宿主细胞的程序描述于ep238023中。在特定的实施方案中,本发明的多肽在异源生物体中作为分泌多肽表达,在此情形中,所述组合物和方法涵盖在异源生物体中作为分泌多肽表达本发明多肽的方法。本发明的多核苷酸本文所公开的一个方面是编码本发明多肽的多核苷酸(包括其变体和片段)。在一个方面,多核苷酸是在表达载体的情况下提供的,该表达载体用于在异源生物体指导本发明多肽的表达,诸如本文所鉴定的那些。编码本发明多肽的多核苷酸可以有效连接至调控元件(例如启动子、终止子、增强子等)以帮助表达编码的多肽。编码本发明多肽的示例性多核苷酸序列具有seqidno:1、3、5、7、9、11、13、15、18、20、22、25、29、33、37、41、45、49、53、57、61或64的核苷酸序列。编码本发明多肽的示例性多核苷酸序列具有seqidno:1、3、5、7、9、11、13、15、18、20、22、25、29、33、37、41、45、49、53或57的核苷酸序列。类似地,包括实质上相同的编码本发明多肽和变体的多核苷酸可存在于自然界中,例如存在于琼脂粘附芽孢杆菌的其它菌株或分离株中。鉴于遗传密码的简并性,应当理解具有不同核苷酸序列的多核苷酸可编码相同的本发明的多肽、变体或片段。在一些实施方案中,编码本发明多肽的多核苷酸与例示的编码本发明多肽的多核苷酸具有特定程度的氨基酸序列同一性,例如与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59、60、62、63、65、66、67、68、69、70、71、72、73、74和81。在一些实施方案中,编码本发明多肽的多核苷酸与例示的编码本发明多肽的多核苷酸具有特定程度的氨基酸序列同一性,例如与选自以下的氨基酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大的同一性:seqidno:2、4、6、8、10、12、14、16、17、19、21、23、24、26、27、28、30、31、32、34、35、36、38、39、40、42、43、44、46、47、48、50、51、52、54、55、56、58、59和60。同源性可例如使用诸如blast、align或clustal之类的程序(如本文中所述)通过氨基酸序列比对来测定。在一些实施方案中,多核苷酸可与例示的本发明多核苷酸具有特定程度的核苷酸序列同一性,例如与选自以下的核苷酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大的同一性:seqidno:1、3、5、7、9、11、13、15、18、20、22、25、29、33、37、41、45、49、53、57、61或64。在一些实施方案中,多核苷酸可与例示的本发明多核苷酸具有特定程度的核苷酸序列同一性,例如与选自以下的核苷酸序列具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大的同一性:seqidno:1、3、5、7、9、11、13、15、18、20、22、25、29、33、37、41、45、49、53或57。同源性可例如使用诸如blast、align或clustal之类的程序(如本文中所述)通过氨基酸序列比对来测定。在一些实施方案中,编码本发明多肽的多核苷酸框内融合于用于引导本发明多肽的细胞外分泌的信号肽的编码序列之后(即下游)。异源信号序列包括来自细菌纤维素酶基因的信号序列。可在适于表达本发明多肽或适于在将表达载体引入合适宿主细胞之前使表达载体增殖的异源宿主细胞中提供表达载体。在一些实施方案中,编码本发明多肽的多核苷酸在指定的杂交条件下杂交到seqidno:1、3、5、7、9、11、13、15、18、20、22、25、29、33、37、41、45、49、53、57、61或64的示例性多核苷酸(或其互补序列)。在一些实施方案中,编码本发明多肽的多核苷酸在指定的杂交条件下杂交到seqidno:1、3、5、7、9、11、13、15、18、20、22、25、29、33、37、41、45、49、53或57的示例性多核苷酸(或其互补序列)。示例性的条件是严格条件和高严格条件,这些条件在本文中进行了描述。本发明的多核苷酸可为天然存在或合成的(即人造的),并且可经过密码子优化以在不同的宿主中表达、经过突变以引入克隆位点或以其它方式改变以增加功能性。载体和宿主细胞为了产生所公开的本发明多肽,编码该多肽的dna可由已公布的序列通过化学方式合成或直接得自具有相应基因的宿主细胞(例如,通过cdna文库筛选或pcr扩增)。在一些实施方案中,将本发明的多核苷酸包含在表达盒中和/或通过标准分子克隆技术克隆到合适的表达载体中。此类表达盒或载体包含有助于转录起始和终止的序列(例如启动子和终止子),并且通常含有可选标记。将表达盒或载体引入合适的表达宿主细胞,该宿主细胞然后表达相应的本发明多核苷酸。尤其合适的表达宿主为包括以下的细菌表达宿主:埃希杆菌属(escherichia)(例如大肠杆菌)、假单胞菌属(pseudomonas)(例如荧光假单胞菌(p.fluorescens)或斯氏假单胞菌(p.stutzerei))、变形杆菌属(proteus)(例如奇异变形杆菌(proteusmirabilis))、罗尔斯通菌属(ralstonia)(例如真养产碱杆菌(ralstoniaeutropha))、链霉菌属(streptomyces)、葡萄球菌属(staphylococcus)(例如肉葡萄球菌(s.carnosus))、乳球菌属(lactococcus)(例如乳酸乳球菌(l.lactis))或芽孢杆菌属(枯草芽孢杆菌、巨大芽胞杆菌、地衣芽孢杆菌等)。也尤其合适的是酵母表达宿主,诸如酿酒酵母、粟酒裂殖酵母(schizosaccharomycespombe)、解脂耶氏酵母(yarrowialipolytica)、多形汉逊酵母(hansenulapolymorpha)、乳酸克鲁维酵母(kluyveromyceslactis)或巴斯德毕赤酵母(pichiapastoris)。特别合适的是真菌表达宿主,诸如黑曲霉、chrysosporiumlucknowense、曲霉菌(例如米曲霉、黑曲霉、构巢曲霉(a.nidulans)等)或里氏木霉。还合适的是哺乳动物表达宿主,诸如小鼠(例如ns0)、中国仓鼠卵巢(cho)或幼仓鼠肾(bhk)细胞系。其它真核宿主例如昆虫细胞或病毒表达系统(例如细菌噬菌体,如m13、t7噬菌体或λ噬菌体,或病毒,如杆状病毒)也适用于产生本发明的多肽。在所关注的特定宿主中与分泌蛋白相关的启动子和/或信号序列是用于在该宿主或其它宿主中进行内切-β-甘露聚糖酶的异源产生和分泌的候选物。例如,在丝状真菌系统中,驱动纤维二糖水解酶i(cbh1)、葡糖淀粉酶a(glaa)、taka-淀粉酶(amya)、木聚糖酶(exla)、gpd-启动子cbh1、cbhll、内切葡聚糖酶基因egi-egv、cel61b、cel74a、egl1-egl5、gpd启动子、pgk1、pki1、ef-1α、tef1、cdna1和hex1的基因的启动子是尤其合适的并可来源于许多不同的生物体(例如黑曲霉、里氏木霉、米曲霉、泡盛曲霉(a.awamori)和构巢曲霉)。在一些实施方案中,本发明的多核苷酸与编码合适的同源或异源信号序列(导致本发明的多肽分泌进细胞外(或周质)空间)的多核苷酸重组相关,从而允许直接在细胞上清液(或周质空间或裂解物)中检测酶活性。本领域已知的大肠杆菌、其它革兰氏阴性菌和其它生物体尤其合适的信号序列包括驱动hlya、dsba、pbp、phoa、pelb、ompa、ompt或m13噬菌体gill基因表达的那些序列。对于本领域已知的枯草芽孢杆菌、革兰氏阳性生物体和其它生物体,尤其合适的信号序列还包括驱动apre、nprb、mpr、amya、amye、blac、sacb表达的那些序列,并且对于酿酒酵母或其它酵母,包括杀伤毒素、bar1、suc2、交配因子α、inu1a或ggplp信号序列。信号序列可通过多种信号肽酶裂解,从而将它们从所表达的蛋白质的其余部分移除。在一些实施方案中,多肽的其余部分单独地或作为与位于n或c端的其它肽、标签或蛋白质(例如6xhis、ha或flag标签)的融合体而表达。合适的融合体包含有利于亲和纯化或检测的标签、肽或蛋白质(例如bce103、6xhis、ha、几丁质结合蛋白、硫氧还蛋白或flag标签)以及有利于目标内切-β-甘露聚糖酶的表达、分泌或加工的那些。合适的加工位点包括肠激酶、ste13、kex2或其它蛋白酶裂解位点以供在体内或体外裂解。可将本发明的多核苷酸通过多种转化方法引入表达宿主细胞,这些方法包括但不限于电穿孔、脂质辅助转化或转染(“脂质转染”)、化学介导的转染(例如cacl和/或cap)、醋酸锂介导的转化(例如,宿主细胞原生质体的转化)、生物弹射“基因枪”转化、peg介导的转化(例如,宿主细胞原生质体的转化)、原生质体融合(例如使用细菌或真核细胞原生质体)、脂质体介导的转化、根癌农杆菌(agrobacteriumtumefaciens)、腺病毒或其它病毒或噬菌体转化或转导。另选地,本发明的多肽可在细胞内表达。任选地,在酶变体在细胞内表达或利用诸如上述那些的信号序列分泌到周质空间后,可采用透化或裂解步骤使多肽释放到上清液中。膜屏障的破坏通过使用机械手段如超声波、加压处理(弗氏压碎器)、空化或使用膜消化酶如溶菌酶或酶混合物而实现。另选地,编码多肽的多核苷酸可通过使用合适的无细胞表达系统而表达。在无细胞系统中,通常将所关注的多核苷酸在启动子帮助下转录,但任选进行连接以形成环状表达载体。在其它实施方案中,以外源方式添加或生成rna而不进行转录,然后在无细胞系统中翻译。本文所公开的本发明多肽可在宽泛的ph条件范围内具有酶活性。在某些实施方案中,公开的本发明多肽在约ph4.0至约ph11.0、或约ph4.5至约ph11.0内具有酶活性。在优选的实施方案中,多肽具有显著的酶活性,例如在约ph4.0至11.0、ph4.5至11.0、ph4.5至9.0、ph5.5至8.5、或ph6.0至7.5内有至少50%、60%、70%、80%、90%、95%或100%活性。应该指出的是,本文所述的ph值可在±0.2内变动。例如,约8.0的ph值可在ph7.8至ph8.2变动。本文所公开的本发明多肽可在宽泛的温度范围内具有酶活性,例如约20℃或更低至90℃、30℃至80℃、40℃至70℃、45℃至65℃、或50℃至60℃。在某些实施方案中,多肽具有显著的酶活性,例如在约20℃或更低至90℃、30℃至80℃、40℃至70℃、45℃至65℃、或50℃至60℃的温度范围内有至少50%、60%、70%、80%、90%、95%或100%活性。应当指出,本文所述的温度值可在±0.2℃内变动。例如,约50℃的温度可在49.8℃至50.2℃变动。包含本发明多肽的洗涤剂组合物本文所公开的组合物和方法的一个方面是包含本发明的分离的多肽(包括其变体或片段)的洗涤剂组合物,以及将此类组合物用于清洁应用中的方法。清洁应用包括但不限于衣物或纺织物清洁、衣物或纺织物软化、餐具洗涤(人工和自动餐具洗涤)、污渍预处理等。特定的应用是其中甘露聚糖(例如刺槐豆胶、瓜尔胶等)为待移除的污垢或污渍的组分的那些应用。洗涤剂组合物通常包含有效量的本文所述的本发明多肽中的任一种,例如至少0.0001重量%、约0.0001至约1重量%、约0.001至约0.5重量%、约0.01至约0.1重量%或甚至约0.1至约1重量%或更高。洗涤剂组合物中有效量的本发明多肽导致本发明多肽具有足以水解含甘露聚糖的底物(诸如刺槐豆胶、瓜尔胶或它们的组合)的酶活性。另外,可将浓度为约0.4g/l至约2.2g/l、约0.4g/l至约2.0g/l、约0.4g/l至约1.7g/l、约0.4g/l至约1.5g/l、约0.4g/l至约1g/l、约0.4g/l至约0.8g/l或约0.4g/l至约0.5g/l的洗涤剂组合物与有效量的本发明的分离多肽混合。洗涤剂组合物也可以约0.4ml/l至约2.6ml/l、约0.4ml/l至约2.0ml/l、约0.4ml/l至约1.5ml/l、约0.4ml/l至约1ml/l、约0.4ml/l至约0.8ml/l或约0.4ml/l至约0.5ml/l的浓度存在。除非另外说明,否则本文提供的所有组分或组合物水平都是指所述组分或组合物的活性水平,而且市售来源中可能存在的杂质(例如残余溶剂或副产物)排除在外。酶组分重量是基于总活性蛋白质计的。除非另外说明,否则所有百分比和比率都按重量计来计算。除非另外说明,否则所有百分比和比率都是基于总组合物来计算。在示例性的洗涤剂组合物中,酶含量是以纯酶占总组合物的重量比表示,并且除非另有说明,否则洗涤剂成分是以占总组合物的重量比表示。在一些实施方案中,洗涤剂组合物包含一种或多种表面活性剂,这些表面活性剂可以是非离子型、半极性型、阴离子型、阳离子型、两性离子型或它们的组合和混合物。表面活性剂通常以约0.1重量%至60重量%的量存在。示例性的表面活性剂包括但不限于:十二烷基苯磺酸钠、c12-14链烷醇聚醚-7、c12-15链烷醇聚醚-7、c12-15链烷醇聚醚硫酸钠、c14-15链烷醇聚醚-4、月桂醇聚醚硫酸钠(例如steolcs-370)、氢化椰油酸钠、c12乙氧基化物(alfonic1012-6、hetoxolla7、hetoxolla4)、烷基苯磺酸钠(例如nacconol90g)以及它们的组合和混合物。可用于本文所述的洗涤剂组合物的阴离子表面活性剂包括但不限于:直链烷基苯磺酸盐(las)、α-烯烃磺酸盐(aos)、烷基硫酸盐(脂肪醇硫酸盐)(as)、醇乙氧基硫酸盐(aeos或aes)、仲烷基磺酸盐(sas)、α-磺基脂肪酸甲基酯、烷基琥珀酸或烯基琥珀酸,或皂。其也可含有0-40%的非离子表面活性剂,如醇乙氧基化物(aeo或ae)、羧化醇乙氧基化物、壬基酚乙氧基化物、烷基多糖苷、烷基二甲基胺氧化物、乙氧基化脂肪酸单乙醇酰胺、脂肪酸单乙醇酰胺、多羟基烷基脂肪酸酰胺(例如,如wo92/06154中所述)以及它们的组合和混合物。可用于本文所述的洗涤剂组合物的非离子表面活性剂包括但不限于:脂肪酸的聚氧乙烯酯、聚氧乙烯脱水山梨糖醇酯(例如tween)、聚氧乙烯醇、聚氧乙烯异醇、聚氧乙烯醚(例如triton和brij)、聚氧乙烯酯、聚氧乙烯-对叔辛基酚或辛基苯基-氧化乙烯缩合物(例如nonidetp40)、氧化乙烯与脂肪醇的缩合物(例如lubrol)、聚氧乙烯壬基酚、聚烷二醇(synperonicf108)、糖基表面活性剂(例如吡喃葡糖苷、硫代吡喃葡糖苷)以及它们的组合和混合物。本文所公开的洗涤剂组合物可具有混合物,所述混合物包括但不限于:5-15%阴离子表面活性剂、<5%的非离子表面活性剂、阳离子表面活性剂、膦酸盐、皂、酶、香料、甲基丙酸丁基苯酯、香叶醇、沸石、聚羧酸酯、己基肉桂醛、柠檬烯、阳离子表面活性剂、香茅醇和苯并异噻唑啉酮。洗涤剂组合物可另外包含一种或多种洗涤剂助洗剂或助洗剂体系、络合剂、聚合物、漂白体系、稳定剂、发泡剂、抑泡剂、抗腐蚀剂、悬污剂、抗污垢再沉积剂、染料、杀菌剂、水溶助长剂(hydrotope)、晦暗抑制剂、荧光增白剂、织物调理剂和香料。洗涤剂组合物还可包含酶,其包括但不限于蛋白酶、淀粉酶、纤维素酶、脂肪酶、果胶降解酶、木葡聚糖酶或另外的羧酸酯水解酶。洗涤剂组合物的ph应为中性到碱性,如本文中所述。在掺入至少一种助洗剂的一些实施方案中,洗涤剂组合物包含按清洁组合物的重量计至少约1%、约3%至约60%或甚至约5%至约40%的助洗剂。助洗剂可包括但不限于:聚磷酸的碱金属盐、铵盐和链烷醇铵盐;碱金属硅酸盐;碱土金属和碱金属碳酸盐;铝硅酸盐;聚羧酸盐化合物;醚羟基聚羧酸盐;马来酸酐与乙烯或乙烯基甲基醚的共聚物;1,3,5-三羟基苯-2,4,6-三磺酸;和羧甲基氧基琥珀酸;聚乙酸(如乙二胺四乙酸和次氮基三乙酸)的多种碱金属盐、铵盐和取代的铵盐;以及聚羧酸酯,如苯六甲酸、琥珀酸、柠檬酸、氧基二琥珀酸、聚马来酸、苯1,3,5-三羧酸、羧甲基氧基琥珀酸以及它们的可溶性盐。实际上,可设想任何合适的助洗剂都可用于本公开的多个实施方案中。在一些实施方案中,助洗剂形成水溶性硬度离子络合物(例如螯合助洗剂),如柠檬酸盐和聚磷酸盐(例如三聚磷酸钠和六水合三聚磷酸钠、三聚磷酸钾以及三聚磷酸钠与三聚磷酸钾的混合物等)。可设想任何合适的助洗剂都可用于本发明中,包括本领域已知的那些(参见例如ep2100949)。如本文所指出的那样,在一些实施方案中,本文所述的清洁组合物还包含辅助材料,其包括但不限于:表面活性剂、助洗剂、漂白剂、漂白活化剂、漂白催化剂、其它酶、酶稳定体系、螯合剂、荧光增白剂、去污聚合物、染料转移剂、分散剂、抑泡剂、染料、香料、着色剂、填料盐、水溶助长剂、光活化剂、荧光剂、织物调理剂、可水解表面活性剂、防腐剂、抗氧化剂、抗收缩剂、抗皱剂、杀菌剂、杀真菌剂、色粒(colorspeckle)、银护理剂(silvercare)、抗晦暗剂和/或抗腐蚀剂、碱度源、增溶剂、载体、加工助剂、颜料和ph控制剂(参见例如美国专利6,610,642;6,605,458;5,705,464;5,710,115;5,698,504;5,695,679;5,686,014;和5,646,101;它们均以引用方式并入本文)。特定清洁组合物材料的实施方案在下文中举例说明。在清洁辅助材料与清洁组合物中的本发明多肽不相容的实施方案中,使用保持清洁辅助材料与内切-β-甘露聚糖酶分离(即,不彼此接触)直到两种组分的组合适宜时的合适方法。这种分离方法包括本领域已知的任何合适方法(例如胶囊锭法(gelcap)、包封法、片剂法、物理分离法等)。有利地,将本文所述的清洁组合物用于例如洗衣应用、硬质表面清洁、餐具洗涤应用,以及化妆品应用,如假牙、牙齿、毛发和皮肤。此外,归因于在较低温度溶液中效果增强的独特优势,使得本文所述的多肽理想地适合于衣物和织物软化应用。此外,本发明的多肽可用于颗粒状和液体组合物。本文所述的多肽或分离的多肽也可用于清洁添加剂产品。在一些实施方案中,可使用低温溶液清洁应用。在一些实施方案中,本公开提供清洁添加剂产品,其包含至少一种所公开的本发明多肽,当需要额外漂白效用时,该清洁添加剂产品理想地适于包括在洗涤过程中。此类情形包括但不限于低温溶液清洁应用。在一些实施方案中,添加剂产品为其最简单的形式,即一种或多种内切-β-甘露聚糖酶。在一些实施方案中,添加剂被包装成用于添加到清洁过程中的剂型。在一些实施方案中,添加剂被包装成用于添加到采用过氧源并且增加的漂白效果是所需的清洁过程中的剂型。任何合适的单一剂量单位形式都可用于本发明,其包括但不限于:丸剂、片剂、软胶囊剂,或其它单一剂量单位如预先测量的粉末或液体。在一些实施方案中,包括填料或载剂材料以增加所述组合物的体积。合适的填料或载体材料包括但不限于各种硫酸盐、碳酸盐和硅酸盐,以及滑石、粘土等。适于液体组合物的填料或载体材料包括但不限于水或低分子量伯醇和仲醇,其包括多元醇和二醇。此类醇的示例包括但不限于甲醇、乙醇、丙醇和异丙醇。在一些实施方案中,组合物含有约5%至约90%的此类材料。酸性填料可用于降低ph。另选地,在一些实施方案中,清洁添加剂包含辅助成分,下文将予以更完整地描述。在一个实施方案中,本发明的清洁组合物或清洁添加剂包含有效量的任选地与其它内切-β-甘露聚糖酶和/或另外的酶组合的至少一种本文所述的多肽。在某些实施方案中,另外的酶包括但不限于至少一种选自以下的酶:酰基转移酶、淀粉酶、α-淀粉酶、β-淀粉酶、α-半乳糖苷酶、阿拉伯聚糖酶、阿拉伯糖苷酶、芳基酯酶、β-半乳糖苷酶、β-葡聚糖酶、角叉菜多糖酶、过氧化氢酶、纤维二糖水解酶、纤维素酶、软骨素酶、角质酶、内切-β-1,4-葡聚糖酶、内切-β-甘露聚糖酶、外切-β-甘露聚糖酶、酯酶、外切-甘露聚糖酶、半乳聚糖酶、葡萄糖淀粉酶、半纤维素酶、透明质酸酶、角蛋白酶、漆酶、乳糖酶、木质素酶、脂酶、脂解酶、脂氧合酶、甘露聚糖酶、金属蛋白酶、氧化酶、果胶酸裂解酶、果胶乙酰酯酶、果胶酶、戊聚糖酶、过水解酶、过氧化物酶、酚氧化酶、磷酸酶、磷脂酶、植酸酶、多聚半乳糖醛酸酶、蛋白酶、支链淀粉酶、还原酶、鼠李半乳糖醛酸酶、β-葡聚糖酶、鞣酸酶、转谷氨酰胺酶、木聚糖乙酰酯酶、木聚糖酶、木葡聚糖酶、木糖苷酶、以及它们的混合物。所需的酶水平通过加入一种或多种所公开的本发明多肽来实现。通常,本发明的清洁组合物将包含至少约0.0001重量%、约0.0001重量%至约10重量%、约0.001重量%至约1重量%、或甚至约0.01重量%至约0.1重量%的至少一种所公开的本发明多肽。通常配制本文的清洁组合物使得在水性清洁操作中使用期间洗涤水的ph将为约3.0至约11。液体产品制剂通常配制成净ph为约5.0至约9.0。颗粒洗衣用产品通常配制成ph为约8.0至约11.0。用于将ph控制在推荐的使用水平的技术包括使用缓冲液、碱、酸等,并且这些技术是本领域技术人员熟知的。合适的低ph清洁组合物通常具有的净ph为约3.0至约5.0,或甚至约3.5至4.5。低ph清洁组合物通常不含在这样的ph环境中水解的表面活性剂。此类表面活性剂包括包含至少一个氧化乙烯部分或甚至约1至约16摩尔的氧化乙烯的烷基硫酸钠表面活性剂。此类清洁组合物通常包含足量的ph调节剂,如氢氧化钠、单乙醇胺或盐酸,以向此类清洁组合物提供约3.0至约5.0的净ph。此类组合物通常包含至少一种酸稳定性酶。在一些实施方案中,所述组合物为液体,而在其它实施方案中,其为固体。此类液体组合物的ph通常是以净ph测量的。此类固体组合物的ph是以组合物的10%固形物溶液度量,其中溶剂是蒸馏水。在这些实施方案中,除非另外指明,否则所有ph测量值都是在20℃下取得。合适的高ph清洁组合物通常具有的净ph为约9.0至约11.0,或甚至9.5至10.5。此类清洁组合物通常包含足量的ph调节剂,如氢氧化钠、单乙醇胺或盐酸,以向此类清洁组合物提供约9.0至约11.0的净ph。此类组合物通常包含至少一种碱稳定性酶。在一些实施方案中,所述组合物为液体,而在其它实施方案中,其为固体。此类液体组合物的ph通常是以净ph测量的。此类固体组合物的ph是以所述组合物的10%固形物溶液度量,其中溶剂是蒸馏水。在这些实施方案中,除非另外指明,否则所有ph测量值都是在20℃下取得。在一些实施方案中,当将本发明的多肽用于颗粒状组合物或液体中时,希望本发明的多肽呈封装的粒子形式以保护本发明的多肽在储存期间免受颗粒状组合物中其它组分的影响。此外,封装还是控制本发明的多肽在清洁过程期间的可用性的手段。在一些实施方案中,封装可增强本发明的多肽和/或其它酶的性能。就这一点而言,本公开的本发明多肽用本领域已知的任何合适的封装材料进行封装。在一些实施方案中,封装材料通常封装本文所述的本发明多肽的催化剂的至少一部分。通常,封装材料是水溶性的和/或水分散性的。在一些实施方案中,封装材料的玻璃化转变温度(tg)为0℃或更高。玻璃转变温度在pct申请wo97/11151中进行了更详细的描述。封装材料通常选自碳水化合物、天然的或合成的树胶、几丁质、壳聚糖、纤维素和纤维素衍生物、硅酸盐、磷酸盐、硼酸盐、聚乙烯醇、聚乙二醇、石蜡以及它们的组合。当封装材料是碳水化合物时,其通常选自单糖、寡糖、多糖以及它们的组合。在一些典型的实施方案中,封装材料为淀粉(参见例如ep0922499;u.s.4,977,252;u.s.5,354,559;和u.s.5,935,826)。在一些实施方案中,封装材料是由诸如热塑性塑料、丙烯腈、甲基丙烯腈、聚丙烯腈、聚甲基丙烯腈及它们的混合物之类的塑料制成的微球体;可使用的市售微球体包括但不限于由(stockviksverken,sweden)以及pm6545、pm6550、pm7220、pm7228、和(pqcorp.,valleyforge,pa)提供的微球体。术语“颗粒组合物”是指分立的固体宏观粒子的聚集物。粉末由于它们的小粒径而为一类特殊的颗粒材料,这使得它们内聚度更高并且更容易悬浮。在清洁应用中使用包含本发明多肽的洗涤剂组合物时,将待清洁的织物、纺织物、器皿或其它表面在存在具有本发明多肽的洗涤剂组合物的情况下温育一段足以允许多肽水解存在于污垢或污渍中的甘露聚糖底物(包括但不限于刺槐豆胶、瓜尔胶以及它们的组合)的时间,然后通常用水或另一水性溶剂漂洗以将洗涤剂组合物连同水解的甘露聚糖一起移除。如本文所述,本发明的多肽尤其可用于清洁行业,包括但不限于衣物和盘碟洗涤剂。这些应用使酶处于各种环境压力下。本发明的多肽因其至多种条件下的稳定性而能够具有优于许多当前所用酶的优点。实际上,洗涤中所涉及的内切-β-甘露聚糖酶暴露于多种洗涤条件,其包括变化的洗涤剂制剂、洗涤水体积、洗涤水温度和洗涤时间长度。此外,不同地理区域中使用的洗涤剂制剂在洗涤水中存在不同浓度的其相关组分。例如,欧洲的洗涤剂通常在洗涤水中具有约4500-5000ppm的洗涤剂组分,而日本的洗涤剂通常在洗涤水中具有大约667ppm的洗涤剂组分。在北美,尤其是在美国,洗涤剂通常在洗涤水中存在约975ppm的洗涤剂组分。低洗涤剂浓度体系包括在洗涤水中存在少于约800ppm的洗涤剂组分的洗涤剂。日本的洗涤剂通常被认为是低洗涤剂浓度体系,因为其在洗涤水中具有大约667ppm的洗涤剂组分。中等洗涤剂浓度包括在洗涤水中存在介于约800ppm和约2000ppm之间的洗涤剂组分的洗涤剂。北美的洗涤剂一般被认为是中等洗涤剂浓度体系,因为其在洗涤水中具有大约975ppm的洗涤剂组分。巴西通常在洗涤水中存在大约1500ppm的洗涤剂组分。高洗涤剂浓度体系包括在洗涤水中存在超过约2000ppm的洗涤剂组分的洗涤剂。欧洲的洗涤剂一般被认为是高洗涤剂浓度体系,因为其在洗涤水中具有大约4500-5000ppm的洗涤剂组分。拉丁美洲的洗涤剂一般是高泡磷酸盐助洗剂洗涤剂,而且拉丁美洲中使用的洗涤剂的范围可落在中等洗涤剂浓度至高洗涤剂浓度之间,因为其在洗涤水中具有1500ppm至6000ppm的洗涤剂组分。