高亲和力、高特异性、多抗原识别表位的具有更高功能性的抗人PD-1抗体的制作方法
本发明属于肿瘤免疫疗法和分子免疫学领域,具体涉及一种高亲和力、高特异性、多抗原识别表位的具有更高功能性的抗人PD-1抗体。
背景技术:
肿瘤免疫治疗已成为肿瘤治疗的一个最重要的手段,只有在识别癌细胞后,免疫系统才能够有效的进攻癌细胞,癌变是正常体细胞失去正常细胞调节功能,基因突变累计到一定成度的结果(Tian et al.,2011),但是,癌细胞能够把自己伪装成正常体细胞,巧妙的避开了免疫系统的攻击。肿瘤免疫治疗通过增强人体的免疫功能,使T细胞能更好的识别癌细胞,从而起到杀死癌细胞的作用。
免疫系统是机体防卫外源物入侵的最有效的机制,由多个免疫器官、组织、细胞和分子相互协作,相互制衡来达到保护机体免受外来侵染和维护体内平衡,这种相互协作,相互制衡需要众多免疫检查点蛋白的协调,刺激性免疫检查点蛋白增强免疫系统的防御反应,抑制性免疫检查点蛋白控制过强的免疫系统,防止产生自身免疫反应(Chen et al.,2013)。肿瘤免疫治疗就是提升抗肿瘤的免疫能力,适可而止的放大和加强T细胞的功能,使得这种免疫功能的增强不会产生自身免疫疾病。T细胞在细胞免疫反应中起主导作用,发育成熟的T细胞分布到各个免疫器官,在抗原的诱导下,T细胞活化,增殖,和分化,形成不同的效应T细胞和记忆T细胞,T细胞的激活需要双信号和细胞因子的协同作用。T细胞激活的第一级信号是通过与其表面的TCR与pMHC呈递的抗原的特异性结合来完成的,然而,T细胞激活并不是仅仅由第一级信号作用就能完成的,还需要第二级信号,T细胞的第二级信号是抗原非依赖性的,不同种的T细胞的第二级信号也各有不同,T细胞激活的第二级信号来自与其细胞表面的受体或配体与在APC上表达的相应的协同刺激因子相互作用后的信号。此两个信号的刺激涉及到不同的免疫检查点蛋白,根据产生的效应不同,免疫检查点蛋白可分为刺激性免疫检查点蛋白和抑制性免疫检查点蛋白。在研发免疫检查点蛋白的治疗性药物时,对刺激性免疫检查点蛋白,要研制激动剂或刺激性抗体,对抑制性免疫检查点蛋白,要研制抑制剂或抑制性抗体。
PD-1(Programmed cell death protein 1或CD279)是表达在T细胞,祖B细胞,被激活的B细胞,以及骨髓细胞上的膜受体(Bennett et al.2003).,它属于B细胞免疫球蛋白超基因家族中的一员,与CD28,CTLA-4,ICOS and BTLA同属于CD28膜受体家族。PD-1有二个已知的配体,PD-L1和PD-L2,PD-1发挥着抑制性免疫调节作用,当PD-1与它的配体(PD-L1或PD-L2)结合时,通过信息传导,它抑制了T细胞的增殖,细胞因子的分泌和功能,目前的研究发现,PD-L1的mRNA在所有的组织中均有表达,但在肿瘤细胞中,PD-L1是高表达,通过与T细胞上的PD-1结合,肿瘤细胞抑制了T细胞的活化与增殖,使得肿瘤细胞能够免疫逃逸。PD-1和PD-L1或PD-L2的关系已成为肿瘤免疫治疗中的重要环节,PD-1/PD-L1或PD-1/PD-L2间的信号通路与肿瘤的发生和治疗有直接关系,研发能够特异性阻断PD-1和PD-L1或PD-1和PD-L2结合的单克隆抗体药物,用它们来阻断PD-1和PD-L1的结合或PD-1和PD-L2的结合而产生的对T细胞负调节作用,增强T细胞对各种抗原的免疫反应来进行肿瘤免疫治疗,是一个非常有用的治疗方法,本专利开发了新的抗人源PD-1功能性单克隆抗体,用它们来阻断PD-1与PD-L1或PD-1与PD-L2的结合。
技术实现要素:
本发明的目的是提供一种人PD-1单克隆抗体及其应用。
本发明的另一目的在于提供上述人PD-1单克隆抗体的编码基因。
本发明的又一目的在于提供上述人PD-1单克隆抗体的制备方法。
本发明的又一目的在于提供一种抗肿瘤制剂。
本发明的目的可以通过以下技术方案实现:
一种人PD-1单克隆抗体,该单克隆抗体的蛋白序列含有重链可变区和轻链可变区,该单克隆抗体选自如下(1)~(3)中的任意一种:
(1)所述的重链可变区具有如SEQ ID NO:1所示的氨基酸序列,所述的轻链可变区具有如SEQ ID NO:3所示的氨基酸序列;
(2)所述的重链可变区具有如SEQ ID NO:5所示的氨基酸序列,所述的轻链可变区具有如SEQ ID NO:7所示的氨基酸序列;
(3)所述的重链可变区具有如SEQ ID NO:9所示的氨基酸序列,所述的轻链可变区具有如SEQ ID NO:11所示的氨基酸序列。
上述人PD-1单克隆抗体的编码基因。该编码基因选自如下(4)~(6)中的任意一种:
(4)含有如SEQ ID NO:2所示的编码所述单克隆抗体重链可变区的核苷酸序列,以及如SEQ IDNO:4所示的编码所述单克隆抗体轻链可变区的核苷酸序列;
(5)含有如SEQ ID NO:6所示的编码所述单克隆抗体重链可变区的核苷酸序列,以及如SEQ IDNO:8所示的编码所述单克隆抗体轻链可变区的核苷酸序列;
