糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用的制作方法
本发明涉及体外核酸检测
技术领域:
,尤其涉及糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用。
背景技术:
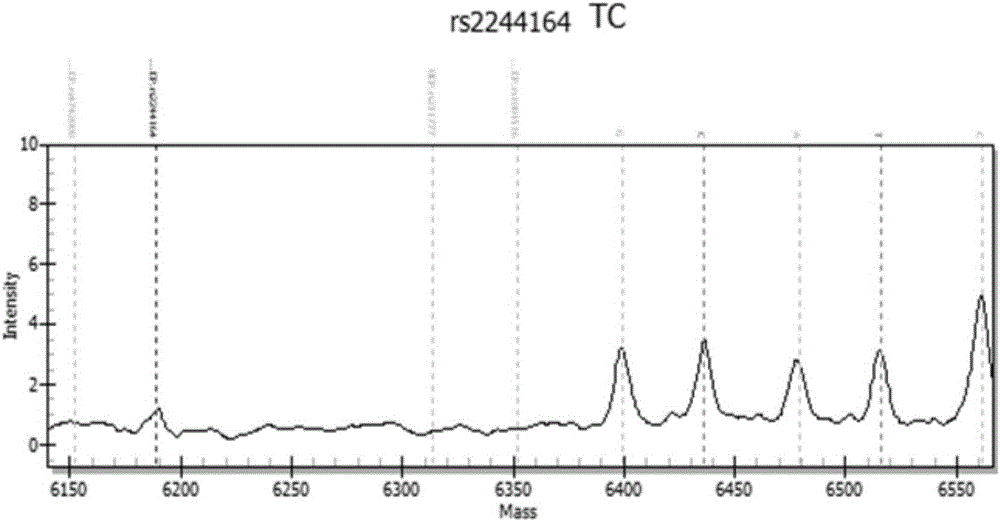
:鼻咽癌(Nasopharyngealcarcinoma,NPC)是一种源于鼻咽上皮的高度侵袭性的恶性肿瘤。据统计,在2012年,鼻咽癌新发病例86,700人,死亡病例50,800人,因此其被认为是全球范围内较罕见的恶性肿瘤。但在流行区域,包括中国南方和东南亚,鼻咽癌的发病率可达到15-50/100000。鼻咽的解剖部位较深,周围临近许多重要的血管和神经,特殊的解剖位置及局部侵袭生长的生物学行为使得手术治疗难以实现;而大部分鼻咽癌的病理类型对放射线较敏感,目前鼻咽癌公认有效的治疗手段为放射治疗。早期的鼻咽癌患者采用单纯放射治疗有较为理想的效果,但由于鼻咽癌早期症状不明显,大部分患者在就诊时已是中晚期,肿瘤组织已向周围侵犯,甚至发生了远处转移,因此单纯放疗治疗鼻咽癌的总生存率并不理想。中晚期鼻咽癌患者由于较高的局部复发率和远处转移率导致总体生存率明显降低,为提高患者总生存率,化疗已经被应用于鼻咽癌的综合治疗之中。尽管目前NPC治疗取得了令人欣喜的进步,但由于鼻咽癌早期症状不明显及易于局部侵袭及远处转移的生长方式,使得很多患者就诊时已处于中晚期,此类患者治疗效果较早期患者差距明显。因此,找到有效的用于NPC临床诊治的分子标志物,对于患者早诊早治,提高生存时间具有重要意义。肿瘤细胞重编码代谢以促进增殖生长及长期生存。这一重编码的代谢过程的最主要特征是增加的葡萄糖摄取及发酵葡萄糖产生乳酸,即使在有足够的氧气及正常的线粒体功能情况下也会发生。这被称为Warburg效应。这一效应有可能是对恶性肿瘤早期发生发展过程中间接性缺氧的适应。增强的糖酵解会损失线粒体大量产能,但内环境的改变的同时也促使肿瘤细胞更加抵抗酸中毒、提供生物合成大分子的原料、及保护细胞免于氧化应激损害。单核苷酸多态性(Singlenucleotidepolymorphism,SNP)是在人群中具有一定的频率(>1%)的变异,确切的讲,是基因组中由于单个碱基变异(包括插入、替换、缺失)造成DNA序列发生了改变,从而使得人类基因组更具有多样性。许多研究已经表明,诸多基因的SNP与包括肿瘤在内的多种疾病的发生发展、预后以及治疗敏感度密切相关,这提示SNP有潜力被应用到临床进行相关疾病的预防、筛查、诊断以及指导治疗,这对于个体化治疗及精准治疗具有非常重要的意义。目前,已有诸多研究显示糖酵解通路基因SNP与多种肿瘤发生发展密切相关,但糖酵解通路基因改变与鼻咽癌风险相关至今尚未被研究过。基于此,以鼻咽癌的糖酵解通路关键基因为切入点,对糖酵解途径己糖激酶2(Hexokinase2,HK2)、乏氧诱导因子-1α(HypoxiaInducibleFactor-1α,HIF-1α)、葡萄糖激酶(Glucokinase,GCK),乳酸脱氢酶(Lactatedehydrogenase,LDH)4个关键基因的30个标签SNP进行检测,这对建立新的鼻咽癌风险筛查技术有重要意义,能够早期、灵敏和稳定的筛查鼻咽癌患病风险,以便进行及时、有效的监测评估及干预,降低医疗成本,节约社会资源。目前,医院内针对鼻咽癌的诊断主要还是依赖于传统的病理学常规方法,早期诊断率较低且对于鼻咽癌的预防效果较差;此外,尚未有针对所述糖酵解相关基因GCK、HK2及HIF1-α的测序引物及相应检测试剂盒面世,因此,本发明的出现,对于鼻咽癌风险筛查的体外诊断新方法的建立具有重要的意义。技术实现要素:为了解决常规鼻咽癌的诊断方法存在早期诊断率低而造成患者病情发展恶化的技术问题,本发明提供糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用。