如上所述,巴西通常在洗涤水中存在大约1500ppm的洗涤剂组分。然而,其它高泡磷酸盐助洗剂洗涤剂地理区域(不限于其它拉丁美洲国家)也可具有在洗涤水中存在最高约6000ppm的洗涤剂组分的高洗涤剂浓度体系。按照前述内容,显然在全世界范围内,典型洗涤溶液中洗涤剂组合物的浓度在低于约800ppm洗涤剂组合物(“低洗涤剂浓度的地理区域”,例如在日本约667ppm)至介于约800ppm至约2000ppm之间(“中等洗涤剂浓度的地理区域”,例如在美国约975ppm,在巴西约1500ppm)再到高于约2000ppm(“高洗涤剂浓度的地理区域”,例如在欧洲约4500ppm至约5000ppm,以及在高泡磷酸盐助洗剂的地理区域中约6000ppm)变动。典型的洗涤溶液的浓度凭经验确定。例如,在美国,典型洗涤机器容纳约64.4l体积的洗涤溶液。因此,为了在洗涤溶液内获得约975ppm的洗涤剂浓度,必须将约62.79g洗涤剂组合物加入到64.4l洗涤溶液中。这个量是由消费者使用随洗涤剂一起提供的量杯计量加到洗涤水中的典型量。再举个例子,不同的地理区域使用不同的洗涤温度。日本的洗涤水温度通常低于欧洲所用的洗涤水温度。例如,北美和日本的洗涤水温度通常介于约10℃和约30℃之间(例如为约20℃),而欧洲的洗涤水温度通常介于约30℃和约60℃之间(例如为约40℃)。因此,在某些实施方案中,本文所述的洗涤剂组合物可在以下温度下利用:约10℃至约60℃,或约20℃至约60℃,或约30℃至约60℃,或约40℃至约60℃,以及在约40℃至约55℃范围内的所有其它组合和在10℃至60℃内的所有范围。然而,为了节省能源,许多消费者转向使用冷水洗涤。此外,在一些另外的区域中,通常将冷水用于衣物洗涤以及餐具洗涤应用。在一些实施方案中,本公开的“冷水洗涤”利用在约10℃至约40℃,或约20℃至约30℃,或约15℃至约25℃,以及在约15℃至约35℃范围内的所有其它组合和在10℃至40℃内的所有范围的温度下的洗涤。再举个例子,不同的地理区域通常具有不同的水硬度。水硬度经常按每加仑中混合的ca2+/mg2+的格令数(grain)来描述。硬度是水中钙(ca2+)和镁(mg2+)的量的量度。在美国,大多数水都较硬,但硬的程度不同。中等硬(60-120ppm)至硬(121-181ppm)水具有60至181ppm(ppm换算成每美制加仑格令数是ppm数除以17.1等于每加仑格令数)硬度的矿物质。表ii:水硬度水平水每加仑格令数ppm软小于1.0小于17略硬1.0至3.517至60中等硬3.5至7.060至120硬7.0至10.5120至180非常硬大于10.5大于180欧洲的水硬度通常是每加仑混合的ca2+/mg2+高于约10.5(例如约10.5至约20.0)格令(例如每加仑混合的ca2+/mg2+为约15格令)。北美的水硬度通常高于日本的水硬度,但低于欧洲的水硬度。例如,北美的水硬度可介于约3至约10格令、约3至约8格令之间或为约6格令。日本的水硬度通常低于北美的水硬度,通常低于约4,例如每加仑混合的ca2+/mg2+为约3格令。因此,在一些实施方案中,本公开提供在至少一组洗涤条件(例如水温、水硬度和/或洗涤剂浓度)下显示出令人惊奇的洗涤性能的本发明多肽。在一些实施方案中,本发明的多肽在洗涤性能方面与其它内切-β-甘露聚糖酶相当。在一些实施方案中,本发明的多肽与当前可商购获得的内切-β-甘露聚糖酶相比表现出增强的洗涤性能。因此,在一些优选的实施方案中,本文中提供的本发明多肽表现出增强的氧化稳定性、增强的热稳定性、增强的在多种条件下的清洁能力和/或增强的螯合剂稳定性。此外,本发明的多肽可用于不包含洗涤剂的清洁组合物,该变体蛋白酶同样是单独使用或与助洗剂和稳定剂组合。在本公开的一些实施方案中,清洁组合物包含含量为按组合物的重量计约0.00001%至约10%的至少一种本公开的本发明多肽,和按组合物的重量计的剩余部分(例如约99.999%至约90.0%),该剩余部分包含清洁辅助材料。在本公开的其它方面,清洁组合物包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的至少一种本发明的多肽,和清洁组合物的剩余部分(例如约99.9999重量%至约90.0重量%、约99.999重量%至约98重量%、约99.995重量%至约99.5重量%),该剩余部分包含清洁辅助材料。除本文提供的本发明多肽之外,任何其它合适的内切-β-甘露聚糖酶均可单独地或与本文所述的多肽结合地用于本文所述组合物。合适的内切-β-甘露聚糖酶包括但不限于糖基水解酶的gh26家族的内切-β-甘露聚糖酶、糖基水解酶的gh5家族的内切-β-甘露聚糖酶、酸性内切-β-甘露聚糖酶、中性内切-β-甘露聚糖酶和碱性内切-β-甘露聚糖酶。碱性内切-β-甘露聚糖酶的示例包括在美国专利6,060,299、6,566,114和6,602,842;wo9535362a1、wo9964573a1、wo9964619a1和wo2015022428中所述的那些。另外,合适的内切-β-甘露聚糖酶包括但不限于来源于动物、植物、真菌或细菌的那些。本公开涵盖经化学或基因修饰的突变体。可用的内切-β-甘露聚糖酶的示例包括芽孢杆菌属内切-β-甘露聚糖酶,诸如枯草芽孢杆菌内切-β-甘露聚糖酶(参见例如,美国专利6,060,299和wo9964573a1)、芽孢杆菌属i633内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、芽孢杆菌属aai12内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、芽孢杆菌属aa349内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、琼脂粘附芽孢杆菌ncimb40482内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、嗜碱孢芽杆菌(b.halodurans)内切-β-甘露聚糖酶、克劳氏芽孢杆菌(b.clausii)内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、地衣芽孢杆菌内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、腐质霉属(humicola)内切-β-甘露聚糖酶,诸如特异腐质霉内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)、以及热解纤维素菌属(caldocellulosiruptor)内切-β-甘露聚糖酶,诸如c.sp.内切-β-甘露聚糖酶(参见例如,美国专利6,566,114和wo9964619a1)。此外,多种已鉴定的甘露聚糖酶(即内切-β-甘露聚糖酶和外切-β-甘露聚糖酶)用于本公开的一些实施方案中,包括但不限于双孢蘑菇(agaricusbisporus)甘露聚糖酶(参见tang等人,[2001]appl.environ.microbiol.(《应用环境微生物学》)第67卷:第2298-2303页)、溜曲霉(aspergillutamarii)甘露聚糖酶(参见civas等人,[1984]biochem.j.(《生物化学杂志》)第219卷:第857–863页)、棘孢曲霉(aspergillusaculeatus)甘露聚糖酶(参见christgau等人,[1994]biochem.mol.biol.int.(《国际生物化学与分子生物学》)第33卷:第917–925页)、泡盛曲霉(aspergillusawamori)甘露聚糖酶(参见setati等人,[2001]proteinexpresspurif.(《蛋白表达与纯化》)第21卷:第105–114页)、烟曲霉(aspergillusfumigatus)甘露聚糖酶(参见puchart等人,[2004]biochimicaetbiophysicaacta.(《生物化学与生物物理学报》)第1674卷:第239–250页)、黑曲霉(aspergillusniger)甘露聚糖酶(参见ademark等人,[1998]j.biotechnol.(《生物技术杂志》)第63卷:第199–210页)、米曲霉(aspergillusoryzae)nrrl甘露聚糖酶(参见regalado等人,[2000]j.sci.foodagric.80:1343–1350)、硫色曲霉(aspergillussulphureus)甘露聚糖酶(参见chen等人,[2007]j.biotechnol.128(3):452–461)、土曲霉(aspergillusterrus)甘露聚糖酶(参见huang等人,[2007]weishengwuxuebao.47(2):280–284)、类芽孢杆菌和芽孢杆菌属物种甘露聚糖酶(参见美国专利6,376,445)、芽孢杆菌am001甘露聚糖酶(参见akino等人,[1989]arch.microbiol.152:10–15)、短芽孢杆菌甘露聚糖酶(参见araujo和ward,[1990]j.appl.bacteriol.,68:253–261)、环状芽孢杆菌k-1甘露聚糖酶(参见yoshida等人,[1998]biosci.biotechnol.biochem.62(3):514–520)、多粘芽孢杆菌(bacilluspolymyxa)甘露聚糖酶(参见araujo和ward,[1990]j.appl.bacteriol.,68:253–261)、芽孢杆菌属jamb-750甘露聚糖酶(参见hatada等人,[2005]extremophiles.(《极端微生物》)9:497-500)、芽孢杆菌属m50甘露聚糖酶(参见chen等人,[2000]weishengwuxuebao.40:62-68)、芽孢杆菌属n16-5甘露聚糖酶(参见yanhe等人,[2004]extremophiles8:447-454)、嗜热脂肪芽胞杆菌(bacillusstearothermophilu)甘露聚糖酶(参见talbot和sygusch,[1990]appl.environ.microbiol.(《应用环境微生物学》)56:3505–3510)、枯草芽孢杆菌甘露聚糖酶(参见mendoza等人,[1994]worldj.microbiol.biotechnol.10:51–54)、枯草芽孢杆菌b36甘露聚糖酶(li等人,[2006]z.naturforsch(c).(《自然历史期刊c辑》)61:840–846)、枯草芽孢杆菌bm9602甘露聚糖酶(参见cui等人,[1999]weishengwuxuebao.39(1):60–63)、枯草芽孢杆菌sa–22甘露聚糖酶(参见sun等人,[2003]shengwugongchengxuebao.19(3):327–330)、枯草芽孢杆菌168甘露聚糖酶(参见helow和khattab,[1996]actamicrobiol.immunol.hung.43:289–299)、卵形拟杆菌(bacteroidesovatus)甘露聚糖酶(参见gherardini等人,[1987]j.bacteriol.169:2038–2043)、栖瘤胃拟杆菌(bacteroidesruminicola)甘露聚糖酶(参见matsushita等人,[1991]j.bacteriol.173:6919–6926)、热解纤维素菌(caldibacilluscellulovorans)甘露聚糖酶(参见sunna等人,[2000]appl.environ.microbiol.(《应用环境微生物学》)66:664–670)、caldocellulosiruptorsaccharolyticus甘露聚糖酶(参见morris等人,[1995]appl.environ.microbiol.(《应用环境微生物学》)61:2262–2269)、解糖热纤维菌(caldocellumsaccharolyticum)甘露聚糖酶(参见bicho等人,[1991]appl.microbiol.biotechnol.36:337–343)、粪碱纤维单胞菌(cellulomonasfimi)甘露聚糖酶(参见stoll等人,[1999]appl.environ.microbiol.(《应用环境微生物学》)65(6):2598–2605)、丁酸梭菌/拜氏梭菌(clostridiumbutyricum/beijerinckii)甘露聚糖酶(参见nakajima和matsuura,[1997]biosci.biotechnol.biochem.61:1739–1742)、解纤维梭菌(clostridiumcellulolyticum)甘露聚糖酶(参见perret等人,[2004]biotechnol.appl.biochem.40:255–259)、第三梭菌(clostridiumtertium)甘露聚糖酶(参见kataoka和tokiwa,[1998]j.appl.microbiol.84:357–367)、热纤维梭菌(clostridiumthermocellum)甘露聚糖酶(参见halstead等人,[1999]microbiol.145:3101–3108)、嗜热网球菌(dictyoglomusthermophilum)甘露聚糖酶(参见gibbs等人,[1999]curr.microbiol.39(6):351–357)、黄杆菌属(flavobacteriumsp)甘露聚糖酶(参见zakaria等人,[1998]biosci.biotechnol.biochem.62:655–660)、腹足纲肺螺亚纲(gastropodapulmonata)甘露聚糖酶(参见charrier和rouland,[2001]j.expt.zool.(《实验动物学杂志》)第290卷:第125–135页)、短滨螺(littorinabrevicula)甘露聚糖酶(参见yamamura等人,[1996]biosci.biotechnol.biochem.(《生物科学、生物技术与生物化学》)第60卷:第674–676页)、番茄(lycopersiconesculentum)甘露聚糖酶(参见filichkin等人,[2000]plantphysiol.(《植物生理学》)第134卷:第1080–1087页)、解凝乳类芽胞杆菌(paenibacilluscurdlanolyticus)甘露聚糖酶(参见pason和ratanakhanokchai,[2006]appl.environ.microbiol.(《应用环境微生物学》)第72卷:第2483–2490页)、多粘类芽孢杆菌(paenibacilluspolymyxa)甘露聚糖酶(参见han等人,[2006]appl.microbiolbiotechnol.(《应用微生物学与生物技术》)73(3):第618–630页)、黄孢原毛平革菌(phanerochaetechrysosporium)甘露聚糖酶(参见wymelenberg等人,[2005]j.biotechnol.(《生物技术杂志》)第118卷:第17–34页)、厌气性瘤胃真菌(piromycessp.)甘露聚糖酶(参见fanutti等人,[1995]j.biol.chem.(《生物化学杂志》),270(49):第29314–29322页)、pomaceainsulars甘露聚糖酶(参见yamamura等人,[1993]biosci.biotechnol.biochem.(《生物科学、生物技术与生物化学》)第7卷:第1316–1319页)、荧光假单胞菌(pseudomonasfluorescens)纤维素亚种甘露聚糖酶(参见braithwaite等人,[1995]biochemj.(《生物化学杂志》)第305卷:第1005–1010页)、海洋红嗜热盐菌(rhodothermusmarinus)甘露聚糖酶(参见politz等人,[2000]appl.microbiol.biotechnol.(《应用微生物学与生物技术》)53(6):第715–721页)、齐整小核菌(sclerotiumrolfsii)甘露聚糖酶(参见sachslehner等人,[2000]j.biotechnol.(《生物技术杂志》)第80卷:第127–134页)、鲜黄链霉菌(streptomycesgalbus)甘露聚糖酶(参见kansoh和nagieb,[2004]anton.van.leeuwonhoek.(《安东尼π范π莱文胡克》)第85卷:第103–114页)、变铅青链霉菌甘露聚糖酶(参见arcand等人,[1993]j.biochem.(《生物化学杂志》)第290卷:第857–863页)、嗜热厌氧解多糖杆菌(thermoanaerobacteriumpolysaccharolyticum)甘露聚糖酶(参见cann等人,[1999]j.bacteriol.(《细菌学杂志》)第181卷:第1643-1651页)、褐色高温单孢菌(thermomonosporafusca)甘露聚糖酶(参见hilge等人,[1998]structure(《结构学》)第6卷:第1433-1444页)、海栖热袍菌(thermotogamaritima)甘露聚糖酶(参见parker等人,[2001]biotechnol.bioeng.(《生物技术与生物工程》)75(3):第322–333页)、新阿波罗栖热袍菌(thermotoganeapolitana)甘露聚糖酶(参见duffaud等人,[1997]appl.environ.microbiol.(《应用环境微生物学》)第63卷:第169–177页)、哈茨木霉(trichodermaharzanium)菌株t4甘露聚糖酶(参见franco等人,[2004]biotechnolappl.biochem.(《生物技术与应用生物化学》)第40卷:第255–259页)、里氏木霉甘露聚糖酶(参见stalbrand等人,[1993]j.biotechnol.(《生物技术杂志》)第29卷:第229–242页)以及弧菌(vibriosp.)甘露聚糖酶(参见tamaru等人,[1997]j.ferment.bioeng.(《发酵与生物工程杂志》)第83卷:第201-205页)。另外合适的内切-β-甘露聚糖酶包括可商购获得的内切-β-甘露聚糖酶,诸如(chemgen);和(novozymesa/s,denmark);purabritetm和mannastartm(genencor,adaniscodivision,paloalto,ca);以及160和200(diversa)。在本公开的一些实施方案中,本公开的清洁组合物还包含含量为按组合物的重量计约0.00001%至约10%的另外的内切-β-甘露聚糖酶,和按所述组合物的重量计的剩余的清洁辅助材料。在本公开的其它方面,本发明的清洁组合物还包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的内切-β-甘露聚糖酶。在本公开的一些实施方案中,可使用任何合适的蛋白酶。合适的蛋白酶包括动物、植物或微生物来源的那些蛋白酶。在一些实施方案中,包括了经化学或基因修饰的突变体。在一些实施方案中,蛋白酶是丝氨酸蛋白酶,优选碱性微生物蛋白酶或胰蛋白酶样蛋白酶。各种蛋白酶描述于pct申请wo95/23221和wo92/21760;美国专利公布2008/0090747;和美国专利5,801,039;5,340,735;5,500,364;5,855,625;u.s.re34,606;5,955,340;5,700,676;6,312,936;6,482,628;以及各种其它专利中。在一些另外的实施方案中,金属蛋白酶可用于本公开,其包括但不限于pct申请wo07/044993中所述的中性金属蛋白酶。可用于本发明的可商购获得的蛋白酶包括但不限于maxacaltm、maxapemtm、oxp、puramaxtm、excellasetm、preferenztm蛋白酶(例如p100、p110、p280)、effectenztm蛋白酶(例如p1000、p1050、p2000)、excellenztm蛋白酶(例如p1000)、和purafasttm(dupont);durazymtm、和(novozymes);blaptm和blaptm变体(henkelkommanditgesellschaftaufaktien,duesseldorf,germany);以及kap(嗜碱芽孢杆菌枯草杆菌蛋白酶,kaocorp.,tokyo,japan)。在本公开的一些实施方案中,可使用任何合适的淀粉酶。在一些实施方案中,也可使用适用于碱性溶液中的任何淀粉酶(例如α淀粉酶和/或β淀粉酶)。合适的淀粉酶包括但不限于来源于细菌或真菌的那些。在一些实施方案中包括了经化学或基因修饰的突变体。可用于本发明的淀粉酶包括但不限于从地衣芽孢杆菌获得的α-淀粉酶(参见例如gb1,296,839)。可应用于本公开的可商购获得的淀粉酶包括但不限于和bantm(novozymesa/s,denmark)、以及powerasetm、和p(genencor,adaniscodivision,paloalto,ca)。在本公开的一些实施方案中,所公开的清洁组合物还包含含量为按组合物的重量计约0.00001%至约10%的另外的淀粉酶,和按组合物的重量计的剩余的清洁辅助材料。在本公开的其它方面,清洁组合物还包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的淀粉酶。在本公开的一些实施方案中,可以使用任何合适的果胶降解酶。如本文所用,“果胶降解酶”涵盖阿拉伯聚糖酶(ec3.2.1.99)、半乳聚糖酶(ec3.2.1.89)、聚半乳糖醛酸酶(ec3.2.1.15)、外切-聚半乳糖醛酸酶(ec3.2.1.67)、外切-聚-α-半乳糖醛酸酶(ec3.2.1.82)、果胶裂解酶(ec4.2.2.10)、果胶酯酶(ec3.2.1.11)、果胶酸裂解酶(ec4.2.2.2)、外切-聚半乳糖醛酸裂解酶(ec4.2.2.9)和半纤维素酶如内切-1,3-β-木糖苷酶(ec3.2.1.32)、木聚糖-1,4-β-木糖苷酶(ec3.2.1.37)和α-l-阿拉伯呋喃糖酶(ec3.2.1.55)。果胶降解酶是上述酶活性的天然混合物。果胶酶因此包括水解果胶甲酯键的甲酯酶,裂解半乳糖醛酸分子之间的糖苷键的聚半乳糖醛酸酶,以及作用于果胶酸引起α-1,4糖苷键非水解裂解以形成半乳糖醛酸的不饱和衍生物的果胶反式消去酶或裂解酶。合适的果胶降解酶包括来源于植物、真菌或微生物的那些。在一些实施方案中,包括了经化学或基因修饰的突变体。在一些实施方案中,果胶降解酶为碱性果胶降解酶,即在约7.0至约12的ph下具有其最大活性的至少10%、优选至少25%、更优选至少40%的酶活性的酶。在某些其它实施方案中,果胶降解酶为在约7.0至约12的ph下具有其最大活性的酶。碱性果胶降解酶通过嗜碱微生物产生,例如细菌、真菌和酵母微生物,如芽孢杆菌物种。在一些实施方案中,微生物为坚强芽孢杆菌(bacillusfirmus)、环状芽孢杆菌和枯草芽孢杆菌,如jp56131376和jp56068393中所述。碱性果胶分解酶可包括但不限于半乳聚糖-1,4-α-半乳糖醛酸酶(ec3.2.1.67)、聚半乳糖醛酸酶活性(ec3.2.1.15)、果胶酯酶(ec3.1.1.11)、果胶酸裂解酶(ec4.2.2.2)以及它们的异酵素。碱性果胶分解酶可通过欧文氏菌属(erwinia)物种产生。在一些实施方案中,碱性果胶分解酶通过菊欧文氏菌(e.chrysanthemi)、胡萝卜软腐欧文氏菌(e.carotovora)、解淀粉欧文氏菌(e.amylovora)、草生欧文氏菌(e.herbicola)和溶解欧文氏菌(e.dissolvens),如jp59066588、jp63042988和worldj.microbiol.microbiotechnol.(《世界微生物学与微生物技术杂志》)(8,2,115-120)1992中所述。在某些其它实施方案中,碱性果胶酶通过芽孢杆菌属物种产生,如jp73006557和agr.biol.chem.(1972),36(2)285-93中所公开。在本公开的一些实施方案中,所公开的清洁组合物还包含含量为按组合物的重量计约0.00001%至约10%的另外的果胶降解酶,和按组合物的重量计的剩余的清洁辅助材料。在本公开的其它方面,清洁组合物还包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的果胶降解酶。在一些其它实施方案中,任何合适的木葡聚糖酶都可用于本公开的清洁组合物中。合适的木葡聚糖酶包括但不限于来源于植物、真菌或细菌的那些。在一些实施方案中包括了经化学或基因修饰的突变体。如本文所用,“木葡聚糖酶”涵盖瓦赫宁根大学(wageningenuniversity)的vincken和voragen所述的酶家族[vincken等人(1994)plantphysiol.(《植物生理学》),第104卷,第99-107页]并且能够降解木葡聚糖,如hayashi等人(1989)plant.physiol.plantmol.biol.(《植物生理学玉植物分子生物学》),第40卷,第139-168页中所述。vincken等人证实通过从绿色木霉(trichodermaviride)纯化的木葡聚糖酶(内切-iv-葡聚糖酶)从分离的苹果细胞壁的纤维素中除去了木葡聚糖包衣。该酶可增强细胞壁包埋的纤维素的酶降解并与果胶酶协同作用。得自吉斯特公司(gist-brocades)的rapidaseliq+含有木葡聚糖酶活性。在本公开的一些实施方案中,所公开的清洁组合物还包含含量为按组合物的重量计约0.00001%至约10%的另外的木葡聚糖酶,和按组合物的重量计的剩余的清洁辅助材料。