(6)含有如SEQ ID NO:10所示的编码所述单克隆抗体重链可变区的核苷酸序列,以及如SEQ IDNO:12所示的编码所述单克隆抗体轻链可变区的核苷酸序列。
含有上述编码基因的重组载体、表达盒、转基因细胞系或重组菌。
上述的重组表达载体、表达盒、转基因细胞系或重组菌在制备人PD-1单克隆抗体中的应用。
一种制备人PD-1单克隆抗体的方法,将包含上述编码基因的重组表达载体转染感受态细胞,并进行培养得到人PD-1单克隆抗体。
本发明技术人员通过以下方法获得了克隆1H10C4D4,2E5E4D11,154G5A5B7的独特V-区域核苷酸/蛋白序列:
1)用重组表达的人PD-1胞外区免疫小鼠,获得针对人PD-1的免疫反应;
2)取步骤1)中小鼠的脾脏细胞进行融合,并对获得的杂交瘤细胞进行筛选,获得特异性识别人PD-1,并且能够阻断PD-1与PD-L1蛋白结合的阳性母克隆;
3)对步骤2)中获得的阳性母克隆进行亚克隆,获得稳定的杂交瘤细胞株;
4)用步骤3)中获得的杂交瘤细胞株进行测序,获得抗体轻链和重链的可变区编码序列。
用步骤4)中获得的可变区编码序列进行重组抗体生产功能性人PD-L1单克隆抗体。
本发明所述的单克隆抗体能够特异性结合人PD-1,能够阻断PD-1与PD-L1蛋白结合,并且能够解除PD-1的免疫负调节,激活T细胞分泌细胞因子。
上述的功能性人PD-1单克隆抗体在制备抗肿瘤药物中的应用。
一种抗肿瘤制剂,其包含上述的功能性人PD-1单克隆抗体。
本发明的有益效果
本发明的PD-1单克隆抗体能够特异性的与PD-L1结合,并且能够有效的阻断PD-L1与PD-1蛋白的结合,特异地解除PD-1的免疫负调节,激活T细胞分泌细胞因子。上述功能接近或达到目前PD-1靶向药物Keytruda(Pembrolizumab)的水准,并且有一个抗体不同于Keytruda的抗原表位,具有更大的多样性。
附图说明
图1:免疫之后的鼠血清效价检测
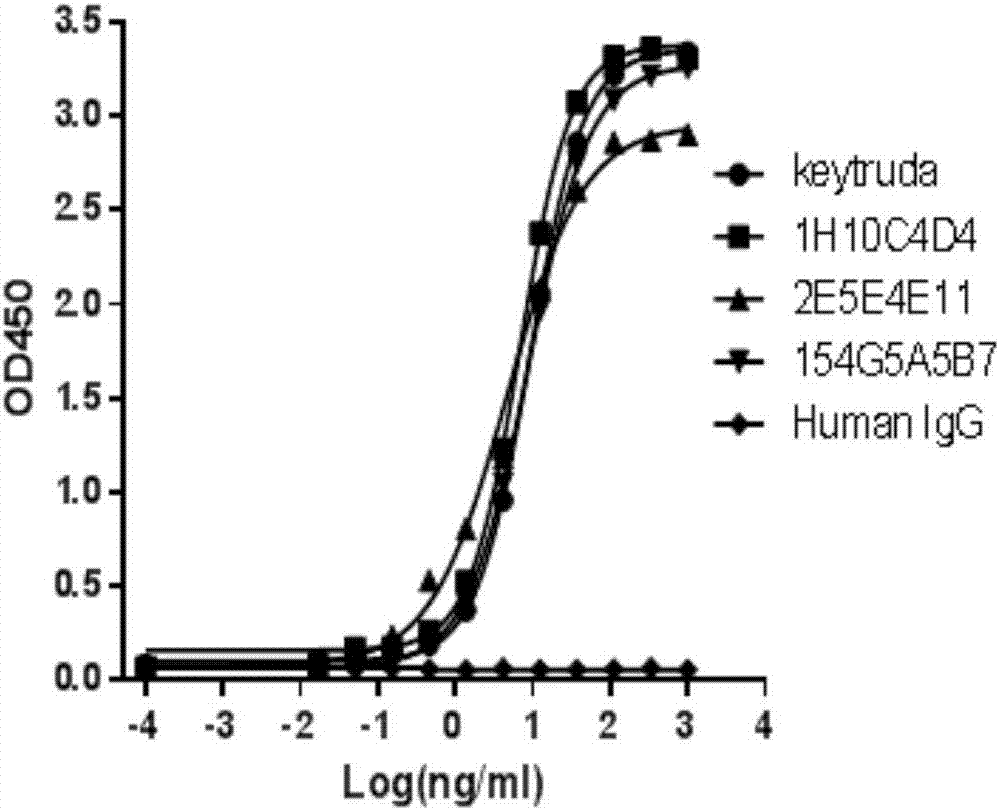
图2:纯化单克隆抗体能够特异性结合人PD-1重组蛋白
PD-1抗体克隆与PD-1-Fc重组蛋白结合ELISA实验,Keytruda,EC50=9.15ng/ml;1H10C4D4,EC50=6.81ng/ml;2E5E4E11,EC50=4.65ng/ml;154G5A5B7,EC50=8.72ng/ml。
图3:纯化单克隆抗体能够特异性结合表达人PD-1的细胞系
PD-1抗体克隆与表达PD-1的CHO-K1/GLP1/Gα15稳定细胞结合(峰2)而不与母细胞CHO结合(峰1)。
图4:纯化单克隆抗体能够阻断PD-1与PD-L1蛋白的结合
重组蛋白PD-1和重组蛋白PD-L1的结合受到PD-1抗体克隆的抑制。Keytruda,IC50=0.2241μg/ml;1H10C4D4,IC50=0.4934μg/ml;2E5E4E11,IC50=0.4289μg/ml;154G5A5B7,IC50=0.3662μg/ml。
图5:纯化单克隆抗体能够解除PD-1的免疫负调节,刺激T细胞分泌白介素2
A.CD4+T细胞及同种异体的树突细胞共培养,在共培养系统中加入不同浓度的PD-1抗体克隆,PD-1抗体克隆阻断表达在CD4+T细胞上的PD-1和表达在树突细胞上的PD-Ll的结合,导致T细胞的激活,IL-2分泌增加,Keyruda:EC50=0.1444μg/ml;1H10C4D4:EC50=0.0640μg/ml;2E5E4E11:EC50=0.9291μg/ml;154G5A5B7:EC50=1.123μg/ml。
B.表达PD-1的效用细胞与表达PD-L1的靶细胞共培养,相对光单位(RLU)用来衡量效用细胞激活的指标。在共培养系统中加入不同浓度的PD-1抗体克隆,PD-1抗体克隆阻断表达在效用细胞上PD-1和表达在靶细胞上的PD-Ll的结合,导致效用细胞的激活,RLU读数增加,Keytruda:EC50=0.3273μg/ml;1H10C4D4:EC50=1.131μg/ml;2E5E4E11:EC50=1.008μg/ml;154G5A5B7:EC50=1.422μg/ml。
具体实施方式
本发明涉及一种具有功能性的人PD-1抗体,下面将结合实施例对本发明的实施方案进行详细描述。除非另有说明,本发明所用的技术和科学术语与本发明所属领域的普通技术员通常所理解的含义相同。除非另有说明,下文描述的实施例的方法和材料均为可以通过市场购买获得的常规产品。本发明所属领域技术员将会理解,下文描述的方法和材料,仅是示例性的,而不应视为限定本发明的范围。
实施例1:人PD-1杂交瘤细胞株的获得以及单克隆抗体的制备
1)动物免疫
