TaGPI1mS543A蛋白及其编码基因和应用的制作方法
本发明涉及一种TaGPI1mS543A蛋白及其编码基因和应用。
背景技术:
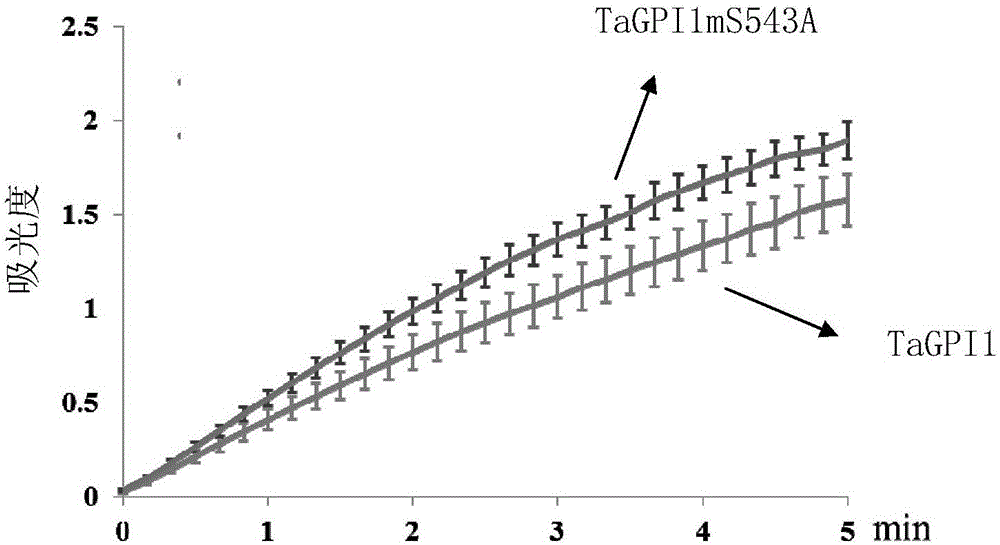
:植物淀粉是一类最初在植物叶绿体中合成、最终在其他异养器官(如种子、根、果实等)贮存的高聚化、非水溶性的碳水化合物。它为地球上异氧生物提供了主要的碳源和能量源;对人类来讲,它是我们必不可少的食物和能量来源。与此同时,淀粉还被广泛的应用于医疗、能源、化工、建筑、材料等多种行业之中,可以说淀粉生产和应用与我们的生活息息相关。6-磷酸葡萄糖异构酶(简称GPI)是植物淀粉合成、代谢途径中的关键酶,它可逆的催化了6-磷酸葡萄糖和6-磷酸果糖的相互转变。在叶绿体中,作为淀粉合成途径的关键酶,它催化了6-磷酸果糖到6-磷酸葡萄糖的生化反应。6-磷酸果糖是卡尔循环重要的终产物之一,而6-磷酸葡萄糖是淀粉合成代谢、糖代谢中的重要中间产物。6-磷酸葡萄糖异构酶是连接卡尔文循环、淀粉合成代谢、糖代谢的重要蛋白(酶)。PGI既存在于质体中,又定位在胞质之中,质体PGI突变后,植物表现为叶片淀粉合成明显减少,生长缓慢等表型,而胞质PGI突变后,植物生长受阻、叶片淀粉明显积累、生殖生长受到严重干扰等表型,因此两种类型的PGI对植物都是十分重要的。在动物中,大量的研究表明它参与了人类能量代谢相关的多种疾病的发生过程。技术实现要素:本发明的目的是提供一种TaGPI1mS543A蛋白及其编码基因和应用。本发明提供了一种蛋白质(命名为TaGPI1mS543A蛋白),是将6-磷酸葡萄糖异构酶蛋白第543位丝氨酸突变为丙氨酸得到的。所述TaGPI1mS543A蛋白是如下(a1)或(a2):(a1)由序列表中序列4所示的氨基酸序列组成的蛋白质;(a2)将序列4的氨基酸序列经过除第543位氨基酸残基以外的一个或几个氨基酸残基的取代和/或缺失和/或添加且与具有相同功能的由序列4衍生的蛋白质。所述6-磷酸葡萄糖异构酶蛋白是如下(a3)或(a4):(a3)由序列表中序列2所示的氨基酸序列组成的蛋白质;(a4)将序列2的氨基酸序列经过除第543位氨基酸残基以外的一个或几个氨基酸残基的取代和/或缺失和/或添加且与具有相同功能的由序列2衍生的蛋白质。为了使(a1)中的蛋白质便于纯化和检测,可在由序列表中序列4所示的氨基酸序列组成的蛋白质的氨基末端或羧基末端连接上如表1所示的标签。表1标签的序列标签残基序列Poly-Arg5-6(通常为5个)RRRRRPoly-His2-10(通常为6个)HHHHHHFLAG8DYKDDDDKStrep-tagII8WSHPQFEKc-myc10EQKLISEEDL上述(a2)中的蛋白质可人工合成,也可先合成其编码基因,再进行生物表达得到。本发明还保护编码权利要求1所述蛋白质的基因。将所述基因命名为TaGPI1mS543A基因。所述基因为如下(b1)-(b3)中任一所述的DNA分子:(b1)编码区如序列表中序列3所示的DNA分子;(b2)在严格条件下与(b1)限定的DNA序列杂交且编码所述蛋白质的DNA分子;(b3)与(b1)或(b2)限定的DNA序列具有90%以上同源性且编码所述蛋白质的DNA分子。上述严格条件可为用0.1×SSPE(或0.1×SSC),0.1%SDS的溶液,在DNA或者RNA杂交实验中65℃下杂交并洗膜。本发明还保护含有TaGPI1mS543A基因的重组表达载体、表达盒或重组菌。所述重组表达载体具体可为在pHUE载体的多克隆位点(例如SacII和KpnI酶切位点间)插入序列表的序列3所示的双链DNA分子得到的重组质粒。本发明还保护TaGPI1mS543A蛋白的应用,为如下(c1)-(c6)中至少一种:(c1)作为6-磷酸葡萄糖异构酶;(c2)催化6-磷酸果糖转化为6-磷酸葡萄糖;(c3)催化6-磷酸葡萄糖转化为6-磷酸果糖;(c4)以6-磷酸果糖为原料制备6-磷酸葡萄糖酸;(c5)促进植物淀粉的合成;(c6)提高植物光合效力。本发明还保护一种重组菌,是将TaGPI1mS543A基因导入宿主菌中得到的。所述TaGPI1mS543A基因可通过含有TaGPI1mS543A基因的重组表达载体导入宿主菌得到重组菌。所述重组表达载体具体可为将pHUE载体的SacII和KpnI酶切位点间插入了序列表的序列3所示的双链DNA分子得到的重组质粒。所述宿主菌可为大肠杆菌,具体可为大肠杆菌BL21(DE3)。本发明还保护一种6-磷酸葡萄糖异构酶的制备方法,包括如下步骤:培养所述重组菌,从重组菌中得到6-磷酸葡萄糖异构酶。所述“从重组菌中得到6-磷酸葡萄糖异构酶”具体可包括步骤(d1)和(d2):(d1)破碎所述重组菌菌体,得到含有6-磷酸葡萄糖异构酶的粗提液;(d2)分离所述粗提液中的6-磷酸葡萄糖异构酶并去除His-Ub融合标签,得到6-磷酸葡萄糖异构酶。