用于结合有机靶的蜘蛛丝融合蛋白结构的制造方法与工艺
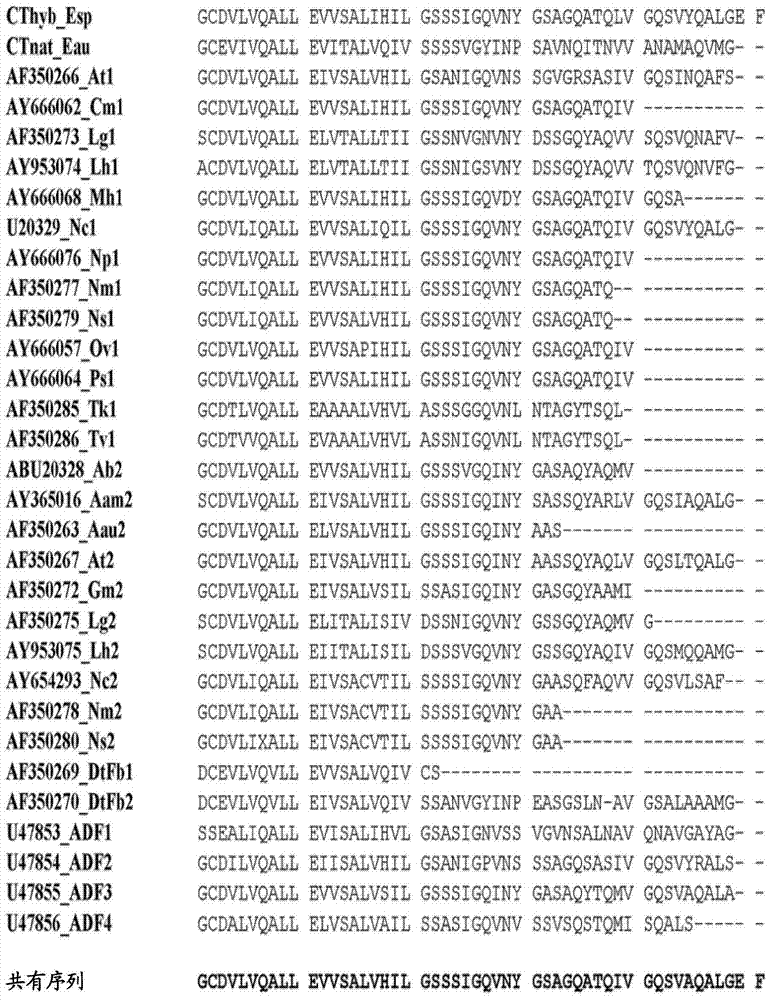
用于结合有机靶的蜘蛛丝融合蛋白结构发明的技术领域本发明涉及重组融合蛋白的领域,更具体地涉及包含衍生自蜘蛛丝蛋白(拖丝蛋白)的部分的融合蛋白。本发明提供用于提供为包含重组融合蛋白的聚合物的蛋白结构的方法,所述重组融合蛋白包含衍生自拖丝蛋白的部分。还提供了用于结合有机靶的新颖蛋白结构。发明背景在应用蛋白化学中,一个常见的问题是如何向相关的活性位点配制或呈现生物活性肽或蛋白,所述活性位点通常是有机靶,诸如核酸、蛋白、蛋白复合体、蛋白和/或脂质和/或碳水化合物和/或核酸的复合体。最简单的解决方案是仅仅提供生物活性肽或蛋白的水溶液。然而,许多应用的确要求一些进一步的手段来实现期望的目标。例如,可将肽/蛋白缔合于脂质混合物或化学地固定于支持结构。用于固定于支持结构的肽/蛋白的应用包括制备和分析性分离程序诸如生物工艺、层析法、细胞捕获和培养、主动过滤器(activefilters)和诊断学。基于胞外基质蛋白例如胶原的结构公开在EP704532和EP985732中。还已经建议在支持结构中使用蜘蛛丝蛋白。蜘蛛丝是天然的高性能聚合物,由于强度和弹性的组合而获得了非同寻常的韧性和延伸性。蜘蛛具有多达七个不同的腺,这些腺产生具有不同机械性质和功能的多种丝类型。由大壶状腺产生的拖丝(draglinesilk)是最坚韧的纤维。它由两种主要的多肽组成,大多被称为大壶状腺拖丝蛋白(spidroin)(MaSp)1和2,但在例如,在十字园蛛(Araneusdiadematus)中被称为ADF-3和ADF-4。这些蛋白质具有200-720kDa范围内的分子量。蜘蛛拖丝蛋白质或MaSp具有分成三部分的组成:无重复的N-端结构域、由许多重复的聚Ala/Gly区段构成的中心重复区域和无重复的C-端结构域。通常认为重复区域在丝纤维中形成分子间接触,但不太清楚末端结构域的准确功能。还认为与纤维形成相联系地,重复区域经历从无规卷曲和α-螺旋构象到β-折叠结构的结构转化。拖丝蛋白的C端区域在蜘蛛种类和丝类型之间通常是保守的。WO07/078239和Stark,M.等人,Biomacromolecules8:1695-1701,(2007)公开了由具有高的Ala和Gly含量的重复片段和蛋白质的C端片段组成的微型蜘蛛丝蛋白,以及包含蜘蛛丝蛋白的可溶性融合蛋白。在蜘蛛丝蛋白从其融合配体释放后,自然地获得蜘蛛丝蛋白的纤维。Rising,A.等人,CMLS68(2):169-184(2010)综述了在产生蜘蛛丝蛋白方面的进展。US2009/0263430公开了酶β-半乳糖苷酶与微型蜘蛛丝蛋白的膜的化学偶联。然而,化学偶联可能要求对蛋白稳定性和/或功能不利的条件。包含衍生自蜘蛛丝蛋白的重复区的区段的多个重复段的蛋白已经被设计以包括RGD细胞结合区段(Bini,E等人,Biomacromolecules7:3139-3145(2006))和/或R5肽(WongPoFoo,C等人,ProcNatlAcadSci103(25):9428-9433(2006))或参与矿化作用(mineralization)的其他蛋白区段(Huang,J等人,Biomaterials28:2358-2367(2007);WO2006/076711)。在这些现有技术文献中,通过在变性的有机溶剂六氟异丙醇(HFIP)中增溶融合蛋白和干燥来形成膜。US2005/261479A1公开了用于纯化具有亲和性标签的重组丝蛋白的方法,包括从复杂混合物中磁亲和性分离单独的丝蛋白,而不形成丝蛋白纤维或其他聚合物结构。已知的支持结构和相关的技术在以下方面具有某些缺陷,例如经济性、效率、稳定性、再生能力、生物活性和生物相容性。发明概述本发明的一个目的是提供能够与有机靶选择性相互作用的新颖蛋白结构。本发明的另一个目的是提供能够与有机靶选择性相互作用的蛋白结构,其中所述结构的形成不使用可能对蛋白的二级结构或活性具有不可预测的作用和/或保持在蛋白结构中的强溶剂。本发明的一个目的是提供能够与有机靶选择性相互作用的稳定蛋白结构,该蛋白结构在使用后可容易地再生,例如通过化学处理。本发明的另一个目的是提供稳定蛋白结构,其是生物相容的,并适于细胞培养和作为植入物。本发明的又另一个目的是提供具有高密度的能够与有机靶选择性相互作用的均匀间隔的官能团的蛋白结构。本发明的另一个目的是提供在+4℃或在室温储存数月后保持其选择性结合能力的蛋白结构。本发明的又一个目的是提供可高压灭菌的蛋白结构,即,在灭菌热处理后保持其选择性结合能力。在第一个方面,本发明提供了以下实施方案:A1.一种蛋白结构,所述蛋白结构能够与选自免疫球蛋白和包含免疫球蛋白或其衍生物的分子组成的组的有机靶选择性相互作用,其中所述蛋白结构是包含能够与所述有机靶选择性相互作用的重组融合蛋白作为重复结构单元的聚合物,所述重组融合蛋白包含部分B、REP和CT,其中:B是多于30个氨基酸残基的非拖丝蛋白部分,所述B提供与所述有机靶选择性相互作用的能力,其中所述B部分选自衍生自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A、和葡萄球菌蛋白A的E、D、A、B和C结构域;和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段组成的组;REP是70至300个氨基酸残基的部分并衍生自蜘蛛丝蛋白的重复片段;和CT是70至120个氨基酸残基的部分并衍生自蜘蛛丝蛋白的C端片段。A2.根据A1所述的蛋白结构,其中所述B部分可选自衍生自葡萄球菌蛋白A的Z结构域、和与衍生自葡萄球菌蛋白A的Z结构域具有至少70%同一性的蛋白片段组成的组。A3.一种蛋白结构,所述蛋白结构能够与有机靶选择性相互作用,其中所述蛋白结构是包含能够与所述有机靶选择性相互作用的重组融合蛋白作为重复结构单元的聚合物,所述重组融合蛋白包含部分B、REP和CT、和任选的NT,其中:B是多于30个氨基酸残基的非拖丝蛋白部分,其提供与所述有机靶选择性相互作用的能力;REP是70至300个氨基酸残基的部分并衍生自蜘蛛丝蛋白的重复片段;CT是70至120个氨基酸残基的部分并衍生自蜘蛛丝蛋白的C端片段;和NT是100至160个氨基酸残基的部分并衍生自蜘蛛丝蛋白的N端片段。A4.根据A3所述的蛋白结构,其中所述重组融合蛋白可选自由式Bx-REP-By-CT-Bz和Bx-CT-By-REP-Bz定义的蛋白组成的组,其中x、y和z是0至5的整数;且x+y+z≥1。A5.根据A4所述的蛋白结构,其中所述重组融合蛋白可选自由式Bx-REP-CT、BX-CT-REP、REP-CT-BZ和CT-REP-BZ定义的蛋白组成的组;其中x和z是1至5的整数。A6.根据A5所述的蛋白结构,其中所述重组融合蛋白可选自由式B-REP-CT、B-CT-REP、REP-CT-B和CT-REP-B定义的蛋白组成的组。A7.根据A1-A6任一个所述的蛋白结构,其中所述B部分可具有与SEQIDNO:6-10的任一种少于30%的同一性。A8.根据A3-A7任一个所述的蛋白结构,其中所述有机靶可选自免疫球蛋白和包含免疫球蛋白或其衍生物的分子组成的组。A9.根据A8所述的蛋白结构,其中所述免疫球蛋白可选自来自人类的免疫球蛋白亚类IgG1、IgG2、IgG4、IgA和IGM。A10.根据A3-A9任一个所述的蛋白结构,其中所述B部分可选自衍生自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A、和葡萄球菌蛋白A的E、D、A、B和C结构域、链球菌蛋白G、和链球菌蛋白G的C1、C2和C3结构域;和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段组成的组。A11.根据A10所述的蛋白结构,其中所述B部分可选自衍生自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A的B结构域、和链球菌蛋白G的C2结构域;和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段组成的组。A12.根据A11所述的蛋白结构,其中所述B部分可选自衍生自葡萄球菌蛋白A的Z结构域和链球菌蛋白G的C2结构域组成的组。A13.根据A3-A7任一个所述的蛋白结构,其中所述有机靶可选自白蛋白和包含白蛋白或其衍生物的分子组成的组。A14.根据A13所述的蛋白结构,其中所述B部分可选自链球菌蛋白G、链球菌蛋白G的白蛋白结合结构域、来自大芬戈尔德菌(Finegoldiamagna)的GA模块;和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段。A15.根据A13-A14任一个所述的蛋白结构,其中所述B部分可包括链球菌蛋白G的白蛋白结合结构域、和与其具有至少70%同一性的蛋白片段。A16.根据A15所述的蛋白结构,其中所述B部分可以是链球菌蛋白G的白蛋白结合结构域。A17.根据A3-A7任一个所述的蛋白结构,其中所述有机靶可选自生物素和包含生物素或其衍生物或类似物的分子组成的组。A18.根据A17所述的蛋白结构,其中所述B部分可选自链霉亲和素、单体链霉亲和素(M4);和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段组成的组。A19.根据A18所述的蛋白结构,其中所述B部分可以是单体链霉亲和素(M4)。A20.根据A1-A19任一个所述的蛋白结构,其中所述蛋白结构可在至少两个维度上具有至少0.1μm的尺寸。A21.根据A1-A20任一个所述的蛋白结构,其中所述蛋白结构可以是以选自由纤维、膜、泡沫、网状物、网、球和胶囊组成的组的物理形态。A22.