抗原采用融合至人IgG1Fc段的人PD-1胞外结构域的重组蛋白PD-1-Fc(GenScript,Z03370)。用含50μg PD-1-Fc融合蛋白的200μl弗氏完全佐剂(Sigma-Aldrich)的1:1乳液皮下免疫雌性Balb/c和C57bl/6小鼠。随后,每二周腹腔/皮下交替注射含25μg PD-1-Fc的弗氏不完全佐剂(Sigma-Aldrich)的1:1乳液最多达3次,从而对小鼠进行加强免疫。10只小鼠血清效价在三免之后均达到105以上。骨髓瘤融合前4天,表现出最高抗体滴度(图1)的两只小鼠(834号和837号)接受了25ug PD-1-Fc(不含佐剂)的腹腔加强免疫。
2)杂交瘤融合和筛选
提取脾脏并进行均质化以产生单细胞悬液,同时准备骨髓瘤细胞(SP2/0)单细胞悬液。使用电融合将8.9×107个脾细胞与4.1×107个SP2/0小鼠骨髓瘤细胞进行融合。将融合的细胞重悬于100ml含杂交瘤细胞选择剂胸腺核苷嘧啶,次黄嘌呤和氨基喋呤的DMEM/10%FBS培养基中,并用移液管以100μl的体积移至50×96孔板中。将板在37℃下在6%CO2中孵育。7天的孵育之后,开始使用下文所述的ELISA结合,ELISA竞争和FACS结合来测试针对PD-1-Fc的抗体的存在情况。
ELISA结合检测方法:间接ELISA用于评估上清液中抗体对于PD-1-Fc的结合能力。将ELISA板(Nunc)用100μl/孔的PBS中0.5μg/ml的重组PD-1-Fc或人IgG1在4℃下包被过夜。用PBS-T(0.05%吐温)洗涤板,并将其用200μl/孔的含1%BSA的PBST在37℃封闭0.5小时。随后弃去封闭液,向每个板加入100μl杂交瘤细胞培养上清液,然后在室温下孵育1小时。将板用PBST洗涤三次,并用100μl/孔的缀合辣根过氧化物酶的山羊抗小鼠IgG(Fab-特异性)(GenScript)37℃孵育0.5小时。将板用PBST洗涤五次,然后加入TMB显色液(GenScript)并在室温下在黑暗中孵育15分钟。通过加入50μl的1MHCl终止液(Sigma)终止反应。使用酶标仪在450nm下读板。
ELISA竞争检测方法:竞争法ELISA被用于评估上清液种的抗体对于PD-1和其配体PD-1蛋白的结合的阻断能力。将ELISA板(Nunc)用100μl/孔的PBS中0.5μg/ml的重组人PD-1蛋白在4℃下包被过夜。用PBS-T(0.05%吐温)洗涤板,并将其用200μl/孔的含1%BSA的PBST在37℃封闭0.5小时。随后弃去封闭液,每个测试孔加入50μl待测上清液,对照孔加入50μl无关上清液。然后每孔添加50μl生物素标记的PD-1-Fc(浓度为0.15μg/ml),在37℃孵育1小时。将板用PBST洗涤三次,并用100μl/孔的抗生物素蛋白链菌素HRP(SA-HRP,GenScript)37℃孵育10分钟。最后将板用PBST洗涤五次,然后加入TMB显色液(GenScript)并在室温下在黑暗中孵育15分钟。通过加入50μl的1MHCl终止液(Sigma)终止反应。使用酶标仪在450nm下读板。
FACS检测方法:FACS结合实验被用于评估上清液中的抗体对于CHO细胞膜表面表达的PD-1的结合能力。收集用于检测的表达PD-1的CHO细胞和阴性对照的母细胞,用PBS清洗3次。在96孔板中加入2.5X105个检测细胞和待测上清液100ul,4℃孵育1小时。随后用PBS清洗细胞3次,添加100μl iFluor标记的山羊抗小鼠IgG,4℃孵育45分钟。最后用PBS清洗细胞3次,用FACS BD Calibur读取信号。
3)杂交瘤亚克隆
使用有限稀释法进行亚克隆。使用血球细胞计数器并在含杂交瘤细胞选择剂胸腺核苷嘧啶,次黄嘌呤和氨基喋呤的DMEM/10%FBS培养基中对细胞进行系列稀释来确定细胞数量,直至细胞密度达到5-15个细胞/ml。对于每个杂交瘤,将200μl的细胞溶液用移液管移至96孔中,密度为1-3个细胞/孔。将培养物在37℃下在5%CO2中培养1周后,对上清液进行上述ELISA结合,ELISA竞争和FACS结合测试,来评估针对PD-1-Fc的抗体的存在情况。
实施例2:单克隆抗体的可变区测序及抗体重组生产
使用快速ELISA小鼠抗体亚型鉴定试剂盒(Clonotyping System-HRP,SouthernBiotech)对单克隆抗体进行亚型鉴定后,使用TRIzol(Ambion)从3×106-5×106个杂交瘤细胞提取总RNA,并利用抗体亚型特异性引物和通用引物(PrimeScriptTM 1stStrand cDNA Synthesis Kit,Takara)将其逆转录为cDNA。随后通过RACE PCR(GenScript)扩增鼠免疫球蛋白重链和轻链V-区域片段,并将所得的PCR片段亚克隆至pMD18-T载体系统(Takara)中,并使用载体特异性引物对插入片段进行测序。最终获得了克隆1H10C4D4,2E5E4D11,154G5A5B7的独特V-区域核苷酸/蛋白序列。
