双特异嵌合抗原受体修饰的T细胞、其制备方法及用途与流程
本发明涉及肿瘤治疗的
技术领域:
。具体地,本发明涉及特异性靶向CEA5和MSLN胞外域的表达IL-15的双特异性嵌合抗体受体修饰的T细胞、其制备方法以及在治疗肿瘤中的用途。
背景技术:
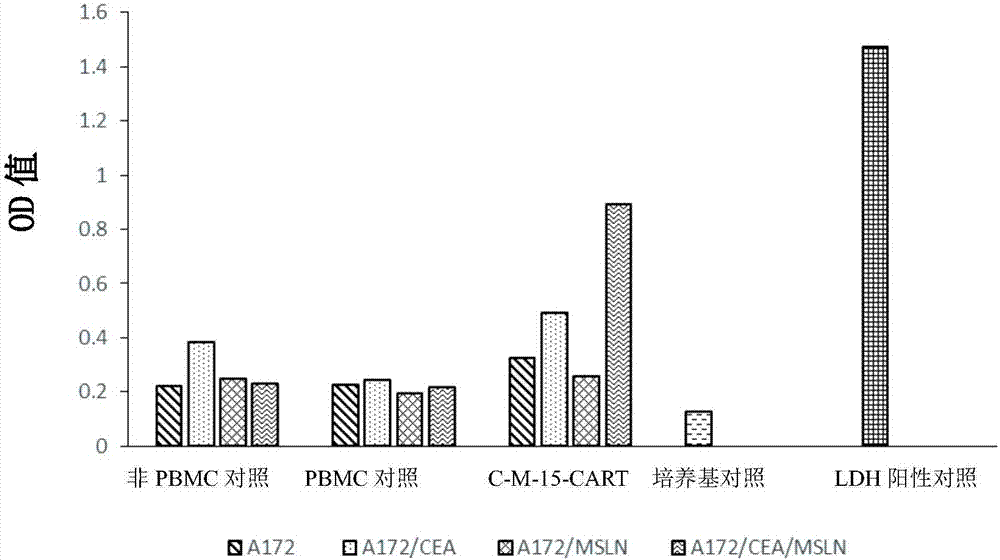
:细胞治疗是继手术、放疗和化疗之后的又一种肿瘤治疗方法,它一般作为手术、放化疗的辅助手段,延长患者的寿命,清除体内手术后残余的肿瘤细胞。淋巴细胞免疫技术在国内外已经用于临床治疗肿瘤,并取得些许临床疗效,例如细胞因子诱导杀伤细胞、细胞毒T淋巴细胞以及TIL等,但均为非特异性杀伤作用,其对体内肿瘤细胞的清除作用还十分有限。嵌合抗原受体CAR由一个scFv单链抗体通过铰链和跨膜结构与胞内信号结构连接构成。表达CAR的T细胞可通过非MHC限制性途径与抗原反应。自1989年,由Eshhar和其同事首次提出CAR的概念以来,其已经历了三个不同的发展阶段。第一代CAR受体,包含胞外特异识别肿瘤抗原的scFv片段,胞内激活信号由CD3ζ或FcεRIγ的ITAM信号链来传递。但是第一代CAR受体缺乏T细胞的共刺激信号,导致T细胞只能发挥瞬间效应,在体内存在时间短、细胞因子分泌少。第二代CAR受体在第一代CAR的基础上增加了一个共刺激信号分子的胞内结构域,提供T细胞活化的两种信号,增强了T细胞的增殖能力。第三代CAR受体,在第二代CAR的基础上,增加了另外一种共刺激信号分子的胞内结构域,产生一个三重信号的CAR受体,第三代CAR受体改造的T细胞具有更好的效应功能和体内存活时间。2017年8月30日美国FDA批准第一个CAR-T细胞(诺华的CD19CART)上市,商品名Kymriah。2017年10月18日,FDA再次批准CAR-T细胞治疗KitePharma的Yescarta上市。伴随这两个产品的上市,CAR-T技术治疗肿瘤进入历史性阶段。目前,国内外进入临床试验的CAR-T项目有200余项。无论是已上市的CAR-T产品,还是正在进行临床试验的项目,均存在CAR-T细胞脱靶效应,在一定程度上导致CAR-T细胞的强烈副作用。因此有必要对CAR的自身应用体系进行改造,提高CAR介导的肿瘤ACT的临床安全性。技术实现要素:目前临床应用的T淋巴细胞技术靶向肿瘤细胞的杀伤特异性差、在体内激活患者自身免疫作用的抗肿瘤效果不足,造成大多数T淋巴细胞靶向技术对恶性肿瘤的临床治疗有限。本发明人在前期研究工作中发现,肺鳞癌、结直肠癌和胰腺导管癌组织和细胞均特异性地共高表达癌胚抗原(CEA5)和间皮素(Mesothelin,MSLN)两个肿瘤特异性抗原。在这一发现的基础上,本发明人通过杂交瘤技术分别获得与肿瘤抗原CEA5和MSLN的胞外区特异性结合的两个单克隆抗体,以及产生该单克隆的细胞株。通过蛋白测序确定单克隆抗体的重链和轻链的可变区,利用基因PCR技术将重链和轻链通过链接子(linker)连接产生单链抗体(scFv),借助酶联免疫法和流式细胞仪检测分别能特异性结合CEA5和MSLN肿瘤抗原的两个scFv,这两个scFv可以作为结合CEA5和MSLN肿瘤抗原的抗体。本发明提供了一种表达IL-15的靶向肺癌、结、直肠癌、胰腺癌等肿瘤细胞的双特异嵌合抗原受体修饰的T淋巴细胞的制备方法。其中癌胚抗原(CEA5)和间皮素(Mesothelin,MSLN)两种靶抗原能够同时在肺鳞癌细胞、结直肠癌细胞以及导管胰腺癌共表达。本发明靶向CEA5和MSLN胞外域,免疫产生特异性结合的单克隆株,通过基因重组获得与两者特异性结合的单链抗体;同时由于IL-15能够刺激T细胞、NK细胞、NKT细胞等加速成熟,间接破坏肿瘤微环境,因而构建成含抗人CEA5和MSLN以及IL-15的双特异性嵌合抗原受体基因,重组到病毒载体上并转染至人T淋巴细胞,高表达该双特异性嵌合抗原受体基因,可特异性结合人CEA5和MSLN共表达的肺癌结直肠癌胰腺癌等肿瘤细胞,激活第一信号和共刺激信号而引发抗癌细胞活性,细胞水平试验抗肿瘤具有很强杀伤活性。进一步地,本发明涉及参与不同信号的两个嵌合抗原受体,其各自独立地传递信号,其中一个嵌合抗原受体由特异性结合肿瘤抗原CEA5胞外区的scFV、CD8铰链区、跨膜区和CD3ζ胞内信号传导域组成,另一个嵌合抗原受体由特异性结合肿瘤抗原MSLN胞外区的scFV、CD8铰链区、跨膜区和CD137胞内信号传导域组成。本发明共表达的细胞因子包括IL-12、IL-15、IFN-γ。在本发明的进一步的方面,通过人工合成MSLN-CAR-T2A-IL-15基因片断,构建慢病毒质粒,包装成慢病毒后,浸染T细胞,借助CAR-T细胞与肿瘤细胞相互作用,内源表达IL-15。在本发明中的一个实施方案中,所述共表达的细胞因子为IL-15。本发明涉及一种内源表达IL-15的靶向肺癌、结直肠癌、胰腺癌等肿瘤细胞的双特异嵌合抗原受体修饰的T淋巴细胞的制备方法。本发明的基础在于通过流式细胞分析技术得知,CEA5和MSLN两种靶抗原能够同时在肺鳞癌细胞、结直肠癌细胞以及导管胰腺癌高度共表达。本发明靶向CEA5和MSLN胞外域,免疫产生特异性结合的单克隆株,通过基因重组获得与两者特异性结合的单链抗体;同时由于IL-15(IL-15)能够刺激T细胞、NK细胞、NKT细胞等加速成熟,间接破坏肿瘤微环境,因而构建成含抗人CEA5和MSLN以及IL-15的双特异性嵌合抗原受体基因重组到病毒载体上并转染至人T淋巴细胞,高表达该双特异性嵌合抗原受体基因,可特异性结合人CEA5和MSLN共表达的肺癌、结肠癌、直肠癌、胰腺癌等肿瘤细胞,在体外试验激活免疫信号而引发很强的抗肿瘤细胞活性。本发明所述双特异性嵌合抗原受体基因的cDNA构建在病毒载体中,并转染T淋巴细胞,再将T淋巴细胞培养至16天,获得双特异性CAR-T细胞;通过流式细胞分析技术,CAR-T细胞阳性率达60%以上。一方面,本发明一种双特异性嵌合抗原受体,其包含特异性结合CEA5胞外区的嵌合抗原受体部分和特异性结合MSLN胞外区的嵌合抗原受体部分,其中所述特异性结合CEA5胞外区的嵌合抗原受体部分由抗CEA5胞外区的特异性抗体、CD8铰链区、CD8跨膜区和CD3ζ胞内信号传导域组成,所述特异性结合MSLN胞外区的嵌合抗原受体部分由抗MSLN胞外区的特异性抗体、CD8铰链区、CD8跨膜区和CD137胞内信号传导域组成。优选地,所述抗CEA5胞外区的特异性抗体是scFv抗体;其由通过接头连接的轻链可变区和重链可变区组成。进一步优选地,所述抗MSLN胞外区的特异性抗体scFv抗体;其由通过接头连接的轻链可变区和重链可变区组成。优选地,根据本发明所述的双特异性嵌合抗原受体,其中所述抗CEA5胞外区的特异性抗体包含如SEQIDNO:2所示的轻链可变区和如SEQIDNO:4所示的重链可变区。优选地,根据本发明所述的双特异性嵌合抗原受体,其中抗MSLN胞外区的特异性抗体包含如SEQIDNO:6所示的轻链可变区和如SEQIDNO:8所示的重链可变区。更优选地,根据本发明所述的双特异性嵌合抗原受体,其中所述CD8铰链区和CD8跨膜区如SEQIDNO:14所示和CD3ζ胞内信号传导域如SEQIDNO:10所示。进一步优选地,根据本发明所述的双特异性嵌合抗原受体,其中所述CD137胞内信号传导域如SEQIDNO:12所示。