所述分离所述粗提液中的6-磷酸葡萄糖异构酶可采用亲和层析的方法对所述粗提液中的6-磷酸葡萄糖异构酶进行纯化,具体可采用Ni-NTA亲和层析柱进行纯化。所述纯化还包括将蛋白液进行透析处理。所述透析的步骤具体可为使用dialysisbuffer(20mMTris-HCL,pH8.0、100mMNaCl)透析过夜。所述去除His-Ub融合标签具体可为采用Usp2-cc蛋白酶对蛋白液进行酶切。所述酶切的步骤具体可为4℃酶切24小时。每1mg蛋白液加入20UUsp2-cc蛋白酶。本发明还保护所述重组菌或所述方法在制备6-磷酸葡萄糖异构酶产品中的应用。本发明还保护一种组合物,包括所述蛋白质和6-磷酸葡萄糖脱氢酶;所述组合物的用途为制备6-磷酸葡萄糖酸或催化6-磷酸果糖到6-磷酸葡萄糖酸的生化反应。所述组合物还包括6-磷酸果糖。所述组合物还包括NADP。所述组合物还包括双甘氨肽和MgCl2。所述蛋白质、6-磷酸葡萄糖脱氢、6-磷酸果糖、NADP、双甘氨肽和MgCl2的配比具体可为3.8U∶0.008U∶0.011μmol∶0.0022μmol∶0.7μmol∶0.011μmol。以上任一所述6-磷酸果糖具体可为D-6-磷酸果糖。本发明提供了一种TaGPI1mS543A蛋白及其编码基因和应用。实验证明,本发明的TaGPI1mS543A蛋白具有6-磷酸葡萄糖异构酶的活性,并且酶活力较现有的6-磷酸葡萄糖异构酶显著提高。本发明有望被用于实际的生产实践以提高植物光合效力及淀粉的合成能力,具有非常广阔的应用前景。附图说明图1为TaGPI1和TaGPI1mS543A蛋白纯化过程中收集样品的SDS-PAGE检测结果。图2为TaGPI1和TaGPI1mS543A蛋白酶活力检测曲线。具体实施方式以下的实施例便于更好地理解本发明,但并不限定本发明。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的试验材料,如无特殊说明,均为自常规生化试剂商店购买得到的。以下实施例中的定量试验,均设置三次重复实验,结果取平均值。小偃54小麦:参考文献:陈海莲,王剑环,王新芳,等.小偃54小麦的抗逆性表现[J].气象与环境科学,2005(2):28-30.;公众可以从中国科学院遗传与发育生物学研究所获得。pHUE载体:参考文献:CatanzaritiA,SobolevaTA,JansDA,etal.Anefficientsystemforhigh-levelexpressionandeasypurificationofauthenticrecombinantproteins[J].ProteinScience,2004,13(5):1331-1339.;公众可以从中国科学院遗传与发育生物学研究所获得。大肠杆菌BL21(DE3):天根生化科技(北京)有限公司,产品目录号:CB105-02。Usp2-cc蛋白酶:北京毅事合生物科技有限公司,货号:G11502。Ni-NTA亲和层析柱:Merck(Novagen),货号:70666。双甘氨肽:Sigma,货号:G-1002。D-6-磷酸果糖:Sigma,货号:F-3627。NADP:Sigma,货号:0505。MgCl2:Sigma,货号:M-0250。6-磷酸葡萄糖脱氢酶:Sigma,货号:G-6378。实施例1、TaGPI1mS543A蛋白及其编码基因的获得对各物种中6-磷酸葡萄糖异构酶(GPI)进行序列分析和功能验证,从小麦中发现一种蛋白质,将其命名为TaGPI1蛋白。TaGPI1蛋白的编码基因如序列表的序列1所示,编码序列表的序列2所示的蛋白质。将序列2所示的蛋白第543位丝氨酸突变为丙氨酸,将突变后得到的蛋白命名为TaGPI1mS543A蛋白。TaGPI1mS543A蛋白的编码基因如序列表的序列3所示,编码序列表的序列4所示的蛋白质。实施例2、小麦TaGPI1蛋白及TaGPI1mS543A蛋白的克隆及原核表达载体的构建1、提取小偃54小麦的总RNA,并反转录为cDNA。2、以步骤1得到的cDNA为模板,采用引物pHUE-TaGPI1-For和引物pHUE-TaGPI1-rev进行PCR扩增,得到扩增产物。pHUE-TaGPI1-For:5′-TCCCCGCGGTGGTATGGCGTCGCCGGC-3′;pHUE-TaGPI1-rev:5′-GGGGTACCTTACACTTTTGGAAGCACTGTTGTGTC-3′。pHUE-TaGPI1-For和pHUE-TaGPI1-rev中,下划线分别标注SacII和KpnI酶切位点。3、用限制性内切酶SacII和KpnI双酶切步骤2的PCR扩增产物,回收酶切产物。4、用限制性内切酶SacII和KpnI双酶切pHUE载体,回收约5927bp的载体骨架。