本发明提供了糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用,所述糖酵解相关基因分别为GCK基因、HK2基因及HIF1-α基因,其序列分别为SEQIDNO:1:3'-AGTATATGTCCCAAATTGTGCATAACATAATGTGTTTTCTCCGCCAGCCCTGGGAAGGGCGTAACTTCCCAGGTATTTCTAGGTGAAGTAACTTTGTAGATCAGGAGTAAG-5'(参见NCBIDBSNP数据库dbSNP数据库NC_000007.14)、SEQIDNO:2:5'-CACTGTGTGTTTAAATTTGGAGTCTGGTGTCTAGCATTAGCTGGGGTTGGAGCTTCCACTCCTCTCAGCATTGGTAAGCCTCCTCACCCACCCCATCCCATGTCCAAGATC-3'(参见NCBIDBSNP数据库dbSNP数据库NC_000002.12)及SEQIDNO:3:5'-CACATATTGCATGTACTTTGTCCAATCACCCTCTGATGCAGTTACTATTATGCTCATTTTACAGATGATAGAAGGCTTATAATGACAACCCTAGGATAACAAAGGCAGTAAAGAACAGAGCTGGTCTTAAA-3'(参见NCBIDBSNP数据库dbSNP数据库NC_000014.9)。在本发明提供的所述糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用的一较佳实施例中,所述试剂盒包括PCR引物、DNA标准品及PCR反应液。在本发明提供的所述糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用的一较佳实施例中,所述PCR引物包括针对GCKrs2244164位点、HK2rs656489位点及HIF1-αrs10136168位点的引物组,所述引物组包括:(1)对于GCKrs2244164位点,扩增引物为:GCKrs2244164正向扩增引物:5’-ACGTTGGATGCATAATGTGTTTTCTCCGCC-3’(SEQIDNO:4);GCKrs2244164反向扩增引物:5’-ACGTTGGATGGGGACTTACTCCTGATCTAC-3’(SEQIDNO:5);(2)对于HK2rs656489位点,扩增引物为:HK2rs656489正向扩增引物:5’-ACGTTGGATGCTGGTGTCTAGCATTAGCTG-3’(SEQIDNO:6);HK2rs656489反向扩增引物:5’-ACGTTGGATGTGATCTTGGACATGGGATGG-3’(SEQIDNO:7);(3)对于HIF1-αrs10136168位点,扩增引物为:HIF1-αrs10136168正向扩增引物:5’-ACGTTGGATGTCACCCTCTGATGCAGTTAC-3’(SEQIDNO:8);HIF1-αrs10136168反向扩增引物:5’-ACGTTGGATGCAGCTCTGTTCTTTACTGCC-3’(SEQIDNO:9)。在本发明提供的所述糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用的一较佳实施例中,所述DNA标准品包括突变型标准品DNA,即阳性对照品,以及野生型标准品DNA,即阴性对照品;其中所述突变型标准品DNA分别为GCKrs2244164突变纯合型及突变杂合型DNA(基因序列参见NCBIDBSNP数据库dbSNP数据库NC_000007.14)、HK2rs656489突变纯合型及突变杂合型DNA(基因序列参见NCBIDBSNP数据库dbSNP数据库NC_000002.12)、HIF1-αrs10136168突变纯合型及突变杂合型DNA(基因序列参见NCBIDBSNP数据库dbSNP数据库NC_000014.9);其中所述野生型标准品DNA分别为GCKrs2244164野生型DNA(基因序列参见NCBIDBSNP数据库dbSNP数据库NC_000007.14)、HK2rs656489野生型DNA(基因序列参见NCBIDBSNP数据库dbSNP数据库NC_000002.12)、HIF1-αrs10136168野生型DNA(基因序列参见NCBIDBSNP数据库dbSNP数据库NC_000014.9)。在本发明提供的所述糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用的一较佳实施例中,所述PCR反应液包括PCRBuffer,MgCl2,dNTP及Taq酶。