另一方面,本发明涉及编码本发明双特异性嵌合抗原受体的cDNA。另一方面,本发明涉及包含编码本发明双特异性嵌合抗原受体的cDNA的表达载体。根据本发明的一个实施方案,可以在一个表达载体中包含编码特异性结合CEA5胞外区的嵌合抗原受体部分的cDNA和编码特异性结合MSLN胞外区的嵌合抗原受体部分的cDNA;其中编码两部分的cDNA通过mRNA自剪切位点,如T2A切割位点连接。根据本发明的另一个实施方案,可以在不同的表达载体中分别包含编码特异性结合CEA5胞外区的嵌合抗原受体部分的cDNA和编码特异性结合MSLN胞外区的嵌合抗原受体部分的cDNA。在本发明的另一个实施方案中,可以在一个表达载体中包含编码特异性结合CEA5胞外区的嵌合抗原受体部分的cDNA、编码特异性结合MSLN胞外区的嵌合抗原受体部分的cDNA,以及包含IL-15基因。优选地,通过T2A切割位点连接编码特异性结合CEA5胞外区的嵌合抗原受体部分的cDNA、编码特异性结合MSLN胞外区的嵌合抗原受体部分的cDNA和包含编码IL-15的基因。根据本发明的另一个实施方案,可以在不同的表达载体中分别包含编码特异性结合CEA5胞外区的嵌合抗原受体部分的cDNA、编码特异性结合MSLN胞外区的嵌合抗原受体部分的cDNA、以及编码IL-15的基因。优选地,根据本发明所述的表达载体是慢病毒载体。另一方面,本发明涉及用根据本发明的表达载体转染的T淋巴细胞,其中所述T淋巴细胞特异性结合人CEA5和MSLN,和/或所述T淋巴细胞表达IL-15。另一方面,本发明涉及根据本发明所述的T淋巴细胞在制备用于抗肿瘤的药物中的用途,其中所述肿瘤的细胞共表达CEA5和MSLN抗原。优选地,所述肿瘤选自肺癌、结肠癌、直肠癌和胰腺癌。附图说明图1显示A172模型靶细胞的荧光蛋白表达图;其中A172/CEA模型细胞显示显著的CEA绿色荧光表达;A172/MSLN模型细胞显示显著的MSLN蛋白红色荧光表达;A172/CEA/MSLN模型细胞显示显著的CEA绿色荧光和MSLN蛋白红色荧光表达。图2通过ELISA检测的双特异CEA-MSLN-CART细胞杀伤A172模型靶细胞的LDH效果;细胞上清中乳酸脱氢酶(LDH)OD值越高,说明效应细胞杀伤该靶细胞效果愈明显,靶细胞凋亡或死亡数量愈多。所以从本结果中可以看出,C-M15-CART细胞(即双特异CEA-MSLN-CART的简写)对A172/CEA/MSLN模型靶细胞的杀伤效果明显优于对其它模型靶细胞的杀伤效果。图3A1-图3E4是显示人结肠癌细胞系SW620、人胰腺癌细胞系PANC-1、人结肠癌细胞系LoVo、人胰腺癌细胞系BxPC-1和人肺癌细胞系NCI-H226的流式细胞分析图。这些图显示经流式细胞检测,上述五种细胞膜表面均共表达CEA和MSLN两种靶抗原,其中,图3A-1至3A-4表示BxPc-3细胞;图3B-1至3B-4表示LoVo细胞;图3C-1至3C-4表示NCI-H226;图3D-1至3D-4表示PANC-1以及图3E-1至3E-4表示SW620细胞。图4是双特异CEA-MSLN-CART细胞杀伤肿瘤细胞效果图示。该结果表明,与PMBC相比,本发明的双特异CEA-MSLN-CART细胞杀伤LoVo、NCI-H226、PANC-1和SW620的效果显著。尽管NCI-H226肺癌细胞膜表面亦共表达CEA5和MSLN双靶标,但CEA-MSLN-CART细胞对其杀伤效果微弱。图5是双特异CEA-MSLN-CART细胞杀伤肿瘤细胞效靶比实验结果。从结果中显示出,随着CART细胞数量增多,其杀伤LoVo、PANC-1和SW620效果增强,当E:T比值达到20时,CART细胞杀伤能力达到最强。图6是ELISA检测双特异CEA-MSLN-CART细胞杀伤A172/CEA/MSLN靶细胞时IL-15表达结果。结果显示,CART细胞杀伤靶细胞时,其上清中IL-15的OD值与其它两组对照细胞相比,有差异。表明IL-15能够正常表达。图7A至图7D是CAR慢病毒侵染PBMC后48h荧光检测结果。结果显示,CAR慢病毒侵染率达60%以上。图8是CEA-MSLN-CAR结构。具体实施方式以下结合附图,通过实施例进一步说明本发明,但不作为对本发明的限制。以下提供了本发明实施方式中所使用的具体材料及其来源。但是,应当理解的是,这些仅仅是示例性的,并不意图限制本发明,与如下试剂和仪器的类型、型号、品质、性质或功能相同或相似的材料均可以用于实施本发明。下述实施例中所使用的实验方法如无特殊说明,均为常规方法。下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。在本发明的具体实施方案中,本发明人通过人工合成构建两个嵌合抗原受体,其中一个嵌合抗原受体由特异性结合肿瘤抗原CEA5胞外区的scFV、CD8铰链区、跨膜区和CD3ζ胞内信号传导域组成,另一个嵌合抗原受体由特异性结合肿瘤抗原MSLN胞外区的scFV、CD8铰链区、跨膜区和CD137胞内信号传导域组成,其中在MSLN特异性嵌合抗体受体中包含IL-15基因片段,即,人工合成MSLN-CAR-T2A-IL-15基因片断。使用上述基因片段构建慢病毒质粒,包装成慢病毒后,浸染T细胞,借助CAR-T细胞与肿瘤细胞相互作用,内源表达IL-15。具体地,本发明的信号肽-scFV(CEA5)-CD8铰链区-CD8跨膜区-CD3ζ胞内区、信号肽-scFV(MSLN)-CD8铰链区-CD8跨膜区-CD137胞内区、以及信号肽-IL15通过T2A切割位点连接在一起,形成重组基因序列,基因序列通过化学合成,形成完整的双特异性嵌合抗原受体基因cDNA(参见图8)。在本发明的实施方案中使用的抗CEA5以及抗MSLN的单克隆抗体的序列以及其它序列如下所示:CEA5scFv编码轻链可变区(VL)的基因序列:GATATCGTGATGACCCAGTCTCAAAGATTCATGTCCACATCAGTAGGAGACAGGGTCAGCGTCACCTGCAAGGCCAGTCAGAATGTGGGTACTAATGTTGCCTGGTATCAACAGAAACCAGGACAATCCCCTAAAGCACTGATTTACTCGGCATCCTACCGGTACAGTGGAGTCCCTGATCGCTTCACAGGCAGTGGATCTGGGACAGATTTCACTCTCACCATCAGCAATGTACAGTCTGAAGACTTGGCGGAGTATTTCTGTCACCAATATTACACCTATCCTCTATTCACGTTCGGCTCGGGGACAAAGTTGGAAATGAAACGTSEQIDNO:1轻链可变区(VL)的氨基酸序列:DIVMTQSQRFMSTSVGDRVSVTCKASQNVGTNVAWYQQKPGQSPKALIYSASYRYSGVPDRFTGSGSGTDFTLTISNVQSEDLAEYFCHQYYTYPLFTFGSGTKLEMKRSEQIDNO:2编码重链可变区(VH)的基因序列:CAGGTGAAGCTGCAGCAGTCAGGACCTGAGTTGAAGAAGCCTGGAGAGACAGTCAAGATCTCCTGCAAGGCTTCTGGATATACCTTCACAGAATTCGGAATGAACTGGGTGAAGCAGGCTCCTGGAAAGGGTTTAAAGTGGATGGGCTGGATAAACACCAAAACTGGAGAGGCAACATATGTTGAAGAGTTTAAGGGACGGTTTGCCTTCTCTTTGGAGACCTCTGCCACCACTGCCTATTTGCAGATCAACAACCTCAAAAATGAGGACACGGCTAAATATTTCTGTGCTCGATGGGATTTCTATGACTATGTTGAAGCTATGGACTACTGGGGCCAAGGGACCACCGTGACCGTCTCCSEQIDNO:3重链可变区(VH)的氨基酸序列:QVKLQQSGPELKKPGETVKISCKASGYTFTEFGMNWVKQAPGKGLKWMGWINTKTGEATYVEEFKGRFAFSLETSATTAYLQINNLKNEDTAKYFCARWDFYDYVEAMDYWGQGTTVTVSSEQIDNO:4MSLNscFv编码轻链可变区(VL)的基因序列:GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTATTGGAGACAGAGTCACCATCACCTGCCGGGCCAGCGAGGGTATTTATCACTGGTTGGCCTGGTATCAGCAGAAGCCAGGGAAAGCCCCTAAACTCCTGATCTATAAGGCCTCTAGTTTAGCCAGTGGGGCCCCATCAAGGTTCAGCGGCAGTGGATCTGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTGCAACTTATTACTGCCAACAATATAGTAATTATCCGCTCACTTTCGGCGGAGGGACCAAGCTGGAGATCAAASEQIDNO:5轻链可变区(VL)的氨基酸序列:DIQMTQSPSTLSASIGDRVTITCRASEGIYHWLAWYQQKPGKAPKLLIYKASSLASGAPSRFSGSGSGTDFTLTISSLQPDDFATYYCQQYSNYPLTFGGGTKLEIKSEQIDNO:6编码重链可变区(VH)的基因序列:CAGGTGCAGCTGGTGCAGTCTGGGGCTGAGGTGAAGAGACCTGGGGCCTCAGTGCAGGTTTCCTGCAGAGCATCTGGATACTCAATCAACACCTACTATATGCAGTGGGTGCGACAGGCCCCTGGAGCAGGGCTTGAGTGGATGGGAGTGATCAACCCTAGTGGTGTGACAAGCTACGCACAGAAGTTCCAGGGCAGAGTCACCCTGACCAACGACACGTCCACGAACACAGTCTACATGCAGCTGAACAGCCTGACCTCTGCAGACACGGCCGTGTATTACTGTGCGAGATGGGCACTGTGGGGGGATTTCGGGATGGACGTGTGGGGCAAGGGAACCCTGGTCACCGTCTCCTCASEQIDNO:7重链可变区(VH)的氨基酸序列:QVQLVQSGAEVKRPGASVQVSCRASGYSINTYYMQWVRQAPGAGLEWMGVINPSGVTSYAQKFQGRVTLTNDTSTNTVYMQLNSLTSADTAVYYCARWALWGDFGMDVWGKGTLVTVSSSEQIDNO:8CD3δ(CD247,CD3zeta)基因序列:ATGAAGTGGAAGGCGCTTTTCACCGCGGCCATCCTGCAGGCACAGTTGCCGATTACAGAGGCACAGAGCTTTGGCCTGCTGGATCCCAAACTCTGCTACCTGCTGGATGGAATCCTCTTCATCTATGGTGTCATTCTCACTGCCTTGTTCCTGAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTACAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTACAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTACCAGGGTCTCAGTACAGCCACCAAGGACACCTACGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCSEQIDNO:9蛋白序列:MKWKALFTAAILQAQLPITEAQSFGLLDPKLCYLLDGILFIYGVILTALFLRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPRSEQIDNO:10CD137基因序列:ATGGGAAACAGCTGTTACAACATAGTAGCCACTCTGTTGCTGGTCCTCAACTTTGAGAGGACAAGATCATTGCAGGATCCTTGTAGTAACTGCCCAGCTGGTACATTCTGTGATAATAACAGGAATCAGATTTGCAGTCCCTGTCCTCCAAATAGTTTCTCCAGCGCAGGTGGACAAAGGACCTGTGACATATGCAGGCAGTGTAAAGGTGTTTTCAGGACCAGGAAGGAGTGTTCCTCCACCAGCAATGCAGAGTGTGACTGCACTCCAGGGTTTCACTGCCTGGGGGCAGGATGCAGCATGTGTGAACAGGATTGTAAACAAGGTCAAGAACTGACAAAAAAAGGTTGTAAAGACTGTTGCTTTGGGACATTTAACGATCAGAAACGTGGCATCTGTCGACCCTGGACAAACTGTTCTTTGGATGGAAAGTCTGTGCTTGTGAATGGGACGAAGGAGAGGGACGTGGTCTGTGGACCATCTCCAGCCGACCTCTCTCCGGGAGCATCCTCTGTGACCCCGCCTGCCCCTGCGAGAGAGCCAGGACACTCTCCGCAGATCATCTCCTTCTTTCTTGCGCTGACGTCGACTGCGTTGCTCTTCCTGCTGTTCTTCCTCACGCTCCGTTTCTCTGTTGTTAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGSEQIDNO:11蛋白序列:MGNSCYNIVATLLLVLNFERTRSLQDPCSNCPAGTFCDNNRNQICSPCPPNSFSSAGGQRTCDICRQCKGVFRTRKECSSTSNAECDCTPGFHCLGAGCSMCEQDCKQGQELTKKGCKDCCFGTFNDQKRGICRPWTNCSLDGKSVLVNGTKERDVVCGPSPADLSPGASSVTPPAPAREPGHSPQIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELSEQIDNO:12CD8α序列基因序列:ATGGCCTTACCAGTGACCGCCTTGCTCCTGCCGCTGGCCTTGCTGCTCCACGCCGCCAGGCCGAGCCAGTTCCGGGTGTCGCCGCTGGATCGGACCTGGAACCTGGGCGAGACAGTGGAGCTGAAGTGCCAGGTGCTGCTGTCCAACCCGACGTCGGGCTGCTCGTGGCTCTTCCAGCCGCGCGGCGCCGCCGCCAGTCCCACCTTCCTCCTATACCTCTCCCAAAACAAGCCCAAGGCGGCCGAGGGGCTGGACACCCAGCGGTTCTCGGGCAAGAGGTTGGGGGACACCTTCGTCCTCACCCTGAGCGACTTCCGCCGAGAGAACGAGGGCTACTATTTCTGCTCGGCCCTGAGCAACTCCATCATGTACTTCAGCCACTTCGTGCCGGTCTTCCTGCCAGCGAAGCCCACCACGACGCCAGCGCCGCGACCACCAACACCGGCGCCCACCATCGCGTCGCAGCCCCTGTCCCTGCGCCCAGAGGCGTGCCGGCCAGCGGCGGGGGGCGCAGTGCACACGAGGGGGCTGGACTTCGCCTGTGATATCTACATCTGGGCGCCCTTGGCCGGGACTTGTGGGGTCCTTCTCCTGTCACTGGTTATCACCCTTTACTGCAACCACAGGAACCGAAGACGTGTTTGCAAATGTCCCCGGCCTGTGGTCAAATCGGGAGACAAGCCCAGCCTTTCGGCGAGATACGTCSEQIDNO:13蛋白序列:MALPVTALLLPLALLLHAARPSQFRVSPLDRTWNLGETVELKCQVLLSNPTSGCSWLFQPRGAAASPTFLLYLSQNKPKAAEGLDTQRFSGKRLGDTFVLTLSDFRRENEGYYFCSALSNSIMYFSHFVPVFLPAKPTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVVKSGDKPSLSARYVSEQIDNO:14接头基因序列:GGTGGAGGTGGATCAGGTGGAGGTGGATCTGGTGGAGGTGGATCTSEQIDNO:15蛋白序列:GGGGSGGGGSGGGGSSEQIDNO:16信号肽序列基因序列:ATGCTTCTCCTGGTGACAAGCCTTCTGCTCTGTGAGTTACCACACCCAGCATTCCTCCTGATCCCASEQIDNO:17蛋白序列:MLLLVTSLLLCELPHPAFLLIPSEQIDNO:18IL-15基因序列:ATGAGAATTTCGAAACCACATTTGAGAAGTATTTCCATCCAGTGCTACTTGTGTTTACTTCTAAACAGTCATTTTCTAACTGAAGCTGGCATTCATGTCTTCATTTTGGGCTGTTTCAGTGCAGGGCTTCCTAAAACAGAAGCCAACTGGGTGAATGTAATAAGTGATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCTSEQIDNO:19蛋白序列:MRISKPHLRSISIQCYLCLLLNSHFLTEAGIHVFILGCFSAGLPKTEANWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSEQIDNO:20实施例1:A172模型靶细胞构建1、胰酶消化A172细胞,将细胞转移至15ml离心管中,1000rpm,离心3min,去上清,用DMEM培养基重悬细胞,制备单细胞悬液,计数。调整细胞浓度为2.5×104/ml。2、96孔细胞培养板每孔加A172细胞悬液100ul,共8孔。37℃,5%CO2,培养24h。3、按MOI值为200稀释病毒液。pWSLV-02-CEA病毒液(滴度为107)稀释取2个1.5mlEP管,标记1号和2号,1号EP管加入200ulDMEM完全培养基,2号EP中加入100ulDMEM完全培养基。取50ulpWSLV-02-CEA病毒原液加至1号EP管中,混匀;从1号EP管中取100ul病毒悬液加至2号EP管中,混匀。pWSLV-05-MSLN病毒液(滴度为108)稀释取2个1.5mlEP管,标记1号和2号,1号EP管加入490ulDMEM完全培养基,2号EP中加入200ulDMEM完全培养基。取10ulpWSLV-02-CEA病毒原液加至1号EP管中,混匀;从1号EP管中取200ul病毒悬液加至2号EP管中,混匀。4、A172细胞培养24h后,吸弃原培养基,后每孔加入100ul含有8ug/ml聚凝胺(polybrene)(原液1:1250倍稀释)的新鲜培养基。第1和2号孔各加入10ul新鲜培养基,第3和4号孔各加入10ulpWSLV-02-CEA2号EP管病毒悬液,第5和6号孔各加入10ulpWSLV-05-MSLN2号EP管病毒悬液,第7和8号孔先各加入10ulpWSLV-02-CEA2号EP管病毒悬液,后各加入10ulpWSLV-05-MSLN2号EP管病毒悬液。混匀。37℃,5%CO2培养5、4小时后每孔各加入100ul新鲜培养基(作用:稀释聚凝胺)。37℃,5%CO2继续培养。6、16小时后,每孔各用200ul新鲜培养基替换含有病毒的培养基。37℃,5%CO2继续培养。7、48后普通倒置显微镜观察观察绿色荧光。8、扩大培养双侵染细胞,流式细胞技术检测病毒侵染效率。实施例2:双特异CAR-T细胞制备1、第1天,取1块24孔平底细胞培养板,每孔加入200ul包被液,移液枪轻轻吹吸,使包被液覆盖板孔底部。(为了后期流式检测,可以包被5孔)。培养板放置于密闭塑料袋内,4℃包被过液。2、第2天,取1支冻存的PBMC,常规方法解冻,离心,用一定量的T细胞完全培养基重悬,制备单细胞悬液。计数,并调整细胞悬液浓度为1×106/ml。3、从4℃环境取出包被培养板,每包被孔加入500ulPBS或生理盐水轻轻清洗2次,去清洗液。4、每包被孔先加入400ulT细胞完全培养基,再加入100ulPBMC悬液(每孔中PBMC为1×105),37℃,5%CO2培养过夜(16~18h)。5、第3天,收集培养孔中的PBMC到15ml离心管,1500rpm,离心8min。去上清,加入1.4ml慢病毒侵染培养基,重悬PBMC,用吸管轻轻吹打细胞到单细胞悬液。然后将细胞悬液平均分至原包被孔中,每孔280ul。6、每孔中加入20ul慢病毒液(未用完的病毒液保存于4℃,用于次日使用),移液枪轻轻吹吸混匀。室温,200g,离心60min。37℃,5%CO2培养过夜。7、第4天,重复步骤(5)、(6)进行第2次慢病毒侵染。8、第5天,收集PBMC到15ml离心管,1500rpm,离心8min。去上清,加入1mlT细胞完全培养基,重悬PBMC,用吸管轻轻吹打细胞到单细胞悬液。将细胞悬液移至6孔板的1个孔中,37℃,5%CO2继续培养。9、每隔2天换1次液。视情况换培养瓶培养。10、第7天时,用荧光倒置显微镜观察细胞,看到绿色荧光说明CAR-T细胞构建成功。11、细胞数量足可以进行流式检测时,流式检测CAR-T细胞占比。实施例3:双特异CAR-T杀伤靶细胞效靶比测定1、制备CEA-MSLN-CART细胞。2、复苏CEA/MSLN/A172靶细胞,并扩大培养。