根据A1-A21任一个所述的蛋白结构,其中所述REP部分可选自L(AG)nL、L(AG)nAL、L(GA)nL、L(GA)nGL的组,其中n是2至10的整数;每个单独的A区段是8至18个氨基酸残基的氨基酸序列,其中所述氨基酸残基中的0至3个不是Ala,且剩余的氨基酸残基是Ala;每个单独的G区段是12至30个氨基酸残基的氨基酸序列,其中至少40%的氨基酸残基是Gly;且每个单独的L区段是0至20个氨基酸残基的接头氨基酸序列。A23.根据A1-A22任一个所述的蛋白结构,其中所述CT部分可具有与SEQIDNO:9的至少50%同一性或与SEQIDNO:7的至少80%同一性。A24.根据A23所述的蛋白结构,其中所述CT部分可具有与SEQIDNO:9的至少50%同一性和与SEQIDNO:7的至少80%同一性。A25.根据A1-A24任一个所述的蛋白结构,其中所述NT部分可具有与SEQIDNO:8的至少50%同一性或与SEQIDNO:6的至少80%同一性。A26.根据A25所述的蛋白结构,其中所述NT部分可具有与SEQIDNO:8的至少50%同一性和与SEQIDNO:6的至少80%同一性。A27.根据A1-A26任一个所述的蛋白结构,其中所述融合蛋白可包括寡肽细胞结合基序。A28.根据A1-A27任一个所述的蛋白结构,其中所述融合蛋白可选自SEQIDNO:14、16、18、22、24和26;和与这些序列的任一种具有至少80%同一性的蛋白组成的组。A29.一种提供根据A1-A28任一个所述的蛋白结构的方法,所述蛋白结构展示对有机靶的结合活性,所述方法包括以下步骤:(a)提供根据A1-A28任一个所述的重组融合蛋白;(b)将所述融合蛋白经受实现包含所述重组融合蛋白的聚合物的形成的条件。A30.一种用于固定有机靶的亲和性介质,所述亲和性介质包含根据A1-A28任一个所述的融合蛋白,其中所述B部分能够与所述有机靶选择性相互作用。A31.根据A30所述的亲和性介质,所述亲和性介质可包含根据A1-A28任一个所述的蛋白结构,所述蛋白结构是包含所述重组融合蛋白的聚合物。A32.根据A31所述的亲和性介质,其中所述蛋白结构可以是根据A8-A19任一个所述的。A33.根据A30-A32任一个所述的亲和性介质,所述亲和性介质还可包含所述有机靶,其中所述B部分能够与所述有机靶选择性相互作用并结合。A34.根据A33所述的亲和性介质,其中所述有机靶能够与第二有机靶选择性相互作用。A35.根据A31-A34任一个所述的亲和性介质,其中所述蛋白结构可以是以膜的物理形态。A36.一种用于培养细胞的细胞支架材料,所述细胞具有存在于所述细胞表面上的有机靶,所述细胞支架材料包含根据A1-A28任一个所述的蛋白结构。A37.根据A36所述的细胞支架材料,其中所述B部分能够与存在于所述细胞表面上的所述有机靶选择性相互作用。A38.根据A36所述的细胞支架材料,其中所述细胞支架材料还可包含中间有机靶,其中所述B部分能够与所述中间有机靶选择性相互作用并结合,且其中所述中间有机靶能够与存在于所述细胞表面上的所述有机靶选择性相互作用。A39.根据A38所述的细胞支架材料,其中所述蛋白结构可以是根据A8-A19任一个所述的。A40.根据A36-A40任一个所述的细胞支架材料,其中所述蛋白结构可以是以膜的物理形态。A41.细胞与根据A36-A40任一个所述的细胞支架材料的组合。A42.根据A1-A28任一个所述的蛋白结构在从样品分离有机靶中的用途。A43.根据A1-A28任一个所述的蛋白结构在培养细胞中的用途。A44.一种从样品分离有机靶的方法,所述方法包括以下步骤:提供包含所述有机靶的样品;提供根据A30-A35任一个所述的亲和性介质,其中所述亲和性介质能够与所述有机靶选择性相互作用;在实现所述亲和性介质与所述有机靶之间的结合的适当条件下将所述亲和性介质与所述样品接触;和除去未结合的样品。A45.根据A44所述的方法,所述方法还可包括在实现第一有机靶与第二有机靶之间的结合的适当条件下将所述亲和性介质和固定的有机靶与第二有机靶接触的步骤,所述第二有机靶能够与第一有机靶选择性相互作用。A46.根据A44-A45任一个所述的方法,其中当将所述亲和性介质与所述样品接触以实现所述亲和性介质与所述有机靶之间的结合时,所述亲和性介质中的所述融合蛋白可以以如根据A1-A28任一个所述的蛋白结构存在。A47.根据A44-A45任一个所述的方法,其中当将所述亲和性介质与所述样品接触以实现所述亲和性介质与所述有机靶之间的结合时,所述亲和性介质中的所述融合蛋白可在溶液中存在,且其中允许融合蛋白与所述有机靶结合的复合体形成根据A1-A28任一个所述的融合蛋白结构。A48.根据A44-A47任一个所述的方法,所述方法还可包括检测、和任选地定量所述亲和性介质上的固定的靶的存在的步骤。A49.根据A44-A48任一个所述的方法,所述方法还可包括从所述亲和性介质释放和收集所述有机靶的步骤。A50.根据A44-A49任一个所述的方法,所述方法还可包括通过化学处理和/或灭菌热处理再生所述亲和性介质的最后步骤。A51.根据A50所述的方法,其中所述化学处理可包括用NaOH和/或脲处理。A52.一种固定细胞的方法,所述方法包括提供:包含目标细胞的样品;将所述样品应用到根据A36-A40任一个所述的细胞支架材料,其中所述细胞支架材料能够与存在于所述细胞表面上的有机靶选择性相互作用;和通过所述细胞表面上的所述有机靶与所述细胞支架材料之间的结合,允许所述细胞固定于所述细胞支架材料。A53.一种培养细胞的方法,所述方法包括:根据A52所述的方法固定目标细胞到细胞支架材料;和在适合细胞培养的条件下保持已对其应用细胞的所述细胞支架材料。A54.根据A44-A53任一个所述的方法,其中所述蛋白结构可以是以膜、纤维或泡沫的物理形态。A55.根据A1-A28任一个所述的重组融合蛋白,所述重组融合蛋白能够与有机靶选择性相互作用。A56.一种分离的多核酸,所述多核酸编码根据A55所述的融合蛋白。A57.根据A56所述的分离的多核酸,所述多核酸可选自由编码根据A28所述的融合蛋白的核酸组成的组和由SEQIDNO:15、17、19、23、25和27组成的组。A58.一种产生融合蛋白的方法,所述方法包括以下步骤:a)在适当的宿主中表达根据A1-A28任一个所述的融合蛋白;和b)获得包含所述融合蛋白的混合物,和任选地分离所述融合蛋白。A59.根据A1-A28任一个所述的重组融合蛋白用于产生能够与有机靶选择性相互作用的蛋白结构的用途,其中所述蛋白结构是包含所述重组融合蛋白的聚合物。在另一个方面,本发明提供了以下实施方案:B1.一种蛋白结构,所述蛋白结构能够与选自IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的有机靶选择性相互作用,其中所述蛋白结构是包含能够与所述有机靶选择性相互作用的重组融合蛋白作为重复结构单元的聚合物,所述重组融合蛋白包含部分B、REP和CT,其中所述聚合物包括多于100个融合蛋白结构单元,且其中:B是多于30个氨基酸残基的非拖丝蛋白部分,所述B提供与所述有机靶选择性相互作用的能力,其中所述B部分选自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A、和葡萄球菌蛋白A的E、D、A、B和C结构域;和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段组成的组;所述REP部分和CT部分提供形成聚合物的能力;REP是70至300个氨基酸残基的部分并选自由L(AG)nL、L(AG)nAL、L(GA)nL、L(GA)nGL组成的组,其中n是2至10的整数;每个单独的A区段是8至18个氨基酸残基的氨基酸序列,其中所述氨基酸残基中的0至3个不是Ala,且剩余的氨基酸残基是Ala;每个单独的G区段是12至30个氨基酸残基的氨基酸序列,其中至少40%的氨基酸残基是Gly;且每个单独的L区段是0至20个氨基酸残基的接头氨基酸序列;和CT是70至120个氨基酸残基的部分并具有与SEQIDNO:9的至少50%同一性或与SEQIDNO:7的至少80%同一性。B2.根据B1所述的蛋白结构,其中所述B部分可选自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A的B结构域;和与这些氨基酸序列的任一种具有至少70%同一性的蛋白片段组成的组。B3.根据B2所述的蛋白结构,其中所述B部分可选自葡萄球菌蛋白A的Z结构域、和与葡萄球菌蛋白A的Z结构域具有至少70%同一性的蛋白片段组成的组。B4.根据B3所述的蛋白结构,其中所述B部分可以是葡萄球菌蛋白A的Z结构域。B5.根据B4所述的蛋白结构,其中所述重组融合蛋白可选自由式Bx-REP-By-CT-Bz和Bx-CT-By-REP-Bz定义的蛋白组成的组,其中x、y和z是0至5的整数;且x+y+z≥1。B6.根据B5所述的蛋白结构,其中所述重组融合蛋白可选自由式Bx-REP-CT、BX-CT-REP、REP-CT-BZ和CT-REP-BZ定义的蛋白组成的组;其中x和z是1至5的整数。B7.根据B6所述的蛋白结构,其中所述重组融合蛋白可选自由式B-REP-CT、B-CT-REP、REP-CT-B和CT-REP-B定义的蛋白组成的组。B8.根据B1-B7任一个所述的蛋白结构,其中所述B部分可具有与SEQIDNO:6-10的任一种少于30%的同一性。B9.根据B1-B8任一个所述的蛋白结构,其中所述蛋白结构可在至少两个维度上具有至少0.1μm的尺寸。B10.根据B1-B9任一个所述的蛋白结构,其中所述蛋白结构可以是以选自由纤维、膜、泡沫、网状物、网、球和胶囊组成的组的物理形态。B11.根据B1-B10任一个所述的蛋白结构,其中所述CT部分可具有与SEQIDNO:9的至少50%同一性和与SEQIDNO:7的至少80%同一性。B12.根据B1-B10任一个所述的蛋白结构,其中所述CT部分可具有与SEQIDNO:7的至少90%同一性。B13.