在本公开的其它方面,清洁组合物还包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的木葡聚糖酶。在某些其它实施方案中,用于具体应用的木葡聚糖酶为碱性木葡聚糖酶,即在7至12范围内的ph下酶活性为其最大活性的至少10%、优选至少25%、更优选至少40%的酶。在某些其它实施方案中,木葡聚糖酶为在约7.0至约12的ph下具有其最大活性的酶。在一些其它的实施方案中,任何合适的纤维素酶都可用于本公开的清洁组合物中。合适的纤维素酶包括但不限于来源于细菌或真菌的那些。在一些实施方案中包括了经化学或基因修饰的突变体。合适的纤维素酶包括但不限于特异腐质霉纤维素酶(参见例如美国专利4,435,307)。特别合适的纤维素酶是具有颜色护理有益效果的纤维素酶(参见例如ep0495257)。可用于本公开的可商购获得的纤维素酶包括但不限于(novozymesa/s,denmark)。另外的可商购获得的纤维素酶包括(加利福尼亚州帕罗奥图的丹尼斯克分公司杰能科公司和kac-500(b)tm(kaocorporation)。在一些实施方案中,纤维素酶作为成熟野生型纤维素酶或变体纤维素酶的部分或片段掺入,其中n末端的一部分缺失(参见例如美国专利5,874,276)。在一些实施方案中,本发明的清洁组合物还包含含量为按清洁组合物重量计约0.00001%至约10%的另外的纤维素酶,和按组合物重量计的剩余的清洁辅助材料。在本公开的其它方面,清洁组合物还包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的纤维素酶。在另外的实施方案中,任何适用于洗涤剂组合物的脂肪酶也可用于本公开中。合适的脂肪酶包括但不限于来源于细菌或真菌的那些。在一些实施方案中包括了经化学或基因修饰的突变体。可用的脂肪酶的示例包括绵毛状腐质菌(humicolalanuginosa)脂肪酶(参见例如ep258068和ep305216)、米黑根毛霉(rhizomucormiehei)脂肪酶(参见例如ep238023)、假丝酵母(candida)脂肪酶诸如南极假丝酵母(c.antarctica)脂肪酶(如南极假丝酵母脂肪酶a或b;参见例如ep214761)、假单胞菌(pseudomonas)脂肪酶诸如产碱假单胞菌(p.alcaligenes)脂肪酶和类产碱假单胞菌(p.pseudoalcaligenes)脂肪酶(参见例如ep218272)、洋葱假单胞菌(p.cepacia)脂肪酶(参见例如ep331376)、施氏假单胞菌(p.stutzeri)脂肪酶(参见例如gb1,372,034)、荧光假单胞菌(p.fluorescens)脂肪酶、芽孢杆菌脂肪酶(例如枯草芽孢杆菌脂肪酶[dartois等人,(1993)biochem.biophys.acta(《生物化学和生物物理学汇编》)第1131卷:第253-260页];嗜热脂肪芽孢杆菌脂肪酶[参见例如jp64/744992];和短小芽孢杆菌脂肪酶[参见例如wo91/16422])。此外,多个克隆的脂肪酶可用于本公开的一些实施方案中,包括但不限于卡门柏青霉(penicilliumcamembertii)脂肪酶(参见yamaguchi等人,[1991]gene(《基因》)103:61-67)、白地霉(geotricumcandidum)脂肪酶(参见schimada等人,[1989]j.biochem.106:383-388)以及各种根霉(rhizopus)脂肪酶例如戴尔根霉(r.delemar)脂肪酶(参见hass等人,[1991]gene109:117-113)、雪白根霉(r.niveus)脂肪酶(kugimiya等人,[1992]biosci.biotech.biochem.(《生物科学、生物技术与生物化学》)第56卷:第716-719页)和米根霉(r.oryzae)脂肪酶。其它类型的脂解酶(如角质酶)也可用于本公开的一些实施方案中,其包括但不限于:源自门多萨假单胞菌(pseudomonasmendocina)的角质酶(参见wo88/09367)和源自豌豆根腐镰孢菌(fusariumsolanipisi)的角质酶(参见wo90/09446)。其它合适的脂肪酶包括可商购获得的脂肪酶,如m1lipasetm、lumafasttm和lipomaxtm(genencor,adaniscodivision,paloalto,ca);和ultra(novozymesa/s,denmark);和lipaseptm“amano”(amanopharmaceuticalco.ltd.,japan)。在一些实施方案中,所公开的清洁组合物还包含含量为按组合物的重量计约0.00001%至约10%的另外的脂肪酶,和按组合物的重量计的剩余的清洁辅助材料。在本公开的其它方面,清洁组合物还包含含量为按约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的脂肪酶。在一些实施方案中,过氧化物酶与过氧化氢或其来源(例如过碳酸盐、过硼酸盐或过硫酸盐)组合用于本公开的组合物中。在一些备选的实施方案中,氧化酶与氧气联合使用。这两种类型的酶优选连同增强剂一起用于“溶液漂白”(即,当织物在洗涤液中一起洗涤时防止纺织物染料从染色的织物转移到另一织物)(参见例如wo94/12621和wo95/01426)。合适的过氧化物酶/氧化酶包括但不限于来源于植物、细菌或真菌的那些。在一些实施方案中包括了经化学或基因修饰的突变体。在一些实施方案中,本发明的清洁组合物还包含含量为按清洁组合物的重量计约0.00001%至约10%的另外的过氧化物酶和/或氧化酶的过氧化物酶和/或氧化酶,和按组合物的重量计的剩余的清洁辅助材料。在本公开的其它方面,清洁组合物还包含含量为按组合物的重量计约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%、约0.005%至约0.5%的过氧化物酶和/或氧化酶。在一些实施方案中,可使用另外的酶,包括但不限于过水解酶(参见例如wo05/056782)。此外,在一些特别优选的实施方案中,本文涵盖上述酶的混合物,尤其一种或多种另外的蛋白酶、淀粉酶、脂肪酶、甘露聚糖酶和/或至少一种纤维素酶。实际上,设想这些酶的多种混合物都可用于本发明中。还设想到,本发明的多肽与一种或多种另外的酶的不同水平都可独立地在最高约10%的范围内,该清洁组合物的剩余物质为清洁辅助材料。易于通过考虑待清洁的表面、物品或织物以及对使用期间(例如通过使用洗涤剂)的清洁条件理想的组合物形式,来具体选择清洁辅助材料。合适的清洁辅助材料的示例包括但不限于表面活性剂、助洗剂、漂白剂、漂白活化剂、漂白催化剂、其它酶、酶稳定体系、螯合剂、光学增亮剂、去污聚合物、染料转移剂、染料转移抑制剂、催化材料、过氧化氢、过氧化氢源、预先形成的过酸、聚合物分散剂、粘土污垢去除剂、结构增弹剂(elasticizingagent)、分散剂、抑泡剂、染料、香料、着色剂、填料盐、水溶助长剂、光活化剂、荧光剂、织物调理剂、织物软化剂、载体、水溶助长剂、加工助剂、溶剂、颜料、可水解表面活性剂、防腐剂、抗氧化剂、抗收缩剂、抗皱剂、杀菌剂、杀真菌剂、色粒、银护理剂、抗晦暗剂和/或抗腐蚀剂、碱度源、增溶剂、载体、加工助剂、颜料和ph控制剂(参见例如美国专利6,610,642;6,605,458;5,705,464;5,710,115;5,698,504;5,695,679;5,686,014;和5,646,101;所有这些专利均以引用方式并入本文)。特定清洁组合物材料的实施方案在下文中举例说明。在清洁辅助材料与所公开的清洁组合物中的本发明多肽不相容的实施方案中,则使用保持清洁辅助材料与内切-β-甘露聚糖酶分离(即,不彼此接触)直到两种组分的组合适宜时的合适方法。这种分离方法包括本领域已知的任何合适方法(例如胶囊锭法(gelcap)、包封法、片剂法、物理分离法等)。在一些优选的实施方案中,在可用于清洁需要去除污渍的多种表面的组合物中包含有效量的一种或多种本文提供的本发明的多肽。这些清洁组合物包括用于诸如清洁硬质表面、织物和餐具之类的应用的清洁组合物。实际上,在一些实施方案中,本公开提供织物清洁组合物,而在其它实施方案中,本公开提供非织物清洁组合物。值得注意的是,本公开还提供适于个人护理的清洁组合物,其包括口腔护理(包括洁牙剂、牙膏、漱口水等,以及假牙清洁组合物)、皮肤和毛发清洁组合物。另外,在其它实施方案中,本公开提供织物软化组合物。意在使本公开涵盖任何形式(即,液体、颗粒状、条状、固体、半固体、凝胶、糊状物、乳液、片剂、胶囊、单位剂量、片、泡沫等)的洗涤剂组合物。举例来说,在下文更详细地描述了几种在其中可使用所公开的本发明多肽的清洁组合物。在所公开的清洁组合物被配制成适用于洗衣机洗涤方法中的组合物的一些实施方案中,本公开的组合物优选含有至少一种表面活性剂和至少一种助洗剂化合物,以及一种或多种清洁辅助材料,所述清洁辅助材料优选选自有机聚合化合物、漂白剂、另外的酶、抑泡剂、分散剂、钙皂分散剂、悬污剂和抗再沉积剂以及腐蚀抑制剂。在一些实施方案中,洗衣组合物还含有软化剂(即作为额外的清洁辅助材料)。本发明的组合物还可使用固体或液体形式的洗涤添加剂产品。此类添加剂产品旨在补充和/或提高常规洗涤剂组合物的性能,并且可在洗涤过程的任何阶段被加入。在一些实施方案中,在20℃下测量时,本文中衣物洗涤剂组合物的密度在约400至约1200g/l的范围内,而在其它实施方案中,其在约500至约950g/l组合物的范围内。在配制为用于人工餐具洗涤方法中的组合物的实施方案中,本公开的组合物优选含有至少一种表面活性剂和优选的至少一种另外的选自如下的清洁辅助材料:有机聚合化合物、泡沫增强剂、第ii族金属离子、溶剂、水溶助长剂和另外的酶。在一些实施方案中,多种清洁组合物如美国专利6,605,458中提供的那些组合物可与本发明的多肽一起使用。因此,在一些实施方案中,包含至少一种本发明多肽的组合物是致密的颗粒状织物清洁组合物,而在其它实施方案中,所述组合物是可用于清洗有色织物的颗粒状织物清洁组合物,在另外的实施方案中,所述组合物是提供通过洗涤软化的能力(softeningthroughthewashcapacit)的颗粒状织物清洁组合物,在其它实施方案中,所述组合物是重垢液体织物清洁组合物。在一些实施方案中,包含至少一种本公开的本发明多肽的组合物是织物清洁组合物,如美国专利6,610,642和6,376,450中所述的那些组合物。此外,本发明的多肽可用于在欧洲或日本洗涤条件下特别具有实用性的颗粒状衣物洗涤组合物中(参见例如美国专利6,610,642)。在一些备选的实施方案中,本公开提供包含至少一种本发明的多肽的硬质表面清洁组合物。因此,在一些实施方案中,包含至少一种本发明多肽的组合物是硬质表面清洁组合物,如美国专利6,610,642;6,376,450;和6,376,450中所述的那些。在另一个实施方案中,本公开提供包含至少一种本发明多肽的盘碟洗涤组合物。因此,在一些实施方案中,包含至少一种本发明多肽的组合物是硬质表面清洁组合物,如美国专利6,610,642和6,376,450中所述的那些组合物。在另一些实施方案中,本公开提供包含至少一种本文提供的本发明多肽的盘碟洗涤组合物。在一些其它实施方案中,包含至少一种本发明多肽的组合物包含口腔护理组合物,如美国专利6,376,450和6,605,458中所述的那些组合物。包含于前述美国专利6,376,450;6,605,458;和6,610,642中的化合物和清洁辅助材料的配制和说明可用于本发明的多肽。在另外的实施方案中,包含至少一种本发明多肽的组合物包含织物软化组合物,如在gb-a1400898、gb-a1514276、ep0011340、ep0026528、ep0242919、ep0299575、ep0313146和美国专利5,019,292中的那些。包含在前述gb-a1400898、gb-a1514276、ep0011340、ep0026528、ep0242919、ep0299575、ep0313146和美国专利5,019,292中的化合物和软化剂的配制和说明可用于本发明的多肽。本公开的清洁组合物可被配制成任何合适的形式并通过配制人员选择的任何方法制备,其非限制性示例描述于美国专利5,879,584;5,691,297;5,574,005;5,569,645;5,565,422;5,516,448;5,489,392;和5,486,303中,所有这些专利都以引用方式并入本文中。当需要低ph清洁组合物时,通过加入诸如单乙醇胺或酸性材料(如hcl)之类的材料来调节此类组合物的ph。在一些实施方案中,本发明的清洁组合物以单位剂型提供,包括片剂、胶囊剂、囊剂(sachet)、袋剂(pouch)、片和多隔室袋剂。在一些实施方案中,对单位剂量形式进行设计以提供多隔室小袋(或其它单位剂量形式)内的成分的受控释放。合适的单位剂量和受控释放形式是本领域已知的(参见例如ep2100949、wo02/102955、美国专利4,765,916和4,972,017,以及wo04/111178关于适用于单位剂量和受控释放形式的材料)。在一些实施方案中,单位剂型以包有水溶性膜或水溶性小袋的片剂提供。各种单位剂型提供于ep2100947和wo2013/165725(其以引用方式并入),并且在本领域中是已知的。尽管不是实现本发明目的所必需的,但下文示例的辅助材料的非限制性表单适用于本发明清洁组合物。在一些实施方案中,掺入这些辅助材料,例如以帮助或增强清洁性能以便处理待清洁的基材,或改变清洁组合物的美观性,如利用芳香剂、着色剂、染料等情形就是如此。应当理解,这些辅助材料是除本发明多肽外的物质。这些另外的组分的精确性质以及其掺入的水平将取决于组合物的物理形式和打算使用组合物的清洁操作的性质。合适的辅助材料包括但不限于:表面活性剂、助洗剂、螯合剂、染料转移抑制剂、沉积助剂、分散剂、另外的酶和酶稳定剂、催化材料、漂白活化剂、漂白增强剂、过氧化氢、过氧化氢源、预先形成的过酸、聚合物分散剂、粘土污垢去除剂/抗再沉积剂、增亮剂、抑泡剂、染料、香料、结构增弹剂、织物软化剂、载体、水溶助长剂、加工助剂和/或颜料。除下文的公开内容外,此类其它辅助材料及使用水平的合适示例见于美国专利5,576,282;6,306,812;和6,326,348(以引用的方式并入本文)中。上述辅助成分可构成本发明本公开清洁组合物的剩余部分。在一些实施方案中,根据本公开的清洁组合物包含至少一种表面活性剂和/或表面活性剂体系,其中所述表面活性剂选自:非离子表面活性剂、阴离子表面活性剂、阳离子表面活性剂、两性表面活性剂、两性离子表面活性剂、半极性非离子表面活性剂以及它们的混合物。在一些低ph清洁组合物实施方案(例如净ph为约3至约5的组合物)中,组合物通常不含烷基乙氧基化硫酸盐,因为据信这种表面活性剂可能会被此类组合物的酸性内含物水解。在一些实施方案中,表面活性剂以按清洁组合物的重量计约0.1%至约60%的含量存在,而在另选的实施方案中,所述含量为约1%至约50%,而在其它实施方案中,所述含量为约5%至约40%。在一些实施方案中,本公开的清洁组合物含有至少一种螯合剂。合适的螯合剂可包括但不限于:铜、铁和/或锰螯合剂以及它们的混合物。在使用至少一种螯合剂的实施方案中,本公开的清洁组合物包含按本发明清洁组合物的重量计约0.1%至约15%或甚至约3.0%至约10%的螯合剂。在一些其它实施方案中,本文中提供的清洁组合物含有至少一种沉积助剂。合适的沉积助剂包括但不限于:聚乙二醇;聚丙二醇;聚羧酸盐;去垢性聚合物,如聚对苯二甲酸;粘土,如高岭土、蒙脱土、绿坡缕石(atapulgite)、伊利石、膨润土、多水高岭土以及它们的混合物。如本文所指出的那样,在一些实施方案中,抗再沉积剂可用于本公开的一些实施方案中。在一些优选的实施方案中,可使用非离子表面活性剂。例如,在自动盘碟洗涤实施方案中,非离子表面活性剂可用于表面修饰目的,尤其用于薄板(sheeting),以避免成膜和起斑以及用于改善光泽度。这些非离子表面活性剂也可用于防止污垢再沉积。在一些优选的实施方案中,抗再沉积剂是本领域已知的非离子表面活性剂(参见例如ep2100949)。在一些实施方案中,本公开的清洁组合物包含一种或多种染料转移抑制剂。合适的聚合物染料转移抑制剂包括但不限于:聚乙烯吡咯烷酮聚合物、聚胺n-氧化物聚合物、n-乙烯吡咯烷酮与n-乙烯咪唑的共聚物、聚乙烯噁唑烷酮和聚乙烯咪唑或它们的混合物。在使用至少一种染料转移抑制剂的实施方案中,本公开的清洁组合物包含按清洁组合物的重量计约0.0001%至约10%、约0.01%至约5%或甚至约0.1%至约3%。在一些实施方案中,硅酸盐包括在本公开的组合物中。在一些此类实施方案中,使用硅酸钠(例如二硅酸钠、偏硅酸钠和结晶页硅酸盐)。在一些实施方案中,硅酸盐以约1%至约20%的含量存在。在一些优选的实施方案中,硅酸盐以按组合物的重量计约5%至约15%的含量存在。在一些另外的实施方案中,本公开的清洁组合物还含有分散剂。合适的水溶性有机材料包括但不限于均聚酸或共聚酸或它们的盐,其中多聚羧酸包含至少两个羧基,彼此以不超过两个碳原子分开。在一些其它实施方案中,通过任何合适的技术使清洁组合物中使用的酶稳定。在一些实施方案中,本文所用的酶由成品组合物中存在的可给该酶提供钙和/或镁离子的水溶性钙和/或镁离子源来稳定。在一些实施方案中,酶稳定剂包括寡糖、多糖和无机二价金属盐(包括碱土金属,如钙盐)。设想用于稳定酶的各种技术可用于本发明中。例如,在一些实施方案中,本文所采用的酶由成品组合物中存在的可给该酶提供锌(ii)、钙(ii)和/或镁(ii)离子的水溶性的这类离子源,以及其它金属离子(例如钡(ii)、钪(ii)、铁(ii)、锰(ii)、铝(iii)、锡(ii)、钴(ii)、铜(ii)、镍(ii)和氧钒(iv))来稳定。氯化物和硫酸盐也可用于本公开的一些实施方案中。合适的寡糖和多糖(例如糊精)的示例是本领域已知的(参见例如wo07/145964)。在一些实施方案中,也可使用可逆的蛋白酶抑制剂,如含硼化合物(例如硼酸盐、4-甲酰基苯基硼酸)和/或必要时,可使用三肽醛进一步改善稳定性。在一些实施方案中,漂白剂、漂白活化剂和/或漂白催化剂存在于本公开的组合物中。在一些实施方案中,本公开的清洁组合物包含无机和/或有机漂白化合物。无机漂白剂可包括但不限于过氧化氢合物盐(例如过硼酸盐、过碳酸盐、过磷酸盐、过硫酸盐和过硅酸盐)。在一些实施方案中,无机过氧化氢合物盐是碱金属盐。在一些实施方案中,以结晶固体形式包括无机过氧化氢合物盐为,而无需额外保护,但在一些其他实施方案中,所述盐被涂覆。本领域已知的任何适合的盐都可用于本发明中(参见例如ep2100949)。在一些实施方案中,将漂白活化剂用于本公开的组合物中。漂白活化剂通常为有机过酸前体,这些有机过酸前体在60℃和低于60℃温度下进行的清洁过程中会增强漂白作用。适用于本文的漂白活化剂包括在过氧化氢解条件下提供优选具有约1至约10个碳原子,尤其约2至约4个碳原子的脂族过氧羧酸的化合物,和/或任选取代的过苯甲酸。另外的漂白活化剂是本领域已知的并且可用于本公开中(参见例如ep2100949)。此外,在一些实施方案中以及如本文中进一步描述的,本公开的清洁组合物还包含至少一种漂白催化剂。在一些实施方案中,可使用三氮杂环壬烷锰和相关络合物,以及钴、铜、锰和铁络合物。另外的漂白催化剂可用于本公开(参见例如美国专利4,246,612;美国专利5,227,084;美国专利4,810,410;wo99/06521;和ep2100949)。在一些实施方案中,本公开的清洁组合物含有一种或多种催化性金属络合物。在一些实施方案中,可使用含金属漂白催化剂。在一些优选的实施方案中,金属漂白催化剂包含催化剂体系,所述催化剂体系包含具有确定的漂白催化活性的过渡金属阳离子(例如铜、铁、钛、钌、钨、钼或锰阳离子)、具有极低或无漂白催化活性的辅助性金属阳离子(例如锌或铝阳离子),和对催化性和辅助性金属阳离子具有确定的稳定性常数的多价螯合剂(sequestrate),尤其可使用乙二胺四乙酸、乙二胺四(亚甲基膦酸)以及它们的水溶性盐(参见例如美国专利4,430,243)。在一些实施方案中,借助于锰化合物来催化本公开的清洁组合物。此类化合物及使用含量是本领域熟知的(参见例如美国专利5,576,282)。在另外的实施方案中,钴漂白催化剂可用于本公开的清洁组合物中。各种钴漂白催化剂是本领域已知的(参见例如美国专利5,597,936和5,595,967)并易于通过已知程序制备。在一些另外的实施方案中,本公开的清洁组合物包括大多环刚性配位体(mrl)的过渡金属络合物。作为一种实践但非限制性的,在一些实施方案中,对本公开提供的组合物和清洁方法进行调整以在水性洗涤介质中提供约至少1ppm的活性mrl物质,并且在一些优选的实施方案中,在洗涤液中提供约0.005ppm至约25ppm,更优选约0.05ppm至约10ppm,并且最优选约0.1ppm至约5ppm的mrl。在一些实施方案中,本发明过渡金属漂白催化剂中的优选过渡金属包括但不限于锰、铁和铬。优选的mrl还包括但不限于交叉桥接的特异性超刚性配位体(例如5,12-二乙基-1,5,8,12-四氮杂双环[6.6.2]十六烷)。合适的过渡金属mrl易于通过已知程序制备(参见例如wo2000/32601和美国专利6,225,464)。在一些实施方案中,本公开的清洁组合物包含金属护理剂。金属护理剂可用于防止和/或减少包括铝、不锈钢和非铁金属(例如银和铜)在内的金属的锈污、腐蚀和/或氧化。合适的金属护理剂包括ep2100949、wo94/26860和wo94/26859中所述的那些。在一些实施方案中,金属护理剂是锌盐。在一些其它实施方案中,本公开的清洁组合物包含约0.1重量%至约5重量%的一种或多种金属护理剂。如上文所述,本公开的清洁组合物可被配制成任何合适的形式并通过配制人员选择的任何方法制备,其非限制性示例在美国专利5,879,584;5,691,297;5,574,005;5,569,645;5,516,448;5,489,392;和5,486,303中有所描述,所有这些专利都以引用方式并入本文中。在一些需要低ph清洁组合物的实施方案中,通过加入诸如hcl的酸性材料来调节此类组合物的ph。本文所公开的清洁组合物可用于清洁部位(situs)(例如表面、餐具或织物)。通常,使所述位置的至少一部分与纯的形式的或在洗涤液中稀释的本发明清洁组合物实施方案接触,随后任选洗涤和/或漂洗所述位置。对本发明来说,“洗涤”包括但不限于擦洗和机械搅动。在一些实施方案中,清洁组合物在溶液中通常以约500ppm至约15,000ppm的浓度使用。当洗涤溶剂为水时,水温通常在约5℃至约90℃的范围内,并且当所述位置包含织物时,水与织物的质量比通常为约1:1至约30:1。作为化学试剂的本发明多肽本发明的多肽对包含甘露糖单元的多糖链(包括但不限于甘露聚糖、半乳甘露聚糖和葡甘露聚糖)水解的偏好使得本发明的多肽尤其可用于进行涉及含有1,4-β-d-甘露糖苷键的多糖底物的甘露聚糖水解反应。一般说讲,在适于进行甘露聚糖水解反应的条件下,将供体分子在存在分离的多肽或本文所述多肽或其片段或变体的情况下温育,随后任选从反应物中分离出产物。另选地,在食品的情形中,产物可不经分离即变为食品的组分。在某些实施方案中,供体分子是包含甘露糖单元的多糖链,包括但不限于甘露聚糖、葡甘露聚糖、半乳甘露聚糖和半乳葡甘露聚糖。用于食品加工和/或动物饲料的本发明多肽在一个实施方案中,包含本文所述多肽的组合物用于加工和/或制造动物饲料和人类食物。在另一个实施方案中,本发明的多肽可为非人类动物饲料的添加剂。在另一个实施方案中,本发明的多肽可用于人类食物,例如人类食物的添加剂。若干营养因子会限制用于制备动物饲料和人类食物的廉价植物材料的量。例如,含有寡甘露聚糖如甘露聚糖、半乳甘露聚糖、葡甘露聚糖和半乳葡甘露聚糖的植物材料可减弱动物消化和吸收营养化合物如矿物质、维生素、糖和脂肪的能力。这些负面影响特别是由于含甘露聚糖的聚合物的高粘度以及含甘露聚糖的聚合物吸收营养化合物的能力。这些影响可通过在饲料中包括降解含甘露聚糖聚合物的酶,例如本文所述内切-β-甘露聚糖酶来降低,从而使得更高比例的含甘露聚糖聚合物通常存在于将包含在饲料内的廉价植物材料中,这最终降低了饲料成本。另外,本文所述的多肽能够使含甘露聚糖聚合物分解为单糖,这能更易于被吸收以提供附加能量。在另一个实施方案中,将含有植物材料的动物饲料在适合分解含甘露聚糖的聚合物的条件下在存在本文所述的多肽和/或分离的多肽或其片段或变体的情况下温育。在另一个实施方案中,面包改善剂组合物包含任选地与甘露聚糖或葡甘露聚糖或半乳甘露聚糖源组合,并且进一步任选地与一种或多种其它酶组合的本文所述多肽。术语“非人类动物”包括所有非反刍动物和反刍动物。在具体的实施方案中,非反刍动物选自但不限于马和单胃动物,诸如但不限于猪、家禽和鱼。在另一个实施方案中,猪可为但不限于仔猪、生长猪和母猪;家禽可为但不限于火鸡、鸭和鸡,包括但不限于肉仔鸡和下蛋鸡;并且鱼包括但不限于大麻哈鱼、鲑鱼、罗非鱼、鲶鱼和鲤鱼;并且甲壳类包括但不限于虾和对虾。在另一个实施方案中,反刍动物选自但不限于牛、小牛、山羊、绵羊、长颈鹿、野牛、驼鹿、麋鹿、牦牛、水牛、鹿、骆驼、羊驼、美洲驼、羚羊、叉角羚和蓝牛。在一些实施方案中,本发明的多肽用于预处理饲料而非作为饲料添加剂。在一些优选的实施方案中,将本发明多肽添加到断奶仔猪、保育猪、仔猪、肥育猪、生长猪、商品猪、产蛋鸡、肉仔鸡、火鸡的饲料中或用于对其进行预处理。在另一个实施方案中,将本发明的多肽添加至得自植物材料的饲料中或用于对其进行预处理,所述植物材料为例如棕榈仁、椰子、魔芋、刺槐豆胶、瓜尔胶、大豆、大麦、燕麦、亚麻、小麦、玉米、亚麻籽、柑橘渣、棉籽、落花生、油菜籽、向日葵、豌豆和羽扇豆。