3、待靶细胞铺满瓶底,消化细胞,离心收集细胞,X-VIVO-15培养基重悬细胞,并计数,调整靶细胞浓度为2×105/ml。4、取一块圆形底96孔细胞培养板,如下设计A1A2A3A4A5A6A7A8A9A10A11A12B1B2B3B4B5B6B7B8B9B10B11B12C1C2C3C4C5C6C7C8C9C10C11C12D1D2D3D4D5D6D7D8D9D10D11D12其中A1、B1孔是靶自发释放(TargetSpontaneousRelease)孔;C1、D1孔是靶最大释放(TargetMaximumRelease)孔;A2、B2孔是培养基背景(CultureMediumBackground)孔;C2、D2孔是体积校正对照(VolumeCorrectionControl)孔;A3至A8和B3至B8孔是效应细胞自发释放(EffectorCellSpontaneousRelease)孔;以及C3至C8和D3至D8孔是实验(Experimental)孔。除A2、B2、C2和D2各孔外,其它每孔中加入50μl靶细胞悬液。A2、B2孔和C2、D2孔分别加入100μlX-VIVO-15完全培养基。A3至A8和B3至B8的各孔中再加入50μlPBMC细胞悬液(E:T值从3至8依次为40、20、10、5、2.5、1.25)。C3至C8和D3至D8的各孔中再加入50μlCAR-T细胞悬液(E:T值从3至8依次为40、20、10、5、2.5、1.25)。A1、B1、C1和D1四孔分别加入50μlX-VIVO-15完全培养基。250g,离心4min,确保CAR-T细胞与靶细胞充分接触。将培养板37℃,5%CO2继续培养4h。5、培养3小时15分钟后,取出细胞培养板,分别向C1、D1、C2、D2的各孔中加入10μl裂解溶液(LysisSolution)(10X),混匀。37℃,5%CO2继续培养45min。6、45min后,取出培养板。250g,离心4min。7、从培养板每孔中吸取50μl转移至对应的ELISA板孔中,然后向每孔中加入50μl试剂,充分混匀。避光室温作用30min。8、每ELISA板孔中加入50μl终止,混匀。9、490nm检测吸光度。10、如下计算E:T值:%细胞毒性=(实验–效应细胞自发–靶自发)/(靶最大–靶自发)实验=实验,20:1细胞比率(平均值)–培养基背景(平均值)靶自发=靶自发(平均值)–培养基背景(平均值)效应细胞自发=效应细胞自发(平均值)–培养基背景(平均值)靶最大=靶最大(平均值)–体积培养物对照(平均值)同样地研究了本发明的双特异性CAR-T细胞对人结肠癌细胞系SW620、人胰腺癌细胞系PANC-1、人结肠癌细胞系LoVo、人肺癌细胞系NCI-H226的杀伤作用的研究。实施例4:双特异CAR-T杀伤肿瘤实验1、制备CEA-MSLN-CART细胞。2、复苏LoVo、NCI-H226、PANC-1和SW620等肿瘤细胞,并扩大培养。消化细胞,并计数。3、取24孔细胞培养板,每种细胞接种3个细胞培养孔,每孔接种1×105细胞。同时做2排平行实验。37℃,5%CO2继续培养6h,至细胞贴壁。4、完全去掉上清培养液,每孔加新鲜T细胞完全培养液300μl。第1列板孔再加入100μl新鲜T细胞完全培养液;第2列板孔再加入100μl新鲜T细胞完全培养液(含PBMC2×106);第3列板孔再加入100μl新鲜T细胞完全培养液(含双特异CAR-T2×106);37℃,5%CO2继续培养。5、普通生物显微镜下每天观察肿瘤细胞生长状态,并确认CAR-T细胞杀伤肿瘤细胞效果。序列表<110>吉林省拓华生物科技有限公司<120>双特异嵌合抗原受体修饰的T细胞、其制备方法及用途<130>380012CG<160>20<170>SIPOSequenceListing1.0<210>1<211>327<212>DNA<213>人工序列(ArtificialSequence)<220><221>misc_feature<222>(1)..(327)<223>CEA5-VL<400>1gatatcgtgatgacccagtctcaaagattcatgtccacatcagtaggagacagggtcagc60gtcacctgcaaggccagtcagaatgtgggtactaatgttgcctggtatcaacagaaacca120ggacaatcccctaaagcactgatttactcggcatcctaccggtacagtggagtccctgat180cgcttcacaggcagtggatctgggacagatttcactctcaccatcagcaatgtacagtct240gaagacttggcggagtatttctgtcaccaatattacacctatcctctattcacgttcggc300tcggggacaaagttggaaatgaaacgt327<210>2<211>109<212>PRT<213>人工序列(ArtificialSequence)<220><221>DOMAIN<222>(1)..(109)<223>CEA5-VL<400>2AspIleValMetThrGlnSerGlnArgPheMetSerThrSerValGly151015AspArgValSerValThrCysLysAlaSerGlnAsnValGlyThrAsn202530ValAlaTrpTyrGlnGlnLysProGlyGlnSerProLysAlaLeuIle354045TyrSerAlaSerTyrArgTyrSerGlyValProAspArgPheThrGly505560SerGlySerGlyThrAspPheThrLeuThrIleSerAsnValGlnSer65707580GluAspLeuAlaGluTyrPheCysHisGlnTyrTyrThrTyrProLeu859095PheThrPheGlySerGlyThrLysLeuGluMetLysArg100105<210>3<211>360<212>DNA<213>人工序列(ArtificialSequence)<220><221>misc_feature<222>(1)..(360)<223>CEA5-VH<400>3caggtgaagctgcagcagtcaggacctgagttgaagaagcctggagagacagtcaagatc60tcctgcaaggcttctggatataccttcacagaattcggaatgaactgggtgaagcaggct120cctggaaagggtttaaagtggatgggctggataaacaccaaaactggagaggcaacatat180gttgaagagtttaagggacggtttgccttctctttggagacctctgccaccactgcctat240ttgcagatcaacaacctcaaaaatgaggacacggctaaatatttctgtgctcgatgggat300ttctatgactatgttgaagctatggactactggggccaagggaccaccgtgaccgtctcc360<210>4<211>120<212>PRT<213>人工序列(ArtificialSequence)<220><221>CONFLICT<222>(1)..