根据B12所述的蛋白结构,其中所述CT部分可以是SEQIDNO:7。B14.根据B1-B13任一个所述的蛋白结构,其中所述重组融合蛋白可选自SEQIDNO:14和与SEQIDNO:14具有至少80%同一性的蛋白组成的组。B15.一种提供根据B1-B14任一个所述的蛋白结构的方法,所述蛋白结构展示对选自由IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的有机靶的结合活性,所述方法包括以下步骤:(a)提供根据B1-B14任一个所述的重组融合蛋白;(b)将所述重组融合蛋白经受实现包含所述重组融合蛋白的聚合物的形成的条件。B16.一种用于固定选自由IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的有机靶的亲和性介质,所述亲和性介质包含根据B1-B14任一个所述的重组融合蛋白,其中所述B部分能够与所述有机靶选择性相互作用。B17.根据B16所述的亲和性介质,所述亲和性介质可包含根据B1-B14任一个所述的蛋白结构,所述蛋白结构是包含所述重组融合蛋白的聚合物。B18.根据B16-B17任一个所述的亲和性介质,所述亲和性介质还可包含所述有机靶,其中所述B部分能够与所述有机靶选择性相互作用并结合。B19.根据B18所述的亲和性介质,其中所述有机靶能够与第二有机靶选择性相互作用。B20.根据B17-B19任一个所述的亲和性介质,其中所述蛋白结构可以是以膜的物理形态。B21.一种用于培养细胞的细胞支架材料,所述细胞具有存在于所述细胞表面上的有机靶,所述细胞支架材料包含根据B1-B14任一个所述的蛋白结构,其中所述细胞支架材料还包含选自由IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的中间有机靶,其中所述B部分能够与所述中间有机靶选择性相互作用并结合,且其中所述中间有机靶能够与存在于所述细胞表面上的所述有机靶选择性相互作用。B22.根据B21所述的细胞支架材料,其中所述蛋白结构可以是以膜的物理形态。B23.细胞与根据B21-B22任一个所述的细胞支架材料的组合。B24.根据B1-B14任一个所述的蛋白结构在从样品分离选自由IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的有机靶中的用途。B25.根据B1-B14任一个所述的蛋白结构在培养细胞中的用途。B26.一种从样品分离选自由IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的有机靶的方法,所述方法包括以下步骤:提供包含所述有机靶的样品;提供根据B16-B20任一个所述的亲和性介质,其中所述亲和性介质能够与所述有机靶选择性相互作用;在实现所述亲和性介质与所述有机靶之间的结合的适当条件下将所述亲和性介质与所述样品接触,从而提供固定的有机靶;和除去未结合的样品。B27.根据B26所述的方法,所述方法还可包括将所述亲和性介质和所述固定的有机靶与另外的有机靶在实现这两个有机靶之间的结合的适当条件下接触的步骤,所述另外的有机靶能够与所述固定的有机靶选择性相互作用。B28.根据B26-B27任一个所述的方法,其中当将所述亲和性介质与所述样品接触以实现所述亲和性介质与所述有机靶之间的结合时,所述亲和性介质中的所述重组融合蛋白可以以如根据B1-B14任一个所述的蛋白结构存在。B29.根据B26-B27任一个所述的方法,其中当将所述亲和性介质与所述样品接触以实现所述亲和性介质与所述有机靶之间的结合时,所述亲和性介质中的所述重组融合蛋白可在溶液中存在,且其中允许融合蛋白与所述有机靶结合的复合体形成根据B1-B14任一个所述的融合蛋白结构。B30.根据B26-B29任一个所述的方法,所述方法还可包括检测、和任选地定量所述亲和性介质上的所述固定的有机靶的存在的步骤。B31.根据B26-B30任一个所述的方法,所述方法还可包括从所述亲和性介质释放和收集所述有机靶的步骤。B32.根据B26-B31任一个所述的方法,所述方法还可包括通过化学处理和/或灭菌热处理再生所述亲和性介质的最后步骤。B33.根据B32所述的方法,其中所述化学处理可包括用NaOH和/或脲处理。B34.一种固定细胞的方法,所述方法包括:提供包含目标细胞的样品;将所述样品应用到根据B21-B22任一个所述的细胞支架材料,其中所述细胞支架材料能够与存在于所述细胞表面上的有机靶选择性相互作用;和通过所述细胞表面上的所述有机靶与所述细胞支架材料之间的结合,允许所述细胞固定于所述细胞支架材料。B35.一种培养细胞的方法,所述方法包括:根据B34所述的方法固定目标细胞到细胞支架材料;和在适合细胞培养的条件下保持已对其应用细胞的所述细胞支架材料。B36.根据B26-B35任一个所述的方法,其中所述蛋白结构可以是以膜、纤维或泡沫的物理形态。B37.一种重组融合蛋白,所述重组融合蛋白由SEQIDNO:14组成。B38.一种分离的多核酸,所述多核酸选自由编码根据B37所述的重组融合蛋白的核酸和SEQIDNO:15组成的组。B39.一种产生重组融合蛋白的方法,所述方法包括以下步骤:a)在适当的宿主中表达根据B37所述的重组融合蛋白;和b)获得包含所述重组融合蛋白的混合物,和任选地分离所述重组融合蛋白。B40.根据B1-B14任一个所述的重组融合蛋白用于产生能够与选自由IgG的可结晶片段(Fc)区域和包含IgG或其衍生物的分子组成的组的有机靶选择性相互作用的蛋白结构的用途,其中所述蛋白结构是包含所述重组融合蛋白的聚合物。附图简述图1显示拖丝蛋白C端结构域的序列比对。图2显示拖丝蛋白N端结构域的序列比对。图3显示包含Z结构域的融合蛋白的宏观纤维。图4显示来自包含Z结构域的融合蛋白的纯化和分析的SDS-PAGE凝胶。图5显示由融合蛋白制成的纤维和对照纤维,示出融合蛋白中Z结构域的功能性(functionality)。图6显示在组织培养板的底部由融合蛋白制成的成型膜(castedfilm)的部分。图7-12显示非还原性SDS-PAGE凝胶,示出融合蛋白结构中Z结构域的功能性。图13-15显示非还原性SDS-PAGE凝胶,示出与商业蛋白A基质相比,融合蛋白结构中的Z结构域的IgG-结合能力。图16-17显示与商业蛋白A基质相比,融合蛋白结构的就地清洗(cleaning-in-place,CIP)程序的非还原性SDS-PAGE凝胶。图18显示来自用生物素化的Atto-565浸泡的蛋白膜的荧光强度。图19显示不同浓度的生物素化的Atto-565在结合融合蛋白膜后荧光强度值的图和线性拟合。图20显示向由融合蛋白制成的膜或对照的孔加入生物素化的Atto-565之前(-)和之后(+)的荧光强度值的图。图21是显示由溶液中游离的生物素化的HRP催化所得的反应速率的标准曲线和线性拟合的图。图22是显示与对照相比,由固定于融合蛋白膜的生物素化的HRP催化的反应速率的图。图23显示增溶的融合蛋白结构的还原性SDS-PAGE凝胶。图24-26显示示出IgG-HRP与包含Z结构域的融合蛋白膜的结合的图。图27显示示出IgG-AlexaFluor633与包含Z结构域的融合蛋白膜的结合的图。图28显示非还原性SDS-PAGE凝胶,示出高压灭菌后融合蛋白中Z结构域的功能性。图29显示蛋白酶3C处理包含Z结构域的融合蛋白纤维的裂解产物的SDS-PAGE凝胶。图30显示非还原性SDS-PAGE凝胶,示出在有机靶(IgG)存在下形成的融合蛋白结构中Z结构域的功能性。图31-32显示非还原性SDS-PAGE凝胶,示出融合蛋白结构中Abd结构域的功能性。图33-34显示非还原性SDS-PAGE凝胶,示出融合蛋白结构中C2结构域的功能性。所附序列的列表SEQIDNOSEQIDNO14Rep24RepCT3NT4Rep4NT5Rep5NT4RepCTHis6NT7CT8共有NT序列9共有CT序列10来自EuprosthenopsaustralisMaSp1的重复序列11共有G区段序列112共有G区段序列213共有G区段序列314HisZQG4Rep4CT15HisZQG4Rep4CT(DNA)16HisAbdQG4RepCT17HisAbdQG4RepCT(DNA)18HisC2QG4RepCT19HisC2QG4RepCT(DNA)204RepCT2214RepCT2(DNA)22M44RepCT23M44RepCT(DNA)24modM44RepCT25modM44RepCT(DNA)264RepCTM4274RepCTM4(DNA)发明详述本发明总体是基于如下洞见:能够与有机靶选择性相互作用的固态蛋白结构可制备为以重组融合蛋白作为重复结构单元的聚合物形式。融合蛋白包含至少一个能够与该有机靶选择性相互作用的多于30个氨基酸残基的非拖丝蛋白部分、和对应于蜘蛛丝蛋白的至少重复片段和C端片段的部分。意外地,衍生自蜘蛛丝蛋白的部分可被诱导以在结构上重排并因而形成聚合、固态结构,而非拖丝蛋白部分不在结构上重排,但保持其期望的结构和功能,即,与该有机靶选择性相互作用的能力。可获得蛋白结构而无化学偶联步骤或变性方法步骤,这使得程序容易并改进获得具有保持其部分的功能性的融合蛋白的机会,尤其是当功能依赖于部分的二级结构时。这些融合蛋白聚合物的形成可被紧密地控制,且这一洞见已被开发为进一步的新颖蛋白结构、产生该蛋白结构的方法、和该蛋白结构在多种应用和方法中的用途。因此,根据本发明的融合蛋白具备期望的选择性相互作用活性和蛋白结构中在生理条件下采用的内部的固态支持活性二者。当拖丝蛋白部分在结构上重排以形成聚合、固态结构时,融合蛋白的结合活性被保持,而非拖丝蛋白部分与拖丝蛋白部分共价连接,一定是被认为令人惊讶的。事实上,提供选择性相互作用活性的部分当被整合在根据本发明的融合蛋白结构中时,可增加其热和/或化学稳定性和/或结合活性。该蛋白结构还提供对有机靶的选择性相互作用活性的高和可预测的密度。具有选择性相互作用活性的有价值的蛋白部分的丢失被减到最小,因为所有表达的蛋白部分与固体支持物缔合。从根据本发明的融合蛋白形成的聚合物是固态结构,由于其物理特征而是有用的,尤其是高强度、弹性和轻的重量的有用的组合。特别有用的特征是,融合蛋白的拖丝蛋白衍生部分是生化牢固的,适于用例如酸、碱或离液剂再生,并适于加热灭菌,例如在120℃高压灭菌20min。该聚合物还因为其支持细胞粘附和生长的能力而是有用的。衍生自拖丝的性质在开发为了医学或技术目的的新材料方面是有吸引力的。尤其是,根据本发明的蛋白结构可用在制备和分析性分离程序中,诸如层析法、细胞捕获、筛选和培养、主动过滤器(activefilters)和诊断学。根据本发明的蛋白结构还可用在医疗装置中,诸如植入物和医学产品,诸如伤口闭合系统、创可贴、缝线、伤口敷料、和用于细胞固定、细胞培养、组织工程和引导细胞再生的支架。本发明提供能够与有机靶选择性相互作用的重组融合蛋白,该融合蛋白包含部分B、REP和CT、和任选的NT。本发明还提供能够与有机靶选择性相互作用的蛋白结构,其中所述蛋白结构是包含根据本发明的重组融合蛋白、和任选地由根据本发明的重组融合蛋白组成的聚合物,即,包含部分B、REP和CT、和任选的NT,和任选地由部分B、REP和CT、和任选的NT组成。尽管在实施例中融合蛋白的REP和CT部分不得已地涉及具体蛋白,例如衍生自来自Euprosthenopsaustralis的大拖丝蛋白1(MaSp1)的蛋白,为了产生根据本发明的融合蛋白结构的目的,考虑本公开内容可适用于任何结构上相似的部分。而且,尽管在实施例中提供融合蛋白的选择性相互作用活性的B部分不得已地涉及具体蛋白部分,例如衍生自蛋白A、蛋白G和链霉亲和素的部分,为了产生根据本发明的融合蛋白结构的目的,考虑本公开内容可适用于能够与有机靶选择性相互作用的任何结构上和/或功能上相似的B部分。根据本发明的具体融合蛋白以式Bx-REP-By-CT-Bz和Bx-CT-By-REP-Bz定义,其中x、y和z是0至5的整数;且x+y+z≥1,任选地在融合蛋白的任一端或融合蛋白中任何两个蛋白部分之间还包含一个NT部分。如果x+y+z>1,即,如果存在两个或多个B部分,它们可以是相同或不同的。两个或多个B部分可具有与相同有机靶或与不同有机靶选择性相互作用的能力。优选地,两个或多个B部分是大致上相同的,各具有与相同有机靶选择性相互作用的能力。在根据本发明的优选融合蛋白中,x、y和z是0至2、优选地0至1的整数。在根据本发明的某些优选融合蛋白中,y=0。在根据本发明的更优选的具体融合蛋白中,y=0且x或z是0,即,融合蛋白以式BX-REP-CT、BX-CT-REP、REP-CT-BZ和CT-REP-BZ定义,其中x和z是1至5的整数。在根据本发明的优选融合蛋白中,y=0,x和z是0至1的整数;且x+z=1。如此,根据本发明的某些优选融合蛋白以式B-REP-CT、B-CT-REP、REP-CT-B和CT-REP-B定义。在根据本发明的优选融合蛋白中,任选的NT部分不存在。术语“融合蛋白”此处指通过由重组核酸,即通过组合正常情况下不会一起出现的两个或更多个核酸序列而人工创造的DNA或RNA表达而制备的蛋白质(遗传工程)。根据本发明的融合蛋白是重组蛋白,且因此其不同于天然存在的蛋白质。特别地,因为野生型拖丝蛋白不是由以上列出的重组核酸表达的,所以其不是根据本发明的融合蛋白。组合的核酸序列编码具有特定功能特性的不同蛋白质、部分蛋白质或多肽。所得的融合蛋白或重组融合蛋白是具有衍生自原始蛋白质、部分蛋白质或多肽中的每一种的功能特性的单一蛋白质。而且,根据本发明的融合蛋白和相应的基因是嵌合的,即,该蛋白/基因部分衍生自至少两种不同的物种。REP和CT部分、以及任选的NT部分,都衍生自蜘蛛丝蛋白。为了避免疑问,根据本发明的B部分是非拖丝蛋白的蛋白或多肽,即,其不是衍生自蜘蛛丝蛋白。具体地,根据本发明的B部分不是衍生自蜘蛛丝蛋白的C端、重复或N端片段。融合蛋白通常由170至2000个氨基酸残基、诸如170至1000个氨基酸残基、诸如170至600个氨基酸残基、优选地170至500个氨基酸残基、诸如170至400个氨基酸残基组成。小的尺寸是有利的,因为包含蜘蛛丝蛋白片段的较长蛋白可能形成无定形的聚集物,这需要使用强力的溶剂来增溶和聚合。重组融合蛋白可包含多于2000个残基,尤其是在蜘蛛丝蛋白包含多于一个B部分和/或当其包含NT部分的情形时。术语"拖丝蛋白(spidroin)"和"蜘蛛丝蛋白(spidersilkprotein)"遍及本说明书可互换地使用,并涵盖所有已知的蜘蛛丝蛋白,包括大壶状腺蜘蛛丝蛋白,其通常缩写为"MaSp",或在十字园蛛的情形缩写为"ADF"。这些大壶状腺蜘蛛丝蛋白一般为两种类型,1和2。这些术语还包括与已知蜘蛛丝蛋白具有高程度的同一性和/或相似性的非天然蛋白。所以,术语"非拖丝蛋白"意指不是衍生自蜘蛛丝蛋白的蛋白,即,与蜘蛛丝蛋白具有低(或无)程度的同一性和/或相似性。根据本发明的蛋白结构能够与有机靶选择性相互作用。这一能力存在于根据本发明的融合蛋白中,更具体地存在于融合蛋白的B部分中。REP和CT部分、以及任选的NT部分,与有机分子的任何相互作用不被术语"能够与有机靶选择性相互作用"涵盖。为了避免疑问,术语"能够与有机靶选择性相互作用"不涵盖根据本发明的融合蛋白的依赖于包括REP和CT部分、以及任选的NT部分的相互作用的二聚、寡聚或聚合。术语"有机靶"涵盖含碳原子的所有化学分子,例外是通常本领域技术人员认为是无机分子的那些,例如碳酸盐、碳的简单氧化物、氰化物、金刚石和石墨。为了避免疑问,无机分子、盐和离子,诸如硅石和氯化钙,不是有机的。有机靶可以是包含有机分子或由有机分子组成的复合体,例如,细胞表面上的受体复合体。有机靶可以是一种或多种有机分子类型的单体、二聚体、寡聚体或聚合物,可以由共价键或其他类型的缔合保持在一起。当然,它还可以简单地是单个有机分子。根据本发明的优选的有机靶包括但不限于,核酸、蛋白和多肽、脂质和碳水化合物、以及其组合。根据本发明的另外的优选的有机靶包括但不限于,免疫球蛋白、包含免疫球蛋白或其衍生物的分子、白蛋白、包含白蛋白或其衍生物的分子、生物素、和包含生物素或其衍生物或类似物的分子。在本发明的上下文中,配体例如根据本发明的融合蛋白的B部分与其靶的"特异"或"选择性"相互作用是指,该相互作用使得特异性与非特异性、或选择性或非选择性的相互作用之间的差别变得有意义。两种蛋白之间的相互作用有时以解离常数测量。解离常数描述两种分子之间的结合强度(或亲和性)。通常抗体与其抗原之间的解离常数是10-7至10-11M。然而,高特异性不必要求高亲和性。对其对应物具有低亲和性(在摩尔范围中)的分子已经显示为与具有高的多的亲和性的分子同样特异性。在本发明的情形中,特异或选择性相互作用是指在指定条件下,在天然存在的或经加工的生物或生化流体的样品中其他蛋白的存在下,特定方法可用于确定特定蛋白、靶蛋白或其片段的存在和/或量的程度。换言之,特异性或选择性是区分相关蛋白的能力。特异和选择性在本说明书中有时可互换地使用。根据本发明的融合蛋白还可包含一个或多个接头肽。接头肽可布置在融合蛋白的任何部分之间,例如,CT和REP部分之间、两个B部分之间、B和CT部分之间、和B和REP部分之间,或可布置在融合蛋白的任一末端。如果融合蛋白包含两个或多个B部分,接头肽还可布置在两个B部分之间。接头可在融合蛋白的功能单元之间提供间隔区,而且还可构成用于鉴定和纯化该融合蛋白的工具,例如,His和/或Trx标签。如果融合蛋白包含用于鉴定和纯化融合蛋白的两个或多个接头肽,优选它们被间隔序列隔开,例如His6-间隔区-His6-。接头还可构成将融合蛋白导向膜和/或致使融合蛋白从宿主细胞分泌到周围介质中的信号肽,例如信号识别颗粒。融合蛋白还可在其氨基酸序列中包括允许裂解并去除接头和/或其他相关部分,通常是一个或多个B部分的裂解位点。多种裂解位点是本领域技术人员已知的,例如,针对化学剂的裂解位点,例如Met残基之后的CNBr裂解位点和Asn-Gly残基之间的羟胺裂解位点,针对蛋白酶例如凝血酶或蛋白酶3C的裂解位点,和自我剪接序列,例如内蛋白(intein)自我剪接序列。REP、CT和B部分彼此直接或间接连接。直接连接指部分之间的直接共价结合而无间插序列例如接头。间接连接也是指部分通过共价键连接,但是存在间插序列,例如接头和/或一个或多个另外的部分,例如NT部分。一个或多个B部分可布置在融合蛋白的内部或任何一端,即,布置在C端或布置在N端。优选一个或多个B部分布置在融合蛋白的N末端。如果融合蛋白包含用于鉴定和纯化融合蛋白的一个或多个接头肽,例如,His或Trx标签,优选地其被布置在融合蛋白的N末端。优选的融合蛋白具有布置在N端的B部分通过1-30个氨基酸残基,经由例如1-10个氨基酸残基的接头肽偶联到布置在C端的REP和CT部分的形式。接头肽可包含裂解位点。任选地,融合蛋白具有可包含纯化标签例如His标签和裂解位点的N端或C端接头肽。另一种优选的融合蛋白具有布置在N端的B部分直接偶联到布置在C端的REP和CT部分的形式。任选地,融合蛋白具有可包含纯化标签例如His标签和裂解位点的N端或C端接头肽。根据本发明的蛋白结构是包含根据本发明的重组融合蛋白作为重复结构单元的聚合物,这是意指,其包含有序的多个根据本发明的融合蛋白,通常远多于100个融合蛋白单元、例如,1000个融合蛋白单元或更多。任选地,聚合物可包含无B部分的互补蛋白、优选地衍生自蜘蛛丝的蛋白作为另外的重复结构单元。如果融合蛋白的B部分是大和/或庞大的,这可以是有益的。这些互补蛋白通常包括REP部分和CT部分、和任选地NT部分。根据本发明的优选的互补蛋白可具有本文列出的结构的任一种,并缺失B部分。优选地,互补融合蛋白与缺失B部分的融合蛋白基本上相同。然而优选地,根据本发明的蛋白结构是由根据本发明的重组融合蛋白作为重复结构单元组成的聚合物,即,根据本发明的蛋白结构是根据本发明的重组融合蛋白的聚合物。聚合物中融合单元的量值意指该蛋白结构获得显著的大小。