5、将步骤3的酶切产物和步骤4的载体连接,得到重组载体pHUE-TaGPI1。根据测序结果,对重组载体pHUE-TaGPI1进行结构描述如下:将pHUE载体的SacII和KpnI酶切位点之间的小片段取代为了序列表的序列1的自5′端第1-1704位核苷酸所示的DNA分子。序列1所示的DNA分子编码序列2所示的蛋白质。6、以步骤5得到的重组载体pHUE-TaGPI1为模板,采用引物pHUE-TaGPI1mS543A-For和引物pHUE-TaGPI1mS543A-rev进行PCR定点突变(方法参照文献:Fisher,C.L.,andPei,G.K.(1997).ModificationofaPCR-basedsite-directedmutagenesismethod.Biotechniques23,570-574.),得到重组载体pHUE-TaGPI1mS543A。pHUE-TaGPI1mS543A-For:5′-CGAGGGCTTCAACCCCAGCGCGGCAAGTTTGCT-3′;pHUE-TaGPI1mS543A-rev:5′-GCTGGGGTTGAAGCCCTCGACGGGCTTTCC-3′。根据测序结果,对重组载体pHUE-TaGPI1mS543A进行结构描述如下:将pHUE载体的SacII和KpnI酶切位点之间的小片段取代为了序列表的序列3的自5′端第1-1704位核苷酸所示的DNA分子。序列3所示的DNA分子编码序列4所示的蛋白质。(序列2和序列4只有第543位氨基酸不同,其余氨基酸相同;序列2第543位氨基酸为丝氨酸,序列4第543位氨基酸为丙氨酸)。实施例3、小麦TaGPI1蛋白及TaGPI1mS543A蛋白体外表达和纯化将实施例2得到的重组载体pHUE-TaGPI1和重组载体pHUE-TaGPI1mS543A分别进行如下步骤:1、将重组载体转化大肠杆菌BL21(DE3),得到重组菌,将重组菌接种至50mlLB液体培养基(氨苄抗性:100μg/ml)中,37℃、220rpm/min震荡培养过夜。2、将20ml步骤1得到的菌液转接到1L新鲜LB液体培养基中,继续37℃、220rpm震荡培养至菌液OD600nm=0.8-1.0,向菌液中加入IPTG并使其在体系中的浓度为0.1mM,16℃、220rpm/min诱导24小时,诱导结束后4000rpm/min离心收集菌体。3、按照如下步骤进行蛋白纯化:(1)用Ni-NTAlysisbuffer(50mMNaH2PO4、300mMNaCl、10mM咪唑)重悬步骤2收集的菌体,置冰上超声破碎后得到全细胞裂解液。(2)将全细胞裂解液50000g离心30分钟,收集上清液。(3)将上清液经0.22μm滤膜过滤后,加载到Ni-NTA亲和层析柱,收集流穿液。(4)向亲和层析柱中加入10倍柱床体积的washbuffer(50mMNaH2PO4、300mMNaCl、25mM咪唑),收集流穿液。(5)向亲和层析柱中加入4倍柱床体积的elutebuffer(50mMNaH2PO4、300mMNaCl、250mM咪唑),收集洗脱蛋白(即为带His-Ub融合标签的目的蛋白)。(6)向洗脱蛋白中加入Usp2-cc蛋白酶(20U/mg洗脱蛋白)进行酶切反应(4℃酶切24小时),以去除His-Ub融合标签,得到酶切反应液。(7)将酶切反应液使用dialysisbuffer(20mMTris-HCL,pH8.0、100mMNaCl)透析过夜后再一次加载到Ni-NTA柱,收集流穿蛋白(即为不带His-Ub融合标签的目的蛋白)。4、将步骤3纯化过程中每一步流程中收集的样品进行SDS-PAGE检测。结果如图1所示。图1A为TaGPI1蛋白纯化过程中收集的样品,图1B为TaGPI1mS543A蛋白纯化过程中收集的样品。图中,泳道1为步骤(1)得到的全细胞裂解液,泳道2为步骤(2)收集的上清液,泳道3为步骤(3)收集的流穿液,泳道4为步骤(4)收集的流穿液,泳道5为步骤(5)收集的洗脱蛋白,泳道6为步骤(6)得到的酶切反应液,泳道7为步骤(7)收集的流穿蛋白,即纯化产物。结果显示大量、可溶且纯度较高TaGPI1蛋白和TaGPI1mS543A蛋白被纯化。重组载体pHUE-TaGPI1进行步骤1至4,收集的流穿蛋白命名为TaGPI1溶液。重组载体pHUE-TaGPI1mS543A进行步骤1至4,收集的流穿蛋白命名为TaGPI1mS543A。5、将步骤4得到的TaGPI1溶液进行BCA定量,蛋白浓度为20.4mg/ml。将步骤4得到的TaGPI1mS543A溶液进行BCA定量,蛋白浓度为30.6mg/ml。结果表明,在相同培养条件下,TaGPI1mS543A较TaGPI1产量提高。