(120)<223>CEA5-VH<400>4GlnValLysLeuGlnGlnSerGlyProGluLeuLysLysProGlyGlu151015ThrValLysIleSerCysLysAlaSerGlyTyrThrPheThrGluPhe202530GlyMetAsnTrpValLysGlnAlaProGlyLysGlyLeuLysTrpMet354045GlyTrpIleAsnThrLysThrGlyGluAlaThrTyrValGluGluPhe505560LysGlyArgPheAlaPheSerLeuGluThrSerAlaThrThrAlaTyr65707580LeuGlnIleAsnAsnLeuLysAsnGluAspThrAlaLysTyrPheCys859095AlaArgTrpAspPheTyrAspTyrValGluAlaMetAspTyrTrpGly100105110GlnGlyThrThrValThrValSer115120<210>5<211>321<212>DNA<213>人工序列(ArtificialSequence)<220><221>misc_feature<222>(1)..(321)<223>MSLN-VL<400>5gacatccagatgacccagtctccttccaccctgtctgcatctattggagacagagtcacc60atcacctgccgggccagcgagggtatttatcactggttggcctggtatcagcagaagcca120gggaaagcccctaaactcctgatctataaggcctctagtttagccagtggggccccatca180aggttcagcggcagtggatctgggacagatttcactctcaccatcagcagcctgcagcct240gatgattttgcaacttattactgccaacaatatagtaattatccgctcactttcggcgga300gggaccaagctggagatcaaa321<210>6<211>107<212>PRT<213>人工序列(ArtificialSequence)<220><221>DOMAIN<222>(1)..(107)<223>MSLN-VL<400>6AspIleGlnMetThrGlnSerProSerThrLeuSerAlaSerIleGly151015AspArgValThrIleThrCysArgAlaSerGluGlyIleTyrHisTrp202530LeuAlaTrpTyrGlnGlnLysProGlyLysAlaProLysLeuLeuIle354045TyrLysAlaSerSerLeuAlaSerGlyAlaProSerArgPheSerGly505560SerGlySerGlyThrAspPheThrLeuThrIleSerSerLeuGlnPro65707580AspAspPheAlaThrTyrTyrCysGlnGlnTyrSerAsnTyrProLeu859095ThrPheGlyGlyGlyThrLysLeuGluIleLys100105<210>7<211>357<212>DNA<213>人工序列(ArtificialSequence)<220><221>misc_feature<222>(1)..(357)<223>MSLN-VH<400>7caggtgcagctggtgcagtctggggctgaggtgaagagacctggggcctcagtgcaggtt60tcctgcagagcatctggatactcaatcaacacctactatatgcagtgggtgcgacaggcc120cctggagcagggcttgagtggatgggagtgatcaaccctagtggtgtgacaagctacgca180cagaagttccagggcagagtcaccctgaccaacgacacgtccacgaacacagtctacatg240cagctgaacagcctgacctctgcagacacggccgtgtattactgtgcgagatgggcactg300tggggggatttcgggatggacgtgtggggcaagggaaccctggtcaccgtctcctca357<210>8<211>119<212>PRT<213>人工序列(ArtificialSequence)<220><221>DOMAIN<222>(1)..(119)<223>MSLN-VH<400>8GlnValGlnLeuValGlnSerGlyAlaGluValLysArgProGlyAla151015SerValGlnValSerCysArgAlaSerGlyTyrSerIleAsnThrTyr202530TyrMetGlnTrpValArgGlnAlaProGlyAlaGlyLeuGluTrpMet354045GlyValIleAsnProSerGlyValThrSerTyrAlaGlnLysPheGln505560GlyArgValThrLeuThrAsnAspThrSerThrAsnThrValTyrMet65707580GlnLeuAsnSerLeuThrSerAlaAspThrAlaValTyrTyrCysAla859095ArgTrpAlaLeuTrpGlyAspPheGlyMetAspValTrpGlyLysGly100105110ThrLeuValThrValSerSer115<210>9<211>489<212>DNA<213>人(Homosapiens)<400>9atgaagtggaaggcgcttttcaccgcggccatcctgcaggcacagttgccgattacagag60gcacagagctttggcctgctggatcccaaactctgctacctgctggatggaatcctcttc120atctatggtgtcattctcactgccttgttcctgagagtgaagttcagcaggagcgcagac180gcccccgcgtaccagcagggccagaaccagctctataacgagctcaatctaggacgaaga240gaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccg300agaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggag360gcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctt420taccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctg480ccccctcgc489<210>10<211>163<212>PRT<213>人(Homosapiens)<400>10MetLysTrpLysAlaLeuPheThrAlaAlaIleLeuGlnAlaGlnLeu151015ProIleThrGluAlaGlnSerPheGlyLeuLeuAspProLysLeuCys202530TyrLeuLeuAspGlyIleLeuPheIleTyrGlyValIleLeuThrAla354045LeuPheLeuArgValLysPheSerArgSerAlaAspAlaProAlaTyr505560GlnGlnGlyGlnAsnGlnLeuTyrAsnGluLeuAsnLeuGlyArgArg65707580GluGluTyrAspValLeuAspLysArgArgGlyArgAspProGluMet859095GlyGlyLysProArgArgLysAsnProGlnGluGlyLeuTyrAsnGlu100105110LeuGlnLysAspLysMetAlaGluAlaTyrSerGluIleGlyMetLys115120125GlyGluArgArgArgGlyLysGlyHisAspGlyLeuTyrGlnGlyLeu130135140SerThrAlaThrLysAspThrTyrAspAlaLeuHisMetGlnAlaLeu145150155160ProProArg<210>11<211>765<212>DNA<213>人(Homosapiens)<400>11atgggaaacagctgttacaacatagtagccactctgttgctggtcctcaactttgagagg60acaagatcattgcaggatccttgtagtaactgcccagctggtacattctgtgataataac120aggaatcagatttgcagtccctgtcctccaaatagtttctccagcgcaggtggacaaagg180acctgtgacatatgcaggcagtgtaaaggtgttttcaggaccaggaaggagtgttcctcc240accagcaatgcagagtgtgactgcactccagggtttcactgcctgggggcaggatgcagc300atgtgtgaacaggattgtaaacaaggtcaagaactgacaaaaaaaggttgtaaagactgt360tgctttgggacatttaacgatcagaaacgtggcatctgtcgaccctggacaaactgttct420ttggatggaaagtctgtgcttgtgaatgggacgaaggagagggacgtggtctgtggacca480tctccagccgacctctctccgggagcatcctctgtgaccccgcctgcccctgcgagagag540ccaggacactctccgcagatcatctccttctttcttgcgctgacgtcgactgcgttgctc600ttcctgctgttcttcctcacgctccgtttctctgttgttaaacggggcagaaagaaactc660ctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggc720tgtagctgccgatttccagaagaagaagaaggaggatgtgaactg765<210>12<211>255<212>PRT<213>人(Homosapiens)<400>12MetGlyAsnSerCysTyrAsnIleValAlaThrLeuLeuLeuValLeu151015AsnPheGluArgThrArgSerLeuGlnAspProCysSerAsnCysPro202530AlaGlyThrPheCysAspAsnAsnArgAsnGlnIleCysSerProCys354045ProProAsnSerPheSerSerAlaGlyGlyGlnArgThrCysAspIle505560CysArgGlnCysLysGlyValPheArgThrArgLysGluCysSerSer65707580ThrSerAsnAlaGluCysAspCysThrProGlyPheHisCysLeuGly859095AlaGlyCysSerMetCysGluGlnAspCysLysGlnGlyGlnGluLeu100105110ThrLysLysGlyCysLysAspCysCysPheGlyThrPheAsnAspGln115120125LysArgGlyIleCysArgProTrpThrAsnCysSerLeuAspGlyLys130135140SerValLeuValAsnGlyThrLysGluArgAspValValCysGlyPro145150155160SerProAlaAspLeuSerProGlyAlaSerSerValThrProProAla165170175ProAlaArgGluProGlyHisSerProGlnIleIleSerPhePheLeu180185190AlaLeuThrSerThrAlaLeuLeuPheLeuLeuPhePheLeuThrLeu195200205ArgPheSerValValLysArgGlyArgLysLysLeuLeuTyrIlePhe210215220LysGlnProPheMetArgProValGlnThrThrGlnGluGluAspGly225230235240CysSerCysArgPheProGluGluGluGluGlyGlyCysGluLeu245250255<210>13<211>705<212>DNA<213>人(Homosapiens)<400>13atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccagg60ccgagccagttccgggtgtcgccgctggatcggacctggaacctgggcgagacagtggag120ctgaagtgccaggtgctgctgtccaacccgacgtcgggctgctcgtggctcttccagccg180cgcggcgccgccgccagtcccaccttcctcctatacctctcccaaaacaagcccaaggcg240gccgaggggctggacacccagcggttctcgggcaagaggttgggggacaccttcgtcctc300accctgagcgacttccgccgagagaacgagggctactatttctgctcggccctgagcaac360tccatcatgtacttcagccacttcgtgccggtcttcctgccagcgaagcccaccacgacg420ccagcgccgcgaccaccaacaccggcgcccaccatcgcgtcgcagcccctgtccctgcgc480ccagaggcgtgccggccagcggcggggggcgcagtgcacacgagggggctggacttcgcc540tgtgatatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactg600gttatcaccctttactgcaaccacaggaaccgaagacgtgtttgcaaatgtccccggcct660gtggtcaaatcgggagacaagcccagcctttcggcgagatacgtc705<210>14<211>