在优选的实施方案中,蛋白结构在至少两个维度上具有至少0.1μm的尺寸。如此,本文使用的术语"蛋白结构"涉及具有至少0.1μm的厚度的融合蛋白聚合物,优选地人眼可见的宏观聚合物,即,具有至少1μm的厚度。术语"蛋白结构"不涵盖无结构的聚集物或沉淀物。尽管融合蛋白的单体是水溶性的,应理解的是,根据本发明的蛋白结构是固态结构,即,不溶于水。该蛋白结构是包含根据本发明的重组融合蛋白作为重复结构单元单体的聚合物。优选地,根据本发明的蛋白结构是以选自由纤维(fiber)、膜(film)、泡沫(foam)、网状物(net)、网(mesh)、球(sphere)和胶囊(capsule)组成的组的物理形态。优选地,根据本发明的蛋白结构是厚度为至少0.1μm、优选地至少1μm的纤维或膜。优选地,纤维或膜具有范围在1-400μm、优选地60-120μm中的厚度。优选地,纤维具有范围在0.5-300cm、优选地1-100cm中的长度。其他优选的范围是0.5-30cm和1-20cm。纤维具有在物理操作期间保持完整的能力,即,可用于旋转、编织、扭转、钩编和类似程序。膜是有利的,因为其是一致的并粘附于固体结构,例如,微量滴定板中的塑料制品。膜的这一特征有助于洗涤和再生程序,对于分离目的是非常有用的。特别有用的蛋白结构是膜或纤维,其中B部分是衍生自葡萄球菌蛋白A的Z结构域或与其具有至少70%同一性的蛋白片段,参见例如,实施例1-6。还优选地,根据本发明的蛋白结构具有高于1MPa、优选地高于2MPa、更优选地10MPa或更高的抗张强度。优选地,根据本发明的蛋白结构具有高于100MPa、更优选地200MPa或更高的抗张强度。REP部分是包含70至300个氨基酸残基的蛋白片段,并衍生自蜘蛛丝蛋白的重复片段。这意指,REP部分具有在富含丙氨酸的区段和富含甘氨酸的区段之间交替的重复性特征。如以下将更详细地解释的,REP部分通常包含多于70,例如多于140且少于300,优选地少于240,例如少于200个氨基酸残基,且自身可分成几个L(接头)区段、A(富含丙氨酸)区段和G(富含甘氨酸)区段。通常,所述接头区段是任选的,位于REP部分末端,而剩余的区段依次是富含丙氨酸和富含甘氨酸的。因此,REP部分通常可具有以下结构中的任何一种,其中n是整数:L(AG)nL,例如LA1G1A2G2A3G3A4G4A5G5L;L(AG)nAL,例如LA1G1A2G2A3G3A4G4A5G5A6L;L(GA)nL,例如LG1A1G2A2G3A3G4A4G5A5L;或L(GA)nGL,例如LG1A1G2A2G3A3G4A4G5A5G6L。其遵循:富含丙氨酸或富含甘氨酸的区段是否与N端或C端接头区段相邻不是关键的。优选n是2至10,优选地2至8,优选地4至8,更优选地4至6,即n=4、n=5或n=6的整数。在优选的实施方案中,根据本发明的REP部分的丙氨酸含量高于20%,优选地高于25%,更优选地高于30%且低于50%,优选地低于40%,更优选地低于35%。这是有利的,因为设想更高的丙氨酸含量提供更硬和/或更强和/或不太可延伸的结构。在某些实施方案中,REP部分不含脯氨酸残基,即REP部分中不存在脯氨酸残基。现在转向构成根据本发明的REP部分的区段,应强调的是每个区段是单独的,即,特定REP部分的任何两个A区段、任何两个G区段或任何两个L区段可以是相同的或可以是不相同的。因此,每种类型的区段在特定REP部分内是相同的不是本发明的一般特征。而是,以下公开内容为技术人员提供了如何设计单独的区段并将其聚集成REP部分的指南,该REP部分从而被认为是来源于蜘蛛丝蛋白的重复片段,且构成根据本发明的功能性融合蛋白的一部分。每个单独的A区段是具有8至18个氨基酸残基的氨基酸序列。优选每个单独的A区段包含13至15个氨基酸残基。大多数或多于两个的A区段包含13至15个氨基酸残基,且少数例如一或两个A区段包含8至18个氨基酸残基例如8-12或16-18个氨基酸残基也是可能的。这些氨基酸残基中的绝大多数是丙氨酸残基。更特别地,这些氨基酸残基中的0至3个不是丙氨酸残基,且剩余的氨基酸残基是丙氨酸残基。因此,每个单独的A区段中的所有氨基酸残基毫无例外地或除了一、二或三个氨基酸残基可以是任何氨基酸以外,都是丙氨酸残基。优选取代丙氨酸的氨基酸是天然氨基酸,优选地单独选自丝氨酸、谷氨酸、半胱氨酸和甘氨酸的组,更优选地是丝氨酸。当然,A区段中的一个或多个是全丙氨酸区段,而剩余的A区段包含1-3个非丙氨酸的残基,例如丝氨酸、谷氨酸、半胱氨酸或甘氨酸是可能的。在优选的实施方案中,每个A区段包含13-15个氨基酸残基,包括10-15个丙氨酸残基和0-3个上述非丙氨酸的残基。在更优选的实施方案中,每个A区段包含13-15个氨基酸残基,包括12-15个丙氨酸残基和0-1个上述非丙氨酸的残基。优选每个单独的A区段与选自SEQIDNO:10的氨基酸残基7-19、43-56、71-83、107-120、135-147、171-183、198-211、235-248、266-279、294-306、330-342、357-370、394-406、421-434、458-470、489-502、517-529、553-566、581-594、618-630、648-661、676-688、712-725、740-752、776-789、804-816、840-853、868-880、904-917、932-945、969-981、999-1013、1028-1042和1060-1073的组的氨基酸序列具有至少80%,优选地至少90%,更优选地95%,最优选地100%的同一性。该组的每个序列对应于EuprosthenopsaustralisMaSp1蛋白质的天然存在的序列的区段,该天然存在的序列经过克隆相应的cDNA而推断得来,参见WO2007/078239。可选择地,每个单独的A区段与选自SEQIDNO:3的氨基酸残基143-152、174-186、204-218、233-247和265-278的组的氨基酸序列具有至少80%,优选地至少90%,更优选地95%,最优选地100%的同一性。该组的每个序列对应于表达的、非天然蜘蛛丝蛋白的区段,这些蛋白具有在合适的条件下形成丝结构的能力。因此,在根据本发明的某些实施方案中,每个单独的A区段与选自上述氨基酸区段的氨基酸序列相同。不期望被任何具体的理论束缚,设想根据本发明的A区段形成螺旋结构或β折叠。如下计算遍及本说明书和所附权利要求书使用的术语“%同一性”。使用CLUSTALW算法(Thompson,J.D.,Higgins,D.G.和Gibson,T.J.,NucleicAcidsResearch,22:4673-4680(1994))比对查询序列与靶序列。在对应所比对的序列中的最短序列的窗口上进行对比。对比每个位置的氨基酸残基,并将在靶序列中具有相同对应物的查询序列中的位置的百分比报告为%同一性。如对“%同一性”所描述的计算遍及本说明书和所附权利要求书使用的术语“%相似性”,但以下除外:疏水残基Ala、Val、Phe、Pro、Leu、Ile、Trp、Met和Cys是相似的;碱性残基Lys、Arg和His是相似的;酸性残基Glu和Asp是相似的;且亲水性的、不带电荷的残基Gln、Asn、Ser、Thr和Tyr是相似的。在该上下文中剩余的天然氨基酸Gly不与任何其他氨基酸相似。遍及本说明书,根据本发明的替代实施方案满足相应百分比的相似性,而不是指定百分比的同一性。其他替代实施方案满足指定百分比的同一性以及另一个较高百分比的相似性,选自对于每个序列的优选百分比的同一性的组。例如,某序列可以与另一序列70%相似;或其可以与另一序列70%相同;或其可以与另一序列70%相同且90%相似。此外,已从实验数据推断出每个单独的G区段是12至30个氨基酸残基的氨基酸序列。优选每个单独的G区段由14至23个氨基酸残基组成。每个G区段的至少40%的氨基酸残基是甘氨酸残基。通常,每个单独的G区段的甘氨酸含量在40-60%的范围内。优选每个单独的G区段与选自SEQIDNO:10的氨基酸残基20-42、57-70、84-106、121-134、148-170、184-197、212-234、249-265、280-293、307-329、343-356、371-393、407-420、435-457、471-488、503-516、530-552、567-580、595-617、631-647、662-675、689-711、726-739、753-775、790-803、817-839、854-867、881-903、918-931、946-968、982-998、1014-1027、1043-1059和1074-1092的组的氨基酸序列具有至少80%,优选地至少90%,更优选地95%,最优选地100%的同一性。该组的每个序列对应于EuprosthenopsaustralisMaSp1蛋白质的天然存在的序列的区段,该天然存在的序列从克隆相应的cDNA推断得来,参见WO2007/078239。可选择地,每个单独的G区段与选自SEQIDNO:3的氨基酸残基153-173、187-203、219-232、248-264和279-296的组的氨基酸序列具有至少80%,优选地至少90%,更优选地95%,最优选地100%的同一性。该组的每个序列对应于表达的、非天然蜘蛛丝蛋白的区段,所述蛋白具有在合适的条件下形成丝结构的能力。因此,在根据本发明的某些实施方案中,每个单独的G区段与选自上述氨基酸区段的氨基酸序列相同。在某些实施方案中,根据本发明的每个G区段的前两个氨基酸残基不是-Gln-Gln-。根据本发明的G区段存在三种亚型。该分类基于对EuprosthenopsaustralisMaSp1蛋白质序列的仔细分析(WO2007/078239),并已在构建新颖、非天然蜘蛛丝蛋白中使用并验证了该信息。根据本发明的G区段的第一种亚型由单字母氨基酸共有序列GQG(G/S)QGG(Q/Y)GG(L/Q)GQGGYGQGAGSS(SEQIDNO:11)代表。