1H10C4D4重链可变区氨基酸序列:SEQ ID NO:1
1H10C4D4重链可变区DNA序列:SEQ ID NO:2
1H10C4D4轻链可变区氨基酸序列:SEQ ID NO:3
1H10C4D4轻链可变区DNA序列:SEQ ID NO:4
2E5E4D11重链可变区氨基酸序列:SEQ ID NO:5
2E5E4D11重链可变区DNA序列:SEQ ID NO:6
2E5E4D11轻链可变区氨基酸序列:SEQ ID NO:7
2E5E4D11轻链可变区DNA序列:SEQ ID NO:8
154G5A5B7重链可变区氨基酸序列:SEQ ID NO:9
154G5A5B7重链可变区DNA序列:SEQ ID NO:10
154G5A5B7轻链可变区氨基酸序列:SEQ ID NO:11
154G5A5B7轻链可变区DNA序列:SEQ ID NO:12
分别合成包含轻链可变区+恒定区与重链可变区+恒定区的DNA片段,将其分别插入pTT5表达载体中,形成表达质粒。
将上述质粒共转染HEK293-6E细胞,并于37℃摇瓶中培养10天后,收取上清用于抗体纯化。纯化之前,将管道和蛋白A柱用0.2M NaOH去热原。将柱用含有0.05M Tris和1.5M NaCl(pH=8.0)的缓冲液重新平衡。随后将收获的细胞培养物上清液,使用2×上述缓冲液1:1稀释并过滤除菌。将过滤的上清液和蛋白A柱室温孵育2小时,用并1×上述缓冲液洗涤柱后,使用无菌0.1M柠檬酸钠(pH3.5)洗脱IgG,收集了洗脱液并用九分之一体积的无菌1M Tris-HCl(pH=9.0)中和。在无菌条件下,将所述产品缓冲液交换为PBS(pH7.4)以除去任何的洗脱缓冲液并浓缩所述样品。浓缩之后,使用1.43的消光系数Ec(0.1%)通过OD280nm对抗体进行定量。
纯化的抗体通过BioRad电泳系统用10%预制胶(GenScript)通过SDS-PAGE来分析。将所述凝胶用Estain2.0(GenScript)染色并通过比较染色带与Protein Ladder(GenScript)来估计分子大小和纯度。
实施例3:单克隆抗体对人PD-1重组蛋白的结合
间接ELISA用于评估纯化抗体对于PD-1-Fc的结合能力。将ELISA板(Nunc)用100μl/孔的PBS中0.5μg/ml的重组PD-1-Fc或人IgG1在4℃下包被过夜。用PBS-T(0.05%吐温)洗涤板,并将其用200μl/孔的含1%BSA的PBST在37℃封闭0.5小时。随后弃去封闭液,向首孔加入10μg/ml的纯化抗体100μl,并按照3倍梯度稀释,共计11个测试浓度梯度。然后在室温下孵育1小时。将板用PBST洗涤3次,并用100μl/孔的缀合辣根过氧化物酶的山羊抗小鼠IgG(Fab-特异性)(GenScript)37℃孵育0.5小时。将板用PBST洗涤五次,然后加入TMB显色液(GenScript)并在室温下在黑暗中孵育15分钟。通过加入50μl的1MHCl终止液(Sigma)终止反应。使用酶标仪在450nm下读板。如图2,PD-1抗体克隆与PD-1-Fc重组蛋白结合ELISA实验,各克隆的EC50如下:Keytruda:EC50=9.15ng/ml;1H10C4D4:EC50=6.81ng/ml;2E5E4E11:EC50=4.65ng/ml;154G5A5B7:EC50=8.72ng/ml;与Keytruda相比,这些测试的克隆均达到或超过到其抗原结合能力。
实施例4:单克隆抗体对表达人PD-1的细胞系的结合
收集用于检测的表达PD-1的CHO细胞和阴性对照的母细胞,用PBS清洗3次。在96孔板中加入2.5X105个检测细胞和5μg/ml纯化抗体100ul,4℃孵育1小时。随后用PBS清洗细胞3次,添加100μliFluor标记的山羊抗小鼠IgG,4℃孵育45分钟。最后用PBS清洗细胞3次,用FACS BD Calibur读取信号。如图3,所有图中克隆和细胞系的结合都表现出很强的结合能力,FACS偏移都在1个log甚至以上。
实施例5:单克隆抗体阻断PD-1与PD-L1蛋白的结合
将ELISA板(Nunc)用100μl/孔的PBS中0.5μg/ml的重组人PD-1蛋白在4℃下包被过夜。用PBS-T(0.05%吐温)洗涤板,并将其用200μl/孔的含1%BSA的PBST在37℃封闭0.5小时。随后弃去封闭液,首个测试孔加入50μg/ml待测纯化抗体50μl,并按照3倍梯度稀释,共计11个测试浓度梯度。然后每孔添加50μl生物素标记的PD-L1-Fc(浓度为0.15μg/ml),在37℃孵育1小时。将板用PBST洗涤三次,并用100μl/孔的抗生物素蛋白链菌素HRP(SA-HRP,GenScript)37℃孵育10分钟。最后将板用PBST洗涤五次,然后加入TMB显色液(GenScript)并在室温下在黑暗中孵育15分钟。通过加入50μl的1MHCl终止液(Sigma)终止反应。使用酶标仪在450nm下读板。如图4,各克隆的IC50如下,Keytruda,IC50=0.2241μg/ml;1H10C4D4,IC50=0.4934μg/ml;2E5E4E11,IC50=0.4289μg/ml;154G5A5B7,IC50=0.3662μg/ml;3株克隆的阻断能力非常接近阳性药Keytruda。