因此,根据本发明的多肽,本文所公开的热稳定性多肽可用于生产粒状饲料的过程,其中在制粒步骤前将热施加于饲料混合物。在另一个实施方案中,将本发明的多肽在制粒步骤前添加到其它饲料成分中,或在制粒步骤后添加到其它饲料成分中(即添加到已形成的饲料颗粒中)。在另一个实施方案中,包含本文所述多肽的食品加工或饲料添加剂组合物还可任选地包含选自着色剂、芳香化合物、稳定剂、维生素、矿物质及其它饲料或食品增强酶的其它成分。这尤其适用于所谓的预混物。在另一个实施方案中,根据本发明的食物添加剂能以合适的量与其它食物成分诸如例如谷类食物或植物蛋白组合,以形成加工食品。在一个实施方案中,动物饲料组合物和/或动物饲料添加剂组合物和/或宠物食物包含本文所述的多肽。另一个实施方案涉及用于制备此类动物饲料组合物和/或动物饲料添加剂组合物和/或宠物食物的方法,包括将本文所述的多肽与一种或多种动物饲料成分和/或动物饲料添加剂成分和/或宠物食物成分混合。另一个实施方案涉及本文所述的多肽用于制备动物饲料组合物和/或动物饲料添加剂组合物和/或宠物食物的用途。短语“宠物食物”意指用于家养动物的食物,诸如但不限于狗;猫;沙鼠;仓鼠;毛丝鼠;心奇鼠(fancyrats);豚鼠;禽类宠物,如金丝雀、长尾小鹦鹉和鹦鹉;爬行动物宠物,如龟、蜥蜴和蛇;以及水生宠物如热带鱼和蛙。术语“动物饲料组合物”、“饲料”和“草料”可互换使用,并且可包含一种或多种选自以下的饲料材料:a)谷物,如小粒谷类作物(例如小麦、大麦、黑麦、燕麦以及它们的组合)和/或大粒谷类作物如玉米或者高粱;b)谷物的副产物,如玉米麸粗粉、干酒糟可溶物(ddgs)(尤其是玉米基干酒糟可溶物(cddgs))、小麦糠、小麦粗麸皮、小麦二级麸皮、米糠、稻壳、燕麦壳、棕榈仁和柑橘渣;c)得自如下来源的蛋白质:如大豆、向日葵、花生、羽扇豆、豌豆、蚕豆、棉花、卡诺拉、鱼粉、干血浆蛋白质、肉和骨粉、马铃薯蛋白、乳清、干椰肉和芝麻;d)得自植物和动物来源的油和脂肪;以及e)矿物质和维生素。在一个方面,食物组合物或者添加剂可为液体或固体。用于发酵饮料如啤酒的本发明多肽在本发明的一个方面,食物组合物为包含本文所述多肽的饮料,其包括但不限于发酵饮料,如啤酒和葡萄酒。在本发明的背景下,术语“发酵饮料”意在包含通过包括发酵工艺如微生物发酵(诸如细菌和/或酵母发酵)的方法生产的任何饮料。在本发明的一个方面,发酵饮料为啤酒。术语“啤酒”意在包含通过含淀粉的植物材料的发酵/酿造生产的任何发酵麦芽汁(wort)。通常,啤酒由麦芽或辅助材料产生,或由麦芽和作为含淀粉植物材料的辅助材料的任何组合产生。如本文所用,术语“麦芽”应被理解为任何发芽的谷物,如发芽大麦或小麦。如本文所用,术语“辅助材料”是指不是麦芽如大麦或小麦麦芽的任何含淀粉和/或糖的植物材料。辅助材料的示例包括例如普通粗磨玉米粉、精制粗磨玉米粉、酿酒用碾磨酵母、大米、高粱、精制玉米淀粉、大麦、大麦淀粉、去壳大麦、小麦、小麦淀粉、焙烤谷类、谷类薄片、黑麦、燕麦、马铃薯、木薯淀粉、木薯以及浆液,如玉米糖浆、甘蔗糖浆、转化糖浆、大麦和/或小麦糖浆等。如本文所用,术语“麦芽浆(mash)”是指任何含有淀粉和/或糖的植物材料如碎麦芽(例如包括压碎的大麦芽、压碎的大麦)和/或其它辅助材料或它们的组合的含水浆液,随后与水混合以分离成麦芽汁和废谷物。如本文所用,术语“麦芽汁”是指在制浆过程中提取碎麦芽后的未发酵液体流出物。在另一方面,本发明涉及制备发酵饮料如啤酒的方法,包括将任何本发明的多肽与麦芽和/或辅助材料混合。啤酒的示例包括:全麦芽啤酒、在“纯净法”下酿造的啤酒、爱尔啤酒、印度淡爱尔啤酒、拉格啤酒、苦啤酒、低麦芽啤酒(第二类啤酒)、第三类啤酒、干啤酒、薄啤酒、淡啤酒、低酒精啤酒、低卡路里啤酒、波特啤酒、博克啤酒、烈性啤酒、麦芽酒、无酒精啤酒、无酒精麦芽酒等,以及可供选择的谷类和麦芽饮料,如水果味麦芽饮料,例如柑橘味如柠檬、甜橙、酸橙、或浆果味麦芽饮料;酒味麦芽饮料,例如伏特加、浪姆酒、或龙舌兰味麦芽酒;或咖啡味麦芽饮料,例如咖啡味麦芽酒;等等。本发明的一个方面涉及任何本发明的多肽在生产发酵饮料如啤酒中的用途。另一方面涉及提供发酵饮料的方法,包括使麦芽浆和/或麦芽汁与任何本发明的多肽接触的步骤。另一个方面涉及提供发酵饮料的方法,该方法包括以下步骤:(a)制备麦芽浆;(b)过滤所述麦芽浆以获得麦芽汁,以及(c)使所述麦芽汁发酵以获得发酵饮料如啤酒,其中任何本发明的多肽被添加至:(i)步骤(a)的麦芽浆和/或(ii)步骤(b)的麦芽汁和/或(iii)步骤(c)的麦芽汁。根据另一方面,通过包括以下的步骤的方法制备或提供发酵饮料例如啤酒:(1)使麦芽浆和/或麦芽汁与任何本发明的多肽接触;和/或(2)(a)制备麦芽浆;(b)过滤所述麦芽浆以获得麦芽汁,以及(c)使所述麦芽汁发酵以获得发酵饮料如啤酒,其中任何本发明的多肽被添加至:(i)步骤(a)的麦芽浆和/或(ii)步骤(b)的麦芽汁和/或(iii)步骤(c)的麦芽汁。用于处理咖啡提取物的本发明多肽本文所述的本发明多肽还可用于水解存在于液体咖啡提取物中的半乳甘露聚糖。在一个方面,本发明的多肽用于抑制液体咖啡提取物冷冻干燥期间的凝胶形成。提取物降低的粘度减少了干燥期间的能量消耗。在某些其它方面,本发明的多肽以固定化形式施用,从而减小酶消耗并避免咖啡提取物的污染。该用途进一步公开于ep676145中。一般说讲,将咖啡提取物在适合水解存在于液体咖啡提取物中的半乳甘露聚糖的条件下在存在本发明的多肽和/或分离的多肽或其片段或变体的情况下温育。用于烘焙食品的本发明多肽在另一方面,本发明涉及制备烘焙产品的方法,包括将任何本发明的多肽添加至生面团,然后烘焙生面团。烘焙产品的示例是本领域技术人员熟知的,并包括面包、面包卷、松饼、甜发酵面团、小圆面包、蛋糕、咸饼干、曲奇、饼干、华夫饼干、薄饼、玉米粉圆饼、早餐谷类食品、挤出产品等。可将任何本发明的多肽作为面包改善剂组合物的一部分添加到生面团中。面包改善剂是含有多种成分的组合物,这些成分可改善生面团的性质和烘焙产品(例如面包和蛋糕)的质量。通常在工业烘焙过程中添加面包改善剂,因为它们具有有益的效果,例如生面团稳定性和面包纹理和体积。面包改善剂通常含有脂肪和油以及添加剂,如乳化剂、酶、抗氧化剂、氧化剂、稳定剂和还原剂。除了任何本发明的多肽外,还可存在于面包改善剂中的或者可与任何本发明的多肽结合使用的其它酶包括淀粉酶、半纤维素酶、淀粉分解复合物、脂肪酶、蛋白酶、木聚糖酶、果胶酶、支链淀粉酶、非淀粉多糖降解酶和氧化还原酶,如葡萄糖氧化酶、脂氧合酶或抗坏血酸氧化酶。在本发明的优选烘焙方面,可将任何本发明的多肽作为面包改善剂组合物的一部分添加至生面团中,所述面包改善剂组合物还包含葡甘露聚糖和/或半乳甘露聚糖源,如魔芋胶、瓜尔胶、刺槐豆胶(长角豆(ceratoniasiliqua))、椰子核粉、象牙椰子(phyteleohasmacrocarpa)甘露聚糖、海藻甘露聚糖提取物、椰子粕和酿酒酵母细胞壁(可进行干燥,或以酿酒酵母提取物的形式使用)。其它可接受用于本发明的甘露聚糖衍生物包括非支链β-1,4-连接的甘露聚糖均聚物和甘露寡糖(甘露二糖、甘露三糖、甘露四糖和甘露五糖)。任何本发明的多肽还可单独地或与葡甘露聚糖和/或半乳甘露聚糖和/或半乳葡甘露聚糖组合使用以改善生面团耐弹性(doughtolerance);生面团柔韧性和/或生面团黏性;和/或面包屑粒结构,以及延迟面包的陈腐。在另一方面,甘露聚糖酶水解产物充当可溶性益生元,例如甘露寡糖(mos),其促进当以有利的种群密度存在于结肠中时通常与身体健康相关的乳酸菌的生长。在一个方面,除纯面粉之外或作为纯面粉的替代,任何本发明的多肽添加至其中的生面团还包含麸皮或燕麦、稻、粟、玉米或豆类面粉(即,不为纯白生面团)。用于乳类食品的本发明多肽在本发明的一个方面,可将任何本发明的多肽添加至还已加入了葡甘露聚糖和/或半乳甘露聚糖的奶或任何其它乳制品中。典型的葡甘露聚糖和/或半乳甘露聚糖来源在上文的烘焙方面列出,并包括瓜尔胶或魔芋胶。任何本发明的多肽与葡甘露聚糖和/或半乳甘露聚糖的组合可释放甘露聚糖酶水解产物(甘露寡糖),这些水解产物通过促进当以有利的种群密度存在于大肠或结肠中时通常与身体健康相关的益生菌(尤其是双歧杆菌(bifidobacteria)和乳杆菌(lactobacillus)乳酸菌)的选择性生长和增殖而作为可溶性益生元发挥作用。另一方面涉及用于制备奶或乳制品的方法,包括添加任何本发明的多肽以及任何葡甘露聚糖或半乳甘露聚糖或半乳葡甘露聚糖。在另一方面,将任何本发明的多肽在添加到乳类食品之前或之后与任何葡甘露聚糖或半乳甘露聚糖组合使用,以产生含有益生元甘露聚糖水解产物的乳类食品。在另一方面,因而产生的含甘露寡糖的乳制品能够增加有益的人类肠道微生物群的群体,在另一个方面,乳类食品可包含与任何葡甘露聚糖和/或半乳甘露聚糖和/或半乳葡甘露聚糖源一起的任何本发明的多肽,并且剂量足以接种已知在人类大肠中具有有益效果的细菌(如双歧杆菌或乳杆菌)的至少一种菌株。在一个方面,所述乳类食品为酸奶或乳饮料。用于纸浆漂白的本发明多肽本文所述的多肽还可用于纸浆(如化学纸浆、半化学纸浆、牛皮纸浆、机械纸浆和通过亚硫酸盐法制备的纸浆)的酶辅助漂白。一般说讲,将纸浆在适合漂白纸浆的条件下与本文所述的多肽和/或分离的多肽或其片段或变体温育。在一些实施方案中,纸浆是用氧、臭氧、过氧化物或过氧酸漂白的无氯纸浆。在一些实施方案中,将本发明的多肽用于表现出具有低木质素含量的通过改善或连续制浆方法产生的纸浆的酶辅助漂白中。在一些其它实施方案中,将本发明的多肽单独地或优选与木聚糖酶和/或内切葡聚糖酶和/或α-半乳糖苷酶和/或纤维二糖水解酶组合地应用。用于降解增稠剂的本发明多肽诸如瓜尔胶和刺槐豆胶之类的半乳甘露聚糖例如在食品和用于织物印花(如t恤印花)的印花色浆中被广泛用作增稠剂。因此,本文所述的多肽还可用于降低含甘露聚糖的底物的稠度或粘度。在某些实施方案中,将本文所述的多肽用于降低加工设备中残余食物的粘度,因而有利于加工后的清洁。在某些其它实施方案中,将本文所公开的多肽用于降低印花色浆的粘度,从而有利于在织物印花后洗出多余的印花色浆。一般说讲,将含有甘露聚糖的底物在适合降低含有甘露聚糖的底物的粘度的条件下与本文所述的多肽和/或分离的多肽或其片段或变体温育。根据前面的描述和以下的实施例,本发明组合物和方法的其它方面和实施方案将显而易见。实施例提供以下实施例以展示和说明本公开的某些优选实施方案和方面,而不应理解为限制性的。实施例1芽孢杆菌属和类芽孢杆菌甘露聚糖酶的鉴定以下由芽孢杆菌属和类芽孢杆菌菌种编码的甘露聚糖酶的核苷酸和氨基酸序列从ncbi数据库提取。从环状芽孢杆菌k-1分离的bciman1基因(ncbi参考序列ab007123.1)的核苷酸序列如seqidno:1所示(编码预测的天然信号肽的序列以粗体示出):gcaagcggattttatgtaagcggtaccaaattattggatgctacaggacaaccatttgtgatgcgaggagtcaatcatgcgcacacatggtataaagatcaactatccaccgcaataccagccattgctaaaacaggtgccaacacgatacgtattgtactggcgaatggacacaaatggacgcttgatgatgtaaacaccgtcaacaatattctcaccctctgtgaacaaaacaaactaattgccgttttggaagtacatgacgctacaggaagcgatagtctttccgatttagacaacgccgttaattactggattggtattaaaagcgcgttgatcggcaaggaagaccgtgtaatcattaatatagctaacgagtggtacggaacatgggatggagtcgcctgggctaatggttataagcaagccatacccaaactgcgtaatgctggtctaactcatacgctgattgttgactccgctggatggggacaatatccagattcggtcaaaaattatgggacagaagtactgaatgcagacccgttaaaaaacacagtattctctatccatatgtatgaatatgctgggggcaatgcaagtaccgtcaaatccaatattgacggtgtgctgaacaagaatcttgcactgattatcggcgaatttggtggacaacatacaaacggtgatgtggatgaagccaccattatgagttattcccaagagaagggagtcggctggttggcttggtcctggaagggaaatagcagtgatttggcttatctcgatatgacaaatgattgggctggtaactccctcacctcgttcggtaataccgtagtgaatggcagtaacggcattaaagcaacttctgtgttatccggcatttttggaggtgttacgccaacctcaagccctacttctacacctacatctacgccaacctcaactcctactcctacgccaagtccgaccccgagtccaggtaataacgggacgatcttatatgatttcgaaacaggaactcaaggctggtcgggaaacaatatttcgggaggcccatgggtcaccaatgaatggaaagcaacgggagcgcaaactctcaaagccgatgtctccttacaatccaattccacgcatagtctatatataacctctaatcaaaatctgtctggaaaaagcagtctgaaagcaacggttaagcatgcgaactggggcaatatcggcaacgggatttatgcaaaactatacgtaaagaccgggtccgggtggacatggtacgattccggagagaatctgattcagtcaaacgacggtaccattttgacactatccctcagcggcatttcgaatttgtcctcagtcaaagaaattggggtagaattccgcgcctcctcaaacagtagtggccaatcagctatttatgtagatagtgttagtctgcaatga。由bciman1基因编码的bciman1前体蛋白的氨基酸序列(ncbi登录号baa25878.1)如seqidno:2所示(预测的天然信号肽以粗体示出):aasgfyvsgtklldatgqpfvmrgvnhahtwykdqlstaipaiaktgantirivlanghkwtlddvntvnniltlceqnkliavlevhdatgsdslsdldnavnywigiksaligkedrviinianewygtwdgvawangykqaipklrnaglthtlivdsagwgqypdsvknygtevlnadplkntvfsihmyeyaggnastvksnidgvlnknlaliigefggqhtngdvdeatimsysqekgvgwlawswkgnssdlayldmtndwagnsltsfgntvvngsngikatsvlsgifggvtptssptstptstptstptptpsptpspgnngtilydfetgtqgwsgnnisggpwvtnewkatgaqtlkadvslqsnsthslyitsnqnlsgksslkatvkhanwgnigngiyaklyvktgsgwtwydsgenliqsndgtiltlslsgisnlssvkeigvefrassnssgqsaiyvdsvslq。从环状芽孢杆菌196分离的bciman3基因的核酸序列(ncbi参考序列ay907668.1,从430至1413,互补序列)如seqidno:3所示(编码预测的天然信号肽的序列以粗体示出):gccacaggattttatgtaaacggtaccaagctgtatgattcaacgggcaaggcctttgtgatgaggggtgtaaatcatccccacacctggtacaagaatgatctgaacgcggctattccggctatcgcgcaaacgggagccaataccgtacgagtcgtcttgtcgaacgggtcgcaatggaccaaggatgacctgaactccgtcaacagtatcatctcgctggtgtcgcagcatcaaatgatagccgttctggaggtgcatgatgcgacaggcaaagatgagtatgcttcccttgaagcggccgtcgactattggatcagcatcaaaggggcattgatcggaaaagaagaccgcgtcatcgtcaatattgctaatgaatggtatggaaattggaacagcagcggatgggccgatggttataagcaggccattcccaaattaagaaacgcgggcattaagaatacgttgatcgttgatgcagcgggatgggggcaatacccgcaatccatcgtggatgagggggccgcggtatttgcttccgatcaactgaagaatacggtattctccatccatatgtatgagtatgccggtaaggatgccgctacggtgaaaacgaatatggacgatgttttaaacaaaggattgcctttaatcattggggagttcggcggctatcatcaaggtgccgatgtcgatgagattgctattatgaagtacggacagcagaaggaagtgggctggctggcttggtcctggtacggaaacagcccggagctgaacgatttggatctggctgcagggccaagcggaaacctgaccggctggggaaacacggtggttcatggaaccgacgggattcagcaaacctccaagaaagcgggcatttattaa。由bciman3基因编码的bciman3前体蛋白的氨基酸序列(ncbi登录号aax87002.1)如seqidno:4所示(预测的天然信号肽以粗体示出):atgfyvngtklydstgkafvmrgvnhphtwykndlnaaipaiaqtgantvrvvlsngsqwtkddlnsvnsiislvsqhqmiavlevhdatgkdeyasleaavdywisikgaligkedrvivnianewygnwnssgwadgykqaipklrnagikntlivdaagwgqypqsivdegaavfasdqlkntvfsihmyeyagkdaatvktnmddvlnkglpliigefggyhqgadvdeiaimkygqqkevgwlawswygnspelndldlaagpsgnltgwgntvvhgtdgiqqtskkagiy。从环状芽孢杆菌cgmcc1554分离的bciman4基因的核酸序列(ncbi参考序列ay913796.1,从785到1765)如seqidno:5所示(编码预测的天然信号肽的序列以粗体示出):gctacaggtttttacgtgaatggaggcaaattgtacgattctacgggtaaaccattttacatgaggggtatcaatcatgggcactcctggtttaaaaatgatttgaacacggctatccctgcgatcgcaaaaacgggtgccaatacggtacgaattgttttatcaaacggtacacaatacaccaaggatgatctgaattccgtaaaaaacatcattaatgtcgtaaatgcaaacaagatgattgctgtgcttgaagtacacgatgccactgggaaagatgacttcaactcgttggatgcagcggtcaactactggataagcatcaaagaagcactgatcgggaaggaagatcgggttattgtaaacattgcaaacgagtggtacggaacatggaacggaagcgcgtgggctgacgggtacaaaaaagctattccgaaattaagagatgcgggtattaaaaataccttgattgtagatgcagcaggctggggtcagtaccctcaatcgatcgtcgattacggacaaagcgtattcgccgcggattcacagaaaaatacggcgttttccattcacatgtatgagtatgcaggcaaggatgcggccaccgtcaaatccaatatggaaaatgtgctgaataaggggctggccttaatcattggtgagttcggaggatatcacaccaatggagatgtcgatgaatatgcaatcatgaaatatggtctggaaaaaggggtaggatggcttgcatggtcttggtacggtaatagctctggattaaactatcttgatttggcaacaggacctaacggcagtttgacgagctatggtaatacggttgtcaatgatacttacggaattaaaaatacgtcccaaaaagcgggaatcttttaa。由bciman4基因编码的bciman4前体蛋白的氨基酸序列(ncbi登录号aax87003.1)如seqidno:6所示(预测的天然信号肽以粗体示出):atgfyvnggklydstgkpfymrginhghswfkndlntaipaiaktgantvrivlsngtqytkddlnsvkniinvvnankmiavlevhdatgkddfnsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrdagikntlivdaagwgqypqsivdygqsvfaadsqkntafsihmyeyagkdaatvksnmenvlnkglaliigefggyhtngdvdeyaimkyglekgvgwlawswygnssglnyldlatgpngsltsygntvvndtygikntsqkagif。从多粘类芽孢杆菌e681分离的ppoman1基因的核酸序列(ncbi参考序列nc_014483.1,从649134到650117,互补序列)如seqidno:7所示(编码预测的天然信号肽的序列以粗体示出):gcttcaggattttatgtaagcggtaccaaattgtatgactctacaggcaagccatttgttatgagaggcgtcaatcatgctcacacttggtacaaaaacgatctttatacagctatcccggcaattgcccagacaggtgctaataccgtccgaattgtcctttctaacggaaaccagtacaccaaggatgacattaattccgtgaaaaatattatctctcttgtctccaactataaaatgattgctgtacttgaagttcatgatgctacaggcaaagacgactacgcgtctttggatgcagctgtgaactactggattagcataaaagatgctctgatcggcaaggaagaccgggttatcgtaaacattgcgaacgaatggtatggttcttggaatggaagtggttgggctgatggatacaagcaagcgattcccaagttgagaaacgcaggtatcaaaaatacgctcatcgtcgattgtgccggatggggacagtatcctcagtctatcaatgactttggtaaatctgtatttgcagctgattctttgaagaatacggtattctctattcatatgtatgagttcgctggtaaagatgctcaaaccgttcgaaccaatattgataacgttctgaatcaaggaattcctctgattattggtgaatttggaggttaccaccagggagcagacgtcgacgagacagaaatcatgagatatggccaatccaaaggagtaggctggttagcctggtcctggtatggtaatagttccaacctttcctaccttgatcttgtaacaggacctaatggcaatctgacggattggggaaaaactgtagttaacggaagcaacgggatcaaagaaacatcgaaaaaagctggtatctactaa。由ppoman1基因编码的ppoman1蛋白质的氨基酸序列(ncbi登录号yp_003868989.1)如seqidno:8所示(预测的天然信号肽以粗体示出):asgfyvsgtklydstgkpfvmrgvnhahtwykndlytaipaiaqtgantvrivlsngnqytkddinsvkniislvsnykmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngsgwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdaqtvrtnidnvlnqgipliigefggyhqgadvdeteimrygqskgvgwlawswygnssnlsyldlvtgpngnltdwgktvvngsngiketskkagiy。