该第一种且通常不是最长的G区段亚型通常包含23个氨基酸残基,但是可包含少至17个氨基酸残基,且缺少带电荷的残基或包含一个带电荷的残基。因此,优选该第一种G区段亚型包含17-23个氨基酸残基,但设想其可包含少至12个或多至30个氨基酸残基。不期望被任何具体的理论束缚,设想该亚型形成卷曲结构或31-螺旋结构。该第一种亚型的代表性G区段是SEQIDNO:10的氨基酸残基20-42、84-106、148-170、212-234、307-329、371-393、435-457、530-552、595-617、689-711、753-775、817-839、881-903、946-968、1043-1059和1074-1092。在某些实施方案中,根据本发明的该第一种亚型的每个G区段的前两个氨基酸残基不是-Gln-Gln-。根据本发明的G区段的第二种亚型由单字母氨基酸共有序列:GQGGQGQG(G/R)YGQG(A/S)G(S/G)S(SEQIDNO:12)代表。该第二种通常中间尺寸的G区段亚型通常包含17个氨基酸残基且缺少带电荷的残基或包含一个带电荷的残基。优选该第二种G区段亚型包含14-20个氨基酸残基,但设想其可包含少至12个或多至30个氨基酸残基。不期望被任何具体的理论束缚,设想该亚型形成卷曲结构。该第二种亚型的代表性G区段是SEQIDNO:10的氨基酸残基249-265、471-488、631-647和982-998;及SEQIDNO:3的氨基酸残基187-203。根据本发明的G区段的第三种亚型由单字母氨基酸共有序列:G(R/Q)GQG(G/R)YGQG(A/S/V)GGN(SEQIDNO:13)代表。该第三种G区段亚型通常包含14个氨基酸残基,且通常是根据本发明的G区段亚型中最短的。优选该第三种G区段亚型包含12-17个氨基酸残基,但设想其可包含多至23个氨基酸残基。不期望被任何具体的理论束缚,设想该亚型形成转角结构。该第三种亚型的代表性G区段是SEQIDNO:10的氨基酸残基57-70、121-134、184-197、280-293、343-356、407-420、503-516、567-580、662-675、726-739、790-803、854-867、918-931、1014-1027;及SEQIDNO:3的氨基酸残基219-232。因此,在优选的实施方案中,每个单独的G区段与选自SEQIDNO:11、SEQIDNO:12和SEQIDNO:13的氨基酸序列具有至少80%,优选地90%,更优选95%的同一性。在REP部分的A和G区段的交替序列的优选实施方案中,每隔一个G区段具有第一种亚型,而剩余的G区段具有第三种亚型,例如...A1G短A2G长A3G短A4G长A5G短...。在REP部分的另一个优选实施方案中,第二种亚型的一个G区段通过插入而中断G区段的规律性,例如...A1G短A2G长A3G中A4G短A5G长...。每个单独的L区段代表可包含0至20个氨基酸残基,例如0至10个氨基酸残基的任选的接头氨基酸序列。虽然该区段是任选的且对于蜘蛛丝蛋白不是功能上关键的,但是其存在仍允许根据本发明的完全功能性的蜘蛛丝融合蛋白形成蛋白结构。在从Euprosthenopsaustralis的MaSp1蛋白质推断的氨基酸序列的重复部分(SEQIDNO:10)中也存在接头氨基酸序列。特别地,接头区段的氨基酸序列可能与所描述的A或G区段的任何一种相似,但是通常不足以满足本文对其定义的标准。如WO2007/078239中所示的,设置在REP部分的C端部分的接头区段可由富含丙氨酸的单字母氨基酸共有序列ASASAAASAASTVANSVS和ASAASAAA代表。实际上,第二序列可被认为是根据本发明的A区段,而第一序列与根据本发明的A区段具有高度的相似性。根据本发明的接头区段的另一实例具有富含甘氨酸的单字母氨基酸序列GSAMGQGS并与根据本发明的G区段具有高度的相似性。接头区段的另一实例是SASAG。代表性L区段是SEQIDNO:10的氨基酸残基1-6和1093-1110;及SEQIDNO:3的氨基酸残基138-142,但是本领域技术人员将易于认识到存在这些区段的许多合适的替代氨基酸序列。在根据本发明的REP部分的一个实施方案中,L区段中的一个包含0个氨基酸,即缺少L区段中的一个。在根据本发明的REP部分的另一个实施方案中,两个L区段都包含0个氨基酸,即不含这两个L区段。因此,根据本发明的REP部分的这些实施方案可示意性地表示如下:(AG)nL、(AG)nAL、(GA)nL、(GA)nGL;L(AG)n、L(AG)nA、L(GA)n、L(GA)nG;和(AG)n、(AG)nA、(GA)n、(GA)nG。这些REP部分中的任何一种适合与以下定义的任何CT部分一起使用。CT部分是包含70至120个氨基酸残基的蛋白片段,并衍生自蜘蛛丝蛋白的C端片段。表述"衍生自"意指在根据本发明的CT部分的上下文中,它与蜘蛛丝蛋白的C端氨基酸序列具有高度的相似性。如图1中所示,该氨基酸序列在各个物种和蜘蛛丝蛋白,包括MaSp1和MaSp2之间相当保守。以SEQIDNO:9提供了MaSp1和MaSp2的C端区域的共有序列。在图1中,比对了以GenBank登记条目(如果可用)表示的下列MaSp蛋白质:表1–拖丝蛋白CT部分哪种特定的CT部分存在于根据本发明的蜘蛛丝蛋白中不是关键的,只要该CT部分没有完全缺失。因此,根据本发明的CT部分可选自图1和表1中示出的氨基酸序列或具有高度相似性的序列中的任何一种。多种多样的C端序列可用在根据本发明的蜘蛛丝蛋白中。根据本发明的CT部分的序列与基于图1的氨基酸序列的共有氨基酸序列SEQIDNO:9具有至少50%的同一性,优选地至少60%,更优选地至少65%的同一性,或甚至至少70%的同一性。根据本发明的代表性的CT部分是Euprosthenopsaustralis序列SEQIDNO:7。因此,根据本发明的一个优选方面,CT部分与SEQIDNO:7或图1和表1中的任何单独的氨基酸序列具有至少80%、优选地至少90%、例如至少95%的同一性。在本发明的优选方面中,CT部分与SEQIDNO:7或图1和表1中的任何单独的氨基酸序列相同。CT部分通常由70至120个氨基酸残基组成。优选CT部分包含至少70、或多于80、优选地多于90个氨基酸残基。还优选CT部分包含至多120、或少于110个氨基酸残基。典型的CT部分包含约100个氨基酸残基。任选的NT部分是包含100至160个氨基酸残基的蛋白片段,并衍生自蜘蛛丝蛋白的N端片段。表述"衍生自"意指在根据本发明的NT部分的上下文中,它与蜘蛛丝蛋白的N端氨基酸序列具有高度的相似性。如图2中所示,该氨基酸序列在各个物种和蜘蛛丝蛋白,包括MaSp1和MaSp2之间相当保守。在图2中,比对了以GenBank登记条目(如果可用)表示的以下拖丝蛋白NT部分:表2-拖丝蛋白NT部分对每个序列显示仅对应N端部分的部分,省略了信号肽。Ncflag和NImflag根据RisingA.等人.Biomacromolecules7,3120-3124(2006)翻译和编辑。哪种特定的NT部分存在于根据本发明的蜘蛛丝蛋白中不是关键的。因此,根据本发明的NT部分可选自图2中示出的氨基酸序列或具有高度相似性的序列中的任何一种。多种多样的N端序列可用在根据本发明的蜘蛛丝蛋白中。基于图2的同源序列,以下序列构成共有NT氨基酸序列:QANTPWSSPNLADAFINSF(M/L)SA(A/I)SSSGAFSADQLDDMSTIG(D/N/Q)TLMSAMD(N/S/K)MGRSG(K/R)STKSKLQALNMAFASSMAEIAAAESGG(G/Q)SVGVKTNAISDALSSAFYQTTGSVNPQFV(N/S)EIRSLI(G/N)M(F/L)(A/S)QASANEV(SEQIDNO:8).根据本发明的NT部分的序列与共有氨基酸序列SEQIDNO:8(其基于图2的氨基酸序列)具有至少50%的同一性、优选至少60%的同一性。在优选的实施方案中,根据本发明的NT部分的序列与共有氨基酸序列SEQIDNO:8具有至少65%的同一性、优选至少70%的同一性。在优选的实施方案中,根据本发明的NT部分进一步地与共有氨基酸序列SEQIDNO:8具有70%、优选80%的相似性。根据本发明的代表性NT部分是Euprosthenopsaustralis序列SEQIDNO:6。根据本发明的优选实施方案,NT部分与SEQIDNO:6或图1中的任何单独的氨基酸序列具有至少80%同一性。在本发明的优选实施方案中,NT部分与SEQIDNO:6或图2中的任何单独的氨基酸序列具有至少90%、诸如至少95%的同一性。在本发明的优选实施方案中,NT部分与与SEQIDNO:6或图1中的任何单独的氨基酸序列、尤其是与EaMaSp1相同。NT部分包含100至160个氨基酸残基。优选NT部分包含至少100、或多于110、优选地多于120个氨基酸残基。还优选NT部分包含至多160、或少于140个氨基酸残基。典型的NT部分包含大约130-140个氨基酸残基。B部分是包含多于30个氨基酸残基的蛋白或多肽片段。B部分优选地包含多于40个氨基酸残基,诸如多于50个氨基酸残基。B部分优选地包含少于500个氨基酸残基,诸如少于200个氨基酸残基、更优选地少于100个氨基酸残基,诸如少于100个氨基酸残基。其能够与有机靶选择性相互作用,且融合蛋白中是B部分提供与有机靶选择性相互作用的能力。B部分是非拖丝蛋白部分。这是意指,其不是衍生自蜘蛛丝蛋白,即,其与蜘蛛丝蛋白具有低(或无)程度的同一性和/或相似性。根据本发明的B部分的序列优选地与本文公开的拖丝蛋白氨基酸序列的任一种、具体地与SEQIDNO:6-10的任一种具有少于30%同一性、诸如少于20%同一性、优选地少于10%同一性。选择B部分被认为是在本领域普通技术人员能力范围内的。然而,以下为了示例起见,提供了可证明用作B部分的亲和配体的实例、以及用于检测和/或定量的形式和条件的实例。