235<212>PRT<213>人(Homosapiens)<400>14MetAlaLeuProValThrAlaLeuLeuLeuProLeuAlaLeuLeuLeu151015HisAlaAlaArgProSerGlnPheArgValSerProLeuAspArgThr202530TrpAsnLeuGlyGluThrValGluLeuLysCysGlnValLeuLeuSer354045AsnProThrSerGlyCysSerTrpLeuPheGlnProArgGlyAlaAla505560AlaSerProThrPheLeuLeuTyrLeuSerGlnAsnLysProLysAla65707580AlaGluGlyLeuAspThrGlnArgPheSerGlyLysArgLeuGlyAsp859095ThrPheValLeuThrLeuSerAspPheArgArgGluAsnGluGlyTyr100105110TyrPheCysSerAlaLeuSerAsnSerIleMetTyrPheSerHisPhe115120125ValProValPheLeuProAlaLysProThrThrThrProAlaProArg130135140ProProThrProAlaProThrIleAlaSerGlnProLeuSerLeuArg145150155160ProGluAlaCysArgProAlaAlaGlyGlyAlaValHisThrArgGly165170175LeuAspPheAlaCysAspIleTyrIleTrpAlaProLeuAlaGlyThr180185190CysGlyValLeuLeuLeuSerLeuValIleThrLeuTyrCysAsnHis195200205ArgAsnArgArgArgValCysLysCysProArgProValValLysSer210215220GlyAspLysProSerLeuSerAlaArgTyrVal225230235<210>15<211>45<212>DNA<213>人工序列(ArtificialSequence)<220><221>misc_feature<222>(1)..(45)<223>接头<400>15ggtggaggtggatcaggtggaggtggatctggtggaggtggatct45<210>16<211>15<212>PRT<213>人工序列(ArtificialSequence)<220><221>PEPTIDE<222>(1)..(15)<223>接头<400>16GlyGlyGlyGlySerGlyGlyGlyGlySerGlyGlyGlyGlySer151015<210>17<211>66<212>DNA<213>人工序列(ArtificialSequence)<220><221>misc_feature<222>(1)..(66)<223>编码信号肽<400>17atgcttctcctggtgacaagccttctgctctgtgagttaccacacccagcattcctcctg60atccca66<210>18<211>22<212>PRT<213>人工序列(ArtificialSequence)<220><221>PEPTIDE<222>(1)..(22)<223>信号肽<400>18MetLeuLeuLeuValThrSerLeuLeuLeuCysGluLeuProHisPro151015AlaPheLeuLeuIlePro20<210>19<211>486<212>DNA<213>人(Homosapiens)<400>19atgagaatttcgaaaccacatttgagaagtatttccatccagtgctacttgtgtttactt60ctaaacagtcattttctaactgaagctggcattcatgtcttcattttgggctgtttcagt120gcagggcttcctaaaacagaagccaactgggtgaatgtaataagtgatttgaaaaaaatt180gaagatcttattcaatctatgcatattgatgctactttatatacggaaagtgatgttcac240cccagttgcaaagtaacagcaatgaagtgctttctcttggagttacaagttatttcactt300gagtccggagatgcaagtattcatgatacagtagaaaatctgatcatcctagcaaacaac360agtttgtcttctaatgggaatgtaacagaatctggatgcaaagaatgtgaggaactggag420gaaaaaaatattaaagaatttttgcagagttttgtacatattgtccaaatgttcatcaac480acttct486<210>20<211>162<212>PRT<213>人(Homosapiens)<400>20MetArgIleSerLysProHisLeuArgSerIleSerIleGlnCysTyr151015LeuCysLeuLeuLeuAsnSerHisPheLeuThrGluAlaGlyIleHis202530ValPheIleLeuGlyCysPheSerAlaGlyLeuProLysThrGluAla354045AsnTrpValAsnValIleSerAspLeuLysLysIleGluAspLeuIle505560GlnSerMetHisIleAspAlaThrLeuTyrThrGluSerAspValHis65707580ProSerCysLysValThrAlaMetLysCysPheLeuLeuGluLeuGln859095ValIleSerLeuGluSerGlyAspAlaSerIleHisAspThrValGlu100105110AsnLeuIleIleLeuAlaAsnAsnSerLeuSerSerAsnGlyAsnVal115120125ThrGluSerGlyCysLysGluCysGluGluLeuGluGluLysAsnIle130135140LysGluPheLeuGlnSerPheValHisIleValGlnMetPheIleAsn145150155160ThrSer当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 金黄色葡萄球菌肠毒素C2的核酸适配体C203及其筛选方法和应用与制造工艺
- 一种全人源化EGFRvIII嵌合抗原受体T细胞及其制备方法与制造工艺
- 嵌合抗原受体及制备方法与制造工艺
- 检测外周血CAR‑T细胞的TaqMan实时荧光定量PCR试剂盒的制造方法与工艺
- CD20特异性嵌合抗原受体及其应用的制造方法与工艺
- 一种用于辣根过氧化物酶染色的染色剂及其制备方法、染色组合、应用及标记酶染色试剂盒与制造工艺
- 对SSEA4抗原具有特异性的嵌合抗原受体的制造方法与工艺
- 具有针对CD79和CD22的特异性的分子的制造方法与工艺
- 具有针对CD45和CD79的特异性的分子的制造方法与工艺
- 一种检测嵌合抗原受体T细胞对肝癌细胞抑制作用的模型和方法与制造工艺