实施例4、小麦TaGPI1蛋白及TaGPI1mS543A蛋白外酶活力的检测和比较对实施例3纯化得到的TaGPI1蛋白和TaGPI1mS543A蛋白进行酶活力检测(方法参照文献:GuilbaultGG.Enzymaticmethodsofanalysis[J].AnalyticaChimicaActa,1970,52(1):75-82.)。TaGPI1蛋白或TaGPI1mS543A蛋白可以作为6-磷酸葡萄糖异构酶,催化6-磷酸果糖转化为6-磷酸葡萄糖,但该反应无法直接通过分光度计直接检测。6-磷酸葡萄糖异构酶与其底物6-磷酸果糖反应产生的6-磷酸葡萄糖,可在6-磷酸葡萄糖脱氢酶的催化下转化为6-磷酸葡萄糖酸,并伴随NADP向NADPH的转化。NADPH在分光度计340nm处有光吸收,因此在6-磷酸葡萄糖脱氢酶过量情况下,NADPH光吸收变化可以反映TaGPI1蛋白或TaGPI1mS543A蛋白的酶活力。反应体系(100μL):42mM双甘氨肽(pH7.4)16.67μL,3.3mMD-6-磷酸果糖3.33μL,0.67mMNADP3.33μL,3.3mMMgCl23.33μL,2.5U/mL6-磷酸葡萄糖脱氢酶3.33μL,H2O65.01μL,蛋白稀释液5μL。蛋白稀释液的制备方法:取实施例3制备的TaGPI1溶液或TaGPI1mS543A溶液,用dialysisbuffer(20mMTris-HCL,pH8.0、100mMNaCl)稀释,得到蛋白浓度为1mg/ml的蛋白母液,将蛋白母液稀释至500倍体积,得到蛋白浓度为0.002mg/ml的蛋白稀释液。反应在25℃条件下进行,分光光度计在340nm处测取5分钟内的吸光度值。结果如图2所示。选取酶反应最初3分钟内的数据进行计算。酶活力计算公式为:酶活力(U/ml)=(Δ340/min×0.1×500)/(6.22×0.005)公式中:Δ340/min为反应时间内340nm处吸光度值变化/反应时间;0.1为实验体系总体积(0.1ml);500为稀释倍数(蛋白母液浓度/蛋白稀释液浓度);6.22为1mmolNADPH在340nm波长的消光系数;0.005为反应体系中加入蛋白溶液的体积(0.005ml)。计算得到的酶活力(U/ml)数值/蛋白母液浓度(1mg/ml)=酶活力(U/mg)经过计算,TaGPI1酶活力为580±55U/mg,而TaGPI1mS543A酶活力为763±47U/mg,TaGPI1mS543A的酶活力对比TaGPI1的酶活力提升了约百分之三十。<110>中国科学院遗传与发育生物学研究所<120>TaGPI1mS543A蛋白及其编码基因和应用<130>GNCYXMN161846<160>4<210>1<211>1704<212>DNA<213>人工序列<220><223><400>1atggcgtcgccggcgctcatctccgacaccgaccagtggaaggccctccaggcgcacgtc60ggcgcgatccacaagacgcacctgcgcgacctcatgacggacgccgaccgatgcaaggca120atgacggcggaattcgaaggcgtctacctggactactcgaggcagcaggccaccacggag180accatcgacaagctgttcaagctggcagaggctgcaaagctcaaggagaagattgacaag240atgtttaaaggcgaaaagataaataccactgagaacagatcagtgctccatgtggctcta300agggctccaagagacgcagtcataaacagtgacggtgtgaatgtggtccccgaagtttgg360gctgttaaggataaaatcaagcagttttcagagactttcagaagtggctcatgggttggg420gcaactgggaaaccattgacaaatgttgtctcggtcgggattggtggtagcttccttgga480cctctgtttgtgcatacggctctccagactgacccggaagcagcggaagctgccaaaggc540cgacaactgagatttcttgcaaatgttgatccagttgatgttgcacggagcatcaaagat600ttagatcctgcaaccactcttgttgtggttgtctcaaagaccttcacgacagctgaaaca660atgttaaatgctcgaactatcaaggagtggattgtctcttctcttggacctcaggctgtt720tccaaacacatgattgctgtcagtactaatcttaagcttgtcaaggagttcggaattgac780cctaacaacgcttttgcgttttgggactgggttggcggccgctatagtgtttgcagtgct840