选择亲和配体所需的生物分子多样性可通过组合改造多个可能的支架分子之一来产生,然后利用适当的选择平台选择特异性和/或选择性亲和配体。可用于针对有机靶产生亲和配体的此类结构的非限制性实例是葡萄球菌蛋白A和其结构域、和这些结构域的衍生物,诸如Z结构域(NordK等人.(1997)Nat.Biotechnol.15:772-777);脂笼蛋白(BesteG等人.(1999)Proc.Natl.Acad.Sci.U.S.A.96:1898-1903);锚蛋白重复结构域(BinzHK等人.(2003)J.Mol.Biol.332:489-503);纤维素结合结构域(CBD)(SmithGP等人.(1998)J.Mol.Biol.277:317-332;LehtioJ等人.(2000)Proteins41:316-322);γ晶体蛋白(crystallines)(FiedlerU和RudolphR,WO01/04144);绿色荧光蛋白(GFP)(PeelleB等人.(2001)Chem.Biol.8:521-534);人类细胞毒性T淋巴细胞相关抗原4(CTLA-4)(HuftonSE等人.(2000)FEBSLett.475:225-231;IrvingRA等人.(2001)J.Immunol.Meth.248:31-45);蛋白酶抑制剂,诸如Knottin蛋白(WentzelA等人.(2001)J.Bacteriol.183:7273-7284;BaggioR等人.(2002)J.Mol.Recognit.15:126-134)和Kunitz结构域(RobertsBL等人.(1992)Gene121:9-15;DennisMS和LazarusRA(1994)J.Biol.Chem.269:22137-22144);PDZ结构域(SchneiderS等人.(1999)Nat.Biotechnol.17:170-175);肽适体,诸如硫氧还蛋白(LuZ等人.(1995)Biotechnology13:366-372;KlevenzB等人.(2002)Cell.Mol.LifeSci.59:1993-1998);葡萄球菌核酸酶(NormanTC等人.(1999)Science285:591-595);淀粉酶抑肽(McConellSJ和HoessRH(1995)J.Mol.Biol.250:460-479;LiR等人.(2003)ProteinEng.16:65-72);基于纤连蛋白III型结构域的trinectins(KoideA等人.(1998)J.Mol.Biol.284:1141-1151;XuL等人.(2002)Chem.Biol.9:933-942);和锌指(BianchiE等人.(1995)J.Mol.Biol.247:154-160;KlugA(1999)J.Mol.Biol.293:215-218;SegalDJ等人.(2003)Biochemistry42:2137-2148)。上述实例包括展现用于产生新的结合特异性的单个随机化环的支架蛋白,具有其中从蛋白表面突出的侧链被随机化以产生新的结合特异性的刚性二级结构的蛋白支架,和展现用于产生新的结合特异性的非连续高变性环区的支架。寡核苷酸也可用作亲和配体。称为适体或诱饵(decoy)的单链核酸,折叠为充分确定的三维结构并以高的亲和性和特异性结合其靶。(EllingtonAD和SzostakJW(1990)Nature346:818-822;BrodyEN和GoldL(2000)J.Biotechnol.74:5-13;MayerG和JenneA(2004)BioDrugs18:351-359)。寡核苷酸配体可以是RNA或DNA,并可结合宽范围的靶分子种类。对于从上述支架结构的任一种的变体池选择期望的亲和配体,大量选择平台可用于分离针对所选靶蛋白的特定新配体。筛选平台包括但不限于,噬菌体展示(SmithGP(1985)Science228:1315-1317)、核糖体展示(HanesJ和PltickthunA(1997)Proc.Natl.Acad.Sci.U.S.A.94:4937-4942)、酵母双杂交系统(FieldsS和Song0(1989)Nature340:245-246)、酵母展示(GaiSA和WittrupKD(2007)CurrOpinStructBiol17:467-473)、mRNA展示(RobertsRW和SzostakJW(1997)Proc.Natl.Acad.Sci.U.S.A.94:12297-12302)、细菌展示(DaughertyPS(2007)CurrOpinStructBiol17:474-480,KronqvistN等人.(2008)ProteinEngDesSel1-9,HarveyBR等人.(2004)PNAS101(25):913-9198)、微珠展示(NordO等人.(2003)JBiotechnol106:1-13,WO01/05808)、SELEX(配体指数富集的系统进化(SystemEvolutionofLigandsbyExponentialEnrichment))(TuerkC和GoldL(1990)Science249:505-510)和蛋白片段互补检验(PCA)(RemyI和MichnickSW(1999)Proc.Natl.Acad.Sci.U.S.A.96:5394-5399)。对免疫球蛋白、白蛋白或其他有机靶具有亲和性的B部分的优选的组是细菌receptin结构域或其衍生物。优选的B部分的组能够与免疫球蛋白和包含免疫球蛋白或其衍生物的分子选择性相互作用。免疫球蛋白亚类的优选的组是被衍生自葡萄球菌蛋白A的Z结构域识别的亚类,即,来自人类的IgG1、IgG2、IgG4、IgA和IgM、来自兔和牛的所有Ig亚类、来自豚鼠的IgG1和IgG2、和来自小鼠的IgG1、IgG2a、IgG2b、IgG3和IgM(参见Hober,S.等人,J.ChromatogrB.848:40-47(2007))、更优选地来自人类的免疫球蛋白亚类IgG1、IgG2、IgG4、IgA和IgM。免疫球蛋白亚类的另一优选的组是被C2结构域链球菌蛋白G识别的亚类;即,IgG的所有人类亚类,包括IgG3、和来自多种动物,包括小鼠、兔和绵羊的IgG。优选的B部分的一个组选自以下组成的组:衍生自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A和其结构域,优选地E、D、A、B或C结构域、链球菌蛋白G和其结构域,优选地C1、C2和C3结构域;和与这些氨基酸序列的任一种具有至少70%同一性、诸如至少80%同一性、或至少90%同一性的蛋白片段。优选地,B部分选自以下组成的组:衍生自葡萄球菌蛋白A的Z结构域、葡萄球菌蛋白A的B结构域、和链球菌蛋白G的C2结构域;和与这些氨基酸序列的任一种具有至少70%同一性、诸如至少80%同一性、或至少90%同一性的蛋白片段。优选地,B部分选自以下组成的组:衍生自葡萄球菌蛋白A的Z结构域、和与这一氨基酸序列具有至少70%同一性、诸如至少80%同一性、或至少90%同一性的蛋白片段。优选地,B部分选自以下组成的组:衍生自葡萄球菌蛋白A的Z结构域和链球菌蛋白G的C2结构域,参见例如,实施例1-6和8。对免疫球蛋白具有亲和性的B部分的优选的组是细菌receptin结构域或其衍生物。优选的B部分的另一组能够与白蛋白和包含白蛋白或其衍生物的分子选择性相互作用。对白蛋白具有亲和性的B部分的优选的组是细菌receptin结构域或其衍生物。优选的B部分选自链球菌蛋白G、链球菌蛋白G的白蛋白结合结构域、来自大芬戈尔德菌(Finegoldiamagna)的GA模块;和与这些氨基酸序列的任一种具有至少70%同一性、诸如至少80%同一性、或至少90%同一性的蛋白片段。优选地,B部分选自链球菌蛋白G的白蛋白结合结构域、和与其具有至少70%同一性、诸如至少80%同一性、或至少90%同一性的蛋白片段。优选地,B部分是链球菌蛋白G的白蛋白结合结构域,参见例如,实施例7。优选的B部分的另一组能够与生物素和包含生物素或其衍生物或类似物的分子选择性相互作用。优选的B部分选自以下组成的组:链霉亲和素、单体链霉亲和素(M4);和与这些氨基酸序列的任一种具有至少70%同一性、诸如至少80%同一性、或至少90%同一性的蛋白片段。优选地,B部分是单体链霉亲和素(M4),参见例如,实施例10-12。根据本发明的具体融合蛋白和蛋白结构在实施例中提供。这些优选的融合蛋白形成由SEQIDNO14、16、18、22、24和26组成的组。另外优选的融合蛋白与这些序列的任一种具有至少80%、优选地至少90%、更优选地至少95%的同一性。本发明还提供编码根据本发明的融合蛋白的分离的多核酸。具体地,具体的多核酸在实施例和所附的序列表中提供,例如,SEQIDNO15、17、19、23、25和27。另外优选的多核酸编码与SEQIDNO14、16、18、22、24和26的任一种具有至少80%、优选地至少90%、更优选地至少95%的同一性的融合蛋白。根据本发明的多核酸可用于产生根据本发明的融合蛋白。本发明提供了制备融合蛋白的方法。第一步骤包括在合适的宿主中表达根据本发明的融合蛋白。合适的宿主是本领域技术人员熟知的且包括,例如细菌和真核细胞,例如酵母、昆虫细胞系和哺乳动物细胞系。通常,该步骤包括在大肠杆菌中表达编码该融合蛋白的多核酸分子。方法的第二步骤包括获得包含该融合蛋白的混合物。混合物可例如通过裂解或机械破坏宿主细胞获得。如果宿主细胞分泌融合蛋白,还可通过收集细胞培养基获得混合物。可使用标准方法分离由此获得的蛋白质。如需要的话,该混合物可进行离心,并收集合适的部分(沉淀或上清液)。包含融合蛋白的混合物还可进行凝胶过滤、层析例如阴离子交换层析、透析、相分离或过滤以导致分离。任选地,脂多糖和其他热原在该阶段被有效地去除。如需要的话,可在该步骤中通过裂解去除接头肽。