从多粘类芽孢杆菌sc2分离的ppoman2基因的核酸序列(ncbi参考序列nc_014622.1,从746871到747854,互补序列)如seqidno:9所示(编码预测的天然信号肽的序列以粗体示出):gcttcaggattttatgtaagcggtaccaatctgtatgactctacaggcaaaccgttcgttatgagaggcgtcaatcatgctcacacttggtacaaaaacgatctttatactgctatcccagcaattgctaaaacaggtgctaatacagtccgaattgtcctttctaacggaaaccagtacaccaaggatgacattaattccgtgaaaaatattatctctctcgtctccaaccataaaatgattgctgtacttgaagttcatgacgctacaggtaaagacgactatgcgtctttggatgcagcagtgaattactggattagtataaaagatgctctgatcggcaaggaagatcgggttatcgtgaacattgcgaacgaatggtatggctcttggaatggaggcggttgggcagatgggtataagcaagcgattcccaagctgagaaacgcaggcatcaaaaatacgctcatcgtcgattgtgctggatggggacaataccctcagtctatcaatgactttggtaaatctgtgtttgcagctgattctttgaaaaataccgttttctccattcatatgtatgaatttgctggcaaagatgttcaaacggttcgaaccaatattgataacgttctgtatcaagggctccctttgattattggtgaatttggcggttaccatcagggagcagacgtcgacgagacagaaatcatgagatacggccaatctaaaagcgtaggctggttagcctggtcctggtatggcaatagctccaaccttaattatcttgatcttgtgacaggacctaacggcaatctgaccgattggggtcgcaccgtggtagagggagccaacgggatcaaagaaacatcgaaaaaagcgggtatcttctaa。由ppoman2基因编码的ppoman2假定蛋白的氨基酸序列(ncbi登录号yp_003944884.1)如seqidno:10所示(预测的天然信号肽以粗体示出):asgfyvsgtnlydstgkpfvmrgvnhahtwykndlytaipaiaktgantvrivlsngnqytkddinsvkniislvsnhkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngggwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdvqtvrtnidnvlyqglpliigefggyhqgadvdeteimrygqsksvgwlawswygnssnlnyldlvtgpngnltdwgrtvvegangiketskkagif。从类芽孢杆菌属a1分离的pspman4基因的核酸序列(ncbi参考序列gq358926.1)如seqidno:11所示(编码预测的天然信号肽的序列以粗体示出):atggctacaggtttttatgtaagcggtaacaagttatacgattccactggcaagccttttgttatgagaggtgttaatcacggacattcctggttcaaaaatgatttgaataccgctatccctgccatcgccaaaacaggtgccaatacggtacgcattgttctttcgaatggtagcctgtacaccaaagatgatctgaacgctgttaaaaatattattaatgtggttaaccagaataaaatgatagctgtactcgaagtacatgacgccacagggaaagatgactataattcgttggatgcggcggtgaactactggattagtattaaggaagctttgattggaaaagaagatcgggtaattgtcaacatcgccaatgaatggtatggaacgtggaatggaagtgcgtgggctgatggttacaaaaaagccattccgaaactccgaaatgcaggaattaaaaatacgctaattgtggatgcagccggatggggacagttccctcaatccatcgtggattatggacaaagtgtatttgcagccgattcacagaaaaataccgtcttctccattcatatgtatgagtatgctggcaaagatgctgcaacggtcaaagccaatatggagaatgtgctgaacaaaggattggctctgatcattggtgaattcgggggatatcacacaaacggtgatgtggatgagtatgccatcatgagatatggtcaggaaaaaggggtaggctggcttgcctggtcttggtacggaaacagctccggtttgaactatctggacatggccacaggtccgaacggaagcttaacgagttttggcaacactgttgttaatgatacctatggtattaaaaacacttcccaaaaagcggggattttctaa。由pspman4基因编码的pspman4蛋白质的氨基酸序列(ncbi登录号acu30843.1)如seqidno:12所示(预测的天然信号肽以粗体示出):matgfyvsgnklydstgkpfvmrgvnhghswfkndlntaipaiaktgantvrivlsngslytkddlnavkniinvvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqfpqsivdygqsvfaadsqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimrygqekgvgwlawswygnssglnyldmatgpngsltsfgntvvndtygikntsqkagif。从类芽孢杆菌属ch-3分离的pspman5基因的核酸序列(ncbi参考序列jn603735.1,从536到1519)如seqidno:13所示(编码预测的天然信号肽的序列以粗体示出):gcaacaggtttttatgtaagcggtaccactctatatgattctactggtaaaccttttgtaatgcgcggtgtcaatcattcgcatacctggttcaaaaatgatctaaatgcagccatccctgctattgccaaaacaggtgcaaatacagtacgtatcgttttatctaatggtgttcagtatactagagatgatgtaaactcagtcaaaaatattatttccctggttaaccaaaacaaaatgattgctgttcttgaggtgcatgatgctaccggtaaagacgattacgcttctcttgatgccgctgtaaactactggatcagcatcaaagatgccttgattggcaaggaagatcgagtcattgttaatattgccaatgaatggtacggtacatggaatggcagtgcttgggcagatggttataagcaggctattcccaaactaagaaatgcaggcatcaaaaacactttaatcgttgatgccgccggctggggacaatgtcctcaatcgatcgttgattacgggcaaagtgtatttgcagcagattcgcttaaaaatacaattttctctattcacatgtatgaatatgcaggcggtacagatgcgatcgtcaaaagcaatatggaaaatgtactgaacaaaggacttcctttgatcatcggtgaatttggcgggcagcatacaaacggcgatgtagatgaacatgcaattatgcgttatggtcagcaaaaaggtgtaggttggctggcatggtcgtggtatggcaacaatagtgaactcagttatctggatttggctacaggtcccgccggtagtctgacaagtatcggcaatacgattgtaaatgatccatatggtatcaaagctacctcgaaaaaagcgggtatcttctaa。由pspman5基因编码的pspman5蛋白质的氨基酸序列(ncbi登录号aex60762.1)如seqidno:14所示(预测的天然信号肽以粗体示出):atgfyvsgttlydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqcpqsivdygqsvfaadslkntifsihmyeyaggtdaivksnmenvlnkglpliigefggqhtngdvdehaimrygqqkgvgwlawswygnnselsyldlatgpagsltsigntivndpygikatskkagif。此外,通过对解淀粉类芽孢杆菌dsm11730、dsm15211和dsm11747、饲料类芽孢杆菌dsm3036、类芽孢杆菌属fel05(重命名为paenibacillushunanensisdsm22170)和paenibacillustundrae(culturecollectiondupont)的基因组测序来鉴定甘露聚糖酶。使用illumina的下一代测序技术通过baseclear(leiden,thenetherlands)对这些生物体的全基因组进行定序并随后通过baseclear组装。通过bioxpr(比利时那慕尔公司(namur,belgium))对重叠群(contig)进行注释。从解淀粉类芽孢杆菌分离的pamman2基因的核苷酸序列如seqidno:15所示(相同的序列见于dsm11730、dsm15211和dsm11747;编码预测的天然信号肽的序列以粗体示出):gctacaggattttatgtaagcggtaacaagttatacgattccacaggcaaggcttttgtcatgagaggtgttaatcacggacattcctggttcaaaaatgatttgaataccgctatccctgcaatcgccaaaacaggtgccaatacggtacgcattgttctttcgaatggtagcctgtacaccaaagatgatctgaacgctgttaaaaatattattaatgtggttaaccaaaataaaatgatagctgtactcgaggtgcatgacgccacagggaaagatgactataattcgttggatgcggcagtgaactactggattagcattaaggaagctttgattggcaaagaagatcgggtcatcgtcaatatcgccaatgaatggtatggaacgtggaatggaagtgcgtgggctgatggttacaaaaaagccattccgaaactccgaaatgcgggaattaaaaatacgctaattgtggatgcagccggatggggacagttccctcaatccatcgtggattatggacaaagtgtatttgcaaccgattctcagaaaaatacggtcttctccattcatatgtatgagtatgctggcaaagatgctgcaaccgtcaaagccaatatggaaaatgtgctgaacaaaggattggctctgatcattggtgagttcgggggataccacacaaacggtgatgtggacgagtatgccatcatgagatatggtcaggaaaaaggggtgggctggctggcctggtcctggtatggaaacagttctggtctgaactacctggacatggctacaggtccgaacggaagtttgacgagcttcggaaacaccgtagtgaatgatacctatggaattaaaaaaacttctcaaaaagcggggattttc。pamman2前体蛋白的氨基酸序列如seqidno:16示出(预测的天然信号肽以粗体示出):atgfyvsgnklydstgkafvmrgvnhghswfkndlntaipaiaktgantvrivlsngslytkddlnavkniinvvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqfpqsivdygqsvfatdsqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimrygqekgvgwlawswygnssglnyldmatgpngsltsfgntvvndtygikktsqkagif。完全加工的成熟pamman2蛋白质(297个氨基酸)的序列如seqidno:17所示:atgfyvsgnklydstgkafvmrgvnhghswfkndlntaipaiaktgantvrivlsngslytkddlnavkniinvvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqfpqsivdygqsvfatdsqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimrygqekgvgwlawswygnssglnyldmatgpngsltsfgntvvndtygikktsqkagif。从饲料类芽孢杆菌dsm3036分离的ppaman2基因的核苷酸序列如seqidno:18所示(编码预测的天然信号肽的序列以粗体示出):gctgctggtttttatgtaagcggtaacaagttgtatgactctacgggtaaagcttttgtcatgcggggcgtcaaccacagtcatacctggttcaagaacgatctaaacacagcgatacccgccattgcaaaaacaggtgcgaacacggtacgtattgtgctctccaatgggacgcaatataccaaagatgatttgaacgccgttaaaaacataatcaacctggtgagtcagaacaaaatgatcgcagtgctcgaagtacatgatgcaactggtaaagatgactacaattcgttggatgcagcagtcaactactggattagcatcaaggaagctctgattggcaaggaagaccgcgttatcgtcaatattgccaatgaatggtacgggacctggaacggcagtgcctgggctgacgggtacaaaaaagcaattccgaaactgagaaatgccggcattaaaaatacattaattgtagatgcagctggctggggccaatatccgcaatctattgtggactatggtcaaagtgtttttgcagcagatgcccagaaaaatacggttttctccattcacatgtatgaatatgcaggtaaagatgccgcaacggtcaaagccaacatggaaaacgtgctgaacaaaggtttggccctgatcatcggtgagtttggtggataccacaccaatggggacgtcgatgaatatgcaatcatgaaatacggtcaggaaaaaggagtaggctggctcgcatggtcctggtatgggaacaactccgatctcaattatctggatttggctacaggtccaaacggaactttaacaagctttggcaacacggtggtttatgacacgtatggaattaaaaacacttcggtaaaagcagggatctat。ppaman2前体蛋白的氨基酸序列如seqidno:19所示(预测的天然信号肽以斜体和粗体示出):aagfyvsgnklydstgkafvmrgvnhshtwfkndlntaipaiaktgantvrivlsngtqytkddlnavkniinlvsqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfaadaqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimkygqekgvgwlawswygnnsdlnyldlatgpngtltsfgntvvydtygikntsvkagiy。从类芽孢杆菌属fel05分离的pspman9基因的核苷酸序列如seqidno:20所示(编码预测的天然信号肽的序列以粗体示出):gctacaggtttttatgtaagcggtaccaaattatacgactctacaggcaagccatttgtgatgcgtggtgtgaatcattcccacacctggttcaaaaatgacctgaatgcagcgatccctgcaattgccaaaacaggcgccaacacggtacgtatcgtattatcgaatggcgtgcagtacaccagagatgatgtaaactccgtcaaaaatatcatctctctcgtcaaccagaacaaaatgatcgcagtactggaggttcatgatgcaacaggcaaggacgattacgcttcgctcgatgccgcaatcaactactggatcagcatcaaggatgcgctgatcggtaaagaggatcgcgttatcgtcaatattgccaacgaatggtatggcacatggaatggaagcgcatgggcagatggctacaaacaggcgattccaaagctccgtaatgcgggtataaaaaatacgctgattgttgacgcagccggctggggtcaatatccacaatcgatcgttgattatggacaaagtgtatttgcagcggattcgttaaaaaatacggttttctcgatccatatgtatgagtatgcaggtggaaccgatgcgatggtcaaagccaacatggagggcgtactcaataaaggtctgccactgatcattggtgaatttggcggacagcacacaaatggagacgtggatgagctggcgatcatgcgttacggacaacaaaaaggagtaggctggctcgcctggtcctggtacggcaacaatagtgatctgagttatctcgatctagcgacaggtccaaatggtagcctgaccacgtttggtaatacggtggtaaatgacaccaacggtatcaaagccacctccaaaaaagcaggtattttccag。pspman9前体蛋白的氨基酸序列如seqidno:21所示(预测的天然信号肽以斜体和粗体示出):atgfyvsgtklydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaainywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqypqsivdygqsvfaadslkntvfsihmyeyaggtdamvkanmegvlnkglpliigefggqhtngdvdelaimrygqqkgvgwlawswygnnsdlsyldlatgpngslttfgntvvndtngikatskkagifq。从paenibacillustundrae分离的ptuman2基因的核苷酸序列如seqidno:22所示(编码预测的天然信号肽的序列以粗体示出):gctacaggattttatgtaagcggaggcaaattgtacgattctactggcaaggcatttgttatgagaggtgtcaatcatggacattcatggtttaagaacgacttgaacacggctattcctgcgatagccaaaacaggtgccaacaccgtacggattgtgctctccaatggcgtacagtacaccaaagacgatctgaactctgttaaaaacatcattaatgttgtaagcgtaaacaaaatgattgcggtgctcgaagtacatgatgcaacaggtaaggatgactataattcgttggatgcagcggtgaactactggattagcatcaaggaagcactcattggcaaagaagacagagttatcgtaaatatcgcgaacgaatggtatggaacatggaacggcagtgcctgggctgacggatacaaaaaagcaattccgaagctgagaaatgccggtattaaaaatacattgatcgtggatgcagcgggctgggggcagtacccgcaatccatcgtggattatggacaaagtgtatttgcagcggattcacagaaaaacaccgtattctcgattcacatgtatgaatatgccggtaaagacgcagcaaccgtaaaagccaacatggaaagcgtattaaacaaaggtctggccctgatcatcggtgaattcggtggatatcacacgaacggggatgtcgatgaatatgcgatcatgaaatatggtcaggaaaaaggggtaggctggctcgcatggtcctggtatggcaatagctccgatttgaactatttggacttggctacgggacctaacggaagtttgactagctttggaaacacagtcgtcaacgacacttatggaatcaaaaatacttcaaaaaaagcagggatctac。ptuman2前体蛋白的氨基酸序列如seqidno:23所示(预测的天然信号肽以粗体示出):atgfyvsggklydstgkafvmrgvnhghswfkndlntaipaiaktgantvrivlsngvqytkddlnsvkniinvvsvnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfaadsqkntvfsihmyeyagkdaatvkanmesvlnkglaliigefggyhtngdvdeyaimkygqekgvgwlawswygnssdlnyldlatgpngsltsfgntvvndtygikntskkagiy。完全加工的成熟ptuman2(303个氨基酸)的序列如seqidno:24所示:atgfyvsggklydstgkafvmrgvnhghswfkndlntaipaiaktgantvrivlsngvqytkddlnsvkniinvvsvnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfaadsqkntvfsihmyeyagkdaatvkanmesvlnkglaliigefggyhtngdvdeyaimkygqekgvgwlawswygnssdlnyldlatgpngsltsfgntvvndtygikntskkagiy。实施例2:甘露聚糖酶的异源表达成熟形式的bciman1、bciman3、bciman4、ppaman2、ppoman1、ppoman2、pspman4、pspman5和pspman9基因的dna序列通过generaybiotech(shanghai,china)合成并插入到枯草芽孢杆菌表达载体p2jm103bbi(vogtentanz,proteinexprpurif,55:40-52,2007)中,从而产生包含apre启动子、用于指导目标蛋白质在枯草芽孢杆菌中分泌的apre信号序列、编码促进目标蛋白质分泌的肽ala-gly-lys的寡核苷酸agk-proapre、以及编码目标基因的成熟区的合成核苷酸序列的表达质粒。pspman4表达质粒(p2jm-pspman4)的代表性质粒图谱示于图1中。采用各个表达质粒对合适的枯草芽孢杆菌宿主菌株进行转化,并将转化的细胞铺在补充有5ppm氯霉素的luria琼脂平板上。为了产生以上所列甘露聚糖酶中的每者,在250ml摇瓶中,使包含质粒的枯草芽孢杆菌转化体在补充有额外5mmcacl2的基于mops的限定培养基中生长。表达质粒p2jm-bciman1中的合成的bciman1基因的核苷酸序列如seqidno:25所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcaagcggcttttatgtttcaggcacaaaactgctggatgcaacaggccaaccgtttgttatgagaggcgttaatcatgcacatacgtggtataaagatcaactgtcaacagcaattccggcaatcgcaaaaacaggcgcaaatacaattagaattgttctggcgaatggccataaatggacactggatgatgttaacacagtcaacaatattctgacactgtgcgaacagaataaactgattgcagttctggaagttcatgatgcgacaggctcagattcactgtcagatctggataatgcagtcaattattggatcggcattaaatcagcactgatcggcaaagaagatcgcgtcattattaacattgcgaacgaatggtatggcacatgggatggcgttgcatgggcaaatggctataaacaagcgattccgaaactgagaaatgcaggcctgacacatacactgattgttgattcagcaggctggggacaatatccggattcagttaaaaactatggcacagaagttctgaacgcagatccgctgaaaaatacagtctttagcatccacatgtacgaatatgcaggcggaaatgcatcaacagtgaaatcaaatattgatggcgtcctgaataaaaacctggcactgattattggcgaatttggcggacaacatacaaatggcgacgttgatgaagcaacgattatgtcatatagccaagaaaaaggcgttggctggcttgcatggtcatggaaaggcaattcatcagatcttgcatatctggatatgacgaatgattgggcaggcaatagcctgacatcatttggcaatacagttgtcaatggcagcaatggcattaaagcaacatcagttctgtcaggcatttttggcggagttacaccgacatcatcaccgacaagcacaccgacgtcaacacctacatcaacgccgacaccgacacctagcccgacaccttcaccgggaaataatggcacaattctgtatgattttgaaacaggcacacaaggctggtcaggcaataacatttcaggcggaccgtgggttacaaatgaatggaaagcgacaggcgcacaaacactgaaagcagatgtttcacttcaaagcaattcaacgcatagcctgtatatcacaagcaatcaaaatctgagcggcaaatcaagcctgaaagcaacagttaaacatgcgaattggggcaatattggcaatggaatttatgcgaaactgtacgttaaaacaggcagcggctggacatggtatgattcaggcgaaaatctgattcagtcaaacgatggaacaatcctgacactttcactttcaggcattagcaatctgagcagcgttaaagaaattggcgtcgaatttagagcaagctcaaatagctcaggccaaagcgcaatttatgttgatagcgtttcactgcag。