gtcggtgttctgcccttatctcttcagtatggatttccaattgttcagaaatttctggag900ggtgcttctagcattgacaatcatgtccatacatcttcatttgagaaaaatatacctgta960ctccttggtttgttgagtgtgtggaatgtttcatttctcggatatccggctagggcaata1020ttgccatactgtcaagcacttgagaaactagcaccacatattcagcagcttagcatggag1080agtaatggaaagggtgtctccattgatggtgttcgacttccatttgaggctggtgaaatt1140gattttggtgaacctggaacaaacgggcaacacagcttctatcaattaatccatcaggga1200agagttattccttgtgattttattggcgtcataaaaagccagcagcccgtttacctgaaa1260ggggaaactgttagcaatcatgatgagttgatgtccaatttctttgctcagcctgatgcg1320cttgcctatgggaagactcctgagcaattacacagcgagaaagttcccgaaaatcttatc1380cctcacaagacttttcagggcaaccggccatcactgagtttcttgctgtcttcgttatct1440gcctatgagattggacagcttttatccatctatgagcaccggatcgcagttcagggtttc1500atatggggaatcaactcgtttgaccagtggggagtggagctgggcaagtcactggcttct1560acagtgaggaaacagttgcatgcatcacgcatggaaggaaagcccgtcgagggcttcaac1620cccagcagcgcaagtttgctcacacggtttcttgcggttaaaccatccaccccatatgac1680acaacagtgcttccaaaagtgtaa1704<210>2<211>567<212>PRT<213>人工序列<220><223><400>2MetAlaSerProAlaLeuIleSerAspThrAspGlnTrpLysAlaLeu151015GlnAlaHisValGlyAlaIleHisLysThrHisLeuArgAspLeuMet202530ThrAspAlaAspArgCysLysAlaMetThrAlaGluPheGluGlyVal354045TyrLeuAspTyrSerArgGlnGlnAlaThrThrGluThrIleAspLys505560LeuPheLysLeuAlaGluAlaAlaLysLeuLysGluLysIleAspLys65707580MetPheLysGlyGluLysIleAsnThrThrGluAsnArgSerValLeu859095HisValAlaLeuArgAlaProArgAspAlaValIleAsnSerAspGly100105110ValAsnValValProGluValTrpAlaValLysAspLysIleLysGln115120125PheSerGluThrPheArgSerGlySerTrpValGlyAlaThrGlyLys130135140ProLeuThrAsnValValSerValGlyIleGlyGlySerPheLeuGly145150155160ProLeuPheValHisThrAlaLeuGlnThrAspProGluAlaAlaGlu165170175AlaAlaLysGlyArgGlnLeuArgPheLeuAlaAsnValAspProVal180185190AspValAlaArgSerIleLysAspLeuAspProAlaThrThrLeuVal195200205ValValValSerLysThrPheThrThrAlaGluThrMetLeuAsnAla210215220ArgThrIleLysGluTrpIleValSerSerLeuGlyProGlnAlaVal225230235240SerLysHisMetIleAlaValSerThrAsnLeuLysLeuValLysGlu245250255PheGlyIleAspProAsnAsnAlaPheAlaPheTrpAspTrpValGly260265270GlyArgTyrSerValCysSerAlaValGlyValLeuProLeuSerLeu275280285GlnTyrGlyPheProIleValGlnLysPheLeuGluGlyAlaSerSer