在本发明提供的所述糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用的一较佳实施例中,所述PCR引物及PCR反应液各试剂组分配比为:相较于现有技术,本发明提供的糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用具有以下有益效果在于:一、与常规的鼻咽癌诊断方法相比,本发明的引物组及试剂盒具有快速、灵敏和特异性好等特点,能在早期及时对人鼻咽癌进行风险评估,以采取必要预防、早诊早治等措施;二、通过结合多重PCR技术、单碱基延伸技术和基质辅助激光解吸附电离飞行时间质谱分析技术进行基因分型检测,具有检测结果准确、特异性高、检测周期短、检测方法灵敏的优点;三、通过在试剂盒中设置了阳性对照品和阴性对照品,使得所述试剂盒在检测糖酵解相关基因GCK、HK2及HIF1-α基因分型时,可以更好的确保检测结果的准确性。附图说明图1为临床样本GCKrs2244164位点野生型的测序图;图2为临床样本GCKrs2244164位点突变杂合型的测序图;图3为临床样本GCKrs2244164位点突变纯合型的测序图;图4为临床样本HK2rs656489位点野生型的测序图;图5为临床样本HK2rs656489位点突变杂合型的测序图;图6为临床样本HK2rs656489位点突变纯合型的测序图;图7为临床样本HIF1-αrs10136168位点野生型的测序图;图8为临床样本HIF1-αrs10136168位点突变杂合型的测序图;图9为临床样本HIF1-αrs10136168位点突变纯合型的测序图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。一、实验对象本临床研究严格遵守赫尔斯基宣言,并得到了中南大学湘雅医学院附属肿瘤医院伦理委员会的批准。研究组病例的纳入标准:1)选取2014年10月至2016年7月在中南大学湘雅医学院附属肿瘤医院住院的且经组织病理学确诊为鼻咽癌的723位患者。2)招募之前没有经过放疗和化疗等其他治疗的。3)既往没有鼻咽癌及其它恶性肿瘤病史。4)血液标本采集之前的6个月没有输血史。5)同意接受与本研究相关的所有的问卷调查和贡献静脉血。6)同意填写《知情同意书》。7)所有受试者彼此间无血缘关系。对照组的纳入标准:1)选取同期在长沙市三甲医院医院进行体检的857位正常居民,流行病学筛查结果无任何恶性肿瘤病史。2)湖南省常驻居民。3)同意接受与本研究相关的所有的问卷调查和贡献静脉血。4)所有研究对象均被同意填写《知情同意书》。二、实验方案进行病例对照研究,设计了病例组和健康对照组。利用MassARRAY系统,通过检测外周血细胞的途径,对糖酵解途径3个关键基因的SNP进行检测:GCKrs2244164位点(基因序列参见NCBIdbSNP数据库NC_000007.14)、HK2rs656489位点(基因序列参见NCBIdbSNP数据库NC_000002.12)、HIF1-αrs10136168位点(基因序列参见NCBIdbSNP数据库NC_000014.9)。利用Haploview、SPSS18.0检测Hardy-Weinberg平衡的符合程度、组间基因型分布比较。采用BioMiaoBiologicalTechnology(Beijing,China)公司的MassArray(Sequenom,USA)进行测序。引物设计采用iPLEXGOLD(Sequenom,USA)。SequenomSNP检测过程结合多重PCR技术、MassARRAYiPLEX单碱基延伸技术和基质辅助激光解吸附电离飞行时间质谱分析技术(Matrix-assistedlaserdesorption/ionization–timeofflight,MALDI-TOF)进行分型检测。具体原理是先根据位点信息设计特异性的PCR引物和延伸引物,将包含SNP位点区域的DNA模板通过PCR技术扩增,扩增产物以SAP酶去除多余dNTPs,然后对待检位点同时进行单碱基延伸,位点特异性的延伸引物将在突变位点处延伸一个碱基并终止。延伸引物将根据突变类型的差异而连接上不同的ddNTPs,形成分子量差异。