根据本发明的蛋白结构在适当的条件下从根据本发明的融合蛋白自发地组装,并且组装为聚合物由剪切力和/或两个不同相之间的界面的存在而促进,所述界面例如,固相与液相之间、气相与液相之间、或在疏水/亲水界面,例如,矿物油-水界面。所得的界面的存在刺激在界面或在界面周围区域中聚合,该区域延伸进入液体介质,从而所述聚合在所述界面或在所述界面区域中开始。通过修改组装期间的条件,可产生多种蛋白结构。例如,如果允许组装在从一侧向一侧轻微摆动的容器中发生,则在空气-水界面形成纤维。如果允许混合物静置,则在空气-水界面形成膜。如果蒸发混合物,则在容器底部形成膜。如果向含水混合物的顶部加入油,则在油-水界面形成膜,无论允许静置或摆动。如果混合物起泡沫,例如,通过鼓入空气或甩动,如果允许干燥,则泡沫是稳定的并固化如此,本发明提供用于提供展示对有机靶的结合活性的蛋白结构的方法。在第一方法步骤中,提供了根据本发明的重组融合蛋白。融合蛋白可例如,通过在适当的宿主中从根据本发明的多核酸表达来提供。在第二方法步骤中,对融合蛋白进行实现形成包含重组融合蛋白的聚合物的条件。注意,尽管自发地组装的蛋白结构可在六氟异丙醇中溶解,溶解的融合蛋白随后不能够自发地再次组装为例如,纤维。蛋白结构可用作固定有机靶的亲和性介质的部分,其中B部分能够与该有机靶选择性相互作用。样品,例如,生物样品可施加到能够结合该生物样品中存在的有机靶的根据本发明的融合蛋白或蛋白结构,然后融合蛋白或蛋白结构可用于从样品分离有机靶。可对已经从受治疗者取出的生物样品,诸如血液、血清或血浆进行有机靶的检测、分离和/或定量。如此,本发明提供从样品分离有机靶的方法。提供了包含有机靶的样品,例如,生物样品,诸如血液、血清或血浆。生物样品可以是较早获得的样品。如果在方法中使用较早获得的样品,方法的步骤都不是对人类或动物体进行的。提供了根据本发明的亲和性介质,其包含根据本发明的融合蛋白或蛋白结构。在某些实施方案中,亲和性介质由根据本发明的融合蛋白或蛋白结构组成。亲和性介质能够借助根据本发明的融合蛋白中的B部分与有机靶选择性相互作用。在实现亲和性介质与有机靶之间结合的适当条件下将亲和性介质与样品接触。在保持亲和性介质与有机靶之间选择性结合的适当条件下除去未结合的样品。这一方法导致有机靶被固定于根据本发明的亲和性介质,具体地被固定于融合蛋白。在根据本发明的优选的方法中,当亲和性介质与样品接触以实现亲和性介质与有机靶之间的结合时,亲和性介质中的融合蛋白作为根据本发明的蛋白结构存在。在这一方面,特别有用的蛋白结构是膜或纤维,其中B部分是衍生自葡萄球菌蛋白A的Z结构域或与其具有至少70%同一性,诸如至少80%同一性、或至少90%同一性的蛋白片段,参见例如,实施例1-6。膜是有利的,因为其粘附于固体结构,例如,微量滴定板中的塑料制品。膜的这一特征有助于洗涤和再生程序,对于分离目的是非常有用的。已经令人惊讶地观察到,当作为根据本发明的蛋白结构中的根据本发明的融合蛋白的部分时,Z结构域的碱稳定性可甚至被增强。这一特征对于洗涤和再生目的可以是非常有用的,例如,允许高浓度的NaOH,诸如0.1M、0.5M、1M或甚至高于1M,例如,2M,和/或允许高浓度的脲,例如,6-8M。化学稳定性还可用于允许为了亲和纯化反复周期地使用Z结构域。这一碱稳定性可通过利用Z结构域的稳定的突变体来进一步增加。另外,已经有利地显示,包括Z结构域的根据本发明的融合蛋白是热稳定的。这允许加热灭菌并保持结合能力。具有Z结构域的传统亲和性基质的一个已知问题是Z结构域从亲和性基质的泄漏。由于Z结构域被肽键稳定地掺入本发明的融合蛋白中,预计Z结构域从根据本发明的蛋白结构的不期望的泄露是低的或不存在。根据本发明的融合蛋白的另一优点是,所得的蛋白结构具有高密度的Z结构域(或其他B部分)。预计这一高密度提供高结合能力。总之,融合蛋白的这些特征对于多种B部分是非常有吸引力的,尤其是对于以良好的生产经济使用蛋白Z的亲和纯化。这些特征在以传统凝胶珠亲和柱以外的形式也是有用的,例如,以滤器样的形式。固定的有机靶能够与第二有机靶选择性相互作用。然后该方法还包括在实现第一和第二有机靶之间的结合的适当条件下,将所述亲和性介质和固定的有机靶与第二有机靶接触的步骤,第二有机靶能够与第一有机靶选择性相互作用。固定的有机靶是可检测和/或可定量的。有机靶的检测和/或定量可以以本领域技术人员已知用于检测和/或定量结合试剂的任何方式、以基于多种生物或非生物相互作用的检验实现。有机靶本身可以用多种标志物标记,或可转而由第二、标记的亲和配体检测以允许检测、可视化和/或定量。这可使用许多标记的任何一种或多种实现,所述标记可与有机靶或任何第二亲和配体轭合,使用本领域技术人员已知的许多技术的任何一种或多种实现,如此不牵涉任何过度的实验。可与有机靶和/或第二亲和配体轭合的标记的非限制性实例包括,荧光染料或金属(例如,荧光素、罗丹明、藻红蛋白、荧光胺)、发色染料(例如,视紫质)、化学发光化合物(例如,鲁米那、咪唑)和生物发光蛋白(例如,萤光素、萤光素酶)、半抗原(例如,生物素)。多种其他可用的荧光剂和发色团描述在StryerL(1968)Science162:526-533,BrandL和GohlkeJR(1972)Annu.Rev.Biochem.41:843-868。有机靶和/或第二亲和配体还可用酶(例如,辣根过氧化物酶、碱性磷酸酶、β-内酰胺酶)、放射性同位素(例如,3H、14C、32P、35S或125I)和颗粒(例如,金)标记。在本公开内容的上下文中,"颗粒"是指适于标记分子的颗粒,诸如金属颗粒。另外,亲和配体还可用荧光半导体纳米晶体(量子点)标记。量子点具有极佳的量子产量,比有机荧光团更耐光,因此更容易检测(Chan等人.(2002)CurrOpiBiotech.13:40-46)。不同类型的标记可使用多种化学反应轭合于有机靶或第二亲和配体,例如,胺反应或硫醇反应。然而,可使用胺和硫醇以外的其他反应基团,例如,醛、羧酸和谷氨酰胺。如果检测和/或定量包括暴露于第二有机靶或第二亲和配体,再次用缓冲液洗涤亲和性介质以除去未结合的第二亲和配体。举例来说,第二亲和配体可以是抗体或其片段或衍生物。之后,可以用常规方法检测和/或定量有机靶。对第二亲和配体的结合特征可以变化,但本领域技术人员将能够通过常规实验确定对每种确定有效和最佳的检验条件。标记的分子的检测、定位和/或定量可包括可视化技术,诸如光显微术或免疫荧光显微术。其他方法可包括经由流式细胞术或发光测定法检测。标记可视化的方法可包括但不限于,荧光测定、发光测定和/或酶促技术。荧光通过如下检测和/或定量:将荧光标记暴露于特定波长的光,之后检测和/或定量特定波长区域中的发射光。发光标记的分子的存在可由在化学反应期间发生的发光检测和/或定量。酶反应的检测是由于化学反应导致的样品的色移。本领域技术人员知晓,为了适当的检测和/或定量,可修改多种不同的实验方案。用于检测和/或定量有机靶的一种可得的方法是通过将其或第二亲和配体与酶连接,随后可在酶免疫测定(诸如EIA或ELISA)中检测和/或定量该酶。此类技术是充分建立的,其实现对本领域技术人员不产生任何过度的困难。在此类方法中,将生物样品与结合有机靶的根据本发明的蛋白结构接触,然后用酶促标记的第二亲和配体检测和/或定量。之后,在适当的缓冲液中,将适当的底物与酶促标记反应产生化学部分,例如使用分光光度计、荧光计、光度计或通过可见手段检测和/或定量。有机靶或第二亲和配体可用放射性同位素标记以使得能够检测和/或定量。本公开内容中适当的放射性标记的非限制性实例是3H、14C、32P、35S或125I。标记的亲和配体的比活性依赖于放射性标记的半衰期、同位素纯度,和标记如何被掺入亲和配体。亲和配体优选地使用公知技术标记(WenselTG和MearesCF(1983)于:RadioimmunoimagingandRadioimmunotherapy(BurchielSW和RhodesBA编著)Elsevier,NewYork,pp185-196中)。如此放射性标记的亲和配体可用于通过检测放射性显现有机靶。放射性核素扫描可用以下进行,例如,γ射线照相机、磁共振光谱学、发射断层照相术、γ射线/β射线计数器、闪烁计数器和放射照相术。如此,可向蛋白结构施加样品以检测、分离和/或定量有机靶。这一程序使得能够不仅检测有机靶,而且另外可显示其分布和相对水平。任选地,可从亲和性介质释放有机靶并收集。如此,用途可包括在其上已经固定有机靶的亲和性介质上亲和纯化。蛋白结构可例如布置在柱中或多孔板(诸如96孔板)中、或在磁珠、琼脂糖珠或sepharose珠上。另外,用途可包括蛋白结构在可溶基质上的用途,例如使用葡聚糖基质,或在表面等离子共振仪器诸如BiacoreTM仪器中的用途,其中分析可例如包括监测对固定的有机靶或多种可能的亲和配体的亲和性。根据本发明的蛋白结构可被洗涤并用多种清洁剂,包括酸、碱和离液剂再生。尤其有用的清洁剂包括NaOH,诸如0.1、0.5或1MNaOH,和脲,诸如6-8M脲。由于根据本发明的蛋白结构令人惊讶地耐受化学处理和/或灭菌性热处理,包括使用蛋白结...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 一种抗CD24人源化抗体融合蛋白的制造方法与工艺
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 一种融合蛋白表达纯化方法与制造工艺
- 抗USP2a蛋白单克隆抗体杂交瘤细胞及其产生的抗USP2a单克隆抗体和应用的制造方法与工艺
- 与癌症相关的基因融合体和基因变异体的制造方法与工艺
- 包含邻近氨基酸端的志贺毒素A亚基效应子区和细胞靶向性免疫球蛋白型结合区的蛋白的制造方法与工艺
- 杀虫融合蛋白改进的制造方法与工艺
- vin‑cdtb在大肠杆菌中的表达和制备的制造方法与工艺
- 一种抗肿瘤侵袭转移的多靶点融合蛋白的制备及用途的制造方法与工艺
- 重组人成纤维细胞生长因子21融合蛋白及其在制备治疗代谢疾病药物中的应用的制造方法与工艺