290295300IleAspAsnHisValHisThrSerSerPheGluLysAsnIleProVal305310315320LeuLeuGlyLeuLeuSerValTrpAsnValSerPheLeuGlyTyrPro325330335AlaArgAlaIleLeuProTyrCysGlnAlaLeuGluLysLeuAlaPro340345350HisIleGlnGlnLeuSerMetGluSerAsnGlyLysGlyValSerIle355360365AspGlyValArgLeuProPheGluAlaGlyGluIleAspPheGlyGlu370375380ProGlyThrAsnGlyGlnHisSerPheTyrGlnLeuIleHisGlnGly385390395400ArgValIleProCysAspPheIleGlyValIleLysSerGlnGlnPro405410415ValTyrLeuLysGlyGluThrValSerAsnHisAspGluLeuMetSer420425430AsnPhePheAlaGlnProAspAlaLeuAlaTyrGlyLysThrProGlu435440445GlnLeuHisSerGluLysValProGluAsnLeuIleProHisLysThr450455460PheGlnGlyAsnArgProSerLeuSerPheLeuLeuSerSerLeuSer465470475480AlaTyrGluIleGlyGlnLeuLeuSerIleTyrGluHisArgIleAla485490495ValGlnGlyPheIleTrpGlyIleAsnSerPheAspGlnTrpGlyVal500505510GluLeuGlyLysSerLeuAlaSerThrValArgLysGlnLeuHisAla515520525SerArgMetGluGlyLysProValGluGlyPheAsnProSerSerAla530535540SerLeuLeuThrArgPheLeuAlaValLysProSerThrProTyrAsp545550555560ThrThrValLeuProLysVal565<210>3<211>1704<212>DNA<213>人工序列<220><223><400>3atggcgtcgccggcgctcatctccgacaccgaccagtggaaggccctccaggcgcacgtc60ggcgcgatccacaagacgcacctgcgcgacctcatgacggacgccgaccgatgcaaggca120atgacggcggaattcgaaggcgtctacctggactactcgaggcagcaggccaccacggag180accatcgacaagctgttcaagctggcagaggctgcaaagctcaaggagaagattgacaag240atgtttaaaggcgaaaagataaataccactgagaacagatcagtgctccatgtggctcta300agggctccaagagacgcagtcataaacagtgacggtgtgaatgtggtccccgaagtttgg360gctgttaaggataaaatcaagcagttttcagagactttcagaagtggctcatgggttggg420gcaactgggaaaccattgacaaatgttgtctcggtcgggattggtggtagcttccttgga480cctctgtttgtgcatacggctctccagactgacccggaagcagcggaagctgccaaaggc540cgacaactgagatttcttgcaaatgttgatccagttgatgttgcacggagcatcaaagat600ttagatcctgcaaccactcttgttgtggttgtctcaaagaccttcacgacagctgaaaca660atgttaaatgctcgaactatcaaggagtggattgtctcttctcttggacctcaggctgtt720tccaaacacatgattgctgtcagtactaatcttaagcttgtcaaggagttcggaattgac780cctaacaacgcttttgcgttttgggactgggttggcggccgctatagtgtttgcagtgct840gtcggtgttctgcccttatctcttcagtatggatttccaattgttcagaaatttctggag900ggtgcttctagcattgacaatcatgtccatacatcttcatttgagaaaaatatacctgta960ctccttggtttgttgagtgtgtggaatgtttcatttctcggatatccggctagggcaata1020ttgccatactgtcaagcacttgagaaactagcaccacatattcagcagcttagcatggag1080agtaatggaaagggtgtctccattgatggtgttcgacttccatttgaggctggtgaaatt1140gattttggtgaacctggaacaaacgggcaacacagcttctatcaattaatccatcaggga1200agagttattccttgtgattttattggcgtcataaaaagccagcagcccgtttacctgaaa1260ggggaaactgttagcaatcatgatgagttgatgtccaatttctttgctcagcctgatgcg1320cttgcctatgggaagactcctgagcaattacacagcgagaaagttcccgaaaatcttatc1380cctcacaagacttttcagggcaaccggccatcactgagtttcttgctgtcttcgttatct1440gcctatgagattggacagcttttatccatctatgagcaccggatcgcagttcagggtttc1500atatggggaatcaactcgtttgaccagtggggagtggagctgggcaagtcactggcttct1560acagtgaggaaacagttgcatgcatcacgcatggaaggaaagcccgtcgagggcttcaac1620cccagcgcggcaagtttgctcacacggtttcttgcggttaaaccatccaccccatatgac1680acaacagtgcttccaaaagtgtaa1704<210>4<211>567<212>PRT<213>人工序列<220><223><400>4MetAlaSerProAlaLeuIleSerAspThrAspGlnTrpLysAlaLeu151015GlnAlaHisValGlyAlaIleHisLysThrHisLeuArgAspLeuMet202530ThrAspAlaAspArgCysLysAlaMetThrAlaGluPheGluGlyVal354045TyrLeuAspTyrSerArgGlnGlnAlaThrThrGluThrIleAspLys505560LeuPheLysLeuAlaGluAlaAlaLysLeuLysGluLysIleAspLys65707580MetPheLysGlyGluLysIleAsnThrThrGluAsnArgSerValLeu859095HisValAlaLeuArgAlaProArgAspAlaValIleAsnSerAspGly100105110ValAsnValValProGluValTrpAlaValLysAspLysIleLysGln115120125PheSerGluThrPheArgSerGlySerTrpValGlyAlaThrGlyLys130135140ProLeuThrAsnValValSerValGlyIleGlyGlySerPheLeuGly145150155160ProLeuPheValHisThrAlaLeuGlnThrAspProGluAlaAlaGlu165170175AlaAlaLysGlyArgGlnLeuArgPheLeuAlaAsnValAspProVal180185190AspValAlaArgSerIleLysAspLeuAspProAlaThrThrLeuVal195200205ValValValSerLysThrPheThrThrAlaGluThrMetLeuAsnAla210215220ArgThrIleLysGluTrpIleValSerSerLeuGlyProGlnAlaVal225230235240SerLysHisMetIleAlaValSerThrAsnLeuLysLeuValLysGlu245250255PheGlyIleAspProAsnAsnAlaPheAlaPheTrpAspTrpValGly260265270GlyArgTyrSerValCysSerAlaValGlyValLeuProLeuSerLeu275280285GlnTyrGlyPheProIleValGlnLysPheLeuGluGlyAlaSerSer290295300IleAspAsnHisValHisThrSerSerPheGluLysAsnIleProVal305310315320LeuLeuGlyLeuLeuSerValTrpAsnValSerPheLeuGlyTyrPro325330335AlaArgAlaIleLeuProTyrCysGlnAlaLeuGluLysLeuAlaPro340345350HisIleGlnGlnLeuSerMetGluSerAsnGlyLysGlyValSerIle355360365AspGlyValArgLeuProPheGluAlaGlyGluIleAspPheGlyGlu370375380ProGlyThrAsnGlyGlnHisSerPheTyrGlnLeuIleHisGlnGly385390395400ArgValIleProCysAspPheIleGlyValIleLysSerGlnGlnPro405410415ValTyrLeuLysGlyGluThrValSerAsnHisAspGluLeuMetSer420425430AsnPhePheAlaGlnProAspAlaLeuAlaTyrGlyLysThrProGlu435440445GlnLeuHisSerGluLysValProGluAsnLeuIleProHisLysThr450455460PheGlnGlyAsnArgProSerLeuSerPheLeuLeuSerSerLeuSer465470475480AlaTyrGluIleGlyGlnLeuLeuSerIleTyrGluHisArgIleAla485490495ValGlnGlyPheIleTrpGlyIleAsnSerPheAspGlnTrpGlyVal500505510GluLeuGlyLysSerLeuAlaSerThrValArgLysGlnLeuHisAla515520525SerArgMetGluGlyLysProValGluGlyPheAsnProSerAlaAla530535540SerLeuLeuThrArgPheLeuAlaValLysProSerThrProTyrAsp545550555560ThrThrValLeuProLysVal565当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 蝎神经毒素AaIT及其编码基因与应用的制造方法与工艺
- 腈水解酶突变体及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白AsTMK1及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种花狭口蛙的基因及其编码的多肽和该多肽的用途的制造方法与工艺
- 一种泽陆蛙基因及其编码的多肽和该多肽的用途的制造方法与工艺
- 降低种子重量的白桦AP2基因及其编码蛋白的制造方法与工艺
- 可编码ArtRD蛋白基因及其蛋白和应用的制造方法与工艺
- 蝎神经毒素AaIT及其编码基因与应用的制造方法与工艺
- 腈水解酶突变体及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白AsTMK1及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 腈水解酶突变体及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白AsTMK1及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种花狭口蛙的基因及其编码的多肽和该多肽的用途的制造方法与工艺
- 一种泽陆蛙基因及其编码的多肽和该多肽的用途的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 蛋白StTrxF、编码基因及其在提高植物淀粉含量中的应用的制造方法与工艺
- 蛋白质及其编码基因在调控植物抗黄萎病性中的应用的制造方法与工艺
- 甘薯耐逆相关蛋白IbFBA2、编码基因、重组载体与应用的制造方法与工艺
- 植物抗旱相关蛋白ZmNAC111及其编码基因与应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 蛋白StTrxF、编码基因及其在提高植物淀粉含量中的应用的制造方法与工艺
- 植物抗旱相关蛋白ZmNAC111及其编码基因与应用的制造方法与工艺
- 核盘菌凝集素SSL‑6蛋白及其编码基因与应用的制造方法与工艺
- 植物抗病毒相关蛋白GmSN1及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 蛋白StTrxF、编码基因及其在提高植物淀粉含量中的应用的制造方法与工艺
- 蛋白质及其编码基因在调控植物抗黄萎病性中的应用的制造方法与工艺
- 植物抗旱相关蛋白ZmNAC111及其编码基因与应用的制造方法与工艺
- 核盘菌凝集素SSL‑6蛋白及其编码基因与应用的制造方法与工艺