延伸产物在经过树脂纯化后,将点样至靶片上,并使用质谱仪对不同延伸产物的分子量差异进行检测,通过数据分析,就可得到各突变位点的具体基因型。根据所检测以上三种基因型推断是否患鼻咽癌高风险。三、实验方法3.1临床样本收集:依据入排标准收集鼻咽癌患者及正常体检人员静脉血2-5ml,用EDTA抗凝,使用Omega试剂盒提取DNA并保存于-20℃冰箱。用MassARRAySequenom(BioMiaoBiologicalTechnology(Beijing,China)公司)时间飞行质谱生物芯片系统对所有入组对象进行GCKrs2244164、HK2rs656489及HIF1-αrs10136168位点的基因分型,分析与鼻咽癌患病风险的相关性。3.2DNA提取:DNA提取试剂盒(OmegaUSA)从全血中提取DNA,严格按照试剂盒说明操作。具体步骤如下:1)将EDTA抗凝管中的血样颠倒几次充分混合;2)将全血加入到15ml离心管中,并加入2.5倍体积的细胞裂解液BufferNL,上下颠倒5次,使细胞充分裂解;所有缓冲溶液的用量按照表2加入。3)2000×g离心5分钟。缓慢弃去上清,将离心管倒置在干净的吸水纸上2分钟,保证沉淀一直在离心管中。4)按照表1配置缓冲液XL和蛋白酶OB的混合液。加入0.5倍体积的混合液,立即涡旋10秒直至沉淀分布完全均匀。5)65℃水浴10-30分钟,期间注意观察沉淀是否溶解完全,并变成澄清墨绿色溶液。6)待澄清墨绿色溶液降至室温时加入异丙醇,颠倒充分混匀至出现白色丝状或簇状的基因组DNA。7)2000×g离心5分钟。缓慢弃去上清。将离心管倒置在干净的吸水纸上直至水流尽。8)加入70%乙醇溶液,上下颠倒10s混匀洗净基因组DNA。9)2000×g离心3分钟。缓慢弃去上清。再次离心1分钟,将上清洗出。将离心管倒置在干净的吸水纸上10-15分钟直至管中的乙醇挥发完全。10)向离心管中加入200-500μl的DNA溶解液EBBuffer,用抢将DNA与缓冲液打匀。11)将离心管置于65℃的水浴锅中孵育10分钟-1小时,确保DNA在此过程中完全溶解。12)应用微量核酸浓度分析仪测定标本的OD值,记录DNA浓度,并置于-20℃环境保存。表1不同体积血液所需各种缓冲液容量3.3基因多态性位点选择:利用生物技术信息和国际HapMap计划数据库国家中心的单核苷酸多态数据库,我们得到了汉族人GCK,HK2,IDH1和HIF-1α基因及上下游500kb的信息。筛选标准是r2<0.8,最小等位基因频率大于5%(在汉族人群中),为标签SNP。3.4基因多态性检测及分析:3.4.1引物设计及合成根据SNP位点序列信息,使用sequenom公司的引物设计软件Assaydesign3.1设计PCR反应和单碱基扩展引物,参见表2。表2癌糖酵解相关基因分型的引物组3.4.2DNA提取使用成品化试剂盒,提取血样、组织、细胞、唾液中的DNA。使用NanoDrop2000仪器(北京科尔德科贸有限公司)进行OD值检测,1.25%琼脂糖凝胶电泳检测,DNA质检合格,转秱至96孔板,-20℃储存备用。3.4.3SequenomMassArray系统基因分型步骤A)PCR扩增反应1)原理聚合酶链式反应(Polymerasechainreaction,PCR)用于扩增位于两端已知序列之间的DNA区域。每个PCR循环,反应混合体系都在模板变性、引物退火和引物延伸三种不同温度下依序温育。该过程可使用一种可编程序的温度热循环仪而达到自动化。2.步骤1)取1.5mlEP管中配置PCR预混液(PCRmastermix),并振荡低速离心。反应组分,参见表3:表3PCRmastermix反应相关试剂配制组分备注:MgCl2最终浓度为3.5mM,其中PCRBuffer中1.875mM,及MgCl2本身添加了1.625mM。2)选用8道或12道秱液器,在384孔板的每个加样孔中加入4μlPCRmastermix,最后加入1μl模板DNA(20ng/ul)混匀,小心盖上384孔封板膜,并压牢每个孔,防止PCR程序时出现蒸发等现象。1000rpm离心1minute。3)设置如下PCR扩增反应体系,参见表4。将PCR反应板放置于PCR仪上,启动程序。表4PCR扩增反应体系B)产物碱性磷酸酶处理1)在PCR反应结束后,将PCR产物用SAP(Shrimpalkalinephosphatase,虾碱性磷酸酶)处理,以去除体系中游离的dNTPs。