实施例6:单克隆抗体表位鉴定
竞争ELISA用于评估纯化抗体的抗原表位。将ELISA板(Nunc)用100μl/孔的PBS中0.5μg/ml的重组PD-1-Fc在4℃下包被过夜。用PBS-T(0.05%吐温)洗涤板,并将其用200μl/孔的含1%BSA的PBST在37℃封闭0.5小时。随后弃去封闭液,每孔分别加入一对(其中一个已标记生物素)用于竞争实验的待测抗体,每个纯化抗体100μl(10μg/ml)。然后在37℃下孵育1小时。将板用PBST洗涤三次,并用100μl/孔的抗生物素蛋白链菌素HRP(SA-HRP,GenScript)37℃孵育10分钟。将板用PBST洗涤五次,然后加入TMB显色液(GenScript)并在室温下在黑暗中孵育15分钟。通过加入50μl的1MHCl终止液(Sigma)终止反应。使用酶标仪在450nm下读板。1H10C4D4,2E5E4E11和154G5A5B7均与阳性对照药是同一个表位,但23F12A9与其他所有克隆的表位都不一样。
实施例7:单克隆抗体的功能性检测
在混合淋巴细胞反应中,通过试剂盒(Miltenyl Biotec),从人的外周血单核细胞分离并纯化获得CD4+T细胞及同种异体的单核细胞。诱导单核细胞成为树突细胞。每孔含有105个CD4+T细胞及104个同种异体的单核细胞,最终工作体积是200μl。不同浓度的抗体样品加入到每个孔内。无抗体孔作为背景对照,人IgG4抗体作为阴性对照,派姆单抗(Pembrolizumab(Keytruda),Merck&Co.,Inc)作为PD-1抗体的阳性对照。37℃及5%CO2条件下,孵育72小时后,从每孔中取100μl上清检测IL-2含量(Cisbio的检测试剂盒)。
在细胞水平的抗体功能性检测实验中,人的PD-1及由NFAT核转录反应元件(NFAT-RE)控制的荧光报告基因稳定转染在效用细胞中,人的PD-L1及细胞表面蛋白抗原多肽/主要组织相容性复合体(MHC)稳定转染在靶细胞中作为人为的抗原提呈细胞,表达PD-1的效用细胞与表达PD-L1的靶细胞共培养,相对光单位(RLU)用来衡量效用细胞激活的指标。在共培养系统中加入不同浓度的PD-1抗体克隆,PD-1抗体克隆阻断表达在效用细胞上PD-1和表达在靶细胞上的PD-l的结合,导致效用细胞的激活,RLU读数增加。如图5所示,与Keytruda相比,这些测试的克隆均达到或超过到其功能。
SEQUENCE LISTING
<110> 南京金斯瑞生物科技有限公司
<120> 高亲和力、高特异性、多抗原识别表位的具有更高功能性的抗人PD-1抗体
<130> 2016
<160> 12
<170> PatentIn version 3.3
<210> 1
<211> 137
<212> PRT
<213> 人工序列
<400> 1
Met Asn Phe Gly Leu Ser Leu Ile Phe Leu Val Leu Ile Leu Lys Gly
1 5 10 15
Val Gln Cys Glu Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Lys
20 25 30
Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Ser Tyr Asp Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu
50 55 60
Glu Trp Val Ala Thr Ile Ser Gly Gly Gly Ser Tyr Thr Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Asn Leu Tyr Leu Gln Met Ser Ser Leu Arg Ser Glu Asp Thr Ala Leu
100 105 110
Tyr Tyr Cys Gly Ser Pro Tyr Gly Lys Tyr Gly Met Glu Tyr Trp Gly
115 120 125
Gln Gly Thr Ser Val Thr Val Ser Ser
130 135
<210> 2
<211> 411
<212> DNA
<213> 人工序列
<400> 2
atgaacttcg ggctcagctt gattttcctt gtcctaattt taaaaggtgt ccagtgtgaa 60