由p2jm-bciman1质粒表达的bciman1前体蛋白的氨基酸序列如seqidno:26所示(预测的信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):asgfyvsgtklldatgqpfvmrgvnhahtwykdqlstaipaiaktgantirivlanghkwtlddvntvnniltlceqnkliavlevhdatgsdslsdldnavnywigiksaligkedrviinianewygtwdgvawangykqaipklrnaglthtlivdsagwgqypdsvknygtevlnadplkntvfsihmyeyaggnastvksnidgvlnknlaliigefggqhtngdvdeatimsysqekgvgwlawswkgnssdlayldmtndwagnsltsfgntvvngsngikatsvlsgifggvtptssptstptstptstptptpsptpspgnngtilydfetgtqgwsgnnisggpwvtnewkatgaqtlkadvslqsnsthslyitsnqnlsgksslkatvkhanwgnigngiyaklyvktgsgwtwydsgenliqsndgtiltlslsgisnlssvkeigvefrassnssgqsaiyvdsvslq。由p2jm-bciman1质粒表达的bciman1成熟蛋白的氨基酸序列如seqidno:27所示(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):asgfyvsgtklldatgqpfvmrgvnhahtwykdqlstaipaiaktgantirivlanghkwtlddvntvnniltlceqnkliavlevhdatgsdslsdldnavnywigiksaligkedrviinianewygtwdgvawangykqaipklrnaglthtlivdsagwgqypdsvknygtevlnadplkntvfsihmyeyaggnastvksnidgvlnknlaliigefggqhtngdvdeatimsysqekgvgwlawswkgnssdlayldmtndwagnsltsfgntvvngsngikatsvlsgifggvtptssptstptstptstptptpsptpspgnngtilydfetgtqgwsgnnisggpwvtnewkatgaqtlkadvslqsnsthslyitsnqnlsgksslkatvkhanwgnigngiyaklyvktgsgwtwydsgenliqsndgtiltlslsgisnlssvkeigvefrassnssgqsaiyvdsvslq。基于天然存在序列的预测切割,bciman1成熟蛋白的氨基酸序列如seqidno:28所示:asgfyvsgtklldatgqpfvmrgvnhahtwykdqlstaipaiaktgantirivlanghkwtlddvntvnniltlceqnkliavlevhdatgsdslsdldnavnywigiksaligkedrviinianewygtwdgvawangykqaipklrnaglthtlivdsagwgqypdsvknygtevlnadplkntvfsihmyeyaggnastvksnidgvlnknlaliigefggqhtngdvdeatimsysqekgvgwlawswkgnssdlayldmtndwagnsltsfgntvvngsngikatsvlsgifggvtptssptstptstptstptptpsptpspgnngtilydfetgtqgwsgnnisggpwvtnewkatgaqtlkadvslqsnsthslyitsnqnlsgksslkatvkhanwgnigngiyaklyvktgsgwtwydsgenliqsndgtiltlslsgisnlssvkeigvefrassnssgqsaiyvdsvslq。p2jm-bciman3中的合成的bciman3基因的核苷酸序列如seqidno:29所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggcgcaacaggcttttatgtcaatggcacgaaactgtatgatagcacaggcaaagcatttgttatgagaggcgttaatcatccgcatacgtggtataaaaacgatctgaatgcagcaattccggctattgcacaaacaggcgcaaatacagttagagttgttctgtcaaatggcagccaatggacaaaagatgatctgaatagcgtcaacagcattatttcactggttagccaacatcaaatgattgcagttctggaagttcatgatgcaacgggcaaagatgaatatgcatcactggaagcagcagtcgattattggatttcaattaaaggcgcactgatcggcaaagaagatagagtcattgtcaatattgcgaacgaatggtatggcaattggaattcatcaggctgggcagatggctataaacaagcgattccgaaactgagaaatgcaggcattaaaaacacactgattgttgatgcagcaggctggggacaatatccgcaatcaattgtcgatgaaggcgcagcagtttttgcatcagatcaactgaaaaacacggtctttagcatccacatgtatgaatacgctggaaaagatgcagcaacagtcaaaacaaatatggatgacgttctgaataaaggcctgccgctgattattggcgaatttggcggatatcatcaaggcgcagatgttgatgaaattgcgattatgaaatacggccagcaaaaagaggttggctggcttgcatggtcatggtatggaaactcaccggaactgaatgatctggatctggcagcaggaccgtcaggcaatctgacaggatggggcaatacagttgttcatggcacagatggcattcaacagacatcaaaaaaagcaggcatctat。由p2jm-bciman3质粒表达的bciman3前体蛋白的氨基酸序列如seqidno:30所示(预测的信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):atgfyvngtklydstgkafvmrgvnhphtwykndlnaaipaiaqtgantvrvvlsngsqwtkddlnsvnsiislvsqhqmiavlevhdatgkdeyasleaavdywisikgaligkedrvivnianewygnwnssgwadgykqaipklrnagikntlivdaagwgqypqsivdegaavfasdqlkntvfsihmyeyagkdaatvktnmddvlnkglpliigefggyhqgadvdeiaimkygqqkevgwlawswygnspelndldlaagpsgnltgwgntvvhgtdgiqqtskkagiy。由p2jm-bciman3表达的bciman3成熟蛋白的氨基酸序列如seqidno:31所示(基于预测裂解位点的三残基氨基端延伸以粗体示出):atgfyvngtklydstgkafvmrgvnhphtwykndlnaaipaiaqtgantvrvvlsngsqwtkddlnsvnsiislvsqhqmiavlevhdatgkdeyasleaavdywisikgaligkedrvivnianewygnwnssgwadgykqaipklrnagikntlivdaagwgqypqsivdegaavfasdqlkntvfsihmyeyagkdaatvktnmddvlnkglpliigefggyhqgadvdeiaimkygqqkevgwlawswygnspelndldlaagpsgnltgwgntvvhgtdgiqqtskkagiy。基于天然存在序列的预测切割,bciman3成熟蛋白的氨基酸序列如seqidno:32所示:atgfyvngtklydstgkafvmrgvnhphtwykndlnaaipaiaqtgantvrvvlsngsqwtkddlnsvnsiislvsqhqmiavlevhdatgkdeyasleaavdywisikgaligkedrvivnianewygnwnssgwadgykqaipklrnagikntlivdaagwgqypqsivdegaavfasdqlkntvfsihmyeyagkdaatvktnmddvlnkglpliigefggyhqgadvdeiaimkygqqkevgwlawswygnspelndldlaagpsgnltgwgntvvhgtdgiqqtskkagiy。表达质粒p2jm-bciman4中的合成的bciman4基因的核苷酸序列如seqidno:33所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcaacaggcttttatgttaatggcggaaaactgtatgatagcacaggcaaaccgttttatatgcgtggcattaatcatggccatagctggtttaaaaacgatctgaatacagcgattccggctattgcaaaaacaggcgcaaatacagttagaattgttctgtcaaatggcacgcagtatacgaaagatgatctgaactcagtcaaaaacatcatcaatgtcgtcaacgcgaacaaaatgattgcagttctggaagttcatgatgcaacgggcaaagatgatttcaattcactggatgcagcagtcaactattggatctcaattaaagaagcgctgatcggcaaagaagatcgcgttattgttaatattgcgaacgaatggtatggcacatggaatggctcagcatgggcagatggctacaaaaaagcaattccgaaactgagagatgcaggcattaaaaacacactgattgttgatgcggcaggctggggacaatatccgcaatcaattgttgattatggccaaagcgtttttgcagcagatagccagaaaaatacagcgtttagcatccacatgtatgaatatgcgggaaaagatgcagcaacagtcaaaagcaatatggaaaacgtcctgaataaaggcctggcactgattattggcgaatttggcggatatcatacaaatggcgacgttgacgaatatgcgattatgaaatatggcctggaaaaaggcgttggctggcttgcatggtcatggtatggaaattcatcaggccttaattatctggatctggcaacaggaccgaatggcagcctgacatcatatggcaatacagttgtcaatgatacgtatggcatcaaaaatacgtcacagaaagcaggcatcttt。由质粒p2jm-bciman4表达的bciman4前体蛋白的氨基酸序列如seqidno:34所示(预测的信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):atgfyvnggklydstgkpfymrginhghswfkndlntaipaiaktgantvrivlsngtqytkddlnsvkniinvvnankmiavlevhdatgkddfnsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrdagikntlivdaagwgqypqsivdygqsvfaadsqkntafsihmyeyagkdaatvksnmenvlnkglaliigefggyhtngdvdeyaimkyglekgvgwlawswygnssglnyldlatgpngsltsygntvvndtygikntsqkagif。由p2jm-bciman4表达的bciman4成熟蛋白的氨基酸序列如seqidno:35所示(基于预测裂解位点的三残基氨基端延伸以粗体示出):atgfyvnggklydstgkpfymrginhghswfkndlntaipaiaktgantvrivlsngtqytkddlnsvkniinvvnankmiavlevhdatgkddfnsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrdagikntlivdaagwgqypqsivdygqsvfaadsqkntafsihmyeyagkdaatvksnmenvlnkglaliigefggyhtngdvdeyaimkyglekgvgwlawswygnssglnyldlatgpngsltsygntvvndtygikntsqkagif。基于天然存在序列的预测切割,bciman4成熟蛋白的氨基酸序列如seqidno:36所示:atgfyvnggklydstgkpfymrginhghswfkndlntaipaiaktgantvrivlsngtqytkddlnsvkniinvvnankmiavlevhdatgkddfnsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrdagikntlivdaagwgqypqsivdygqsvfaadsqkntafsihmyeyagkdaatvksnmenvlnkglaliigefggyhtngdvdeyaimkyglekgvgwlawswygnssglnyldlatgpngsltsygntvvndtygikntsqkagif。质粒p2jm-ppaman2中的合成的ppaman2基因的核苷酸序列如seqidno:37所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcagcaggcttttatgtttcaggcaacaagctgtatgattcaacaggaaaagcatttgttatgagaggcgttaatcattcacatacatggtttaagaacgatcttaatacagccattccggcaatcgcgaagacaggagcaaatacagtgagaattgttctttcaaacggaacgcaatatacaaaagatgacctgaacgccgttaagaatatcattaatctggtttcacaaaataagatgattgcagttctggaggttcatgatgcaacaggcaaggatgactacaatagcctggatgcagcggtcaattactggatttcaattaaagaagcacttattggcaaagaggatagagttattgttaatatcgcaaatgaatggtatggaacgtggaacggctcagcatgggcagatggctacaaaaaagcaattccgaaactgagaaatgcaggaatcaaaaatacactgattgttgacgccgcaggctggggacaatatccgcaaagcatcgttgattatggccaaagcgtttttgccgcagacgcacagaaaaacacggttttctcaattcatatgtacgagtatgctggaaaggatgctgcaacggttaaagctaacatggaaaatgttctgaataaaggcctggcactgatcattggcgaatttggaggctatcacacaaatggcgatgttgatgaatacgcaattatgaaatatggacaagaaaaaggcgttggatggcttgcatggtcatggtacggaaacaactcagaccttaattacctggacctggctacgggaccgaatggcacactgacatcattcggcaatacggtcgtttatgacacgtatggcatcaagaacacgagcgtgaaagccggcatttat。由质粒p2jm-ppaman2表达的ppaman2前体蛋白的氨基酸序列如seqidno:38所示(预测的信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):aagfyvsgnklydstgkafvmrgvnhshtwfkndlntaipaiaktgantvrivlsngtqytkddlnavkniinlvsqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfaadaqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimkygqekgvgwlawswygnnsdlnyldlatgpngtltsfgntvvydtygikntsvkagiy。由p2jm-ppaman2表达的ppaman2成熟蛋白的氨基酸序列如seqidno:39所示(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):aagfyvsgnklydstgkafvmrgvnhshtwfkndlntaipaiaktgantvrivlsngtqytkddlnavkniinlvsqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfaadaqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimkygqekgvgwlawswygnnsdlnyldlatgpngtltsfgntvvydtygikntsvkagiy。基于天然存在序列的预测切割,ppaman2成熟蛋白的氨基酸序列如seqidno:40所示:aagfyvsgnklydstgkafvmrgvnhshtwfkndlntaipaiaktgantvrivlsngtqytkddlnavkniinlvsqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfaadaqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimkygqekgvgwlawswygnnsdlnyldlatgpngtltsfgntvvydtygikntsvkagiy。质粒p2jm-ppoman1中的合成的ppoman1基因的核苷酸序列如seqidno:41所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcaagcggcttttatgtttcaggcacaaaactgtatgatagcacaggcaaaccgtttgttatgagaggcgttaatcatgcacatacgtggtataaaaacgatctgtatacggcaattccggctattgcacaaacaggcgcaaatacagttagaattgttctgagcaatggcaaccagtatacgaaagatgatatcaacagcgtcaaaaacattatcagcctggtcagcaactataaaatgattgcagttctggaagtccatgatgcaacgggcaaagatgattatgcatcactggatgcagcagtcaattattggattagcattaaagatgcgctgatcggcaaagaagatcgcgttattgttaatattgcgaacgaatggtatggctcatggaatggctcaggctgggcagatggctataaacaagcaattccgaaactgagaaatgcaggcattaaaaacacactgattgttgattgcgcaggctggggacaatatccgcaatcaattaatgattttggcaaaagcgtttttgcagcggatagcctgaaaaatacagtctttagcatccatatgtatgaatttgcgggaaaagatgcacagacagtccgcacaaatattgataatgtcctgaatcaaggcatcccgctgattattggcgaatttggcggatatcatcaaggcgcagatgttgatgaaacagaaattatgagatacggccaatcaaaaggcgttggctggcttgcatggtcatggtatggaaattcaagcaatctgtcatatctggatctggttacaggaccgaatggcaatcttacagattggggcaaaacagttgttaatggctcaaatggcatcaaagaaacgtcaaaaaaagcaggcatctat。由质粒p2jm-ppoman1表达的ppoman1前体蛋白的氨基酸序列如seqidno:42所示(预测的信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):asgfyvsgtklydstgkpfvmrgvnhahtwykndlytaipaiaqtgantvrivlsngnqytkddinsvkniislvsnykmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngsgwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdaqtvrtnidnvlnqgipliigefggyhqgadvdeteimrygqskgvgwlawswygnssnlsyldlvtgpngnltdwgktvvngsngiketskkagiy。由p2jm-ppoman1表达的ppoman1成熟蛋白的氨基酸序列如seqidno:43所示(基于预测裂解位点的三残基氨基端延伸以粗体示出):asgfyvsgtklydstgkpfvmrgvnhahtwykndlytaipaiaqtgantvrivlsngnqytkddinsvkniislvsnykmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngsgwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdaqtvrtnidnvlnqgipliigefggyhqgadvdeteimrygqskgvgwlawswygnssnlsyldlvtgpngnltdwgktvvngsngiketskkagiy。基于天然存在序列的预测切割,ppoman1成熟蛋白的氨基酸序列如seqidno:44所示:asgfyvsgtklydstgkpfvmrgvnhahtwykndlytaipaiaqtgantvrivlsngnqytkddinsvkniislvsnykmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngsgwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdaqtvrtnidnvlnqgipliigefggyhqgadvdeteimrygqskgvgwlawswygnssnlsyldlvtgpngnltdwgktvvngsngiketskkagiy。