2)在新1.5mlEP管中配制碱性磷酸酶处理反应液,SAPMix反应组分,参见表5:表5SAPMix反应组分SAPmix试剂浓度体积(1rxn)水,HPLC级别NA1.53μlSAPBuffer10X0.17μlSAP酶1U/ul0.30μl总计-2.00μl3)将SAPmix加入384孔PCR反应板,对于每个碱性磷酸酶处理反应孔,反应总体积为7ul,其中PCR产物5ul,SAPmix2ul。4)秱液完成后,小心盖上384孔封板膜,并压牢每个孔,防止PCR程序时出现蒸发等现象,离心后进行如下反应程序。5)设置SAP反应程序:37℃20min;85℃5min;4℃∞。并将384孔反应板放置于PCR仪上,启动程序。C)单碱基延伸反应1)在碱性磷酸酶处理结束后,进行单碱基延伸反应,反应体系总体积9μl。2)在新1.5mlEP管中配制单碱基延伸反应液,EXTENDMix反应组分,参见表6:表6EXTENDMix反应组分EXTENDMix试剂浓度(in9μl)体积(1rxn)水,HPLC级别NA0.619μliPLEXBufferPlus0.222X0.200μliPLEX终止混合物1X0.200μl引物组(7μM:14μM)0.625uM:1.25uM0.940μliPLEX酶1X0.041μl总计-2.0μl备注:(7μM:14μM)表示为高质量引物组的双倍浓度。即在最终9μl浓度反应液中低质量引物组浓度为0.625uM及高质量引物组浓度为1.25uM。3)将EXTENDMix对应加入384孔反应板。对于每个反应孔,单碱基延伸反应体系,参见表7:表7单碱基延伸反应体系试剂体积(ul)EXTENDMix2SAP+PCR反应液7总计94)秱液完成后,小心盖上384孔封板膜,并压牢每个孔,防止PCR程时出现蒸发等现象,离心后进行如下反应程序。5)设置延伸反应程序,参见表8:表8延伸反应程序D)树脂纯化1)在384/6MGDimple板里均匀填充树脂并放置10分钟使其晾干。2)在384样本板的每个孔中加16μL水。3)将384样本板轻轻翻转过来扣在Dimple板上,然后轻敲使树脂落入样本板的每个孔中。4)将384样本板放置翻转离心机中室温旋转混匀30分钟。E)芯片点样启动MassARRAYNanodispenserRS1000点样仪,将树脂纯化后的延伸产物秱至384-wellSpectroCHIPbioarray上。F)质谱检测及数据输出将点样后的SpectroCHIP芯片使用MALDI-TOF质谱仪(德国Bruker公司)分析,检测结果使用TYPER4.0软件获取原始数据及基因分型图,检查数据文件的完整性和正确性,将结果保存入相应存储媒介,继而进行生物信息学分析。四、结果分析采用SPSSStatistics18软件,HAPLOVIEW4.2软件。Hardy-Weinberg平衡模型被用来检测样本基因型和等位基因频率。Pearson’s卡方检验或Fisher’s精确检验(当出现任一期望频数小于5时)被用来比较病例组与对照组间基因型与等位基因分布频率。计算风险比(Oddsratios,OR)和95%可信区间(Confidenceintervals,CI)来评估各基因型与等位基因的相对风险。对于每一种基因型与参照基因型进行对比,并根据性别分类进行了亚组分析。组间临床特征数据采用卡方检验进行检测。当p值小于0.05时被认为有统计学意义。结果如下:1、有意义的SNP位点在病例组及对照组中的分布,参见表9。表9SNP位点在病例组及对照组中的分布HIF-1ars10136168是位于基因上游的单核苷酸多态,本发明发现,在该位点,相对于野生型GG及突变纯合型GA人群,携带突变杂合型GA的人群是患鼻咽癌的高发人群,95%可信区间1.042-1.618。2、SNP位点在男性亚组中的分布,参见表10。表10SNP位点在男性亚组中的分布在男性亚组中,HIF1-αrs17113978位点各基因型分布之间各人群中,未发现有统计学意义的研究结论。3、SNP位点在女性亚组中的分布,参见表11。表11SNP位点在女性亚组中的分布在女性亚组中发现,GCKrs2244164突变型纯合子CC有着显著的患鼻咽癌高风险,其患病风险是未突变人群的1.97倍,95%可信区间1.067-3.653。