gtgaagctgg tggagtctgg gggaggctta gtgaagcctg gagggtccct gaagctctcc 120
tgtgcagcct ctggattcac tttcagtagt tatgacatgt cttgggttcg ccagactccg 180
gacaagaggc tggagtgggt cgcaaccatt agtggtggtg gcagttacac ctactatcca 240
gacagtgtga aggggcgatt caccatctcc agagacaatg ccaagaacaa cctgtaccta 300
caaatgagca gtctgaggtc tgaggacacg gccttgtatt actgtggaag cccgtatggt 360
aaatatggta tggagtactg gggtcaagga acctcagtca ccgtctcctc a 411
<210> 3
<211> 131
<212> PRT
<213> 人工序列
<400> 3
Met Gly Ile Lys Met Glu Thr His Ser Gln Val Phe Val Tyr Met Leu
1 5 10 15
Leu Trp Leu Ser Gly Val Glu Gly Asp Ile Val Met Thr Gln Ser His
20 25 30
Lys Phe Met Ser Thr Ser Val Gly Asp Arg Val Ser Ile Thr Cys Lys
35 40 45
Ala Ser Gln Asp Val Gly Ser Val Val Ala Trp Tyr Gln Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg His Thr
65 70 75 80
Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Thr Ile Ser Asn Val Gln Ser Glu Asp Leu Ala Asp Tyr Phe Cys
100 105 110
Gln Gln Tyr Ser Ser Tyr Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu
115 120 125
Glu Leu Lys
130
<210> 4
<211> 393
<212> DNA
<213> 人工序列
<400> 4
atgggcatca agatggagac acattctcag gtctttgtat acatgttgct gtggttgtct 60
ggtgttgaag gagacattgt gatgacccag tctcacaaat tcatgtccac atcagtagga 120
gacagggtca gcatcacctg caaggccagt caggatgtgg gttctgttgt agcctggtat 180
caacagaaac cagggcaatc tcctaaacta ctgatttact gggcatccac ccggcacact 240
ggagtccctg atcgcttcac aggcagtgga tctgggacag atttcactct caccattagc 300
aatgtgcagt ctgaagactt ggcagattat ttctgtcagc aatatagtag ctatccgctc 360
acgttcggtt ctgggaccaa gctggagctg aaa 393
<210> 5
<211> 138
<212> PRT
<213> 人工序列
<400> 5
Met Asn Phe Gly Leu Ser Leu Ile Phe Leu Val Leu Val Leu Lys Gly
1 5 10 15
Val Leu Cys Glu Val Lys Leu Val Glu Ser Gly Gly Val Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Ser Tyr Thr Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu
50 55 60
Glu Trp Val Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Pro
65 70 75 80
Asp Thr Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Thr Leu Tyr Leu Gln Met Asn Ser Leu Lys Ser Gly Asp Thr Ala Met
100 105 110
Tyr Tyr Cys Ala Arg His Gly Tyr Asp Ala Ala Cys Phe Ala Tyr Trp