质粒p2jm-ppoman2中的合成的ppoman2基因的核苷酸序列如seqidno:45所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcaagcggcttttatgtttcaggcacaaatctgtatgatagcacaggcaaaccgtttgttatgagaggcgttaatcatgcacatacgtggtataaaaacgatctgtatacggcaattccggcaatcgcaaaaacaggcgcaaatacagttagaattgttctgagcaatggcaaccagtatacgaaagatgatatcaacagcgtcaaaaacattatcagcctggtcagcaaccataaaatgattgcagttctggaagttcatgatgcaacgggcaaagatgattatgcatcactggatgcagcagtcaattattggattagcattaaagatgcgctgatcggcaaagaagatcgcgttattgttaatattgcgaacgaatggtatggctcatggaatggcggaggctgggcagatggctataaacaagcaattccgaaactgagaaatgcaggcattaaaaacacactgattgttgattgcgcaggctggggacaatatccgcaatcaattaatgattttggcaaaagcgtttttgcagcggatagcctgaaaaatacagtctttagcatccatatgtatgaatttgcaggcaaagacgtccaaacagtccgcacaaatattgataatgtcctgtatcaaggcctgccgctgattattggcgaatttggcggatatcatcaaggcgcagatgttgatgaaacagaaattatgagatacggccagtcaaaatcagttggctggcttgcatggtcatggtatggaaattcaagcaatctgaactatctggatctggttacaggaccgaatggcaatcttacagattggggcagaacagttgttgaaggcgctaatggaattaaagaaacgtcaaaaaaagcaggcattttt。由质粒p2jm-ppoman2表达的ppoman2前体蛋白的氨基酸序列如seqidno:46所示(预测信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):asgfyvsgtnlydstgkpfvmrgvnhahtwykndlytaipaiaktgantvrivlsngnqytkddinsvkniislvsnhkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngggwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdvqtvrtnidnvlyqglpliigefggyhqgadvdeteimrygqsksvgwlawswygnssnlnyldlvtgpngnltdwgrtvvegangiketskkagif。由p2jm-ppoman2表达的ppoman2成熟蛋白的氨基酸序列如seqidno:47示出(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):asgfyvsgtnlydstgkpfvmrgvnhahtwykndlytaipaiaktgantvrivlsngnqytkddinsvkniislvsnhkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngggwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdvqtvrtnidnvlyqglpliigefggyhqgadvdeteimrygqsksvgwlawswygnssnlnyldlvtgpngnltdwgrtvvegangiketskkagif。基于天然存在序列的预测切割,ppoman2成熟蛋白的氨基酸序列如seqidno:48所示:asgfyvsgtnlydstgkpfvmrgvnhahtwykndlytaipaiaktgantvrivlsngnqytkddinsvkniislvsnhkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygswngggwadgykqaipklrnagikntlivdcagwgqypqsindfgksvfaadslkntvfsihmyefagkdvqtvrtnidnvlyqglpliigefggyhqgadvdeteimrygqsksvgwlawswygnssnlnyldlvtgpngnltdwgrtvvegangiketskkagif。质粒p2jm-pspman4中的合成的pspman4基因的核苷酸序列如seqidno:49所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctatggcgacaggcttttatgtttcaggcaacaaactgtatgatagcacaggcaaaccgtttgttatgagaggcgttaatcatggccatagctggtttaaaaacgatctgaatacagcgattccggctattgcaaaaacaggcgcaaatacagttagaattgttctgtcaaatggcagcctgtatacgaaagatgatctgaatgcagtcaaaaacatcatcaatgtcgtcaaccagaacaaaatgattgcagttctggaagttcatgatgcaacgggcaaagatgattacaattcactggatgcagcagtcaactattggatctcaattaaagaagcgctgatcggcaaagaagatcgcgttattgttaatattgcgaacgaatggtatggcacatggaatggctcagcatgggcagatggctacaaaaaagcaattccgaaactgagaaatgcaggcatcaaaaacacactgattgttgatgcggcaggctggggacaatttccgcaatcaattgttgattatggccaaagcgtttttgcagcagatagccagaaaaatacagtctttagcatccatatgtacgaatacgctggaaaagatgcagcaacagttaaagcgaatatggaaaacgtcctgaataaaggcctggcactgattattggcgaatttggcggatatcatacaaatggcgacgttgatgaatatgcgattatgagatatggccaagaaaaaggcgttggctggcttgcatggtcatggtatggaaattcatcaggccttaactatctggatatggcaacaggaccgaatggatcactgacatcatttggcaatacagtcgtcaatgatacgtatggaatcaaaaatacgagccagaaagctggcatcttt。由质粒p2jm-pspman4表达的pspman4前体蛋白的氨基酸序列如seqidno:50所示(预测信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):matgfyvsgnklydstgkpfvmrgvnhghswfkndlntaipaiaktgantvrivlsngslytkddlnavkniinvvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqfpqsivdygqsvfaadsqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimrygqekgvgwlawswygnssglnyldmatgpngsltsfgntvvndtygikntsqkagif。由p2jm-pspman4表达的确认的pspman4成熟蛋白的氨基酸序列如seqidno:51所示(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):matgfyvsgnklydstgkpfvmrgvnhghswfkndlntaipaiaktgantvrivlsngslytkddlnavkniinvvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqfpqsivdygqsvfaadsqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimrygqekgvgwlawswygnssglnyldmatgpngsltsfgntvvndtygikntsqkagif。基于天然存在序列的预测切割,确认的pspman4成熟蛋白的氨基酸序列如seqidno:52所示:matgfyvsgnklydstgkpfvmrgvnhghswfkndlntaipaiaktgantvrivlsngslytkddlnavkniinvvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqfpqsivdygqsvfaadsqkntvfsihmyeyagkdaatvkanmenvlnkglaliigefggyhtngdvdeyaimrygqekgvgwlawswygnssglnyldmatgpngsltsfgntvvndtygikntsqkagif。质粒p2jm-pspman5中的合成的pspman5基因的核苷酸序列如seqidno:53所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcaacaggcttttatgtttcaggcacaacactgtatgattcaacaggcaaaccgtttgttatgagaggcgttaatcatagccatacgtggtttaaaaacgatctgaatgcagcaattccggcaatcgcaaaaacaggcgcaaatacagttagaattgttctgtcaaatggcgtccagtatacaagagatgatgtcaatagcgtcaaaaacattatcagcctggtcaaccagaacaaaatgattgcagttctggaagttcatgatgcgacaggcaaagatgattatgcatcactggatgcagcagtcaattattggattagcattaaagatgcgctgatcggcaaagaagatcgcgttattgttaatattgcgaacgaatggtatggcacatggaatggctcagcatgggcagatggctataaacaagcgattccgaaactgagaaatgcaggcattaaaaacacactgattgttgatgcggcaggctggggacaatgtccgcaatcaattgttgattatggccaatcagtttttgcagcggatagcctgaaaaacacaatctttagcatccatatgtatgaatatgcaggcggaacggatgcaattgtcaaaagcaatatggaaaacgtcctgaataaaggcctgccgctgattattggcgaatttggcggacaacatacaaatggcgacgttgatgaacatgcaattatgagatatggccaacaaaaaggcgttggctggcttgcatggtcatggtatggaaataattcagaactgagctatctggatctggcaacaggaccggcaggctcactgacatcaattggaaatacaattgtgaacgatccgtatggcattaaagcgacatcaaaaaaagcaggcattttt。由质粒p2jm-pspman5表达的pspman5前体蛋白的氨基酸序列如seqidno:54所示(预测的信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):atgfyvsgttlydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqcpqsivdygqsvfaadslkntifsihmyeyaggtdaivksnmenvlnkglpliigefggqhtngdvdehaimrygqqkgvgwlawswygnnselsyldlatgpagsltsigntivndpygikatskkagif。由p2jm-pspman5表达的pspman5成熟蛋白的氨基酸序列如seqidno:55示出(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):atgfyvsgttlydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqcpqsivdygqsvfaadslkntifsihmyeyaggtdaivksnmenvlnkglpliigefggqhtngdvdehaimrygqqkgvgwlawswygnnselsyldlatgpagsltsigntivndpygikatskkagif。基于天然存在序列的预测切割,pspman5成熟蛋白的氨基酸序列如seqidno:56所示:atgfyvsgttlydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaavnywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqcpqsivdygqsvfaadslkntifsihmyeyaggtdaivksnmenvlnkglpliigefggqhtngdvdehaimrygqqkgvgwlawswygnnselsyldlatgpagsltsigntivndpygikatskkagif。质粒p2jm-pspman9中的合成的pspman9基因的核苷酸序列如seqidno:57所示(基因具有备选起始密码子(gtg),编码三残基加成(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcaacaggcttttatgtttcaggaacaaaactttatgatagcacgggaaaaccgtttgtgatgagaggcgttaatcactcacatacatggtttaagaatgatctgaatgcagctatccctgcgattgcgaagacaggcgcaaacacggttagaattgttctgtcaaacggcgttcaatatacgagagatgatgttaattcagtcaagaatatcatttcactggtgaatcaaaataagatgattgcagttctggaagttcatgatgctacaggaaaagacgattatgcatcactggatgcagcaattaactattggatttcaattaaagatgcactgattggcaaagaagatagagttattgtgaacattgcaaatgaatggtatggcacatggaatggctcagcatgggcagatggatataaacaagctattcctaaactgagaaatgcgggcatcaaaaatacgctgatcgtggatgcggctggctggggccaatatccgcaatcaattgttgattacggccagtcagtttttgcagcagattcactgaagaacacagtgtttagcatccatatgtatgaatatgcaggcggcacagatgcaatggttaaagctaatatggaaggagttctgaataaaggcctgccgctgattattggagaatttggcggacaacatacaaatggcgatgttgacgaactggcaattatgagatatggccaacaaaaaggcgtgggatggctggcatggtcatggtacggcaacaacagcgatctgtcatatcttgatctggcaacgggaccgaatggatcactgacaacgtttggaaatacagtggtgaacgatacgaacggaattaaggcaacgagcaagaaggcgggaatttttcaa。由质粒p2jm-pspman9表达的pspman9前体蛋白的氨基酸序列如seqidno:58所示(预测信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):atgfyvsgtklydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaainywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqypqsivdygqsvfaadslkntvfsihmyeyaggtdamvkanmegvlnkglpliigefggqhtngdvdelaimrygqqkgvgwlawswygnnsdlsyldlatgpngslttfgntvvndtngikatskkagifq由p2jm-pspman9表达的pspman9成熟蛋白的氨基酸序列如seqidno:59示出(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):atgfyvsgtklydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaainywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqypqsivdygqsvfaadslkntvfsihmyeyaggtdamvkanmegvlnkglpliigefggqhtngdvdelaimrygqqkgvgwlawswygnnsdlsyldlatgpngslttfgntvvndtngikatskkagifq。基于天然存在序列的预测切割,pspman9成熟蛋白的氨基酸序列如seqidno:60所示:atgfyvsgtklydstgkpfvmrgvnhshtwfkndlnaaipaiaktgantvrivlsngvqytrddvnsvkniislvnqnkmiavlevhdatgkddyasldaainywisikdaligkedrvivnianewygtwngsawadgykqaipklrnagikntlivdaagwgqypqsivdygqsvfaadslkntvfsihmyeyaggtdamvkanmegvlnkglpliigefggqhtngdvdelaimrygqqkgvgwlawswygnnsdlsyldlatgpngslttfgntvvndtngikatskkagifq。实施例3:甘露聚糖酶的纯化bciman1、bciman4和pspman4蛋白质经由两个色谱步骤进行纯化:阴离子交换和疏水作用色谱法。将经浓缩并脱盐的粗蛋白样品上载到70mlq-sepharose高效柱上,该柱预先用缓冲液a(tris-hcl,ph7.5,20mm)平衡。在洗柱之后,用0-50%梯度的含1mnacl的缓冲液a在5个柱体积内洗脱蛋白质。目标蛋白质在流出物之中。然后将硫酸铵加入到流出物中至0.8-1m的最终浓度。将溶液上载到phenyl-sepharosefastflow柱上,该柱预先用含有0.8-1m硫酸铵的20mmtrisph7.5(缓冲液b)平衡。以4个柱体积进行梯度洗脱(0-100%缓冲液a),之后进行3个柱体积步骤洗脱(100%缓冲液a),目标蛋白质最终被洗脱下来。用sds-page检测级分的纯度,并且结果示出目标蛋白质已被完全纯化。将活性级分合并,并用10kdaamiconultra-15装置进行浓缩。样品纯度高于90%,保存在-20℃至-80℃下的40%甘油中直至使用。bciman3、ppoman1、ppoman2蛋白质使用三个步骤进行纯化:阴离子交换、疏水作用色谱法和凝胶过滤纯化策略。通过vivaflow200(截留值10kda)浓缩得自摇瓶的700ml粗制液体培养基并将缓冲液交换为20mmtris-hcl(ph7.5)。然后将液体上载到50mlq-sepharose高效柱上,该柱预先用20mmtris-hcl,ph7.5(缓冲液a)平衡。用线性梯度为0至50%的缓冲液b(包含1mnacl的缓冲液a)以3个柱体积洗脱柱,之后用3个柱体积的100%缓冲液b洗脱柱。在梯度洗脱部分中检测目标蛋白质并合并纯级分。随后,将3m硫酸铵溶液加入到活性级分中至1m的最终浓度。接着将预处理的级分上载到50mlphenyl-sepharosefastflow柱上,该柱用含有1m硫酸铵的20mmtris(ph7.5)平衡。进行4个柱体积梯度洗脱(0-100%缓冲液a),之后进行3个柱体积步骤洗脱(100%缓冲液a),合并相应的纯级分。将收集的级分浓缩为10ml并上载到hiloadtm26/60,superdex-75柱(1个柱体积=320ml)上,该柱预先用含0.15mnacl的20mm磷酸钠缓冲液(ph7.0)平衡。将纯级分合并,使用10kdaamiconultra-15装置进行浓缩。使经纯化的样品在-20℃下保存于具有40%甘油的20mm磷酸钠缓冲液(ph7.0)中直至使用。为了纯化pspman5和pspman9蛋白质,将硫酸铵加入到粗制样品中至1m的最终浓度。将溶液施加到hipreptm16/10phenylff柱上,该柱预先用20mmtris(ph8.5)、1m硫酸铵(缓冲液a)平衡。用1至0m线性盐梯度的硫酸盐从柱洗脱目标蛋白质。合并活性级分,用vivaflow200超滤装置(sartoriusstedim)浓缩并将缓冲液交换为20mmtris(ph8.5)。将所得的溶液施加到预先用20mmtris(ph8.5)平衡的hipreptmqxl16/10柱上。采用线性盐梯度为0至0.6m的nacl的缓冲液a从柱洗脱目标蛋白质。然后合并所得的活性蛋白质级分并经由10kdaamiconultra装置浓缩,并在-20℃下保存于40%甘油中直至使用。ppaman2利用疏水作用色谱法和阳离子交换色谱法进行纯化。通过vivaflow200(截留值10kda)浓缩800ml液体培养基并添加硫酸铵至0.8m的最终浓度。接着将样品上载到50mlphenyl-sepharose高效柱上,该柱预先用缓冲液a(含有0.8m硫酸铵的20mm乙酸钠,ph5.5)平衡。采用5个柱体积的0-100%缓冲液b(20mm乙酸钠,ph5.5)梯度洗脱,之后采用3个柱体积的100%缓冲液b处理柱。合并相对的纯活性级分并将缓冲液交换为缓冲液b。溶液变混浊并将其分配到50ml管中,以3800rpm离心20min。收集上清液和沉淀物。根据sds-page凝胶分析结果,鉴定上清液中的目标蛋白质,该上清液然后被施加到sp-sepharosefastflow柱上,用0-50%缓冲液c(包含1m氯化钠的20mm乙酸钠)在4个柱体积内进行线性梯度洗脱,之后进行3个柱体积的步骤洗脱(100%缓冲液c)。各个级分的纯度用sds-page进行评估。合并纯级分,使用10kdaamiconultra-15装置浓缩。使经纯化的样品在-20℃下保存于具有40%甘油的20mm乙酸钠缓冲液(ph5.5)中。实施例4:甘露聚糖酶的活性将0.5%刺槐豆胶半乳甘露聚糖(sigmag0753)和魔芋葡甘露聚糖(megazymep-glcml)用作底物来测量甘露聚糖酶的β1-4甘露聚糖酶活性。该测定在50℃下进行10分钟,使用两种不同的缓冲液体系:50mm乙酸钠(ph5),和50mmhepes(ph8.2)。在两组测定中,释放的还原糖采用pahbah(对羟基苯甲酸酰肼)测定定量(lever,anal.biochem.(《分析生物化学》)47:248,1972)。对各缓冲液产生利用甘露糖的标准曲线,并用于计算酶活性单位。在该测定中,将一个甘露聚糖酶单位定义为每分钟生成1微摩尔甘露糖还原糖当量所需的酶的量。甘露聚糖酶的比活性汇总于表1中。实施例5:甘露聚糖酶的ph特征通过使用刺槐豆胶作为底物在2至9范围内的各种ph值下,于50℃测定甘露聚糖酶活性10min来测定甘露聚糖酶的ph特征。基于剂量响应曲线,用0.005%tween-80将蛋白质稀释至合适的浓度。在热混合器中,使经不同ph单位的柠檬酸钠/磷酸钠缓冲液缓冲的底物溶液于50℃预温育5min。反应通过加入甘露聚糖酶而开始。使混合物在50℃下温育10min,然后通过将10微升的反应混合物转移至包含100微升pahbah溶液的96-孔pcr板中而停止。在bio-raddnaengine中,使pcr板于95℃加热5分钟。然后,从各个孔转移100微升至新的96孔板中。通过在分光光度计中测量410nm处的光密度来定量从底物释放的还原糖。各ph下的酶活性以相对活性报告,其中将最佳ph下的酶活性设为100%。在这些测定条件下,甘露聚糖酶活性≥70%的最佳ph和ph范围示于表2。*ppaman2和pspman9示出ph高于9的甘露聚糖酶活性。实施例6:甘露聚糖酶的温度特征在各种温度下,通过使用刺槐豆胶作为底物在50mm柠檬酸钠缓冲液中于ph6.0测定甘露聚糖酶活性10min来测定甘露聚糖酶的温度特征。酶活性以相对活性记录,其中将最适温度下的酶活性设为100%。在这些测定条件下甘露聚糖酶活性≥70%的最佳温度和温度范围示于表3中。实施例7:类芽孢杆菌和芽孢杆菌属甘露聚糖酶的热稳定性在50mm柠檬酸钠缓冲液中于ph6.0测定类芽孢杆菌和芽孢杆菌属甘露聚糖酶的温度稳定性。在热循环仪中,使酶在40℃至90℃的温度范围内温育2小时。将刺槐豆胶用作底物来测量保留的酶活性。将保持在冰上的样品的活性定义为100%活性。在这些测定条件下,2小时温育时间后酶保留50%活性的温度(t50)示于表4中。实施例8:甘露聚糖酶的清洁性能清洁性能使用高通量测定法来测量,该高通量测定法被开发用于测量从技术污垢移除的半乳甘露聚糖。该测定法测量刺槐豆胶从包含刺槐豆胶的技术污垢的释放。