这一单核苷酸多态位于葡萄糖激酶编码基因的内含子,具有增强子特性,可能会加速糖酵解通路。HK2rs656489中突变型等位基因A是患病的保护性因素,患病风险为未突变人群的0.655倍,95%可信区间0.449-0.985。其位于基因基因5’端的非编码区,可能与调节转录、mRNA稳定及转移相关由此,以上单核苷酸多态可能对Warburg效应产生显著影响。此外,测序结果图参见图1-图9。其中图1-3分别为临床样本GCKrs2244164位点野生型、突变杂合型及突变纯合型的测序图;图4-6分别为临床样本HK2rs656489位点野生型、突变杂合型及突变纯合型的测序图;图7-9分别为临床样本HIF1-αrs10136168位点野生型、突变杂合型及突变纯合型的测序图。上述测序结果真实可靠,符合临床检测对基因分型的标准要求。本发明提供的糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用具有以下有益效果在于:一、与常规的鼻咽癌诊断方法相比,本发明的引物组及试剂盒具有快速、灵敏和特异性好等特点,能在早期及时对人鼻咽癌进行风险评估,以采取必要预防、早诊早治等措施;二、通过结合多重PCR技术、单碱基延伸技术和基质辅助激光解吸附电离飞行时间质谱分析技术进行基因分型检测,具有检测结果准确、特异性高、检测周期短、检测方法灵敏的优点;三、通过在试剂盒中设置了阳性对照品和阴性对照品,使得所述试剂盒在检测糖酵解相关基因GCK、HK2及HIF1-α基因分型时,可以更好的确保检测结果的准确性。以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书内容所作的等效流程变换,或直接或间接运用在其它相关的
技术领域:
,均同理包括在本发明的专利保护范围内。SEQUENCELISTING<110>王晖<120>糖酵解相关基因在制备鼻咽癌诊断试剂盒中的应用<130>2016<160>9<170>PatentInversion3.3<210>1<211>111<212>DNA<213>人工序列<400>1agtatatgtcccaaattgtgcataacataatgtgttttctccgccagccctgggaagggc60gtaacttcccaggtatttctaggtgaagtaactttgtagatcaggagtaag111<210>2<211>111<212>DNA<213>人工序列<400>2cactgtgtgtttaaatttggagtctggtgtctagcattagctggggttggagcttccact60cctctcagcattggtaagcctcctcacccaccccatcccatgtccaagatc111<210>3<211>131<212>DNA<213>人工序列<400>3cacatattgcatgtactttgtccaatcaccctctgatgcagttactattatgctcatttt60acagatgatagaaggcttataatgacaaccctaggataacaaaggcagtaaagaacagag120ctggtcttaaa131<210>4<211>30<212>DNA<213>人工序列<400>4acgttggatgcataatgtgttttctccgcc30<210>5<211>30<212>DNA<213>人工序列<400>5acgttggatggggacttactcctgatctac30<210>6<211>30<212>DNA<213>人工序列<400>6acgttggatgctggtgtctagcattagctg30<210>7<211>30<212>DNA<213>人工序列<400>7acgttggatgtgatcttggacatgggatgg30<210>8<211>30<212>DNA<213>人工序列<400>8acgttggatgtcaccctctgatgcagttac30<210>9<211>30<212>DNA<213>人工序列<400>9acgttggatgcagctctgttctttactgcc30当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1