115 120 125
Gly Gln Gly Thr Leu Val Thr Val Ser Ala
130 135
<210> 6
<211> 414
<212> DNA
<213> 人工序列
<400> 6
atgaatttcg ggctcagctt gattttcctt gtccttgttt taaaaggtgt cctgtgtgaa 60
gtgaagctgg tggagtctgg gggagtttta gtgcagcctg gagggtccct gaaactctcc 120
tgtgcagcct ctggattcac tttcagtagc tataccatgt cttgggttcg ccagactccg 180
gagaagaggc tggagtgggt cgcatacatt agtggtggtg gtggtgacac ctactatcca 240
gacactgtga agggccgatt caccatctcc agagacaatg ccaagaacac cctgtacctg 300
caaatgaaca gtctgaagtc tggggacacg gccatgtatt actgtgcaag acatggttac 360
gacgctgcct gttttgctta ctggggccaa gggactctgg tcactgtctc tgca 414
<210> 7
<211> 131
<212> PRT
<213> 人工序列
<400> 7
Met Gly Ile Lys Met Glu Ser Gln Ile Gln Ala Phe Val Phe Val Phe
1 5 10 15
Leu Trp Leu Ser Gly Val Asp Gly Asp Ile Val Met Thr Gln Ser His
20 25 30
Lys Phe Met Ser Thr Ser Val Gly Asp Arg Val Ser Phe Thr Cys Lys
35 40 45
Ala Ser Gln Asp Val Asn Thr Ala Val Ala Trp Tyr Gln Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg His Thr
65 70 75 80
Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr
85 90 95
Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Leu Tyr Tyr Cys
100 105 110
Gln Gln His Tyr Ser Ile Pro Trp Thr Val Gly Gly Gly Thr Lys Leu
115 120 125
Glu Ile Lys
130
<210> 8
<211> 393
<212> DNA
<213> 人工序列
<400> 8
atgggcatca agatggagtc acagattcag gcatttgtat tcgtgtttct ctggttgtct 60
ggtgttgacg gagacattgt gatgacccag tctcacaaat tcatgtccac atcagttgga 120
gacagggtca gcttcacctg caaggccagt caggatgtga atactgctgt ggcctggtat 180
caacaaaaac cagggcaatc tcctaaacta ctgatttact gggcatccac ccggcacact 240
ggagtccctg atcgcttcac aggcagtgga tctgggacag attatactct caccatcagc 300
agtgtgcagg ctgaagacct ggcgctttat tactgtcagc aacactatag cattccgtgg 360
acggtcggtg gaggcaccaa gctggaaatc aaa 393
<210> 9
<211> 135
<212> PRT
<213> 人工序列
<400> 9
Met Ala Val Leu Ala Leu Leu Phe Cys Leu Val Thr Phe Pro Ser Cys
1 5 10 15
Ile Leu Ser Gln Val Gln Leu Lys Glu Ser Gly Pro Gly Leu Val Ala
20 25 30
Pro Ser Gln Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu
35 40 45
Thr Val Tyr Gly Val Asn Trp Val Arg Gln Pro Pro Gly Lys Gly Leu
50 55 60