bca试剂测量了相比于空白(无酶)对照在甘露聚糖酶存在下释放的低聚糖的还原端。该测量与酶的清洁性能相关联。在甘露聚糖酶水解半乳甘露聚糖时,具有新还原端的不同长度的低聚糖从棉制样本释放。bca试剂中的二辛可宁酸允许高灵敏度的比色检测,因为通过还原cu2+形成cu1+。将两个5.5cm直径的刺槐豆胶cs-73微样(microswatches)(cft,vlaardingen,holland)置入平底非结合性96-孔分析板的各个孔中。将酶稀释到50mmmops,ph7.2,0.005%tween-80中。将经稀释的酶和微样测定缓冲液(25mmhepes,ph8,2mmcacl2,0.005%tween-80)加入到各个孔中,混合体积为100微升。密封平板,并在iems机器中以1150rpm于25℃温育20分钟。为了测量所产生的新还原端,将100微升的bca测定试剂(thermoscientificpierce,rockford,il)移取到新pcr板的各个孔中。在温育阶段完成后,从微样测定板的各个孔移除15微升的洗涤液体,并将其转移至包含bca试剂的板中。密封平板,并在pcr机器中于95℃温育2-3分钟。在使板冷却至25℃后,将100微升的上清液转移到新的微升平底分析板中并在分光光度计中测量562nm处的吸光度。图2a和2b示出该测定中甘露聚糖酶的响应。所测的全部甘露聚糖酶表现出半乳甘露聚糖去除活性。实施例9同源甘露聚糖酶的鉴定使用ppaman2(seqidno:40)、pspman4(seqidno:52)和pspman9(seqidno:60)的成熟蛋白氨基酸序列在ncbi非冗余蛋白质数据库通过blast搜索(altschul等人,nucleicacidsres《核酸研究期刊》,25:3389-402,1997)来鉴定相关的蛋白质,并且结果的子集分别示于表5a、6a和7a中。使用ppaman2(seqidno:40)、pspman4(seqidno:52)和pspman9(seqidno:60)的成熟蛋白质氨基酸序列作为查询序列,采用设为默认值的搜索参数针对genomequestpatent数据库运行类似的搜索,并且结果的子集分别示于表5b、6b和7b中。两个搜索组的百分比同一性(pid)被定义为逐对比对中相同残基的数目除以所比对残基的数目。栏标记的“序列长度”是指与所列出的登录号相关联的蛋白质序列的(氨基酸的)长度,而栏标记的“比对长度”是指用于pid计算的比对的蛋白质序列的(氨基酸的)长度。实施例10:同源序列的分析成熟bciman1(seqidno:28)、bciman3(seqidno:32)、bciman4(seqidno:36)、pamman2(seqidno:17)、ppaman2(seqidno:40)、ppoman1(seqidno:44)、ppoman2(seqidno:48)、pspman4(seqidno:52)、pspman5(seqidno:56)、pspman9(seqidno:60)和ptuman2(seqidno:24)甘露聚糖酶的氨基酸序列与得自表5a、6a和7a的(从ncbi搜索鉴定的)一些成熟形式的甘露聚糖酶的序列的比对示于图3中。用clustalw软件(thompson等人,nucleicacidsresearch《核苷酸研究期刊》,22:4673-4680,1994)在默认参数下比对全长的未修切序列,其中图3显示出氨基酸1-300的比对而非整个全长的未修切序列的比对。构建图3中比对的甘露聚糖酶的氨基酸序列的系统发育树,并且示于图4中。在vectorntiadvancesuite中输入全长的未修切序列,并且用neighborjoining(nj)方法(saitou和nei,molbiolevol,4:406-425,1987)创建guidetree。采用以下参数计算树构造:kimura的序列距离校正以及忽略具有间隙的位置。alignx显示出图4所示的树上所显示的分子名称后面的括号中的计算距离值。实施例11:ndl-clade甘露聚糖酶的独特特征当比对实施例10所述的甘露聚糖酶时,在bciman3、bciman4、pamman2、ppaman2、ppoman1、ppoman2、pspman4、pspman5、pspman9和ptuman2甘露聚糖酶之间共享有共同的特性。在一种情况下,在残基trp30与ile39之间存在共同的保守氨基酸模式,其中多肽的氨基酸位置通过与seqidno:32中所示的氨基酸序列对应来编号。ndl甘露聚糖酶共享有共同的特征以创建后续被称为ndl-clade的分化体,其中术语ndl来源于靠近n-端处的完全保守的残基ndl(asn-asp-leu33-35)。甘露聚糖酶残基的编号为连续的线性序列并且通过与seqidno:32中所示的氨基酸序列对应来编号。与ndl-clade有关的保守氨基酸模式在图5中突出显示,并且可描述为wxakndlxxai,其中xa为f或y并且x为任何氨基酸;wxakndlxbxcai,其中xa为f或y,xb为n、y或a,并且xc为a或t;或wf/ykndlx1t/aai,其中x1为n、y或a。实施例10中所述的系统发育树示出ndl-clade甘露聚糖酶和其它甘露聚糖酶之间的分化。分化体进一步分化成ndl-clade1和ndl-clade2,其中ndl-clade1包括ptuman2、pamman2、pspman4、bciman4、ppaman2、pspman9和pspman5,而ndl-clade2包括bciman3、ppoman2和ppoman1。ndl-clade的所有成员均具有并不存在于芽孢杆菌属jamb-602及其它参考甘露聚糖酶序列中的带有缺失关键特征的保守基序(在下文中为“缺失基序”)。缺失基序开始于图6所示氨基酸序列的保守线性序列的第262位,并且包括序列ldxxxgpxgxlt,其中x为任何氨基酸或ldm/lv/at/agpx1gx2lt,其中x1为n、a或s并且x2为s、t或n。所述序列进一步分化成ndl-clade1甘露聚糖酶的ldm/latgpn/ags/tlt;ndl-clade2甘露聚糖酶的ldla/va/tgps/ngnlt;和ndl-clade3甘露聚糖酶的ldl/vs/at/ngpsgnlt。ndl-clade的所有成员均具有未在芽孢杆菌属jamb-602_bad99527.1、b_nealsonii_agu71466.1和bciman1_环状芽胞杆菌_baa25878.1中显示的保守的缺失基序。图6中所示的ndl-clade缺失基序(即ldm/lv/at/agpx1gx2lt,其中x1为n、a或s,并且x2为s、t或n)发生于保守的残基leu262-asp263(ld)和leu272-thr273(lt)之间。与ndl-clade甘露聚糖酶最接近的相关结构为来自于芽孢杆菌属jamb-602(1wky.pdb)的结构,因此这将被用作参照以了解ndl-clade甘露聚糖酶分化特性的可能结果。图7示出芽孢杆菌属jamb-602(黑色)的结构和ndl-clade甘露聚糖酶pspman4、pspman9和ppaman2的模型(灰色)。pspman4、pspman9和ppaman2的结构用molecularoperatingenvironment(moe)软件(chemicalcomputinggroup,montreal,quebec,canada)中的“比对”选项进行建模以寻找结构的相似性。比对应用保守结构基序,作为用于常规序列对比的附加指导。该比对使用存在于2012.10发行的moe中的标准程序默认值进行。缺失基序片段用箭头指示。该缺失基序位于c-端结构中的环内。认为芽孢杆菌属jamb-602甘露聚糖酶的c-端区域对于理解这些甘露聚糖酶如何在碱性环境中相互作用很重要(akita等人,actacryst,60:1490-1492,2004)。据推测,缺失影响该环的结构、长度和柔韧性,其继而影响ndl-clade甘露聚糖酶的活性和性能。实施例12来自类芽孢杆菌属n021的另外甘露聚糖酶的鉴定通过合成技术用定序对类芽孢杆菌属n021菌株(dupontculturecollection)的全基因组进行测序。在序列组装和注释之后,从该菌株鉴定的基因中的一者即pamman3示出与ndl-clade甘露聚糖酶成员的同源性。从类芽孢杆菌属n021分离的pamman3基因的核苷酸序列如seqidno:61所示(编码预测的天然信号肽的序列以粗体示出):gcatccggtttttatgtaagcgggaataagttatatgactcgactggcaagccttttgtcatgagaggaatcaatcacggccattcctggttcaaaaatgatctgaatacagccatacctgctattgcgaaaacaggcgccaacacggtacgaattgttctctcgaatggaacactgtacaccaaagatgatctgaattcagttaaaaacataatcaatctggtcaatcagaataagatgatcgccgtgcttgaagtgcatgatgcaacaggcaaagacgattataactcgctggatgcagccgtgaattactggatcagcatcaaagaagcgttgattggcaaggaagatcgagtgatcgttaatatcgccaacgaatggtatggaacctggaacggcagcgcttgggcagacggttacaaaaaggctattccgaagctcagaaacgcaggcatcaaaaatacgttgattgttgatgctgcaggctggggtcaatatccacaatcgattgtcgattatggtcaaagcgtattcgcaacagatacgctcaaaaatacggtgttttccattcatatgtatgaatatgcgggtaaggatgcggcaacggtgaaagctaatatggagaatgtgctgaacaaaggacttgcagtaatcattggtgagttcggtggatatcacacaaatggtgatgtggatgaatatgccattatgagatatggacaagagaagggtgtaggctggcttgcatggtcatggtacggcaacagttccggtctgggttatctggatctggctaccggtccgaacggaagtctcacaagttatggcaatacggtagttaatgacacatacggaatcaaaaatacgtcccaaaaagcagggatatttcaatag。pamman3前体蛋白的氨基酸序列如seqidno:62所示(预测的天然信号肽以粗体示出):asgfyvsgnklydstgkpfvmrginhghswfkndlntaipaiaktgantvrivlsngtlytkddlnsvkniinlvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfatdtlkntvfsihmyeyagkdaatvkanmenvlnkglaviigefggyhtngdvdeyaimrygqekgvgwlawswygnssglgyldlatgpngsltsygntvvndtygikntsqkagifq。完全加工的成熟pamman3蛋白质(297个氨基酸)的序列如seqidno:63所示:asgfyvsgnklydstgkpfvmrginhghswfkndlntaipaiaktgantvrivlsngtlytkddlnsvkniinlvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfatdtlkntvfsihmyeyagkdaatvkanmenvlnkglaviigefggyhtngdvdeyaimrygqekgvgwlawswygnssglgyldlatgpngsltsygntvvndtygikntsqkagifq。实施例13pamman3的表达合成成熟形式的pamman3基因的dna序列,并且如实施例2所述表达pamman3蛋白质。质粒p2jm-pamman3中的合成的pamman3基因的核苷酸序列如seqidno:64所示(基因具有备选起始密码子(gtg),编码三残基氨基端延伸(agk)的寡核苷酸以粗体示出):gtgagaagcaaaaaattgtggatcagcttgttgtttgcgttaacgttaatctttacgatggcgttcagcaacatgagcgcgcaggctgcatcaggcttttatgtttcaggcaataaactttatgattcaacaggaaaaccgtttgttatgagaggaattaatcacggacattcatggttcaaaaatgatcttaacacagctattccggcgattgcgaagacaggcgcaaatacagttagaattgttctgtcaaatggcacgctgtacacaaaggacgatctgaacagcgttaaaaacatcattaatctggttaatcaaaataagatgattgcagttctggaagtccatgatgctacaggcaaagacgattacaattcactggatgctgcagtcaattactggatttcaattaaagaagcactgattggaaaagaggacagagttattgttaatatcgcaaatgaatggtatggaacatggaatggcagcgcatgggcagatggctataagaaagcaattccgaaactgagaaacgcaggcatcaagaacacgcttatcgttgatgcagcaggctggggacaatatccgcaatcaattgttgattatggccaaagcgtttttgcaacagacacactgaaaaacacagttttctcaattcatatgtacgaatatgccggaaaggatgcggcaacggttaaagcaaatatggaaaatgttctgaataaaggcctggcagttattatcggcgaatttggcggctatcatacgaatggcgatgttgacgaatacgcgatcatgagatatggacaggagaaaggcgttggctggcttgcgtggtcatggtacggaaatagctcaggactgggctatctggatcttgcaacgggaccgaacggctcacttacatcatatggcaacacggtcgtgaatgatacatacggcattaagaatacatcacaaaaagccggcatttttcaa。由质粒p2jm-pamman3表达的pamman3前体蛋白的氨基酸序列如seqidno:65所示(预测信号序列以斜体表示,三残基氨基端延伸(agk)以粗体示出):asgfyvsgnklydstgkpfvmrginhghswfkndlntaipaiaktgantvrivlsngtlytkddlnsvkniinlvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfatdtlkntvfsihmyeyagkdaatvkanmenvlnkglaviigefggyhtngdvdeyaimrygqekgvgwlawswygnssglgyldlatgpngsltsygntvvndtygikntsqkagifq。由p2jm-pamman3质粒表达的pamman3成熟蛋白的氨基酸序列如seqidno:66所示(基于预测裂解位点的三残基氨基端延伸(agk)以粗体示出):asgfyvsgnklydstgkpfvmrginhghswfkndlntaipaiaktgantvrivlsngtlytkddlnsvkniinlvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfatdtlkntvfsihmyeyagkdaatvkanmenvlnkglaviigefggyhtngdvdeyaimrygqekgvgwlawswygnssglgyldlatgpngsltsygntvvndtygikntsqkagifq。基于天然存在序列的预测切割,pamman3成熟蛋白的氨基酸序列如seqidno:67所示:asgfyvsgnklydstgkpfvmrginhghswfkndlntaipaiaktgantvrivlsngtlytkddlnsvkniinlvnqnkmiavlevhdatgkddynsldaavnywisikealigkedrvivnianewygtwngsawadgykkaipklrnagikntlivdaagwgqypqsivdygqsvfatdtlkntvfsihmyeyagkdaatvkanmenvlnkglaviigefggyhtngdvdeyaimrygqekgvgwlawswygnssglgyldlatgpngsltsygntvvndtygikntsqkagifq.实施例14pamman3的纯化pamman3经由两个色谱步骤进行纯化:疏水作用色谱法和阴离子交换色谱法。将经浓缩并脱盐的粗蛋白样品上载到phenyl-sepharose高效柱上,该柱预先用包含2.0m硫酸铵的20mmhepes(ph7.4)平衡。进行梯度洗脱,并且将具有酶活性的级分合并,并上载到30mlq-sepharose高效柱上,该柱预先用缓冲液a(20mmhepes,ph7.4)平衡。使柱进行5个柱体积的0-50%的缓冲液b(包含1m氯化钠的缓冲液a)的梯度洗脱,之后进行4个柱体积的100%缓冲液b洗脱。通过sds-page分析各个级分的纯度,结果示出目标蛋白质已被有效纯化。合并具有较高纯度的级分,用具有10kmwco的amiconultra-15装置浓缩。使最终经纯化的蛋白质保存在-20℃下的40%甘油中直至使用。实施例15pamman3的甘露聚糖酶活性如实施例4所述测量pamman3的β1-4甘露聚糖酶活性。经纯化的pamman3的具体活性汇总于表8中。实施例16pamman3的ph特征如实施例5所述测定pamman3的ph特征。在这些测定条件下,pamman3的活性≥70%的最佳ph和ph范围示于表9中。实施例17bspman4的温度特征如实施例6所述测定pamman3的温度特征。在这些测定条件下,pamman3的活性≥70%的最佳温度和温度范围示于表10中。实施例18pamman3的热稳定性如实施例7所述测定pamman3的温度稳定性。在这些测定条件下,2小时温育时间后pamman3保留50%活性的温度(t50)示于表11中。实施例19pamman3的清洁性能在高通量微样测定中估计pamman3的清洁性能,该测定被开发用于测量从技术污垢释放的半乳甘露聚糖。将释放的还原糖在pahbah(对羟基苯甲酸酰肼)测定法中定量(lever,anal.biochem.(《分析生物化学》)47:248,1972)。将两个5.5cm直径的刺槐豆胶cs-73(cft,vlaardingen,holland)微样置入平底非结合性96-孔分析板的各个孔中。将酶稀释到50mmmops,ph7.2,0.005%tween-80中。将经稀释的酶和微样测定缓冲液(25mmhepes,ph8,2mmcacl2,0.005%tween-80)加入到各个孔中,混合体积为100微升。密封平板,并在iems机器中以1150rpm于25℃温育30分钟。将10微升的反应混合物转移到其每个孔包含100微升pahbah溶液的pcr板中。密封平板,并在pcr机器中于95℃温育5分钟。在使板冷却至4℃后,将80微升的上清液转移到新平底微升板中并在分光光度计中测量410nm处的吸光度。图8示出pamman3相比于基准(可商购获得的甘露聚糖酶,)的清洁响应。实施例20同源甘露聚糖酶的鉴定针对ncbi非冗余蛋白质数据库,对成熟形式的pamman3(seqidno:67)的氨基酸序列(297个残基)(altschul等人,nucleicacidsres《核酸研究期刊》,25:3389-402,1997)进行blast搜索。使用idno:67作为查询序列,采用设为默认值的搜索参数针对genomequestpatent数据库运行类似的搜索。搜索结果的子集示于表12a和12b中。两个搜索组的百分比同一性(pid)被定义为逐对比对中相同残基的数目除以所比对残基的数目。栏标记的“序列长度”是指与所列出的登录号相关联的蛋白质序列的(氨基酸的)长度,而栏标记的“比对长度”是指用于计算pid的比对的蛋白质序列的(氨基酸的)长度。实施例21同源甘露聚糖酶序列的分析使用如图5所示的修切的氨基酸序列和以下项的修切的成熟氨基酸序列来构建多个甘露聚糖酶氨基酸序列对比:pamman3(seqidno:67)、类芽孢杆菌属_ett37549.1(seqidno:68)、类芽孢杆菌属_wp_024633848.1(seqidno:70)、bleman1(seqidno:75)、芽孢杆菌属_wo2015022428-0015(seqidno:78)、2whl_a(seqidno:79)和胶质类芽孢杆菌_yp_006190599.1(seqidno:81)甘露聚糖酶,并且示于图9中。用clustalw软件(thompson等人,nucleicacidsresearch《核酸研究期刊》,22:4673-4680,1994)在默认参数下比对这些序列。覆盖ndl-clade独特残基(参见图9)的区域中的序列对比的评述示出,甘露聚糖酶胶质类芽孢杆菌_yp_006190599.1(seqidno:81)、类芽孢杆菌属_wp_019912481.1(seqidno:74)、bciman3(seqidno:32)、类芽孢杆菌属wp_009593769.1(seqidno:73)、ppoman1(seqidno:44)、ppoman2(seqidno:48)、类芽孢杆菌属_wp_017427981.1(seqidno:72)、pspman9(seqidno:60)、pspman5(seqidno:56)、类芽孢杆菌属_wp_017813111.1(seqidno:71)、ppaman2(seqidno:40)、ptuman2(seqidno:24)、类芽孢杆菌属_wp_024633848.1(seqidno:70)、pamman3(seqidno:67)、bciman4(seqidno:36)、pspman4(seqidno:52)、pamman2(seqidno:17)、类芽孢杆菌属_ett37549.1(seqidno:68)和类芽孢杆菌属_wp_017688745.1(seqidno:69)全部属于ndl-clade,其中修切的氨基酸序列的进一步的序列比对使用clustalw软件(thompson等人,nucleicacidsresearch《核酸研究期刊》,22:4673-4680,1994)在默认参数下提供并且在图11中示出。ndl-clade可进一步分化成ndl-clade1、ndl-clade2和ndl-clade3。ndl-clade1包括ptuman2、pamman2、pamman3、pspman4、bciman4、ppaman2、pspman9、pspman5、类芽孢杆菌属_wp_017813111.1、类芽孢杆菌属_wp_024633848.1、类芽孢杆菌属_ett37549.1和类芽孢杆菌属_wp_017688745.1。ndl-clade2包括bciman3、类芽孢杆菌属wp_009593769.1、ppoman1、ppoman2和类芽孢杆菌属_wp_017427981.1。ndl-clade3包括胶质类芽孢杆菌_yp_006190599.1和类芽孢杆菌属_wp_019912481.1。构建ndl分化体甘露聚糖酶的修切的氨基酸序列的系统发育树:bciman1(seqidno:28)、bciman3(seqidno:32)、bciman4(seqidno:36)、pamman2(seqidno:17)、ppaman2(seqidno:40)、ppoman1(seqidno:44)、ppoman2(seqidno:48)、pspman4(seqidno:52)、pspman5(seqidno:56)、pspman9(seqidno:60)和ptuman2(seqidno:24)、pamman3(seqidno:67)、类芽孢杆菌属_ett37549.1(seqidno:68)、类芽孢杆菌属_wp_017688745.1(seqidno:69)、类芽孢杆菌属_wp_024633848.1(seqidno:70)、类芽孢杆菌属_wp_017813111.1(seqidno:71)、类芽孢杆菌属_wp_017427981.1(seqidno:72)、类芽孢杆菌属wp_009593769.1(seqidno:73)、类芽孢杆菌属_wp_019912481.1(seqidno:74)、bleman1(seqidno:75)、bac.nealsonii_agu71466.1(seqidno:76)、芽孢杆菌属._bad99527.1(seqidno:77)、芽孢杆菌属_wo2015022428-0015(seqidno:78),以及2whl_a(seqidno:79)和胶质类芽孢杆菌_yp_006190599.1(seqidno:81),并且示于图10中。在vectorntiadvancesuite中输入修切的序列,随后将比对文件导入到geneioustreebuilder程序(geneious8.1.2)中,使用geneioustreebuilder,neighbor-joining树构建法构建图10中所述的系统发育树。计算这些序列之间的百分比序列同一性并示于表13中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1