Glu Trp Leu Gly Met Ile Trp Gly Asp Gly Thr Thr Asp Tyr Asn Ser
65 70 75 80
Ala Leu Lys Ser Arg Leu Ile Ile Asn Lys Asp Asn Ser Lys Ser Gln
85 90 95
Val Phe Leu Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Arg Tyr
100 105 110
Tyr Cys Ala Arg Asp Asp Tyr Gly Thr Phe Leu Tyr Trp Gly Gln Gly
115 120 125
Thr Leu Val Thr Val Ser Ala
130 135
<210> 10
<211> 405
<212> DNA
<213> 人工序列
<400> 10
atggctgtcc tggcattact cttctgcctg gtaacattcc caagctgtat cctttcccag 60
gtgcagctga aggagtcagg acctggcctg gtggcgccct cacagagcct gtccatcaca 120
tgcaccgtct cagggttctc attaaccgtc tatggtgtaa actgggttcg ccagcctcca 180
ggaaagggtc tcgagtggct ggggatgatt tggggtgatg gaaccacaga ctataattca 240
gctctcaaat ccagactgat catcaacaag gacaactcca agagccaagt tttcttaaaa 300
atgaacagtc tgcaaactga tgacacagcc aggtactact gtgccagaga tgactatggt 360
accttccttt actggggcca agggactctg gtcactgtct ctgca 405
<210> 11
<211> 132
<212> PRT
<213> 人工序列
<400> 11
Met Asp Ser Gln Ala Gln Val Leu Ile Leu Leu Leu Leu Trp Val Ser
1 5 10 15
Gly Thr Cys Gly Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala
20 25 30
Val Ser Ala Gly Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser
35 40 45
Leu Leu Asn Ser Arg Thr Arg Lys Asn Tyr Leu Ala Trp Tyr Gln Gln
50 55 60
Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Phe Trp Ala Ser Thr Arg
65 70 75 80
Glu Ser Gly Val Pro Asp Arg Phe Thr Gly Ser Val Ser Gly Thr Asp
85 90 95
Phe Thr Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr
100 105 110
Tyr Cys Lys Gln Ser Tyr Thr Leu Arg Thr Phe Gly Gly Gly Thr Lys
115 120 125
Leu Glu Ile Lys
130
<210> 12
<211> 396
<212> DNA
<213> 人工序列
<400> 12
atggattcac aggcccaggt tcttatattg ctgctgctat gggtatctgg tacctgtggg 60
gacattgtga tgtcacagtc tccatcctcc ctggctgtgt cagcaggaga gaaggtcact 120
atgagttgca aatccagtca gagtctgctc aacagtagaa cccgaaagaa ctacttggct 180
tggtatcagc agaaaccagg gcagtctcct aaactgctga tcttctgggc atccactagg 240
gaatctgggg tccctgatcg cttcacaggc agtgtatctg ggacagattt cactctcacc 300
atcagcagtg tgcaggctga agacctggca gtttattact gcaagcaatc ttatactctt 360
cggacgttcg gtggaggcac caagctggaa atcaaa 396
- 还没有人留言评论。精彩留言会获得点赞!